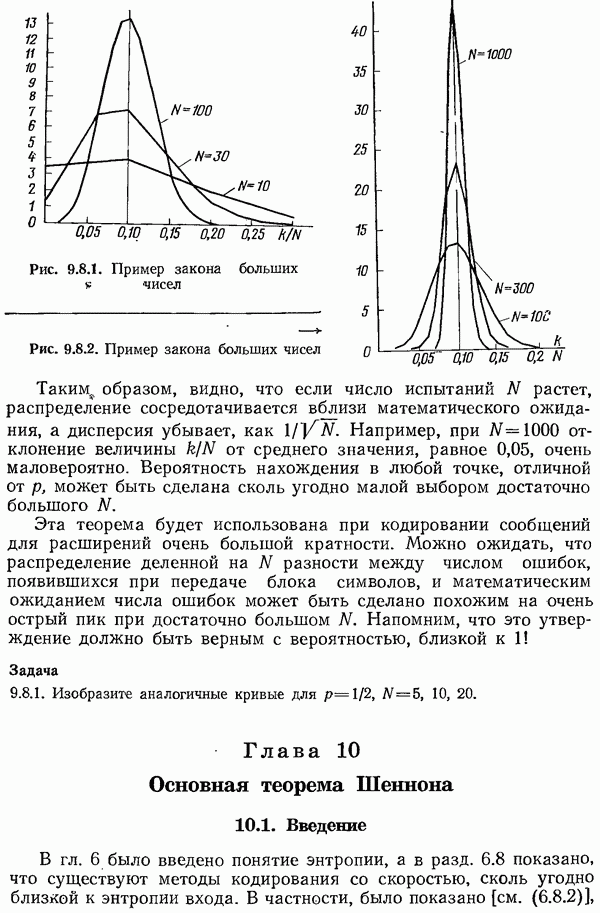
различных позициях независимы, то при  много меньших
много меньших  вероятное число одиночных ошибок равно пр. Вероятность двойной ошибки примерно равна
вероятное число одиночных ошибок равно пр. Вероятность двойной ошибки примерно равна  примерно половине квадрата одиночной ошибки. Поэтому оптимальная длина проверяемого сообщения зависит как от требуемого уровня надежности (вероятности того, что двойная ошибка останется необнаруженной), так и от вероятности
примерно половине квадрата одиночной ошибки. Поэтому оптимальная длина проверяемого сообщения зависит как от требуемого уровня надежности (вероятности того, что двойная ошибка останется необнаруженной), так и от вероятности  единичной ошибки на любой позиции. Дальнейшие подробности излагаются в разд. 2.4.
единичной ошибки на любой позиции. Дальнейшие подробности излагаются в разд. 2.4.
Подсчет числа 1 и выбор четного их числа эквивалентен использованию арифметики по модулю 2. Модуль 2 означает, что каждое число делится на 2 (основание) и заменяется остатком. В этой арифметике (в которой последовательный счет идет так:  производится подсчет по модулю 2 числа единиц в первых
производится подсчет по модулю 2 числа единиц в первых  позициях сообщения, и затем результат помещается в
позициях сообщения, и затем результат помещается в  позицию. Таким образом, среди
позицию. Таким образом, среди  посылаемых символов содержится четное число единиц. Такая проверка на четность часто рассматривается в теории. На практике обычно оказывается удобным принять проверку на нечетность с тем, чтобы сообщение, состоящее из всех нулей, не было верным. Легко провести необходимые изменения в теории кодирования, поэтому в дальнейшем будем продолжать применять проверку на четность.
посылаемых символов содержится четное число единиц. Такая проверка на четность часто рассматривается в теории. На практике обычно оказывается удобным принять проверку на нечетность с тем, чтобы сообщение, состоящее из всех нулей, не было верным. Легко провести необходимые изменения в теории кодирования, поэтому в дальнейшем будем продолжать применять проверку на четность.
Для того чтобы вычислить четность последовательности, состоящей" из нулей и единиц, можно использовать конечный автомат с двумя состояниями (рис. 2.2.1). Автомат начинает работу в состоянии О и меняет его при появлении в сообщении каждой 1. Состояние автомата в конце сообщения дает окончательную четность.
Во многих ЭВМ есть специальная команда для подсчета числа 1 в накапливающем регистре. Самая правая цифра полученной суммы дает нужную четность. Если в ЭВМ нет этой или какой-нибудь эквивалентной команды, то следует заметить, что при логическом сложении (исключающее ИЛИ, см. разд. 2.8) одной половины сообщения с другой четность суммы остается такой же, как у первоначального сообщения. Повторяя эту процедуру, мы каждый раз уменьшаем длину сообщения вдвое, и в конце концов получаем требуемую сумму всех 1 по модулю 2. Таким образом, необходимое число логических сложений равно первому целому числу, большему или равному 

Рис. 2.2.1. Диаграмма для вычисления четности































































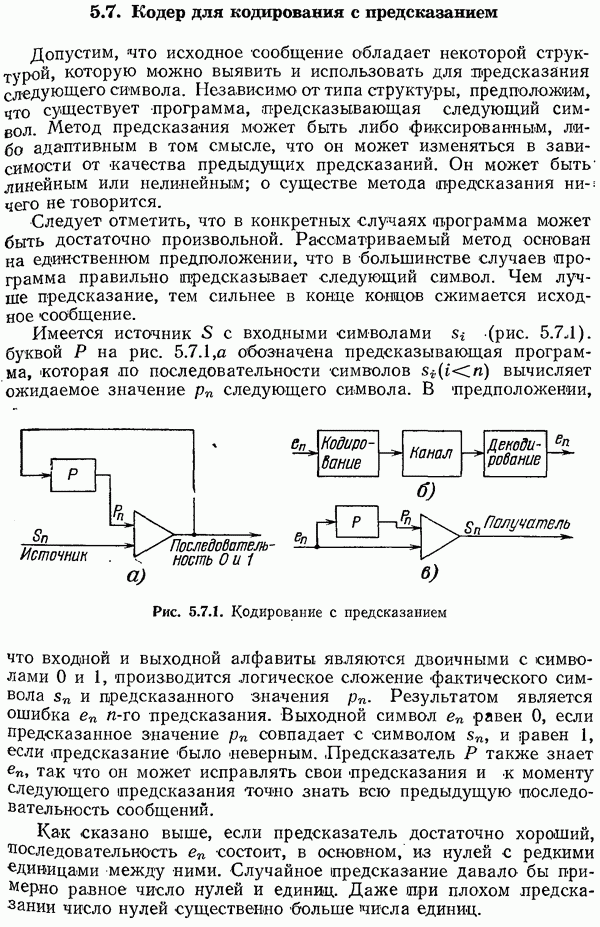


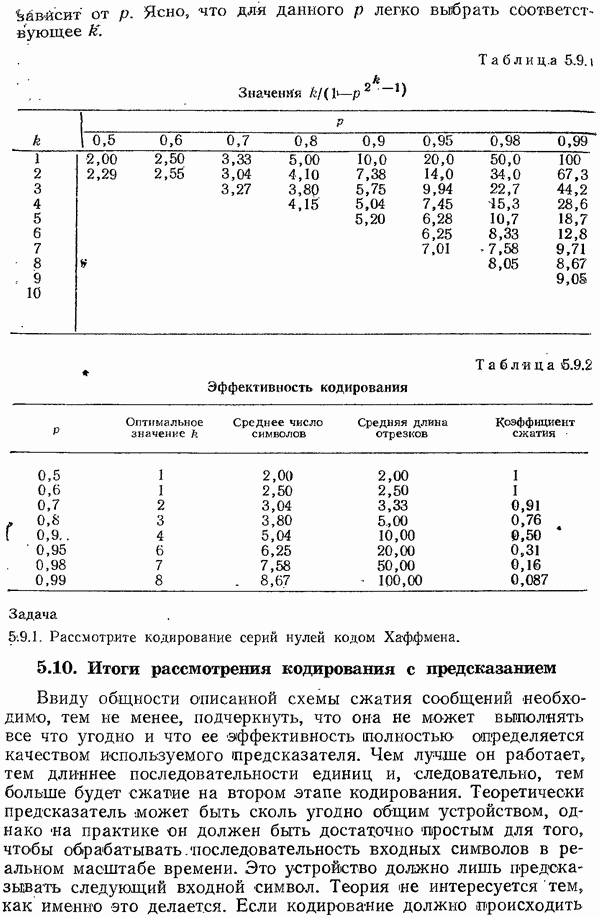










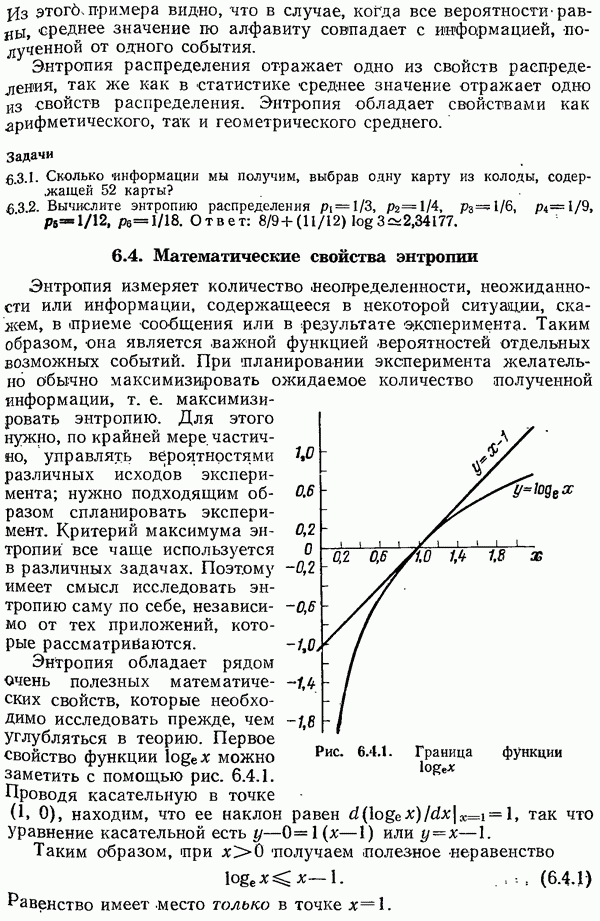

































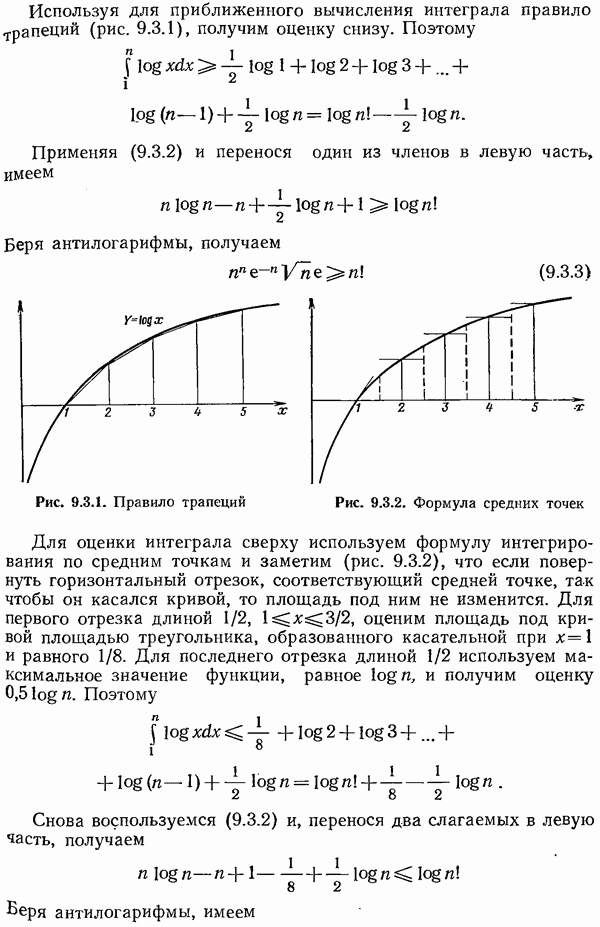



















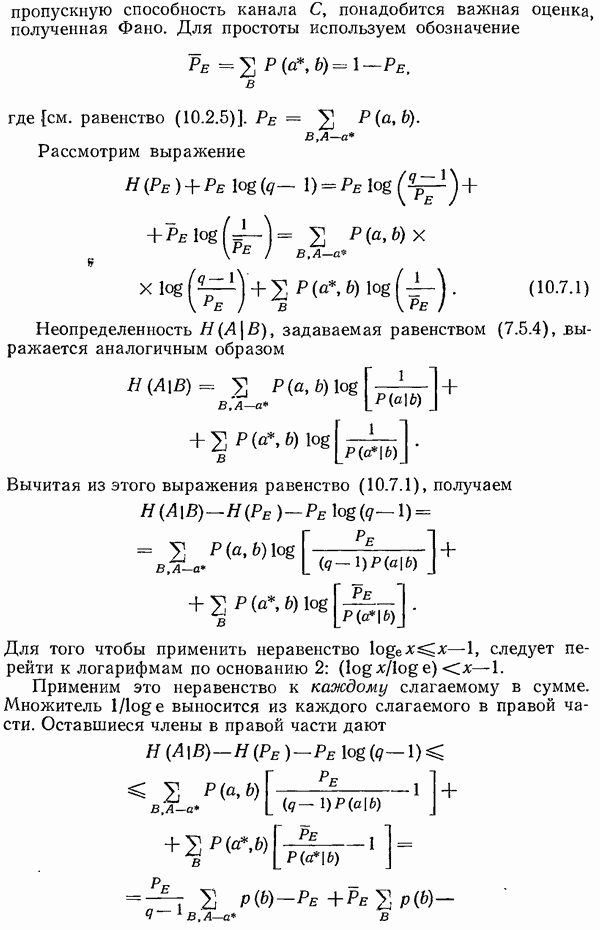


























 символам сообщения добавляется
символам сообщения добавляется  позиция для проверки на четность. На приемном конце производится подсчет числа 1, и не четное число 1 во всех
позиция для проверки на четность. На приемном конце производится подсчет числа 1, и не четное число 1 во всех  позициях указывает на появление по крайней мере одной ошибки.
позициях указывает на появление по крайней мере одной ошибки.
 во-вторых, ошибки в
во-вторых, ошибки в
