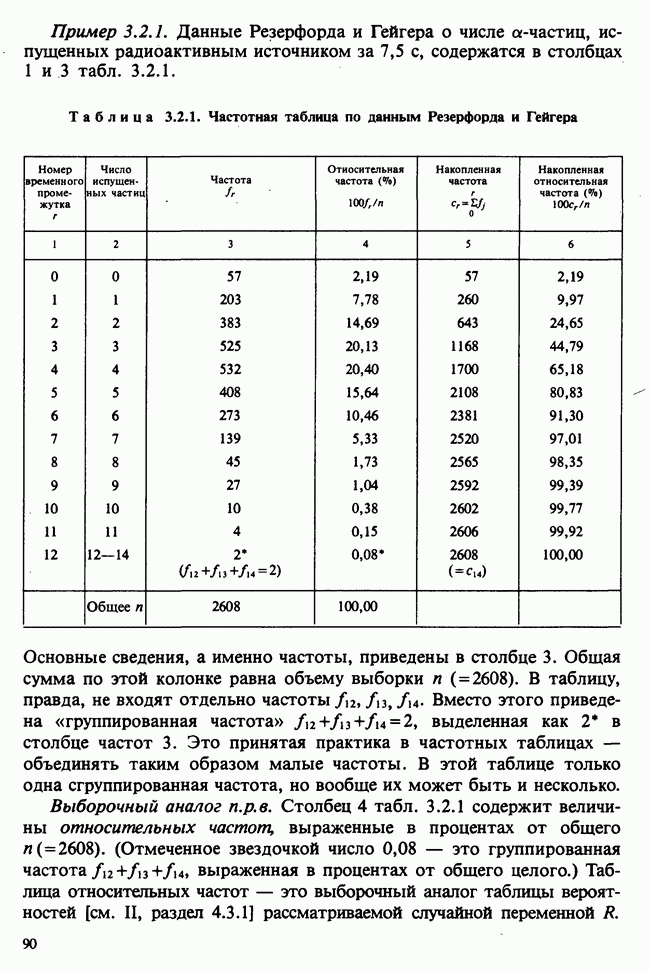
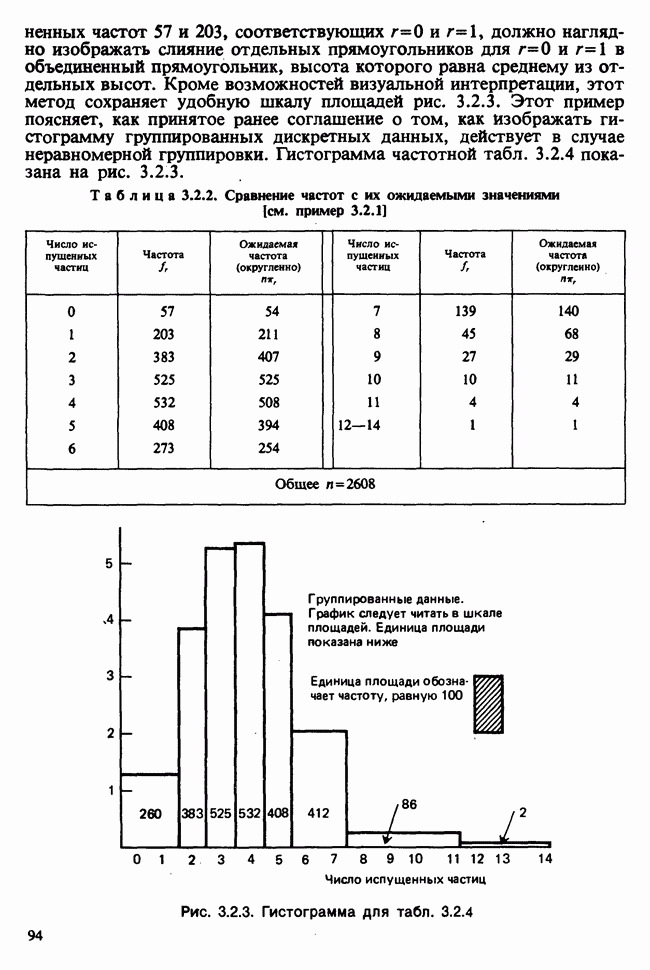
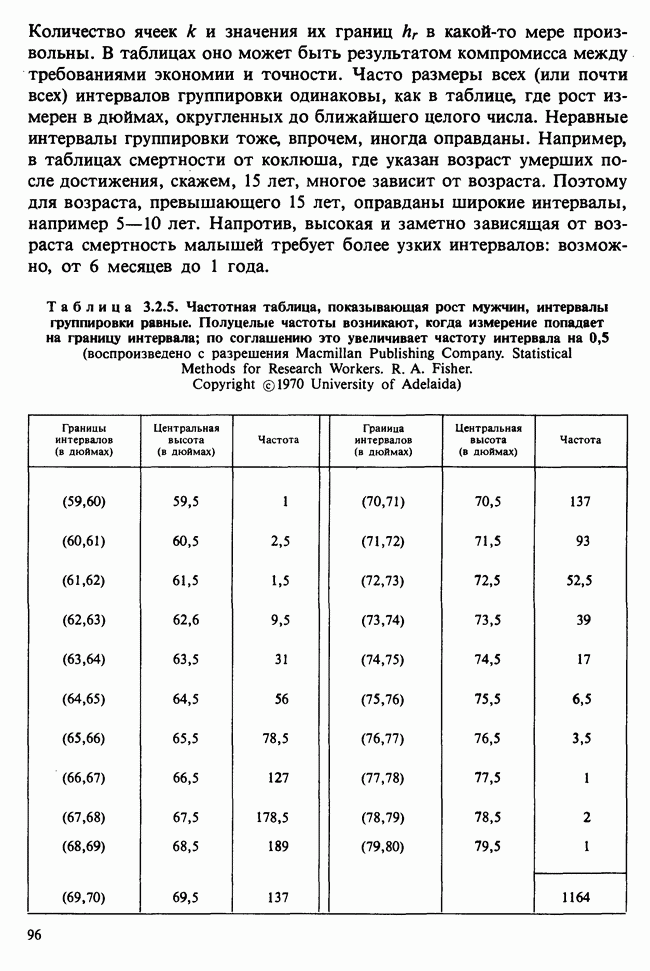
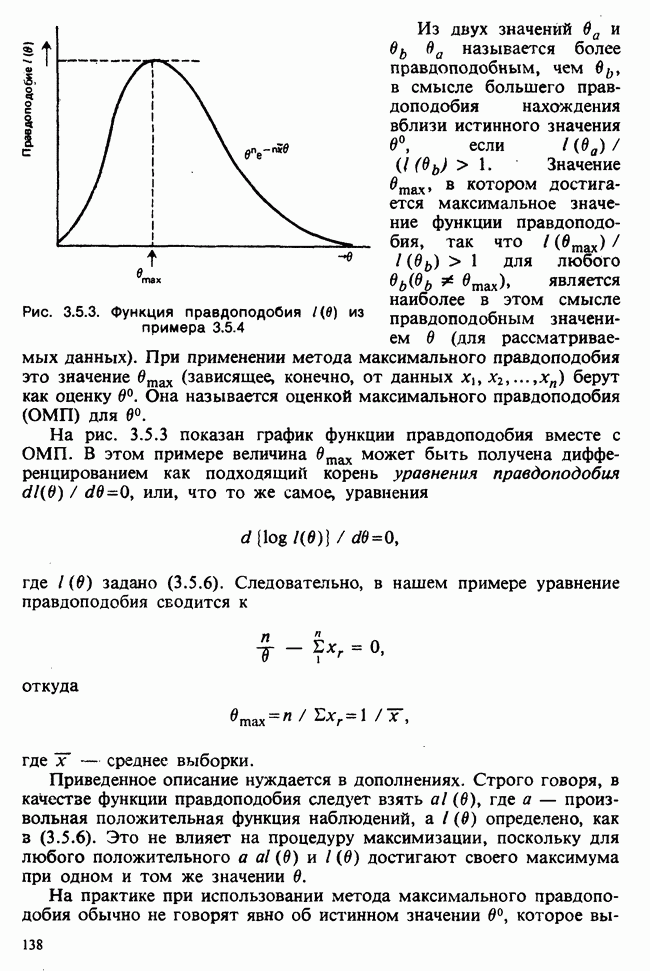
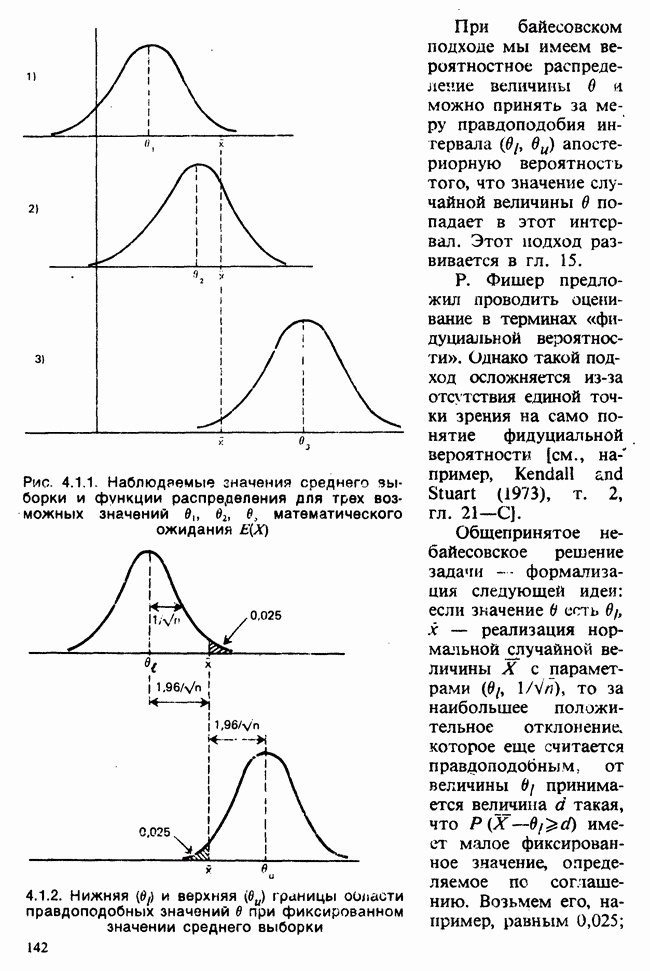
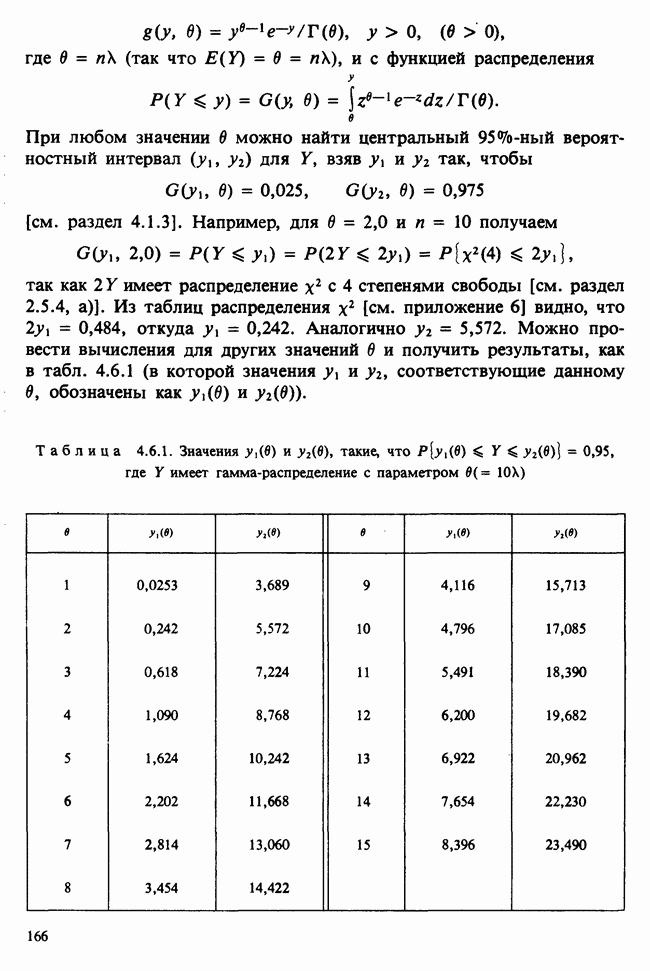
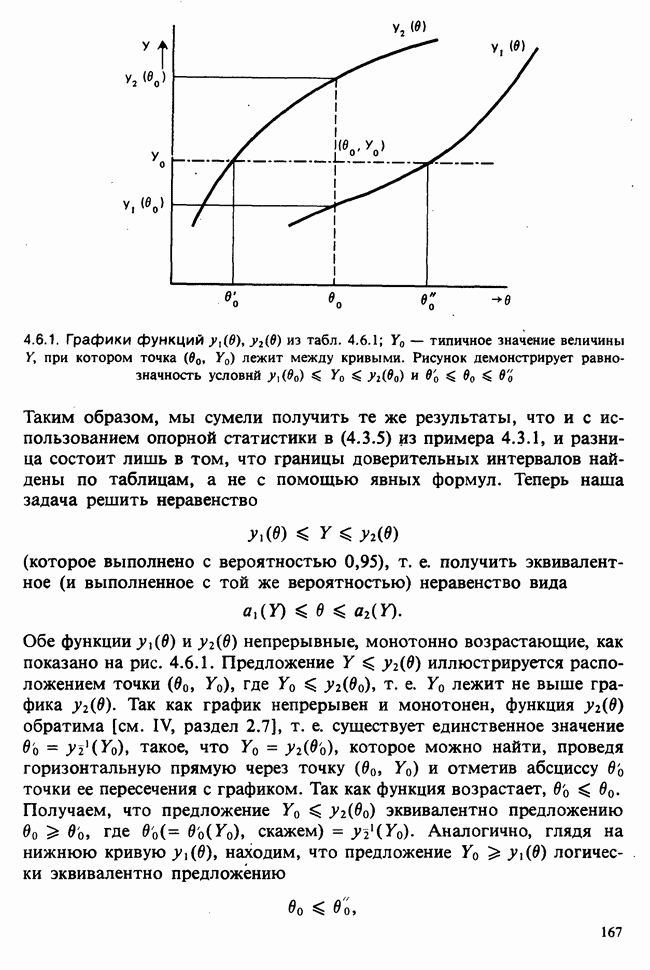
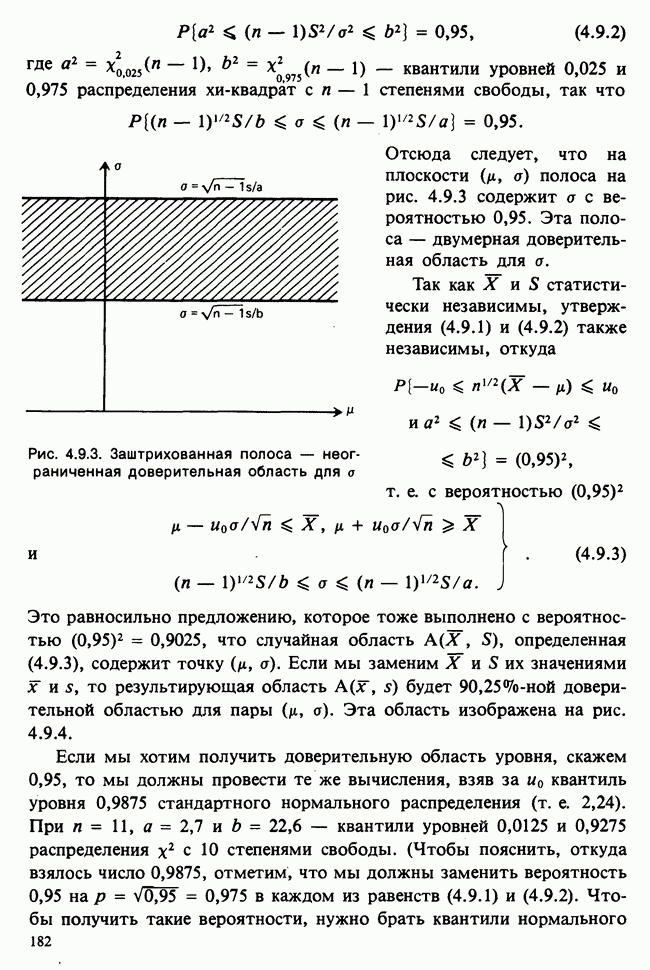
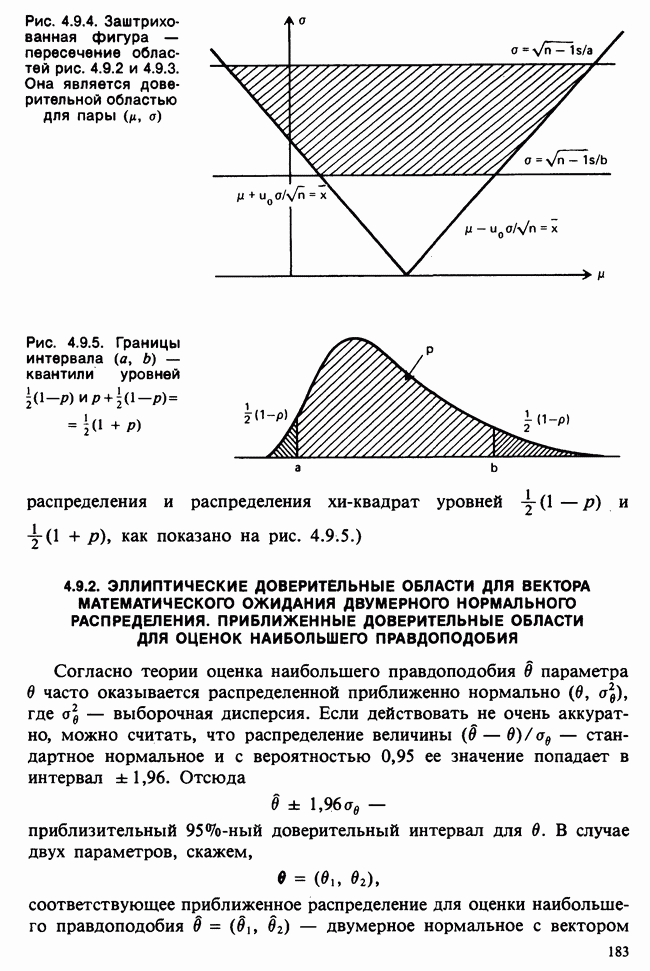
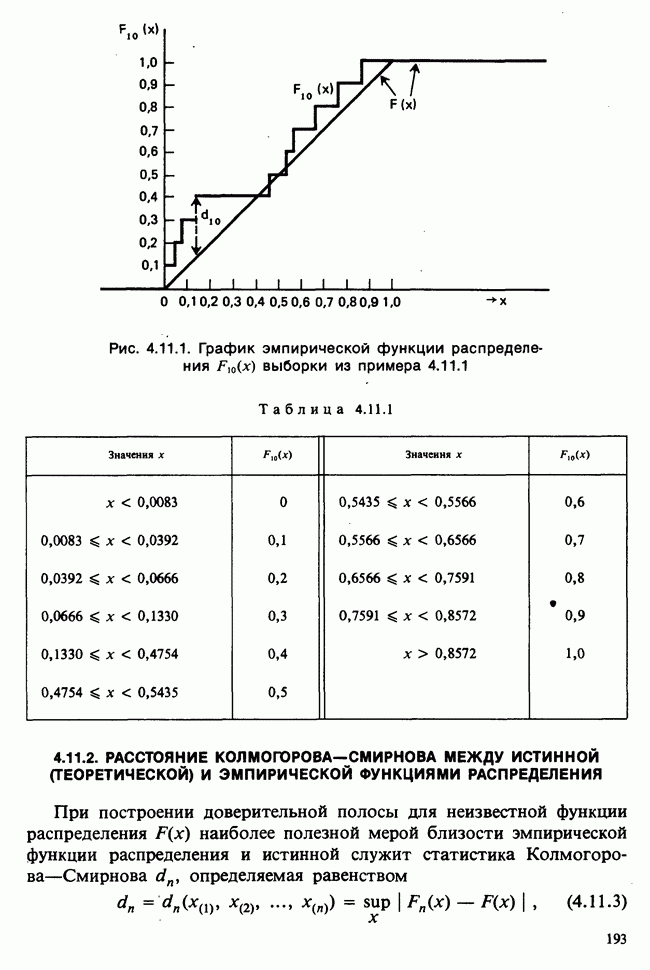
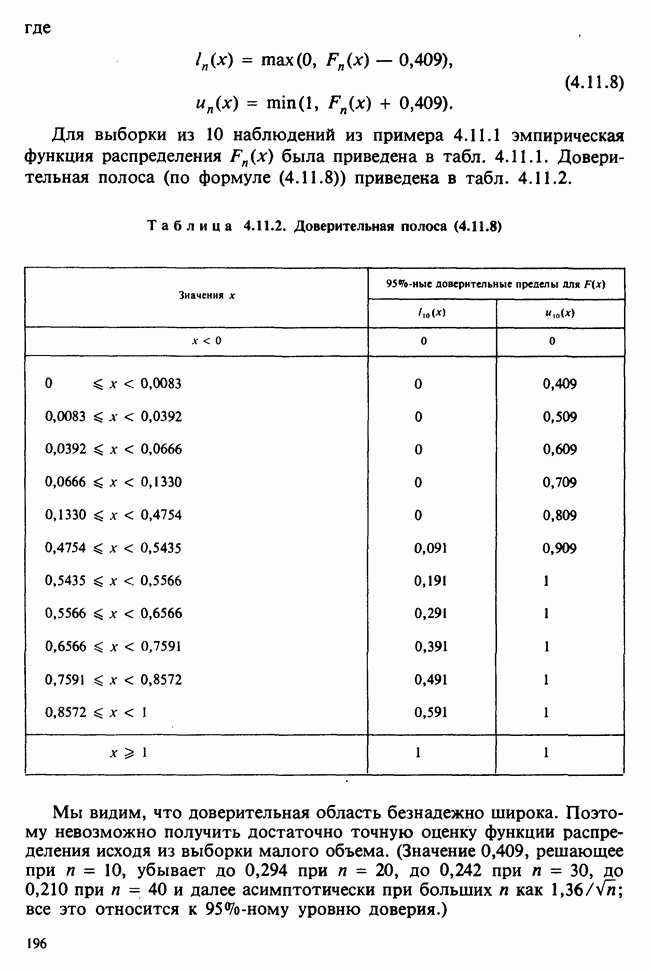
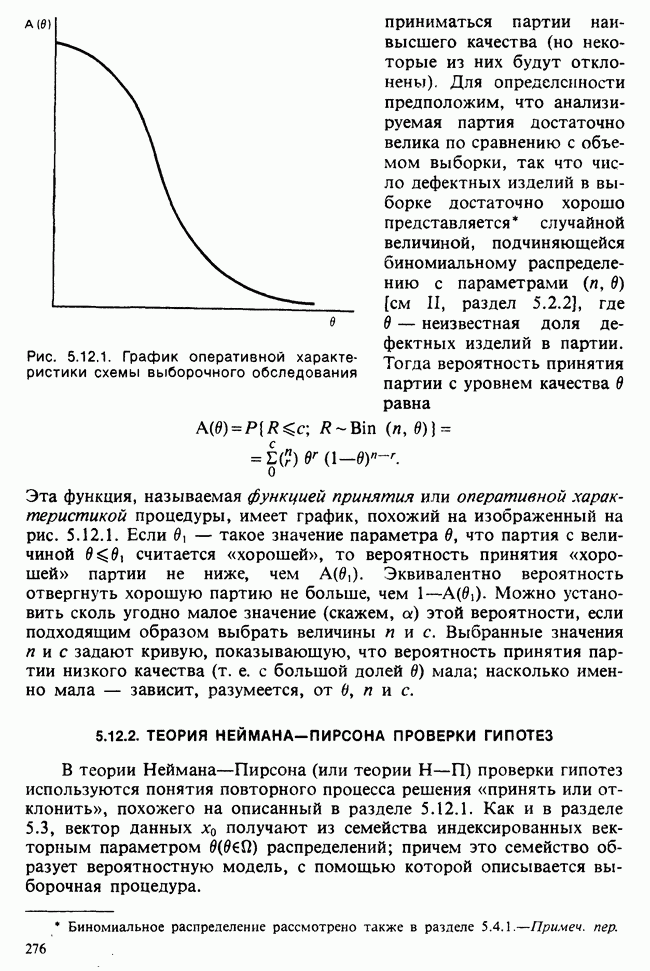
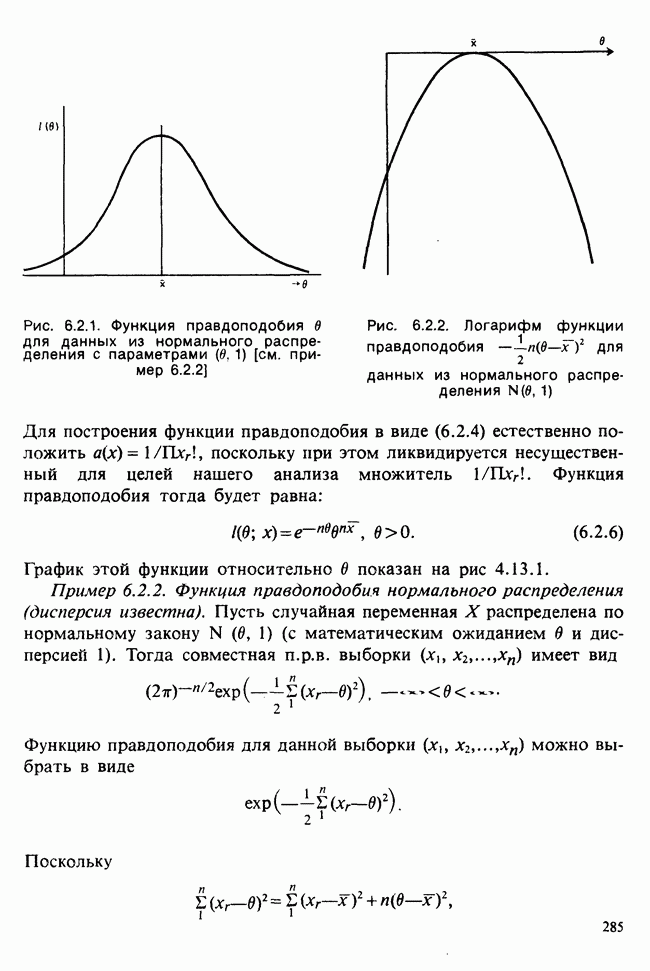
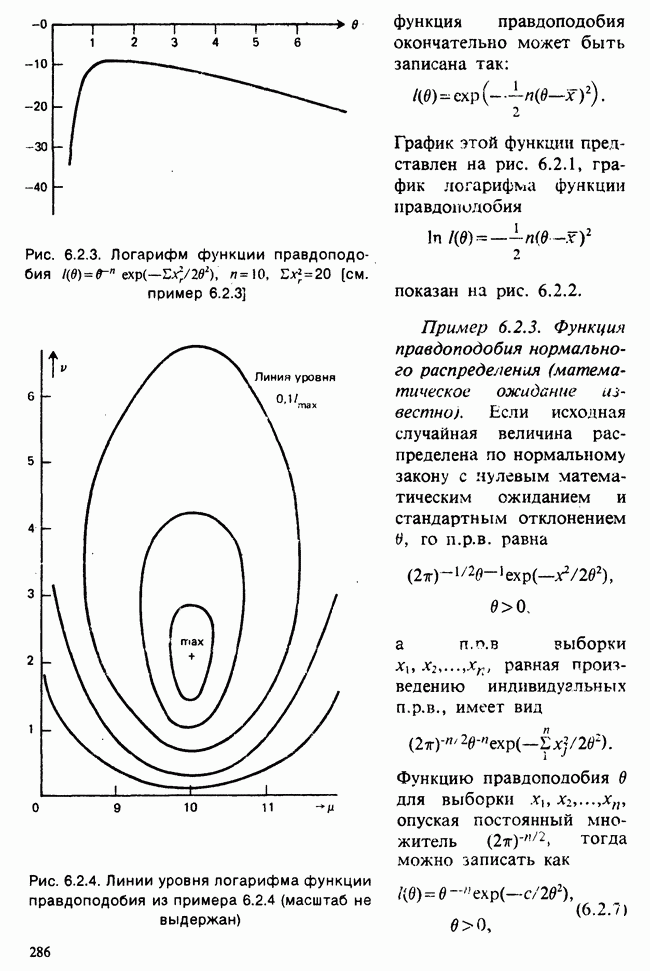
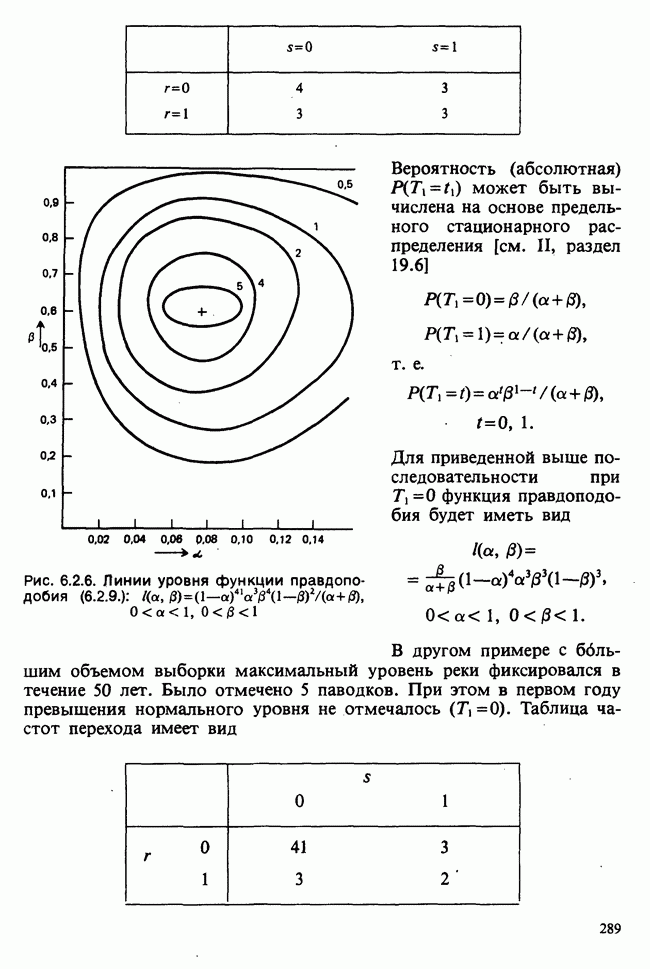
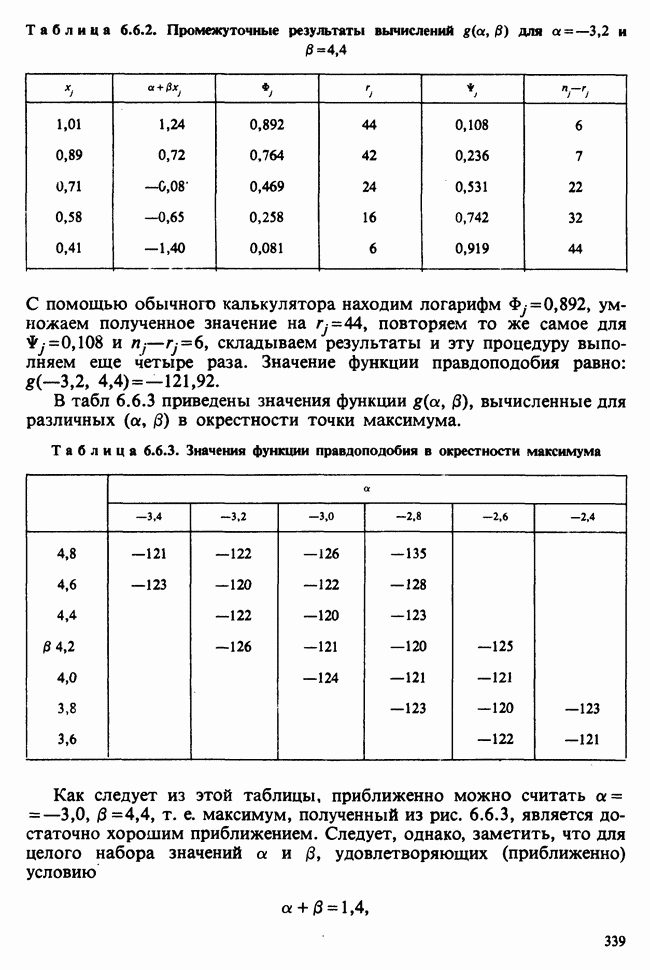
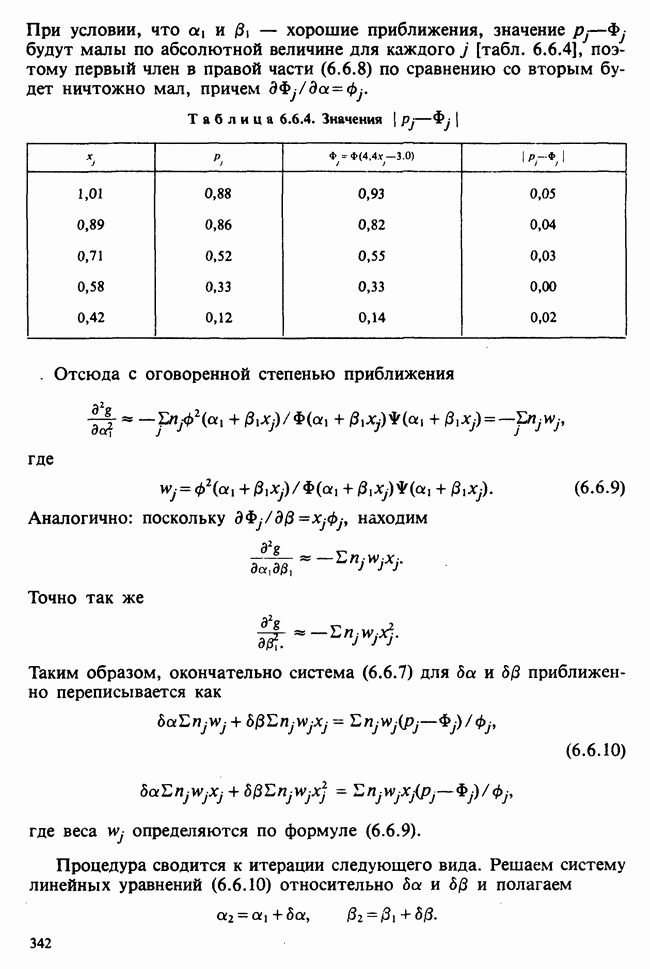
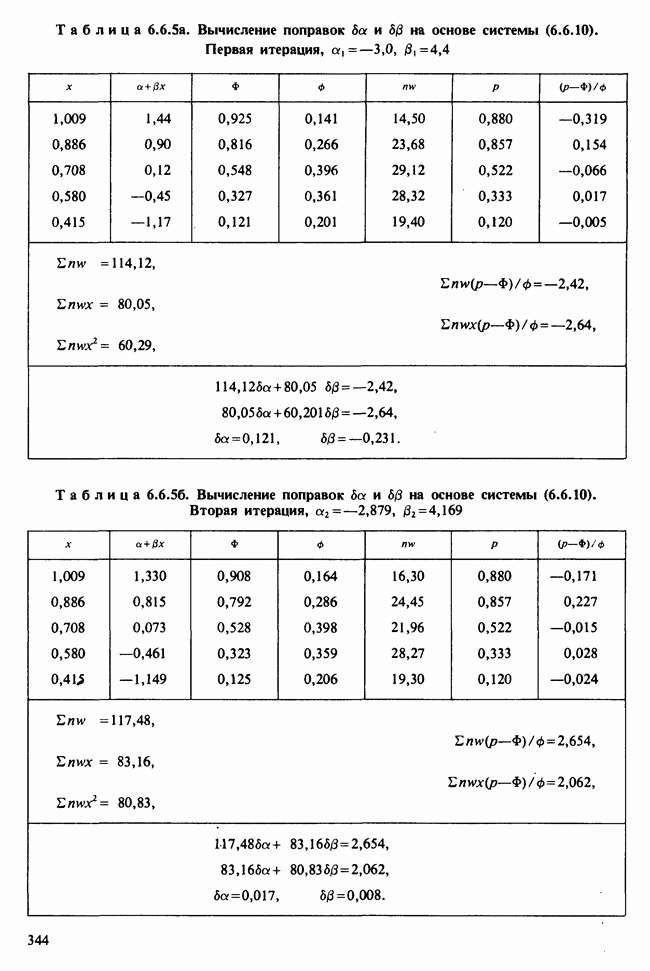
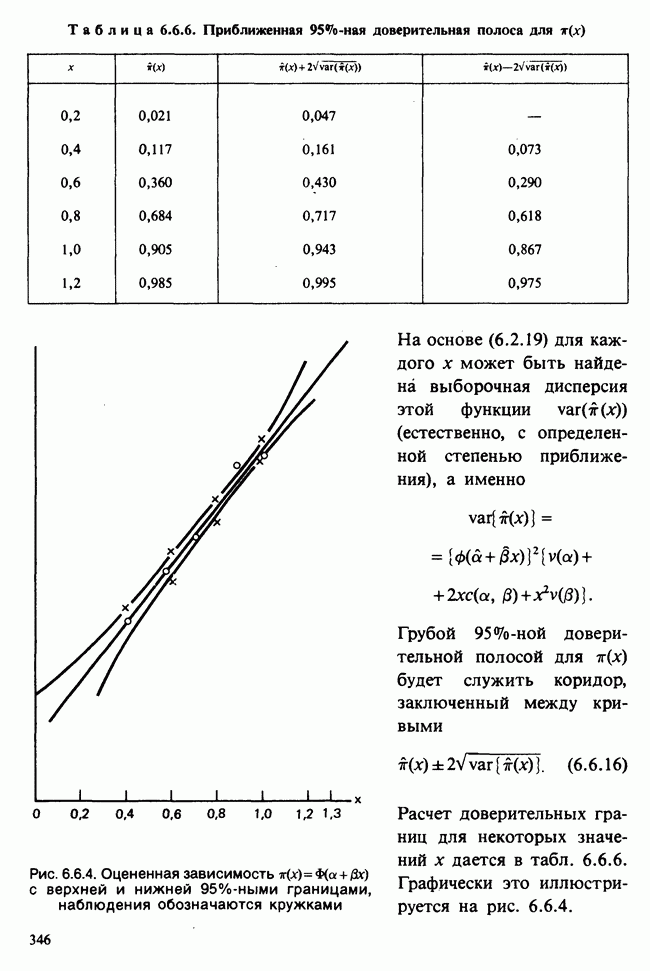
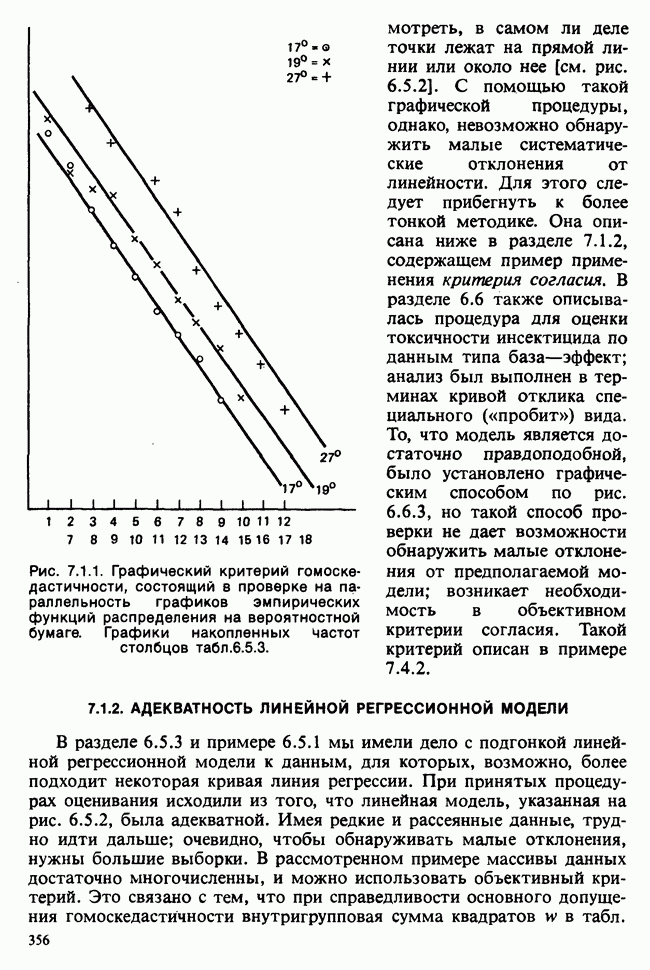
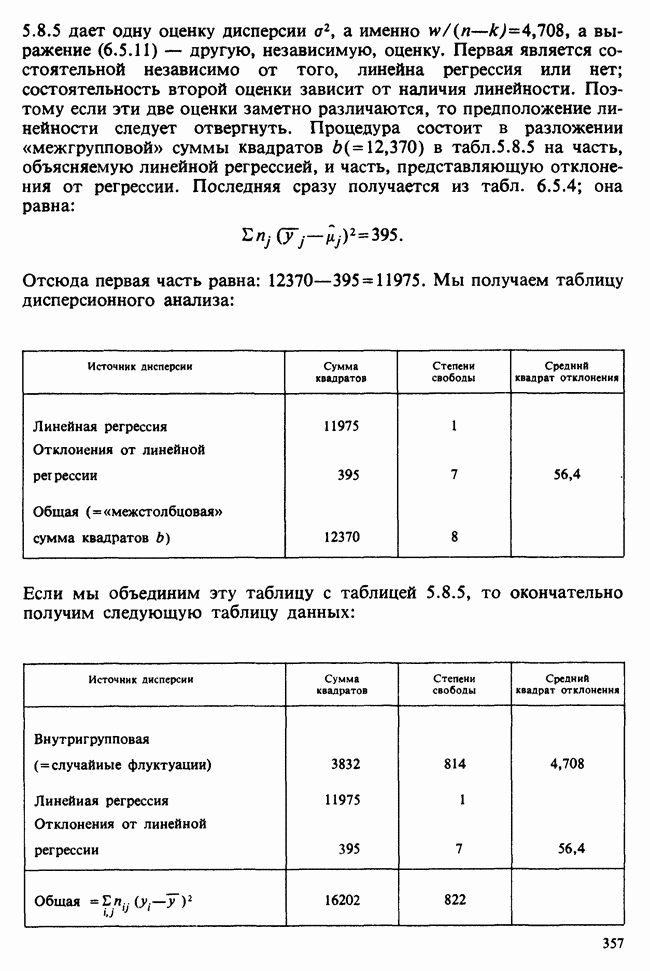
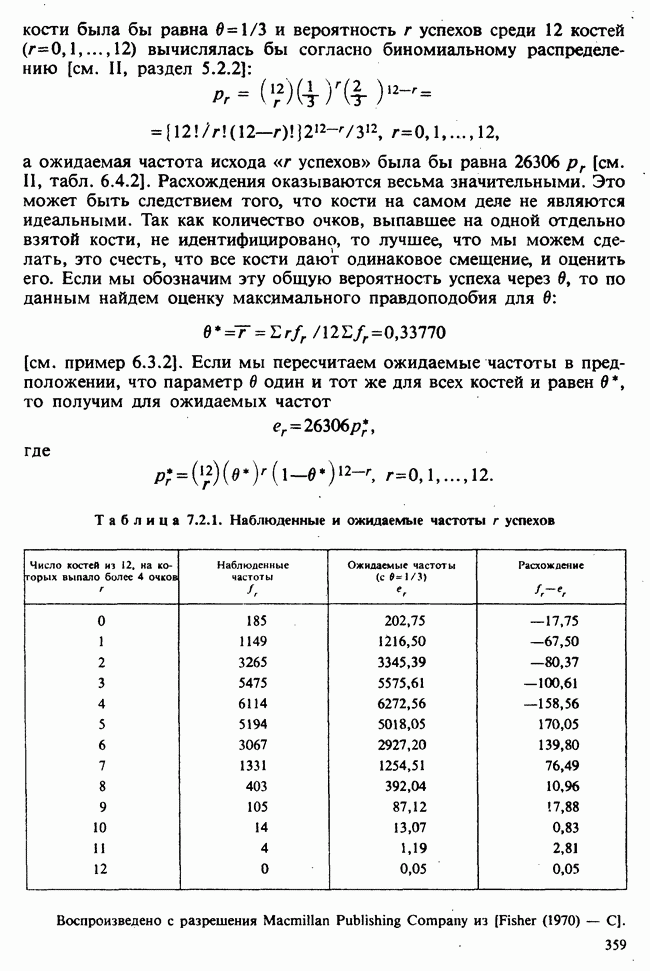
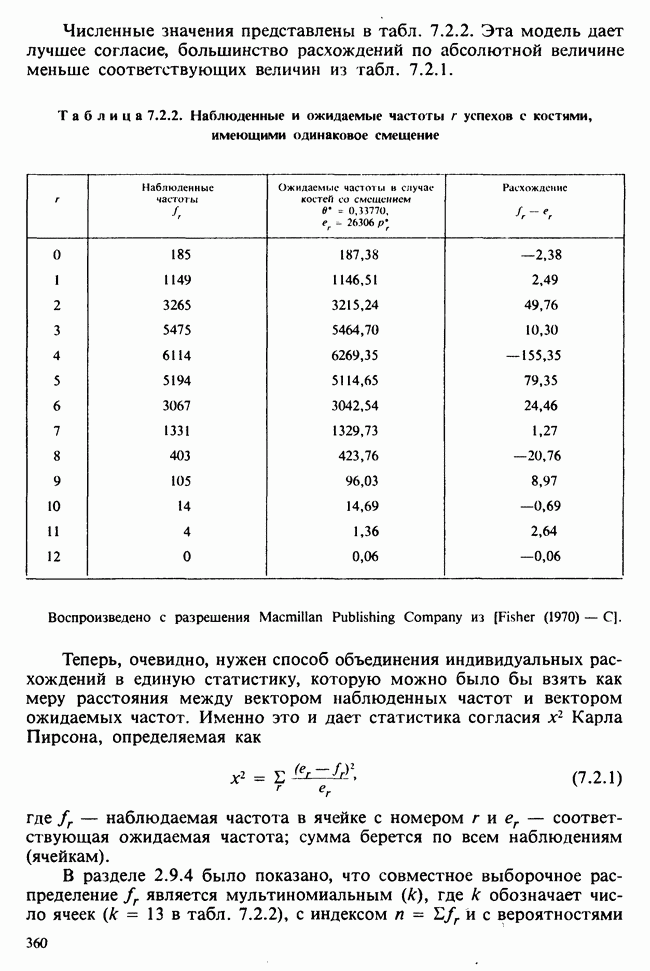
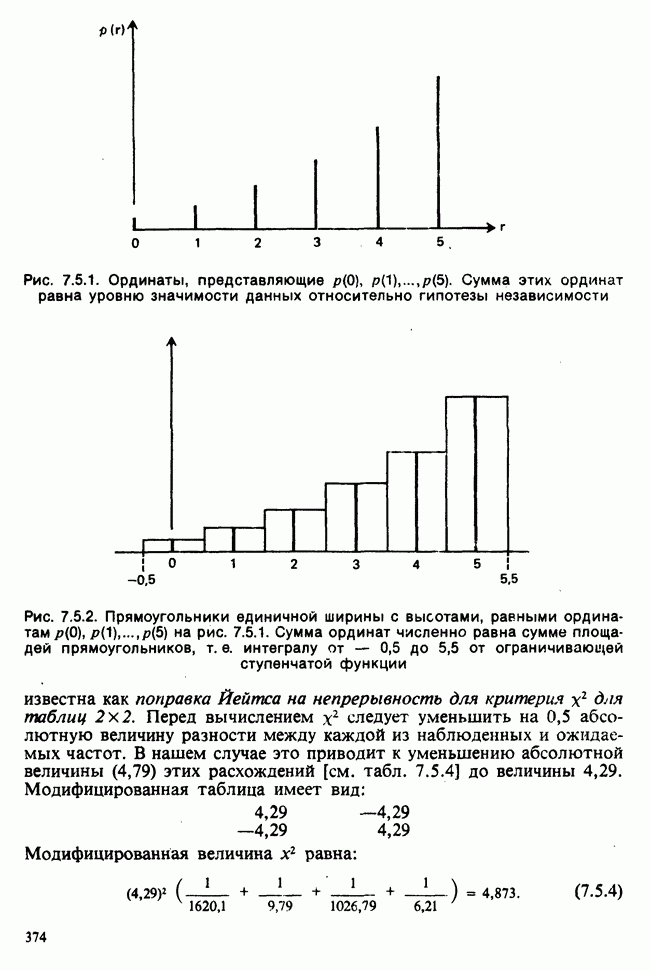
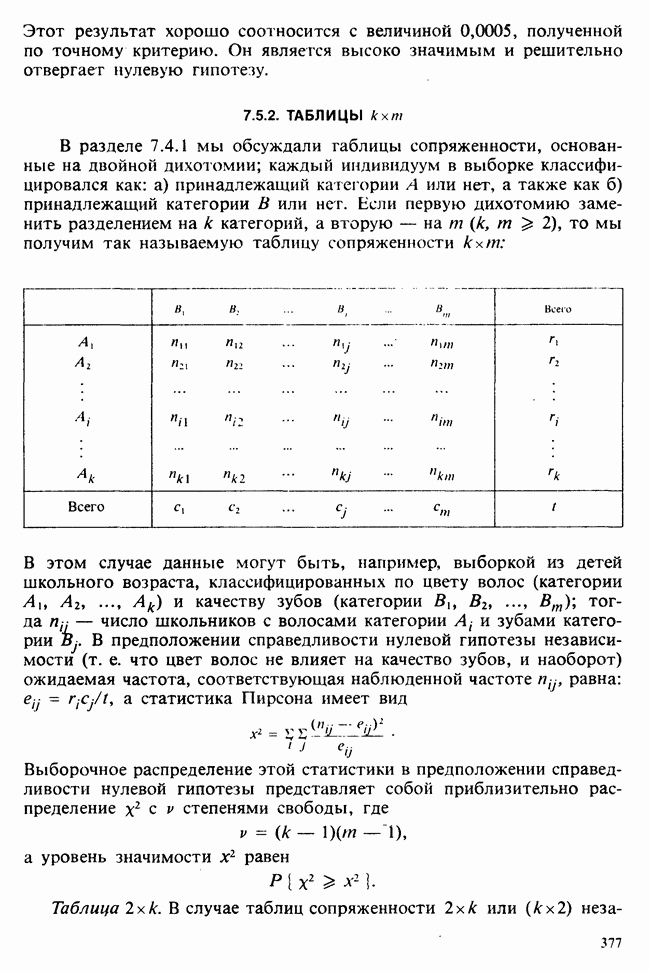
Глава 2. ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯ
2.1. МОМЕНТЫ И ДРУГИЕ СТАТИСТИКИ
2.1.1. СТАТИСТИКА
Как уже объяснялось в гл. 1, если мы стремимся описать изменчивые и неопределенные черты природы, то разумно это сделать, пользуясь понятиями случайной величины и ее распределений вероятностей (см. II, гл. 4). При этом обычно постулируется, что эти распределения должны принадлежать к определенным семействам, предполагаемым в явном виде или подразумеваемым. Тогда одной из целей статистического исследования будет выделение того члена заданного семейства рассматриваемого распределения, с которым мы имеем дело, исключение (по крайней мере, условное) некоторых возможных членов в семействе или отрицание либо подтверждение принадлежности к постулированному семейству в целом. Эти цели могут быть достигнуты в результате проведения соответствующего анализа доступных данных. Оказывается, что основную роль в анализе играют комбинации величин, получаемых из имеющихся данных, каждая из которых называется статистикой. Эти комбинации, заслуживающие отдельного рассмотрения, зависят от природы распределений вероятностей, включенных в анализ, а также от характера выводов, которые пытаются получить.
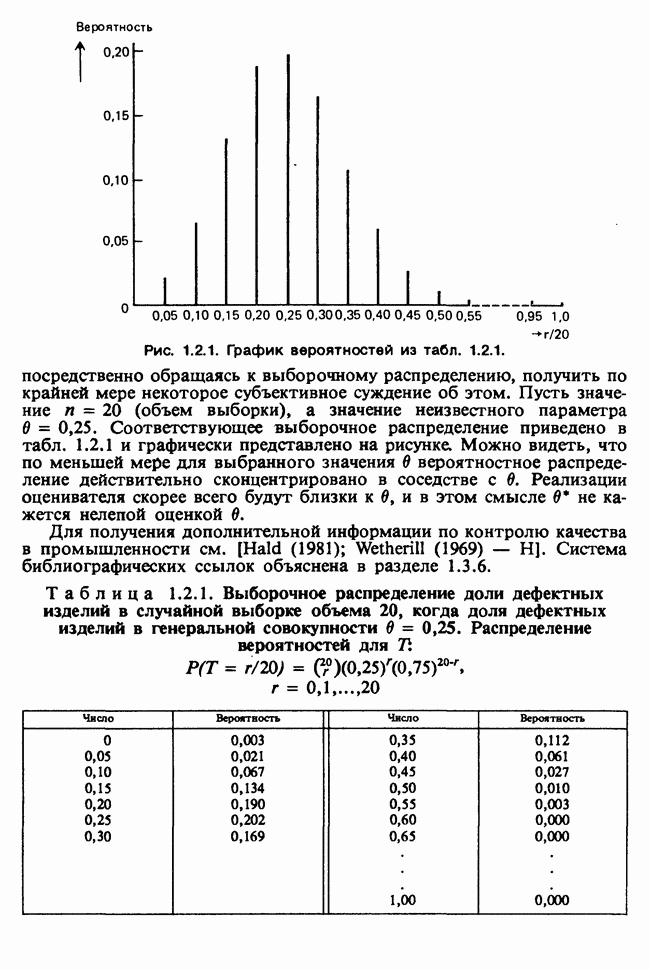
Пример 2.1.1. Выборочная проверка. Рассмотрим набор (группу или партию) более или менее схожих предметов, состоящих из отдельных единиц, которые, однако, различаются по определенному признаку, измеряемому или наблюдаемому. Например, это могли бы быть обработанные бруски длиной номинально 50 мм. Действительная же длина их несколько меняется вследствие флуктуаций в процессе производства. Желательно оценить долю брусков, длина которых колеблется в заданном диапазоне, например между 49 и 51 мм. Такие бруски будем называть годными, в то время как остальные будут называться дефектными. По практическим соображениям оказывается неприемлемым проверить все бруски в партии. Вместо этого можно проверить выборку из брусков, определив заранее ее объем, например 100 штук. При этом потенциально доступная информация — размещение меток
«годный», «дефектный» на каждом из 100 проверенных брусков. Если бы выборка формировалась случайно (и были бы предприняты обычные предосторожности, чтобы гарантировать ее случайность), т. е. так, чтобы у каждого из различимых (неупорядоченных) подмножеств по 100 брусков были бы одинаковые шансы оказаться выбранным, то полной информации об этих 100 метках на брусках не потребовалось бы. При последующем анализе понадобилось бы только общее число дефектных единиц в выборке (например, четыре).
В этом примере статистикой является просто общее число дефектных единиц в выборке.
Для выборки объема  извлеченной из партии объема
извлеченной из партии объема  содержащей
содержащей  дефектных единиц (где
дефектных единиц (где  неизвестно), число дефектных единиц будет случайной величиной (скажем,
неизвестно), число дефектных единиц будет случайной величиной (скажем,  Вероятность того, что в данной выборке окажется определенное число (например,
Вероятность того, что в данной выборке окажется определенное число (например,  ) дефектных единиц, равняется
) дефектных единиц, равняется

Это элемент семейства гипергеометрических распределений [см. II, раздел 5.3]. Неизвестным параметром, с помощью которого идентифицируют члены семейства, является переменная  относящаяся к партии в целом. Выводы относительно значения
относящаяся к партии в целом. Выводы относительно значения  должны основываться на статистике (в нашем примере равной четырем), т. е. на полном числе дефектных единиц в выборке [см. пример 2.1.1].
должны основываться на статистике (в нашем примере равной четырем), т. е. на полном числе дефектных единиц в выборке [см. пример 2.1.1].
Пример 2.1.2 (продолжение). Использование упрощенных аппроксимирующих семейств распределений. Если бы в примере 2.1.1 объем партии был гораздо больше, чем объем выборки (например,  то можно было бы с небольшой погрешностью заменить гипергеометрическое распределение (2.1.1) биномиальным (см. II, раздел
то можно было бы с небольшой погрешностью заменить гипергеометрическое распределение (2.1.1) биномиальным (см. II, раздел

Полное число дефектных единиц в выборке по-прежнему оставалось бы подходящей статистикой.
Пример 2.1.3 (продолжение). Введенное в примере 2.1.1 семейство распределений предопределяется процедурой формирования выборки. Теперь предположим, что вместо того, чтобы пытаться оценить долю  скажем, брусков, длина которых х лежит в заданном интервале
скажем, брусков, длина которых х лежит в заданном интервале  надо для всех пар значений и и
надо для всех пар значений и и  оценить долю
оценить долю  тех брусков, длина которых х принадлежит интервалу Эта задача эквивалентна следующей: будем считать измеренную длину х определенного бруска реализацией непрерывной случайной величины X [см. II, раздел 10.1] и оценим распределение вероятностей X. Это в свою очередь можно было бы интерпретировать следующим образом: постулируем для X нормальное распределение с математическим ожиданием
тех брусков, длина которых х принадлежит интервалу Эта задача эквивалентна следующей: будем считать измеренную длину х определенного бруска реализацией непрерывной случайной величины X [см. II, раздел 10.1] и оценим распределение вероятностей X. Это в свою очередь можно было бы интерпретировать следующим образом: постулируем для X нормальное распределение с математическим ожиданием  и стандартным отклонением а [см. II, раздел 11.4] и оценим значения параметров распределения
и стандартным отклонением а [см. II, раздел 11.4] и оценим значения параметров распределения  . [Естественно подумать, что это несостоятельный постулат, так как в принципе
. [Естественно подумать, что это несостоятельный постулат, так как в принципе
можно получить сколь угодно большие наблюдаемые значения  если величина X нормально распределена. В то же время длина наших брусков не может быть меньше нуля и практически не будет больше, чем например, 60 мм. Однако фактически предположение нормальности может оказаться вполне разумным, если стандартное отклонение будет малым [см. II, разделы 9.2 и 11.4.3], так как тогда становится пренебрежимо малой вероятность очень больших отклонений от среднего.] В этом случае подходящими статистиками были бы
если величина X нормально распределена. В то же время длина наших брусков не может быть меньше нуля и практически не будет больше, чем например, 60 мм. Однако фактически предположение нормальности может оказаться вполне разумным, если стандартное отклонение будет малым [см. II, разделы 9.2 и 11.4.3], так как тогда становится пренебрежимо малой вероятность очень больших отклонений от среднего.] В этом случае подходящими статистиками были бы  раздел 6.4.1] (при условии, что заданы длины
раздел 6.4.1] (при условии, что заданы длины  брусков в выборке объема
брусков в выборке объема  существенно меньше, чем объем партии).
существенно меньше, чем объем партии).
Пример 2.1.4. Нестатическая ситуация. В примерах 2.1.1, 2.1.2 и 2.1.3 мы имели дело с выборками, взятыми из фиксированного распределения. Такие случаи можно назвать статическими. Рассмотрим нестатическую ситуацию. На пружине, закрепленной с одного конца, подвешен определенный груз На результат измерения длины пружины  влияют ошибки измерения. Процедура повторяется для
влияют ошибки измерения. Процедура повторяется для  Веса
Веса  считаются точно известными числами. Переменные такого типа часто называют неслучайными переменными. Соответствующие длины пружины
считаются точно известными числами. Переменные такого типа часто называют неслучайными переменными. Соответствующие длины пружины  содержат ошибки. Удобная модель: для каждого
содержат ошибки. Удобная модель: для каждого  будем рассматривать у, как реализацию нормально распределенной случайной переменной У, - с математическим ожиданием [см. II, раздел 8.1]
будем рассматривать у, как реализацию нормально распределенной случайной переменной У, - с математическим ожиданием [см. II, раздел 8.1]  (закон Гука) и дисперсией [см. II, раздел
(закон Гука) и дисперсией [см. II, раздел  (одинаковой для всех
(одинаковой для всех  ). Цель эксперимента состоит в том, чтобы оценить модуль упругости 0. Оказывается, что соответствующими этому случаю статистиками будут и
). Цель эксперимента состоит в том, чтобы оценить модуль упругости 0. Оказывается, что соответствующими этому случаю статистиками будут и  [см. пример 4.5.3]. Они представляют собой комбинации наблюдаемых значений
[см. пример 4.5.3]. Они представляют собой комбинации наблюдаемых значений  случайных переменных и связанных с ними неслучайных переменных
случайных переменных и связанных с ними неслучайных переменных 
Теперь суммируем результаты анализа рассмотренных примеров в виде следующего определения.
Определение 2.1.1. Статистика. Пусть  обозначает множество наблюдаемых значений случайных переменных, а
обозначает множество наблюдаемых значений случайных переменных, а  — множество (известных) значений связанных с ними неслучайных переменных. Статистикой называется любая функция этих переменных, например
— множество (известных) значений связанных с ними неслучайных переменных. Статистикой называется любая функция этих переменных, например  количественное значение которой может быть рассчитано, как только будут указаны выборочные значения
количественное значение которой может быть рассчитано, как только будут указаны выборочные значения  и величины связанных с ними переменных
и величины связанных с ними переменных 
В любой процедуре вывода могут быть использованы только статистики. Например, согласно теории оценивания надо указать, каким членом заданного семейства распределений порождена выборка. При этом требуется дать численное значение (оценку) каждому параметру, который содержится в математических формулах, определяющих семейство
[см. гл. 3]. Каждое такое численное значение должно быть статистикой. Практические правила оценивания сводятся к выбору статистик, наиболее подходящих для этой цели.
Статистики, которые строятся в теории оценивания и в теории проверки статистических гипотез, часто оказываются комбинациями простой системы статистик, известных как выборочные моменты и являющихся выборочными аналогами моментов генеральной совокупности.