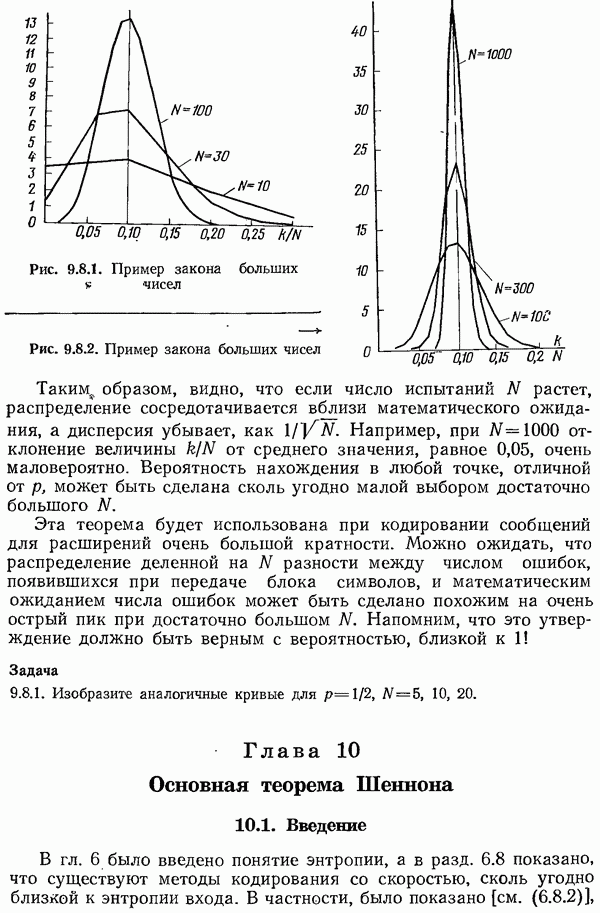
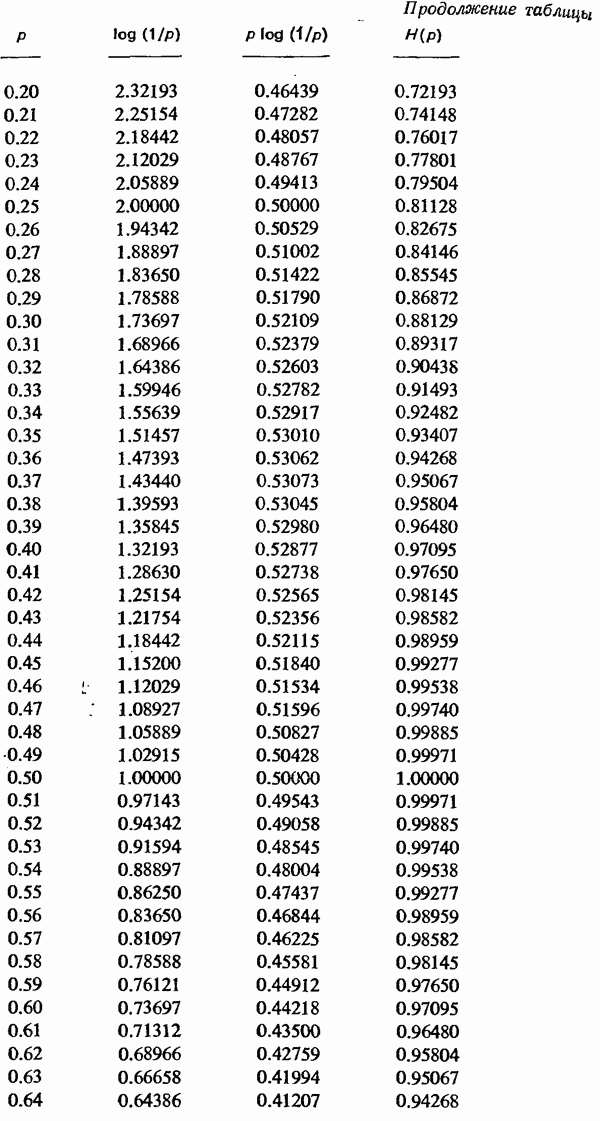
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.4. Коды Хэмминга для исправления ошибокВ этом разделе используется алгебраический подход к задаче, рассмотрение которой началось в предыдущем разделе, т. е. к задаче построения наилучшей схемы кодирования для исправления одиночных ошибок при белом шуме. Предположим, что имеется
являются зависимыми, поскольку сумма любых двух Строк совпадают с третьей строкой. Таким образом, третья проверка на четность не доставляет никакой новой информации по сравнению с двумя первыми и является лишней. Синдром, который получается, если написать символ
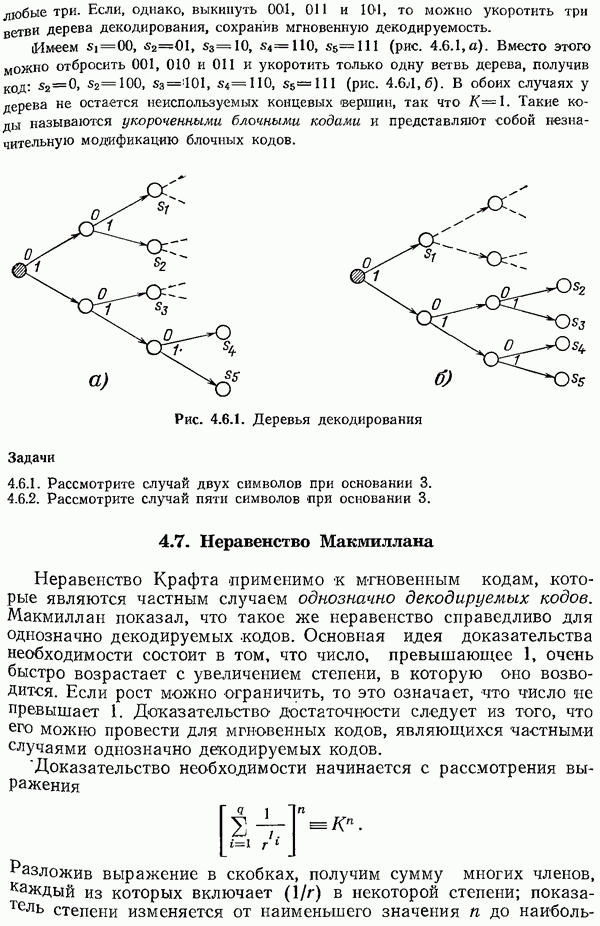
Можно ли найти такой код? Ниже показано, как построить коды, для которых в условии (3.4.1) стоит равенство. Они дают частичное решение задачи построения подходящего кода и известны как коды Хэмминга. Простая идея, лежащая в основе кодов Хэмминга, состоит в требовании того, чтобы синдром давал фактическое положение ошибки, а равный двоичное представление номеров позиций (табл. 3.4.1). Ясно, что если синдром указывает позицию ошибки (когда она произошла), то каждая позиция, для которой последняя цифра ее номера, записанного в двоичном представлении, равна 1, должна входить в первую проверку на четность (см. крайний правый столбец). Аккуратно продумайте, почему это так. Аналогично, во вторую проверку на четность должны входить те позиции, для которых равна 1 вторая справа цифра их номера, записанного в двоичном представлении и т. д. Таблица 3.4.1 (см. скан) Проверочные позиции Таким образом, в первую проверку на четность входят позиции 1, 3, 5, 7, 9, 11, 13, 15, .., во вторую - 2, 3, 6, 7, 10, 11, 14, 15, ..., в третью - 5, 6, 7, 12, 13, .14, 15, ..., в следующую - 8, 9, 10, 11, 12, 13, 14, 15 и т. д. Для иллюстрации сказанного (табл. 3.4.2) построим простой код с исправлением ошибки для четырех двоичных символов. Таблица 3.4.2 (см. скан) Кодирование Должно выполняться неравенство Заметим, что вместе с информационными символами в одинаковой мере исправляются проверочные. Таким образом, код является равномерно защищенным: после кодирования информационные и проверочные символы принимают равное участие в кодовом слове. Привлекательная черта кода Хэмминга состоит в легкости кодирования и исправления ошибок. Заметим также, что синдром Указывает положение ошибки независимо от того, какое сообщение было послано; логическое прибавление 1 к символу, номер позиции которого определяется синдромом, исправляет получение сообщение. Равенство нулю всех символов синдрома означает, конечно, что в сообщении нет ошибок. Избыточность в примере с четырьмя информационными и тремя проверочными символами оказывается довольно большой. Если, однако, число проверочных символов равно 10, то из неравенства (3.4.1) имеем Задачи3.4.1. Рассмотрите код Хэмминга с четырьмя проверками. 3.4.2. Рассмотрите код Хэмминга с двумя проверками. Ответ: Код с утроением. 3.4.3. Покажите, что 1111111 — правильное сообщение. 3.4.4. Исправьте и декодируйте последовательность 1001111. 3.4.5. Найдите позицию ошибки в сообщении 3.4.6. Найдите вероятность того, что случайная последовательность из
|
 |
Оглавление
|










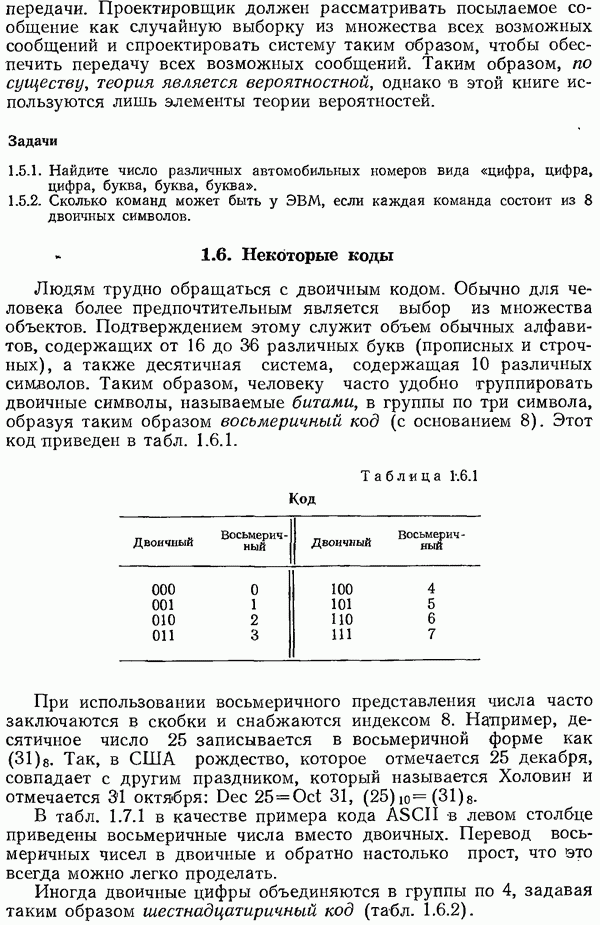






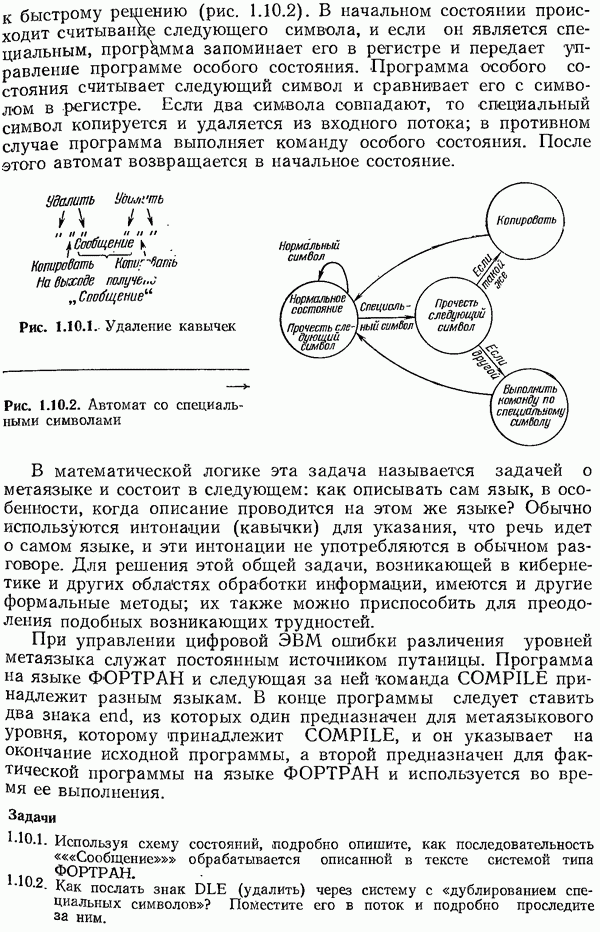






































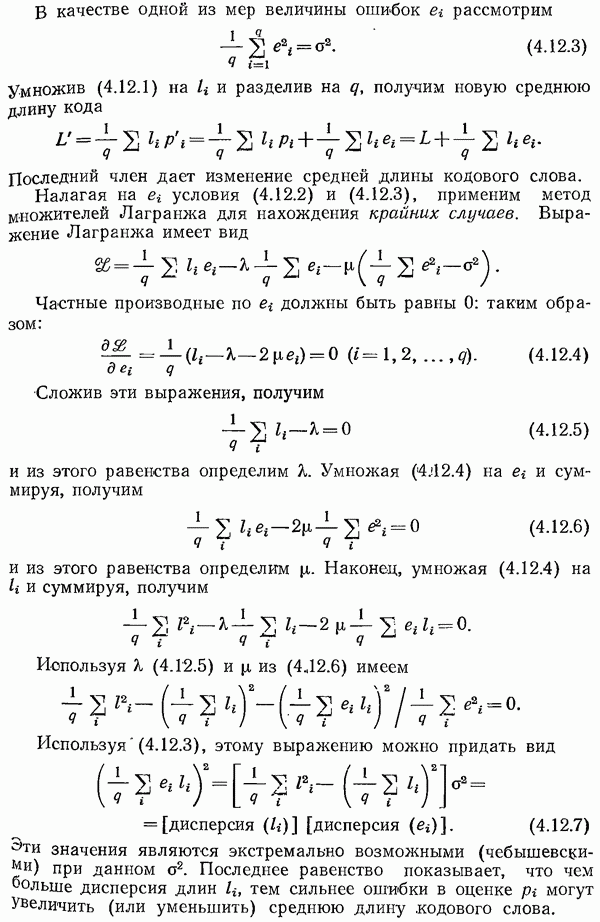









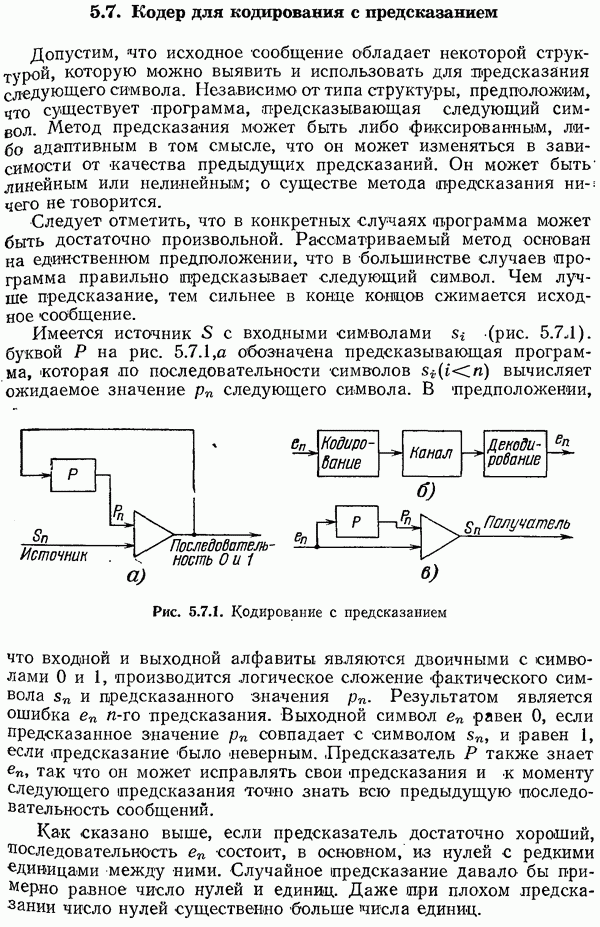


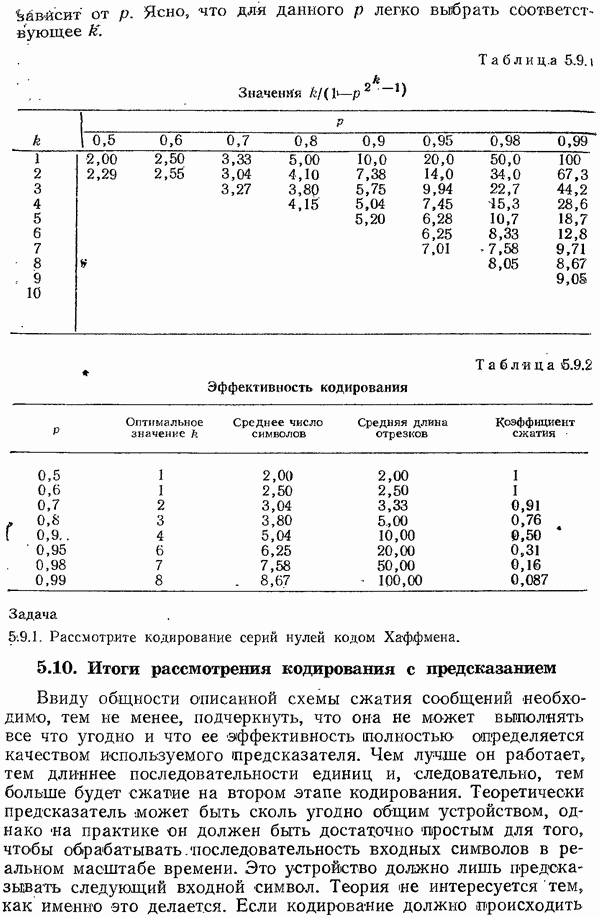










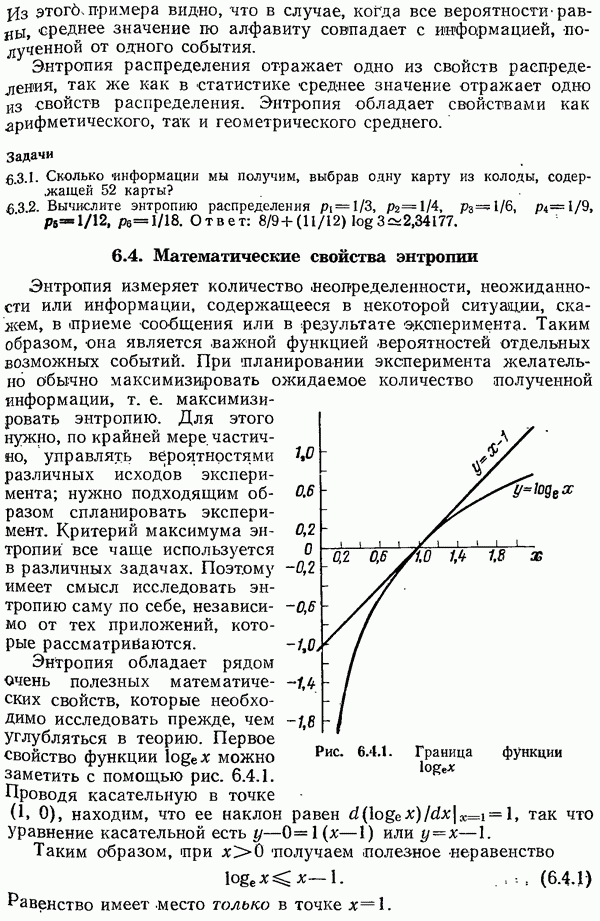

































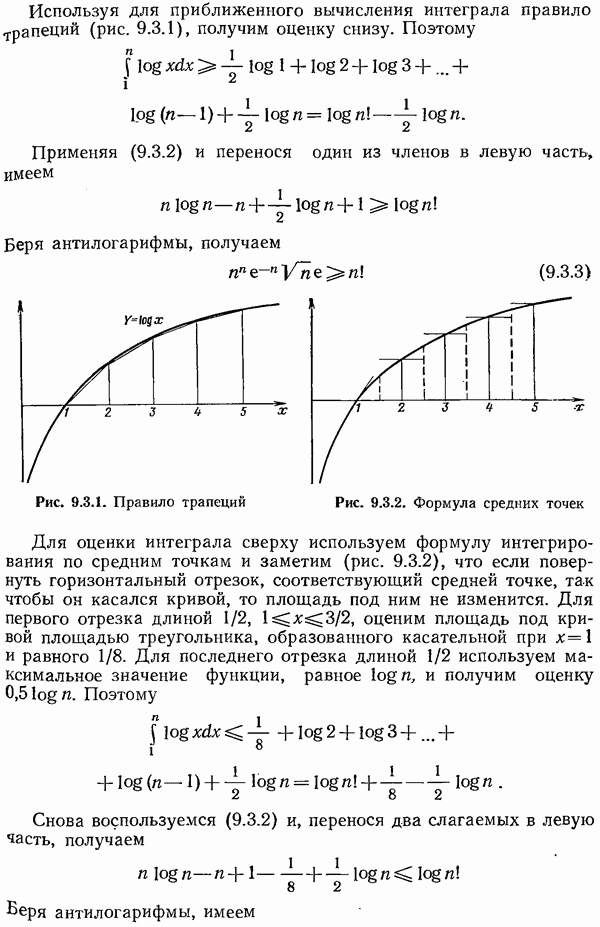



















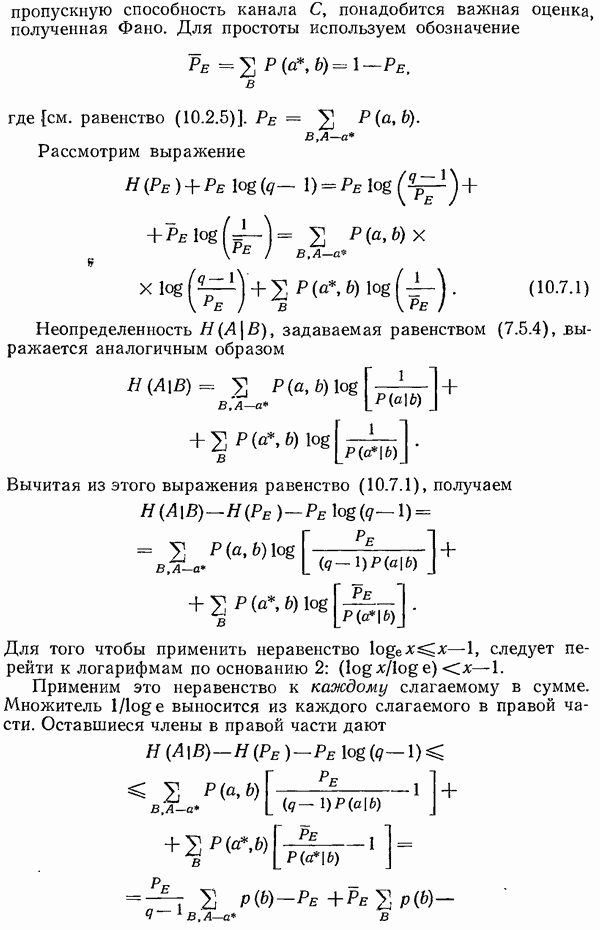


























 независимых проверок, на четность. Слово «независимые» означает, конечно, что никакая сумма одних проверок не совпадает ни с какой другой проверкой (напомним, что складывать нужно в системе счисления по модулю 2). Так, три проверки на четность в позициях
независимых проверок, на четность. Слово «независимые» означает, конечно, что никакая сумма одних проверок не совпадает ни с какой другой проверкой (напомним, что складывать нужно в системе счисления по модулю 2). Так, три проверки на четность в позициях

 для каждой из выполненных проверок на четность и символ 1 для каждой из невыполненных проверок, можно рассматривать как число, состоящее из
для каждой из выполненных проверок на четность и символ 1 для каждой из невыполненных проверок, можно рассматривать как число, состоящее из  цифр. Это число может различать не более
цифр. Это число может различать не более  событий. Необходимо иметь синдром, соответствующий тому, что все символы сообщения правильны, а также местоположение ошибки в любой из
событий. Необходимо иметь синдром, соответствующий тому, что все символы сообщения правильны, а также местоположение ошибки в любой из  позиций сообщения. Это приводит к неравенству
позиций сообщения. Это приводит к неравенству

 синдром означал, что ошибка отсутствует. Какими должны быть проверки на четность? Посмотрим на
синдром означал, что ошибка отсутствует. Какими должны быть проверки на четность? Посмотрим на
 -битового сообщения и определение ошибки
-битового сообщения и определение ошибки
 при этом легко видеть, что
при этом легко видеть, что  Таким образом, нужно иметь
Таким образом, нужно иметь  проверок на четность и тогда
проверок на четность и тогда  общее число символов (информационных и проверочных). Для удобства пусть позиции 1, 2 и 4 используются для проверок на четность. Тогда информационными являются позиции с номерами 3, 5, 6 и 7. Для того чтобы закодировать информационное сообщение, запишем его в этих позициях и вычислим проверки на четность. Пусть, скажем, сообщение имеет вид
общее число символов (информационных и проверочных). Для удобства пусть позиции 1, 2 и 4 используются для проверок на четность. Тогда информационными являются позиции с номерами 3, 5, 6 и 7. Для того чтобы закодировать информационное сообщение, запишем его в этих позициях и вычислим проверки на четность. Пусть, скажем, сообщение имеет вид  пробелы указывают места, в которых должны находиться проверочные символы. Первая проверка на четность, дающая значение первого символа, включает символы, стоящие на позициях 1, 3, 5 и 7; рассматривая сообщение, получаем, что первый символ равен 0. Теперь сообщение имеет вид
пробелы указывают места, в которых должны находиться проверочные символы. Первая проверка на четность, дающая значение первого символа, включает символы, стоящие на позициях 1, 3, 5 и 7; рассматривая сообщение, получаем, что первый символ равен 0. Теперь сообщение имеет вид  Вторая проверка на четность, включающая символы на позициях 2, 3, 6 и 7, приводит к тому, что второй символ равен 1. Таким образом, частично закодированное сообщение получает вид
Вторая проверка на четность, включающая символы на позициях 2, 3, 6 и 7, приводит к тому, что второй символ равен 1. Таким образом, частично закодированное сообщение получает вид  Третья проверка на четность символов на позициях 4, 5, 6 и 7 дает четвертый символ, равный 0. Тогда полностью закодированное сообщение имеет вид
Третья проверка на четность символов на позициях 4, 5, 6 и 7 дает четвертый символ, равный 0. Тогда полностью закодированное сообщение имеет вид  Для того чтобы увидеть, как код исправляет изолированную ошибку, предположим, что послано сообщение
Для того чтобы увидеть, как код исправляет изолированную ошибку, предположим, что послано сообщение  и канал добавляет 1 к третьему слева символу. В результате искаженное сообщение имеет вид
и канал добавляет 1 к третьему слева символу. В результате искаженное сообщение имеет вид  На приемном конце по очереди производятся проверки на четность. Первая проверка, включающая символы на позициях 1, 3, 5 и 7, очевидно, не выполнена, так что последняя цифра синдрома равна 1. Вторая проверка на четность, включающая символы на позициях 2, 3, 6, 7, также не выполнена, так что вторая цифра синдрома также равна 1. Третья проверка на четность, включающая символы на позициях 4, 5, 6, 7, выполнена, так что старшая цифра равна 0. Рассмотрение синдрома как двоичного числа показывает, что он соответствует десятичному числу 3. Поэтому следует изменить (логически добавляя 1) символ на третьей позиции принятого сообщения с
На приемном конце по очереди производятся проверки на четность. Первая проверка, включающая символы на позициях 1, 3, 5 и 7, очевидно, не выполнена, так что последняя цифра синдрома равна 1. Вторая проверка на четность, включающая символы на позициях 2, 3, 6, 7, также не выполнена, так что вторая цифра синдрома также равна 1. Третья проверка на четность, включающая символы на позициях 4, 5, 6, 7, выполнена, так что старшая цифра равна 0. Рассмотрение синдрома как двоичного числа показывает, что он соответствует десятичному числу 3. Поэтому следует изменить (логически добавляя 1) символ на третьей позиции принятого сообщения с  на 1. Полученная последовательность нулей и единиц является верной, и, выкидывая проверочные позиции 1, 2 и 4, получаем исходное информационное сообщение
на 1. Полученная последовательность нулей и единиц является верной, и, выкидывая проверочные позиции 1, 2 и 4, получаем исходное информационное сообщение  стоящее на позициях 3, 5, 6, 7.
стоящее на позициях 3, 5, 6, 7.
 число информационных символов. Это значит, что число информационных символов не превышает
число информационных символов. Это значит, что число информационных символов не превышает  Поэтому чистая избыточность растет как двоичный логарифм числа информационных символов.
Поэтому чистая избыточность растет как двоичный логарифм числа информационных символов.
 закодированном, как в задаче 3.4.1, с четырьмя проверками. Укажите правильное сообщение.
закодированном, как в задаче 3.4.1, с четырьмя проверками. Укажите правильное сообщение.
 нулей и единиц является кодовым словом.
нулей и единиц является кодовым словом.