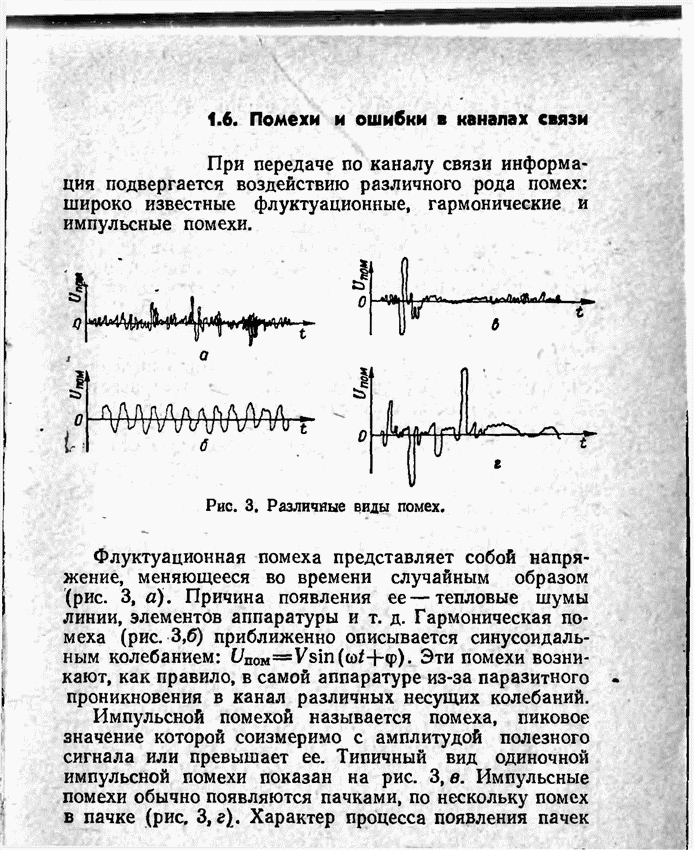
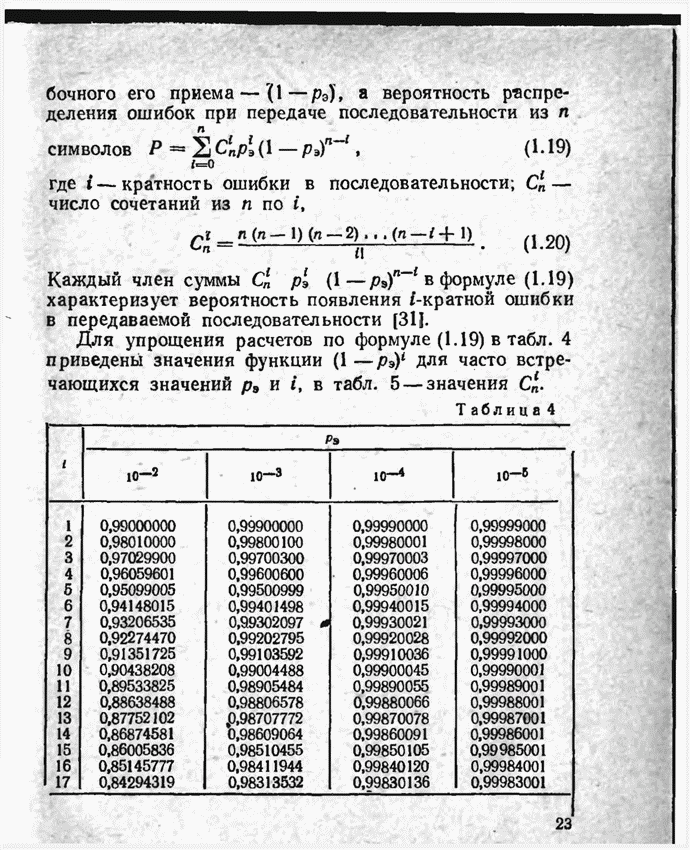
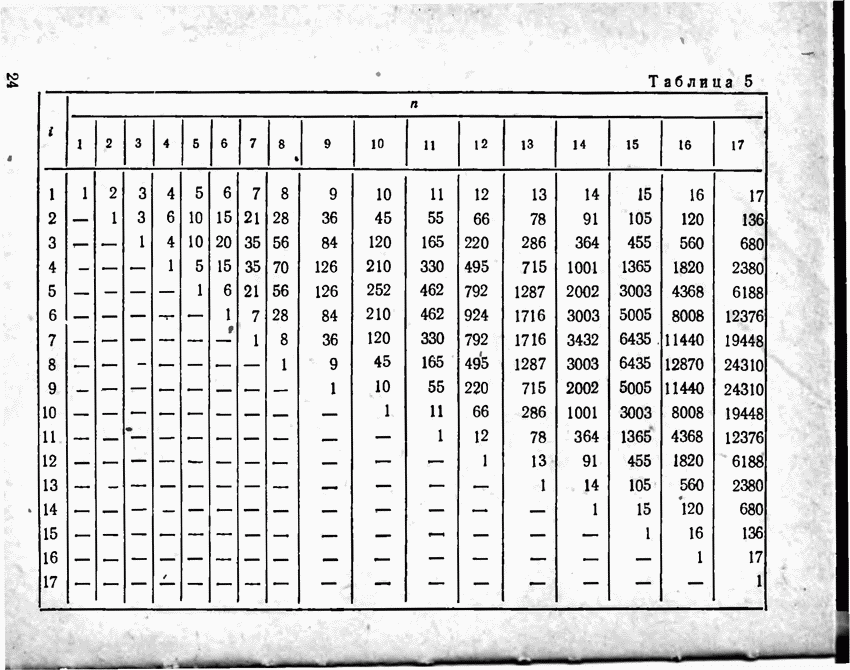
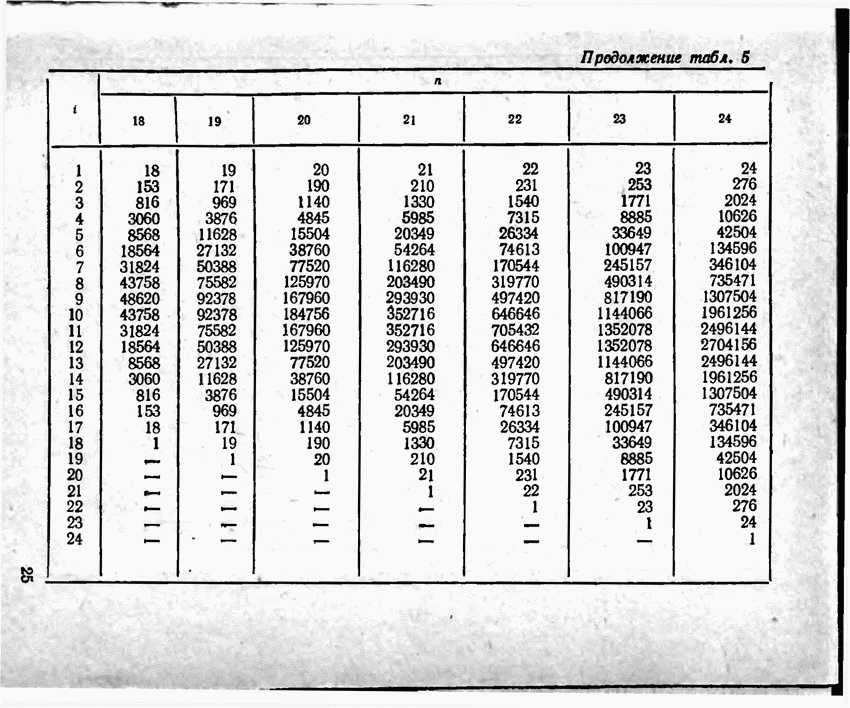
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
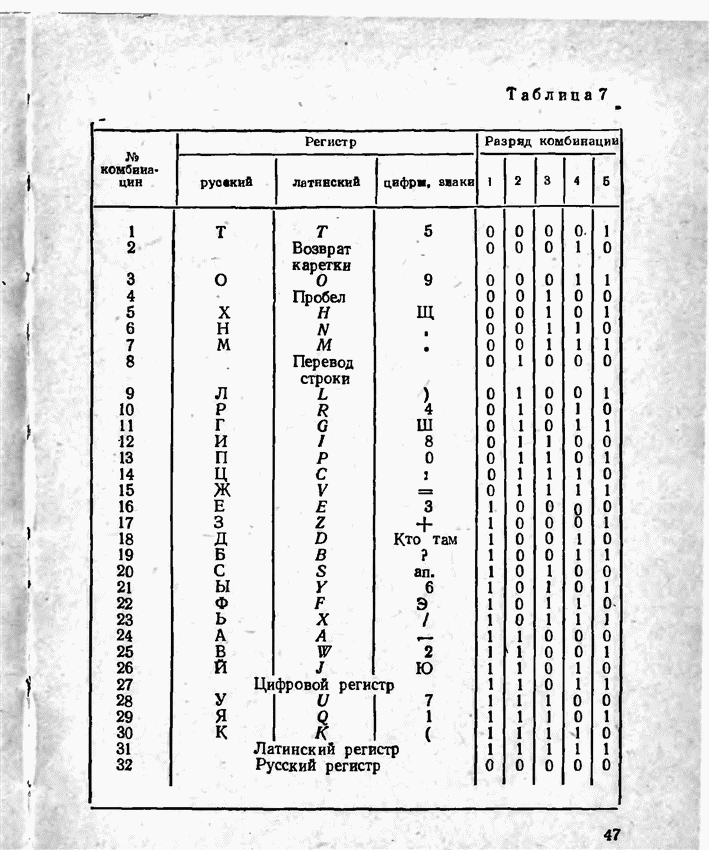
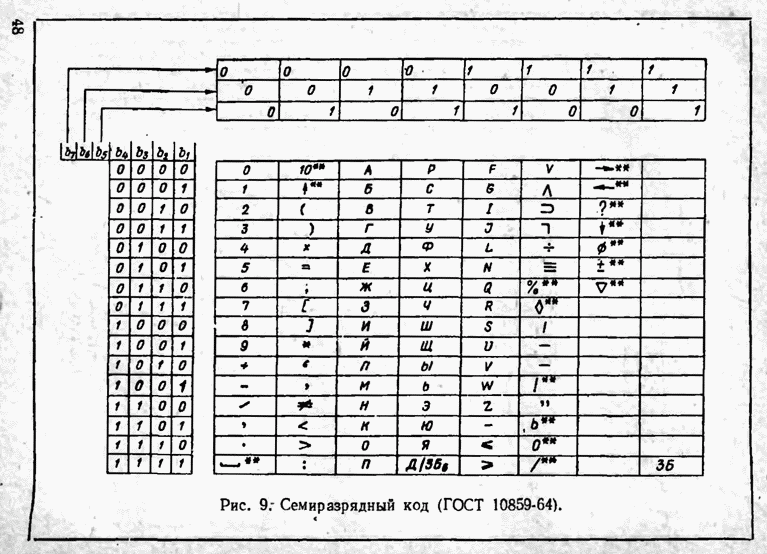
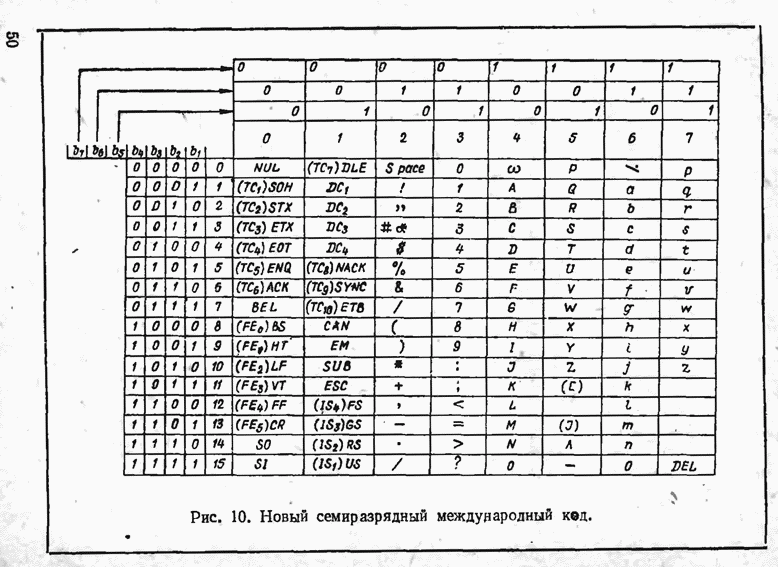
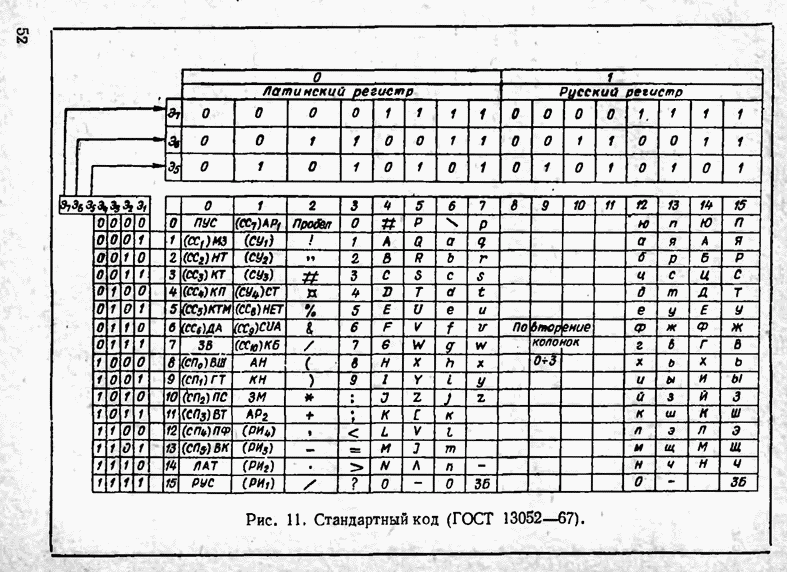
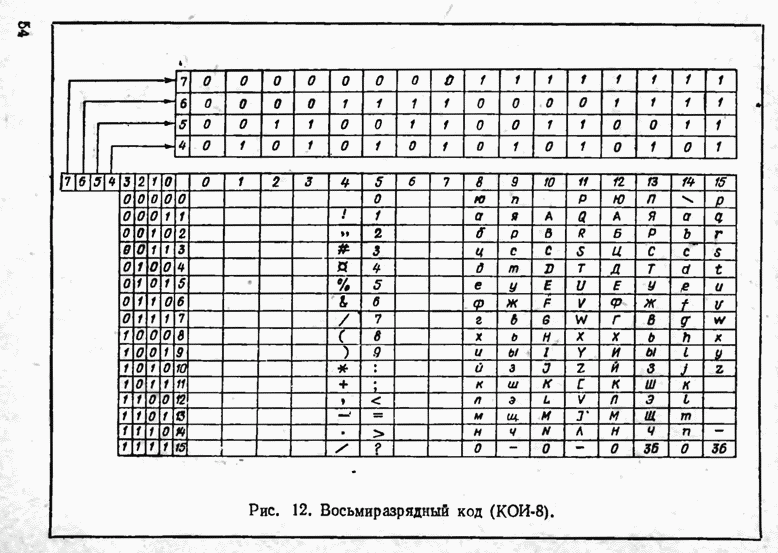
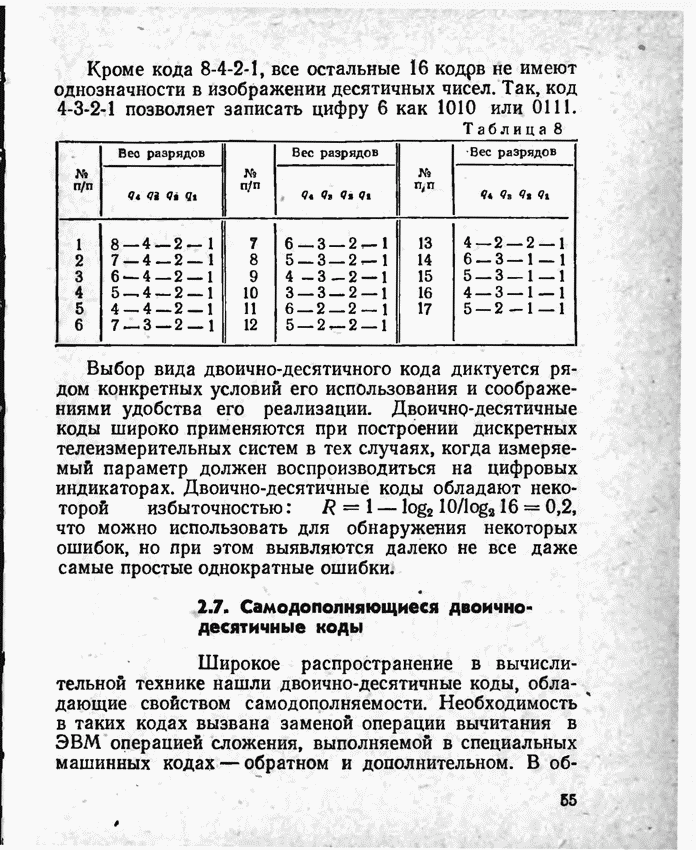
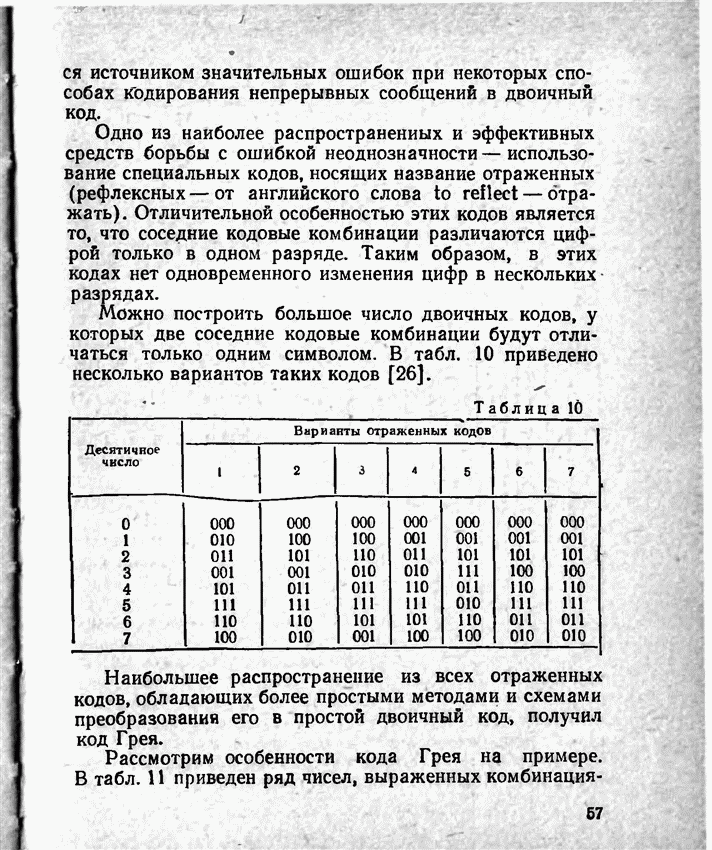
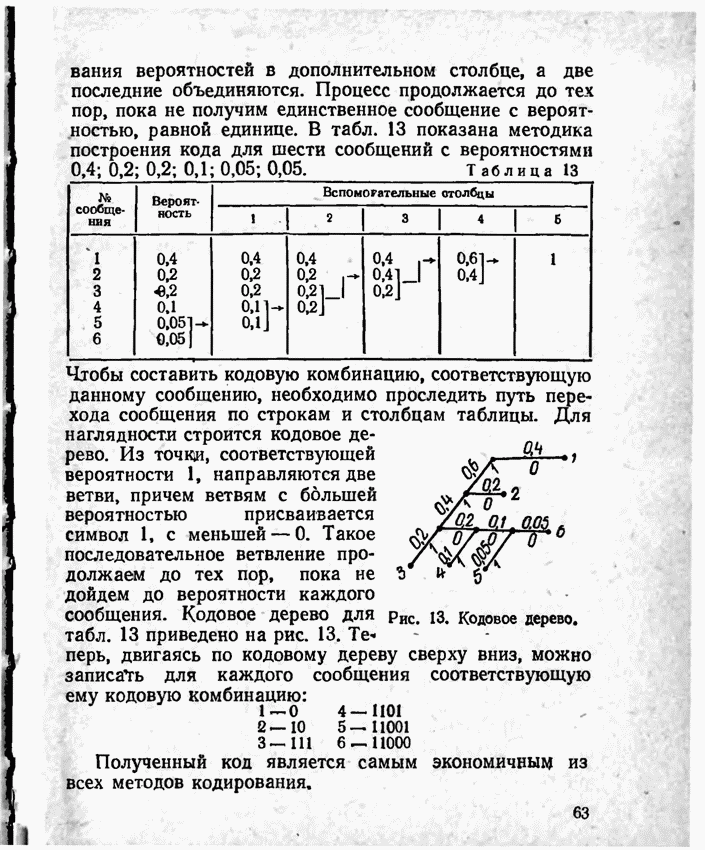
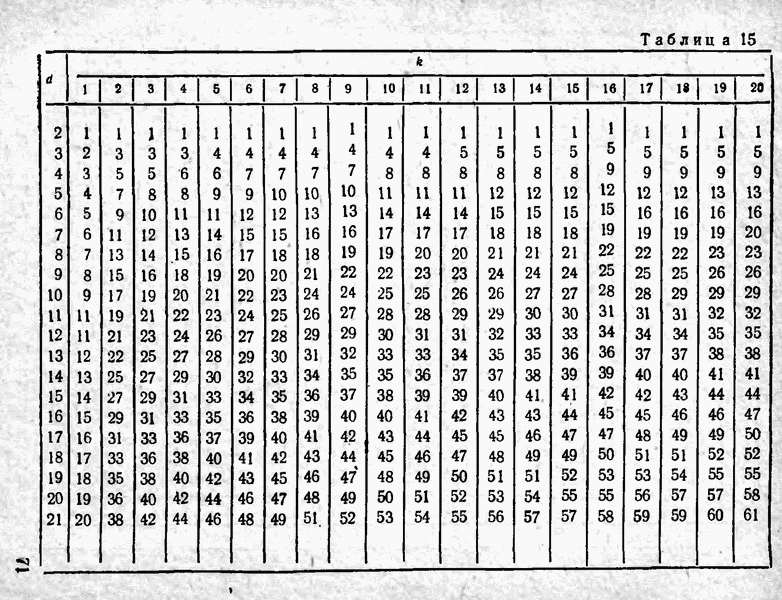
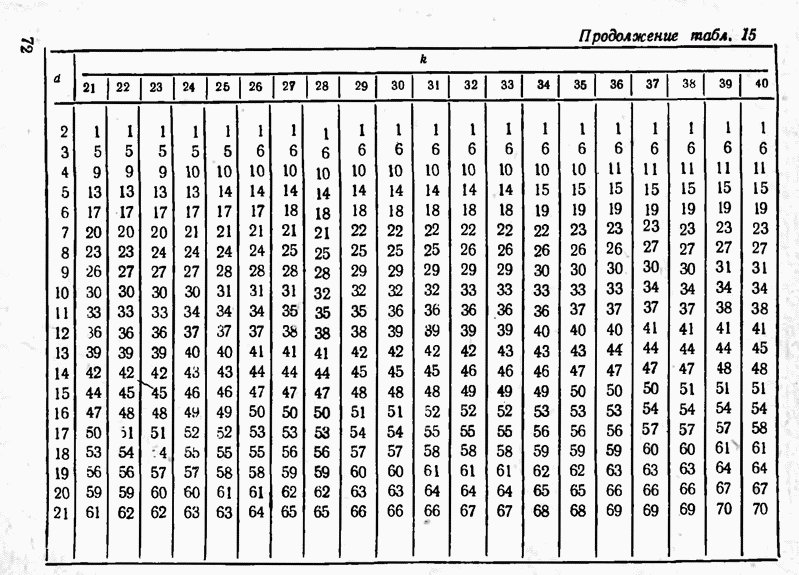
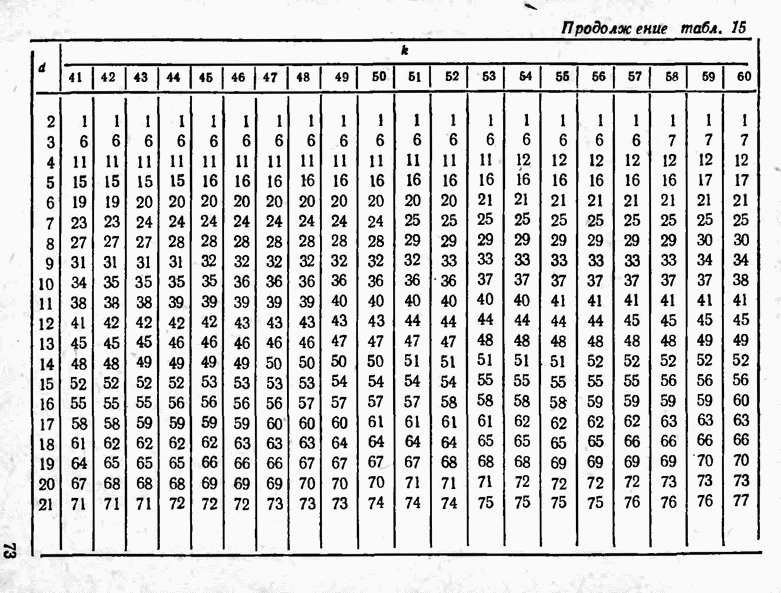
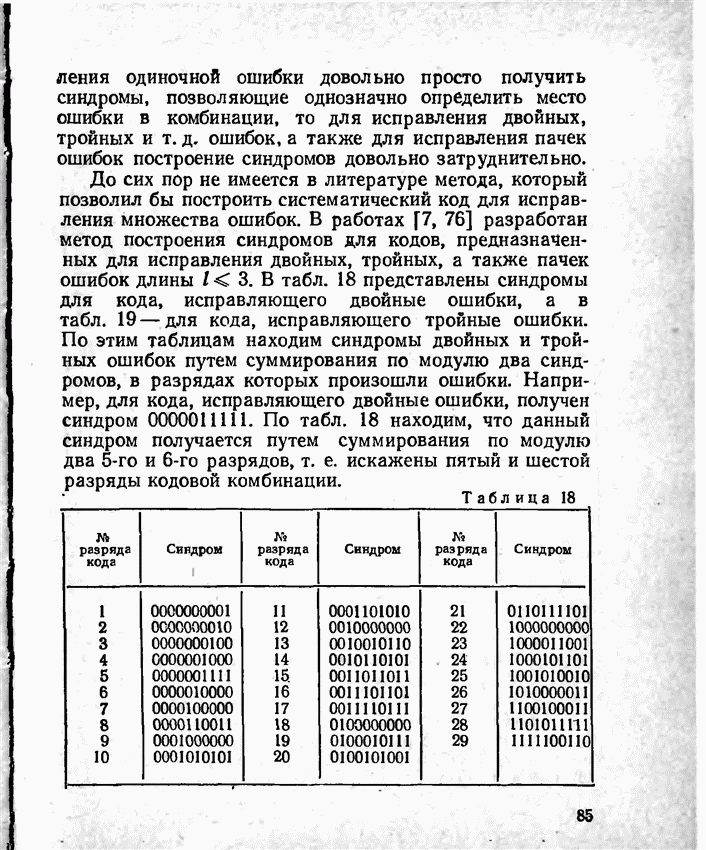
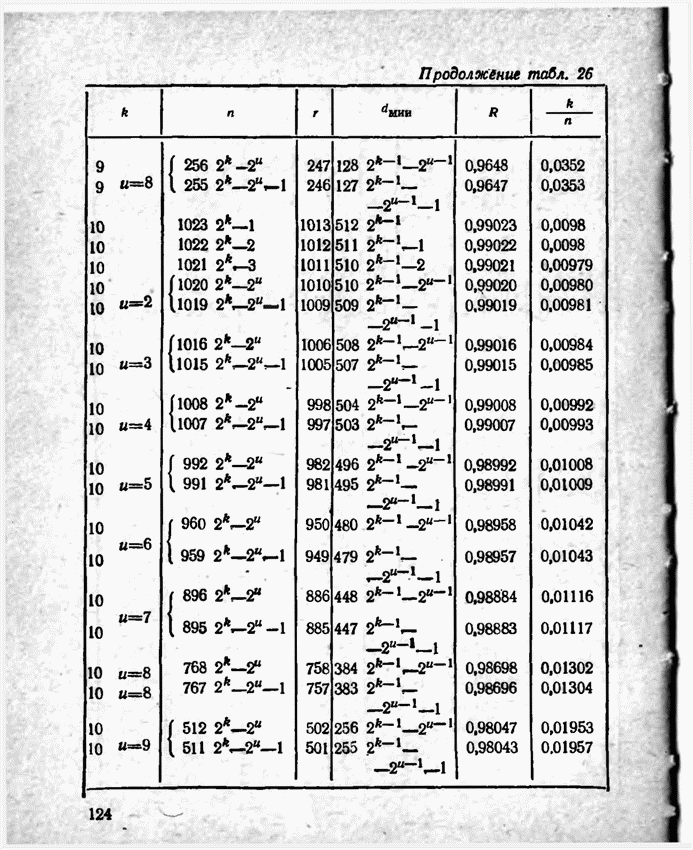
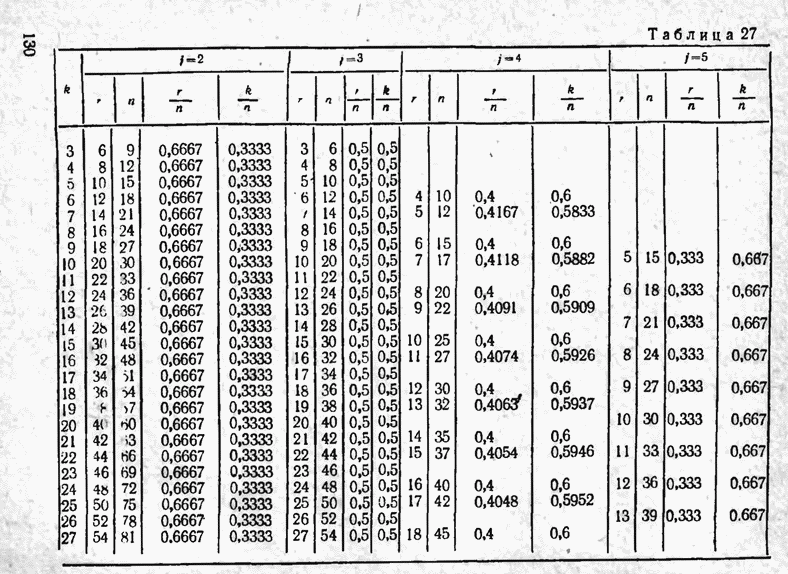
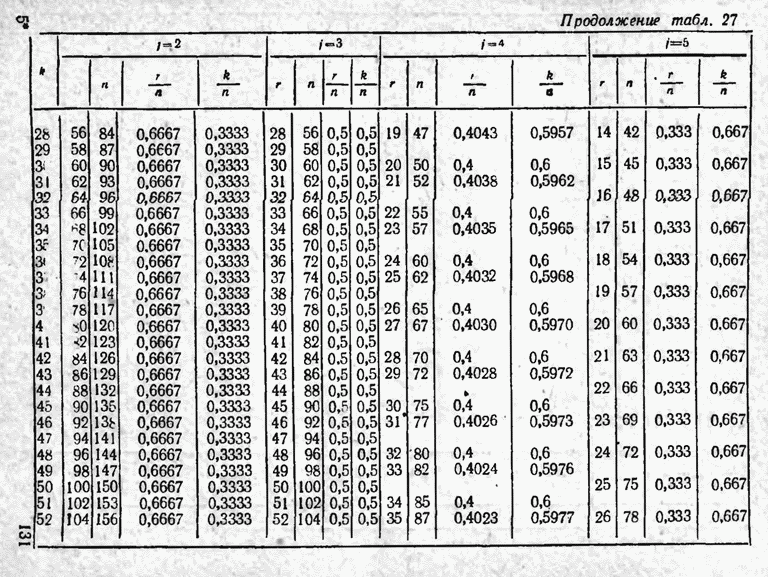
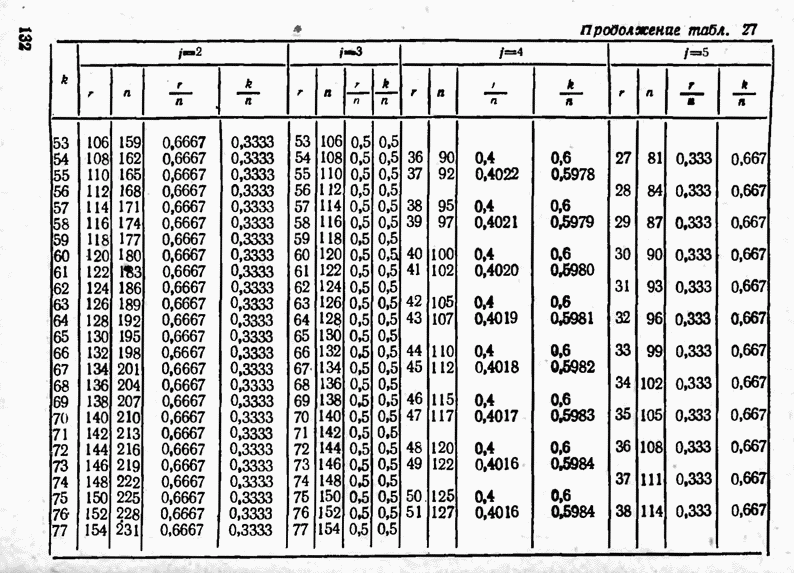
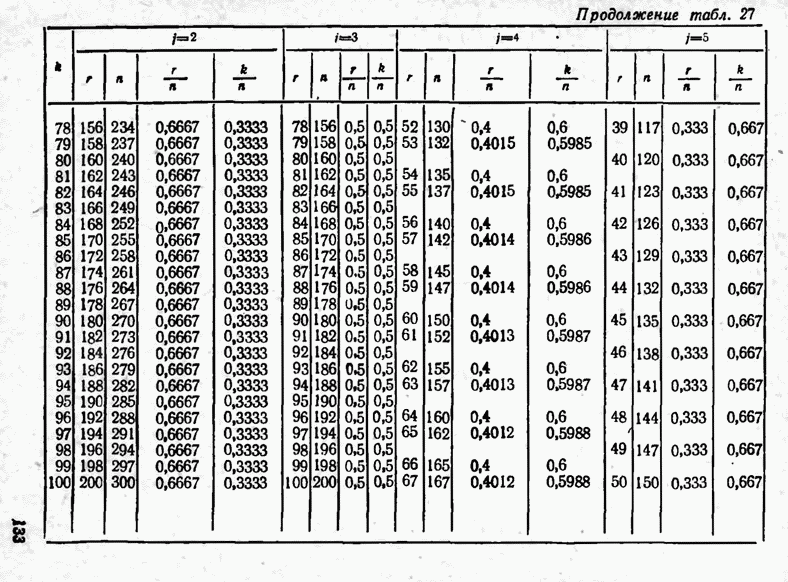
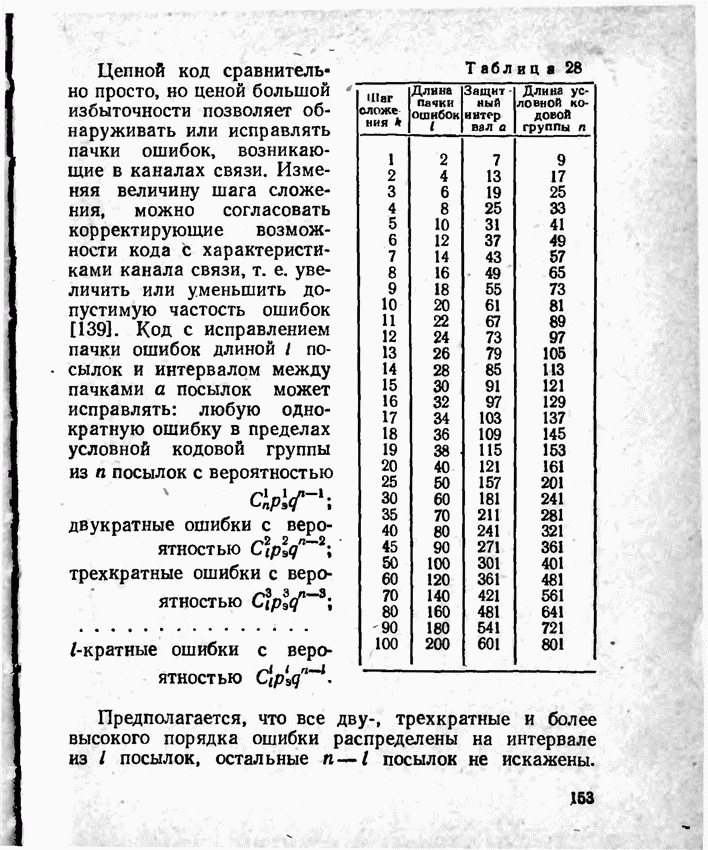
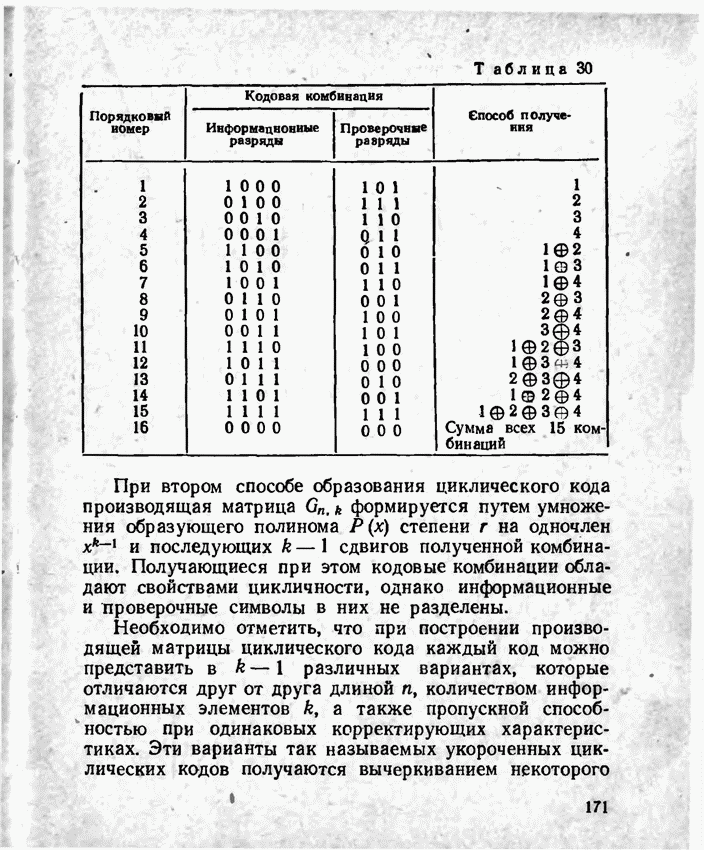
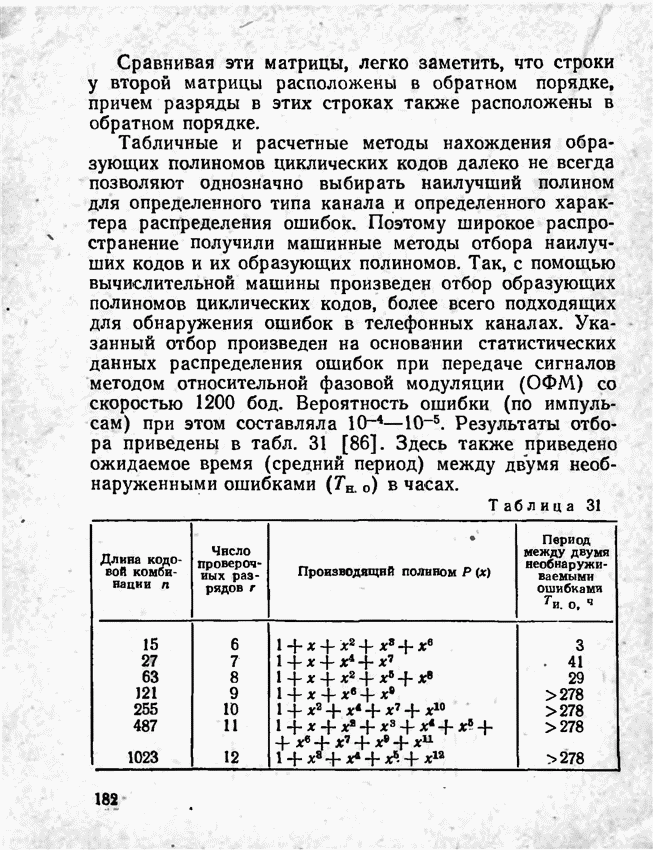
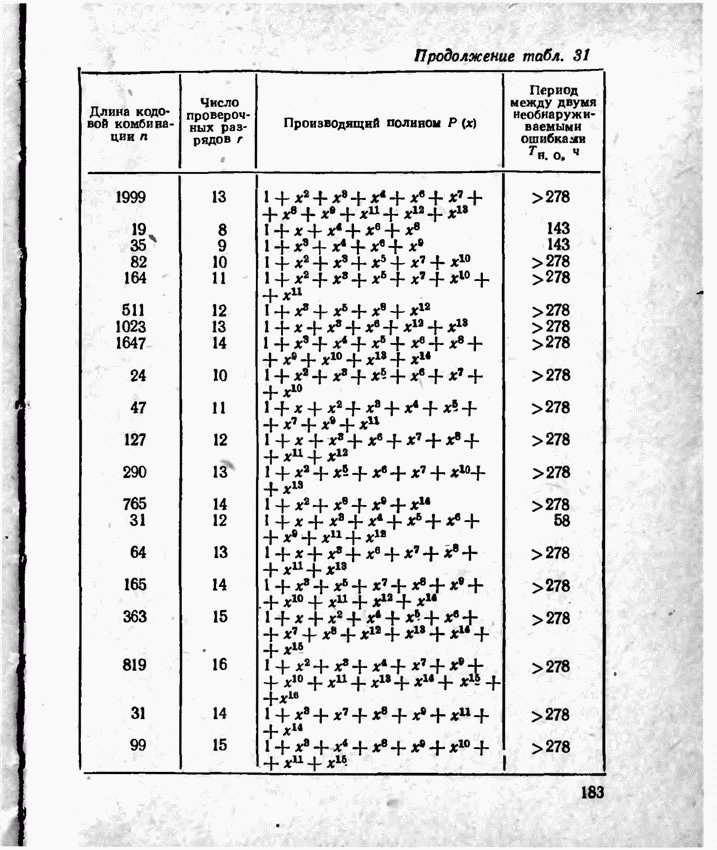
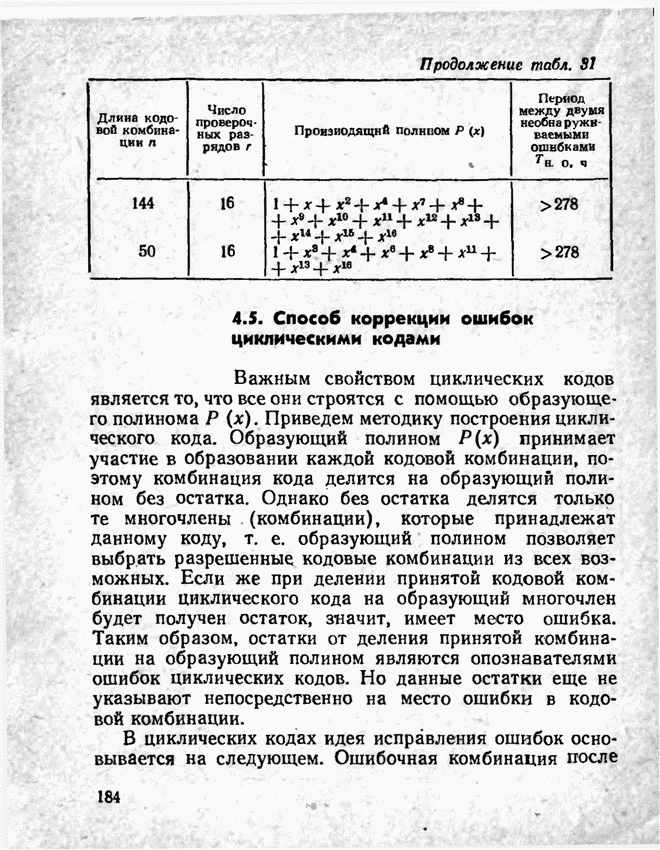
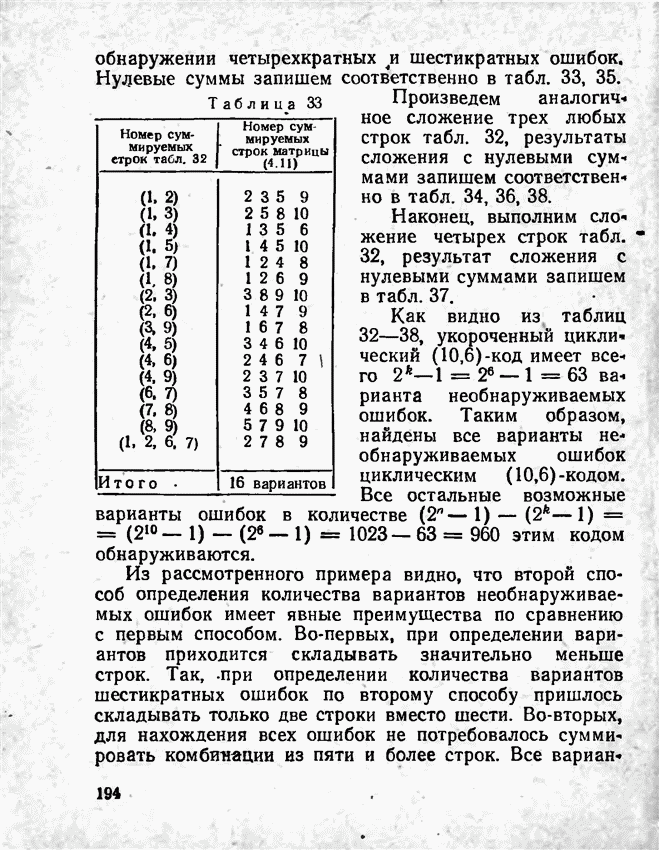
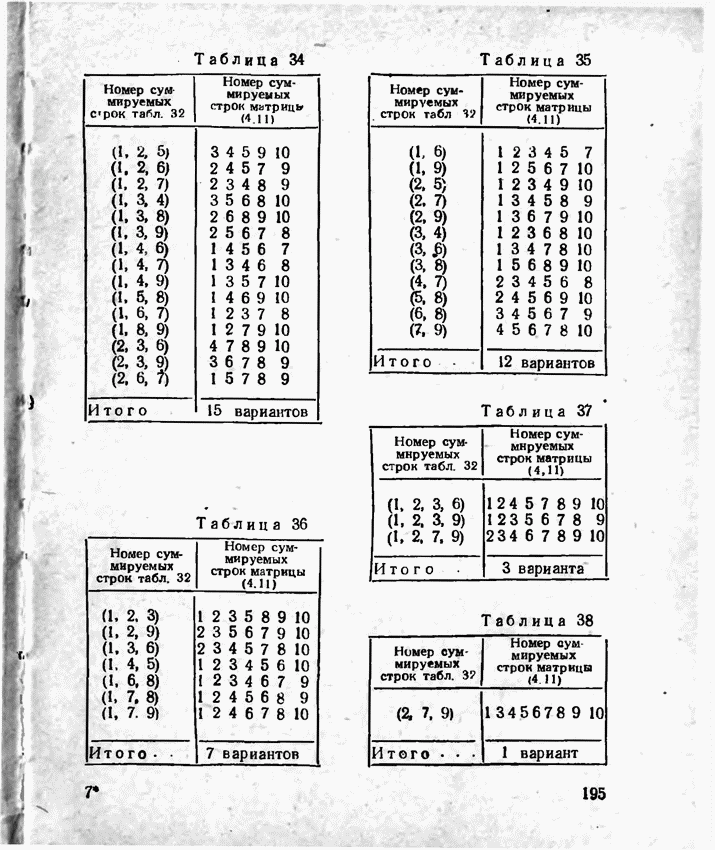
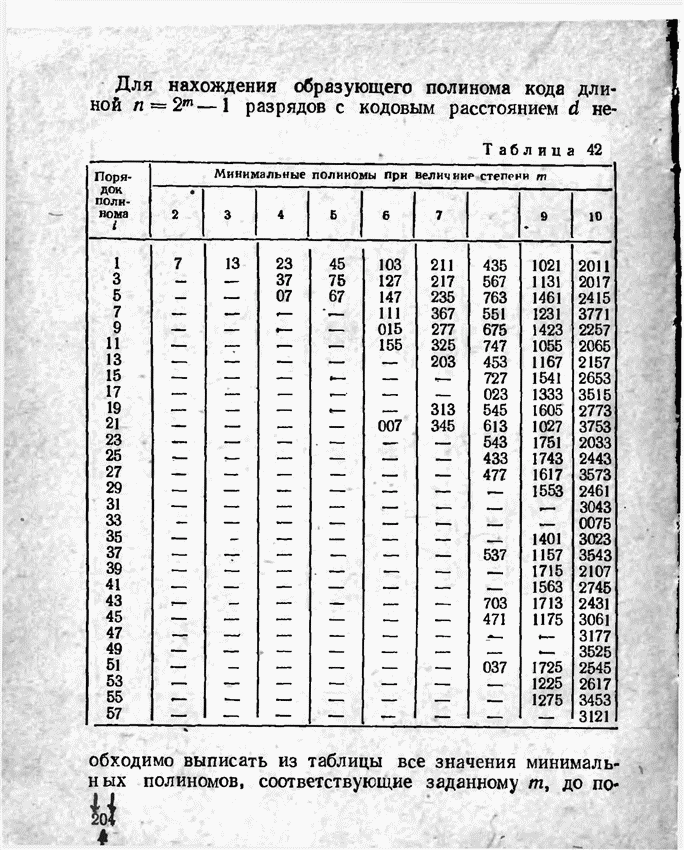
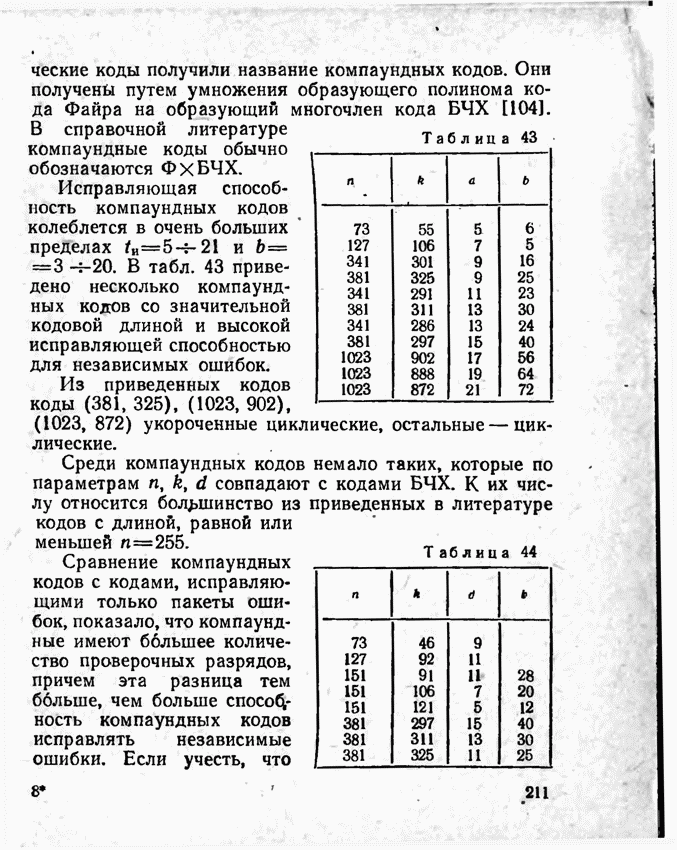
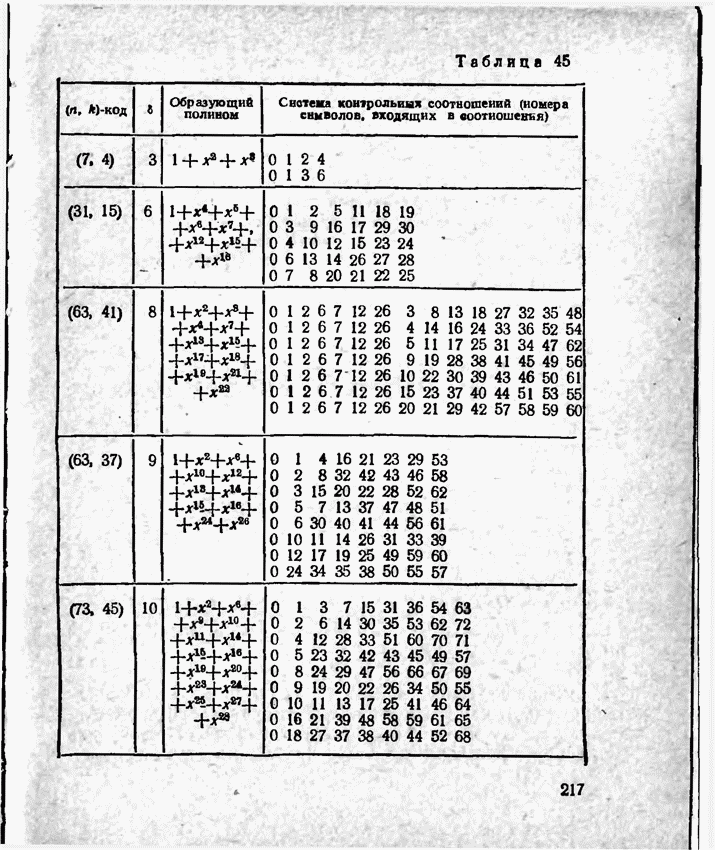
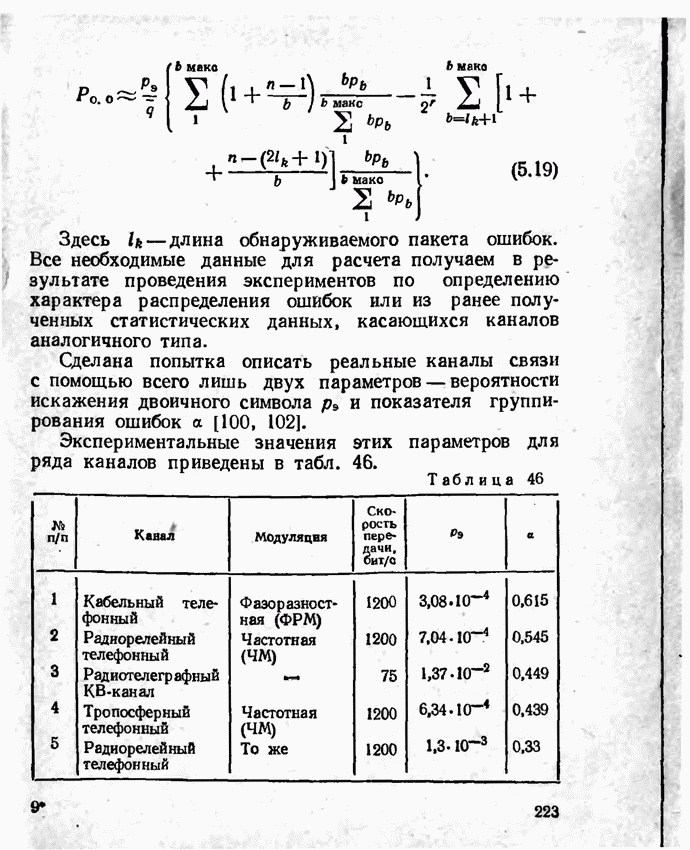
2.9. Неравномерные коды Шеннона — Фано и ХаффменаПри передаче сообщений, закодированных двоичным равномерным кодом, обычно не учитывают статистическую структуру передаваемых сообщений. Все сообщения независимо от вероятности их появления представляют собой кодовые комбинации одинаковой длины, т. е. количество двоичных символов, приходящееся на одно сообщение, строго постоянно. Из теоремы Шеннона о кодировании сообщений в каналах без шумов следует, что если передача дискретных сообщений ведется при отсутствии помех, то всегда можно найти такой метод кодирования, при котором среднее число двоичных символов на одно сообщение будет сколь угодно близким к энтропии источника этих сообщений, но никогда не может быть меньше ее. На основании этой теоремы можно ставить вопрос о построении такого неравномерного кода, в котором часто встречающимся сообщениям присваиваются более короткие кодовые комбинации, а редко встречающимся символам — более длинные. Таким образом, учет статистических закономерностей сообщения позволяет построить более экономичный код. Методы построения таких кодов впервые предложили в 1948-1949 гг. независимо друг от друга Р. Фано и К. Шеннон, поэтому код назвали кодом Шеннона — Фано [80, 134, 135]. Код Шеннона — Фано строится так же, как и двоичный код (табл. 6), только сообщения вписываются в таблицу в порядке убывания вероятностей. Деление на группы производится таким образом, чтобы суммы вероятностей в каждой из групп были бы по возможности одинаковыми. Например, если количество сообщений Таблица 12 (см. скан) Основной принцип, положенный в основу кодирования по методу Шеннона — Фано, заключается в том, что при выборе каждой цифры кодового обозначения следует стремиться к тому, чтобы содержащееся в ней количество информации было наибольшим, т. е. чтобы независимо от значений всех предыдущих цифр эта цифра принимала оба возможных для нее значения (0 и 1) по возможности с одинаковой вероятностью. Разумеется, количество цифр в различных обозначениях при этом различно, т. е. данный код является неравномерным. Сообщениям, имеющим большую вероятность, соответствуют короткие кодовые комбинации, имеющие меньшую вероятность — более длинные кодовые комбинации. Среднее количество символов на одно сообщение для рассмотренного кода составляет В случае использования простого двоичного кода необходимое число символов составило бы 3. Еще более удобен близкий к коду Шеннона — Фано код Хаффмена [134, 148]. Метод его построения сводится к следующему. Сообщения выписываются в столбец в порядке убывания вероятностей. Два последние сообщения объединяются в одно вспомогательное сообщение, которому приписывается суммарная вероятность. Вероятности сообщений снова располагаются в порядке убывания вероятностей в дополнительном столбце, а две последние объединяются. Процесс продолжается до тех пор, пока не получим единственное сообщение с вероятностью, равной единице. В табл. 13 показана методика построения кода для шести сообщений с вероятностями 0,4; 0,2; 0,2; 0,1; 0,05; 0,05. Таблица 13 (см. скан) Чтобы составить кодовую комбинацию, соответствующую данному сообщению, необходимо проследить путь перехода сообщения по строкам и столбцам таблицы. Для наглядности строится кодовое дерево. Из точки, соответствующей вероятности 1, направляются две ветви, причем ветвям с большей вероятностью присваивается символ 1, с меньшей — 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до вероятности каждого сообщения. Кодовое дерево для табл. 13 приведено на рис.
Полученный код является самым экономичным из всех методов кодирования.
Рис. 13. Кодовое дерево.
|
 |
Оглавление
|
































































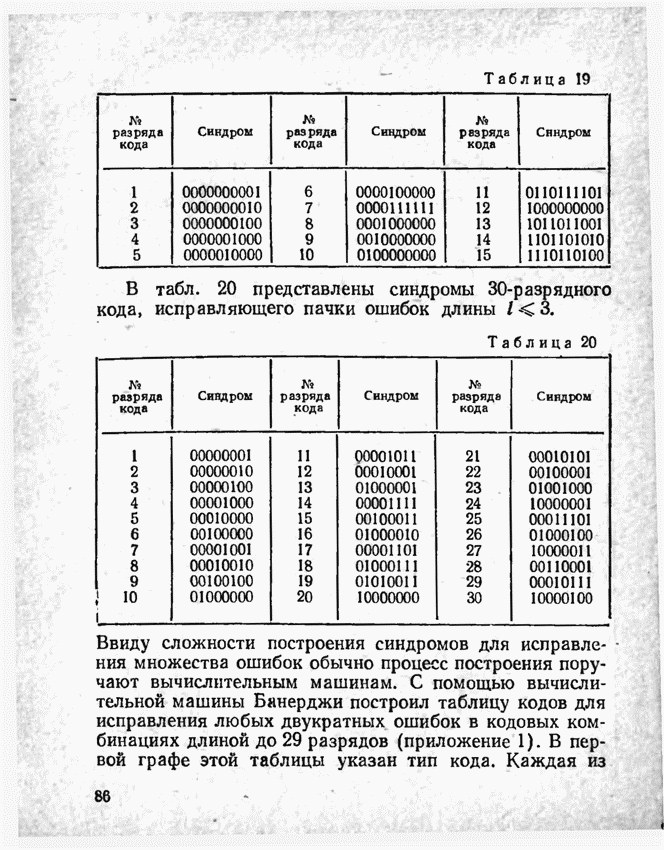








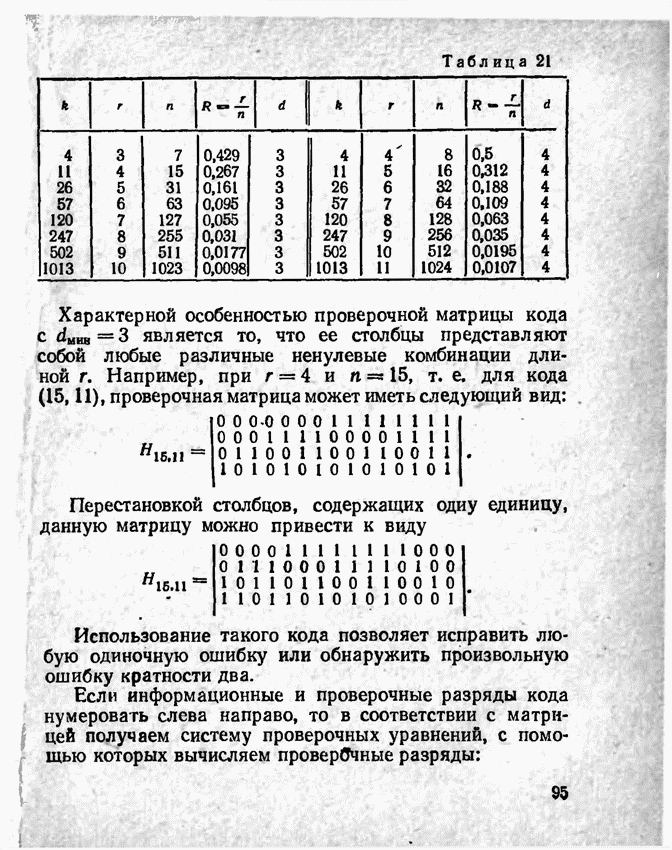


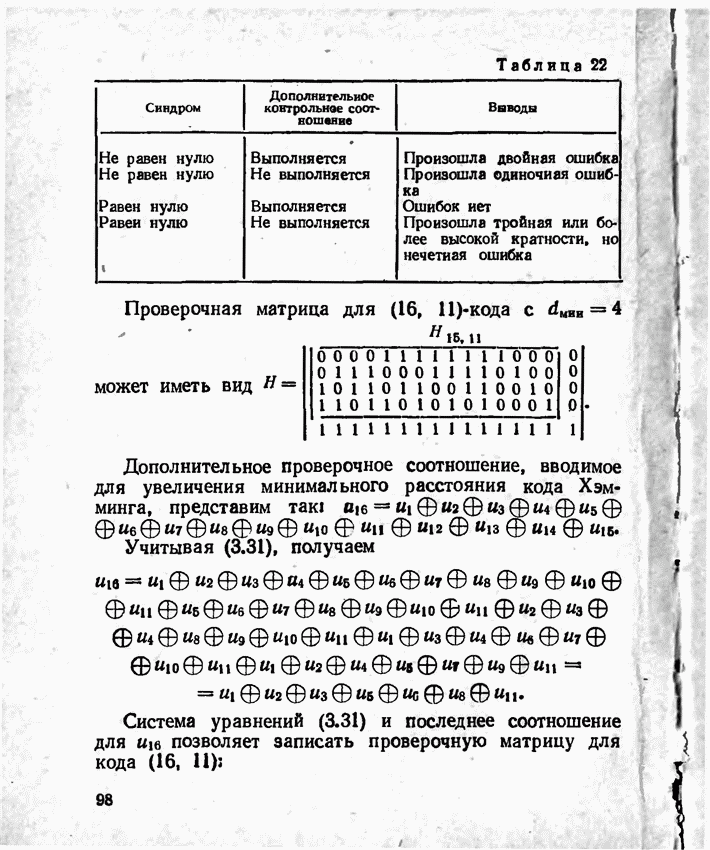


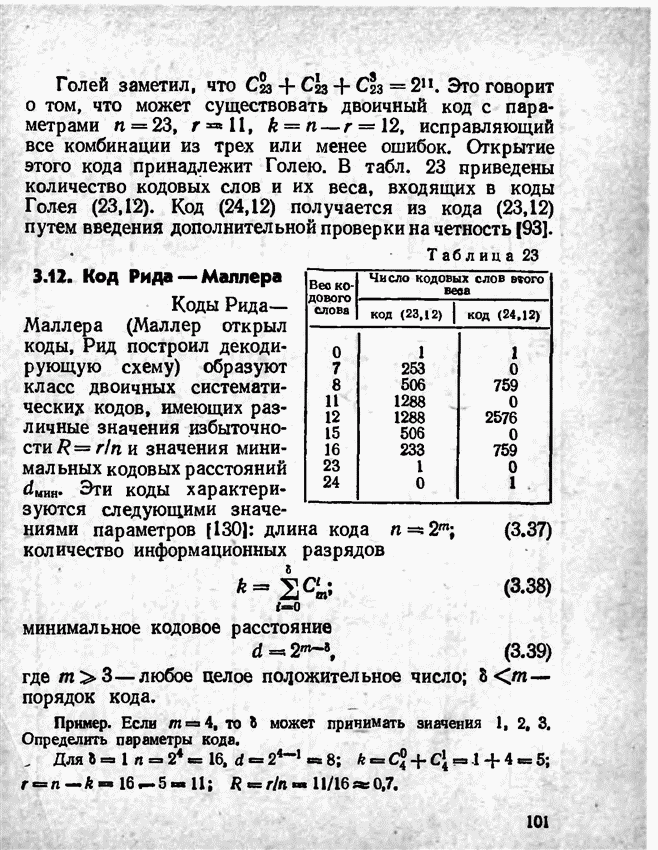














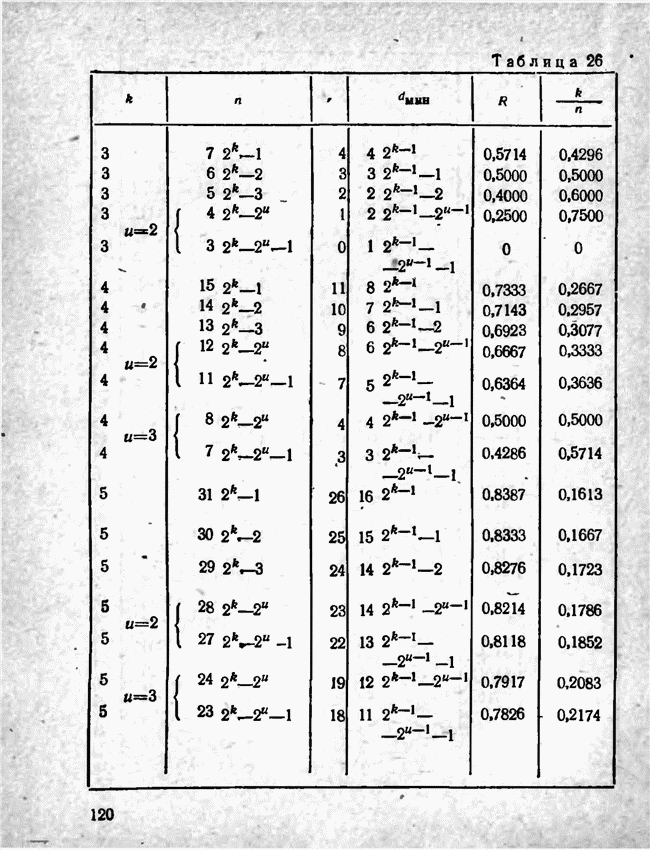
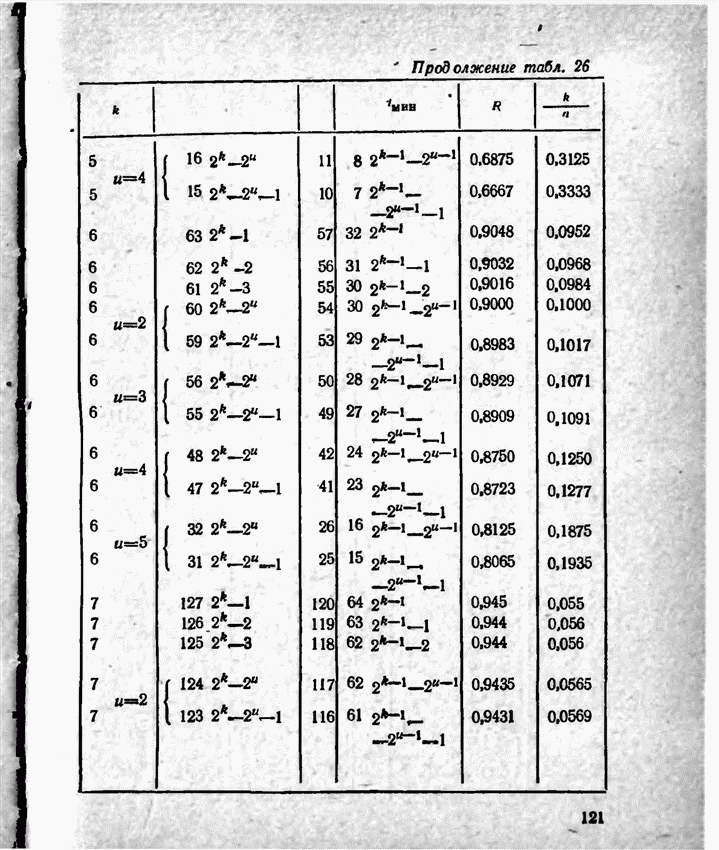
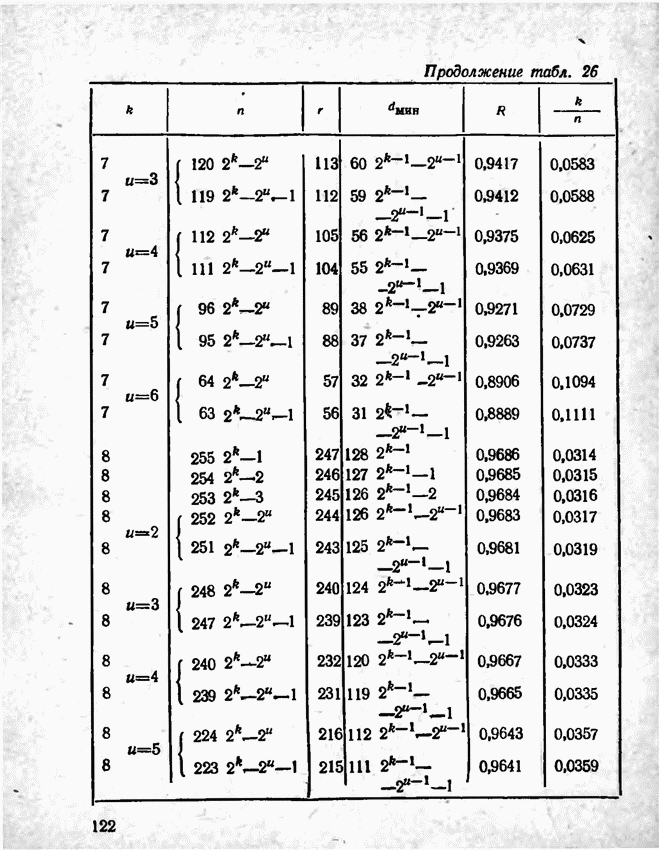
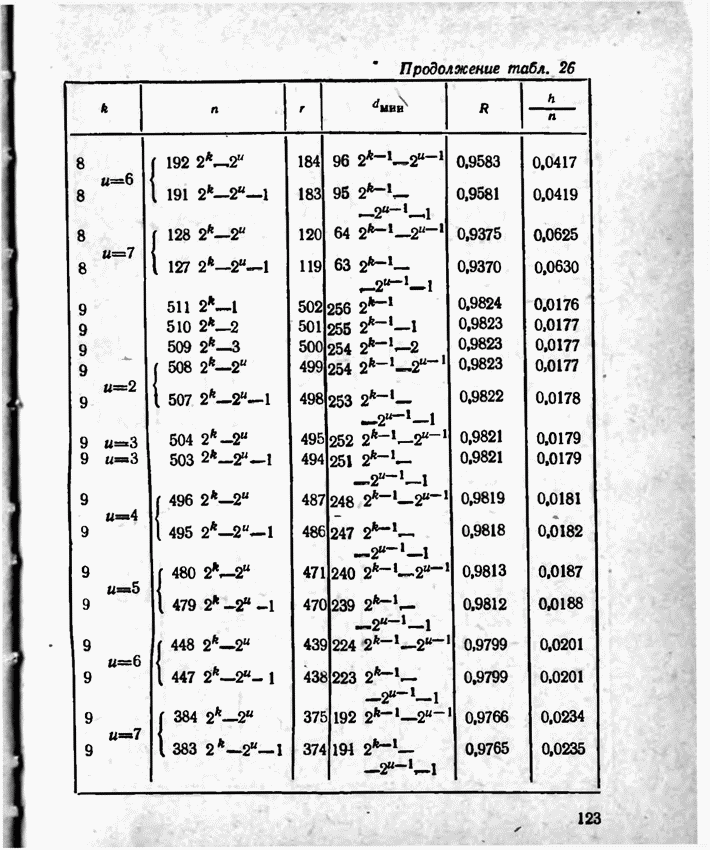





























































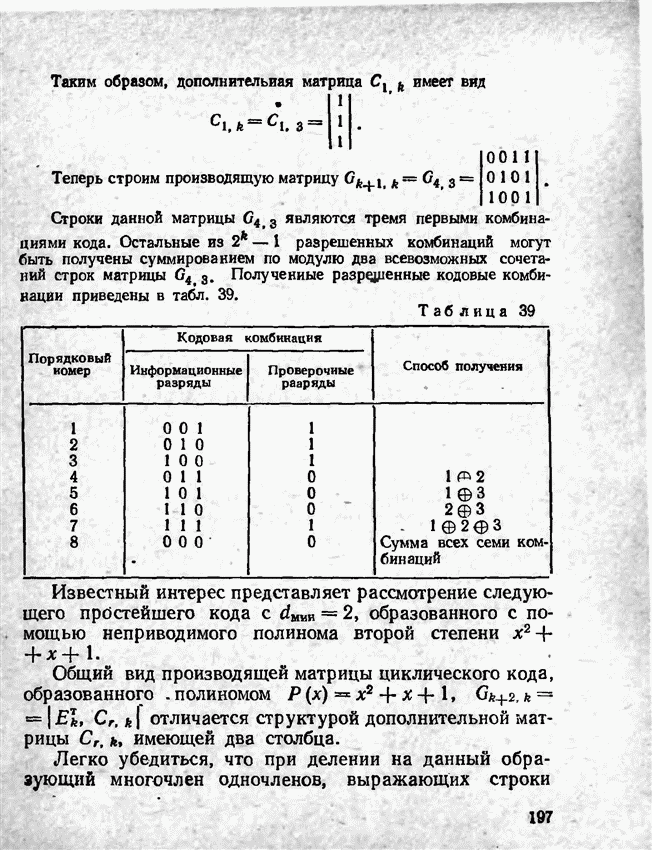


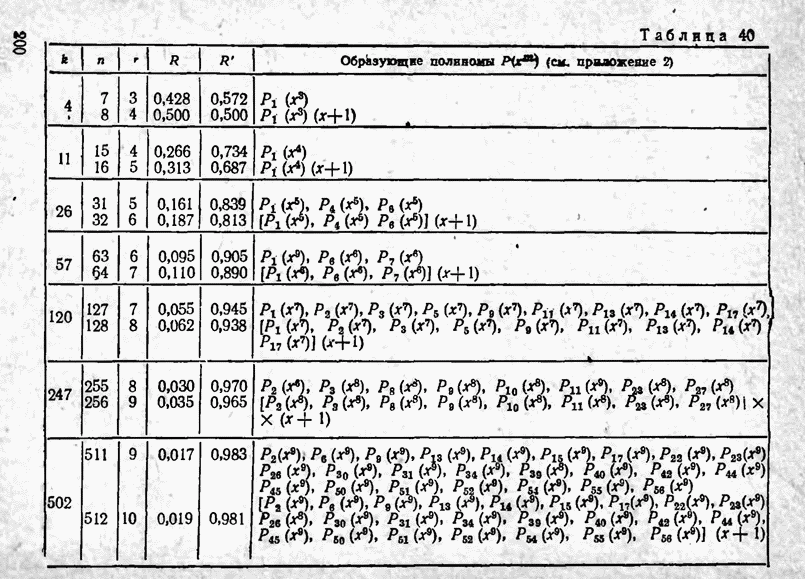

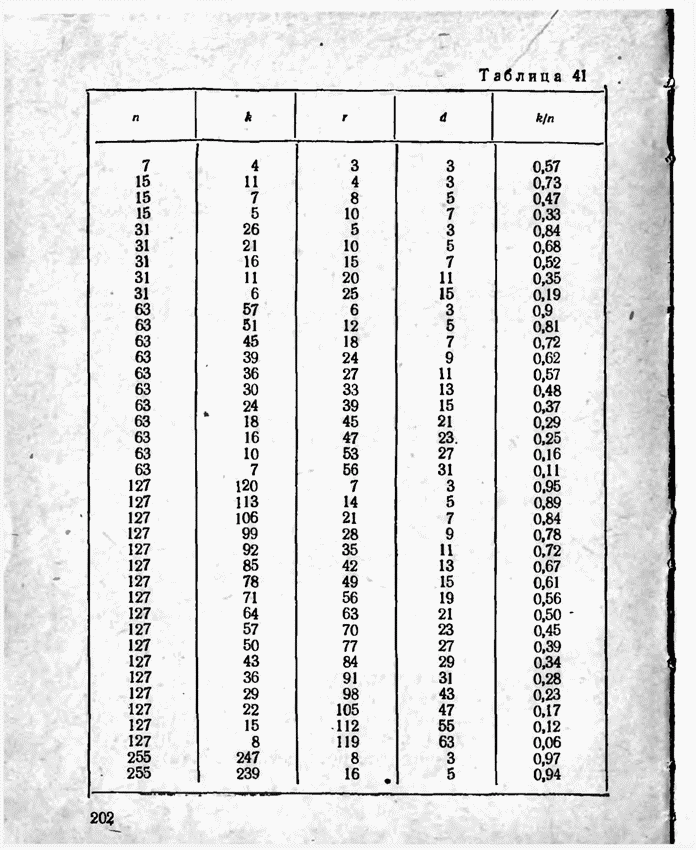
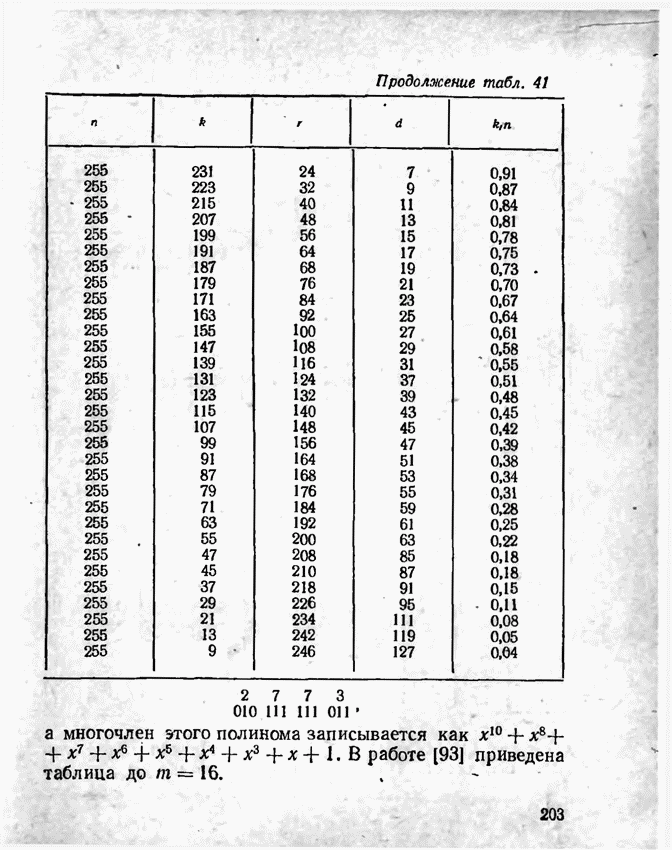




















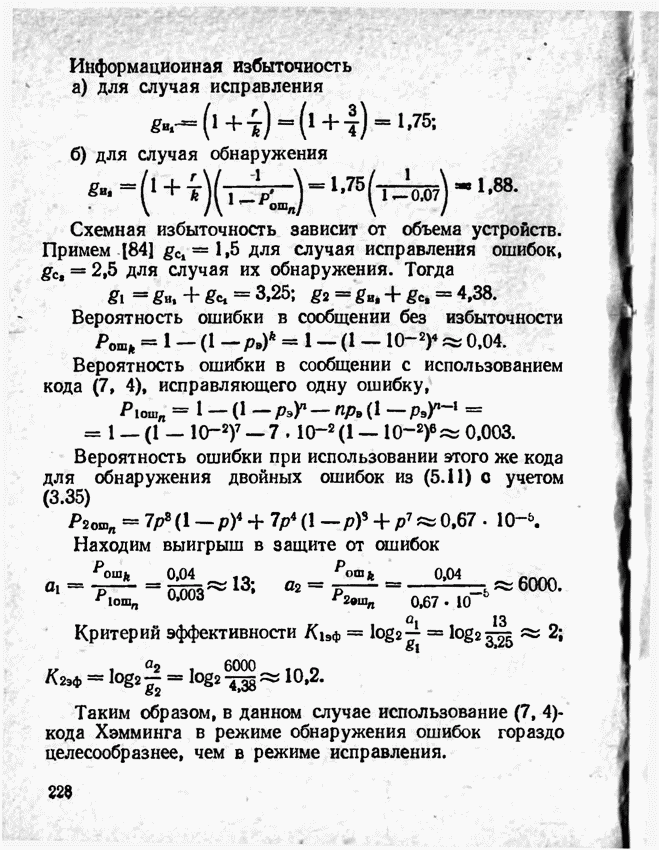

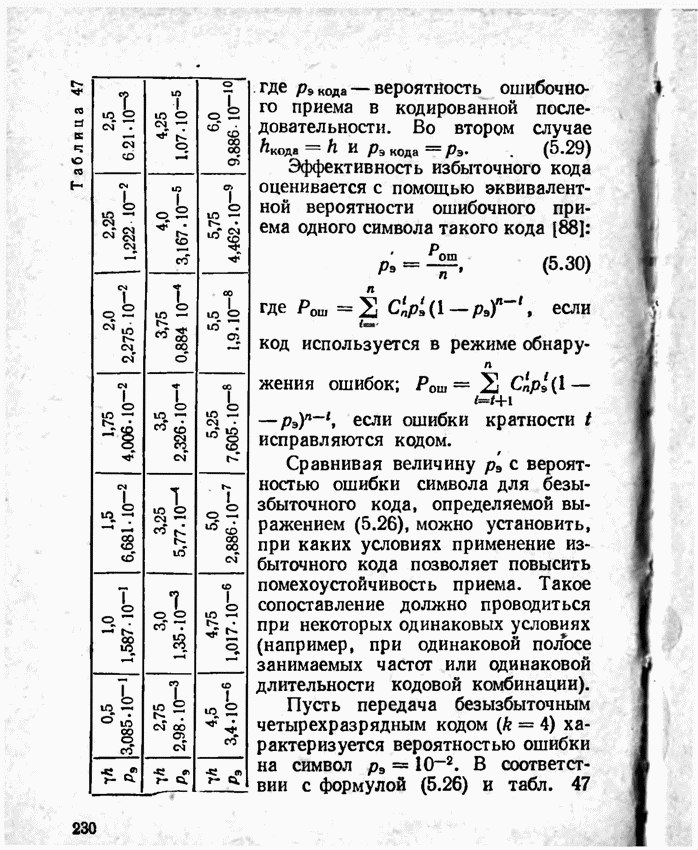


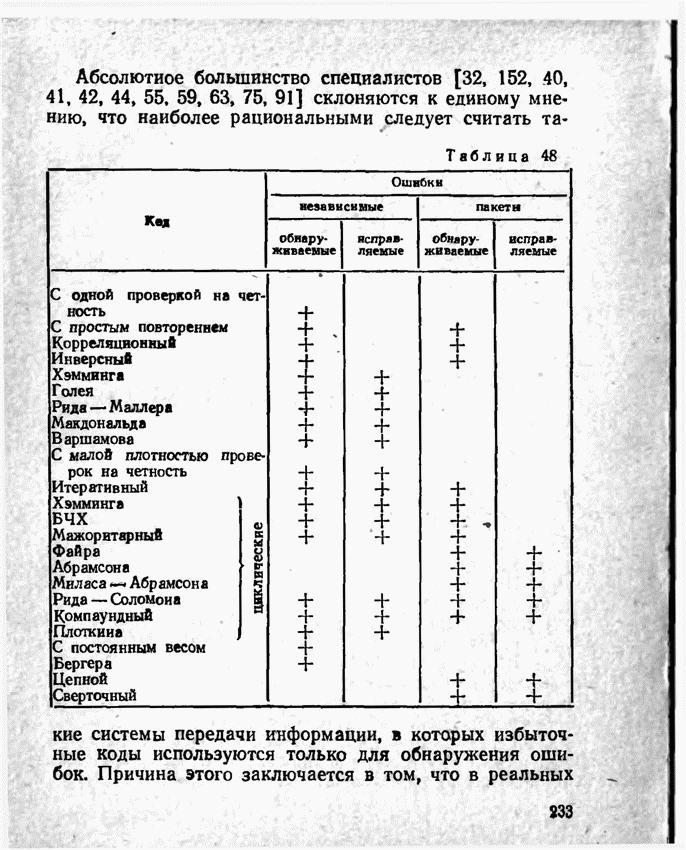

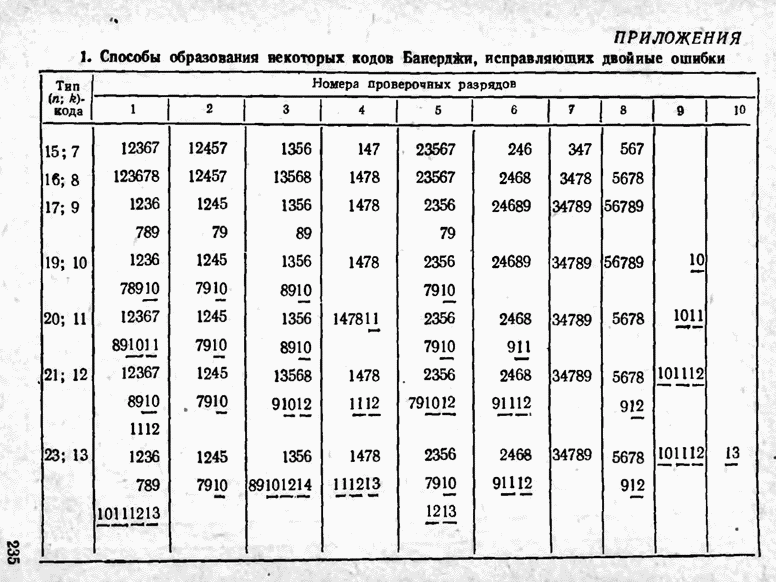
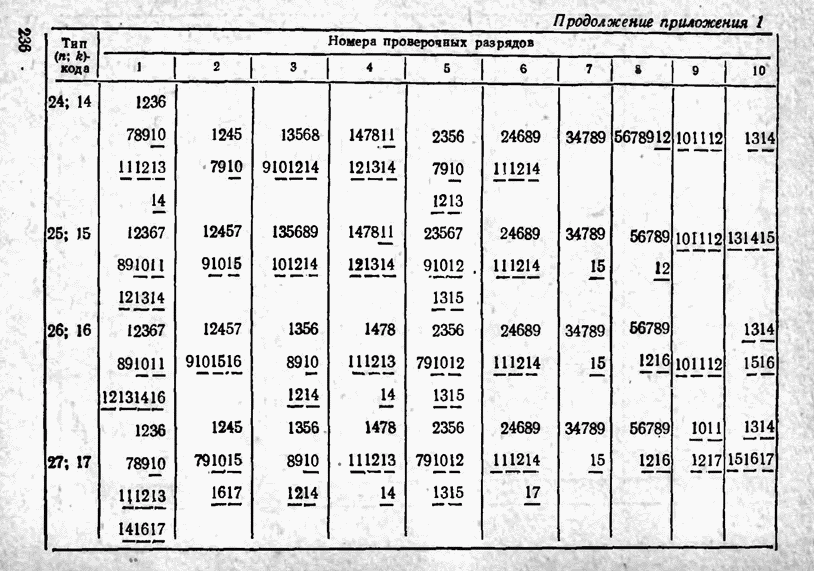



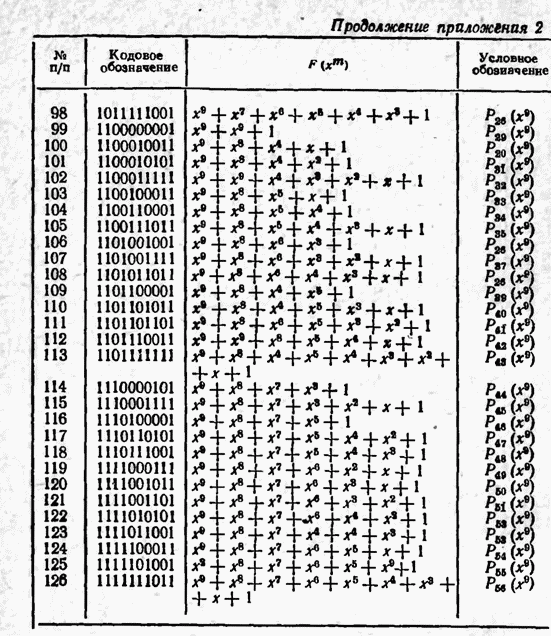









 а вероятности их (в порядке убывания) равны 0,4; 0,2; 0,2; 0,1; 0,05; 0,05, то на первом этапе деления на группы отделим лишь первое сообщение (группа I), оставив группе II все остальные. Далее, второе сообщение составит первую подгруппу II группы; вторая подгруппа той же группы, состоящая из оставшихся четырех сообщений, будет и далее последовательно делиться на части так, что каждый раз первая часть будет состоять из одного лишь сообщения. Построение кода приведено в табл 12.
а вероятности их (в порядке убывания) равны 0,4; 0,2; 0,2; 0,1; 0,05; 0,05, то на первом этапе деления на группы отделим лишь первое сообщение (группа I), оставив группе II все остальные. Далее, второе сообщение составит первую подгруппу II группы; вторая подгруппа той же группы, состоящая из оставшихся четырех сообщений, будет и далее последовательно делиться на части так, что каждый раз первая часть будет состоять из одного лишь сообщения. Построение кода приведено в табл 12.
 Это значение не очень далеко от энтропии:
Это значение не очень далеко от энтропии: 
 перь, двигаясь по кодовому дереву сверху вниз, можно записать для каждого сообщения соответствующую ему кодовую комбинацию:
перь, двигаясь по кодовому дереву сверху вниз, можно записать для каждого сообщения соответствующую ему кодовую комбинацию:

