Пред.
След.
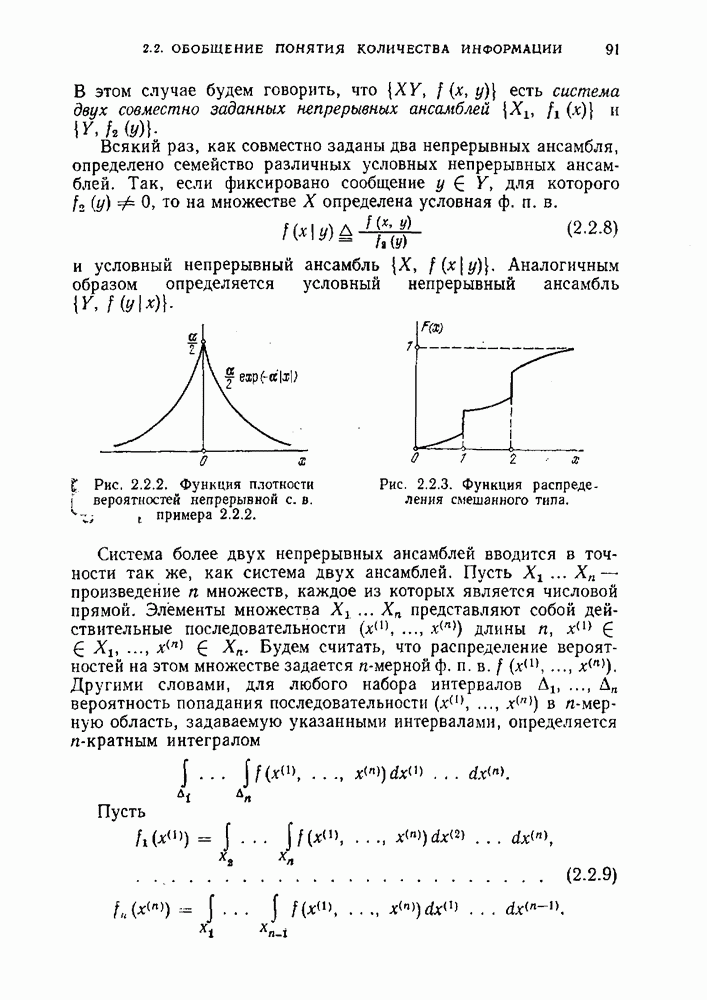
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
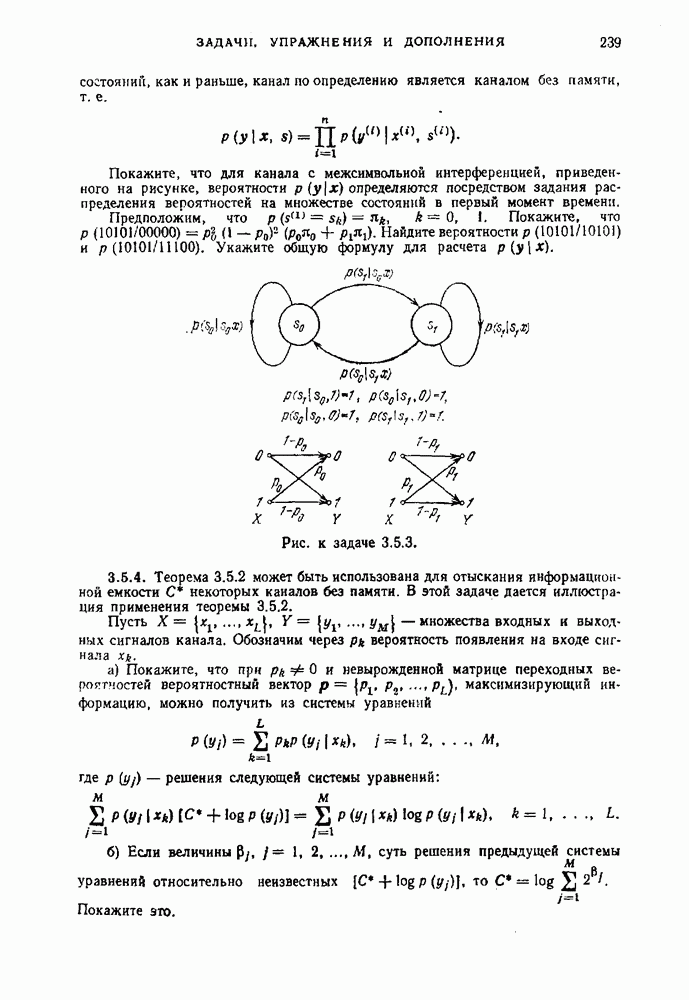
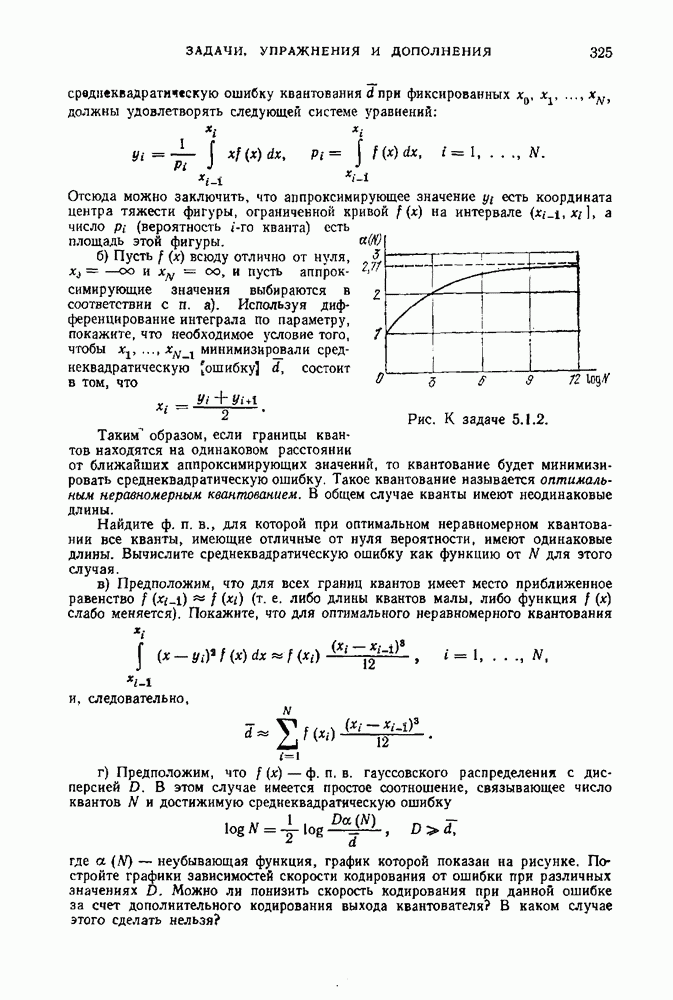
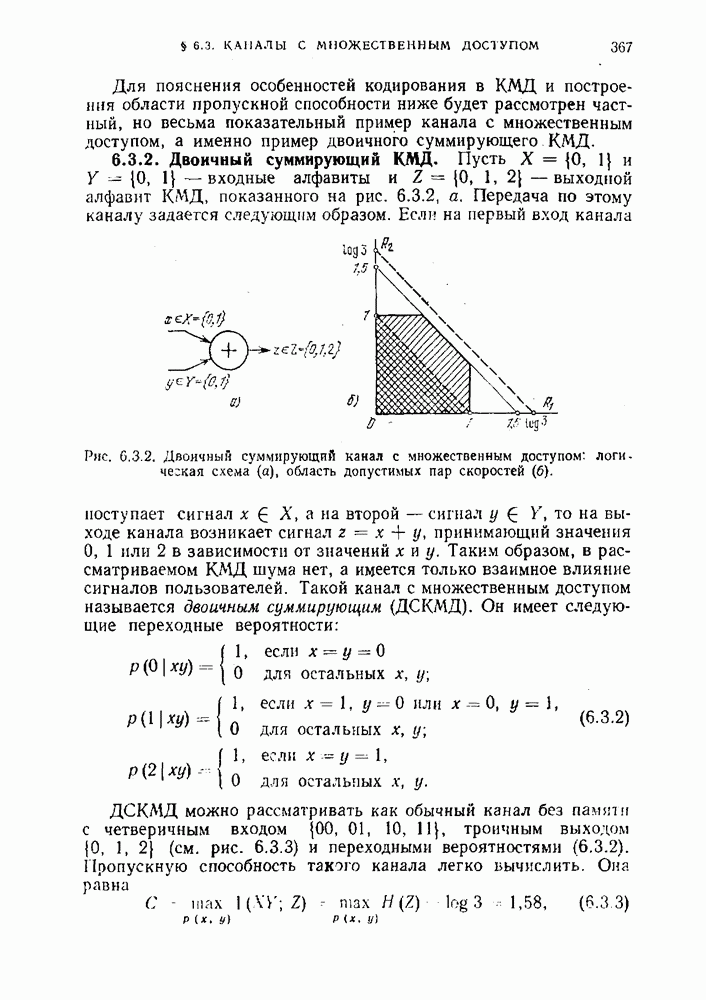
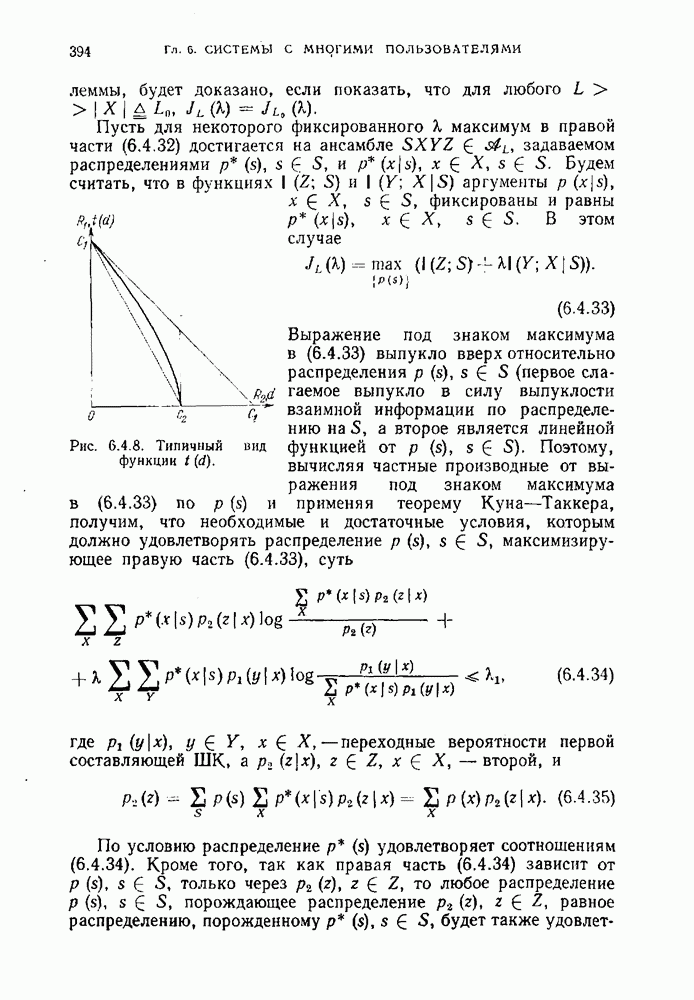
§ 1.14. Обсуждение основных результатовМы познакомились с двумя задачами кодирования дискретных источников — с задачей равномерного кодирования и задачей неравномерного кодирования. Отличие постановок этих задач состоит в том, что в первом случае требуется восстановление сообщений источника с заданной, обычно малой, вероятностью ошибки, а во втором случае требуется точное восстановление сообщений источника. Теперь мы обсудим работу равномерного и неравномерного кодеров. При этом мы коснемся двух вопросов. Первый — это вопрос о том, как можно охарактеризовать выходную последовательность достаточно хорошего кодера, а второй — вопрос об организации работы кодера в типичном для практики случае, когда источник порождает сообщения независимо от процесса кодирования (т. е. в случае неуправляемых источников). Как мы увидим, и равномерные и неравномерные коды приводят к однотипному поведению соответствующих кодеров. Из теорем 1.12.3 и 1.12.4 следует, что при неравномерном кодировании скорость создания информации дискретным стационарным источником равна энтропии на сообщение Наш интерес к величине средней скорости кодирования обусловлен прежде всего тем, что по этой величине в ряде случаев можно судить о работе кодера с каждой отдельной реализацией на выходе источника, а не только в среднем по множеству всех реализаций. В следующем примере показано, что эргодичность является необходимым условием для того, чтобы можно было судить о количестве символов на сообщение на выходе неравномерного кодера. Пример 1.14.1. Предположим, что неэргодический источник имеет две равновероятные эргодические компоненты (см. рис. 1.9.1), причем одна компонента — источник, который в каждый момент времени порождает одно и то же сообщение, скажем 0, а другая компонента — источник, порождающий независимо и с равными вероятностями два других сообщения, скажем 1 и 2. Если кодировать последовательности сообщений длины Из этого примера следует, что для неэр годи чес них источников количество символов на сообщение на выходе кодера не определяется средней скоростью кодирования. Покажем теперь, что одного условия эргодичности недостаточно. Действительно, пусть источник порождает последовательность из
где
Хотя (1.14.2) по форме напоминает определение эргодичности, но в действительности из эргодичности не выводится, так как для каждого Предположим теперь, что источник является эргодическим, а при неравномерном кодировании — и блочно эргодическим. Пусть
где D - число элементов в множестве А. Первое неравенство обращается в равенство в том и только том случае, когда символы на выходе кодера статистически независимы и равновероятны. Второе неравенство должно выполняться вследствие требования однозначности кодирования: среднее количество информации в кодовых словах не может быть меньше, чем среднее количество информации в сообщениях, которые отображаются с помощью этих слов. Последнее неравенство — следствие предположения о стационарности источника. Для достаточно хорошего кода (и соответственно кодера) среднее чисую символов на сообщение должно быть близким к
где
и, следовательно, все величины, фигурирующие в неравенствах (1.14.3), должны быть близкими друг к другу. Здесь для нас существенным является близость величин Таким образом, действие оптимального кодера источника можно описать следующим образом. На вход кодера поступают в общем случае зависимые и неравновероятные сообщения. На выходе кодера появляется последовательность почти независимых и почти равновероятных кодовых символов, по которым точно или сколь угодно точно можно восстановить сообщения, порождаемые источником. Этим мы закончим обсуждение первого вопроса и перейдем ко второму. Источники сообщений можно подразделить на управляемые и неуправляемые (в литературе иногда встречаются соответствующие термины — источники с переменной и источники с постоянной скоростью). Управляемые источники имеют специальный управляющий вход. Каждое очередное сообщение появляется на выходе источника только после того, как будет подан сигнал на управляющий вход. Типичным примером такого источника является запоминающее устройство, считывание из ячеек памяти которого происходит только при подаче соответствующих управляющих сигналов. Неуправляемые источники являются более типичными для различных систем сбора и передачи информации. Такие источники порождают сообщения с некоторой фиксированной скоростью, например, по одному сообщению каждую секунду, и никакие управляющие воздействия не могут замедлить или ускорить процесс появления сообщений. При кодировании с помощью равномерных кодов никаких дополнительных проблем не возникает. Если источник эргодический, то с высокой вероятностью для кодирования Проблема возникает при использовании неравномерных кодов для кодирования неуправляемых источников. Так как длины кодовых слов отличаются друг от друга, то и время кодирования для различных сообщений будет различным. Это приводит к появлению очередей на входе кодера. При появлении на выходе источника сообщений, кодируемых длинными словами, кодер не будет успевать кодировать, тогда как при появлении сообщений, кодируемых короткими словами, он будет простаивать. Хотя в среднем на одно сообщение будет по-прежнему тратиться примерно Частично эта трудность преодолевается, если между источником и кодером поставить буферное запоминающее устройство, которое теперь будет играть роль управляемого источника. Считыванием из буфера можно управлять по мере окончания кодирования каждого очередного сообщения. Однако теперь следует учитывать вероятность переполнения буфера и рассматривать эту вероятность как вероятность ошибки при кодировании. Таким образом, ошибки присущи не только кодированию с помощью равномерных кодов, но также и кодированию неуправляемых источников, с помощью неравномерных кодов. Задачи, упражнения и дополнения(см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) КРАТКИЙ ИСТОРИЧЕСКИЙ КОММЕНТАРИЙ И ЛИТЕРАТУРАОсновные результаты этой главы принадлежат К. Шеннону [8]. Он получил теоремы кодирования для равномерного и неравномерного кодирования постоянных и марковских источников. Метод построения оптимальных неравномерных кодов принадлежит Д. Хаффмену [7]. Определение эргодического процесса, данное в этой главе, является удобнгм, как представляется авторам, для первого введения в предмет. Более глубокое изложение, связывающее эргодическую теорию и теорию информации, можно найти у П. Биллингслея [I] и у М. С. Пинскера [3]. Изложение этой главы в достаточной степени стандартно и следует книгам Р. Фано [5] и Р. Галлагера |2], а также книге Ф. П. Тарасенко [4]. С теоретиковероятностными вопросами лучше всего познакомиться по книге В. Феллера [6]. (см. скан) (см. скан)
|
 |
Оглавление
|











































































































































































































































































































































































































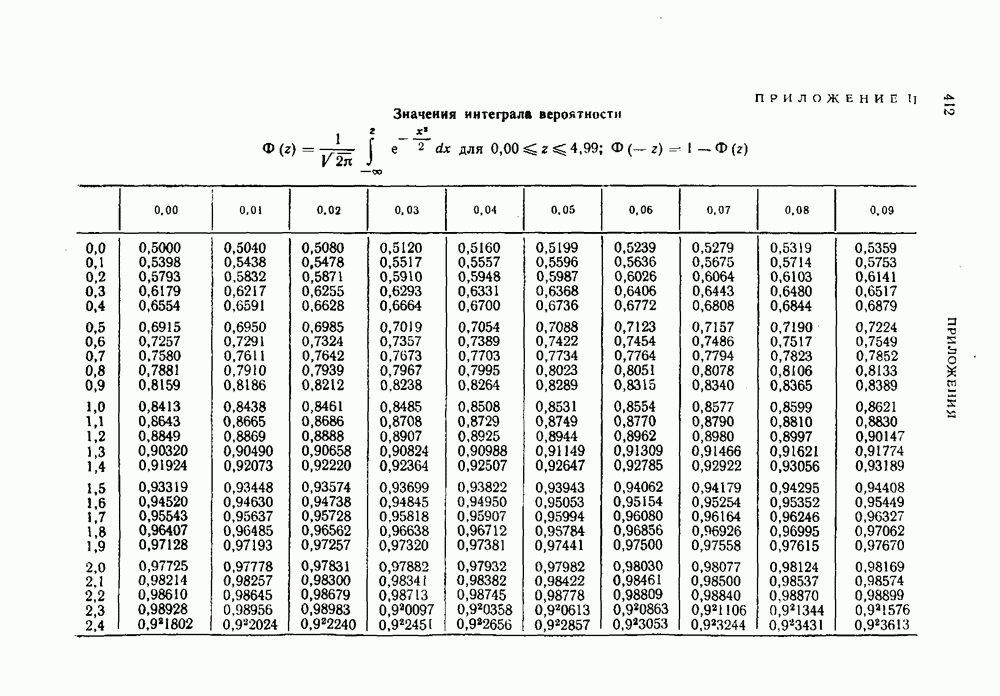
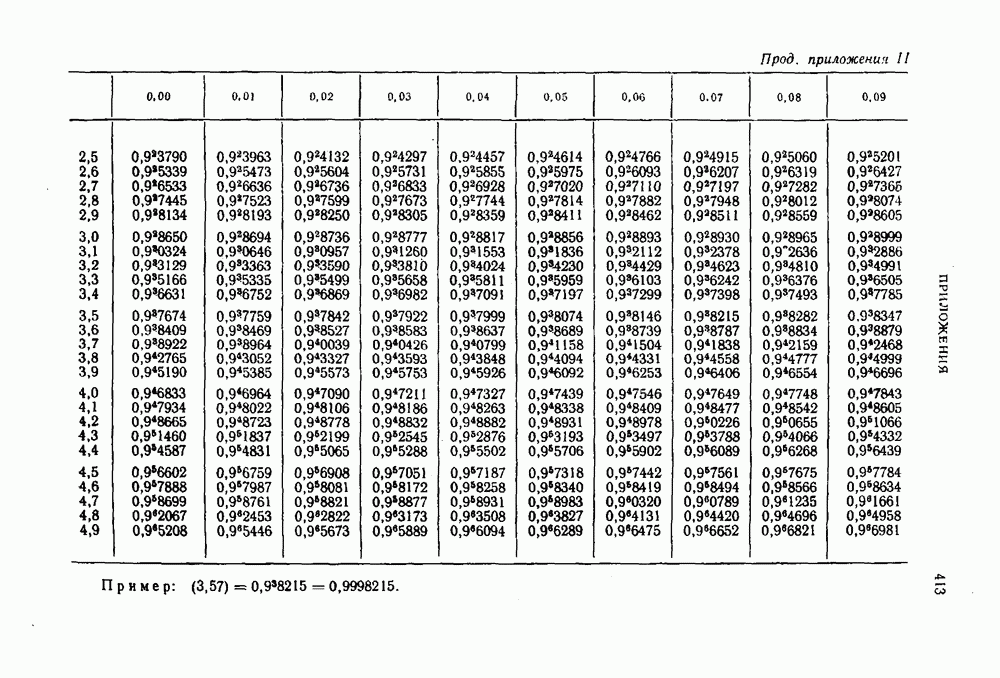
 т. е. той же величине, что и при равномерном кодировании. Это означает, что минимальное количество символов, затрачиваемое в среднем на кодирование одного сообщения
т. е. той же величине, что и при равномерном кодировании. Это означает, что минимальное количество символов, затрачиваемое в среднем на кодирование одного сообщения  -ичным кодом, равно
-ичным кодом, равно  как при равномерном, так и при неравномерном кодировании. Если источник эргодичен, то при равномерном кодировании это утверждение верно и для каждой отдельной достаточно длинной лизации последовательности сообщений на выходе источника. Во втором случае это не так. При неравномерном кодировании мы можем говорить только о среднем по множеству источников (по множеству реализаций) количестве символов на сообщение.
как при равномерном, так и при неравномерном кодировании. Если источник эргодичен, то при равномерном кодировании это утверждение верно и для каждой отдельной достаточно длинной лизации последовательности сообщений на выходе источника. Во втором случае это не так. При неравномерном кодировании мы можем говорить только о среднем по множеству источников (по множеству реализаций) количестве символов на сообщение.
 с помощью двоичного кода, то, как было показано в § 1.13, средняя длина
с помощью двоичного кода, то, как было показано в § 1.13, средняя длина  минимизируется выбором одного слова длины 1 для первой компоненты и
минимизируется выбором одного слова длины 1 для первой компоненты и  слов длины
слов длины  — для второй. Так как выбранная случайно один раз компонента никогда более не меняется, то либо все кодовые слова будут иметь длину 1, либо
— для второй. Так как выбранная случайно один раз компонента никогда более не меняется, то либо все кодовые слова будут иметь длину 1, либо  Для такого источника
Для такого источника  (см. задачу 1.14.1). Следовательно, средняя длина наилучшего кода равна
(см. задачу 1.14.1). Следовательно, средняя длина наилучшего кода равна  но не равна количеству символов на сообщение на выходе кодера.
но не равна количеству символов на сообщение на выходе кодера.
 сообщений. Для этой последовательности количество кодовых символов на сообщение
сообщений. Для этой последовательности количество кодовых символов на сообщение  может быть определено по формуле
может быть определено по формуле

 количество блоков длины
количество блоков длины  длина слова, кодирующего
длина слова, кодирующего  блок,
блок,  количество символов на сообщение на
количество символов на сообщение на  блоке. Величины
блоке. Величины  случайны, но для стационарного источника одинаковы для всех
случайны, но для стационарного источника одинаковы для всех  и при больших
и при больших  могут быть сделаны близкими к
могут быть сделаны близкими к  Будет ли величина
Будет ли величина  близкой к
близкой к  зависит от свойств источника. Это так, если при любых положительных
зависит от свойств источника. Это так, если при любых положительных  и при достаточно больших
и при достаточно больших 

 величина
величина  есть функция
есть функция  блока длины
блока длины  Можно показать, что (1.14.2) выводится из предположения об эргодичности блоков длины
Можно показать, что (1.14.2) выводится из предположения об эргодичности блоков длины  (из так называемого свойства блочной эргодичности). То, что из эргодичности в общем случае не следует блочная эргодичность, иллюстрируется в задаче 1.14.2.
(из так называемого свойства блочной эргодичности). То, что из эргодичности в общем случае не следует блочная эргодичность, иллюстрируется в задаче 1.14.2.
 есть количество кодовых символов на выходе кодера, появляющееся при подаче на его вход блока из
есть количество кодовых символов на выходе кодера, появляющееся при подаче на его вход блока из  сообщений источника. Пусть
сообщений источника. Пусть  -ичный кодовый алфавит, тогда можно записать следующую цепочку неравенств:
-ичный кодовый алфавит, тогда можно записать следующую цепочку неравенств:

 т. е.
т. е.

 — достаточно малое положительное число. Отсюда следует, что
— достаточно малое положительное число. Отсюда следует, что

 из которой следует, что символы на выходе кодера (равномерного или неравномерного) являются почти независимыми и почти равновероятными. Близость к независимости и равновероятности тем сильнее, чем ближе скорость кодирования к
из которой следует, что символы на выходе кодера (равномерного или неравномерного) являются почти независимыми и почти равновероятными. Близость к независимости и равновероятности тем сильнее, чем ближе скорость кодирования к 
 сообщений будет использовано примерно
сообщений будет использовано примерно  кодовых символов. Если
кодовых символов. Если  длина кодируемых сообщений, то на каждые
длина кодируемых сообщений, то на каждые  сообщений источника появляется одно кодовое слово длины
сообщений источника появляется одно кодовое слово длины  где
где  скорость кодирования. Число
скорость кодирования. Число  определяет, с одной стороны, близость
определяет, с одной стороны, близость  а с другой достижимую вероятность ошибки. Выбирая
а с другой достижимую вероятность ошибки. Выбирая  достаточно большим, можно для сколь угодно малых положительных
достаточно большим, можно для сколь угодно малых положительных  сделать
сделать  и сделать вероятность ошибки меньшей или равной
и сделать вероятность ошибки меньшей или равной  .
.
 кодовых символов, но для каждой отдельной реализации могут возникнуть сильные колебания числа сообщений, ожидающих кодирования.
кодовых символов, но для каждой отдельной реализации могут возникнуть сильные колебания числа сообщений, ожидающих кодирования.