Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
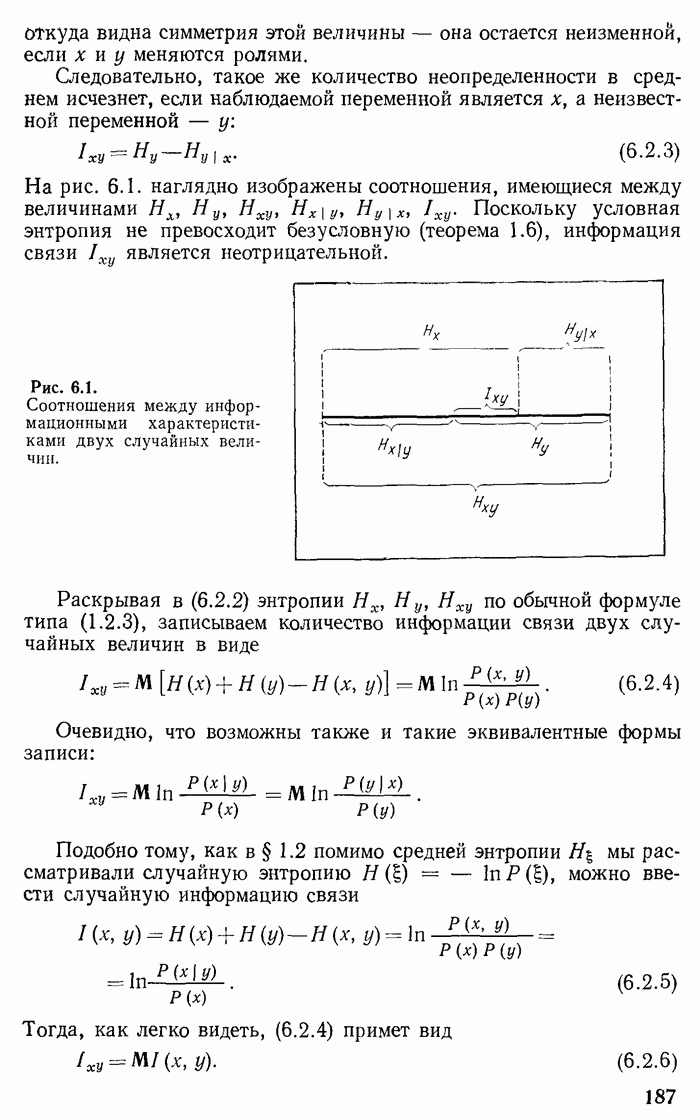
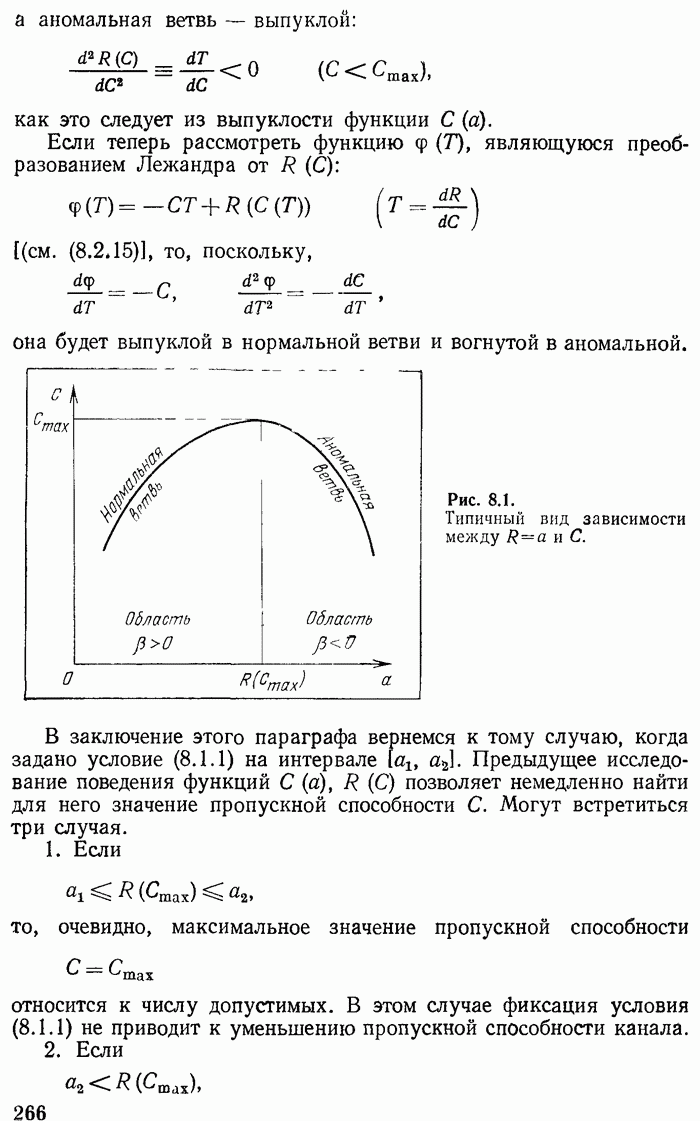
2.2. Основные теоремы для кодирования без помех. Равнораспределенные независимые сообщенияРассмотрим тот случай, когда имеется неограниченная (в одну сторону) последовательность Для исследования кодирования в отсутствие помех, имеется, однако, и другая возможность — избегнуть разбиения последовательности на блоки и отбрасывания несущественных реализаций. Соответствующую теорию мы изложим в этом параграфе. Код (2.1.7), пригодный для передачи (или записи) единичного сообщения, не приспособлен для передачи последовательности таких сообщений. Например, запись расшифровать сообщение, и мы должны его забраковать, если хотим передавать последовательность сообщений. Обязательное условие, чтобы длинную последовательность кодовых символов можно было однозначно разбить на слова, существенно ограничивает класс допустимых кодов. Назовем дешифруемыми кодами такие коды, в которых любая полубесконечная последовательность кодовых слов разбивается на слова однозначным образом. Как доказывается, например в книге Файнстейна
Удобнее рассматривать несколько более узкий класс дешифруемых кодов — назовем их дешифруемые коды Крафта (см. работу
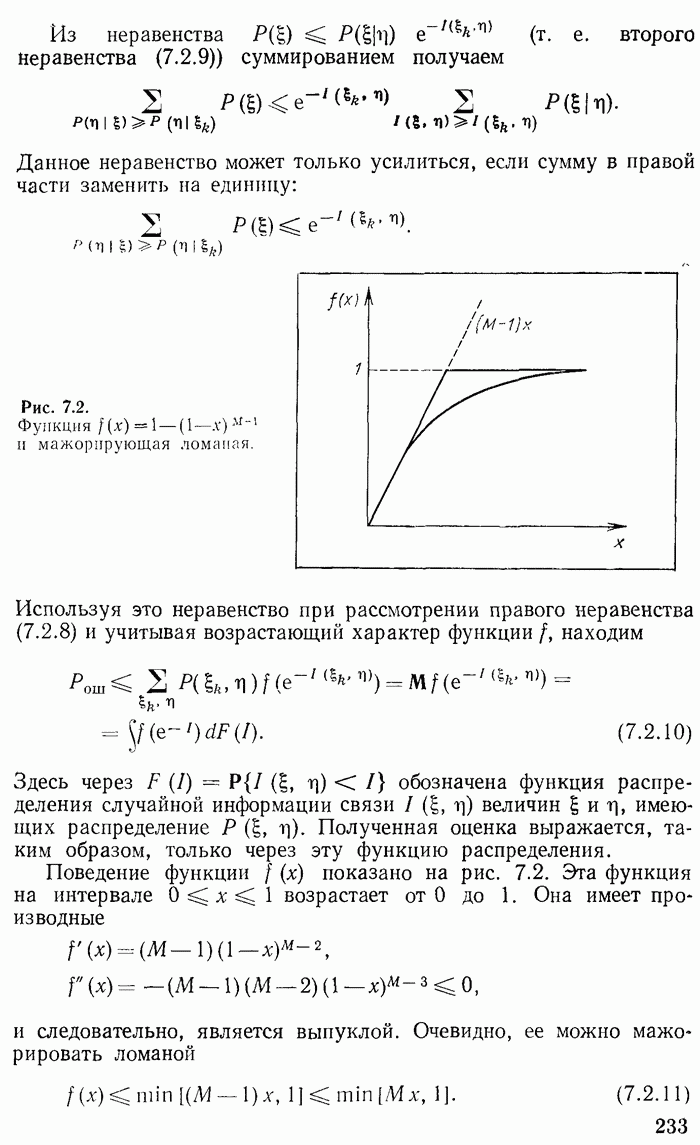
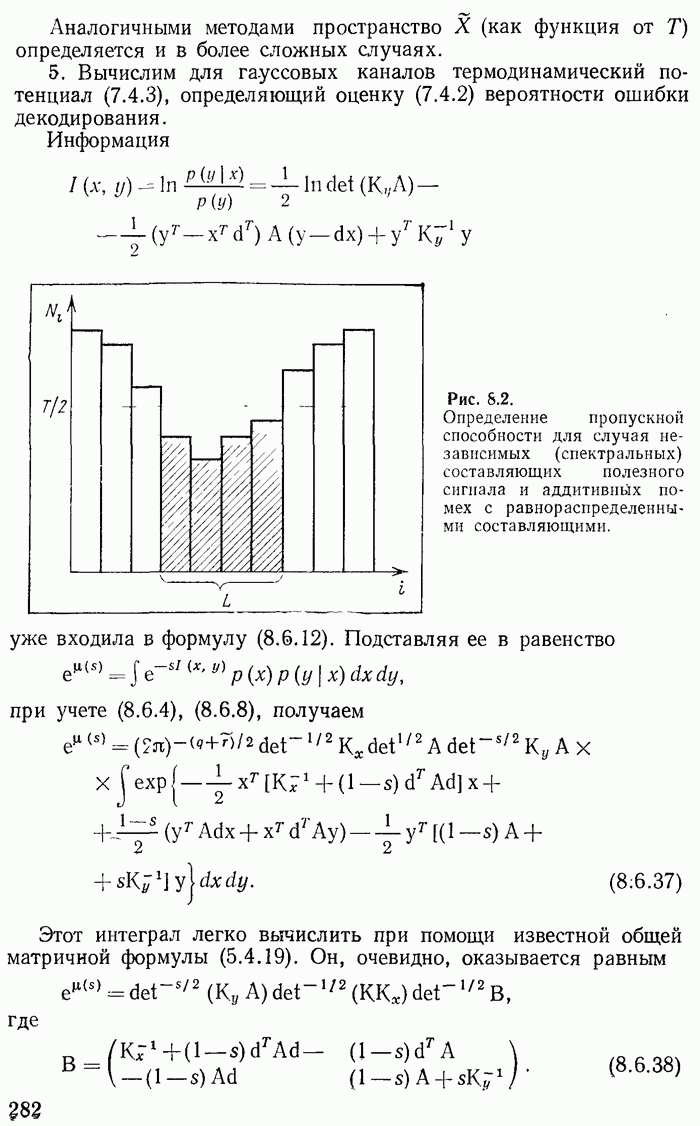
Рис. 2.1. Пример кодового «дерева». Крафта [1]). В этих кодах ни одно кодовое слово не является передней частью («префиксом») другого слова. В коде (2.1.7) это условие нарушено в слове Для дешифруемых кодов Крафта ни один конечный узел не лежит на другой кодовой линии. Теорема 2.1. Неравенство (2.2.1) является необходимым и достаточным условием существования кода, дешифруемого по Крафту. Доказательство. Докажем сначала, что неравенство (2.2.1) выполняется для любого кода Крафта. Из каждого конечного узла кодового дерева выпустим максимальное число (равное делится на
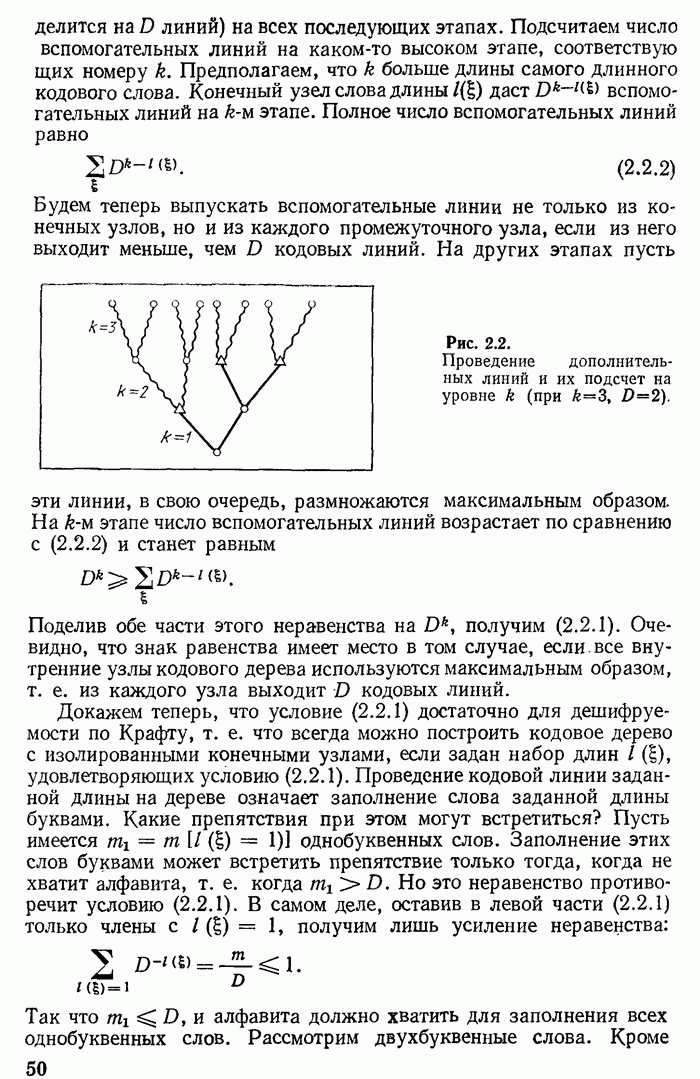
Будем теперь выпускать вспомогательные линии не только из конечных узлов, но и из каждого промежуточного узла, если из него выходит меньше, чем
Рис. 2.2. Проведение дополнительных линий и их подсчет на уровне На других этапах пусть эти линии, в свою очередь, размножаются максимальным образом. На
Поделив обе части этого неравенства на Докажем теперь, что условие (2.2.1) достаточно для дешифруемости по Крафту, т. е. что всегда можно построить кодовое дерево с изолированными конечными узлами, если задан набор длин
Так что использованных букв, стоящих на первом месте, имеется еще
т. е.
в (2.2.1). Доказательство закончено. Как видно из приведенного доказательства, не представляет труда фактическое построение кода (заполнение слов буквами), если задан приемлемый набор длин Перейдем теперь к основным теоремам. Теорема 2.2. Средняя длина слова
Используя очевидное неравенство
получаем
т. е.
так как
Учитывая (2.2.1), отсюда находим Вместо неравенства (2.2.3), можно использовать неравенство (1.2.4) Следующие теоремы утверждают, что к значению Теорема 2.3. Можно указать такой способ кодирования равнораспределенных независимых сообщений, что
Доказательство. Выберем длины
Такой выбор возможен, ибо в этом диапазоне заведомо имеется одно целое число. Из левого неравенства следует
т. е. выполняется условие дешифруемости (2.2.1). Как видно из рассуждений перед теоремой 2.2, нетрудно фактически построить кодовые слова с выбранными длинами Приведем следующую теорему, которая носит асимптотический характер. Теорема 2.4. Существуют такие способы кодирования бесконечного сообщения Доказательство. Возьмем произвольное целое
где
Увеличивая Приведенные результаты получены для случая стационарной последовательности независимых случайных величин (сообщений). Эти результаты могут быть распространены на случай зависимых сообщений, на нестационарный случай и др. При этом существенным является то, чтобы последовательность удовлетворяла определенным свойствам энтропийной устойчивости (см. § 1.5).
|
 |
Оглавление
|




















































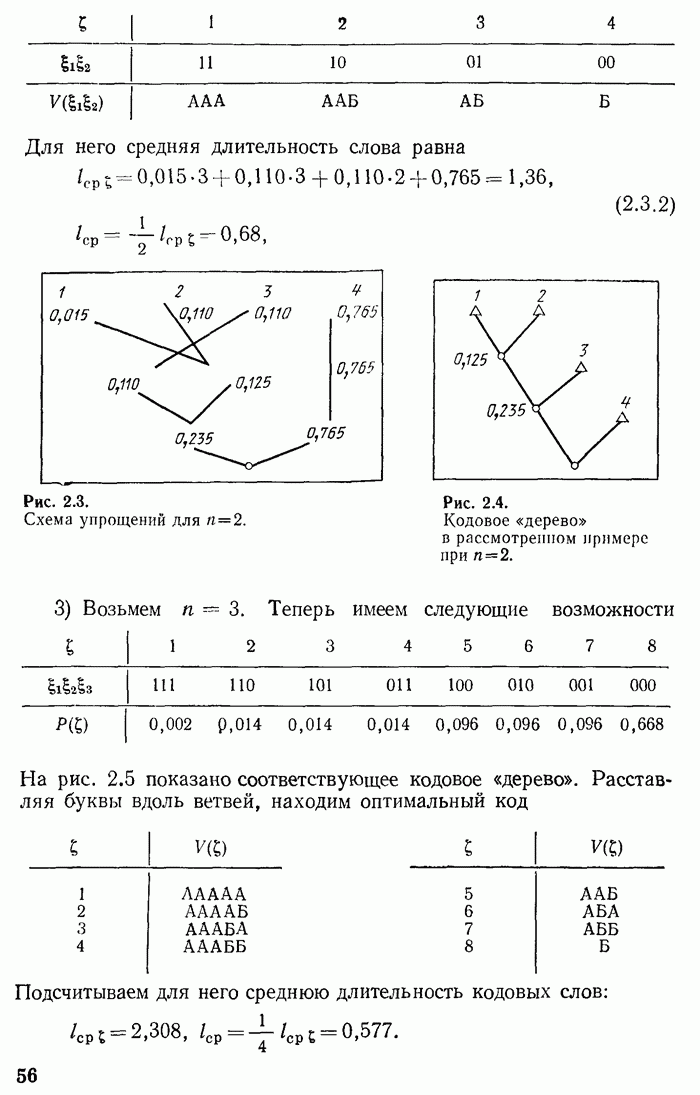

















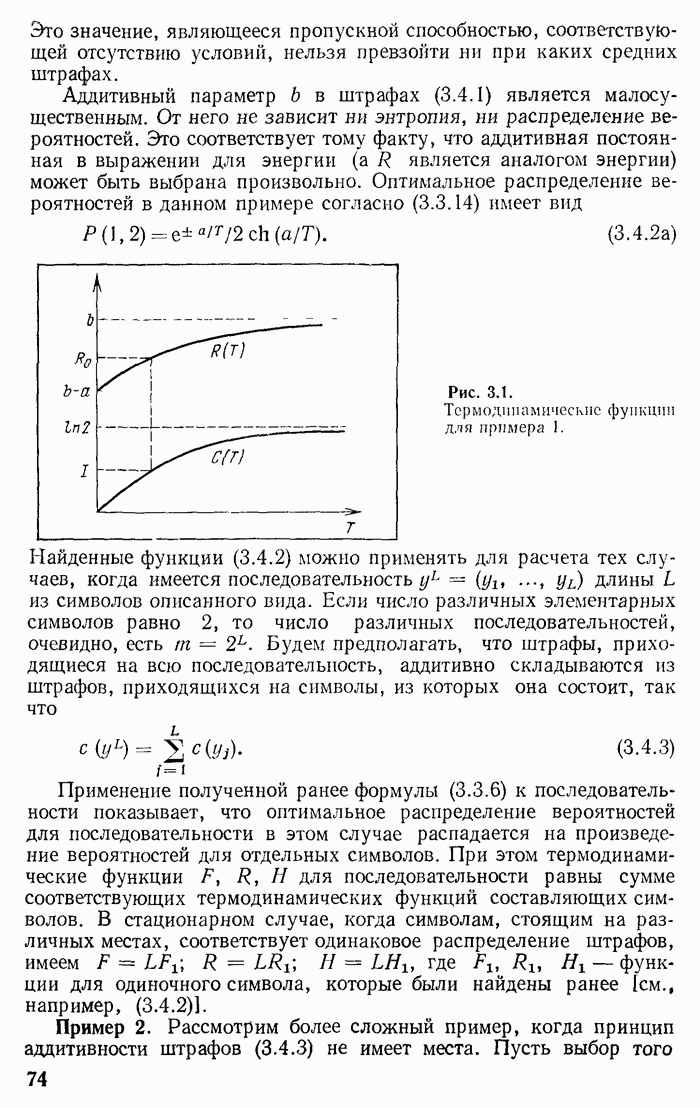












































































































































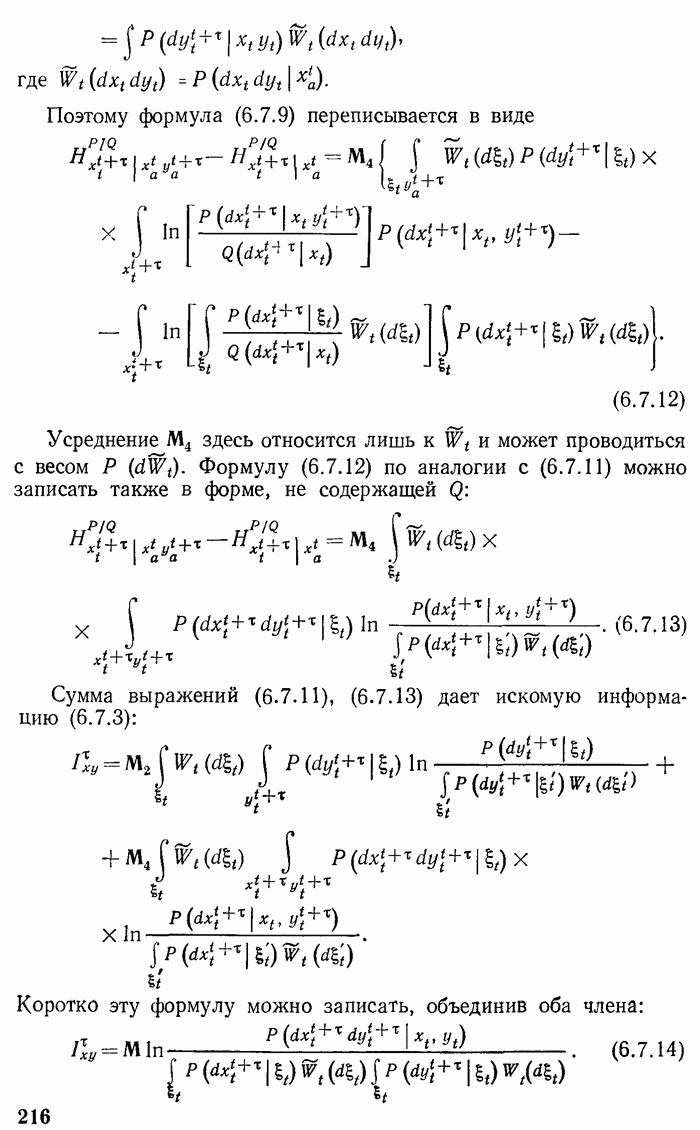































































































































































































 одинаковых независимых сообщений. Требуется осуществить ее кодирование. Чтобы применить рассуждения предыдущего параграфа, требуется разбить эту последовательность на отрезки, называемые блоками, содержащие по
одинаковых независимых сообщений. Требуется осуществить ее кодирование. Чтобы применить рассуждения предыдущего параграфа, требуется разбить эту последовательность на отрезки, называемые блоками, содержащие по  элементарных сообщений каждый. Тогда при больших
элементарных сообщений каждый. Тогда при больших  можно использовать описанные выше общие асимптотические («термодинамические») соотношения.
можно использовать описанные выше общие асимптотические («термодинамические») соотношения.
 можно истолковать как запись
можно истолковать как запись  сообщения
сообщения  и как запись
и как запись  сообщения (3 1 2) (при
сообщения (3 1 2) (при  ), не говоря уже о сообщениях
), не говоря уже о сообщениях  , которые соответствуют другим
, которые соответствуют другим  Он не дает возможности однозначно
Он не дает возможности однозначно
 для этих кодов выполняется неравенство
для этих кодов выполняется неравенство


 поскольку оно является передней частью слова
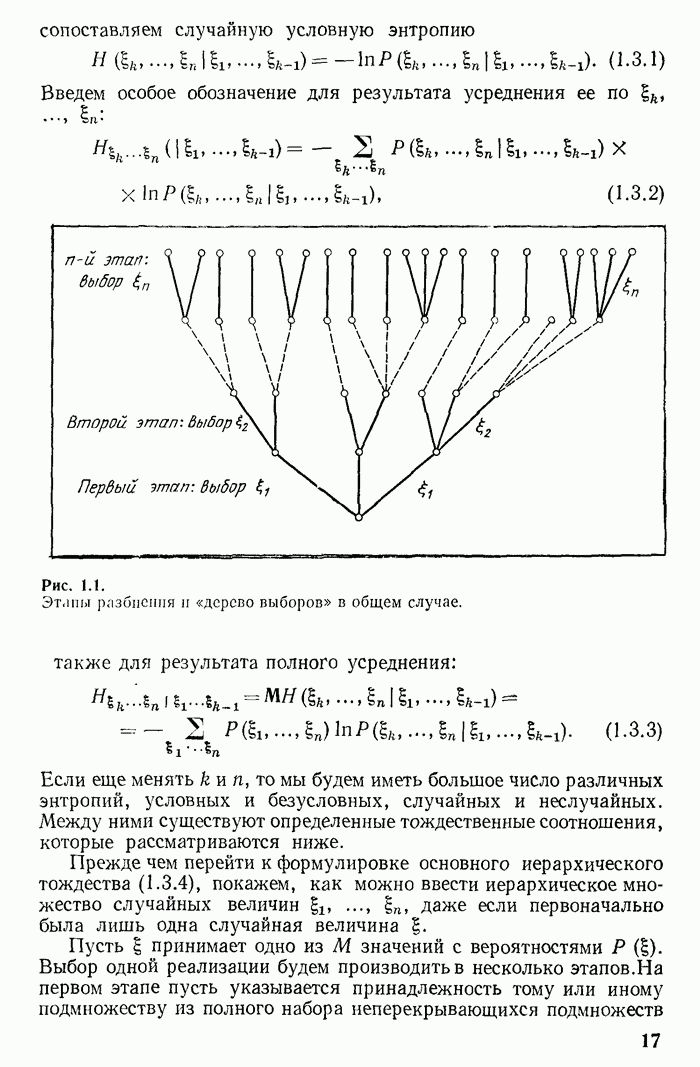
поскольку оно является передней частью слова  Коды можно рисовать в форме «дерева» (рис. 2.1), наподобие «деревьев», изображенных на рис. 1.1 и 1.2. Однако (если рассматривать код отдельно от сообщения
Коды можно рисовать в форме «дерева» (рис. 2.1), наподобие «деревьев», изображенных на рис. 1.1 и 1.2. Однако (если рассматривать код отдельно от сообщения  в отличие от них «ветвям» «кодового дерева» не сопоставляются вероятности. Выбор ветви осуществляется по этапам записью очередной буквы
в отличие от них «ветвям» «кодового дерева» не сопоставляются вероятности. Выбор ветви осуществляется по этапам записью очередной буквы  слова. Концу слова соответствует особый конечный узел, который мы на рисунке обозначаем треугольником. Каждому кодовому слову соответствует кодовая линия, идущая
слова. Концу слова соответствует особый конечный узел, который мы на рисунке обозначаем треугольником. Каждому кодовому слову соответствует кодовая линия, идущая  начального узла до конечного. На рис. 2.1 изображено «дерево», соответствующее коду (2.1.5).
начального узла до конечного. На рис. 2.1 изображено «дерево», соответствующее коду (2.1.5).
 вспомогательных линий, изображенных волнистыми линиями на рис. 2.2. Пусть они размножаются максимальным образом (каждая
вспомогательных линий, изображенных волнистыми линиями на рис. 2.2. Пусть они размножаются максимальным образом (каждая
 линий) на всех последующих этапах. Подсчитаем число вспомогательных линий на каком-то высоком этапе, соответствующих номеру
линий) на всех последующих этапах. Подсчитаем число вспомогательных линий на каком-то высоком этапе, соответствующих номеру  Предполагаем, что
Предполагаем, что  больше длины самого длинного кодового слова. Конечный узел слова длины
больше длины самого длинного кодового слова. Конечный узел слова длины  даст
даст  вспомогательных линий на
вспомогательных линий на  этапе. Полное число вспомогательных линий равно
этапе. Полное число вспомогательных линий равно

 кодовых линий.
кодовых линий.


 этапе число вспомогательных линий возрастает по сравнению с (2.2.2) и станет равным
этапе число вспомогательных линий возрастает по сравнению с (2.2.2) и станет равным

 получим (2.2.1). Очевидно, что знак равенства имеет место в том случае, если все внутренние узлы кодового дерева используются максимальным образом, т. е. из каждого узла выходит
получим (2.2.1). Очевидно, что знак равенства имеет место в том случае, если все внутренние узлы кодового дерева используются максимальным образом, т. е. из каждого узла выходит  кодовых линий.
кодовых линий.
 удовлетворяющих условию (2.2.1). Проведение кодовой линии заданной длины на дереве означает заполнение слова заданной длины буквами. Какие препятствия при этом могут встретиться? Пусть имеется
удовлетворяющих условию (2.2.1). Проведение кодовой линии заданной длины на дереве означает заполнение слова заданной длины буквами. Какие препятствия при этом могут встретиться? Пусть имеется  однобуквенных слов. Заполнение этих слов буквами может встретить препятствие только тогда, когда не хватит алфавита, т. е. когда
однобуквенных слов. Заполнение этих слов буквами может встретить препятствие только тогда, когда не хватит алфавита, т. е. когда  Но это неравенство противоречит условию (2.2.1). В самом деле, оставив в левой части (2.2.1) только члены с
Но это неравенство противоречит условию (2.2.1). В самом деле, оставив в левой части (2.2.1) только члены с  получим лишь усиление неравенства:
получим лишь усиление неравенства:

 и алфавита должно хватить для заполнения всех однобуквенных слов. Рассмотрим двухбуквенные слова. Кроме
и алфавита должно хватить для заполнения всех однобуквенных слов. Рассмотрим двухбуквенные слова. Кроме
 букв, которые мы можем поставить на первое место. К первой букве можно прибавить любую из
букв, которые мы можем поставить на первое место. К первой букве можно прибавить любую из  букв. Всего имеется
букв. Всего имеется  возможностей. На «дереве» любой узел из
возможностей. На «дереве» любой узел из  неконечных узлов первого этапа дает
неконечных узлов первого этапа дает  линий. Этих возможных двухбуквенных сочетаний (линий) должно хватить для заполнения всех двухбуквенных слов, число которых обозначим
линий. Этих возможных двухбуквенных сочетаний (линий) должно хватить для заполнения всех двухбуквенных слов, число которых обозначим  В самом деле, оставляя в левой части (2.2.1) лишь члены с
В самом деле, оставляя в левой части (2.2.1) лишь члены с  имеем
имеем

 Это и означает, что двухбуквенных сочетаний хватит для заполнения двухбуквенных слов. После этого заполнения остаются свободными
Это и означает, что двухбуквенных сочетаний хватит для заполнения двухбуквенных слов. После этого заполнения остаются свободными  двухбуквенных сочетаний, которые можно использовать для прибавления новых букв. Числа трехбуквенных сочетаний, равного
двухбуквенных сочетаний, которые можно использовать для прибавления новых букв. Числа трехбуквенных сочетаний, равного  достаточно для заполнения трехбуквенных слов и т. д. Каждый раз при доказательстве используется часть членов суммы
достаточно для заполнения трехбуквенных слов и т. д. Каждый раз при доказательстве используется часть членов суммы


 меньшая, чем
меньшая, чем  является недостижимой ни при каком кодировании. Доказательство. Рассмотрим разность
является недостижимой ни при каком кодировании. Доказательство. Рассмотрим разность





 Доказательство закончено.
Доказательство закончено.
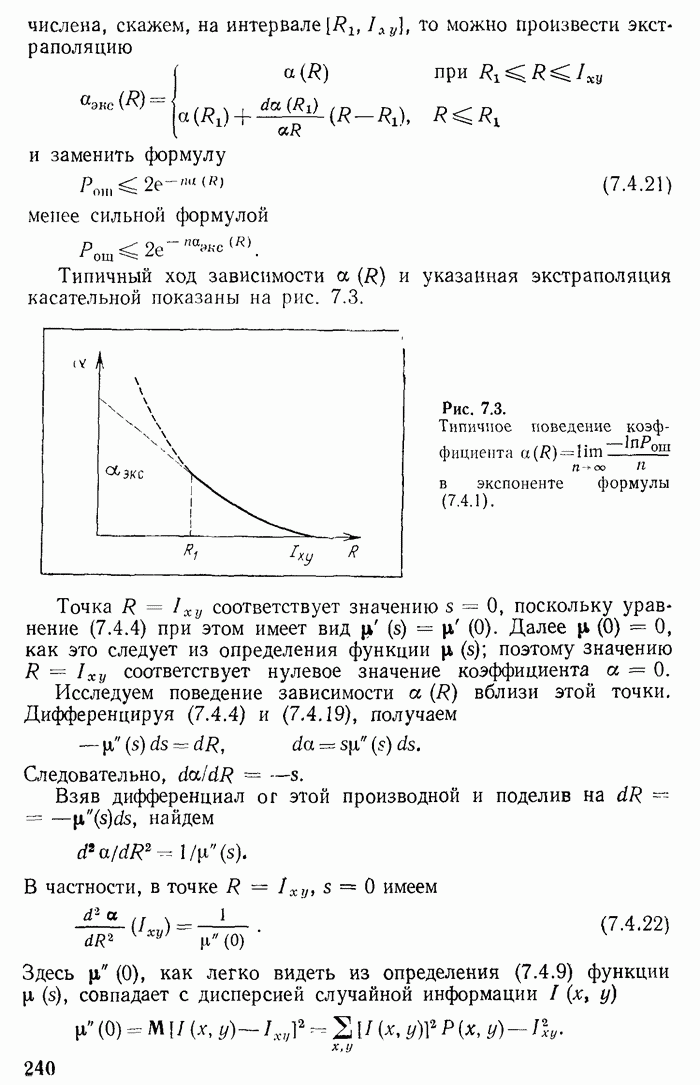
 ограничивающему среднюю длину
ограничивающему среднюю длину  снизу, можно подойти довольно близко, выбирая подходящий способ кодирования.
снизу, можно подойти довольно близко, выбирая подходящий способ кодирования.

 кодовых слов так, чтобы они удовлетворяли неравенству
кодовых слов так, чтобы они удовлетворяли неравенству

 так что
так что

 Усредняя обе части правого неравенства (2.2.5), получаем (2.2.4). Доказательство закончено.
Усредняя обе части правого неравенства (2.2.5), получаем (2.2.4). Доказательство закончено.
 что средняя длина элементарного сообщения может быть сделана сколь угодно близкой к
что средняя длина элементарного сообщения может быть сделана сколь угодно близкой к 
 разобьем последовательность
разобьем последовательность  на группы по
на группы по  случайных величин. Каждую такую группу будем рассматривать как одну случайную величину
случайных величин. Каждую такую группу будем рассматривать как одну случайную величину  и применим к ней теорему 2.3. Неравенство (2.2.4) для нее примет вид
и применим к ней теорему 2.3. Неравенство (2.2.4) для нее примет вид

 средняя длина слова, передающего сообщение
средняя длина слова, передающего сообщение  Очевидно, что
Очевидно, что  поэтому (2.2.6) дает
поэтому (2.2.6) дает

 величину
величину  можно сделать сколь угодно малой, что доказывает теорему.
можно сделать сколь угодно малой, что доказывает теорему.