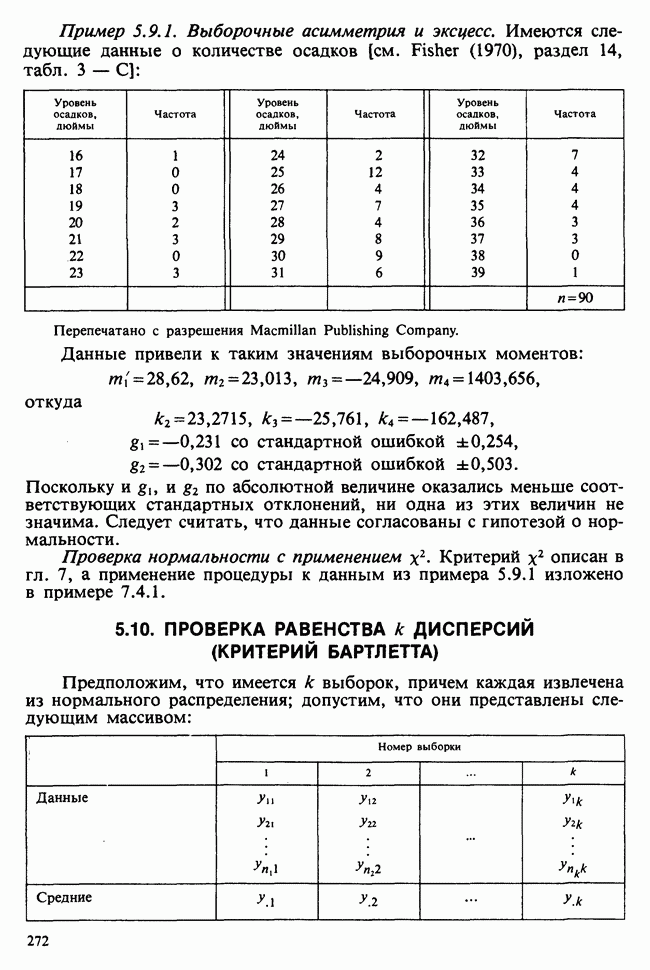
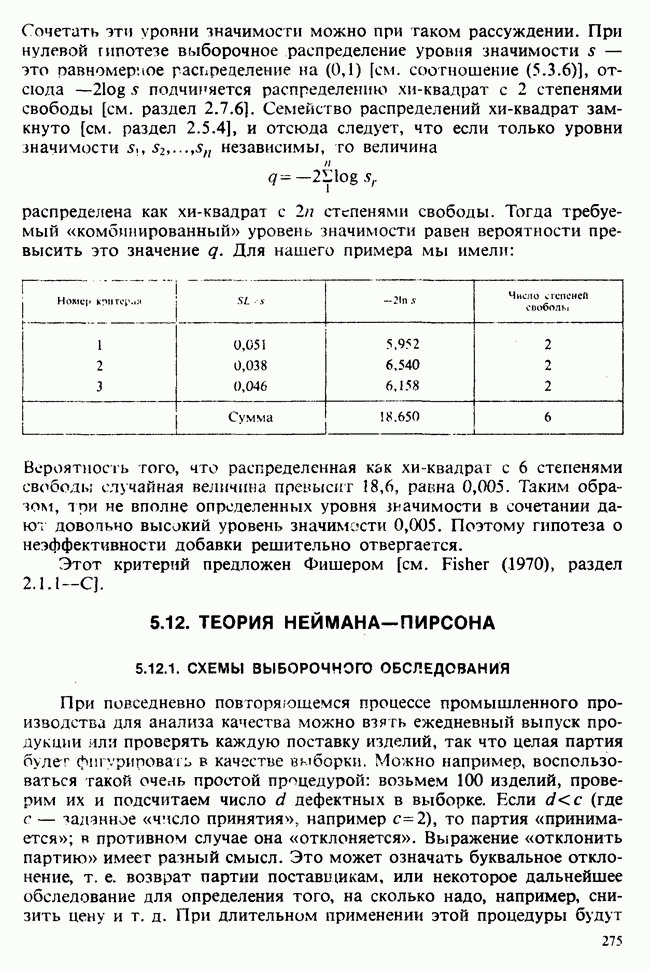
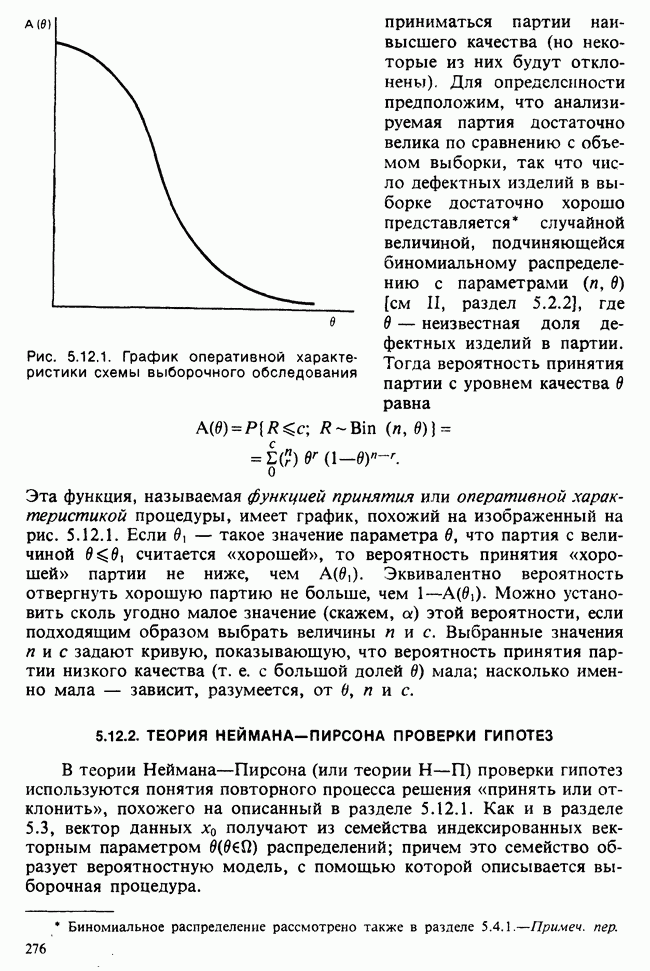
4.5. ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ ПРИ НЕСКОЛЬКИХ ПАРАМЕТРАХ
Из числа вопросов, возникающих при переходе к доверительным интервалам для нескольких параметров, выделим следующие:
1) можно ли получить индивидуальные (отдельные) доверительные интервалы для каждого из параметров?
 можно ли получить доверительные интервалы для различных комбинаций параметров, таких, как их сумма, разность, отношение и т. д.?
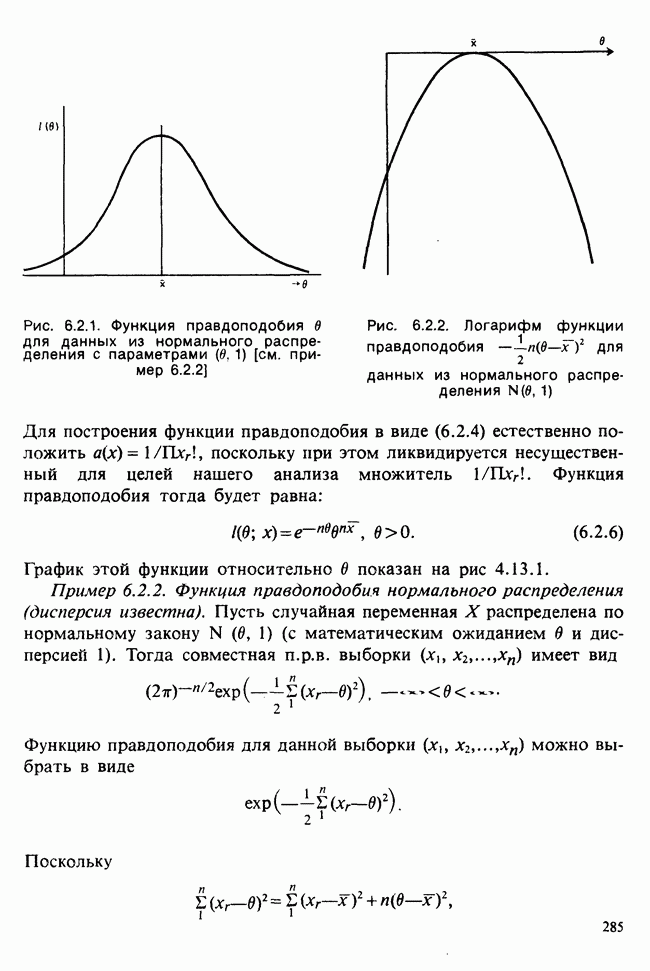
можно ли получить доверительные интервалы для различных комбинаций параметров, таких, как их сумма, разность, отношение и т. д.?
3) можно ли получить (многомерные) доверительные области для нескольких параметров сразу?
Эти и близкие им проблемы излагаются в гл. 8 в аспекте дисперсионного анализа. Вопросы 1) и 2) мы коротко обсудим в этом разделе. Более глубокое рассмотрение, затрагивающее также вопрос 3), содержится в разделе 4.9.
4.5.1. ИНДИВИДУАЛЬНЫЕ ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ
Прежде всего мы приведем примеры индивидуальных доверительных интервалов для каждого из одномерных параметров, взяв дисперсию  и математическое ожидание семейства
и математическое ожидание семейства  [см. пример 4.5.1], а также каждый из трех параметров, рассматриваемых в теории линейной регрессии [см. пример 4.5.3].
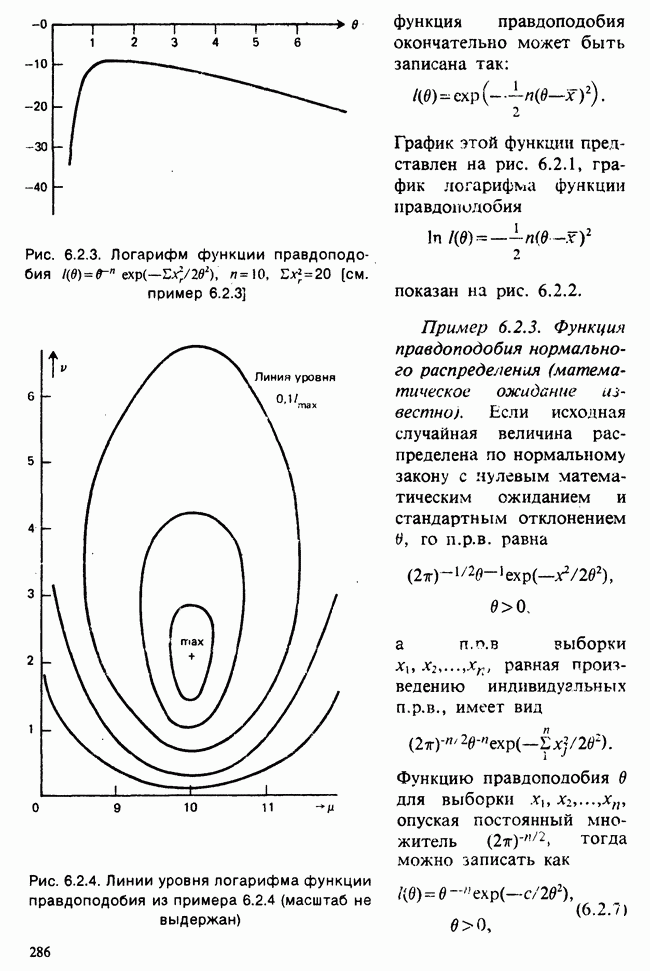
[см. пример 4.5.1], а также каждый из трех параметров, рассматриваемых в теории линейной регрессии [см. пример 4.5.3].
Пример 4.5.1. Доверительные интервалы для дисперсии (или для стандартного отклонения)  распределения. Пусть
распределения. Пусть  — выборка из нормального
— выборка из нормального  распределения. Тогда при
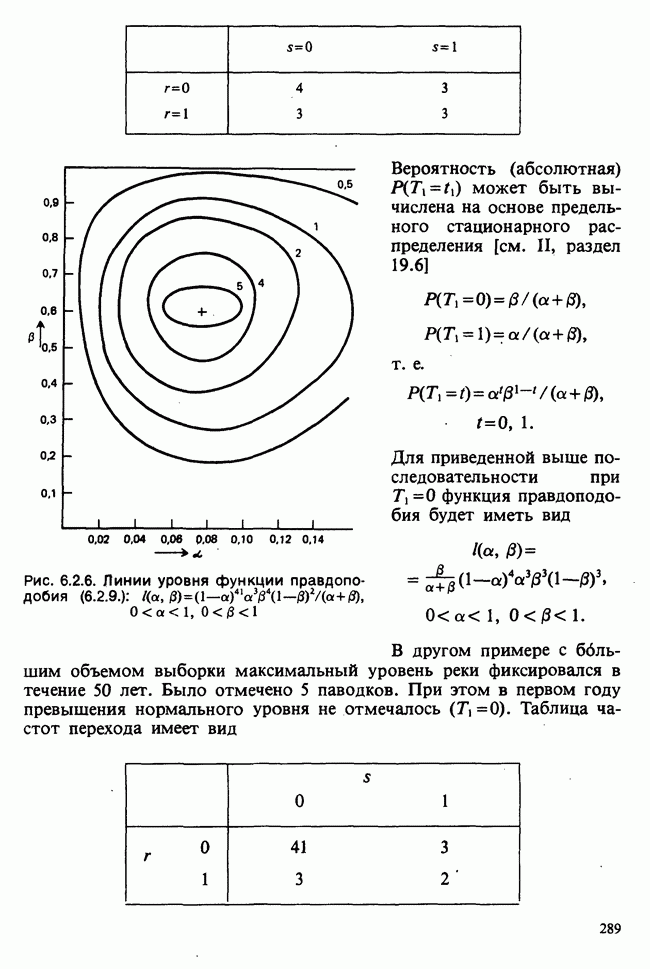
распределения. Тогда при  статистика
статистика  несмещенная оценка
несмещенная оценка  есть реализация случайной величины
есть реализация случайной величины  , где
, где  — независимые
— независимые  случайные величины,
случайные величины,  . Тогда величина
. Тогда величина  распределена по закону
распределена по закону  , т. е. по закону
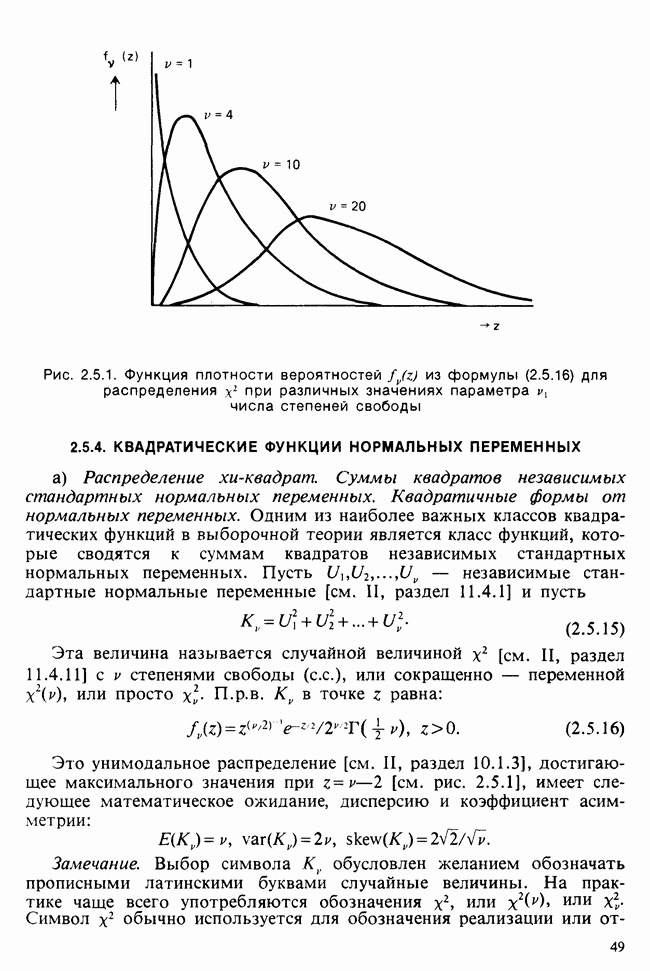
, т. е. по закону  степенями свободы [см. раздел 2.5.4, II, раздел 11.4.11].
степенями свободы [см. раздел 2.5.4, II, раздел 11.4.11].
Для нее мы можем построить симметричный  -ный вероятностный интервал
-ный вероятностный интервал  , где
, где  определяются так, чтобы
определяются так, чтобы

Значения  могут быть найдены по таблицам распределения
могут быть найдены по таблицам распределения  [см. приложение 6]. Тогда с вероятностью
[см. приложение 6]. Тогда с вероятностью 

или, что равносильно,

Это в свою очередь равносильно

Таким образом,  -ные доверительные интервалы для
-ные доверительные интервалы для  следующие:
следующие:

а для 

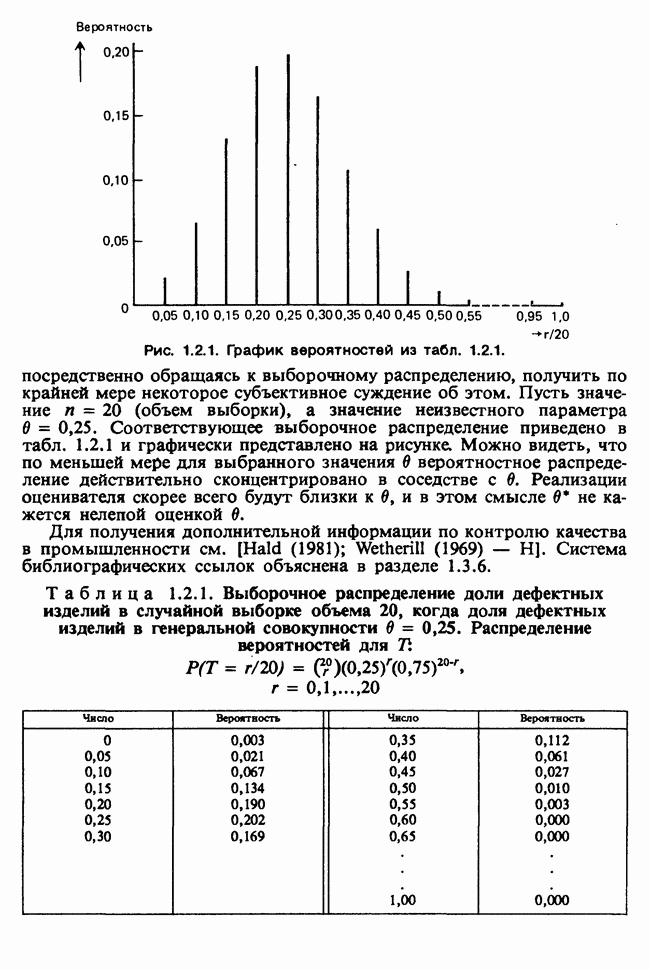
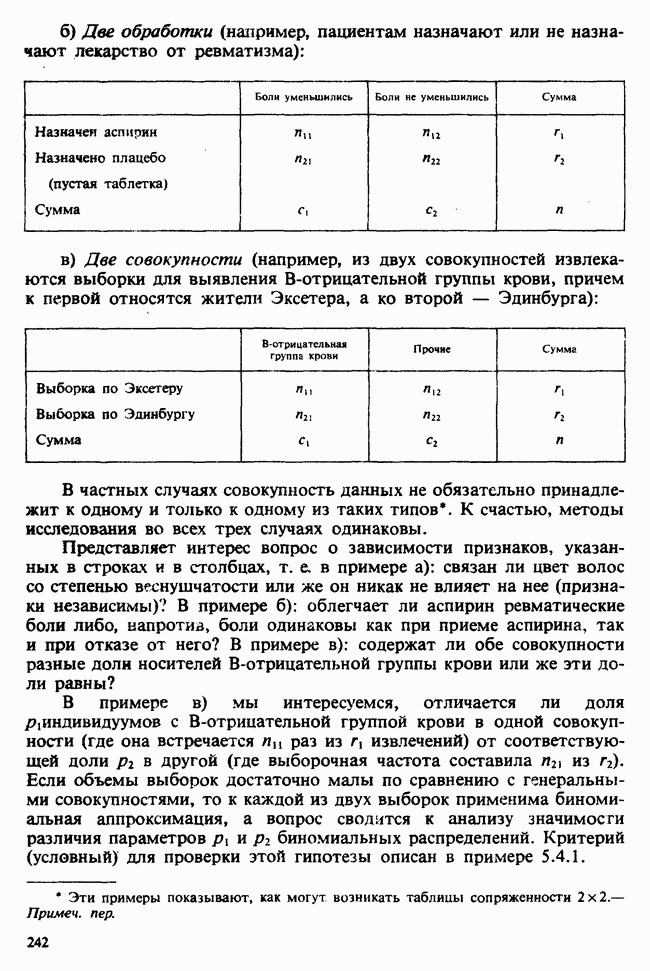
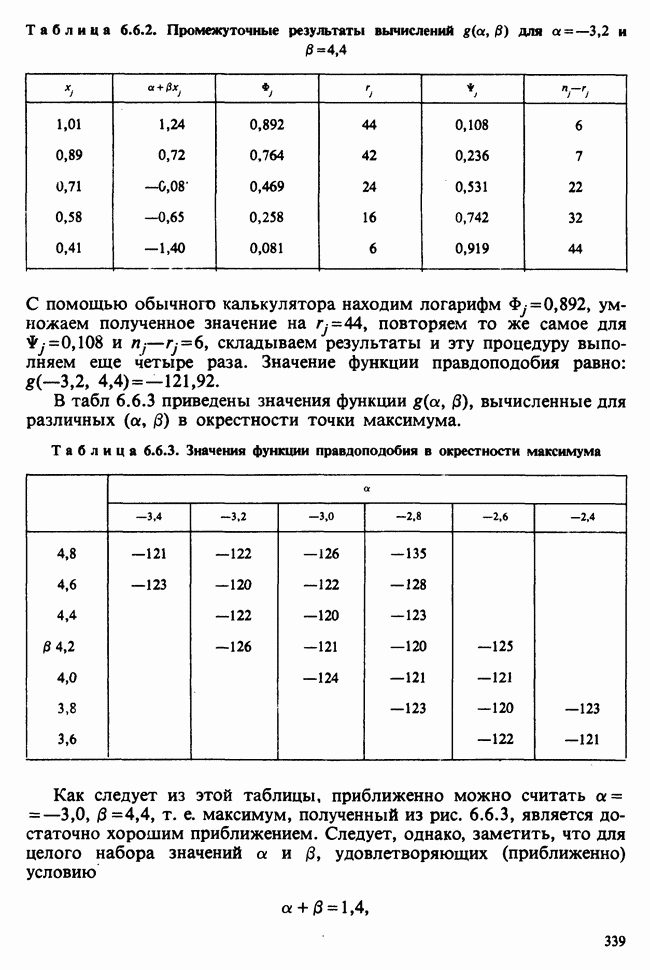
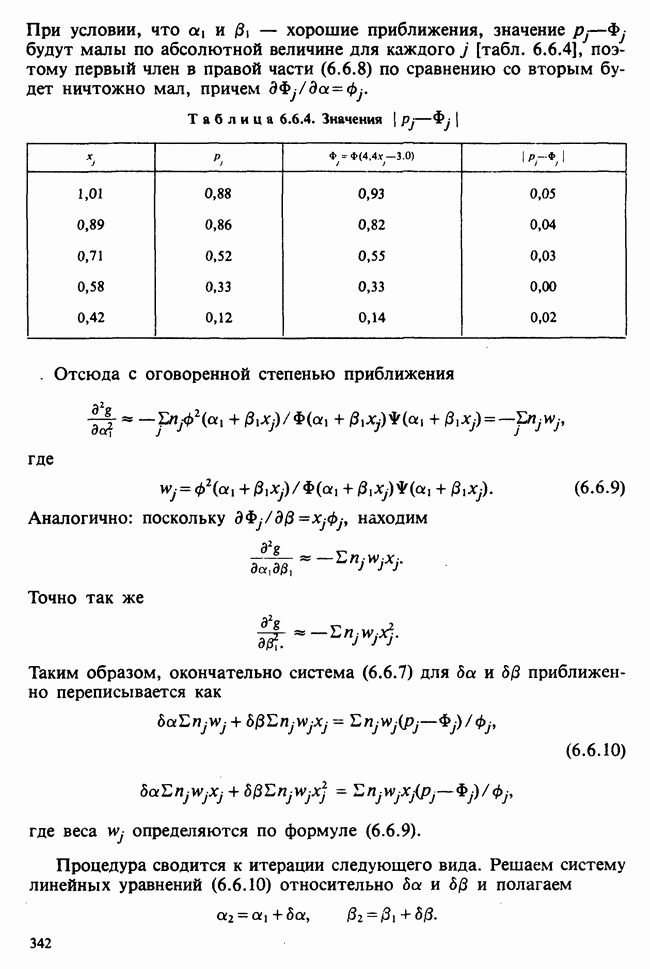
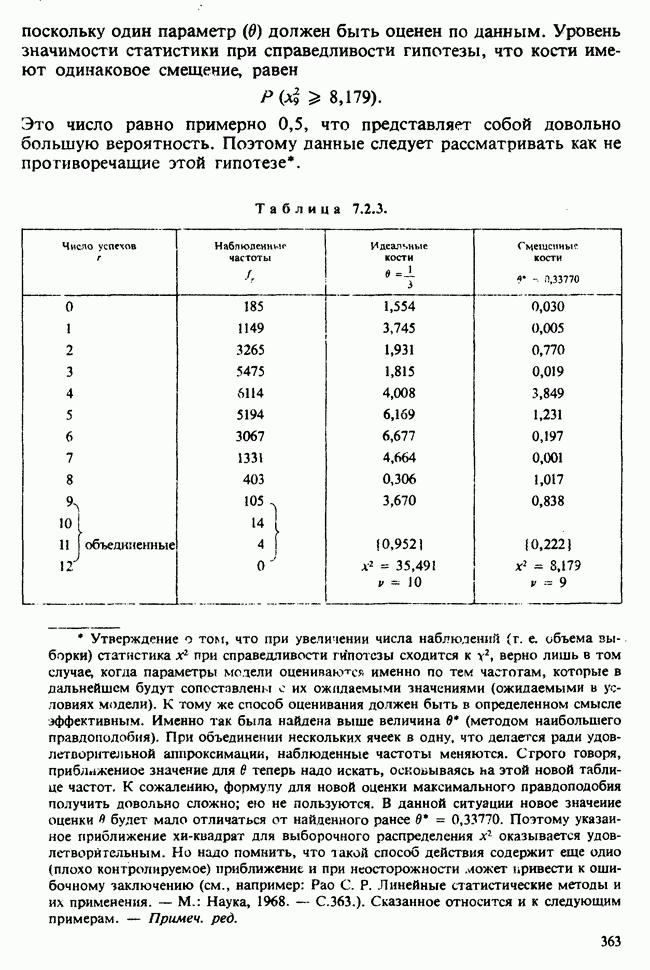
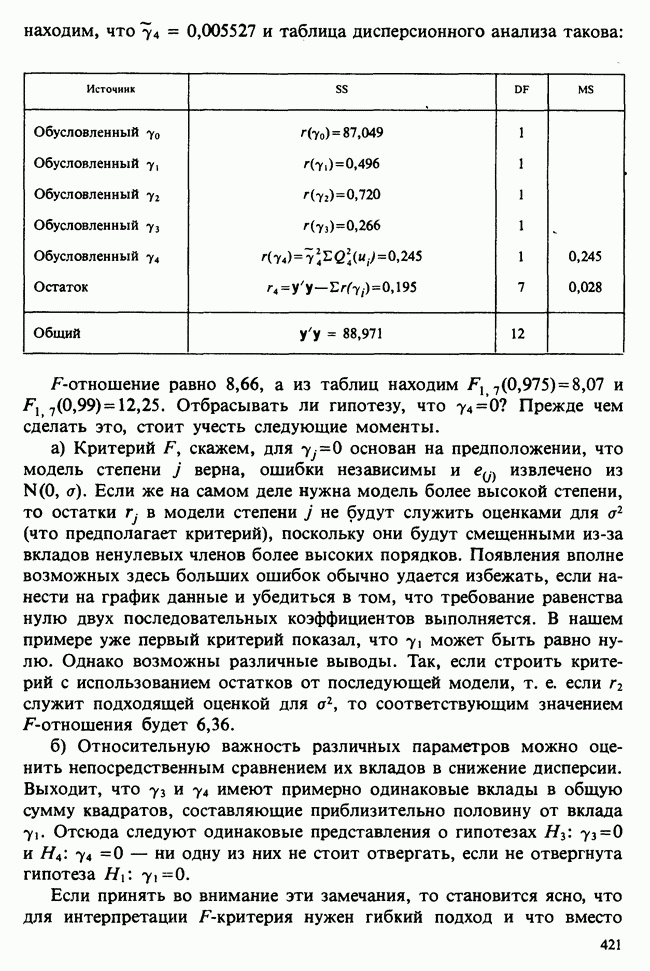
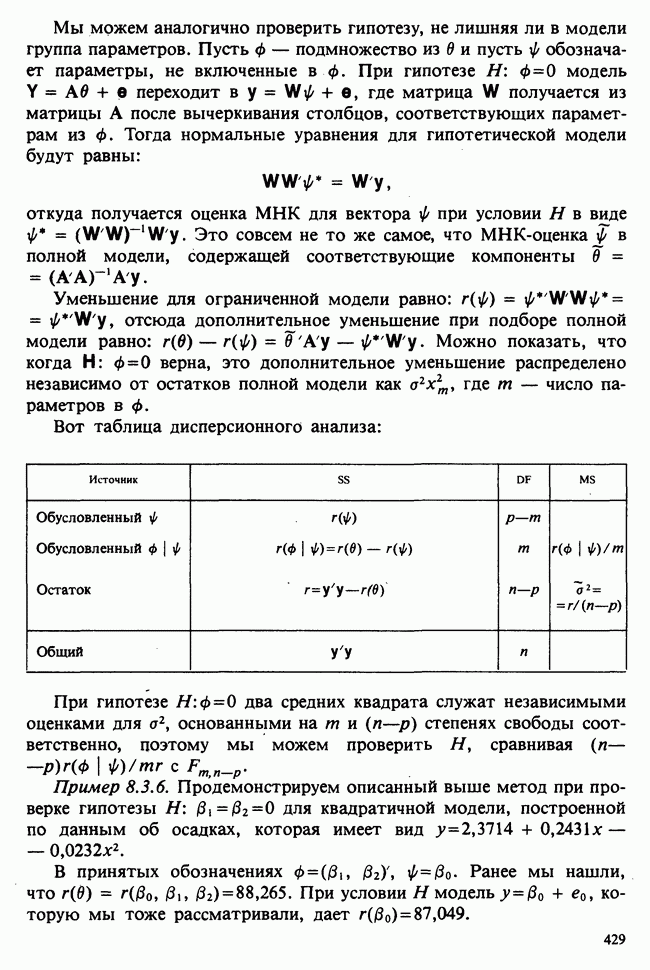
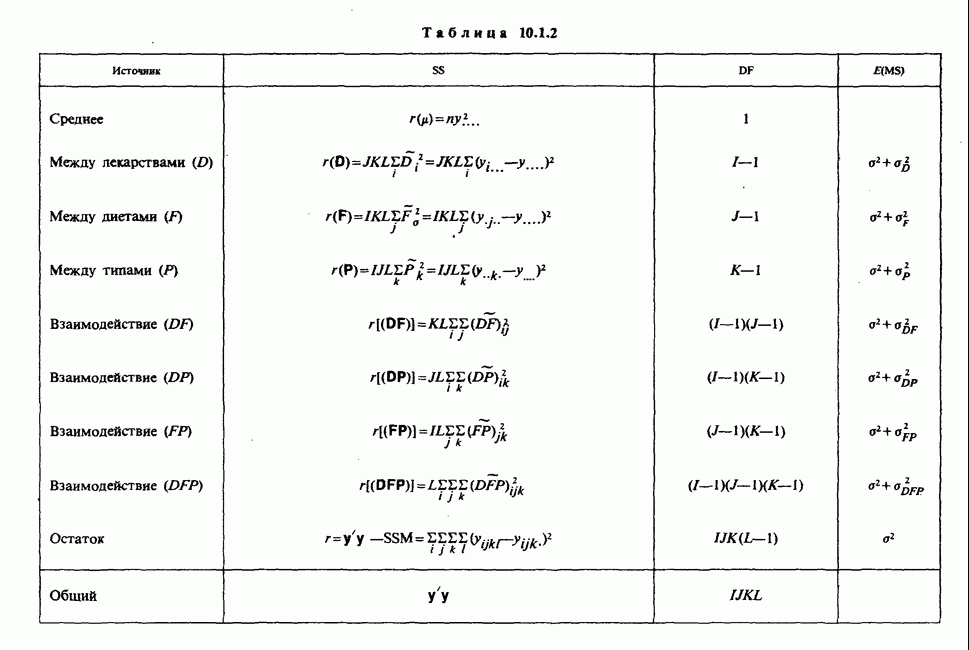
В этом примере наличие второго неизвестного параметра  ничуть не изменило нашего вывода [ср. с примером 5.8.6]. Данные, представленные в табл. 4.5.1, связаны с эффективностью двух разных видов снотворного [см. Fisher (1970)-С]. Пациенты принимали каждый из этих препаратов через промежутки времени достаточно большие, чтобы можно было считать его действие независимым.
ничуть не изменило нашего вывода [ср. с примером 5.8.6]. Данные, представленные в табл. 4.5.1, связаны с эффективностью двух разных видов снотворного [см. Fisher (1970)-С]. Пациенты принимали каждый из этих препаратов через промежутки времени достаточно большие, чтобы можно было считать его действие независимым.
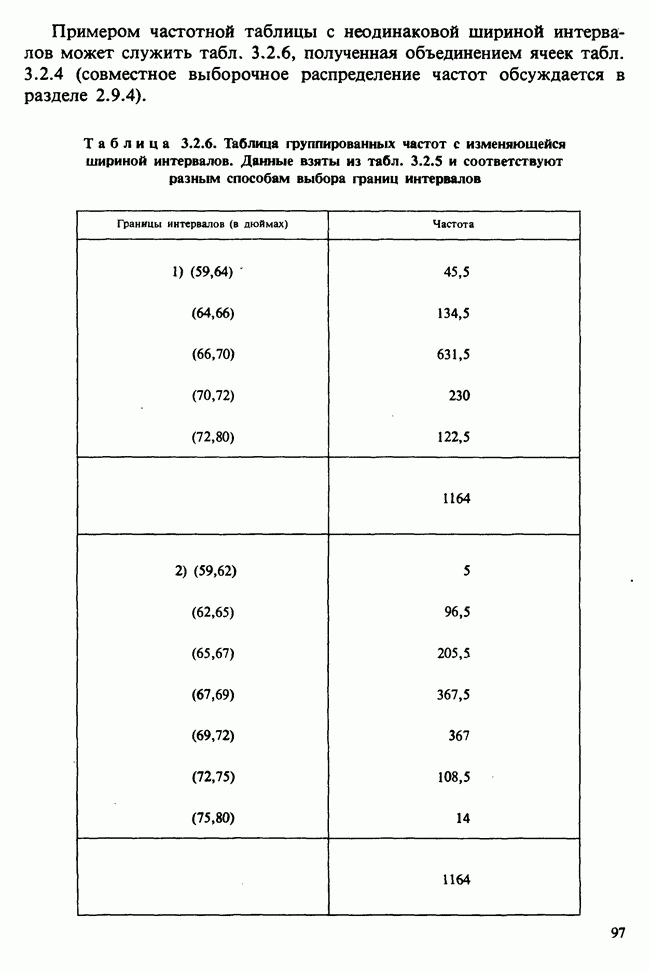
Таблица 4.5.1. (см. скан) Перепечатано с разрешения Macmillan Publishing Company из книги Statistical Methods foi Research Vorkers, 14th edition, by Sir Ronald A. Fischer, copyright 1970 University of Adelaide
Числа в последнем столбце могут рассматриваться как независимые наблюдения  над мерой сравнительной эффективности препаратов, за которую здесь взята разность их действия. Мы предполагаем, что
над мерой сравнительной эффективности препаратов, за которую здесь взята разность их действия. Мы предполагаем, что  — распределены нормально с параметрами
— распределены нормально с параметрами  , и берем
, и берем  качестве оценки для
качестве оценки для  статистику
статистику

с

Итак, оценки для  есть
есть  соответственно. Симметричный 95%-ный вероятностный интервал для
соответственно. Симметричный 95%-ный вероятностный интервал для  с 9 степенями свободы
с 9 степенями свободы  следовательно, 95%-ный доверительный интервал для
следовательно, 95%-ный доверительный интервал для  т. е. (0,716, 5,044). Соответствующий интервал для
т. е. (0,716, 5,044). Соответствующий интервал для 
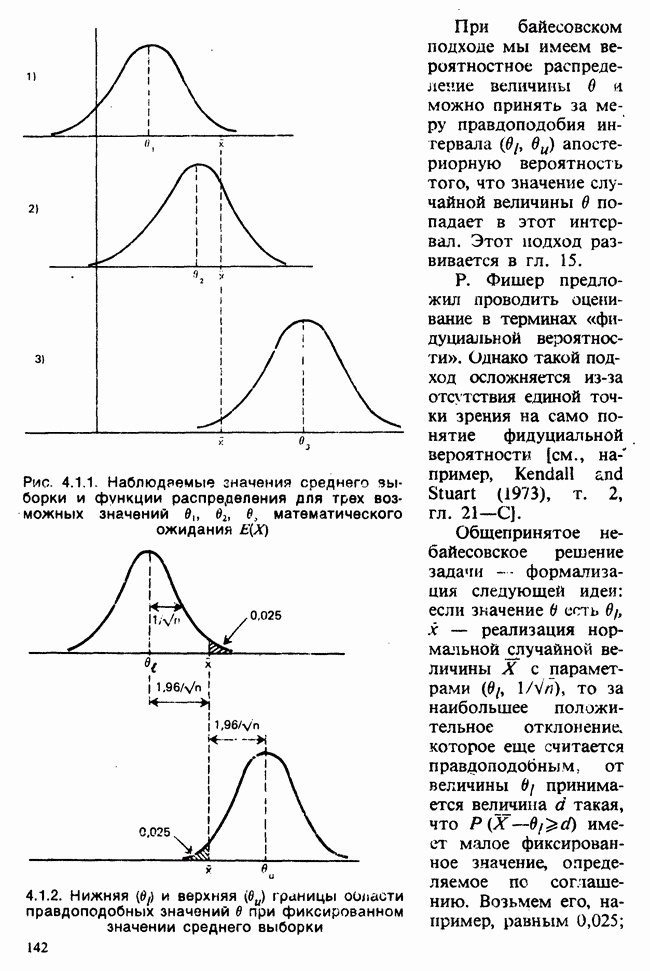
Пример 4.5.2. Доверительный интервал для математического ожидания нормального распределения.
а) Значение дисперсии известно. Этот случай рассмотрен в примере 4.2.1 для выборки  -ный доверительный интервал для
-ный доверительный интервал для  есть
есть  , где х — среднее выборки.
, где х — среднее выборки.
б) Значение дисперсии неизвестно. Вот метод оценки «на скорую руку» с использованием стандартной ошибки: заменяем неизвестное значение а в  его оценкой
его оценкой  . В более общем случае предположим, что
. В более общем случае предположим, что  — несмещенная оценка параметра в и выборочное распределение
— несмещенная оценка параметра в и выборочное распределение  приближенно нормальное; тогда, грубо говоря, 95%-ный доверительный интервал для
приближенно нормальное; тогда, грубо говоря, 95%-ный доверительный интервал для  есть
есть

где  означает стандартную ошибку в (т. е. подходящую оценку выборочного стандартного отклонения
означает стандартную ошибку в (т. е. подходящую оценку выборочного стандартного отклонения  . Это имеет некоторое отношение к методу наибольшего правдоподобия.
. Это имеет некоторое отношение к методу наибольшего правдоподобия.
в) Значение дисперсии неизвестно. Вычисление точных доверительных интервалов с помощью распределения Стьюдента. Здесь возникает новое осложнение: мы ищем доверительный интервал для одного параметра  когда значение другого неизвестно. Эта задача была блестяще решена на основе идеи Стьюдента, которая состоит в исключении
когда значение другого неизвестно. Эта задача была блестяще решена на основе идеи Стьюдента, которая состоит в исключении  с помощью процесса, известного теперь как «стьюдентизация». Если
с помощью процесса, известного теперь как «стьюдентизация». Если  выборка из
выборка из  и
и

то величина  инвариантна относительно изменения значений
инвариантна относительно изменения значений  если о заменить на
если о заменить на  то тем не менее
то тем не менее

Удобнее использовать величину

которую называют величиной Стьюдента с  степенями свободы. Она имеет не зависящее от параметра
степенями свободы. Она имеет не зависящее от параметра  выборочное распределение [см. раздел 2.5.5] и, следовательно, является опорной для
выборочное распределение [см. раздел 2.5.5] и, следовательно, является опорной для  .
.
Это распределение симметрично, и если а — значение, которое  не превосходит с вероятностью
не превосходит с вероятностью  то
то  -ный доверительный интервал для
-ный доверительный интервал для  есть
есть

Значения а, соответствующие рассматриваемым  могут быть найдены из таблиц [см. приложение 5, ср. с примером 5.8.2]. Если, например,
могут быть найдены из таблиц [см. приложение 5, ср. с примером 5.8.2]. Если, например,  , то число степеней свободы 9, и, взяв
, то число степеней свободы 9, и, взяв  мы получим для а значение 2,262. Если взять те же исходные данные, что в примере 4.5.1, то мы будем иметь
мы получим для а значение 2,262. Если взять те же исходные данные, что в примере 4.5.1, то мы будем иметь  . Таким образом, 95%-ный доверительный интервал для
. Таким образом, 95%-ный доверительный интервал для  будет
будет

или

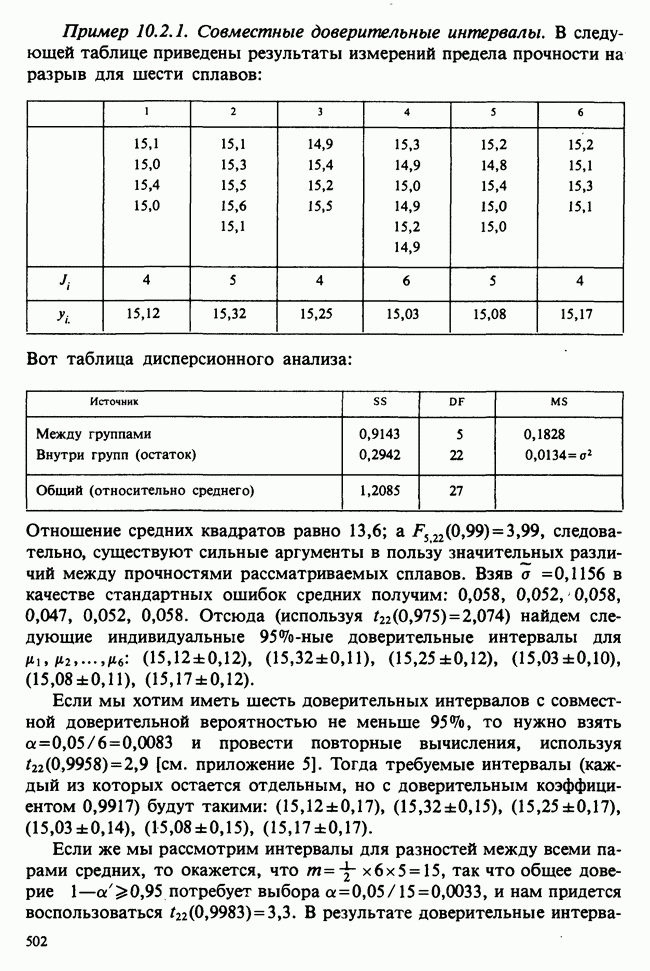
Это показывает, что разница в действии лекарств существует: добавочное время сна после приема препарата В превышает время после приема препарата А в среднем на  (или, более точно, на
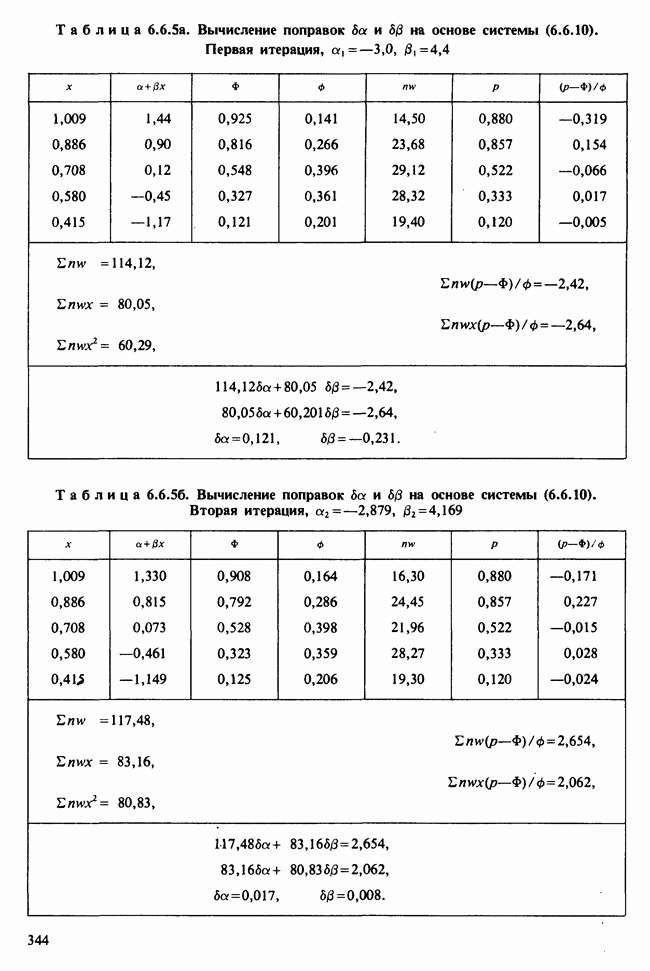
(или, более точно, на  (с 95%-ной точностью)). Численные значения, использованные здесь, показаны на графике распределения Стьюдента на рис. 4.5.1.
(с 95%-ной точностью)). Численные значения, использованные здесь, показаны на графике распределения Стьюдента на рис. 4.5.1.
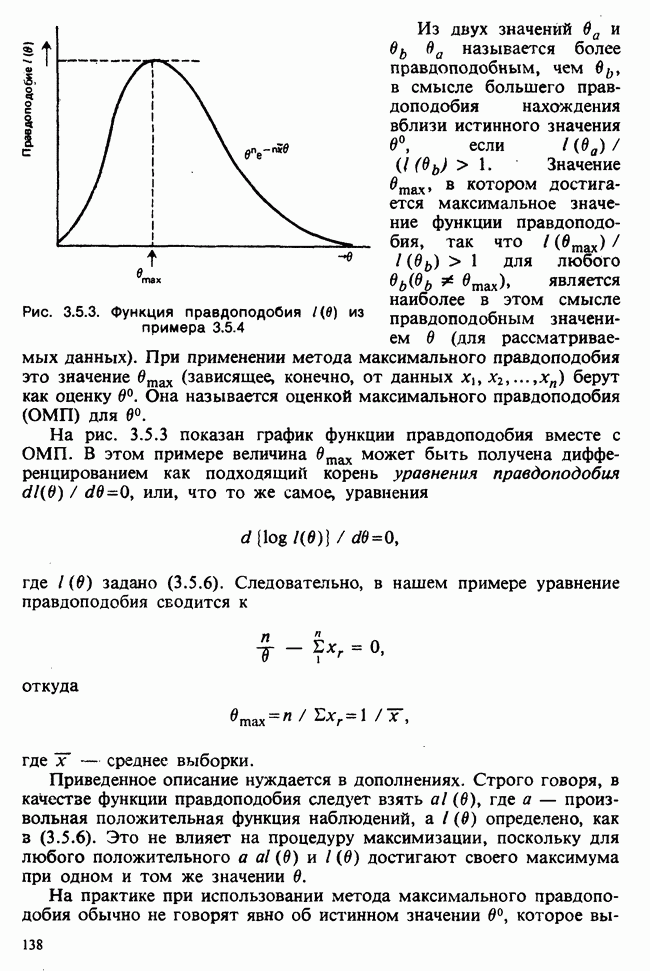
Интуитивный подход, продемонстрированный в примере 4.1.1, находит применение и здесь: нужно только заменить плотность

Рис. 4.5.1. Плотность распределения Стьюдента с 9 степенями свободы

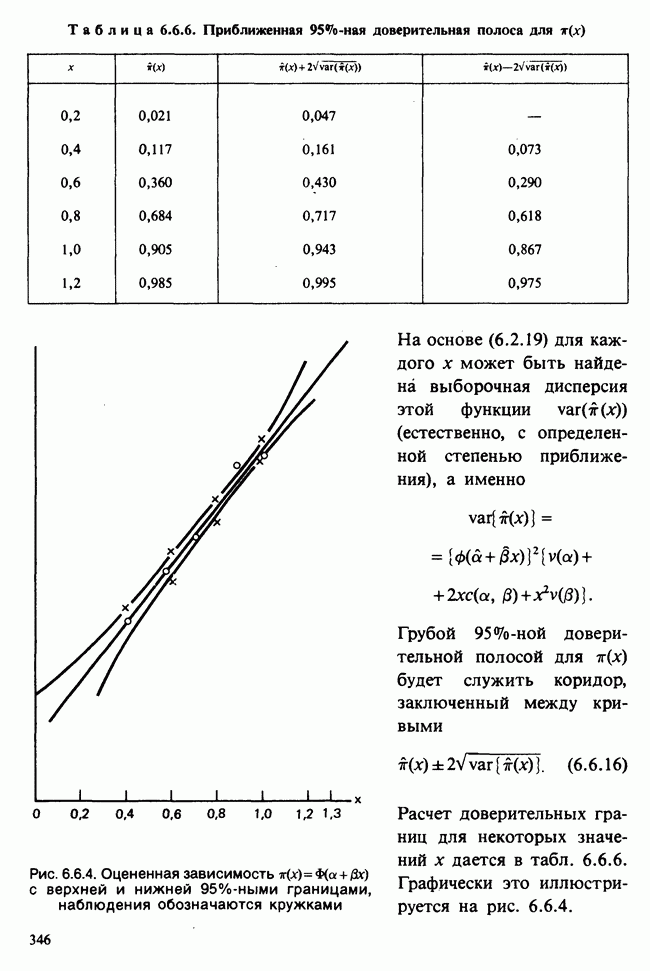
Рис. 4.5.2.  — неправдоподобно большое отрицательное значение величины
— неправдоподобно большое отрицательное значение величины  — слишком сильно превосходит
— слишком сильно превосходит  Аналогично
Аналогично  соответствует слишком малому значению
соответствует слишком малому значению  соответствует правдоподобному значению
соответствует правдоподобному значению 
нормального распределения из примера 4.1.1 на плотность распределения Стьюдента.
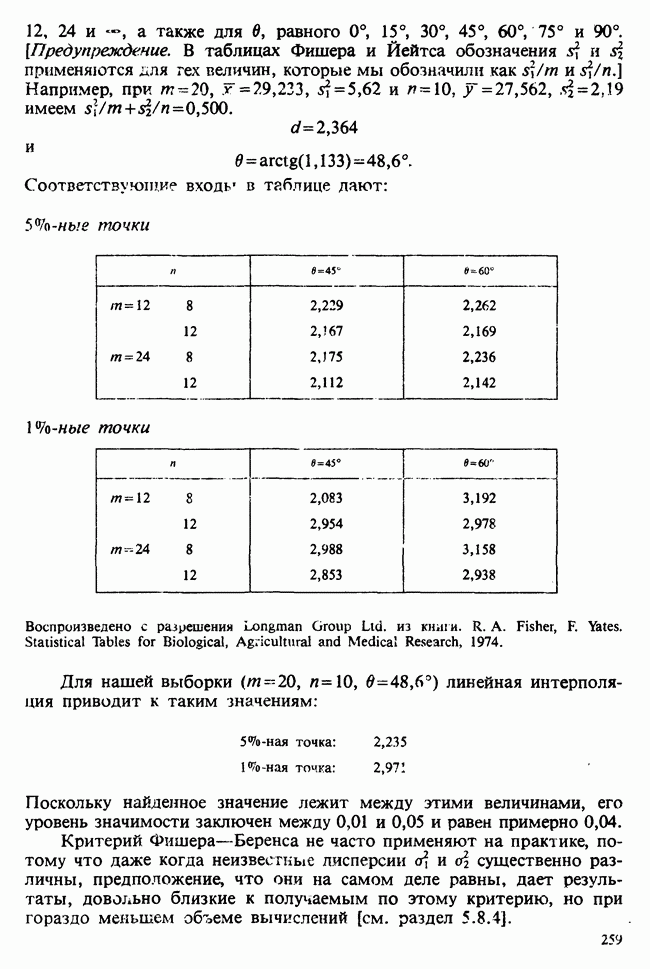
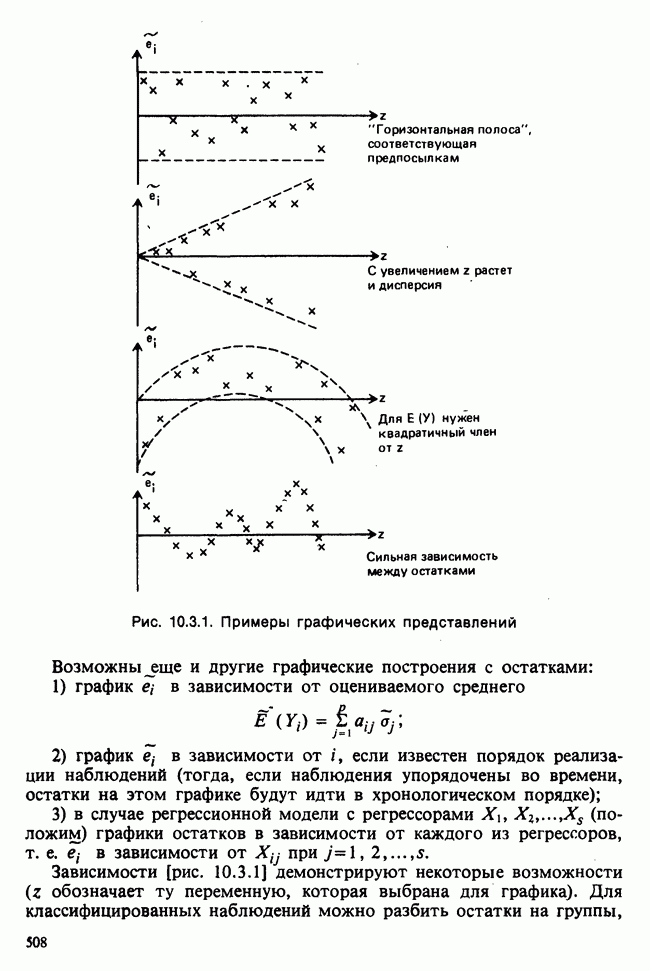
На рисунке 4.5.2 изображен график плотности распределения Стьюдента с 9 степенями свободы, при разных значениях, 
Значение  для
для  и, следовательно, соответствующее значение
и, следовательно, соответствующее значение  а именно
а именно  слишком маловероятно, чтобы можно было его принять. То же относится и к
слишком маловероятно, чтобы можно было его принять. То же относится и к  . Значение
. Значение  лежит в зоне больших значений плотности, так что
лежит в зоне больших значений плотности, так что  совместимо с исходными данными. Условная граница между «приемлемыми» и «неприемлемыми» значениями
совместимо с исходными данными. Условная граница между «приемлемыми» и «неприемлемыми» значениями  -ной точностью) определяется точками
-ной точностью) определяется точками  и
и  на рис. 4.5.1, где — квантиль уровня 0,025 и
на рис. 4.5.1, где — квантиль уровня 0,025 и  — квантиль уровня 0,975 распределения Стьюдента с 9 степенями свободы. Эти значения следующие:
— квантиль уровня 0,975 распределения Стьюдента с 9 степенями свободы. Эти значения следующие:  а доверительный интервал —
а доверительный интервал —  где
где 
Пример 4.5.3. Простая линейная регрессия. Если пара случайных величин  имеет совместное распределение [см. II, раздел 13.1.1], то условное математическое ожидание
имеет совместное распределение [см. II, раздел 13.1.1], то условное математическое ожидание  [см. II, раздел 8.9] называется регрессией
[см. II, раздел 8.9] называется регрессией  на X. Если
на X. Если  линейна по х, скажем,
линейна по х, скажем,  , то мы имеем простую линейную регрессию. Если наблюдаемое значение У соответствующее заранее заданному значению
, то мы имеем простую линейную регрессию. Если наблюдаемое значение У соответствующее заранее заданному значению  есть
есть  , то удобно переписать формулу для
, то удобно переписать формулу для  в виде
в виде






















































































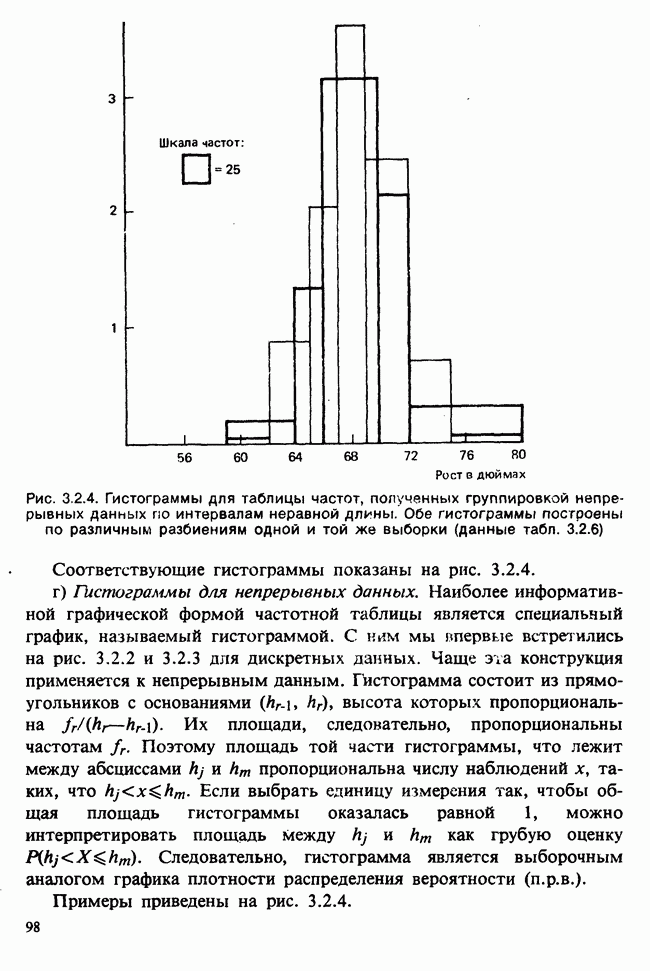































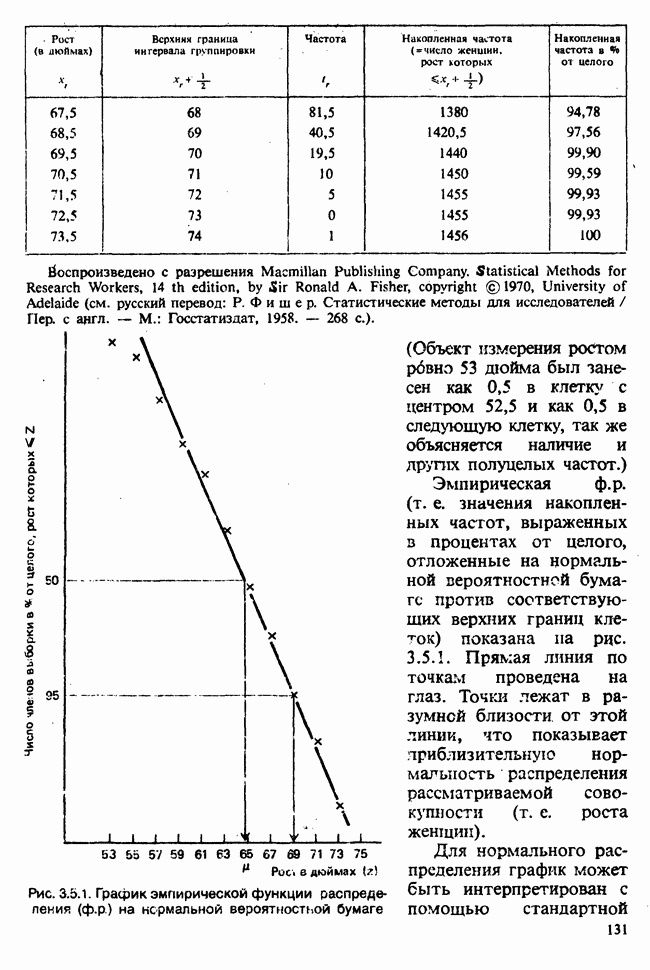































































































































































































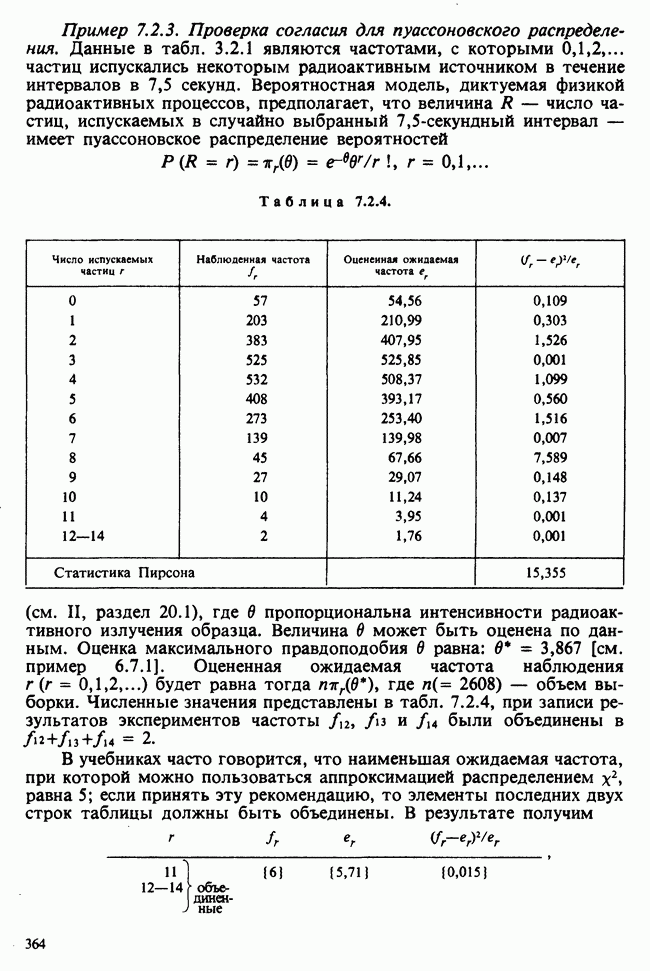


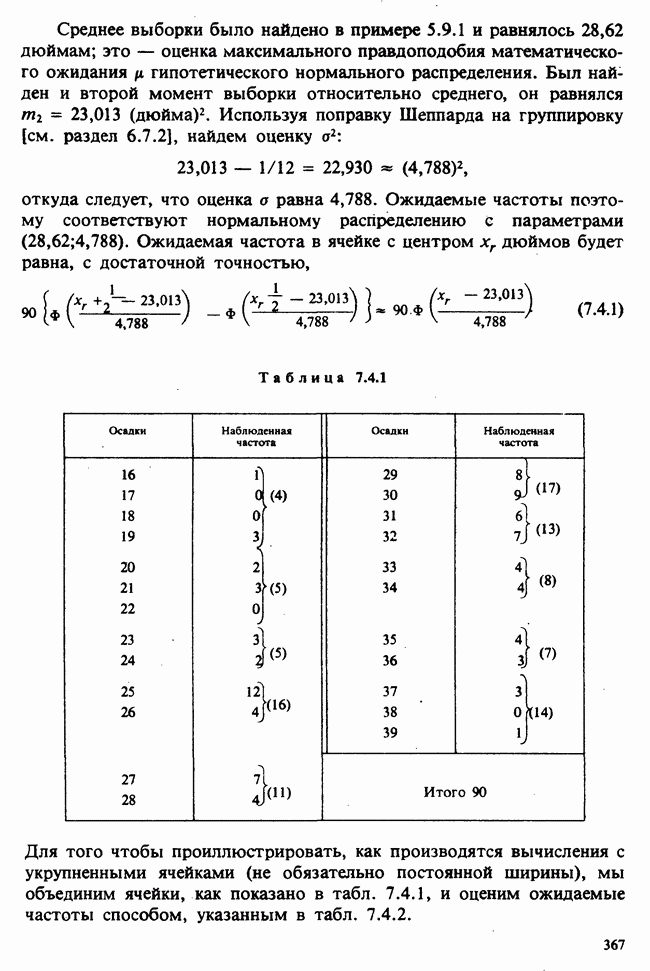
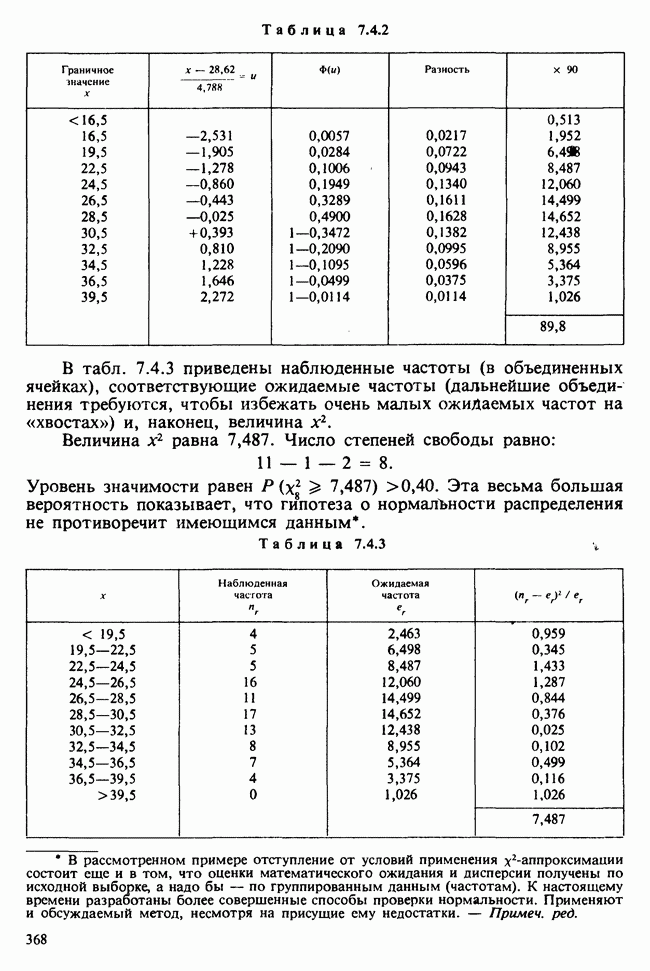


































































































































 Если условное распределение У при фиксированном
Если условное распределение У при фиксированном  при любом х, то оценки наибольшего правдоподобия для
при любом х, то оценки наибольшего правдоподобия для  [см. пример 6.4.4] будут следующими:
[см. пример 6.4.4] будут следующими:

 равна:
равна:



 степенями свободы, в то время как величина
степенями свободы, в то время как величина  имеет распределение
имеет распределение  степенями свободы. Таким образом, 95%-ные доверительные интервалы для
степенями свободы. Таким образом, 95%-ные доверительные интервалы для  будут следующими:
будут следующими:


 — верхняя
— верхняя  -нач точка распределения Стьюдента с
-нач точка распределения Стьюдента с  степенями свободы,
степенями свободы,  — нижняя и верхняя
— нижняя и верхняя  -ные точки случайной величины, распределенной по закону
-ные точки случайной величины, распределенной по закону  степенями свободы [см. также пример 4.5.4 и раздел 5.8.5]. Численный пример и более подробное обсуждение линейной регрессии содержатся в разделе 6.5.
степенями свободы [см. также пример 4.5.4 и раздел 5.8.5]. Численный пример и более подробное обсуждение линейной регрессии содержатся в разделе 6.5.
