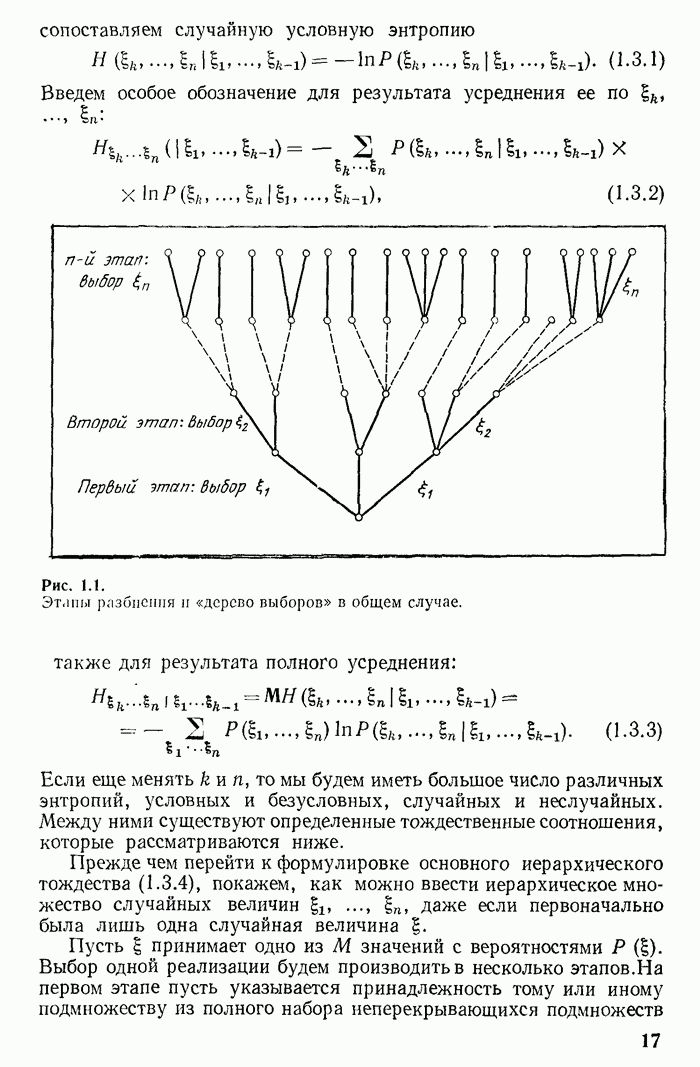
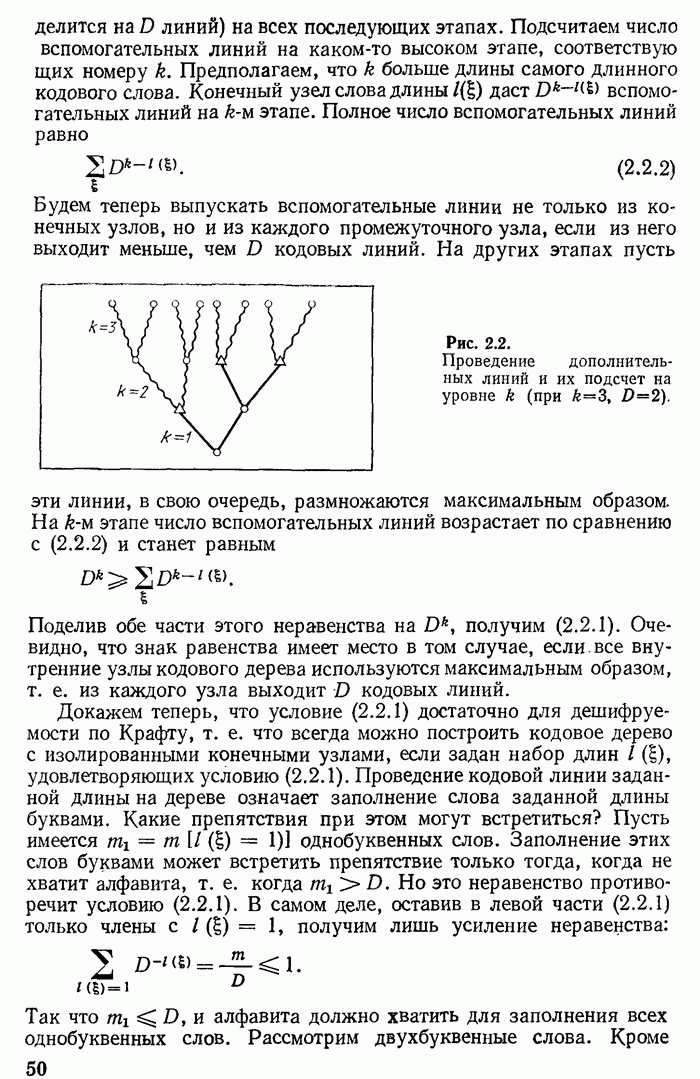
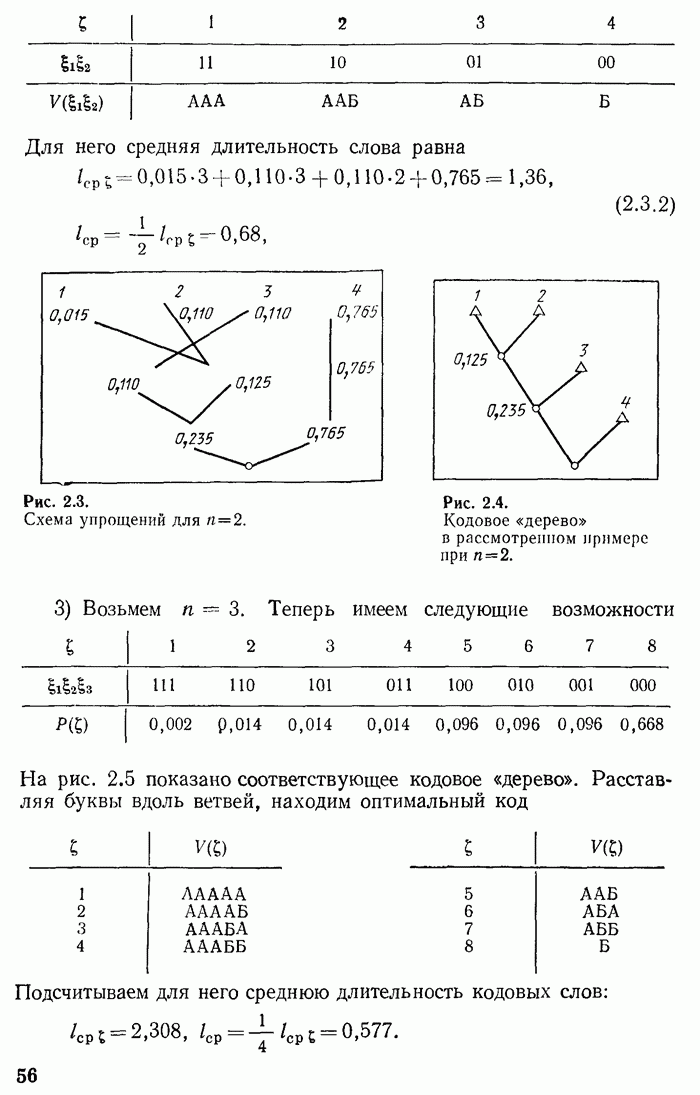
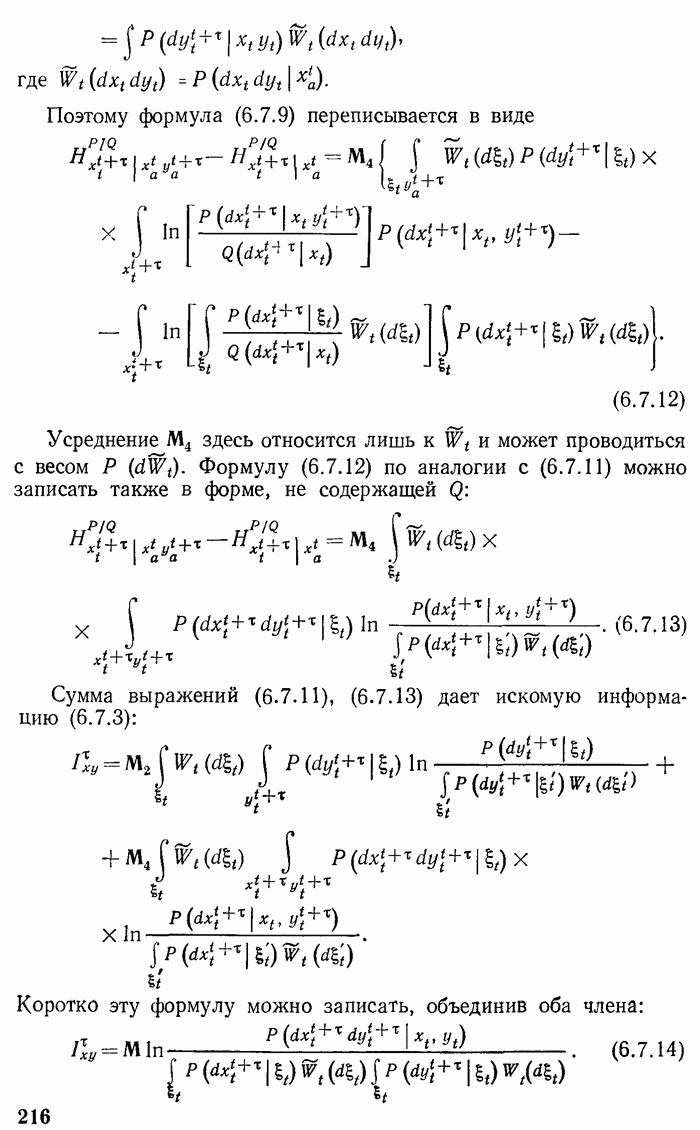7.2. Случайный код и средняя вероятность ошибки
При фиксированном правиле декодирования, например, при описанном в предыдущем параграфе оптимальном правиле, вероятность ошибки (т. е. вероятность выбора получателем не того кодового слова которое было передано) зависит от выбранного кода. Чтобы реже были ошибки декодирования, обусловленные помехами, кодовые слова желательно выбирать по возможности более «непохожими», лежащими в некотором смысле как можно «дальше» друг от друга. Ввиду того, что одновременно увеличивать
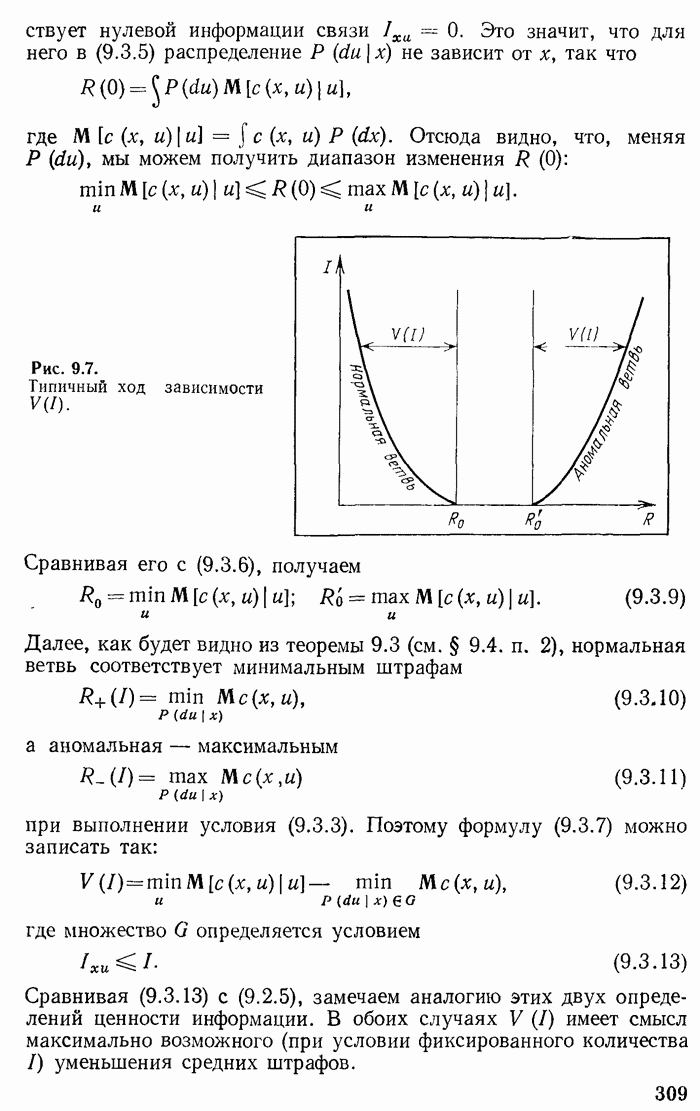
«расстояние» между кодовыми точками  нельзя без уменьшения их числа М, то желательно располагать кодовые точки «как можно равномерней» в пространстве
нельзя без уменьшения их числа М, то желательно располагать кодовые точки «как можно равномерней» в пространстве  значений
значений  Желаемая «равномерность» достигается по законам массовых явлений при больших
Желаемая «равномерность» достигается по законам массовых явлений при больших  если выбирать кодовые точки независимо друг от друга случайным образом.
если выбирать кодовые точки независимо друг от друга случайным образом.
Случайный код Шеннона конструируется следующим образом. Кодовая точка получается в результате выбрасывания случайной величины  с вероятностями
с вероятностями  Вторая точка (а также третья и прочие) выбрасывается независимо от других подобным же образом и является, следовательно, независимой случайной величиной с вероятностями
Вторая точка (а также третья и прочие) выбрасывается независимо от других подобным же образом и является, следовательно, независимой случайной величиной с вероятностями  Все кодовые точки
Все кодовые точки  в совокупности описываются распределением вероятностей
в совокупности описываются распределением вероятностей 
Для каждого фиксированного кода  полученного описанным способом, и фиксированного сообщения
полученного описанным способом, и фиксированного сообщения  имеется некоторая вероятность ошибки декодирования. Обозначим эту вероятность
имеется некоторая вероятность ошибки декодирования. Обозначим эту вероятность  Согласно (7.1.9) она равна
Согласно (7.1.9) она равна

Согласно определению области  данному в § 7.1, суммирование в (7.2.1) должно проводиться по той области, где все
данному в § 7.1, суммирование в (7.2.1) должно проводиться по той области, где все

поэтому

Вместо того чтобы вычислить вероятности ошибок

значительно удобнее вычислить вероятность

усредненную по различным случайным кодам. В этом удобстве и состоит преимущество случайных кодов. Вероятность (7.2.3), как это очевидно из соображений симметрии, не зависит от номера передаваемого сообщения, и дополнительного усреднения по  стоящего в (7.1.11), в данном случае не требуется:
стоящего в (7.1.11), в данном случае не требуется:

Вычисления показывают, что средняя вероятность (7.2.3) имеет удовлетворительные асимптотические свойства (при 
Отсюда вытекает, что среди реализаций случайных кодов имеются коды со свойствами, по меньшей мере, такими же удовлетворительными.
Перейдем к вычислению вероятности (7.2.3), (7.2.4). Подставляя (7.2.2) в (7.2.3) и учитывая (7.2.4), находим

Иначе

если ввести возрастающую функцию  и учесть, что
и учесть, что

В формулах (7.2.2.), (7.2.5), (7.2.6) знак  исключает знака Дело в том, что могут иметься «спорные» точки
исключает знака Дело в том, что могут иметься «спорные» точки  равноудаленные от нескольких конкурирующих кодовых точек, скажем
равноудаленные от нескольких конкурирующих кодовых точек, скажем  Такие точки с равным основанием можно отнести и к области
Такие точки с равным основанием можно отнести и к области  и к области Если учесть неоднозначность, связанную с такими точками, то, как легко понять, вместо (7.2.6) будем иметь неравенство
и к области Если учесть неоднозначность, связанную с такими точками, то, как легко понять, вместо (7.2.6) будем иметь неравенство

где под знаком суммы слева стоит строгое неравенство. В выражении слева исключены вклады всех «спорных» точек, в выражении справа они учтены несколько раз.
Рассмотрим выражение  являющееся аргументом функции
являющееся аргументом функции  Неравенство
Неравенство  или
или  эквивалентно неравенствам
эквивалентно неравенствам

поскольку в силу (6.2.5)

Из неравенства  второго неравенства
второго неравенства  суммированием получаем
суммированием получаем

Данное неравенство может только усилиться, если сумму в правой части заменить на единицу:


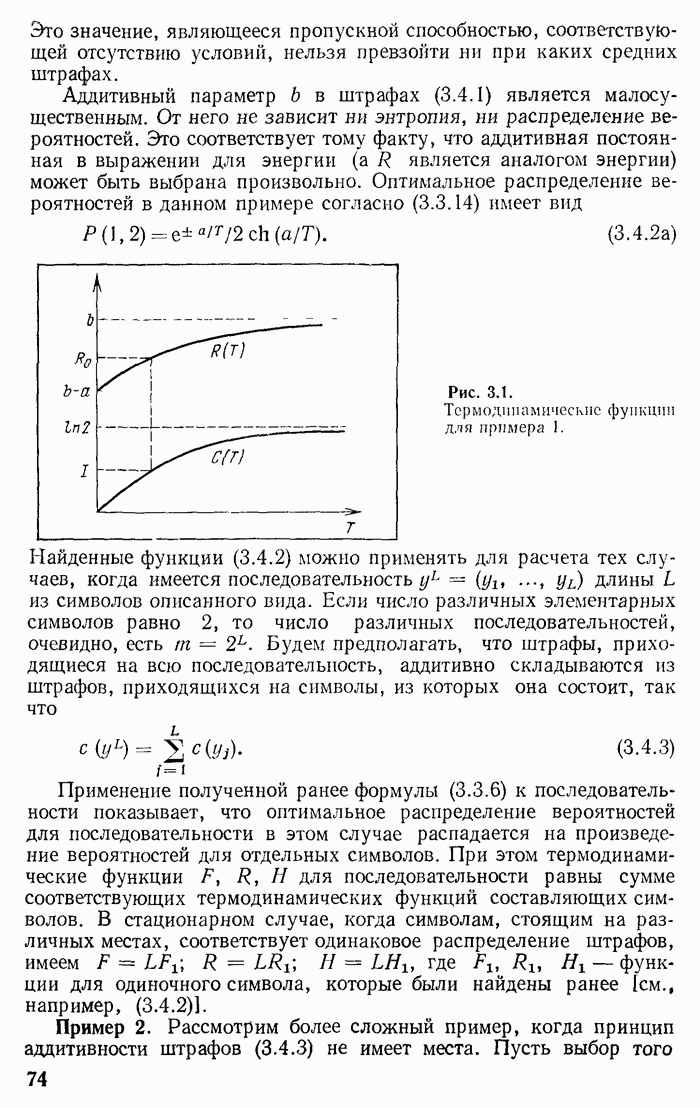
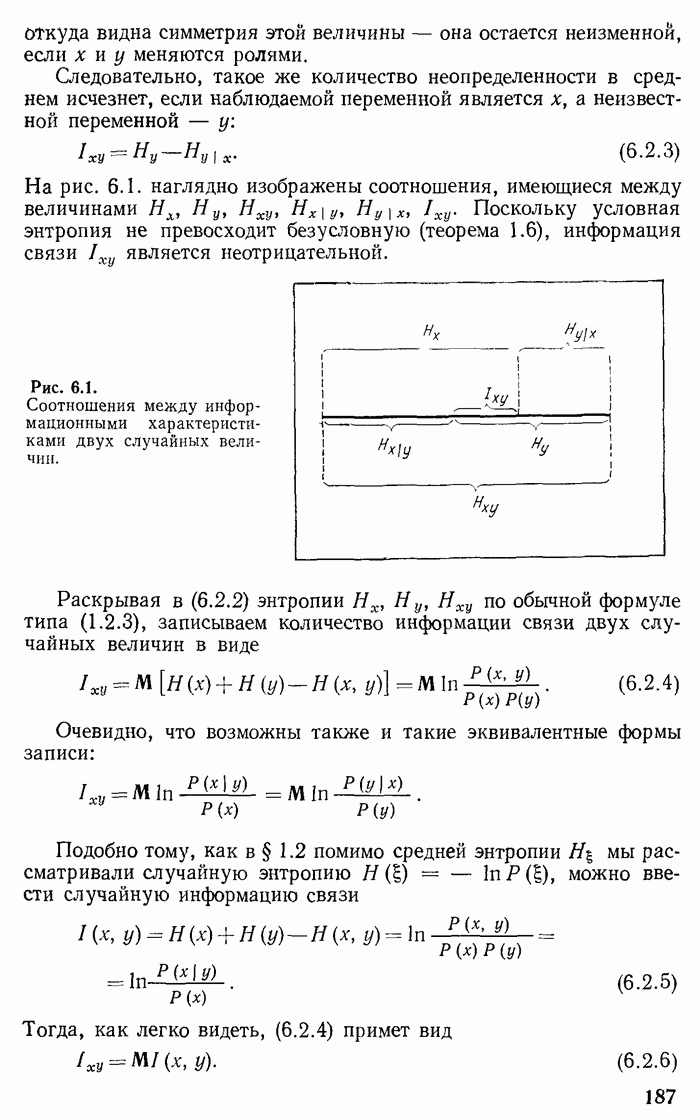
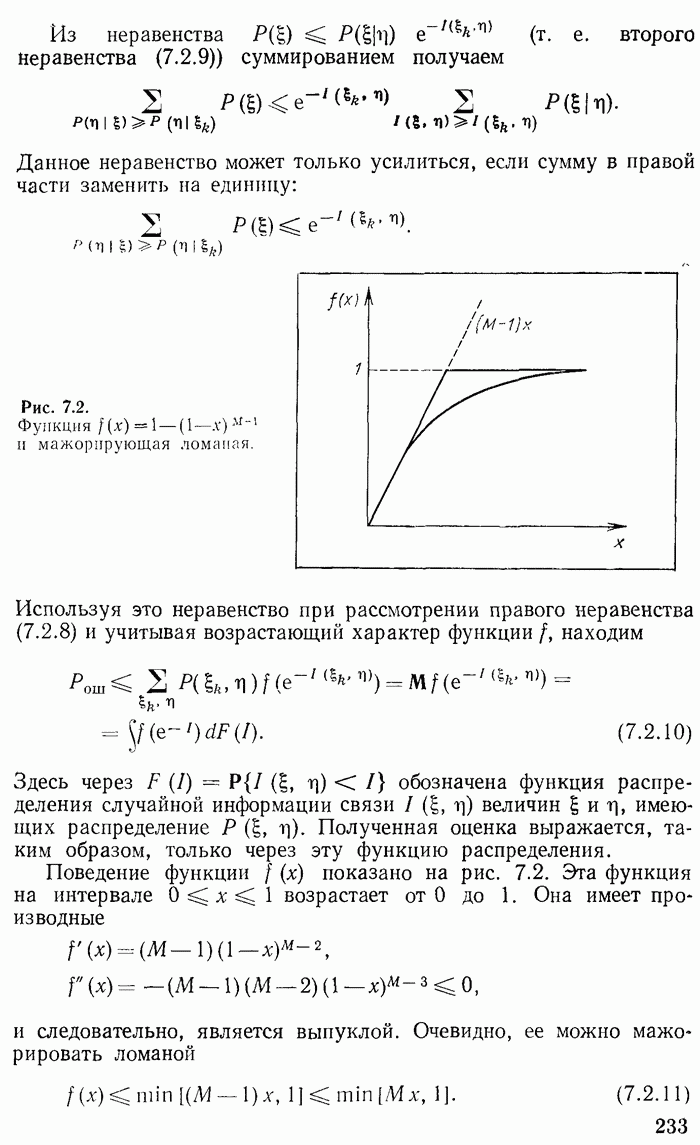
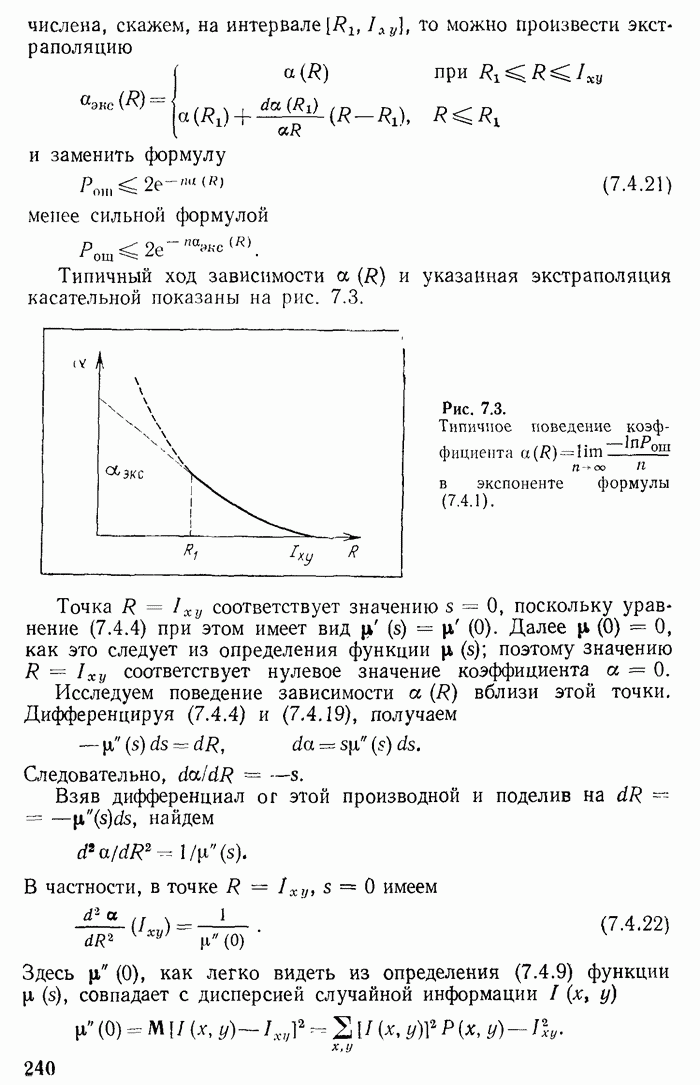
Рис. 7.2.
Функция  и мажорирующая ломаная.
и мажорирующая ломаная.
Используя это неравенство при рассмотрении правого неравенства (7.2.8) и учитывая возрастающий характер функции  находим
находим

Здесь через  обозначена функция распределения случайной информации связи
обозначена функция распределения случайной информации связи  величин
величин  имеющих распределение
имеющих распределение  Полученная оценка выражается, таким образом, только через эту функцию распределения.
Полученная оценка выражается, таким образом, только через эту функцию распределения.
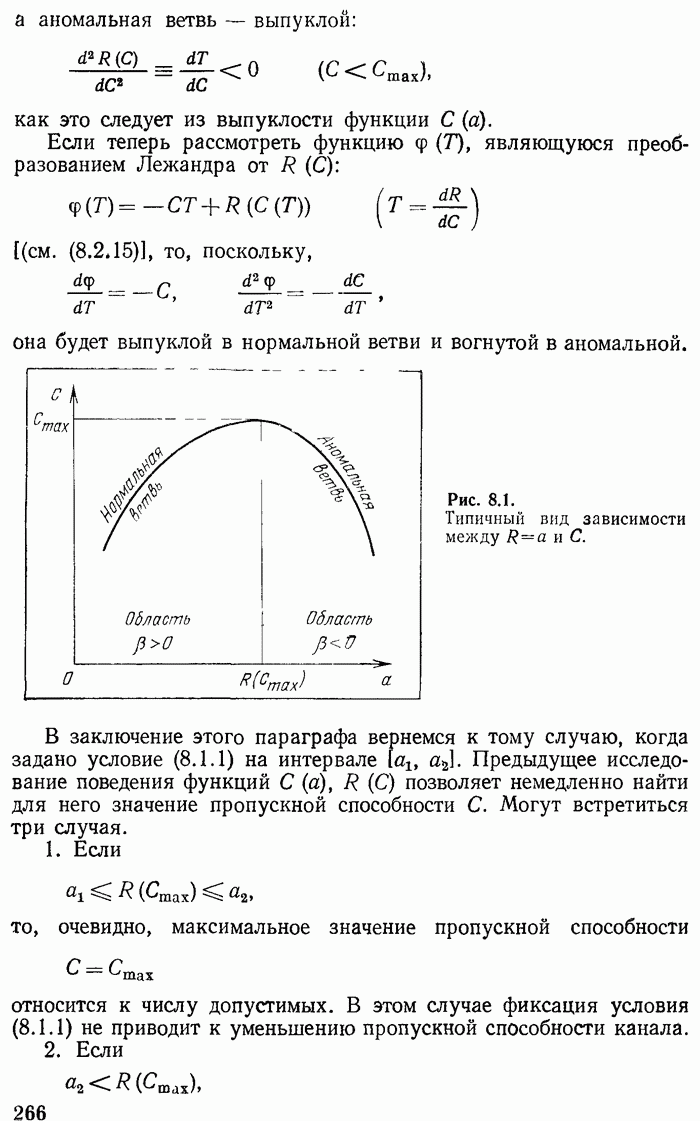
Поведение функции  показано на рис. 7.2. Эта функция на интервале
показано на рис. 7.2. Эта функция на интервале  возрастает от 0 до 1. Она имеет производные
возрастает от 0 до 1. Она имеет производные

и следовательно, является выпуклой. Очевидно, ее можно мажорировать ломаной

После этого формула (7.2.10) примет вид

т. е.

Точку излома  в (7.2.12) можно заменить на любую другую точку
в (7.2.12) можно заменить на любую другую точку  от этого неравенство только усилится. Полученные неравенства будут использованы в дальнейшем.
от этого неравенство только усилится. Полученные неравенства будут использованы в дальнейшем.