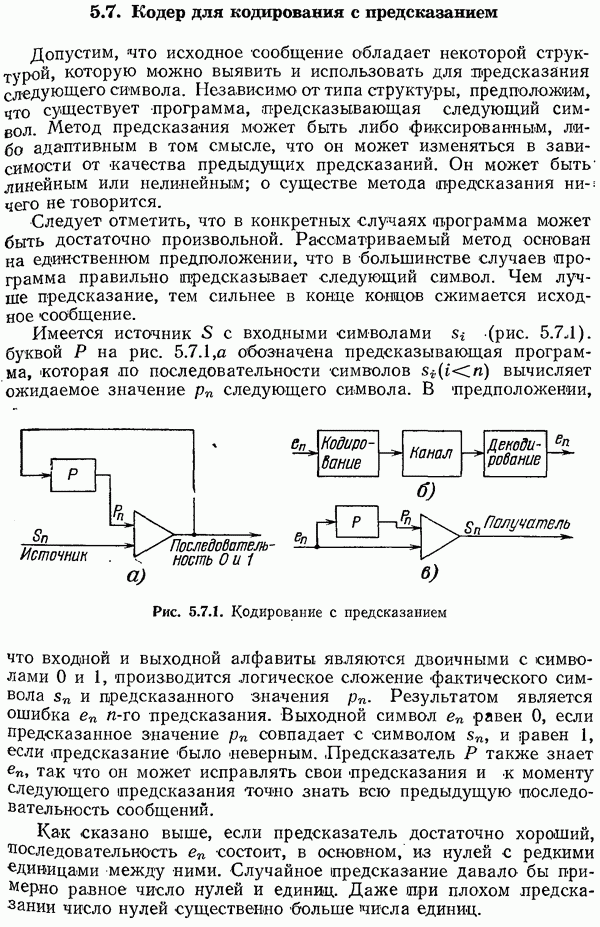
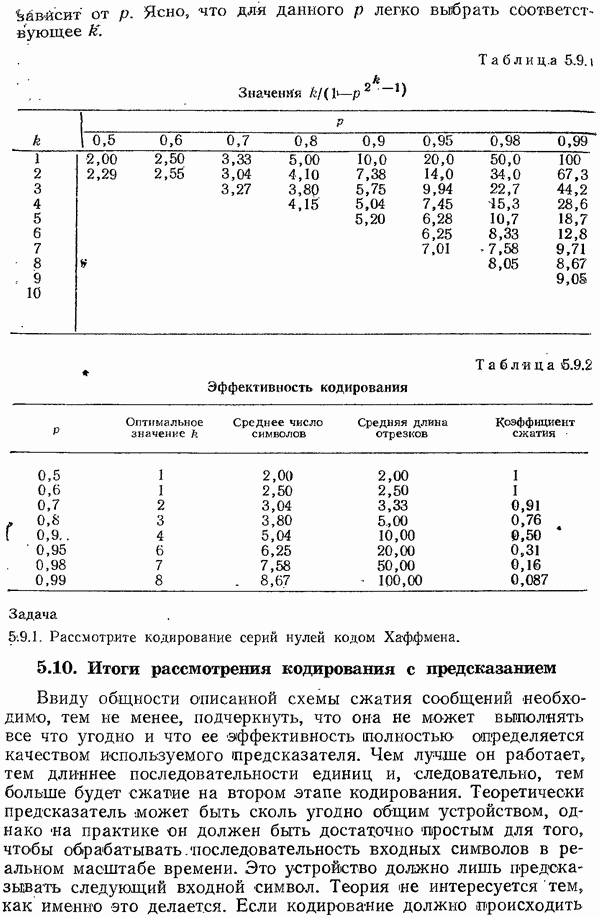
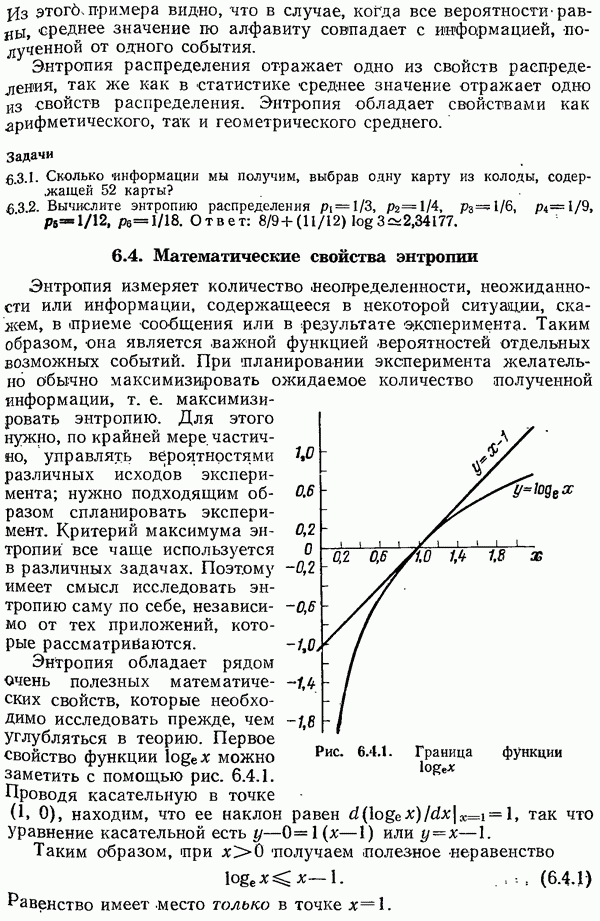
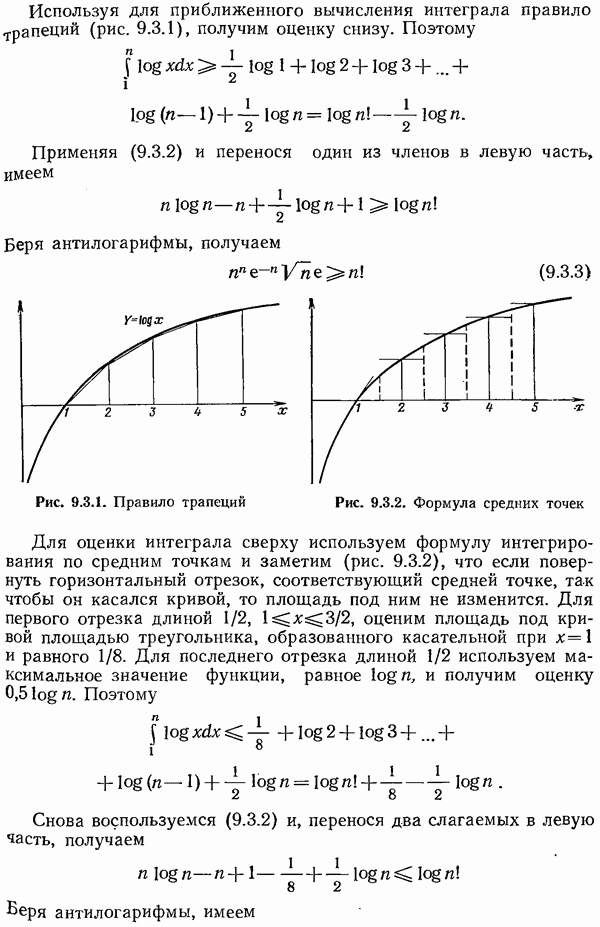
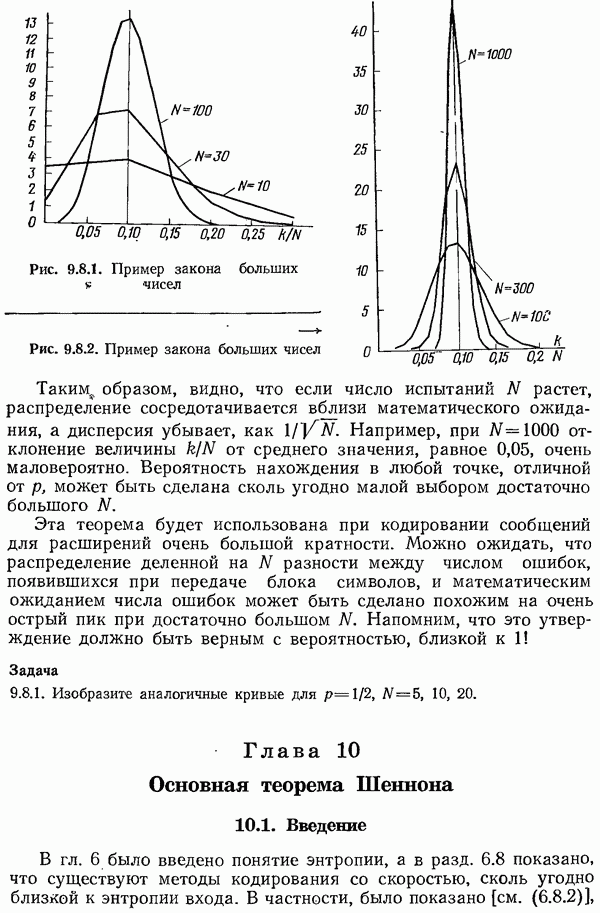
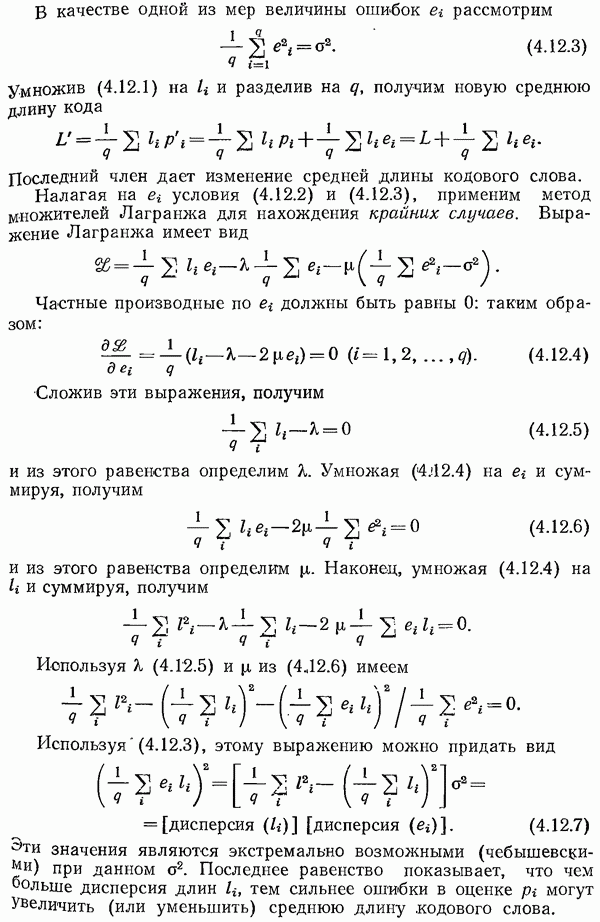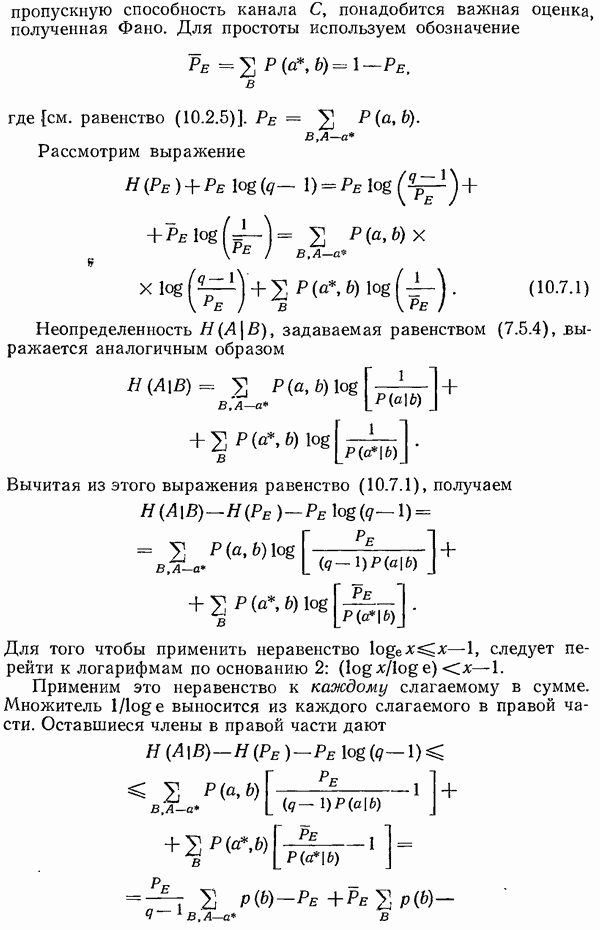7.7. Теорема Шеннона для семейств кодов
Выше указывалось, что в случае марковского процесса выгодно использовать в различных состояниях различные алфавиты. Зададим следующий вопрос: «Каков наиболее эффективный метод кодирования источника?» При этом не будем обращать внимание на практическую возможность реализации метода. Предположим, что принят некоторый символ  каким образом можно было осуществить оптимальное кодирование
каким образом можно было осуществить оптимальное кодирование  Ответ дается неравномерным кодом Хаффмена, который зависит от
Ответ дается неравномерным кодом Хаффмена, который зависит от  Этот код будет, конечно, меняться с изменением
Этот код будет, конечно, меняться с изменением  Если использовать в качестве
Если использовать в качестве  кода более удобный, но несколько менее эффективный код Шеннона — Фано, то при получении
кода более удобный, но несколько менее эффективный код Шеннона — Фано, то при получении  для различных
для различных  следует выбирать кодовые слова, длины
следует выбирать кодовые слова, длины  которых определяются при обычных условиях (для всех
которых определяются при обычных условиях (для всех  и фиксированного
и фиксированного 

или

Поскольку  для
для  кода выполнено неравенство Крафта, и для каждого
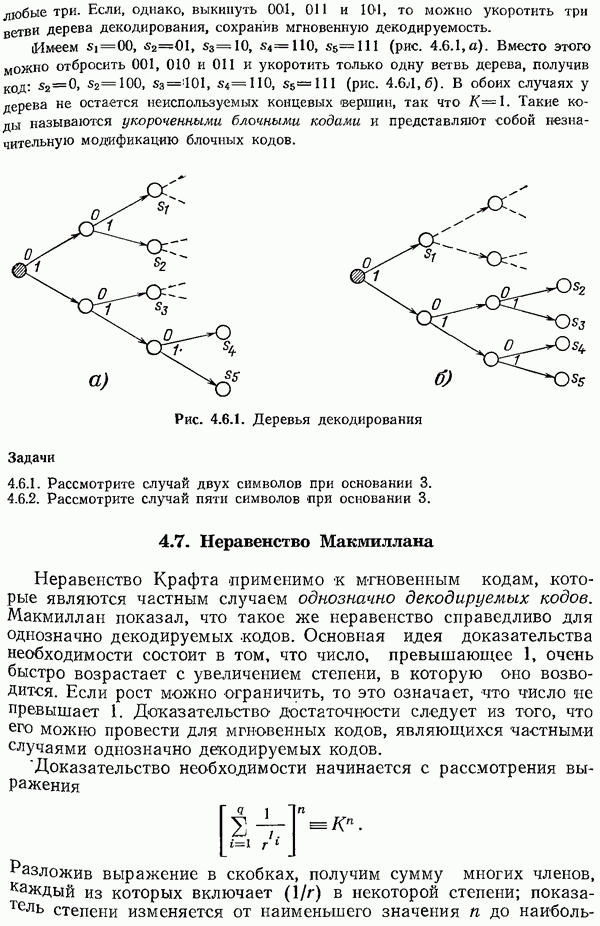
кода выполнено неравенство Крафта, и для каждого  существует мгновенный код. Пусть длины для различных кодов такие, как указаны в таблице:
существует мгновенный код. Пусть длины для различных кодов такие, как указаны в таблице:
(см. скан)
Умножим соотношение (7.7.1) на  и просуммируем по всем
и просуммируем по всем  По первой теореме Шеннона для
По первой теореме Шеннона для  кода имеем
кода имеем

где  средняя длина
средняя длина  кода. Этот код должен использоваться только в том случае, когда получен символ
кода. Этот код должен использоваться только в том случае, когда получен символ 
Поскольку вероятность получения  равна
равна  то, усредняя, получим
то, усредняя, получим

где  средняя длина кода, и снова
средняя длина кода, и снова

Переход к расширениям требует громоздких обозначений. Ясно, однако, что при этом происходит: энтропии возрастают в  раз. Поэтому, как и ранее, для
раз. Поэтому, как и ранее, для  расширения имеем
расширения имеем

При достаточно большом  можно получить среднюю длину кода, сколь угодно близкую к условной энтропии
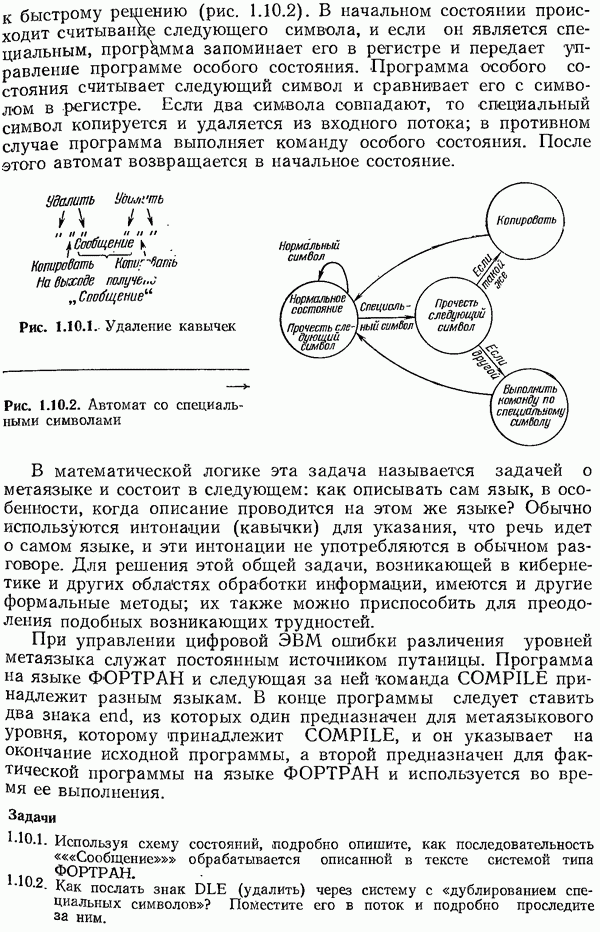
можно получить среднюю длину кода, сколь угодно близкую к условной энтропии  Таким образом, теорема Шеннона о кодировании без шума обобщена на семейство мгновенных (однозначно декодируемых) кодов.
Таким образом, теорема Шеннона о кодировании без шума обобщена на семейство мгновенных (однозначно декодируемых) кодов.