Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 1.6. Постановка задачи кодирования дискретных источников равномерными кодамиОбозначим через А некоторое множество, состоящее из Последовательность кодовых символов называется кодовым словом, а любое семейство кодовых слов — кодом над алфавитом А. Пример 1.6.1. Пусть А—множество букв русского алфавита (включая пробел). Любая последовательность букв заданной длины Пример 1.6.2. Пусть Определение 1.6.1. Код называется разномерным, если все его слова имеют одинаковую длину Количество различных слов равномерного кода длины Определение 1.6.2. Кодированием сообщений ансамбля X посредством кода называется отображение (необязательно взаимно однозначное) множества сообщений в множество кодовых слов. Пример 1.6.3. Пусть
Рассмотрим теперь кодирование дискретного источника. Для того чтобы лучше понять основные проблемы, возникающие при кодировании, мы рассмотрим несколько подробных примеров. Пример 1.6.4. Предположим, что на центральном телеграфе введена автоматическая обработка телеграмм, записанных в алфавите, объем которого для простоты будем считать равным 64 буквам (сюда входят сами буквы, русские и латинские, цифры, знак пробела и некоторые вспомогательные знаки). Предположим, что эффективность такой обработки определяется количеством телеграмм, которые можно ввести в запоминающее устройство Рассмотрим вначале так называемое побу к венное кодирование. В этом случае используют код, содержащий Второй способ кодирования состоит в том, что выделяется специальный словарь, например, из При кодировании можно условиться о том, что всякое слово, не содержащееся в словаре, кодируется так же, как слово «ошибка». При декодировании вместо этих слов будет воспроизводиться слово «ошибка». Таким образом, второй способ является значительно более эффективным. Полученный эффект объясняется тем, что далеко не всякая последовательность букв встречается в языке, а тем более среди слов телеграмм. Имеются почти невероятные буквосочетания, например, Заметим, что при побуквенном кодировании все слова телеграмм могут быть однозначно (безошибочно) закодированы. Изложенная в примере 1.6.4 идея может быть применена для кодирования произвольных дискретных источников равномерными кодами. Предположим, что множество всех последовательностей длиной Описанный метод кодирования дискретного источника мы будем называть равномерным кодированием. Ошибкой равномерного кодирования является событие, состоящее в появлении неоднозначного кодируемого блока. При равномерном кодировании количество D-ичных кодовых символов, приходящихся на одно сообщение, равно Определение 1.6.3. Число
называется скоростью равномерного кодирования источника посредством кода с Количество двоичных символов на сообщение естественно измерять числом Как видно из примера 1.6.4, существенной частью задания равномерного кода является указание множества последовательностей сообщений источника, которые кодируются с помощью кодовых слов однозначно. Все коды, которые имеют одинаковое число кодовых слов и однозначно кодируют одно и то же множество сообщений, имеют одинаковую скорость и одинаковую вероятность ошибки. Поэтому ни сами кодовые слова, ни способ сопоставления кодовых слов и однозначно кодируемых сообщений не имеют значения с точки зрения качества кода. При кодировании с помощью равномерных кодов основная задача состоит в определении наименьшей возможной скорости кодирования, при которой вероятность ошибки может быть сделана произвольно малой. Наименьшая достижимая скорость кодирования является характеристикой источника сообщений и называется скоростью создания информации. Определение 1.6.4. Скоростью создания информации дискретным источником при равномерном кодировании называется наименьшее число В следующем примере показано, что по крайней мере для некоторых источников можно построить код с заданной малой вероятностью ошибки декодирования. Пример 1.6.5. Рассмотрим двоичный источник без памяти, независимо выбирающий сообщения из множества Предположим, что допускается некоторая достаточно малая вероятность ошибки при кодировании. Рассмотрим множество
Согласно закону больших чисел (см. пример 1.2.3) вероятность появления на выходе источника последовательности, принадлежащей множеству Рассмотрим кодирование, при котором имеется равномерный код, состоящий из Оценим теперь скорость кодирования. Для этого необходимо оценить число
где
где
стремится к Возьмем, например,
откуда получается
Выбирая Ниже мы покажем, что энтропия определяет наименьшее возможное значение скорости кодирования и согласно определению 1.6.4 дает величину скорости создания информации при равномерном кодировании. В последующей части этой главы мы будем заниматься определением скорости создания информации различными дискретными источниками. Для того чтобы установить, что некоторая величина, скажем Я, является скоростью создания информации, необходимо доказать два утверждения: 1. Для любого 2. Для любого Вначале, в §§ 1.7-1.9, мы будем рассматривать задачу равномерного кодирования дискретных источников. Затем, в
|
 |
Оглавление
|











































































































































































































































































































































































































 элементов:
элементов:  Назовем его алфавитом кода источника. Элементы множества А будем называть кодовыми символами.
Назовем его алфавитом кода источника. Элементы множества А будем называть кодовыми символами.
 является кодовым словом длины
является кодовым словом длины  над алфавитом А. Так,
над алфавитом А. Так,  есть слово длины 8
есть слово длины 8  -пробел). Другим примером кодового алфавита является множество десятичных цифр, включая пробел. Следующие последовательности
-пробел). Другим примером кодового алфавита является множество десятичных цифр, включая пробел. Следующие последовательности  являются примерами двух кодовых слов длины 5 и 4 соответственно.
являются примерами двух кодовых слов длины 5 и 4 соответственно.
 двоичный алфавит. Множество последовательностей
двоичный алфавит. Множество последовательностей  является кодом объема 4 над двоичным алфавитом. Это пример кода, слова которого имеют разную длину. Множество последовательностей
является кодом объема 4 над двоичным алфавитом. Это пример кода, слова которого имеют разную длину. Множество последовательностей  также является двоичным кодом объема 4.
также является двоичным кодом объема 4.
 это число называется длиной кода. Если хотя бы два кодовых слова имеют различные длины, то код называют неравномерным.
это число называется длиной кода. Если хотя бы два кодовых слова имеют различные длины, то код называют неравномерным.
 не превосходит
не превосходит  числа различных D-ичных последовательностей длины
числа различных D-ичных последовательностей длины  Количество различных слов неравномерного кода с максимальной длиной кодовых слов
Количество различных слов неравномерного кода с максимальной длиной кодовых слов  не превышает
не превышает  (см. задачу 1.6.1).
(см. задачу 1.6.1).
 Возможны следующие способы кодирования посредством двоичных кодов:
Возможны следующие способы кодирования посредством двоичных кодов:

 кодирований однозначно. В пп. б) и в) приведены два различных способа кодирования с одним и тем же множеством кодовых слов.
кодирований однозначно. В пп. б) и в) приведены два различных способа кодирования с одним и тем же множеством кодовых слов.
 обрабатывающего устройства. Пусть объем
обрабатывающего устройства. Пусть объем  равен
равен  двоичным ячейкам. Чтобы осуществить запись телеграмм в
двоичным ячейкам. Чтобы осуществить запись телеграмм в  необходимо закодировать телеграммы с помощью двоичного кода.
необходимо закодировать телеграммы с помощью двоичного кода.
 кодовых слова, и каждой букве телеграммы сопоставляют некоторое кодовое слово. Предположим, что используется равномерный код, в котором все слова имеют длину 6 двоичных символов. При этом в
кодовых слова, и каждой букве телеграммы сопоставляют некоторое кодовое слово. Предположим, что используется равномерный код, в котором все слова имеют длину 6 двоичных символов. При этом в  можно записать
можно записать  букв. Если считать, что средняя длина телеграммы — 20 слов, а средняя длина слова 8 букв, то в
букв. Если считать, что средняя длина телеграммы — 20 слов, а средняя длина слова 8 букв, то в  можно поместить примерно
можно поместить примерно  телеграмм.
телеграмм.
 слов (такого словаря достаточно для составления практически любой телеграммы). Каждое слово словаря может быть закодировано с помощью двоичной последовательности длиной 13 символов. В этом случае в
слов (такого словаря достаточно для составления практически любой телеграммы). Каждое слово словаря может быть закодировано с помощью двоичной последовательности длиной 13 символов. В этом случае в  можно записать
можно записать  телеграмм, т. е. в три-четыре раза больше, чем в первом случае.
телеграмм, т. е. в три-четыре раза больше, чем в первом случае.
 Однако необходимо помнить о том, что вероятность такого буквосочетания хотя и мала, но не равна нулю. Последнее следует, например, из того, что оно появляется в настоящем тексте. Поэтому при кодировании возможны ошибки.
Однако необходимо помнить о том, что вероятность такого буквосочетания хотя и мала, но не равна нулю. Последнее следует, например, из того, что оно появляется в настоящем тексте. Поэтому при кодировании возможны ошибки.
 из сообщений источника разбито на два подмножества. Первое из них образовано всеми теми последовательностями (блоками длиной
из сообщений источника разбито на два подмножества. Первое из них образовано всеми теми последовательностями (блоками длиной  ), которые сопоставлены с кодовыми словами взаимно однозначно. Это подмножество называется множеством однозначно кодируемых и декодируемых блоков. Второе подмножество образовано всеми остальными блоками, каждому из которых сопоставляется одно и то же кодовое слово
), которые сопоставлены с кодовыми словами взаимно однозначно. Это подмножество называется множеством однозначно кодируемых и декодируемых блоков. Второе подмножество образовано всеми остальными блоками, каждому из которых сопоставляется одно и то же кодовое слово  Последнее подмножество называется множеством неоднозначно кодируемых и декодируемых блоков. Все кодовые слова имеют одинаковую длину ту которая определяется числом
Последнее подмножество называется множеством неоднозначно кодируемых и декодируемых блоков. Все кодовые слова имеют одинаковую длину ту которая определяется числом  кодовых слов:
кодовых слов:  наименьшее целое, удовлетворяющее неравенству
наименьшее целое, удовлетворяющее неравенству  где
где  объем кодового алфавита. При кодировании последовательность сообщений на выходе источника разбивается на блоки длиной
объем кодового алфавита. При кодировании последовательность сообщений на выходе источника разбивается на блоки длиной  каждому блоку кодер сопоставляет соответствующее кодовйе слово.
каждому блоку кодер сопоставляет соответствующее кодовйе слово.


 кодовыми словами при разбиении последовательности сообщений на блоки длины
кодовыми словами при разбиении последовательности сообщений на блоки длины  Скорость равномерного кодирования измеряется в двоичных символах на сообщение.
Скорость равномерного кодирования измеряется в двоичных символах на сообщение.
 а не
а не  Очевидно, что эти два числа совпадают, когда число кодовых слов равно
Очевидно, что эти два числа совпадают, когда число кодовых слов равно  В остальных случаях именно первое из этих чисел равно количеству двоичных символов на сообщение (см. задачу 1.6.2).
В остальных случаях именно первое из этих чисел равно количеству двоичных символов на сообщение (см. задачу 1.6.2).
 такое, что для любого
такое, что для любого  и любого сколь угодно малого положительного числа 6 найдется
и любого сколь угодно малого положительного числа 6 найдется  (длина кодируемых сообщений) и равномерный код со скоростью кодирования
(длина кодируемых сообщений) и равномерный код со скоростью кодирования  для которого вероятность неправильного декодирования не превосходит 6.
для которого вероятность неправильного декодирования не превосходит 6.
 причем единица выбирается с вероятностью
причем единица выбирается с вероятностью  Этот источник возможно кодировать побуквенно. При этом на каждое сообщение будет затрачиваться 1 двоичный символ. При любом безошибочном кодировании с помощью равномерного кода скорость кодирования не будет меньше единицы.
Этот источник возможно кодировать побуквенно. При этом на каждое сообщение будет затрачиваться 1 двоичный символ. При любом безошибочном кодировании с помощью равномерного кода скорость кодирования не будет меньше единицы.
 всех последовательностей длины
всех последовательностей длины  на выходе источника. Оно содержит
на выходе источника. Оно содержит  последовательностей. Пусть
последовательностей. Пусть  это подмножество множества
это подмножество множества  состоящее из всех последовательностей, в которых число единиц
состоящее из всех последовательностей, в которых число единиц  удовлетворяет условию
удовлетворяет условию

 не меньше чем
не меньше чем  и может быть сделана как угодно близкой к единице
и может быть сделана как угодно близкой к единице  выбором достаточно большого
выбором достаточно большого 
 кодовых слов, где
кодовых слов, где  количество различных последовательностей в
количество различных последовательностей в  и каждой последовательности из
и каждой последовательности из  сопоставляется свое кодовое слово. Всем же последовательностям, не принадлежащим
сопоставляется свое кодовое слово. Всем же последовательностям, не принадлежащим  ставится в соответствие одно и то же слово, например, первое. При таком кодировании все последовательности сообщений из
ставится в соответствие одно и то же слово, например, первое. При таком кодировании все последовательности сообщений из  будут воспроизводиться правильно, а при появлении на выходе источника последовательности, не принадлежащей
будут воспроизводиться правильно, а при появлении на выходе источника последовательности, не принадлежащей  будет происходить ошибка. Очевидно, что вероятность ошибки может быть сделана как угодно малой выбором достаточно большого
будет происходить ошибка. Очевидно, что вероятность ошибки может быть сделана как угодно малой выбором достаточно большого 


 количество слагаемых в сумме,
количество слагаемых в сумме,  соответствует максимальному слагаемому. При
соответствует максимальному слагаемому. При  максимальное слагаемое получается при
максимальное слагаемое получается при  , где
, где  целая часть х (см. задачу 1.6.3 (в)). Используя верхнюю границу для числа сочетаний (та же задача
целая часть х (см. задачу 1.6.3 (в)). Используя верхнюю границу для числа сочетаний (та же задача  получим, что
получим, что

 При этом скорость кодирования
При этом скорость кодирования

 при больших
при больших 
 Если положить
Если положить  и найти
и найти  из уравнения
из уравнения  то получим
то получим  Вероятность ошибки
Вероятность ошибки  при кодировании последовательности сообщений длины
при кодировании последовательности сообщений длины  т. е. вероятность появления такой последовательности, количество единиц в которой удовлетворяет неравенству
т. е. вероятность появления такой последовательности, количество единиц в которой удовлетворяет неравенству  можно оценить, правда весьма грубо, с помощью неравенства Чебышева (см. (1.2.14))
можно оценить, правда весьма грубо, с помощью неравенства Чебышева (см. (1.2.14))

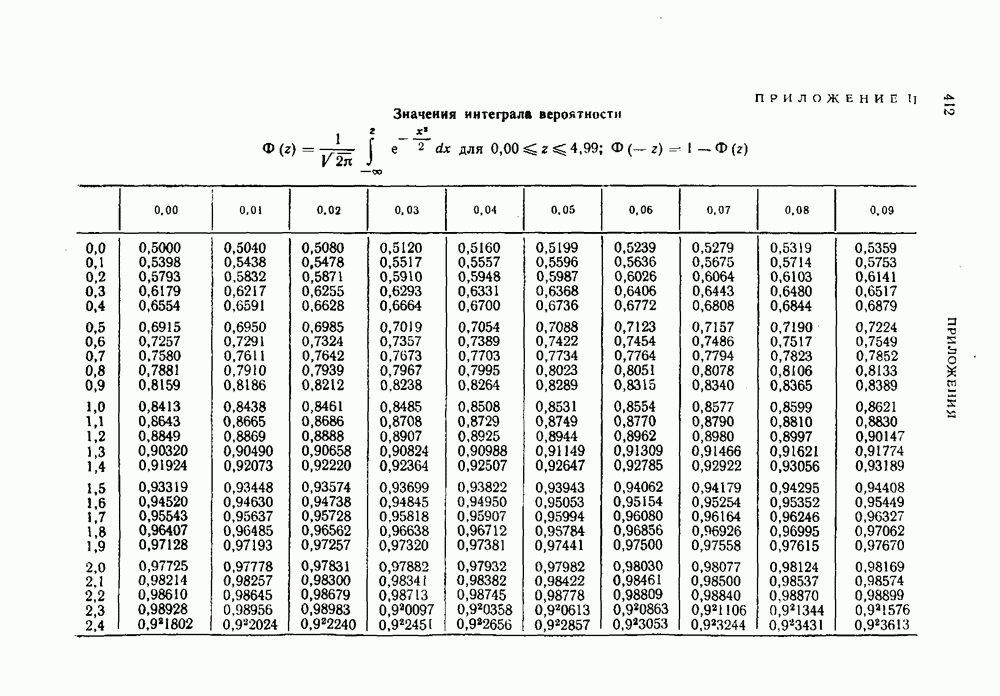
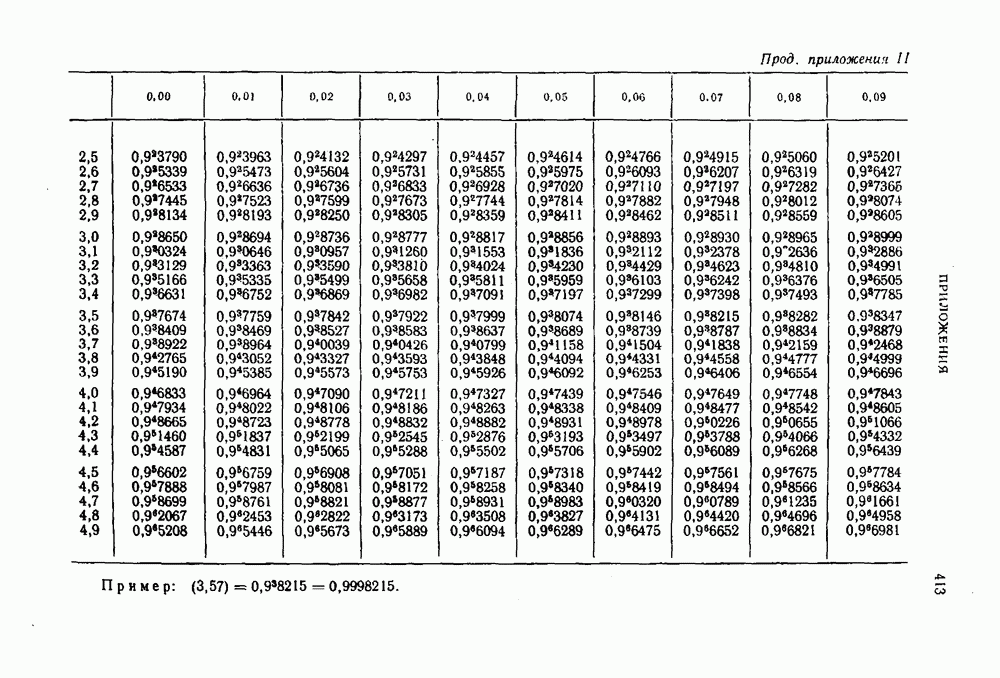
 Использование для оценки
Использование для оценки  асимптотической формулы Муавра-Лапласа [6] дает при больших
асимптотической формулы Муавра-Лапласа [6] дает при больших 

 достаточно малым, можно приближать скорость кодирования как угодно близко к величине
достаточно малым, можно приближать скорость кодирования как угодно близко к величине  энтропии двоичного ансамбля, для которого одно из сообщений имеет вероятность
энтропии двоичного ансамбля, для которого одно из сообщений имеет вероятность 
 и произвольного положительного
и произвольного положительного  найдутся
найдутся  и код со скоростью
и код со скоростью  кодирующий отрезки сообщений длины
кодирующий отрезки сообщений длины  для которого вероятность ошибйчне больше 6. Такое утверждение называется прямой теоремой кодирования.
для которого вероятность ошибйчне больше 6. Такое утверждение называется прямой теоремой кодирования.
 найдется зависящее от
найдется зависящее от  положительное число
положительное число  такое, что для всех
такое, что для всех  и для всех равномерных кодов со скоростью
и для всех равномерных кодов со скоростью  вероятность ошибки при декодировании больше, чем это
вероятность ошибки при декодировании больше, чем это  Другими словами, вероятность ошибки не может быть сделана равной нулю или сколь угодно малой. Это утверждение называется обратной теоремой кодирования,
Другими словами, вероятность ошибки не может быть сделана равной нулю или сколь угодно малой. Это утверждение называется обратной теоремой кодирования,
 мы рассмотрим задачу неравномерного кодирования. В заключение этой главы будут сопоставлены эти две задачи и соответствующие методы кодирования.
мы рассмотрим задачу неравномерного кодирования. В заключение этой главы будут сопоставлены эти две задачи и соответствующие методы кодирования.