Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
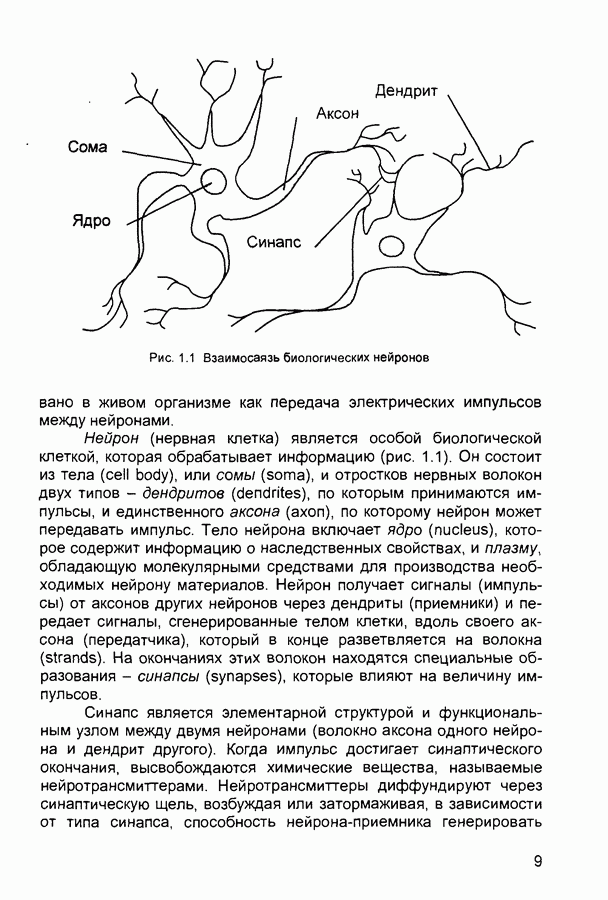
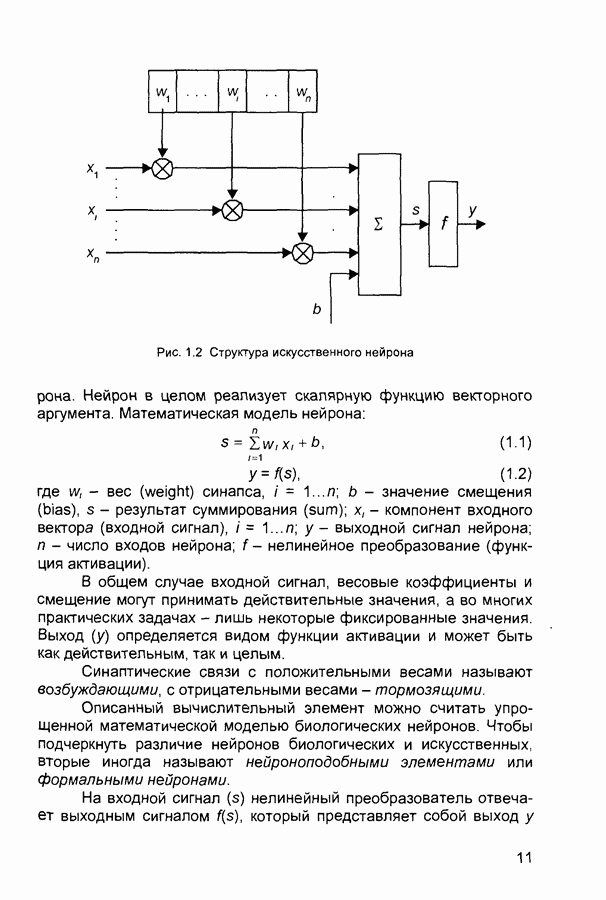
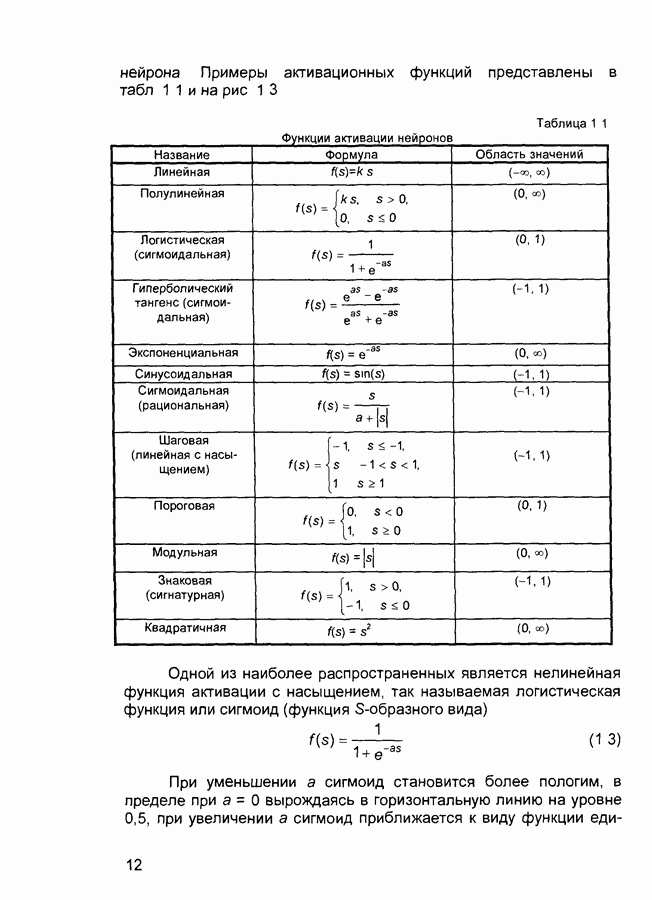
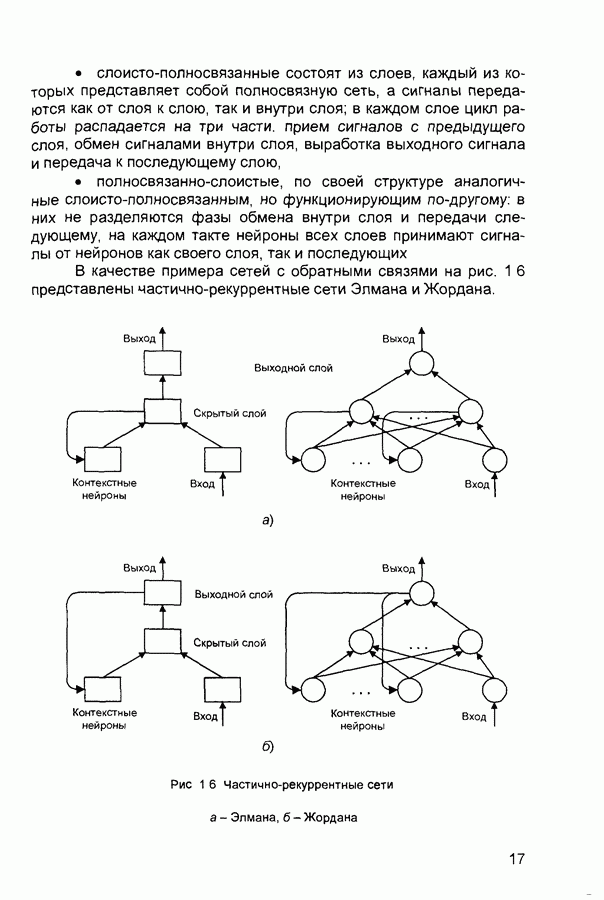
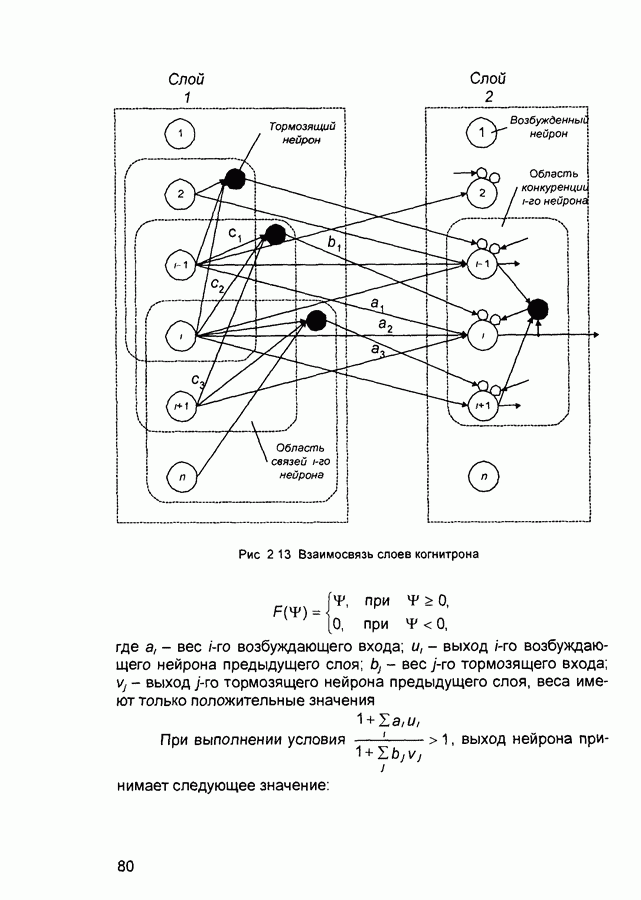
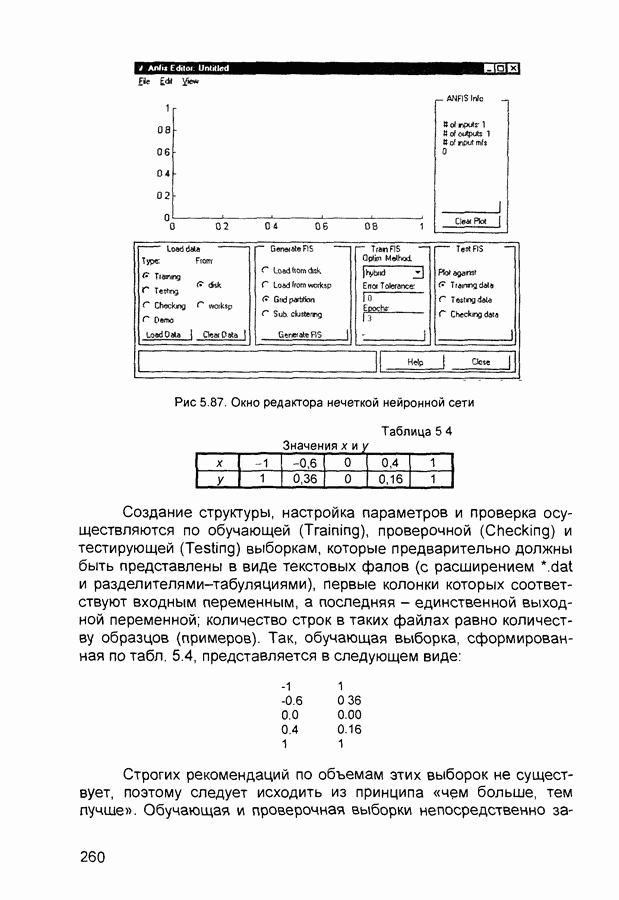
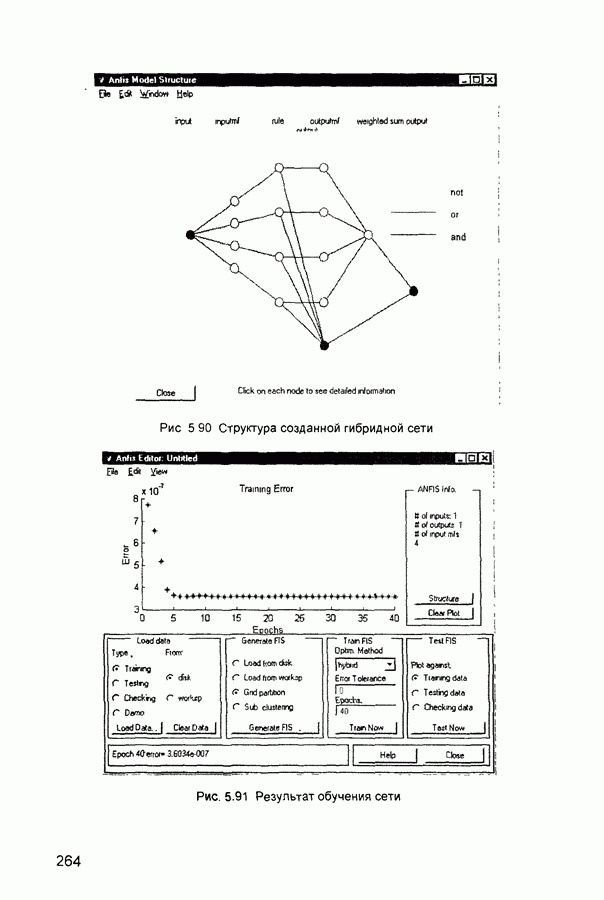
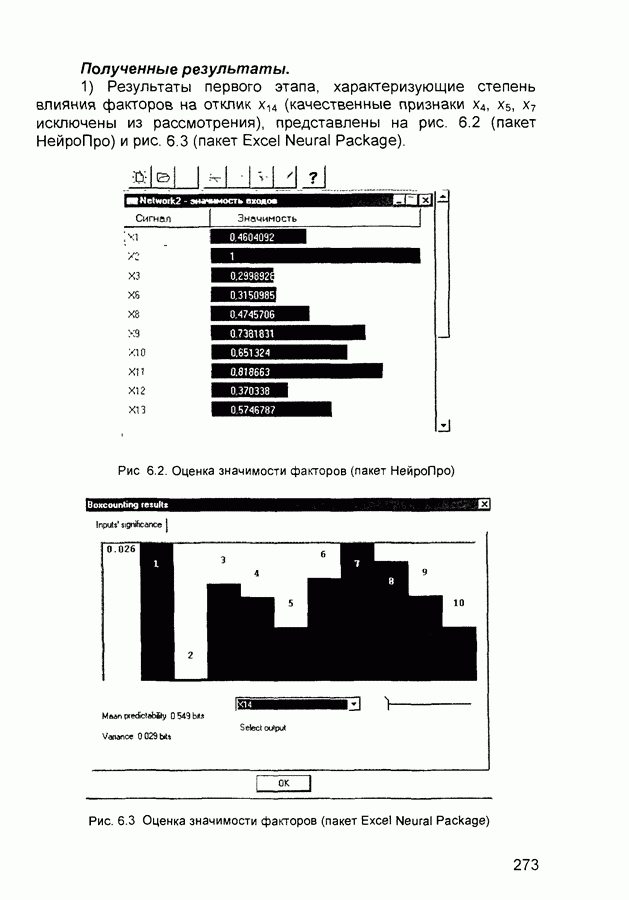
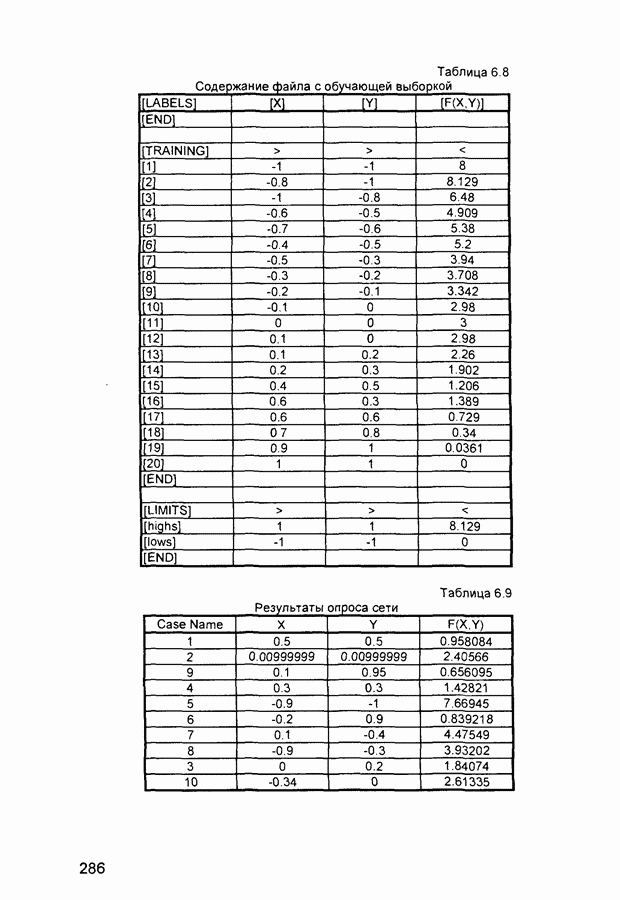
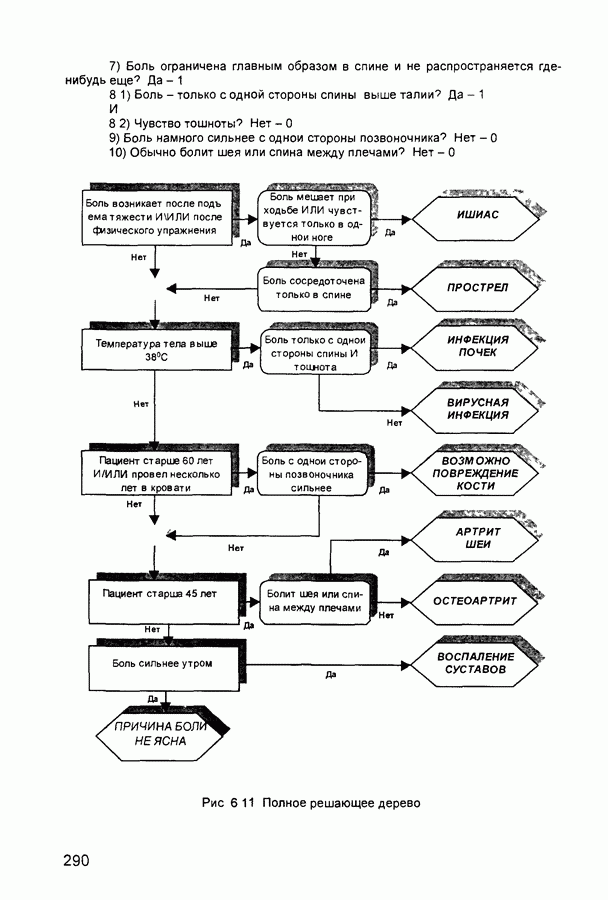
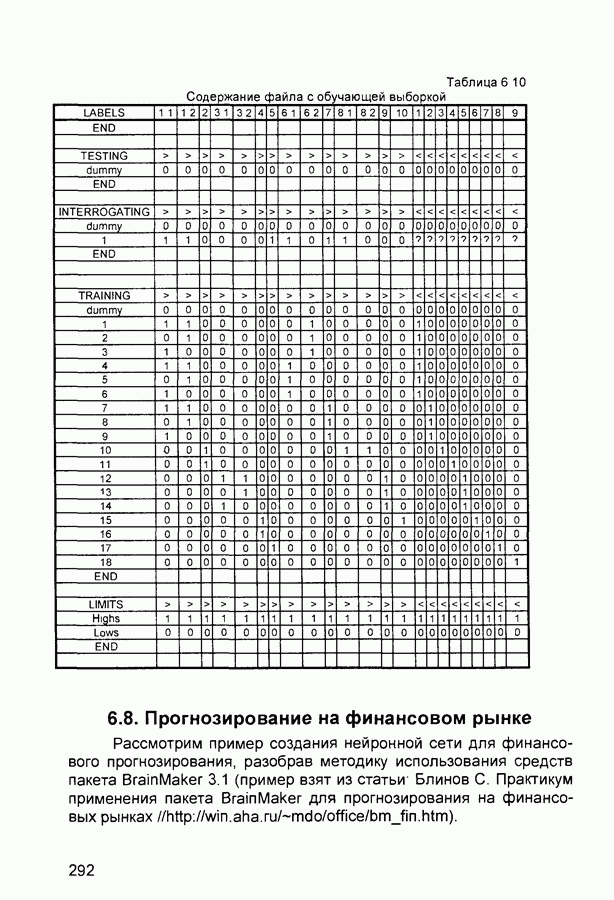
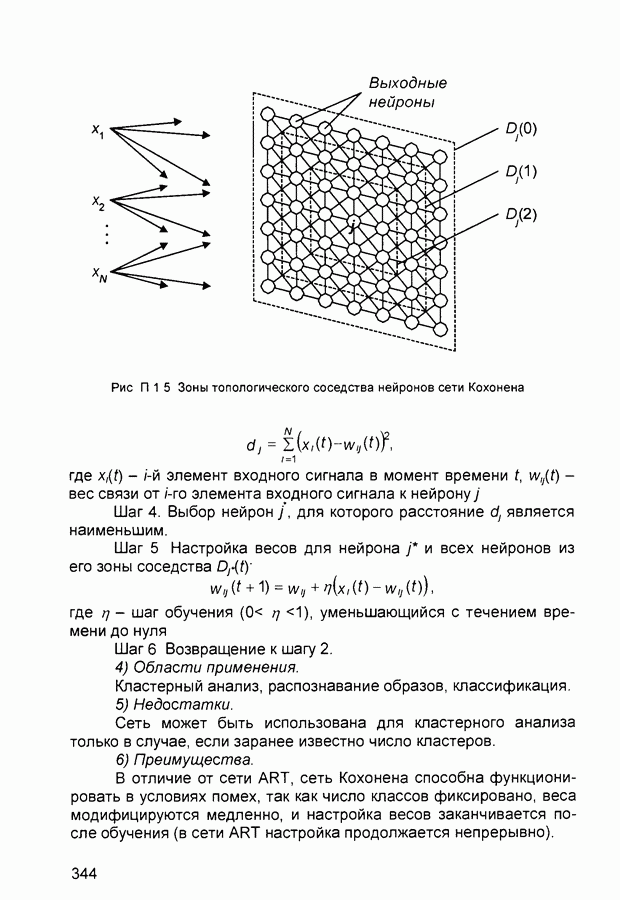
П.3. ГлоссарийADALINE - Адалина - одно из наименований для линейного нейрона: ADAptive LINear Element. adaptive learning rate - адаптивный параметр обучения - параметр процедуры обучения, который изменяется по определенному алгоритму так, чтобы минимизировать время обучения. rchitecture - архитектура - описание числа слоев в нейронной сети, передаточных функций каждого слоя, числа нейронов в каждом слое и связей между слоями. artificial neural networks (ANN) - искусственные нейронные сети (ИНС). average error - средняя ошибка сети по всему набору обучающих векторов. backpropagation batch - разновидность алгоритма обучения с обратным распространением ошибки, когда коррекция весов и смещений производится один раз за период обучения - после предъявления всех векторов обучающей последовательности («пачки» векторов, batch). backpropagation learning rule - обратного распространения правило - обучающее правило, в котором веса и смещения регулируются (подстраиваются) по производной ошибки от выхода сети через промежуточные слои к первому, в соответствии с выражением:
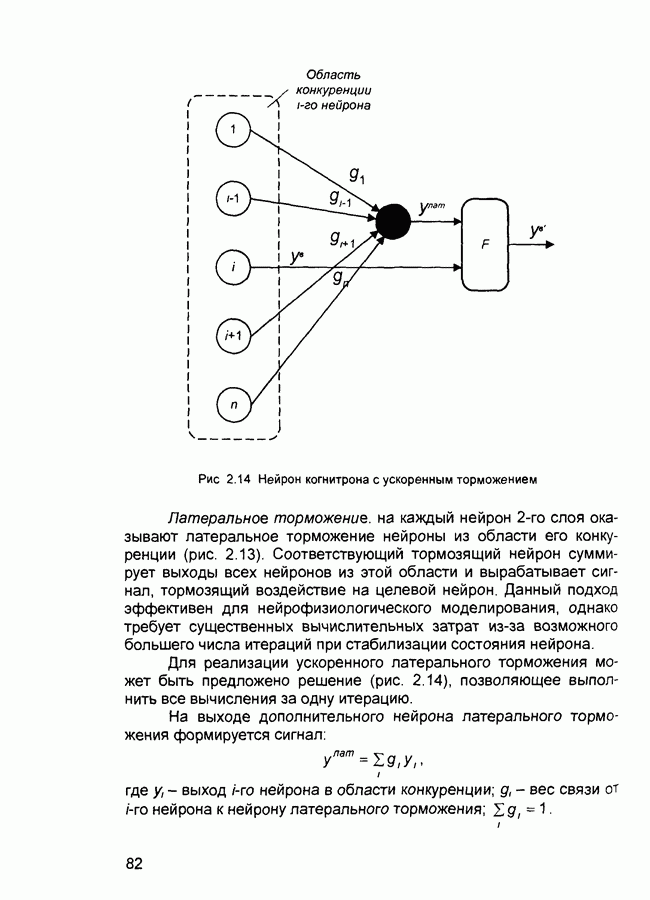
где Обычно применяется для обучения многослойных сетей прямого распространения. Иногда называется обобщенным дельта-правилом (generalized delta rule). backpropagation online - обратное распространение в режиме реального времени - модификация алгоритма обучения по методу обратного распространения ошибки, когда веса и смещения сети корректируются после предъявления каждого нового образа (вектора) обучающей последовательности. acktracking search - поиск с возвратом - одномерный поисковый алгоритм, который начинает поиск с единичным шагом и возвращается в исходную точку с уменьшением шага до тех пор, пока не будет получено приемлемое уменьшение целевой функции. batch - пачка - матрица входных или целевых векторов, приложенных к сети одновременно, изменение (подстройка) весов и смещений сети происходит после просмотра (обработки) всех векторов входной матрицы. batching - процесс представления матрицы (пачки) входных векторов для одновременного вычисления матрицы выходных векторов и/или новых весов и смещений. Bayesian framework - байесовский подход - допущение, что веса и смещения сети являются случайными переменными с определенными распределениями. BFGS quasi-Newton algorithm - разновидность оптимизационного алгоритма Ньютона, в котором аппроксимация матрицы Гессе (матрицы вторых производных) получается из градиентов, вычисленных на каждой итерации алгоритма. bias - смещение - параметр нейрона, который суммируется со взвешенными входами нейрона, образуя входную величину (аргумент) для функции активации нейрона. bias vector - вектор смещения - вектор-столбец величин смещений для слоя нейронов. Brent’s search - одномерный поисковый метод оптимизации, который является комбинацией метода золотого сечения и квадратичной интерполяции. Charalambous’ search - одномерный гибридный поисковый метод, использующий кубическую интерполяцию. classification - классификация - ассоциация входного вектора с некоторым выходным (целевым). competitive layer - конкурирующий слой - слой нейронов в которых только нейрон с максимальным входом имеет активизированный выход (например, выход 1), а все другие нейроны - выход 0. Нейроны конкурируют друг с другом за возможность реагировать на данный входной вектор. competitive learning - конкурирующее обучение - обучение без учителя в слое конкурирующих нейронов После обучения слой распределяет входные векторы среди своих нейронов. competitive transfer function - конкурирующая передаточная (активационная) функция - преобразует входной (для слоя конкурирующих нейронов) вектор в нулевой для всех нейронов за исключением нейрона-«победителя», для которого выход будет равен единице. concurrent input vectors - параллельные входные векторы - имя, данное матрице входных векторов, которые должны представляться в сети «одновременно». Все векторы в матрице используются для получении одного набора изменений в весах и смещениях нейронной сети conjugate gradient algorithm - метод сопряженных градиентов -разновидность градиентного метода поиска минимума функции. connection - соединение - односторонняя связь между нейронами в сети. connection strength - сила связи (соединзния) - уровень связи между двумя нейронами в сети. Часто количественно выражается весом и определяет эффект влияния одного нейрона на другой. convergence tolerance - это максимально допустимая величина ошибки во время обучения. Если cycle - цикл - однократное представление входного вектора, соответствующие ему вычисления выходного вектора и новых весов и смещений сети. dead neurons - «мертвые» нейроны - нейроны конкурирующего слоя, которые никогда не выигрывают любую конкуренцию за входной вектор в процессе обучения decision boundary - граница решения - линия в гиперпространстве, определяемая векторами весов и смещений, для которой вход сети является нулем. delta-bar-delta - метод обучения сети с адаптивным (и индивидуальным для каждого веса) подбором коэффициента скорости обучения (learning rate). Адаптация осуществляется по следующим формулам.
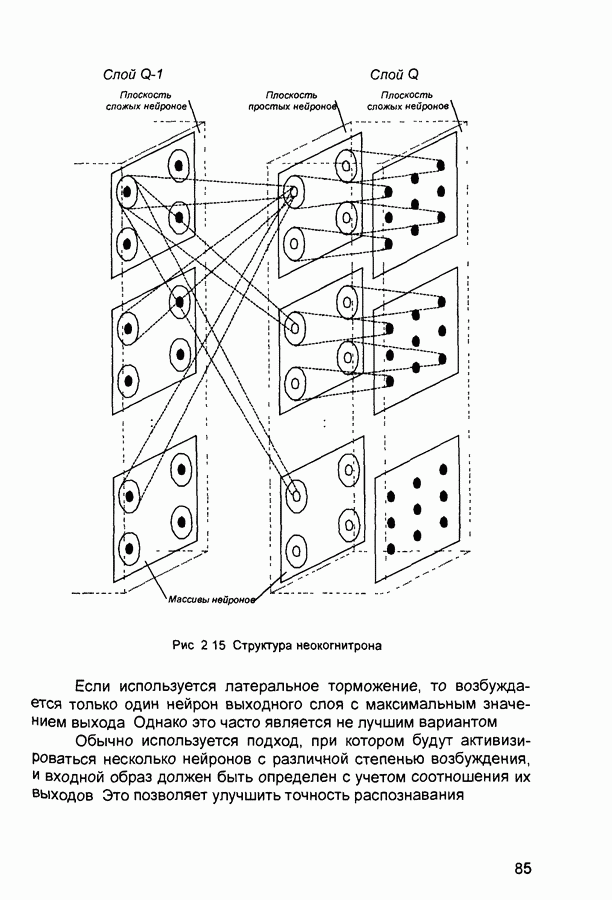
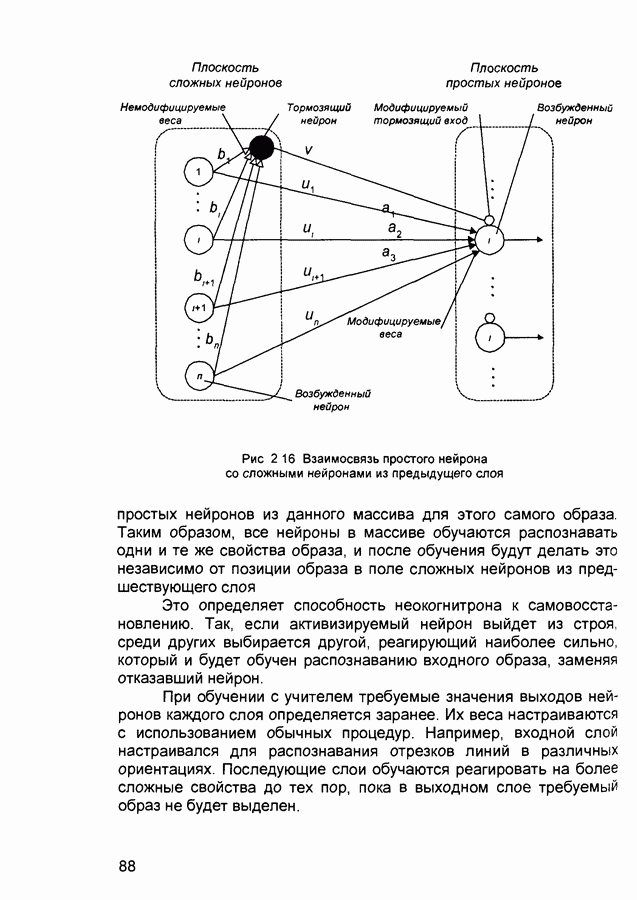
где Метод применяется в сочетании с алгоритмом backpropagation batch. delta rule - дельта-правило - правило обучения Уидроу-Хоффа the Widrow-Hoff rule) Как известно, возможности персептрона ограничены бинарными выходами Уидроу и Хофф расширили алгоритм обучения персептрона для случая непрерывных выходов с использованием сигмоидальной функцией активации. Кроме того, они доказали, что сеть при определенных условиях будет сходиться к любой функции, которую она может представить. Их первая модель - Адалин - имеет один выходной нейрон, более поздняя модель - Мадалин - обобщена для случая с многими выходными нейронами. delta vector - дельта-вектор - вектор производных ошибки выхода сети по отношению к выходам какого-либо слоя сети. distance - расстояние - расстояние между нейронами, определяемое в каком-либо смысле. early stopping - ранняя остановка - техника, базирующаяся на разбиении исходных данных на три подмножества. Первое подмножество является обучающим и используется для вычисления градиента и коррекции (обновления) весов и смещений сети. Второе подмножество используется для проверки правильности сделанных коррекций Когда для данного подмножества и определенного количества итераций ошибка увеличивается, обучение прекращается, а веса и смещения принимаются соответствующими минимальной ошибке на этом подмножестве. Третье подмножество является тестирующим для обученной сети. epoch - период (эпоха) - представление набора обучающих (входных и выходных - целевых) векторов сети и вычисление новых весов и смещений. Векторы могут предъявляться поочередно или все вместе, пакетом, «пачкой». error jumping - скачок ошибки - внезапное возрастание суммарной квадратической ошибки сети в процессе ее обучения. Часто возникает из-за слишком большой величины параметра обучения (learning rate). error margin - граница ошибки - выходы сети, для которых ошибка меньше данной величины будут считаться «правильными», корректными rror ratio - коэффициент ошибки - один из параметров процедуры обучения в сетях с обратным распространением ошибки. error vector - вектор ошибки - различие между целевым вектором и выходным вектором сети. feedback network - сеть с обратной связью - сеть с соединениями с выхода сети на ее вход Соединение обратной связи может охватывать различные слои. feedforward network - сеть с прямой связи - многослойная сеть, в который каждый слой своими входами имеет выходы только предшествующих слоев. Fletcher-Reeves update - метод Флетчера-Ривса - метод для вычисления сопряженных направлений, которые используются в оптимизационной процедуре метода сопряженных градиентов. function approximation - аппроксимация функций - одна из задач, которую может выполнить нейронная сеть после ее обучения. gaussian transfer function - активационная функция в виде функции Гаусса (см. radial basis transfer function). generalization - обобщение - свойство сети устанавливать свой выход для нового входного вектора близким к выходам похожих на него (в смысле какого-либо расстояния) входных векторов из обучающей последовательности. eneralized regression network - обобщенная сетевая регрессия -приближение непрерывной функции с произвольной точностью с помощью нейронной сети, которое может быть получено при достаточном числе скрытых нейронов. global minimum - глобальный минимум - наименьшее значение функции во всей области входных параметров. Методы градиентного спуска изменяют веса и смещения так, чтобы найти (достичь) глобальный минимум ошибки сети. golden section search - метод золотого сечения - один из одномерных поиска экстремума функции, не требующий вычисления производной и отличающийся высокой скоростью сходимости. gradient descent - градиентный спуск - процесс получения изменений (коррекций) в весах и смещениях сети, при котором данные изменения пропорциональны производным сетевой ошибки по этим весам и смещениям, приводящий к минимизации сетевой ошибки. hard limit transfer function - пороговая активационная функция -отображает неотрицательные числа в единицу, отрицательные в ноль. Hebb learning rule - Хебба правило обучения - исторически первое предложенное правило обучения нейронной сети. Веса корректируются пропорционально произведению выходов предыдущего и последующего нейронов. hidden layer - скрытый слой - слой нейронов, непосредственно не соединенный с выходом сети. home neuron - внутренний нейрон - нейрон в центре некоторой окрестности. hybrid bisection-cubicsearch - гибридная одномерная поисковая процедура оптимизации, объединяющая методы половинного деления (бисекции) и кубической интерполяции. initialization - инициализация - установка начальных значений весов и смещений нейронной сети, обычно, присваивание синаптическим весам и смещениям сети случайных значений из заданного диапазона. input layer - входной слой - слой нейронов, на который непосредственно поступают входы сети. input noise - входной шум - опция обучения, определяющая уровень нормально распределенного шума, добавляемого к входным обучающим образцам. При обучении с таким дополнительным шумом обычно предотвращается «переобучение» сети (overfitting) и улучшается ее способность к обобщению. input space - входное пространство - область всех возможных значений входного вектора. input vector - входной вектор сети. input weights - входные веса - веса, с которыми входные сигналы поступают в сеть. input weight vector - вектор входных весов. interrogate - опрос - предъявление обученной сети входного вектора и вычисление сетью соответствующего выходного. Jacobian matrix - Якобиан - матрица первых производных ошибки сети по отношению к ее весам и смещениям. Kohonen learning rule - правило обучения Кохонена - правило обучения, согласно которому веса нейронов выбираются в соответствии с элементами входного вектора. layer - слой - группа нейронов, имеющие соединения с одними и теми же источниками-входами и посылающие свои выходные сигнала к одним и тем же потребителям. layer diagram - диаграмма слоев - представление архитектуры нейронной сети в виде образующих ее слоев нейронов и матриц весовых коэффициентов. Активационные функции отображаются символически. Показываются размеры данных матриц, а также размеры входного и выходного векторов сети. Отдельные нейроны не отображаются. layer weights - веса (весовые коэффициенты) слоя нейронов, соединяющие данный слой с другими. В случае рекуррентных связей должны иметь ненулевые задержки. learning - обучение - процесс коррекции весов и смещений сети, при котором достигается ее желательное функционирование. learning rate - коэффициент скорости обучения (параметр обучения), который определяет скорость изменения величин весов и смещений сети в процессе ее обучения, обычно при использовании алгоритма обратного распространения ошибки. Чем он больше, тем быстрее обучается сеть. Допустимые значения параметра от 0,0 до 1,0; хорошим начальным приближением считается величина 0,1. Если данный параметр велик, процесс обучения может потерять устойчивость. learning rule - обучающее правило - метод модификации весов и смещений сети в процессе ее обучения. Levenberg-Marquardt - алгоритм обучения Левенберга-Марквардта, обеспечивающий в 10-100 раз более быстрое обучения сети, чем алгоритм обратного распространения ошибки, использующий градиентную оптимизацию. line search function - одномерная поисковая процедура - процедура поиска минимума функции по заданному направлению. linear transfer function - линейная передаточная (активационная) функция. local minimum - локальный минимум - минимальное значение функции в некоторой ограниченной области изменения аргумента. Не обязательно является глобальным минимумом. log-sigmoid transfer function - лог-сигмоидная передаточная (активационная) функция, определяемая выражением:
Manhattan distance - расстояние Манхэттена - расстояние между двумя векторами х и у, определяемое соотношением:
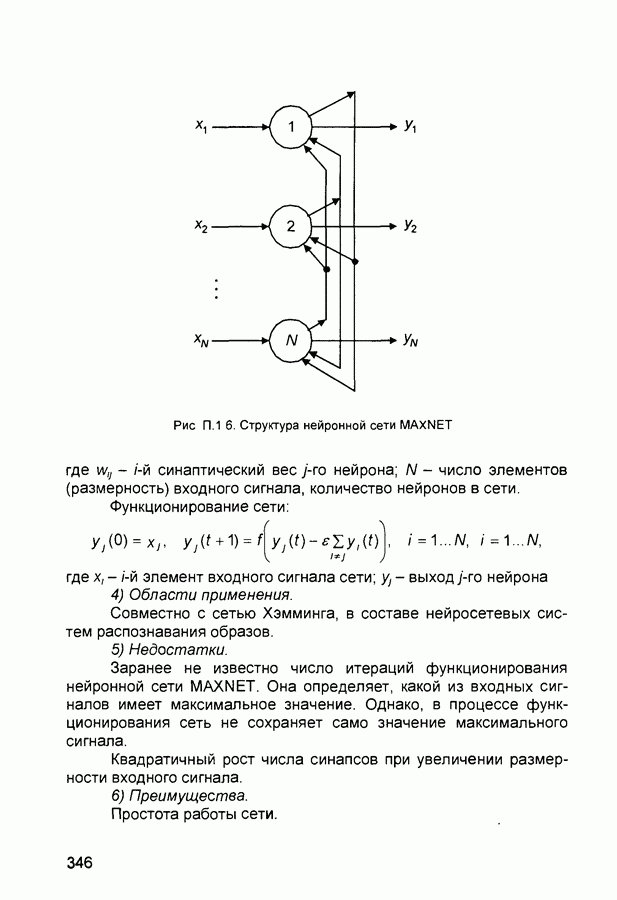
maximum number of epochs - максимальное число периодов (эпох), которые нужно использовать для обучения. Один период эквивалентен одному полному представлению всех образцов (векторов) обучающей выборки. maximum step size - максимальный шаг - максимальный шаг изменения аргумента в одномерной поисковой процедуре. Величина вектора весовых коэффициентов в процессе обучения сети на одной итерации не может увеличиваться более, чем на размер максимального шага. mean square error function - средняя квадратическая ошибка сети (средний квадрат разности между реальным и требуемым выходами). momentum - импульс - метод ускорения процесса обучения для алгоритма обратного распространения. Заключается в добавлении к корректируемому весу числа, пропорционального предыдущему значению веса. Используя метод импульса, сеть стремится идти по дну узких оврагов поверхности ошибки (если таковые имеются), а не двигаться от склона к склону. Метод хорошо работает на одних задачах, но может дать отрицательный эффект на других. momentum constant - коэффициент импульса - константа, используемая в методе импульса и устанавливаемая обычно на уровне 0,9. neighborhood - окрестность - в данном случае группа нейронов, находящихся в пределах определенного расстояния от выбранного нейрона. net input vector - входной вектор сети. neuron - нейрон - базовый элемент нейронных сетей. Имеет входы, снабженные весами, смещение, суммирующий элемент и выходную активационную функцию. Является аналогом биологического нейрона. neuron diagram - диаграмма нейронов - сетевая архитектура, отображаемая фигурой, показывающей нейроны и веса связей между ними. Активационные функции нейронов отображаются символически. neuron saturation - насыщение нейрона - состояние нейрона, когда значительные изменения его входов приводят к незначительному изменению выхода. Когда нейрон насыщается, процесс его обучения становится неэффективным. number of hidden layers - число скрытых слоев в нейронной сети. output layer - выходной слой - слой нейронов, выход которого является выходом всей сети. output vector - выходной вектор - выход нейронной сети. Каждый элемент этого вектора является выходом одного из нейронов выходного слоя. output weight vector - выходной вектор весовых коэффициентов -вектор-столбец весовых коэффициентов для выходов нейрона. outstar learning rule - правило обучения выходной звезды - в то время как входная звезда возбуждается при предъявлении определенного входного вектора, выходная звезда имеет дополнительную функцию; она вырабатывает требуемый возбуждающий сигнал для других нейронов всякий раз, когда возбуждается. В процессе обучения нейрона выходной звезды, его веса настраиваются в соответствии с требуемым целевым вектором. overfitting - «переобучение» - ситуация, когда на обучающей последовательности ошибки сети были очень малы, но на новых данных становятся большими. partan method - партан-метод - улучшенная модификация градиентного метода (метода наискорейшего спуска) минимизации функций. Известны итерационный ( pass - проход - каждое прохождение через все обучающие и целевые векторы. pattern - образ (вектор). pattern association - образов ассоциация - задача, решаемая обученной нейронной сетью и заключающаяся в соотнесении «правильного» выходного вектора каждому предъявляемому входному. pattern recognition - образов распознавание - задача, решаемая обученной нейронной сетью и заключающаяся в отнесении предъявленного входного вектора (изображения) к одному из классов. performance function - функция эффективности - обычно средняя квадратическая ошибка сети. perceptron - персептрон - обычно однослойная сеть с пороговой активационной функцией нейронов. Обучение такой сети производится по специальному алгоритму. perceptron learning rule - правило обучения персептрона. Гарантирует обучение однослойного персептрона с пороговой активационной функцией за конечное число шагов. positive linear transfer function - положительно-линейная активационная функция - функция, значения которой равны нулю при отрицательных значениях аргумента и пропорциональны аргументу для его положительных значений. postprocessing - послеобработка - преобразует нормализованное значение выхода сети в его естественное значение Powell-Beale restarts - метод Поуэлла-Била - метод определения сопряженных направлений Используется в оптимизационном алгоритме сопряженных градиентов preprocessing - предобработка - выполнение некоторых преобразований входных или целевых (выходных) данных перед их представлением нейронной сети, обычно заключающаяся в приведении данных к некоторому одинаковому (единичному) масштабу principal component analysis - метод главных компонентов - орто-гонализация компонентов входных векторов сети Процедура может быть также использована для понижения (уменьшения) размерности входных векторов путем исключения неинформативных компонентов quasi-Newton algorithm - квази-ньютоновский алгоритм - класс алгоритмов оптимизации, основанных на методе Ньютона Аппроксимация матрицы Гессе (матрицы вторых частных производных) вычисляется на каждой итерации с использованием градиента quickprop - быстрое распространение - алгоритм обучения сети, базирующийся на следующих допущениях • зависимость • изменение какого-либо веса в процессе настройки не оказывает влияние на другие веса Правило изменения (коррекции) весов определяется формулой.
где Заметим, что знаменатель приведенной дроби представляет собой, по сути, оценку (с точностью до знака) второй производной ошибки по
Параметр radial basis function networks (RBFN) - сеть радиального основания - любая сеть, которая содержит скрытый слой нейронов с радиально симметричной активационной функцией, каждый из которых предназначен для хранения отдельного эталонного вектора (в виде вектора весов) Для построения BFN необходимо выполнение следующих условий • наличие эталонов, представленных в виде весовых векторов нейронов скрытого слоя, • наличие способа измерения расстояния входного вектора от эталона, обычно это стандартное евклидово расстояние, • наличие специальной функции активации нейронов скрытого слоя, задающей выбранный способ измерения расстояния radial basis transfer function - радиальная базисная функция активации (или функция Гаусса) - функция активации для радиального базисного нейрона, определяемая соотношением
randomize patterns - рандомизация (случайное перемешивание) образцов обучающей последовательности перед каждым периодом (epoch) обучения Зачастую улучшает сходимость процесса обучения сети regularization - регуляризация - модификация функции эффективности сети (обычно являющейся средней квадратической ошибкой) путем добавления помноженной на некоторый коэффициент суммы квадратов весовых коэффициентов RMS error (root mean squared error) - средняя квадратическая ошибка сети RPROP (resilient propagation) - «упругое распространение» - один из алгоритмов обучения нейронных сетей, основанный на использовании не величины производной ошибки сети, а ее знака Веса корректируются в соответствии с выражениями
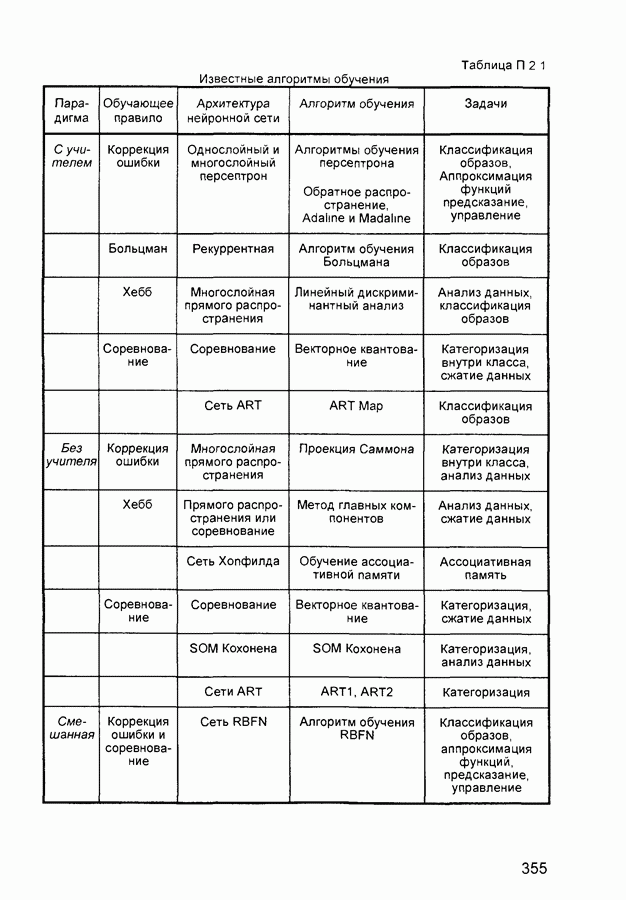
где saturating linear transfer function - линейная функция активации с насыщением - функция активации, линейная на интервале sequential input vectors - последовательные входные векторы - комплект векторов, которые должны представляться в сети «один после другого» Веса и смещения сети корректируются после представление каждого входного вектора sigmoid - сигмоид - монотонная simulation - моделирование - процесс определения сетью выходного вектора при заданном входном spread constant - константа распространения - расстояние между входным и весовым векторами нейрона, при котором выход равен 0,5 squashing function - сжимающая функция - монотонно возрастающая функция, преобразующая значения аргумента из интервала star learning rule - правило обучения звезды - входная звезда обучается реагировать на определенный входной вектор и ни на какой другой Это обучение реализуется путем настройки весов таким образом, чтобы они соответствовали входному вектору Выход звезды определяется как взвешенная сумма ее входов С другой точки зрения, выход можно рассматривать как свертку входного вектора с весовым вектором Следовательно, нейрон должен реагировать наиболее сильно на входной образ, которому был обучен sum-squared error - суммарная квадратическая ошибка - сумма квадратов ошибок сети для предъявленного набора входных векторов supervised learning - обучение с учителем - процесс обучения сети, предполагающий, что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход, вместе они называются обучающей парой Обычно сеть обучается на некотором множестве таких обучающих пар symmetric hard limit transfer function - симметричная пороговая передаточная (активационная) функция - равна +1 при неотрицательном аргументе и равна -1 при отрицательном symmetric saturating linear transfer function - линейная функция активации с симметричным ограничением (насыщением) - пропорционально преобразует значения аргумента из интервала (-1, +1) в значения функции в таком же интервале При значениях аргумента вне данного интервала значения функции равны знаку аргумента (т. е. -1 или +1) tan-sigmoid transfer function - функция активации типа гиперболического тангенса apped delay line - набор звеньев задержки - последовательный набор задержек с выходами от каждой задержки target error - допустимая ошибка - параметр, задаваемый при обучении сети, обучение прекращается, когда средняя (реальная) ошибка сети становится меньше заданной допустимой Обычно устанавливается на уровне 0,05 target vector - целевой вектор - требуемый выходной вектор для заданного входного training - обучение - процедура, посредством которой сеть настраивается на решение конкретной задачи, заключается в подстройке по определенному алгоритму весов и смещений сети training data - исходные данные для обучения сети (набор входных и соответствующих им выходных векторов) training vector - обучающий вектор - входной иили выходной (целевой) вектор, используемый для обучения сети transfer function - передаточная (активационная) функция - функция, которая преобразует сумму взвешенных входов нейрона в его выход underdetermined system - недоопределенная система - система, которая имеет больше переменных, чем связывающих их ограничений unsupervised learning - обучение без учителя - процесс обучения сети, при котором изменения (настройки, коррекции) весов и смещений сети происходят не по предъявлении эталонных образцов, а автоматически, в зависимости от характеристик входных и выходных векторов сети Обучающий алгоритм подстраивает веса сети так, чтобы получились согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало близкие (или одинаковые) выходы update - коррекция - изменения в весах и смещениях сети в процессе ее обучения Коррекция может произойти после представления единственного входного вектора или после предъявления и соответствующей обработки группы векторов weighted input vector - взвешенный входной вектор - результат умножения входного вектора для слоя нейронов на их веса weight matrix - матрица весов - матрица, составленная из весовых коэффициентов слоя нейронов Элемент Widrow-Hoff learning rule - Уидроу-Хоффа правило обучения -правило обучения сети с одним скрытым слоем Оно является предшественником алгоритма обратного распространения ошибки и на него иногда ссылаются как на дельта-правило Как известно, персептрон ограничивается бинарными выходами Уидроу и Хофф расширили алгоритм обучения персептрона на случай непрерывных выходов, используя сигмоидальную функцию Кроме того, они доказали того, что сеть при определенных условиях будет сходиться к любой функции, которую она может представить Их первая модель - Адалин - имеет один выходной нейрон, более поздняя модель - Мадалин - представляет расширение на случай с многими выходными нейронами автоассоциативная сеть - сеть (обычно многослойный персептрон), предназначенная для воспроизведения на выходе входной информации после сжатия данных в промежуточном слое, имеющем меньшую размерность Используется для сжатия информации и понижения размерности данных алгоритм К ближайших соседей - алгоритм выбора отклонений для радиальных элементов Каждое отклонение равно усредненному расстоянию до К ближайших точек алгоритм К средних - алгоритм, предназначенный для выбора К центров, представляющих кластеры в алгоритмы минимизации функции - алгоритмы, используемые для поиска минимума, в частности, в нелинейном оценивании, при этом здесь минимизируется заданная функция потерь. алгоритмы минимизации функций, свободные от производных - алгоритмы минимизации функций, использующие различные стратегии поиска (которые не зависят от производных второго порядка) для нелинейного оценивания. Эти стратегии наиболее эффективны при минимизации функции потерь, имеющей локальные минимумы. байесовы сети - сети, чей принцип действия основан на теореме Байеса, позволяющей сделать выводы о распределении вероятностей на основании имеющихся данных. быстрое распространение - эвристическая модификация алгоритма обратного распространения, где для ускорения сходимости применяется простая квадратичная модель поверхности ошибок (которая вычисляется отдельно для каждого веса). вероятностные нейронные сети (PNN) - вид нейронных сетей для задач классификации, где плотность вероятности принадлежности классам оценивается посредством ядерной аппроксимации. Один из видов так называемых байесовых сетей. встряхивание весов - добавление к весам нейронной сети небольших случайных величин с целью обойти локальные минимумы в пространстве ошибок. выбросы - нетипичные или редкие значения, которые существенно отклоняются от распределения остальных выборочных данных. Эти данные могут отражать истинные свойства изучаемого явления (переменной), а могут быть связаны с ошибками измерения или аномальными явлениями, и поэтому не должны включаться в модель. гауссово распределение - то же, что и нормальное распределение (с формой колокола). генетический алгоритм - алгоритм поиска оптимальной битовой строки, который случайным образом выбирает начальную популяцию таких строк и затем подвергает их процессу искусственных мутаций, скрещивания и отбора по аналогии с естественным отбором. генетический алгоритм отбора входных данных - применение генетического алгоритма к нахождению оптимального набора входных переменных путем построения битовых масок, обозначающих, какие из переменных следует оставить на входе, а какие удалить. Этот алгоритм может служить этапом построения модели, на котором отбираются наиболее существенные переменные; затем отобранные переменные используются для построения обычной аналитической модели (например, линейной регрессии или нелинейного оценивания). гетероассоциативная сеть - сеть, в которой устанавливаются соответствия между произвольно выбранными входными и выходными векторами. гиперболический тангенс (tanh) - симметричная функция с гиперплоскость - гиперсфера - градиентный спуск - совокупность методов оптимизации нелинейных функционалов (например, функции ошибок нейронной сети, когда веса сети рассматриваются как аргументы функции), где с целью поиска минимума происходит последовательное продвижение во все более низкие точки в пространстве поиска. два значения (для нейронных сетей) - способ кодирования значений номинальных переменных, принимающих только два значения, при котором номинальной переменной соответствует один входной или выходной элемент, который может быть активен или неактивен. дельта - дельта с чертой (delta-bar-delta) - эвристическая модификация алгоритма обратного распространения для нейронных сетей, имеющая целью автоматическую коррекцию скорости обучения по каждой из координатных осей в пространстве поиска с тем, чтобы учесть особенности его топологии диаграмма кластеров (для нейронных сетей) - точечная диаграмма, на которой наблюдения из разных классов представлены на плоскости. Координаты на плоскости соответствуют выходным уровням некоторых нейронов сети. интерполяция - восстановление значения функции в промежуточной точке по известным ее значениям в соседних точках. квадратическая функция ошибок - функция ошибок, равная сумме (взятой по всем наблюдениям) квадратов разностей требуемых и реальных значений. квази-ньютоновский метод - процедура нелинейного оценивания, вычисляющая на каждом шаге значения функции в различных точках для оценивания первой и второй производной, и использующая эти данные для определения направления изменения параметров и минимизации функции потерь. классификация - отнесение наблюдения к одному из нескольких, заранее известных классов (представленных значениями номинальной выходной переменной). кодирование N-в-один (для нейронных сетей) - для номинальных переменных с числом значений, большим двух, - способ представления переменной с помощью одного элементов сети через его различные выходные значения. кодирование один-из-N (для нейронных сетей) - представление номинальной переменной с помощью набора входных или выходных элементов - по одному на каждое возможное номинальное значение. Во время обучения сети один из этих элементов бывает активен, а остальные -неактивны Кохонена обучение - алгоритм, размещающий центры кластеров радиального слоя посредством последовательной подачи на вход сети обучающих наблюдений и корректировки положения центра выигравшего (ближайшего) радиального элемента и соседних с ним в сторону обучающего наблюдения. Кохонена сети - нейронные сети, основанные на воспроизведении топологических свойств человеческого мозга. Известны также как самоорганизующиеся карты признаков (SOFM). кросс-проверка - процедура оценки точности прогнозирования с помощью данных из специальной тестовой выборки (используется также термин «кросс-проверочная выборка») путем сравнения точности прогноза с той, что достигается на обучающей выборке. В идеале, когда имеется достаточно большая выборка, часть наблюдений (например, половину или две трети) можно использовать для обучающей выборки, а оставшиеся наблюдения - для тестовой. Если на тестовой выборке модель дает результаты того же качества, что и на обучающей выборке, то говорят, что модель хорошо прошла кросс-проверку. Для выполнения кросс-проверки при малых объемах выборки разработаны специальные методы, в которых тестовая и обучающая выборки могут частично пересекаться. кросс-проверка (для нейронных сетей) - то же самое, что и вообще кросс-проверка. Применительно к нейронным сетям заключается в использовании во время итерационного обучения дополнительного множества данных (контрольного множества). В то время, как обучающее множество используется для корректировки весов сети, контрольное множество служит для независимой проверки того, как нейронная сеть научилась обобщать информацию. кросс-энтропия (для нейронных сетей) - функция ошибок, основанная на теоретико-информационных характеристиках. Особенно хорошо подходит для задач классификации. Имеется два варианта: для сетей с одним выходом и для сетей с несколькими выходами. В первом варианте используются логистические функции активации, во втором - так называемые функции софтмакс. Левенберга-Марквардта алгоритм - алгоритм нелинейной оптимизации, использующий для поиска минимума комбинированную стратегию - линейную аппроксимацию и градиентный спуск. Переключение с одной стратегии на другую происходит в зависимости от того, была ли успешной линейная аппроксимация. Такой подход называется моделью доверительных областей. линейная функция активации - тождественная функция активации. выходной сигнал элемента совпадает с его уровнем активации. линейное моделирование - аппроксимация дискриминантной или регрессионной функции с помощью гиперплоскости. Для этой гиперплоскости с помощью простых вычислений может быть найден глобальный оптимум. Однако таким образом нельзя построить адекватные модели для многих реальных задач. линейные нейроны - нейроны, имеющие линейную пост-синаптическую (PSP) функцию. Уровень активации такого нейрона представляет собой взвешенную сумму его входов, из которой вычитается пороговое значение (это называется также скалярным произведением или линейной комбинацией). Этот тип нейронов обычно используется в многослойных персептронах. Несмотря на название, линейные нейроны могут иметь нелинейные функции активации логистическая функция - функция с локальные минимумы - в большинстве практических приложений локальные минимумы функции потерь приводят к неправдоподобно большим или неправдоподобно малым значениям параметров с очень большими стандартными ошибками. Симплекс-метод нечувствителен к таким минимумам, поэтому он может быть использован для отыскания подходящих начальных значений для сложных функций. матрица несоответствий (для нейронных сетей) - в задачах классификации так иногда называют матрицу, в которой для каждого класса наблюдений приводится количество наблюдений, отнесенных сетью к этому и другим классам. матрица потерь - квадратная матрица, при умножении которой на вектор вероятностей принадлежности к классам получается вектор оценок потерь от ошибок классификации. На основе этого вектора можно принимать решения, приводящие к наименьшим потерям. метод наименьших квадратов - общий смысл оценивания по методу наименьших квадратов заключается в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной от значений, предсказанных моделью. метод Розенброка - метод нелинейного оценивания, вращающий пространство параметров, располагая одну ось вдоль «гребня» поверхности (он называется также методом вращения координат - method of rotating coordinates), при этом все другие остаются ортогональными относительно выбранной оси. Если поверхность графика функции потерь имеет одну вершину и различимые «гребни» в направлении минимума этой функции, то данный метод приводит к очень точным значениям параметров, минимизирующим функцию потерь. метод сопряженных градиентов - быстрый метод обучения многослойных персептронов, осуществляющий последовательный линейный поиск в пространстве ошибок. Последовательные направления поиска выбираются сопряженными (не противоречащими друг другу). метод Хука-Дживса - метод нелинейного оценивания, который при каждой итерации сначала определяет схему расположения параметров, оптимизируя текущую функцию потерь перемещением каждого параметра по отдельности. При этом вся совокупность параметров сдвигается в новое положение. Это новое положение в минимакс - алгоритм определения коэффициентов линейного масштабирования для набора чисел. Находятся минимальное и максимальное значения, затем масштабирующие коэффициенты выбираются таким образом, чтобы преобразованный набор данных имел заранее заданные минимальное и максимальное значения. многослойные персептроны - нейронные сети с прямой передачей сигнала, линейными PSP-функциями и, как правило, нелинейными функциями активации. нейрон - элемент нейронной сети. нейронные сети - класс аналитических методов, построенных на (гипотетических) принципах функционирования мозга и позволяющих прогнозировать значения некоторых переменных в новых наблюдениях по данным других наблюдений (для этих же или других переменных) после прохождения этапа так называемого обучения на имеющихся данных. нелинейное оценивание - используется при неадекватности линейной модели путем добавления в уравнение модели нелинейных членов. В нелинейном оценивании выбор характера зависимости остается за исследователем. Например, можно определить зависимую переменную как логарифмическую функцию от предикторной переменной, как степенную функцию или как любую другую композицию элементарных функций от предикторов. неуправляемое обучение или обучение без учителя (для нейронных сетей) - алгоритмы обучения, в которых на вход нейронной сети подаются данные, содержащие только значения входных переменных. Такие алгоритмы предназначены для нахождения кластеров во входных данных. номинальные переменные - переменные, которые могут принимать конечное множество значений. В нейронных сетях номинальные выходные переменные используются в задачах классификации, в отличие от задач регрессии. нормировка - корректировка длины вектора посредством некоторой суммирующей функции (например, на единичную длину или на единичную сумму компонент). обобщение (для нейронных сетей) - способность нейронной сети делать точный прогноз на данных, не принадлежащих исходному обучающему множеству (но взятых из того же источника). Обычно это качество сети достигается разбиением имеющихся данных на три подмножества; первое из них используется для обучения сети, второе - для кросспроверки алгоритма обучения во время его работы, и третье - для окончательного независимого тестирования обобщенно-регрессионная нейронная сеть (GRNN) - вид нейронной сети, где для регрессии используются ядерная аппроксимация. Один из видов так называемых байесовых сетей. обратное распространение (backpropagation learning rule) - алгоритм обучения многослойных персептронов. Надежный и хорошо известный, однако существенно более медленный по сравнению с некоторыми современными алгоритмами. окрестность (для нейронных сетей) - в обучении по Кохонену - «квадрат», составленный из нейронов, окружающих «выигравший» нейрон, которые одновременно корректируются при обучении. отдельное наблюдение (для нейронных сетей) - наблюдение, данные которого вводятся с клавиатуры и которые затем подаются на вход нейронной сети отдельно (а не как часть какого-то файла данных; в обучении такие наблюдения не участвуют) отклика поверхность - поверхность, изображенная в трехмерном пространстве, представляющая отклик одной или нескольких переменных (в нейронной сети) в зависимости от двух входных переменных при постоянных остальных. отклонение - в радиальных элементах - величина, на которую умножается квадрат расстояния от элемента до входного вектора, в результате чего получается аргумент, который затем пропускается через функцию активации элемента. отношение стандартных отклонений - в задачах регрессии - отношение стандартного отклонения ошибки прогноза к стандартному отклонению исходных выходных данных Чем меньше отношение, тем выше точность прогноза. Эта величина равна единице минус объясненная доля дисперсии модели. перемешивание данных (для нейронных сетей) - случайное разбиение наблюдений на обучающее и контрольное множества, таким образом, чтобы они (насколько это возможно) получились статистически несмещенными. перемешивание, обратное распространение (для нейронных сетей) - подача обучающих наблюдений на каждой эпохе в случайном порядке с целью предотвращения различных нежелательных эффектов, которые могут иметь место без этого приема (например, осцилляции и сходимость к локальным минимумам) переобучение (для нейронных сетей) - при итерационном обучении - чрезмерно точная подгонка, которая имеет место, если алгоритм обучения работает слишком долго (а сеть слишком сложна для такой задачи или для имеющегося объема данных). пост-синаптическая потенциальная функция ( радиальные (промасштабированный квадрат расстояния от вектора весов до входного вектора) PSP-функции присоединение сети - действие, позволяющее сделать из двух нейронных сетей (совместимых по выходному и входному слоям) одну составную сеть промежуточные (скрытые) слои (для нейронных сетей) - все слои нейронной сети, кроме входного и выходного, придают сети способность моделировать нелинейные явления прямой передачи сети - нейронные сети с различной структурой слоев, в которых все соединения ведут только в от входов к выходам Иногда используется как синоним для многослойных персептронов псевдо-обратных метод - эффективный метод оптимизации линейных моделей, известен также под названием «сингулярное разложение матрицы» радиальные базисные функции - вид нейронной сети, имеющей промежуточный слой из радиальных нейронов и выходной слой из линейных элементов Сети этого типа довольно компактны и быстро обучаются расстояние «городских кварталов» (расстояние Манхэттена) -это расстояние является средним разностей по координатам В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного евклидова расстояния Однако отметим, что для этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как они не возводятся в квадрат) расстояние Махаланобиса - независимые переменные в уравнении регрессии можно представлять точками в многомерном пространстве (каждое наблюдение - точка) В этом пространстве можно построить «средняя точка» - центроид, т. е. центр тяжести Расстояние Махаланобиса определяется как расстояние от наблюдаемой точки до центра тяжести в многомерном пространстве, определяемом коррелированными (неортогональными) независимыми переменными Эта мера позволяет, в частности, определить является ли данное наблюдение выбросом по отношению к остальным значениям независимых переменных Если независимые переменные некоррелированы, то расстояние Махаланобиса совпадает с евклидовым расстоянием регрессия - категория задач, где цель состоит оценке значений непрерывной выходной переменной по значениям входных переменных регуляризация (для нейронных сетей) - модификация алгоритмов обучения, имеющая цель предотвратить пере- и недо-подгонку на обучающих данных за счет введения штрафа за сложность сети (обычно штрафуются большие значения весов - они означают, что отображение, моделируемое сетью, имеет большую кривизну) самоорганизующиеся карты признаков (SOFMs, сети Кохонена) - нейронные сети, основанные на воспроизведении топологических свойств человеческого мозга, известны также как сети Кохонена сигмоидная функция - функция, график которой имеет симплекс-метод - метод нелинейного оценивания, не использующий производные функции потерь Вместо этого, при каждой итерации функция оценивается в скорость обучения (для нейронных сетей) - управляющий параметр некоторых алгоритмов обучения, который контролирует величину шага при итерационной коррекции весов софтмакс - функция активации, предназначенная для классификационных сетей с кодированием по методу один-из-N Вычисляет нормированную экспоненту (т. е. сумма выходов равна единице) В сочетании с кросс-энтропийной функцией ошибок позволяет модифицировать многослойный персептрон для оценки вероятностей принадлежности классам сохранение лучшей сети - возможность автоматически запоминать лучшую из сетей, обнаруженных в процессе обучения, с тем, чтобы по окончании экспериментов восстановить ее среднего/стандартного отклонения алгоритм (для нейронных сетей) - алгоритм для определения коэффициентов линейного масштабирования набора чисел Находятся среднее значение и стандартное отклонение данных, затем масштабирующие коэффициенты выбираются таким образом, чтобы преобразованный набор данных имел заранее заданные значения среднего и стандартного отклонения среднее - показывает «центральное положение» переменной среднеквадратическая (RMS) ошибка - для вычисления среднеквадратической ошибки все отдельные ошибки возводятся в квадрат, суммируются, сумма делится на общее число ошибок, затем из всего извлекается квадратный корень Полученное в результате число характеризует суммарную ошибку управляемое обучение или обучение с учителем (для нейронных сетей) - алгоритмы обучения, в которых на вход нейронной сети подаются данные, содержащие известные значения выходных переменных, а корректировка весов сети производится по результатам сравнения фактических выходных значений с требуемыми условия остановки - для итерационного процесса (подгонки, поиска, обучения) - условия, при выполнении которых процесс завершается Например, для нейронных сетей условиями остановки могут быть максимальное число эпох, целевое значение ошибки или порог ее минимального улучшения функция активации нейронной сети - функция, которая используется для преобразования уровня активации нейрона в выходной сигнал Вместе с PSP-функцией (которая применяется сначала) определяет тип нейрона сети функция ошибок (для нейронных сетей) - служит для определения качества работы нейронной сети во время итерационного обучения и последующих рабочих запусков. Градиент функции ошибок используется в формулах алгоритмов итерационного обучения. функция ошибок городских кварталов (для нейронных сетей) - вычисляет расстояние между двумя векторами как сумму модулей разностей их компонент. Менее чувствительна к выбросам, чем квадратическая функция ошибок, но при этом обычно дает худшие результаты обучения. функция потерь - функция, которая минимизируется в процессе подгонки модели. Она представляет выбранную меру несогласия наблюдаемых данных и данных, предсказываемых подогнанной функцией. Например, в большинстве традиционных методов построения общих линейных моделей, функция потерь (часто называемая наименьшими квадратами) вычисляется как сумма квадратов отклонений от подогнанной линии или плоскости. Одним из свойств (которое обычно рассматривается как недостаток) этой распространенной функции потерь является высокая чувствительность к наличию выбросов. Распространенной альтернативой минимизации функции потерь наименьших квадратов (см. выше) является максимизация функции правдоподобия или логарифма функции правдоподобия (или минимизация функции правдоподобия со знаком минус). Эти функции обычно используются для подгонки нелинейных моделей. частота выигрышей (для нейронных сетей) - для радиальных элементов сети Кохонена - число раз, когда нейрон выигрывал при прогоне файла данных. Часто, выигрывавшие нейроны представляют центры кластеров на топологической карте. чрезмерно близкая подгонка - при восстановлении функции по набору ее значений - построение кривой с большой кривизной, которая хорошо удовлетворяет заданным значениям, но плохо моделирует исходное отображение, поскольку форма кривой искажена помехами, присутствующими в данных. шум, добавление (для нейронных сетей) - способ предотвращения переобучения при обучении нейронной сети методом обратного распространения. Во время обучения к данным входных наблюдений добавляется случайный шум (в результате чего обучающие данные «смазываются»), эвристика - в противоположность алгоритму (который описывает вполне определенный набор операций для получения конкретного результата), эвристики - это общие рекомендации, основанные на статистической очевидности или теоретических рассуждениях. экстраполяция - прогнозирование неизвестных значений путем продолжения функций за границы области известных значений. эпоха (для нейронных сетей) - в итерационном обучении нейронной сети - один проход по всему обучающему множеству с последующей проверкой на контрольном множестве. ядерные функции - функции известного типа (как правило, гауссовы), которые размещаются в соответствии с известными данными, которые затем суммируются, и, таким образом, строится аппроксимация выборочного распределения.
|
 |
Оглавление
|





































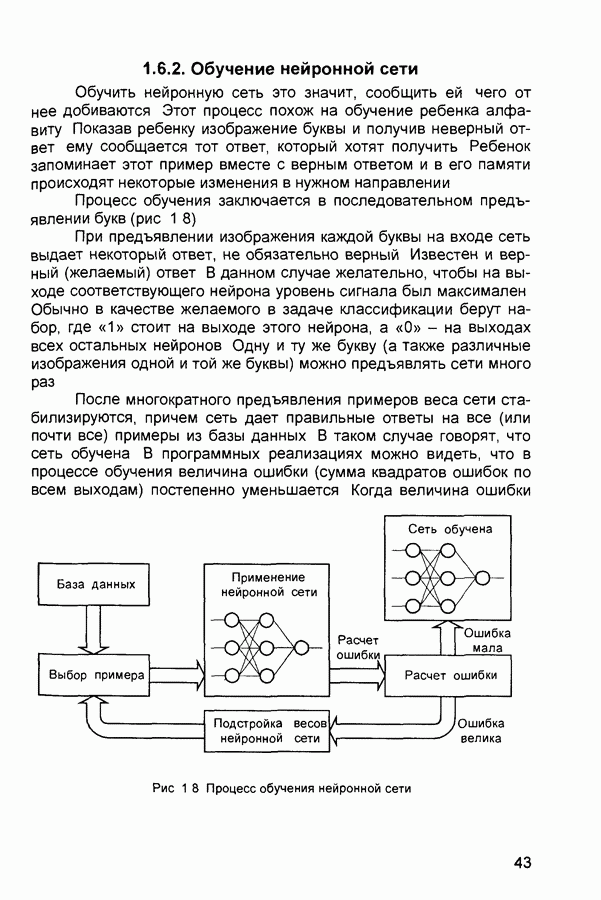


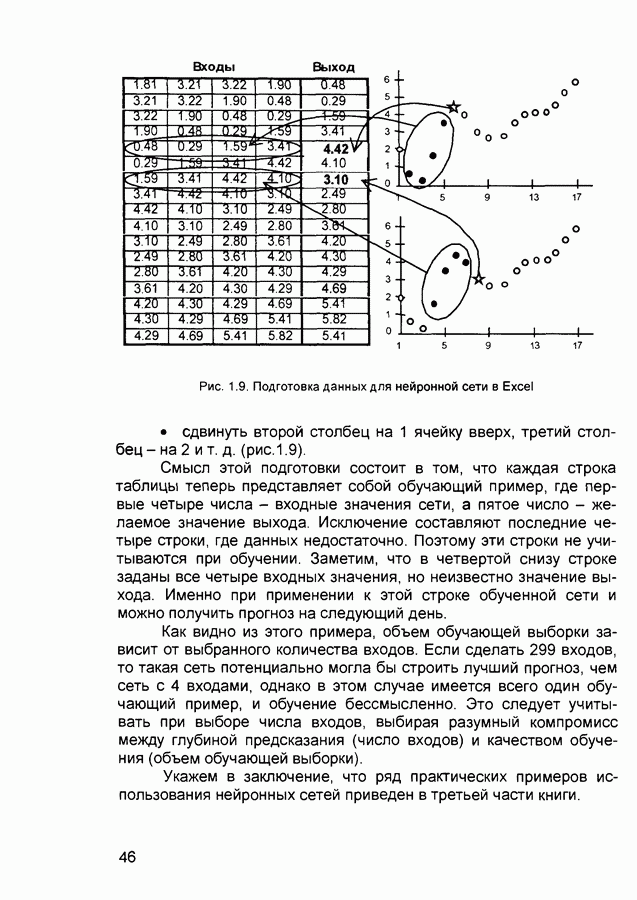









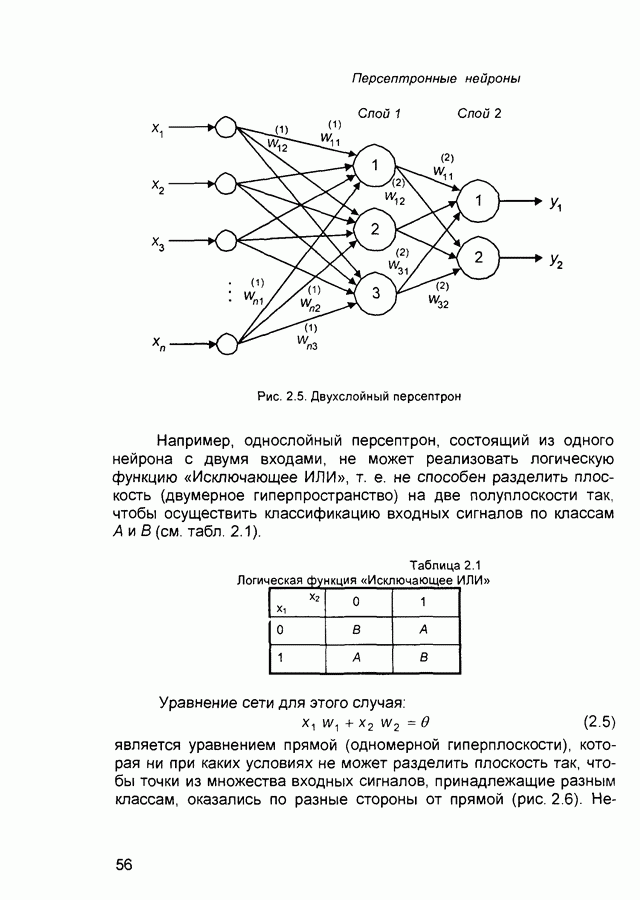


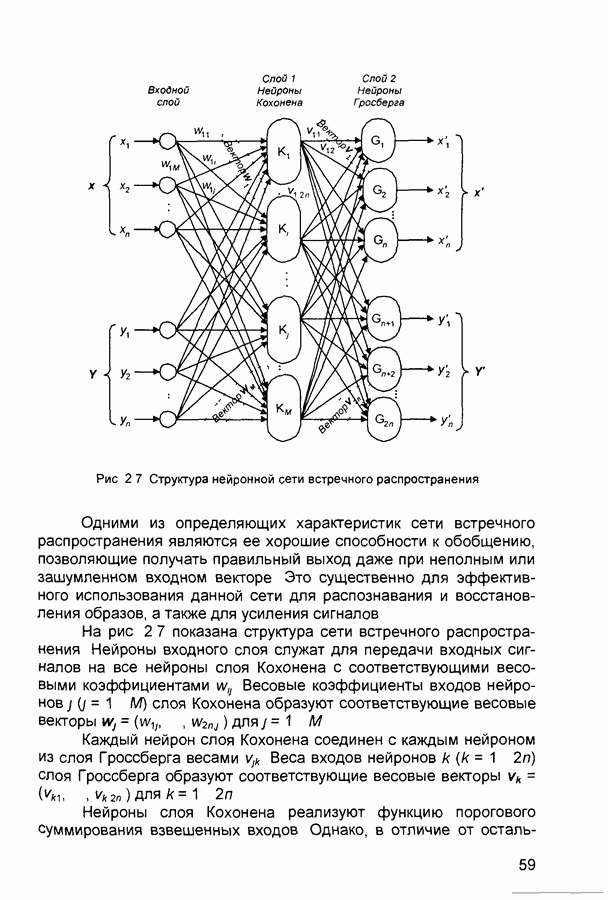






























































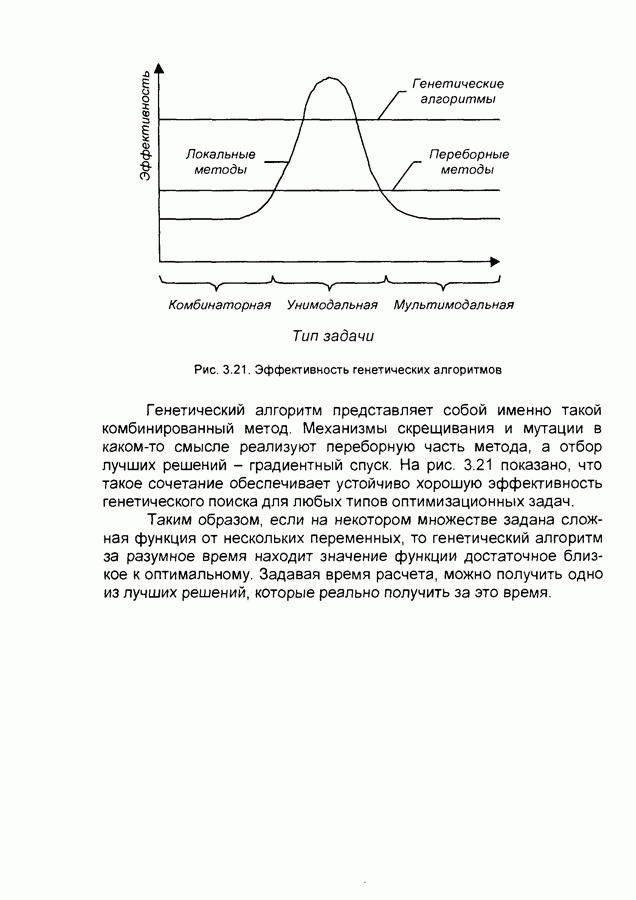




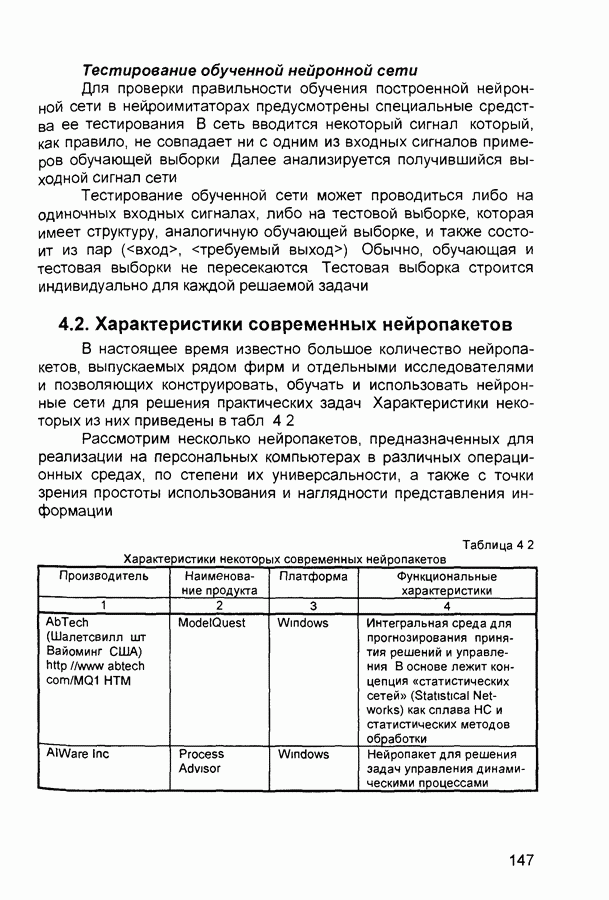
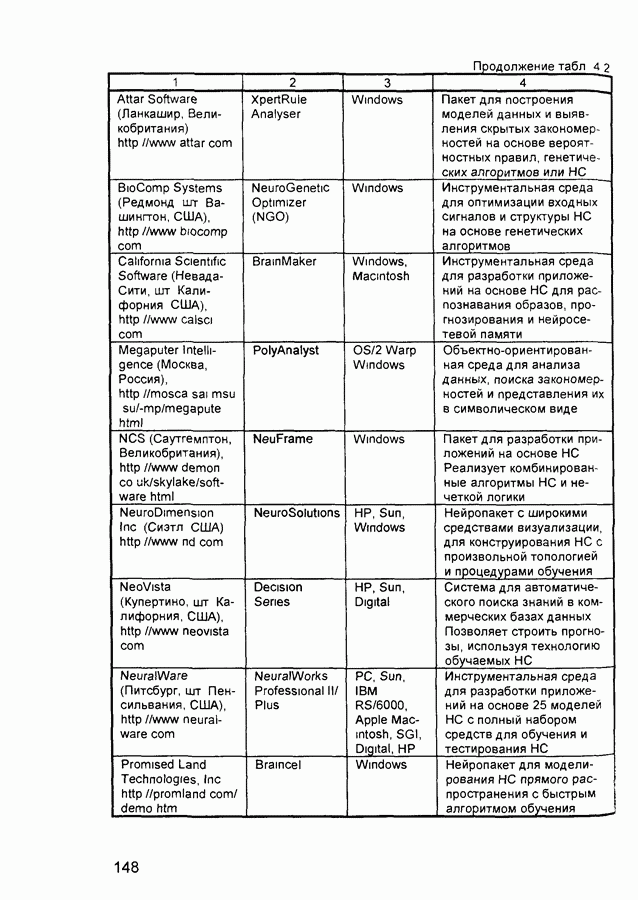
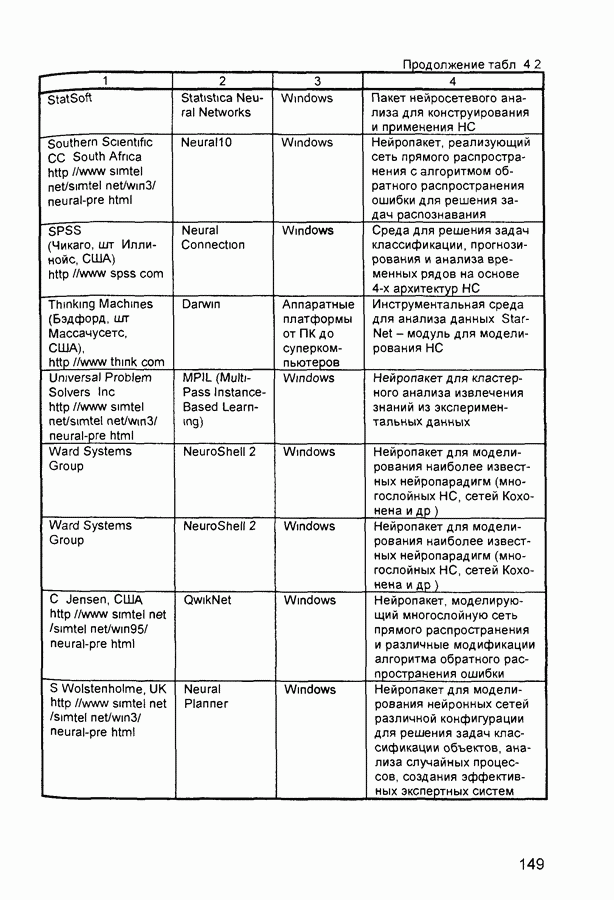





























































































































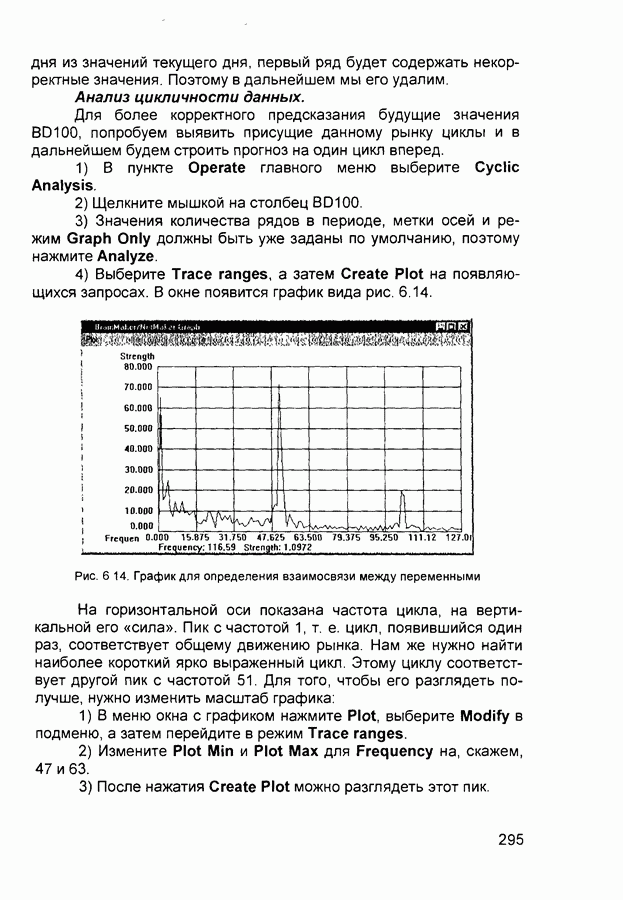

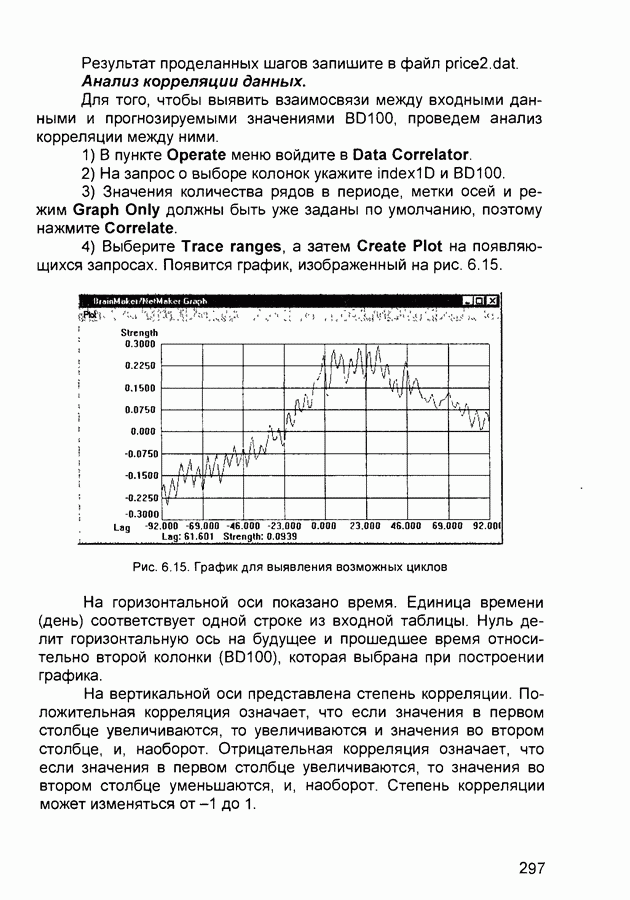




































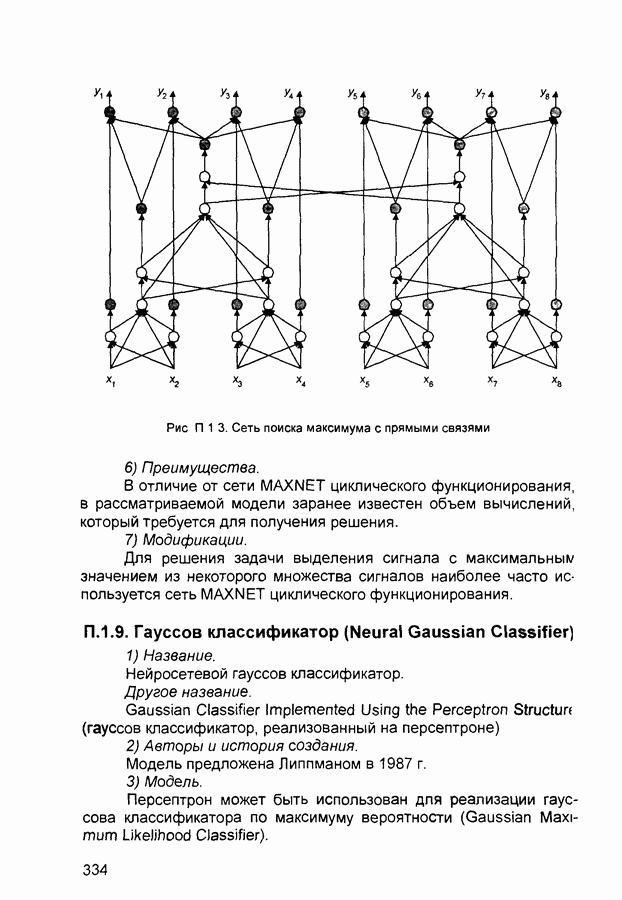







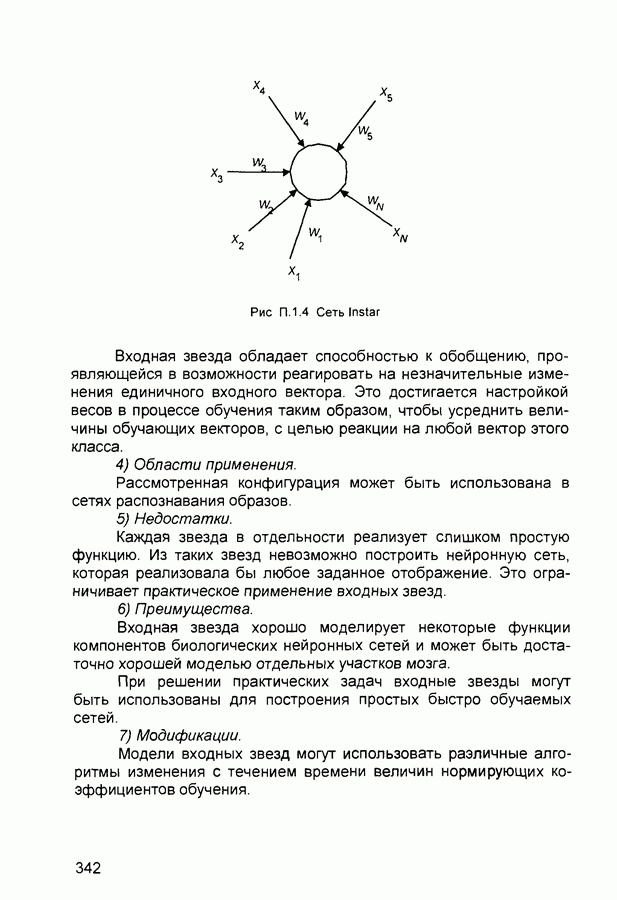


































 квадрат ошибки сети на
квадрат ошибки сети на  шаге обучения,
шаге обучения,  коэффициент скорости обучения (learning rate), а - коэффициент импульса (momentum) или коэффициент инерционности.
коэффициент скорости обучения (learning rate), а - коэффициент импульса (momentum) или коэффициент инерционности.
 то выходной результат (output), выдаваемый нейронной сетью, должен абсолютно точно совпадать с образцом для обучения (pattern). В большинстве случаев это нереально. При
то выходной результат (output), выдаваемый нейронной сетью, должен абсолютно точно совпадать с образцом для обучения (pattern). В большинстве случаев это нереально. При  выход нейронной сети (output) будет рассматриваться как корректный, если он отличается не более чем на 10% (в среднем квадратическом смысле) от заданного значения (pattern). Процесс обучения будет продолжаться до тех пор, пока значение ошибки не снизится до установленного параметром tolerance предела.
выход нейронной сети (output) будет рассматриваться как корректный, если он отличается не более чем на 10% (в среднем квадратическом смысле) от заданного значения (pattern). Процесс обучения будет продолжаться до тех пор, пока значение ошибки не снизится до установленного параметром tolerance предела.

 производная ошибки сети по весовому коэффициенту;
производная ошибки сети по весовому коэффициенту;  взвешенное среднее.
взвешенное среднее.


 -партан) и модифицированный партан-методы. Итерационный партан-метод строится следующим образом. В начальной базовой точке вычисляется градиент и делается шаг наискорейшего спуска. Далее - снова наискорейший спуск и так к раз. После к шагов наискорейшего спуска проводится одномерная оптимизация с начальным шагом, равным единице в направлении между начальной базовой точкой и полученной после к шагов. После этого цикл повторяется.
-партан) и модифицированный партан-методы. Итерационный партан-метод строится следующим образом. В начальной базовой точке вычисляется градиент и делается шаг наискорейшего спуска. Далее - снова наискорейший спуск и так к раз. После к шагов наискорейшего спуска проводится одномерная оптимизация с начальным шагом, равным единице в направлении между начальной базовой точкой и полученной после к шагов. После этого цикл повторяется.
 ошибки сети от каждого весового коэффициента может быть аппроксимирована выпуклой параболой,
ошибки сети от каждого весового коэффициента может быть аппроксимирована выпуклой параболой,

 - производная ошибки сети по весовому коэффициенту
- производная ошибки сети по весовому коэффициенту  на
на  шаге обучения
шаге обучения
 так что формула коррекции отображает метод Ньютона минимизации скалярной функции
так что формула коррекции отображает метод Ньютона минимизации скалярной функции

 как и в других алгоритмах - это коэффициент скорости обучения (learning rate)
как и в других алгоритмах - это коэффициент скорости обучения (learning rate)



 и постоянная вне его
и постоянная вне его
 -образная функция, преобразующая значения аргумента из интервала
-образная функция, преобразующая значения аргумента из интервала  в значения функции из конечного интервала, например,
в значения функции из конечного интервала, например,  или
или 
 в значения функции, образующие интервал конечной длины
в значения функции, образующие интервал конечной длины
 данной матрицы (матрицы
данной матрицы (матрицы  отображает вес связи от
отображает вес связи от  входа ку-му нейрону
входа ку-му нейрону
 точках
точках  Начиная со случайной выборки из
Начиная со случайной выборки из  точек, расположение центров кластеров последовательно корректируется таким образом, чтобы каждая из
точек, расположение центров кластеров последовательно корректируется таким образом, чтобы каждая из  точек относилась ровно к одному из К кластеров, и центр каждого кластера совпадал с центром тяжести относящихся к нему точек.
точек относилась ровно к одному из К кластеров, и центр каждого кластера совпадал с центром тяжести относящихся к нему точек.
 -образной (сигмоидальной) формой графика; используется как альтернатива логистической функции.
-образной (сигмоидальной) формой графика; используется как альтернатива логистической функции.
 -мерный аналог прямой линии или плоскости, делит (
-мерный аналог прямой линии или плоскости, делит ( -мерное пространство на две части.
-мерное пространство на две части.
 -мерный аналог окружности или сферы, горизонт (для нейронных сетей) - у нейронных сетей для анализа временных рядов - число шагов по времени, считая от последнего входного значения, на которое нужно спрогнозировать значения выходной переменной.
-мерный аналог окружности или сферы, горизонт (для нейронных сетей) - у нейронных сетей для анализа временных рядов - число шагов по времени, считая от последнего входного значения, на которое нужно спрогнозировать значения выходной переменной.
 -образной (сигмоидной) формой графика, принимающая значения из интервала
-образной (сигмоидной) формой графика, принимающая значения из интервала  .
.
 -мерном пространстве параметров определяется экстраполяцией вдоль линии, соединяющей текущую базовую точку с новой. Размер шага этого процесса постоянно меняется для попадания в оптимальную точку. Этот метод обычно очень эффективен, и его следует использовать в том случае, когда ни квази-ньютоновский, ни симплекс-метод не дают удовлетворительных оценок.
-мерном пространстве параметров определяется экстраполяцией вдоль линии, соединяющей текущую базовую точку с новой. Размер шага этого процесса постоянно меняется для попадания в оптимальную точку. Этот метод обычно очень эффективен, и его следует использовать в том случае, когда ни квази-ньютоновский, ни симплекс-метод не дают удовлетворительных оценок.
 -функция) -функция, которая применяется к входным сигналам нейрона, его весам и порогам и выдает уровень активации этого нейрона. Наиболее часто используются линейные (взвешенная сумма входов минус порог) и
-функция) -функция, которая применяется к входным сигналам нейрона, его весам и порогам и выдает уровень активации этого нейрона. Наиболее часто используются линейные (взвешенная сумма входов минус порог) и
 -образную форму, дающая приблизительно линейный отклик в середине входного диапазона и эффект насыщения на его концах
-образную форму, дающая приблизительно линейный отклик в середине входного диапазона и эффект насыщения на его концах
 точках
точках  -мерного пространства Например, на плоскости (т. е. при оценивании двух параметров) программа будет вычислять значение функции потерь в трех точках в окрестности текущего минимума Эти три точки определяют треугольник, в многомерном пространстве получаемая фигура называется симплексом
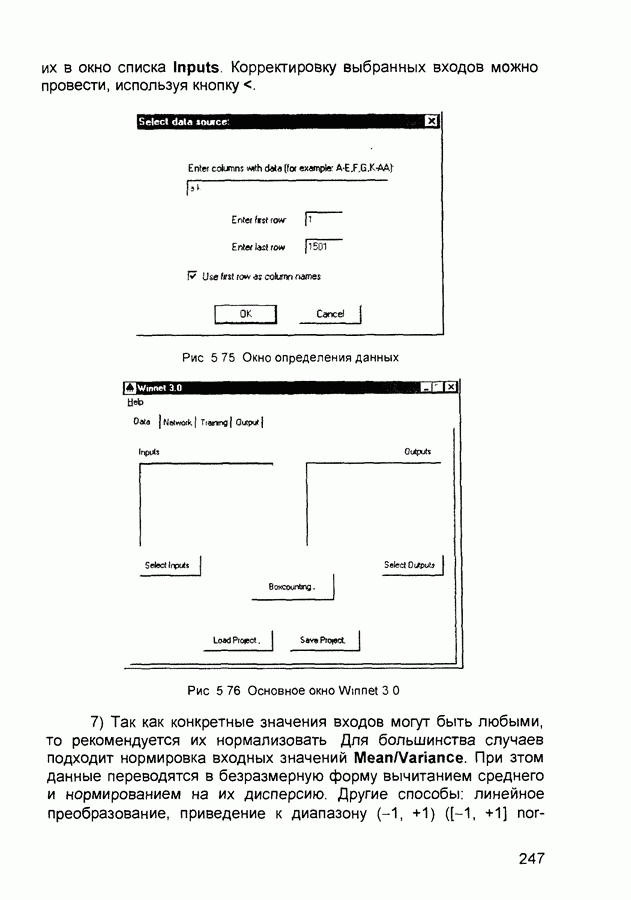
-мерного пространства Например, на плоскости (т. е. при оценивании двух параметров) программа будет вычислять значение функции потерь в трех точках в окрестности текущего минимума Эти три точки определяют треугольник, в многомерном пространстве получаемая фигура называется симплексом