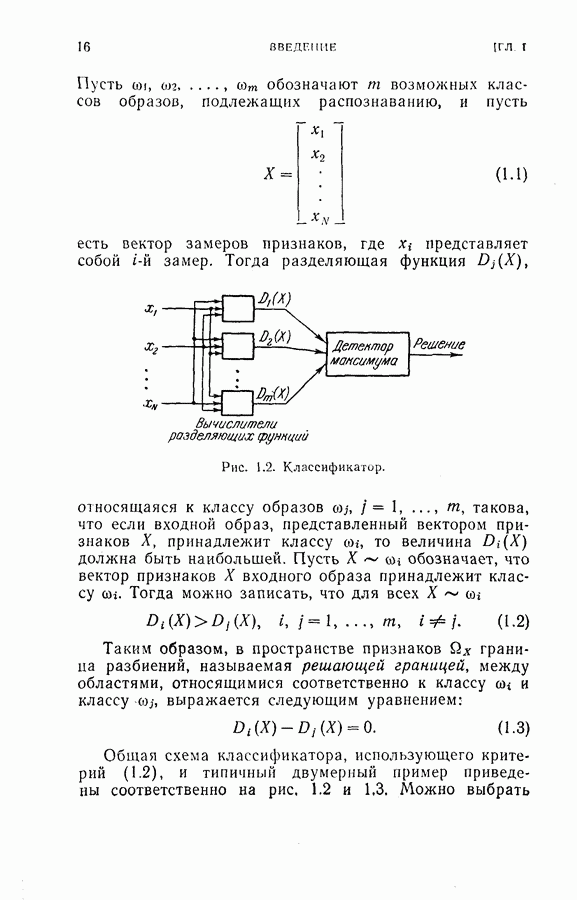
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
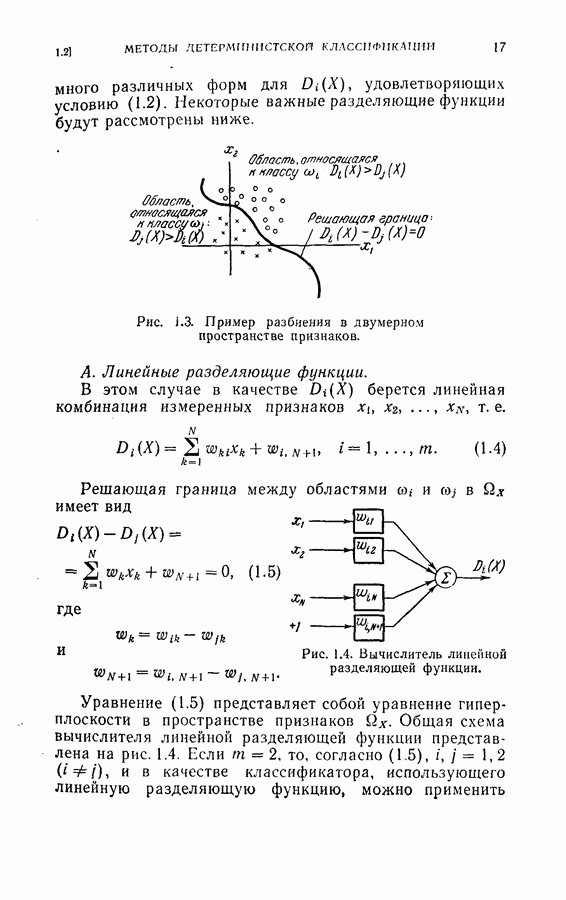
ZADANIA.TO
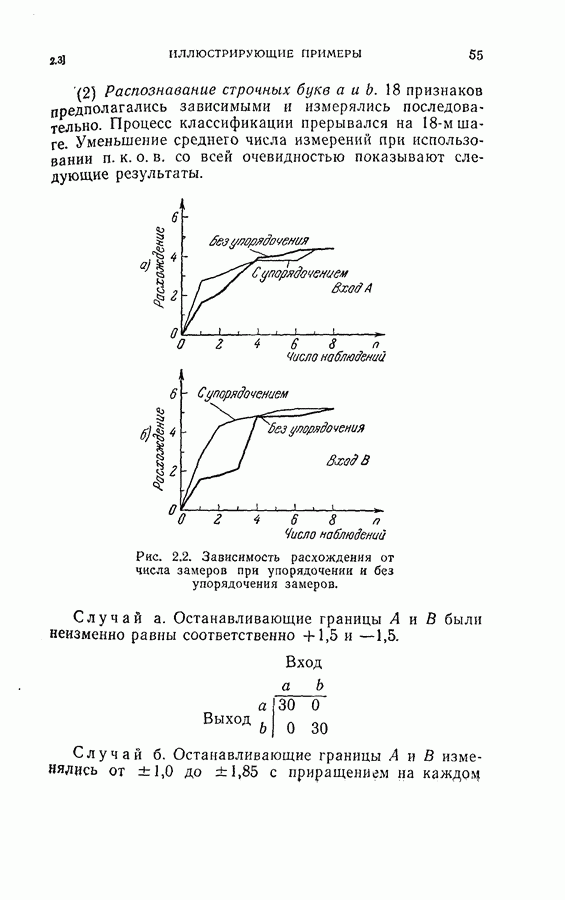
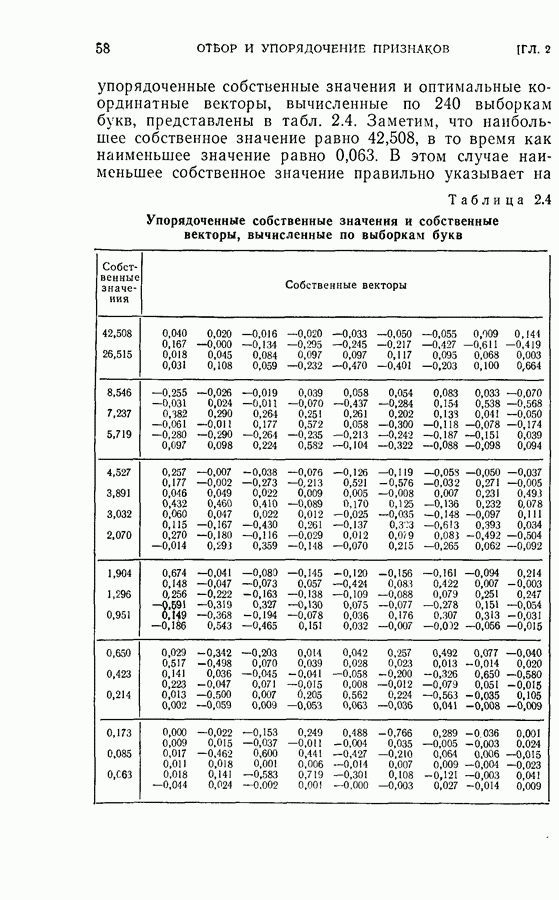
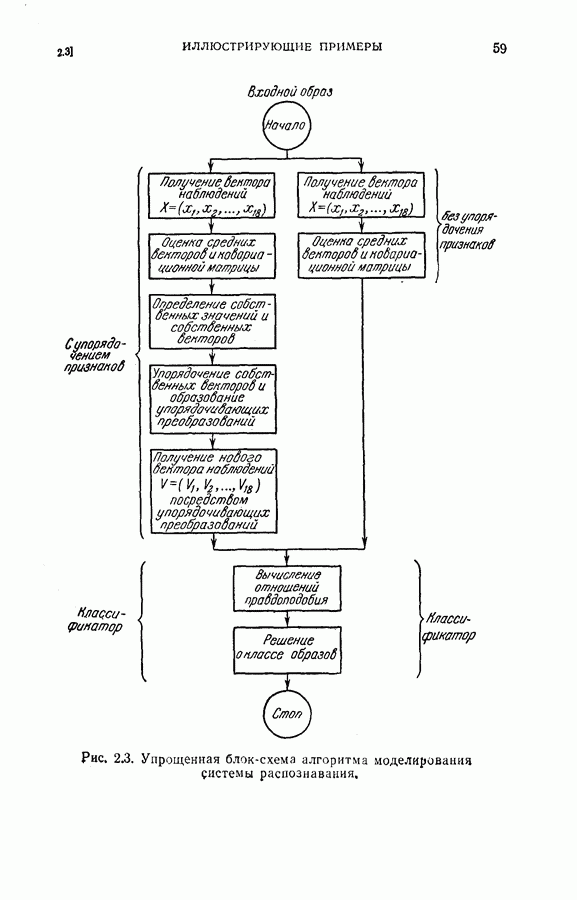
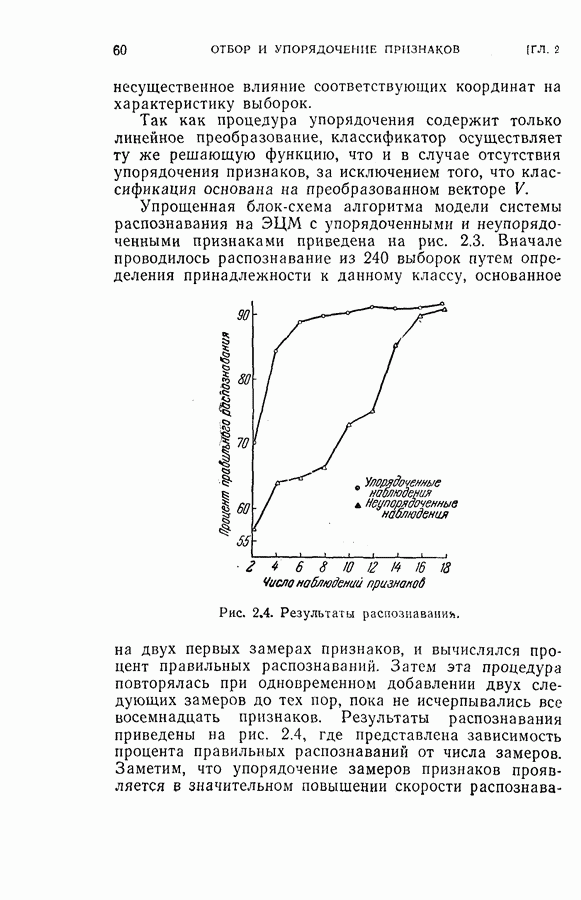
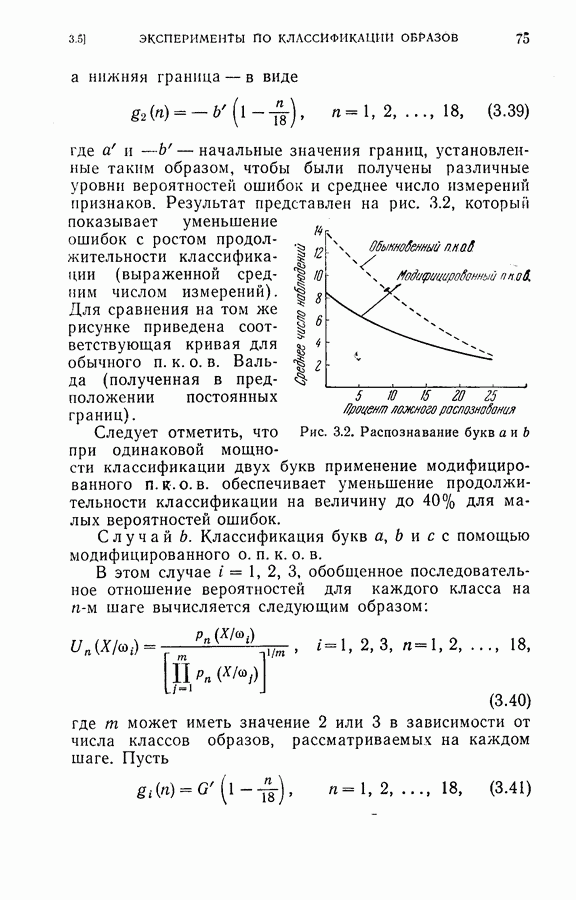
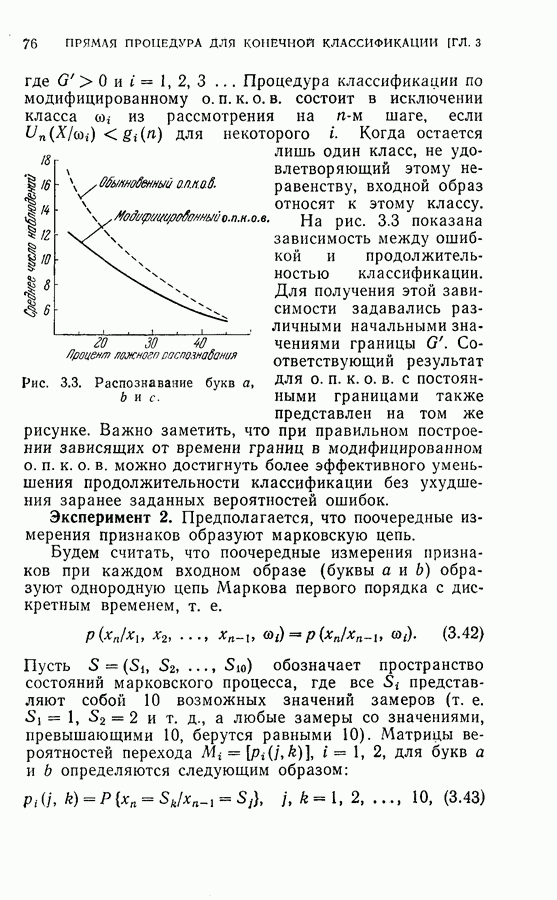
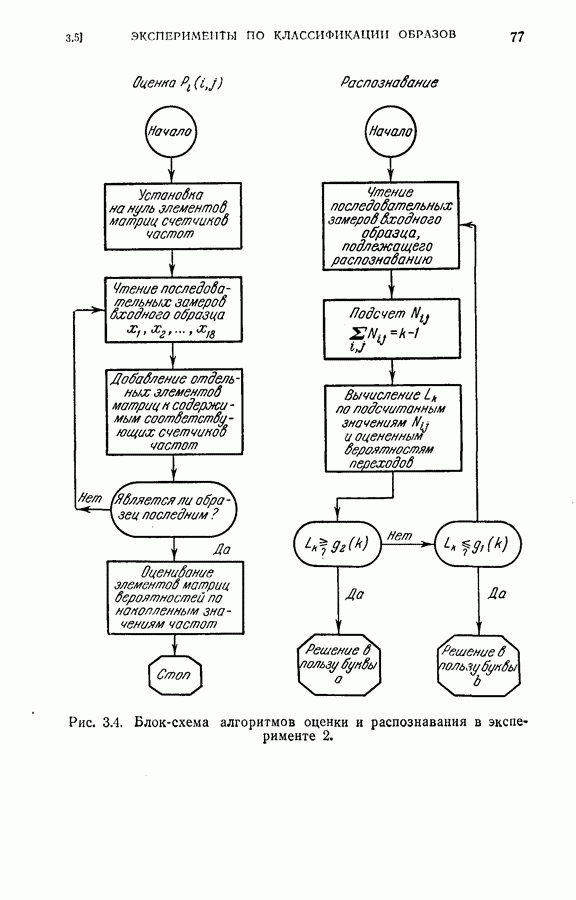
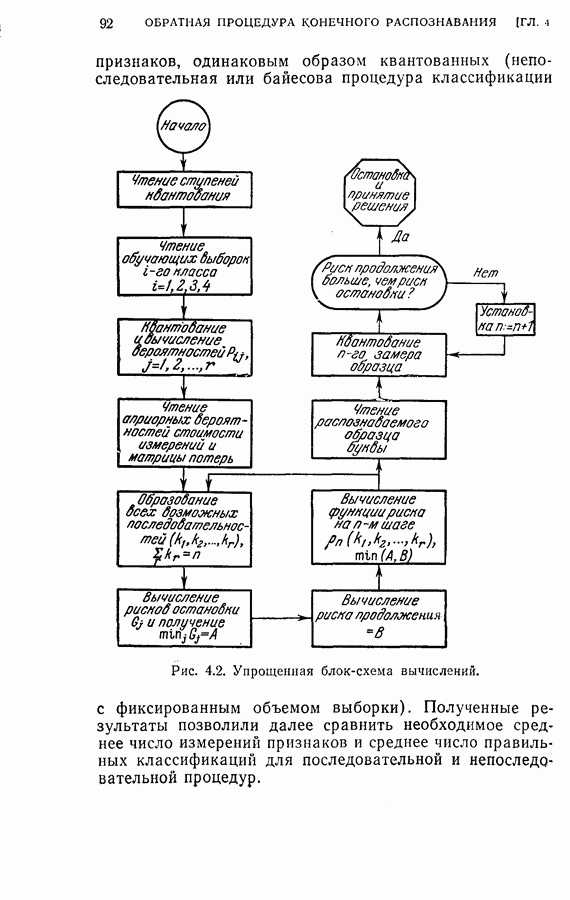
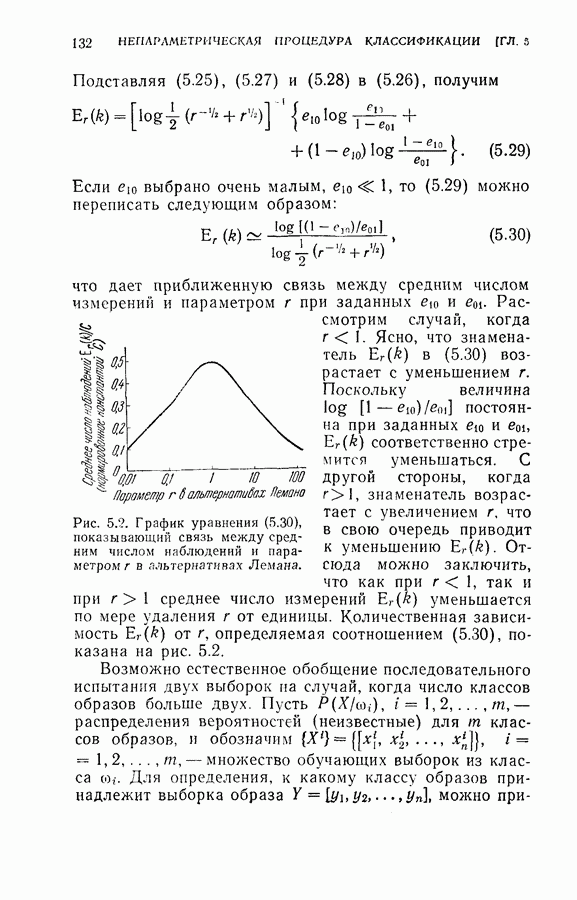
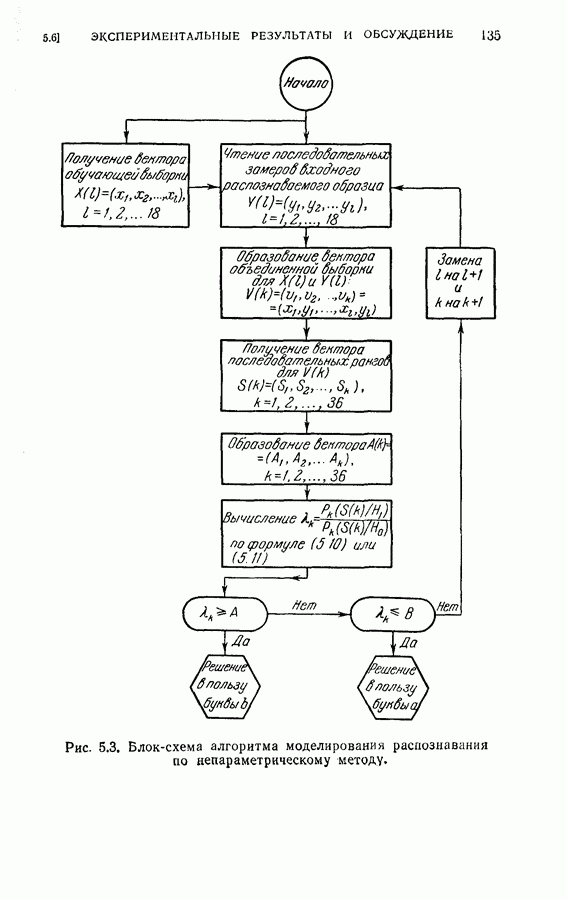
4.6. Эксперименты по упорядочению признаков и по классификации образовДля проверки изложенных в § 4.5 постановки задачи и оптимальных свойств процедуры вновь была использована задача распознавания букв, описанная в § 4.4. Рассматривались только три класса образов в данную ступень квантования. Все замеры признаков предполагались статистически независимыми. Для уменьшения объема вычислений использовалась байесова статистика (апостериорная вероятность). На каждом шаге процесса вычислялась условная вероятность принадлежности образа данному классу при данной истории предыдущих измерений признаков. Таким образом, после измерения
где
Таким образом, при применении этой процедуры вся информация, полученная ранее при отборе признаков и в результате измерений, содержится в апостериорных вероятностях, вычисленных с помощью формулы (4.23). Классифицирующее решение на последнем шаге зависит от потерь за счет ложного распознавания и от апостериорной вероятности появления каждого класса, у которого измерены все восемь признаков. Для упрощения вычислений каждая апостериорная вероятность квантовалась на двадцать равных долей. Таким образом, как показано на рис. 4.3, пространство вероятностей квантовалось всего на 210 частей. Потери вследствие ложного распознавания предполагались равными единице во всех случаях, т. е.
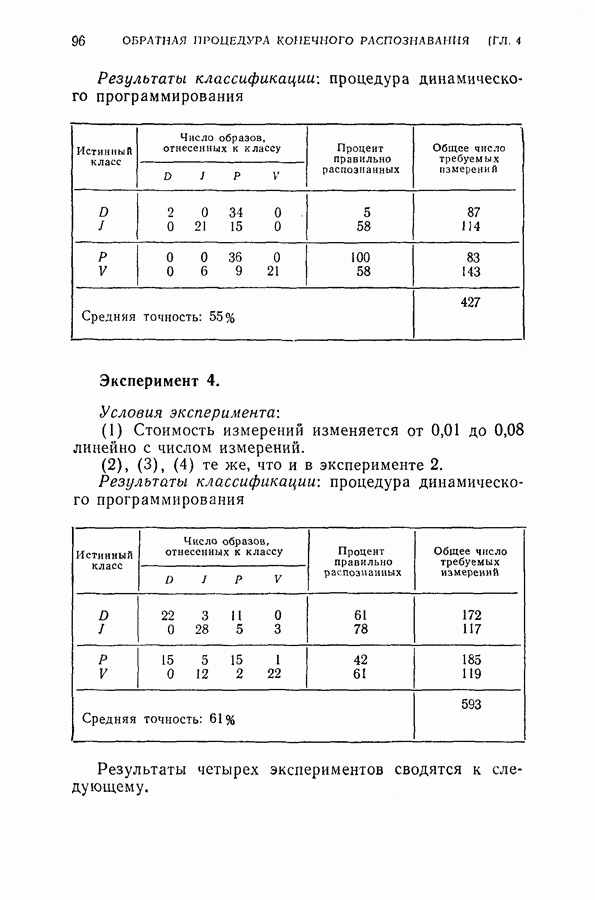
Стоимость измерения признаков равна 0,01 на одно измерение. Во всех экспериментах априорная вероятность каждого класса бралась равной одной трети. Средний риск принятия решения при различных апостериорных вероятностях напечатан в соответствующей позиции в таблице.
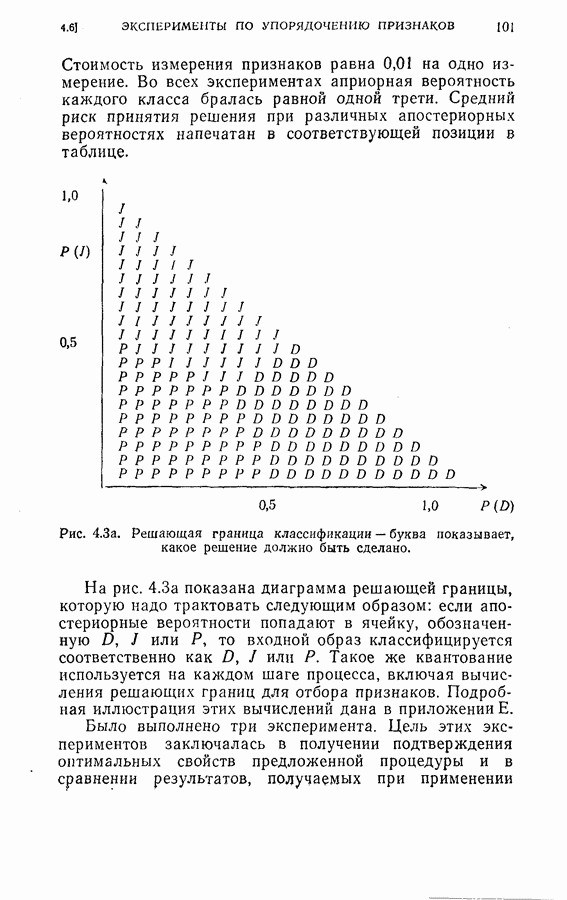
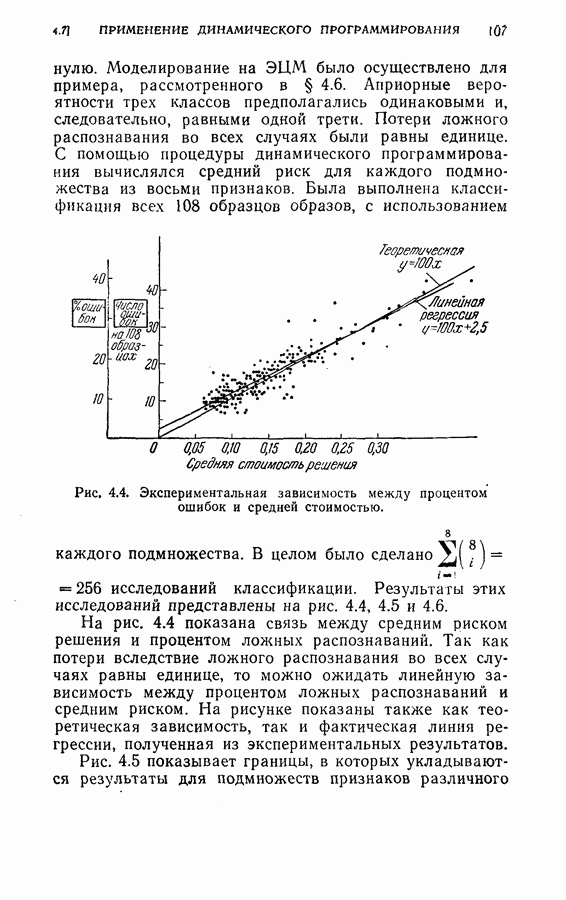
Рис. 4.3а. Решающая граница классификации — буква показывает, какое решение должно быть сделано. На рис. 4.3а показана диаграмма решающей границы, которую надо трактовать следующим образом: если апостериорные вероятности попадают в ячейку, обозначенную Было выполнено три эксперимента. Цель этих экспериментов заключалась в получении подтверждения оптимальных свойств предложенной процедуры и в сравнении результатов, получаемых при применении
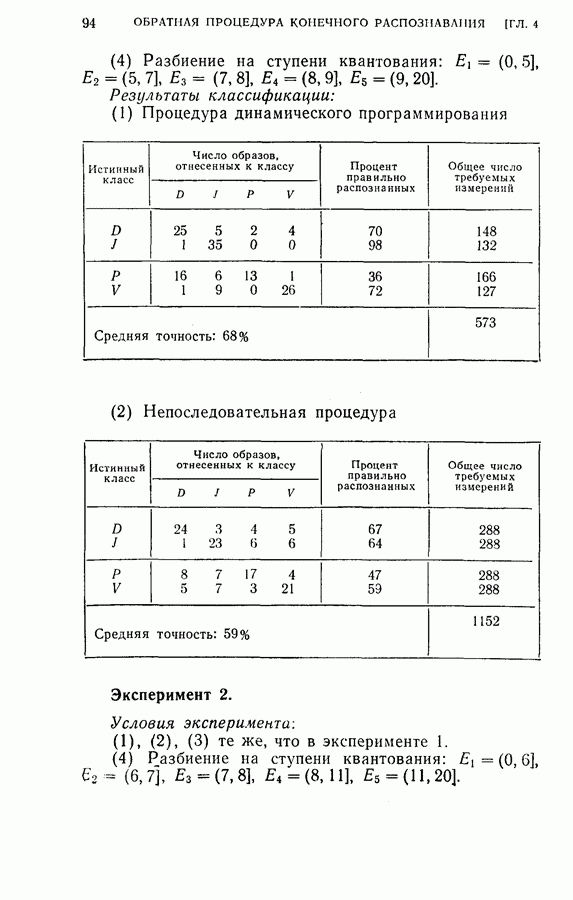
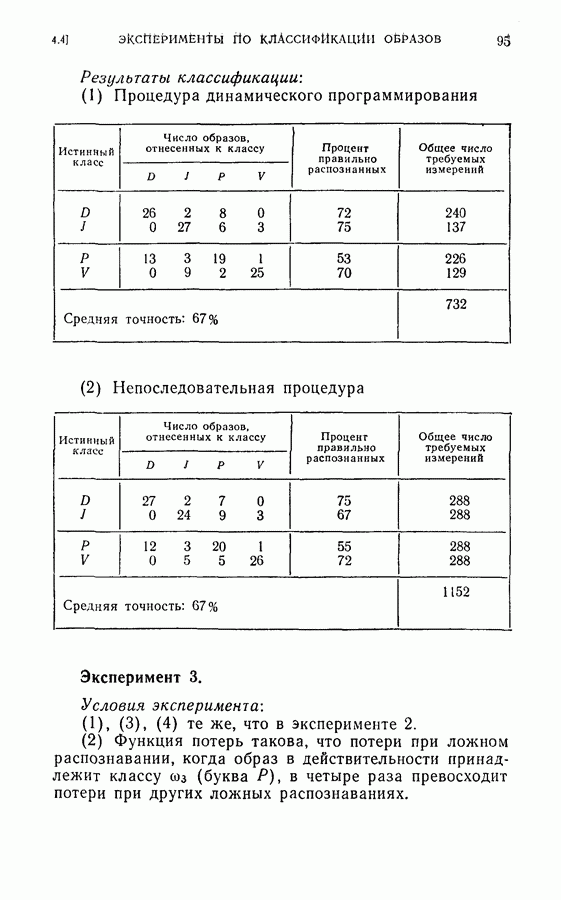
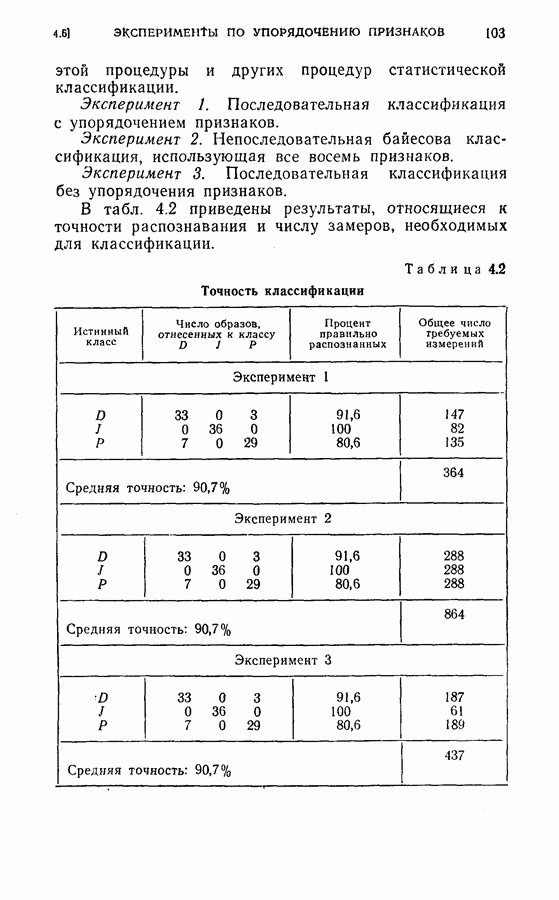
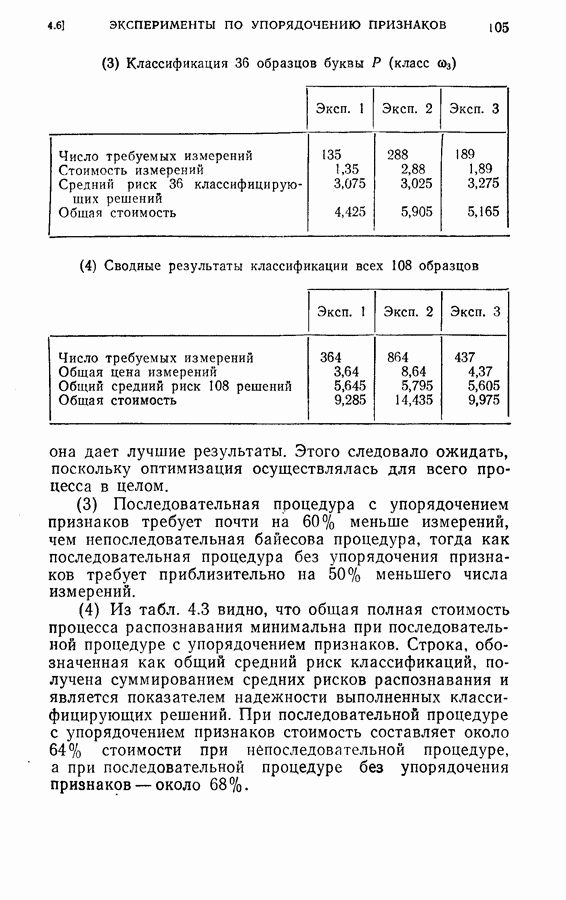
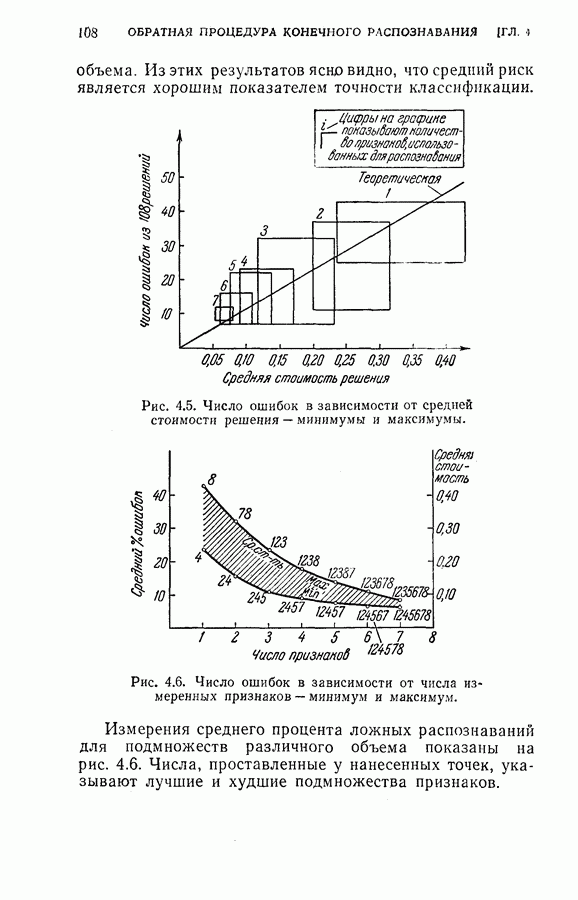
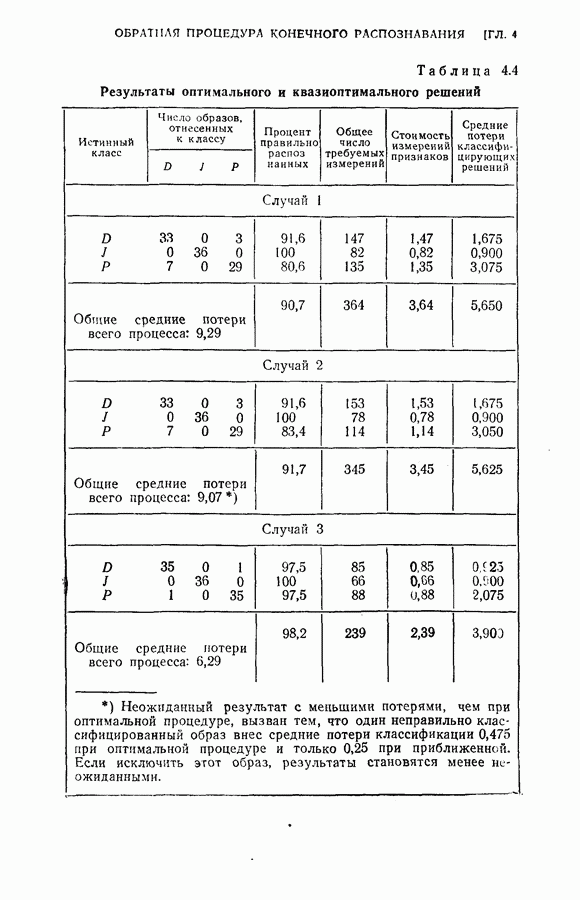
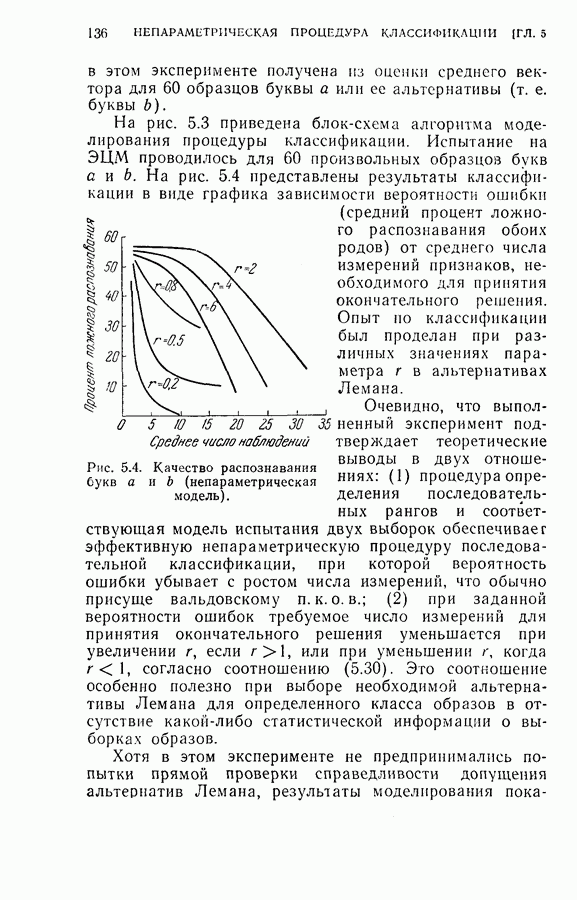
(кликните для просмотра скана) этой процедуры и других процедур статистической классификации. Эксперимент 1. Последовательная классификация с упорядочением признаков. Эксперимент 2. Непоследовательная байесова классификация, использующая все восемь признаков. Эксперимент 3. Последовательная классификация без упорядочения признаков. В табл. 4.2 приведены результаты, относящиеся к точности распознавания и числу замеров, необходимых для классификации. Таблица 4.2 (см. скан) Точность классификации В табл. 4.3 приведены стоимости различных процедур классификации. Ниже приводятся и анализируются результаты этих трех экспериментов. (1) Видно, что один и тот же процент правильных распознаваний получается при всех трех процедурах классификации. Фактически оказывается, что ложные распознавания происходили на одних и тех же образах. (2) Из табл. 4.2 видно, что последовательная процедура классификации без упорядочения признаков требует меньшего числа измерений для классификации образов из класса Таблица 4.3 (см. скан) Стоимость процессов классификации (см. скан) она дает лучшие результаты. Этого следовало ожидать, поскольку оптимизация осуществлялась для всего процесса в целом. (3) Последовательная процедура с упорядочением признаков требует почти на 60% меньше измерений, чем непоследовательная байесова процедура, тогда как последовательная процедура без упорядочения признаков требует приблизительно на 50% меньшего числа измерений. (4) Из табл. 4.3 видно, что общая полная стоимость процесса распознавания минимальна при последовательной процедуре с упорядочением признаков. Строка, обозначенная как общий средний риск классификаций, получена суммированием средних рисков распознавания и является показателем надежности выполненных классифицирующих решений. При последовательной процедуре с упорядочением признаков стоимость составляет около 64% стоимости при непоследовательной процедуре, а при последовательной процедуре без упорядочения признаков — около 68%.
|
 |
Оглавление
|









































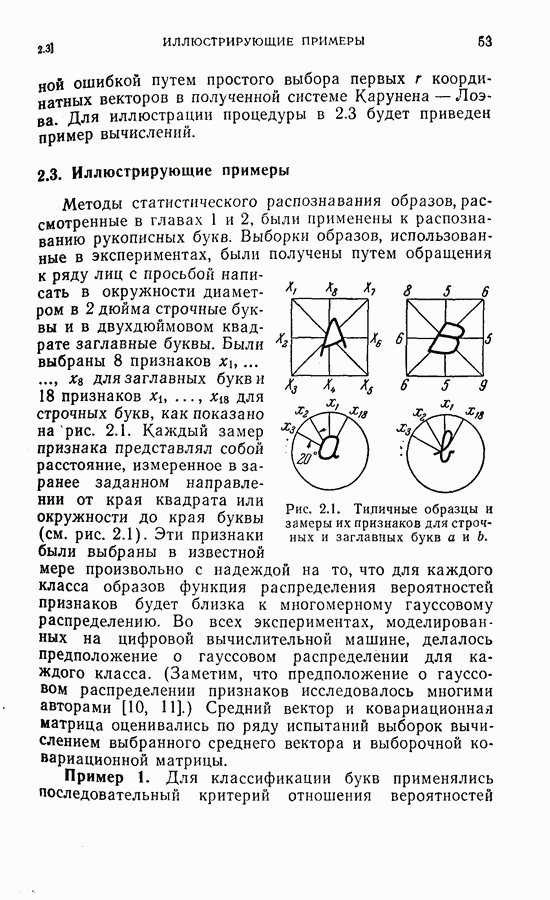
















































































































































































 каждый представленный 36 образцами, которые обрабатывались как для получения распределения вероятностей, так и для испытания данного метода. Так же как и в примере из § 4.4, в качестве признаков использовались размеры восьми радиальных отрезков, квантованных на двадцать долей (ступеней), и построена гистограмма для оценки вероятности попадания того или иного признака
каждый представленный 36 образцами, которые обрабатывались как для получения распределения вероятностей, так и для испытания данного метода. Так же как и в примере из § 4.4, в качестве признаков использовались размеры восьми радиальных отрезков, квантованных на двадцать долей (ступеней), и построена гистограмма для оценки вероятности попадания того или иного признака


 признак, избранный для измерения классификатором, и
признак, избранный для измерения классификатором, и  результат измерения (замер). Далее эти величины используются как априорные вероятности для следующего шага (в данном случае второго шага) процесса. Процедуру можно определить рекуррентно. Тогда для
результат измерения (замер). Далее эти величины используются как априорные вероятности для следующего шага (в данном случае второго шага) процесса. Процедуру можно определить рекуррентно. Тогда для  шага
шага



 или
или  то входной образ классифицируется соответственно как
то входной образ классифицируется соответственно как  или
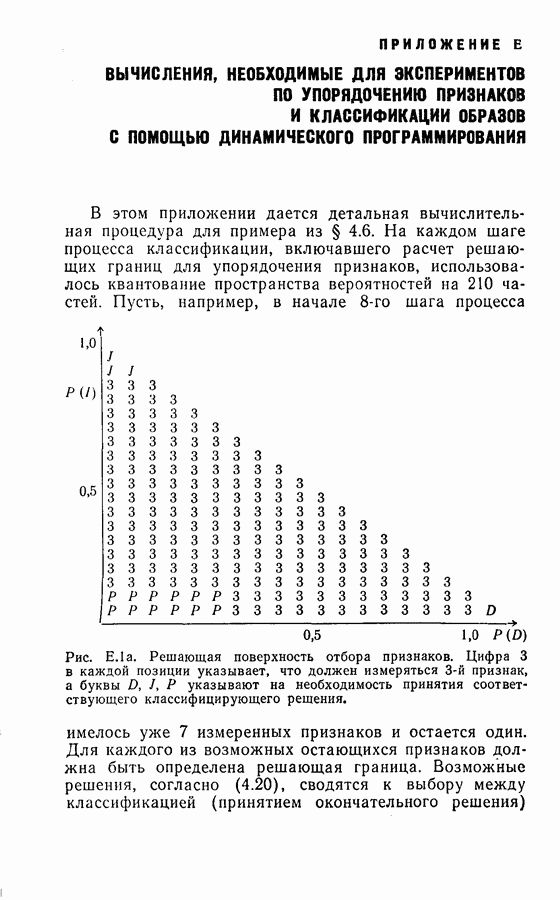
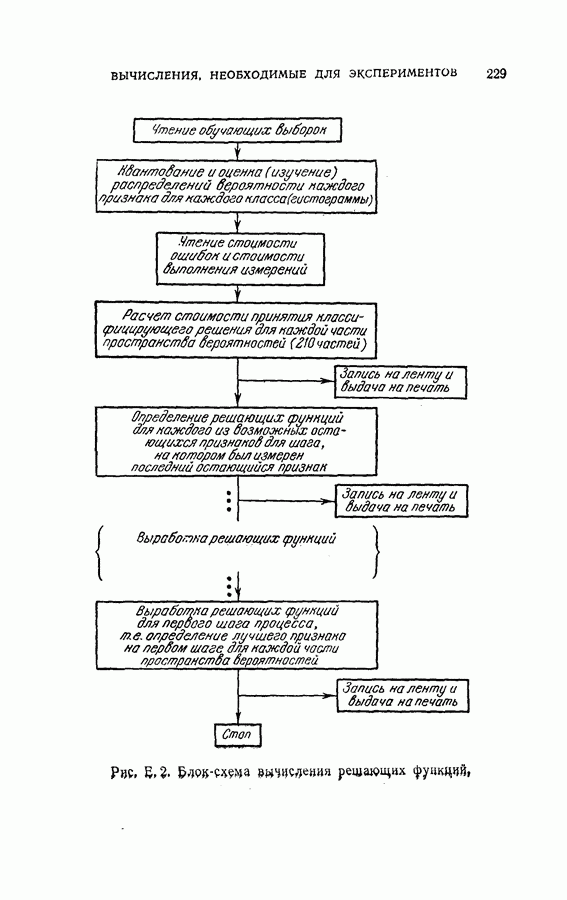
или  Такое же квантование используется на каждом шаге процесса, включая вычисления решающих границ для отбора признаков. Подробная иллюстрация этих вычислений дана в приложении
Такое же квантование используется на каждом шаге процесса, включая вычисления решающих границ для отбора признаков. Подробная иллюстрация этих вычислений дана в приложении 

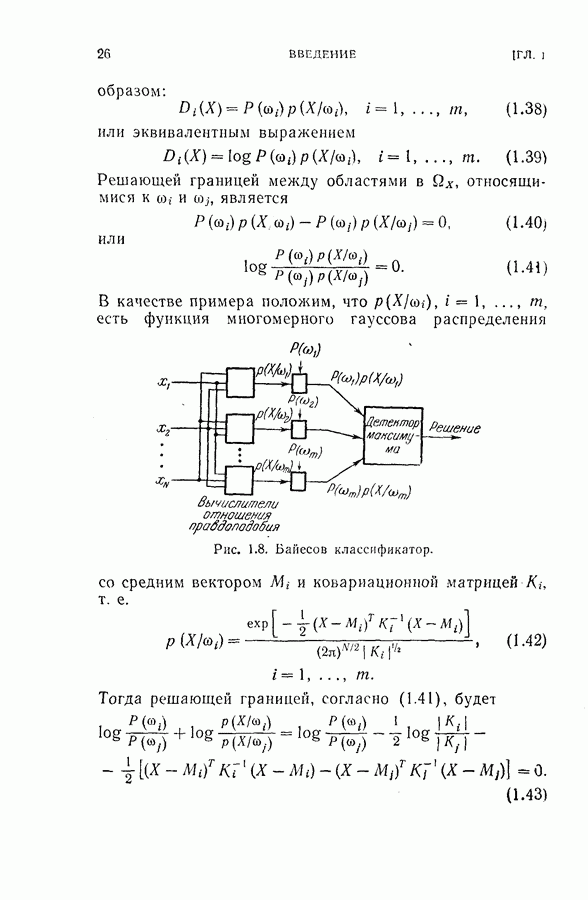
 чем последовательная процедура с упорядочением признаков. Однако она требует больше измерений для всего процесса в целом. Отсюда следует, что последовательная процедура с упорядочением признаков может дать худшее качество в некоторых частных случаях, но в среднем по всему процессу в целом
чем последовательная процедура с упорядочением признаков. Однако она требует больше измерений для всего процесса в целом. Отсюда следует, что последовательная процедура с упорядочением признаков может дать худшее качество в некоторых частных случаях, но в среднем по всему процессу в целом