применить закон больших чисел, из которого следует, что при любых  найдется
найдется  такое, что при всех
такое, что при всех 

или

Нетрудно увидеть, что вероятность  равна левой части неравенства (1.7.7) и, следовательно, неравенство (1.7.3) справедливо.
равна левой части неравенства (1.7.7) и, следовательно, неравенство (1.7.3) справедливо.
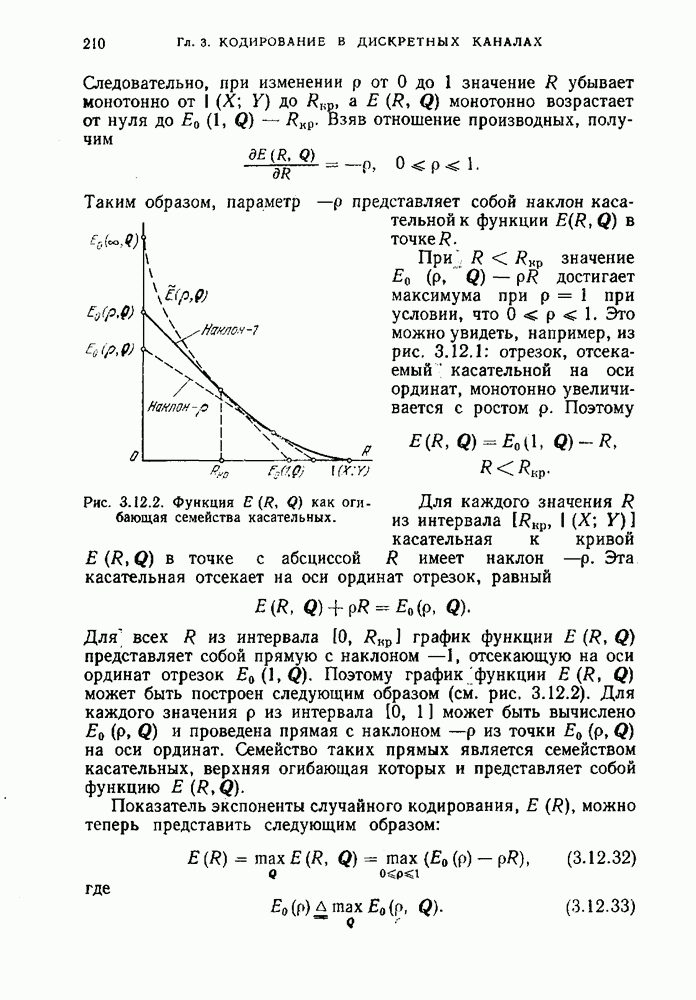
С другой стороны, из определения множества  следует, что для всякой последовательности
следует, что для всякой последовательности 

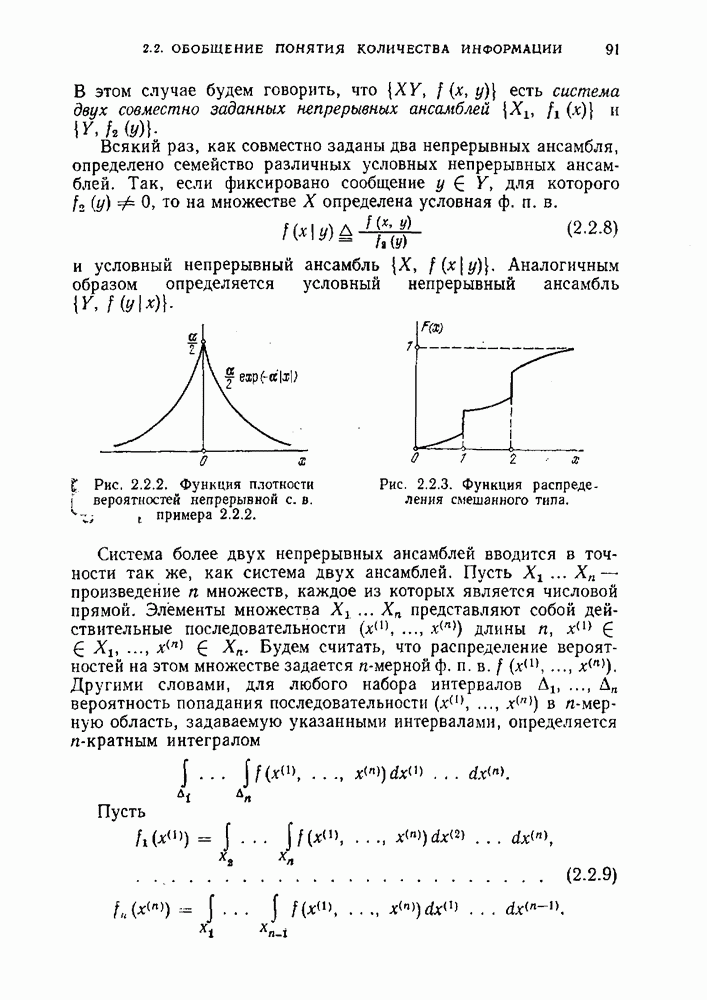
Суммируя обе части левого неравенства по всем элементам  получим следующую цепочку неравенств:
получим следующую цепочку неравенств:

откуда следует правое неравенство в (1.7.4). Суммируя теперь обе части правого неравенства в (1.7.8) по всем элементам  получим, что для достаточно больших
получим, что для достаточно больших 

что дает левое неравенство в (1.7.4). Теорема доказана.
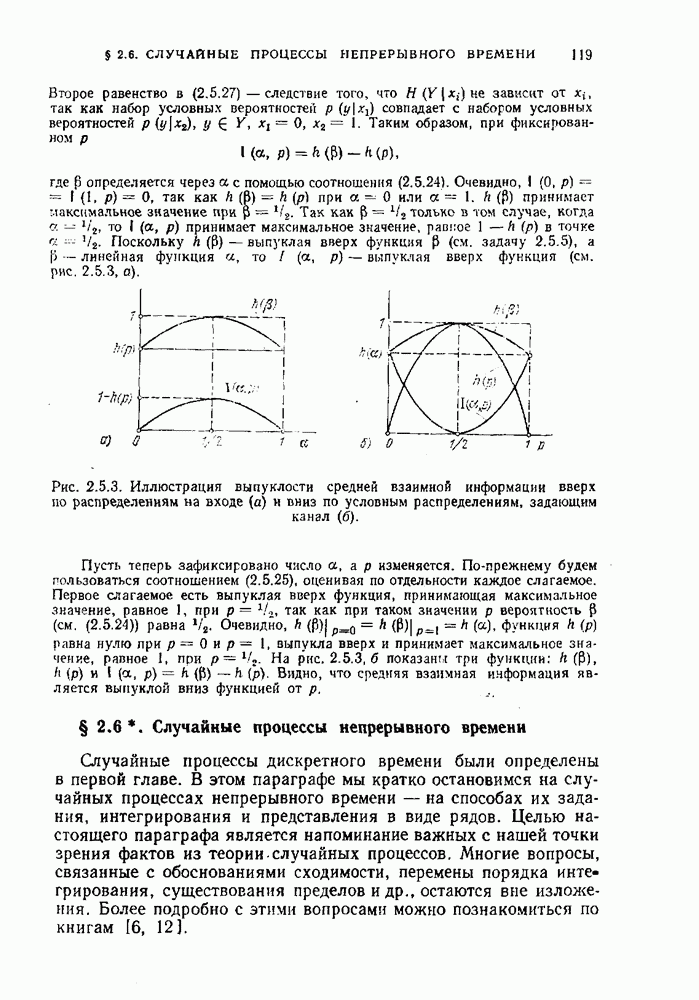
Теорема показывает, что последовательности сообщений на выходе дискретного источника без памяти могут быть подразделены на две группы:  где второе множество — это дополнение первого до
где второе множество — это дополнение первого до  Последовательности из первой группы обладают тем свойством, что их вероятности достаточно близки друг к другу (см. (1.7.8)) и суммарная вероятность всех элементов этого множества весьма близка к единице (см.
Последовательности из первой группы обладают тем свойством, что их вероятности достаточно близки друг к другу (см. (1.7.8)) и суммарная вероятность всех элементов этого множества весьма близка к единице (см.  Тем не менее, множество
Тем не менее, множество  может составлять лишь очень малую долю по числу элементов от множества
может составлять лишь очень малую долю по числу элементов от множества  Действительно, если обозначить число элементов в X через
Действительно, если обозначить число элементов в X через  то
то  ?. Доля а множества
?. Доля а множества 

Если  т. е. если энтропия источника строго меньше, чем
т. е. если энтропия источника строго меньше, чем  достаточно мало, то а убывает к нулю при увеличении
достаточно мало, то а убывает к нулю при увеличении  как
как 








































































































































































































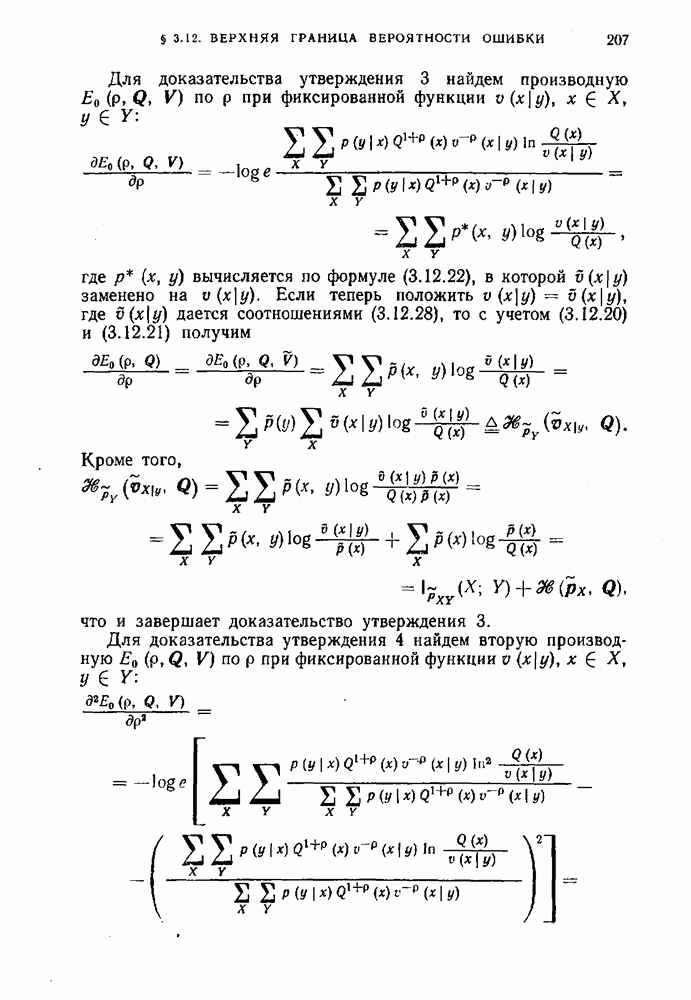






























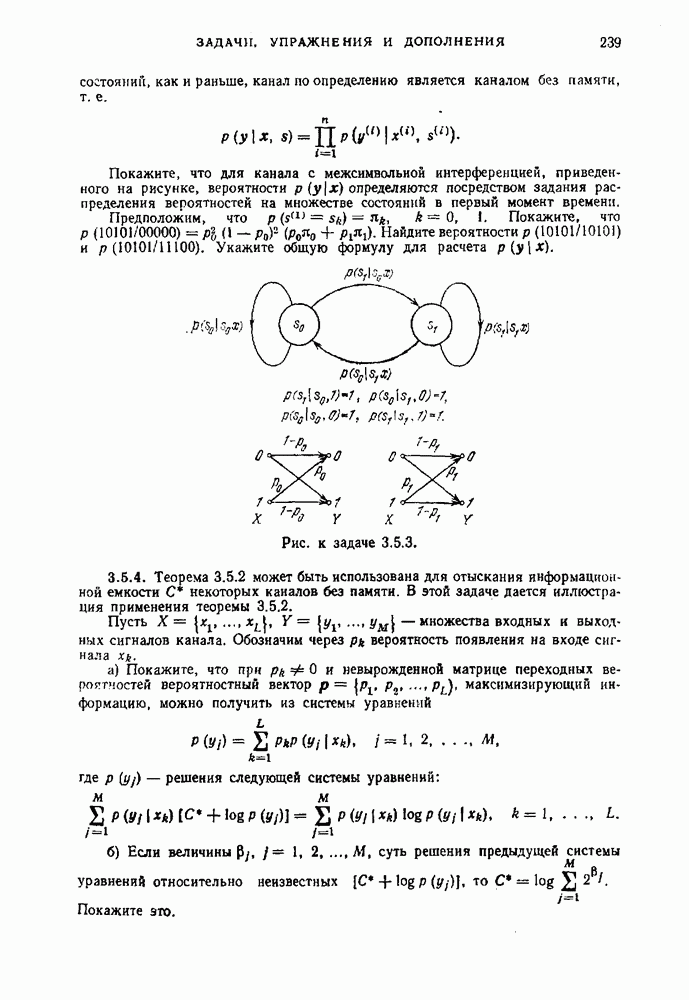





















































































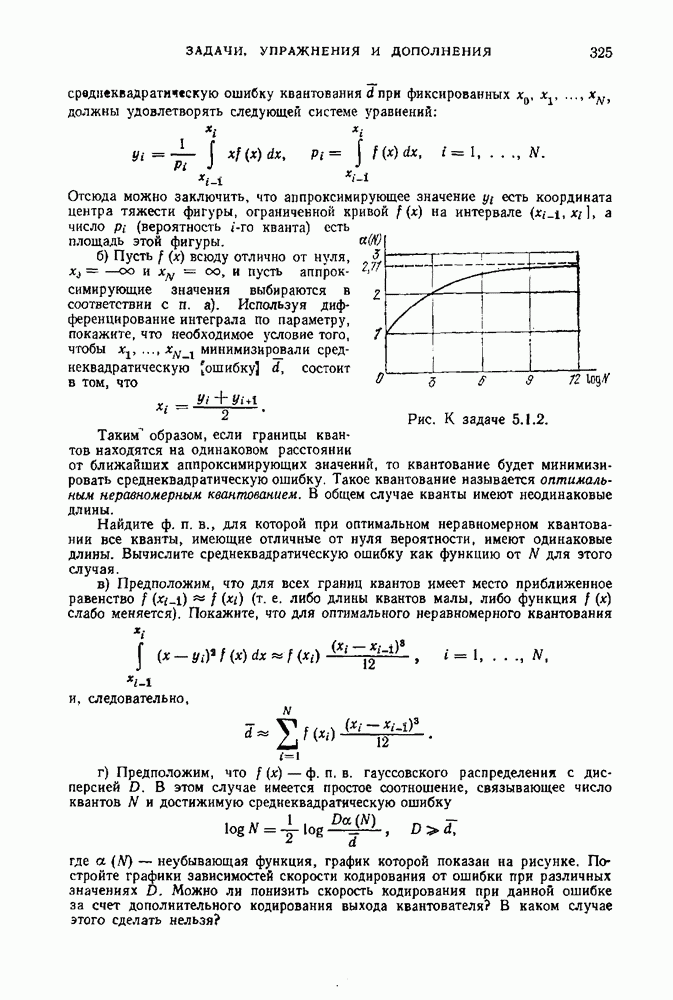









































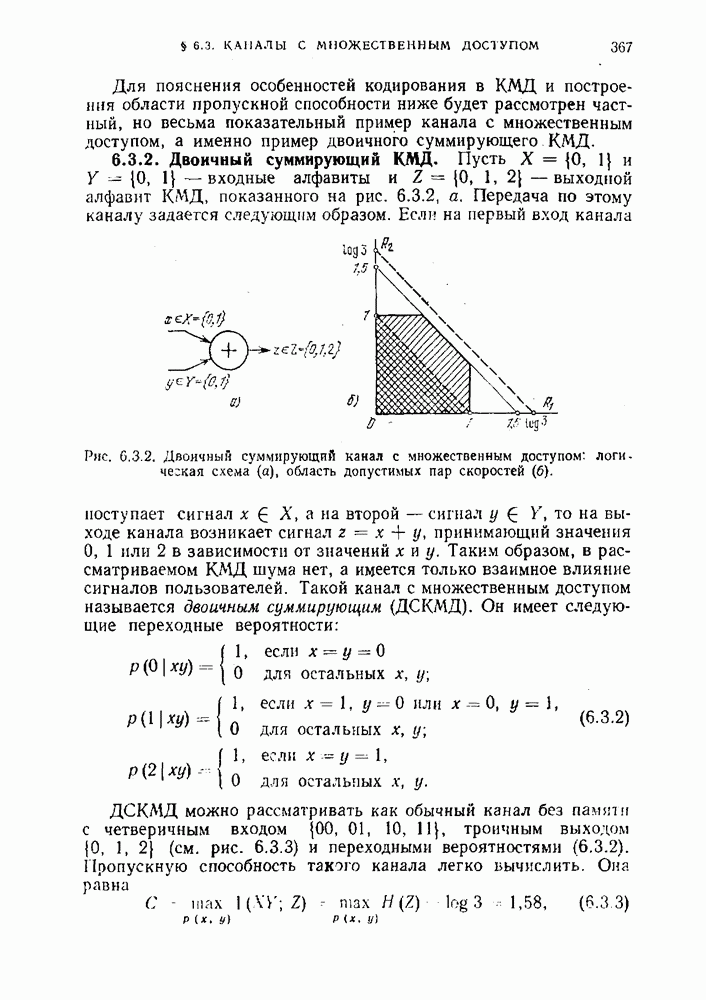


























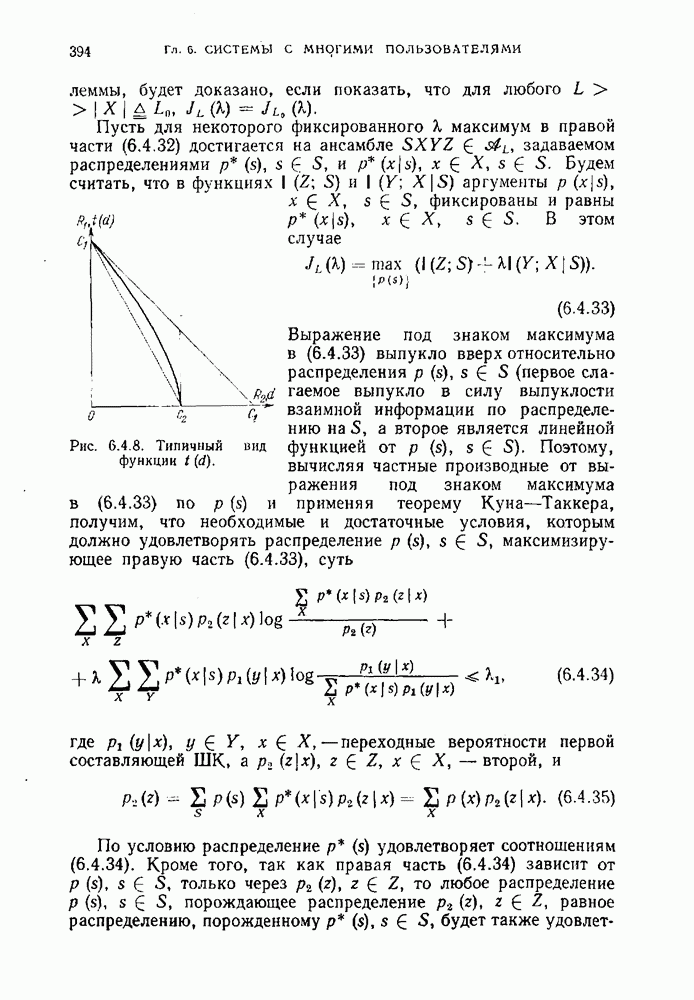













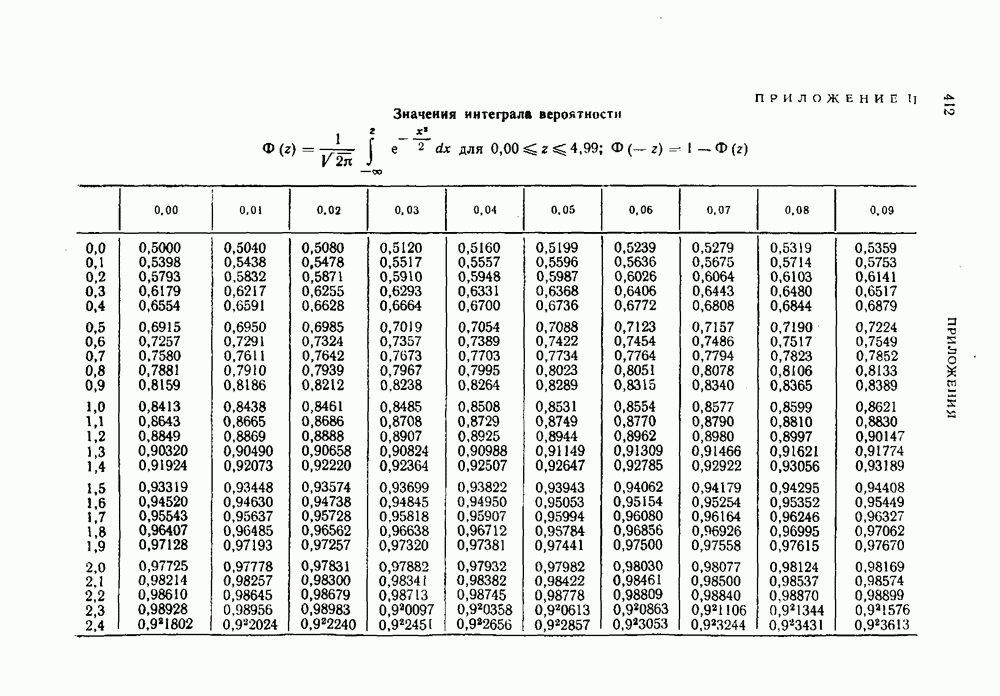
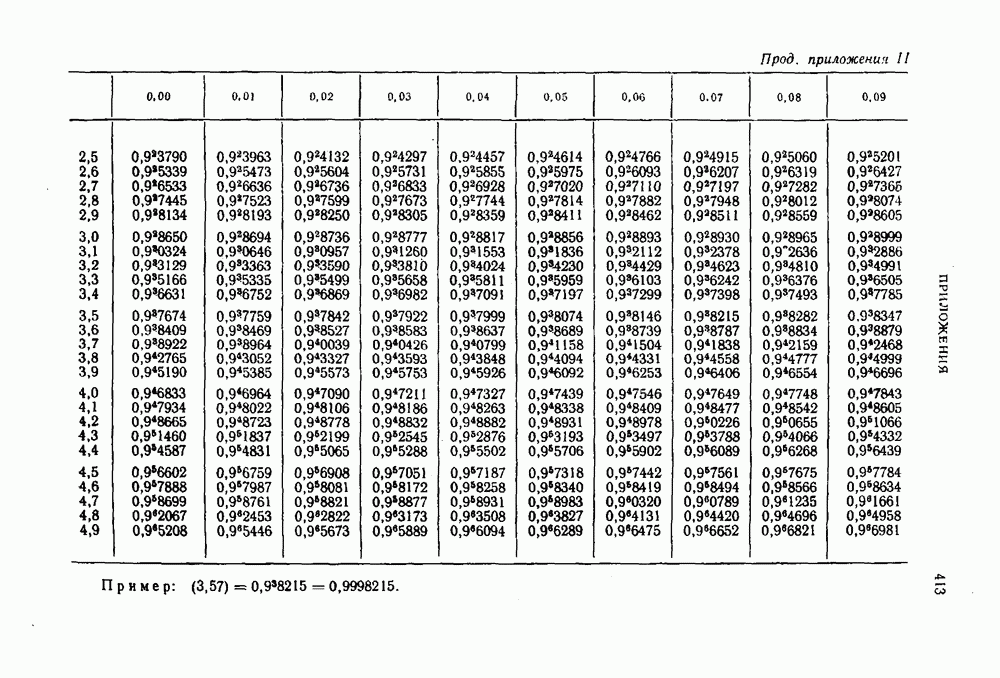
 Согласно определению источника без памяти вероятность каждой последовательности сообщений
Согласно определению источника без памяти вероятность каждой последовательности сообщений  на его выходе может быть записана в виде
на его выходе может быть записана в виде

 распределение вероятностей на множестве
распределение вероятностей на множестве  Будем полагать, что
Будем полагать, что  для всех
для всех  . В противном случае всегда можно перейти к рассмотрению суженного множества, для которого это предположение верно.
. В противном случае всегда можно перейти к рассмотрению суженного множества, для которого это предположение верно.
 энтропия ансамбля
энтропия ансамбля  некоторое положительное число. Определим подмножество
некоторое положительное число. Определим подмножество  множества
множества  следующим образом:
следующим образом:

 собственная информация последовательности
собственная информация последовательности 
 и 6 найдется
и 6 найдется  такое, что для всех
такое, что для всех  выполняются следующие неравенства:
выполняются следующие неравенства:

 число элементов в множестве
число элементов в множестве 

 независимые одинаково распределенные случайные величины, принимающие ограниченные значения. К поеледовательности таких случайных величин можно
независимые одинаково распределенные случайные величины, принимающие ограниченные значения. К поеледовательности таких случайных величин можно
 позволяют называть его множеством типичных последовательностей или высоковероятным множеством дискретного источника без памяти.
позволяют называть его множеством типичных последовательностей или высоковероятным множеством дискретного источника без памяти.
 Энтропия такого ансамбля
Энтропия такого ансамбля  Вероятность любой последовательности сообщений длины
Вероятность любой последовательности сообщений длины  не зависит от последовательности и равна
не зависит от последовательности и равна  Отсюда следует, что
Отсюда следует, что  т. е. все последовательности из
т. е. все последовательности из  принадлежат множеству
принадлежат множеству  при любом
при любом  Другими словами, для этого источника
Другими словами, для этого источника  и высоковероятное множество совпадает с множеством всех последовательностей.
и высоковероятное множество совпадает с множеством всех последовательностей.
 причем 1 появляется с вероятностью
причем 1 появляется с вероятностью  Для такого источника
Для такого источника 

 количество единиц в последовательности х. Обозначая —
количество единиц в последовательности х. Обозначая —  получим
получим


 Таким образом, высоковероятное множество для рассматриваемого источника состоит из таких последовательностей
Таким образом, высоковероятное множество для рассматриваемого источника состоит из таких последовательностей  число единиц в которых близко к
число единиц в которых близко к  . Например, если
. Например, если  , то
, то  . Высоковероятное множество состоит из последовательностей, число единиц в которых близко к
. Высоковероятное множество состоит из последовательностей, число единиц в которых близко к  Количество последовательностей в этом множестве близко к
Количество последовательностей в этом множестве близко к  Доля множества
Доля множества  близка к
близка к  Так, при
Так, при  это число примерно равно
это число примерно равно 
