Пред.
След.
Макеты страниц
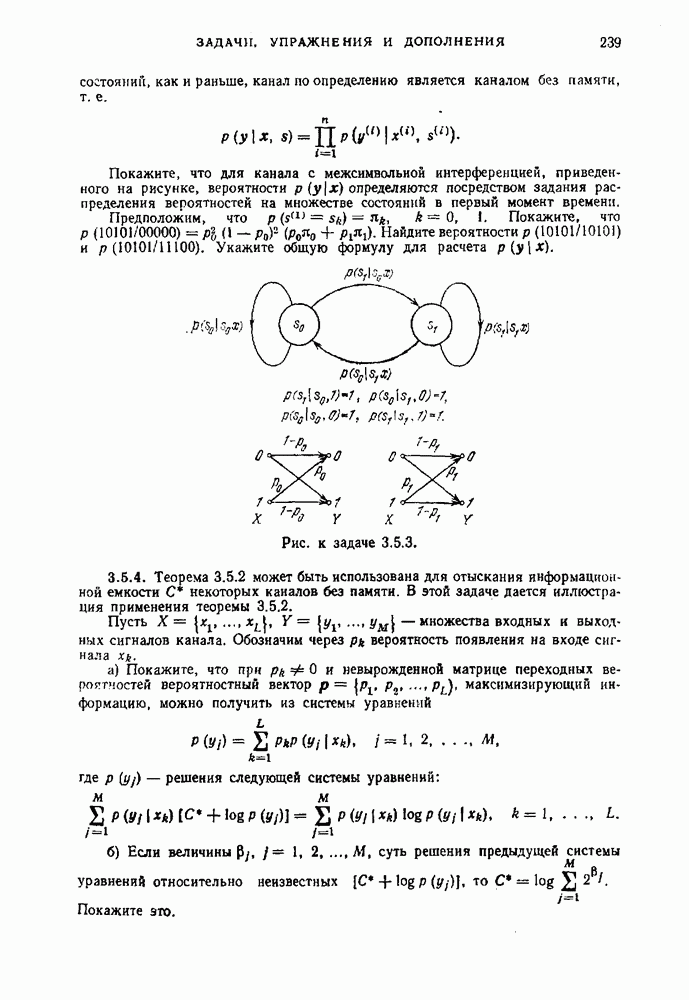
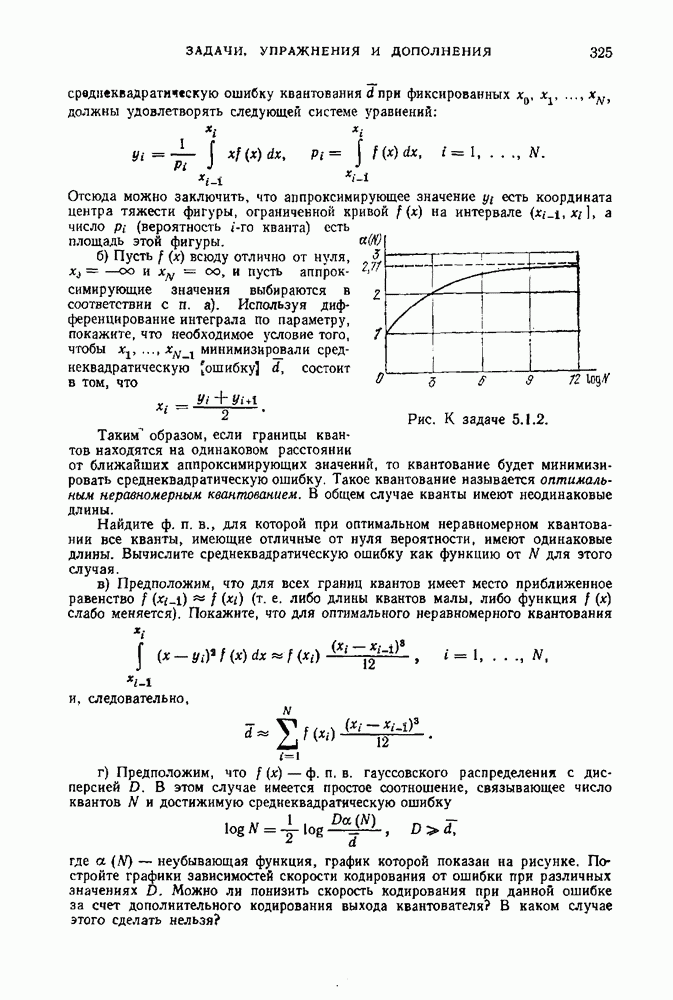
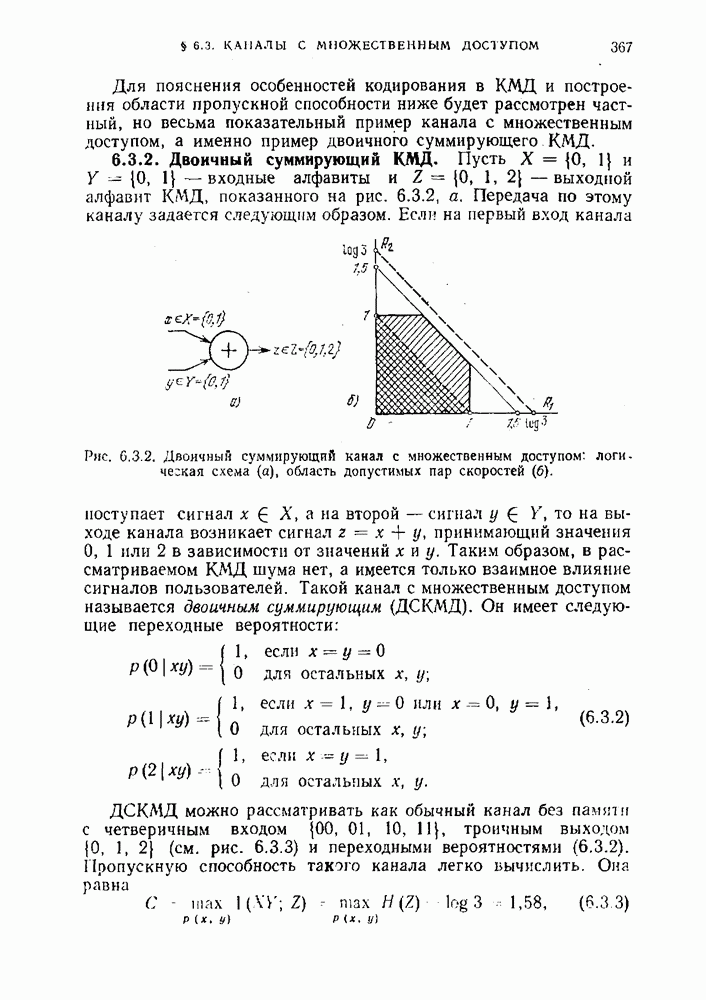
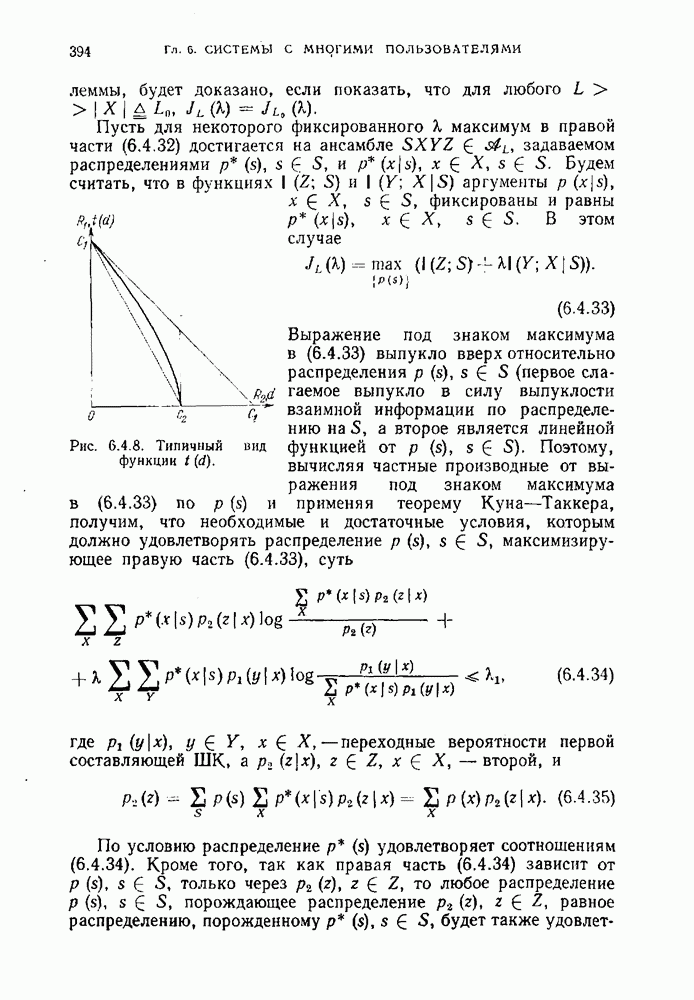
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 1.13. Оптимальные неравномерные кодыВ этом параграфе будет описан метод построения оптимальных однозначно декодируемых неравномерных кодов для дискретных ансамблей сообщений Рассмотрим вначале простейший случай, когда вероятности сообщений ансамбля являются целыми отрицательными степенями числа
В этом случае существует оптимальный D-ичный однозначно декодируемый код, для которого средняя длина кодовых слов
Известен следующий метод построения такого дерева (метод Шеннона-Фано): 1. Подразделить множество сообщений на D подмножеств, так, чтобы вероятности каждого из подмножеств были одинаковыми, произвольным образом перенумеровать подмножества. Для всех сообщений из
— кодовый алфавит. 2. Каждое из подмножеств рассматривать как некоторое новое множество сообщений. Выполнить на Пример 1.13.1. Неравномерный код, приведенный в примере 1.10.1, получен методом Шеннона-Фано. Процесс построения кода показан в табл. 1.13.1. Здесь первое и второе подмножества, получающиеся при разбиениях, обозначены через I и II соответственно, причем всем первым подмножествам соответствует символ 0, а вторым — 1. Таблица 1.13.1 (см. скан) Рассмотрим теперь общий случай, когда сообщения в ансамбле X имеют произвольные вероятности. Мы ограничимся рассмотрением префиксных кодов, так как любой набор длин кодовых слов однозначно декодируемого кода может быть получен и на префиксном коде. Ниже будут даны условия, которым должен удовлетворять оптимальный префиксный код, а затем будет показано, как построить код, удовлетворяющий этим условиям. Будет рассмотрен только двоичный случай Лемма 1.13.1. В оптимальном коде слово, соответствующее наименее вероятному сообщению, имеет наибольшую длину. Доказательство. Пусть — длина слова, кодирующего сообщение
Предположим, что в оптимальном коде
что противоречит предположению об оптимальности исходного кода. Лемма 1.13.2. В оптимальном двоичном префиксном коде два наименее вероятных сообщения кодируются словами одинаковой длины, одно из которых оканчивается нулем, а другое единицей. Доказательство. Обозначим через Рассмотрим новый ансамбль X, состоящий из
Любой декодируемый префиксный код для ансамбля X можно превратить в декодируемый код для ансамбля X приписыванием к кодовому слову, кодирующему сообщение Лемма 1.13.3. Если оптимален однозначно декодируемый префиксный код для ансамбля X, то оптимален полученный из него префиксный код для ансамбля Доказательство. Обозначим через
где использовано то обстоятельство, что длины
Из (1.13.6) следует, что Таким образом, задача построения оптимального префиксного кода сводится к задаче построения оптимального префиксного кода для ансамбля, содержащего на одно сообщение меньше. В этом ансамбле снова можно выделить два наименее вероятных сообщения и, объединяя их, получить новый ансамбль, содержащий теперь уже на два сообщения меньше, чем исходный. Очевидно, что таким образом можно дойти до ансамбля, содержащего всего два слова, оптимальным кодом для которого является просто 0 для одного сообщения и I для другого. Описанный метод построения оптимального префиксного кода называется методом Хаффмена. Пример 1.13.2. Рассмотрим ансамбль, состоящий из 7 сообщений, вероятности которых равны 0,3; 0,2; 0,15; 0,15; 0,1; 0,05; 0,05. В следующей таблице показаны 6 последовательных шагов, на каждом из которых происходит образование нового ансамбля с помощью склеивания наименее вероятных сообщений предыдущего ансамбля. Как видно из этого примера, процесс склеивания приводит к дереву и, следовательно, к однозначно декодируемому коду. Таблица 1.13.2 (см. скан) Средняя длина кодовых слов равна 2,6. Нижняя граница согласно теореме 1.12.1 равна 2,354. Кода со средней длиной меньшей, чем 2,6, не существует. Движению вверх по дереву сопоставлен символ 1, движению вниз — символ 0.
|
 |
Оглавление
|






















































































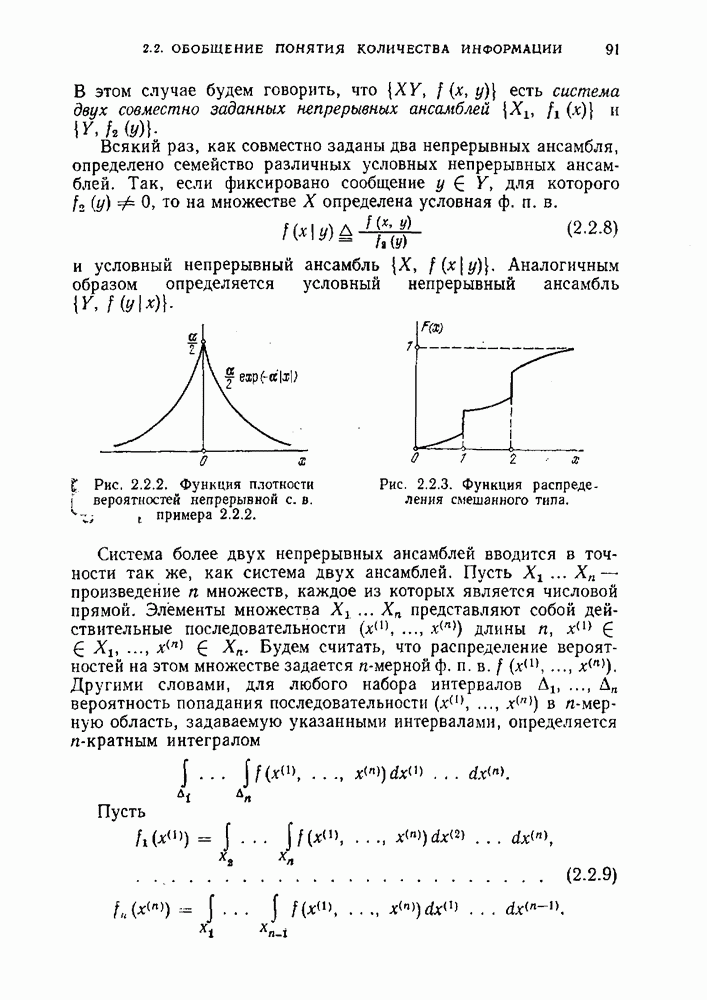



























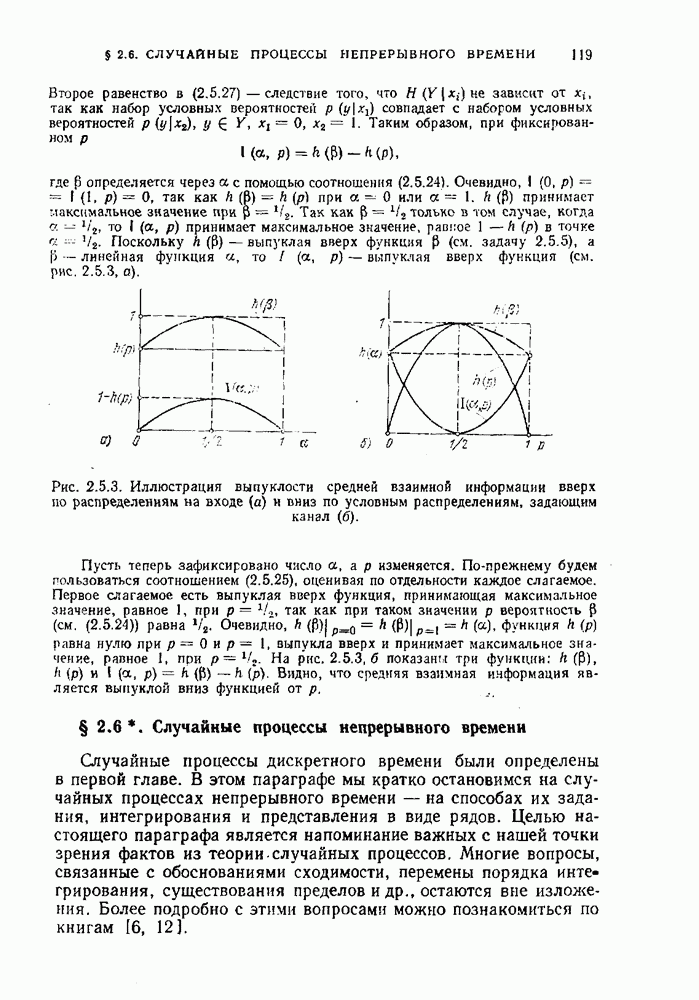























































































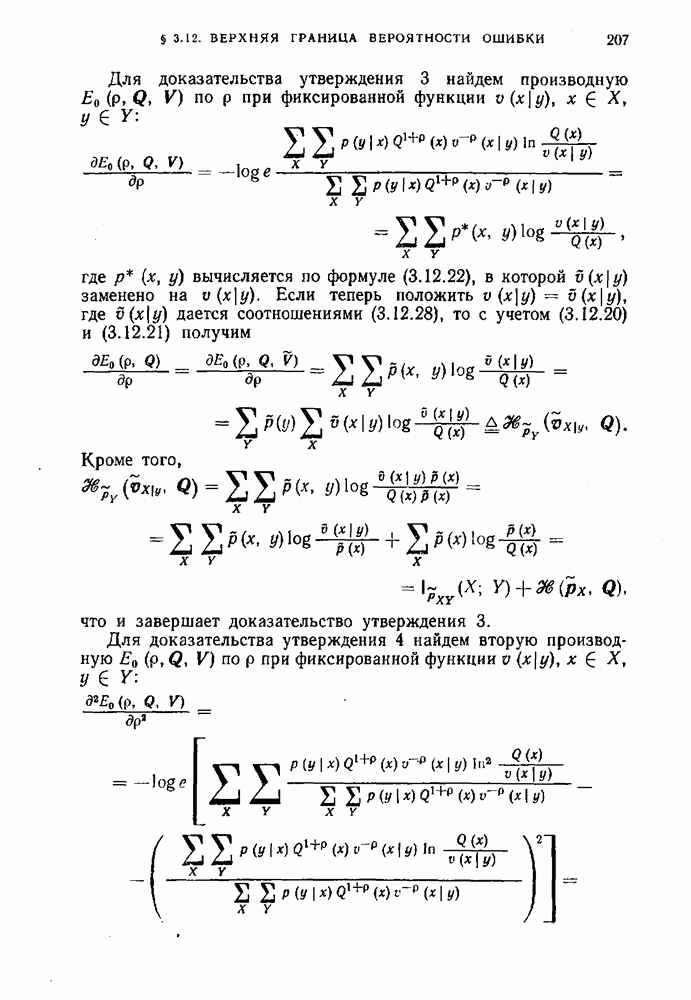


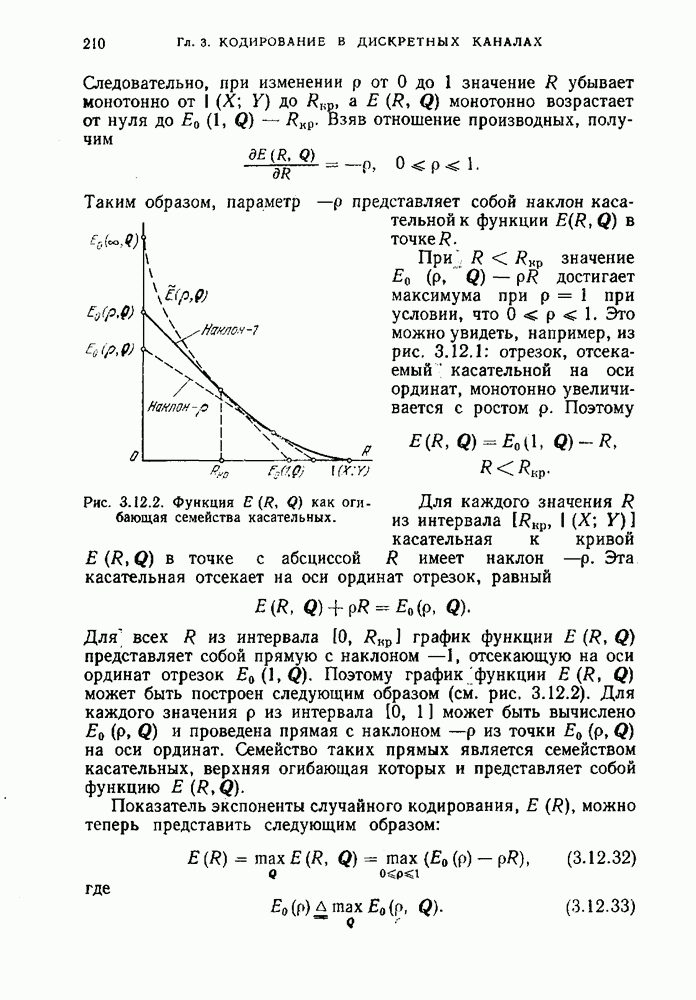

































































































































































































 Оптимальным называется код, средняя длина кодовых слов которого равна минимально возможной.
Оптимальным называется код, средняя длина кодовых слов которого равна минимально возможной.
 объема кодового алфавита:
объема кодового алфавита:


 теорему 1.12.1 и следующее за ней замечание). В таком коде сообщению
теорему 1.12.1 и следующее за ней замечание). В таком коде сообщению  сопоставляется слово длины
сопоставляется слово длины  Поэтому всякое дерево с набором концевых вершин порядков
Поэтому всякое дерево с набором концевых вершин порядков  и указанным правилом сопоставления дает оптимальный код.
и указанным правилом сопоставления дает оптимальный код.
 подмножества,
подмножества,  положить первый символ кодовых слов равным
положить первый символ кодовых слов равным  где
где

 шаге,
шаге,  действия, указанные в
действия, указанные в  для определения
для определения  символа кодовых слов. Считать, что действия над данным подмножеством закончены, если оно содержит одно сообщение.
символа кодовых слов. Считать, что действия над данным подмножеством закончены, если оно содержит одно сообщение.
 Недвоичный случай легко получить как обобщение двоичного. Всюду ниже будет предполагаться, что сообщения в ансамбле упорядочены так, что
Недвоичный случай легко получить как обобщение двоичного. Всюду ниже будет предполагаться, что сообщения в ансамбле упорядочены так, что 
 средняя длина кодовых слов:
средняя длина кодовых слов:

 для некоторого
для некоторого  Рассмотрим код, в котором
Рассмотрим код, в котором  слова исходного кода заменены одно другим. Средняя длина
слова исходного кода заменены одно другим. Средняя длина  для этого кода
для этого кода

 слово, кодирующее сообщение
слово, кодирующее сообщение  Пусть
Пусть  — слово наибольшей длины оптимального кода. Тогда существует еще одно слово, скажем
— слово наибольшей длины оптимального кода. Тогда существует еще одно слово, скажем  такой же длины. В противном случае единственное слово наибольшей длины можно было бы укоротить без нарушения декодируемости и получить меньшую среднюю длину. Таким образом, слова им и
такой же длины. В противном случае единственное слово наибольшей длины можно было бы укоротить без нарушения декодируемости и получить меньшую среднюю длину. Таким образом, слова им и  должны отличаться в последнем символе. Покажем теперь, что эти два слова кодируют наименее вероятные сообщения. Предположим противное, т. е. что
должны отличаться в последнем символе. Покажем теперь, что эти два слова кодируют наименее вероятные сообщения. Предположим противное, т. е. что  Тогда
Тогда  . В этом случае среднюю длину кода можно было бы уменьшить, заменив слово
. В этом случае среднюю длину кода можно было бы уменьшить, заменив слово  на
на  на
на  Следовательно, это предположение не справедливо и наибольшую длину имеют слова
Следовательно, это предположение не справедливо и наибольшую длину имеют слова  . Лемма доказана.
. Лемма доказана.
 сообщений
сообщений  с вероятностями
с вероятностями

 символов 0, 1 для получения слов, кодирующих сообщения
символов 0, 1 для получения слов, кодирующих сообщения  Теперь нетрудно указать последовательную процедуру построения оптимального префиксного кода. Для этого необходимо обосновать, что оптимизация на каждом шаге приведет к оптимизации кода. Это обоснование выполняется с помощью следующего утверждения.
Теперь нетрудно указать последовательную процедуру построения оптимального префиксного кода. Для этого необходимо обосновать, что оптимизация на каждом шаге приведет к оптимизации кода. Это обоснование выполняется с помощью следующего утверждения.

 среднюю длину кодовых слов кода для ансамбля
среднюю длину кодовых слов кода для ансамбля  Тогда средняя длина
Тогда средняя длина  кодовых слов кода для ансамбля X
кодовых слов кода для ансамбля X

 кодовых слов кода для ансамбля X связаны с длинами
кодовых слов кода для ансамбля X связаны с длинами  кодовых слов кода для ансамбля X следующими соотношениями:
кодовых слов кода для ансамбля X следующими соотношениями:

 отличаются на константу
отличаются на константу  которая не зависит от выбора кодовых слов, и строя декодируемый код для ансамбля X с минимальным значением
которая не зависит от выбора кодовых слов, и строя декодируемый код для ансамбля X с минимальным значением  мы получаем декодируемый код для ансамбля X с минимальным значением
мы получаем декодируемый код для ансамбля X с минимальным значением  Лемма доказана.
Лемма доказана.