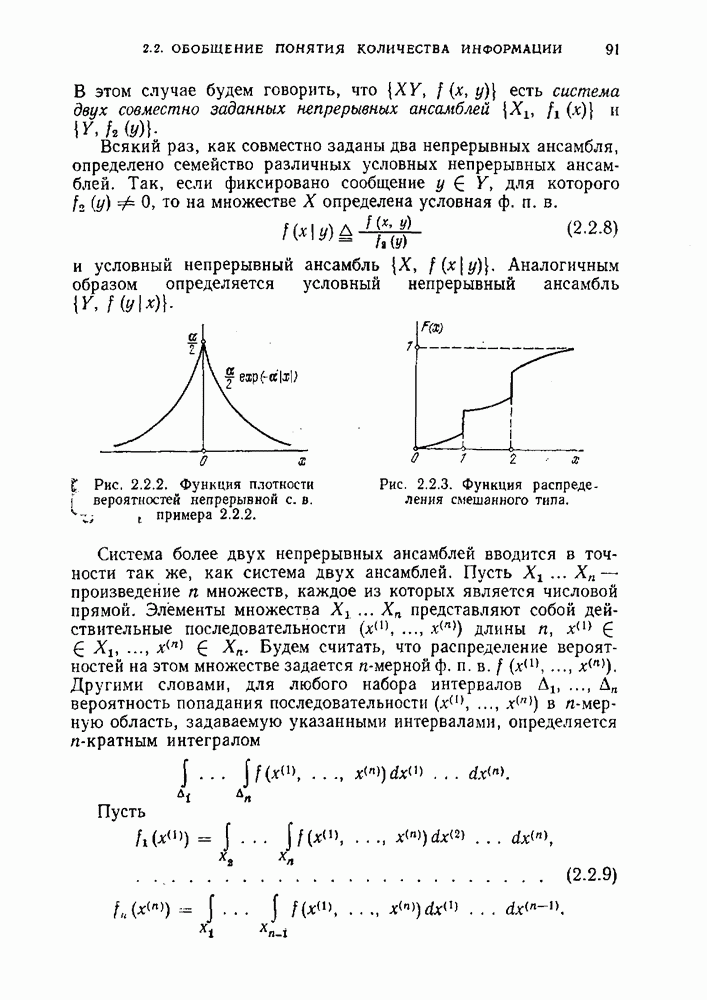
Пред.
След.
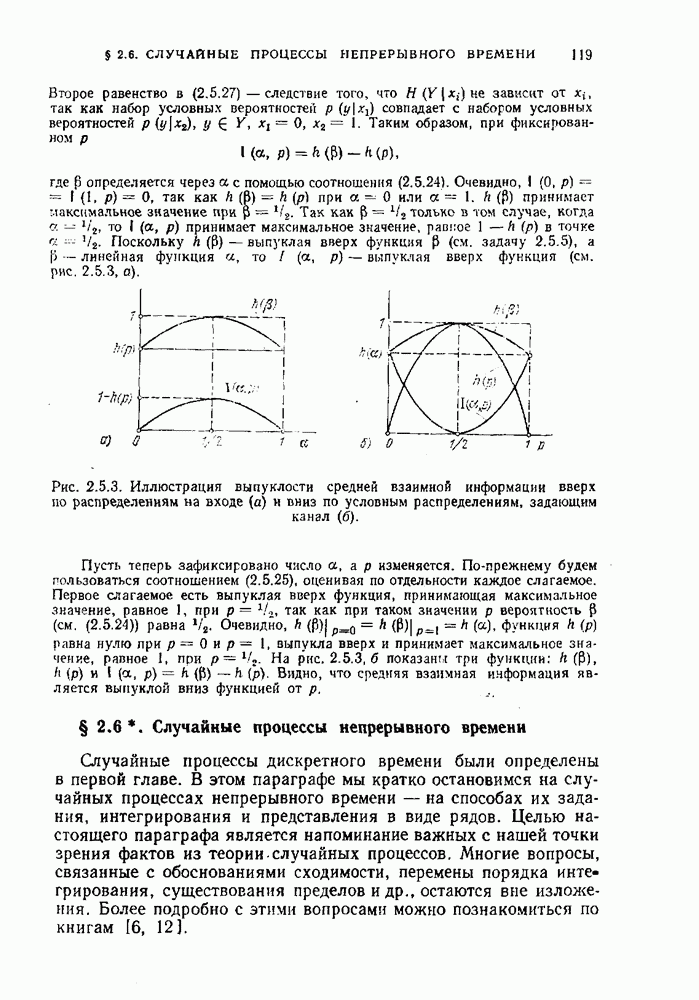
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 1.8. Скорость создания информации дискретным источником без памяти при равномерном кодированииВ этом параграфе мы покажем, что скорость создания информации дискретным источником без памяти при равномерном кодировании равна его энтропии. Как отмечалось в § 1.6, для доказательства этого утверждения нужно доказать прямую и обратную теоремы кодирования. Каждый код, кодирующий сообщения источника, характеризуется скоростью кодирования — отношением логарифма числа кодовых слов к длине кодируемых сообщений, множеством однозначно кодируемых сообщений и вероятностью ошибки. Поэтому, говоря о том, что существует код со скоростью Предположим, что дискретный источник без памяти выбирает сообщения из множества X с распределением вероятностей Теорема 1.8.1 (прямая теорема). Пусть
Рис. 1.8.1. К доказательству обратной теоремы кодирования. Доказательство. Согласно теореме 1.7.1 для любых положительных
откуда следует, что Замечание. В теореме утверждается существование кода, кодирующего дискретный источник без памяти с произвольно малой вероятностью ошибки. В действительности доказано нечто большее, а именно, что для любых Теорема 1.8.2 (обратная теорема). Пусть Кроме того, для любой последовательности кодов со скоростью
где Доказательство. Докажем сначала справедливость соотношения (1.8.2). Пусть
Для каждого
где
Рассмотрим теперь вероятность
Учитывая (1.8.5) и (1.8.6), из (1.8.4) получим (1.8.2). Докажем теперь первое утверждение теоремы. Для этого заметим, что при
получим, что для любого
Теорема доказана. Таким образом, прямая и обратная теоремы кодирования показывают, что скорость создания информации при равномерном кодировании дискретного источника без памяти равна его энтропии. Этот вывод позволяет дать энтропии следующее толкование. Представим себе, что источник подсоединен к некоторому устройству (кодеру источника), осуществляющему кодирование со скоростью
|
 |
Оглавление
|






































































































































































































































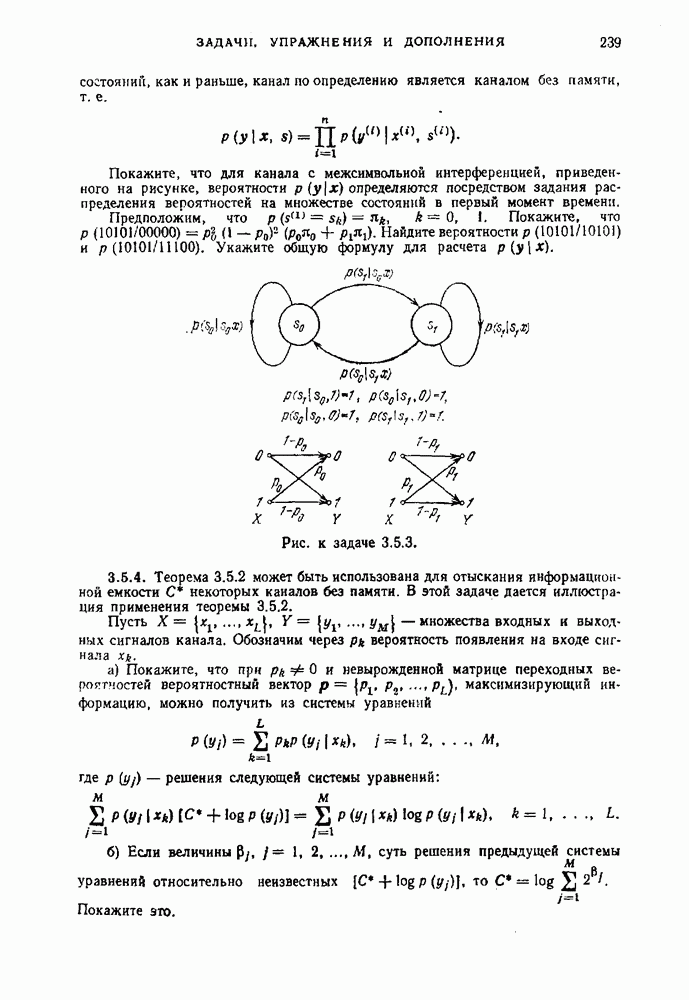





















































































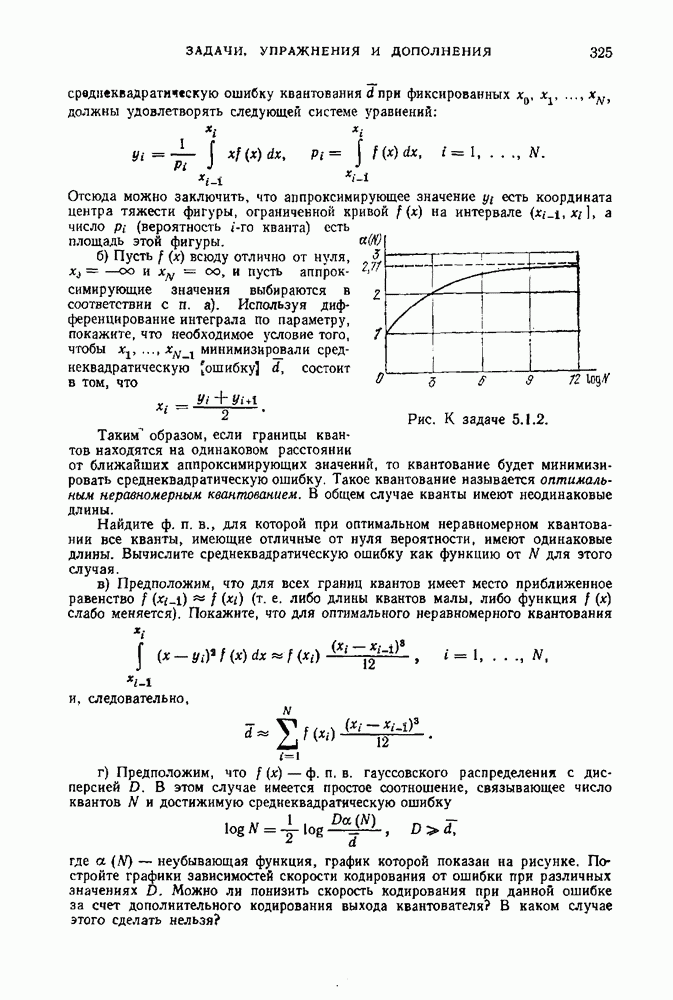









































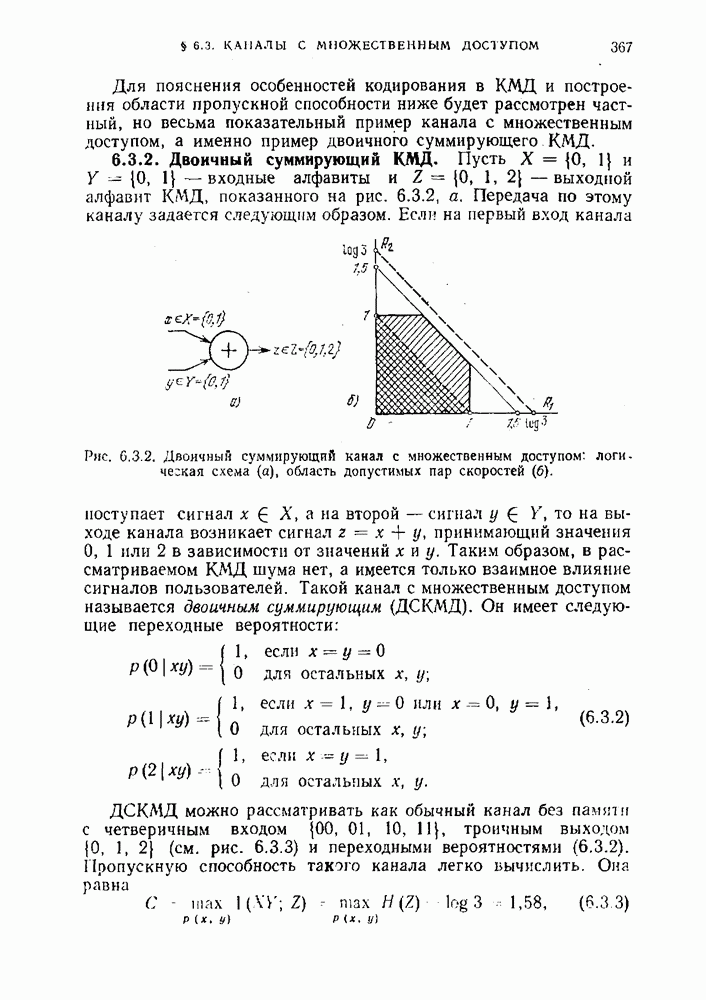


























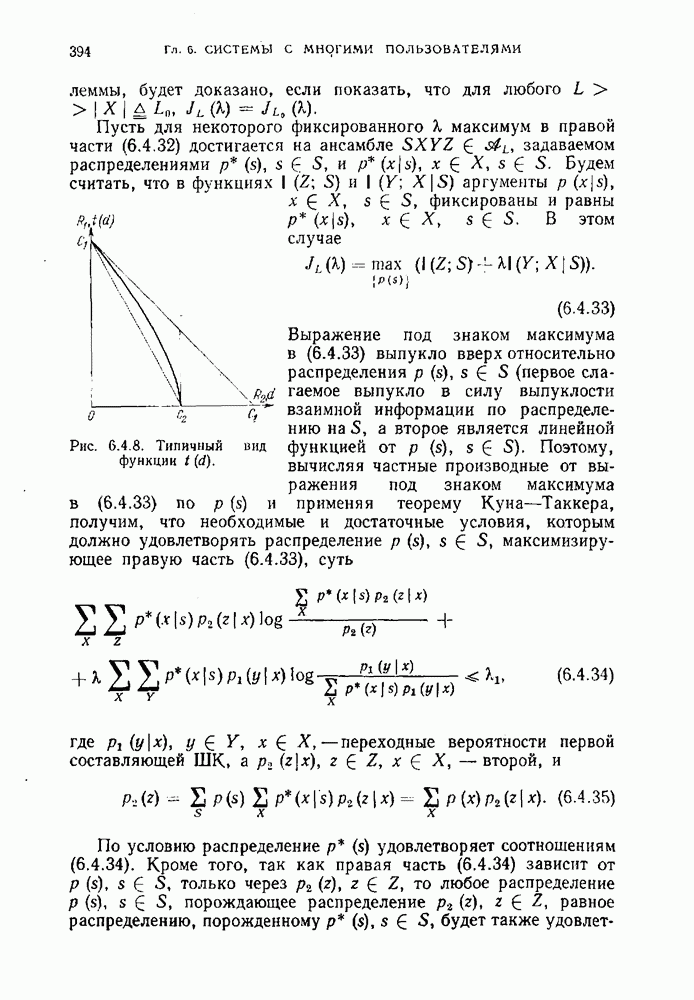













 кодирующий источник с вероятностью ошибки
кодирующий источник с вероятностью ошибки  мы подразумеваем, что существуют
мы подразумеваем, что существуют  код с
код с  кодовыми словами и множество однозначно кодируемых последовательностей сообщений
кодовыми словами и множество однозначно кодируемых последовательностей сообщений  для которых вероятность ошибки равна
для которых вероятность ошибки равна 
 для всех
для всех  и
и  энтропия ансамбля
энтропия ансамбля 
 тогда для любого положительного
тогда для любого положительного  существует код со скоростью
существует код со скоростью 

 найдется
найдется  такое, что для любого
такое, что для любого  вероятность появления на выходе источника последовательности сообщений х, не принадлежащей высоковероятному множеству
вероятность появления на выходе источника последовательности сообщений х, не принадлежащей высоковероятному множеству  не превосходит
не превосходит  Если выбрать
Если выбрать  в качестве множества однозначно кодируемых последовательностей, то вероятность ошибки декодирования не будет превышать
в качестве множества однозначно кодируемых последовательностей, то вероятность ошибки декодирования не будет превышать  При этом количество кодовых слов не должно быть меньше числа элементов в множестве
При этом количество кодовых слов не должно быть меньше числа элементов в множестве  Это условие будет удовлетворено, если
Это условие будет удовлетворено, если

 Теорема доказана.
Теорема доказана.
 найдется
найдется  и последовательность кодов, кодирующих отрезки сообщений длины
и последовательность кодов, кодирующих отрезки сообщений длины  и имеющих скорость
и имеющих скорость  причем для каждого кода этой последовательности вероятность ошибки не превосходит
причем для каждого кода этой последовательности вероятность ошибки не превосходит 
 тогда существует зависящее от
тогда существует зависящее от  положительное число
положительное число  такое, что для каждого кода, кодирующего дискретный источник без памяти со скоростью
такое, что для каждого кода, кодирующего дискретный источник без памяти со скоростью  вероятность ошибки
вероятность ошибки  не меньше, чем
не меньше, чем 


 вероятность ошибки для кода, кодирующего отрезки сообщений длины
вероятность ошибки для кода, кодирующего отрезки сообщений длины 
 последовательность высоковероятных множеств. Обозначим через
последовательность высоковероятных множеств. Обозначим через  последовательность произвольных множеств таких, что
последовательность произвольных множеств таких, что  и
и

 множество
множество  будем рассматривать как множество однозначно кодируемых последовательностей сообщений. Поэтому (см. рис. 1.8.1)
будем рассматривать как множество однозначно кодируемых последовательностей сообщений. Поэтому (см. рис. 1.8.1)

 дополнение множества
дополнение множества  до
до  и
и  символ пересечения множеств. Из теоремы о высоковероятных множествах следует, что
символ пересечения множеств. Из теоремы о высоковероятных множествах следует, что

 Для всякой последовательности
Для всякой последовательности  имеем
имеем  так как при этом
так как при этом  Число элементов в множестве
Число элементов в множестве  не превосходит
не превосходит  следовательно,
следовательно,

 множество
множество  не пусто при каждом
не пусто при каждом  Так как
Так как  для всех
для всех  то каждая последовательность
то каждая последовательность  имеет ненулевую вероятность. Следовательно, для каждого конечного
имеет ненулевую вероятность. Следовательно, для каждого конечного  найдется такое
найдется такое  что
что  . С другой стороны, в силу (1.8.2) найдется такое
. С другой стороны, в силу (1.8.2) найдется такое  что для всех
что для всех  выполняется неравенство
выполняется неравенство  Полагая
Полагая

 и любого
и любого 

 Если кодовый алфавит содержит D символов, то в среднем на каждое сообщение источника будет появляться
Если кодовый алфавит содержит D символов, то в среднем на каждое сообщение источника будет появляться  символов на выходе кодера. Для наилучшего кодера это количество будет весьма близким к
символов на выходе кодера. Для наилучшего кодера это количество будет весьма близким к  Следовательно, энтропия источника есть наименьшее количество двоичных символов на сообщение на выходе наилучшего двоичного кодера для этого источника при условии, что сообщения источника могут быть восстановлены по выходу кодера сколь угодно точно.
Следовательно, энтропия источника есть наименьшее количество двоичных символов на сообщение на выходе наилучшего двоичного кодера для этого источника при условии, что сообщения источника могут быть восстановлены по выходу кодера сколь угодно точно.