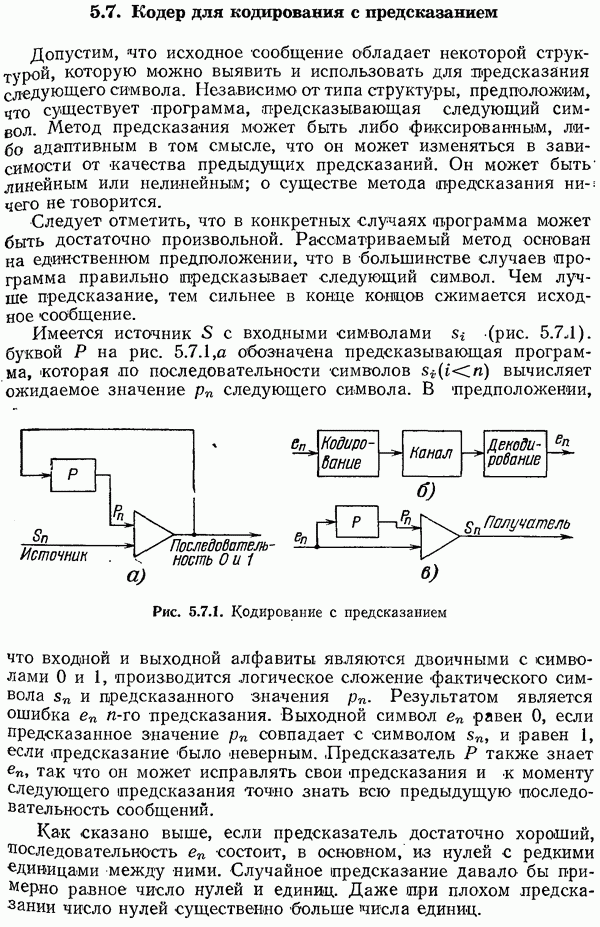
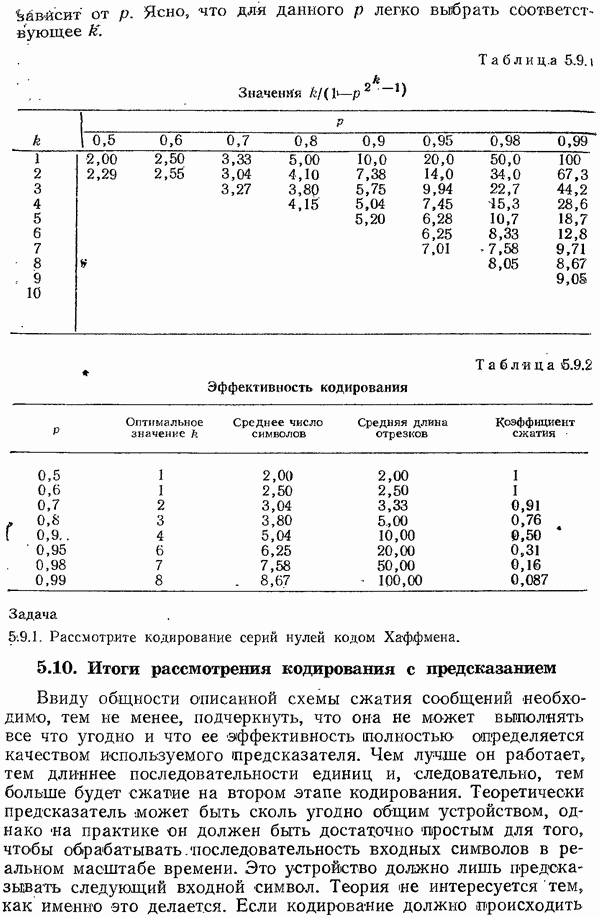
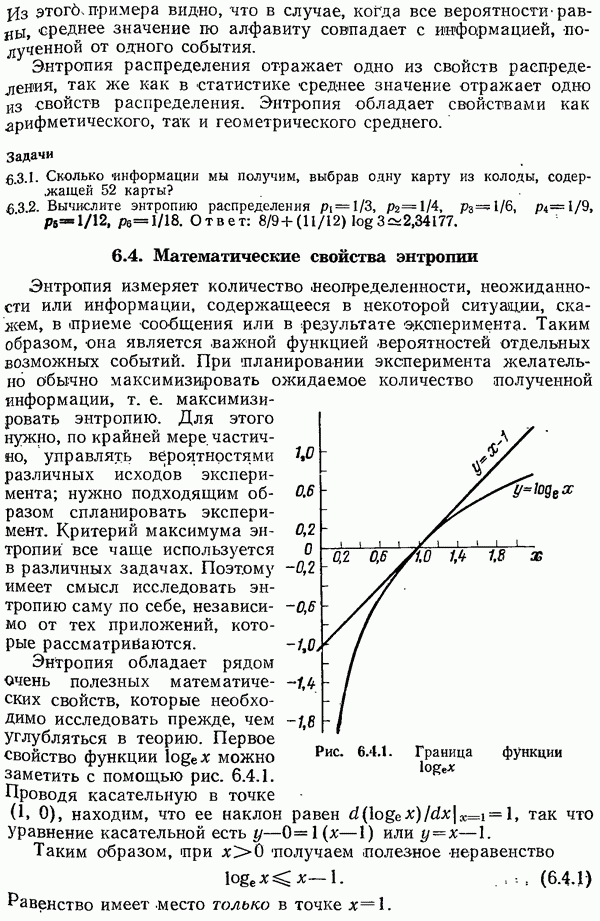
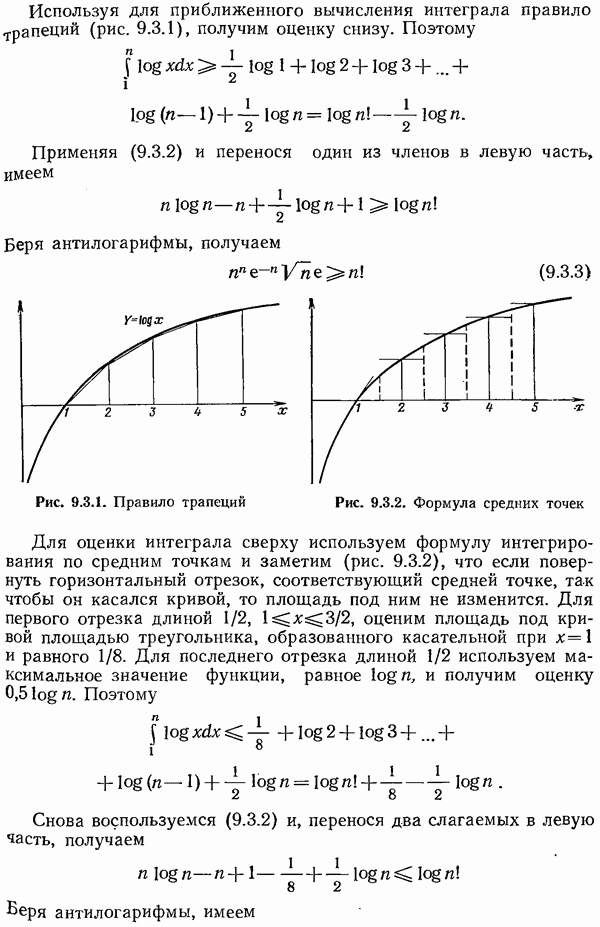
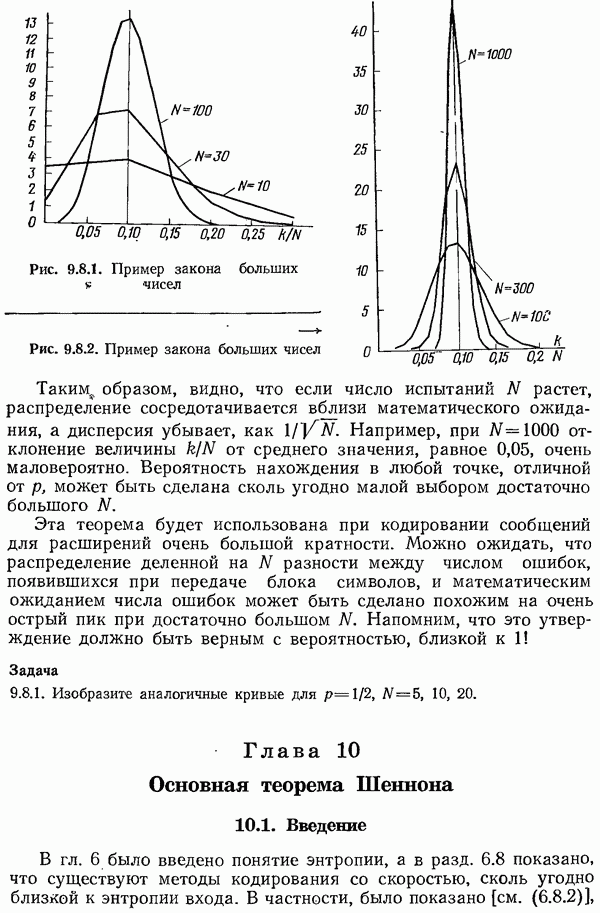
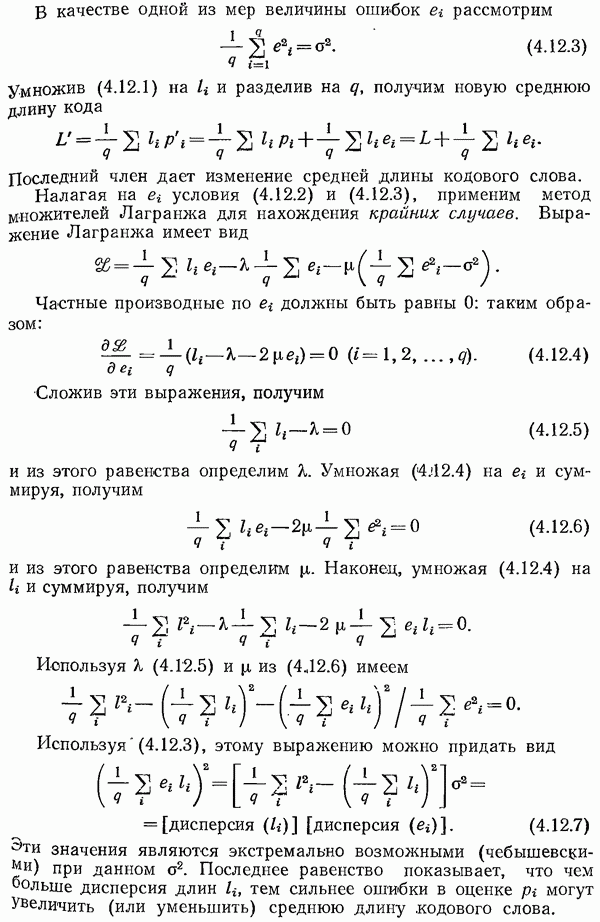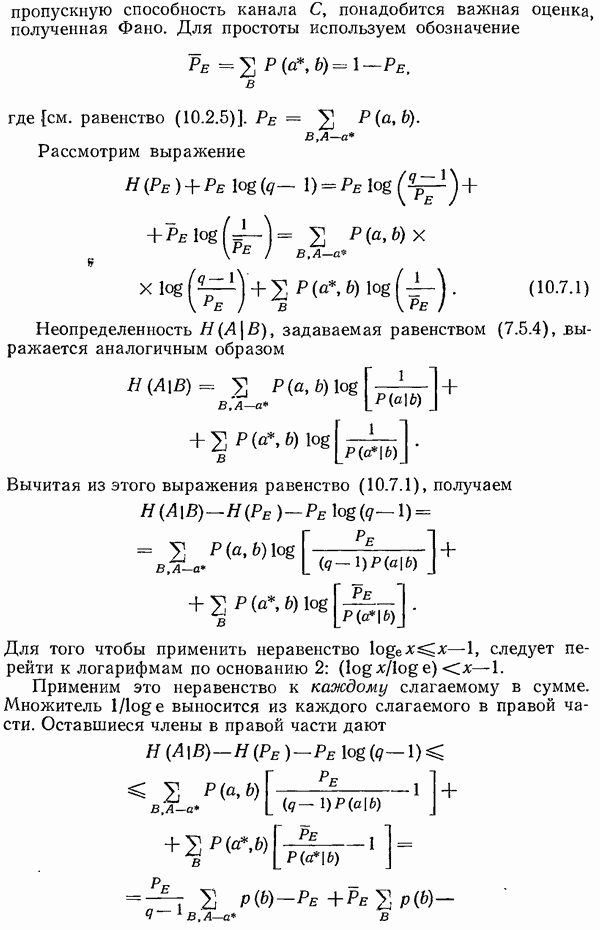4.12. Шум в вероятностях кода Хаффмена
Предположим, что оценки вероятностей  неточны. Как при этом ухудшается средняя длина кода? Короче говоря, будут ли малые ошибки в оценках сильно ухудшать (или улучшать) систему?
неточны. Как при этом ухудшается средняя длина кода? Короче говоря, будут ли малые ошибки в оценках сильно ухудшать (или улучшать) систему?
Для ответа на этот вопрос обозначим через  вероятности, которые должны использоваться при построении кодов Хаффмена, и пусть
вероятности, которые должны использоваться при построении кодов Хаффмена, и пусть

являются фактически используемыми вероятностями. Ясно, что

поскольку как  так и
так и  распределения вероятностей, и их суммы равны 1.
распределения вероятностей, и их суммы равны 1.
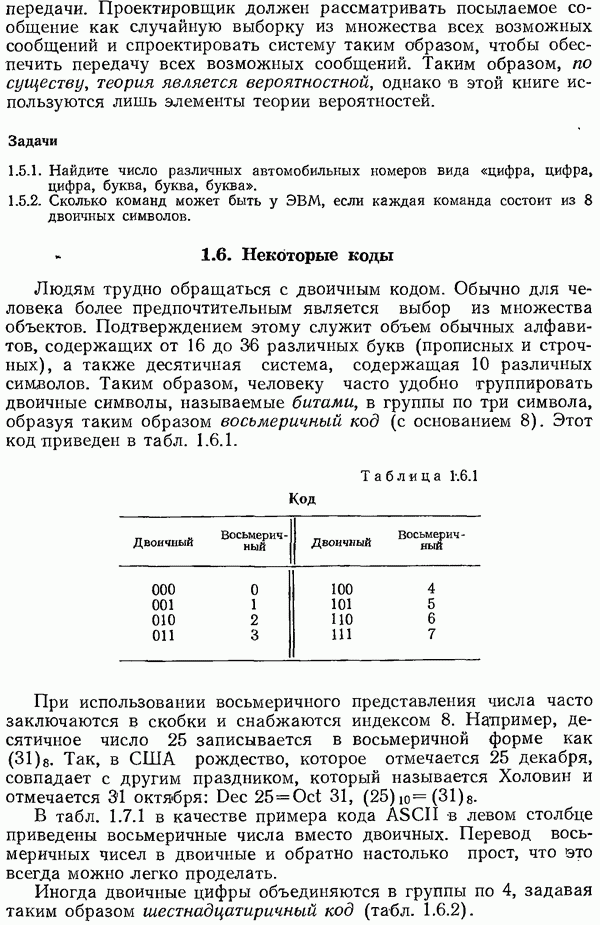
Б качестве одной из мер величины ошибок  рассмотрим
рассмотрим

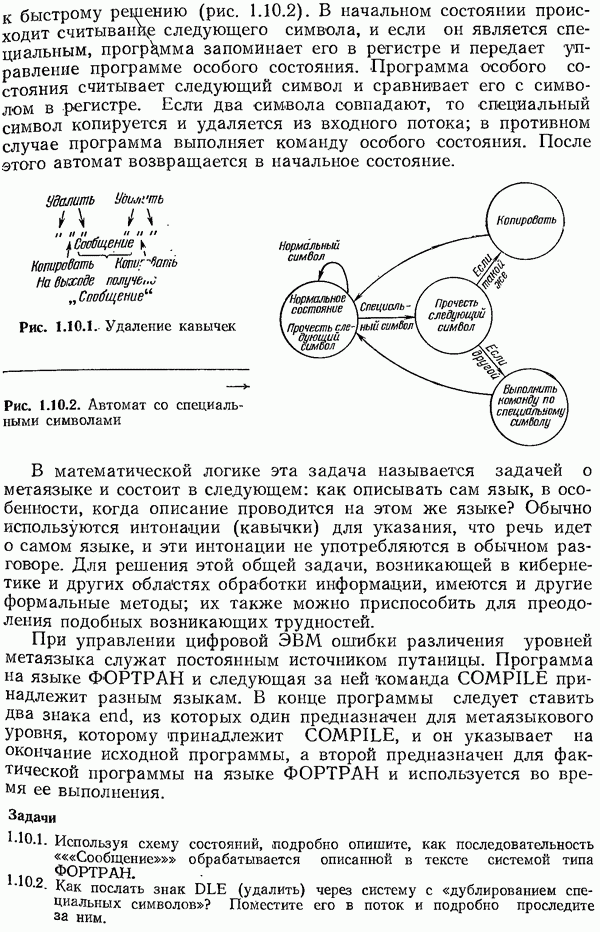
Умножив (4.12.1) на  и разделив на
и разделив на  получим новую среднюю длину кода
получим новую среднюю длину кода

Последний член дает изменение средней длины кодового слова.
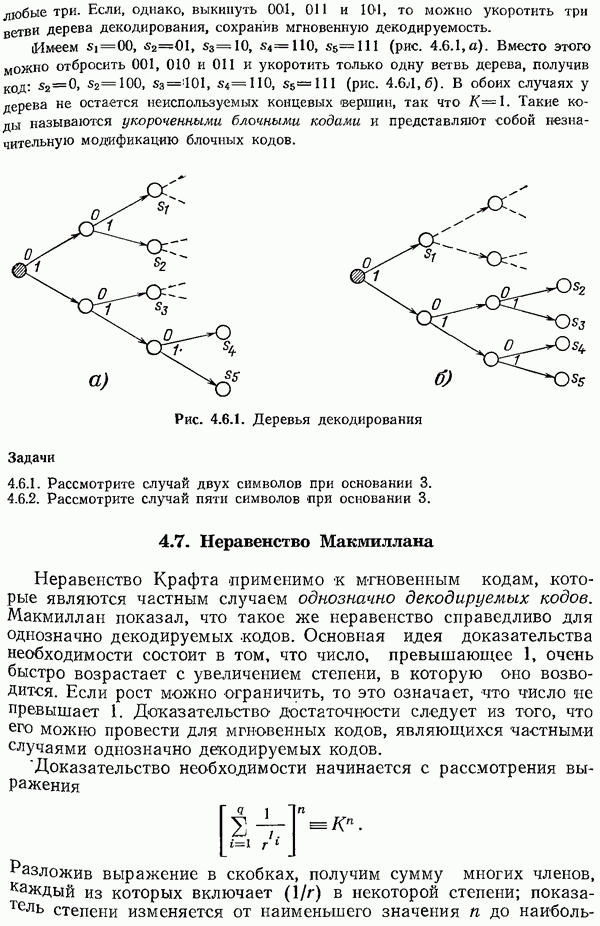
Налагая на условия (4.12.2) и (4.12.3), применим метод множителей Лагранжа для нахождения крайних случаев. Выражение Лагранжа имеет вид

Частные производные по  должны быть равны 0: таким образом:
должны быть равны 0: таким образом:

Сложив эти выражения, получим

и из этого равенства определим А. Умножая  на
на  и суммируя, получим
и суммируя, получим

и из этого равенства определим  Наконец, умножая (4.12.4) на
Наконец, умножая (4.12.4) на  и суммируя, получим
и суммируя, получим

Используя  и
и  из
из  имеем
имеем

Используя (4.12.3), этому выражению можно придать вид

Эти значения являются экстремально возможными (чебышевскими) при данном  Последнее равенство показывает, что чем больше дисперсия длин
Последнее равенство показывает, что чем больше дисперсия длин  тем сильнее ошибки в оценке
тем сильнее ошибки в оценке  могут Увеличить (или уменьшить) среднюю длину кодового слова.
могут Увеличить (или уменьшить) среднюю длину кодового слова.
Следующий пример показывает, что ошибки  могут оставить среднюю длину без изменения. Пусть 3 и для некоторого
могут оставить среднюю длину без изменения. Пусть 3 и для некоторого  -имеем
-имеем

Ясно, что 
Для нахождения соответствующего  из выражения (4.12.3) имеем
из выражения (4.12.3) имеем

Рассмотрим теперь изменение средней длины кода:

Поэтому  из (4.12.8) не изменяют среднюю длину кода.
из (4.12.8) не изменяют среднюю длину кода.
На основании этого можно заключить, что коды Хаффмена являются сравнительно грубыми; небольшие изменения вероятностей не могут серьезно ухудшить систему. Однако мы не рассматриваем вопрос о возможном улучшении системы в делом от использования новых вероятностей при ее проектировании.