§ 6.1. Кодирование зависимых источников
6.1.1. Постановка задачи.
Начнем со следующего примера. Предположим, что имеется ряд рассредоточенных в пространстве датчиков метеорологических данных, которые передают эти данные в центр обработки для составления картины погоды. Датчики можно рассматривать как источники сообщений, причем сообщения отдельных датчиков, как правило, являются зависимыми случайными величинами: сообщение на выходе одного датчика в значительной степени определяется сообщениями на выходах других, поскольку погодные условия в близких районах зависимы. Из-за наличия такой зависимости сообщения всех датчиков в совокупности избыточны, и в действительности для того, чтобы воспроизвести всю картину погоды, от каждого датчика можно было бы брать только часть данных. Сокращение общего объема передаваемых данных является выгодным с многих точек зрения. Поэтому естественным является вопрос о том, какая часть всех данных достаточна.
Датчики рассредоточены в пространстве и каждый из них снабжен кодером, работающим независимо от остальных кодеров. Кодеры устраняют избыточную информацию, содержащуюся в совместных измерениях системы датчиков. Интуитивно ясно, что возможно по-разному кодировать сообщения различных датчиков, затрачивая различное количество двоичных символов на сообщение.
Например, возможно кодировать сообщения первого датчика, используя большое количество двоичных символов на сообщение, а второго — малое; возможно поступить наоборот. И в том, и в другом случае общая картина погоды может быть восстановлена. Другими словами, возможно независимое кодирование системы источников с различным набором скоростей кодирования  для
для  независимо работающих кодеров. С точки зрения теории информации задача заключается в определении всех таких наборов скоростей, при которых возможно восстановление сообщений всех датчиков системы.
независимо работающих кодеров. С точки зрения теории информации задача заключается в определении всех таких наборов скоростей, при которых возможно восстановление сообщений всех датчиков системы.
Ниже мы рассмотрим наиболее простой случай независимого кодирования зависимых источников, а именно, будет предполагаться, что имеются два дискретных источника без памяти и требуется восстановление с произвольно малой вероятностью ошибки. Эта задача аналогична задаче кодирования дискретных источников равномерными кодами, которая была рассмотрена в первой главе.
Пусть  два зависимых дискретных источника и
два зависимых дискретных источника и  ансамбли их сообщений с совместным распределением вероятностей
ансамбли их сообщений с совместным распределением вероятностей  Будем рассматривать такие источники
Будем рассматривать такие источники  что распределение вероятностей на парах
что распределение вероятностей на парах
последовательностей сообщений  задается соотношением
задается соотношением

Другими словами, предполагается, что источники зависимы, но пары сообщений  статистически независимы и одинаково распределены. Пару источников
статистически независимы и одинаково распределены. Пару источников  для которых выполнено соотношение (6.1.1), будем называть парой зависимых источников без памяти.
для которых выполнено соотношение (6.1.1), будем называть парой зависимых источников без памяти.

Рис. 6.1.1. Независимое кодирование зависимых источников.
Кодирование каждого из источников осуществляется своим кодером, работающим независимо от другого. Отметим, что именно независимое кодирование является специфической особенностью рассматриваемой задачи. Пусть  отображения множеств
отображения множеств  на множества целых чисел
на множества целых чисел  соответственно. Каждый элемент
соответственно. Каждый элемент  может быть взаимно однозначно представлен двоичной последовательностью
может быть взаимно однозначно представлен двоичной последовательностью  длины
длины  (двоичной записью номера
(двоичной записью номера  в множестве V). Аналогично каждый элемент
в множестве V). Аналогично каждый элемент  может быть представлен двоичной последовательностью
может быть представлен двоичной последовательностью  длины
длины  Кодирование источников
Кодирование источников  задается отображениями
задается отображениями  соответственно. Если на выходе источника
соответственно. Если на выходе источника  появляется последовательность х, а на выходе источника
появляется последовательность х, а на выходе источника  последовательность у, то на выходе первого кодера появляется последовательность
последовательность у, то на выходе первого кодера появляется последовательность  а на выходе второго —
а на выходе второго —  (см. рис. 6.1.1).
(см. рис. 6.1.1).
Восстановление пары  появившейся на выходах источников
появившейся на выходах источников  осуществляется декодером, работа которого задается отображением
осуществляется декодером, работа которого задается отображением  пары чисел
пары чисел  в множество
в множество  При декодировании возможно неправильное восстановление. Вероятность ошибки X определяется как вероятность того, что хотя бы один элемент пары будет восстановлен неверно:
При декодировании возможно неправильное восстановление. Вероятность ошибки X определяется как вероятность того, что хотя бы один элемент пары будет восстановлен неверно:

Будем говорить, что задан код  с длиной
с длиной  для независимого кодирования пары дискретных источников, если кодируются последовательности сообщений длины
для независимого кодирования пары дискретных источников, если кодируются последовательности сообщений длины  и заданы три
и заданы три
отображения  (кодирование) и
(кодирование) и  (декодирование). Величины
(декодирование). Величины

называются при этом скоростями кодирования источников  и
и  соответственно.
соответственно.
Определение 6.1.1. Пара чисел  »
»  называется допустимой парой скоростей при независимом кодировании двух дискретных источников, если для любых
называется допустимой парой скоростей при независимом кодировании двух дискретных источников, если для любых  найдется
найдется  такое, что для любого
такое, что для любого  найдется код
найдется код  со скоростями кодирования
со скоростями кодирования  кодирующими отображениями
кодирующими отображениями  и декодирующим отображением
и декодирующим отображением  для которого
для которого 
Очевидно, что пара скоростей  где
где  и
и  энтропии ансамблей
энтропии ансамблей  соответственно, допустима при независимом кодировании пары зависимых дискретных источников без памяти. При этом, как показано в гл. 1, отображения
соответственно, допустима при независимом кодировании пары зависимых дискретных источников без памяти. При этом, как показано в гл. 1, отображения  задают взаимно однозначное кодирование только для элементов высоковероятных множеств источников
задают взаимно однозначное кодирование только для элементов высоковероятных множеств источников  . С другой стороны, если бы каждому из кодеров 1 и 2 были доступны сообщения на выходах обоих источников, то кодирование можно было бы рассматривать как кодирование дискретного источника без памяти с ансамблем сообщений
. С другой стороны, если бы каждому из кодеров 1 и 2 были доступны сообщения на выходах обоих источников, то кодирование можно было бы рассматривать как кодирование дискретного источника без памяти с ансамблем сообщений  . При таком зависимом кодировании была бы допустимой любая такая пара скоростей
. При таком зависимом кодировании была бы допустимой любая такая пара скоростей  что
что  Так как
Так как  причем строгое неравенство является следствием зависимости источников, то во втором случае можно было бы достичь меньшей суммарной скорости, чем в первом. Замечательный факт, который будет обоснован ниже, состоит в том, что независимое кодирование не приводит к увеличению минимальной допустимой суммарной скорости кодирования.
причем строгое неравенство является следствием зависимости источников, то во втором случае можно было бы достичь меньшей суммарной скорости, чем в первом. Замечательный факт, который будет обоснован ниже, состоит в том, что независимое кодирование не приводит к увеличению минимальной допустимой суммарной скорости кодирования.
Множество всех допустимых пар скоростей  при независимом кодировании пары источников будем обозначать через
при независимом кодировании пары источников будем обозначать через  Основной задачей настоящего раздела является характеризация области 31.
Основной задачей настоящего раздела является характеризация области 31.
Следующая лемма устанавливает выпуклость множества  . В этой лемме вводится один из важнейших методов кодирования для систем с многими пользователями — метод разделения времени.
. В этой лемме вводится один из важнейших методов кодирования для систем с многими пользователями — метод разделения времени.
Лемма 6.1.1. Пусть  произвольное число из интервала [0, 1], тогда пара скоростей
произвольное число из интервала [0, 1], тогда пара скоростей  допустима.
допустима.
Доказательство. Предположим, что  где
где  целые числа. Пусть фиксированы
целые числа. Пусть фиксированы  и пусть
и пусть
 коды с длиной
коды с длиной  и скоростями
и скоростями  для которых вероятности ошибок удовлетворяют неравенствам:
для которых вероятности ошибок удовлетворяют неравенствам:  соответственно. Будем кодировать последовательности сообщений длины
соответственно. Будем кодировать последовательности сообщений длины  на выходах источников
на выходах источников  и
и  следующим образом. Первые I блоков длины
следующим образом. Первые I блоков длины  будем кодировать с помощью кода а остальные
будем кодировать с помощью кода а остальные  блоков — с помощью кода
блоков — с помощью кода  При этом скорости кодирования для источников
При этом скорости кодирования для источников  и
и  будут равными:
будут равными:

а вероятность ошибки на блок длины  будет удовлетворять неравенствам
будет удовлетворять неравенствам


Рис. 6.1.2. Область допустимых пар скоростей при независимом кодировании зависимых источников.
Так как  произвольны, а
произвольны, а  могут быть выбраны сколь угодно большими, то это и доказывает утверждение леммы.
могут быть выбраны сколь угодно большими, то это и доказывает утверждение леммы.
Использование части времени для одного кода, а остальной части времени — для другого, называется разделением времени. Применение разделения времени дает целое семейство допустимых пар скоростей, соответствующих различному выбору параметра а. Геометрически это семейство можно представить как множество точек прямой, соединяющей в плоскости  точки с координатами
точки с координатами  Поэтому для рассматриваемой задачи граница области допустимых пар скоростей представляет собой выпуклую вниз кривую, возможно, составленную из отрезков прямых.
Поэтому для рассматриваемой задачи граница области допустимых пар скоростей представляет собой выпуклую вниз кривую, возможно, составленную из отрезков прямых.
Ниже будет показано, что область допустимых пар скоростей при независимом кодировании представляет собой заштрихованную область на рис. 6.1.2. Область с двойной штриховкой представляет собой область допустимых пар скоростей при кодировании, не учитывающем зависимость источников. Область выше прямой  область допустимых пар скоростей в случае, когда обоим кодерам доступны сообщения обоих источников (полностью зависимое кодирование).
область допустимых пар скоростей в случае, когда обоим кодерам доступны сообщения обоих источников (полностью зависимое кодирование).
6.1.2. Обратная теорема кодирования.
В этом пункте мы докажем обратную теорему кодирования для независимого кодирования пары зависимых источников. Иными словами, мы укажем условия, при выполнении которых пара  не является допустимой.
не является допустимой.
Прежде всего отметим, что недопустимы все пары скоростей  которые удовлетворяют неравенству
которые удовлетворяют неравенству  Это следует из обратной теоремы кодирования дискретных источников без памяти для случая источников с ансамблем сообщений
Это следует из обратной теоремы кодирования дискретных источников без памяти для случая источников с ансамблем сообщений  Кроме этого ограничения, имеются также ограничения на минимально возможные значения
Кроме этого ограничения, имеются также ограничения на минимально возможные значения  Эти ограничения могут быть пояснены с помощью следующих рассуждений.
Эти ограничения могут быть пояснены с помощью следующих рассуждений.
Пусть последовательность сообщений  источника
источника  известна как кодеру 1, так и декодеру. Для типичной последовательности
известна как кодеру 1, так и декодеру. Для типичной последовательности  При этом высоковероятное множество сообщений источника
При этом высоковероятное множество сообщений источника  будет состоять примерно из
будет состоять примерно из  последовательностей. Следовательно, скорость кодирования для источника
последовательностей. Следовательно, скорость кодирования для источника  не может быть меньшей, чем
не может быть меньшей, чем  Аналогичные рассуждения приводят к тому, что скорость кодирования для источника
Аналогичные рассуждения приводят к тому, что скорость кодирования для источника  не может быть меньшей, чем
не может быть меньшей, чем  Точное доказательство этих утверждений, основанное на использовании неравенства Фано, дается в следующей теореме.
Точное доказательство этих утверждений, основанное на использовании неравенства Фано, дается в следующей теореме.
Теорема 6.1.1 (Обратная теорема кодирования). Пусть  пара зависимых дискретных источников без памяти,
пара зависимых дискретных источников без памяти,  — ансамбль сообщений для этой пары источников и
— ансамбль сообщений для этой пары источников и  определяемые распределением
определяемые распределением  энтропии. Для любой пары чисел
энтропии. Для любой пары чисел  удовлетворяющей хотя бы одному из следующих трех неравенств:
удовлетворяющей хотя бы одному из следующих трех неравенств:

найдется число  такое, что для любого
такое, что для любого  и для любого кода
и для любого кода  вероятность ошибки удовлетворяет неравенству
вероятность ошибки удовлетворяет неравенству  .
.
Доказательство. Как уже отмечалось выше, при выполнении условия  утверждение теоремы следует из обратной теоремы кодирования для дискретного источника без памяти с ансамблем сообщений
утверждение теоремы следует из обратной теоремы кодирования для дискретного источника без памяти с ансамблем сообщений  Покажем теперь справедливость теоремы для всех таких пар
Покажем теперь справедливость теоремы для всех таких пар  что
что 
Обозначим через  множество всех последовательностей
множество всех последовательностей  которые могут появиться на выходе декодера,
которые могут появиться на выходе декодера,  Заметим, что распределение вероятностей на
Заметим, что распределение вероятностей на  кодирование
кодирование  и декодирование
и декодирование  задают распределение вероятностей на произведении множеств
задают распределение вероятностей на произведении множеств  При этом имеют место
При этом имеют место
следующие соотношения: 

где первое неравенство следует из того, что энтропия любого ансамбля не превосходит логарифма числа его элементов, второе — из того, что  и третье — из невозрастания информации при преобразованиях.
и третье — из невозрастания информации при преобразованиях.
Предположим, что фиксирована последовательность  Рассмотрим ансамбль
Рассмотрим ансамбль  и обозначим через
и обозначим через  вероятность ошибки при декодировании последовательности
вероятность ошибки при декодировании последовательности  при условии, что источник
при условии, что источник  породил последовательность у. Очевидно,
породил последовательность у. Очевидно,  и можно воспользоваться неравенством Фано (см. § 3.3), применив его к ансамблю
и можно воспользоваться неравенством Фано (см. § 3.3), применив его к ансамблю 

где  число элементов в
число элементов в  Усредняя левую и правую части последнего неравенства по ансамблю
Усредняя левую и правую части последнего неравенства по ансамблю  и используя выпуклость функции
и используя выпуклость функции  получим
получим

где  средняя вероятность ошибки декодирования сообщений источника
средняя вероятность ошибки декодирования сообщений источника  Если
Если  , где
, где  то из (6.1.3) и (6.1.4) имеем
то из (6.1.3) и (6.1.4) имеем

откуда следует, что для некоторого  при любом
при любом  Аналогично показывается, что при
Аналогично показывается, что при  имеет место неравенство
имеет место неравенство  Утверждение теоремы следует из того, что
Утверждение теоремы следует из того, что 
6.1.3. Прямая теорема кодирования.
Теперь мы покажем, что любая пара скоростей, которая принадлежит заштрихованной
области на рис. 6.1.2, является допустимой при независимом кодировании пары зависимых дискретных источников без памяти. Заметим вначале, что для доказательства этого утверждения достаточно показать, что допустимыми являются пары скоростей  и
и  Допустимость остальных пар, принадлежащих заштрихованной области, будет следовать из возможности разделения времени (см. лемму 6.1.1).
Допустимость остальных пар, принадлежащих заштрихованной области, будет следовать из возможности разделения времени (см. лемму 6.1.1).
Рассмотрим пару скоростей  Доказательство допустимости этой пары будет выполнено посредством построения кода
Доказательство допустимости этой пары будет выполнено посредством построения кода  который обеспечивает вероятность ошибки
который обеспечивает вероятность ошибки  для любых положительных чисел
для любых положительных чисел  Метод построения такого кода основан на следующих соображениях. Множества
Метод построения такого кода основан на следующих соображениях. Множества  и
и  можно рассматривать соответственно как множества входных и выходных последовательностей дискретного канала без памяти, задаваемого переходными вероятностями
можно рассматривать соответственно как множества входных и выходных последовательностей дискретного канала без памяти, задаваемого переходными вероятностями  где
где

 распределение вероятностей, определяющее пару рассматриваемых источников. Для такого канала при любом
распределение вероятностей, определяющее пару рассматриваемых источников. Для такого канала при любом  можно построить код
можно построить код  содержащий
содержащий  кодовых слов и обеспечивающий вероятность ошибки не большую, чем
кодовых слов и обеспечивающий вероятность ошибки не большую, чем  , Если бы на выходе источника
, Если бы на выходе источника  появлялись только слова этого кода, а последовательность у была бы известна декодеру, то он мог бы восстановить х с вероятностью ошибки, не большей чем
появлялись только слова этого кода, а последовательность у была бы известна декодеру, то он мог бы восстановить х с вероятностью ошибки, не большей чем  Однако на выходе источника
Однако на выходе источника  с вероятностью, близкой к единице, появляется одна из
с вероятностью, близкой к единице, появляется одна из  последовательностей высоковероятного множества, в то время как код
последовательностей высоковероятного множества, в то время как код  содержит самое большое
содержит самое большое  слов. Поэтому для того, чтобы исчерпать все высоковероятное множество последовательностей источника
слов. Поэтому для того, чтобы исчерпать все высоковероятное множество последовательностей источника  понадобится по крайней мере
понадобится по крайней мере  кодов. Ниже мы покажем, что, действительно, может быть построено множество, состоящее примерно из такого числа кодов для канала без памяти с переходными вероятностями
кодов. Ниже мы покажем, что, действительно, может быть построено множество, состоящее примерно из такого числа кодов для канала без памяти с переходными вероятностями  причем кодовые слова всех кодов из этого множества покрывают почти все высоковероятное множество источника
причем кодовые слова всех кодов из этого множества покрывают почти все высоковероятное множество источника 
Код для кодирования источника  будет строиться следующим образом. Кодирующая функция
будет строиться следующим образом. Кодирующая функция  указывает номер кода, которому принадлежит
указывает номер кода, которому принадлежит  если последовательность х не принадлежит ни одному коду, то положим
если последовательность х не принадлежит ни одному коду, то положим  В последнем случае происходит ошибка декодирования, вероятность
В последнем случае происходит ошибка декодирования, вероятность
которой мы будем обозначать через V Кодирующая функция  указывает номер последовательности у в высоковероятном множестве источника
указывает номер последовательности у в высоковероятном множестве источника  Если у не принадлежит этому множеству, то положим
Если у не принадлежит этому множеству, то положим  Вероятность ошибки декодирования, возникающей в последнем случае, будем обозначать через
Вероятность ошибки декодирования, возникающей в последнем случае, будем обозначать через  Декодер сначала восстанавливает последовательность у, а затем по номеру кода, самому коду
Декодер сначала восстанавливает последовательность у, а затем по номеру кода, самому коду  восстанавливает кодовое слово, которое и принимается за х. При этом, кроме указанных выше ошибок декодирования, с вероятностью
восстанавливает кодовое слово, которое и принимается за х. При этом, кроме указанных выше ошибок декодирования, с вероятностью  может произойти ошибка декодирования кода
может произойти ошибка декодирования кода  Общая вероятность ошибки декодирования X, очевидно, не превышает
Общая вероятность ошибки декодирования X, очевидно, не превышает  Из приведенных выше соображений следует, что при
Из приведенных выше соображений следует, что при  величины
величины  могут быть сделаны сколь угодно малыми путем выбора достаточно большого
могут быть сделаны сколь угодно малыми путем выбора достаточно большого  Аналогичные соображения могут быть приведены для обоснования допустимости пары
Аналогичные соображения могут быть приведены для обоснования допустимости пары 
Перейдем теперь к точным формулировкам и доказательствам.
Лемма 6.1.2. Пусть фиксированы дискретный канал без памяти с переходными вероятностями  и дискретный источник без памяти
и дискретный источник без памяти  с ансамблем сообщений
с ансамблем сообщений  Для любых
Для любых  найдется
найдется  такое, что при
такое, что при  существует такая совокупность кодов
существует такая совокупность кодов  для канала
для канала  что
что

2) вероятность ошибки каждого кода не превосходит  и
и

где  множество кодовых слов кода
множество кодовых слов кода 
Доказательство. Положим  смотрим высоковероятное множество источника
смотрим высоковероятное множество источника 

и будем считать, что при фиксированных  величина
величина  выбрана из условия
выбрана из условия  Построим код
Построим код  для канала
для канала  с вероятностью ошибки
с вероятностью ошибки  выбирая кодовые слова в множестве
выбирая кодовые слова в множестве  Согласно неравенству Файнстейна (теорема 3.8.1), такой код может быть построен, причем число кодовых слов
Согласно неравенству Файнстейна (теорема 3.8.1), такой код может быть построен, причем число кодовых слов  может быть выбрано не меньшим чем
может быть выбрано не меньшим чем


Пусть  тогда
тогда 

где

Положим  Тогда
Тогда

Оценим теперь вероятность  Из определения множества
Из определения множества 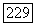 следует, что найдется
следует, что найдется 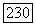 такое, что при
такое, что при 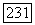

где последнее неравенство следует из того, что при достаточно большом 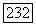 величина
величина  -может быть сделана как угодно малой. Таким образом, мы доказали существование не более чем
-может быть сделана как угодно малой. Таким образом, мы доказали существование не более чем  кодов с вероятностью ошибки каждого из них, не превосходящей заданного числа
кодов с вероятностью ошибки каждого из них, не превосходящей заданного числа  и которые своими кодовыми словами покрывают высоковероятное множество
и которые своими кодовыми словами покрывают высоковероятное множество  с точностью до подмножества, вероятность которого не превосходит
с точностью до подмножества, вероятность которого не превосходит 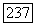 Заметим, что неравенство в (6.1.6) следует из того, что, начиная с некоторого
Заметим, что неравенство в (6.1.6) следует из того, что, начиная с некоторого 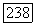 вероятности
вероятности 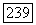 могут все равняться нулю, поэтому количество кодов на самом деле может оказаться меньшим, чем
могут все равняться нулю, поэтому количество кодов на самом деле может оказаться меньшим, чем 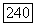 Лемма доказана.
Лемма доказана.
Теорема 6.1.2. (Прямая теорема кодирования.) Пусть  пара зависимых дискретных источников без памяти,
пара зависимых дискретных источников без памяти,











































































































































































































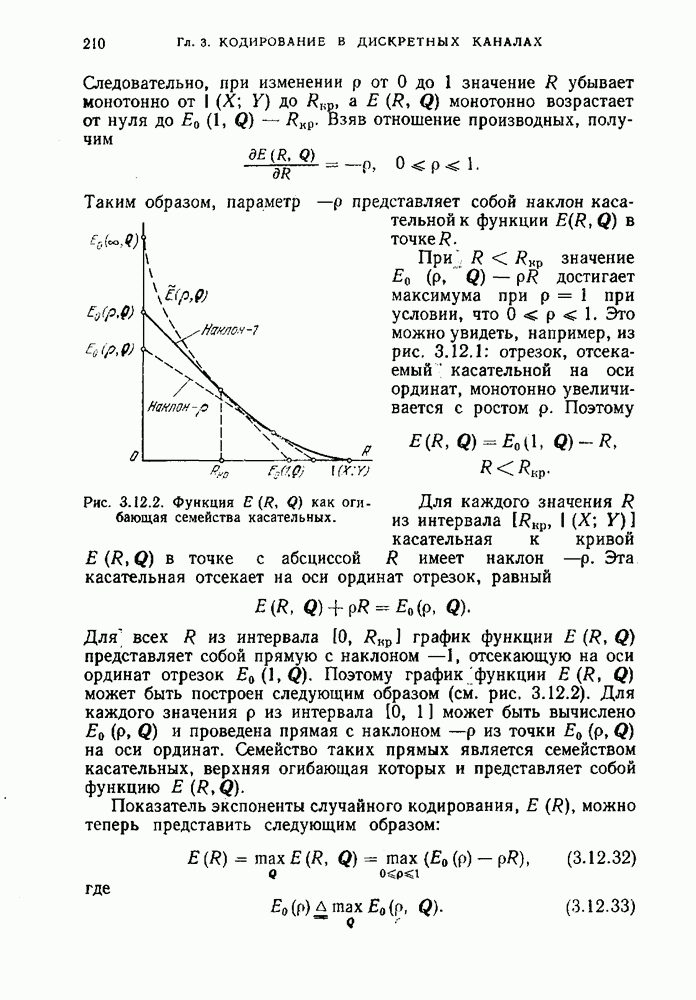

























































































































































































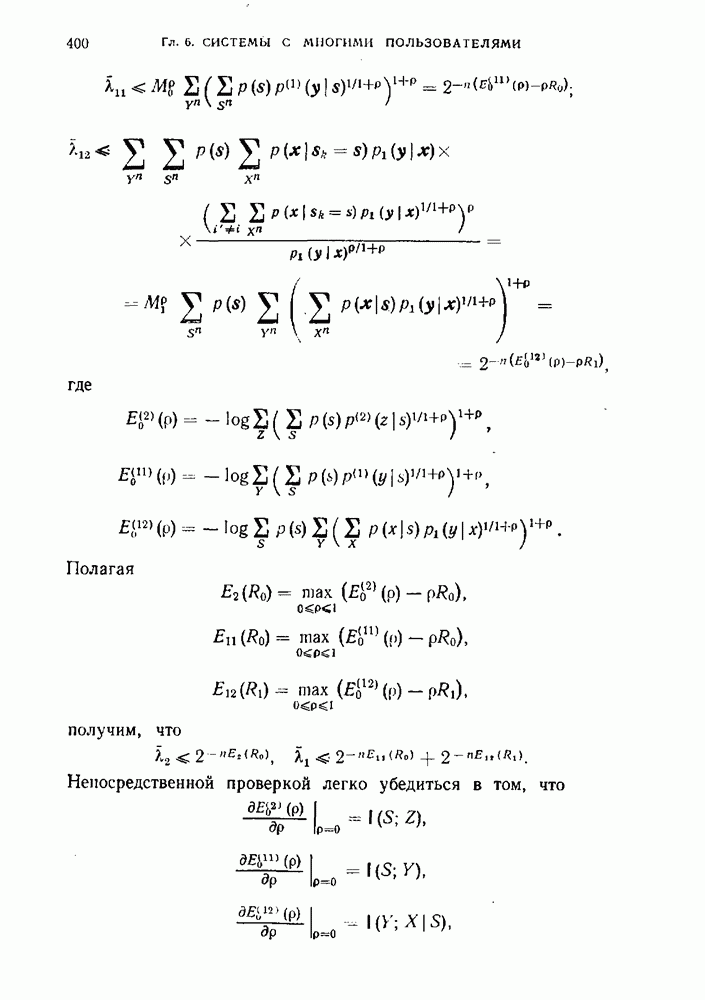








 и множество
и множество  определено соотношением (3.8.3). Полагая
определено соотношением (3.8.3). Полагая  и учитывая (см. доказательство теоремы
и учитывая (см. доказательство теоремы

 можно построить код
можно построить код  с числом кодовых слов
с числом кодовых слов


 где
где  множество слов кода
множество слов кода  и построим код
и построим код  для канала
для канала  с вероятностью ошибки к
с вероятностью ошибки к  выбирая кодовые слова в множестве
выбирая кодовые слова в множестве  Аналогично предыдущему можно показать, что количество слов этого кода при достаточно большом
Аналогично предыдущему можно показать, что количество слов этого кода при достаточно большом  может быть выбрано равным
может быть выбрано равным

 где
где  множество слов кода построим код
множество слов кода построим код  для канала
для канала  с вероятностью ошибки
с вероятностью ошибки  выбирая слова из множества
выбирая слова из множества  Количество слов кода
Количество слов кода  при достаточно большом
при достаточно большом  может быть выбрано равным
может быть выбрано равным

 Для этого заметим, что для любой последовательности
Для этого заметим, что для любой последовательности 



 ансамбль сообщений для этой пары источников и
ансамбль сообщений для этой пары источников и 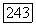 энтропии, определяемые распределением
энтропии, определяемые распределением  Любая пара чисел
Любая пара чисел 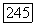 такая, что
такая, что 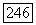 является парой допустимых скоростей.
является парой допустимых скоростей.
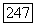 следует из леммы и описания конструкции кода, данного непосредственно перед ней. Допустимость остальных пар скоростей, удовлетворяющих условию теоремы, вытекает из возможности использования разделения времени. Теорема доказана.
следует из леммы и описания конструкции кода, данного непосредственно перед ней. Допустимость остальных пар скоростей, удовлетворяющих условию теоремы, вытекает из возможности использования разделения времени. Теорема доказана.