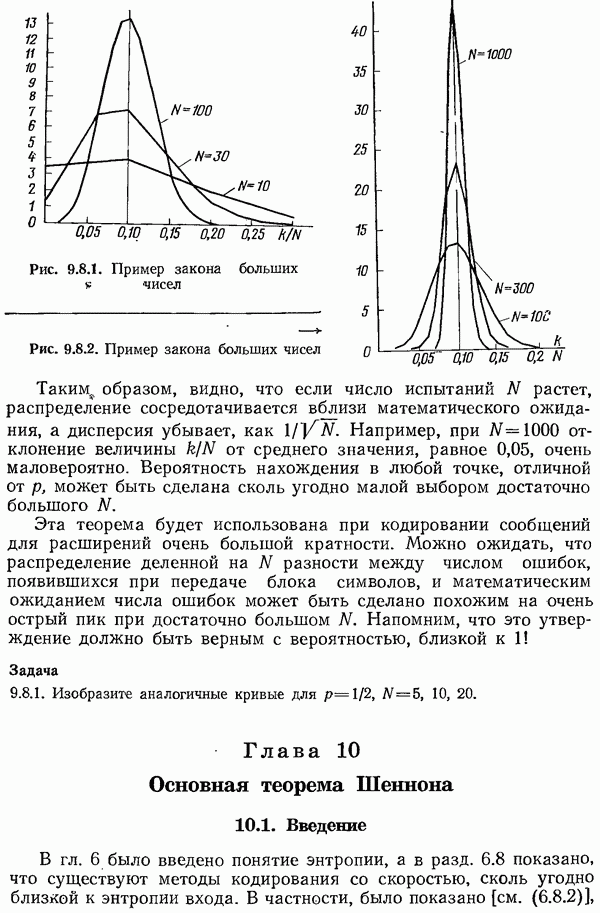
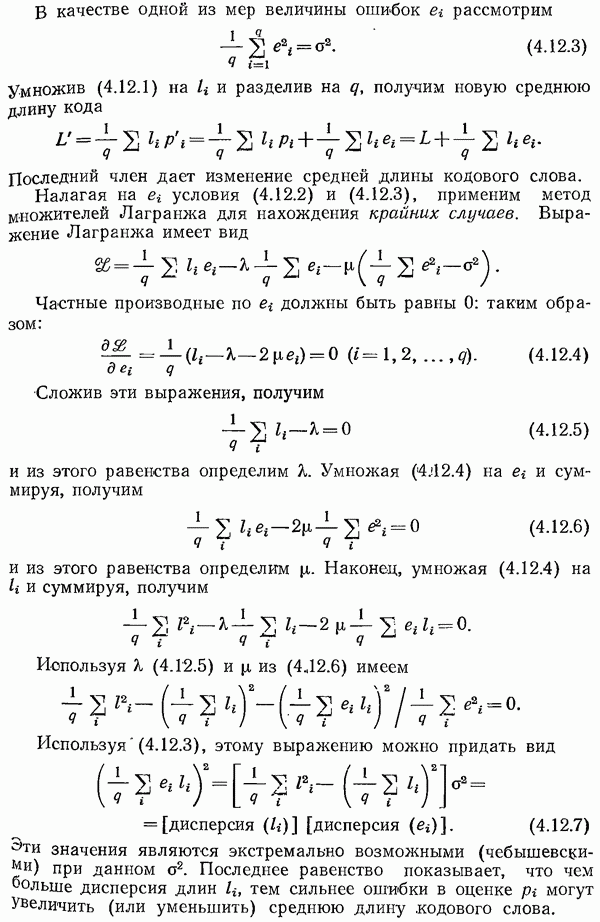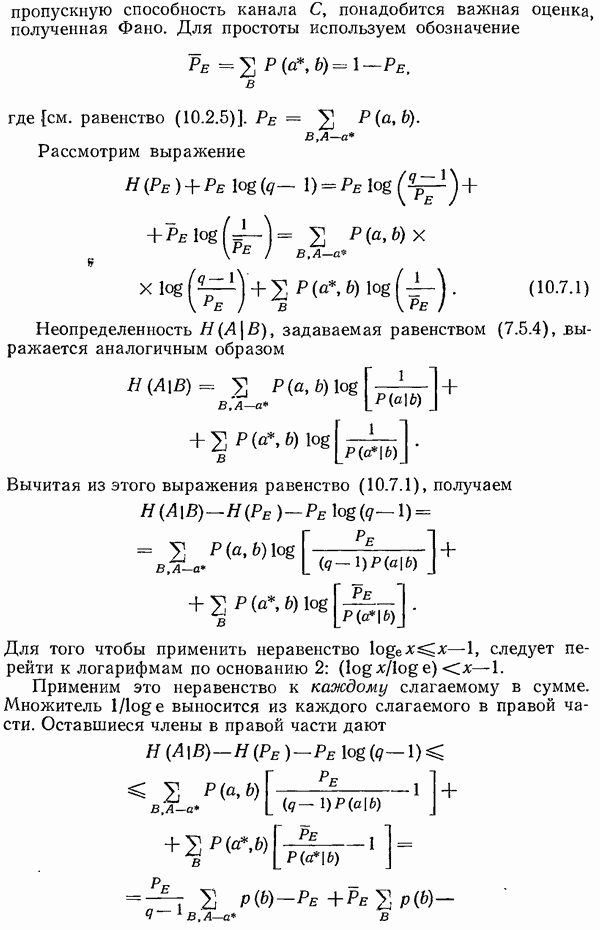11.3. Еще раз о кодах Хэмминга
В разд. 3.4 рассматривались коды с исправлением одной ошибки. В этих кодах использовались следующие проверки на четность:

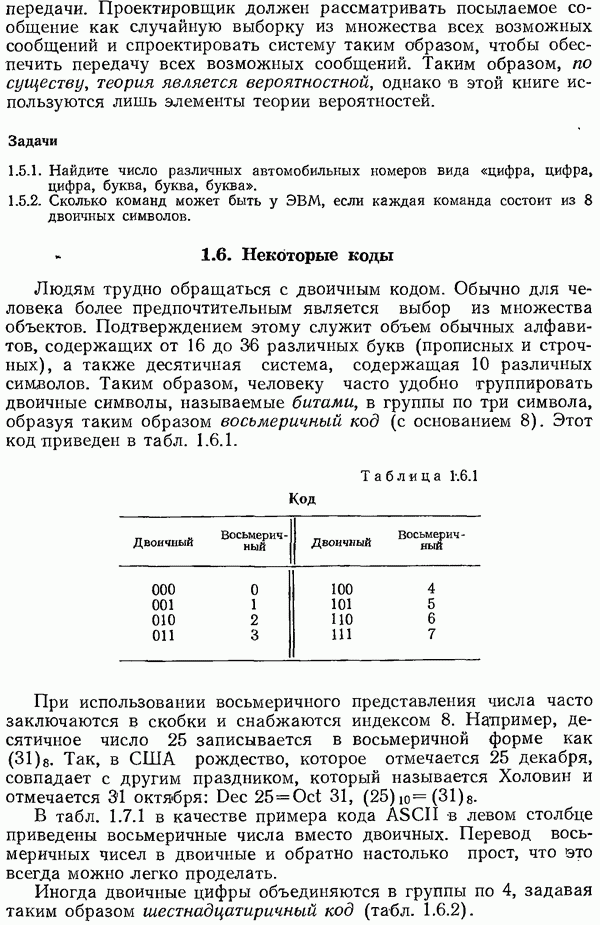
Для част ого случая  напишем матрицу
напишем матрицу

в которой проверки перечислены в обратном порядке.
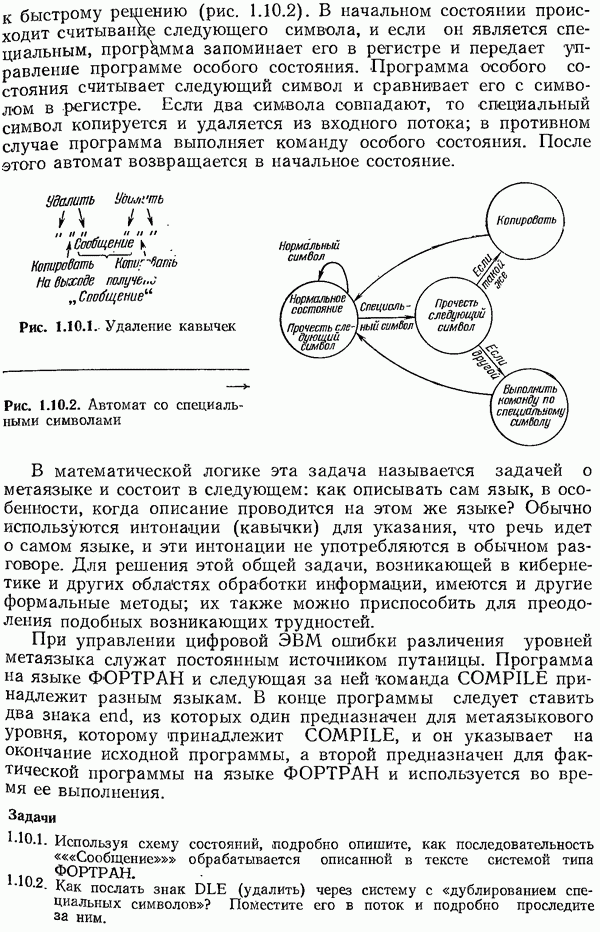
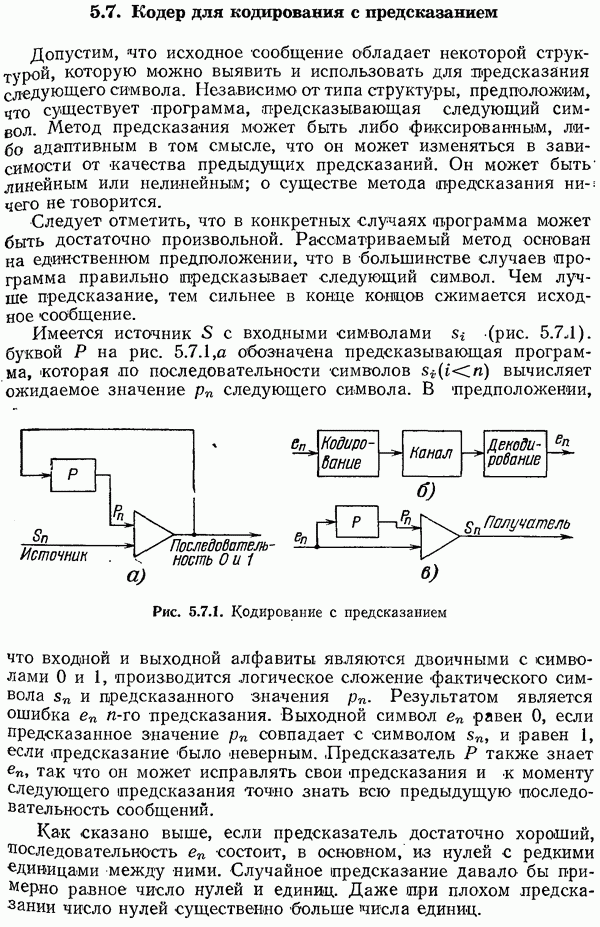
Пусть снова с — кодовое слово. Для каждого кодового слова имеет место равенство

поскольку оно фактически эквивалентно определению кодового слова. Иначе говоря, матрица  переводит каждое кодовое слово в нулевой вектор. Одиночная ошибка
переводит каждое кодовое слово в нулевой вектор. Одиночная ошибка  приведет к тому, что будет принято сообщение
приведет к тому, что будет принято сообщение  и снова
и снова

Таким образом, синдром зависит только от ошибки и не зависит от посланного кодового слова.
Произведение матрицы на вектор ошибок (у которого одна компонента равна 1) дает соответствующий столбец матрицы. Поэтому из формулы (11.3.2) вытекает, что столбцы проверочной матрицы — это в точности те синдромы, которые могут возникнуть в случае одиночной ошибки.
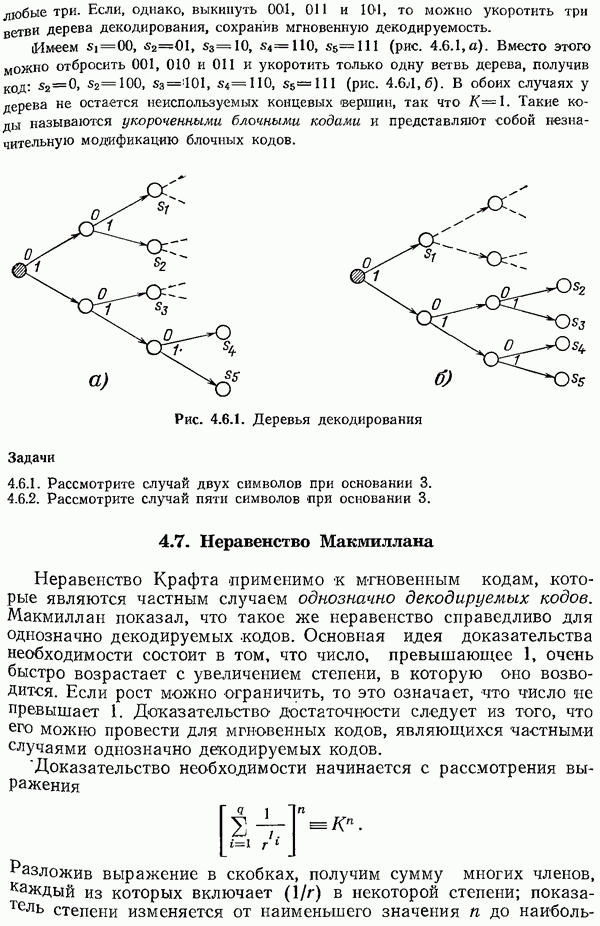
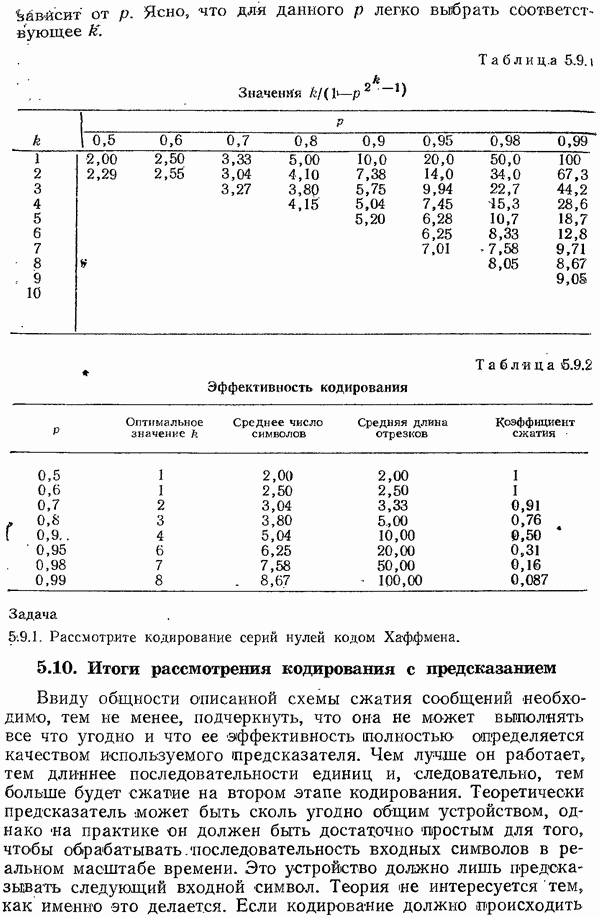
Для любого кода с проверками на четность можно образовать проверочную матрицу; в каждой строке этой матрицы равны 1 те элементы, которые отвечают символам, входящим в соответствующую проверку на четность,  элементы, отвечающие символам, не входящим в соответствующую проверку на четность. Будем предполагать, что ранг этой проверочной матрицы
элементы, отвечающие символам, не входящим в соответствующую проверку на четность. Будем предполагать, что ранг этой проверочной матрицы  равен
равен
числу строк в ней (используя, конечно, арифметику по модулю 2). Например, ранг матрицы

(см. разд. 3.4) равен 2, поскольку справедливость первой проверки вытекает из справедливости двух остальных проверок (сумма всех трех строк есть  Если строки зависимы, то по крайней мере один символ синдрома определяется по остальным и нельзя получить все возможные синдромы, т. е. происходит напрасная трата пропускной способности.
Если строки зависимы, то по крайней мере один символ синдрома определяется по остальным и нельзя получить все возможные синдромы, т. е. происходит напрасная трата пропускной способности.
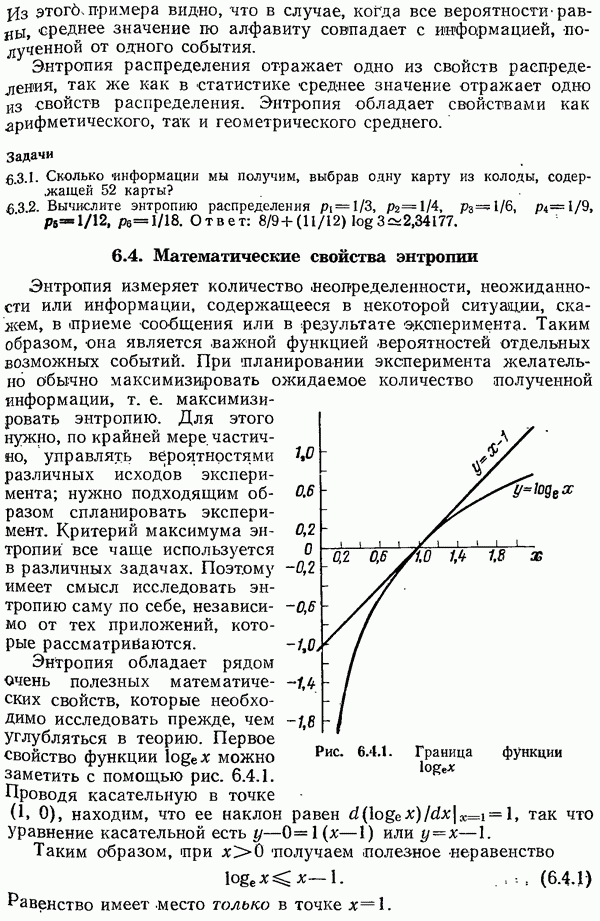
Процедура кодирования в случае произвольных проверок на четность обеспечивает выполнение равенства  для всех правильных кодовых слов. Таким образом, снова имеем, что ошибка
для всех правильных кодовых слов. Таким образом, снова имеем, что ошибка  приводит к приему сообщения
приводит к приему сообщения  и
и

Синдром снова зависит только от ошибки.
В случае одиночной ошибки имеется следующий алгоритм декодирования: синдром равен соответствующему столбцу проверочной матрицы. Поэтому, сравнивая синдромы со столбцами проверочной матрицы до получения полного совпадения, можно установить положение ошибки.
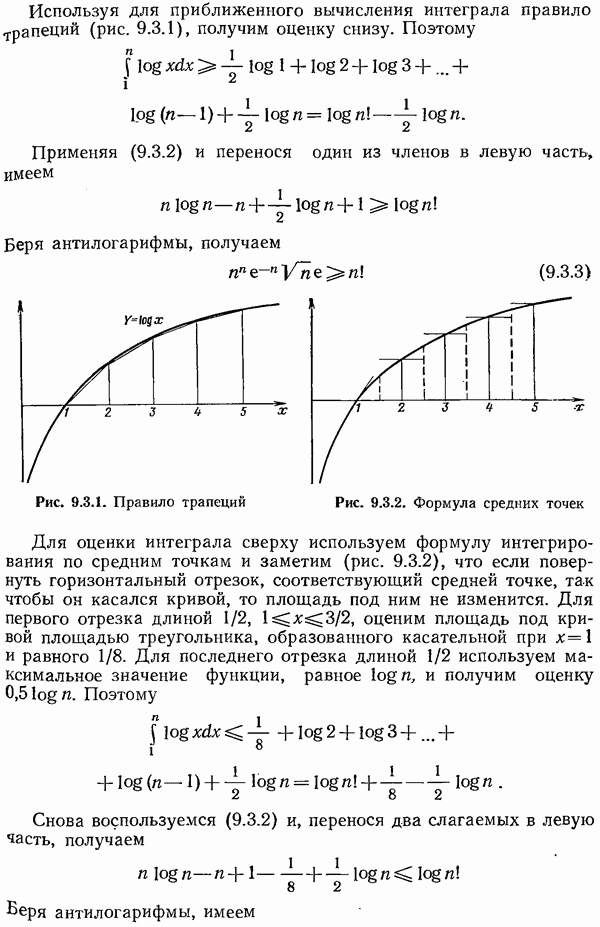
Таким образом, для каждого кода с исправлением одиночной ошибки по синдрому можно найти соответствующий столбец проверочной матрицы  (число нулевой синдром означает отсутствие ошибки).
(число нулевой синдром означает отсутствие ошибки).
Для кодов с исправлением кратных ошибок синдром равен сумме (по модулю 2) столбцов проверочной матрицы, соответствующих позициям прошедших ошибок. Если требуется найти соответствующие столбцы проверочной матрицы, т. е. положения ошибок, то это соответствие должно быть взаимно однозначным. Если [появился синдром, который не является суммой разрешенного читала столбцов, то возникшие ошибки исправить нельзя. Можно лишь сказать, что ошибки произошли.
Например, в случае кода с исправлением двойных ошибок [каждый синдром, который может возникнуть в результате появления двух ошибок, должен ровно одним способом представляться в виде суммы двух столбцов проверочной матрицы, т. е. не должно существовать двух различных пар столбцов, приводящих к одному и тому же синдрому, поскольку в противном случае оказалось бы невозможным узнать, какая пара ошибок привела к наблюдаемому синдрому. Кроме того, никакая сумма двух столбцов не должна быть равна никакому третьему столбцу. Другими словами,

и каждый синдром должен однозначно появляться ровно из одной пары ошибок  или из одной одиночной ошибки.
или из одной одиночной ошибки.
Такие же рассуждения можно применить к кодам с исправлением кратных ошибок.