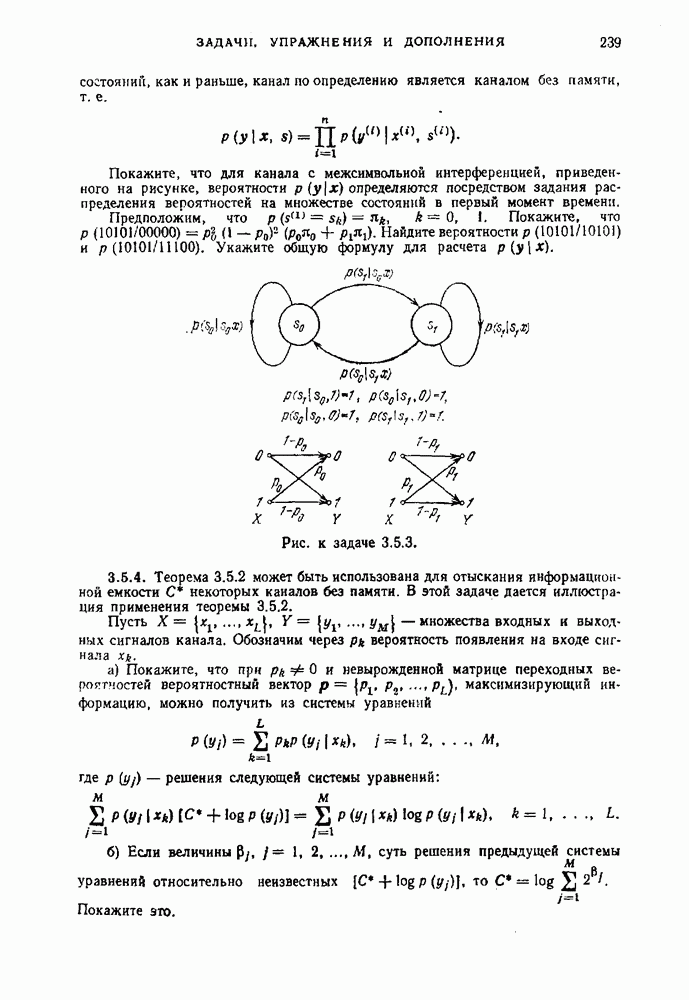
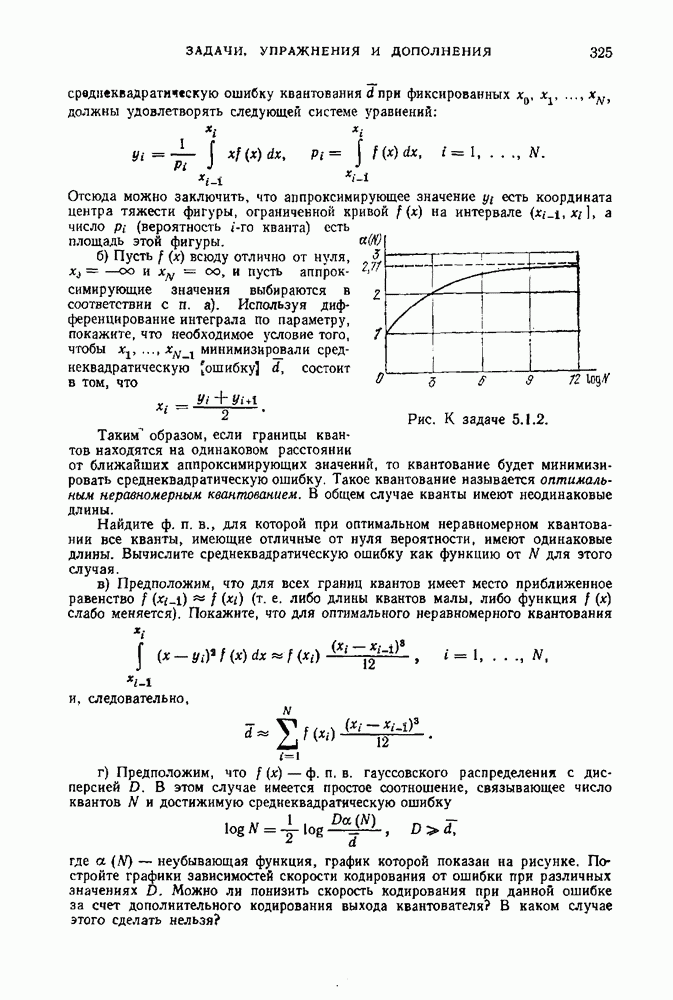
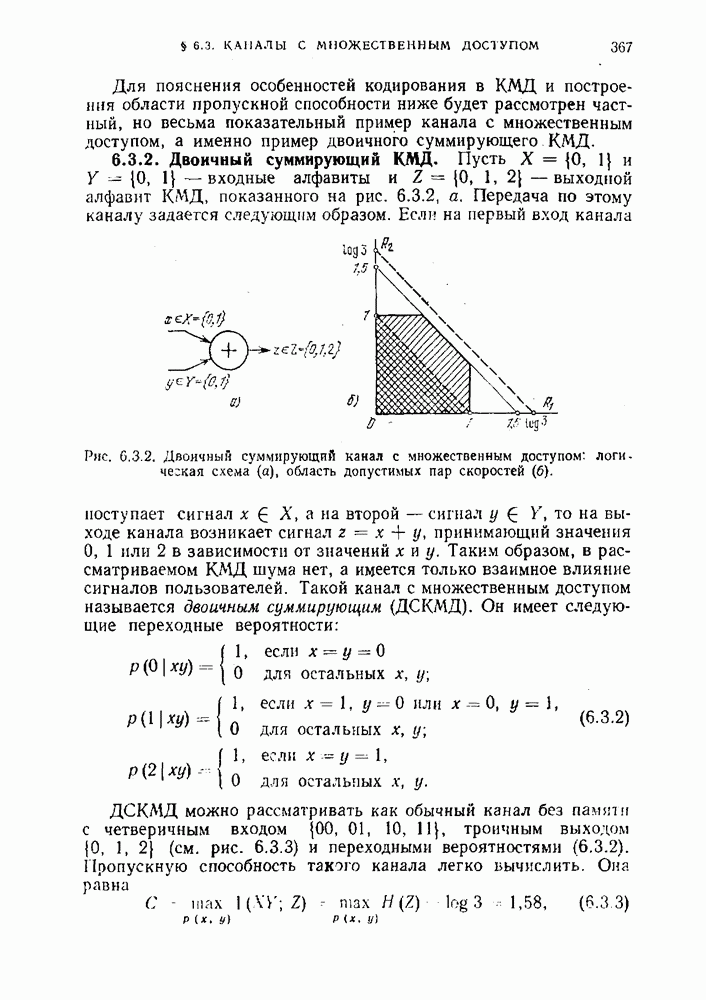
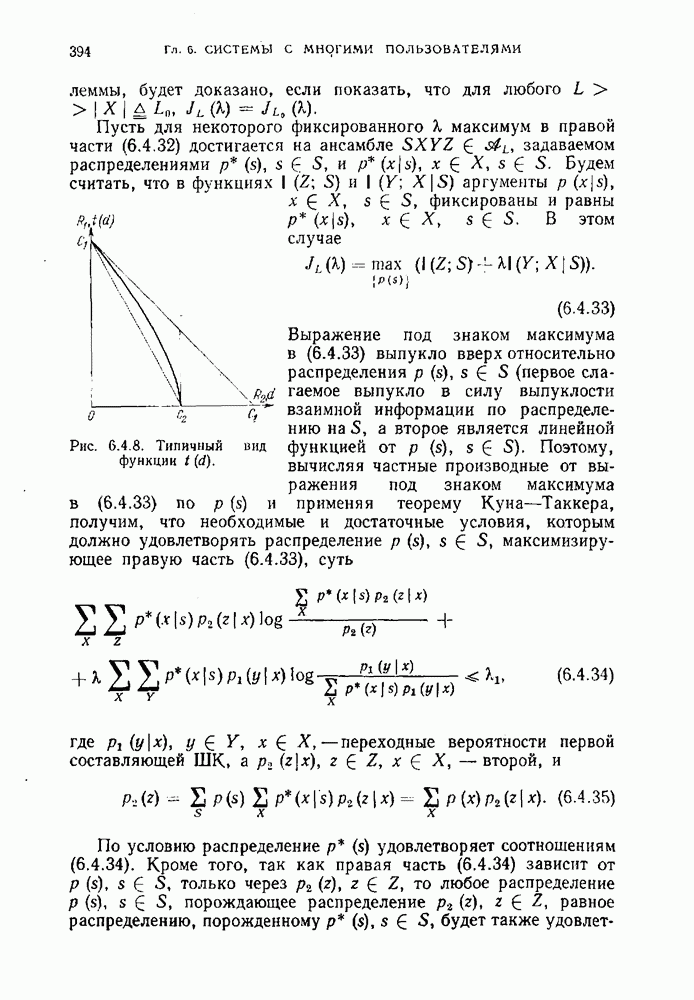
Пред.
След.
Макеты страниц
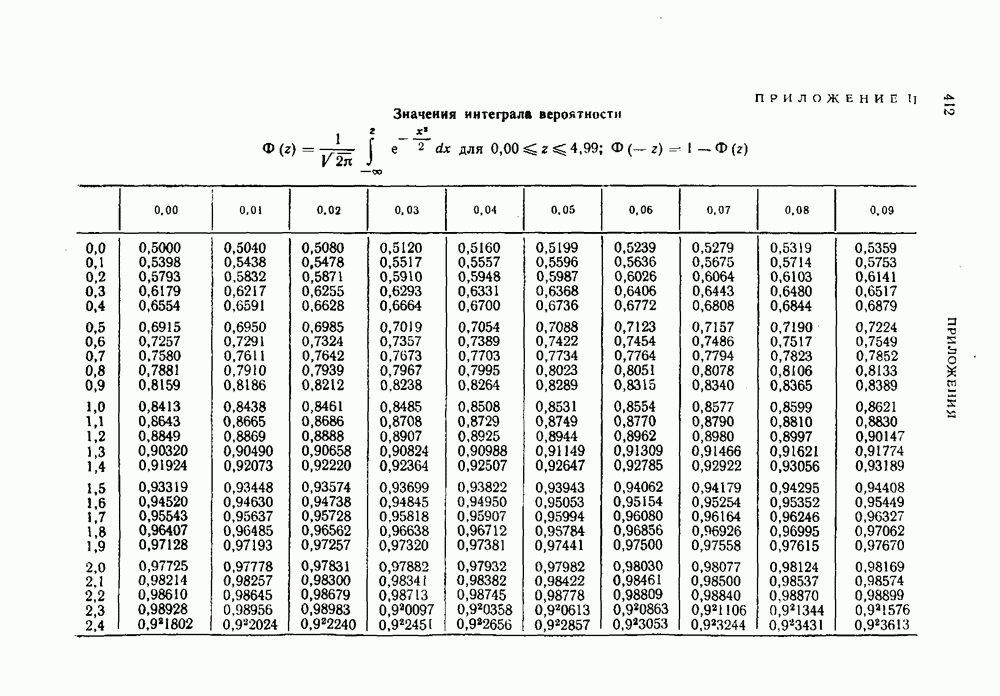
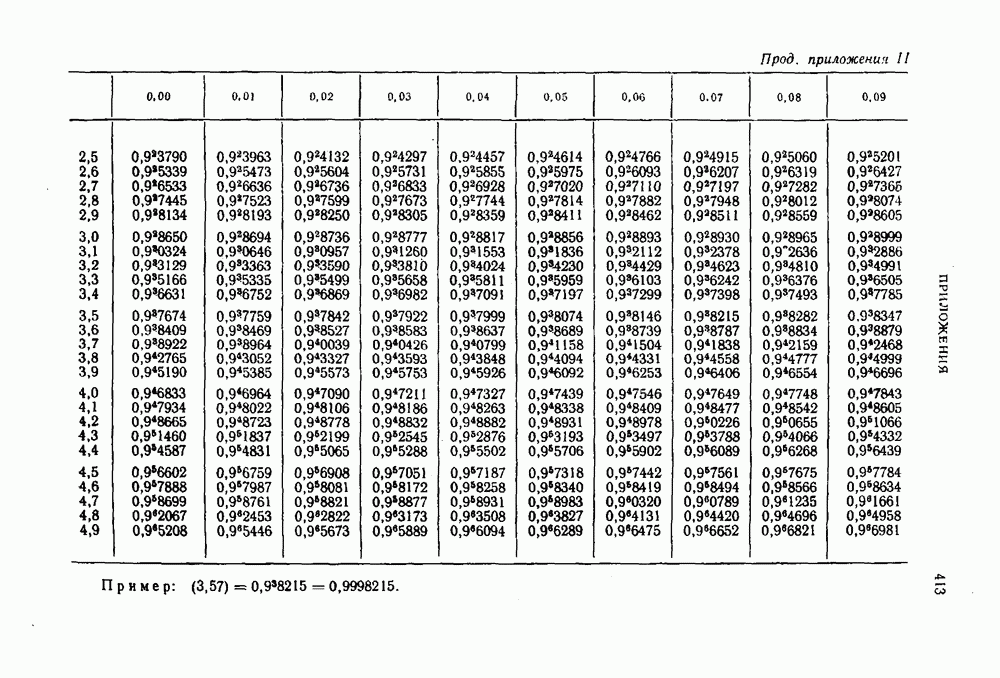
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
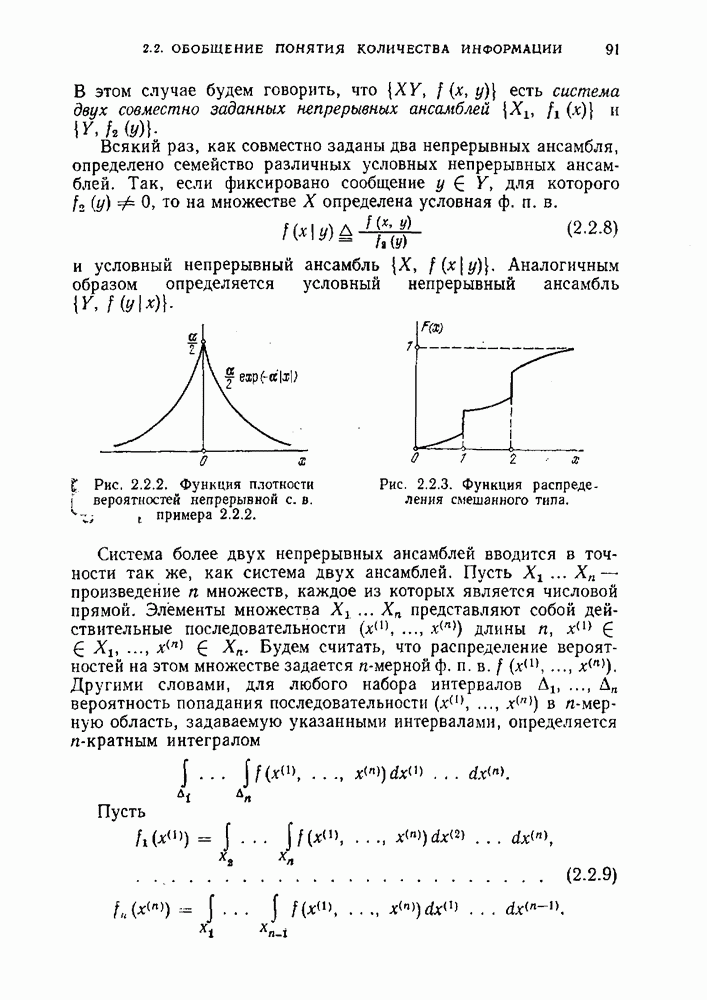
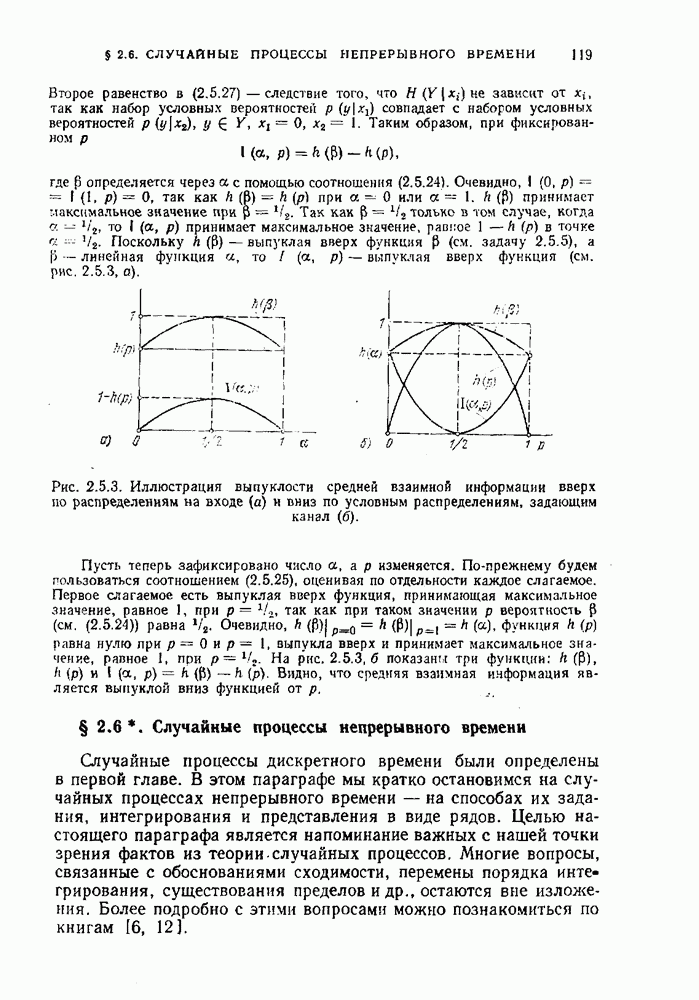
§ 1.10. Постановка задачи неравномерного кодирования дискретных источников. Коды с однозначным декодированиемВ предыдущих параграфах мы познакомились с задачей равномерного кодирования дискретных источников и показали, что при таком кодировании скорость создания информации равна энтропии источника на сообщение. Здесь будет рассмотрен другой подход к задаче кодирования. Для того чтобы его пояснить, вернемся к примеру 1.6.4. В этом примере были разобраны два метода кодирования телеграмм. Один метод, так называемый метод побуквенного кодирования, позволяет закодировать и затем безошибочно декодировать любую телеграмму, затрачивая на одну букву 6 двоичных символов. Второй метод оказался ключевым для задачи равномерного кодирования. Он позволяет однозначно кодировать не все телеграммы, а только некоторые типичные для данного источника. При таком кодировании на одну букву будет затрачиваться примерно 13/8 двоичных символов — существенно меньше, чем при побуквенном кодировании. При кодировании телеграмм есть еще один метод кодирования, о котором не было, ничего сказано раньше. Предположим, что известно, с какими вероятностями появляются те или другие буквы в телеграммах. Тогда можно использовать неравномерный код, в котором длины кодовых слов подобраны так, что часто встречающиеся буквы кодируются относительно короткими двоичными словами, а редкие — длинными. При таком способе побуквенного кодирования, использующем неравномерные коды, любая телеграмма может быть однозначно закодирована и однозначно декодирована, а среднее количество двоичных символов на букву может быть сделано меньшим, чем в случае равномерного побуквенного кодирования. Как и для любого метода кодирования источника, основной характеристикой неравномерного кодирования является количество символов, затрачиваемых на кодирование одного сообщения. В случае равномерного кодирования это количество одно и то же для любого сообщения источника. Действительно, каждый отрезок из затрачиваемых при кодировании, зависит от сообщений источника и поэтому представляет собой случайную величину. В этом случае разумной мерой качества кодирования является среднее количество символов на сообщение. Обозначим через длину слова, кодирующего сообщение
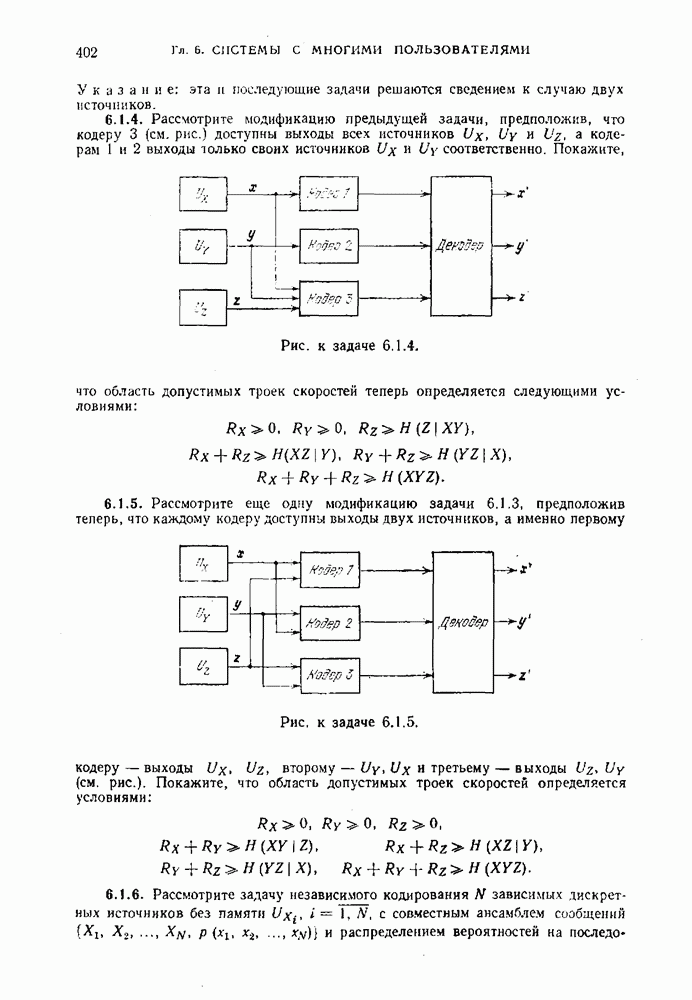
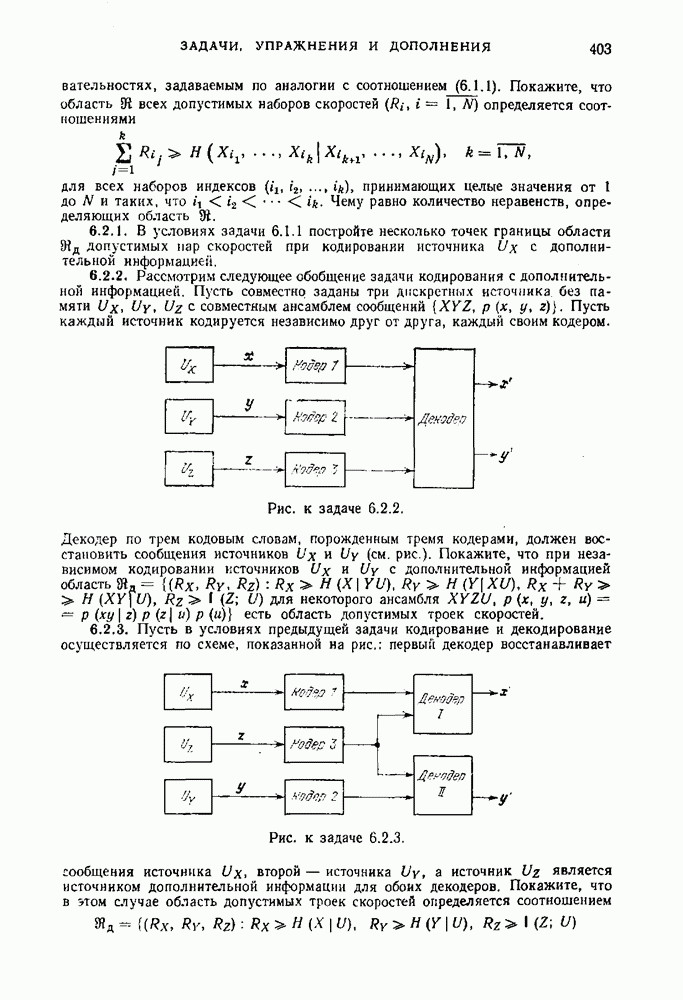
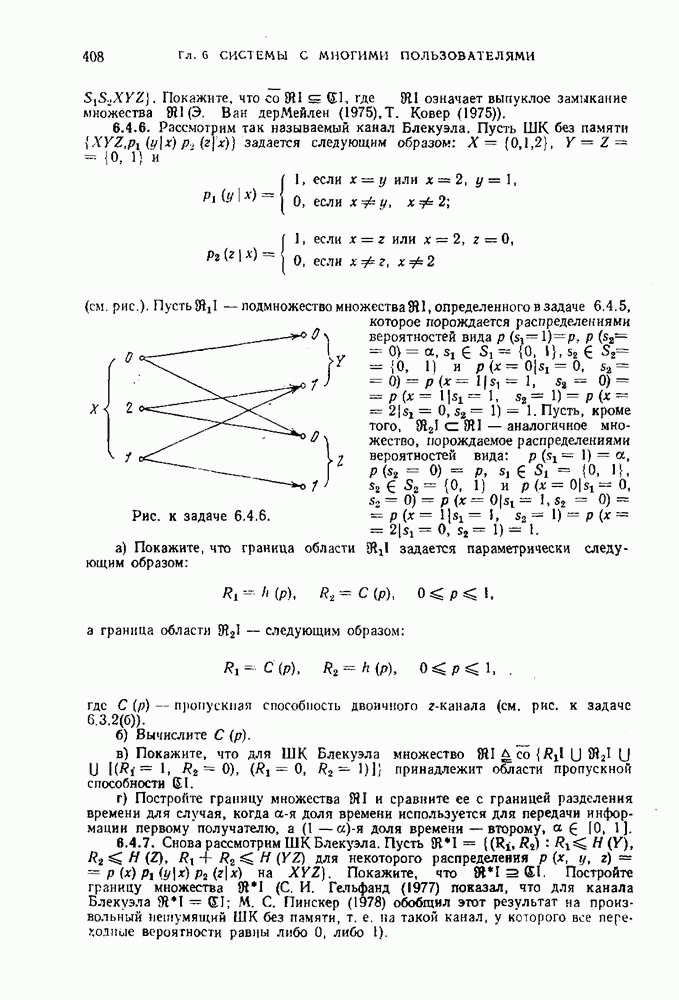
будет средней длиной кодовых слов, кодирующих ансамбль сообщений Определение 1.10.1. Число
называется средней скоростью неравномерного кодирования посредством D-ичного кода при разбиении последовательности сообщений на блоки длины Пример 1.10.1. Предположим, что Таблица 1.10.1 (см. скан) Заметим, что энтропия ансамбля сообщений этого примера равна 2,75 бит. В таблице приведены два двоичных кода — равномерный и неравномерный, которые однозначно кодируют указанное множество сообщений. Для первого кода все слова имеют одинаковую длину, равную 3. Для второго — слова имеют различные длины и, как нетрудно подсчитать средняя длина равна 2,75 символов (совпадение с энтропией неслучайно). Средняя скорость неравномерного кодирования зависит от выбора Пример 1.10.2. Предположим, что источник порождает сообщения Коды, в которых ни одно слово не является началом другого, называются префиксными. Коды, в которых любая последовательность кодовых слов допускает однозначное разбиение на кодовые слова, называются кодами со свойством однозначного декодирования. Префиксные коды являются кодами со свойством однозначного декодирования, но не наоборот. Пример 1.10.3. Код, образованный словами Таким образом, для кодирования сообщений источника пригодны только те коды, которые допускают однозначное декодирование. Определение 1.10.2. Скоростью создания информации дискретным источником при неравномерном кодировании называется наименьшее число Ниже мы покажем, что скорость создания информации при неравномерном кодировании совпадает со скоростью создания информации при равномерном кодировании и равна энтропии источника на сообщение. Для того чтобы доказать, что число Прежде чем приступить к детальному изучению задачи неравномерного кодирования, докажем теорему, в которой формулируется необходимое условие того, чтобы код был однозначно декодируем. Теорема 1.10.1. Предположим, что однозначно декодируемый код состоит из
Доказательство. Пусть
Заметим, что в выражении, стоящем в правой части равенства (1.10.4), каждое слагаемое соответствует каждой возможной последовательности из
где
или
Неравенство (1.10.7) справедливо при всех положительных целых Таким образом, мы получили необходимое условие того, чтобы код обладал свойством однозначного декодирования. Ниже будут изучены коды, для которых легко показать, что это условие является также достаточным.
|
 |
Оглавление
|



































































































































































































































































































































































































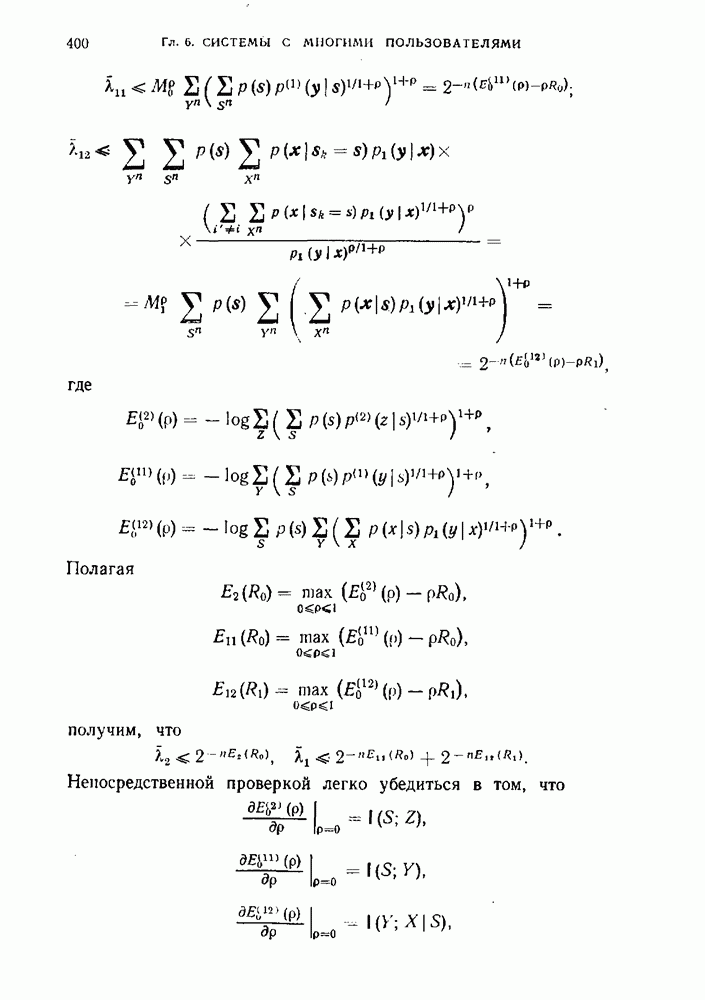








 сообщений при равномерном кодировании отображается в последовательность
сообщений при равномерном кодировании отображается в последовательность  -ичных кодовых символов, представляющую собой D-ичную запись номера кодируемого отрезка. При неравномерном кодировании это не так. Количество символов,
-ичных кодовых символов, представляющую собой D-ичную запись номера кодируемого отрезка. При неравномерном кодировании это не так. Количество символов,
 Пусть
Пусть  — вероятность этого сообщения, тогда
— вероятность этого сообщения, тогда

 Предположим, что неравномерный код используется для кодирования отрезков сообщений длины
Предположим, что неравномерный код используется для кодирования отрезков сообщений длины  т. е. для кодирования ансамбля
т. е. для кодирования ансамбля  где
где  распределение вероятностей на
распределение вероятностей на  задаваемое с помощью задания источника. Пусть
задаваемое с помощью задания источника. Пусть  средняя длина кодовых слов.
средняя длина кодовых слов.

 Средняя скорость неравномерного кодирования измеряется в двоичных символах на сообщение.
Средняя скорость неравномерного кодирования измеряется в двоичных символах на сообщение.
 и источник порождает в каждый момент времени одно из восьми сообщений
и источник порождает в каждый момент времени одно из восьми сообщений  Вероятности сообщений приведены во втором столбце табл. 1.10.1.
Вероятности сообщений приведены во втором столбце табл. 1.10.1.
 кода осуществляют побуквенное кодирование. Скорость кодирования в первом случае равна 3 бит/сообщение, а во втором — 2,75 бит/сообщение.
кода осуществляют побуквенное кодирование. Скорость кодирования в первом случае равна 3 бит/сообщение, а во втором — 2,75 бит/сообщение.
 и множества кодовых слов. Наша цель состоит в определении наименьшей достижимой средней скорости. Прежде чем перейти к решению этой задачи, необходимо ответить на следующий вопрос: любой ли неравномерный код пригоден для кодирования сообщений источника, и если нет, то какие ограничения на него должны быть наложены? Покажем существо этого вопроса следующим примером.
и множества кодовых слов. Наша цель состоит в определении наименьшей достижимой средней скорости. Прежде чем перейти к решению этой задачи, необходимо ответить на следующий вопрос: любой ли неравномерный код пригоден для кодирования сообщений источника, и если нет, то какие ограничения на него должны быть наложены? Покажем существо этого вопроса следующим примером.
 и эти сообщения кодируются следующим образом:
и эти сообщения кодируются следующим образом:  Кодовый алфавит состоит из двух символов 0 и 1. Пусть на выходе источника появилась следующая последовательность сообщений
Кодовый алфавит состоит из двух символов 0 и 1. Пусть на выходе источника появилась следующая последовательность сообщений  Кодер вырабатывает для каждого сообщения свое кодовое слово. На его выходе возникает последовательность
Кодер вырабатывает для каждого сообщения свое кодовое слово. На его выходе возникает последовательность  Нет специального разделительного знака пробела между словами. Если бы он был, то следовало бы рассматривать кодовый алфавит, состоящий из 0, 1 и пробела, что привело бы к задаче кодирования с кодовым алфавитом из трех символов. Декодеру известно лишь начало указанной выше двоичной последовательности, но неизвестно, с какого символа начинается второе кодовое слово, третье и т. д. Оказывается, что эта последовательность допускает несколько различных способов декодирования:
Нет специального разделительного знака пробела между словами. Если бы он был, то следовало бы рассматривать кодовый алфавит, состоящий из 0, 1 и пробела, что привело бы к задаче кодирования с кодовым алфавитом из трех символов. Декодеру известно лишь начало указанной выше двоичной последовательности, но неизвестно, с какого символа начинается второе кодовое слово, третье и т. д. Оказывается, что эта последовательность допускает несколько различных способов декодирования:  правильное декодирование,
правильное декодирование,  неправильные декодирования. В этом примере причиной неоднозначности декодирования является то, что кодовое слово 0 является началом слова
неправильные декодирования. В этом примере причиной неоднозначности декодирования является то, что кодовое слово 0 является началом слова  а это слово в свою очередь является началом слова
а это слово в свою очередь является началом слова  Коды примера 1.10.1 позволяют декодировать однозначно. Для равномерного кода это так потому, что все слова имеют одинаковую длину; последовательно отсчитывая по три символа, мы будем получать кодовые слова. Для неравномерного кода этого примера ни одно слово не является началом другого, и поэтому разбиение на кодовые слова происходит однозначно.
Коды примера 1.10.1 позволяют декодировать однозначно. Для равномерного кода это так потому, что все слова имеют одинаковую длину; последовательно отсчитывая по три символа, мы будем получать кодовые слова. Для неравномерного кода этого примера ни одно слово не является началом другого, и поэтому разбиение на кодовые слова происходит однозначно.
 не является префиксным, но является однозначно декодируемым. Покажите это самостоятельно.
не является префиксным, но является однозначно декодируемым. Покажите это самостоятельно.
 такое, что для любого
такое, что для любого  найдется
найдется  (длина кодируемых сообщений) и неравномерный код со средней скоростью кодирования
(длина кодируемых сообщений) и неравномерный код со средней скоростью кодирования  который допускает однозначное декодирование.
который допускает однозначное декодирование.
 есть скорость создания информации при неравномерном кодировании, нужно, как и раньше, доказывать прямую и обратную теоремы. Первая из них будет утверждать, что для всех
есть скорость создания информации при неравномерном кодировании, нужно, как и раньше, доказывать прямую и обратную теоремы. Первая из них будет утверждать, что для всех  найдется
найдется  и однозначно декодируемый неравномерный код со средней скоростью
и однозначно декодируемый неравномерный код со средней скоростью  а вторая будет утверждать, что для любого
а вторая будет утверждать, что для любого  не существует однозначно декодируемого кода ни при каком
не существует однозначно декодируемого кода ни при каком 
 слов, длины которых равны
слов, длины которых равны  и кодовый алфавит содержит D символов. Тогда
и кодовый алфавит содержит D символов. Тогда

 произвольное положительное целое число. Имеет место следующее равенство:
произвольное положительное целое число. Имеет место следующее равенство:

 кодовых слов. Сумма
кодовых слов. Сумма  равна суммарной длине соответствующей последовательности кодовых слов. Если через
равна суммарной длине соответствующей последовательности кодовых слов. Если через  обозначить число последовательностей из
обозначить число последовательностей из  кодовых слов, имеющих суммарную длину
кодовых слов, имеющих суммарную длину  то (1.10.4) можно переписать следующим образом:
то (1.10.4) можно переписать следующим образом:

 максимальное из чисел
максимальное из чисел  Код однозначно декодируем, если при любом
Код однозначно декодируем, если при любом  и любом
и любом  имеется единственная последовательность кодовых символов длины
имеется единственная последовательность кодовых символов длины  образованная
образованная  кодовыми словами. Так как
кодовыми словами. Так как  максимальное количество различных последовательностей длины
максимальное количество различных последовательностей длины  то
то  Подставляя это неравенство в (1.10.5), получим
Подставляя это неравенство в (1.10.5), получим


 Переходя к пределу при
Переходя к пределу при  получим утверждение теоремы.
получим утверждение теоремы.