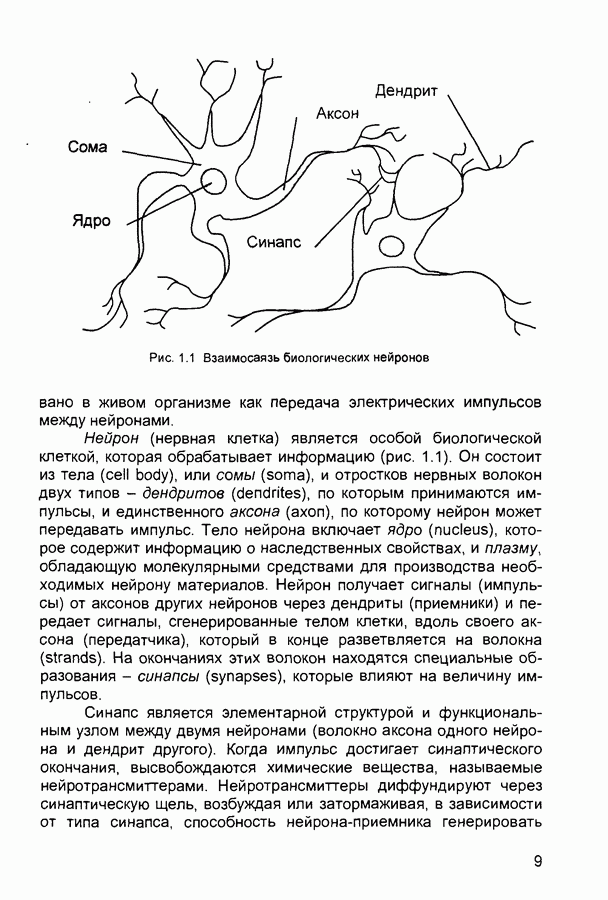
Пред.
След.
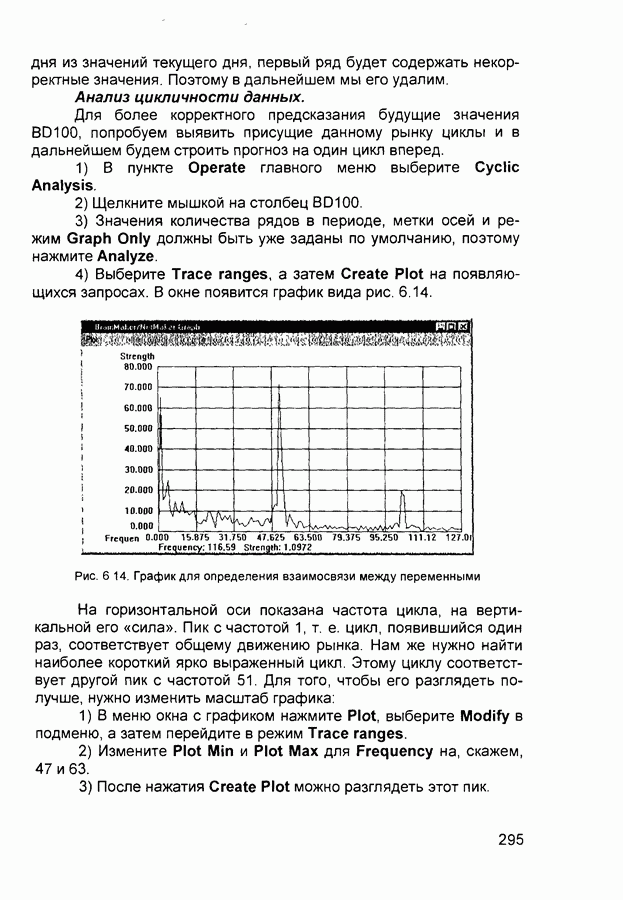
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
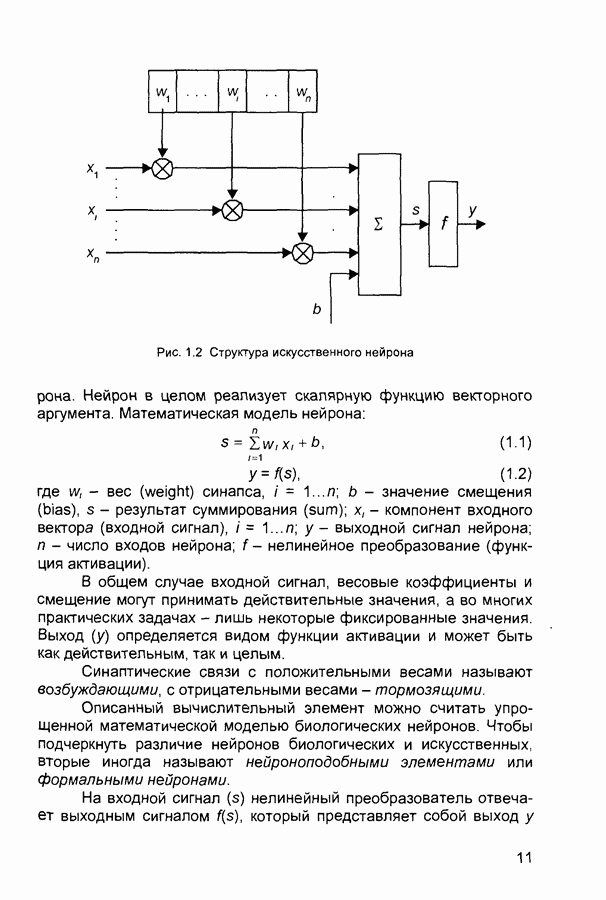
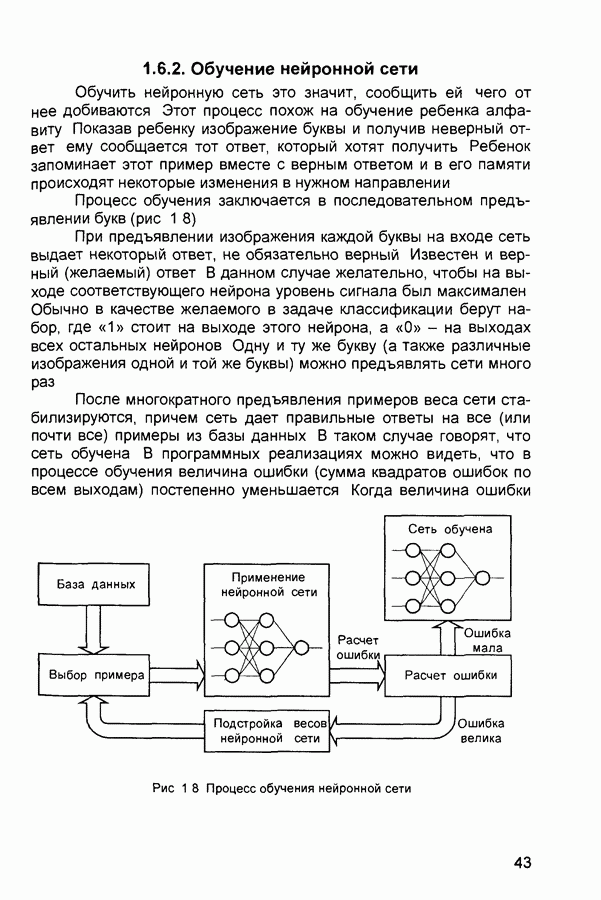
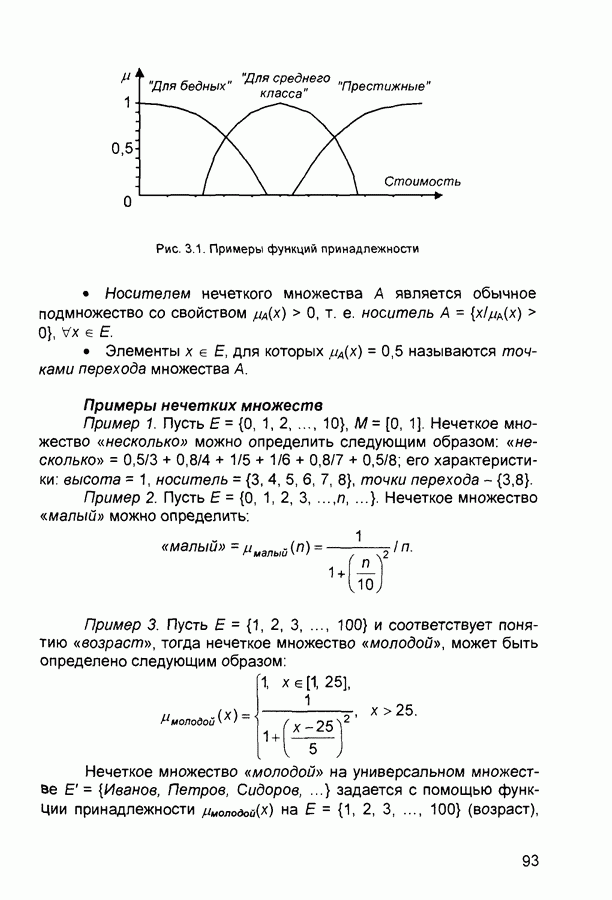
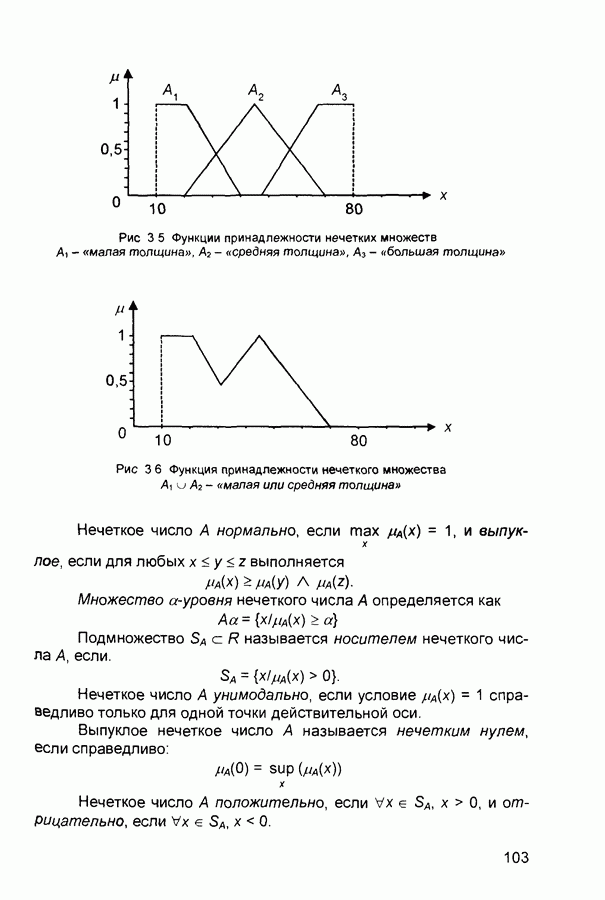
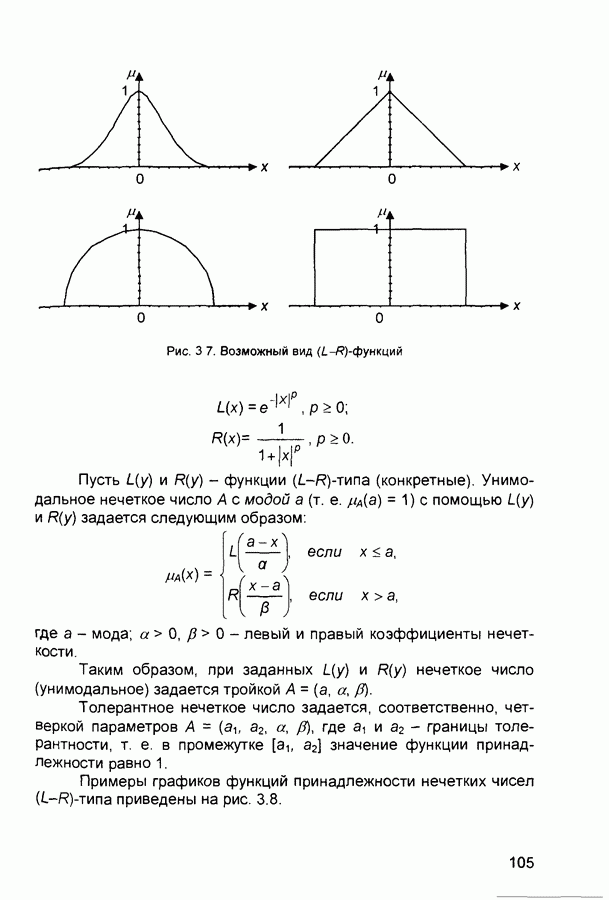
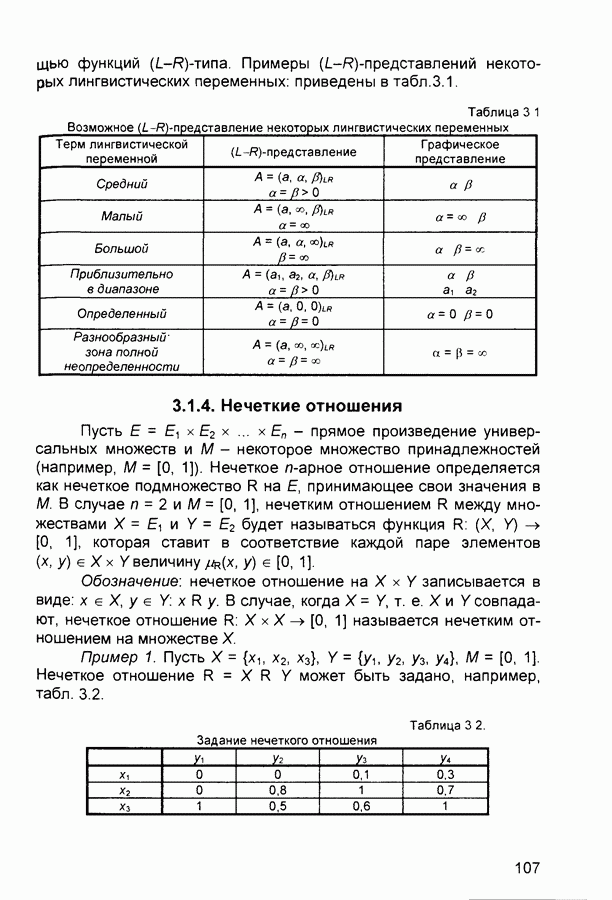
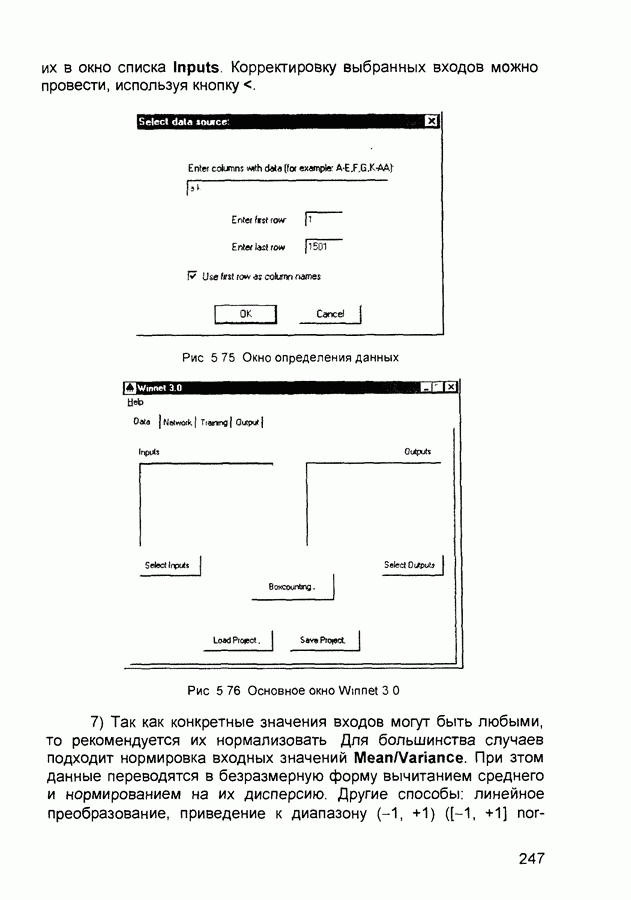
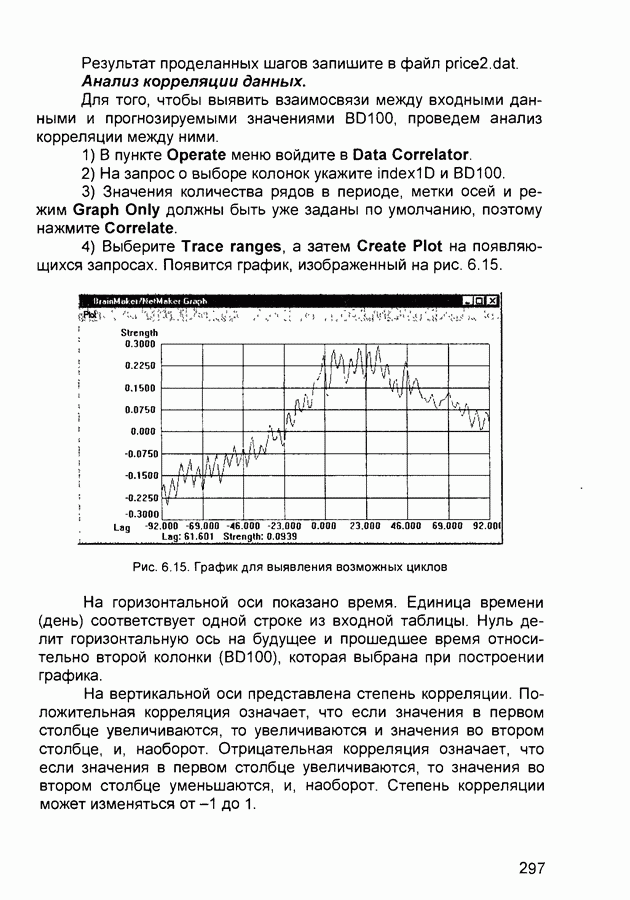
1.4. Постановка и возможные пути решения задачи обучения нейронных сетейОчевидно, что процесс функционирования нейронной сети, сущность действий, которые она способна выполнять, зависит от величин синаптических связей. Поэтому, задавшись определенной структурой сети, соответствующей какой-либо задаче, необходимо найти оптимальные значения всех переменных весовых коэффициентов (некоторые синаптические связи могут быть постоянными). Этот этап называется обучением нейронной сети, и от того, насколько качественно он будет выполнен, зависит способность сети решать поставленные перед ней проблемы во время функционирования. В процессе функционирования нейронная сеть формирует выходной сигнал У в соответствии с входным сигналом X, реализуя некоторую функцию то вид функции Пусть решение некоторой задачи есть функция Решить поставленную задачу с помощью нейронной сети заданной архитектуры - это значит построить (синтезировать) функцию Таким образом, задача обучения нейронной сети определяется совокупностью пяти компонентов:
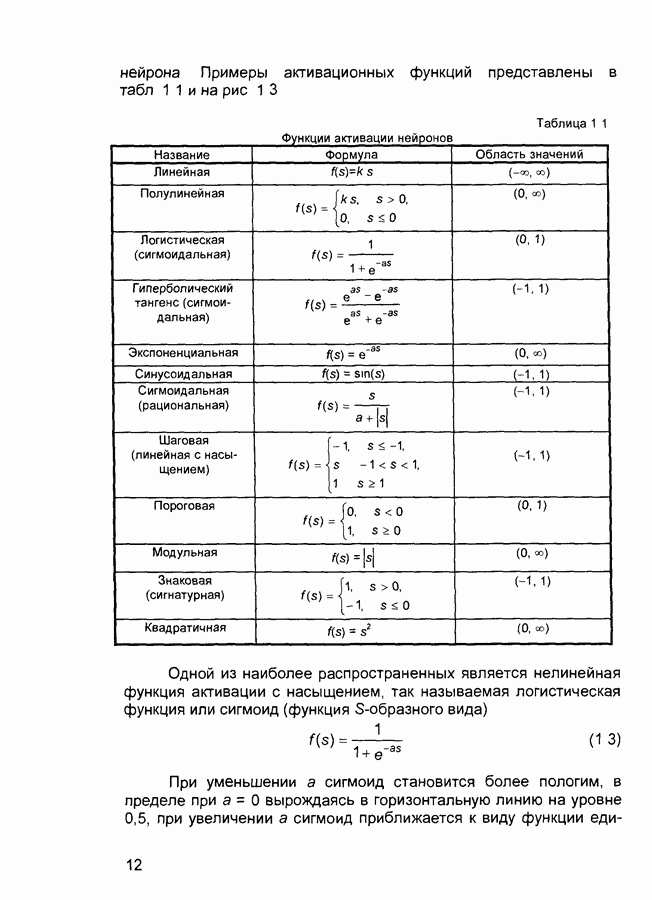
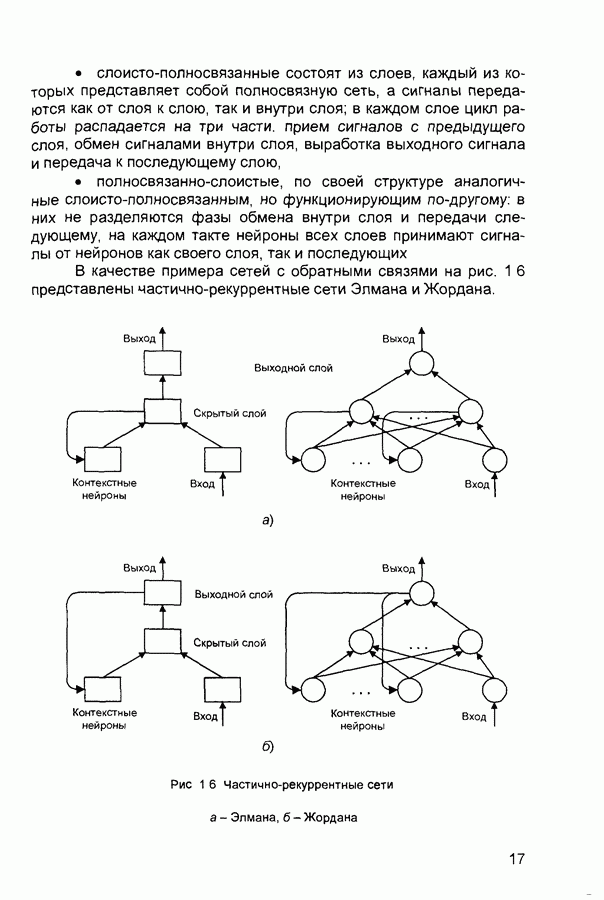
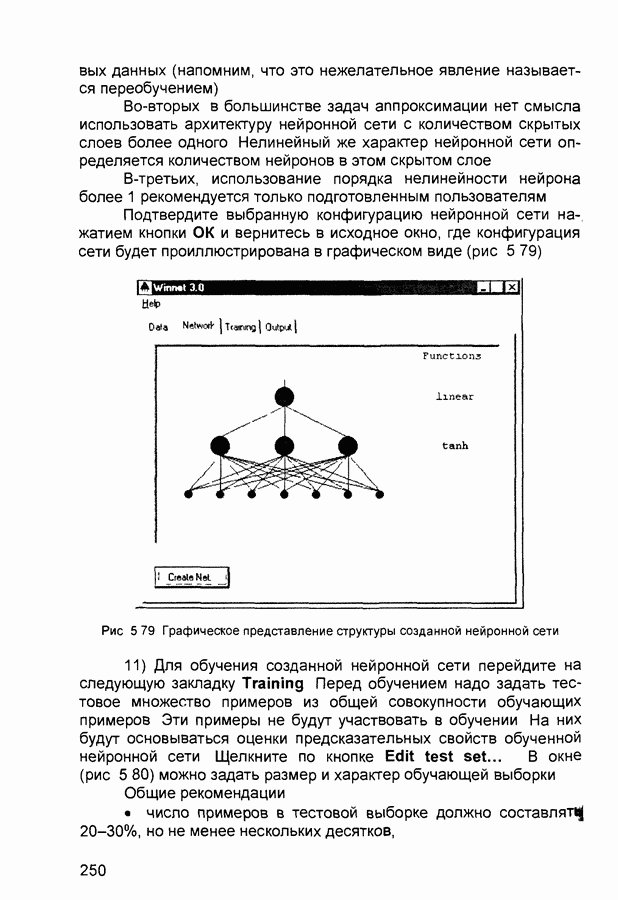
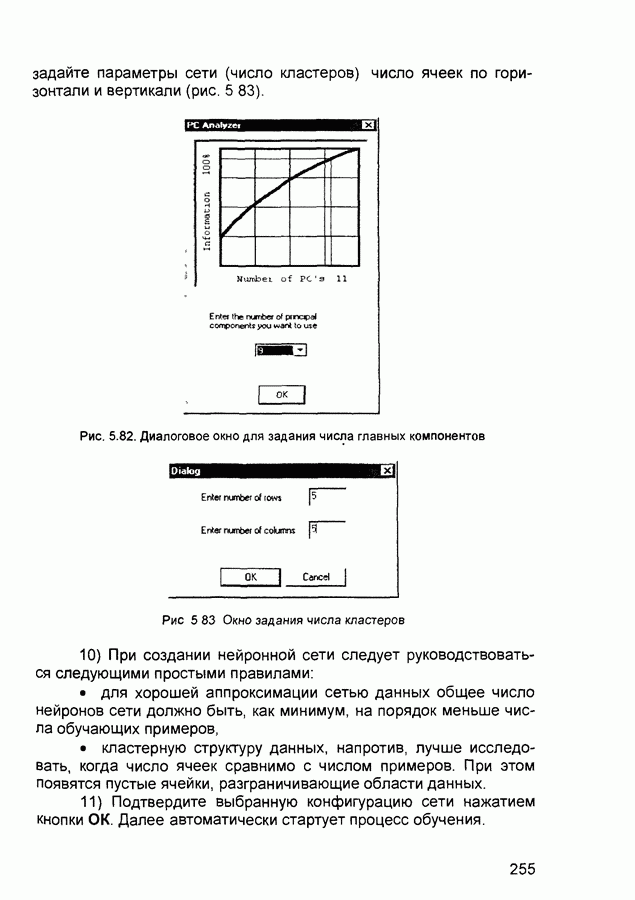
Обучение состоит в поиске (синтезе) функции Функция Е может иметь произвольный вид. Если выбраны множество обучающих примеров и способ вычисления функции ошибки, обучение нейронной сети превращается в задачу многомерной оптимизации, для решения которой могут быть использованы следующие методы: • локальной оптимизации с вычислением частных производных первого порядка; • локальной оптимизации с вычислением частных производных первого и второго порядка; • стохастической оптимизации; • глобальной оптимизации. К первой группе относятся: градиентный метод (наискорейшего спуска); методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента; метод сопряженных градиентов; методы, учитывающие направление антиградиента на нескольких шагах алгоритма. Ко второй группе относятся метод Ньютона, методы оптимизации с разреженными матрицами Гессе, квазиньютоновские методы, метод Гаусса-Ньютона, метод Левенберга-Маркардта. Стохастическими методами являются: поиск в случайном направлении, имитация отжига, метод Монте-Карло (численный метод статистических испытаний). Задачи глобальной оптимизации решаются с помощью перебора значений переменных, от которых зависит целевая функция. Для сравнения методов обучения нейронных сетей необходимо использовать два критерия: • количество шагов алгоритма для получения решения; • количество дополнительных переменных для организации вычислительного процесса. Для иллюстрации термина «дополнительные переменные» приведем следующий пример. Пусть Предпочтение следует отдавать тем методам, которые позволяют обучить нейронную сеть за небольшое число шагов и требуют малого числа дополнительных переменных. Это связано с ограничением ресурсов вычислительных средств. Как правило, для обучения используются персональные компьютеры. Пусть нейронная сеть содержит Р изменяемых параметров (синаптических весов и смещений). Существует лишь две группы алгоритмов обучения, которые требуют менее Хотя указанные алгоритмы дают возможность находить только локальные экстремумы, они могут быть использованы на практике для обучения нейронных сетей с многоэкстремальными целевыми функциями (функциями ошибки), так как экстремумов у целевой функции, как правило, не очень много. Достаточно лишь раз или два вывести сеть из локального минимума с большим значением целевой функции для того, чтобы в результате итераций в соответствии с алгоритмом локальной оптимизации сеть оказалась в локальном минимуме со значением целевой функции, близким к нулю Если после нескольких попыток вывести сеть из локального минимума нужного эффекта добиться не удается, необходимо увеличить число нейронов во всех слоях с первого по предпоследний и присвоить случайным образом их синаптическим весам и смещениям значения из заданного диапазона Эксперименты по обучению нейронных сетей показали, что совместное использование алгоритма локальной оптимизации процедуры вывода сети из локального минимума и процедуры увеличения числа нейронов приводит к успешному обучению нейронных сетей Кратко опишем недостатки других методов Стохастические алгоритмы требуют очень большого числа шагов обучения Это делает невозможным их практическое использование для обучения нейронных сетей больших размерностей Экспоненциальный рост сложности перебора с ростом размерности задачи в алгоритмах глобальной оптимизации при отсутствии априорной информации о характере целевой функции также делает невозможным их использование для обучения нейронных сетей больших размерностей Метод сопряженных градиентов очень чувствителен к точности вычислений, особенно при решении задач оптимизации большой размерности Для методов, учитывающих направление антиградиента на нескольких шагах алгоритма, и методов, включающих вычисление матрицы Гессе, необходимо более чем Рассмотрим один из самых распространенных алгоритмов обучения - алгоритм обратного распространения ошибки
|
 |
Оглавление
|






























































































































































































































































































































 Если архитектура сети задана,
Если архитектура сети задана,
 определяется значениями синаптических весов и смещений сети. Обозначим через
определяется значениями синаптических весов и смещений сети. Обозначим через  множество всех возможных функций
множество всех возможных функций  соответствующих заданной архитектуре сети.
соответствующих заданной архитектуре сети.
 заданная парами входных-выходных данных
заданная парами входных-выходных данных  , для которых
, для которых  - функция ошибки (функционал качества), показывающая для каждой из функций
- функция ошибки (функционал качества), показывающая для каждой из функций  степень близости к
степень близости к 
 подобрав параметры нейронов (синаптические веса и смещения) таким образом, чтобы функционал качества обращался в оптимум для всех пар (X, У.
подобрав параметры нейронов (синаптические веса и смещения) таким образом, чтобы функционал качества обращался в оптимум для всех пар (X, У.

 , оптимальной по Е. Оно требует длительных вычислений и представляет собой итерационную процедуру. Число итераций может составлять от 103 до 108. На каждой итерации происходит уменьшение функции ошибки.
, оптимальной по Е. Оно требует длительных вычислений и представляет собой итерационную процедуру. Число итераций может составлять от 103 до 108. На каждой итерации происходит уменьшение функции ошибки.
 - некоторые параметры нейронной сети с заданными значениями. В процессе обучения сети на каждом шаге, по меньшей мере, два раза потребуется выполнить умножение
- некоторые параметры нейронной сети с заданными значениями. В процессе обучения сети на каждом шаге, по меньшей мере, два раза потребуется выполнить умножение  Дополнительная переменная требуется для сохранения значение произведения после первого умножения.
Дополнительная переменная требуется для сохранения значение произведения после первого умножения.
 дополнительных параметров и при этом дают возможность обучать нейронные сети за приемлемое число шагов. Это алгоритмы с вычислением частных производных первого порядка и, возможно, одномерной оптимизации. Именно эти алгоритмы и будут рассмотрены в следующих разделах.
дополнительных параметров и при этом дают возможность обучать нейронные сети за приемлемое число шагов. Это алгоритмы с вычислением частных производных первого порядка и, возможно, одномерной оптимизации. Именно эти алгоритмы и будут рассмотрены в следующих разделах.
 дополнительных переменных В зависимости от способа разрежения, вычисление матрицы Гессе требует от
дополнительных переменных В зависимости от способа разрежения, вычисление матрицы Гессе требует от  до
до  дополнительных переменных
дополнительных переменных