Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ПРИЛОЖЕНИЕ I. О РАСПРЕДЕЛЕНИИ ОШИБОК ОКРУГЛЕНИЯМы сравнивали точность численных методов линейной алгебры по мажорантным оценкам норм эквивалентных возмущений. Но мажорантные оценки достигаются не так уж часто. Поэтому в целях создания более полной картины распределения ошибок округления весьма заманчиво считать отдельные ошибки случайными независимыми величинами. Заманчиво потому, что подобная гипотеза производит к вероятностным оценкам, лучшим по сравнению с мажорантными. Однако не менее заманчиво считать отдельные ошибки зависимыми случайными величинами, так как можно предположить, что знание характера зависимости также приведет к лучшим оценкам. Но тогда какими же их считать и каковы они в действительности? В общем случае ответ на этот вопрос связан со сложными теоретико-числовыми исследованиями, выполнение которых не входит сейчас в нзшу задачу. Мы ограничимся здесь лишь изложением нескольких наиболее простых фактов. Тем не менее даже эти факты позволит показать интересные свойства ошибок округления и дадут веские основания для выбора правдоподобной гипотезы совместного распределения всей совокупности ошибок округления вычислительного процесса. Для знакомства с технической стороной исследований мы отсылаем читателей к монографии [3]. Изучение вероятностных свойств ошибок округления невозможно без внесения в их поведение некоторого элемента случайности, Эту случайность нередко связывают с многократным решением одной и той же задачи на различных ЭВМ, с решением задачи при случайном числе верных знаков в промежуточных вычислениях и даже при случайном округленци результатов выполнения арифметических операций. Однако в условиях реальных вычислений внесение случайности можно осуществить, вообще говоря, единственным способом. На всех современных ЭВМ операция округления является детерминированной. Следовательно, ошибка округления при выполнении любой арифметической операции однозначно определяется значениями аргументов самой операции. Поэтому при фиксированных входных данных задачи и фиксированном алгорифме ее решения вся совокупность ошибок округления определена однозначно и никакой случайности в поведении самих ошибок не возникает. Если вычислительный алгорифм не связан с не зависящими от него случайными процессами, то единственным источником случайности в ошибках округления может служить лишь случайность входных данных задачи. Мы будем изучать распределение ошибок округления, рассматривая их как функции случайно заданных входных данных и предполагая выполнение всех вычислений в режиме плавающей запятой с правильным округлением. Так как сейчас нас интересует в основном качественная картина распределения, то мы ограничимся асимптотическими исследованиями при Исследование зависимости ошибок округления от входных данных связано с преодолением многих трудностей, причину возникновения которых можно заметить уже на следующем примере. Представим величину
Здесь
Функция Ошибки округления не очень удобны для исследования. Вместо них мы будем изучать величины типа Если входные данные являются случайными величинами, то нормализованная ошибка выполнения любой арифметической операции будет случайной величиной, распределенной каким-то образом на полусегменте Любой вычислительный процесс начинается с ввода входных данных в ЭВМ. Возникающие при этом ошибки округления описывает Теорема 1. Пусть в ЭВМ вводится случайная величина, имеющая непрерывную плотность распределения. Тогда, независимо от того, какова была плотность распределения, нормализованная ошибка округления при вводе асимптотически распределена равномерно на полусегменте Дальнейшие шаги процесса связаны с вычислением различных функций от одной или нескольких случайных величин, введенных в ЭВМ. Имеет место Теорема 2. Пусть в ЭВМ вводятся случайные величины, имеющие непрерывную плотность совместного распределения. Предположим, что введенные величины являются аргументами некоторой гладкой функции, у которой почти всюду хотя бы одна из координат градиента принимает иррациональное значение. Тогда, независимо от того, какова была плотность распределения входных данных, нормализованная ошибка округления при вычислении этой функции асимптотически распределена равномерно на полусегменте Условиям этой теоремы удовлетворяют функции, у которых в любой конечной области градиент совпадает не более, чем в конечном числе точек. К ним, очевидно, относятся обратная величина, произведение и деление, степенная и логарифмическая функции, все тригонометрические функции и многие другие. Для этих функций нормализованная ошибка округления при их вычислении распределена согласно теореме 2. Важно подчеркнуть, что асимптотический характер распределения ошибки не зависит от распределения входных данных, от основания системы счисления, и в известной мере даже от вычисляемой функции. Это свойство ошибок является одним из самых замечательных. Перечисленные факторы не влияют на вид асимптотического распределения, но, конечно, влияют на характер сходимости реального распределения к асимптотическому. Можно понять некоторые особенности, если рассмотреть ошибки вычисления функций, не удовлетворяющих условиям теоремы 2. Наиболее интересным примером таких функций является сложение. Асимптотическое распределение его ошибок округления описывает Теорема 3. Пусть в ЭВМ вводятся две случайные величины, имеющие непрерывную плотность совместного распределения. Предположим, что во всей области определения разность порядков этих величин постоянна и равна Асимптотическое распределение нормализованной ошибки округления будет дискретным и при вычислении линейной комбинации любого числа введенных в ЭВМ случайных величин, если только все коэффициенты линейной комбинации являются рациональными числами, днако в общем случае уже сложнее описать множество допустимых значений ошибки и вероятности их появления. Из последней теоремы вытекает одно интересное следствие, показывающее неравноправие различных оснований систем счисления с точки зрения свойств ошибок округления. Именно, математическое ожидание нормализованной ошибки округления при сложении двух чисел равно нулю при любом нечетном основании и равно Данный факт требует некоторого пояснения. Строго говоря, утверждение теоремы 3 справедливо лишь для тех реализаций правильного округления, при которых ошибка округления однозначно определяется «хвостом» мантиссы, выходящим за Эти свойства систем счисления с четным основанием объясняются в конце концов тем, что невозможно построить округление, основанное на анализе лишь «хвоста» мантиссы таким образом, чтобы ошибки асимптотически компенсировали друг друга. Одним из лучших способов округления для этих систем счисления является классический, однако и здесь ошибка округления мантиссы, имеющей «хвост» величиной в Мы уже отмечали в главе I, что правильное округление в системе с четным основанием может быть реализовано неоднозначно. Это связано с неоднозначностью округления чисел, мантиссы которых имеют «хвост», равный Большинство современных ЭВМ работает в двоичной системе счисления. Правильная реализация округления на таких мзтттлрх вы? зывает определенные трудности и известно не так уж много ЭВМ, где эти трудности преодолены. Экспериментальная проверка показала наличие систематического смещения в ошибках округления почти на всех ЭВМ с двоичной системой. На некоторых из них величина смещения в несколько раз превышает максимальное значение ошибки правильного округления. В этом отношении выгодно выделяются ЭВМ, использующие представление чисел в сокращенной троичной системе. На таких машинах ошибки округления не имеют смещения. Если операция округления реализована неправильно, то асимптотические распределения нормализованных ошибок при вычислении похожих функций Мы рассмотрели только первые шаги вычислительного процесса, связанные с вводом данных в ЭВМ и вычислением различных функций от введенных данных. При этом изучение ошибок осуществлялось лишь на основе вычислительного алгорифма без привлечения каких-либо дополнительных предположений о. поведении самих ошибок. Аналогичные исследования можно продолжить и дальше. Однако приходится констатировать, что технические трудности проведения доказательств начинают расти неизмеримо более быстрыми темпами, чем новые результаты. Не касаясь описания этих исследований, заметим, что уже сейчас можно высказать некоторые соображения о том, какими должны быть результаты изучения дальнейших шагов вычислительного процесса. Одним из важнейших свойств, обнаруженных у нормализованных ошибок округления, является независимость вида асимптотического распределения от входных данных. Пусть входные данные имеют непрерывную плотность совместного распределения. Как правило, при точных вычислениях любая совокупность промежуточных результатов будет также иметь непрерывную плотность совместного распределения. Следовательно, кажется правдоподобным предположение, что почти все результаты приближенных вычислений на любых этапах можно трактовать как результаты ввода в ЭВМ некоторых величин, имеющих непрерывную плотность совместного распределения. В этом случае нормализованные ошибки округления при дальнейших вычислениях будут снова вести себя согласно теоремам 1, 2. Кажется правдоподобным и то, что независимость вида асимптотического распределения ошибок от входных данных должна влечь за собой независимость ошибок округления как случайных величин. При этом трудно лишь надеяться на практическую независимость ошибок в совокупности. Таким образом, выполненные исследования и приведенные выше аргументы показывают, что при оценке суммарного влияния ошибок округления в массовых вычислениях, по-видимому, может быть использована следующая Гипотеза. Все нормализованные ошибки округления вычислительного процесса в режиме плавающей запятой являются случайными попарно независимыми величинами, распределение которых не зависит от входных данных и результатов промежуточных вычислений. Они распределены на полусегменте При практическом применении этой гипотезы следует проявлять определенную осторожность в отношении предполагаемых значений математического ожидания и дисперсии, что связано лишь с особенностями распределения нормализованных ошибок в операциях типа сложения. Гипотеза подтверждена рядом теоретических исследований, связанных с линейными преобразованиями векторов, разложением матриц на множители, итерационными пррцессами в лилейной алгебре, вычислением определенных интегралов. Информация об этих исследованиях имеется в монографии [3] и библиографическом указателе [8]. Рассмотрим теперь примеры использования высказанной гипотезы для вывода некоторых вероятностных оценок, связанных с ошибками округления. Важнейшим моментом в изучении устойчивости численных методов линейной алгебры было получение мажорантных оценок евклидовых норм эквивалентных возмущений
Для всех вероятностных исследований аналогичное значение имеют оценки вида
где Функции анализом. Поэтому мы ограничимся здесь лишь кратким рассмотрением некоторых односторонних преобразований. Пусть в соответствии с обозначениями § 19 над вектором
Ясно, что для циклических индексов в последовательности матриц вращения будет выполняться неравенство
Это означает, что для всех рассмотренных ранее разложений матрицы на множители с помощью преобразований вращения функции Предположим далее, что в соответствии с обозначениями § 21 над вектором
где
Снова Если при реализации преобразований отражения не использовать накопление скалярных произведений, то соответствующий анализ ошибок показывает, что функция Вероятностный анализ ошибок округления в преобразованиях Гаусса основан на формуле (24.7), из которой сразу же вытекает, что
Опять для функции Для остальных типов разложений функции Вероятностные оценки дают возможность сделать более точные выводы о соотношении между собой различных методов разложения матрицы на множители. Если относительно большой разброс значений функций С точки зрения устойчивости к ошибкам округления между прямыми методами разложения матрицы на множители нет принципиального различия. Конечно, этот вывод в полной мере относится и к прямым методам решения систем линейных алгебраических уравнений. Согласно (36.15) мажорантная оценка погрешности в решении системы определяется формулой
Вероятностный анализ приводит к соотношению
Аналогический вывод можно сделать и относительно любых других численных методов, основанных на прямых разложениях матрицы на множители. На этом заканчивается наше краткое знакомство с вероятностным анализом. Мы надеемся, что приведенное описание основ распределения ошибок округления поможет правильно ориентироваться при чтении соответствующей литературы. К тому же оно открывает перед читателем широкие возможности для более точного изучения вычислительных процессов.
|
 |
Оглавление
|






















































































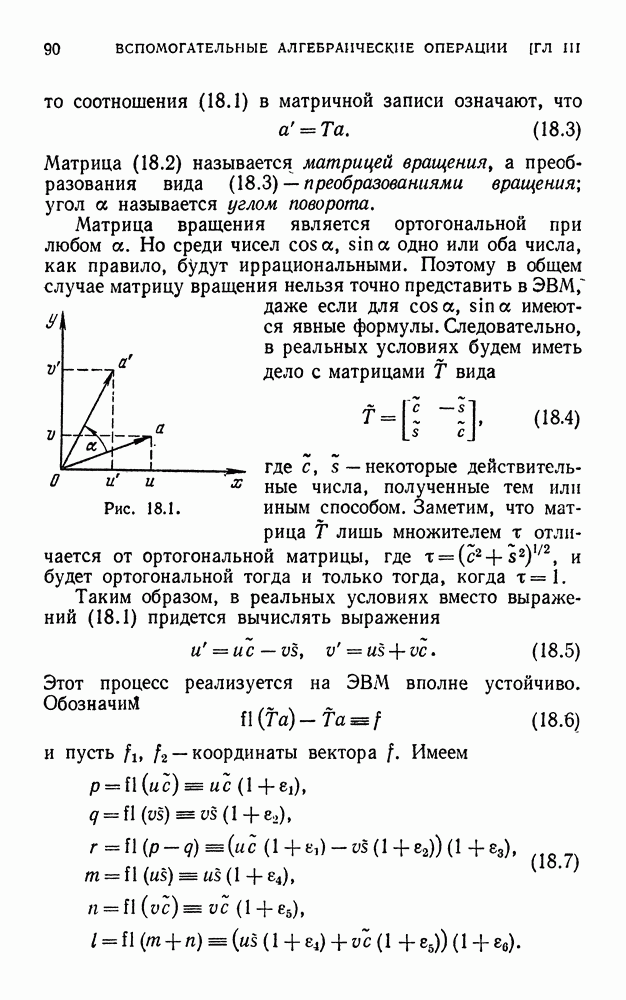


















































































































































































































 в виде
в виде  где а — ее мантисса,
где а — ее мантисса,  — порядок. Легко проверить, что справедливо равенство
— порядок. Легко проверить, что справедливо равенство


 не зависит от
не зависит от  Она кусочно-постоянная и имеет разрывы в точках
Она кусочно-постоянная и имеет разрывы в точках  при всех целых
при всех целых  Функция же
Функция же  является кусочно-линейной с периодом
является кусочно-линейной с периодом  следовательно, с таким же периодом имеет разрывы. Поэтому нет никаких оснований ожидать, что в общем случае ошибки округления будут какими-либо гладкими функциями входных данных. Более того, почти очевидно, что при
следовательно, с таким же периодом имеет разрывы. Поэтому нет никаких оснований ожидать, что в общем случае ошибки округления будут какими-либо гладкими функциями входных данных. Более того, почти очевидно, что при  множество точек разрыва ошибок округления будет всюду плотно на множестве входных данных. Это обстоятельство и определяет сложность исследований.
множество точек разрыва ошибок округления будет всюду плотно на множестве входных данных. Это обстоятельство и определяет сложность исследований.
 и называть их нормализованными ошибками округления.
и называть их нормализованными ошибками округления.
 Одна из важнейших задач заключается в том, чтобы понять, какими свойствами будет обладать асимптотическое распределение нормализованных ошибок округления.
Одна из важнейших задач заключается в том, чтобы понять, какими свойствами будет обладать асимптотическое распределение нормализованных ошибок округления.


 Тогда, независимо от того, какова была плотность распределения входных данных, нормализованная ошибка округления при вычислении суммы введенных величин дискретно распределена на полусегменте
Тогда, независимо от того, какова была плотность распределения входных данных, нормализованная ошибка округления при вычислении суммы введенных величин дискретно распределена на полусегменте  и принимает на нем асимптотически равновероятно значения вида
и принимает на нем асимптотически равновероятно значения вида  для целых
для целых  удовлетворяющих неравенствам
удовлетворяющих неравенствам 
 при любом четном основании.
при любом четном основании.
 разрядов. И дело не в Том, что рассматривается именно правильное округление. Можно показать, что математическое ожидание ошибки при сложении двух чисел асимптотически отлично от нуля и при любых других способах округления, если только ошибка округления однозначно определяется «хвостом».
разрядов. И дело не в Том, что рассматривается именно правильное округление. Можно показать, что математическое ожидание ошибки при сложении двух чисел асимптотически отлично от нуля и при любых других способах округления, если только ошибка округления однозначно определяется «хвостом».
 не может быть скомпенсирована.
не может быть скомпенсирована.
 Чтобы исключить появление систематического смещения, необходимо мантиссу с «хвостом» величиной
Чтобы исключить появление систематического смещения, необходимо мантиссу с «хвостом» величиной  округлять равновероятно как с избытком, так и с недостатком. При этом датчик случайного округления должен быть связан с каким-либо из последних разрядов мантиссы, чтобы иметь возможность получить два одинаковых результата при повторном счете. Например, мантиссу с «хвостом»
округлять равновероятно как с избытком, так и с недостатком. При этом датчик случайного округления должен быть связан с каким-либо из последних разрядов мантиссы, чтобы иметь возможность получить два одинаковых результата при повторном счете. Например, мантиссу с «хвостом»  можно, округлять с избытком, если ее
можно, округлять с избытком, если ее  разряд принимает четное значение, и с недостатком, если нечетное. Такая модификация операции округления особенно удобна на ЭВМ с двоичной системой счисления, так как не требует выполнения дополнительного сложения.
разряд принимает четное значение, и с недостатком, если нечетное. Такая модификация операции округления особенно удобна на ЭВМ с двоичной системой счисления, так как не требует выполнения дополнительного сложения.
 в действительности оказываются совершенно различными. В первом случае распределение дискретное и имеет заметное смещение, во втором — равномерное и без смещения. На ЭВМ с неправильным округлением особенно полезно использование операций накопления. Это не только снижает общий уровень ошибок, но и во многих случаях позволяет устранить систематическое смещение.
в действительности оказываются совершенно различными. В первом случае распределение дискретное и имеет заметное смещение, во втором — равномерное и без смещения. На ЭВМ с неправильным округлением особенно полезно использование операций накопления. Это не только снижает общий уровень ошибок, но и во многих случаях позволяет устранить систематическое смещение.
 дискретно для операций сложения и вычитания и равномерно для большинства других операций. За исключением некоторых случаев можно считать, что математическое ожидание нормализованных ошибок округления равно нулю, а дисперсия не превосходит 1/12.
дискретно для операций сложения и вычитания и равномерно для большинства других операций. За исключением некоторых случаев можно считать, что математическое ожидание нормализованных ошибок округления равно нулю, а дисперсия не превосходит 1/12.
 при разложении матрицы А на множители. Согласно формуле (34.1) эти оценки таковы:
при разложении матрицы А на множители. Согласно формуле (34.1) эти оценки таковы:


 есть математическое ожидание
есть математическое ожидание  Как следует из табл. 34.1, функции
Как следует из табл. 34.1, функции  по порядку зависимости от
по порядку зависимости от  принимают значения для различных методов между п° и
принимают значения для различных методов между п° и  Однако
Однако  при тех же режимах вычислений принимают свои значения уже только между п° и
при тех же режимах вычислений принимают свои значения уже только между п° и
 находятся по тем же самым схемам, что и функции
находятся по тем же самым схемам, что и функции  за исключением однотипных изменений, связанных с вероятностным
за исключением однотипных изменений, связанных с вероятностным
 выполняется последовательность преобразований с реально заданными матрицами вращения
выполняется последовательность преобразований с реально заданными матрицами вращения  Согласно гипотезе относительно распределения ошибок имеем
Согласно гипотезе относительно распределения ошибок имеем


 не превосходят по порядку
не превосходят по порядку  Пример из § 22 показывает неулучшаемость оценок для
Пример из § 22 показывает неулучшаемость оценок для 
 выполняется последовательность преобразований с реально заданными матрицами отражения
выполняется последовательность преобразований с реально заданными матрицами отражения  По аналогии с формулой (21.3) будем иметь
По аналогии с формулой (21.3) будем иметь

 — эквивалентное возмущение, возникающее при реализации
— эквивалентное возмущение, возникающее при реализации  шага. Вероятностные оценки ошибок одного шага приводят теперь к неравенству
шага. Вероятностные оценки ошибок одного шага приводят теперь к неравенству

 не превосходит по порядку
не превосходит по порядку  и эта оценка для нее не может быть улучшена.
и эта оценка для нее не может быть улучшена.
 принимает значения порядка
принимает значения порядка  Однако вероятностный анализ приводит к оценкам порядка
Однако вероятностный анализ приводит к оценкам порядка  или
или  для функции
для функции  в зависимости от того, какой из способов суммирования, описанных в § 6, используется при вычислении скалярных произведений. Отсюда, пожалуй, можно прийти к
в зависимости от того, какой из способов суммирования, описанных в § 6, используется при вычислении скалярных произведений. Отсюда, пожалуй, можно прийти к  чению, что в реальных вычислениях применение операций накопления скалярных произведений не должно давать столь же значительный эффект в отношении точности, как при получении гарантированных оценок. Этот вывод подтверждается анализом самых различных алгорифмов, содержащих вычисление скалярных произведений.
чению, что в реальных вычислениях применение операций накопления скалярных произведений не должно давать столь же значительный эффект в отношении точности, как при получении гарантированных оценок. Этот вывод подтверждается анализом самых различных алгорифмов, содержащих вычисление скалярных произведений.

 получаем неулучшаемую оценку порядка
получаем неулучшаемую оценку порядка 
 имеют один и тот же порядок п°. Это объясняется тем, что в этих разложениях каждый элемент матриц эквивалентных возмущений определяется лишь одной элементарной ошибкой округления. Поэтому вероятностные оценки норм эквивалентных возмущений не могут быть существенно лучше, чем мажорантные.
имеют один и тот же порядок п°. Это объясняется тем, что в этих разложениях каждый элемент матриц эквивалентных возмущений определяется лишь одной элементарной ошибкой округления. Поэтому вероятностные оценки норм эквивалентных возмущений не могут быть существенно лучше, чем мажорантные.
 позволял еще отдать предпочтение одному из методов, то малый разброс значений
позволял еще отдать предпочтение одному из методов, то малый разброс значений  говорит, что
говорит, что

