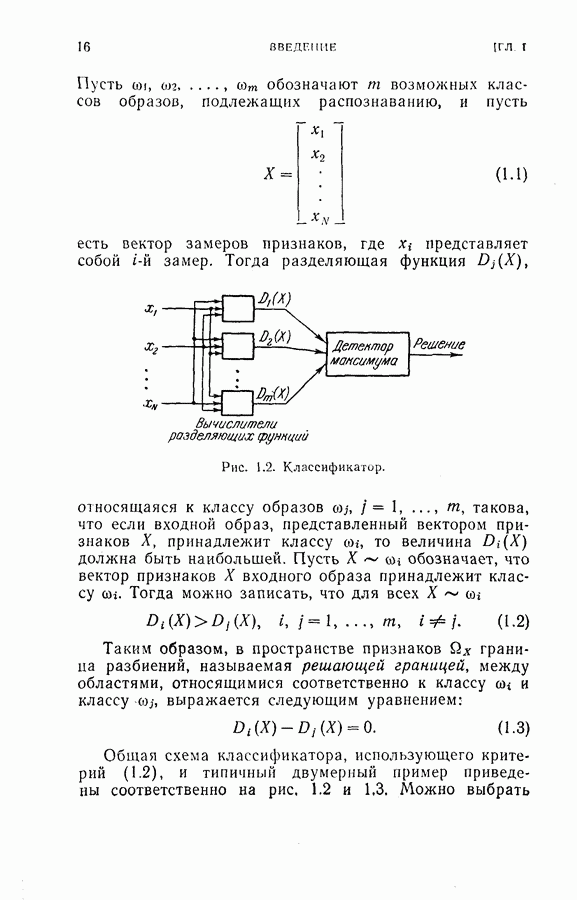
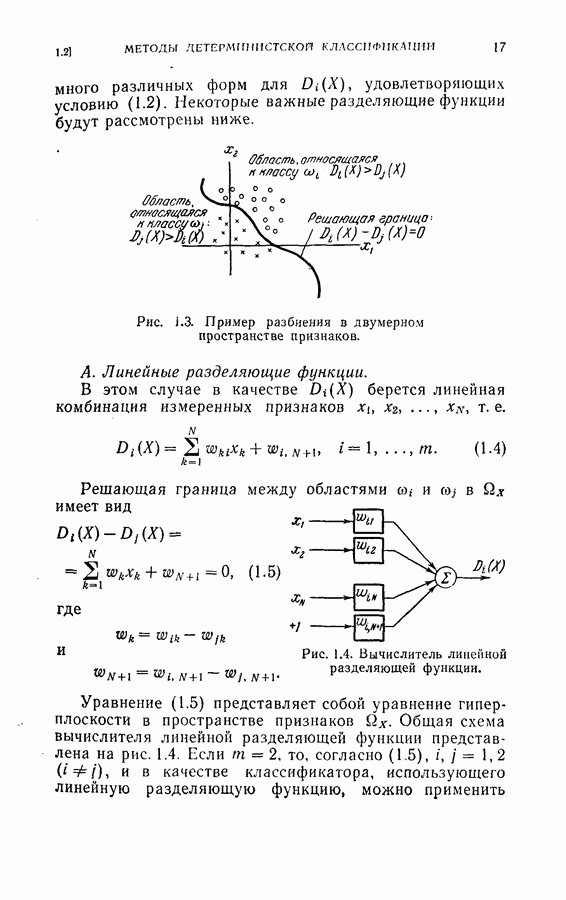
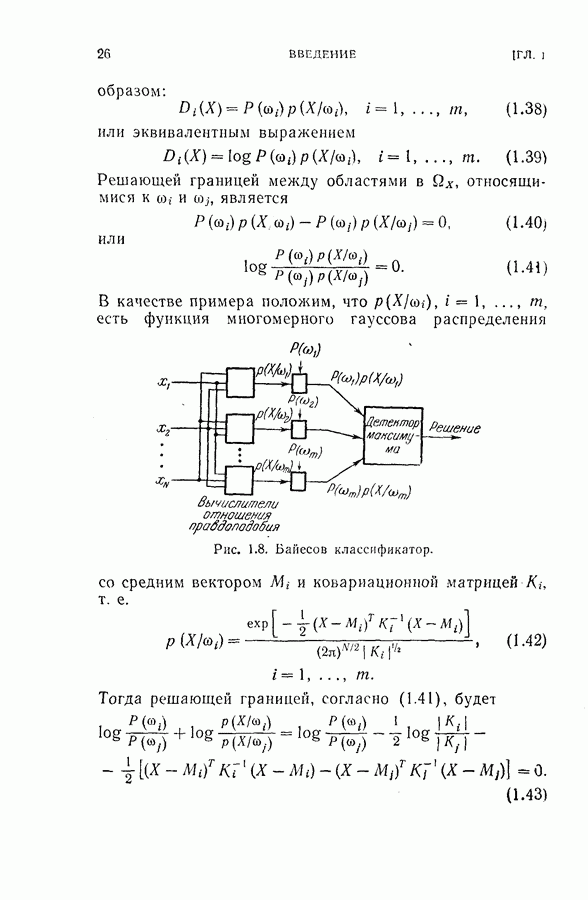
5.6. Экспериментальные результаты и обсуждение
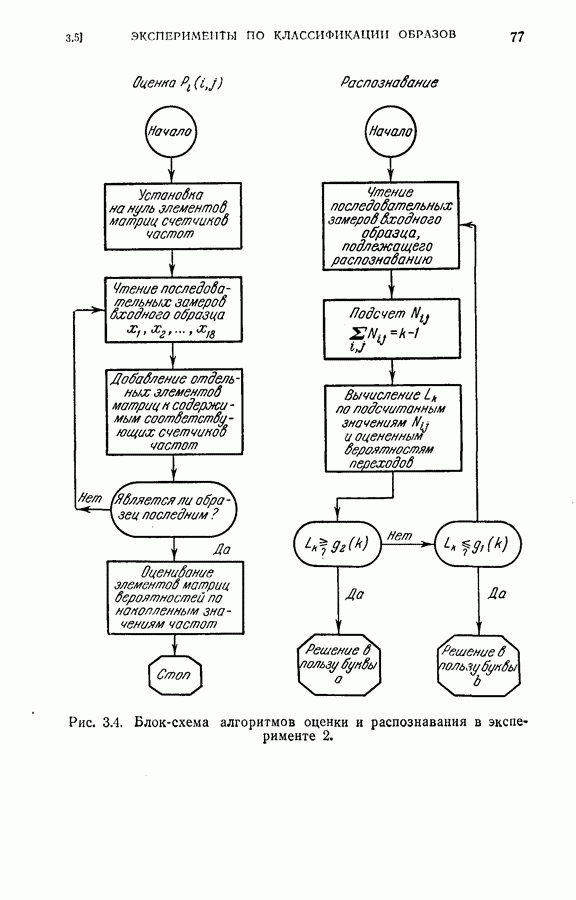
С целью проверки эффективности процедуры последовательного определения рангов для построения непараметрического последовательного классификатора был выполнен эксперимент путем моделирования на ЭЦМ. Эксперимент состоял в классификации рукописных букв  как описывалось в § 2.3, за исключением того, что распределения вероятностей для образов каждого класса предполагались непараметрическими и неизвестными. Обучающая выборка для буквы а
как описывалось в § 2.3, за исключением того, что распределения вероятностей для образов каждого класса предполагались непараметрическими и неизвестными. Обучающая выборка для буквы а


(кликните для просмотра скана)
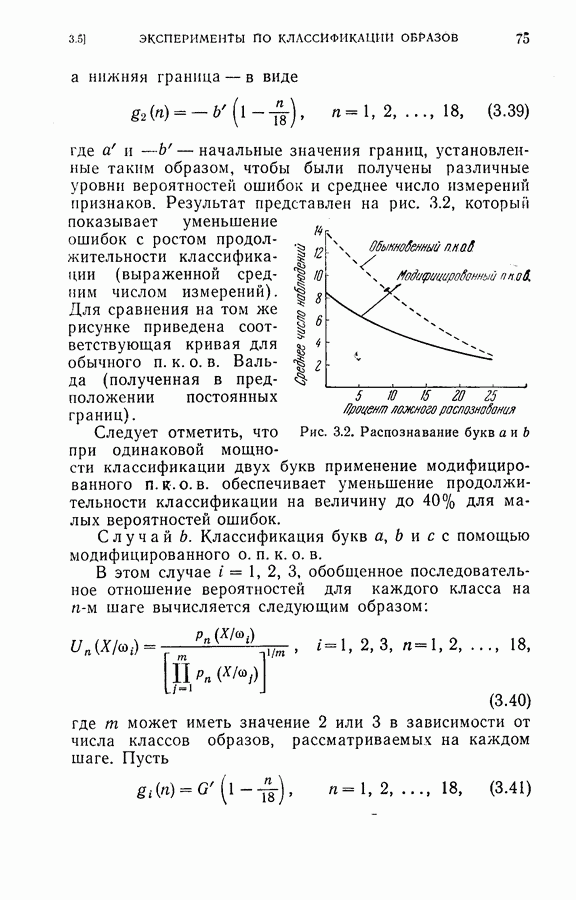
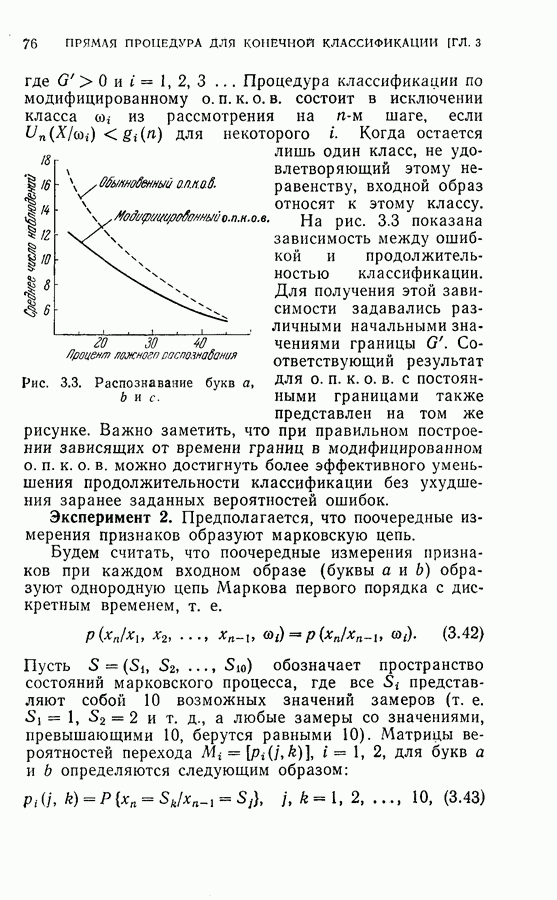
показывают, что вероятности ошибок при классификации образов букв могут быть сделаны довольно малыми при надлежащем выборе альтернатив Лемана и достаточном числе измерений.























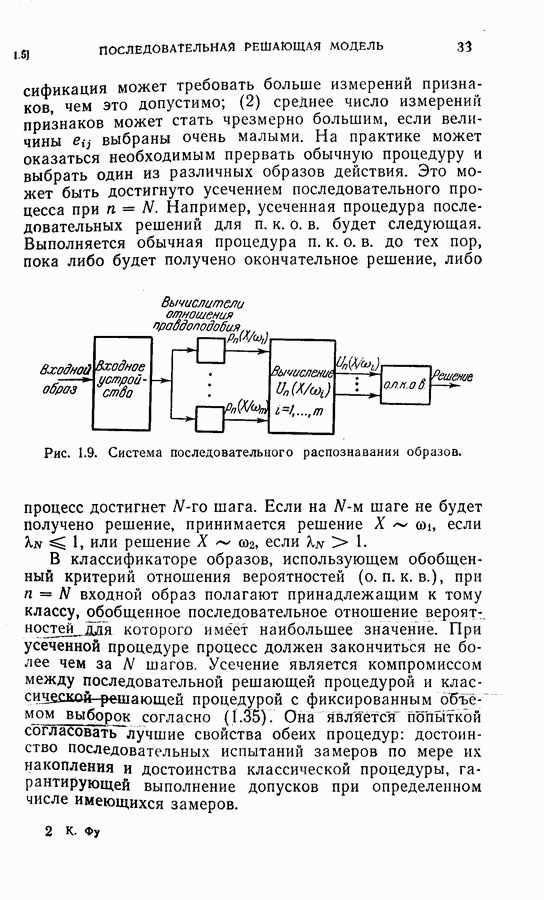


















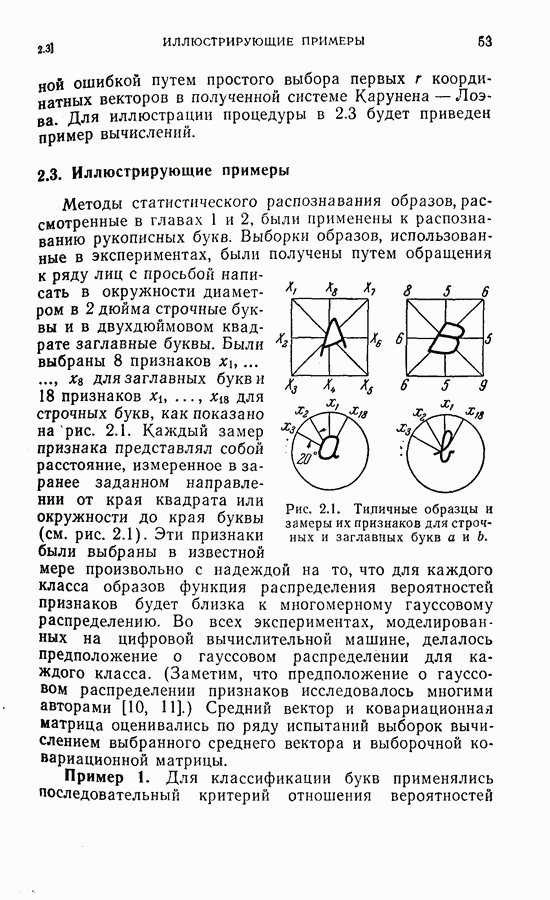

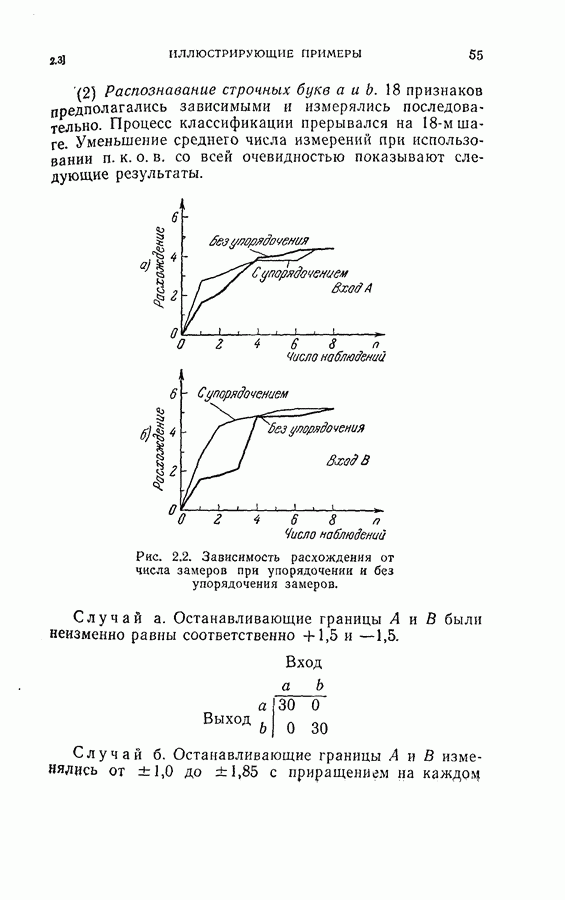


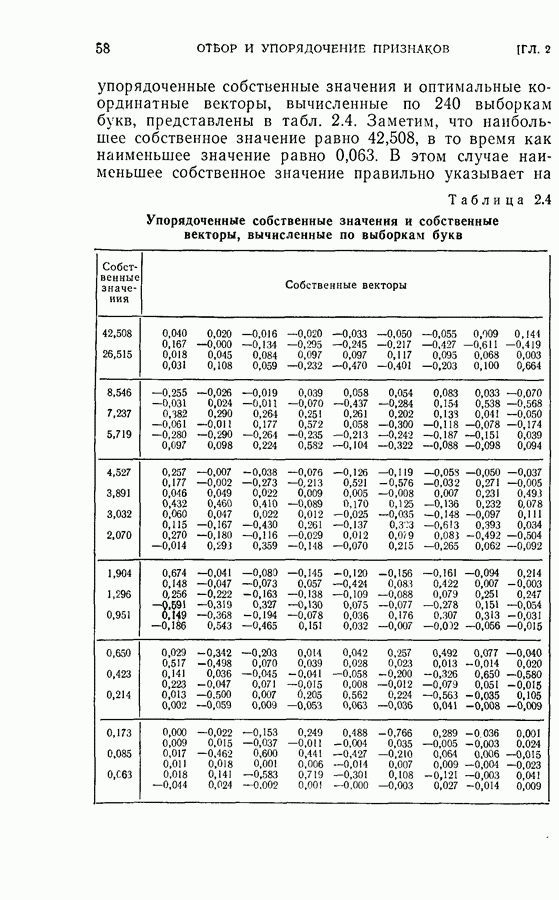
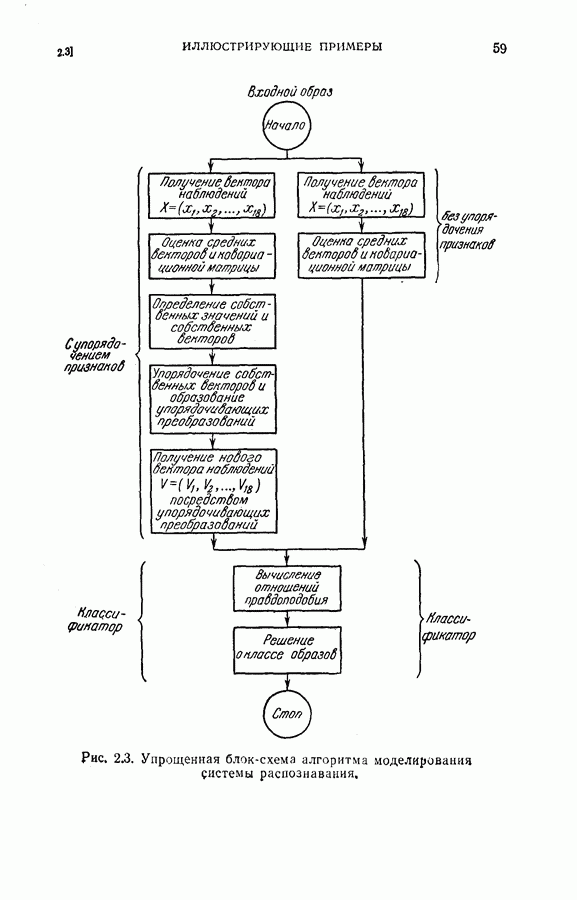
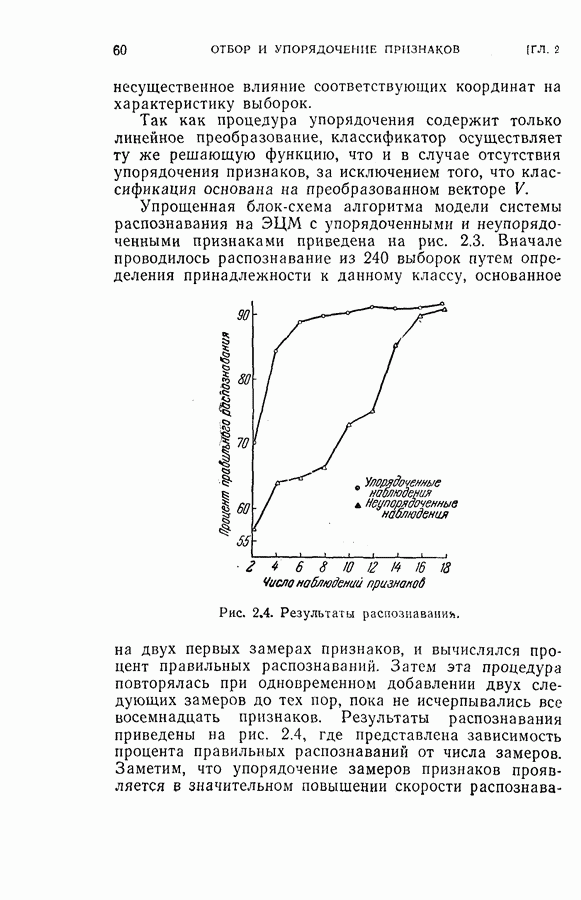




























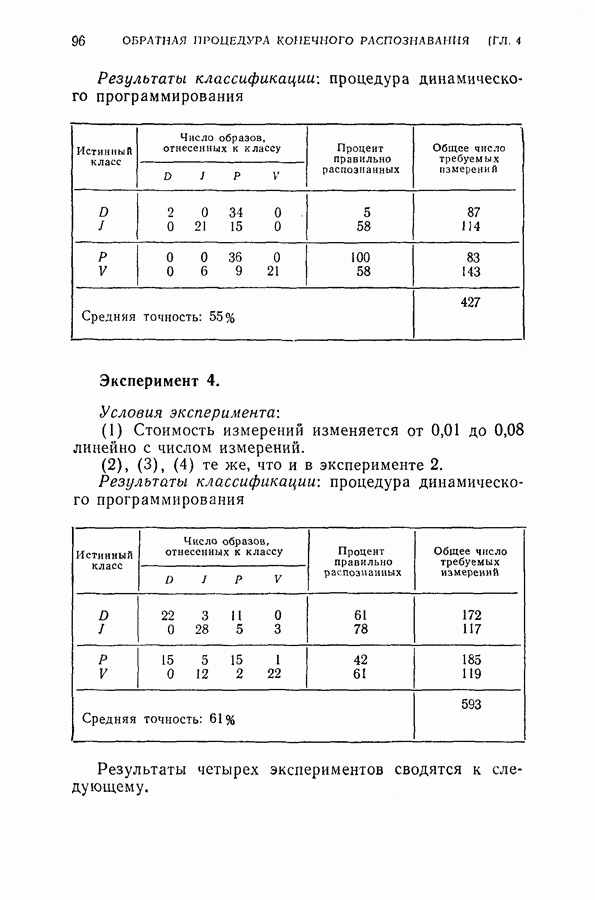




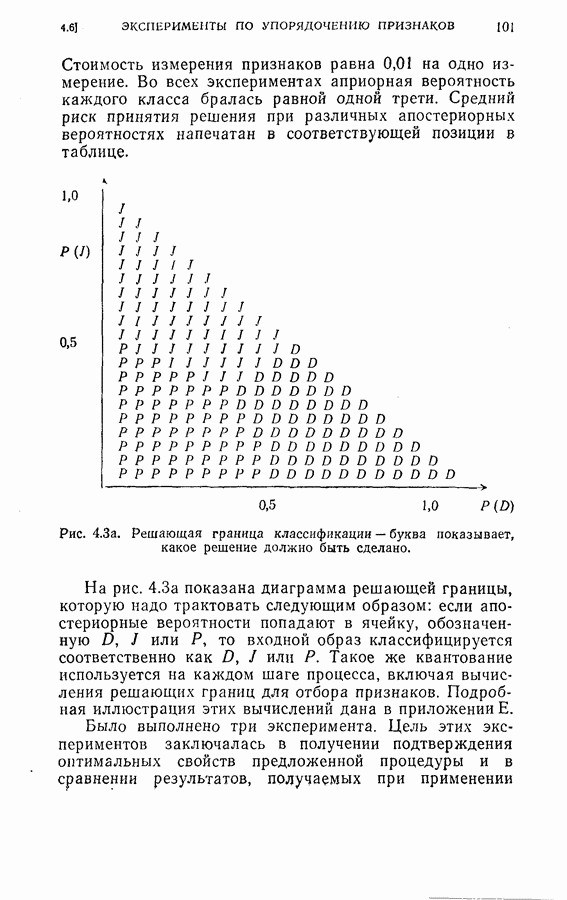

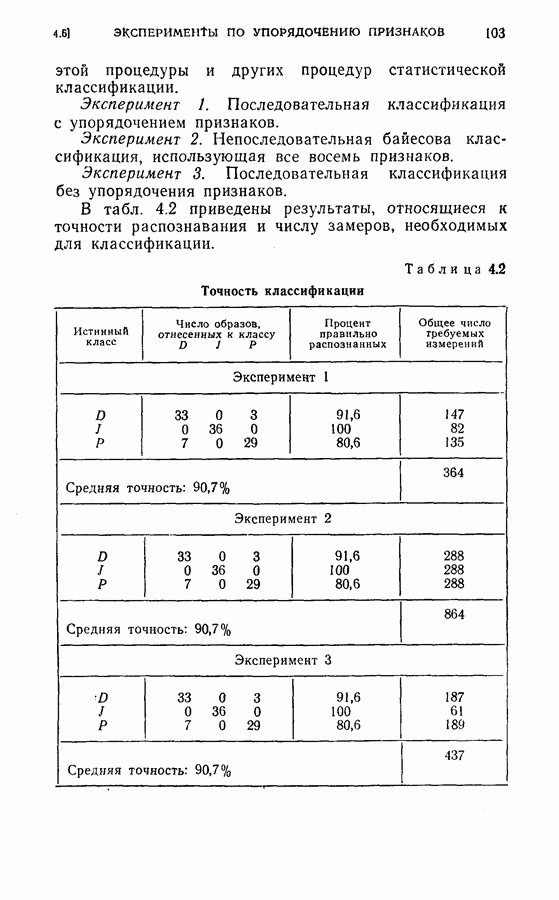

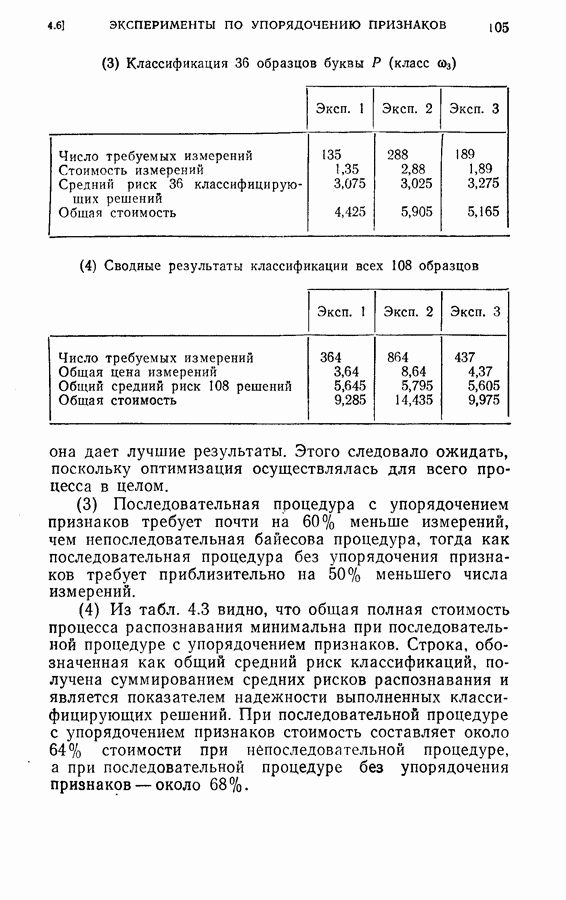

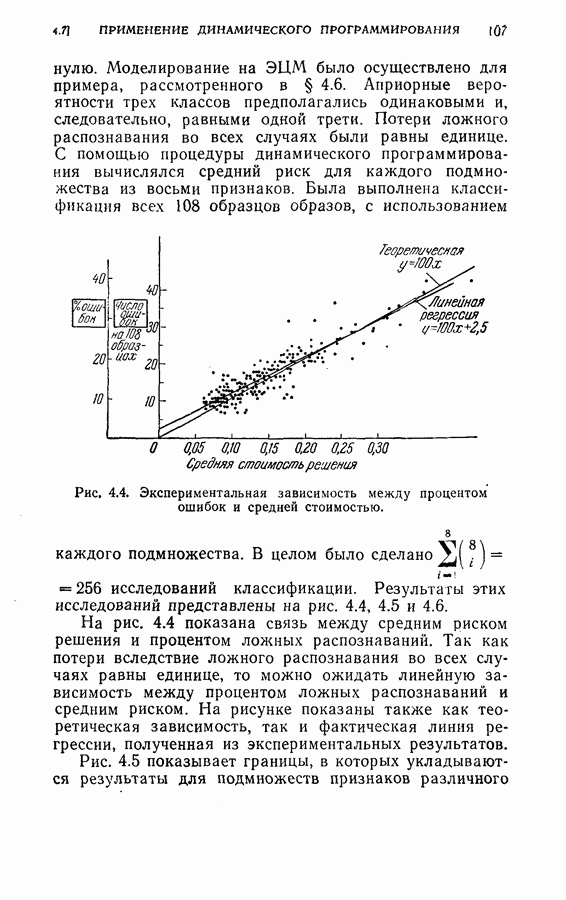
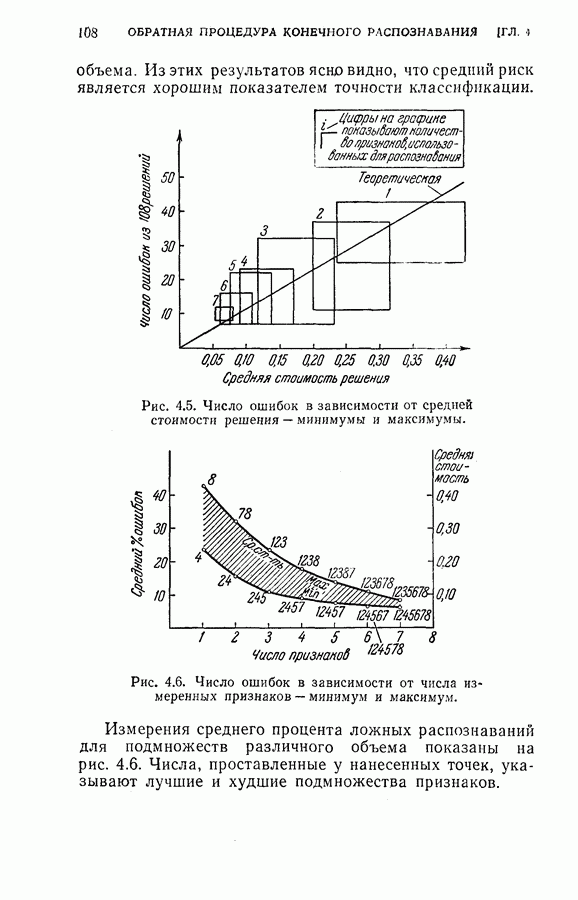



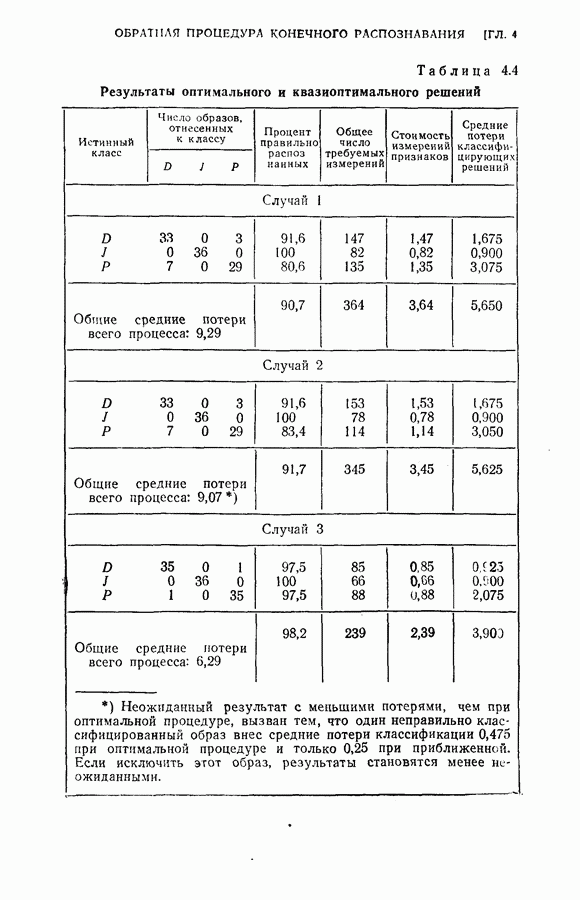


















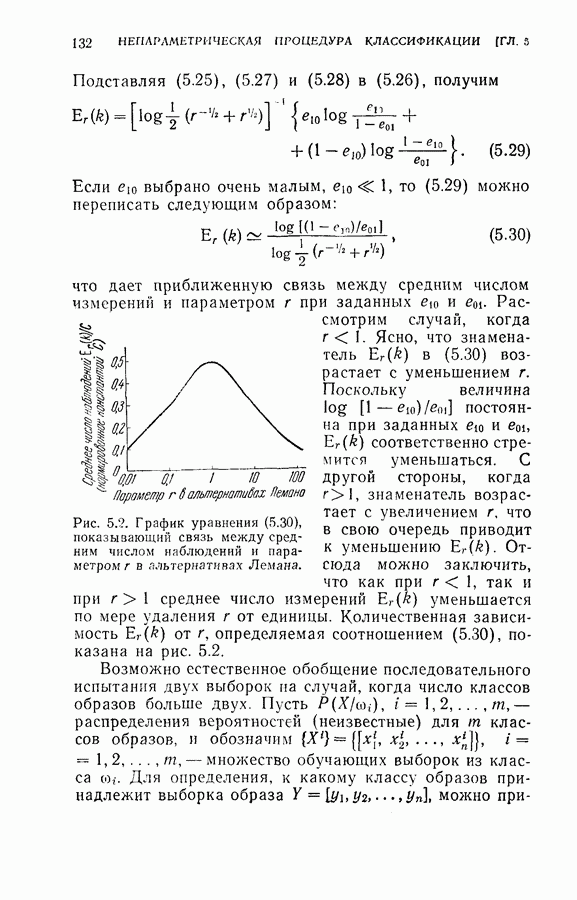


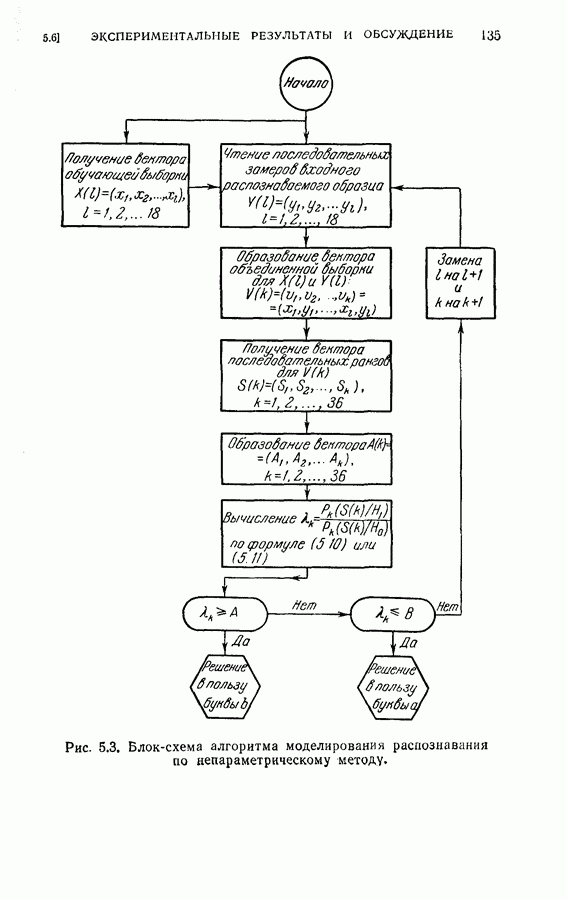
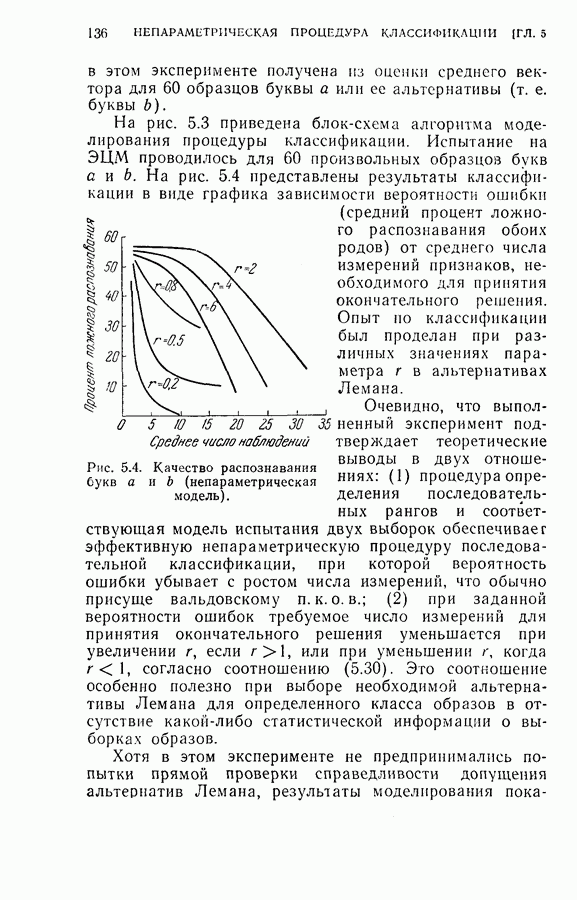




















































































































 На рис. 5.4 представлены результаты классификации в виде графика зависимости вероятности ошибки (средний процент ложного распознавания обоих родов) от среднего числа измерений признаков, необходимого для принятия окончательного решения. Опыт по классификации был проделан при различных значениях параметра
На рис. 5.4 представлены результаты классификации в виде графика зависимости вероятности ошибки (средний процент ложного распознавания обоих родов) от среднего числа измерений признаков, необходимого для принятия окончательного решения. Опыт по классификации был проделан при различных значениях параметра  в альтернативах Лемана.
в альтернативах Лемана.

 (непараметрическая модель).
(непараметрическая модель).
 если
если  или при уменьшении
или при уменьшении  когда
когда  согласно соотношению (5.30). Это соотношение особенно полезно при выборе необходимой альтернативы Лемана для определенного класса образов в отсутствие какой-либо статистической информации о выборках образов.
согласно соотношению (5.30). Это соотношение особенно полезно при выборе необходимой альтернативы Лемана для определенного класса образов в отсутствие какой-либо статистической информации о выборках образов.
