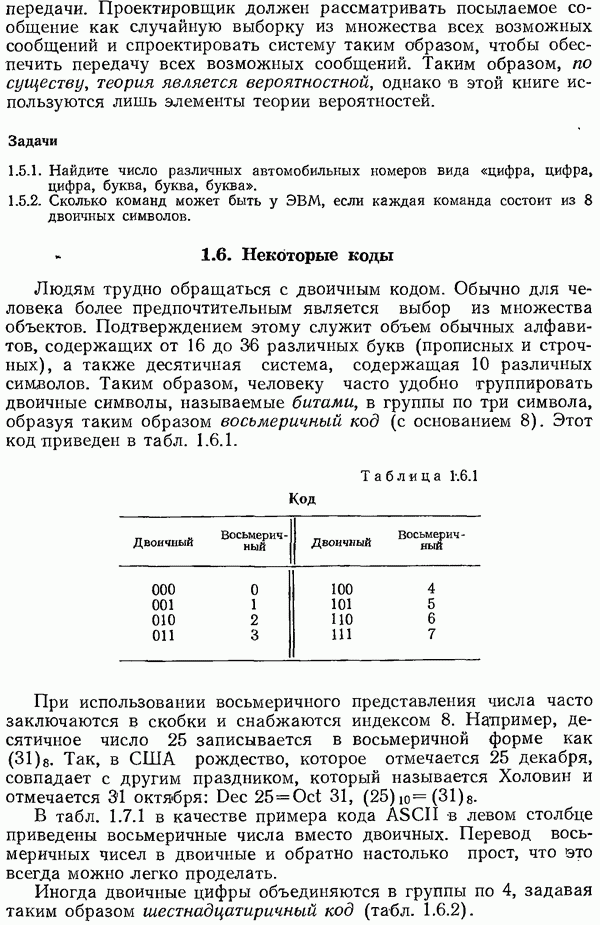
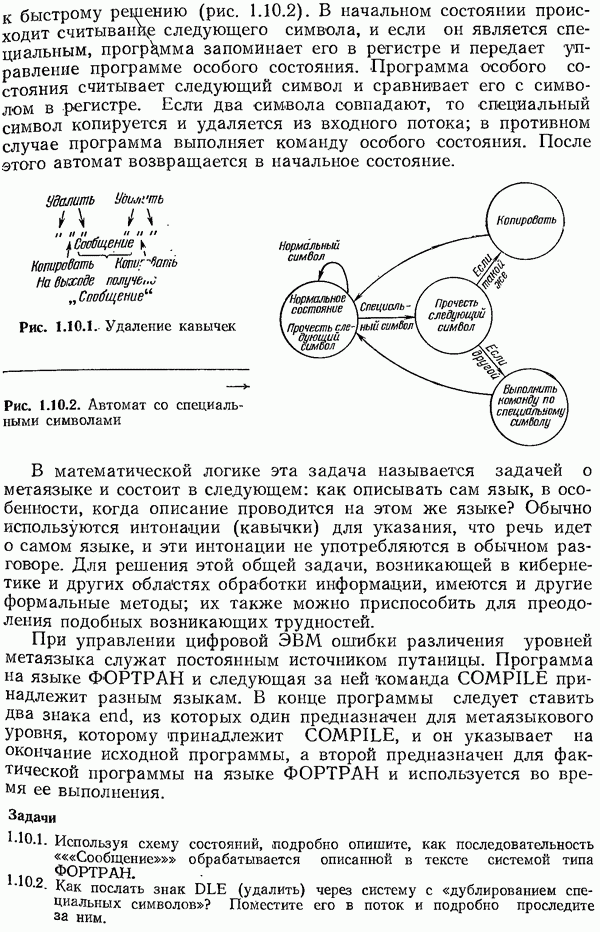
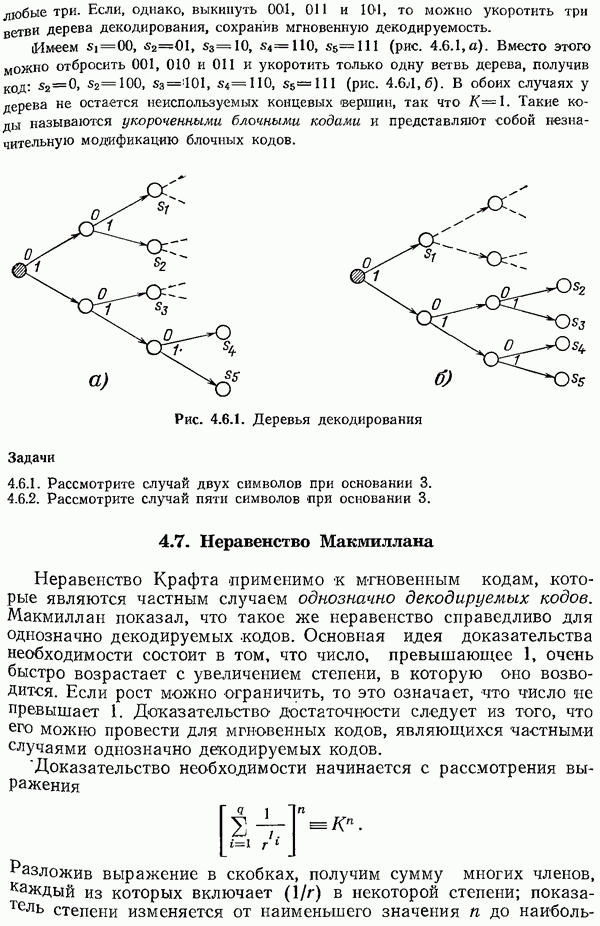
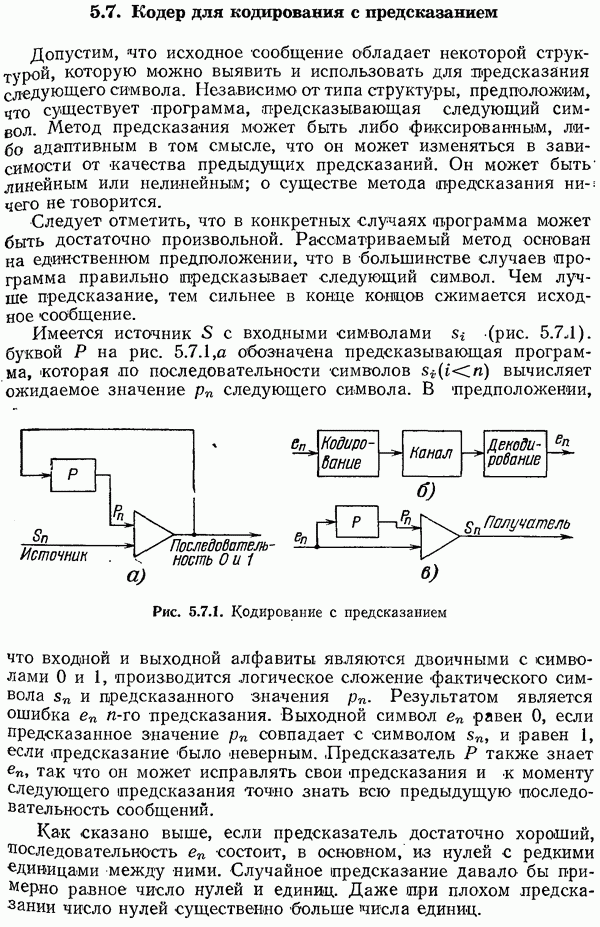
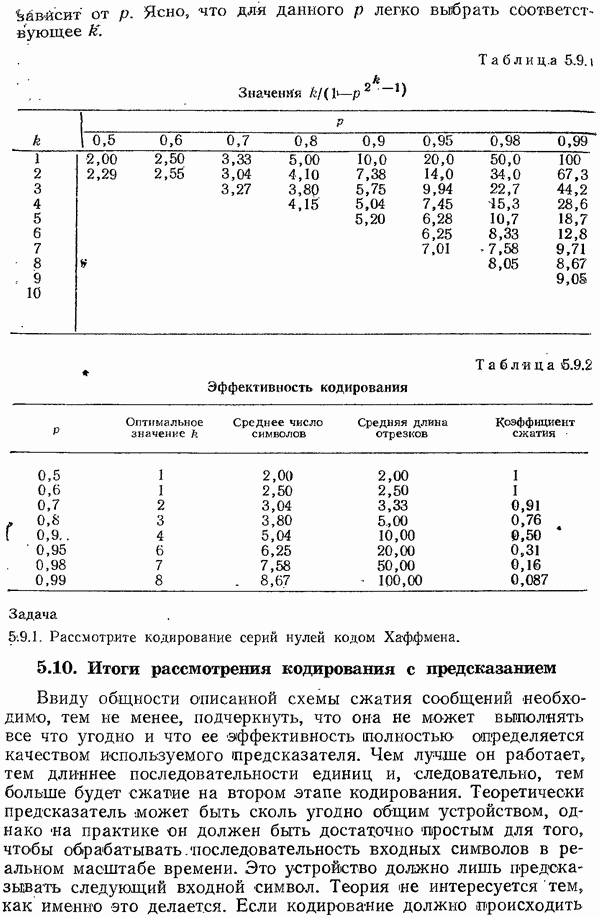
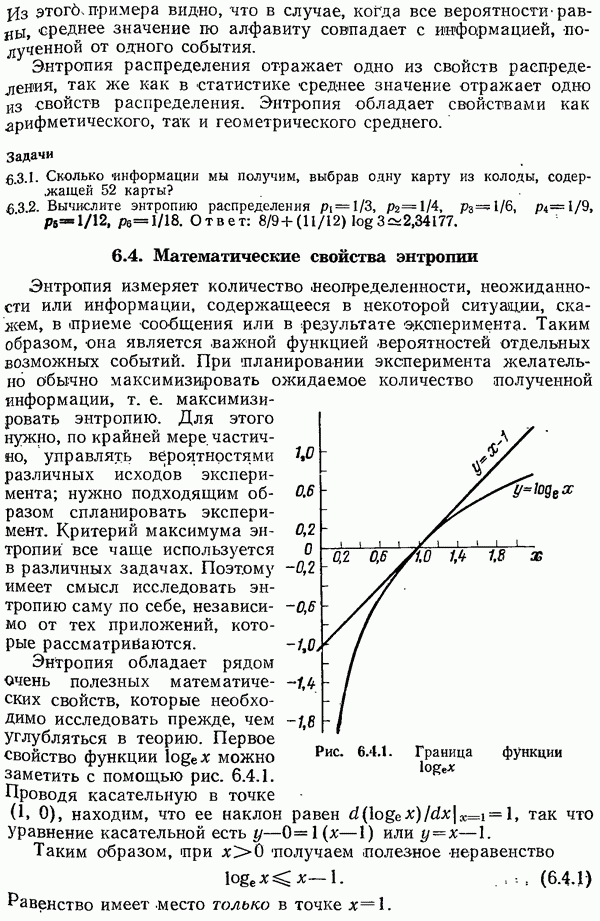
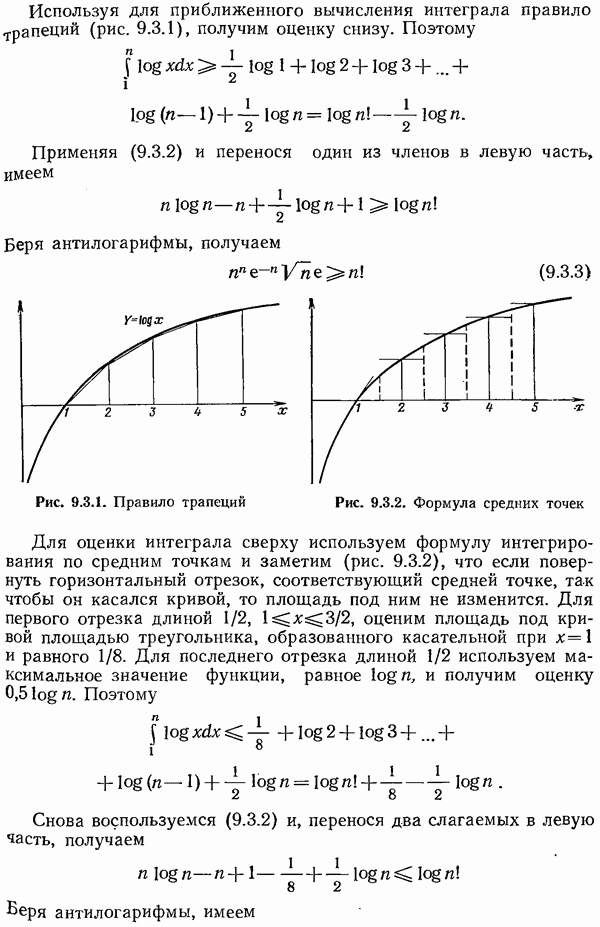
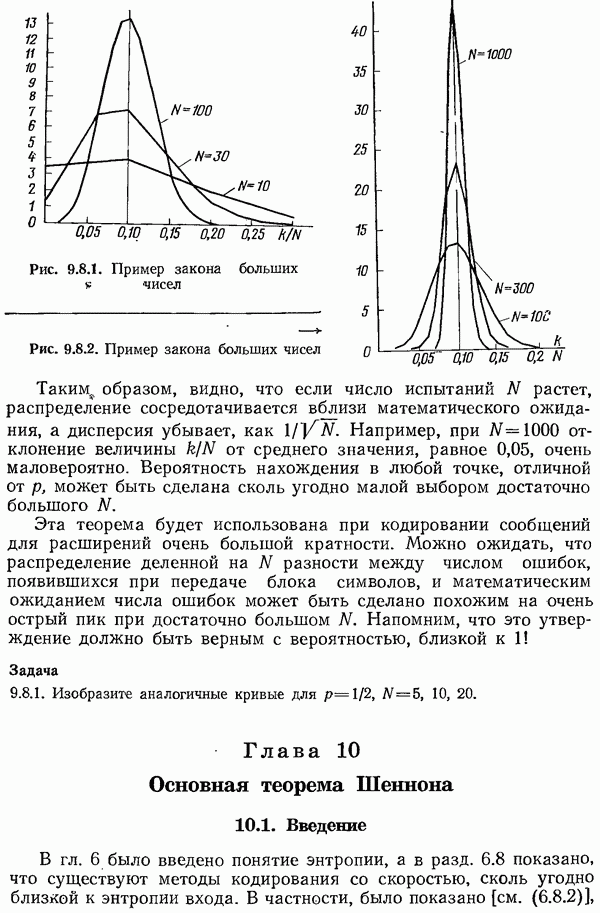
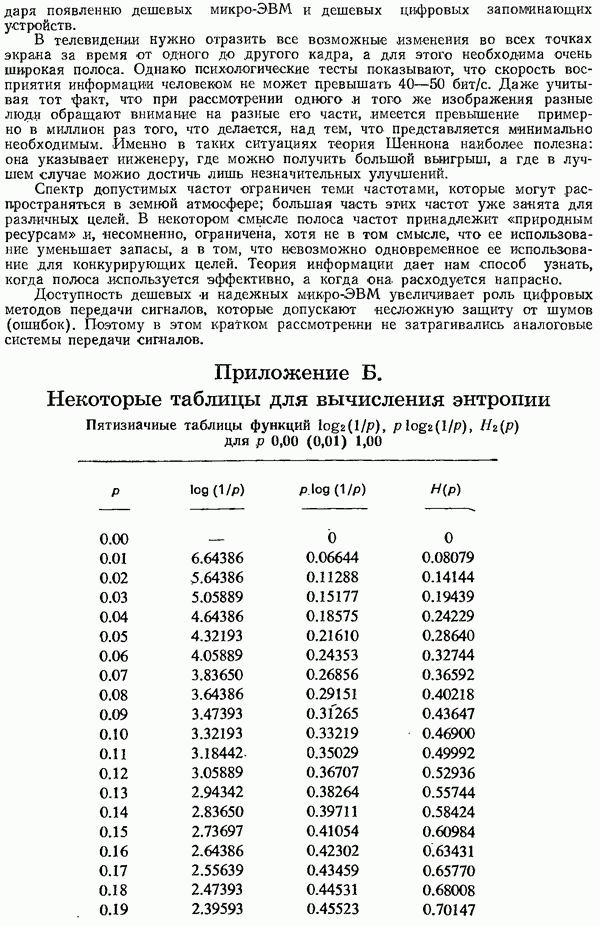
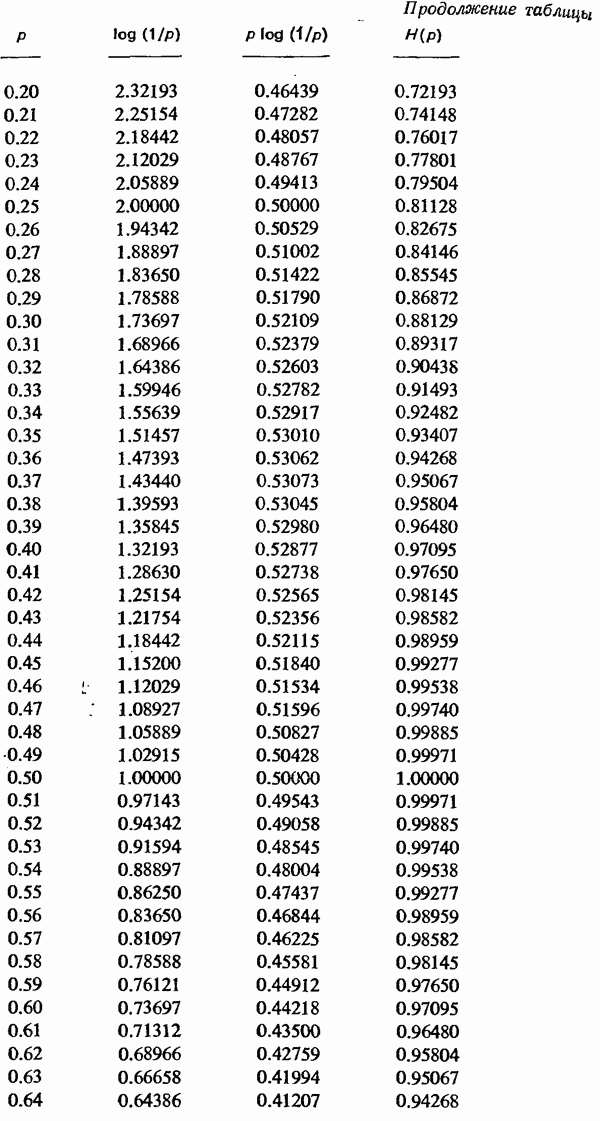
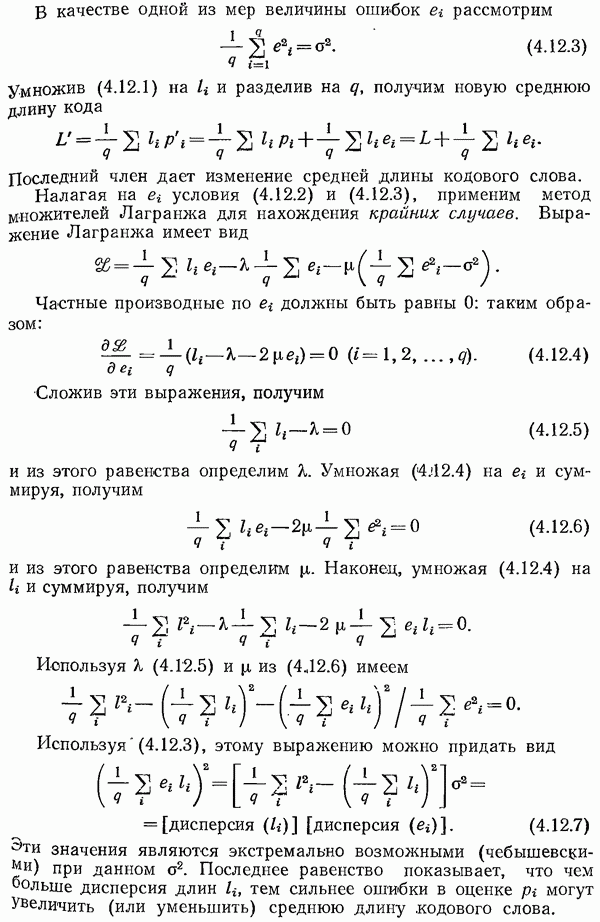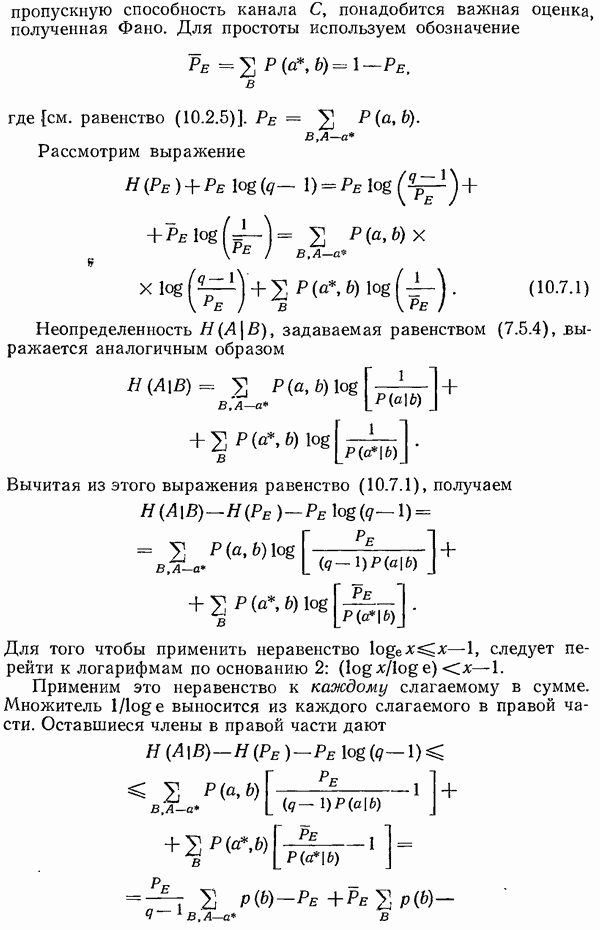8.4. Коды с исправлением ошибок
В разд. 1.3 указывалось, что иногда процесс кодирования разбивается на два этапа, первый — для надлежащего согласования источника информации, а второй — для согласования канала. При желании можно дать определение канала так, чтобы второй этап включался в канал. В действительности, иногда такое определение канала представляется более естественным с точки
зрения пользователя. Посмотрим, что представляет собой такой канал.
Пусть задан совершенный двоичный код с исправлением ошибок и длина кода равна  а вероятность правильного приема символа в канале с белым шумом —
а вероятность правильного приема символа в канале с белым шумом —  Тогда с точки зрения пользователя вероятности ошибок
Тогда с точки зрения пользователя вероятности ошибок  равны следующим выражениям:
равны следующим выражениям:

Напомним, что в таком канале одиночная ошибка исправляется, а двойная ошибка превращается в тройную.
Таким образом, ошибки в этом канале, выраженные через первоначальные ошибки, имеют весьма специфический вид. Однако к этому симметричному по входу каналу по-прежнему можно применять методы, приведенные в предыдущем разделе.
Если исправление ошибок реализовано либо аппаратурно, либо автоматически включается в программу обработки принятых сигналов, то пользователь видит описанную выше картину. Кроме того, как указывалось выше, в практических ситуациях, когда имеется источник с неравными вероятностями появления различных символов, разумно использовать код Хаффмена, согласованный с источником, а затем применить какой-нибудь код с исправлением ошибок к блокам, составленным из сообщений кода Хаффмена. При проектировании ЭВМ все чаще предусматривается аппаратурное обнаружение и (или) исправление ошибок. Вопрос о том, рассматривать ли это как один процесс кодирования, как два разных процесса или включать второй этап кодирования в канал, зависит от вашего желания. На практике всегда ясно, как поступать в конкретном случае.
Задачи
8.4.1. Примените изложенное в этом разделе к коду длины 7, исправляющему одну ошибку.
8.4.2. Обобщите материал этого раздела на коды с минимальным расстоянием 4.