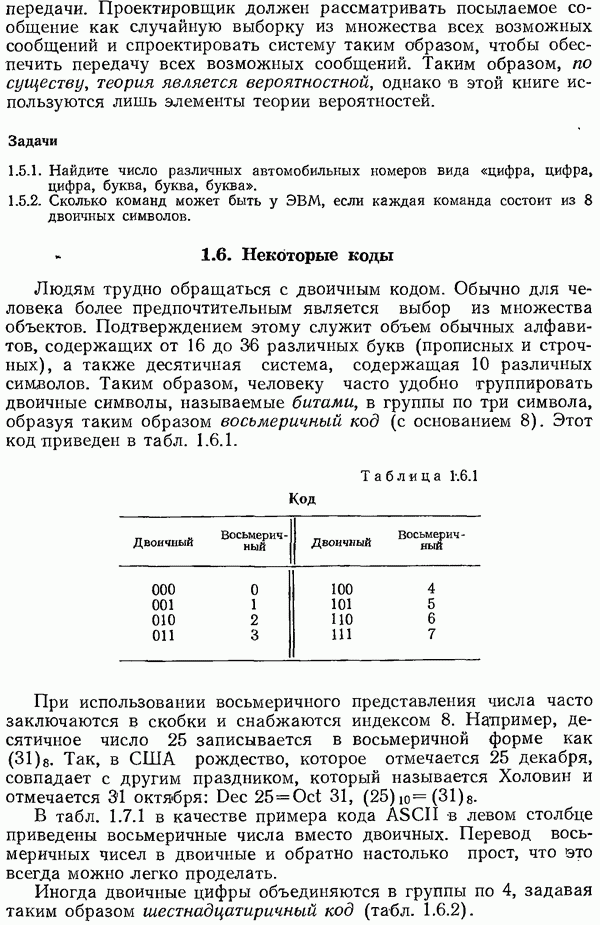
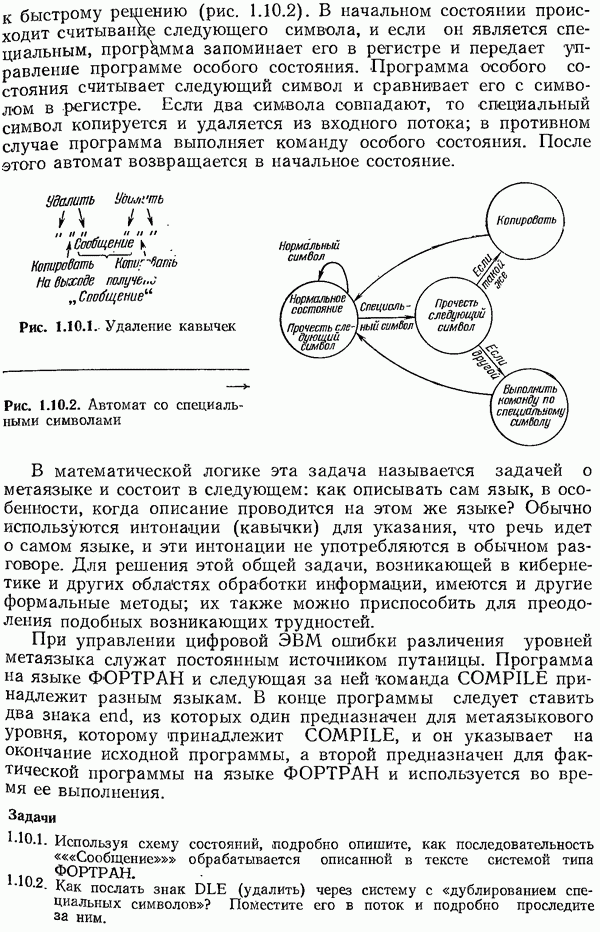
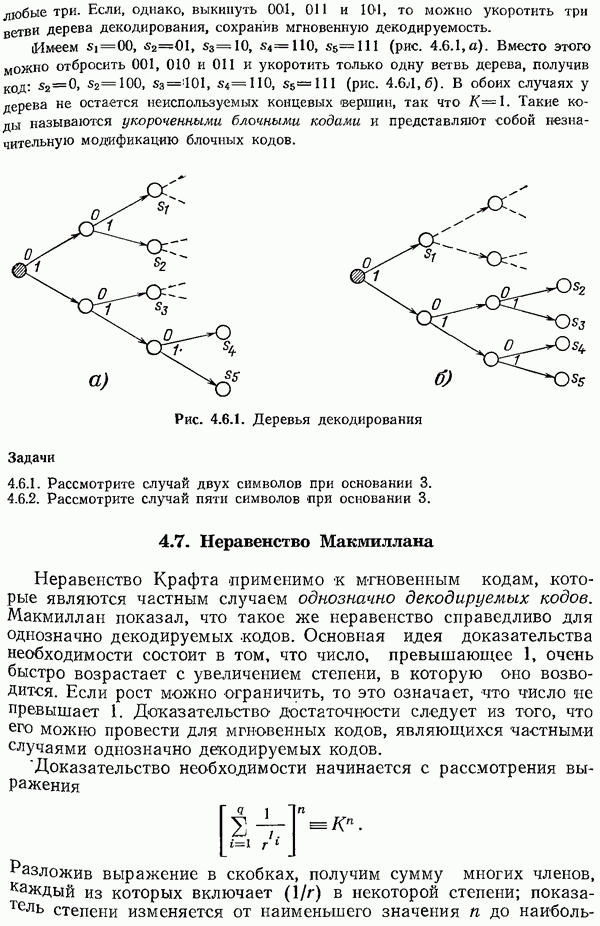
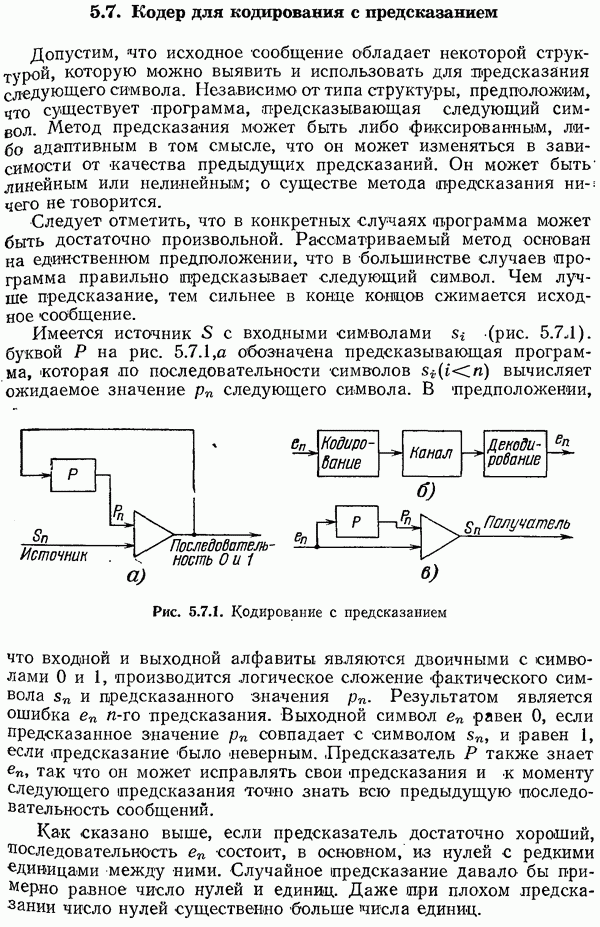
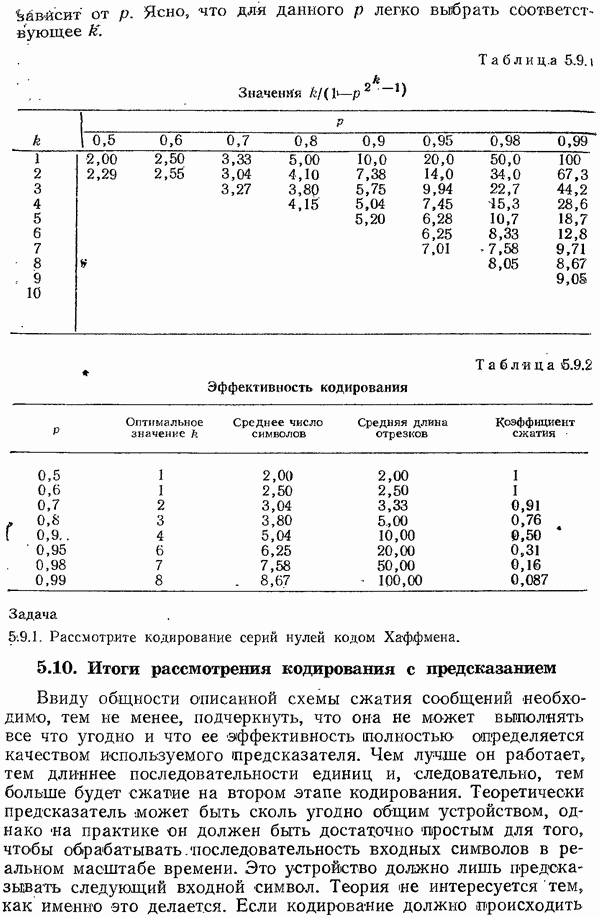
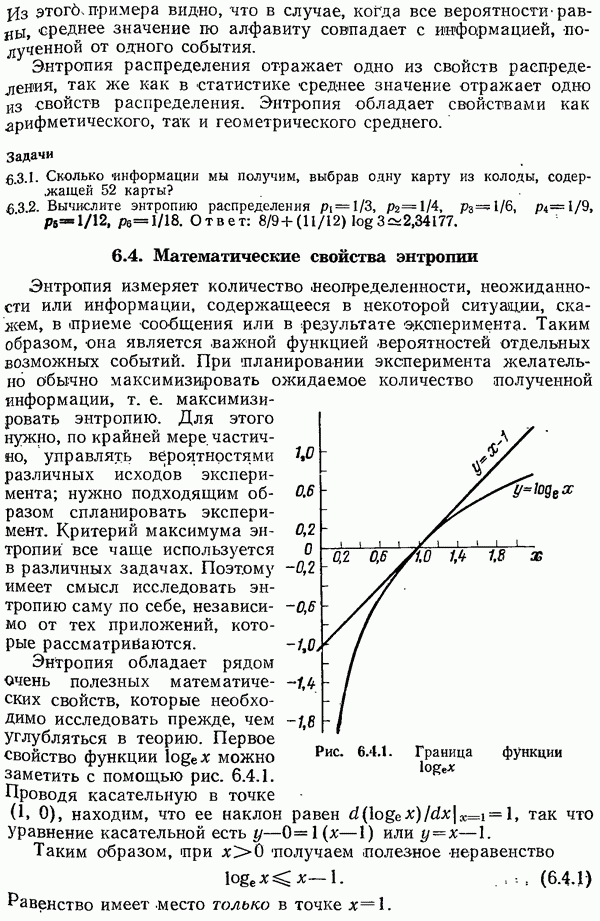
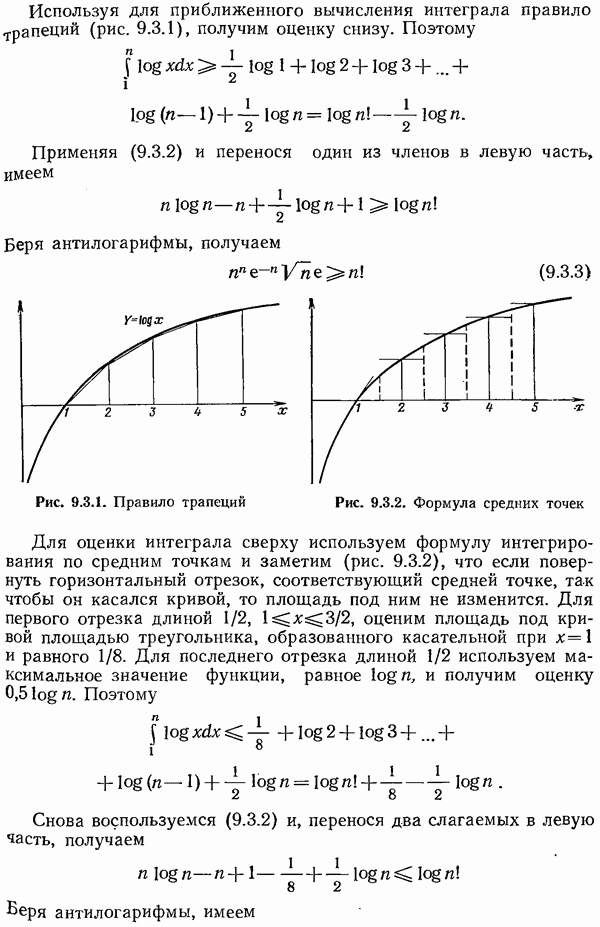
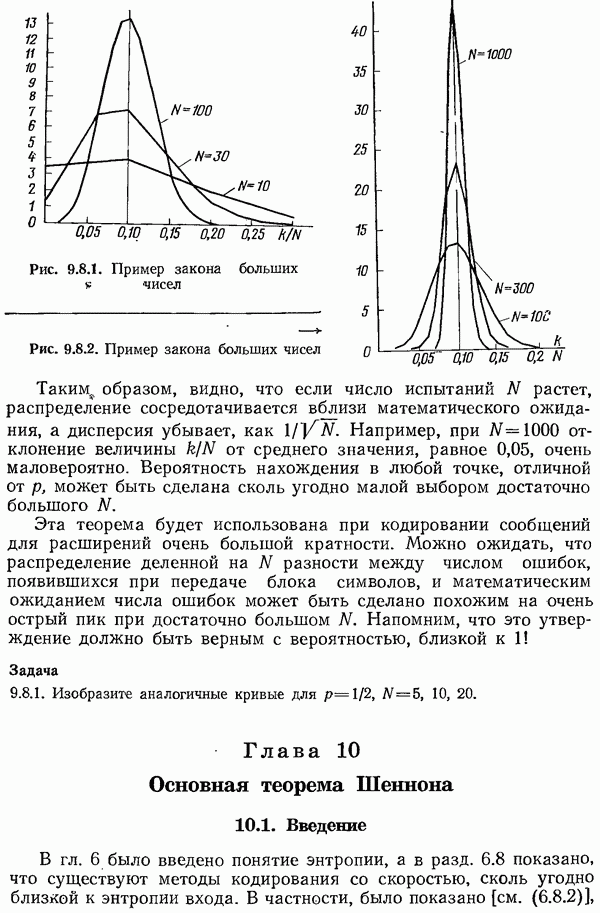
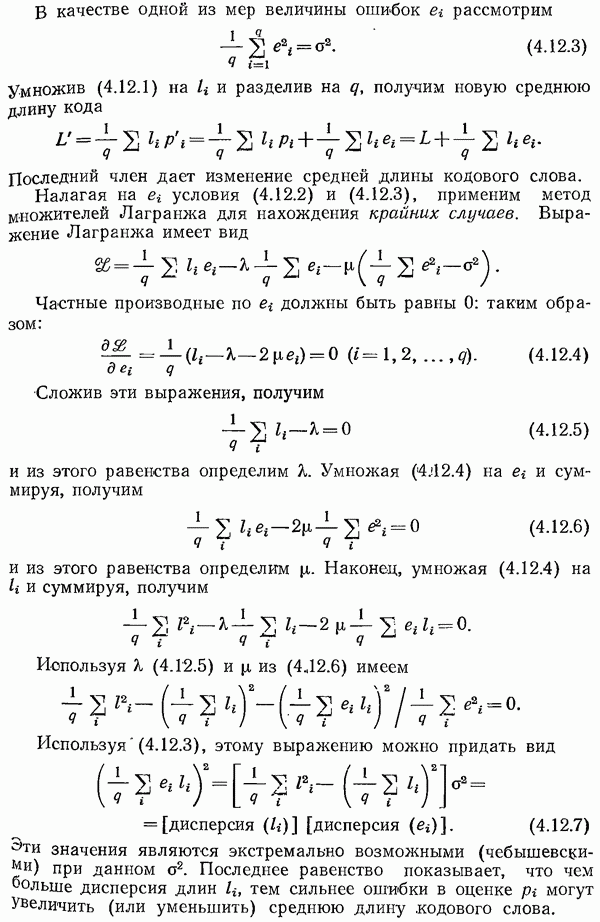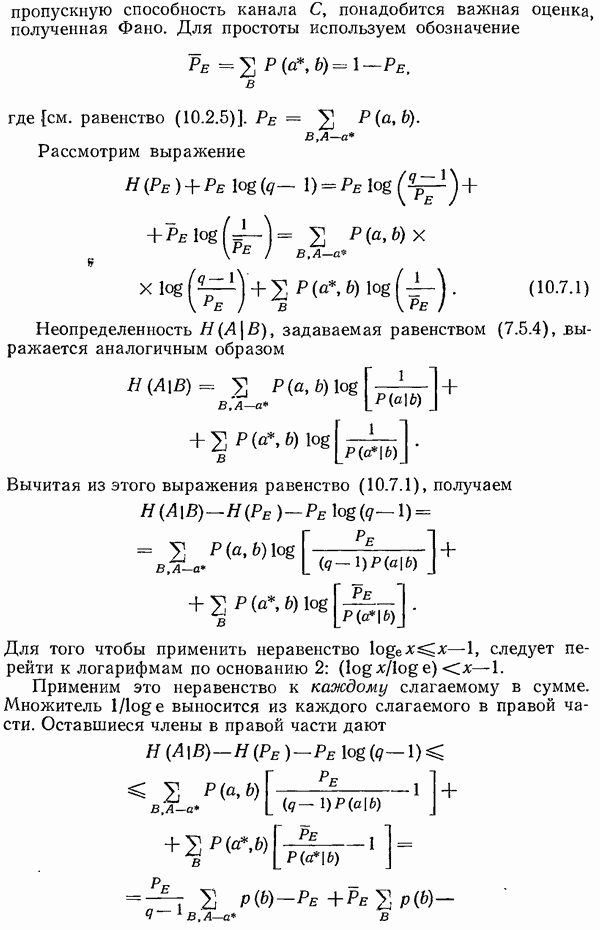11.13. Итоги
В этой главе показано, почему желательно применять хорошо структурированные коды; при кодировании и декодирований таких кодов можно использовать систематические (неслучайные) методы. Показано, как достаточно просто производить деление одного многочлена на другой.
Показано, что синдром определяется ошибкой и не зависит от сообщения. Далее обоснована необходимость использования множества многочленов по модулю данного простого многочлена. Кроме того, рассмотрена необходимость дополнительного условия существования у многочлена примитивного корня, при котором обеспечивается возможность записи всех элементов в виде степеней этого корня; в некотором смысле эта процедура эквивалентна введению логарифмов.
Наконец, в качестве иллюстрации описанных методов был разработан один код с исправлением двойных ошибок.
Мы не пытались изложить всю необходимую для обоснования теорию конечных полей или построить общую теорию кодов. Мы хотели показать лишь то, как построить код. Теория излагалась таким образом, чтобы можно было легко выделить и исследовать частные случаи; любой материал, выходящий за эти рамки, сделал бы книгу слишком длинной и практически ничего не добавил бы к имеющимся руководствам [2, 6, 8, 11, 13, 15, 16].