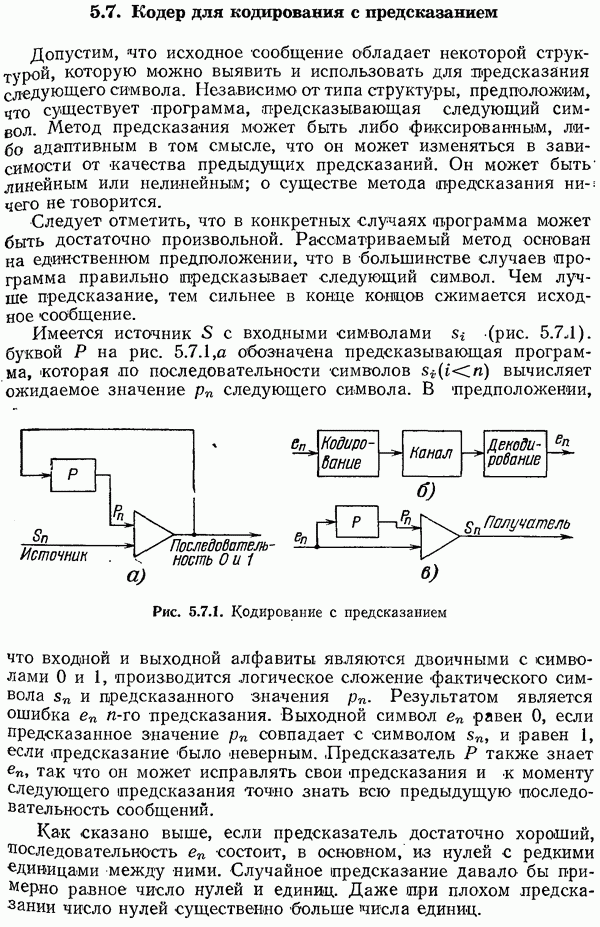
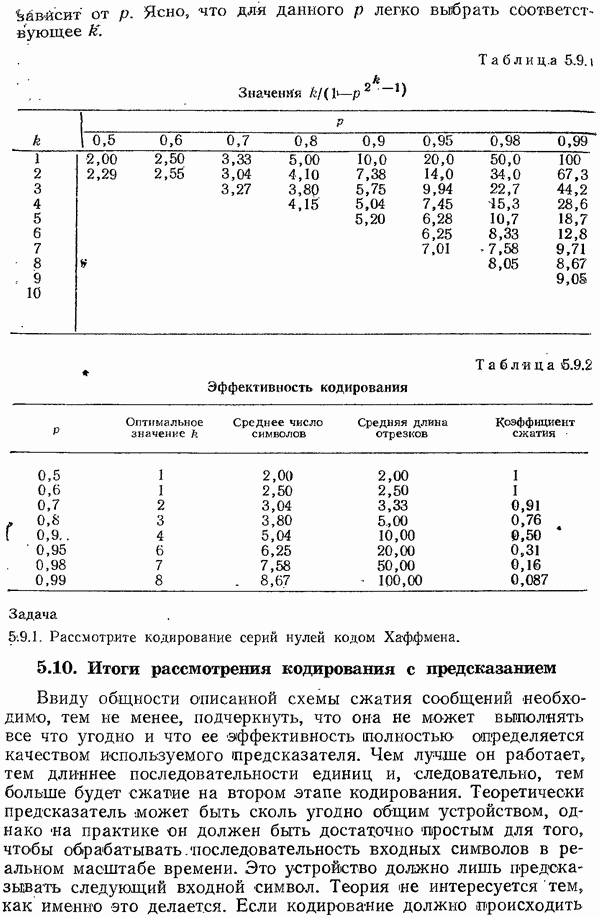
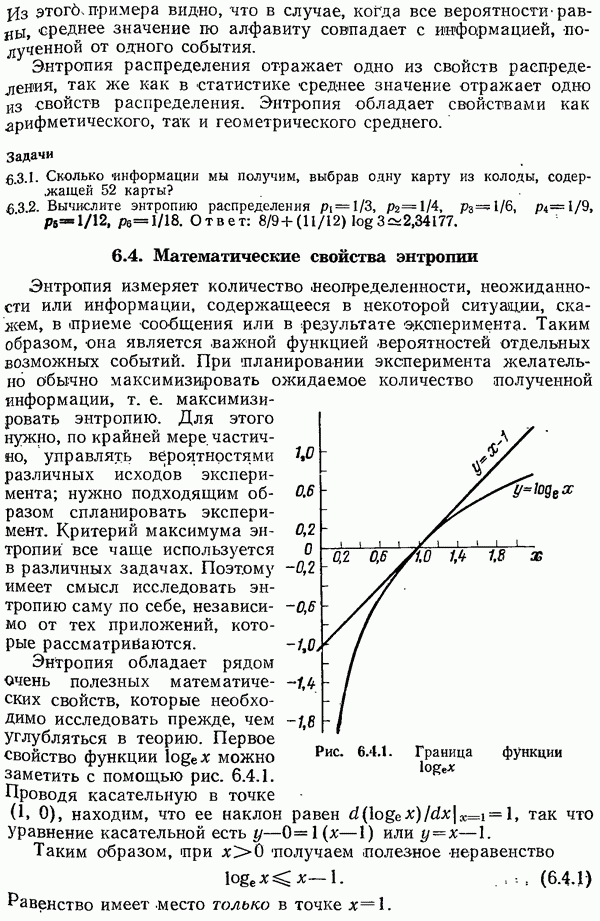
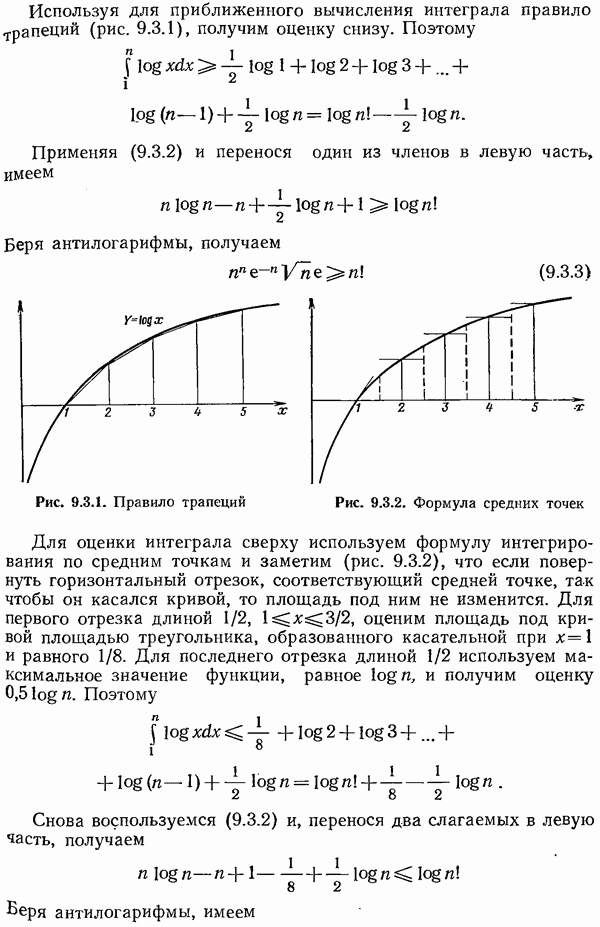
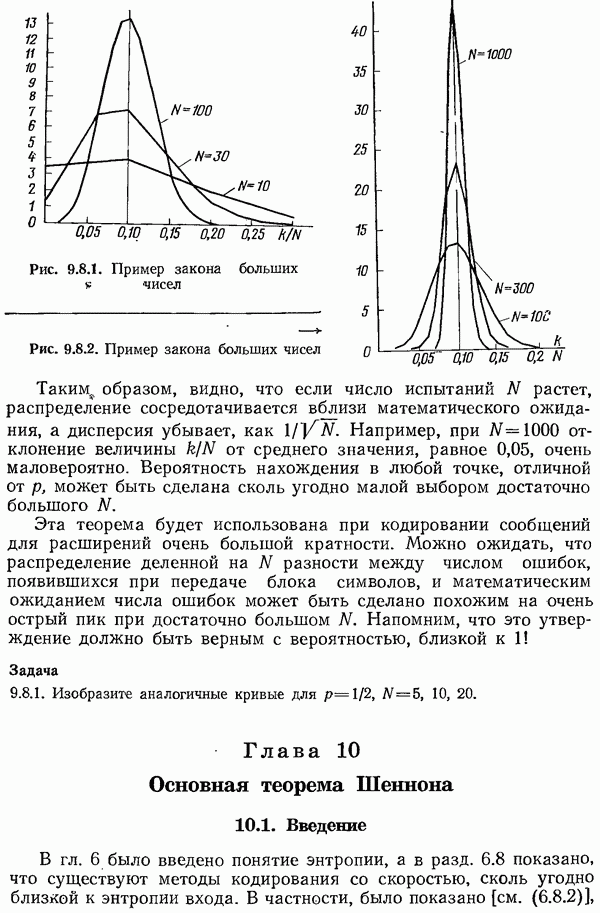
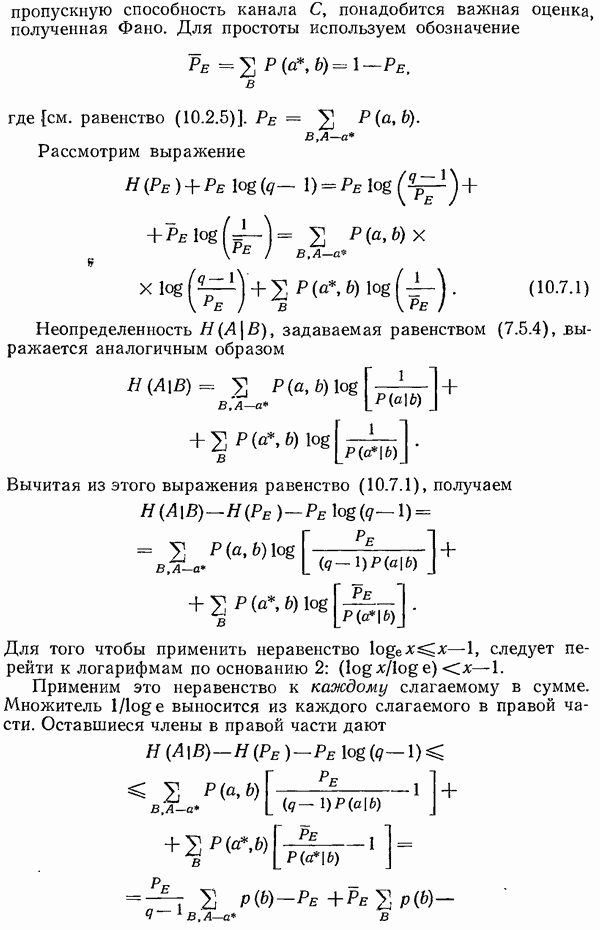5.14. Итоги рассмотрения перемешивания
Если имеется набор имен, которые представляются очень длинными последовательностями символов (по крайней мере некоторые из них), то описанный метод сжимает их до последовательностей, длина которых лишь слегка превосходит минимальную. Некоторое превышение минимальной избыточности уменьшает частоту столкновений и сопутствующие им затраты машинного времени. Вопрос о том, насколько превысить минимально возможную длину (в битах), должен решаться инженерами. В нашем примере использовался один лишний двоичный символ, и примерно половина ячеек таблицы оставалась пустой. Применение двух лишних символов резко уменьшит число столкновений, однако увеличит вдвое объем требуемой памяти.
Таким образом, случайное кодирование основано на использовании числа, а не структуры ожидаемых записей. Оно позволяет употреблять сильно сжатую таблицу в режиме прямого
обращения, а не поиска. Вместо поиска применяются вычислительные Методы (аглоритм перемешивания), поскольку происходит непосредственный переход к вычисленному адресу, и для нахождения нужной записи, если только она существует, требуются в худшем случае простые логические операции.
Случайное кодирование основано на том, что алгоритм перевешивания дает случайные кодовые слова. Ясно, что два имени, отличающиеся одной буквой, дают разные слова. Столкновение двух сильно различающихся друг от друга слов может произойти лишь случайно. Используемый здесь алгоритм перемешивания очень прост, и существует развитая теория построения алгоритма перемешивания для различного типа данных [10]. Ясно, что этот алгоритм весьма эффективен, но, возможно, его можно еще улучшать. Здесь этот вопрос не рассматривается.
Случайное кодирование приводит к некоторой равномерности данных от источника, обладающего неизвестной, но сложной структурой; оно стремится сгладить неоднородности.
Мы хотим подчеркнуть два основных результата. Во-первых, метод случайного кодирования в некоторых случаях является полезным методом кодирования данных; он уменьшает избыточность, не используя фактически называющую эту избыточность структуру сообщений (имен). Во-вторых, рассмотренный метод является примером общего метода случайного кодирования (см. гл. 10).