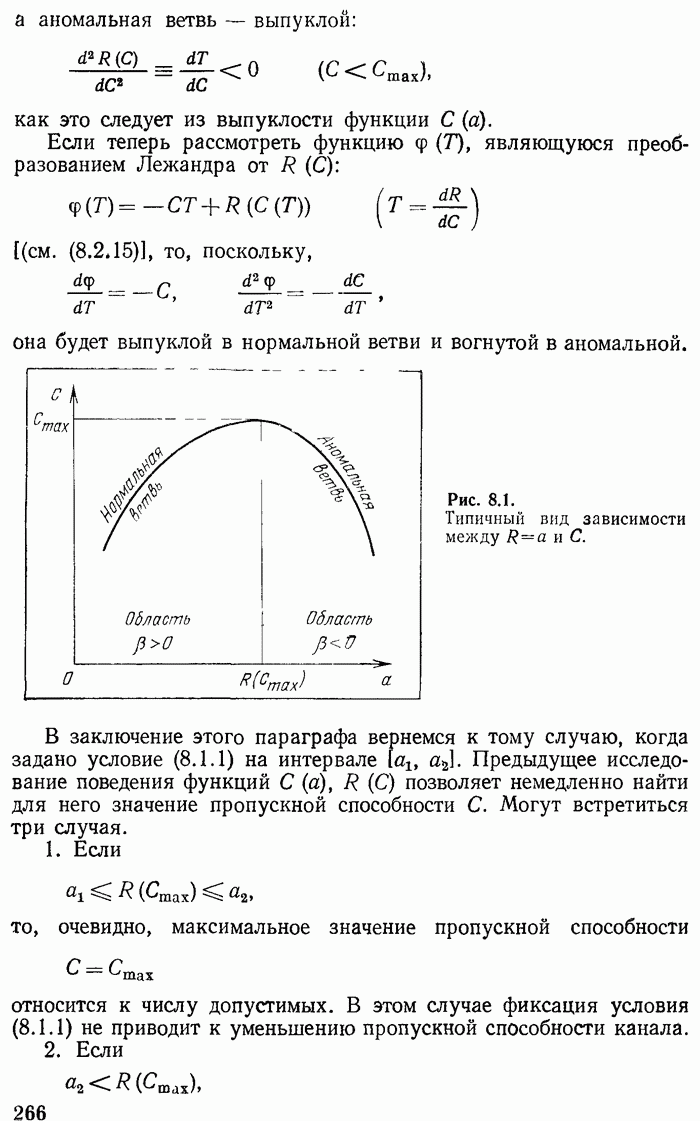
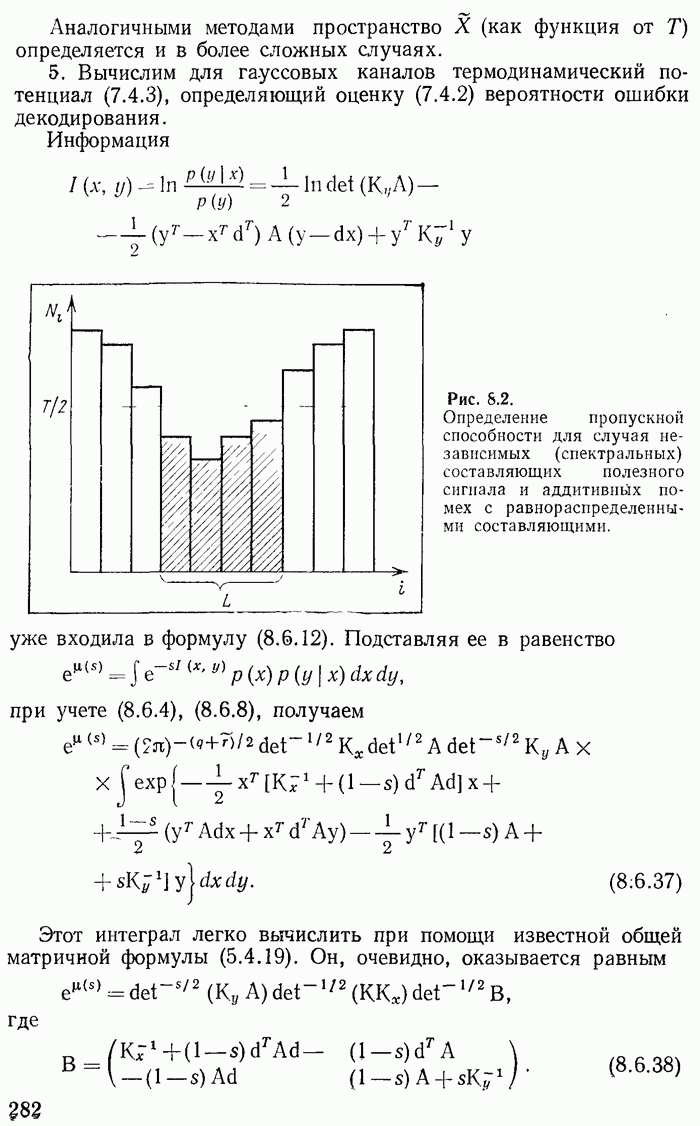
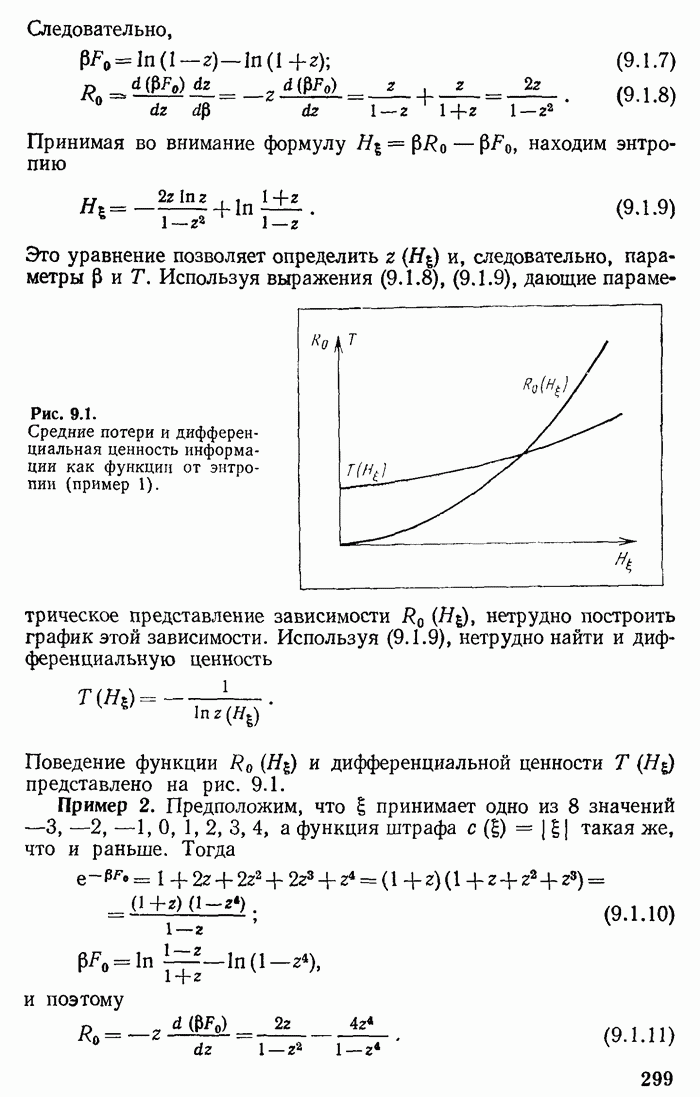
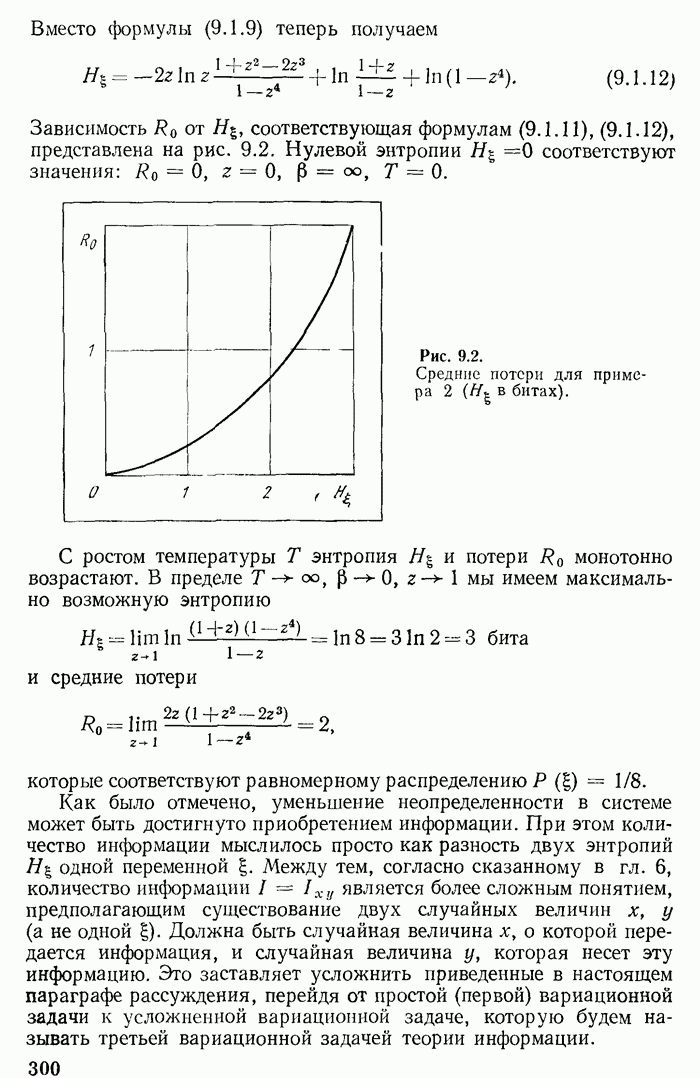
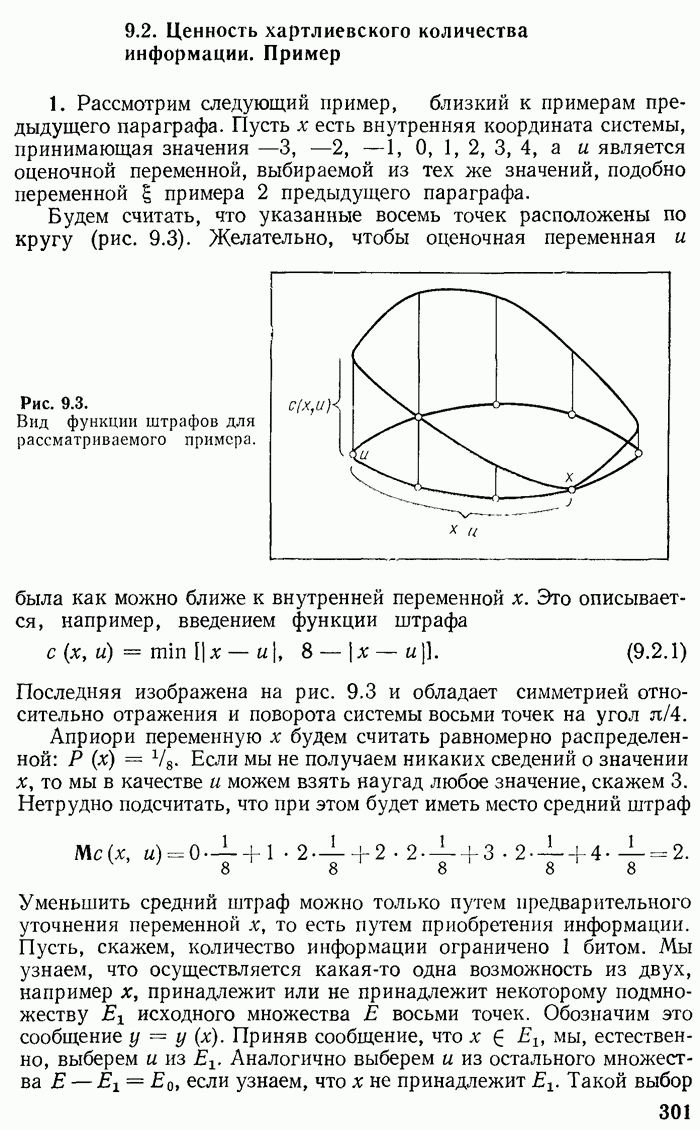
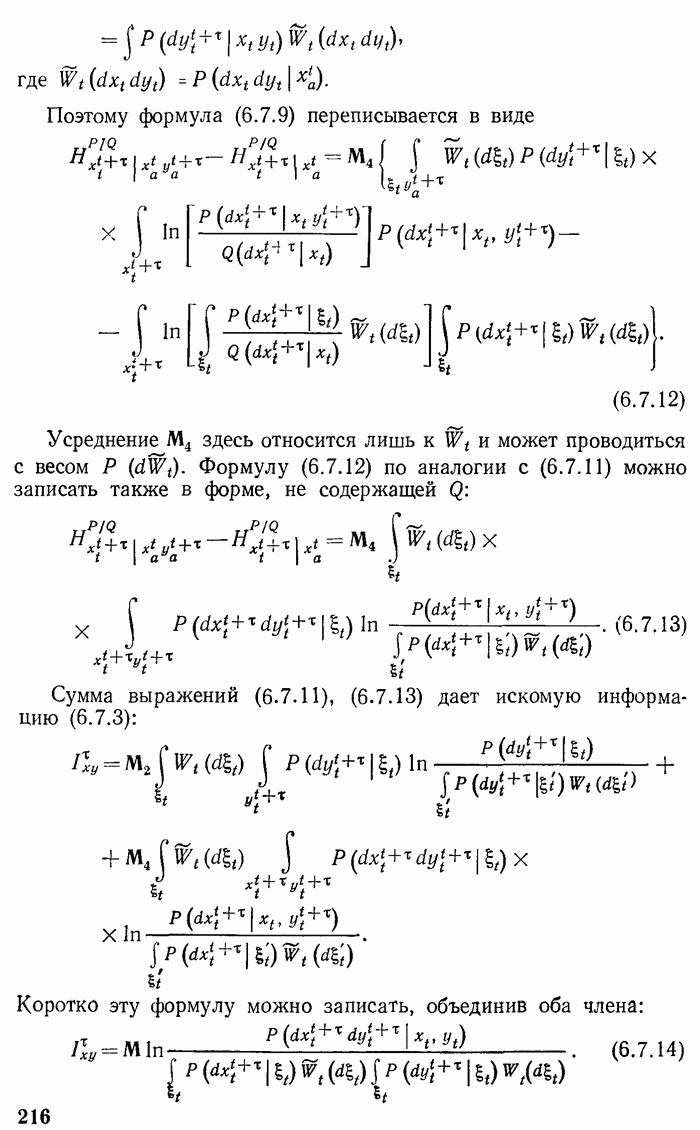2.3. Оптимальное кодирование по Хуфману. Примеры
Предыдущее рассмотрение не только решает принципиальные вопросы существования асимптотически оптимальных кодов, т. е. кодов, для которых средняя длина сообщения стремится к минимальному значению, но и дает практические способы их отыскания. Выбрав  и определив длины кодовых слов при помощи неравенства
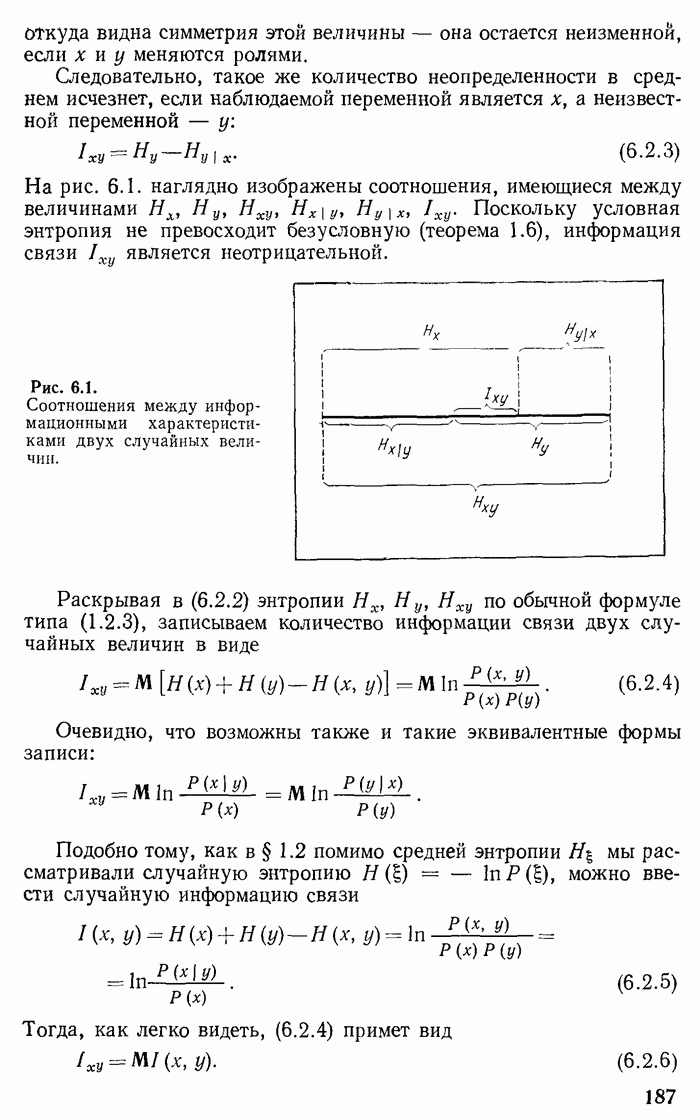
и определив длины кодовых слов при помощи неравенства

получим код, который согласно теореме 2.4 является асимптотически оптимальным. Такой код, однако, может быть не вполне оптимальным для фиксированного  . Другими словами, может оказаться, что сообщение
. Другими словами, может оказаться, что сообщение  можно закодировать лучше, т. е. с меньшей длительностью
можно закодировать лучше, т. е. с меньшей длительностью 
Хуфман [1] (см. также Фано [1]) нашел несложный способ оптимального кодирования, которому соответствует минимальная средняя длительность из всех возможных для данного сообщения.
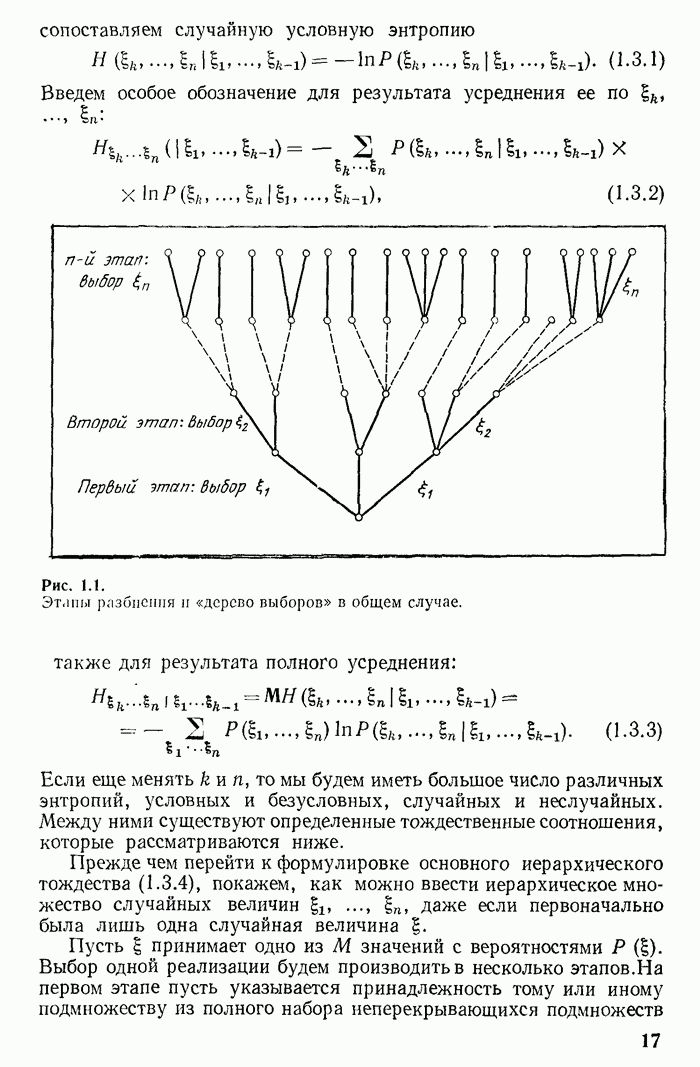
Рассмотрим сначала случай  и зададимся некоторым конкретным оптимальным кодом К для сообщения ?. Исследуем, какими обязательными свойствами должен обладать оптимальный код или соответствующее ему «дерево».
и зададимся некоторым конкретным оптимальным кодом К для сообщения ?. Исследуем, какими обязательными свойствами должен обладать оптимальный код или соответствующее ему «дерево».
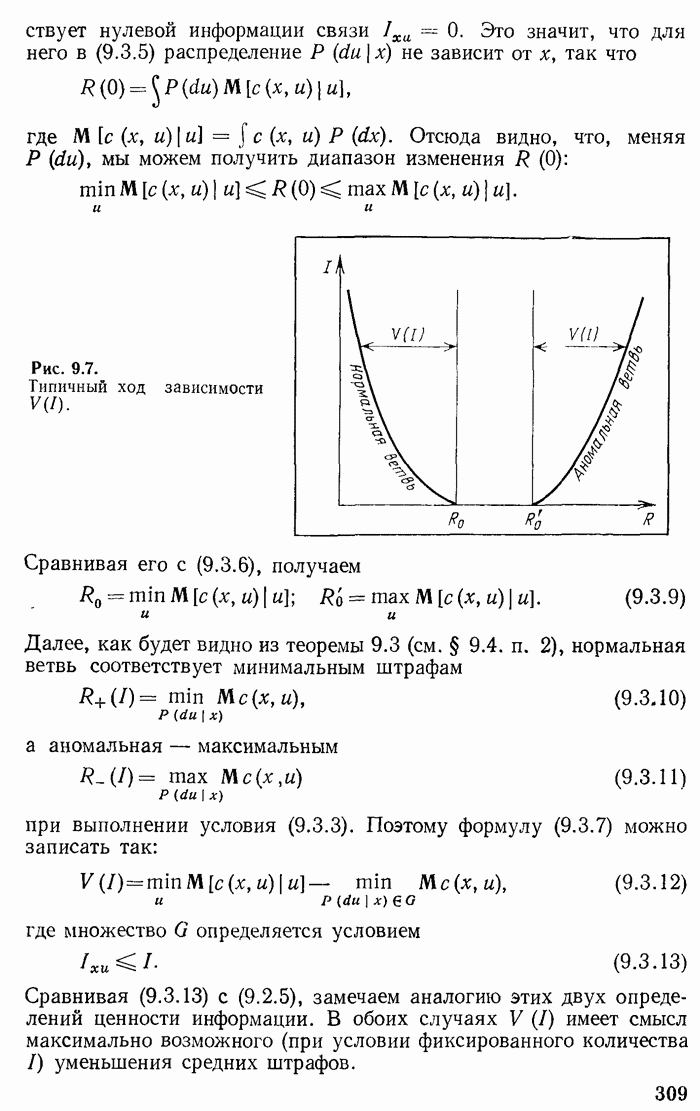
На каждом этапе, кроме, может быть, последнего, из каждого неконечного узла должно выходить максимальное число  линий. В противном случае конечную линию с последнего этапа можно было бы перенести в этот «неполный» узел и этим сократить длину
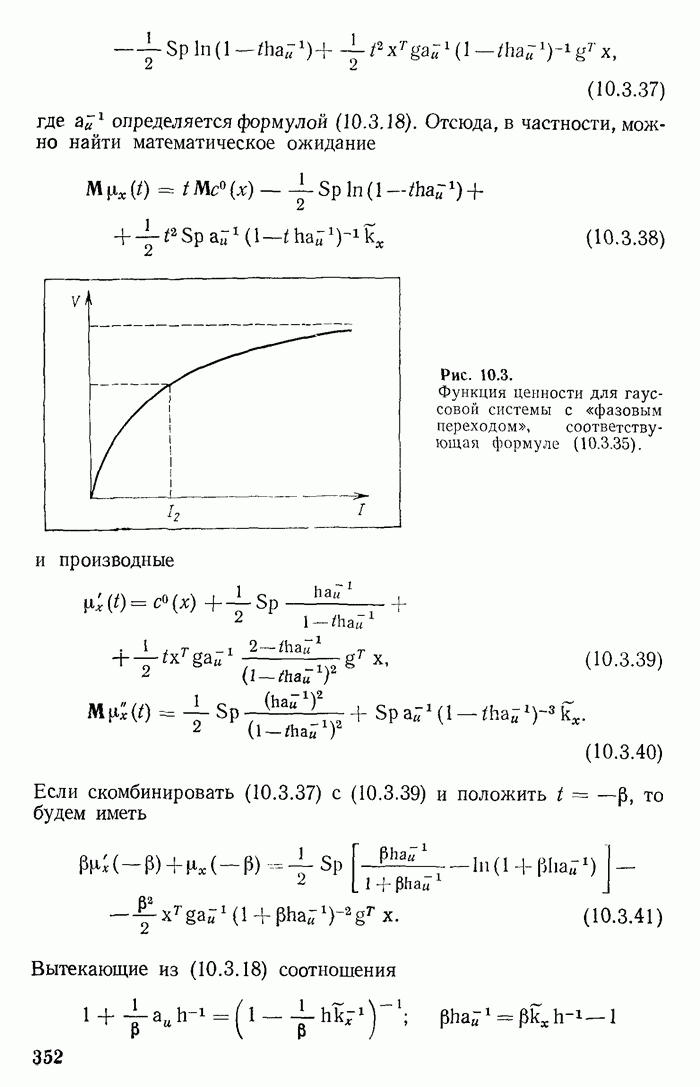
линий. В противном случае конечную линию с последнего этапа можно было бы перенести в этот «неполный» узел и этим сократить длину  На последнем этапе должно быть как минимум две линии. Иначе последний этап был бы излишним] и его можно было бы исключить, укоротив соответствующую кодовую линию. Среди линий последнего этапа есть две линии, которым соответствуют две наименее вероятные реализации
На последнем этапе должно быть как минимум две линии. Иначе последний этап был бы излишним] и его можно было бы исключить, укоротив соответствующую кодовую линию. Среди линий последнего этапа есть две линии, которым соответствуют две наименее вероятные реализации  сообщения из всех реализаций
сообщения из всех реализаций  В противном случае можно было бы поменять местами сообщения, приписав более длинному слову менее вероятную реализацию сообщения и тем самым укоротить среднюю длительность слова.
В противном случае можно было бы поменять местами сообщения, приписав более длинному слову менее вероятную реализацию сообщения и тем самым укоротить среднюю длительность слова.
Но если два наименее вероятных сообщения имеют кодовые слова, кончающиеся на последнем этапе, то можно считать, что их линии выходят из одного узла предпоследнего этапа. Если в К это не так, то поменяв местами два сообщения и добившись этого,
мы будем иметь другой конкретный код, имеющий ту же среднюю длительность и, следовательно, не хуже первоначального К.
Превратим узел предпоследнего этапа, из которого выходят две рассмотренные ранее линии в конечный узел. Соответственно этому две наименее вероятные реализации  будем считать за одну. Число различных реализаций будет теперь равно
будем считать за одну. Число различных реализаций будет теперь равно  и им будут соответствовать вероятности
и им будут соответствовать вероятности 
Можно считать, что имеется новая («упрощенная») случайная величина, новый код и новое («урезанное») «дерево». Средняя длительность слова для этой величины может быть выражена через прежнюю среднюю длительность по формуле

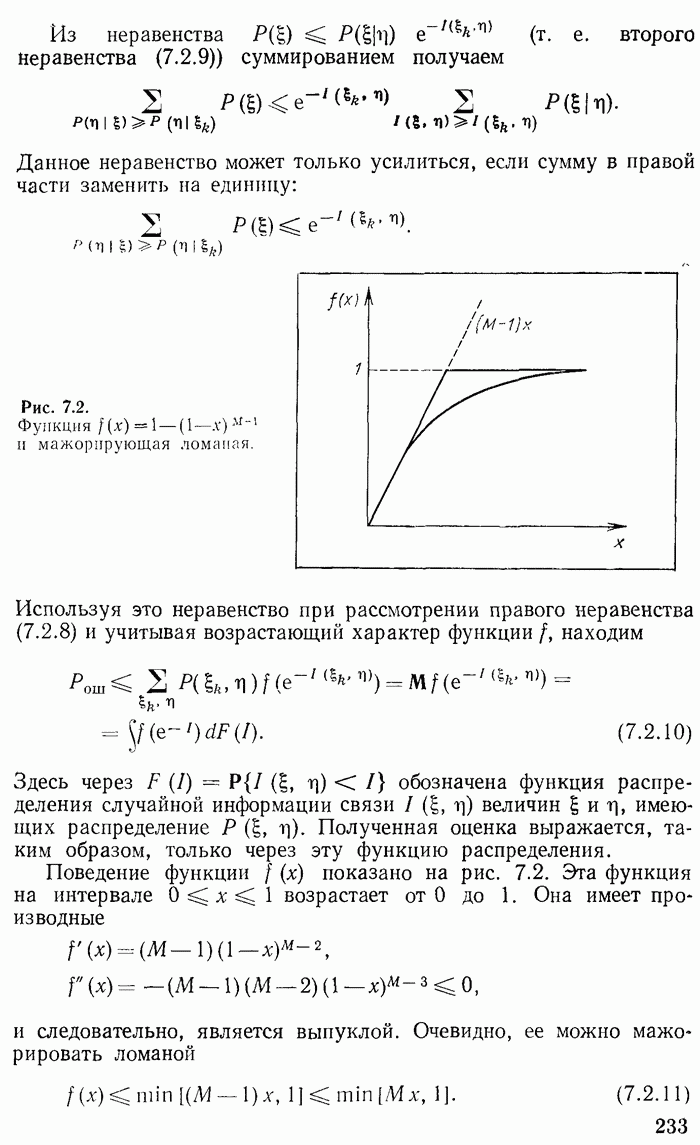
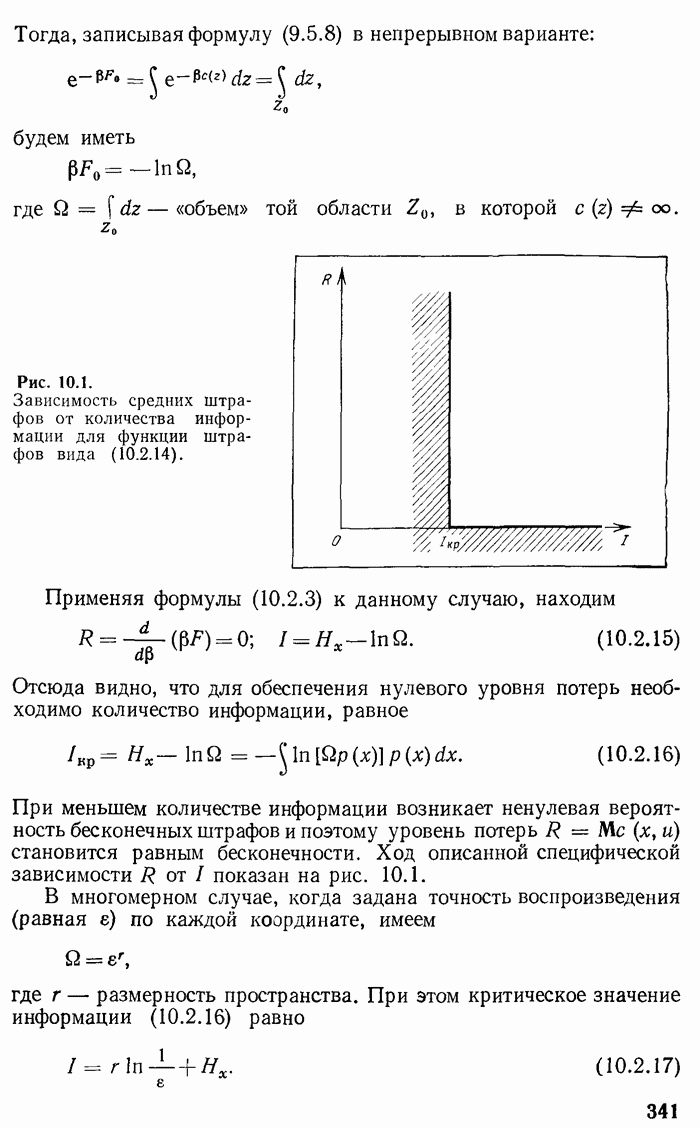
Очевидно, если первоначальное кодовое «дерево» минимизирует  то «урезанное» кодовое «дерево» минимизирует
то «урезанное» кодовое «дерево» минимизирует  и наоборот. Следовательно, задача отыскания оптимального кодового «дерева» свелась к задаче отыскания оптимального «урезанного» кодового «дерева» для сообщения с
и наоборот. Следовательно, задача отыскания оптимального кодового «дерева» свелась к задаче отыскания оптимального «урезанного» кодового «дерева» для сообщения с  возможностями. К этому «упрощенному» сообщению можно применить все те рассуждения, которые относились выше к первоначальному сообщению, и получить «дважды упрощенное» сообщение с
возможностями. К этому «упрощенному» сообщению можно применить все те рассуждения, которые относились выше к первоначальному сообщению, и получить «дважды упрощенное» сообщение с  возможностями. К последнему также применяется вышеприведенное рассуждение и т. д., пока не получится тривиальное сообщение с двумя возможностями. В процессе описанного упрощения кодового «дерева» и сообщения две ветви кодового «дерева» на каждом шаге сливаются в одну и в конце полностью выясняется его структура.
возможностями. К последнему также применяется вышеприведенное рассуждение и т. д., пока не получится тривиальное сообщение с двумя возможностями. В процессе описанного упрощения кодового «дерева» и сообщения две ветви кодового «дерева» на каждом шаге сливаются в одну и в конце полностью выясняется его структура.
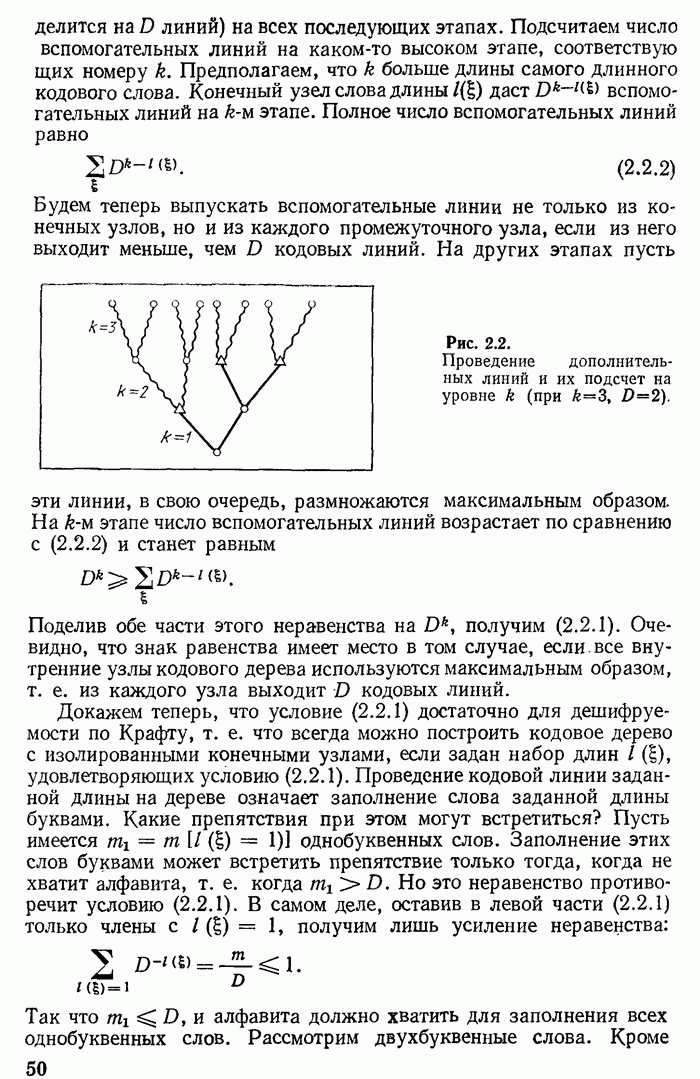
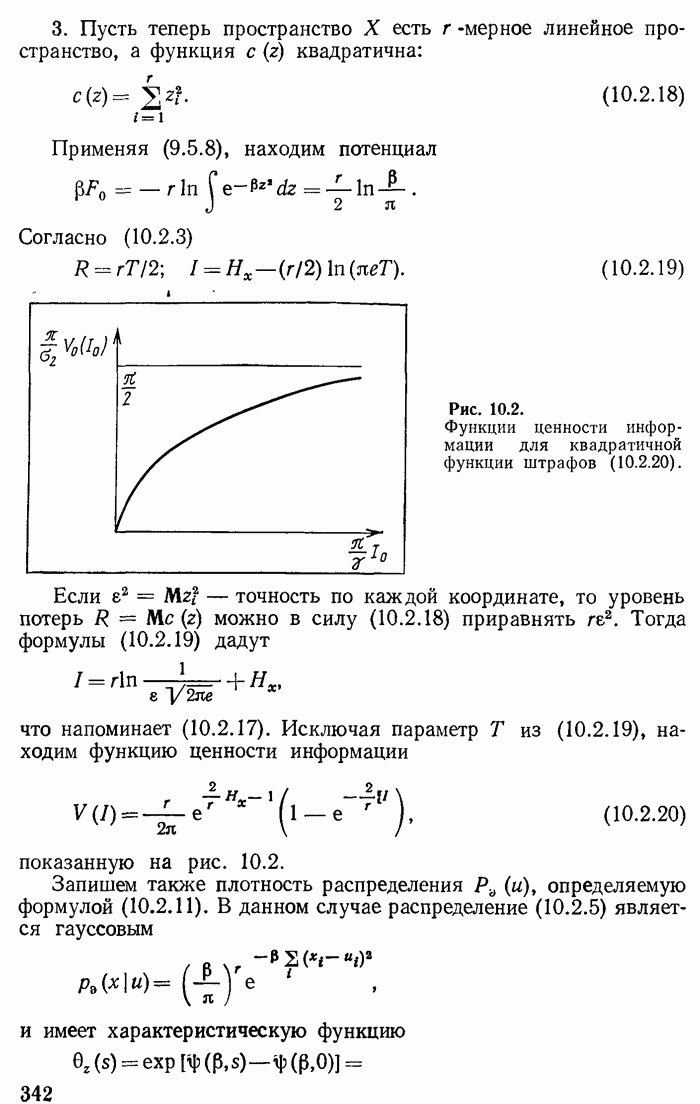
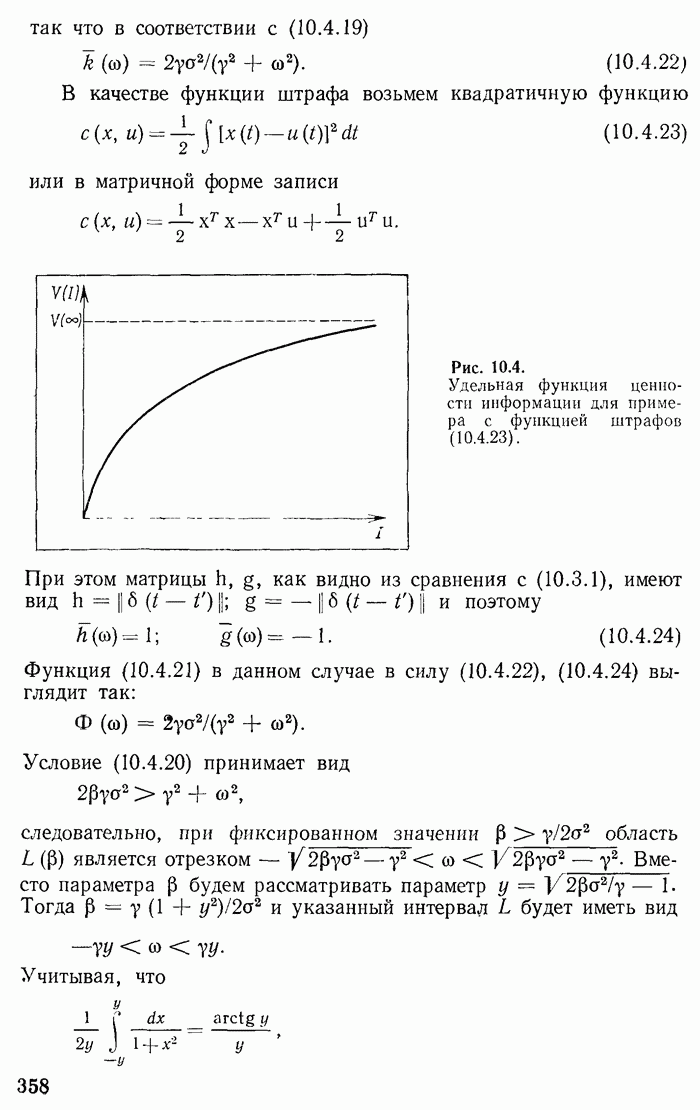
Аналогичное рассмотрение можно провести и при  Предположим, что все узлы кодового «дерева» полностью заполнены. Это имеет место, когда
Предположим, что все узлы кодового «дерева» полностью заполнены. Это имеет место, когда  без остатка делится на
без остатка делится на  самом деле, каждый узел (кроме конечных) добавляет
самом деле, каждый узел (кроме конечных) добавляет  новых линий (если считать, что к первому узлу подходит снизу одна линия) и частное
новых линий (если считать, что к первому узлу подходит снизу одна линия) и частное  равно числу узлов. Каждое «упрощение» в этом случае уменьшает число реализаций случайной величины на
равно числу узлов. Каждое «упрощение» в этом случае уменьшает число реализаций случайной величины на  При этом сливаются воедино
При этом сливаются воедино  наименее Вероятных возможностей;
наименее Вероятных возможностей;  самых длинных ветвей кодового «дерева» из оставшихся укорачиваются на единицу и заменяются на один конечный узел.
самых длинных ветвей кодового «дерева» из оставшихся укорачиваются на единицу и заменяются на один конечный узел.
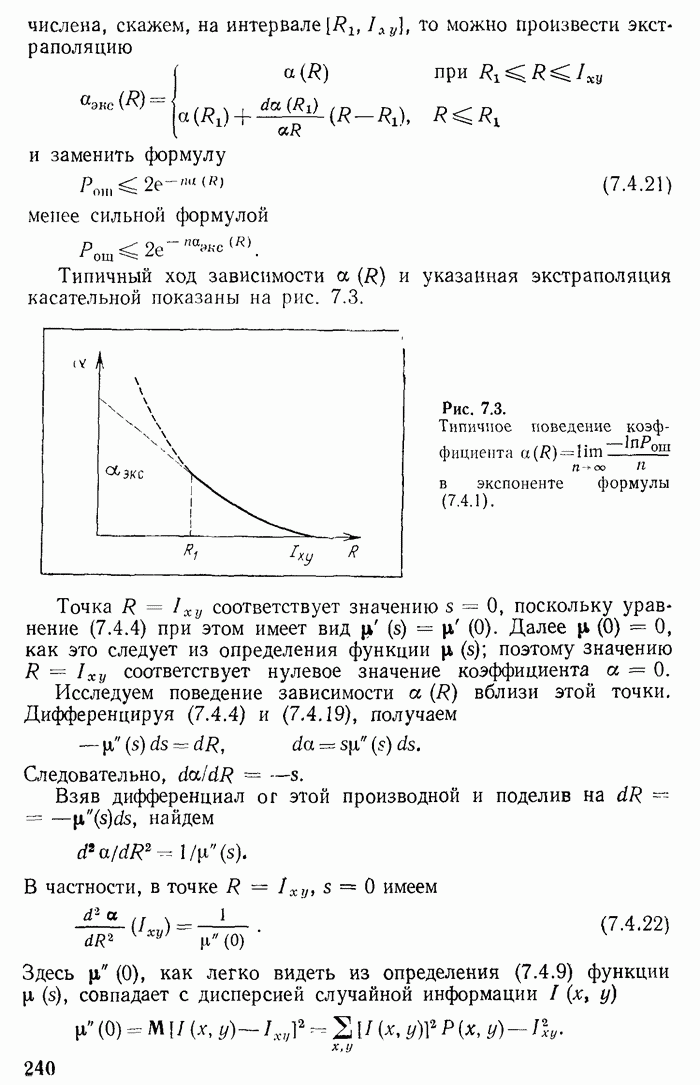
Некоторое осложнение вносит тот случай, когда число  не целое. Это значит, что из внутренних узлов кодового «дерева» хотя бы один должен быть неполным. Но в оптимальном дереве, как отмечалось, неполные узлы могут принадлежать лишь последнему этапу, относиться к последнему выбору. Без ухудшения «дерева» можно так переставить сообщения, относящиеся к словам максимальной длины, что: 1) неполным будет лишь один единственный узел и 2) сообщения, относящиеся к этому узлу, будут иметь самую меньшую вероятность. Обозначим через
не целое. Это значит, что из внутренних узлов кодового «дерева» хотя бы один должен быть неполным. Но в оптимальном дереве, как отмечалось, неполные узлы могут принадлежать лишь последнему этапу, относиться к последнему выбору. Без ухудшения «дерева» можно так переставить сообщения, относящиеся к словам максимальной длины, что: 1) неполным будет лишь один единственный узел и 2) сообщения, относящиеся к этому узлу, будут иметь самую меньшую вероятность. Обозначим через  остаток, получающийся от деления
остаток, получающийся от деления  на
на  Тогда единственный неполный узел будет иметь
Тогда единственный неполный узел будет иметь  ветвей. В соответствии с вышесказанным первое «обрезание»
ветвей. В соответствии с вышесказанным первое «обрезание»
дерева и упрощение случайной величины будет заключаться в следующем: выбираются  наименее вероятных реализаций из
наименее вероятных реализаций из  и заменяются на одну реализацию с суммарной вероятностью. «Урезанное» дерево будет иметь уже заполненные внутренние узлы. При дальнейшем упрощении берутся
и заменяются на одну реализацию с суммарной вероятностью. «Урезанное» дерево будет иметь уже заполненные внутренние узлы. При дальнейшем упрощении берутся  наименее вероятных реализаций из получившихся при предыдущем упрощении и заменяются на одну с суммарной вероятностью. То же самое производится и в дальнейшем. В этом заключается рецепт построения оптимального кода по Хуфману. Приведенные выше рассуждения говорят о том, что полученное в результате кодовое «дерево», возможно, не совпадает с оптимальным «деревом» К, но не хуже его, т. е. имеет такую же среднюю длину
наименее вероятных реализаций из получившихся при предыдущем упрощении и заменяются на одну с суммарной вероятностью. То же самое производится и в дальнейшем. В этом заключается рецепт построения оптимального кода по Хуфману. Приведенные выше рассуждения говорят о том, что полученное в результате кодовое «дерево», возможно, не совпадает с оптимальным «деревом» К, но не хуже его, т. е. имеет такую же среднюю длину 
Пример. Рассмотрим кодирование в двоичном  алфавите
алфавите  бесконечной последовательности
бесконечной последовательности  одинаковых элементарных сообщений. Каждое элементарное сообщение
одинаковых элементарных сообщений. Каждое элементарное сообщение  пусть будет такого же типа, как и в примере из § 1.2, т. е.
пусть будет такого же типа, как и в примере из § 1.2, т. е. 
1) Если взять  т. е. кодировать каждое элементарное сообщение в отдельности, то в качестве кода остается лишь выбрать тривиальный код:
т. е. кодировать каждое элементарное сообщение в отдельности, то в качестве кода остается лишь выбрать тривиальный код:

Для него  в то время как
в то время как

и, следовательно, возможно  Сравнение последней цифры с 1, показывает, что можно добиться значительного выигрыша в краткости, если перейти к усложненным вариантам кодирования — к
Сравнение последней цифры с 1, показывает, что можно добиться значительного выигрыша в краткости, если перейти к усложненным вариантам кодирования — к 
2) Положим  Тогда будут такие возможности и вероятности
Тогда будут такие возможности и вероятности

Здесь  означает номер пары
означает номер пары 
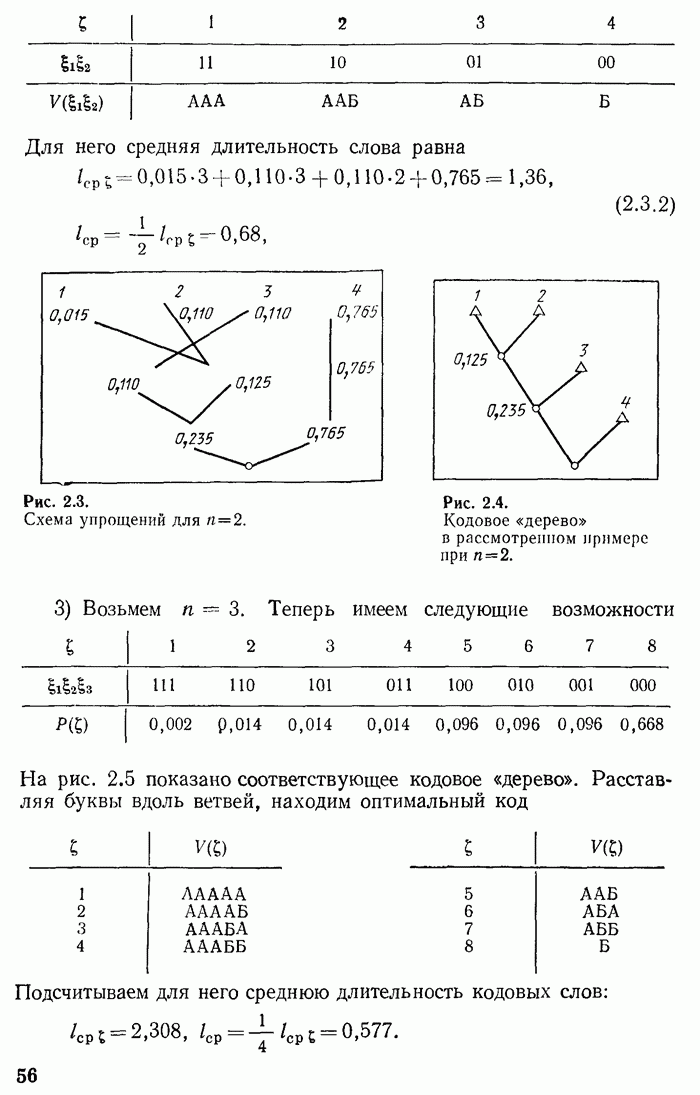
При первом «упрощении» можно объединить реализации  в одну реализацию, имеющую вероятность
в одну реализацию, имеющую вероятность  Среди оставшихся после «упрощения» реализаций, имеющих вероятность 0,110; 0,125; 0,765, снова объединяем две наименее вероятные. Схема этих «упрощений» и соответствующее им кодовое «дерево» показаны на рис. 2.3, 2.4.
Среди оставшихся после «упрощения» реализаций, имеющих вероятность 0,110; 0,125; 0,765, снова объединяем две наименее вероятные. Схема этих «упрощений» и соответствующее им кодовое «дерево» показаны на рис. 2.3, 2.4.
Остается лишь расставить буквы  вдоль ветвей, чтобы получить следующий оптимальный код:
вдоль ветвей, чтобы получить следующий оптимальный код:

Для него средняя длительность слова равна


Рис. 2.3.
Схема упрощений для 

Рис. 2.4.
Кодовое «дерево» в рассмотренном примере при 
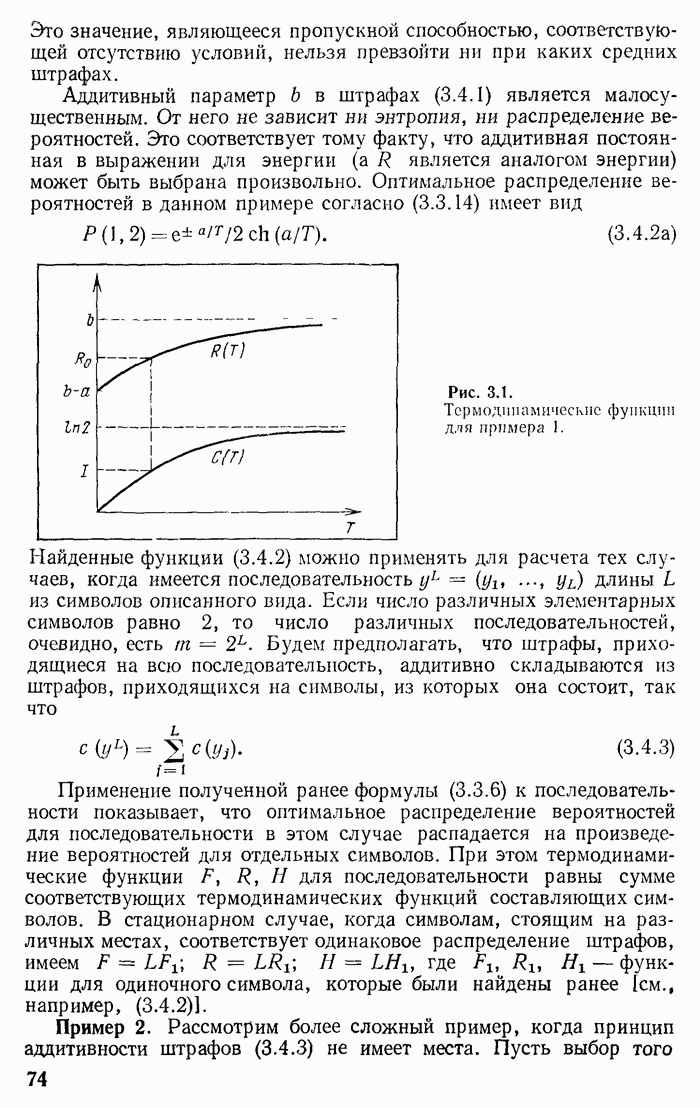
3) Возьмем  Теперь имеем следующие возможности
Теперь имеем следующие возможности

На рис. 2.5 показано соответствующее кодовое «дерево». Расставляя буквы вдоль ветвей, находим оптимальный код

Подсчитываем для него среднюю длительность кодовых слов:

Эта величина уже значительно ближе к предельному значению  чем
чем 

Рис. 2.5.
Кодовое «дерево» при 
Увеличивая  далее и конструируя оптимальные коды описанным способом, можно сколь угодно близко приблизиться к значению 0,544. Это достигается, конечно, усложнением кодирующей системы.
далее и конструируя оптимальные коды описанным способом, можно сколь угодно близко приблизиться к значению 0,544. Это достигается, конечно, усложнением кодирующей системы.