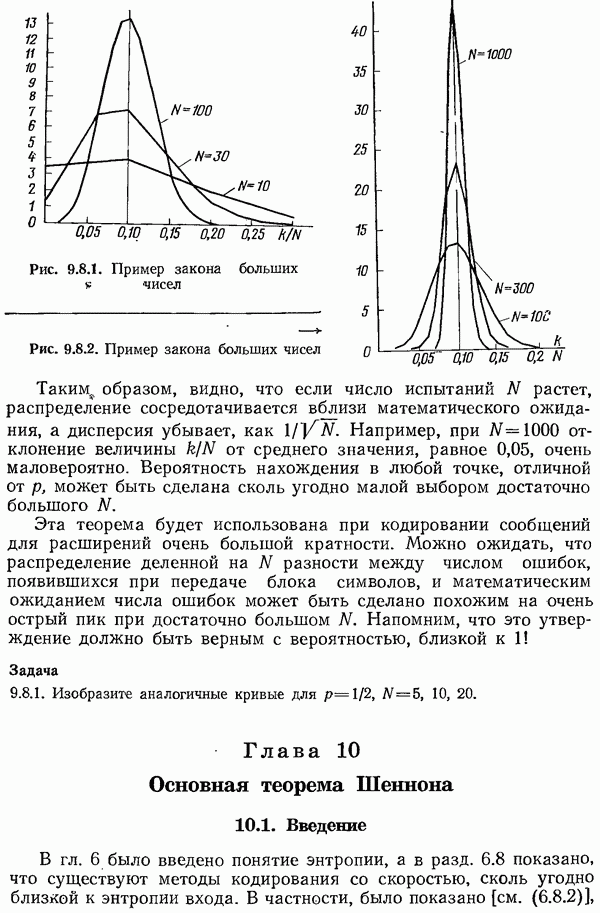
6.8. Расширения кода
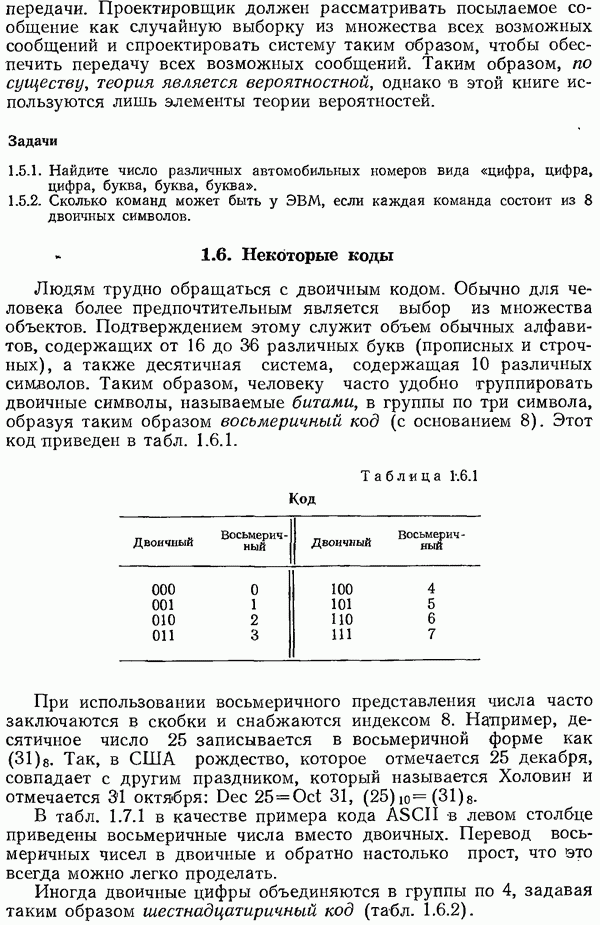
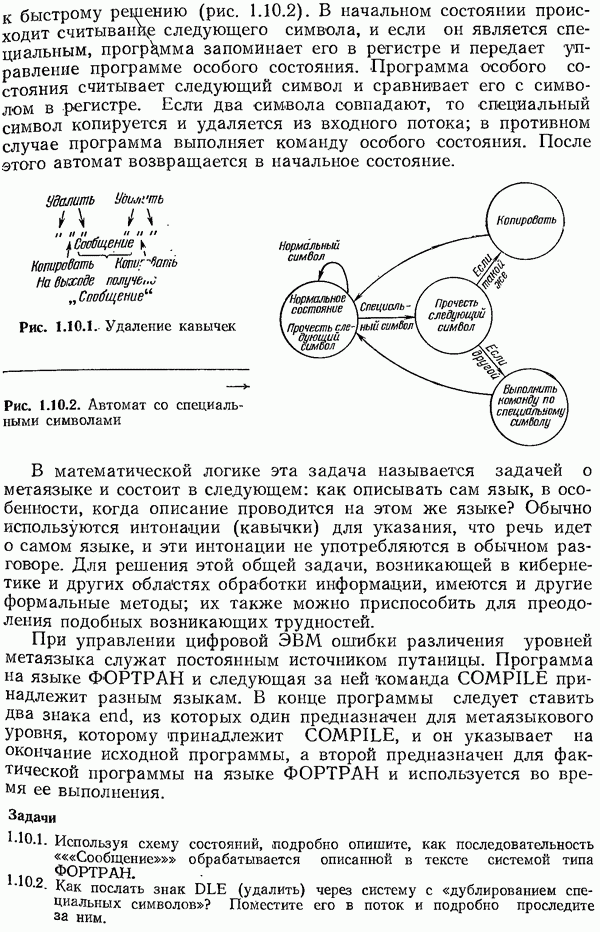
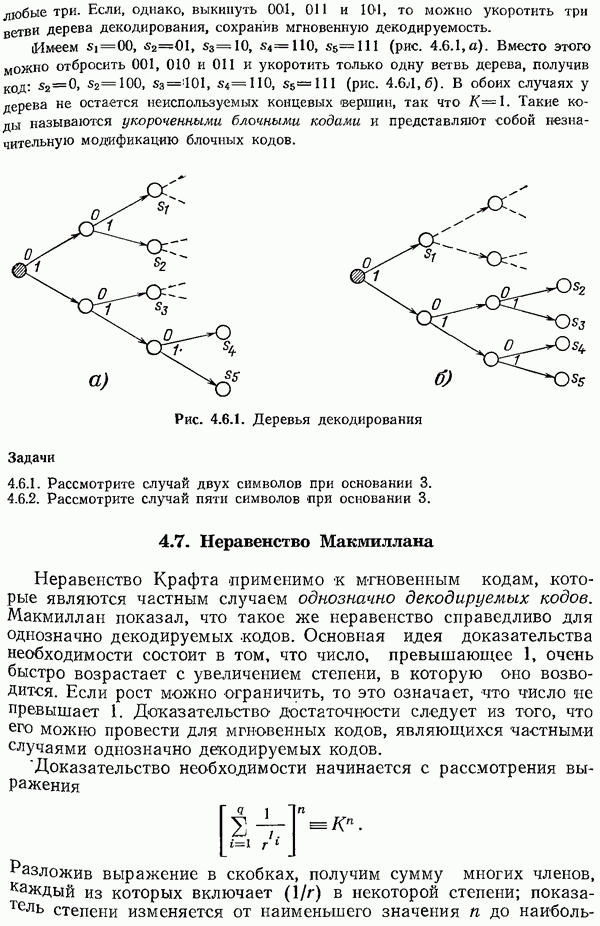
Понятие энтропии было введено для простой ситуации, а именно, в случае независимых символов  с фиксированными вероятностями появления
с фиксированными вероятностями появления  Далее следует обобщить (понятие (Энтропии для расширений ,(см. разд. 4.2) и для марковских процессов (см. разд. 5.2-5.15). Это приводится в разд. 6.8 и 6.10.
Далее следует обобщить (понятие (Энтропии для расширений ,(см. разд. 4.2) и для марковских процессов (см. разд. 5.2-5.15). Это приводится в разд. 6.8 и 6.10.
Потери при использовании кода Шеннона — Фано вместо «ода Хаффмена, которые измеряются в терминах энтропии, возникают тогда, когда величины, обратные вероятностям появления символов, не являются точными степенями основания  Если проводить кодирование не по одному символу за один раз, а строить код для блоков из
Если проводить кодирование не по одному символу за один раз, а строить код для блоков из  символов, то можно рассчитывать ближе подойти к нижней границе
символов, то можно рассчитывать ближе подойти к нижней границе 
Еще важнее, что (см. разд. 4.10) вероятности в расширений источника более разнообразны, чем вероятности исходного источника; поэтому можно ожидать, что чем выше кратность расширения, тем более эффективными окажутся как коды Хаффмена































































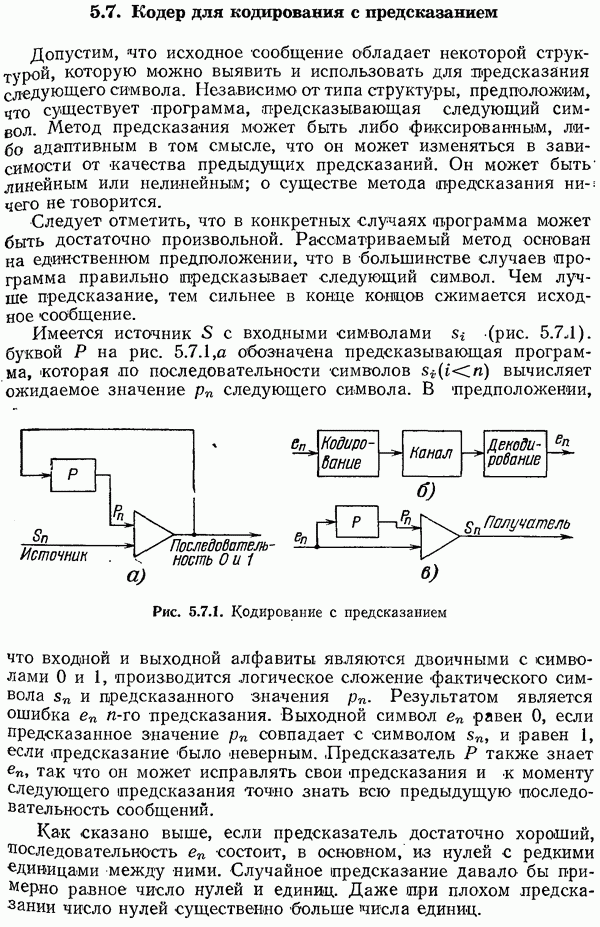


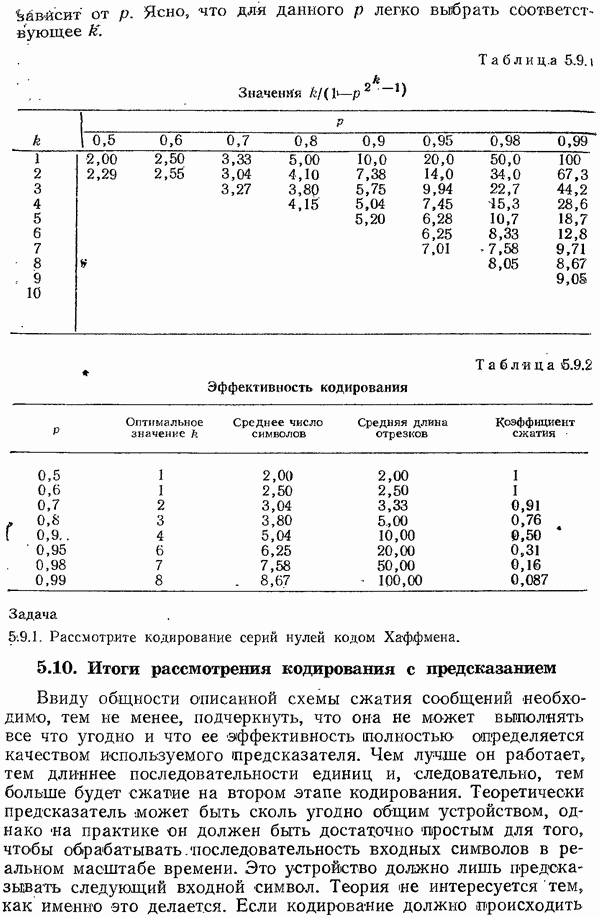










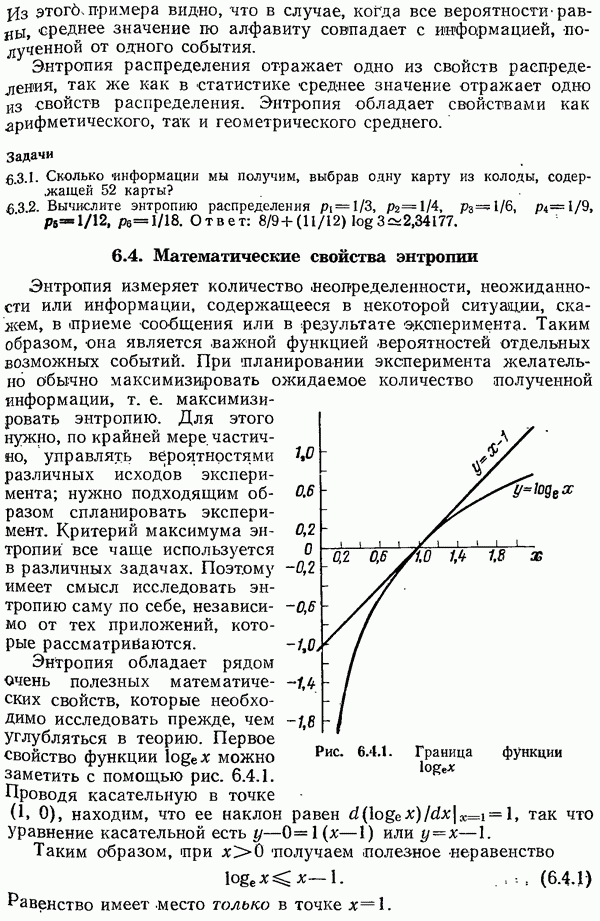

































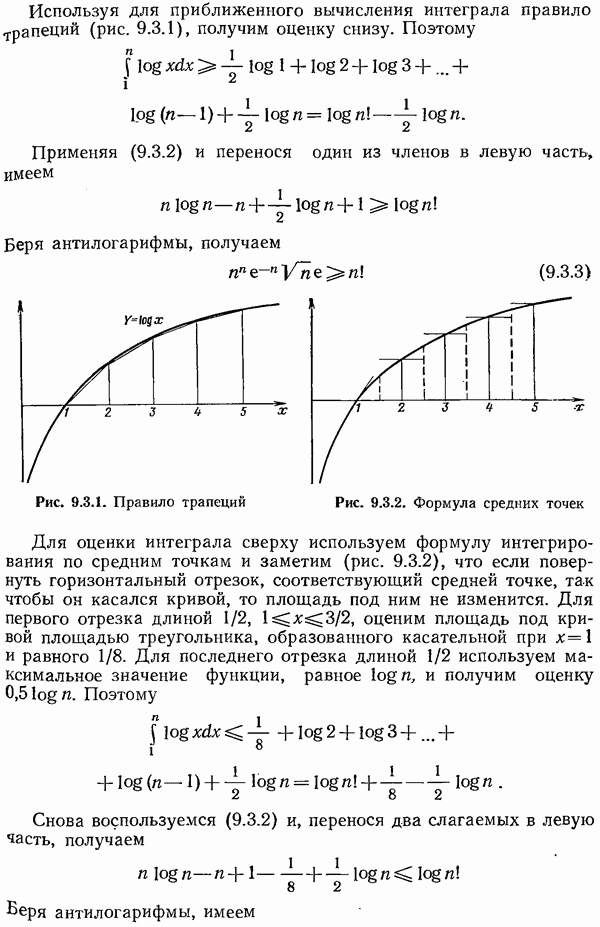



















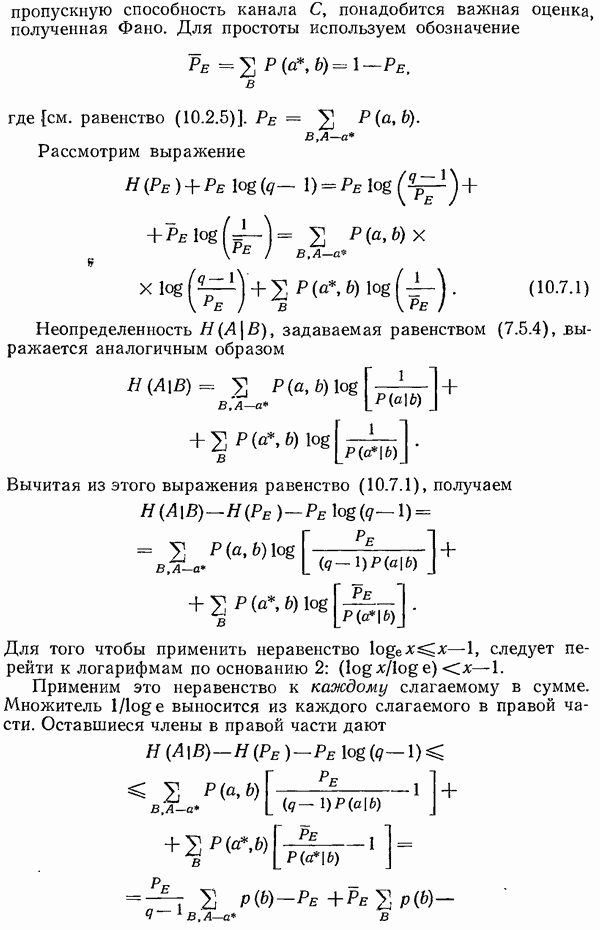


























 -кратное расширение алфавита источника состоит из символов вида
-кратное расширение алфавита источника состоит из символов вида  с вероятностями
с вероятностями  Каждый блок из
Каждый блок из  первоначальных символов становится одним символом
первоначальных символов становится одним символом  с вероятностью
с вероятностью  значим этот алфавит
значим этот алфавит 


 имеем
имеем

 равна 1 (поскольку сумма всех вероятностей равна 1). Поэтому остается только сумма по
равна 1 (поскольку сумма всех вероятностей равна 1). Поэтому остается только сумма по  Но
Но

 равны, то
равны, то

 -кратного расширения источника
-кратного расширения источника  раз больше энтропии первоначального источника. Заметим, однако, что в нем имеется
раз больше энтропии первоначального источника. Заметим, однако, что в нем имеется  символов.
символов.
 результат (6.6.3). Имеем
результат (6.6.3). Имеем  где
где  средняя длина
средняя длина  слова для
слова для  -кратного расширения. Применяя (6.8.1) и производя деление на
-кратного расширения. Применяя (6.8.1) и производя деление на  получаем
получаем

 соответствует
соответствует  символов
символов  правильнее использовать меру
правильнее использовать меру  Таким об, разом, для расширения достаточно высокой кратности оредн длина кодового слова
Таким об, разом, для расширения достаточно высокой кратности оредн длина кодового слова  может быть сколь угодно близкой
может быть сколь угодно близкой  Это составляет содержание теоремы Шеннона о кодировании без шума: для
Это составляет содержание теоремы Шеннона о кодировании без шума: для  -кратного расширения справедливы границы (6.8.2).
-кратного расширения справедливы границы (6.8.2).
