Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
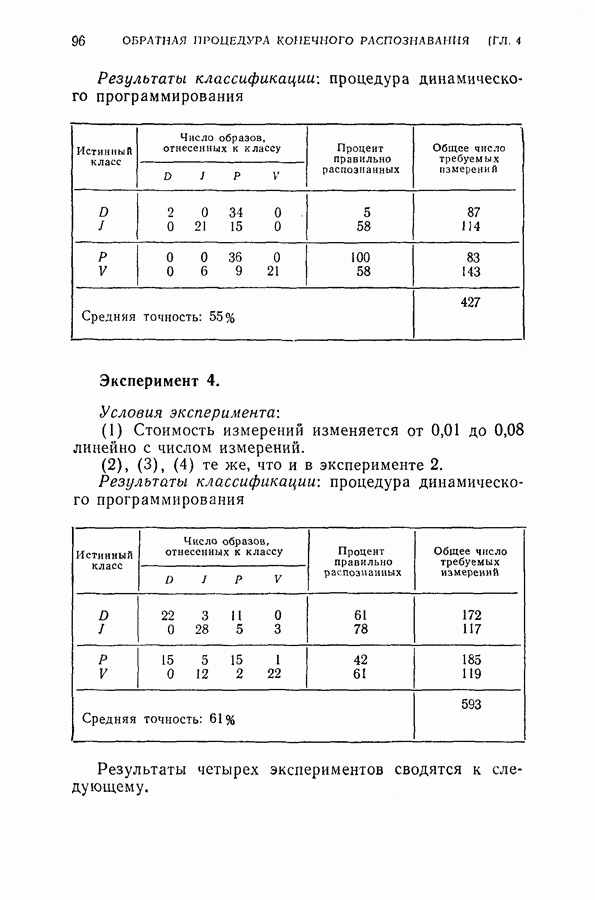
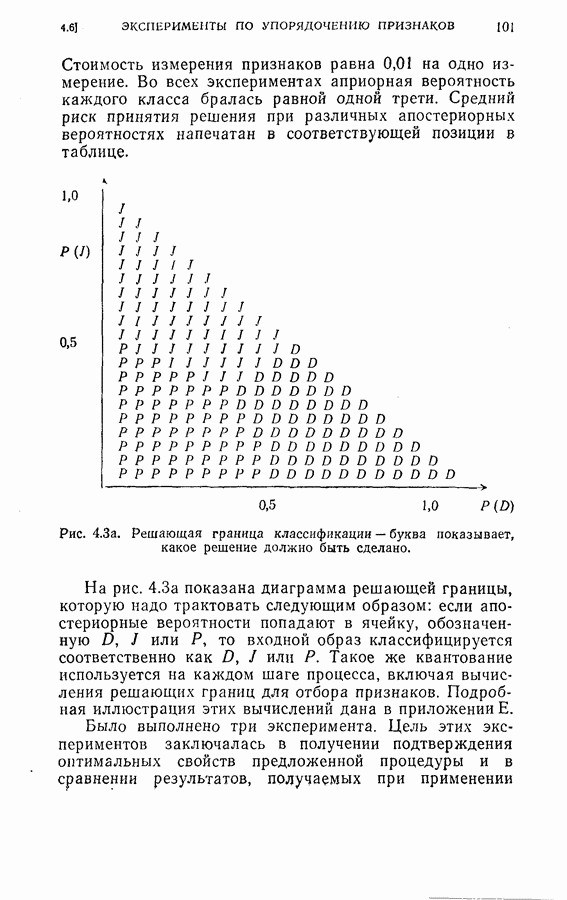
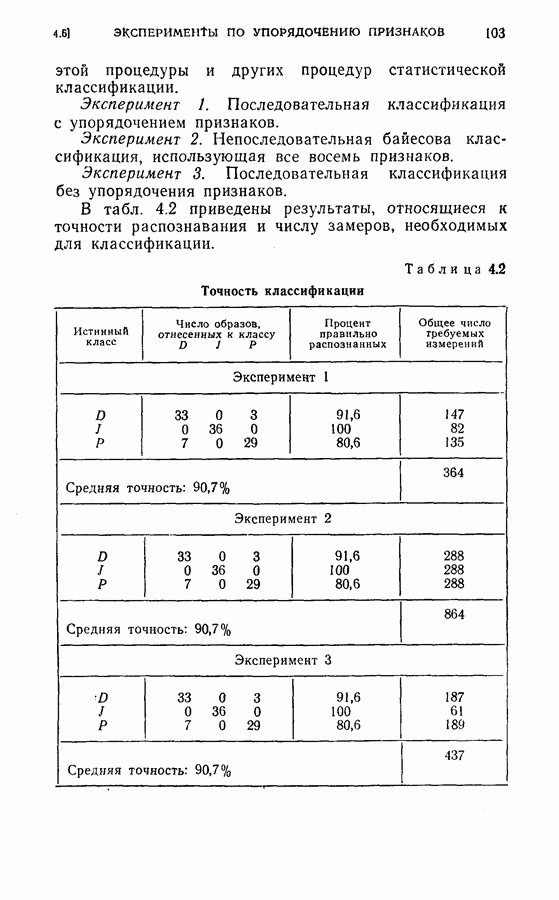
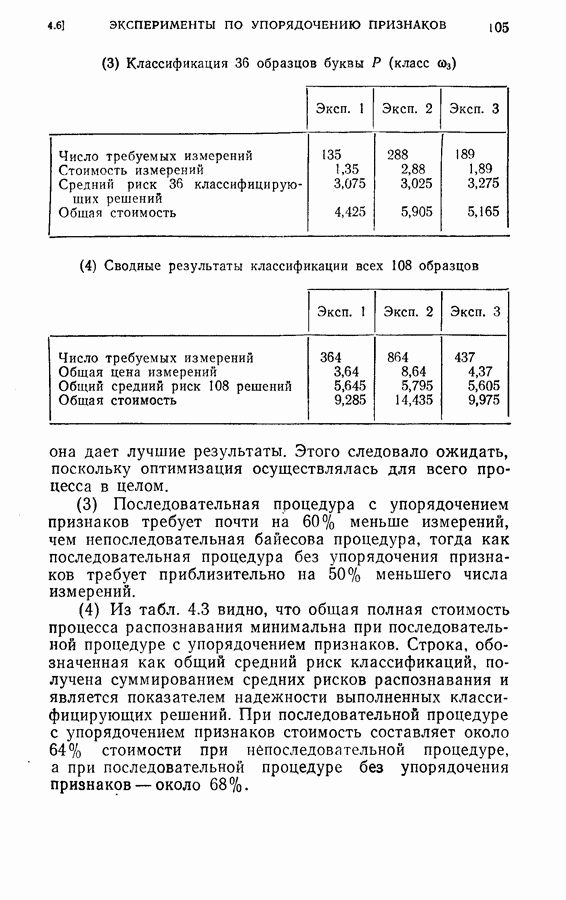
ГЛАВА 4. ОБРАТНАЯ ПРОЦЕДУРА КОНЕЧНОГО ПОСЛЕДОВАТЕЛЬНОГО РАСПОЗНАВАНИЯ С ПОМОЩЬЮ ДИНАМИЧЕСКОГО ПРОГРАММИРОВАНИЯ4.1. ВведениеКак указывалось в § 1.5, распознавание образов во многих задачах можно рассматривать как процесс последовательного решения с конечным числом наблюдений. Описанный в главе 3 модифицированный последовательный критерий отношения вероятностей представляет собой один из подходов к решению этого класса задач. При этом, однако, часто приходится жертвовать оптимальностью основной решающей процедуры, особенно в случае большого числа классов В настоящей главе мы намерены показать, что динамическое программирование [2-8] представляет собой иной подход к модифицированному п. к. о. в. Он дает один из возможных способов вычислений для некоторого класса систем последовательного распознавания с решающими правилами, обеспечивающими конечную длительность процедуры. Соображения, относящиеся к применению динамического программирования к задачам конечного последовательного распознавания, можно сформулировать следующим образом. Рассмотрим последовательный решающий процесс. При поочередно выполняемых наблюдениях каждый шаг этого процесса является некоторой задачей средний риск, связанный с выполнением дополнительного наблюдения. Для случая выполнения одного дополнительного наблюдения средний риск относится к выполнению следующего шага и лучшего из возможных продолжений. Соответственно, чтобы определить лучшее решение на данном шаге (т. е. продолжать ли процесс или не продолжать), необходимо знать лучшее решение в будущем. Другими словами, поскольку речь идет о поиске оптимальной решающей процедуры, порядок действия в натуральном времени от настоящего к будущему оказывается малоэффективным, так как оптимум в данный момент по существу включает в себя будущий оптимум. Единственная альтернатива, при которой сохраняется истинная оптимальность, заключается в том, чтобы действовать обратно во времени, т. е. по оптимальному будущему поведению определять оптимальное поведение в настоящем, и далее продолжать двигаться назад в прошлое. При решении, продолжать ли процесс или прекратить его, должна быть учтена вся имеющаяся информация о будущем. Именно такую процедуру оптимизации, действующую обратно от предварительно определенного последнего шага к самому первому, представляет собой метод динамического программирования. В задачах последовательного распознавания, в которых решающая процедура должна закончиться за конечное число наблюдений, для обратной процедуры точка окончания (т. е. последний шаг) используется в качестве начальной точки.
|
 |
Оглавление
|









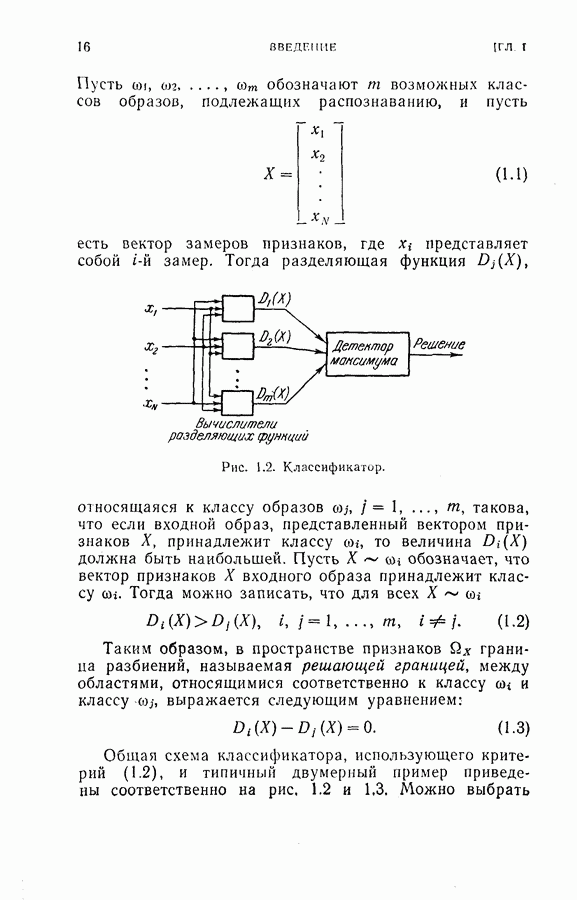
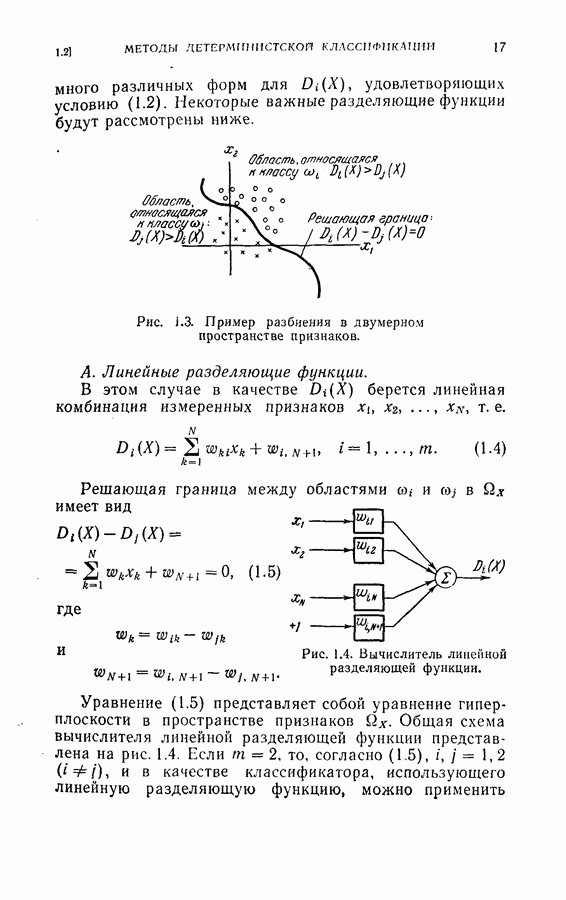








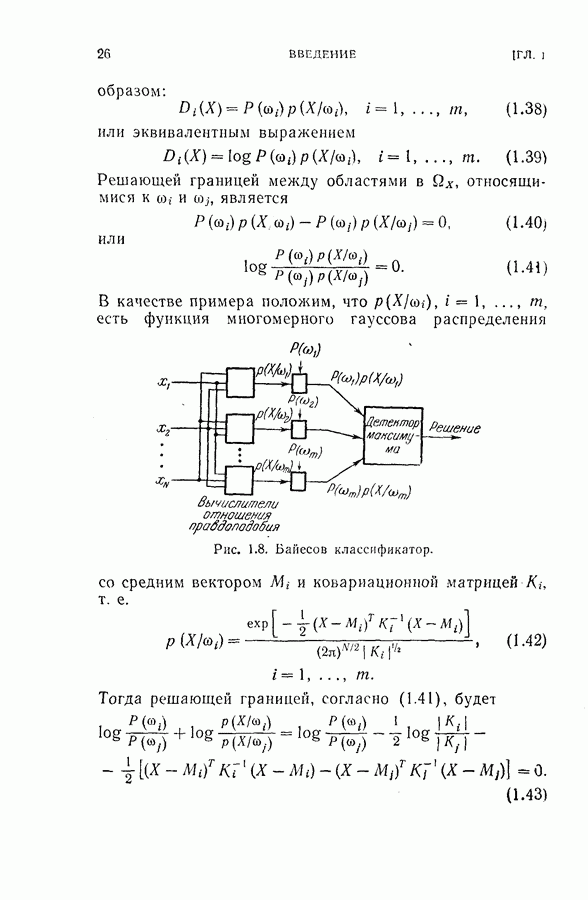






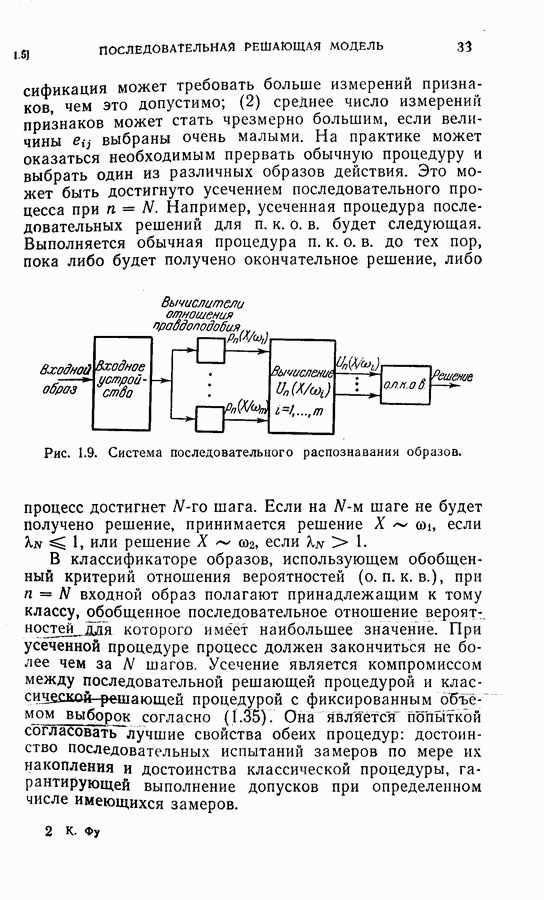



















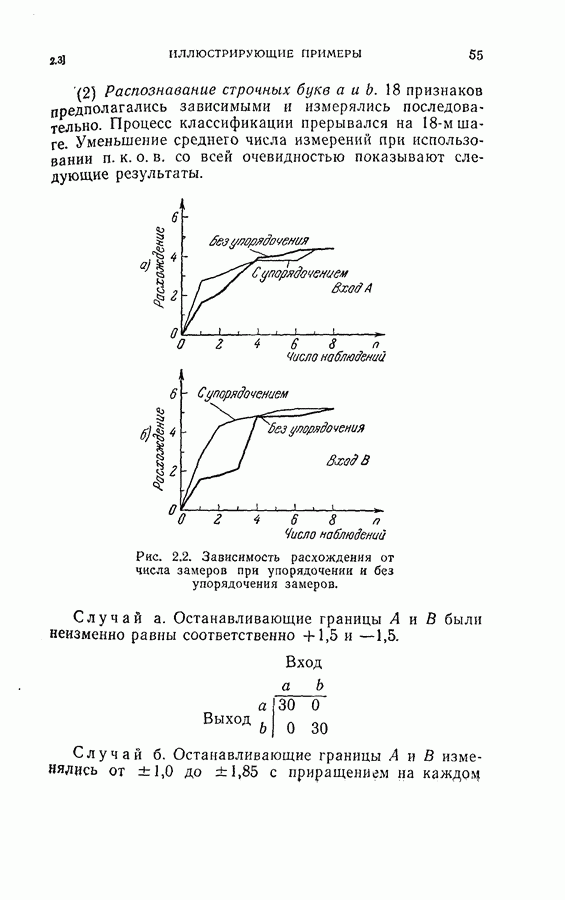


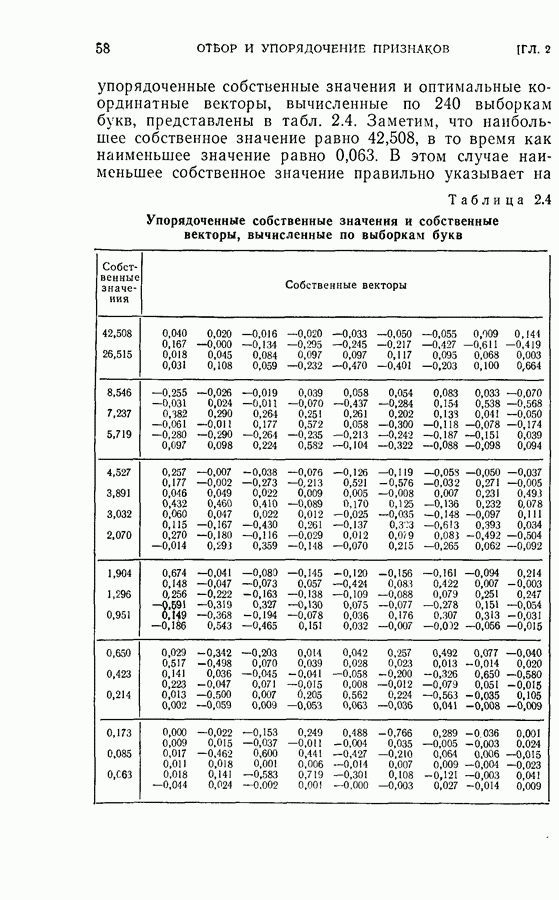
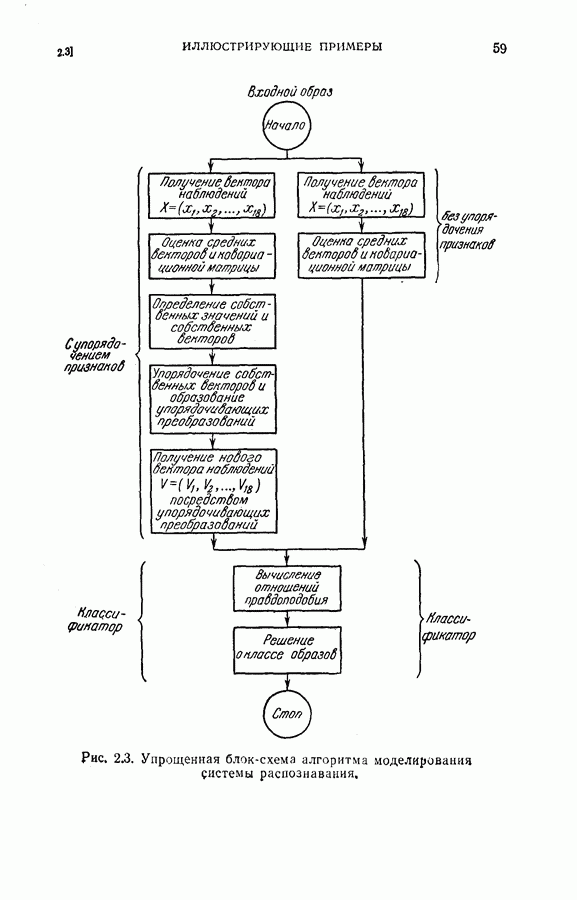



























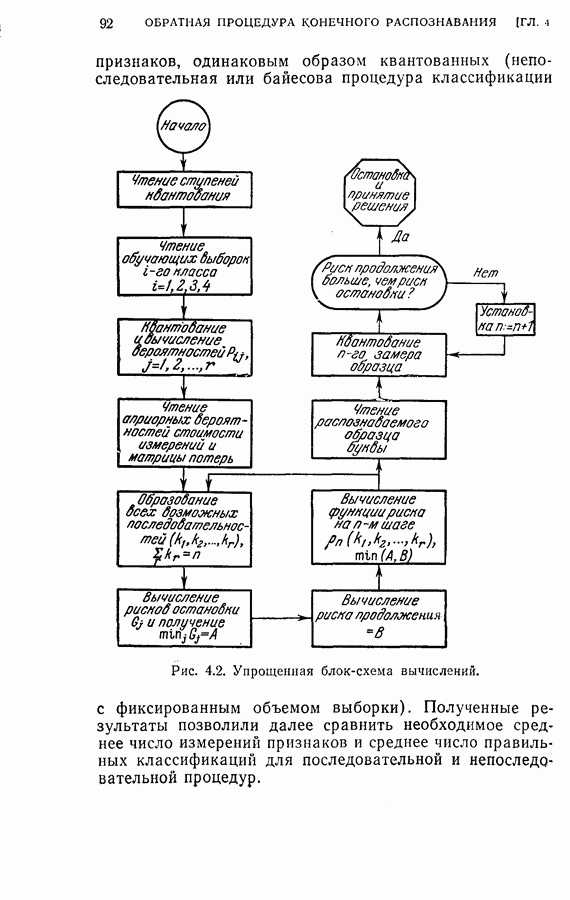








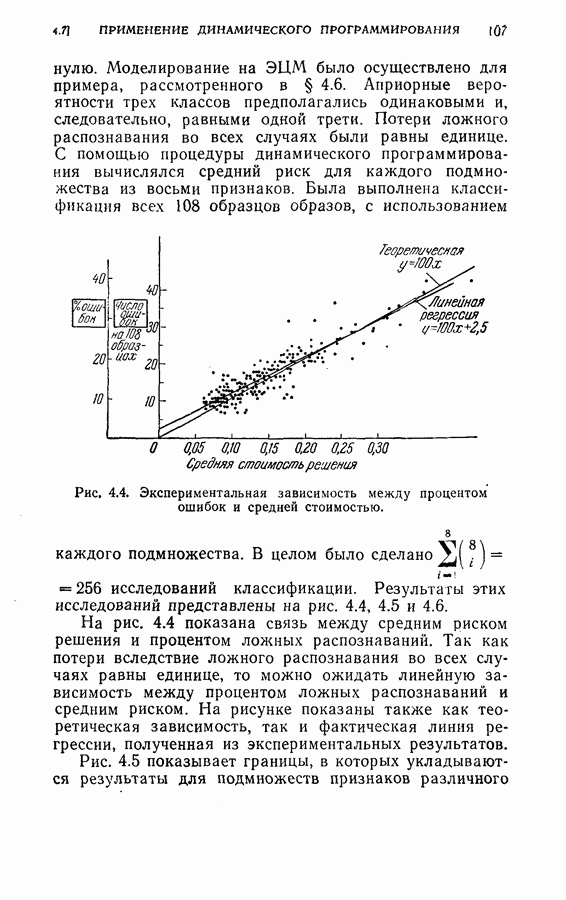
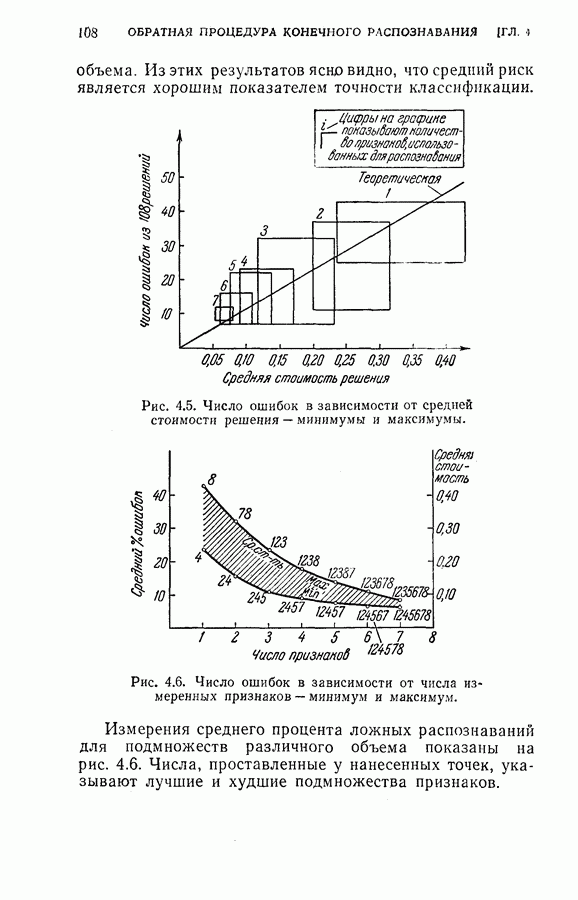



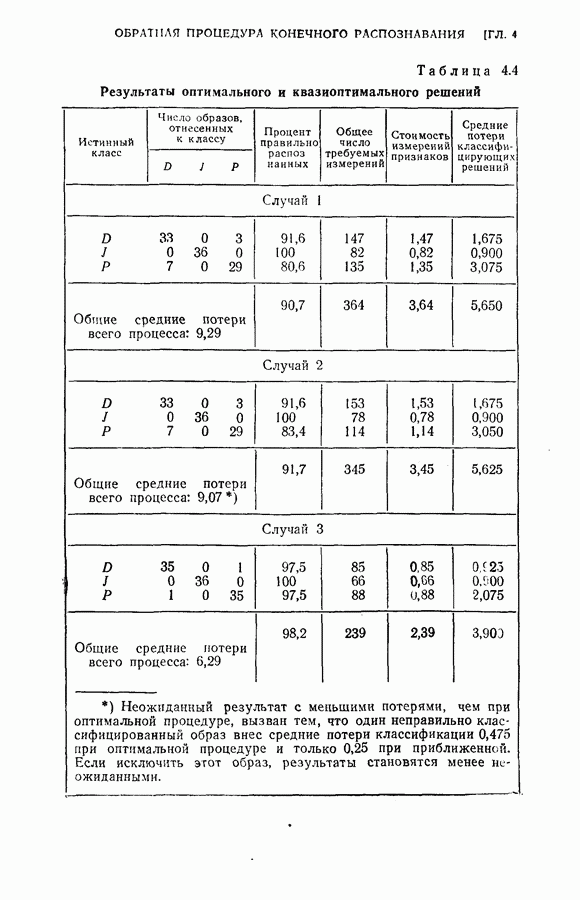













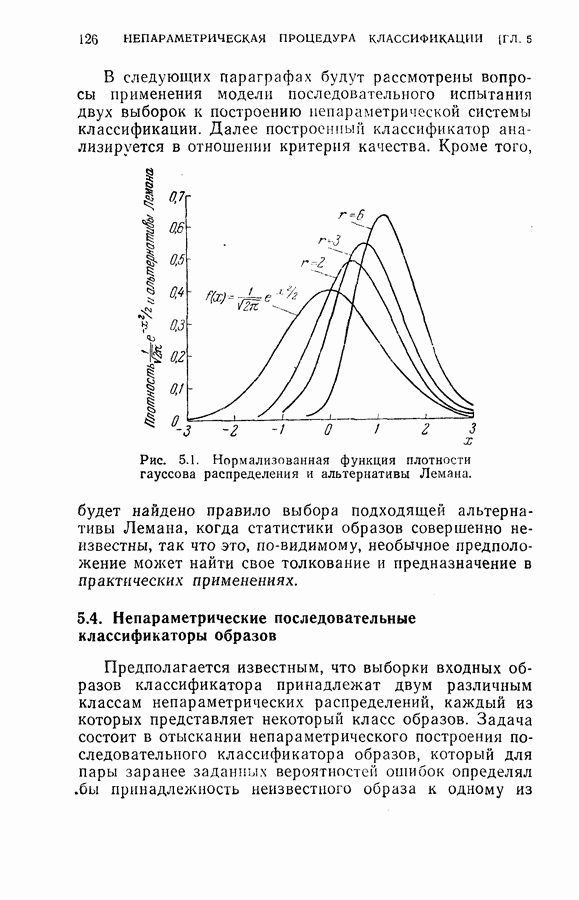


































































































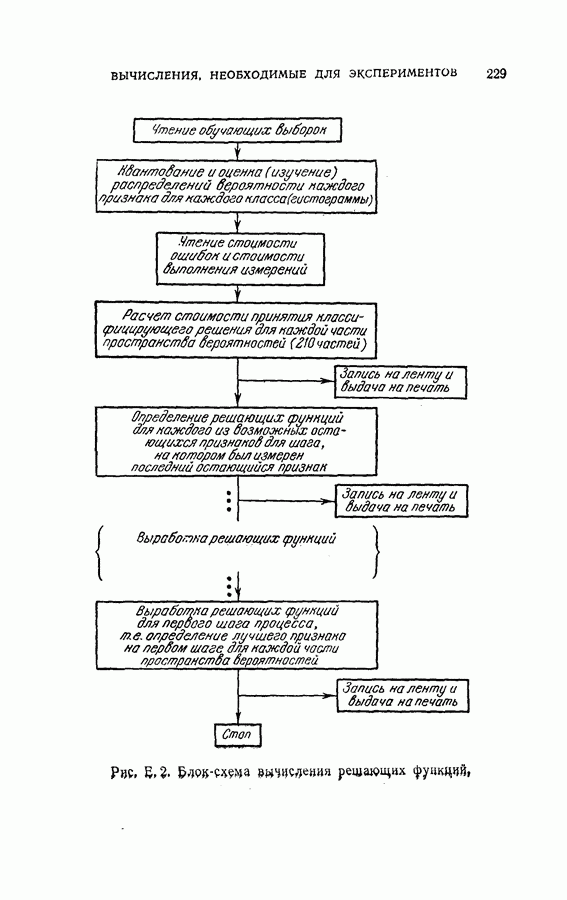
























 Оптимальная байесова процедура последовательных решений, которая минимизирует средний риск с учетом стоимости наблюдений, по существу является обратной процедурой [1].
Оптимальная байесова процедура последовательных решений, которая минимизирует средний риск с учетом стоимости наблюдений, по существу является обратной процедурой [1].
 решения, которое сводится к выбору либо завершения последовательности наблюдений и принятия окончательного решения, либо проведения дополнительного наблюдения. Легко определить средний риск, связанный с решением об окончании процедуры, однако не легко найти
решения, которое сводится к выбору либо завершения последовательности наблюдений и принятия окончательного решения, либо проведения дополнительного наблюдения. Легко определить средний риск, связанный с решением об окончании процедуры, однако не легко найти