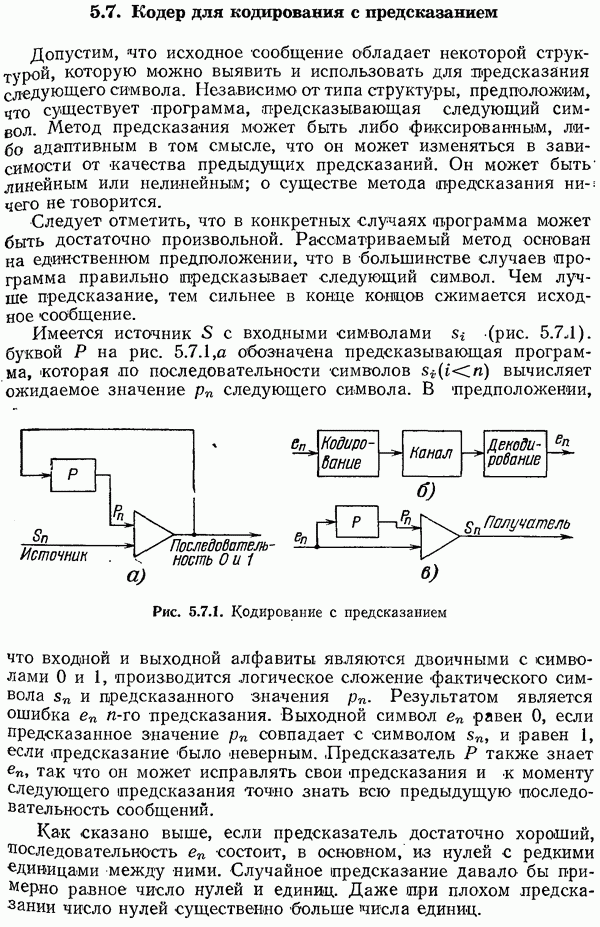
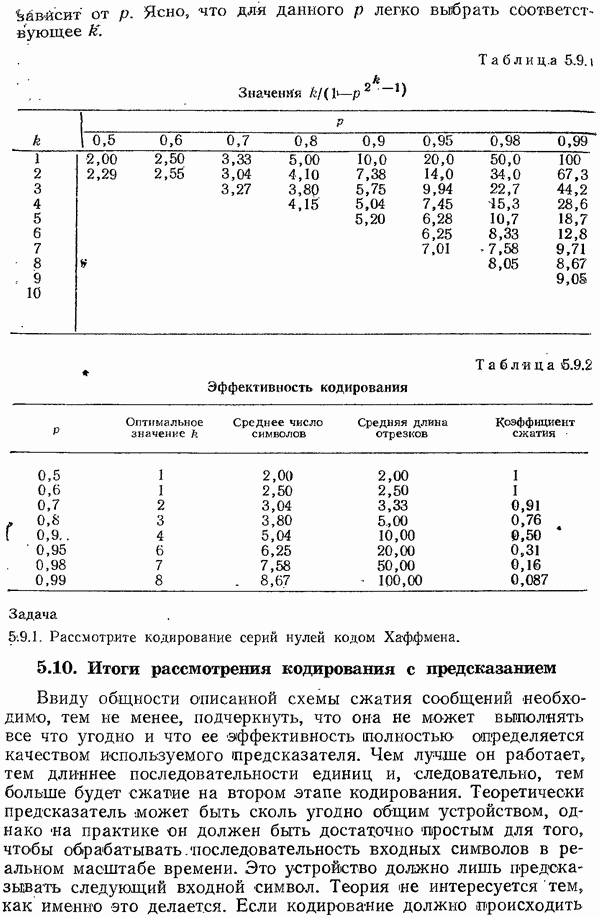
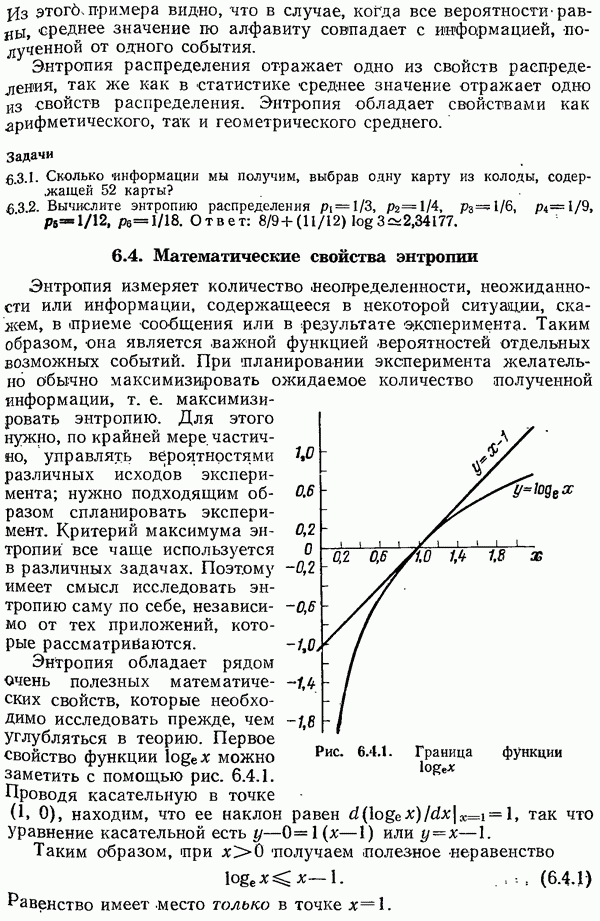
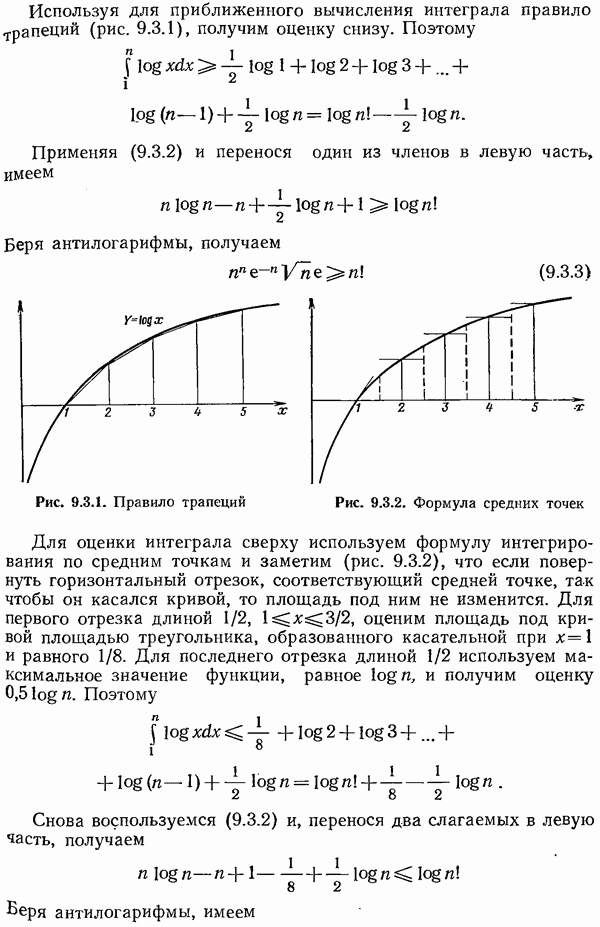
Глава 4. Неравномерные коды — коды Хаффмена
4.1. Введение
Все рассматривавшиеся до сих пор коды были равномерными. Они называются блочными, поскольку все сообщения, на которые разбивается поток посылаемых символов, имеют заданную длину блока. Код Морзе, о котором говорилось в гл. 1, является примером неравномерного кода. Рассмотрим теперь такие коды более подробно. Преимущество кодов, в которых сообщения кодируются словами не обязательно равной длины, состоит в большей эффективности-, при их применении для представления информации можно в среднем использовать меньше символов. Для этого нужно иметь какие-то сведения о статистике посылаемых сообщений. Если все символы источника равновероятны, то блочные коды практически столь же хороши, как любые другие возможные коды (см. разд. 4.6). Если, однако, некоторые символы более вероятны по сравнению с другими, то это можно использовать, кодируя чаще встречающиеся — более длинными словами. Именно это делается в коде Морзе. Буква Е алфавита английского языка встречается чаще других и кодируется точкой.
Однако в случае неравномерных кодов возникает фундаментальная проблема: как на приемном конце различить отдельные кодовые слова? Например, как в двоичной системе различить, где кончается одно кодовое слово и начинается следующее?
Если вероятности появления различных символов источника сильно отличаются друг от друга, то неравномерные коды могут быть существенно более эффективными, чем блочные.
В этой главе учитываются лишь частоты появления различных символов источника и не принимается во внимание более тонкая структура, которую возможно имеют сообщения. Примером такой
более тонкой структуры в английском языке является то, что за буквой  как правило, следует буква
как правило, следует буква  Подобная корреляция в посылаемом сообщении учитывается в гл. 5.
Подобная корреляция в посылаемом сообщении учитывается в гл. 5.
Задачи
4.1.1. Перечислите достоинства и недостатки неравномерных кодов.