Пред.
След.
Макеты страниц
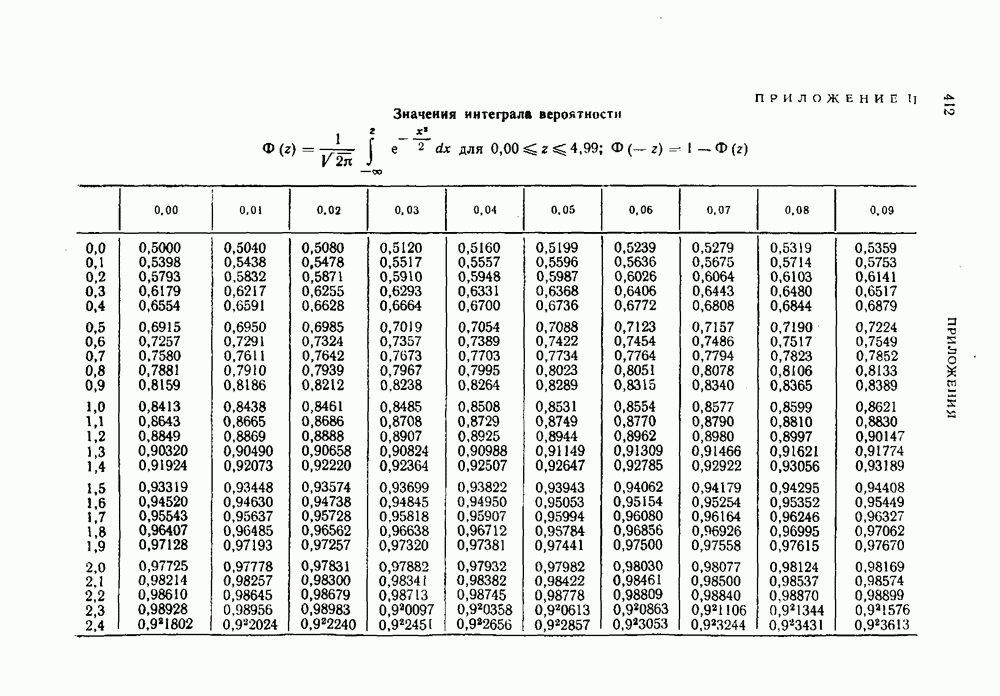
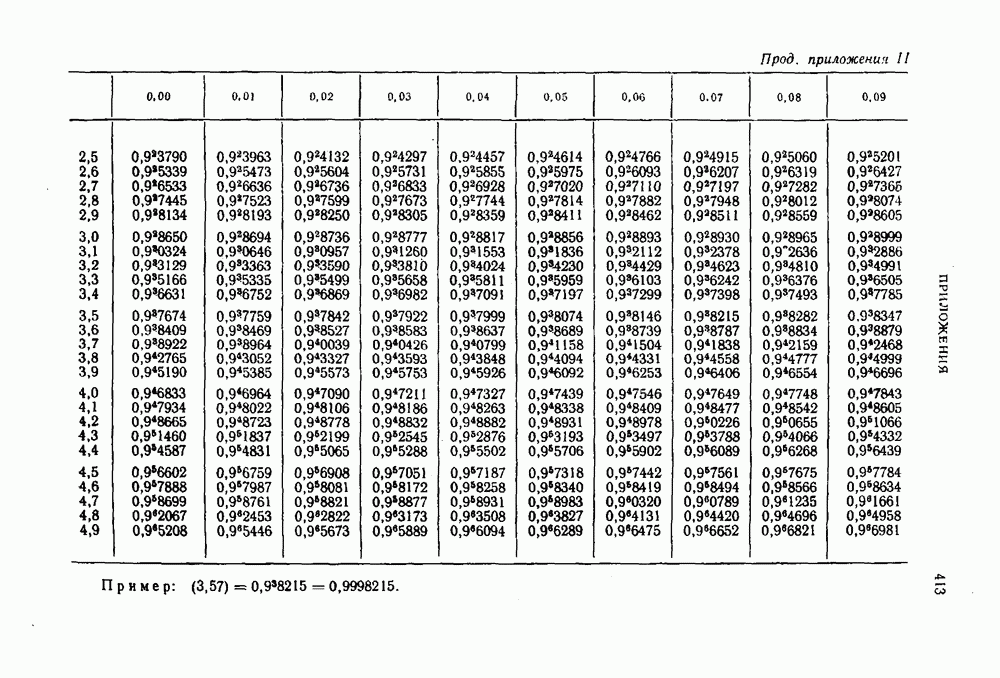
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
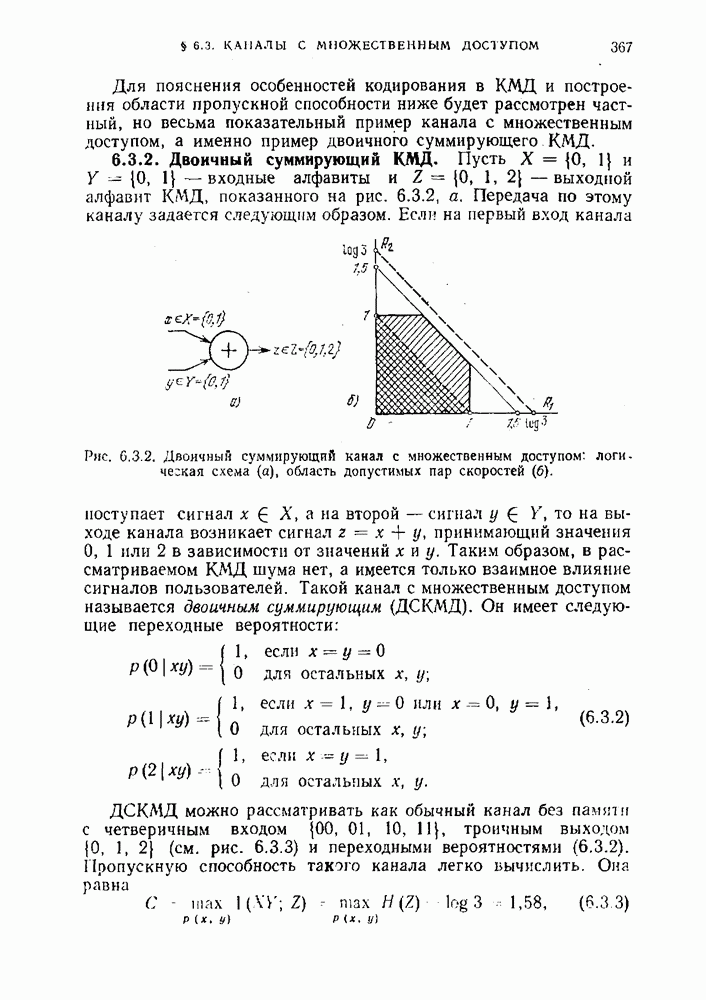
§ 3.8. Неравенство ФайнстейнаВ этом параграфе будет рассмотрено одно из важнейших теоретико-информационных неравенств, с помощью которого могут быть доказаны прямые теоремы кодирования для различных каналов связи, а именно неравенство Файнстейна. Рассмотрим дискретный канал, задаваемый переходными вероятностями
где
Теорема 3.8.1 (неравенство Файнстейна). Пусть вероятность
где
и
Доказательство. Для доказательства существования кода, указанного в теореме, мы будем пользоваться методом, который называется методом максимальных кодов. В соответствии с этим методом, содержание которого будет изложено ниже, мы покажем, что для всякого фиксированного
Рис. 3.8.1. К доказательству теоремы 3.8.1. Очевидно, что это неравенство эквивалентно неравенству (3.8.3) и, следовательно, доказательство существования кода, скорость которого удовлетворяет неравенству (3.8.5), эквивалентно доказательству утверждения теоремы. Далее мы будем предполагать, что Зафиксируем некоторое
Тогда множество
Пусть
где Предположим, что можно выбрать
где а — произвольное заданное число из интервала Покажем, что
Тогда должно выполняться следующее неравенство:
С другой стороны, из формулы (3.8.7) следует, что
Так как
то
что противоречит исходному предположению о том, что Как было сказано,
В противном случае выбор кодовых слов можно было бы продолжить, положив Так как для произвольных событий
Это неравенство имеет место для всех последовательностей
Из соотношений (3.8.11) и (3.8.12) следует, что
Используя это и предыдущее неравенство, можно получить, что
Теперь, чтобы завершить доказательство теоремы, необходимо связать левую часть этого неравенства с числом
Оценим вероятность
и, следовательно,
Суммируя обе части последнего неравенстга по всем
где последнее неравенство — следствие того, что
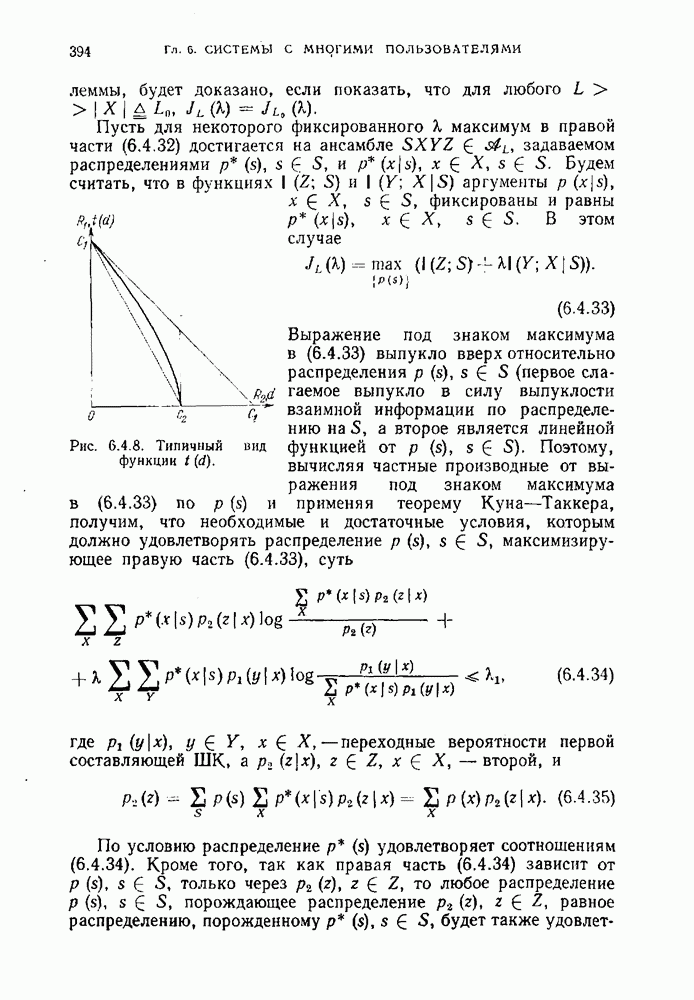
Учитывая неравенства (3.8.15), (3,8.16), (3.8.19), а также что Вернемся теперь к формулировке теоремы и обсудим возможности ее применения. В теореме утверждается существование кода, слова которого принадлежат множеству Предположим, что
где С — информационная емкость дискретного по времени канала, определяемая соотношением
и верхняя грань разыскивается по всем
Предположим, что при каждом взаимной информации
и
Для моделей каналов связи, представляющих интерес, верхняя грань в (3.8.21) достигается при Ниже мы применим неравенство Файнстейна и указанное выше рассуждение для доказательства прямых теорем кодирования для некоторых каналов. Мы покажем, что в рассматриваемых каналах существуют коды с произвольно малой вероятностью ошибки при условии, что скорость кода не превосходит информационную емкость канала. Фактически вместе с обратной теоремой кодирования это является доказательством того, что информационная емкость и пропускная способность, определенная ранее в § 3,2, совпадают.
|
 |
Оглавление
|

















































































































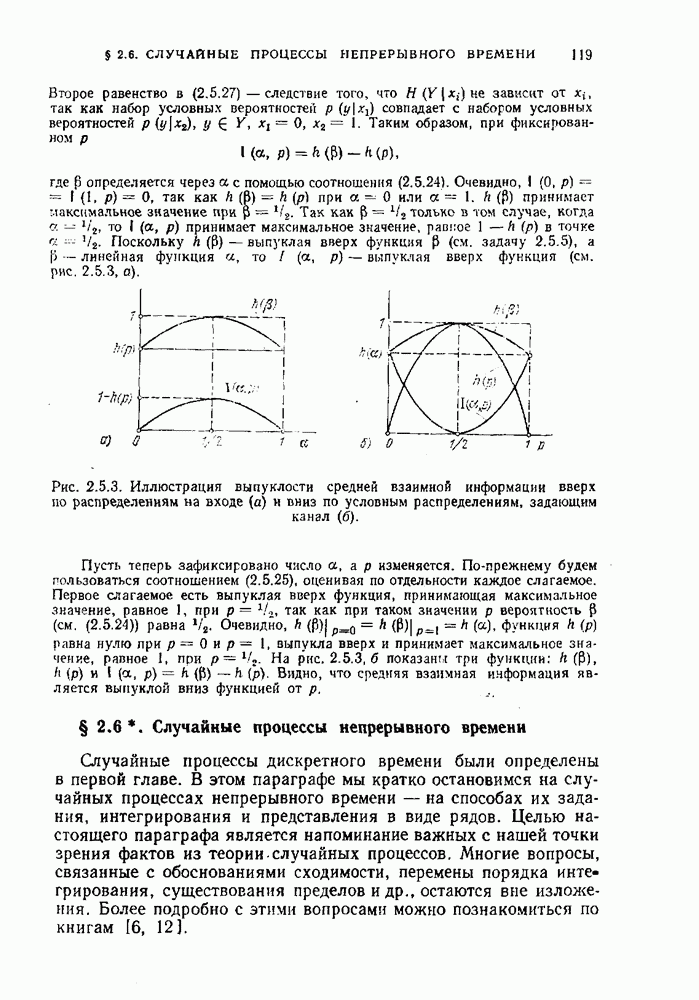























































































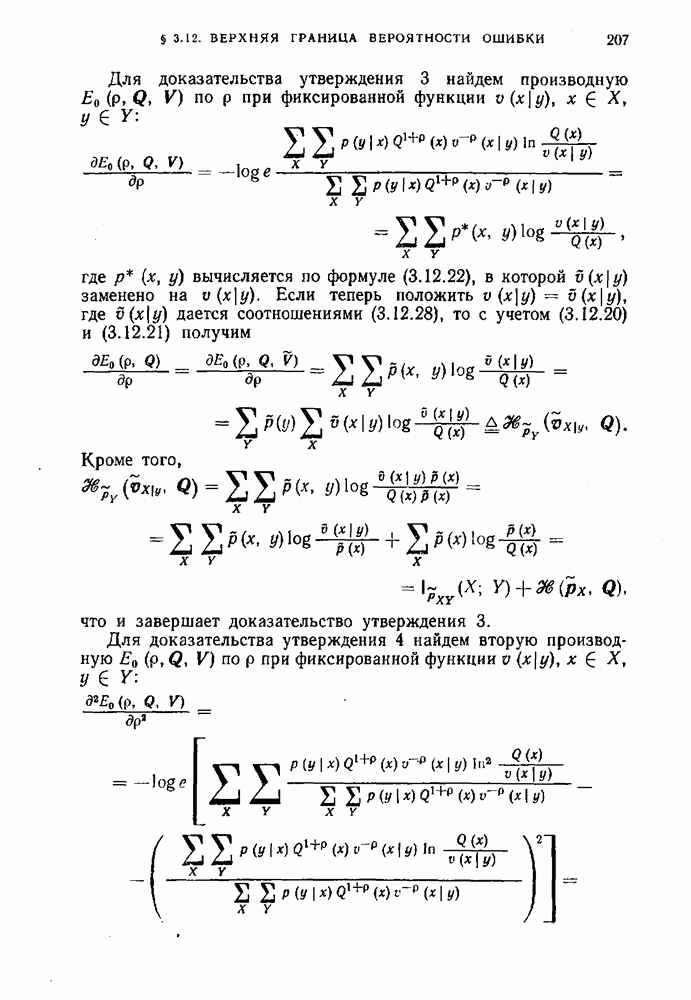
































































































































































































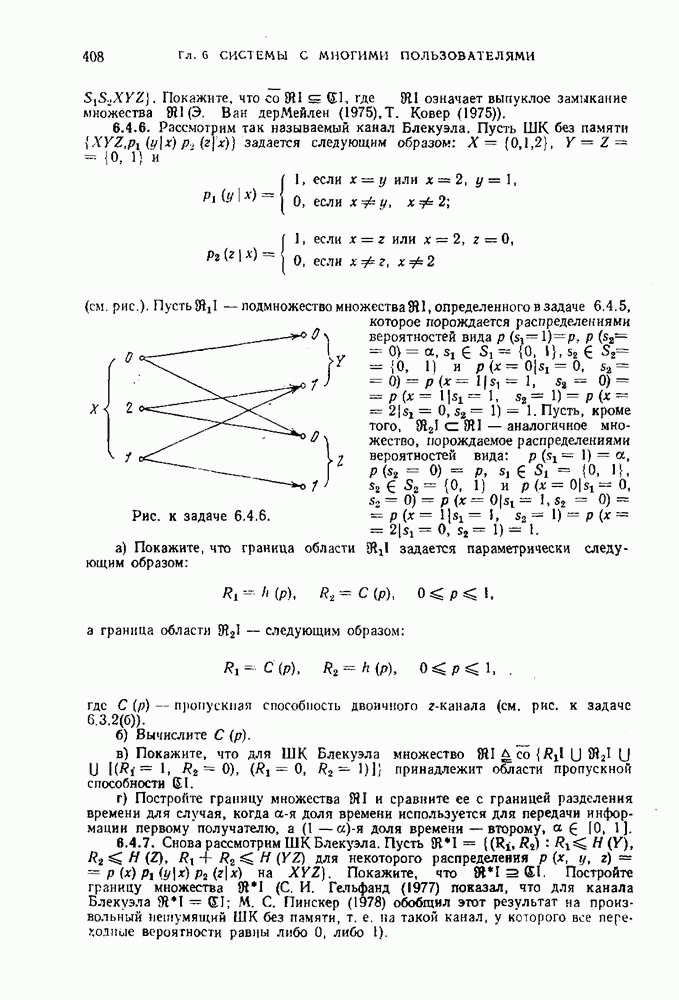



 Пусть
Пусть  некоторое распределение вероятностей на входных последовательностях канала и
некоторое распределение вероятностей на входных последовательностях канала и  информация между двумя последовательностями
информация между двумя последовательностями  вычисленная по распределению
вычисленная по распределению 

 Будем обозначать через
Будем обозначать через  некоторое подмножество множества
некоторое подмножество множества  а через V — множество таких пар
а через V — множество таких пар  что взаимная информация
что взаимная информация  каждой пары больше, чем
каждой пары больше, чем  где
где  некоторое положительное число:
некоторое положительное число:

 произвольное положительное число,
произвольное положительное число,  произвольное подмножество множества
произвольное подмножество множества  произвольное распределение вероятностей на
произвольное распределение вероятностей на  Тогда для каждого
Тогда для каждого  существует код
существует код  каждое слово которого принадлежит
каждое слово которого принадлежит  а максимальная
а максимальная
 ошибки декодирования удовлетворяет неравенству
ошибки декодирования удовлетворяет неравенству



 можно построить код
можно построить код  каждое слово которого принадлежит
каждое слово которого принадлежит  а скорость
а скорость  удовлетворяет неравенству
удовлетворяет неравенству


 . В противном случае утверждение теоремы тривиально, так как неравенство (3.8.5) выполняется при
. В противном случае утверждение теоремы тривиально, так как неравенство (3.8.5) выполняется при  а код из одного кодового слова имеет вероятность ошибки декодирования, равную нулю.
а код из одного кодового слова имеет вероятность ошибки декодирования, равную нулю.
 и построим код длины
и построим код длины  выбирая кодовые слова из множества
выбирая кодовые слова из множества  Для того чтобы определить решающие области, введем в рассмотрение для каждого
Для того чтобы определить решающие области, введем в рассмотрение для каждого  множество
множество  (см. рис. 3.8.1):
(см. рис. 3.8.1):

 можно определить следующим образом:
можно определить следующим образом:

 — кодовые слова. Будем считать, что решающие области
— кодовые слова. Будем считать, что решающие области  определяются следующим способом:
определяются следующим способом:

 знак вычитания множеств
знак вычитания множеств  есть множество всех элементов, принадлежащих С, но не принадлежащих
есть множество всех элементов, принадлежащих С, но не принадлежащих 
 кодовых слов, каждое из которых принадлежит множеству
кодовых слов, каждое из которых принадлежит множеству  и
и  решающих областей, удовлетворяющих условиям (3.8.8), причем условные вероятности ошибок декодирования Я удовлетворяют неравенствам
решающих областей, удовлетворяющих условиям (3.8.8), причем условные вероятности ошибок декодирования Я удовлетворяют неравенствам

 Предположим также, что
Предположим также, что  это максимальное число, для которого можно осуществить
это максимальное число, для которого можно осуществить  указанный выбор.
указанный выбор.
 т. е. что существует по крайней мере одно кодовое слово из
т. е. что существует по крайней мере одно кодовое слово из  удовлетворяющее указанным выше условиям. Для этого предположим противное, а именно что для всех
удовлетворяющее указанным выше условиям. Для этого предположим противное, а именно что для всех  выполняется неравенство
выполняется неравенство





 Таким образом,
Таким образом,  и хотя бы один шаг при построении кода выполнить можно.
и хотя бы один шаг при построении кода выполнить можно.
 есть объем максимального кода. Другими словами, к выбранному коду нельзя добавить ни одного слова так, чтобы оно принадлежало множеству
есть объем максимального кода. Другими словами, к выбранному коду нельзя добавить ни одного слова так, чтобы оно принадлежало множеству  и не были нарушены условия (3.8.9). Следовательно, для любого
и не были нарушены условия (3.8.9). Следовательно, для любого  должно выполняться неравенство
должно выполняться неравенство

 при этом
при этом  и построенный код не был бы максимальным.
и построенный код не был бы максимальным.
 выполняется неравенство
выполняется неравенство  то, используя это неравенство для оценки левой части соотношения (3.8.13), получим
то, используя это неравенство для оценки левой части соотношения (3.8.13), получим

 поэтому левую и правую его части можно осредннть по 5. Для этого умножим обе части (3.8.14) на
поэтому левую и правую его части можно осредннть по 5. Для этого умножим обе части (3.8.14) на  и просуммируем по
и просуммируем по  . В результате получим
. В результате получим



 объемом кода. Для этого заметим, что
объемом кода. Для этого заметим, что

 того, что выходная последовательность канала попадет в решающую область
того, что выходная последовательность канала попадет в решающую область  Для любой пары
Для любой пары  для которой
для которой  имеет место неравенство
имеет место неравенство


 получим следующую цепочку неравенств:
получим следующую цепочку неравенств:

 -подмножество множества Таким образом,
-подмножество множества Таким образом,

 получим неравенство (3.8.3). Теорема доказана.
получим неравенство (3.8.3). Теорема доказана.
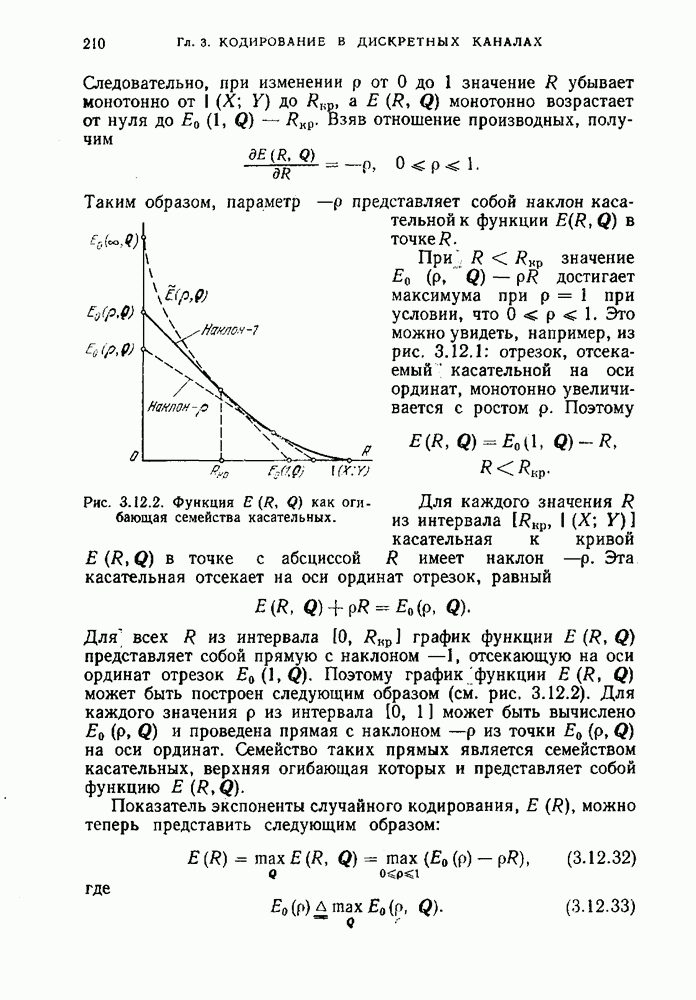
 и максимальная вероятность ошибки декодирования удовлетворяет неравенству (3.8.3). Значение правой части этого неравенства можно варьировать, изменяя величины слагаемых и соотношение между ними за счет выбора параметра
и максимальная вероятность ошибки декодирования удовлетворяет неравенству (3.8.3). Значение правой части этого неравенства можно варьировать, изменяя величины слагаемых и соотношение между ними за счет выбора параметра  и распределения вероятностей на входе. Для доказательства прямой теоремы кодирования необходимо установить, можно ли подобрать
и распределения вероятностей на входе. Для доказательства прямой теоремы кодирования необходимо установить, можно ли подобрать  и входное распределение так, чтобы оба слагаемых убывали к нулю при возрастании
и входное распределение так, чтобы оба слагаемых убывали к нулю при возрастании  Покажем, что эта задача сводится к исследованию поведения случайной величины
Покажем, что эта задача сводится к исследованию поведения случайной величины  информации на одно сообщение между входными и выходными последовательностями канала.
информации на одно сообщение между входными и выходными последовательностями канала.
 тогда
тогда  при любом распределении на входе. Положим
при любом распределении на входе. Положим  и
и


 и по всем распределениям вероятностей
и по всем распределениям вероятностей  на входных последовательностях. Тогда, как это следует из (3.8.3), первое слагаемое равно
на входных последовательностях. Тогда, как это следует из (3.8.3), первое слагаемое равно  и стремится к нулю при возрастании
и стремится к нулю при возрастании  Второе слагаемое определяется поведением вероятности
Второе слагаемое определяется поведением вероятности  которую можно представить следующим образом:
которую можно представить следующим образом:

 выбирается такое входное распределение
выбирается такое входное распределение  при котором достигается максимум средней
при котором достигается максимум средней
 Тогда найдется
Тогда найдется  такое, что
такое, что


 поэтому неравенство (3.8.23) выполняется для всех достаточно больших
поэтому неравенство (3.8.23) выполняется для всех достаточно больших  и вопрос о поведении вероятности ошибки сводится к исследованию правой части неравенства (3.8.24). Если вероятность того, что информация на сообщение
и вопрос о поведении вероятности ошибки сводится к исследованию правой части неравенства (3.8.24). Если вероятность того, что информация на сообщение  отличается от среднего количества информации на сообщение
отличается от среднего количества информации на сообщение  на величину, большую чем
на величину, большую чем  убывает с ростом
убывает с ростом  тогда убывает с ростом
тогда убывает с ростом  также и максимальная вероятность ошибки.
также и максимальная вероятность ошибки.