Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
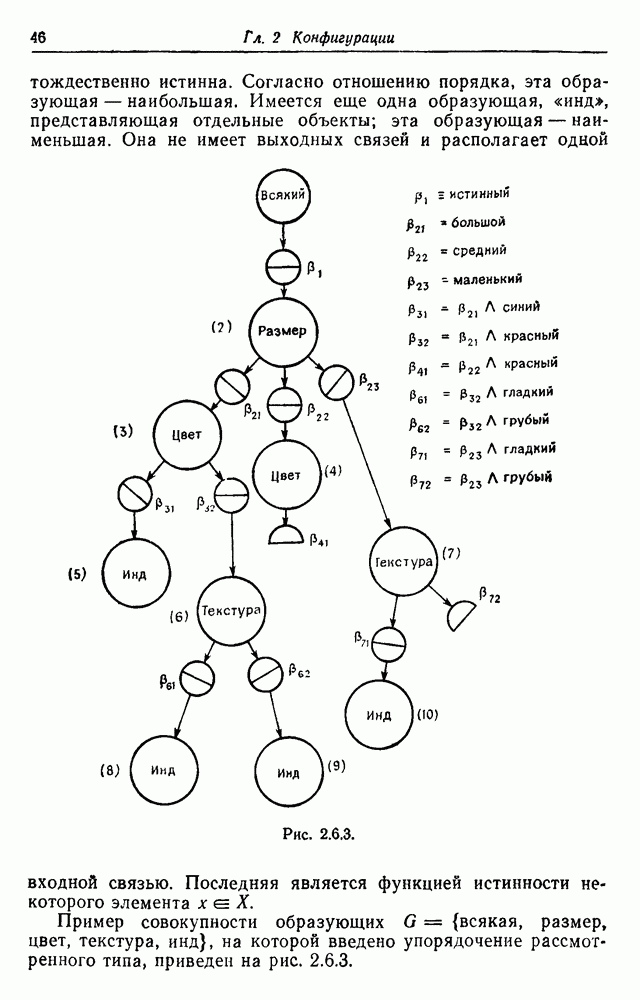
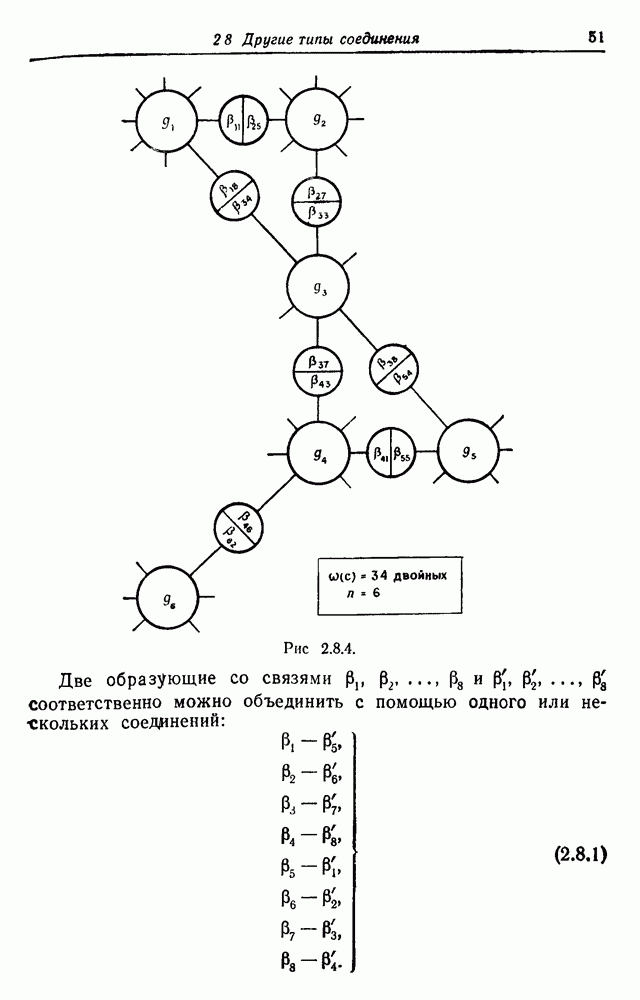
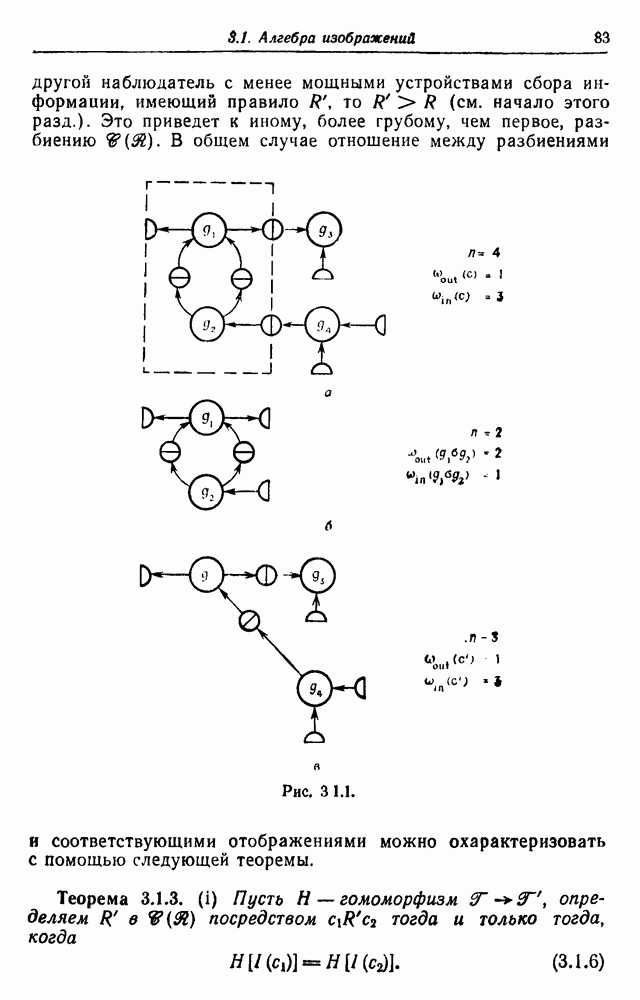
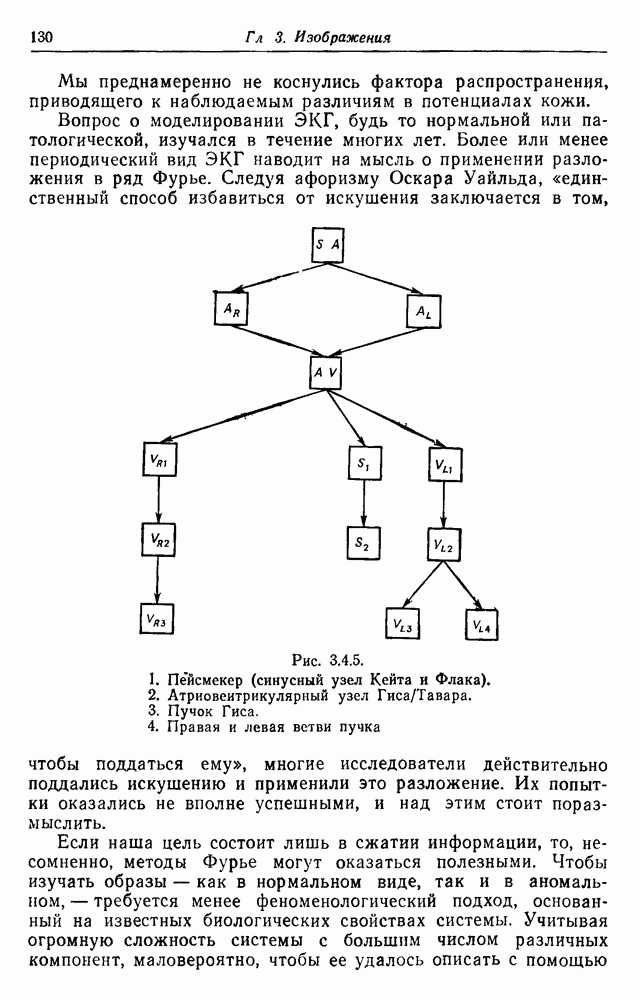
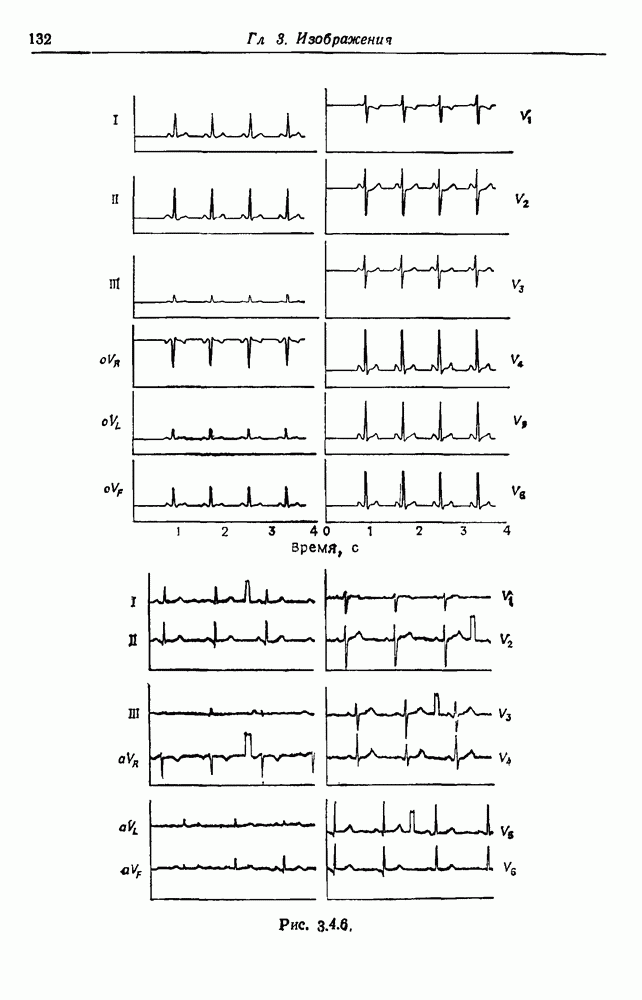
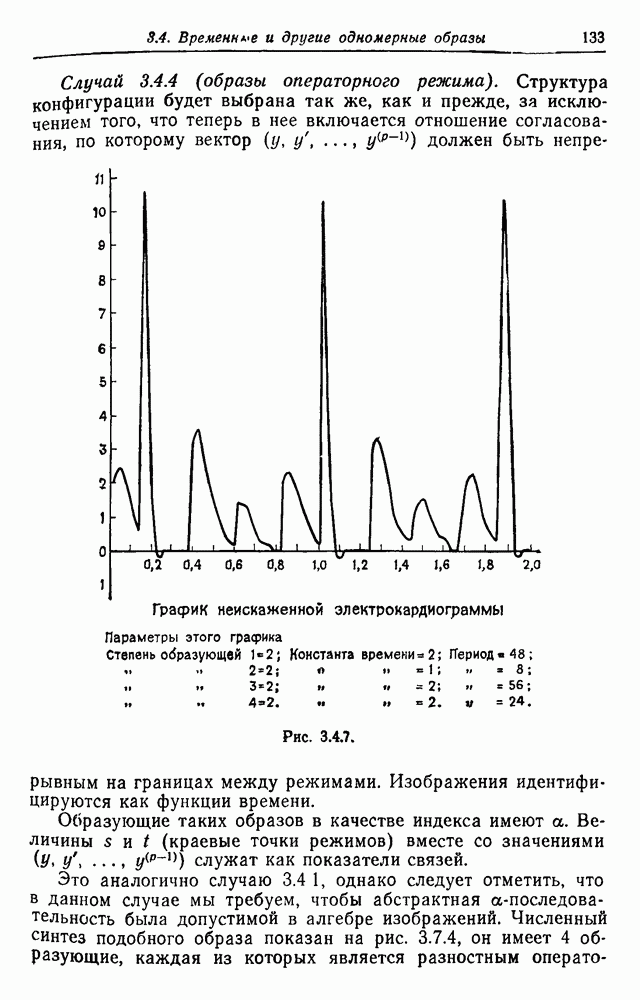
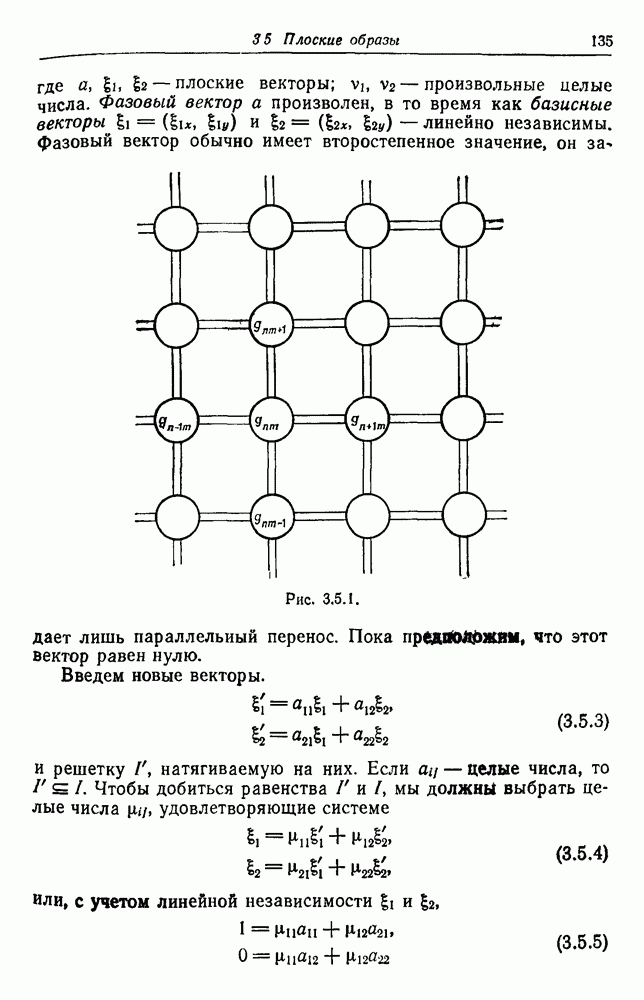
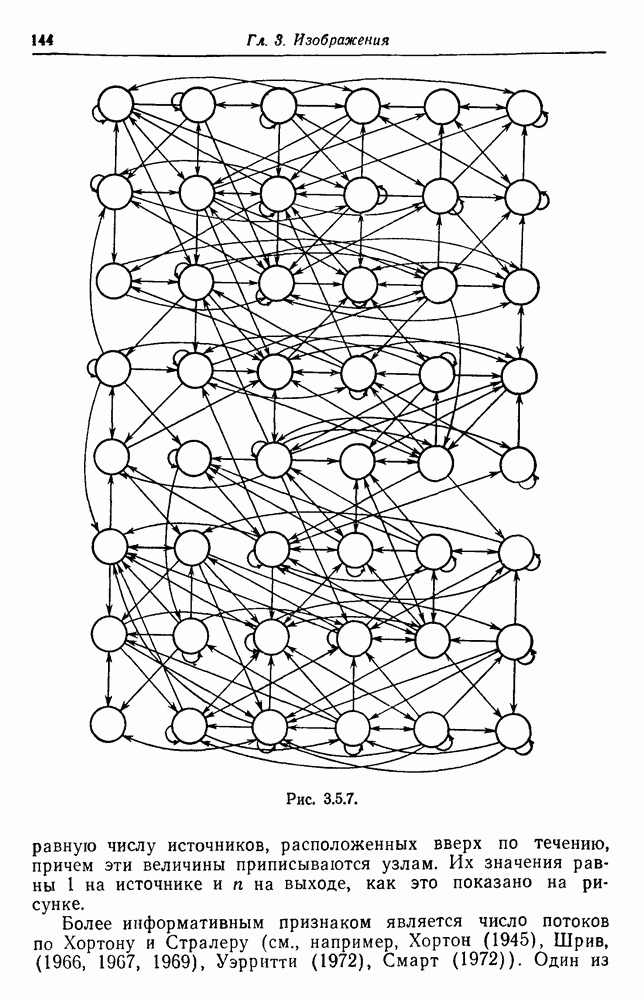
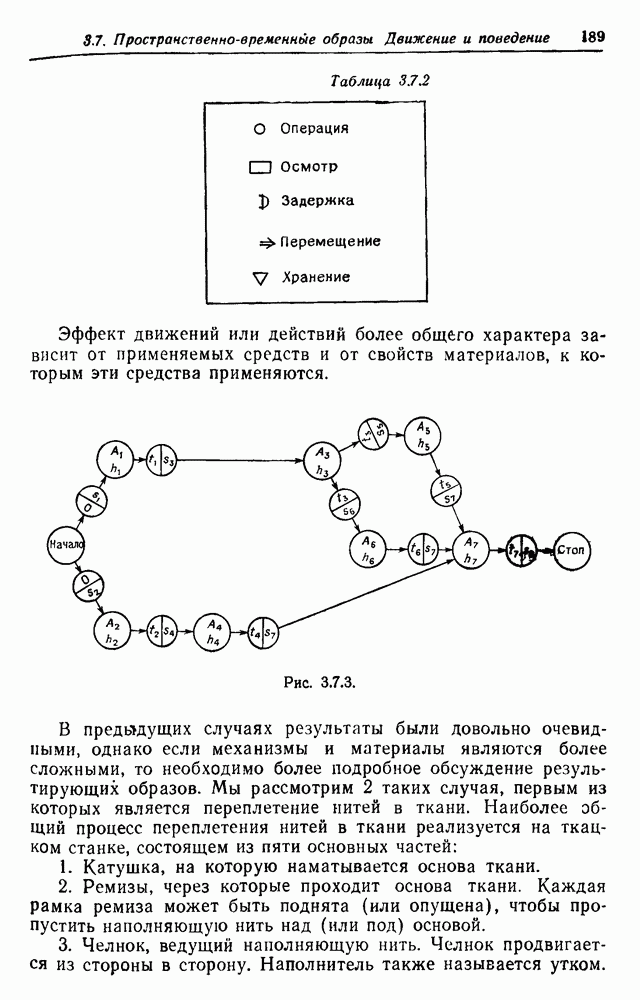
3.2. Изображения в виде абстрактной последовательностиВ этом разделе рассмотрим конфигурации, состоящие из абстрактных образующих, принадлежащих конечному множеству
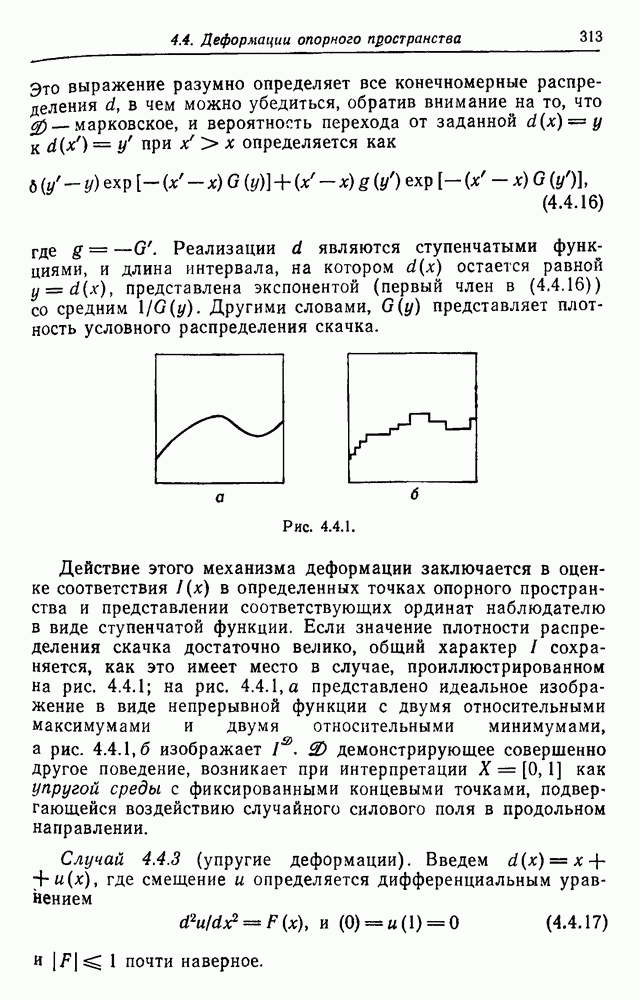
Рис. 3.2.1. Начнем со случая, когда образующими являются буквы английского алфавита, включая промежутки, а конфигурации образуются при помощи 2 — «линейный». Когда на Будем идентифицировать регулярные конфигурации по их внешним связям и цепочкам терминальных символов. Заметим, что изображение не является только терминальной цепочкой, оно также имеет внешние связи, хотя последние не всегда явно указываются. В известном эксперименте, проведенном Шенноном (1949), выдавались цепочки вида
Эта цепочка имеет мало общего с естественным английским языком. Если образующие имеют на рис. 3.2.1 вид (а), указывая переходы от одной буквы к другой при Другие цепочки, полученные в шенноновском эксперименте, имеющие вид
чуть больше напоминают английские фразы. Можно показать, что выбор образующих в виде (в) на рис. 3.2.1 и типа соединения, как в (г), индуцирует вероятностную меру марковской цепи Р порядка
Теперь эти «слова» больше похожи на английские слова. Предпочитая выбирать образующие в виде слов, а не букв, Шеннон для простого случайного источника получил
и аналогично для марковской цепи первого порядка —
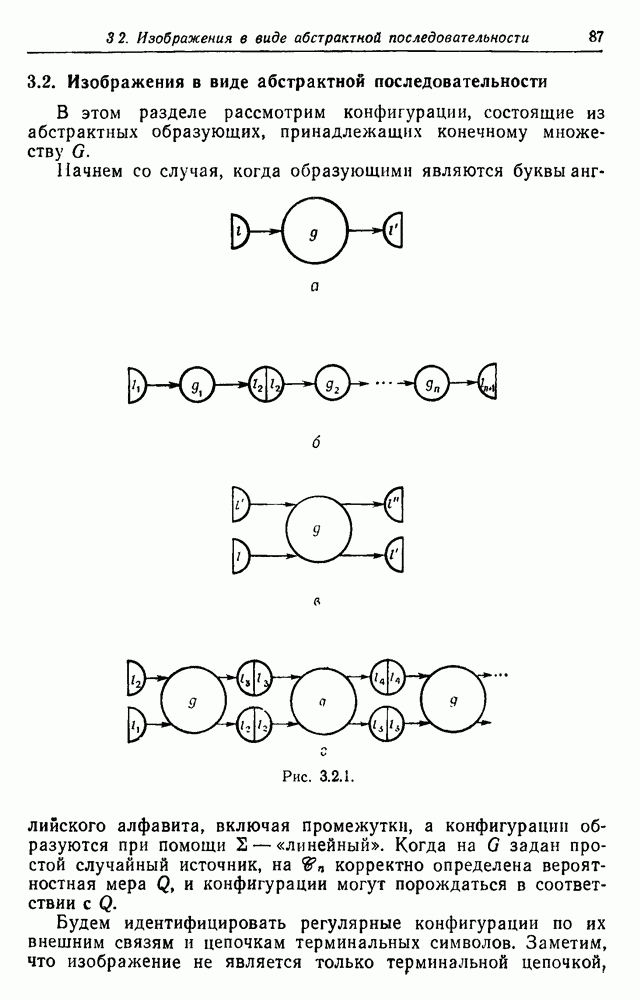
Последняя цепочка даже имеет подцепочки, которые кажутся осмысленными. Таким образом, увеличивая порядок, мы можем ожидать, что случайным источником будут порождаться все более и более реалистичные цепочки. Ценой большего реализма является сложность модели. Если
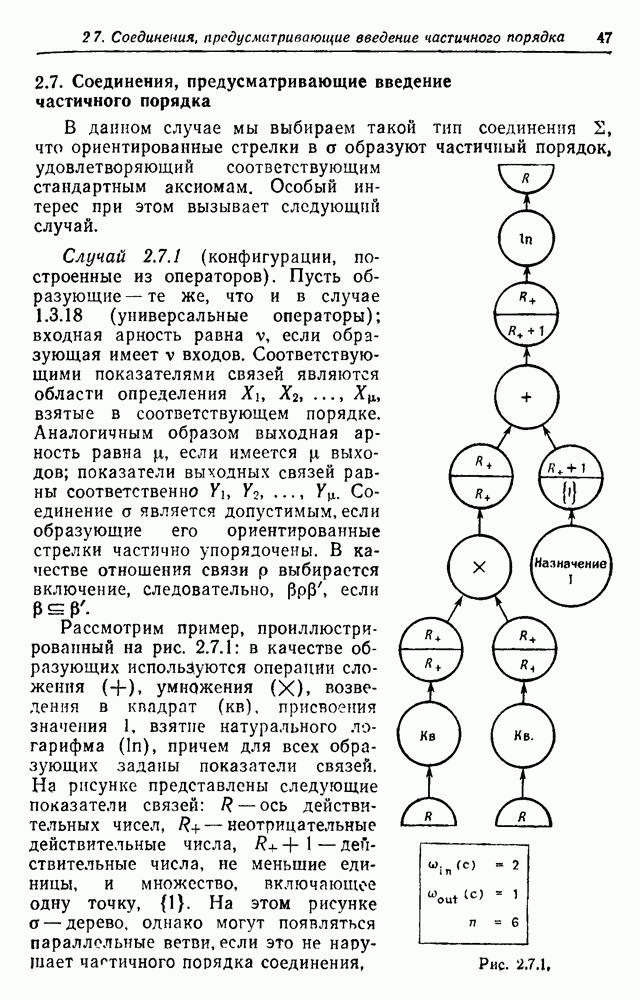
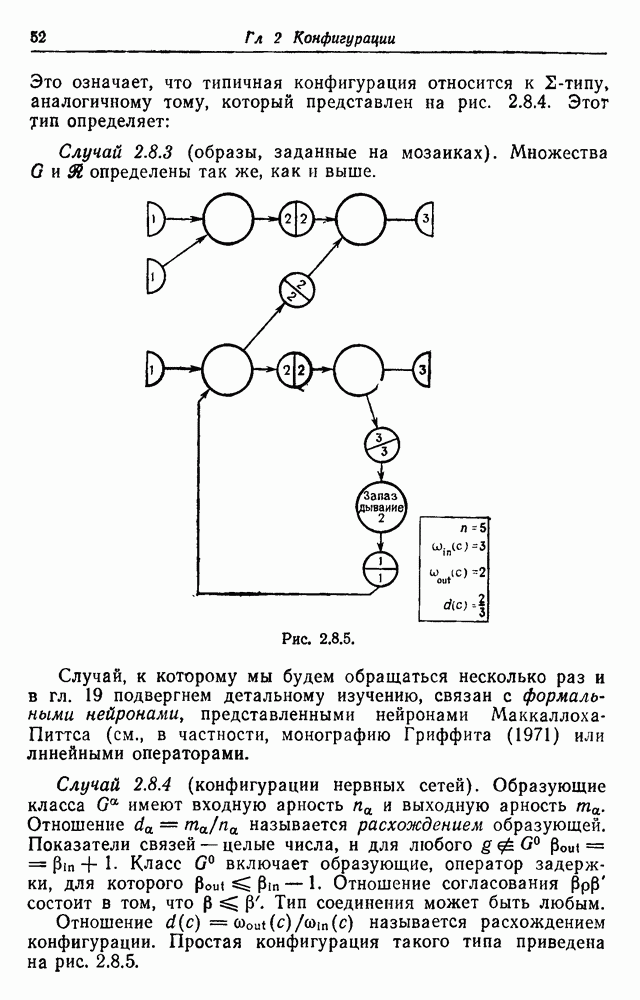
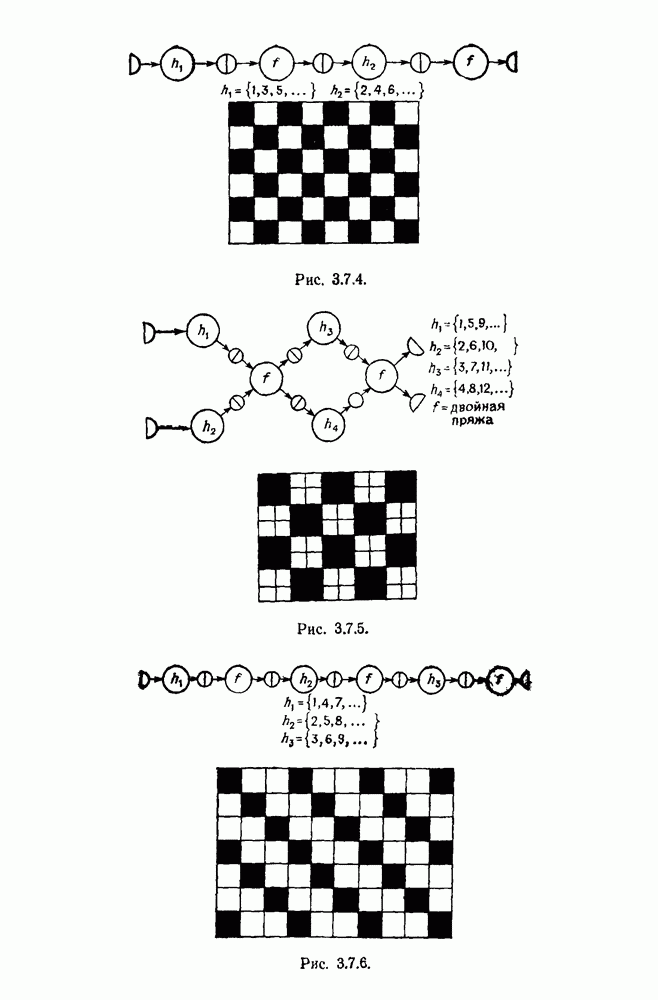
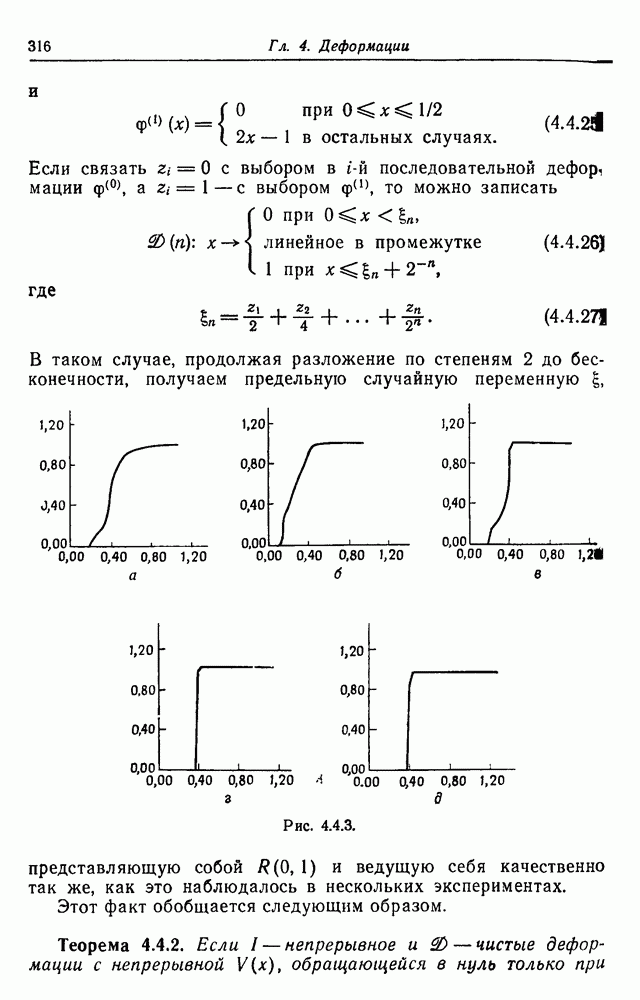
Рис. 3.2.2. Эти вероятности должны удовлетворять Одна возможная альтернатива — синтаксически управляемые вероятности — была обсуждена в разд. 2.10. Чтобы проиллюстрировать это, рассмотрим конечный автомат с шестью состояниями, с начальным состоянием 1 и заключительным состоянием 6. Диаграмма перехода автомата приведена на рис. 3.2.2. Соответствующие правила для правосторонней линейной грамматики имеют пять синтаксических переменных а Таблица 9.2.1 (см. скан) Таблица 3.2.2 (см. скан) Для простоты предположим, что Моделирование автомата с псевдослучайным генератором чисел дает цепочки, приведенные в табл. 3.2.2, где они следуют в порядке формирования. Оставляя этот пример, перейдем к конечно-автоматному языку общего вида, для которого конфигурации можно представить в виде Это означает, что лишь первое и последнее состояния конфигурации
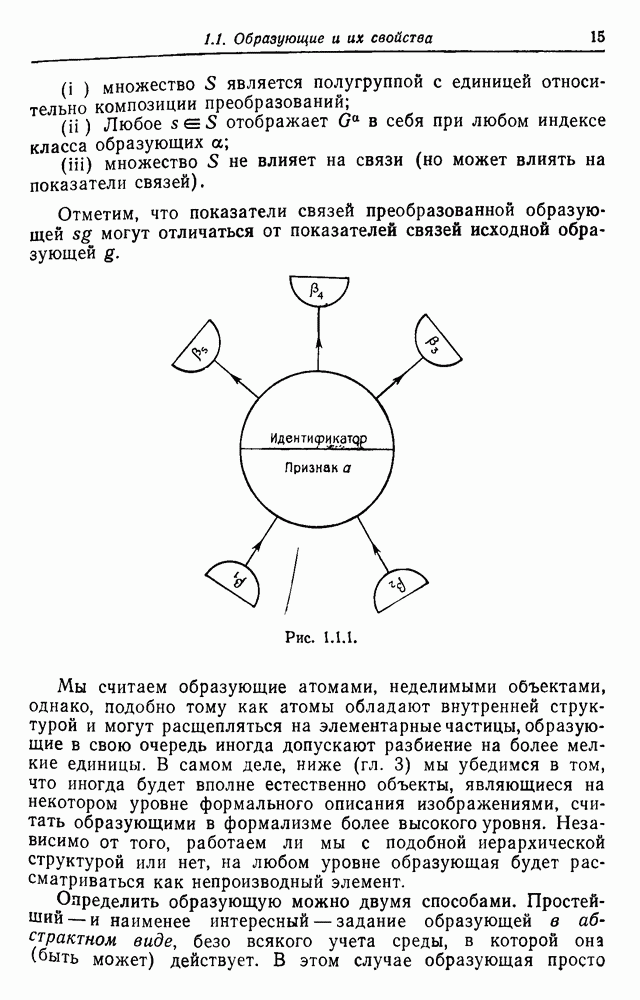
составляющие множество Обозначая соответствующие вероятности через
или в матрично-векторном обозначении
и
Мы также вводим вектор Предположим, что выполняются условия теоремы 2.10.7. Какую вероятность придает Р данному изображению-цепочке? Построим вывод изображений грамматически правильных цепочек от начального состояния до конечного состояния. Общий случай может быть рассмотрен точно таким же способом. Имея терминальную цепочку
Это можно записать в виде
Чтобы распределение вероятностей было корректным, будем считать, что конечное состояние может быть достигнуто из любого состояния. Пользуясь удобным матричным представлением вероятностей, можно вывести компактные выражения для многих величин, которые необходимо будет проанализировать в части III (см. приложение). Какова вероятность получения цепочки вида
Просуммировав (3.2.6) по всем неопределенным терминальным символам, получим вероятность
Здесь мы воспользовались соотношением
Теперь вычислим вероятность того, что цепочка начинается с заданной цепочки
где
Наконец, каково ожидаемое число вхождений подцепочки у? Обозначим через
здесь и обозначает произвольную цепочку, возможно пустую, в то время как
Итак, нами доказана Теорема 3.2.1. Если конечное состояние может быть достигнуто из любого состояния с положительной вероятностью, то
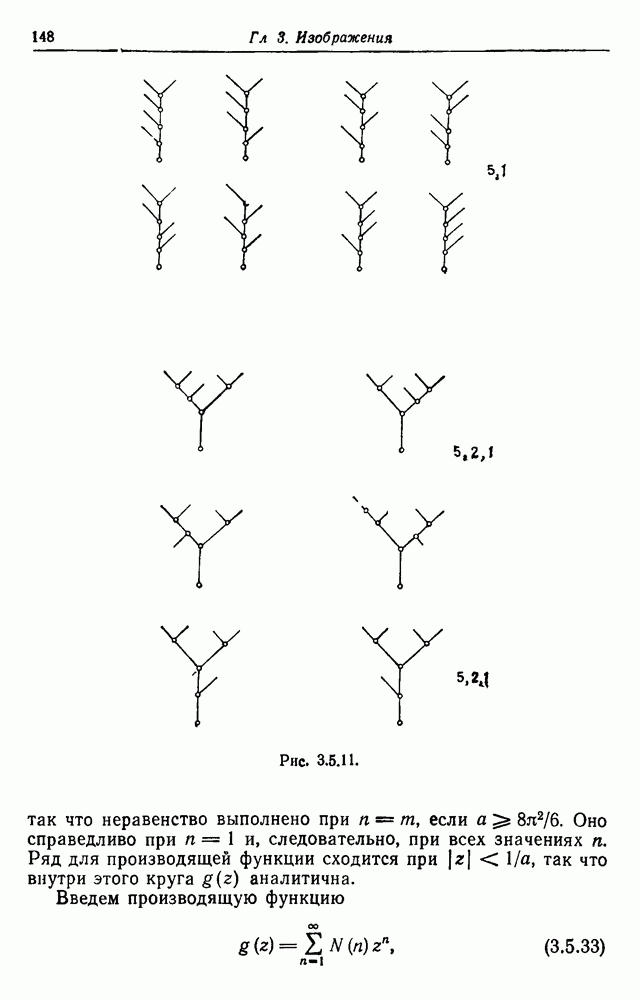
Ситуация, предсказываемая соотношением Таблица 3.2.3 (см. скан) Таблица 3.2.4 (см. скан) С другой стороны, для бесконтекстных языков в разд. 2.10 мы обсуждали способ вычисления вероятности конфигурации, в которой используется крайне левый вывод цепочки. Такие конфигурации имеют тип древовидного соединения. Теорема 2.10.5 гарантирует, что Р — допустимая вероятностная мера В данном случае естественное правило идентификации — считать идентичными те конфигурации, выводы которых начинаются с одной и той же синтаксической переменной и которые имеют одну и ту же последовательность символов в нижних узлах. При этом гарантируется совпадение их внешних структур. Можно проверить, что действительно данное правило идентификации соответствует определению 3.1.1. Для заданной бесконтекстной грамматики может существовать несколько Естественно, называть стилистическими параметрами вероятности, появляющиеся в Чтобы проиллюстрировать это, был проведен небольшой вычислительный эксперимент (см. разд. 4.6). Когда
Одна из цепочек длинная и имеет высокую степень скобочного вложения. Теперь изменим значения трех стилистических параметров
сохраняя остальные неизменными. Были сгенерированы следующие двадцать терминальных цепочек:
Уже поверхностная проверка показывает, что наблюдается тенденция к удлинению цепочек и более частому вхождению в них символа В данном случае образы формального языка представляются при помощи диффузных образов, причем синтаксис соответствует алгебре изображений а стиль задается посредством вероятностной меры на Тогда стиль характеризуется при помощи стилистических параметров и дополнительных переменных — стилистических переменных, необходимых для достижения приемлемой аппроксимации характера использования языка в исследуемой группе его пользователей. Можно поставить вопрос о более точных мерах стиля. Одним из простых критериев является коэффициент Юла (см. разд. 1.4), однако он применим скорее к изображениям, чем к образующим. Более информативной величиной оказывается вводимая ниже ранговая функция. Рассмотрим случай, когда число состояний конечно, и допустим, что мы образовали Формальное типовое отношение Чтобы выяснить действительное положение вещей, можно использовать следующие два метода. Один из них численный и основан на теореме 3.2.1. Пусть детерминированный конечный автомат со словарем, включающим слова
вероятности правил
с вероятностями
задается интересным выражением
с матрицами
и векторами
и
Перечисляя все грамматически правильные предложения в некотором порядке,
каждая из которых положительна. Когда это выполняется численно, мы сталкиваемся с трудностью, связанной с тем, что большое число цепочек окажется грамматически недопустимыми. Они, следовательно, будут иметь нулевую вероятность и не внесут вклада в ранговую функцию (см. ниже). Это означает, что мы должны перебрать очень большое число цепочек и оценить их вероятности, пока не получим достаточное число правильных предложений. Чтобы избежать этого, применим аналитический подход. Видимо, для такой цели можно было бы использовать выражение (3.2.18), однако оно кажется менее обещающим, когда выясняется, что матрицы
Эта функция является невозрастающей, ступенчатой и неограниченной, так как мы исключили тривиальный случай, когда число правильных предложений конечно. Ранговая функция является удобным средством при изучении поставленного вопроса, и мы сначала приведем некоторые предварительные результаты, с которыми можно ознакомиться более подробно в работе Бушара (1967). Теорема 3.2.2. Ранговая функция
б) среднее значение формального типового отношения
в) нормализованное отношение Доказательство, а) Ранговая функция неотрицательна и интегрирование по частям дает
б) Имеем
Так как интегрируема, то из сходимости мажоранты последнего выражения следует, что
По виду второй суммы в (3.2.26) также ясно, что
где
Но ковариации не могут быть положительными, поскольку при
Следовательно, так что Ранговая функция имеет некоторые свойства плотности. Интересно посмотреть, чему равно среднее этой плотности. Мы имеем
так что среднее пропорционально коэффициенту повторения Юла. В качестве иллюстрации рассмотрим формальное типовое отношение для закона Зипфа
так что,
и
со степенным законом убывания и показателем степени Вместо того чтобы ограничиться иллюстрацией этой задачи лишь примерами, мы предпочтем систематический подход, разработав аналитический метод, который, видимо, является мощным средством при рассмотрении вопросов такого рода. Правильные предложения, порожденные грамматикой конечного автомата, могут быть также получены детерминированным конечным автоматом с начальным состоянием, отвечающим, например, переменной 1, и конечным состоянием, соответствующим терминальным правилам вывода. Нас интересует поведение ранговой функции
Видимо, еще никто не замечал, что эта функция и ее преобразование Лапласа являются естественными средствами для изучения стилистических признаков стохастически порожденных языков, соответствующих синтаксически управляемой модели. На простейшем уровне стиль характеризуется вероятностями правил Более сложный тип стиля описывается вероятностями правил Конкретной стилистической величиной, изучаемой нами в данной работе, является гибкость, связанная с ранговой функцией при малых значениях аргументов. Она указывает на широту использования языка. Если Рассмотрим переменную
Обозначим через Обозначим через Рассматривая правила в (3.2.35), заметим, что цепочки в 2,- составлены из цепочек
поскольку благодаря свойству детерминированности системы никакого объединения вероятностей не происходит. Если одно из состояний в правой части (3.2.35) совпадает с начальным состоянием 1, то мы получаем дополнительный член для (3.2.36):
так как мы всегда отправляемся от состояния 1. Значением Выразим эту систему уравнений через логарифмические ранговые функции, так что при всех действительных у
с отрицательными константами, Необходимо найти (верхние) границы для (функций)
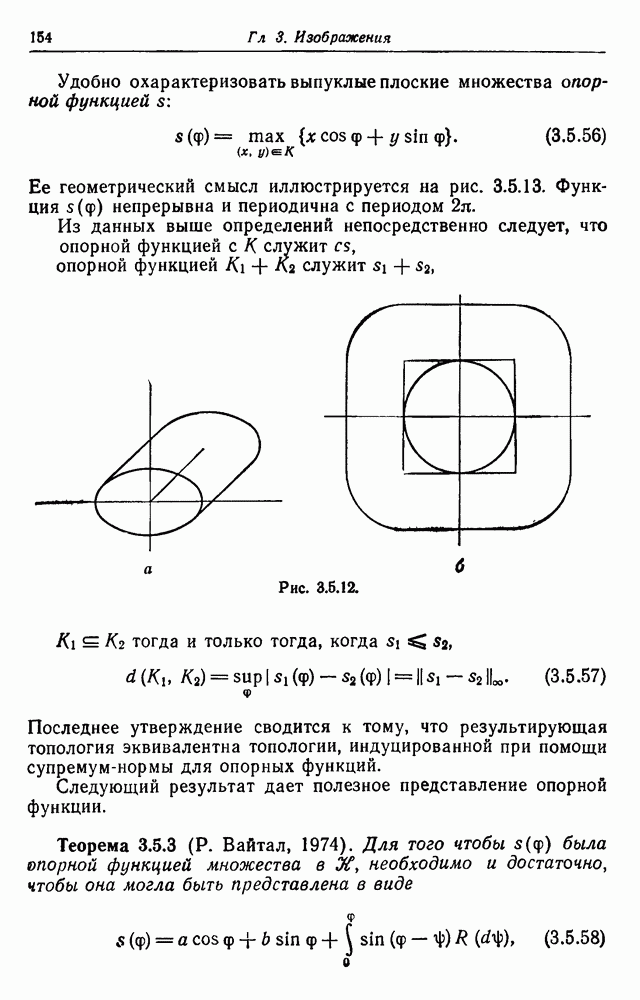
Следовательно, ранговые функции имеют оценки
так что
В связи с тем что
Мы будем рассматривать только такие значения
или, если начальное состояние входит в правую часть (3.2.35), включается дополнительный член
Поэтому при фиксированном которых служат экспоненциальные функции Общим элементом матрицы
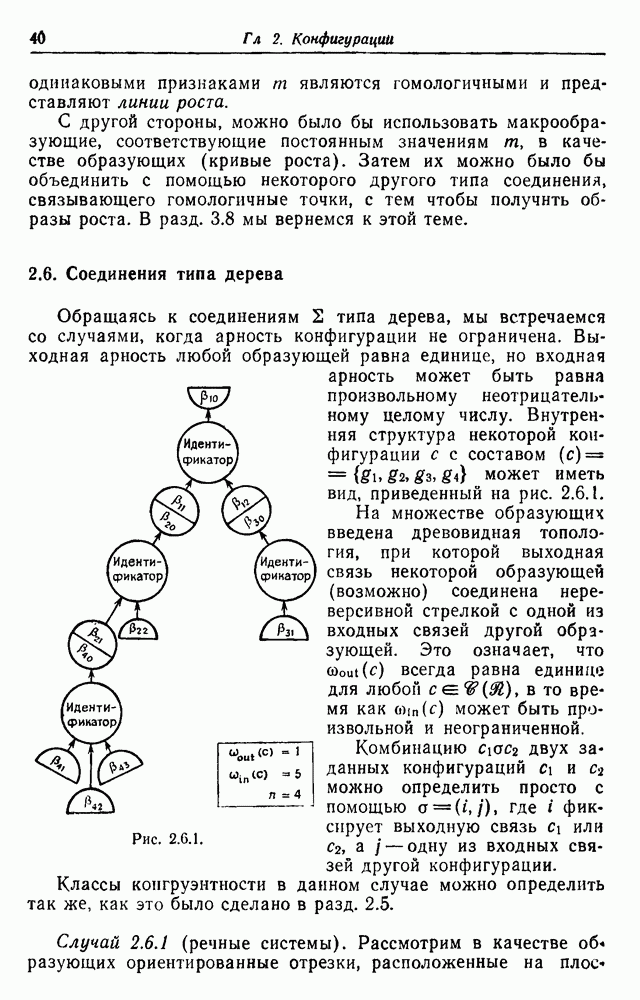
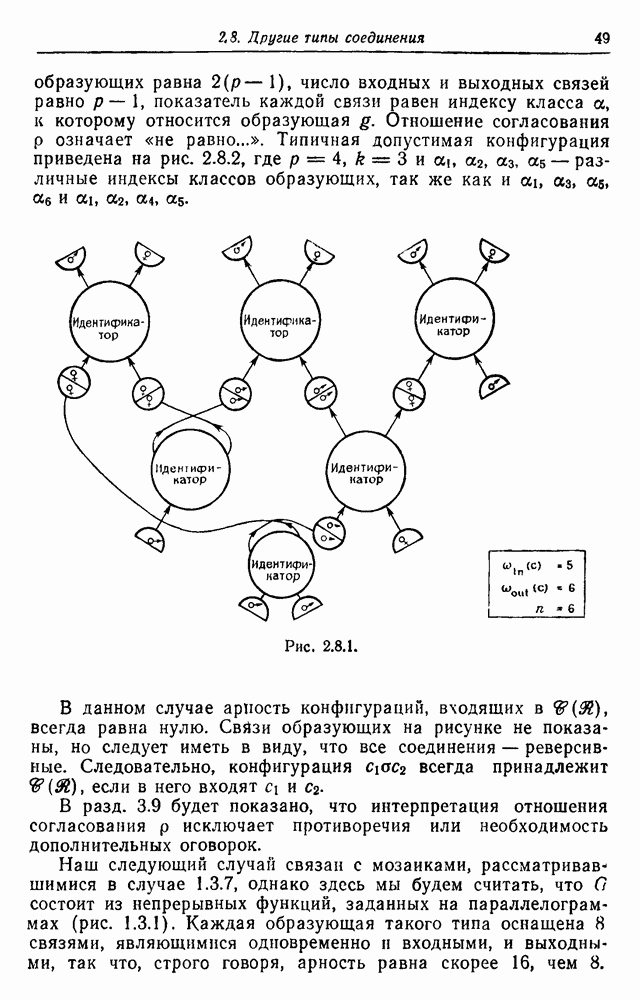
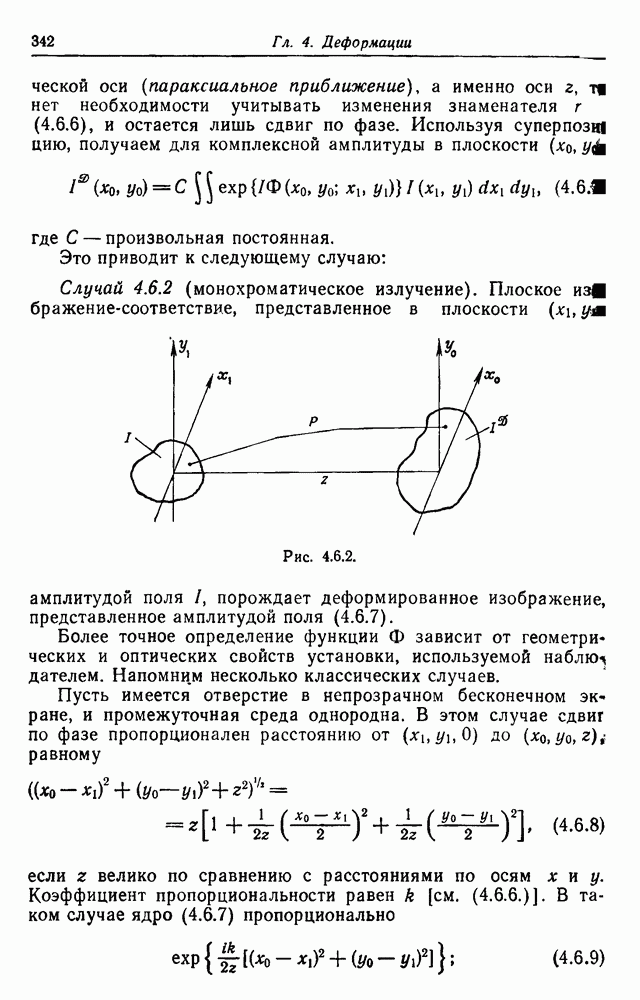
если пары
Рис. 3.2.3. Абсолютная величина определителя Теорема 3.2.3. Синтаксически управляемая вероятностная модель для грамматики конечного автомата порождает диффузный язык, логарифмические ранговые функции которого обладают преобразованиями Лапласа вида
где Чтобы изучить возможные типы поведения, необходимо выразить Рассмотрим сначала машину с двумя словами а и
где
так что
Поведение при
так что по стандартной теореме Таубера (см. Феллер (1957), том 2, гл. 8)
и ранговая функция
По сравнению с поведением по закону Ципфа Чтобы показать, что это не всегда так, мы выберем случай, когда диаграмма переходов автомата имеет совершенно другую топологию. Рассмотрим схему соединений каскадного вида, приведенную на рис. 3.2.3,б. Словарь состоит из двух слов Преобразование Лапласа логарифмических ранговых функций должно удовлетворить соотношениям
где все вероятности переходов предполагаются равными 1/2. Следовательно,
и окончательно
Поведение
где
Для
Это означает, что
и
причем, выбирая
|
 |
Оглавление
|















































































































































































































































































































 задан простой случайный источник, на корректно определена вероятностная мера
задан простой случайный источник, на корректно определена вероятностная мера  и конфигурации могут порождаться в соответствии с
и конфигурации могут порождаться в соответствии с 

 «равенство», то, как известно, простой случайный источник на
«равенство», то, как известно, простой случайный источник на  задает меру марковской цепи Р на
задает меру марковской цепи Р на  (см. разд. 2.10). В данном случае образующая имеет две связи, и значениями
(см. разд. 2.10). В данном случае образующая имеет две связи, и значениями  являются буквы.
являются буквы.

 и цепочка может иметь вид
и цепочка может иметь вид



 то марковская цепь
то марковская цепь  порядка должна задать
порядка должна задать  вероятностей перехода.
вероятностей перехода.

 линейным соотношениям, так что в действительности мы имеем
линейным соотношениям, так что в действительности мы имеем  свободных параметров модели. Ясно, что экспоненциальная зависимость от
свободных параметров модели. Ясно, что экспоненциальная зависимость от  в этом выражении делает марковские источники высших порядков непрактичными, и поэтому необходимы другие типы источников.
в этом выражении делает марковские источники высших порядков непрактичными, и поэтому необходимы другие типы источников.
 с правилами вывода, которые здесь играют роль Образующих:
с правилами вывода, которые здесь играют роль Образующих:
 определена приписыванием всем образующим равных вероятностей; можно вычислить
определена приписыванием всем образующим равных вероятностей; можно вычислить  так же, как и в разд. 2.10.
так же, как и в разд. 2.10.
 где образующей
где образующей  является переход из состояния
является переход из состояния  в состояние
в состояние  с записью терминального символа
с записью терминального символа  Тогда естественно использовать такое правило идентификации:
Тогда естественно использовать такое правило идентификации:  если с — допустимая конфигурация, отличная от
если с — допустимая конфигурация, отличная от  , с тем же числом образующих, с теми же внешними связями и той же терминальной цепочкой. Легко проверить, что
, с тем же числом образующих, с теми же внешними связями и той же терминальной цепочкой. Легко проверить, что  имеет все свойства правила идентификации (см. определение 3.1.1).
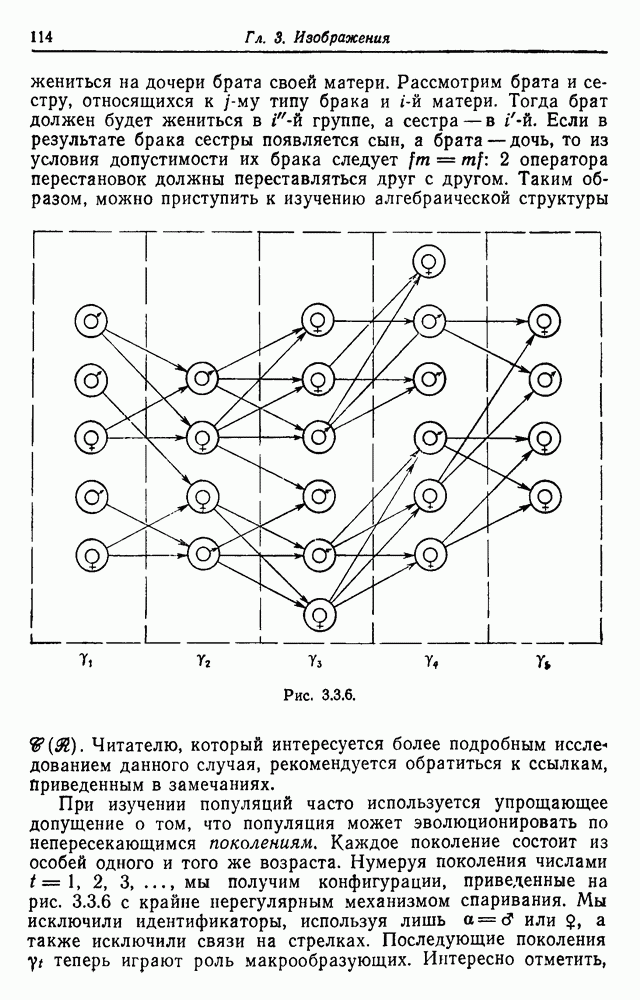
имеет все свойства правила идентификации (см. определение 3.1.1).
 со всеми ее терминалами могут быть доступны наблюдателю. Другими словами, он не сможет идентифицировать-вывод, если грамматика не однозначна. Чтобы получить
со всеми ее терминалами могут быть доступны наблюдателю. Другими словами, он не сможет идентифицировать-вывод, если грамматика не однозначна. Чтобы получить  для данного изображения, пронумеруем синтаксические переменные числами
для данного изображения, пронумеруем синтаксические переменные числами  и рассмотрим все правила
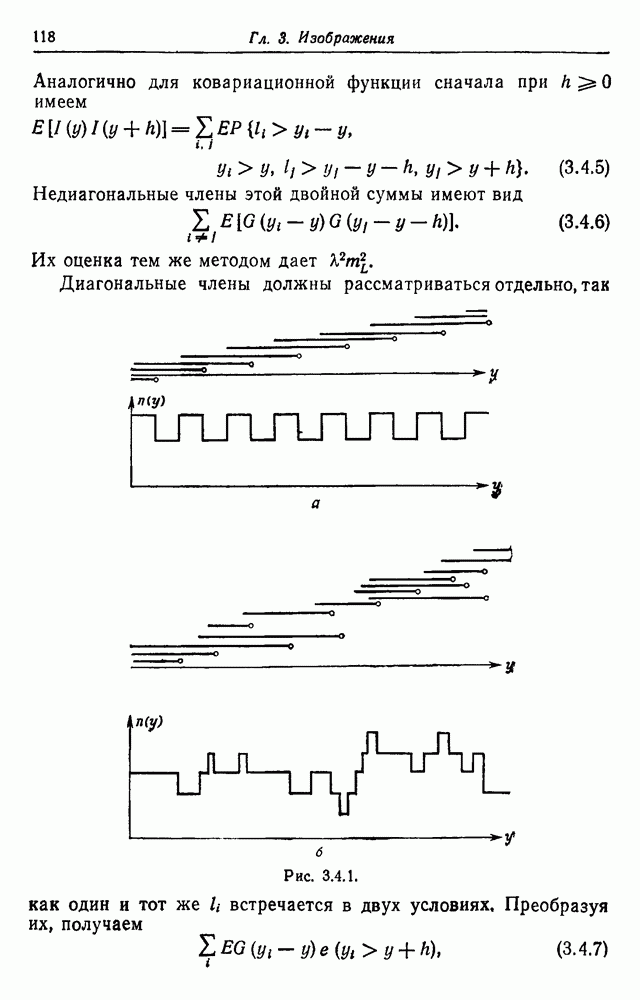
и рассмотрим все правила

 получим
получим



 . Тогда (3.2.3) можно переписать в виде
. Тогда (3.2.3) можно переписать в виде  где
где  вектор-столбец, все
вектор-столбец, все  компонент которого равны 1.
компонент которого равны 1.
 сразу можно получить
сразу можно получить




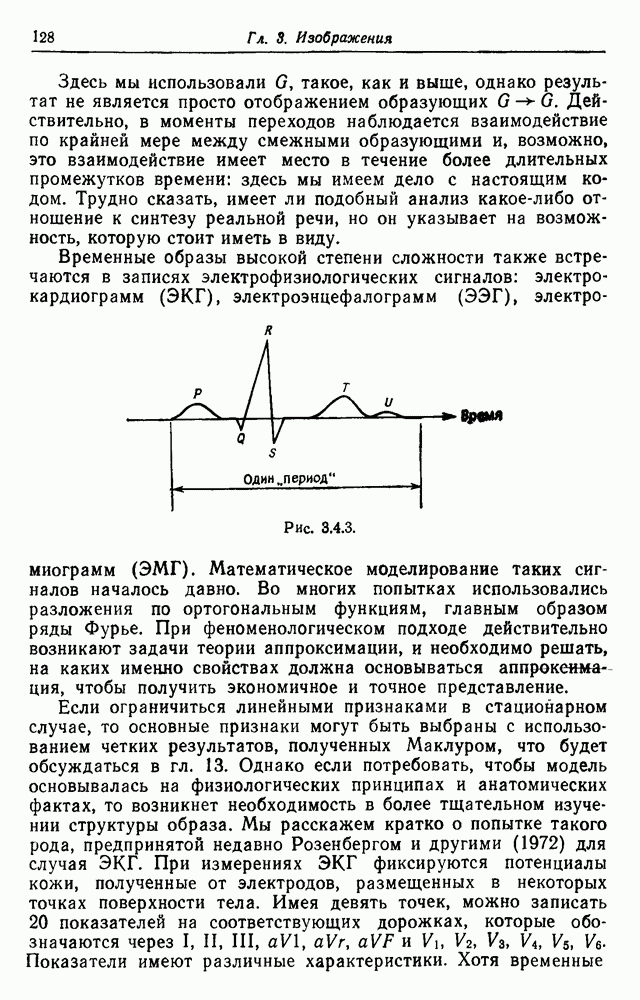
 Частный случай соотношения (3.2.6) получается, когда мы интересуемся тем, что происходит, если все терминалы (скажем,
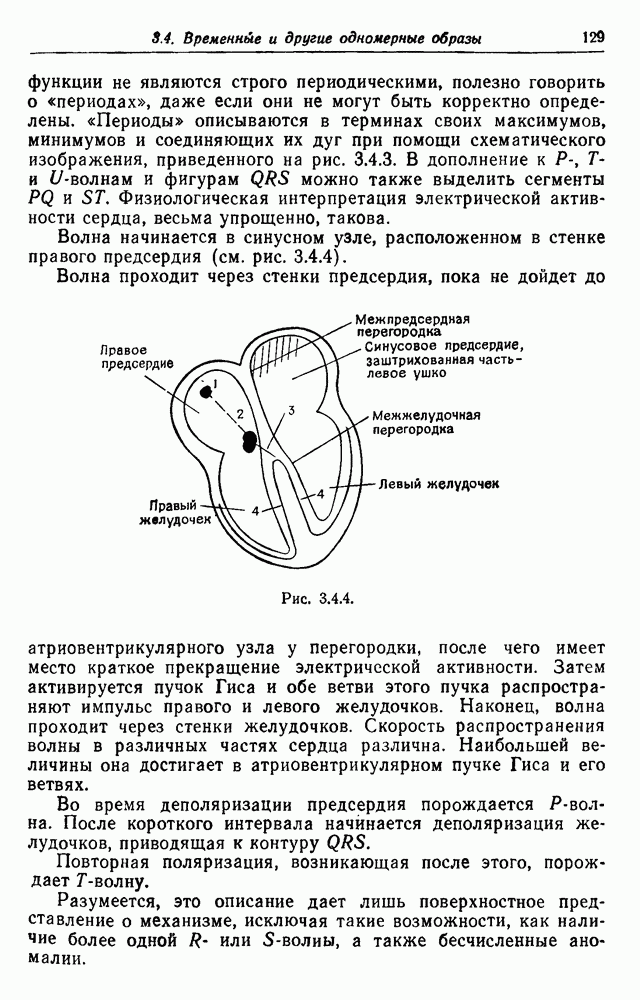
Частный случай соотношения (3.2.6) получается, когда мы интересуемся тем, что происходит, если все терминалы (скажем,  штук) остаются неопределенными. Тогда из (3.2.8) получаем распределение предложений по длине
штук) остаются неопределенными. Тогда из (3.2.8) получаем распределение предложений по длине

 Мы получим сумму
Мы получим сумму


 число вхождений подцепочки у в цепочку
число вхождений подцепочки у в цепочку  . Перечисляя возможности, приводящие к положительным значениям
. Перечисляя возможности, приводящие к положительным значениям  получаем
получаем

 обозначает произвольную цепочку из
обозначает произвольную цепочку из  терминальных символов. Используя (3.2.6), выразим (3.2.12) в виде
терминальных символов. Используя (3.2.6), выразим (3.2.12) в виде


 иллюстрируется табл. 3.2.3, в которой дано наблюдаемое распределение предложений по длине в упомянутом эксперименте моделирования.
иллюстрируется табл. 3.2.3, в которой дано наблюдаемое распределение предложений по длине в упомянутом эксперименте моделирования.

 следовательно,
следовательно,  детализаций.
детализаций.
 предпочтительно в нормализованном виде для каждого правила вывода. Они описывают способы применения различных синтаксических конструкций и частоту их использования, т. е. лингвистическую употребляемость в противоположность лингвистической правильности.
предпочтительно в нормализованном виде для каждого правила вывода. Они описывают способы применения различных синтаксических конструкций и частоту их использования, т. е. лингвистическую употребляемость в противоположность лингвистической правильности.
 определяется, как в табл. 3.2.4, получаем следующее множество из двадцати терминальных цепочек:
определяется, как в табл. 3.2.4, получаем следующее множество из двадцати терминальных цепочек:



 Это объясняется тем, что правило
Это объясняется тем, что правило  с малым скобочным вложением встречается реже, чем правило
с малым скобочным вложением встречается реже, чем правило  Изменение стиля в этом примере легко наблюдаемо; в более сложном примере может потребоваться более систематический анализ, и мы вернемся к этому в частях III и IV.
Изменение стиля в этом примере легко наблюдаемо; в более сложном примере может потребоваться более систематический анализ, и мы вернемся к этому в частях III и IV.
 предложений, представляющих собой грамматически правильные цепочки. Обозначим через число различных предложений.
предложений, представляющих собой грамматически правильные цепочки. Обозначим через число различных предложений.
 выражает частоту повторения предложений: если мало, то повторения встречаются часто, и наоборот. В некоторых имитационных экспериментах было установлено, что формальное типовое отношение довольно незначительно, однако было неясно, происходит ли это из-за случайных изменений или является внутренним свойством рассматриваемых диффузных образов.
выражает частоту повторения предложений: если мало, то повторения встречаются часто, и наоборот. В некоторых имитационных экспериментах было установлено, что формальное типовое отношение довольно незначительно, однако было неясно, происходит ли это из-за случайных изменений или является внутренним свойством рассматриваемых диффузных образов.
 и переменными
и переменными  порождает предложения при помощи правил вывода
порождает предложения при помощи правил вывода

 и терминальные правила вывода
и терминальные правила вывода

 . Тогда вероятность цепочки, состоящей из слов,
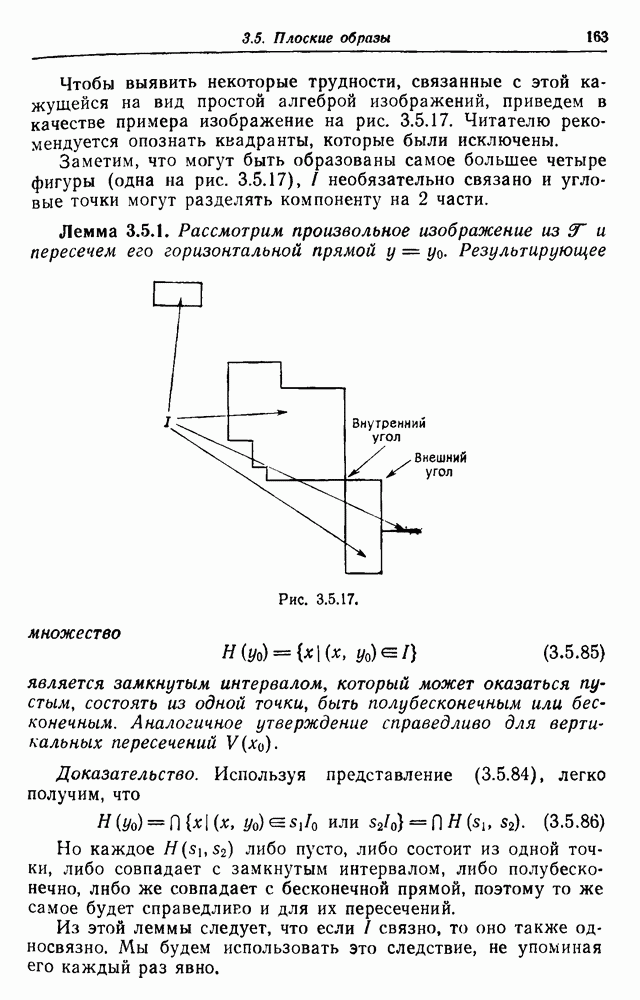
. Тогда вероятность цепочки, состоящей из слов,





 можно изучить поведение величин
можно изучить поведение величин

 необязательно перестановочны, и это создает трудности при изучении асимптотических свойств. Вместо этого применим описанное ниже преобразование Лапласа логарифмических ранговых функций. Введем целочисленную ранговую функцию
необязательно перестановочны, и это создает трудности при изучении асимптотических свойств. Вместо этого применим описанное ниже преобразование Лапласа логарифмических ранговых функций. Введем целочисленную ранговую функцию

 имеет следующие свойства:
имеет следующие свойства:


 , оно обладает выпуклым поведением, т.е.
, оно обладает выпуклым поведением, т.е. 
 сходится в среднем к 1.
сходится в среднем к 1.


 . Свойство выпуклости устанавливается непосредственно, поскольку
. Свойство выпуклости устанавливается непосредственно, поскольку

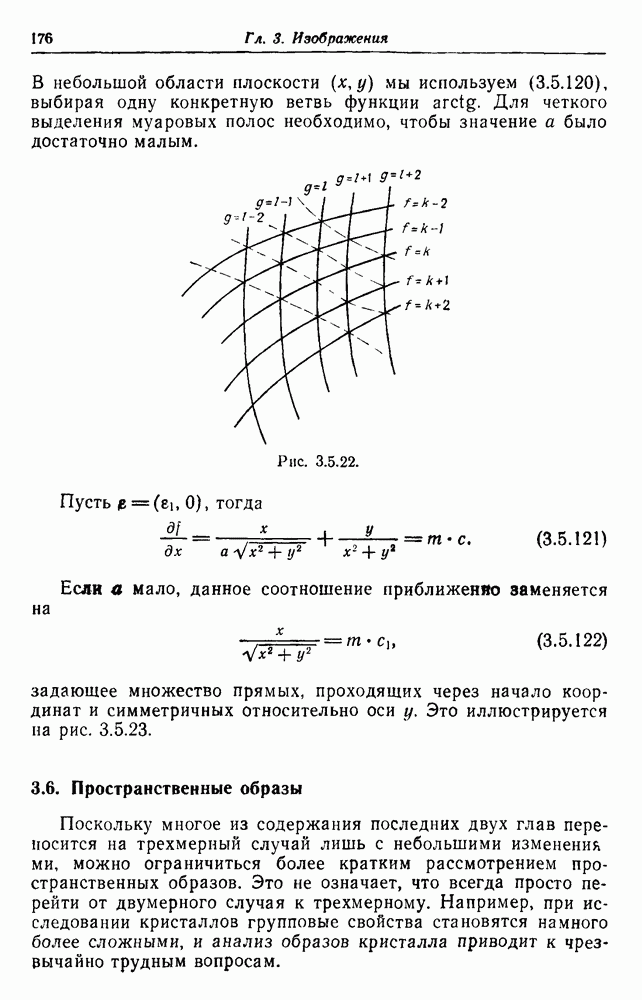
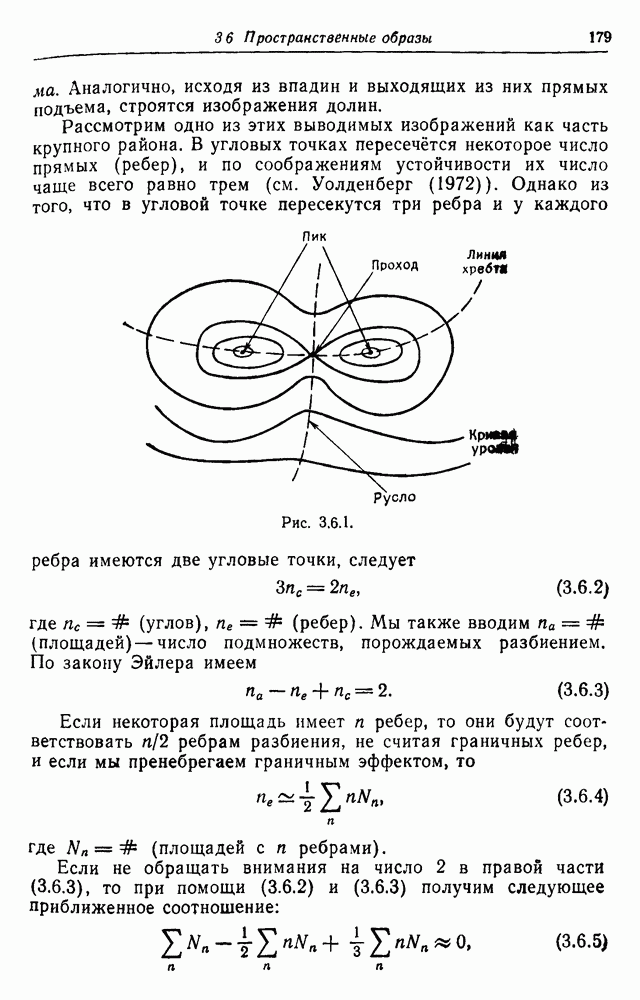
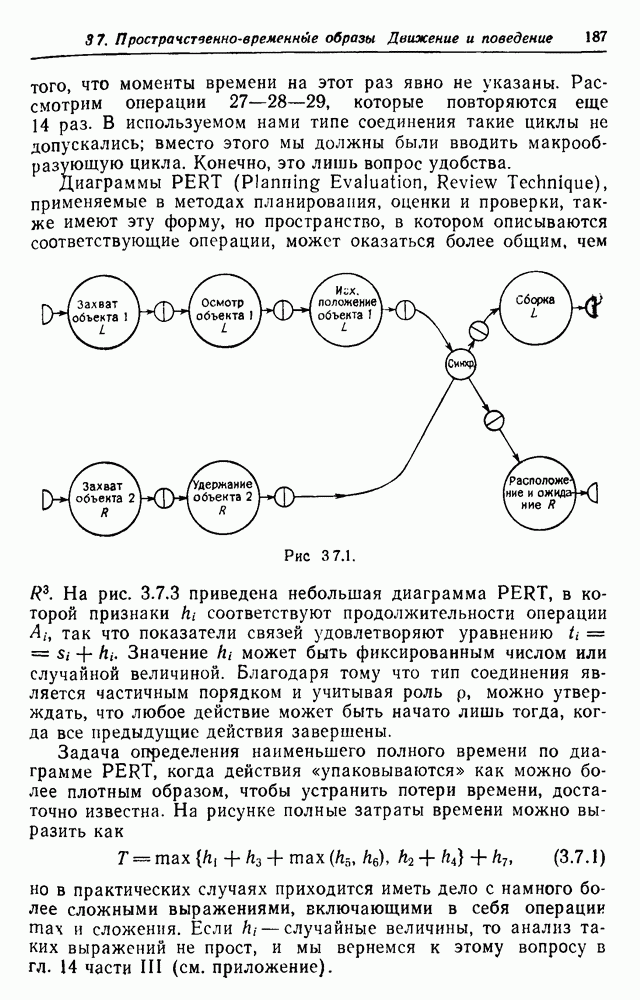
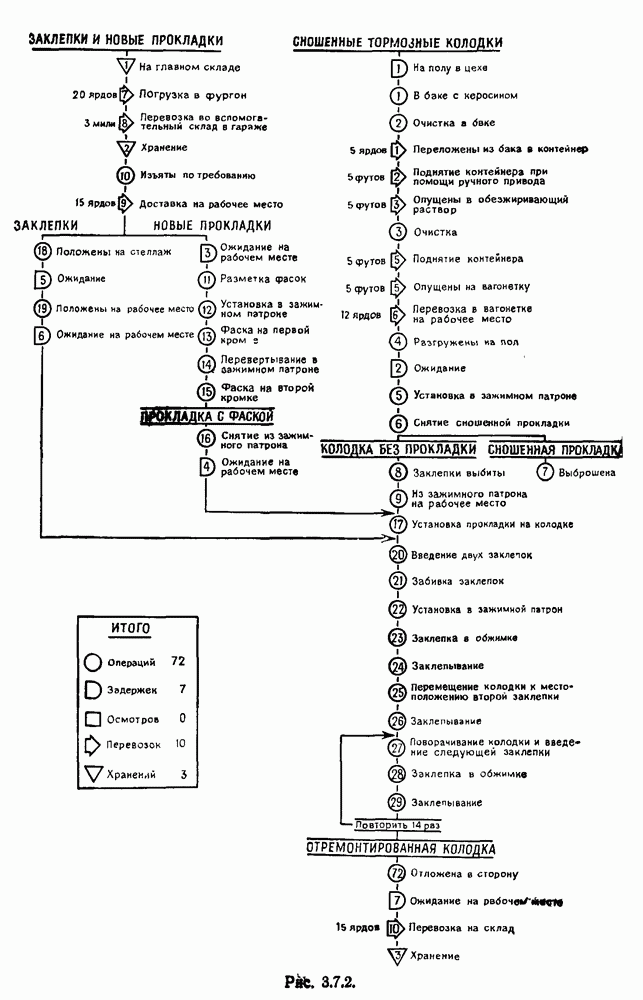
 при
при 

 - переменная, указывающая на появление предложения
- переменная, указывающая на появление предложения  Однако
Однако



 в среднем.
в среднем.




 , меняющимся в пределах от 0 до 1. Следует отметить, что такого рода обсуждений формального типового отношения обычно касается скорее слов, чем предложений. Поскольку анализирующей машине (см. часть IV) предъявляется неизвестный синтаксис, она, конечно, должна разбирать целые предложения, а не только отдельные слова, что служит причиной такого различия.
, меняющимся в пределах от 0 до 1. Следует отметить, что такого рода обсуждений формального типового отношения обычно касается скорее слов, чем предложений. Поскольку анализирующей машине (см. часть IV) предъявляется неизвестный синтаксис, она, конечно, должна разбирать целые предложения, а не только отдельные слова, что служит причиной такого различия.
 и в особенности ее поведение при
и в особенности ее поведение при  Мы будем пользоваться логарифмической ранговой функцией
Мы будем пользоваться логарифмической ранговой функцией

 где
где  «Словарю». Именно так можно определить частоту использования различных слов в заданных частях речи или других синтаксических конструкциях.
«Словарю». Именно так можно определить частоту использования различных слов в заданных частях речи или других синтаксических конструкциях.
 . В данном случае можно надеяться найти более информативные дескрипторы, которые оказались бы более мощными при выборе характеристик лингвистического качества.
. В данном случае можно надеяться найти более информативные дескрипторы, которые оказались бы более мощными при выборе характеристик лингвистического качества.
 велико при малых
велико при малых  то
то  велико (см. 3.2.24), и наоборот.
велико (см. 3.2.24), и наоборот.
 и приводящие к ней правила вывода
и приводящие к ней правила вывода

 множество цепочек, которые могут быть выведены от начального состояния 1 до заключительного состояния I в соответствии с правилами грамматики. Поскольку мы используем детерминированный автомат, все множества
множество цепочек, которые могут быть выведены от начального состояния 1 до заключительного состояния I в соответствии с правилами грамматики. Поскольку мы используем детерминированный автомат, все множества  -различны: любой конкретной цепочке соответствует лишь одно состояние.
-различны: любой конкретной цепочке соответствует лишь одно состояние.
 ранговую функцию, связанную с вероятностями, порождаемыми при помощи ветвящихся решений, которые привели к цепочкам в
ранговую функцию, связанную с вероятностями, порождаемыми при помощи ветвящихся решений, которые привели к цепочкам в  Мы также используем логарифмические ранговые функции
Мы также используем логарифмические ранговые функции 
 и т.д., вероятность каждой из которых получается умножением вероятностей для
и т.д., вероятность каждой из которых получается умножением вероятностей для  и т. д. на
и т. д. на  Это означает, что
Это означает, что


 служит вероятность перехода из состояния 1 в состояние
служит вероятность перехода из состояния 1 в состояние  Если
Если  заключительное состояние, что соответствует терминальным правилам вывода, то имеем
заключительное состояние, что соответствует терминальным правилам вывода, то имеем  так что если нам удается решить систему (3.2.36) при
так что если нам удается решить систему (3.2.36) при  , то мы получим требуемую
, то мы получим требуемую 

 и т. д.
и т. д.
 для этого положим
для этого положим  равным минимуму всех вероятностей переходов, используемых при порождении правильных предложений. Тогда для произвольного
равным минимуму всех вероятностей переходов, используемых при порождении правильных предложений. Тогда для произвольного  (состояний
(состояний  )
)



 растет самое большее экспоненциально, ее преобразование Лапласа для достаточно больших
растет самое большее экспоненциально, ее преобразование Лапласа для достаточно больших  имеет вид
имеет вид

 Известно, что преобразование Лапласа однозначно определяет преобразованную функцию, если она задана при
Известно, что преобразование Лапласа однозначно определяет преобразованную функцию, если она задана при  Тогда система (3.2.38) преобразуется к виду
Тогда система (3.2.38) преобразуется к виду


 на (3.2.43) можно смотреть как на неоднородную систему линейных уравнений, коэффициентами
на (3.2.43) можно смотреть как на неоднородную систему линейных уравнений, коэффициентами
 , а их постоянные члены имеют вид
, а их постоянные члены имеют вид  либо равны 0.
либо равны 0.
 является
является

 соответствуют возможным переходам,
соответствуют возможным переходам,  и
и


 матрицы М при больших значениях
матрицы М при больших значениях  должна быть близка к 1, так как
должна быть близка к 1, так как  будет мало отличаться от единичной матрицы. Следовательно,
будет мало отличаться от единичной матрицы. Следовательно,  обратима и определитель в виде полинома от функций
обратима и определитель в виде полинома от функций  появится в знаменателе решения. Тем самым получен следующий результат, отвечающий на вопрос, поставленный в первом разделе.
появится в знаменателе решения. Тем самым получен следующий результат, отвечающий на вопрос, поставленный в первом разделе.

 рациональные функции экспонент
рациональные функции экспонент  .
.
 через элементарные дроби и воспользоваться обратным преобразованием Лапласа. Следует отметить, что полюс рациональной функции порождает бесконечное число полюсов
через элементарные дроби и воспользоваться обратным преобразованием Лапласа. Следует отметить, что полюс рациональной функции порождает бесконечное число полюсов  расположенных периодически на вертикальных прямых в комплексной плоскости. Это вызвано тем, что
расположенных периодически на вертикальных прямых в комплексной плоскости. Это вызвано тем, что  кусочно-постоянна и не является гладкой, стремясь к бесконечности при
кусочно-постоянна и не является гладкой, стремясь к бесконечности при  Чтобы выяснить ситуацию, поучительно рассмотреть преобразование Лапласа для
Чтобы выяснить ситуацию, поучительно рассмотреть преобразование Лапласа для  Однако асимптотическое поведение
Однако асимптотическое поведение  при этом не меняется.
при этом не меняется.
 состоянием, с начальным состоянием 1 и заключительным состоянием
состоянием, с начальным состоянием 1 и заключительным состоянием  , все вероятности переходов которой равны 1/2 (см. рис. 3.2.3,а). Тогда
, все вероятности переходов которой равны 1/2 (см. рис. 3.2.3,а). Тогда

 Следовательно,
Следовательно,


 таково:
таково:



 не слишком велика для
не слишком велика для  близких к нулю. Поэтому, видимо, вполне правдоподобна гипотеза о том, что стиль этих языков характеризуется малой гибкостью.
близких к нулю. Поэтому, видимо, вполне правдоподобна гипотеза о том, что стиль этих языков характеризуется малой гибкостью.
 число состояний равно
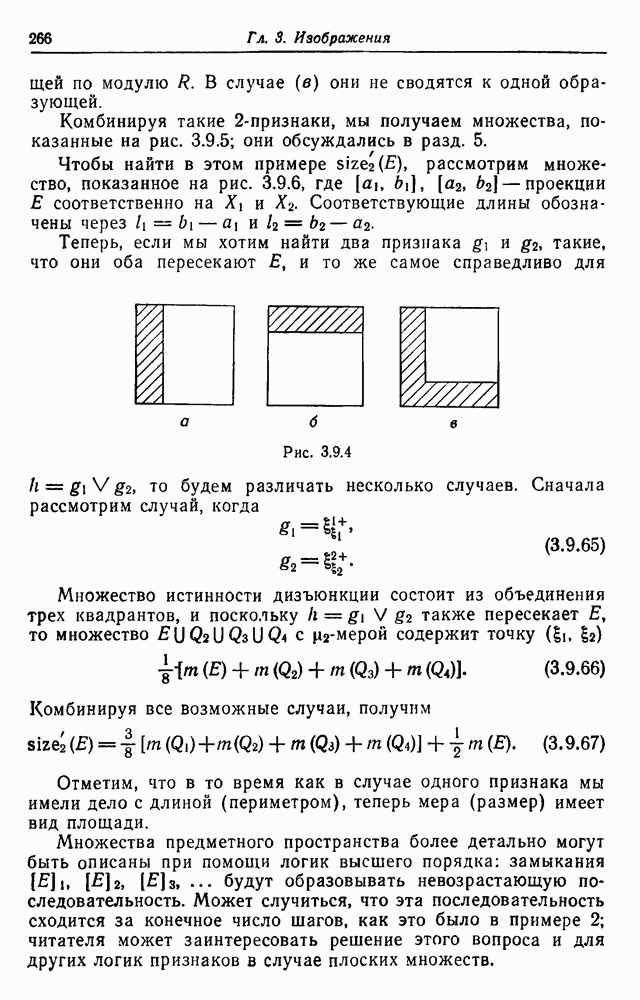
число состояний равно  начальным состоянием является 1, а заключительным —
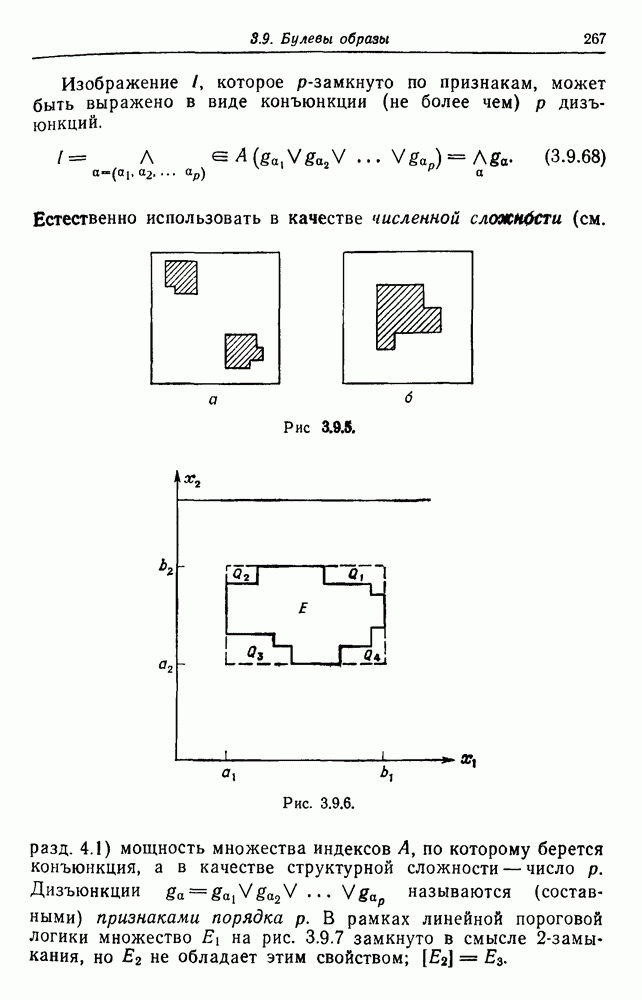
начальным состоянием является 1, а заключительным —  .
.



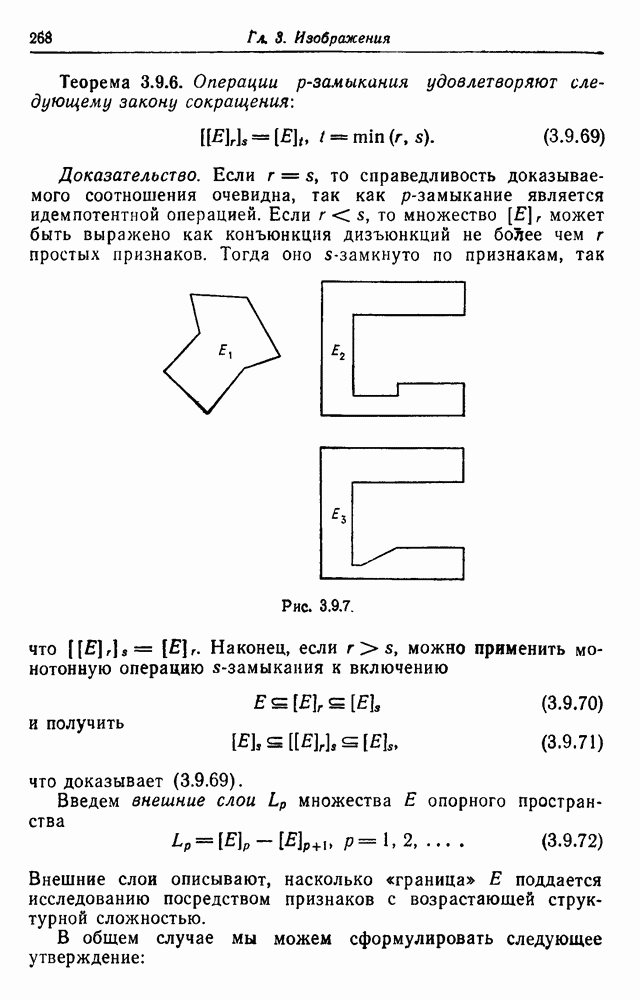
 зависит от значения положительного корня
зависит от значения положительного корня  уравнения
уравнения

 . Он близок к 1/2, если
. Он близок к 1/2, если  велико. Тогда
велико. Тогда  окажется регулярной в той полуплоскости, в которой
окажется регулярной в той полуплоскости, в которой

 близких к
близких к  , поведение
, поведение  определяется
определяется



 большим, можно добиться того, чтобы убыла сколь угодно близка к 1. Отсюда можно заключить, что синтаксически управляемая модель может обладать очень большой гибкостью.
большим, можно добиться того, чтобы убыла сколь угодно близка к 1. Отсюда можно заключить, что синтаксически управляемая модель может обладать очень большой гибкостью.