Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
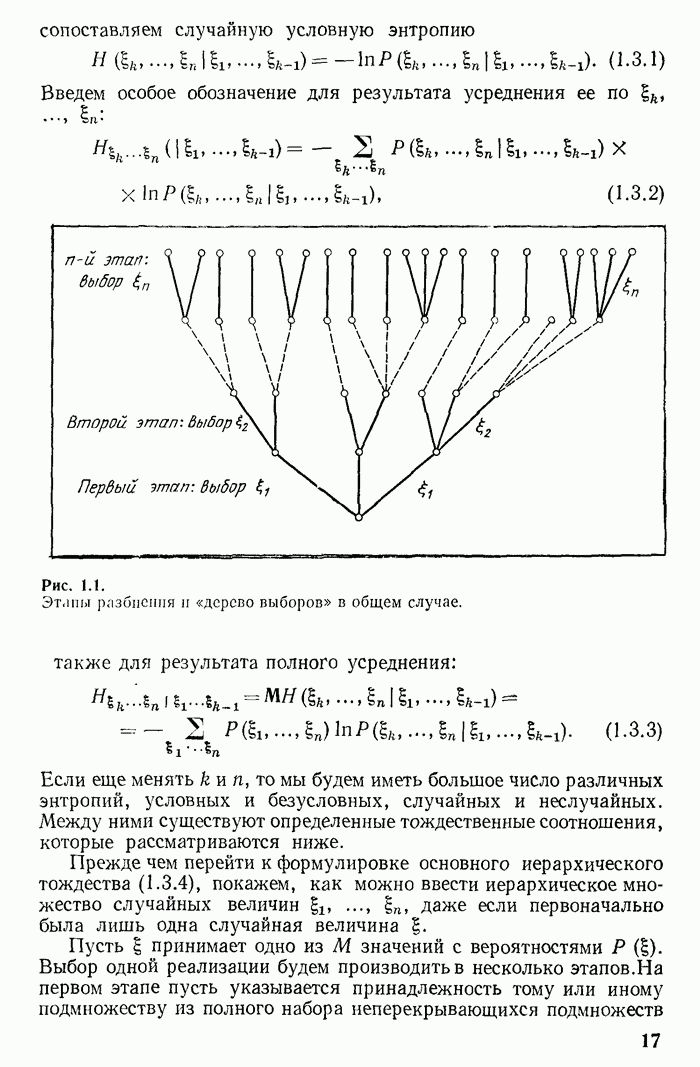
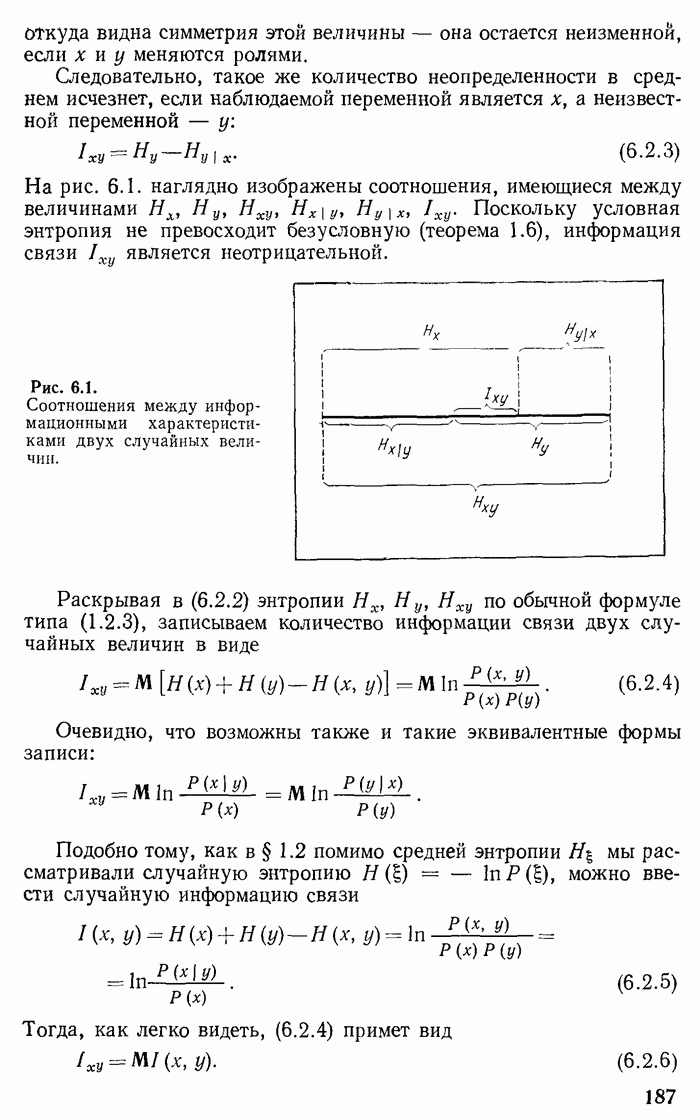
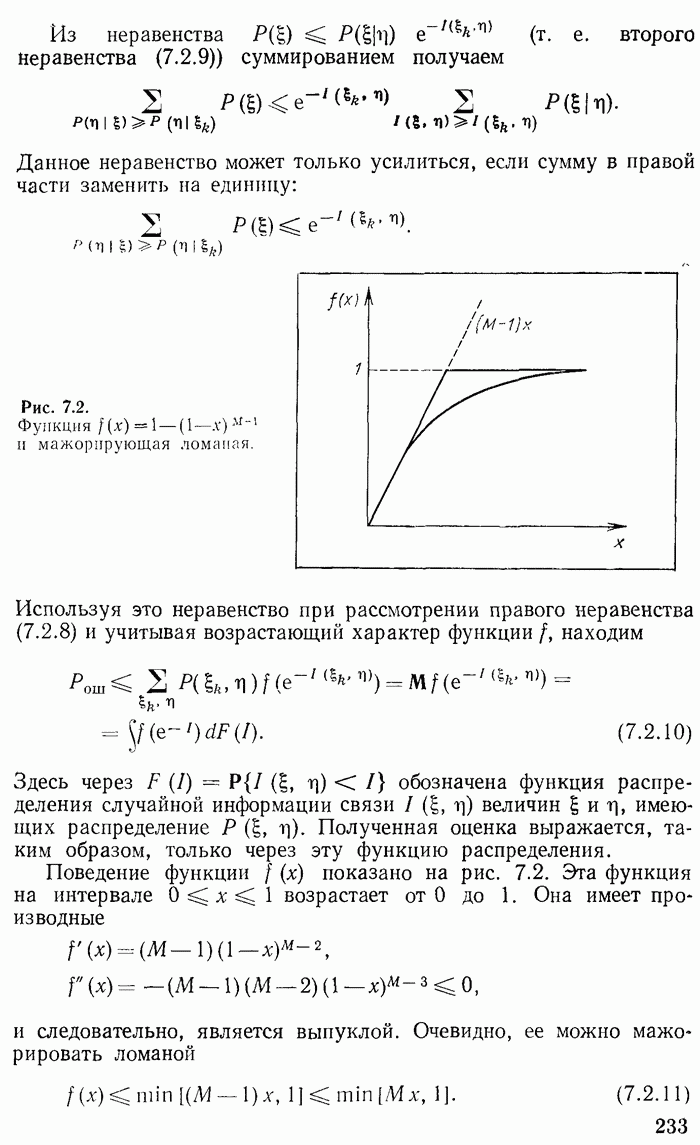
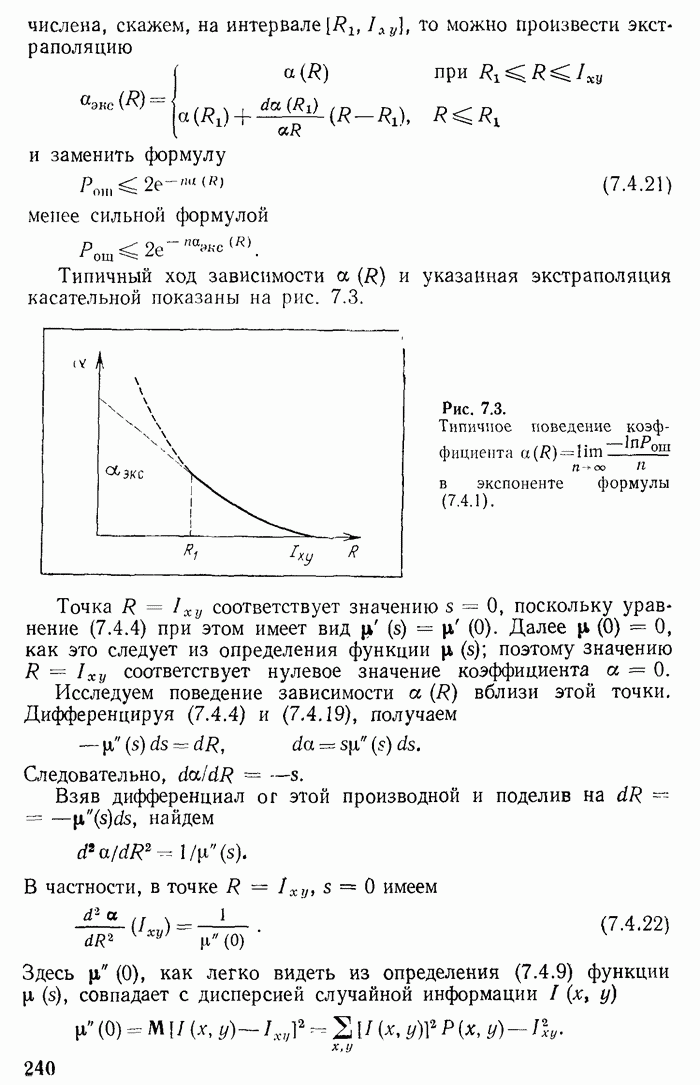
Глава 2. КОДИРОВАНИЕ ДИСКРЕТНОЙ ИНФОРМАЦИИ ПРИ ОТСУТСТВИИ ПОМЕХ И ШТРАФОВОпределение количества информации, данное в гл. 1, получает свое оправдание при рассмотрении преобразования информации из одного вида в другой, т. е. при рассмотрении кодирования информации. Существенно, что при таком преобразовании выполняется закон сохранения количества информации. Полезно провести аналогию с законом сохранения энергии. Этот закон является главным основанием для введения понятия энергии. Правда, закон сохранения информации сложнее закона сохранения энергии в двух отношениях. Закон сохранения энергии устанавливает точное равенство энергий при переходе энергии из одного вида в другой. При превращении же информации имеет место более сложное соотношение, а именно «не больше» Второе осложняющее обстоятельство заключается в том, что равенство не является точным. Оно является приближенным, асимптотическим, справедливым для сложных (больших) сообщений, для сложных случайных величин. Чем больше система сообщений, тем точнее выполняется указанное соотношение. Точный знак равенства имеет место лишь в предельном случае. В этом отношении имеется аналогия с законами статистической термодинамики, которые справедливы для больших термодинамических систем, состоящих из большого числа (практически порядка числа Авогадро) молекул. При выполнении кодирования предполагается заданной (большая) последовательность, сообщений Возможен двоякий подход к решению задачи кодирования. Может осуществляться кодирование бесконечной последовательности сообщений, т. е. текущее (или «скользящее»). Такой же характер будет носить и обратная процедура — процедура декодирования. Для текущей обработки характерно, что количественное равенство между кодируемой и закодированной информацией поддерживается лишь в среднем. При этом возникает и нарастает с течением времени случайная временная задержка или опережение. Для фиксированной длины последовательности сообщений длина ее записи будет иметь случайный разброс, растущий с течением времени, и наоборот: при фиксированной длине записи число элементарных переданных сообщений будет характеризоваться нарастающим разбросом. Другой подход можно назвать «блочным». При нем подлежит кодировке конечная совокупность (блок) элементарных сообщений. Различные блоки, если их несколько, кодируются и декодируются независимо. При таком подходе не происходит нарастания случайных временных сдвигов, но зато происходит потеря некоторых реализаций сообщения. Некоторая небольшая часть реализаций сообщений не может быть записана и теряется, так как для нее не хватает реализаций записи. Если блок является энтропийно устойчивой величиной, то вероятность такой потери достаточно мала. Следовательно, при блочном подходе необходимо исследование вопросов, связанных с энтропийной устойчивостью. Следуя традиции, мы рассматриваем в этой главе в основном скользящее кодирование. В последнем параграфе изучаются погрешности рассмотренного ранее вида кодирования, возникающие при конечной длине кодирующей последовательности. 2.1. Основные принципы кодирования дискретной информацииПодтвердим правильность и эффективность принятого ранее определения энтропии и количества информации рассмотрением преобразования информации из одной конкретной формы в другую. Такое преобразование носит название кодирования и применяется при передаче и хранении информации. Пусть сообщение, которое требуется передать или записать, представляет собой последовательность Ввиду того, что число элементарных сообщений никак не связано с числом букв алфавита, тривиальное «кодирование» одного сообщения одной особой буквой является в общем случае неприемлемым. Будем сопоставлять каждому отдельному сообщению, т.е. каждой реализации
где под Ввиду того, что все слова Желательно сделать запись сообщения как можно короче, если только это возможно без какой-либо потери содержания. Теория информации указывает границы, до которых можно сжимать длину записи (или время передачи сообщения, если сообщение передается в течение какого-то времени). Поясним выводы теории рассуждением, используя результаты § 1.4, 1.5. Пусть полное сообщение
Если использовать более короткую запись, то в некоторых случаях сообщение неизбежно будет искажаться, а если использовать запись длины больше Выводы из § 1.4, 1.5 можно применить не только к последовательности вероятностях сообщений остается подбирать кодовые слова и стараться достичь указанных выше оптимальных распределений букв. Если при некотором коде достигается максимальная энтропия
Это соотношение говорит о том, что каждая буква используется как бы на «полную мощность»; оно является признаком оптимального кода. Возьмем какую-либо конкретную реализацию сообщения
Усреднение этого неравенства дает
что согласуется с (2.1.1), поскольку Итак, теория указывает, чего нельзя достичь (нельзя сделать, чтобы длительность Пример. Пусть имеется случайная величина 1 со следующими значениями и вероятностями:
Сообщение записывается в двоичном алфавите
Чтобы сказать, хорош этот код или нет, сравним его с оптимальным кодом, для которого выполняется соотношение (2.1.1). Вычисляя по формуле (1.2.3) энтропию элементарного сообщения, имеем
В коде (2.1.4) на элементарное сообщение тратится три буквы, тогда как в оптимальном коде на это сообщение может быть согласно (2.1.1) затрачено
Легко проверить, что вероятность появления буквы А на первом месте равна 1/2. Поэтому энтропия первого символа равна
Итак, каждая буква независимо от ее места несет одну и ту же информацию 1 бит. Случайная информация элементарного сообщения § при этом условии равна длине соответствующего кодового слова:
Следовательно, средняя длина слова равна информации элементарного сообщения:
Это согласуется с (2.1.1), так что код является оптимальным. Соотношение Соотношение (2.1.3) со знаком равенства справедливо в предположении, что асимптотически. Для конечного Покажем это для случая
соответствующий
|
 |
Оглавление
|

















































































































































































































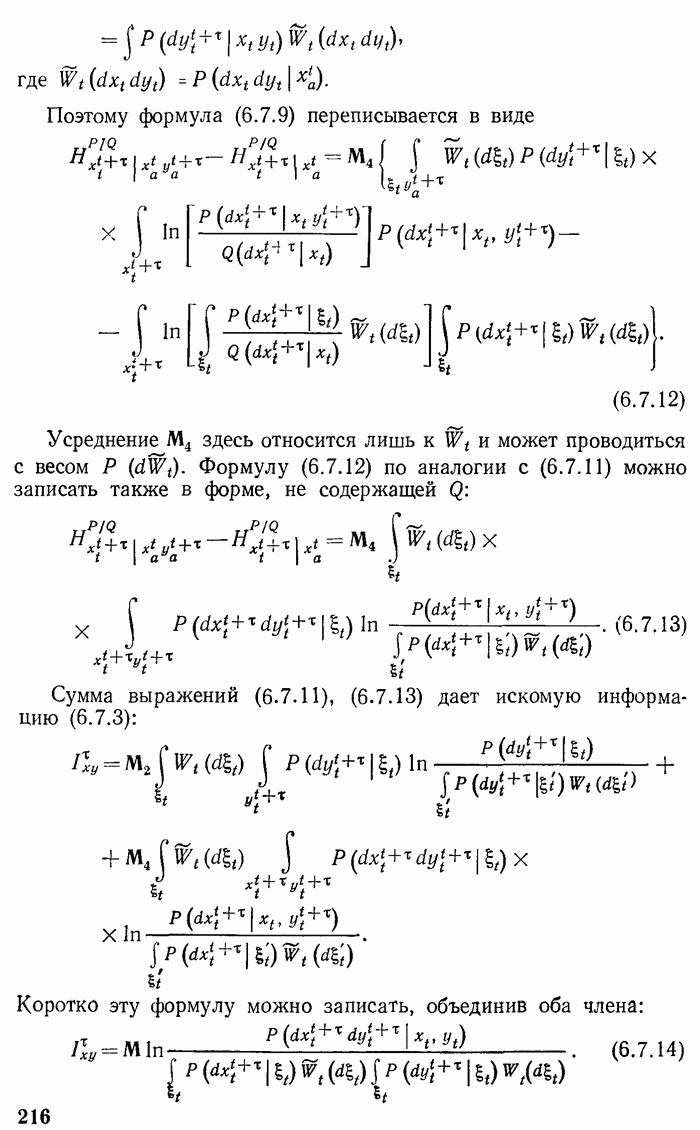















































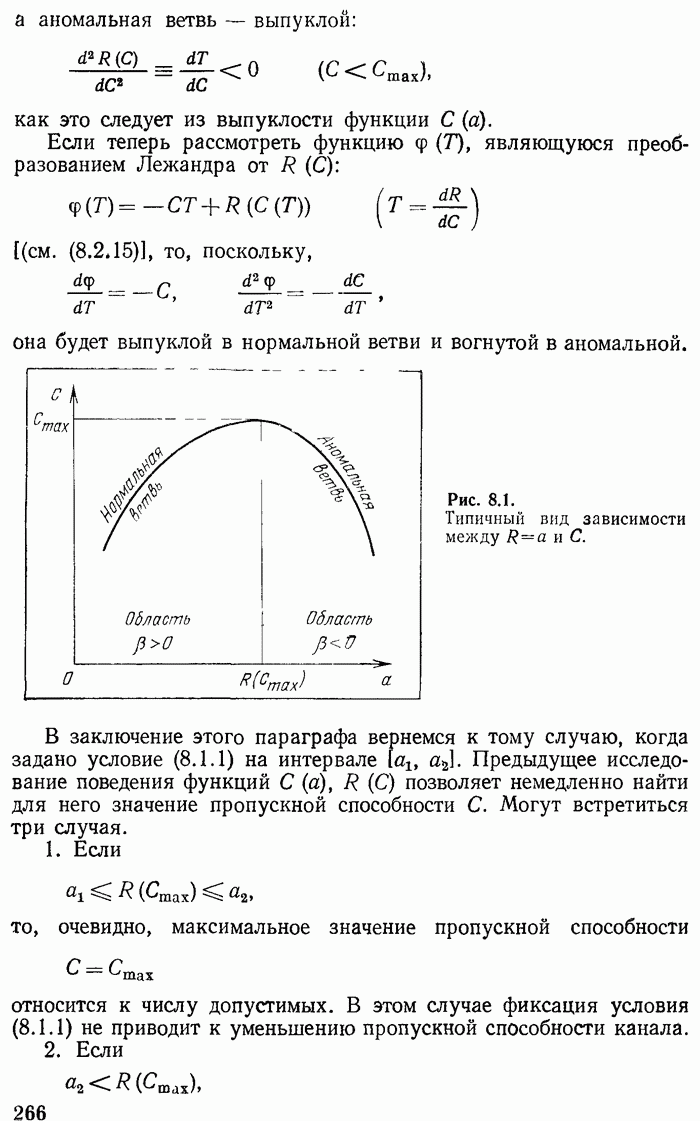















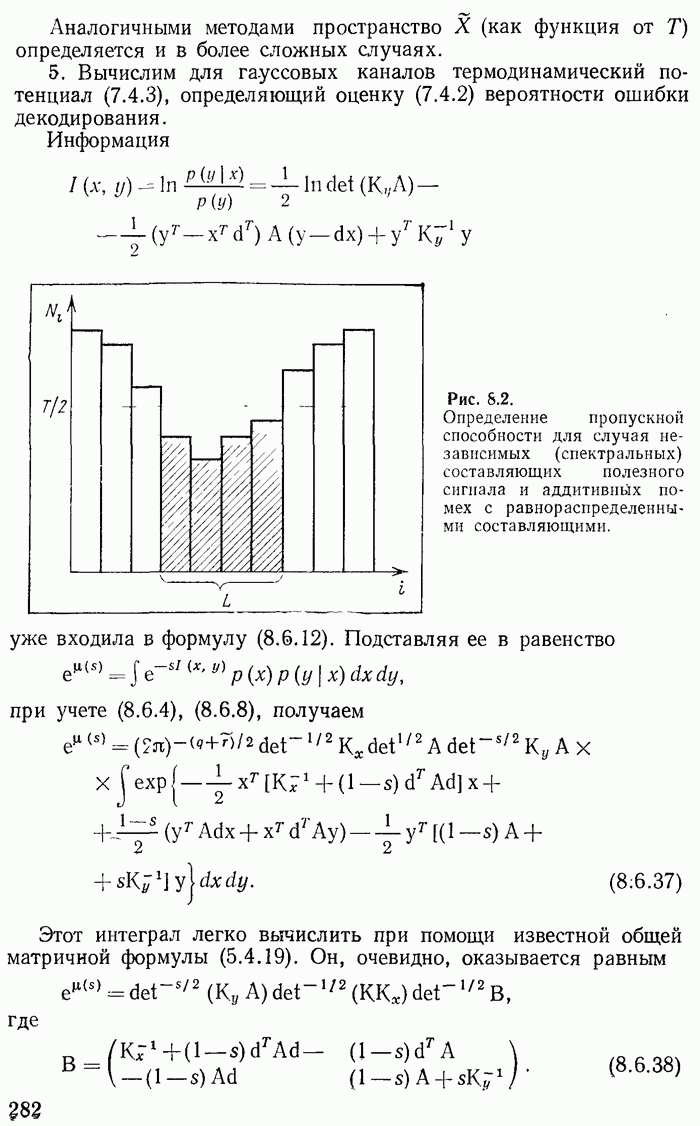
















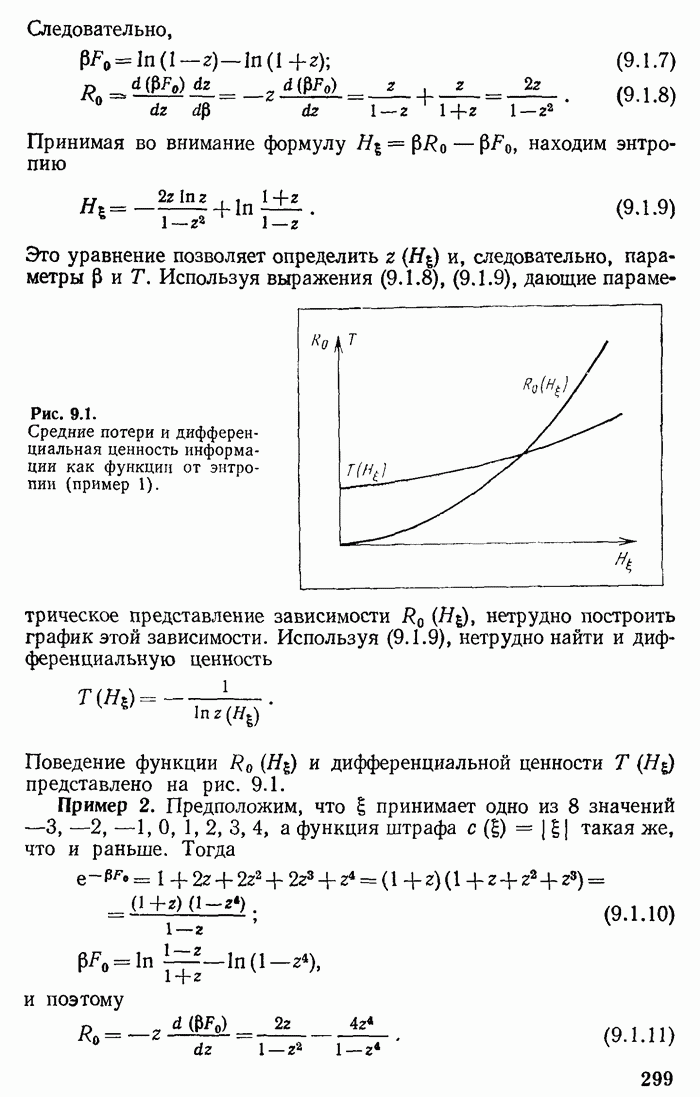
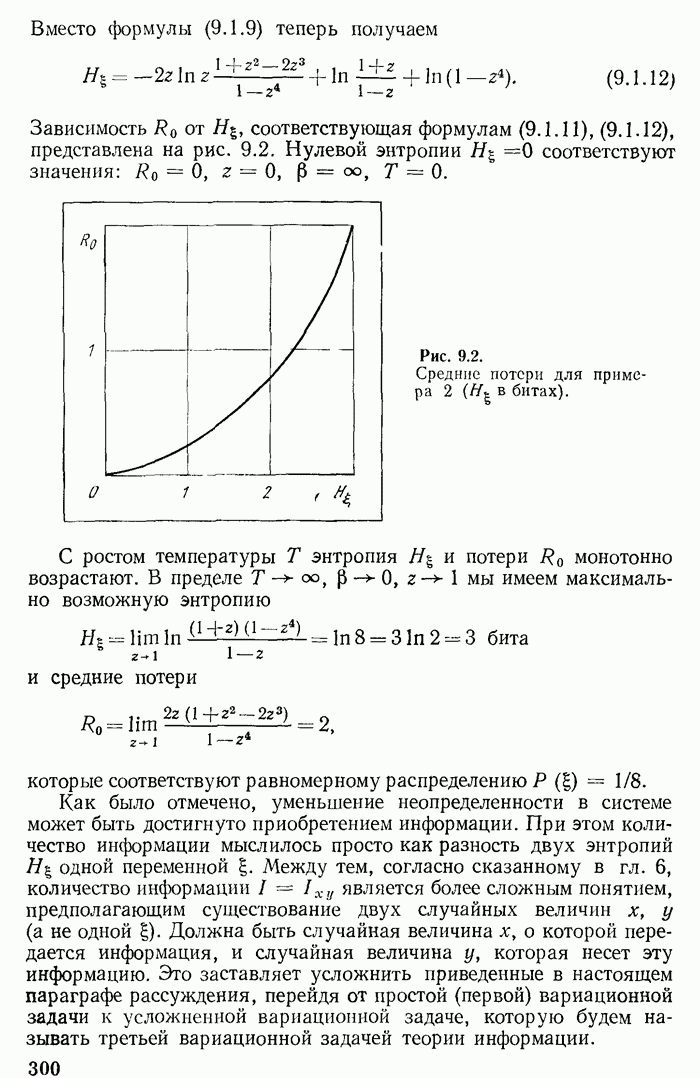

















































































































 т. е. информация не может вырасти. Знак равенства соответствует оптимальному кодированию. Поэтому при формулировке закона сохранения информации приходится говорить, что возможно (существует) такое кодирование, при котором имеет место равенство количеств информации.
т. е. информация не может вырасти. Знак равенства соответствует оптимальному кодированию. Поэтому при формулировке закона сохранения информации приходится говорить, что возможно (существует) такое кодирование, при котором имеет место равенство количеств информации.
 вместе со своими вероятностями, т. е. как последовательность случайных величин. Следовательно, может быть вычислено соответствующее ей количество информации (энтропия Я). Эта информация может быть записана или передана различными реализациями записи или передачи. Если М — число таких реализаций, то указанный закон сохранения количества информации заключается в равенстве
вместе со своими вероятностями, т. е. как последовательность случайных величин. Следовательно, может быть вычислено соответствующее ей количество информации (энтропия Я). Эта информация может быть записана или передана различными реализациями записи или передачи. Если М — число таких реализаций, то указанный закон сохранения количества информации заключается в равенстве  осложненном двумя отмеченными обстоятельствами (т. е. в действительности
осложненном двумя отмеченными обстоятельствами (т. е. в действительности  .
.
 элементарных сообщений или случайных величин. Каждое элементарное сообщение пусть представляет собой дискретную случайную величину принимающую одно из
элементарных сообщений или случайных величин. Каждое элементарное сообщение пусть представляет собой дискретную случайную величину принимающую одно из  значений (скажем
значений (скажем  ) с вероятностью
) с вероятностью  . Требуется преобразовать сообщение в последовательность
. Требуется преобразовать сообщение в последовательность  букв некоторого алфавита
букв некоторого алфавита  Число букв алфавита обозначим через
Число букв алфавита обозначим через  Интервал между словами, знаки препинания и т. п. включаем в число букв алфавита, так что сообщение записывается в этих обозначениях слитно. Требуется так записать сообщение, чтобы по записи можно было восстановить сообщение без потерь и ошибок. Теория должна указывать, при каких условиях и как это можно сделать.
Интервал между словами, знаки препинания и т. п. включаем в число букв алфавита, так что сообщение записывается в этих обозначениях слитно. Требуется так записать сообщение, чтобы по записи можно было восстановить сообщение без потерь и ошибок. Теория должна указывать, при каких условиях и как это можно сделать.
 случайной величины свое «слово»
случайной величины свое «слово»  в алфавите
в алфавите  длина этого слова). Полная совокупность таких слов (число их равно
длина этого слова). Полная совокупность таких слов (число их равно  образует код. Зная код, мы по реализации сообщения
образует код. Зная код, мы по реализации сообщения  записываем это сообщение в алфавите
записываем это сообщение в алфавите  Оно, очевидно, примет вид
Оно, очевидно, примет вид

 следует понимать последовательность букв.
следует понимать последовательность букв.
 пишутся слитно друг с другом, возникает непростая задача разделения последовательности букв
пишутся слитно друг с другом, возникает непростая задача разделения последовательности букв  на слова
на слова  (раздельная запись слов означала бы некоторый частный вид — и к тому же неэкономный — вышеописанного кодирования, поскольку интервал можно считать рядовой буквой). Об этой задаче будет речь ниже (см. § 2.2).
(раздельная запись слов означала бы некоторый частный вид — и к тому же неэкономный — вышеописанного кодирования, поскольку интервал можно считать рядовой буквой). Об этой задаче будет речь ниже (см. § 2.2).
 состоит из
состоит из  одинаковых независимых элементарных сообщений
одинаковых независимых элементарных сообщений  Тогда
Тогда  будет энтропийно устойчивой случайной величиной. Если
будет энтропийно устойчивой случайной величиной. Если  велико, то согласно сказанному в § 1.4, 1.5, можно рассматривать следующую упрощенную модель полного сообщения: можно считать, что осуществляется только одно из
велико, то согласно сказанному в § 1.4, 1.5, можно рассматривать следующую упрощенную модель полного сообщения: можно считать, что осуществляется только одно из  равновероятных сообщений, где
равновероятных сообщений, где  . В то же время в буквенной записи, содержащей последовательно
. В то же время в буквенной записи, содержащей последовательно  букв, реализуется одна из
букв, реализуется одна из  возможностей. Приравнивая эти два числа, мы получаем, что длина
возможностей. Приравнивая эти два числа, мы получаем, что длина  записи определяется уравнением
записи определяется уравнением

 то такая запись будет неэкономной, неоптимальной.
то такая запись будет неэкономной, неоптимальной.
 но и к буквенной последовательности
но и к буквенной последовательности  Максимальная энтропия (равная
Максимальная энтропия (равная  такой последовательности достигается при распределении для каждой буквы, независимом от соседних букв и при равновероятном распределении по всему алфавиту. Но вероятности букв однозначно определяются вероятностями сообщений и выбором кода. При фиксированных
такой последовательности достигается при распределении для каждой буквы, независимом от соседних букв и при равновероятном распределении по всему алфавиту. Но вероятности букв однозначно определяются вероятностями сообщений и выбором кода. При фиксированных
 буквенной записи, то тогда имеется
буквенной записи, то тогда имеется  существенных реализаций записи и устанавливается взаимно-однозначное соответствие между ними и существенными реализациями сообщения, число которых
существенных реализаций записи и устанавливается взаимно-однозначное соответствие между ними и существенными реализациями сообщения, число которых  При этом выполняется оптимальное соотношение (2.1.1). Такие коды назовем оптимальными. Поскольку буквы записи для них независимы, имеем
При этом выполняется оптимальное соотношение (2.1.1). Такие коды назовем оптимальными. Поскольку буквы записи для них независимы, имеем  а так как осуществляется равновероятное распределение
а так как осуществляется равновероятное распределение  по алфавиту, то каждая буква несет одинаковую информацию
по алфавиту, то каждая буква несет одинаковую информацию

 Она содержит согласно (1.2.1) случайную информацию
Она содержит согласно (1.2.1) случайную информацию  Но каждая буква алфавита в силу (2.1.2) при оптимальном коде несет информацию
Но каждая буква алфавита в силу (2.1.2) при оптимальном коде несет информацию  Отсюда следует, чтокодовое слово
Отсюда следует, чтокодовое слово  этого сообщения, в оптимальном коде также несущее информацию
этого сообщения, в оптимальном коде также несущее информацию  должно состоять из
должно состоять из  букв. При неоптимальном кодировании каждая буква несет меньше информации, чем
букв. При неоптимальном кодировании каждая буква несет меньше информации, чем  Поэтому длина кодового слова
Поэтому длина кодового слова  несущего информацию
несущего информацию  должна быть больше. Следовательно, для любого кода
должна быть больше. Следовательно, для любого кода



 записи была меньше, чем
записи была меньше, чем  чего можно достичь (можно сделать, чтобы длительность
чего можно достичь (можно сделать, чтобы длительность  была близка к
была близка к  и как этого достичь (подбирая код, дающий по возможности независимые равновероятные распределения букв по алфавиту).
и как этого достичь (подбирая код, дающий по возможности независимые равновероятные распределения букв по алфавиту).

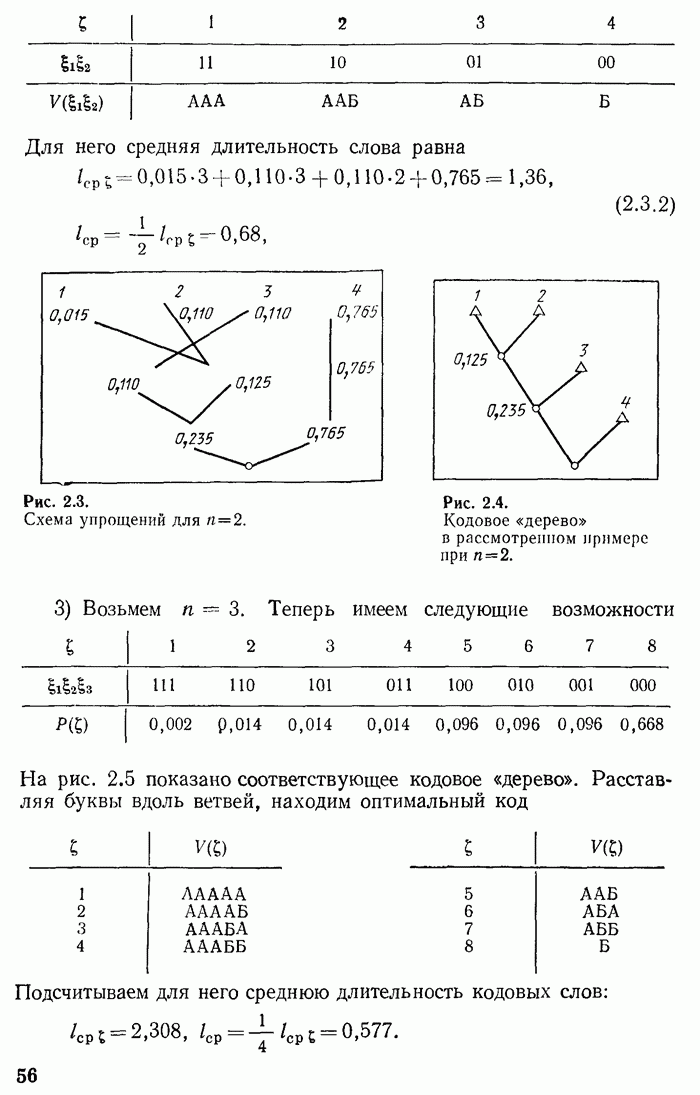
 , так что
, так что  Возьмем кодовые слова
Возьмем кодовые слова


 буквы. Следовательно, возможно сокращение записи на 8,4%. В качестве оптимального кода можно выбрать код
буквы. Следовательно, возможно сокращение записи на 8,4%. В качестве оптимального кода можно выбрать код

 бит. Далее, при фиксированном первом символе условная вероятность появления буквы А на втором месте по-прежнему равна 1/2. Это дает условные энтропии
бит. Далее, при фиксированном первом символе условная вероятность появления буквы А на втором месте по-прежнему равна 1/2. Это дает условные энтропии  бит;
бит;  бит. Аналогично
бит. Аналогично



 которое эквивалентно равенству (2.1.6), является следствием независимости распределения букв в буквенной записи сообщения.
которое эквивалентно равенству (2.1.6), является следствием независимости распределения букв в буквенной записи сообщения.
 велико, когда можно пренебречь вероятностью
велико, когда можно пренебречь вероятностью  несущественных реализаций последовательности (см. теоремы 1.7, 1.9). В этом смысле оно является правильным
несущественных реализаций последовательности (см. теоремы 1.7, 1.9). В этом смысле оно является правильным
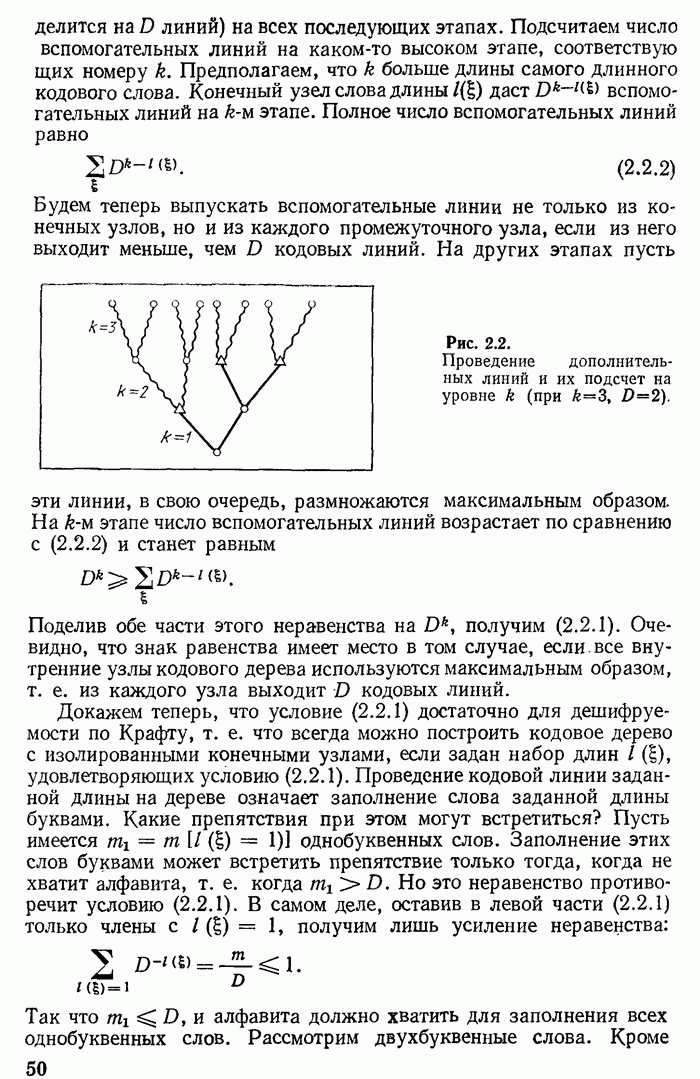
 подобного соотношения установить не удается. В самом деле, если мы потребуем пунктуального воспроизведения буквально всех сообщений конечной длины
подобного соотношения установить не удается. В самом деле, если мы потребуем пунктуального воспроизведения буквально всех сообщений конечной длины  их число
их число  то длина
то длина  записи будет определяться из соотношения
записи будет определяться из соотношения  Сократить ее (например до значения
Сократить ее (например до значения  окажется невозможным без потери некоторых сообщений, вероятность которых при конечных
окажется невозможным без потери некоторых сообщений, вероятность которых при конечных  конечна. С другой стороны, допуская непостоянство длины
конечна. С другой стороны, допуская непостоянство длины  при конечных
при конечных  можно так закодировать сообщения, что (2.1.3) заменится на обратное неравенство
можно так закодировать сообщения, что (2.1.3) заменится на обратное неравенство 
 Пусть имеются три возможности
Пусть имеются три возможности  , с вероятностями 1/2, 1/4, 1/4. Выбрав код
, с вероятностями 1/2, 1/4, 1/4. Выбрав код

 получаем
получаем  , в то время как
, в то время как  бита. Следовательно, для данного единичного сообщения неравенство (2.1.3) нарушается.
бита. Следовательно, для данного единичного сообщения неравенство (2.1.3) нарушается.