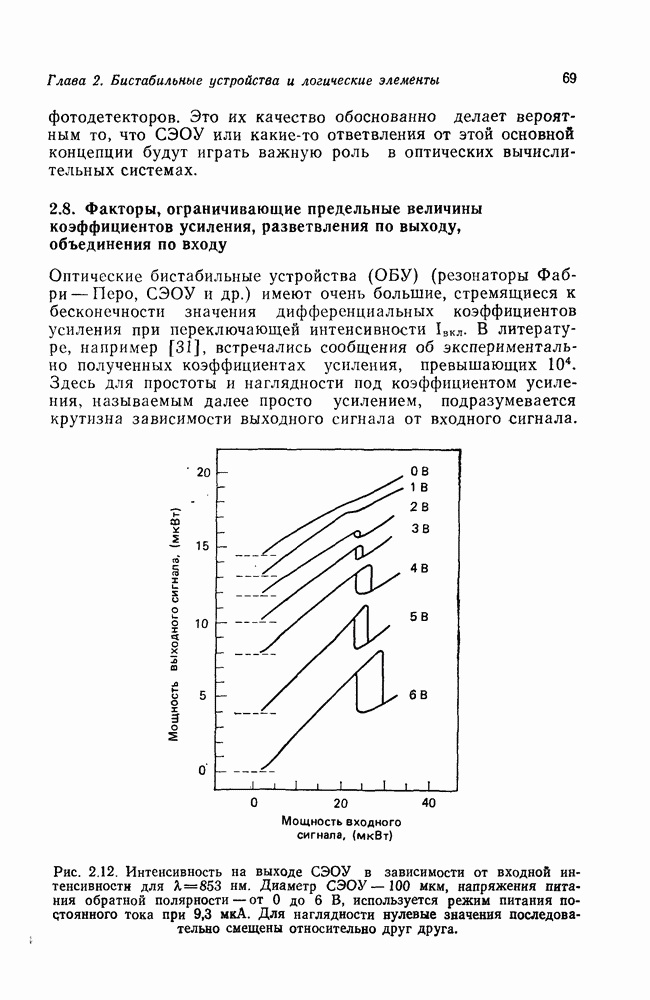
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
10.3.4. Понимание естественного языкаЧасто задают вопрос: «Что такое обработка естественного языка и чем она отличается от понимания речи?». Чтобы ответить на него, сначала определим понятие понимания естественного языка (ПЕЯ), а затем исследуем его взаимосвязь с различными типами знаний, используемых в понимании речи. После этого с помощью примера, взятого из хорошо известного литературного источника, будут рассмотрены некоторые из методик, используемых в системах ПЕЯ. На этой основе в разд. 10.3.5 будет описан метод экспертных систем. Наиболее известное определение естественного языка, являющееся столь же точным, как и все другие определения, состоит в том, что это язык, используемый в устной или письменной форме в качестве основного средства связи между людьми. Отсюда в ряде стран и в большей части США естественным языком обычно называют английский, в других странах это испанский, китайский или какой-либо еще. Из этого следует, что лингвистические признаки играют важную роль в обработке знаний, связанных с естественным языком, и что естественный язык тесно связан с областью вычислительной лингвистики. Как это уже имело место для систем обработки речи и технического зрения, ПЕЯ имеет свою историю развития в области исследования интерфейсных устройств для сопряжения человека с машиной. Здесь задача состояла в создании машины, понимающей фразы или предложения на английском языке, вводимых в нее с помощью каких-либо периферийных устройств (обычно клавиатуры). На ранних этапах развития этого направления основной целью (помимо перевода языка) являлось создание систем, позволяющих обращаться с запросами к большим базам данных. Сама структура запроса и его интерпретация имели очень большое значение, и пользователю следовало быть очень внимательным, следя за точным переводом запроса на язык базы данных. Для приведенного ранее в данной главе примера запрос по обнаружению в базе данных сведений, посвященных нелинейным оптическим материалам для двумерных пространственных модуляторов света, мог бы, в случае ввода сигнала на естественном языке, иметь следующую структуру: «Найти все сообщения по нелинейным оптическим материалам, применяемым в двумерных пространственных модуляторах света». Первые варианты таких систем были способны интерпретировать такую входную команду только в том случае, если все эти слова входили в словарный запас системы. При соответствующей системе индексирования эта входная команда трансформировалась бы так: Класс: двумерный (w) пространственный (w) модуляторы света (w) Подуказатель: нелинейный (w) оптический (w) материал где (w) относится к связкам слов. Даже в настоящее время многие системы запросов к базам данных все еще действуют таким же образом. Чтобы далее проиллюстрировать это утверждение, предположим, что требуется получить сообщения о рабочих характеристиках двумерных ПМС. Запрос «Требуется найти все сообщения об их рабочих параметрах» привел бы только к появлению сообщения об ошибке, даже если бы данное утверждение непосредственно следовало за первым. Это обусловлено тем, что вторая фраза содержит косвенное указание на элемент первого предложения, так что подлежащее второй фразы не было бы однозначно идентифицировано. В этом случае система понимания естественного языка, называемая системой диалогового языкового общения, требует использования знания прагматики (см. разд. 10.3.2), что позволяет облегчить решение указанных выше проблем. Таким образом, при обсуждении ПЕЯ речь по существу идет о реализации возможностей, аналогичных таким человеческим способностям, как умение читать и понимать тексты, вести диалоги. Однако не существует прямых аналогий между обработкой естественных языков и обработкой сигнала и изображения, так же как и в случае обработки речи низкого уровня и систем технического зрения. На практике используют преобразование сигнал-символ, но это применяется непосредственно на стадии ввода сигнала, а после этого момента вся обработка носит символьный характер. Однако спасает ситуацию то обстоятельство, что большая часть знаний, используемая в системе ПЕЯ, непосредственно применима для понимания речи высокого уровня. Чтобы получить лучшее представление, о способах обработки естественного языка, следует проанализировать возможности практического применения ПЕЯ. Поскольку здесь будут рассматриваться лишь наиболее важные применения, то за более полной информацией читателю следует обратиться к монографии [18]. За исключением случая использования ПЕЯ для создания входных интерфейсов, главное применение ПЕЯ лежит в области компьютерного программирования. Здесь цель состоит в замене выражений, таких, как
на следующее выражение: «Вычислить среднее значение для 50 величин». В настоящее время разрабатываются языки, являющиеся более похожими на английский, особенно для задач в области ИИ; это будет показано в разд. 10.3,5 на примере обсуждаемых в нем экспертных систем. Другой аспект ПЕЯ состоит в обработке текстов, под которой подразумевается обработка ряда предложений или параграфов с целью извлечения важной информации. Это целенаправленное выделение информации очень полезно при работе с литературными источниками, как, например, сбор информации по оптическим вычислениям из всех журналов, издаваемых Институтом инженеров но электротехнике и радиоэлектронике (IEEE) и Американским институтом физики (AIP). Другим приложением обработки текстов служит механический перевод текстов, например с английского языка на испанский. Наконец, задача создания систем, выдающих информацию на естественном языке, так же как и реализация способностей давать разъяснения в экспертных системах, является наиболее важной прикладной задачей ПЕЯ. Сведение процесса получения заключений по какому-то вопросу к серии простых предложений представляет, однако, труднейшую проблему даже для людей. Любая система обработки естественного языка включает ряд основных компонентов. Входной сигнал вводится с терминала, хотя иногда в этих целях используется микрофон. В этом случае, однако, микрофон применяется для ввода букв, идентифицируемых с помощью программных средств, и он не позволяет выделять отдельные слова и предложения Вслед за вводом входного сигнала система ПЕЯ с целью идентификации взаимосвязей и взаимозависимостей между словами разлагает или подвергает предложение синтаксическому анализу. Программа синтаксического анализа основывается на знаниях грамматики языка и направлена на обнаружение подлежащего и связей имен существительных и глаголов с производными от них формами. Например, хорошо известная фраза, заимствованная из журнала Applied Optics «Оптика подразумевает работу света» (Optics is light work), может иметь различные варианты синтаксического разбора, примеры которых показаны на рис. 10.20. При синтаксическом разборе осуществляется разложение введенной в систему фразы и выделяются взаимосвязи между словами, которые заносятся в память в символьном виде. После синтаксического разбора семантический интерпретатор получает соответствующую информацию и, используя уже имеющуюся информацию из базы знаний, присваивает каждому слову фразы некоторый коэффициент. Это осуществляется либо в процессе поиска, либо с помощью преобразования в промежуточный формат, известный как «язык представления значений». Данный язык не изменяет значения и выраженные в виде символов взаимоотношения слов, но он реализован так, что обеспечивает более эффективное отображение на словарный запас системы. Из приведенного выше примера следует, что система может определить истинность любого из ниже следующих высказываний:
Оценить каждую из этих интерпретаций можно с помощью обработки на более высоком уровне. Для этого словесная конструкция передается в процессор проблемной области и языкового общения, который, используя прагматические знания, вырабатывает гипотезу о значении введенного сообщения. Гипотеза либо сравнивается с информацией, хранящейся в базе знаний, либо требует проведения дополнительной семантической и контекстуальной обработки, а также изменения проблемной области. В приведенном выше примере парадигма восходящей схемы решения использовалась для объяснения процесса обработки знаний аналогично тому, как это делалось при анализе систем понимания речи и технического зрения. Метод восходящей
Рис. 10.20. Возможные варианты синтаксического анализа фразы «Оптика подразумевает работу света» («Optics is light work»). Ф — фраза; СФ — фраза с существительным; ГФ — глагольная фраза; С — существительное; Г — глагол; Д — дополнение. схемы решения показан в виде схемы на рис. 10.21. Однако возможны и другие подходы. В качестве примера можно рассмотреть архитектуру системы, использующей рабочую область общего доступа, приведенную на рис. 10.22. Она может быть использована для объединения знаний, получаемых от различных процессоров в случае неполного понимания этих знаний. Рис. 10.21. (см. скан) Компоненты системы обработки естественного языка. Рис. 10.22. (см. скан) Система обработки естественного языка с рабочей областью общего доступа. Указанная схема позволяет быстро достичь полного понимания входных данных, реализуя это параллельными методами. Например, если синтаксический анализатор находит два различных синтаксических значения одного и того же предложения «Оптика подразумевает работу света», то используемые процессоры должны будут определить наиболее вероятную интерпретацию путем использования дополнительных знаний. К сожалению, существующие в настоящее время системы обработки естественного языка неспособны однозначно определить значения входных предложений или эффективно использовать контекст и прагматические знания. Каждая фраза обработки имеет свои «узкие места», особенно когда вводимая информация содержит ошибки в пунктуации и орфографии. При вводе в систему обработки естественного языка неотредактированных текстов требуется предусмотреть дополнительные программные средства. В настоящее время такие системы работают медленно и их возможности ограничены пониманием текстов в очень узких областях, с низкой степенью точности интерпретации. Как это было в случае речевых систем и систем технического зрения, в системах обработки естественного языка также приходится искать компромисс между общностью поставленных задач и получаемыми рабочими характеристиками. Общая цель исследования проблем понимания естественного языка заключается в разработке достаточно гибкой системы, обладающей перестраиваемой проблемной областью, которая может достигать высокого уровня точности интерпретации. Как это уже встречалось ранее, стремление оптимизировать рабочие характеристики положило начало разработке параллельных алгоритмов, направленных на достижение оптических или мультипроцессорных реализаций. Однако, как и в случае технического зрения, достигнутого уровня понимания принципов параллельной организации прохождения задач в настоящее время недостаточно для их реализации. После предшествующей дискуссии можно начать рассмотрение вопроса о том, как мультипроцессор или оптический процессор может быть использован для понимания естественного языка в реальном времени. Процесс синтаксического анализа может осуществляться параллельно, так как во многих случаях различные морфемы, лексические нюансы и синтаксические структуры анализируются параллельно. Организация рабочей области общего доступа для основных процессоров незамедлительно позволила бы реализовать параллельную обработку. Последнее, на чем следовало бы остановиться особо, заключается в том, что при описании обработки естественного языка обсуждается поведение компьютерных систем. В данном случае анализируются возможности таких систем давать интерпретацию и делать заключения относительно входных данных, а также, если это удается, учиться на своих ошибках. В свою очередь вопрос об интерпретации данных требует выяснения того, где заканчивается сфера обработки естественного языка и начинается обработка, присущая экспертным системам. В обоих случаях становится все более общей форма представления знаний, поскольку накопленные знания будут использоваться для понимания новых естественных языков, вводимых в систему. Общие знания об окружающем мире, т. е. общеизвестные истины, так же как и специальные значения по конкретной области, должны использоваться для определения того, следует ли вновь введенную информацию понимать буквально, или она содержит элементы метафоры, юмора или сарказма. Указанные вопросы будут затрагиваться еще раз в следующей части раздела при рассмотрении экспертных систем.
|
 |
Оглавление
|