6.7. Насколько плохим является кодирование Шеннона — Фано?
Поскольку кодирование Хаффмена оптимально и мы временно перешли к неоптимальному (в смысле затрат времени) кодированию Шеннона — Фано, естественно задать вопрос: «Насколько плохим является кодирование Шеннона — Фано?».






















































































































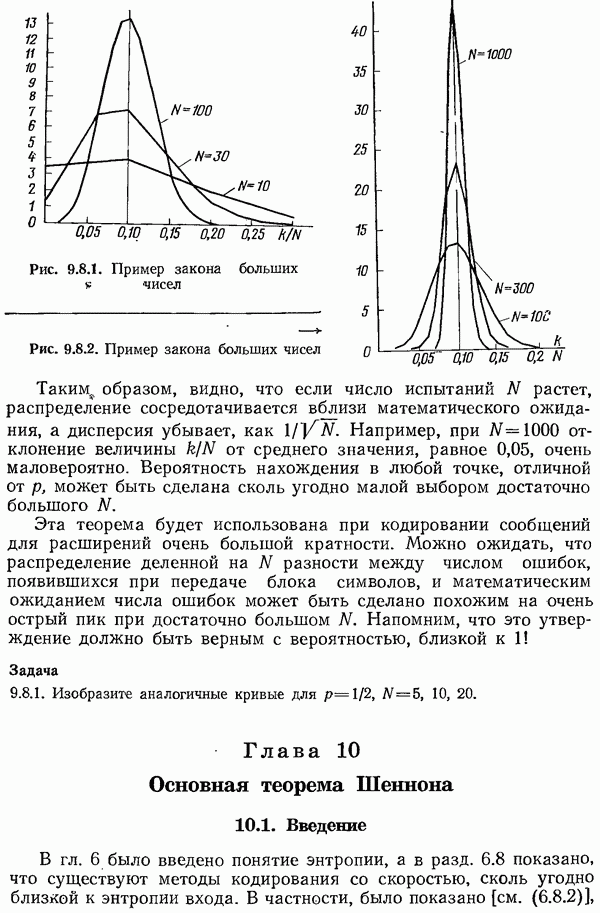









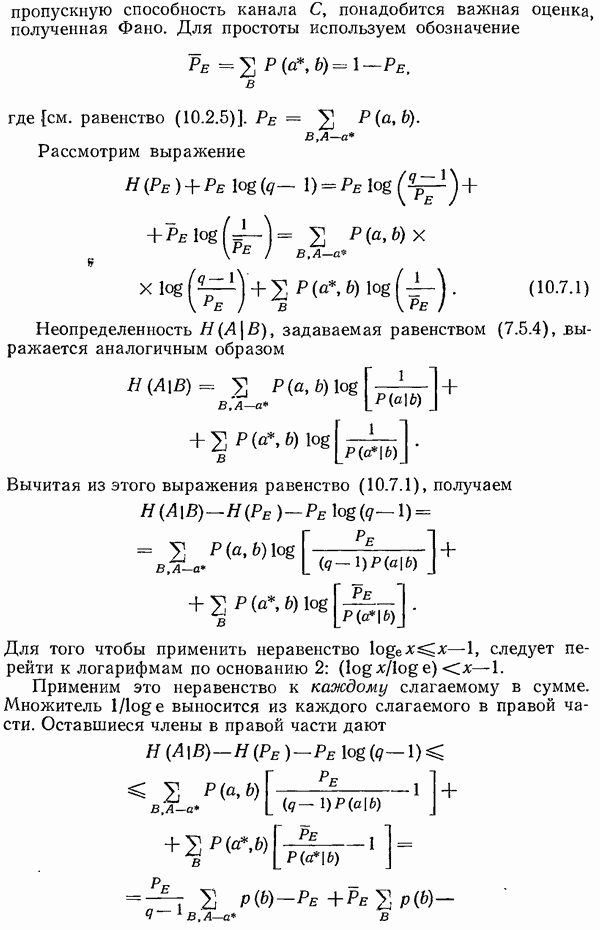


























 и вероятностями
и вероятностями  получает
получает  Поэтому
Поэтому  Однако для
Однако для  имеем
имеем 

 дла
дла  и слова длины
и слова длины 
 Для кода Шеннона — Фано имеем
Для кода Шеннона — Фано имеем

 Код Шеннона — Фано дает
Код Шеннона — Фано дает  Если
Если  не есть степень
не есть степень  то некоторые слова будут укорочены в коде Хаффмена и не будут в коде Шеннона — Фано.
то некоторые слова будут укорочены в коде Хаффмена и не будут в коде Шеннона — Фано.
