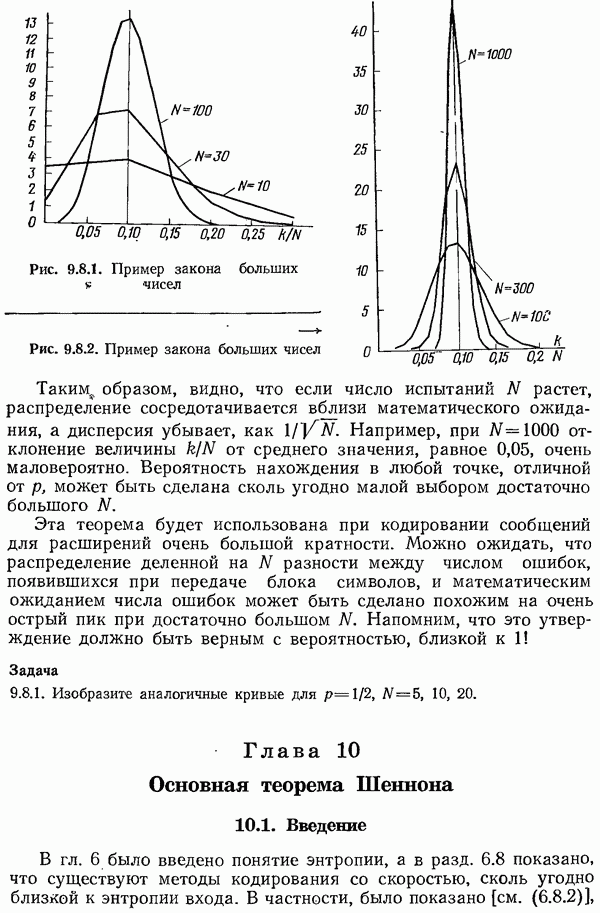
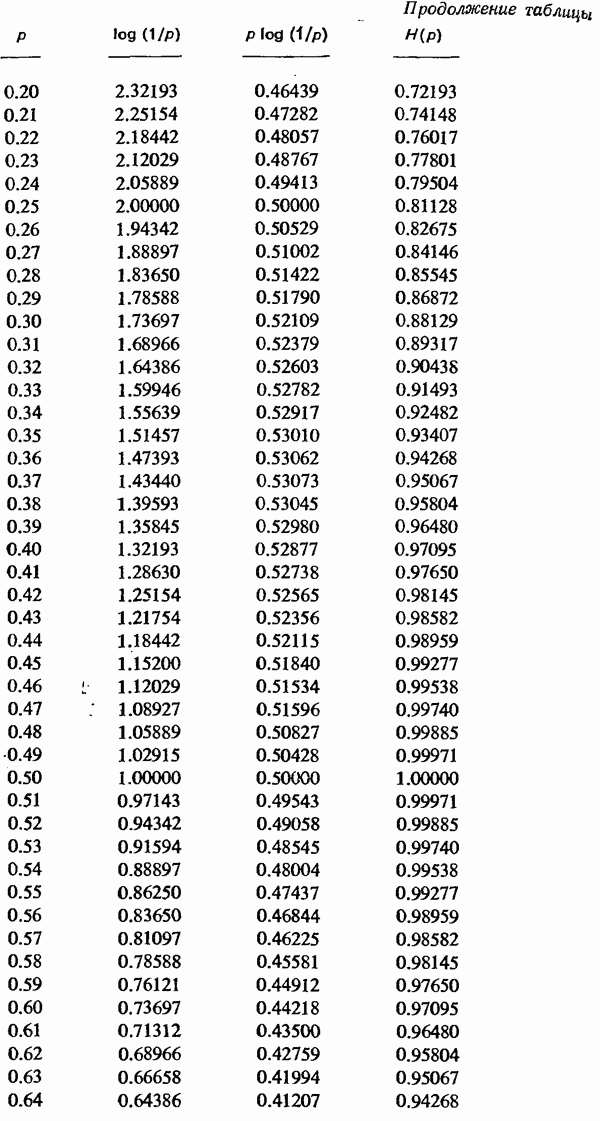
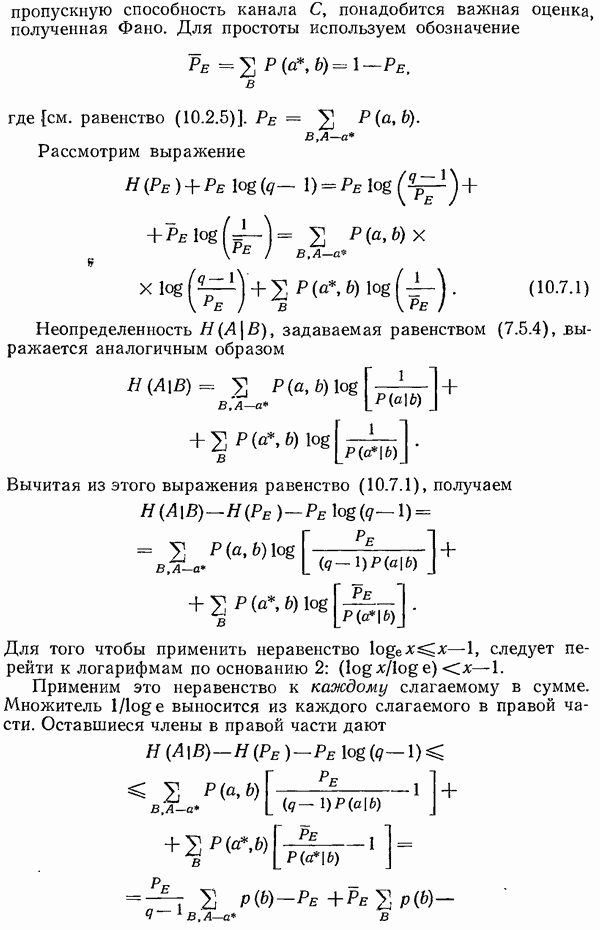Глава 11. Алгебраическая теория кодирования
11.1. Введение
Основная теорема Шеннона показывает, что можно передавать сигналы со скоростью, сколь угодно близкой к максимально возможной, делая при этом сколь угодно малое число ошибок. Доказательство основано на случайном кодировании, использующем очень длинные коды; в очень длинном слове с большой вероятностью произойдет много ошибок, которые должны быть исправлены приемником. В гл. 3 показано, как построить коды с исправлением одиночных и обнаружением двойных ошибок. Покажем теперь, как построить и реализовать некоторые коды с исправлением многократных ошибок.
Идея случайного кодирования кажется привлекательной до тех пор, пока не начинаешь думать об аппаратуре, которую нужно использовать на приемном и передающем концах. Если длина кода очень велика, то кодовая таблица должна быть очень большой, так как по определению в случайном коде не может быть никаких закономерностей, т. е. каждое кодовое слово нужно искать отдельно, поскольку не может быть никакой формулы, позволяющей вычислять закодированное сообщение по информации от источника. Хотя передавалось только одно из  возможных сообщений, таблица для декодирования должна быть еще длиннее, вследствие того, что принятым может оказаться любая из
возможных сообщений, таблица для декодирования должна быть еще длиннее, вследствие того, что принятым может оказаться любая из  последовательностей длины
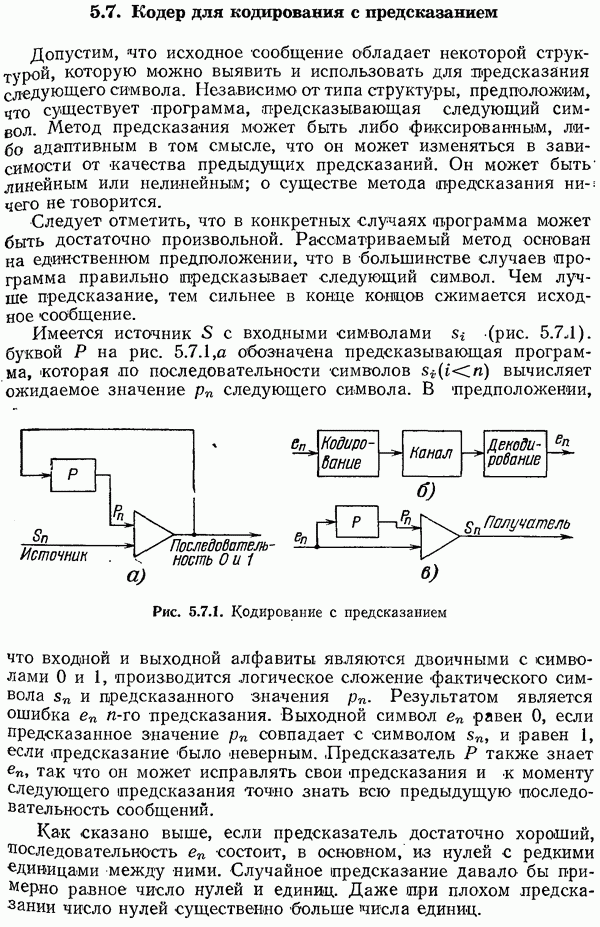
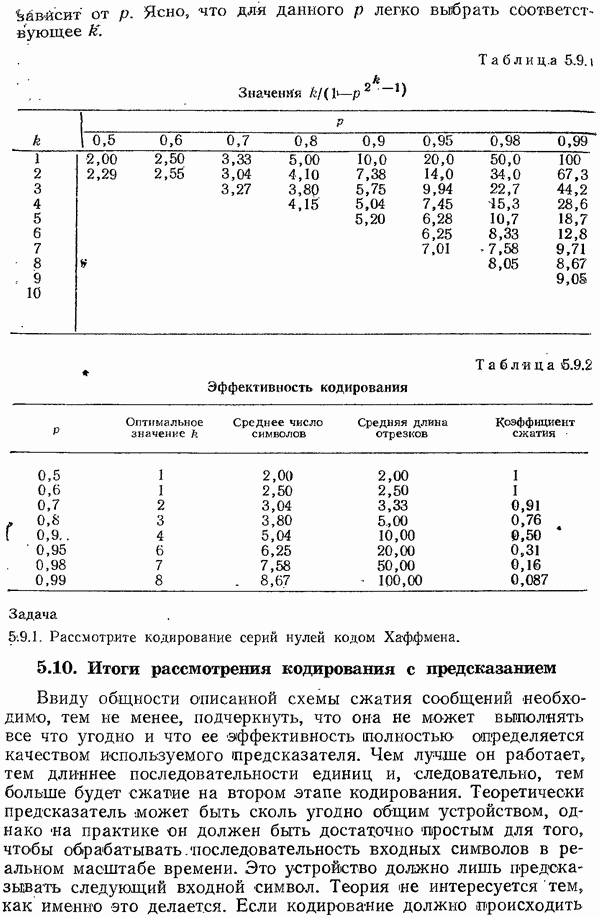
последовательностей длины  (в двоичном канале), и для каждой такой последовательности должно быть отведено место в таблице. В противном случае для нахождения правильного сообщения нужно проделать очень много вычислений. Следовательно, практическое использование случайных кодов представляется безнадежным. Здесь уместно напомнить о кодах с перемешиванием (разд. 5.11-5.14).
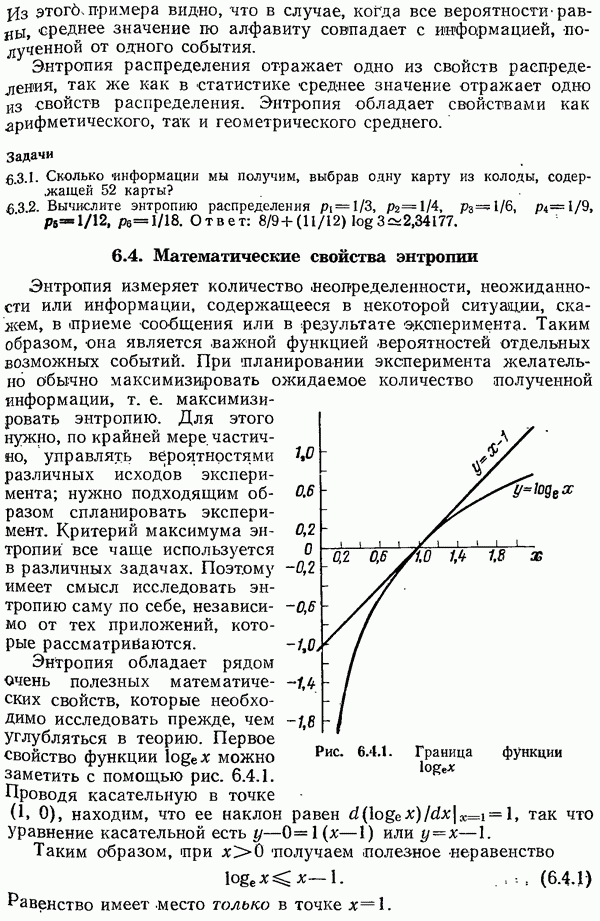
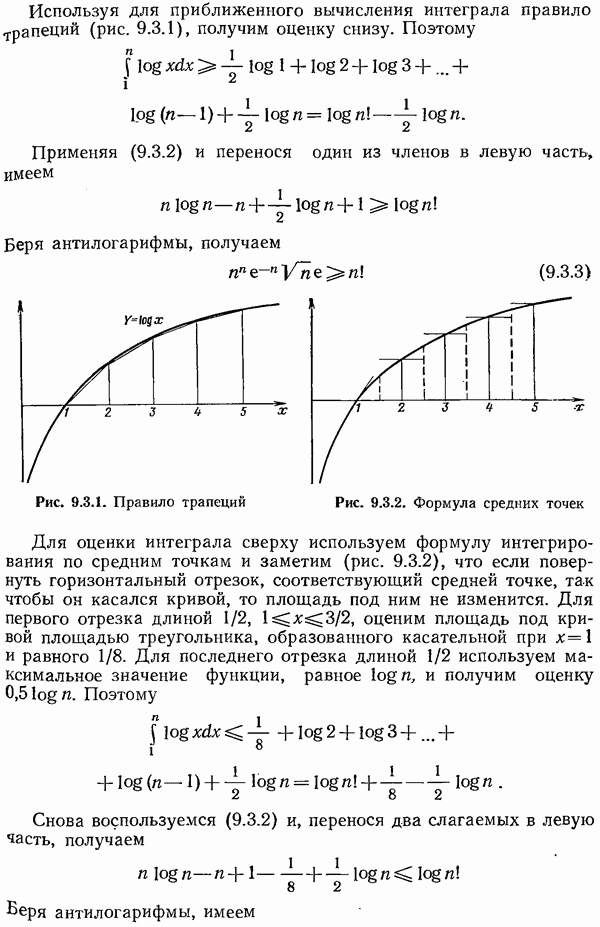
(в двоичном канале), и для каждой такой последовательности должно быть отведено место в таблице. В противном случае для нахождения правильного сообщения нужно проделать очень много вычислений. Следовательно, практическое использование случайных кодов представляется безнадежным. Здесь уместно напомнить о кодах с перемешиванием (разд. 5.11-5.14).
Таким образом, следует искать коды, обладающие некоторой структурой. Для этого нужна алгебраическая теория конечных
полей (полей Галуа). Алгебраическая теория кодирования является очень обширной, и здесь она будет лишь слегка затронута, что позволит показать некоторые идеи, лежащие в основе построения (кодов с исправлением многократных ошибок.
Настоящая книга не предназначена для специалистов, проектирующих системы кодирования, хорошо приспособленные к сложным ситуациям; она предназначена для тех, кто хочет познакомиться с имеющимися достижениями. Если возникнет ситуация, требующая более сложной теории, то, как мы надеемся, читатель сможет по крайней мере уяснить себе имеющиеся у него возможности и обратиться к другим книгам для выяснения дальнейших подробностей (например, [2, 6, 8, 11 —13, 15, 16]). Следует, однако, предостеречь читателя, сказав, что на практике шум известен недостаточно хорошо для того, чтобы использовать многие сложные коды (обычно основанные на предположении о том, что шум является белым). Иногда, однако, он известен достаточно хорошо.
Основное внимание уделим двоичным кодам потому, что они чаще всего используются и потому, что коды с основанием  до известной степени более сложны в обозначениях, хотя требуемые для их рассмотрения идеи отличаются обычно несущественно.
до известной степени более сложны в обозначениях, хотя требуемые для их рассмотрения идеи отличаются обычно несущественно.