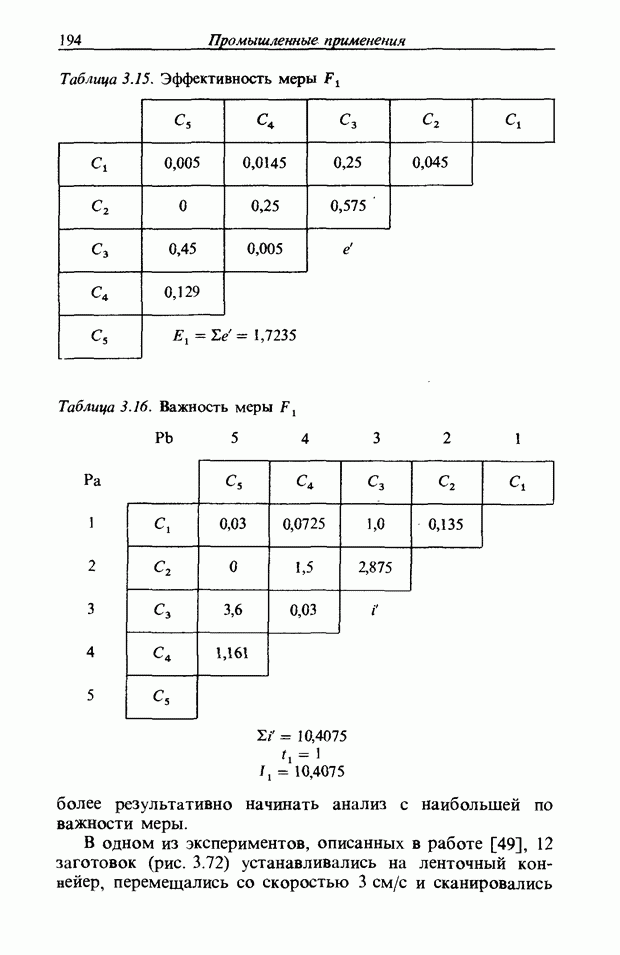
Пред.
След.
Макеты страниц
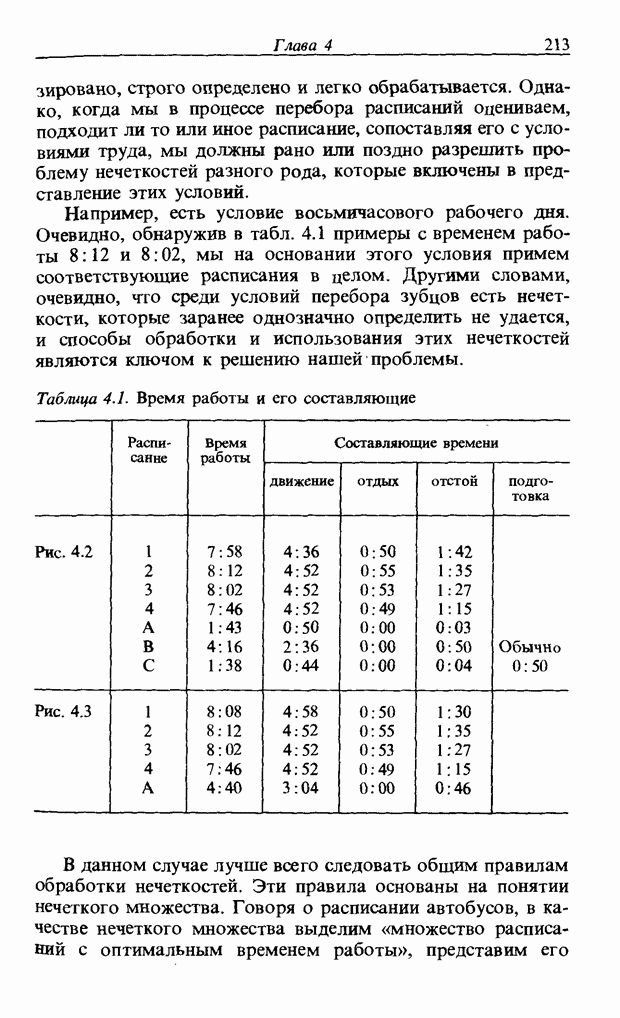
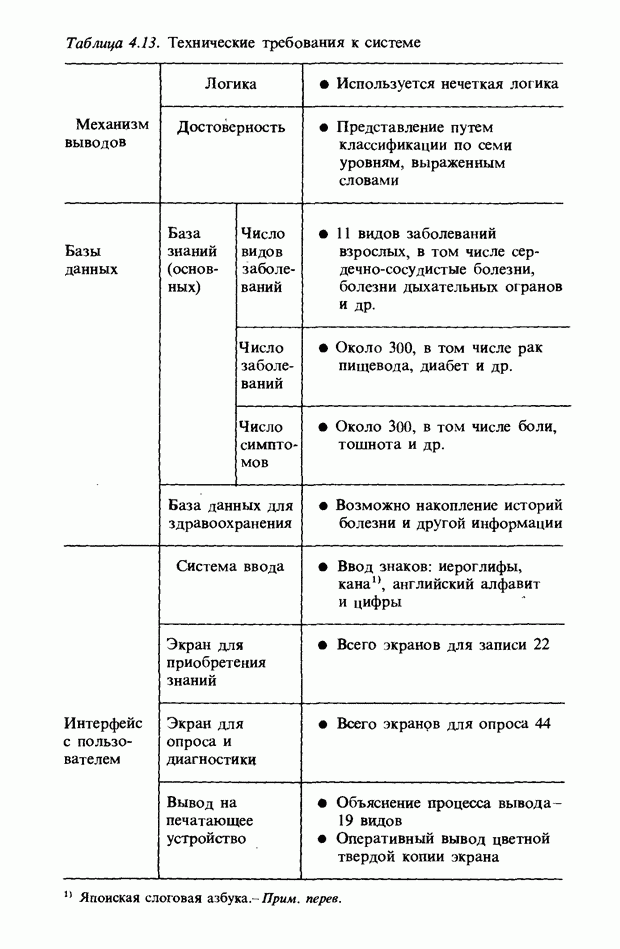
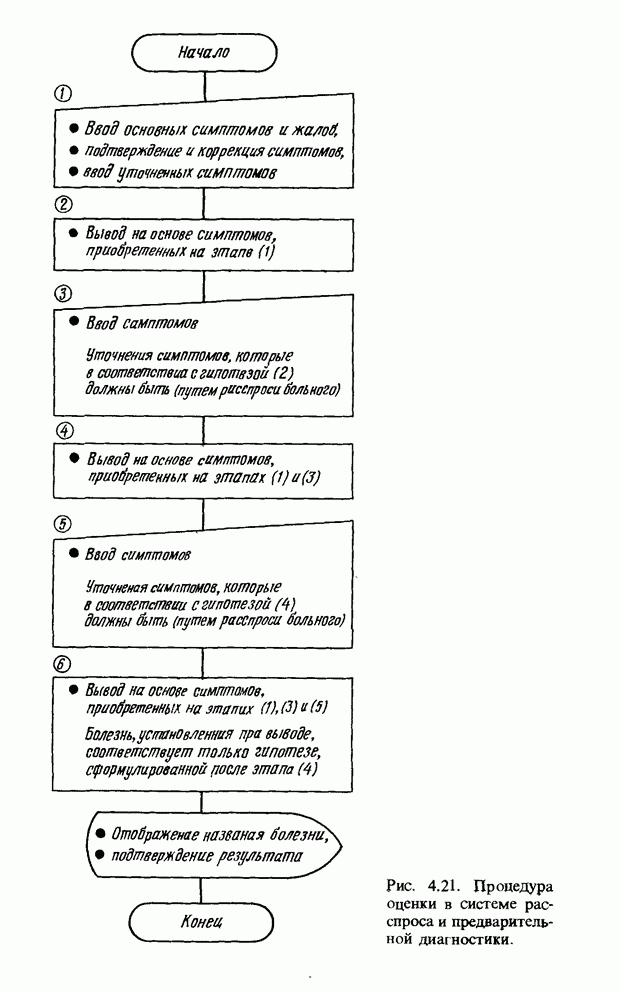
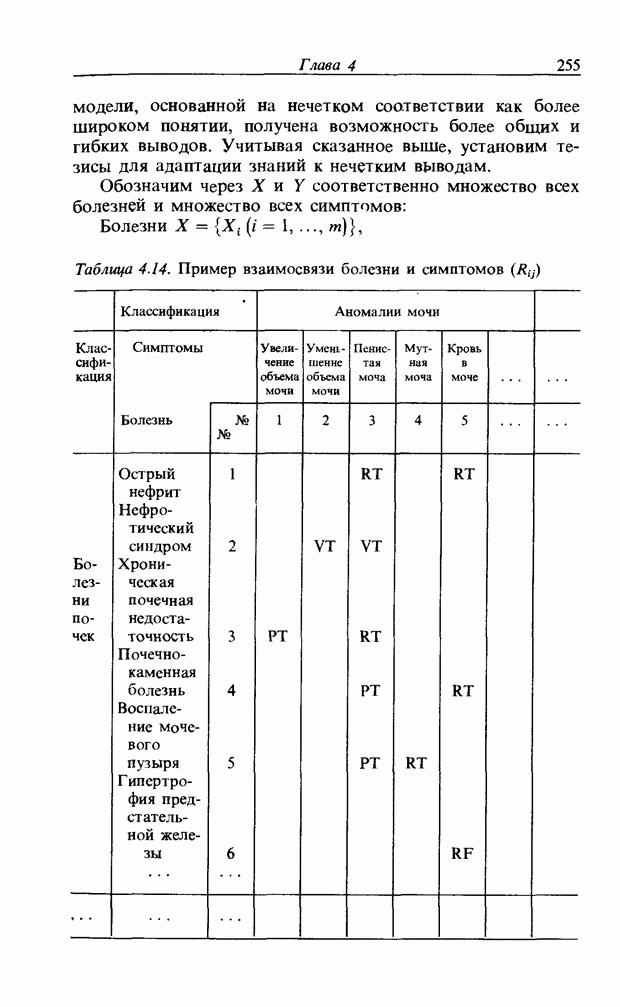
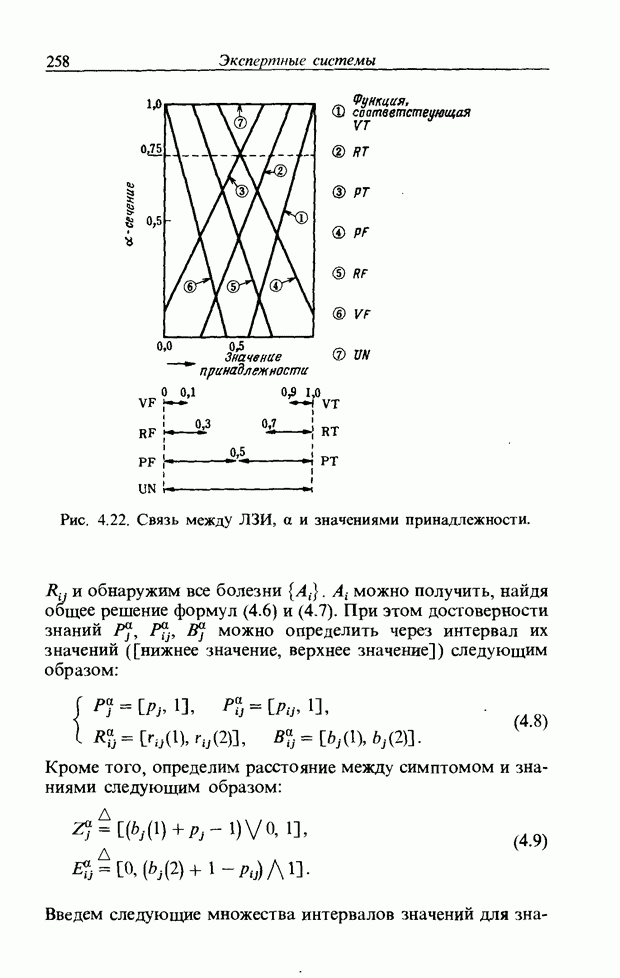
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
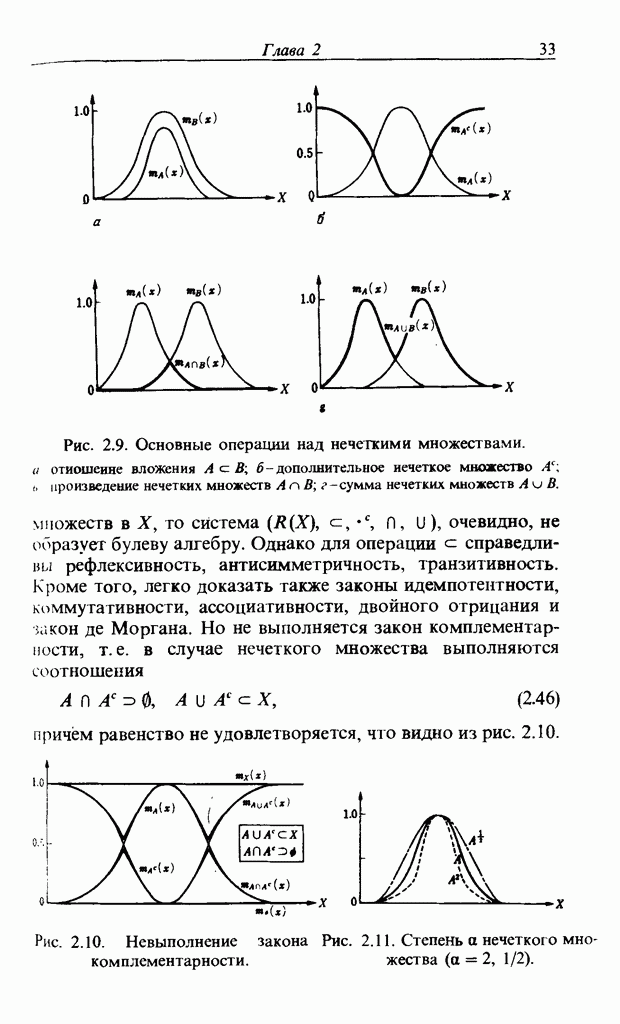
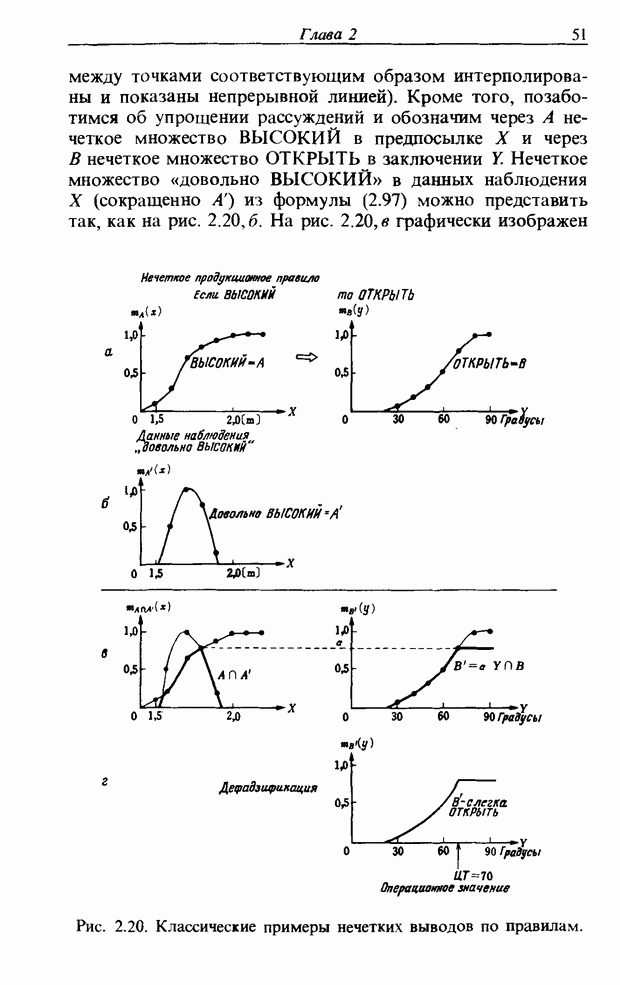
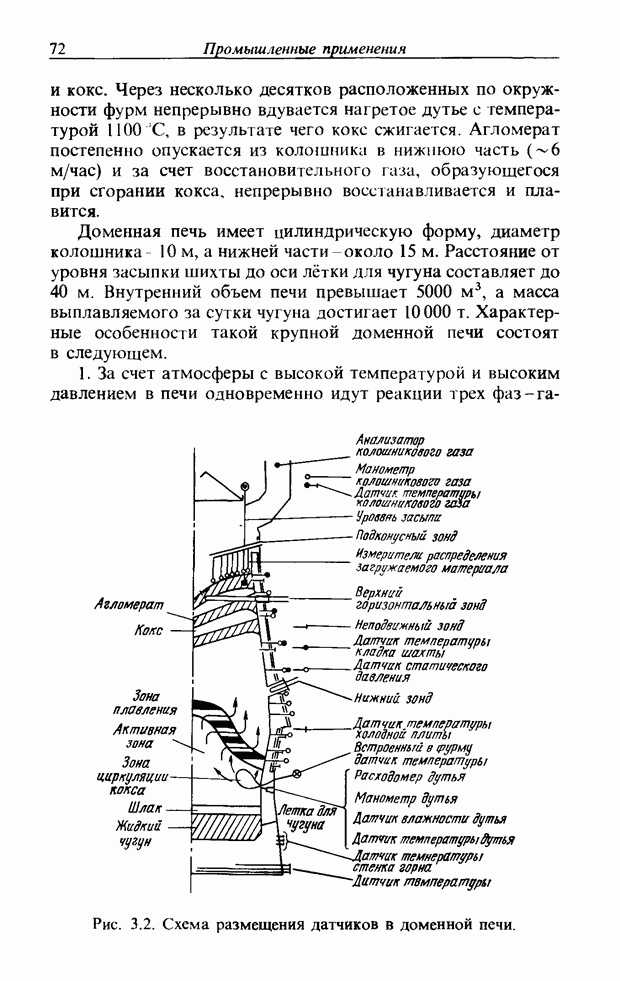
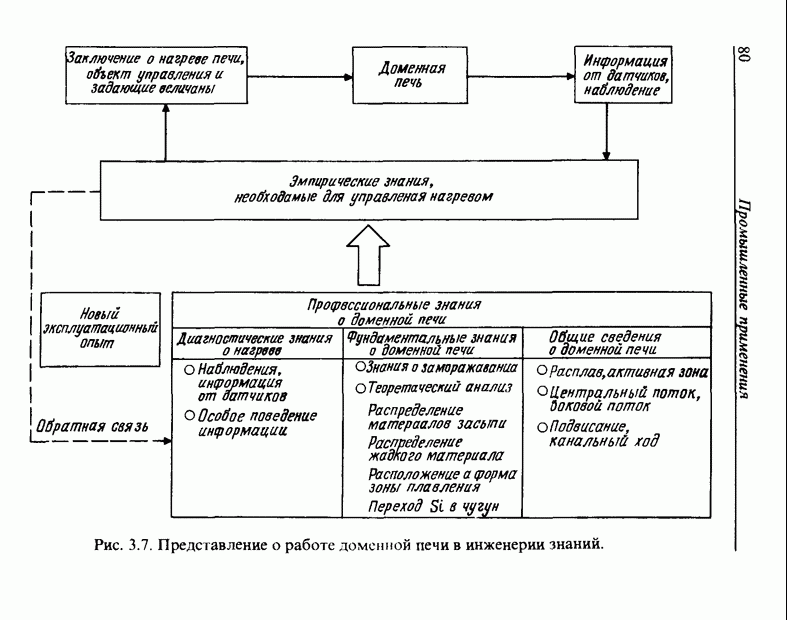
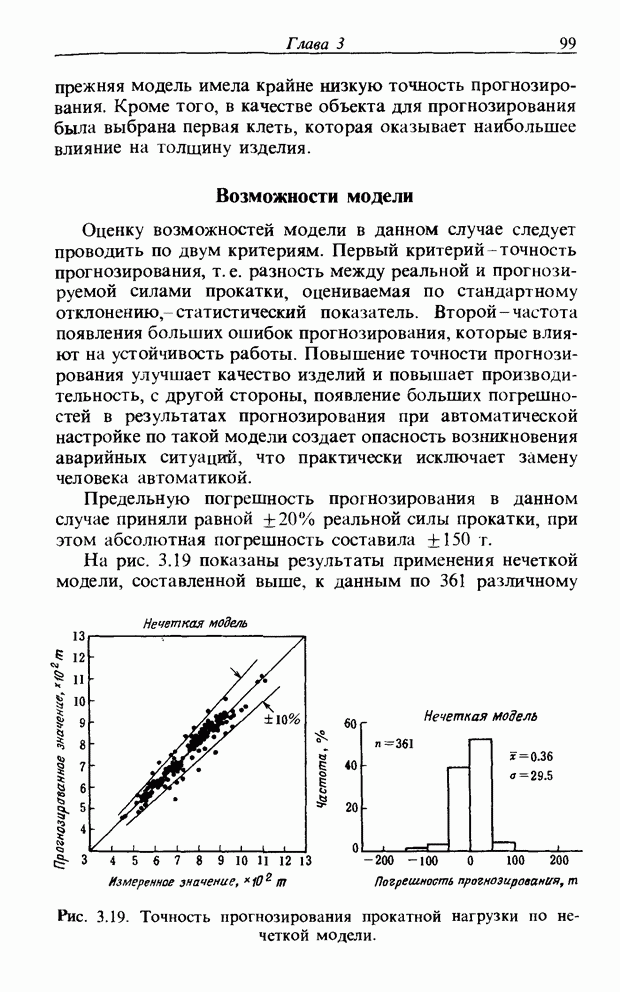
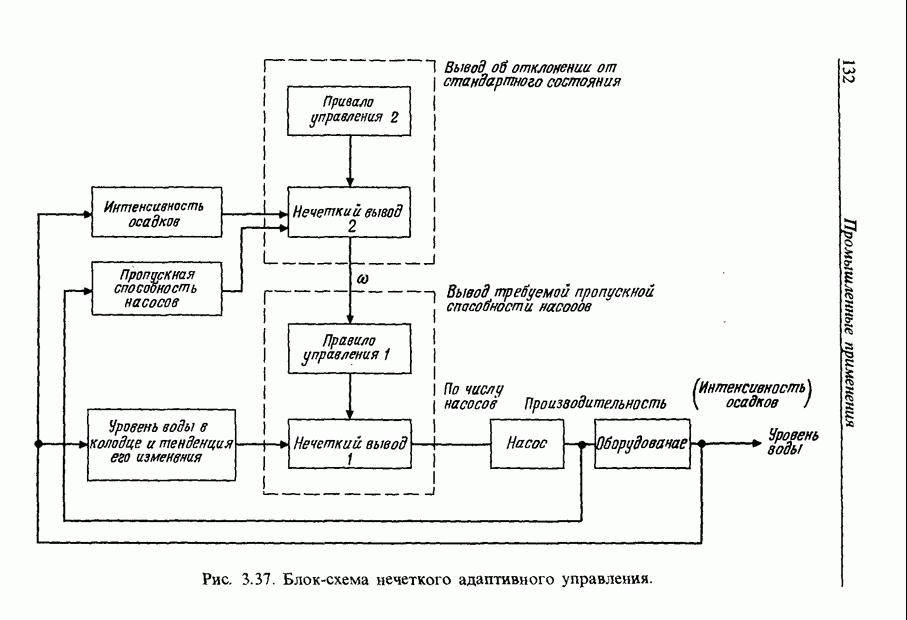
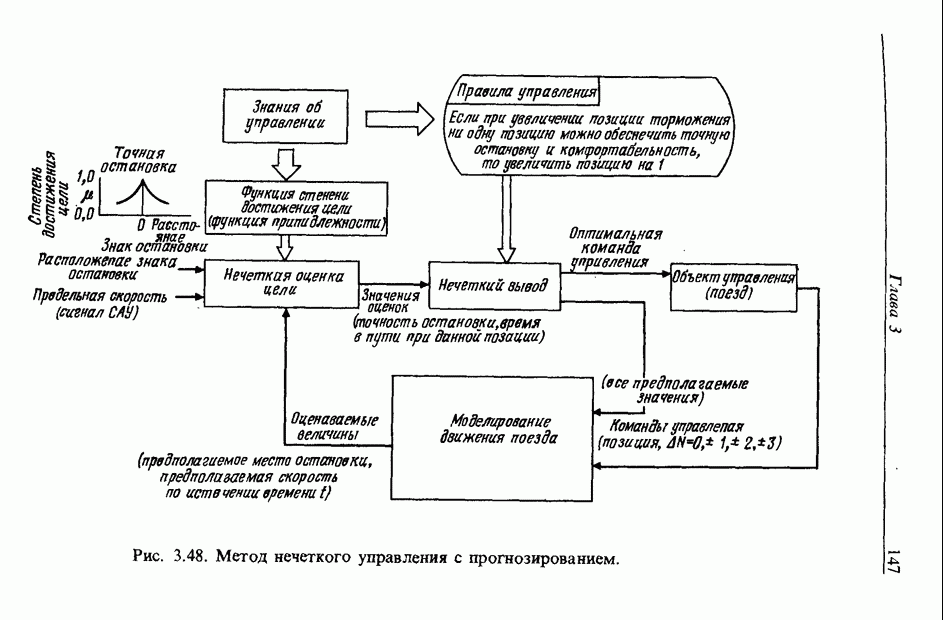
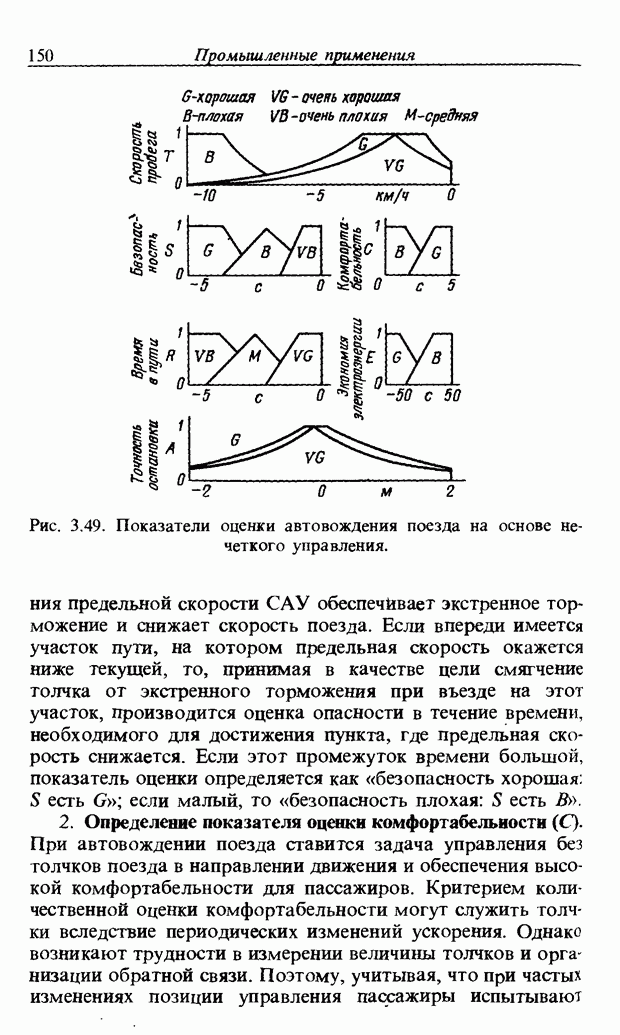
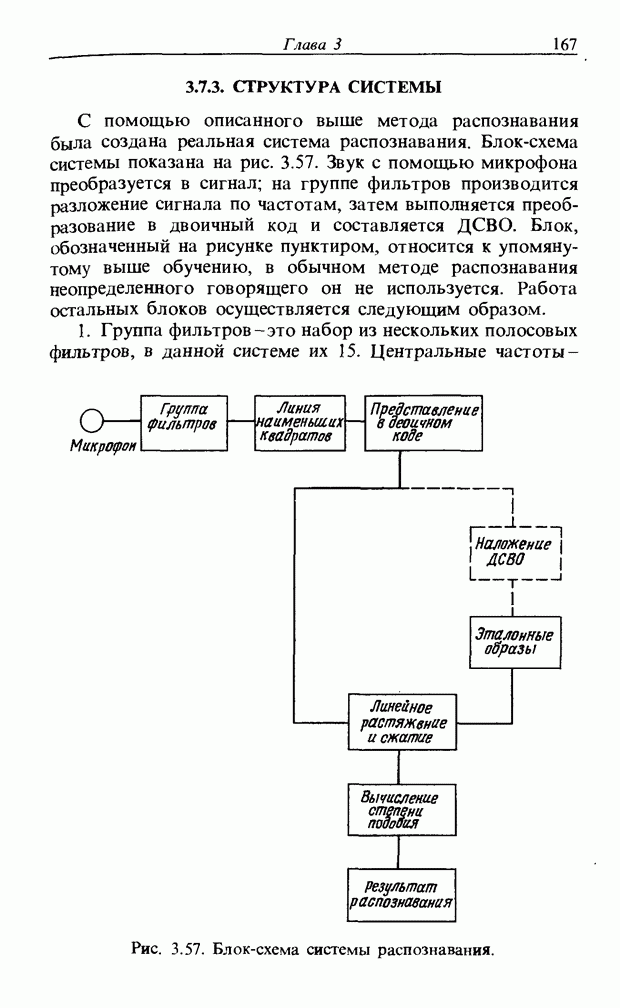
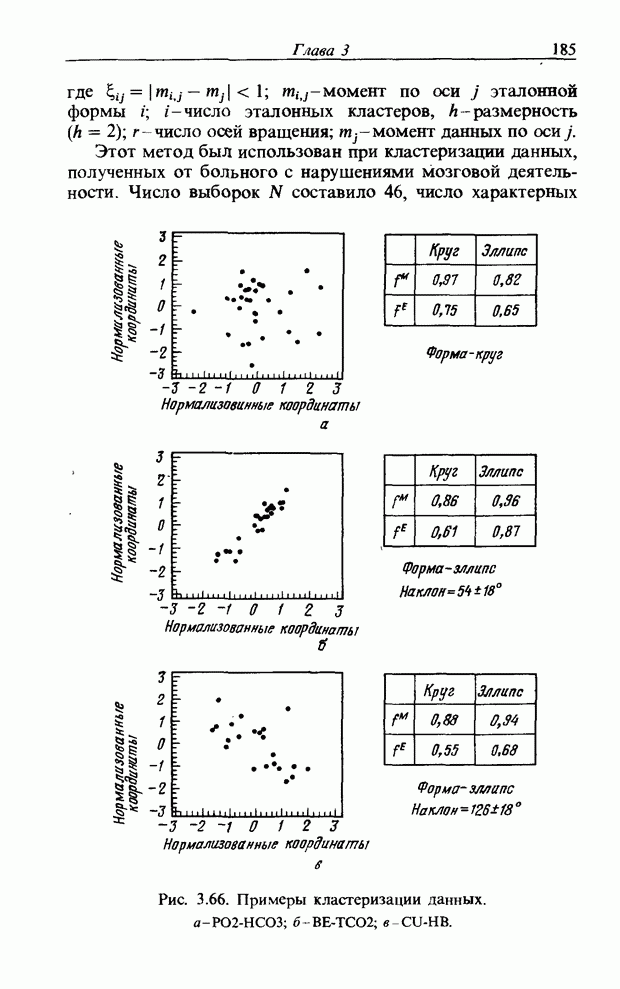
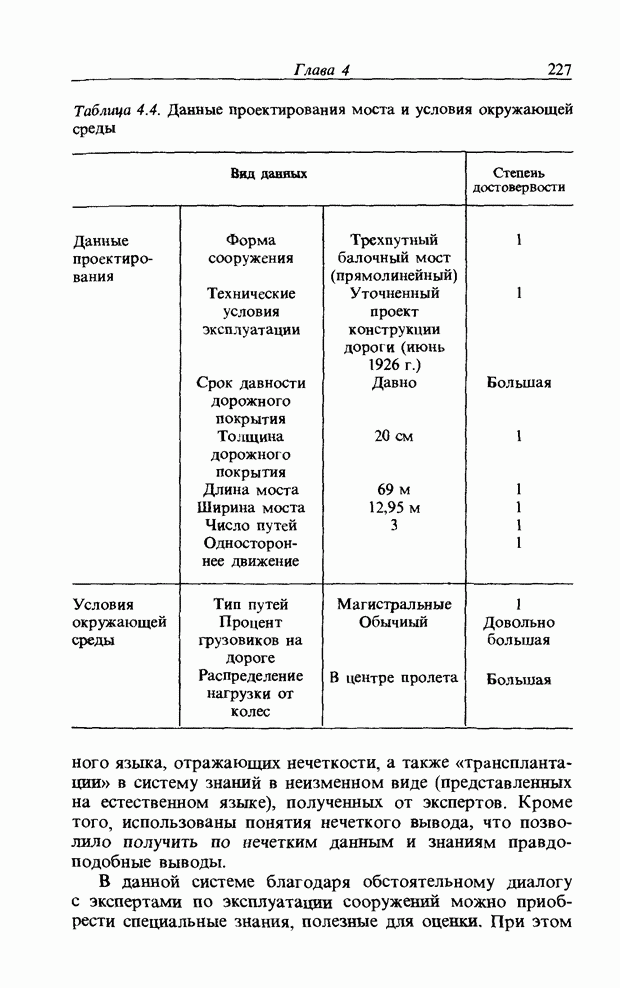
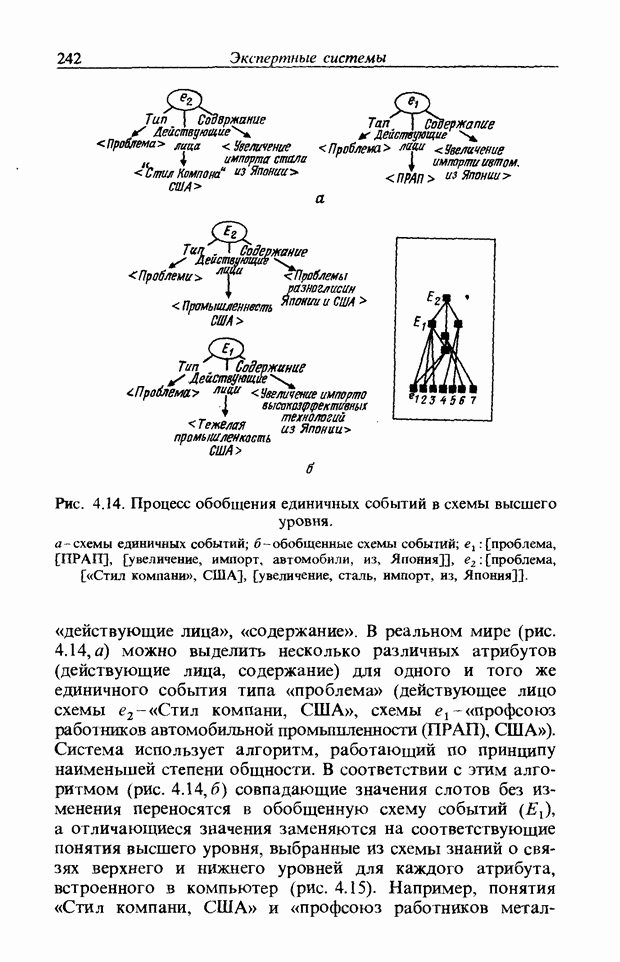
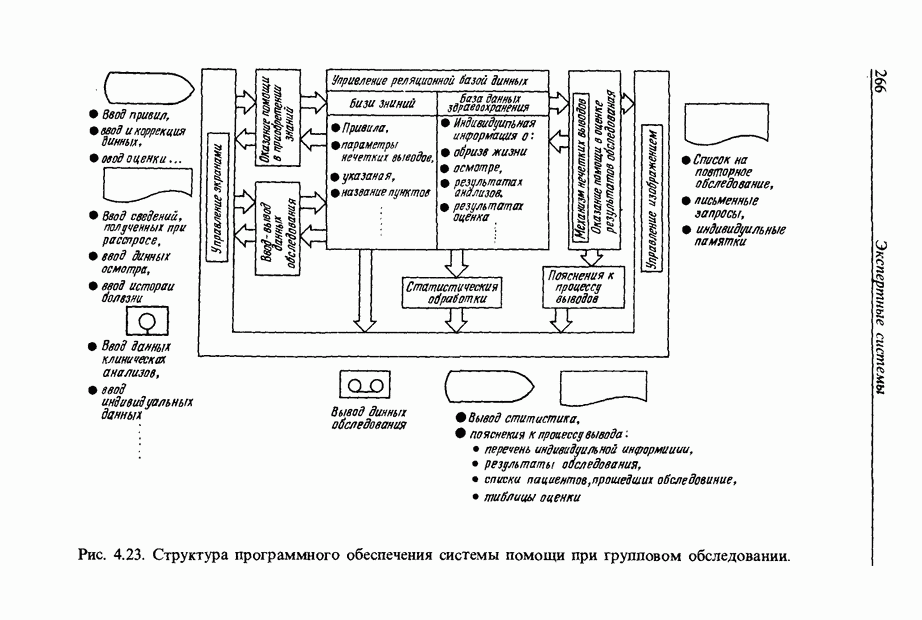
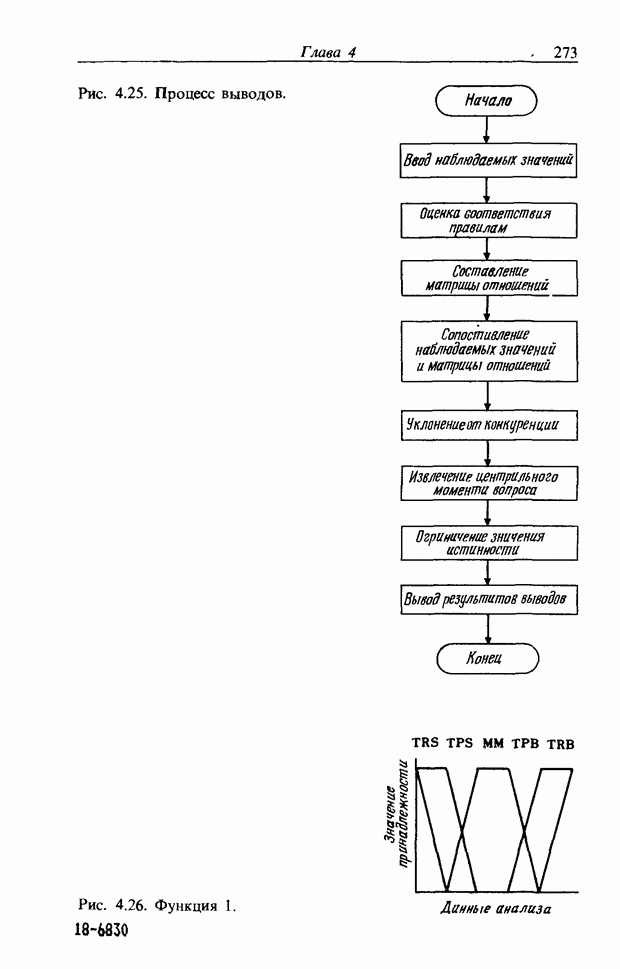
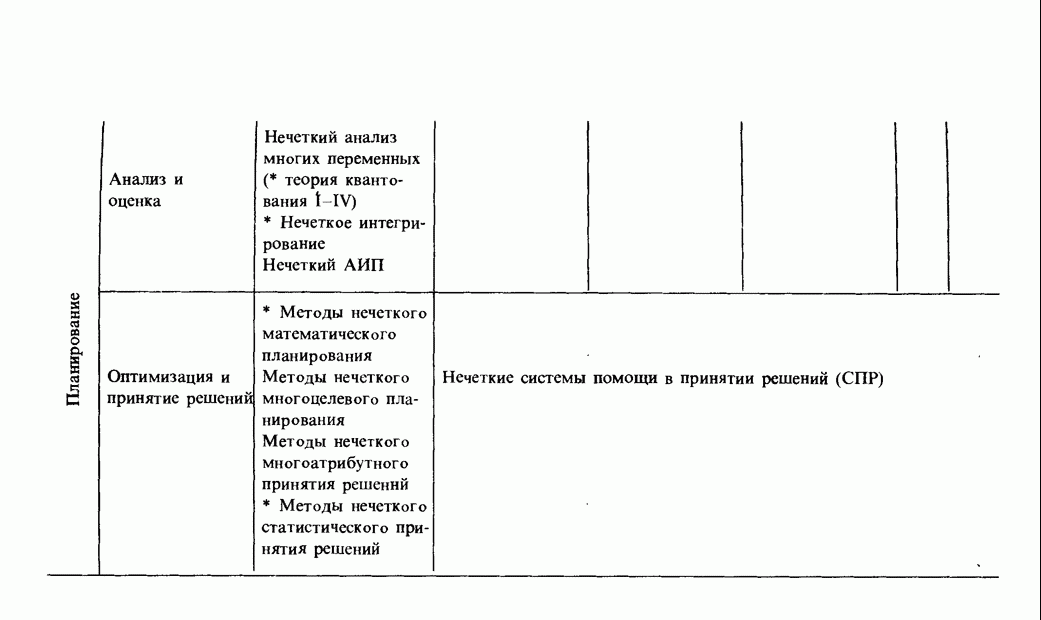
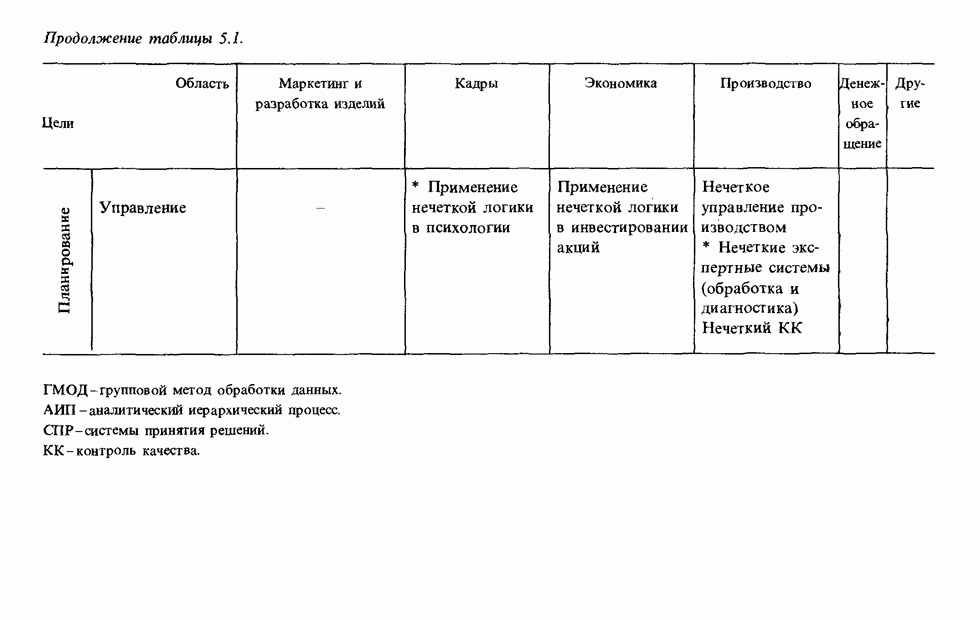
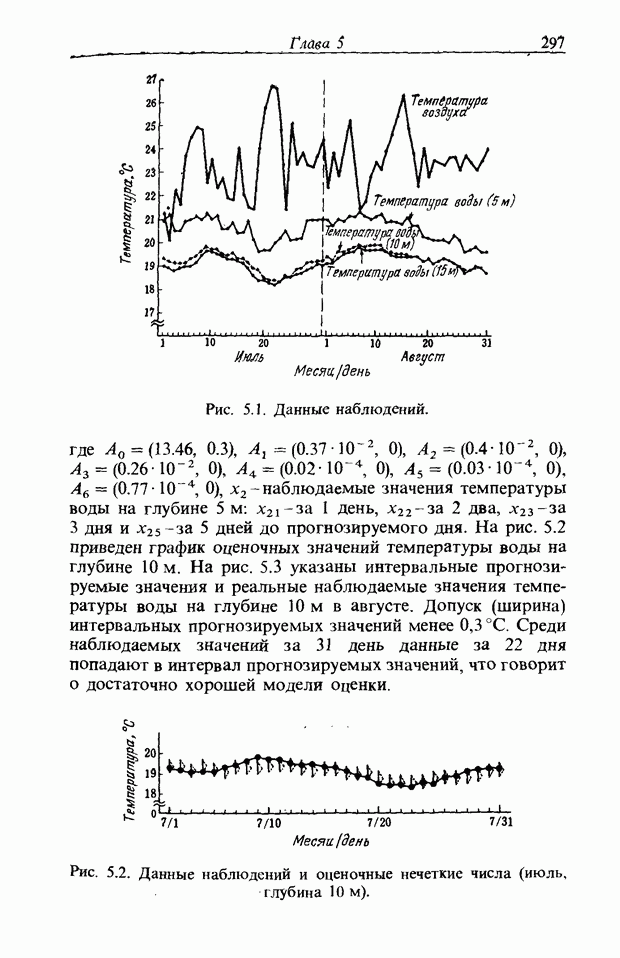
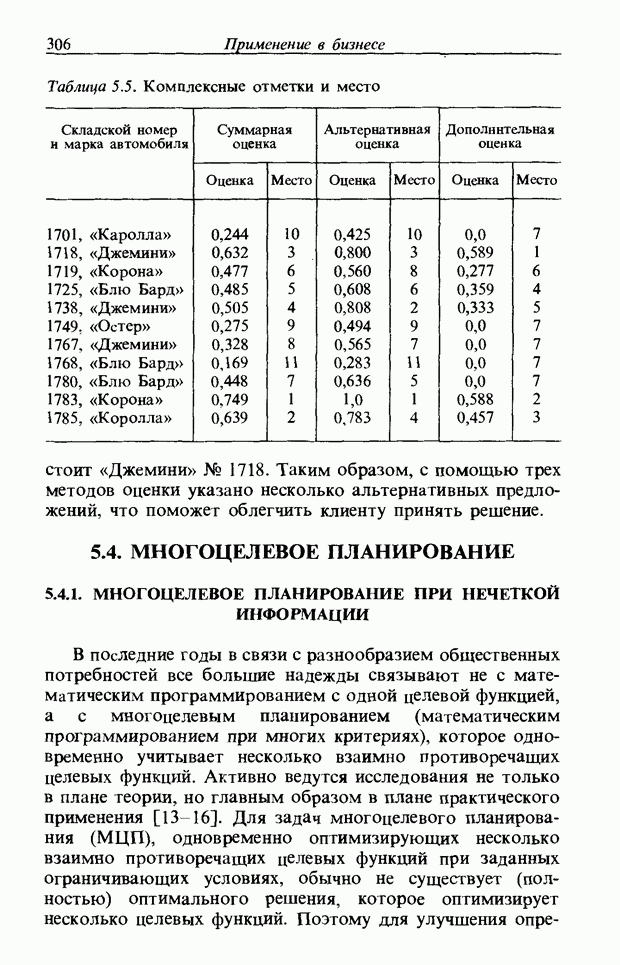
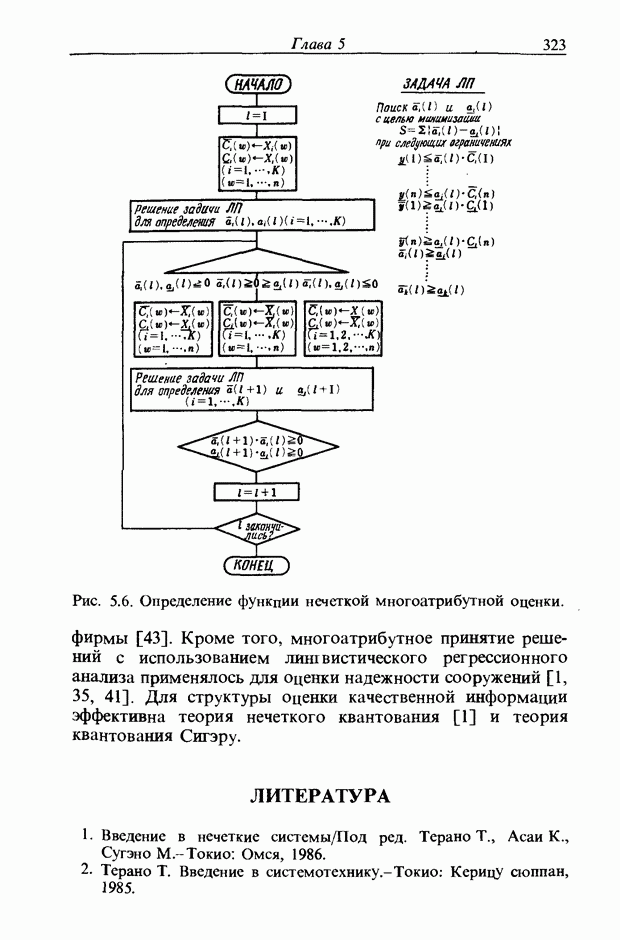
3.7.2. НЕЧЕТКОЕ СОПОСТАВЛЕНИЕ ОБРАЗОВРассмотрим прежде всего характерные образы для распознавания речи. В качестве признаков, извлекаемых из речи, хорошо известны LPC (коэффициент линейного предсказания), кепстр, спектр и др. Среди этих признаков авторы выбрали спектр, позволяющий легко установить соответствие с физической величиной. На спектральном временном образе (СВО), по осям которого откладываются время и частоты, получаемые в результате деления речи на короткие интервалы и спектрального анализа на этих интервалах, хорошо выражены особенности речи. Считывая спектр, человек может «читать» по СВО произносимые звуки. Как указывалось выше, человек произносит слова, изменяя органом речи резонансную частоту, поэтому особенно важными в СВО являются резонансные частоты, т. е. выбросы. Резонансные частоты для гласных звуков называют формантами, однако используют и название «локальный выброс» как расширение понятия форманта на согласные звуки [29]. В рассматриваемом здесь методе распознавание произносимого слова осуществляется путем определения, какой локальный выброс присутствует и как он меняется во времени. Две проблемы, указанные в разд. 3.7.1, в данном случае проявляются как изменение длительности образа и изменение частоты локальных выбросов, обусловленные говорящим. Поскольку интерес представляет лишь местоположение локального выброса, данные можно представить в двоичном виде: На рис. 3.54 представлены примеры образов: а - СВО слова END, произнесенного мужчиной; б - ДСВО, полученный из СВО путем преобразования в двоичный код. По горизонтальной оси отложена частота, по вертикальной - время, на оси частот на каждые Обозначим число записанных слов через и, множество слов через
Рис. 3.54. Пример звукового образа слова END. а - СВО; б - ДСВО. множество из
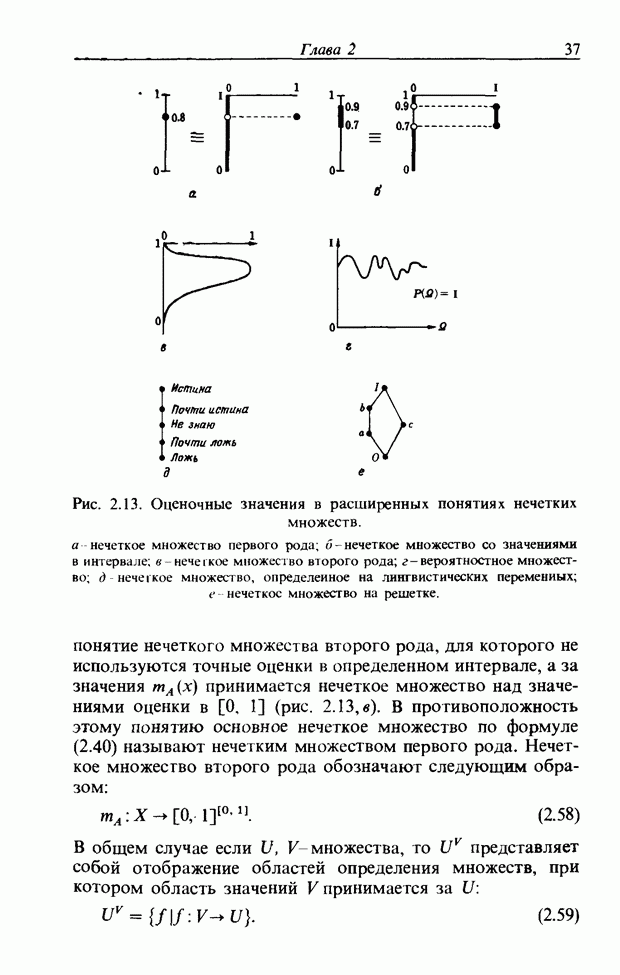
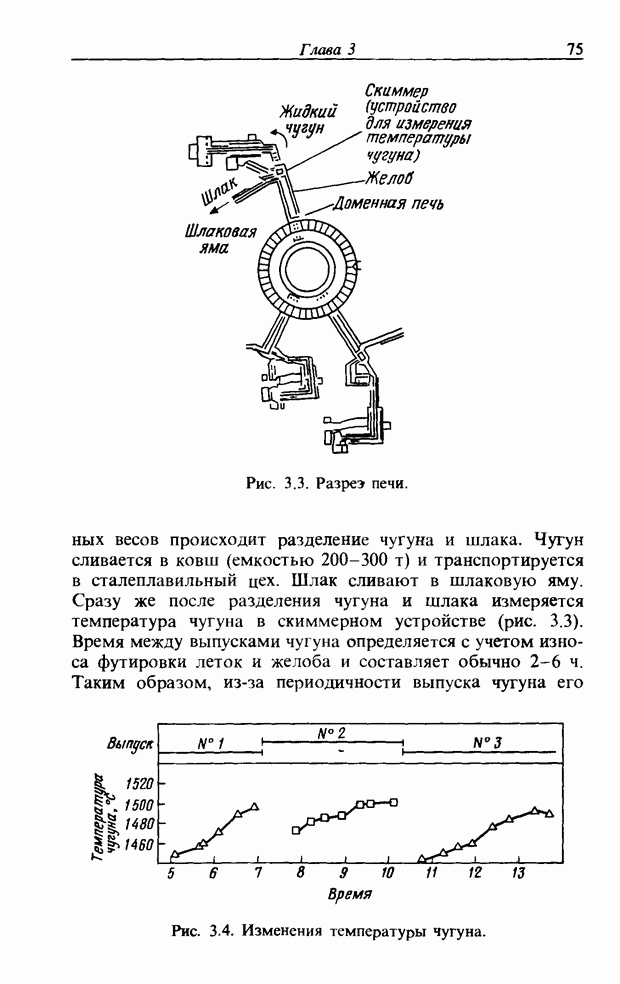
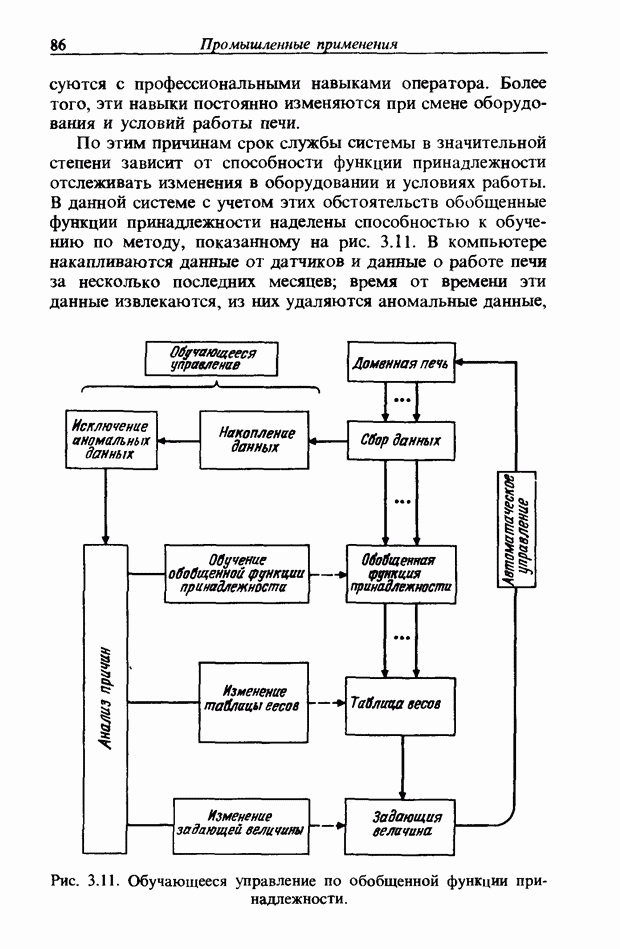
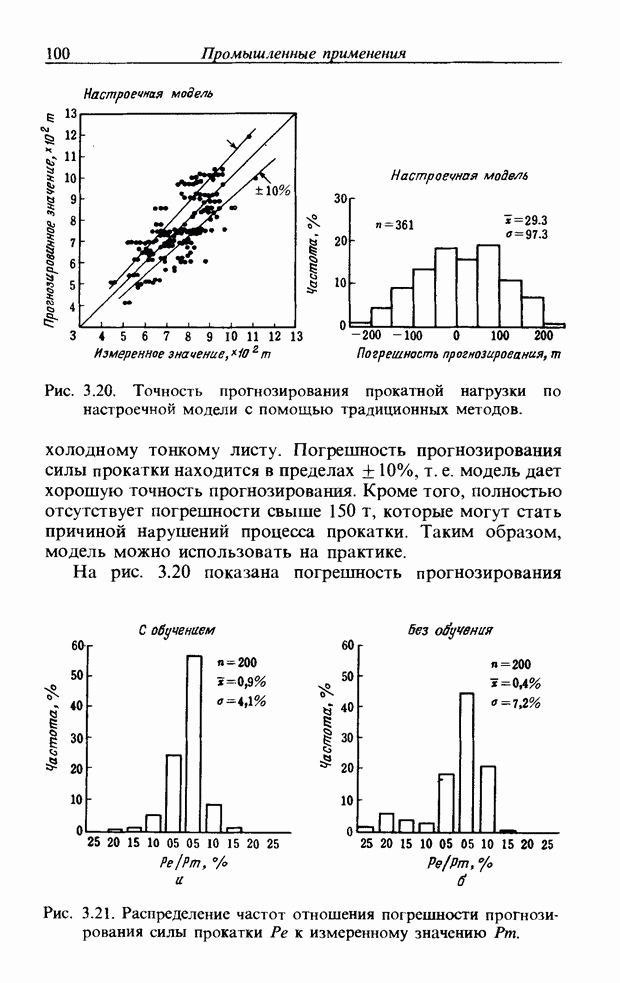
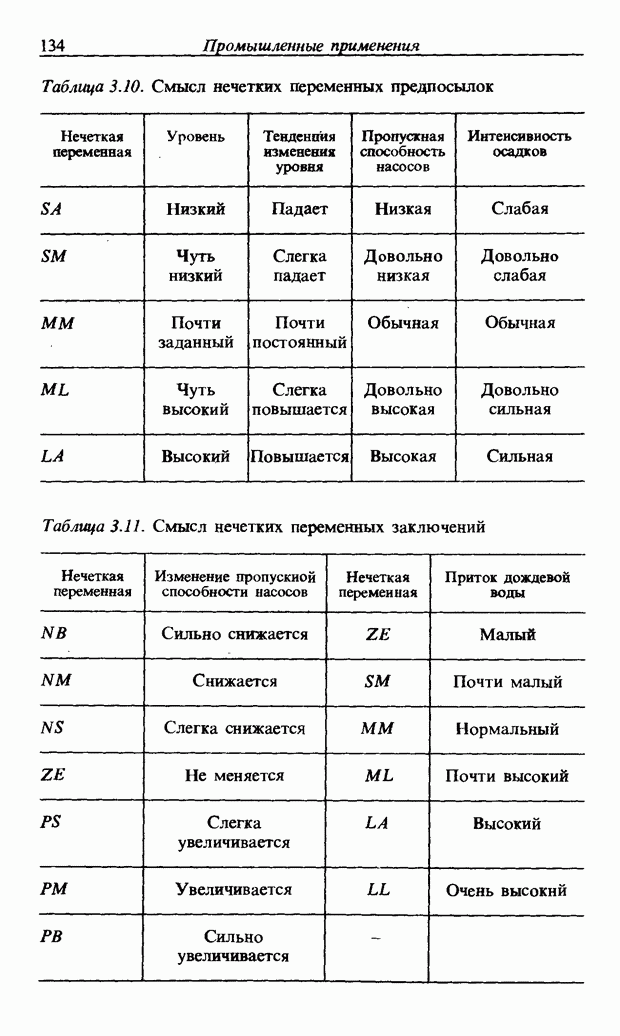
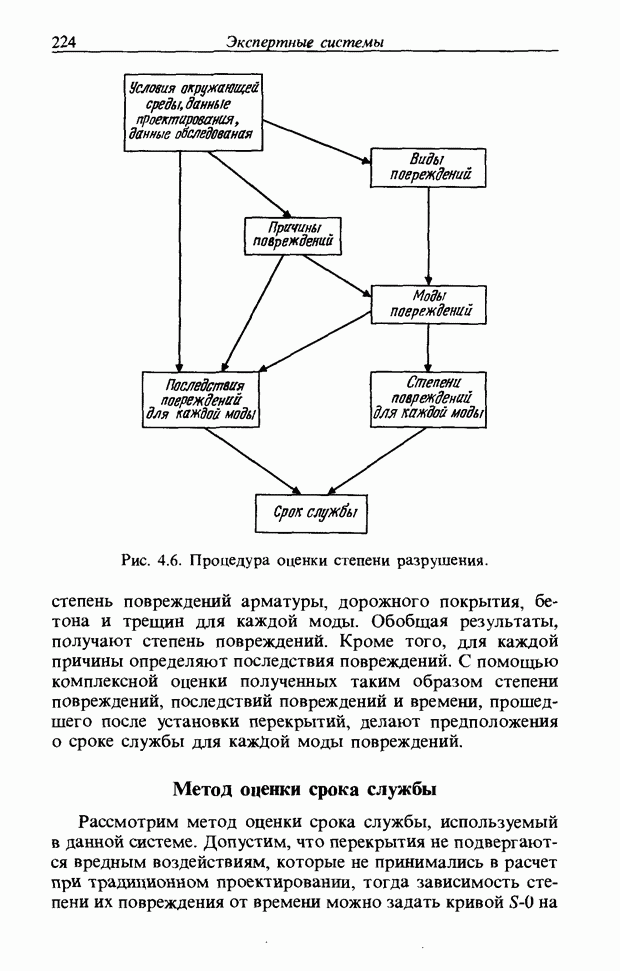
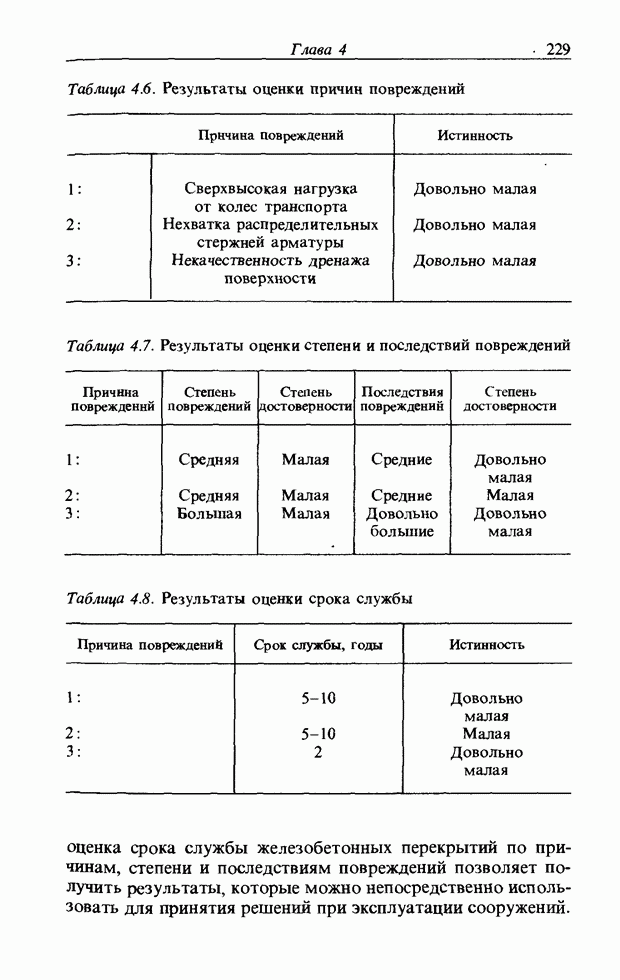
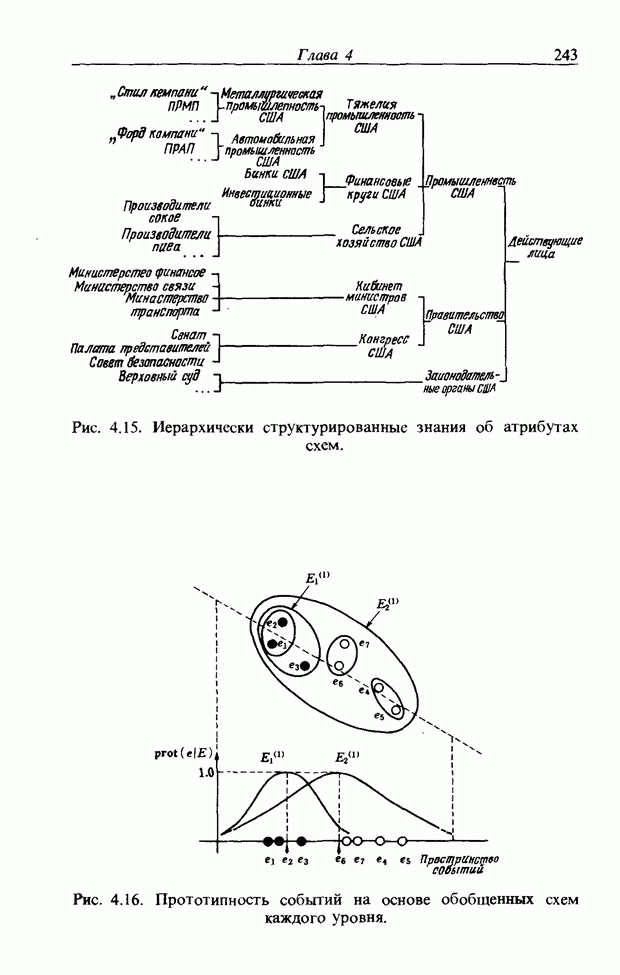
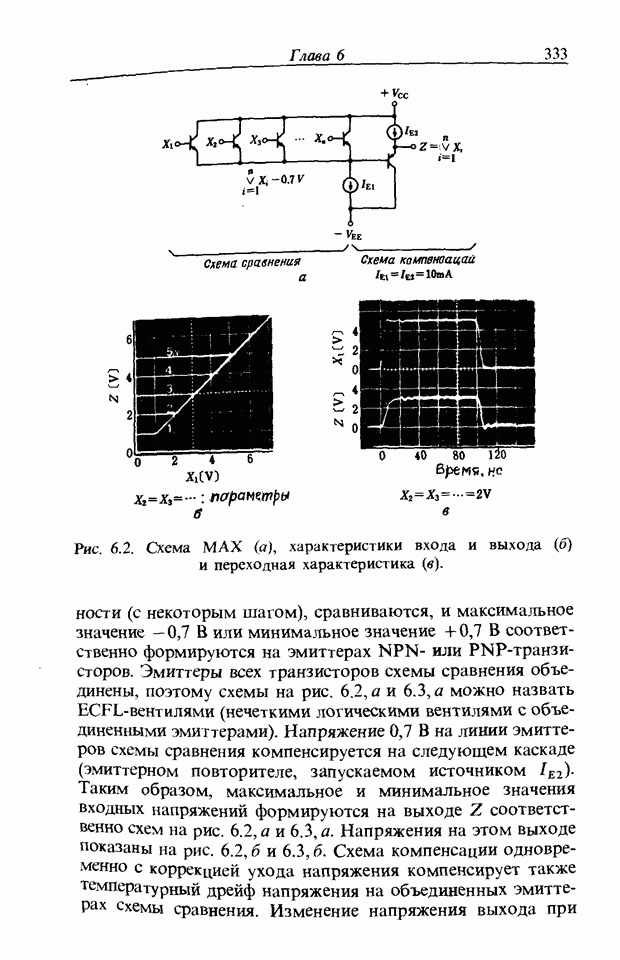
При использовании нечеткой логики часто возникает проблема определения функции принадлежности. В данном случае следует решить, как определить сходство образов слов Для всех слов, которые должны быть записаны, собираются голоса многих говорящих и преобразуются в ДСВО. Для каждого слова суммируются все образы и составляется двумерная функция принадлежности, в которой из этих данных выбраны изменения в представлении слова. В частности, определяется среднее арифметическое образов, отобранных в соответствии с некоторым критерием из ДСВО одного слова. При суммировании возникает одна трудность. Среди двух типов упомянутых ранее изменений частотные изменения вызывают лишь изменение на оси частот положений 1, которые являются элементами, показывающими резонансную частоту в образе, в то время как при временных изменениях происходит изменение длин образа, что затрудняет суммирование. В связи с этим перед суммированием с помощью линейного растяжения/сжатия осуществляется согласование длин образов. Эта процедура представляет собой простой способ выравнивания длин сравниваемых образов за счет прореживания и вставок. По сравнению с нелинейным растяжением Определим теперь степень подобия. Пусть
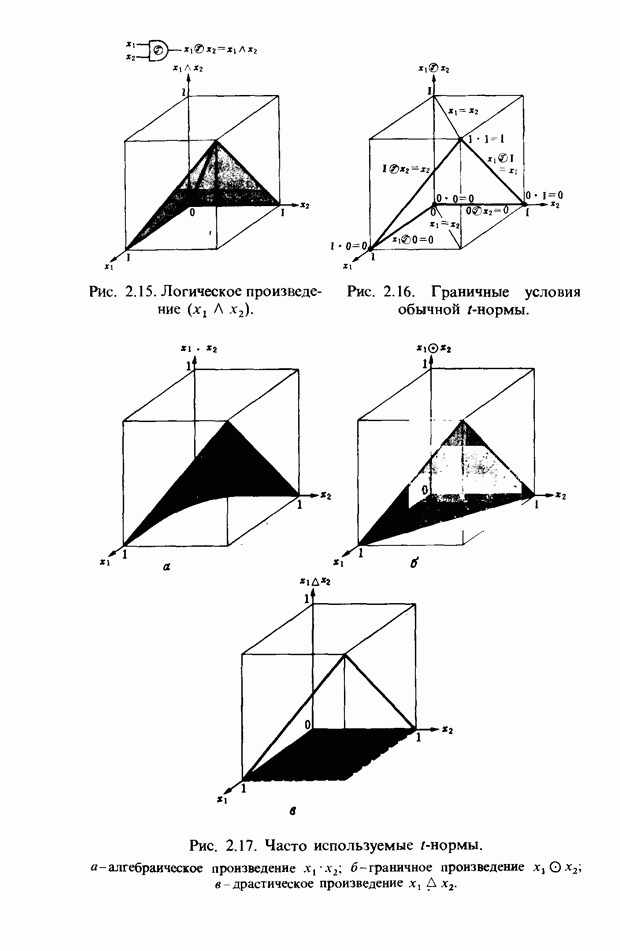
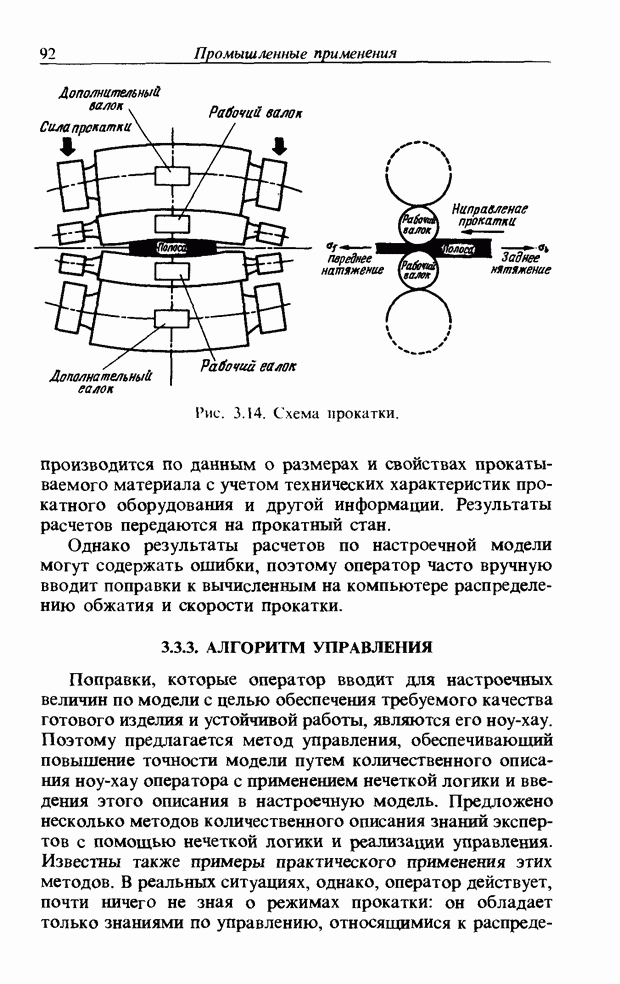
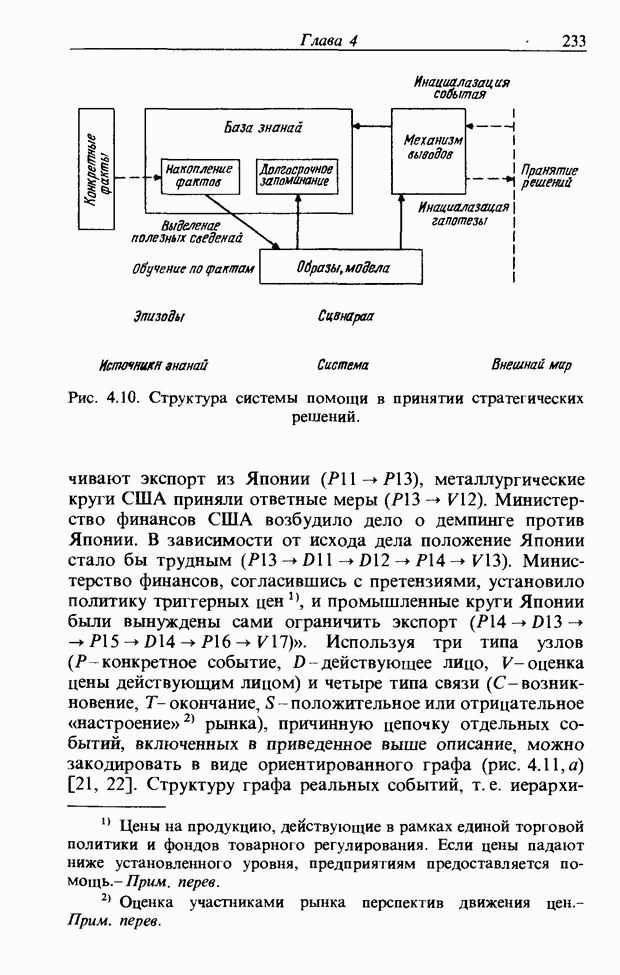
Рис. 3.55. Пример функции принадлежности слова START. функций принадлежности На рис. 3.56, а показаны локальные выбросы некоторого голоса. Если выбросы есть для частот
где 1 обозначает следующую функцию:
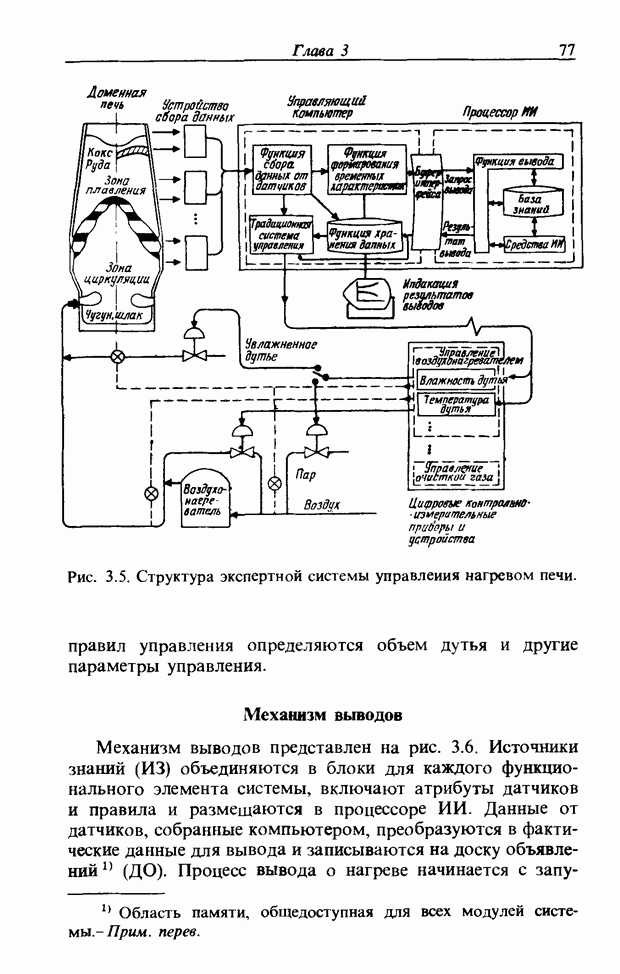
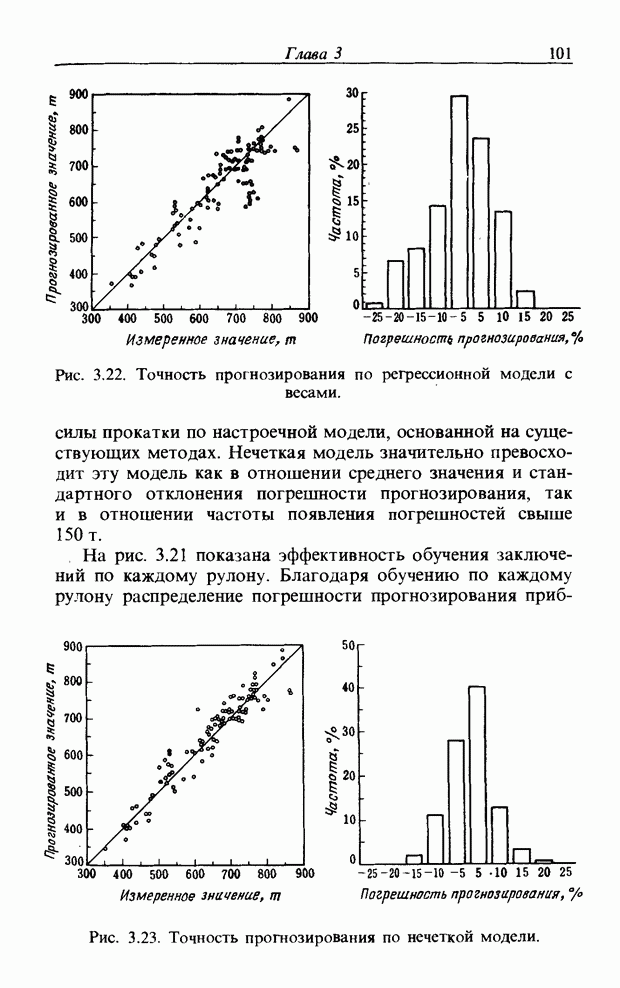
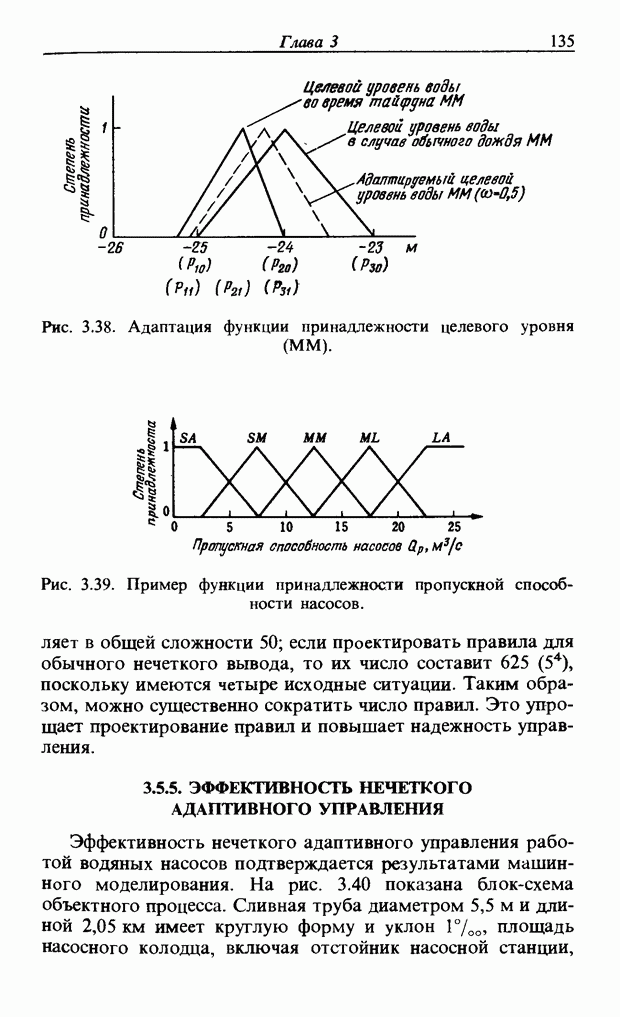
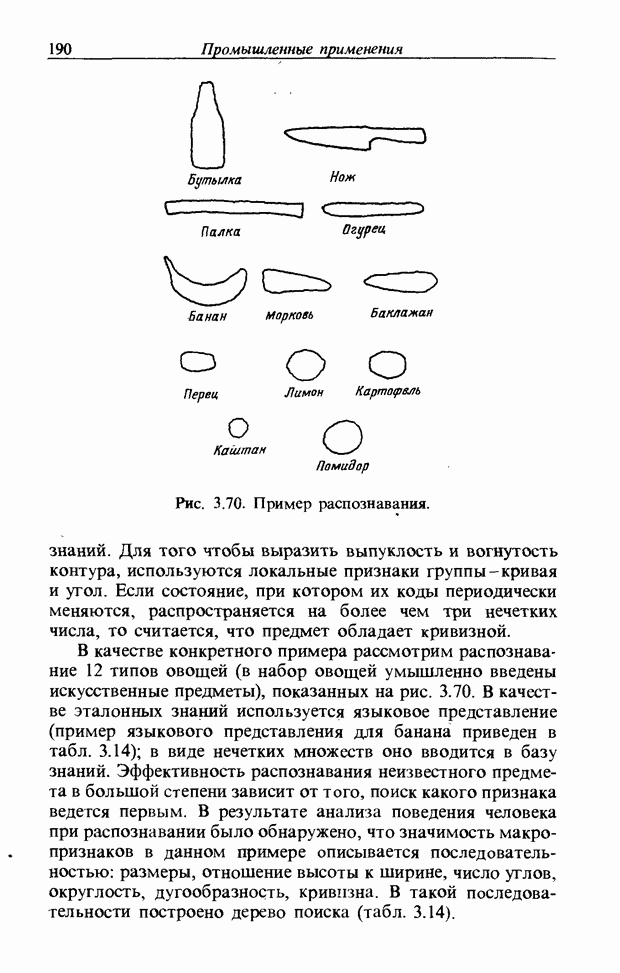
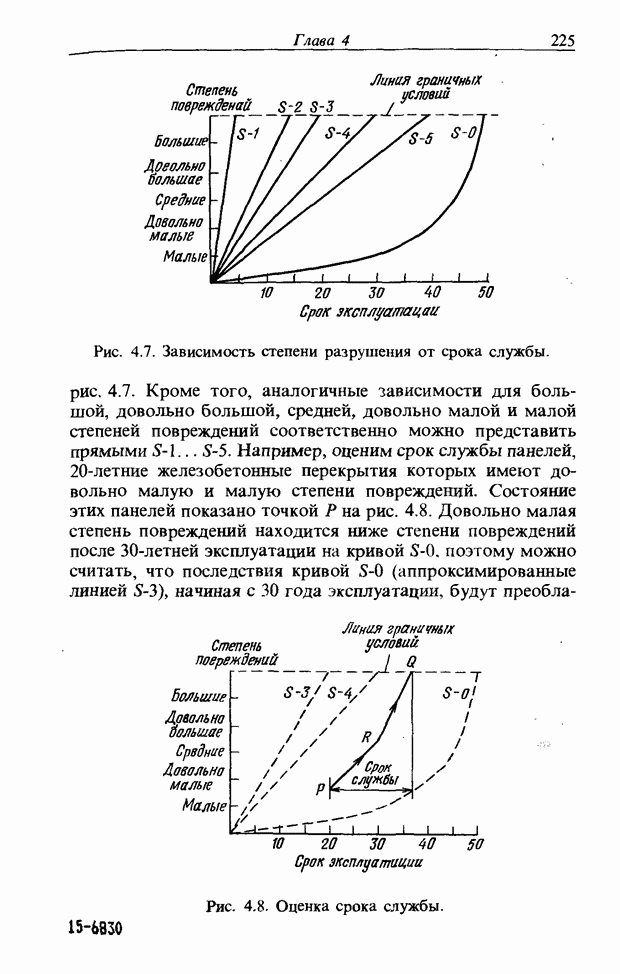
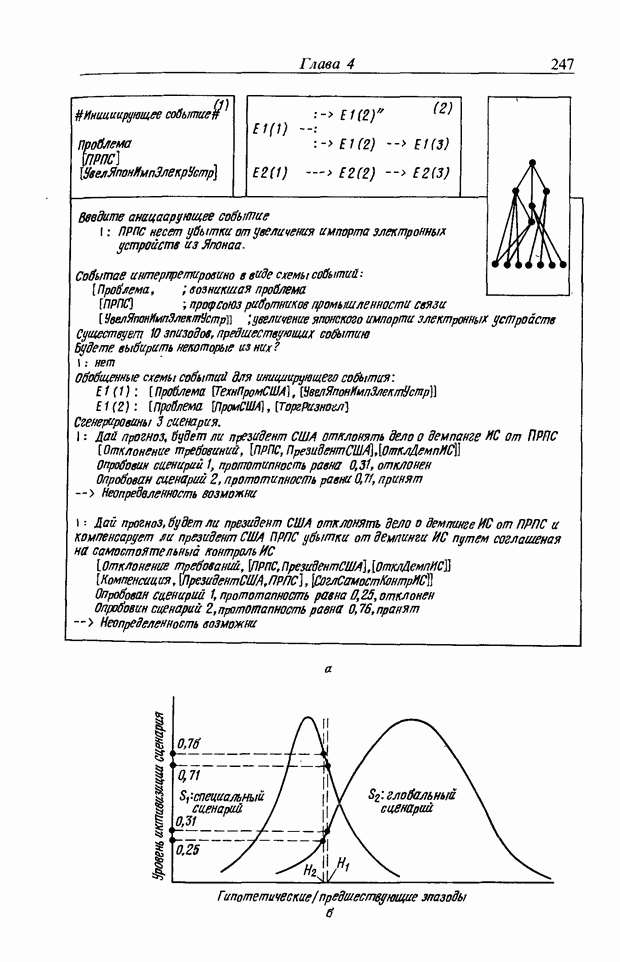
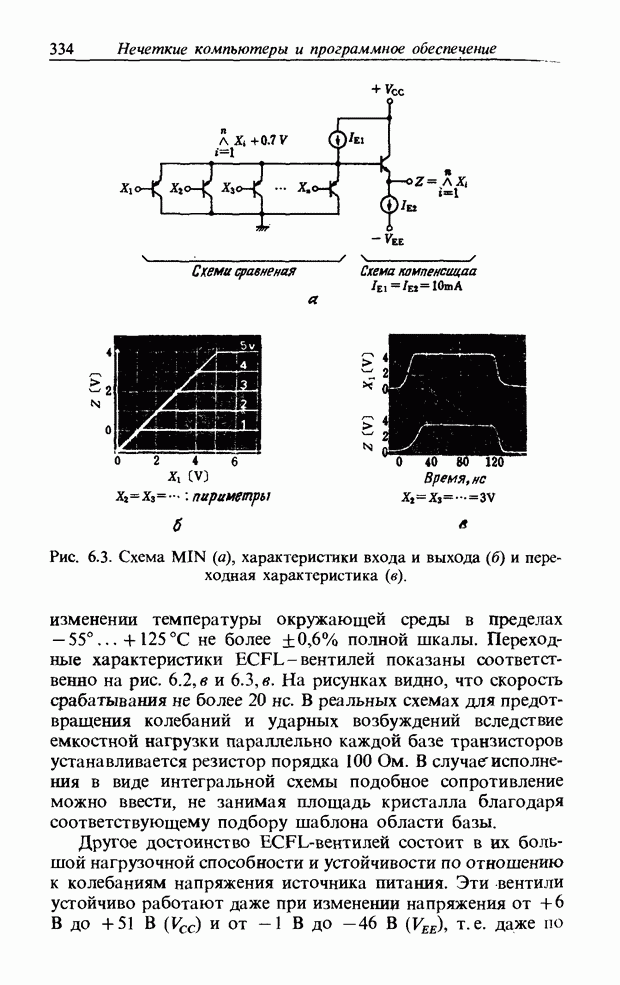
На рис. 3.56, б и в приведены функции принадлежности множеств образов слов j и к, причем на рис. 3.56, б имеются
Рис. 3.56. Неизвестный образ и принадлежность голоса. два локальных выброса, на рис. 3.56, в - один. Местоположение двух локальных выбросов в первом случае полностью совпадает с максимумами функции принадлежности, их степень принадлежности равна 1. Поэтому максимумы функции принадлежности нормализуются до значения 0,5. Степень принадлежности
В случае рис. 3.56, а она почти равна 1 и показывает сходство со словом
где В рассуждениях, представленных выше, мы ограничились только частотой, уменьшив для простоты размерность; фактически имеет место двумерное распределение. В этом случае не только трудно учесть число локальных выбросов и нормализовать значение выбросов функции принадлежности, но и нецелесообразно отводить четыре бита на каждый элемент. Для вычисления степени подобия без нормализации определим ее как отношение формул (3.34) и (3.35):
В случае когда нормализация не производится, В реальном устройстве распознавания приходится оперировать с дискретными величинами. В этом случае исполь зуется следующее выражение для степени подобия:
где
Знак
Если значения элементов функции принадлежности представлены четырьмя битами, то чаще всего Формула (3.37) состоит из двух членов, причем оба по виду похожи на формулу (3.36). Числитель и знаменатель левого члена - это соответственно
|
 |
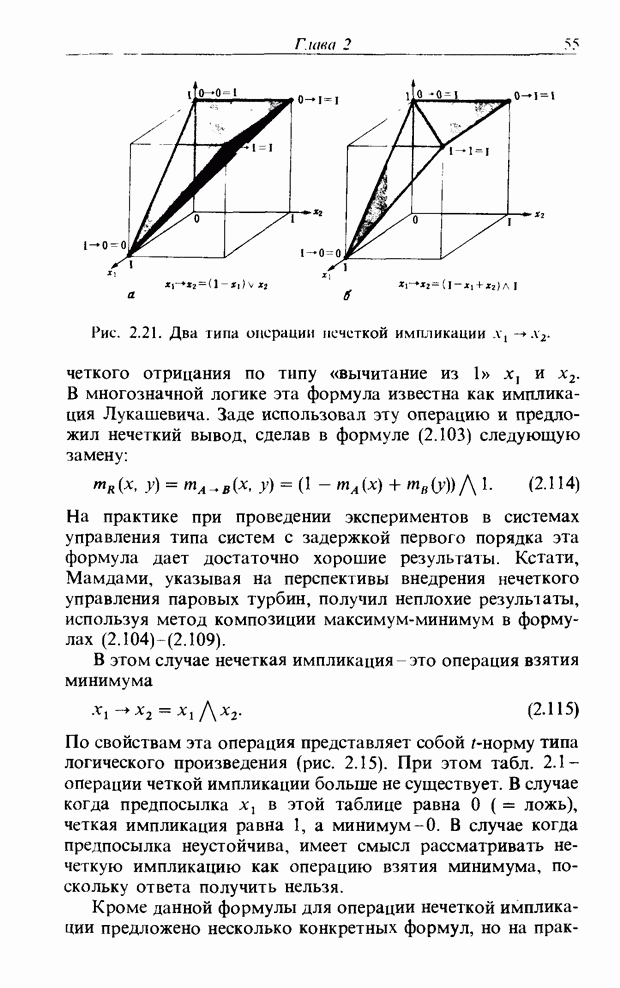
Оглавление
|























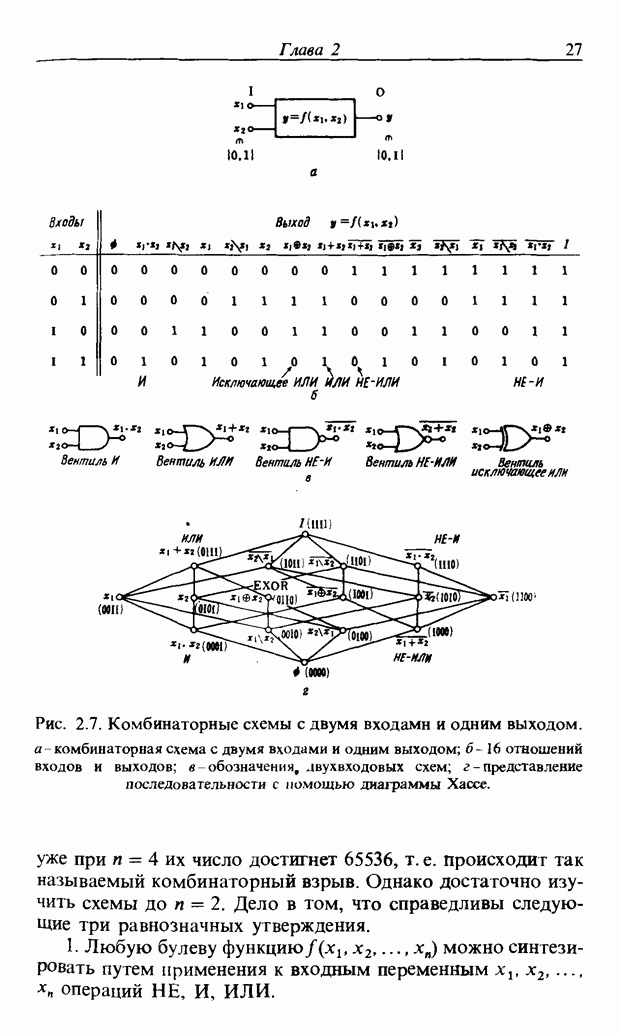














































































































































































































































































 месте локального выброса,
месте локального выброса,  других местах, локализовав тем самым положение выброса и сократив объем данных. Полученный образ называют двоичным спектральным временным образом (ДСВО) и используют его как особенность речи. Применение ДСВО при сопоставлении образов заключается в том, что для слова, выраженного с помощью ДСВО, рассматривается функция принадлежности, учитывающая то, как проявляются на ДСВО изменения частоты для разных людей и как происходят изменения во времени. Этот метод называют нечетким сопоставлением образов [30].
других местах, локализовав тем самым положение выброса и сократив объем данных. Полученный образ называют двоичным спектральным временным образом (ДСВО) и используют его как особенность речи. Применение ДСВО при сопоставлении образов заключается в том, что для слова, выраженного с помощью ДСВО, рассматривается функция принадлежности, учитывающая то, как проявляются на ДСВО изменения частоты для разных людей и как происходят изменения во времени. Этот метод называют нечетким сопоставлением образов [30].
 приходится 15 выборок. На рис. 3.54, а значение каждого элемента представлено восемью битами, в ДСВО (рис. 3.54, б) данные по 15 выборкам можно представить двумя байтами, что очень удобно Для ввода в компьютер.
приходится 15 выборок. На рис. 3.54, а значение каждого элемента представлено восемью битами, в ДСВО (рис. 3.54, б) данные по 15 выборкам можно представить двумя байтами, что очень удобно Для ввода в компьютер.
 и множество образов этих слов через
и множество образов этих слов через  Множество
Множество  -это обычное
-это обычное

 элементов, а множество X можно рассматривать как нечеткое множество, в котором
элементов, а множество X можно рассматривать как нечеткое множество, в котором  представляет различные образы слова
представляет различные образы слова  Таким образом можно определить множество функций принадлежности
Таким образом можно определить множество функций принадлежности  подобно тому, как определяется множество образов
подобно тому, как определяется множество образов  слова
слова  Рассматриваемое здесь нечеткое сопоставление образов заключается в следующем. При вводе неизвестного образа
Рассматриваемое здесь нечеткое сопоставление образов заключается в следующем. При вводе неизвестного образа  с использованием функции принадлежности М вычисляется степень сходства
с использованием функции принадлежности М вычисляется степень сходства  образов
образов  и
и  и результатом распознавания является слово j, такое что
и результатом распознавания является слово j, такое что

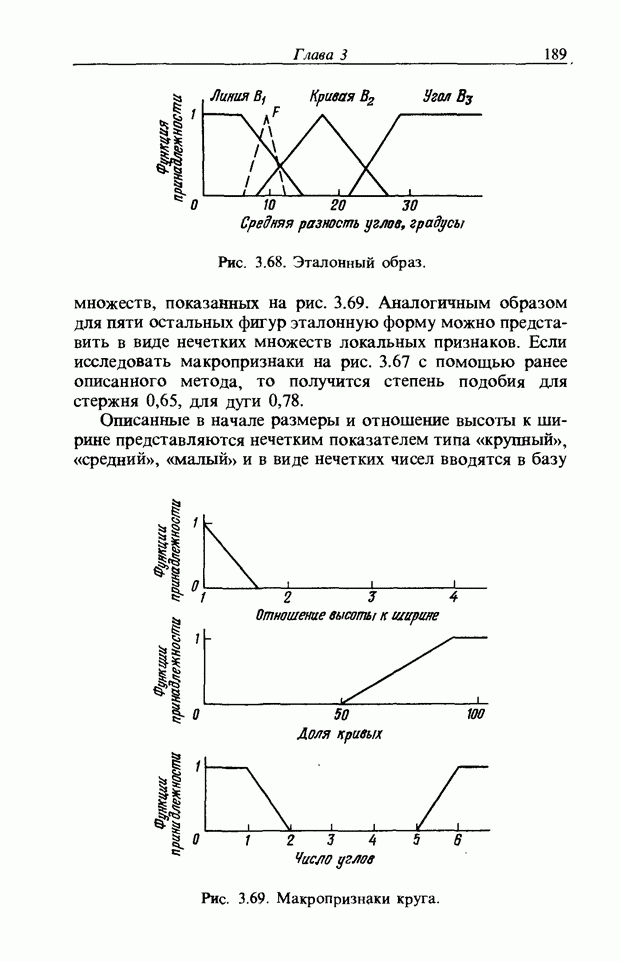
 Функция принадлежности должна иметь какое-то отношение к человеку, однако по причинам, изложенным в разд. 3.7.5, ее целесообразно приписать устройству распознавания. Поэтому, считая сходство главной целью, приняли следующую последовательность построения функции принадлежности.
Функция принадлежности должна иметь какое-то отношение к человеку, однако по причинам, изложенным в разд. 3.7.5, ее целесообразно приписать устройству распознавания. Поэтому, считая сходство главной целью, приняли следующую последовательность построения функции принадлежности.
 сжатием он дает существенно меньший объем вычислений. Пример функции принадлежности, полученный в соответствии с этой процедурой, показан на рис. 3.55. Объектом распознавания является слово START. Прежде всего выполняется согласование по длине и совмещение левого ДСВО с соседним. Соответствующие элементы при этом суммируются. Затем прибавляется следующий ДСВО; такой процесс повторяется до получения образа справа, который используется как функция принадлежности. Обычная функция принадлежности принимает значения от 0 до 1, однако в данном случае она представлена в виде целых чисел со значениями от 0 до 15, т.е. по четыре бита на элемент.
сжатием он дает существенно меньший объем вычислений. Пример функции принадлежности, полученный в соответствии с этой процедурой, показан на рис. 3.55. Объектом распознавания является слово START. Прежде всего выполняется согласование по длине и совмещение левого ДСВО с соседним. Соответствующие элементы при этом суммируются. Затем прибавляется следующий ДСВО; такой процесс повторяется до получения образа справа, который используется как функция принадлежности. Обычная функция принадлежности принимает значения от 0 до 1, однако в данном случае она представлена в виде целых чисел со значениями от 0 до 15, т.е. по четыре бита на элемент.
 - ДСВО неизвестного входного голоса. Если с помощью
- ДСВО неизвестного входного голоса. Если с помощью

 определить его степени принадлежности ко всем нечетким множествам, то можно узнать, какое это слово. Однако использование введенной выше функции принадлежности приводит к ряду проблем. Поясним это с помощью рис. 3.56.
определить его степени принадлежности ко всем нечетким множествам, то можно узнать, какое это слово. Однако использование введенной выше функции принадлежности приводит к ряду проблем. Поясним это с помощью рис. 3.56.
 можно записать
можно записать



 образа у к
образа у к  будет иметь вид
будет иметь вид

 . С другой стороны, функция на рис. 3.56, в принадлежит к типу функций с одним локальным выбросом, что свойственно согласным звукам. Ее максимум равен 1. Если определить по формуле (3.34) степень принадлежности образа рис 3.56, а к образу
. С другой стороны, функция на рис. 3.56, в принадлежит к типу функций с одним локальным выбросом, что свойственно согласным звукам. Ее максимум равен 1. Если определить по формуле (3.34) степень принадлежности образа рис 3.56, а к образу  определенному через функцию принадлежности на рис. 3.56, в, то также получим значение, почти равное 1. Возникает противоречие: образ на рис. 3.56, а обладает одинаковым сходством и с
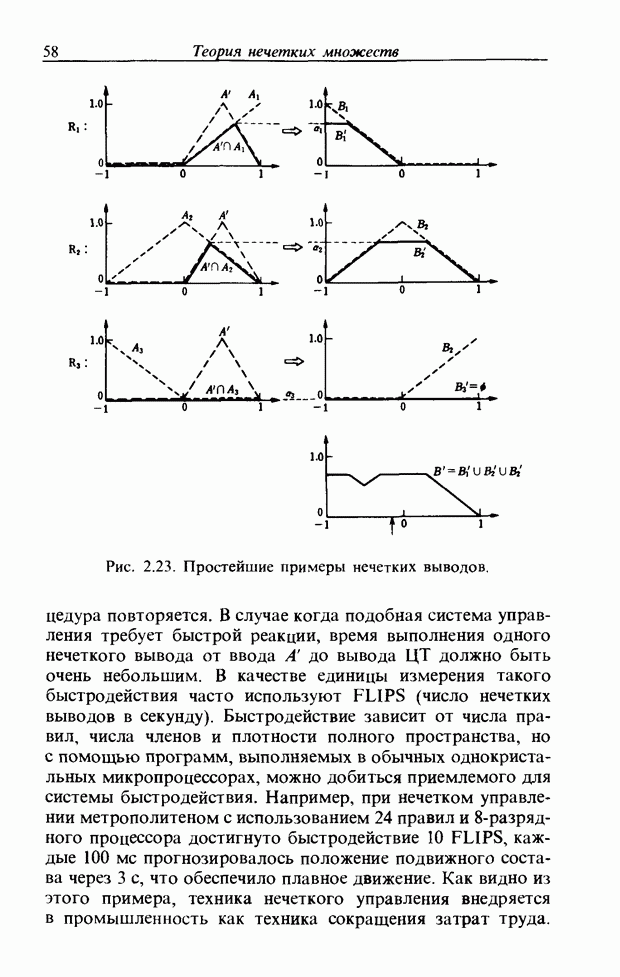
определенному через функцию принадлежности на рис. 3.56, в, то также получим значение, почти равное 1. Возникает противоречие: образ на рис. 3.56, а обладает одинаковым сходством и с  Поэтому определяем инверсную степень принадлежности
Поэтому определяем инверсную степень принадлежности

 -функция принадлежности, представляющая известный образ дополнительного множества j. За счет введения формулы (3.35) инверсная степень принадлежности для рис. 3.56, а и в становится большой и появляется возможность выделить близость рис. 3.56, а к б.
-функция принадлежности, представляющая известный образ дополнительного множества j. За счет введения формулы (3.35) инверсная степень принадлежности для рис. 3.56, а и в становится большой и появляется возможность выделить близость рис. 3.56, а к б.

 стоящее в числителе этой формулы, будет возрастать с увеличением числа локальных выбросов в у, но за счет того, что в знаменателе стоит величина
стоящее в числителе этой формулы, будет возрастать с увеличением числа локальных выбросов в у, но за счет того, что в знаменателе стоит величина  которая, как и
которая, как и  легко принимает большие значения при увеличении числа локальных выбросов, нормализация не требуется.
легко принимает большие значения при увеличении числа локальных выбросов, нормализация не требуется.


 обозначает произведение элементов
обозначает произведение элементов  и у, а
и у, а  - логическое произведение
- логическое произведение  и у уровня а, т. е.
и у уровня а, т. е.

 в противном случае.
в противном случае.

 , правого -
, правого -  .
.