Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
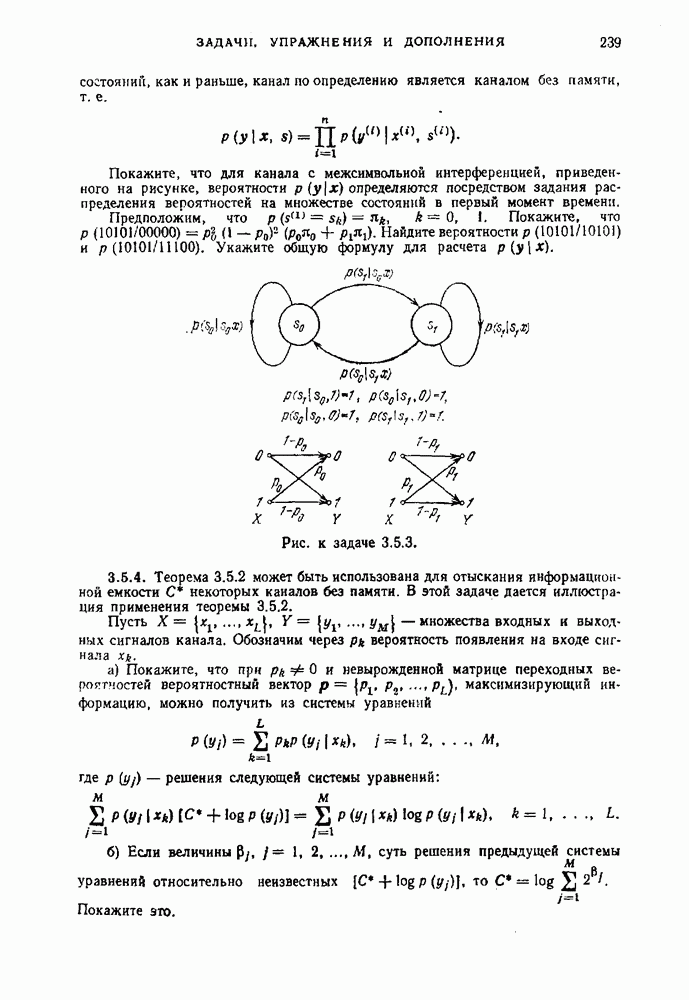
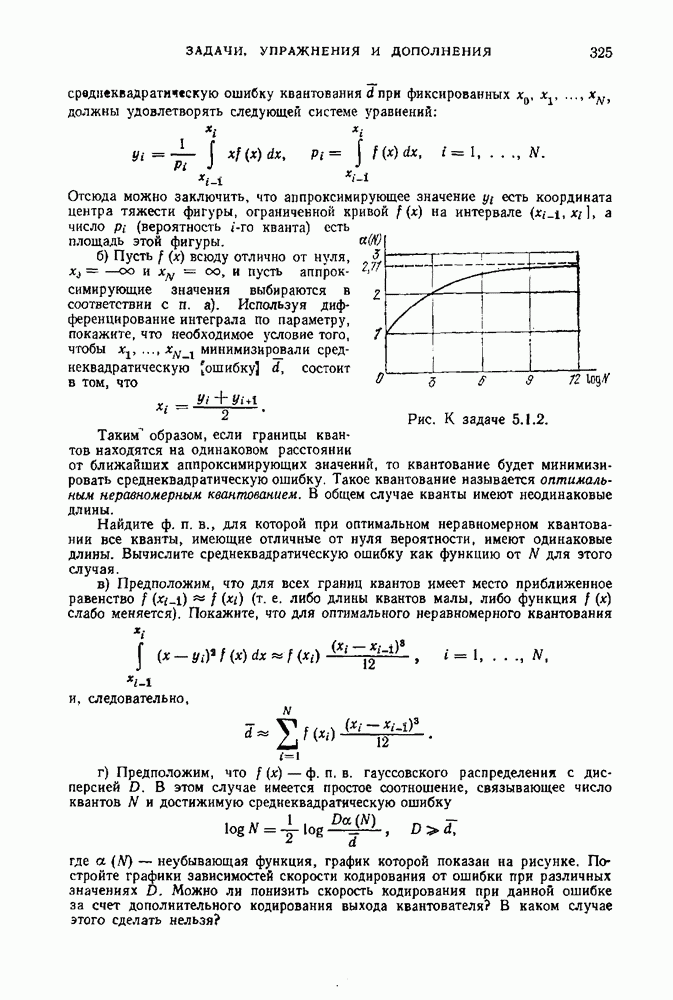
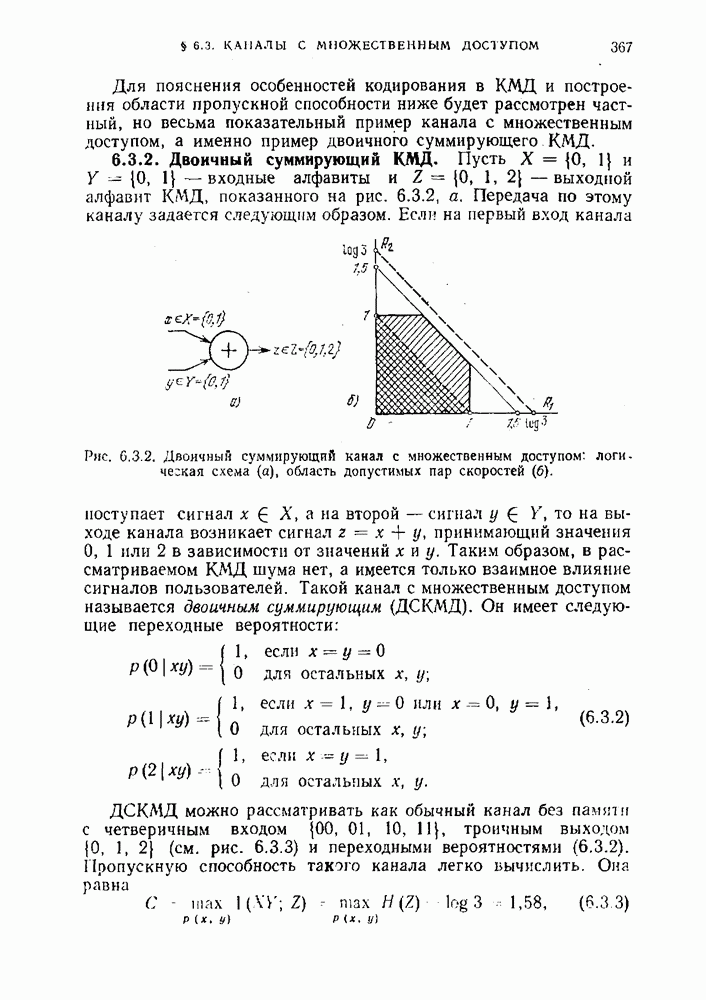
§ 3.11. Декодирование для кодов с заданным множеством кодовых словРассмотрим некоторый код для канала Пусть
где
— безусловное распределение вероятностей на выходе канала. Обозначим через
Для всех у из
Тогда соотношение (3.11.3) дает
Таким образом, при данном наборе кодовых слов средняя вероятность ошибки минимальна, если
Всякое разбиение множества выходных последовательностей канала на решающие области задает некоторое правило декодирования. Правило декодирования, определяемое разбиением (3.11.6), выбирает при каждом МАВ-декодирование зависит от априорного распределения вероятностей
Когда все кодовые слова равновероятны, т. е. Пример 3.11.1. Рассмотрим МП-декодирование в двоичном симметричном канале (ДСК). Предположим, что в этом канале вероятность ошибки
где Количество позиций, в которых последовательность х отличается от последовательности у, называется расстоянием Хемминга между х и у. Поэтому МП-декодирование в ДСК отображает выходную последовательность канала в такое кодовое слово, которое находится на наименьшем расстоянии Хемминга от него. В этом случае принято говорить, что декодирование производится по минимуму расстояния Хемминга. Пример 3.11.2. Рассмотрим МП-декодирование в двоичном стирающем канале (ДСтК). Предположим теперь, что в рассматриваемом канале вероятность ошибки равна
где Согласно определению, взаимная информация между входной х и выходной у последовательностями канала
Поэтому МП-декодирование эквивалентно выбору такого кодового слова, которое при данной выходной последовательности у максимизирует величину взаимной информации между ним и у. При выводе неравенства Файнстейна строился код, решающие области которого образовывались, исходя из другого принципа. Последовательность у относилась в решающую область
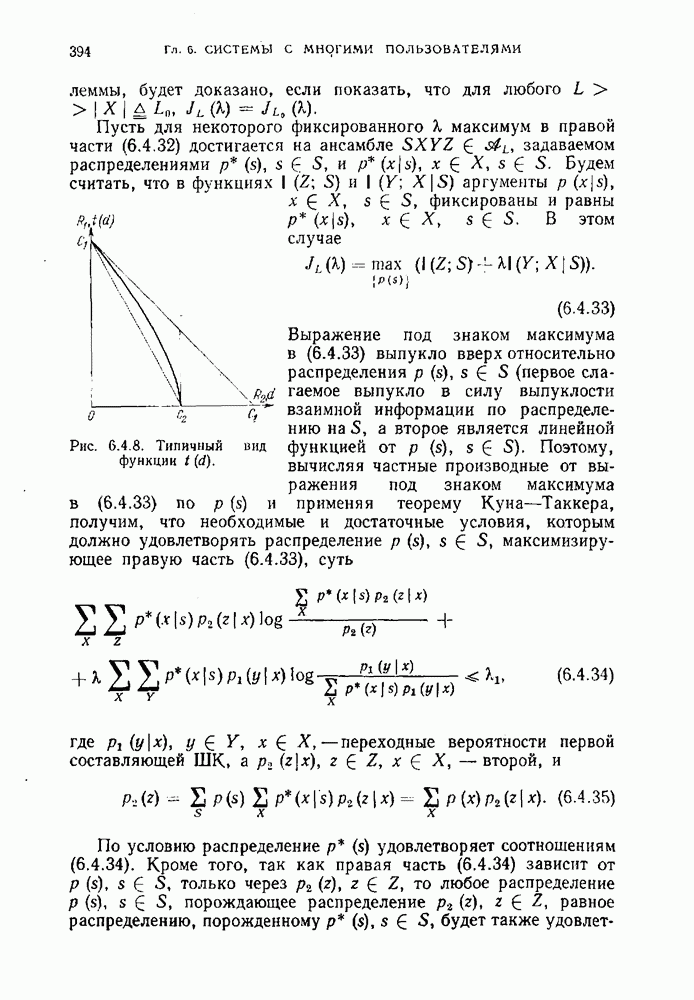
а не обязательно максимальной. При этом потребовалась некоторая коррекция решающих областей для того, чтобы сделать их непересекающимися, поскольку могли найтись два кодовых слова а, и Для такого выбора решающих областей удалось достаточно простыми средствами доказать существование кода, максимальная вероятность ошибки которого могла быть сделана сколь угодно малой при условии, что скорость кода меньше пропускной способности. В предыдущих параграфах нас не интересовала скорость сходимости вероятности ошибки декодирования к нулю с ростом длины кода. Вместе с тем, с точки зрения практических приложений представляет существенный интерес исследование зависимости величины вероятности ошибки от длины кода. Очевидно, что вероятность ошибки декодирования зависит как от кодовых слов, так и вида решающих областей. Выше мы показали, что в случае равновероятных сообщений наилучший выбор решающих областей соответствует декодированию по максимуму правдоподобия. В следующих разделах будет выведена верхняя и нижняя оценка для вероятности ошибки МП-декодирования в канале без памяти, показывающая ее экспоненциальное убывание с ростом длины кода при всех скоростях, меньших пропускной способности канала.
|
 |
Оглавление
|










































































































































































































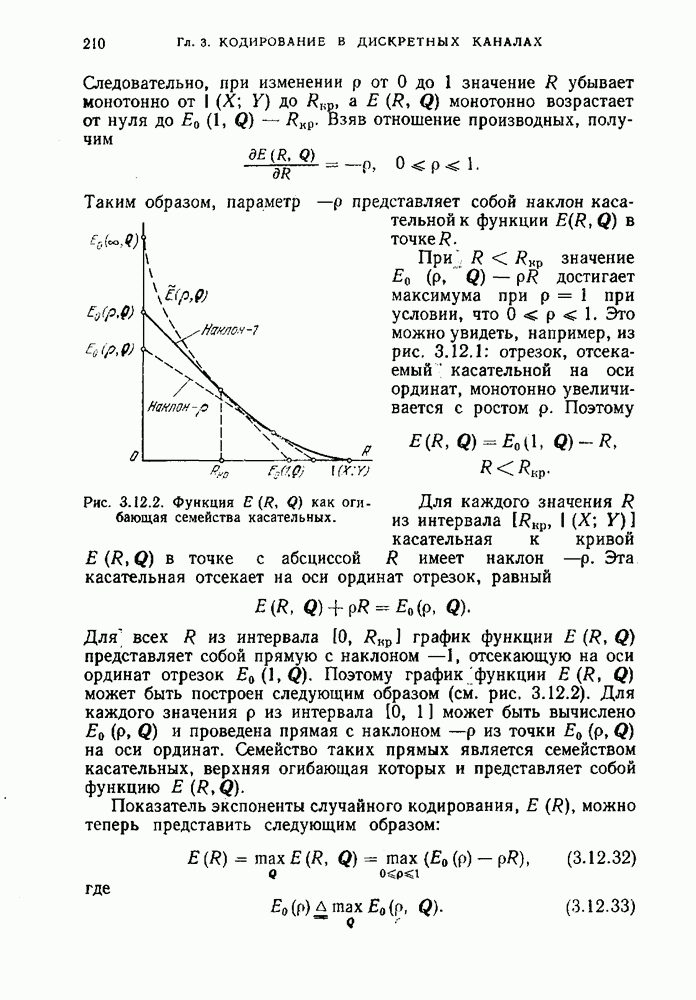

































































































































































































 и обозначим через
и обозначим через  им,
им,  его кодовые слова. Предположим, что набор кодовых слов фиксирован, а требуется указать наилучший выбор решающих областей
его кодовые слова. Предположим, что набор кодовых слов фиксирован, а требуется указать наилучший выбор решающих областей  при котором средняя или максимальная вероятность ошибки минимизируются. В общем случае решающие области (3.8.8), которые участвуют в доказательстве неравенства Файнстейна, не являются оптимальными в указанном выше смысле.
при котором средняя или максимальная вероятность ошибки минимизируются. В общем случае решающие области (3.8.8), которые участвуют в доказательстве неравенства Файнстейна, не являются оптимальными в указанном выше смысле.
 распределение вероятностей на множестве кодовых слов,
распределение вероятностей на множестве кодовых слов,  Тогда апостериорные вероятности кодовых слов могут быть найдены для каждого
Тогда апостериорные вероятности кодовых слов могут быть найдены для каждого  по следующим формулам:
по следующим формулам:


 вероятность ошибки при условии, что на выходе канала появилась последовательность у. Среднюю вероятность ошибки тогда можно представить следующим образом:
вероятность ошибки при условии, что на выходе канала появилась последовательность у. Среднюю вероятность ошибки тогда можно представить следующим образом:

 ошибка декодирования происходит в том случае, когда переданное слово отличается от
ошибка декодирования происходит в том случае, когда переданное слово отличается от  следовательно,
следовательно,



 то кодовое слово, которое имеет наибольшую апостериорную вероятность
то кодовое слово, которое имеет наибольшую апостериорную вероятность  . В связи с этим оно называется декодированием по максимуму апостериорной вероятности (МАВ-декодирование). Как выше показано, МАВ-декодирование минимизирует среднюю вероятность ошибки.
. В связи с этим оно называется декодированием по максимуму апостериорной вероятности (МАВ-декодирование). Как выше показано, МАВ-декодирование минимизирует среднюю вероятность ошибки.
 на множестве кодовых слов. Рассмотрим декодирование по максимуму правдоподобия (МП-декодирование), которое по построению не зависит от априорного распределения. МП-декодированием называют такое правило декодирования, которое задается разбиением
на множестве кодовых слов. Рассмотрим декодирование по максимуму правдоподобия (МП-декодирование), которое по построению не зависит от априорного распределения. МП-декодированием называют такое правило декодирования, которое задается разбиением

 для всех
для всех  разбиения на решающие области (3.11.6) и
разбиения на решающие области (3.11.6) и  совпадают. Действительно, из (3.11.1) следует, что если
совпадают. Действительно, из (3.11.1) следует, что если  максимизирует апостериорную вероятность
максимизирует апостериорную вероятность  то это же
то это же  максимирует также функцию правдоподобия
максимирует также функцию правдоподобия 
 Пусть
Пусть  Тогда
Тогда

 количество позиций, в которых последовательность
количество позиций, в которых последовательность  отличается от последовательности у. В случае МП-декодирования у отображается в то слово используемого кода, которому соответствует минимальное значение
отличается от последовательности у. В случае МП-декодирования у отображается в то слово используемого кода, которому соответствует минимальное значение 
 и вероятность стирания равна
и вероятность стирания равна  причем
причем  Из стационарности канала следует, что
Из стационарности канала следует, что

 число стираний в последовательности у и
число стираний в последовательности у и  -количество нестертых позиций, в которых последовательности х и у отличаются. Число
-количество нестертых позиций, в которых последовательности х и у отличаются. Число  определяется только выходом канала и не зависит от того, какое кодовое слово передавалось. Нетрудно проверить, что при фиксированном
определяется только выходом канала и не зависит от того, какое кодовое слово передавалось. Нетрудно проверить, что при фиксированном  и при
и при  правая часть (3.11.9) монотонно убывает с ростом
правая часть (3.11.9) монотонно убывает с ростом  Поэтому МП-декодирование в
Поэтому МП-декодирование в  отображает выходную последовательность канала в такое кодовое слово, которому соответствует минимальное значение
отображает выходную последовательность канала в такое кодовое слово, которому соответствует минимальное значение  Другими словами, МП-декодирование осуществляется по минимуму расстояния Хемминга на нестертых позициях.
Другими словами, МП-декодирование осуществляется по минимуму расстояния Хемминга на нестертых позициях.

 если информация
если информация  при данном кодовом слове
при данном кодовом слове  была достаточно большой:
была достаточно большой:

 для каждого из которых выполняется условие (3.11.11).
для каждого из которых выполняется условие (3.11.11).