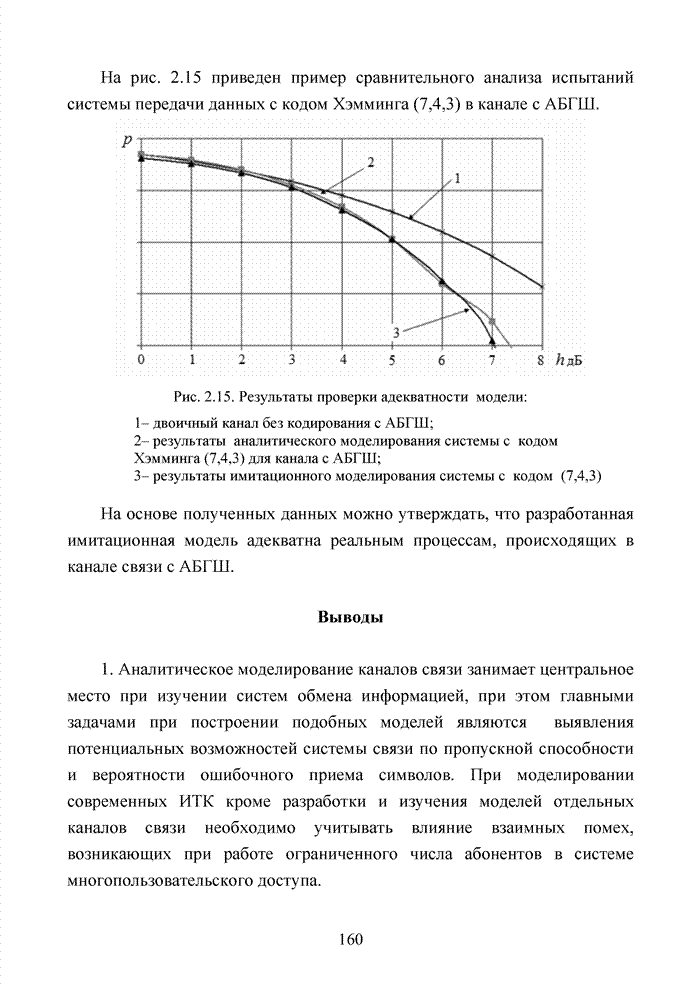
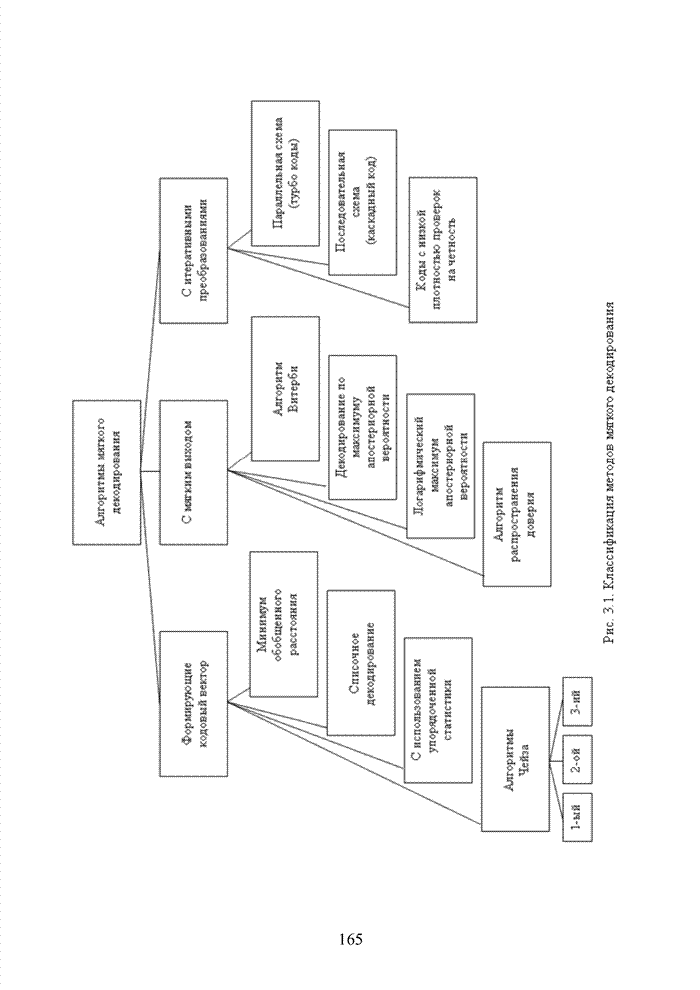
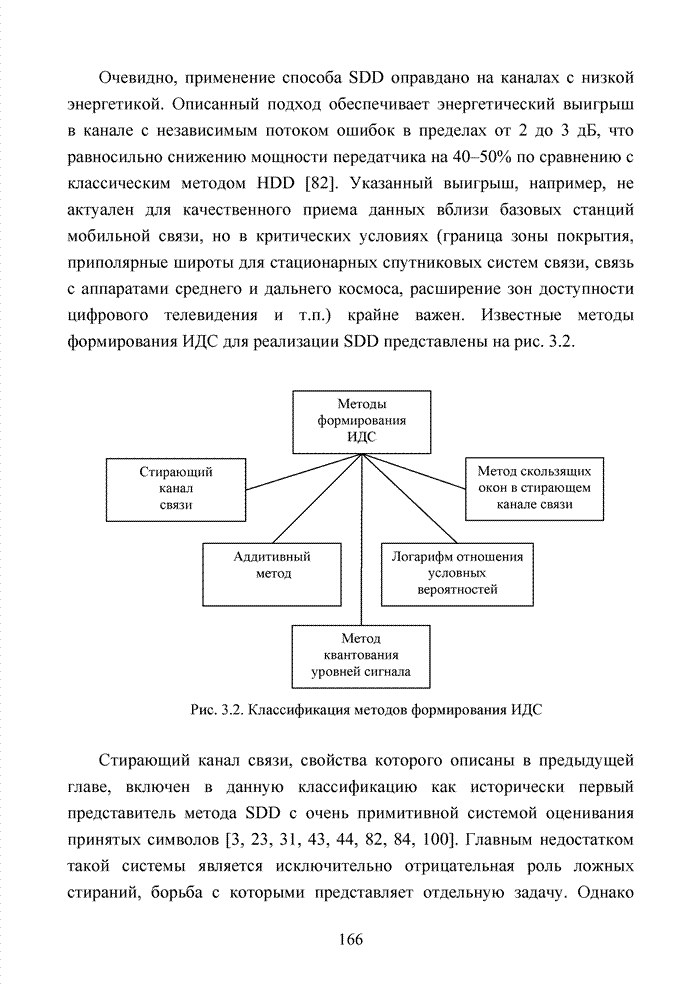
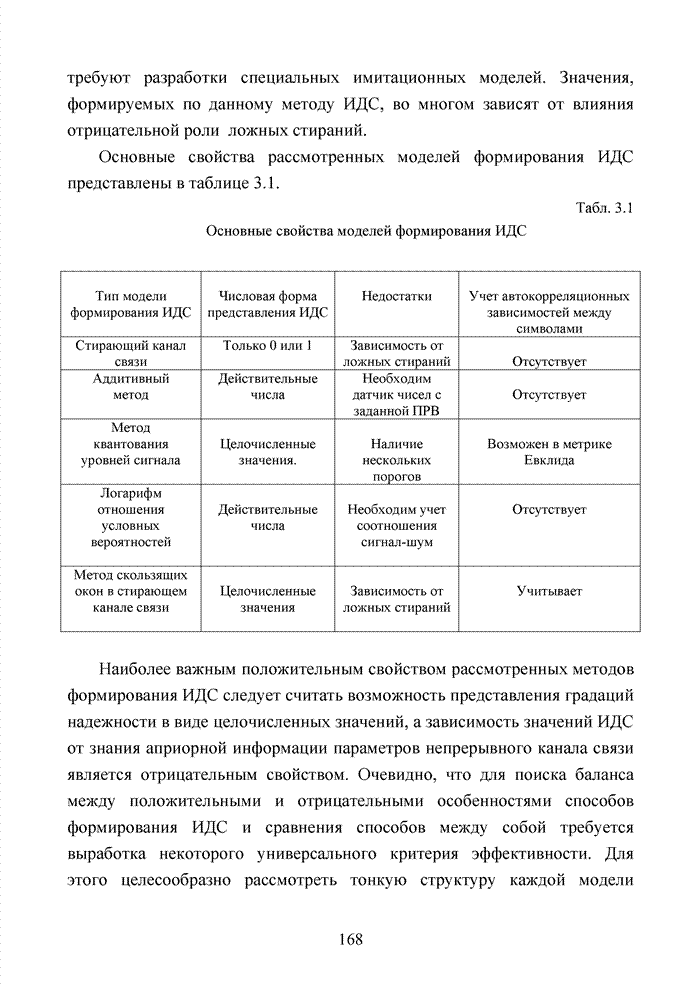
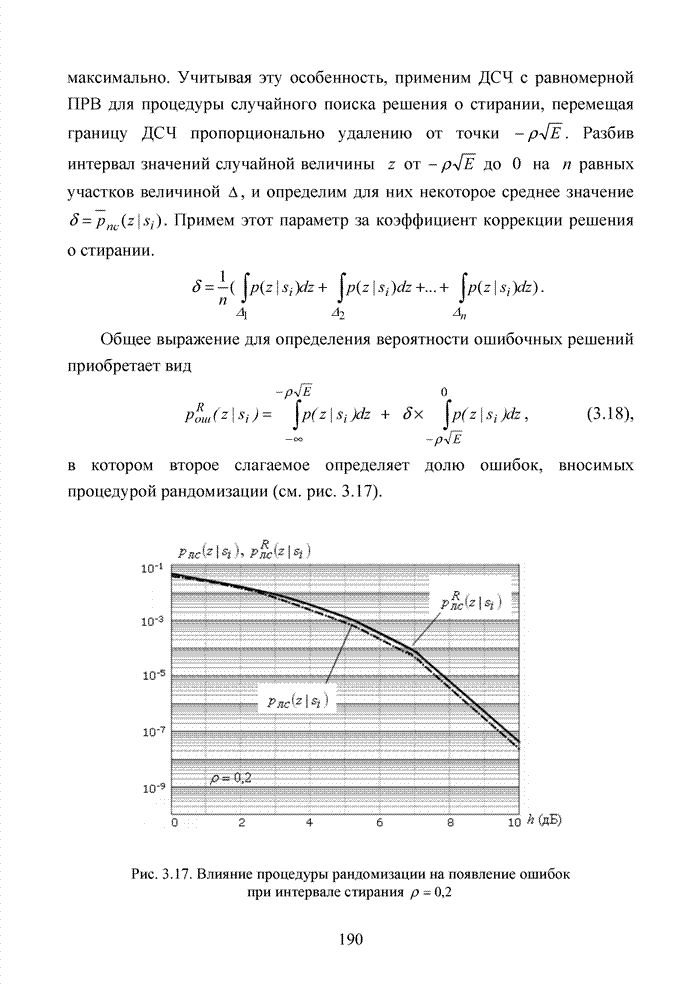
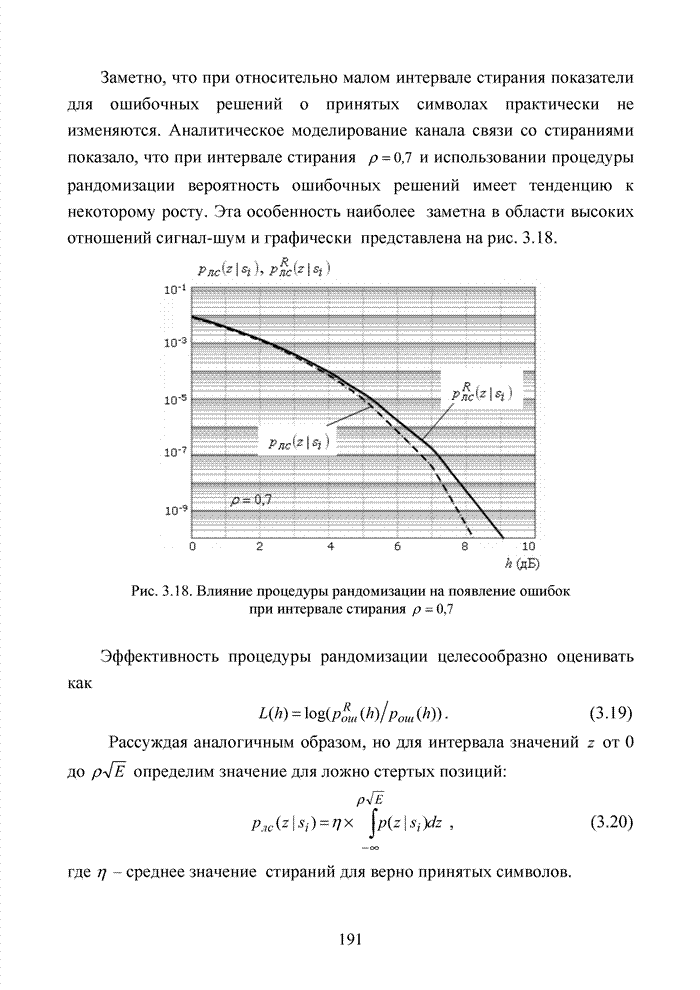
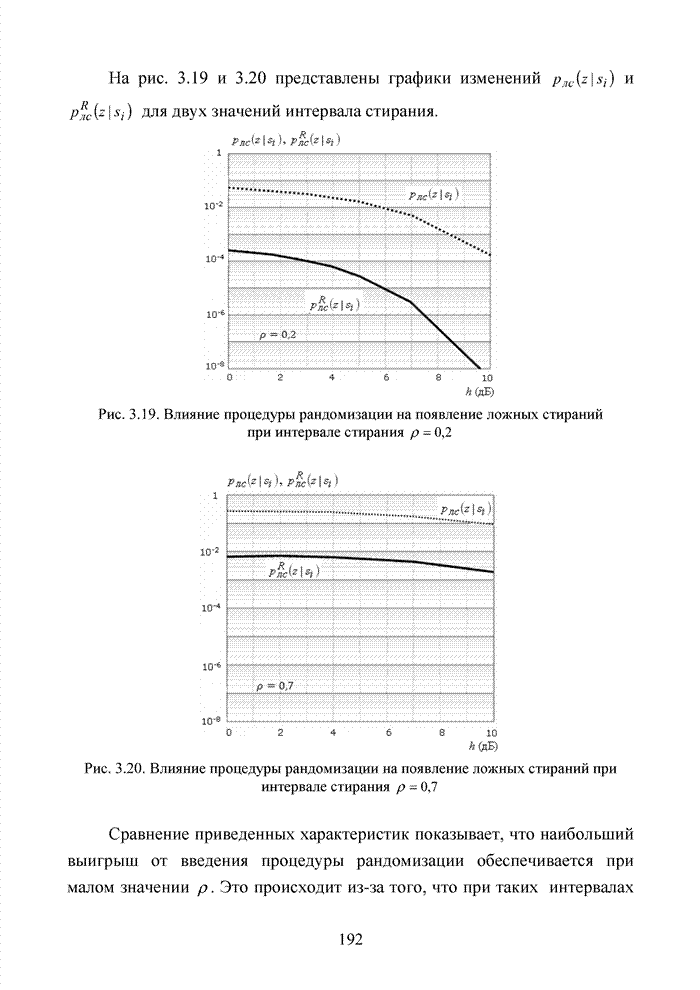
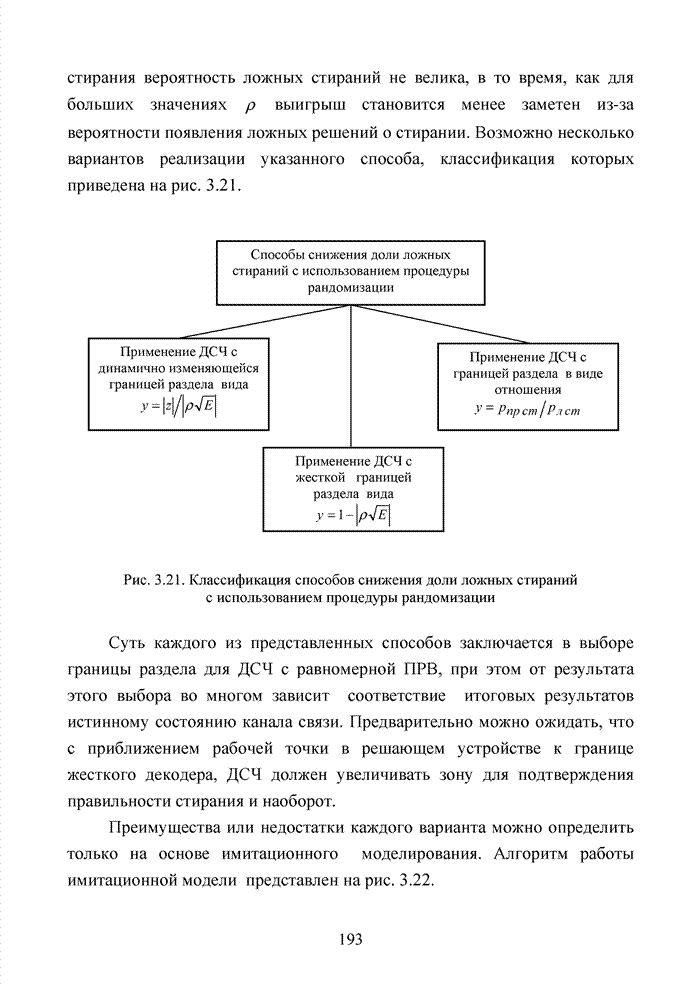
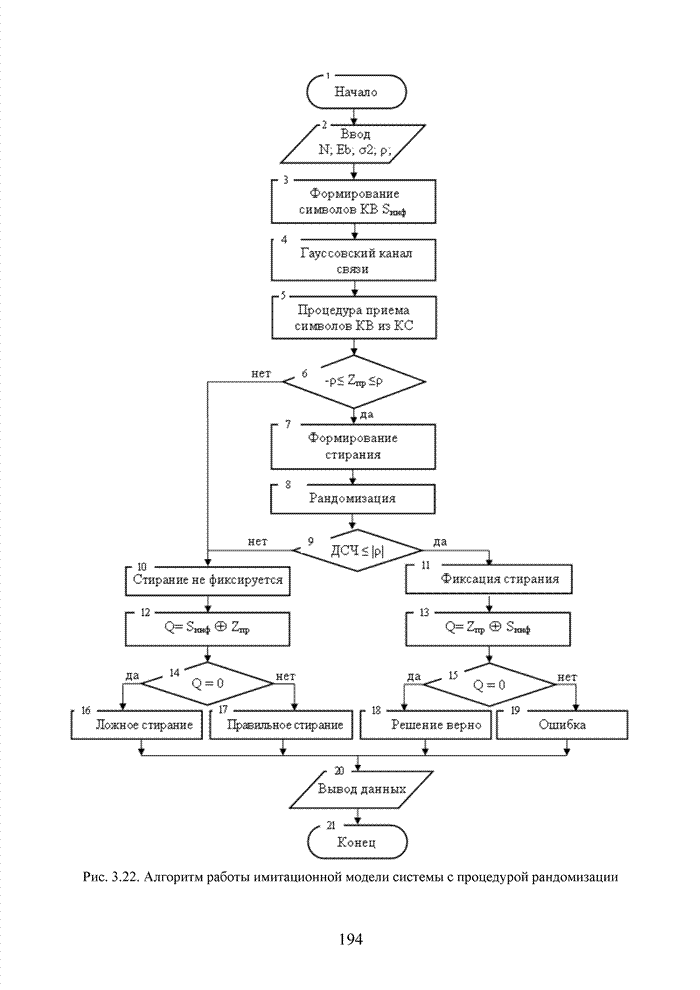
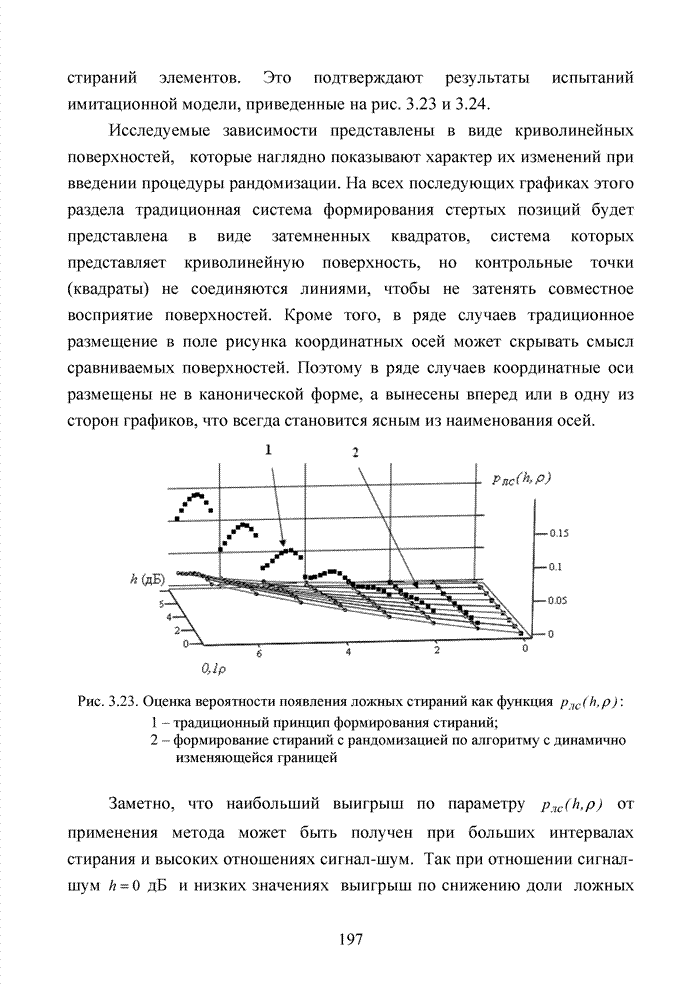
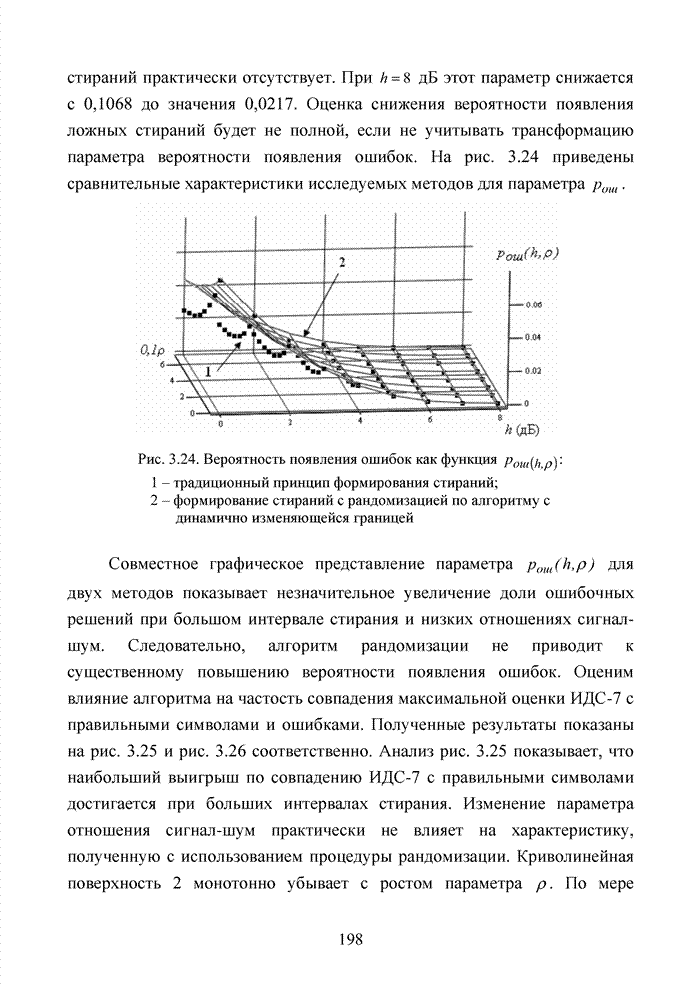
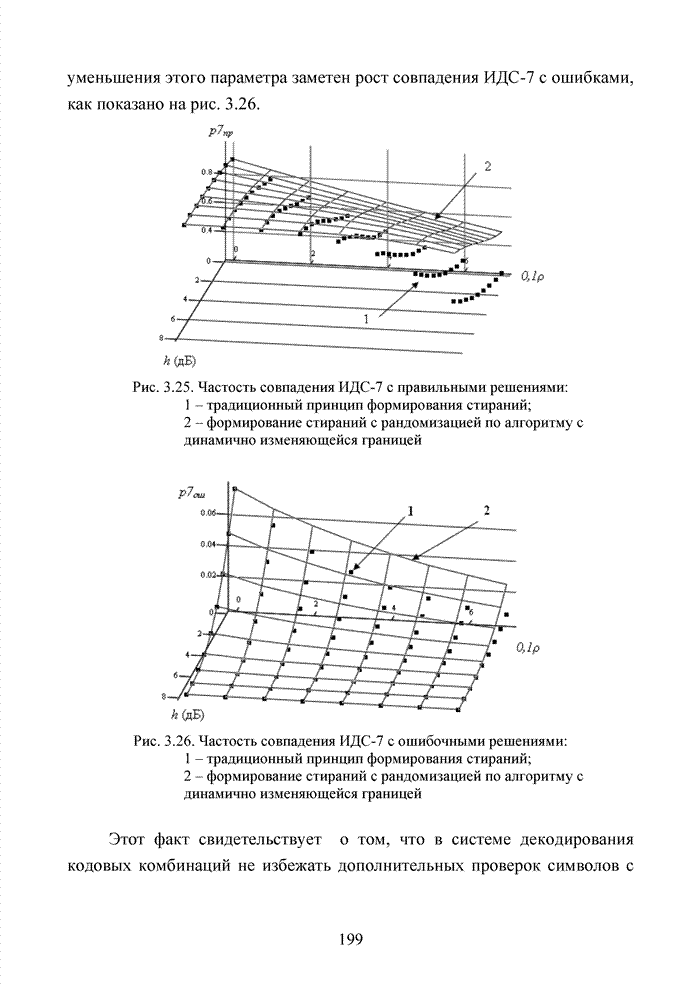
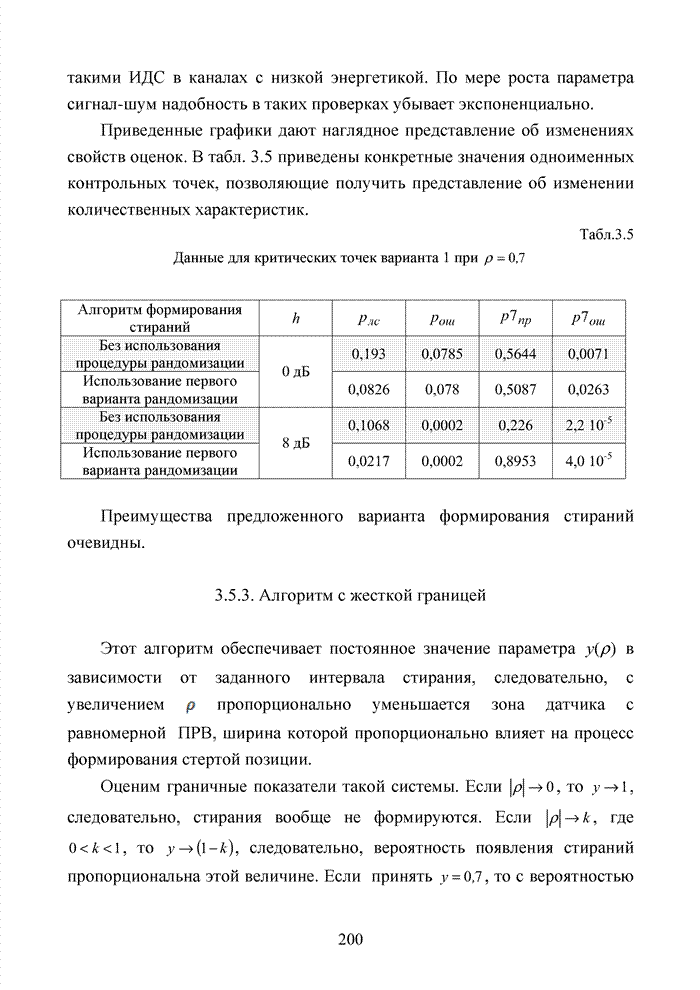
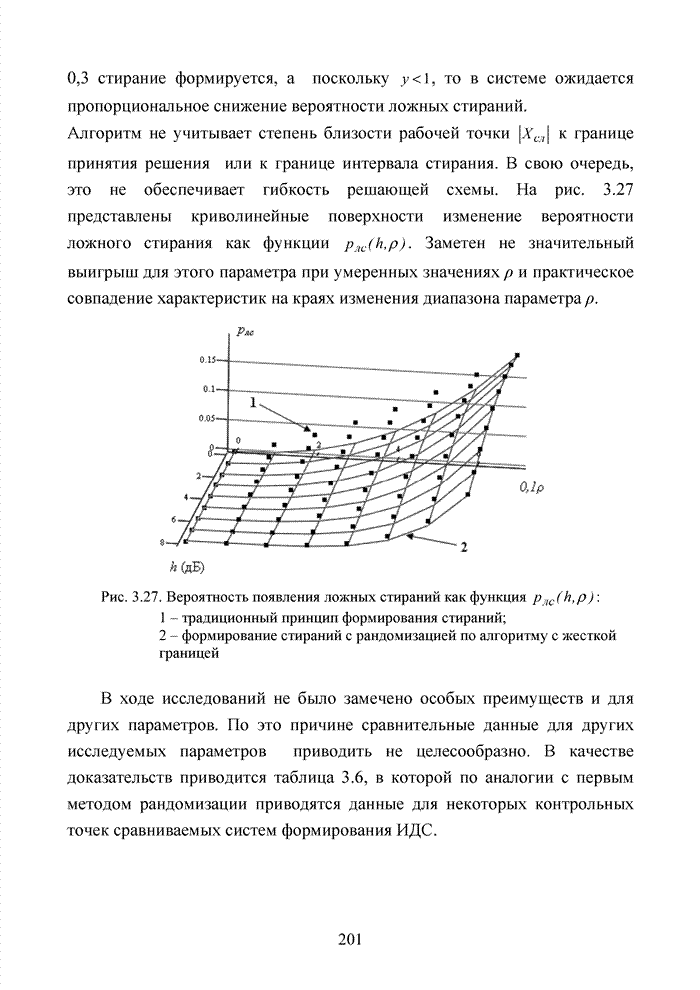
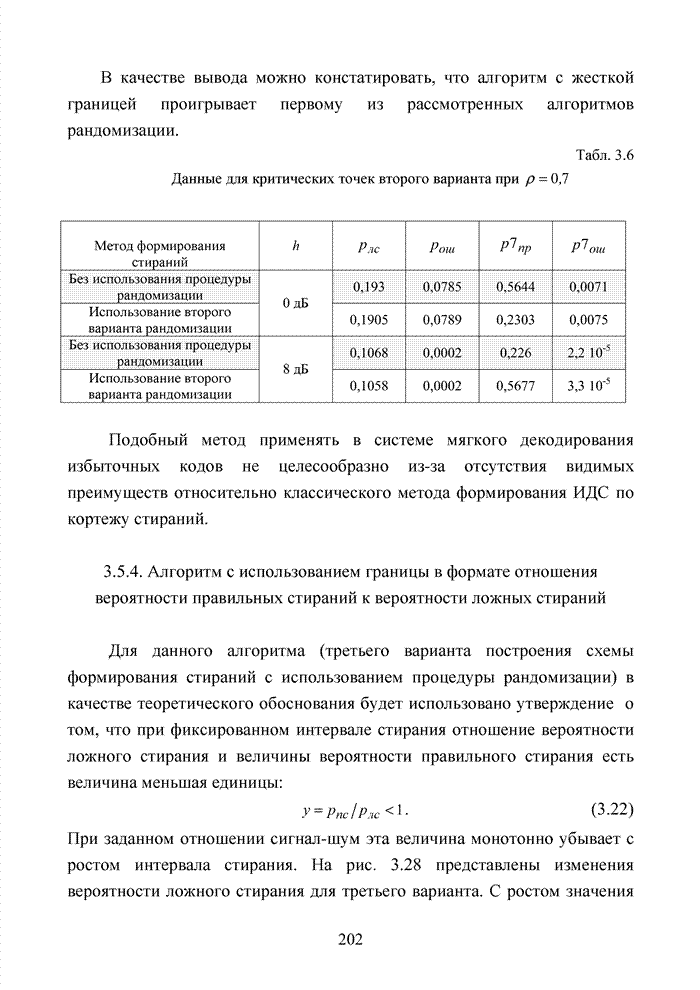
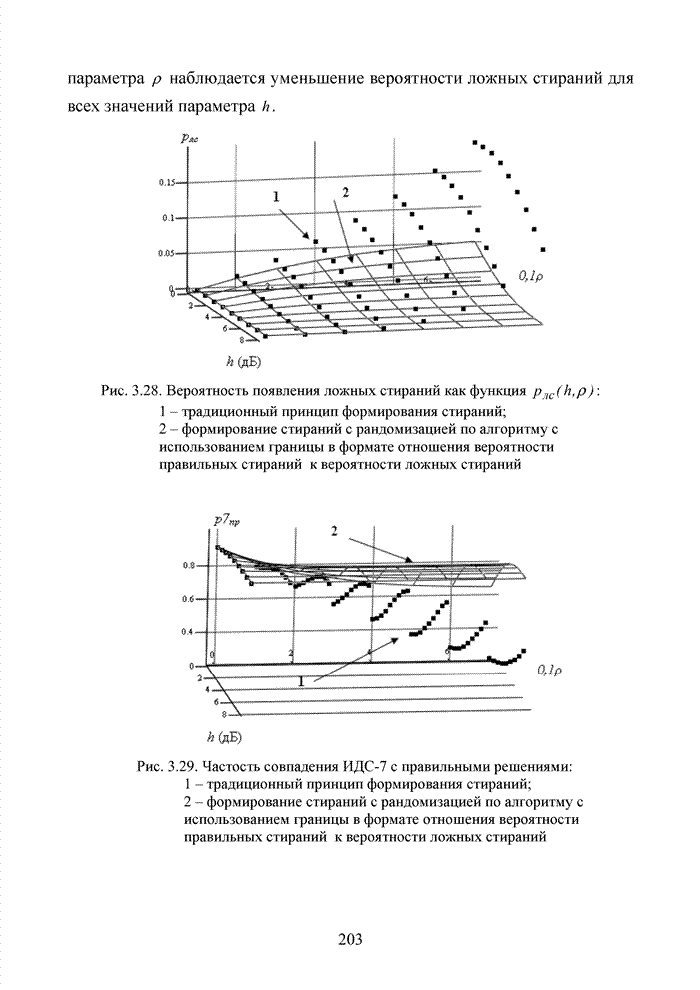
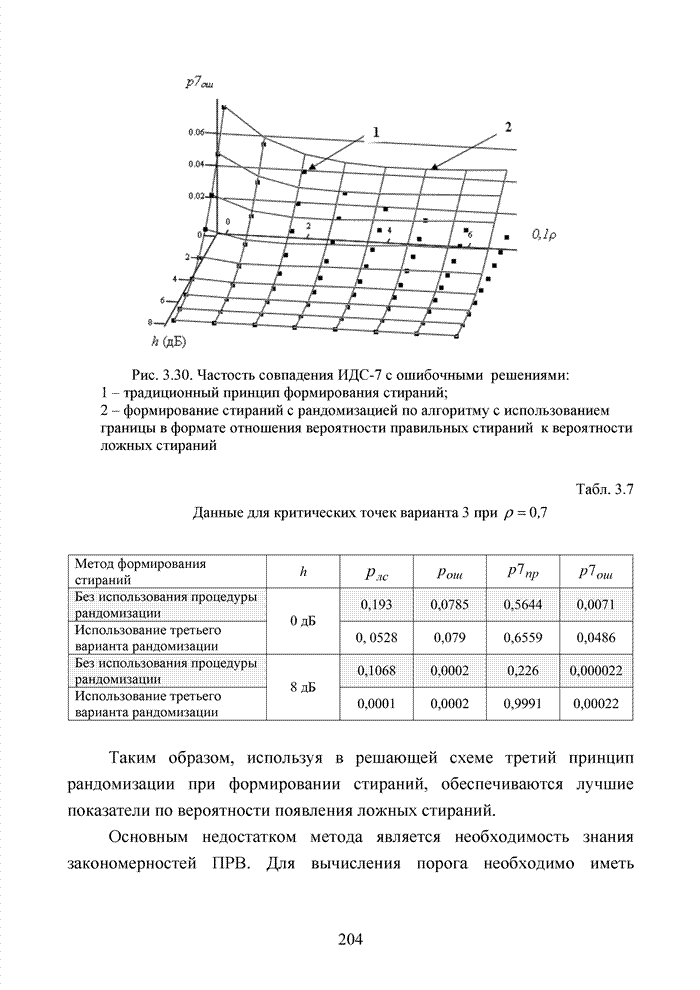
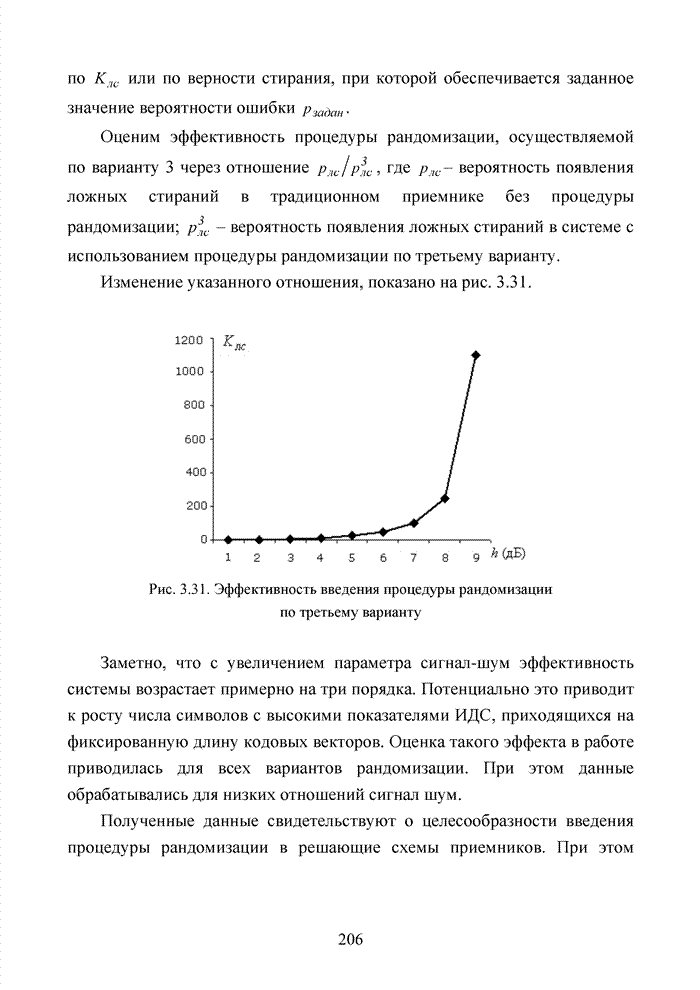
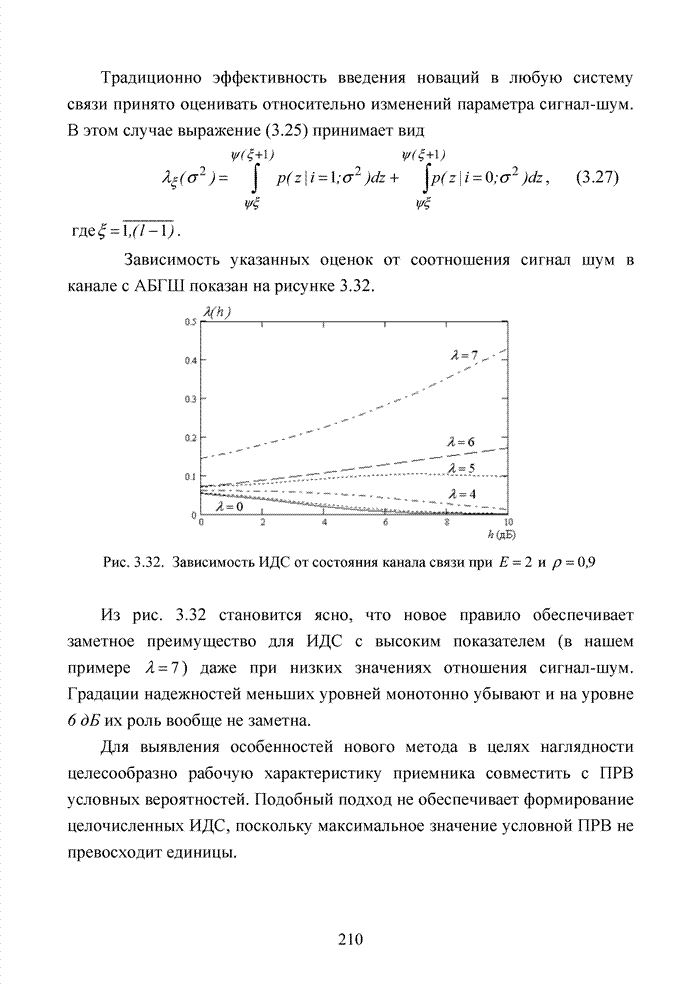
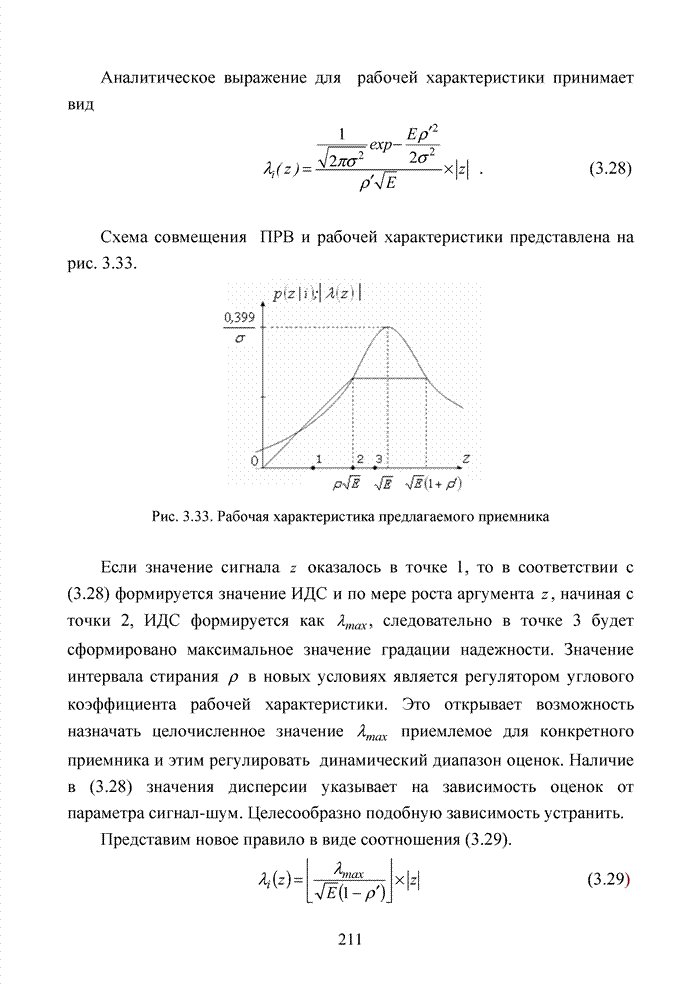
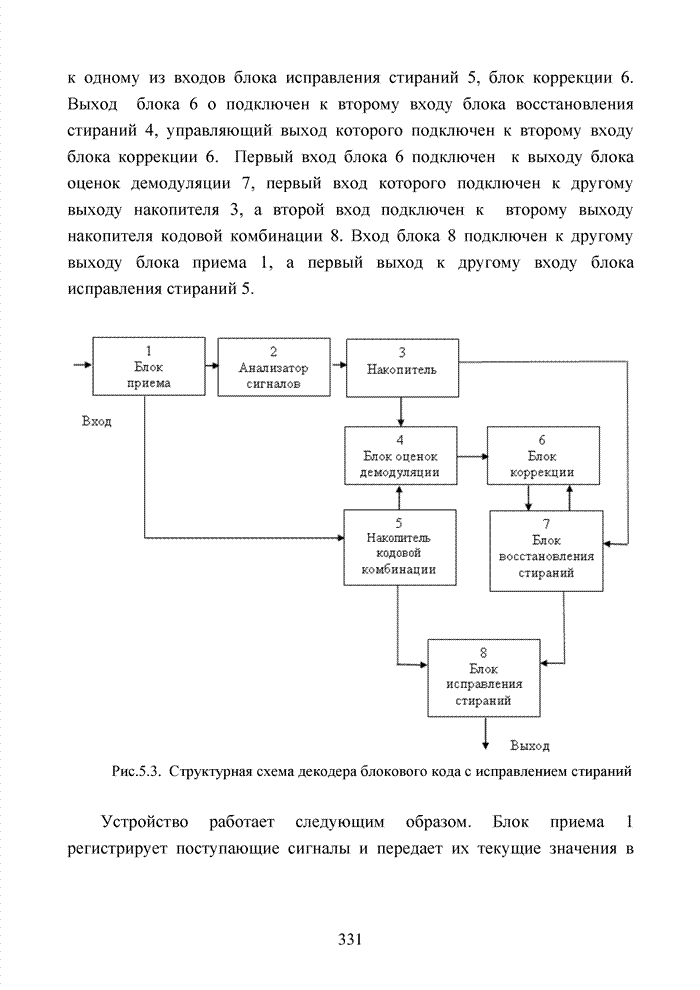
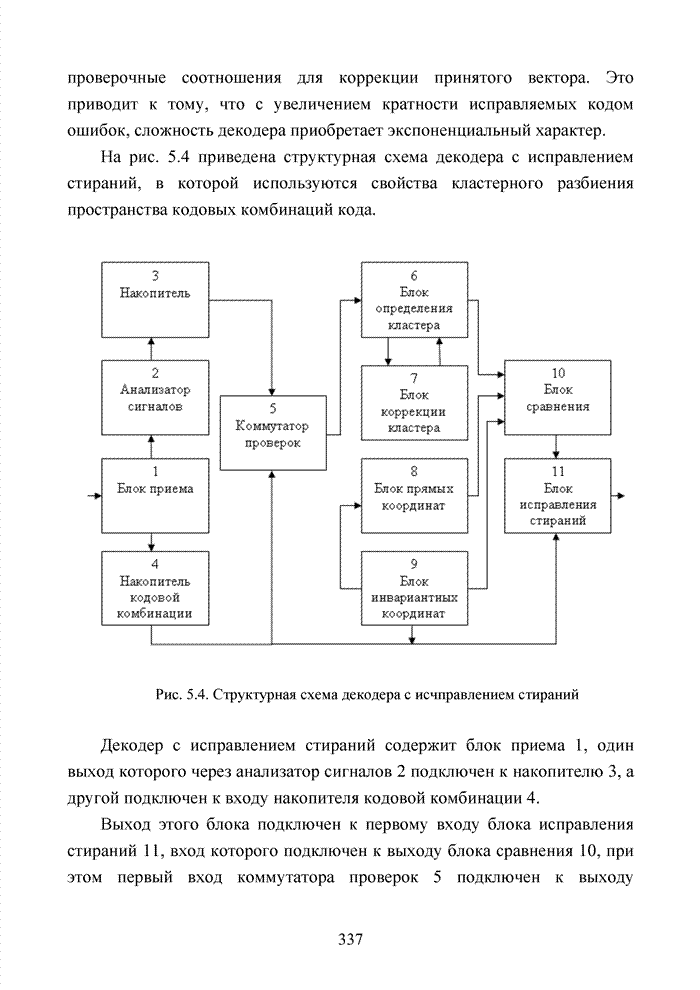
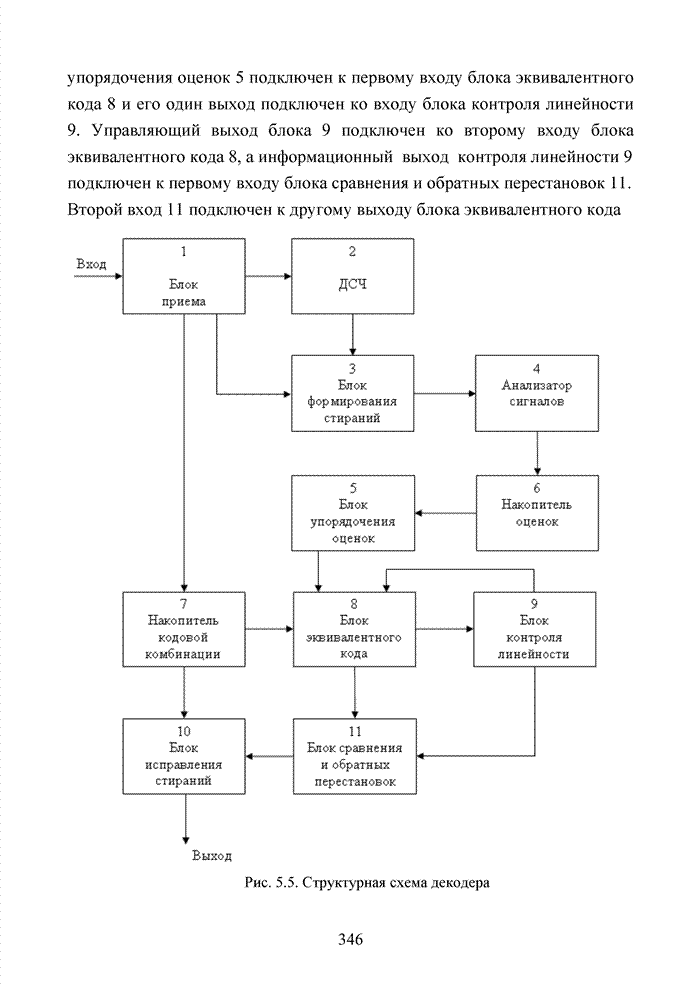
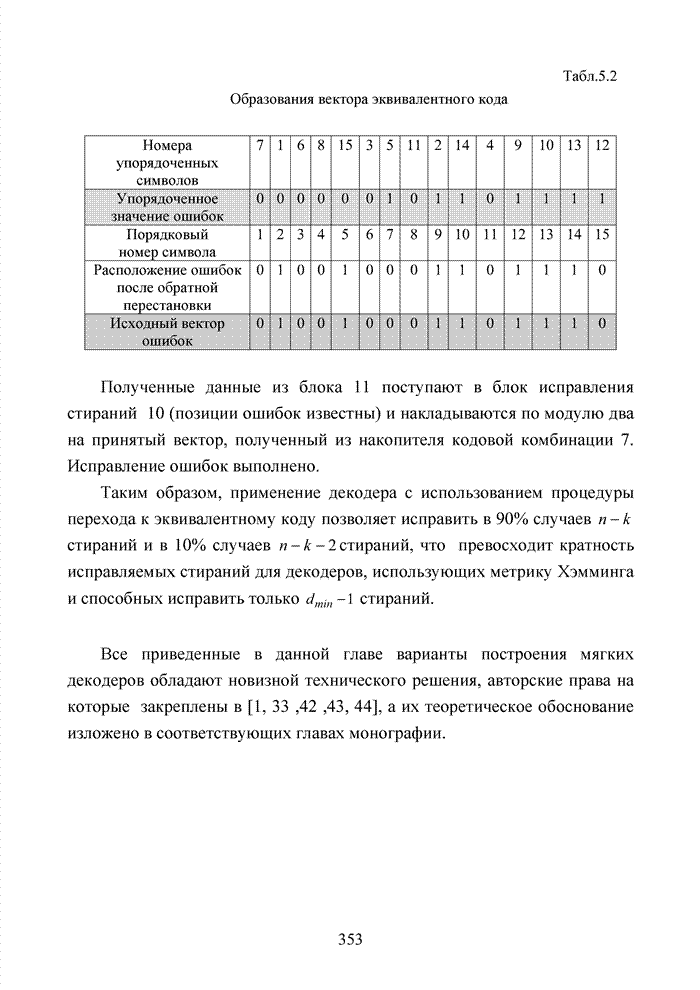
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
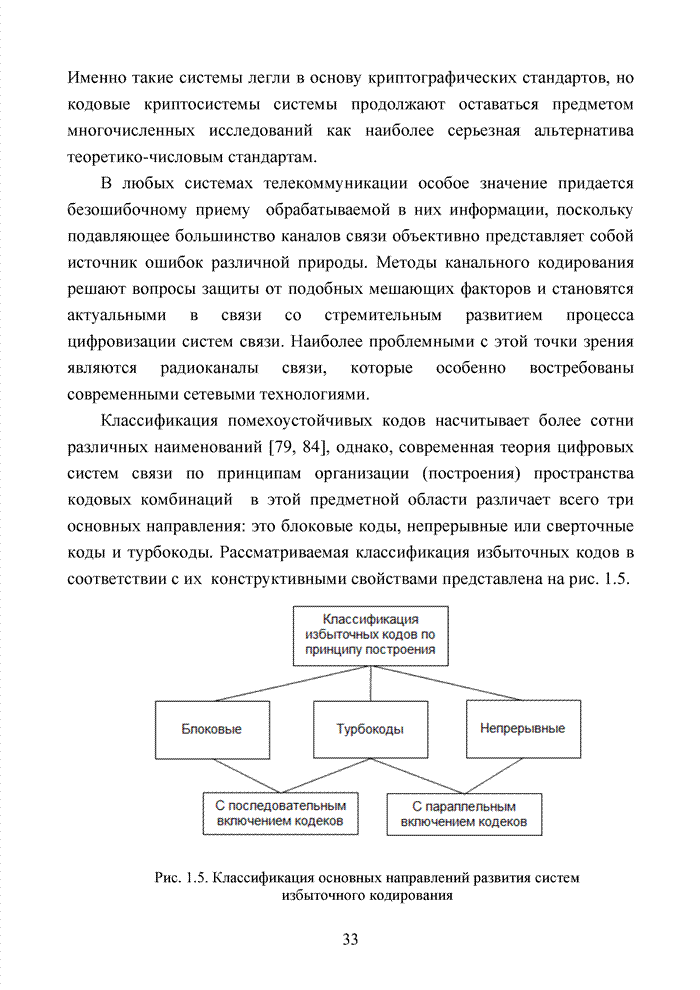
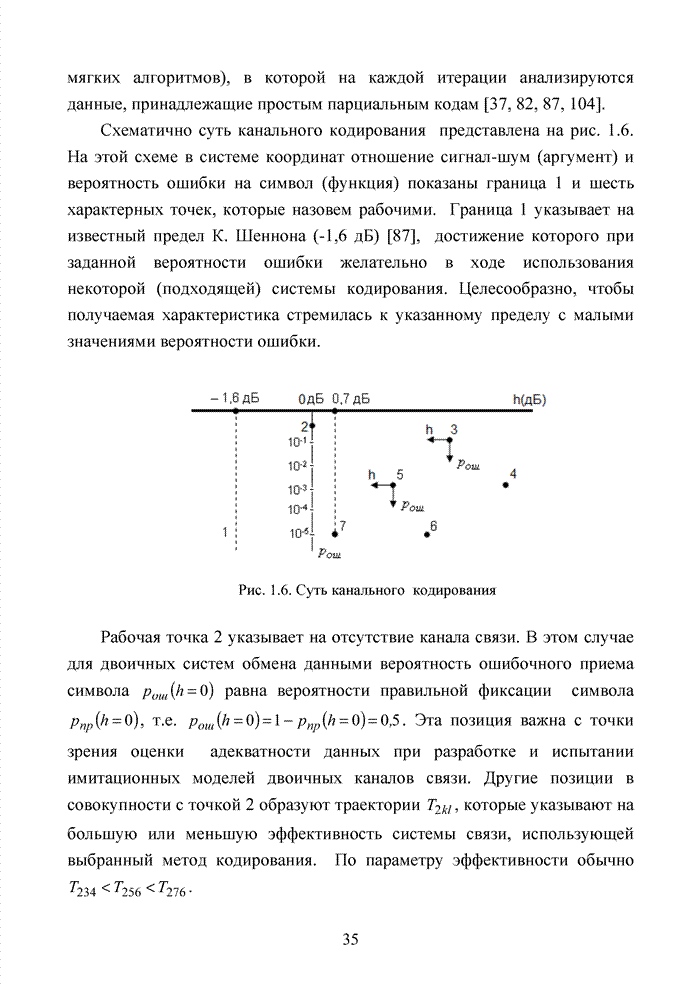
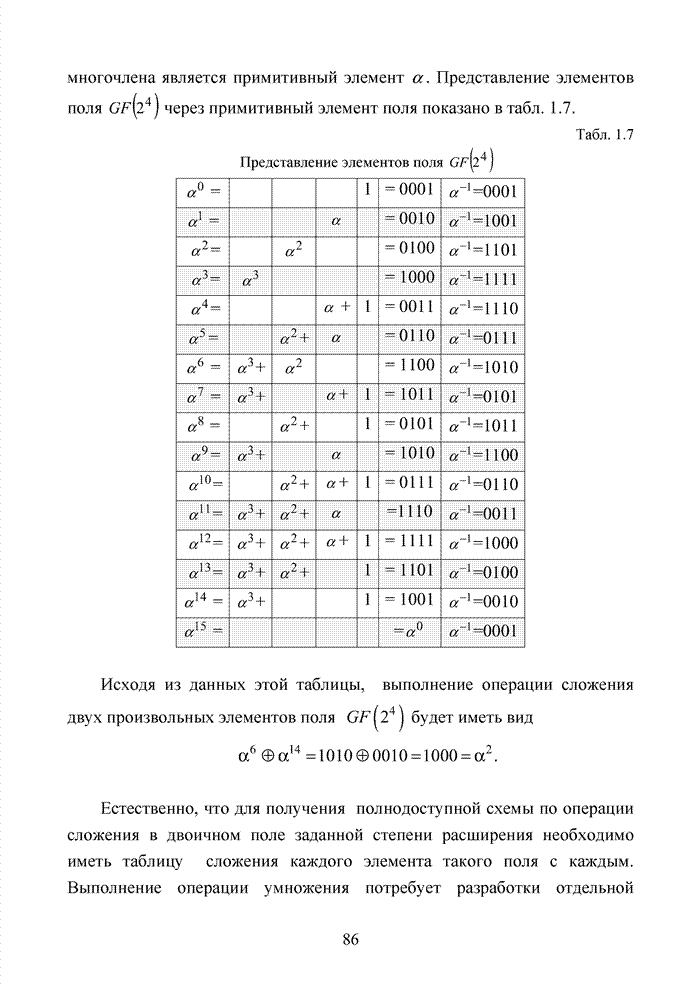
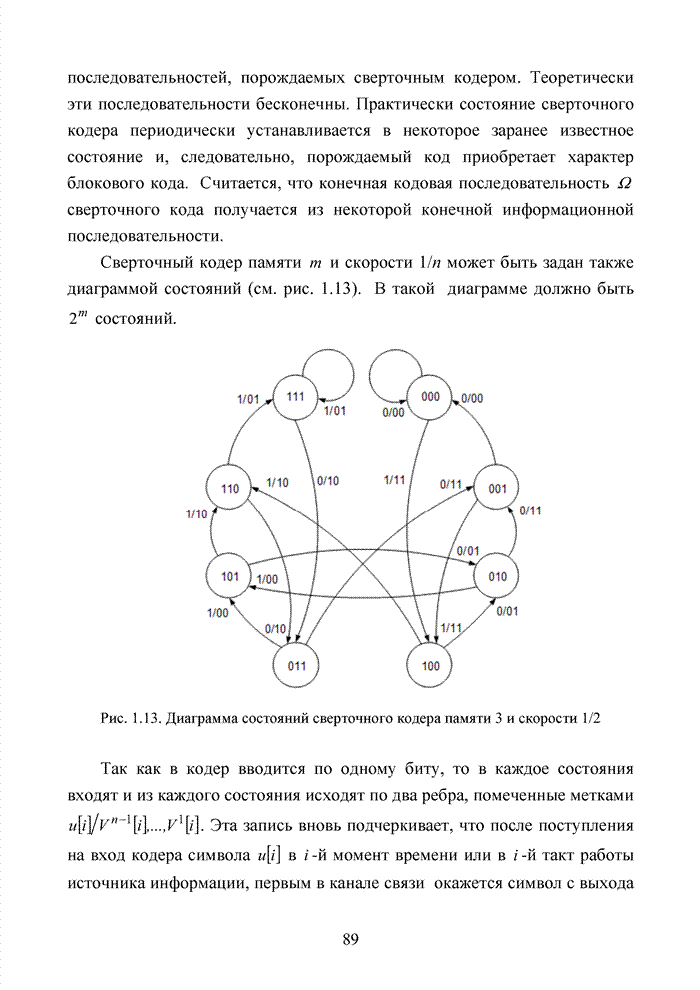
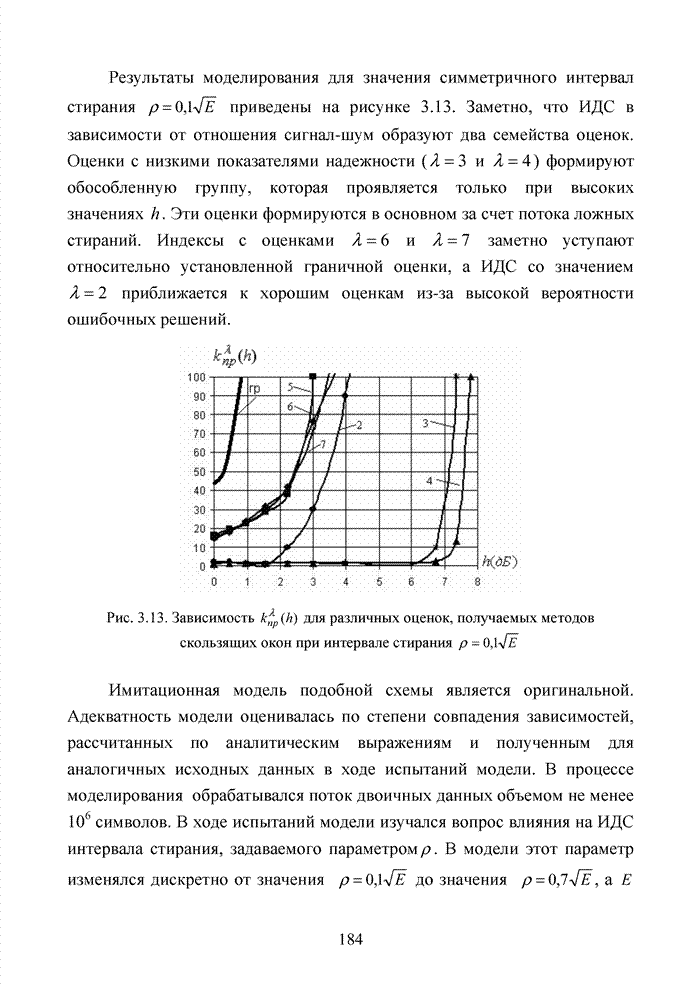
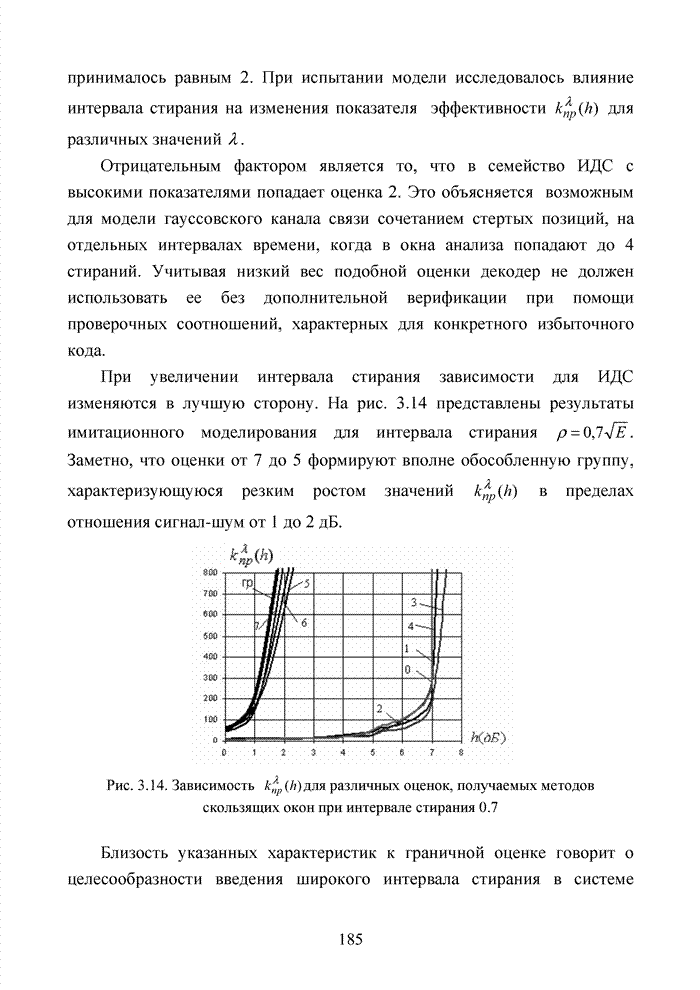
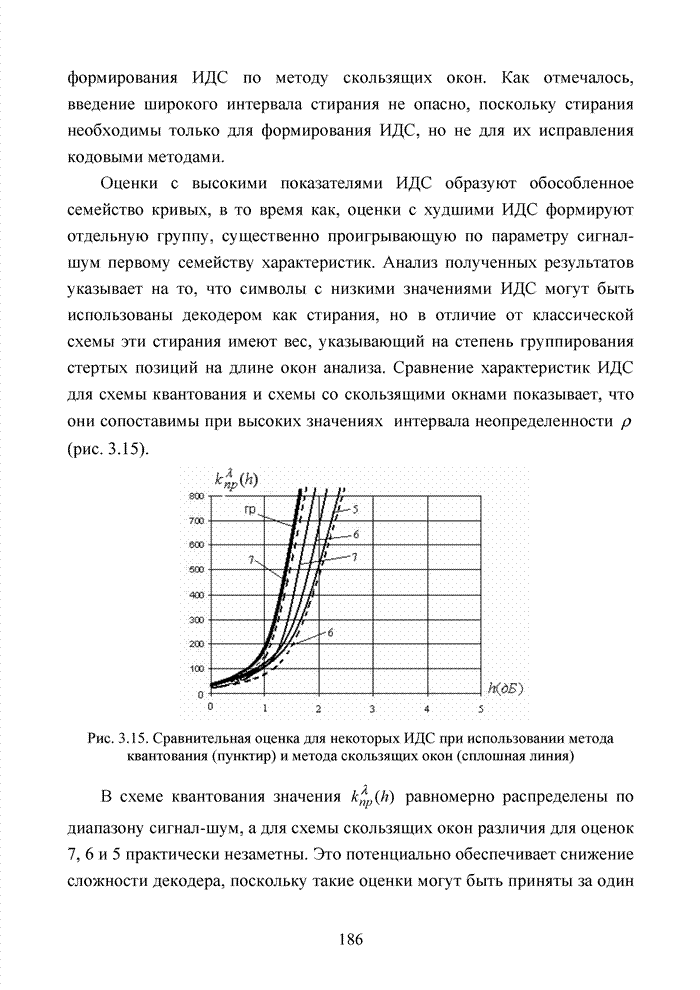
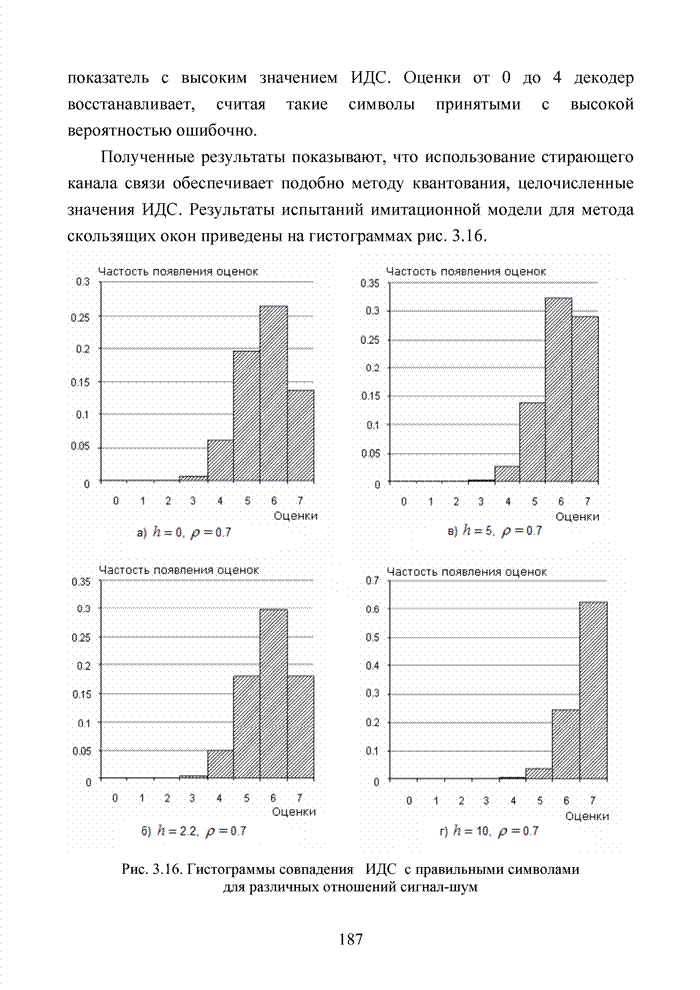
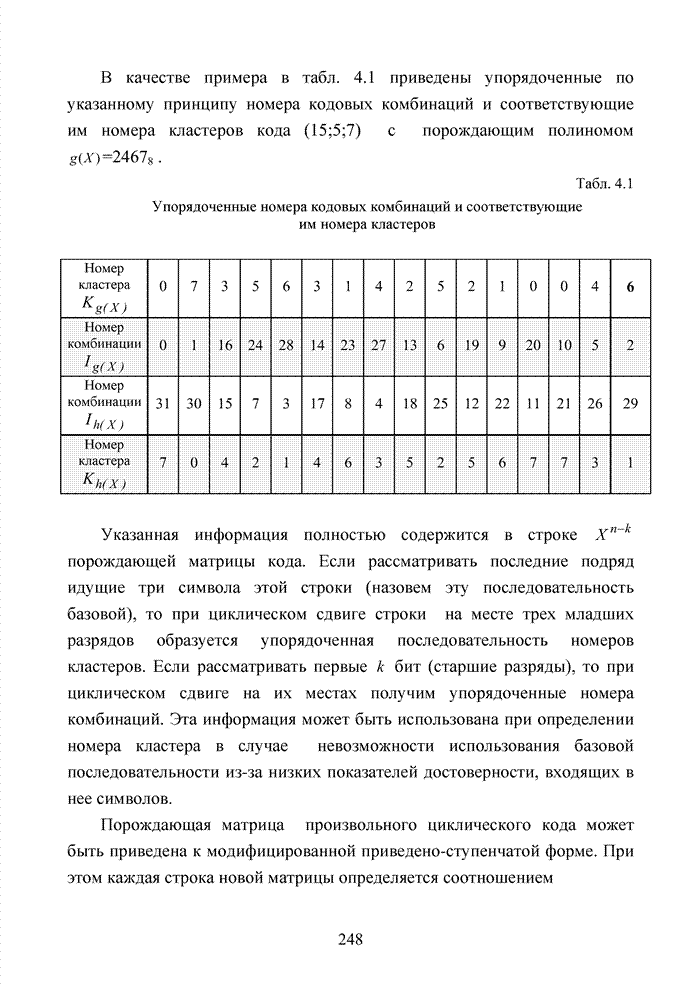
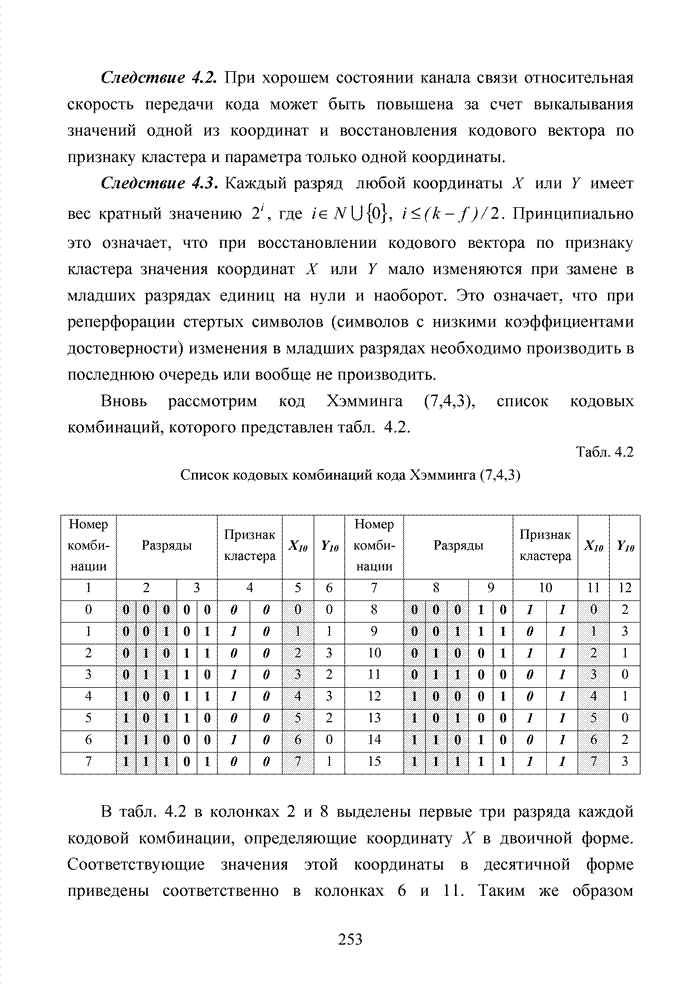
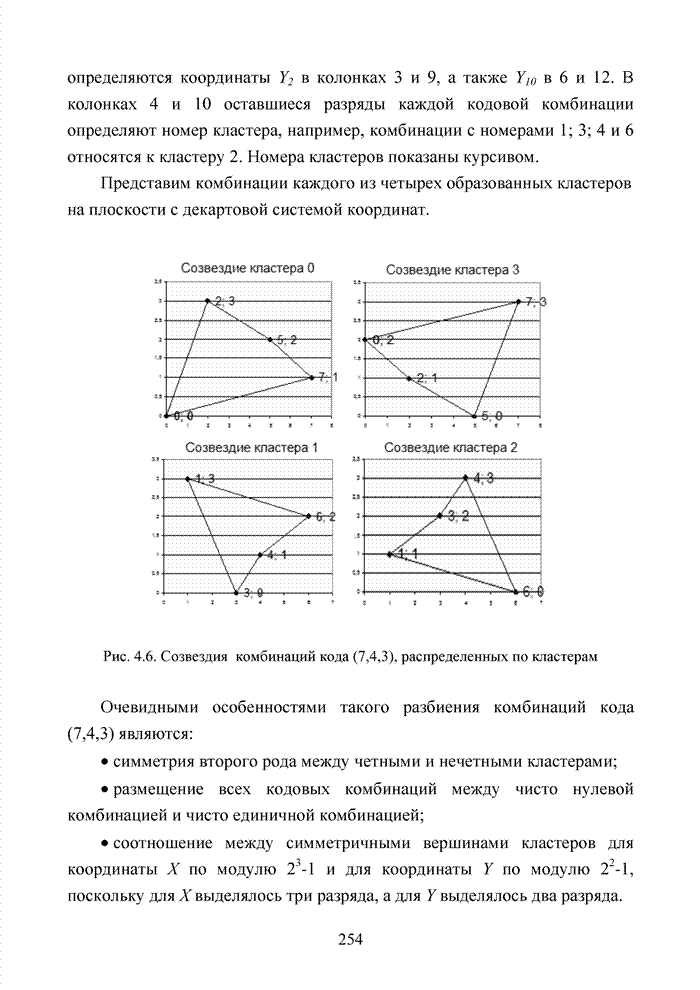
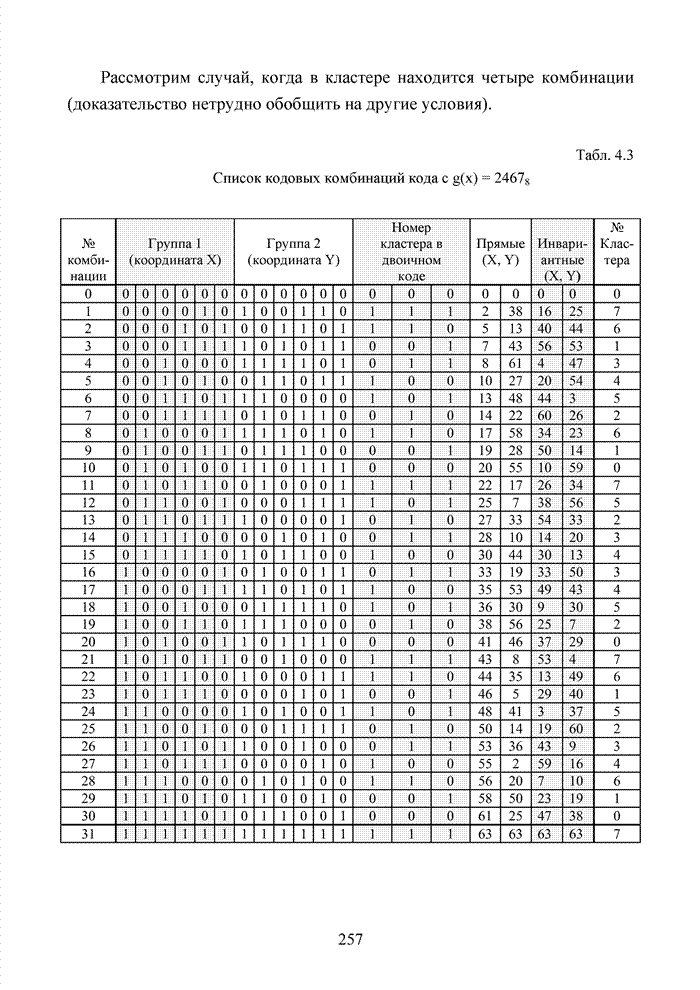
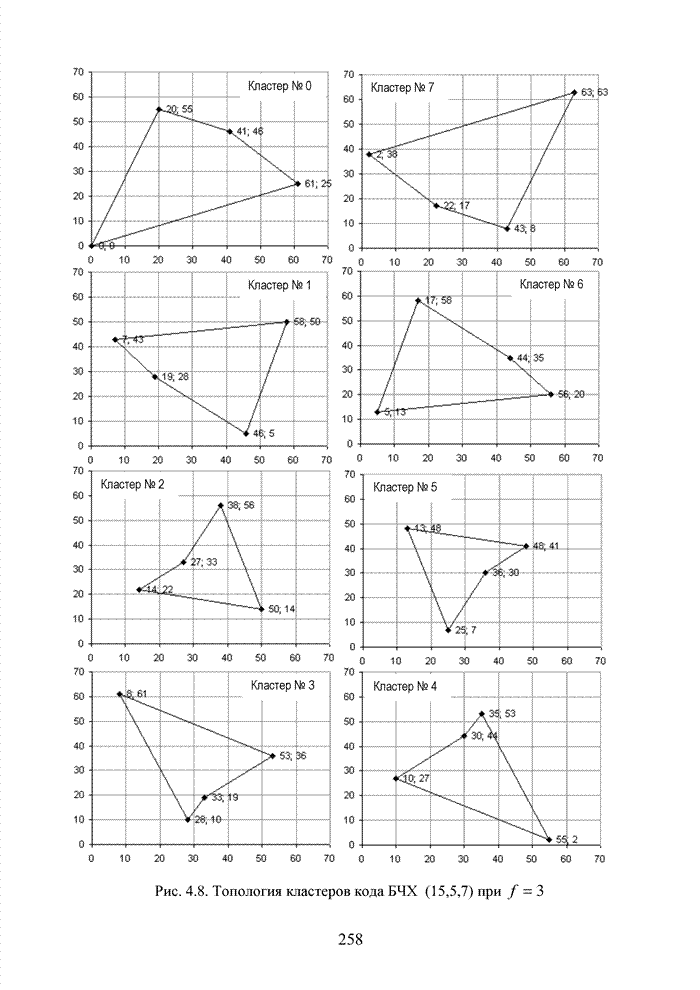
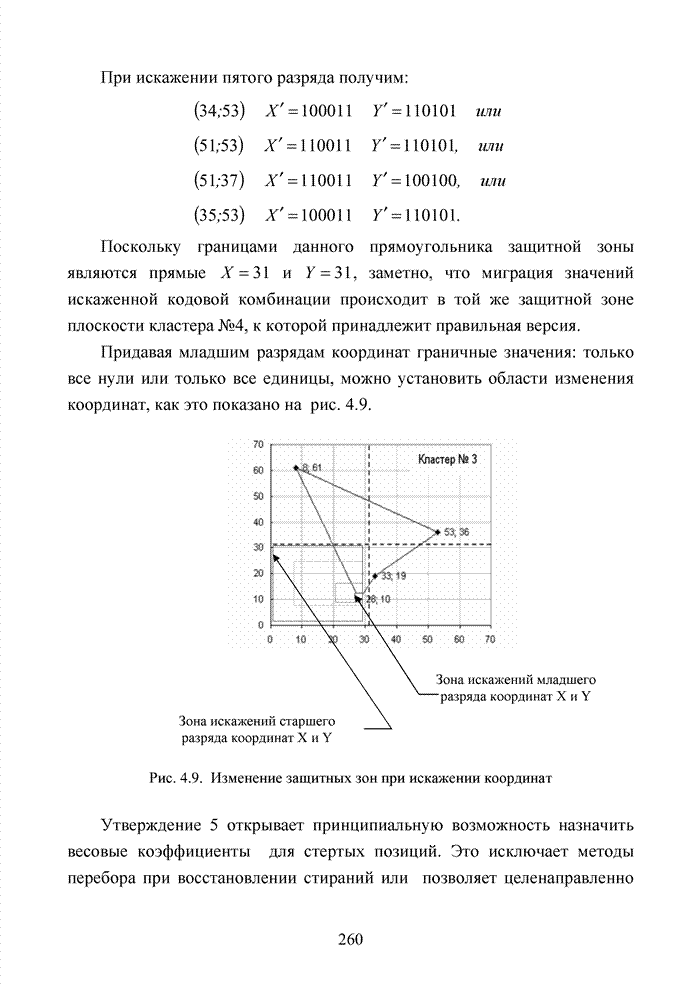
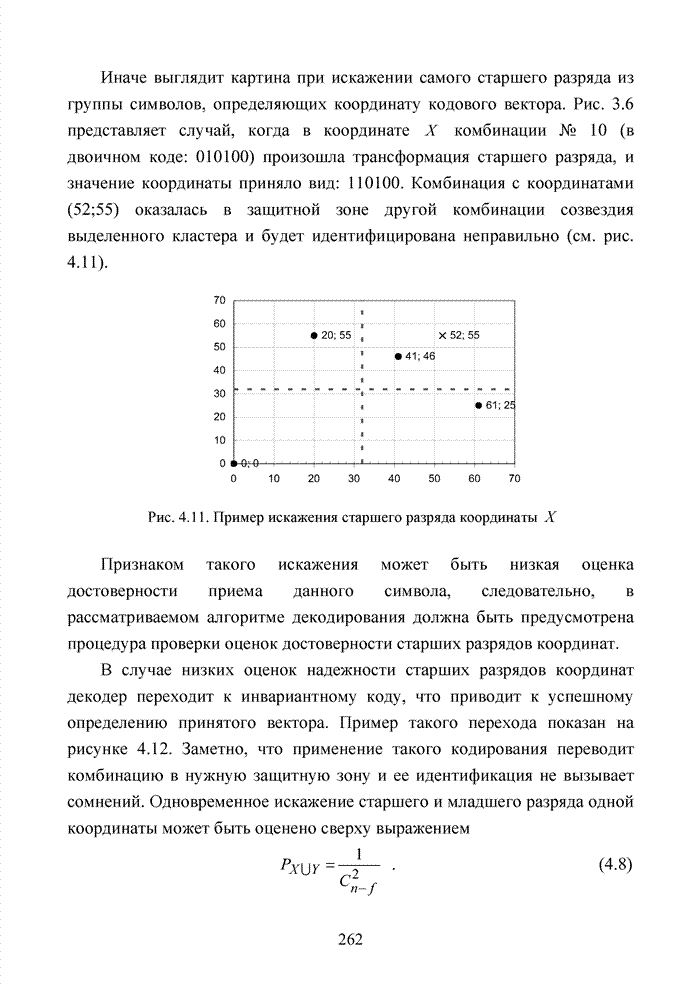
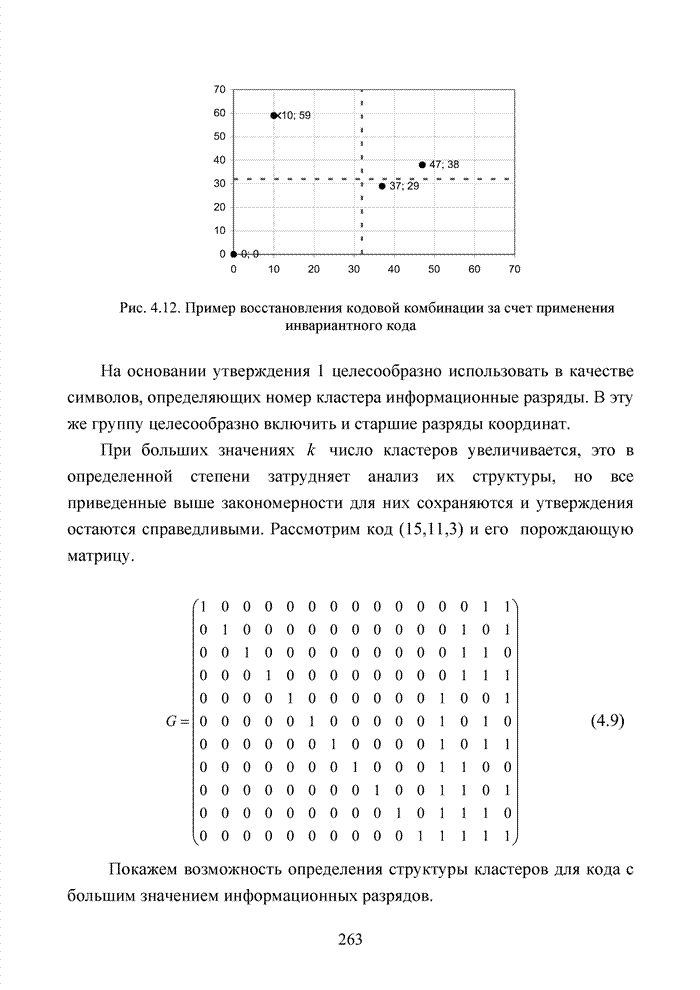
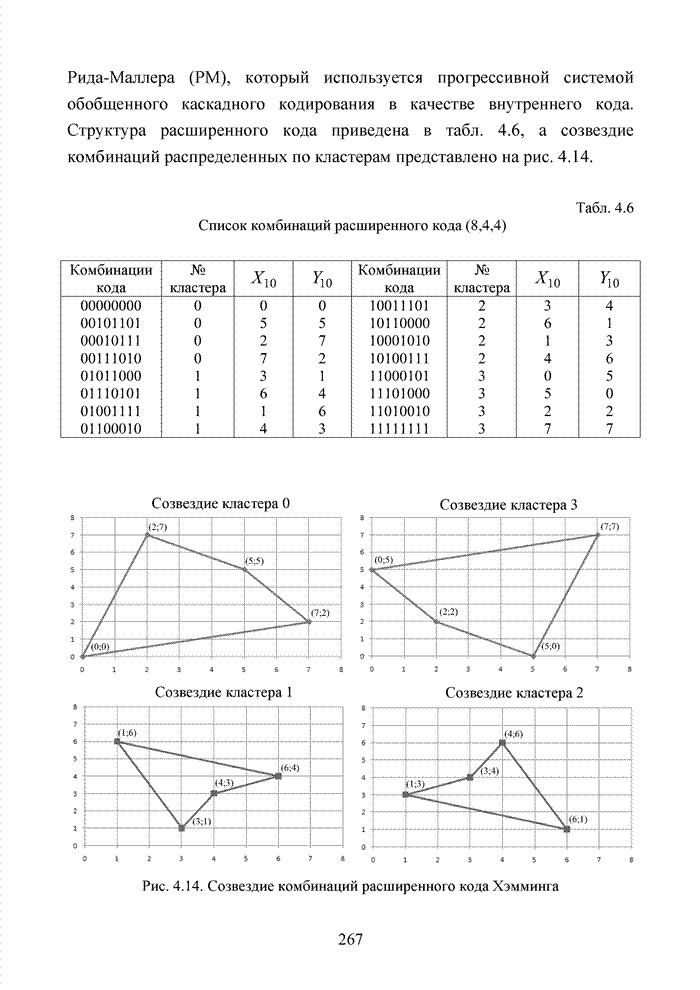
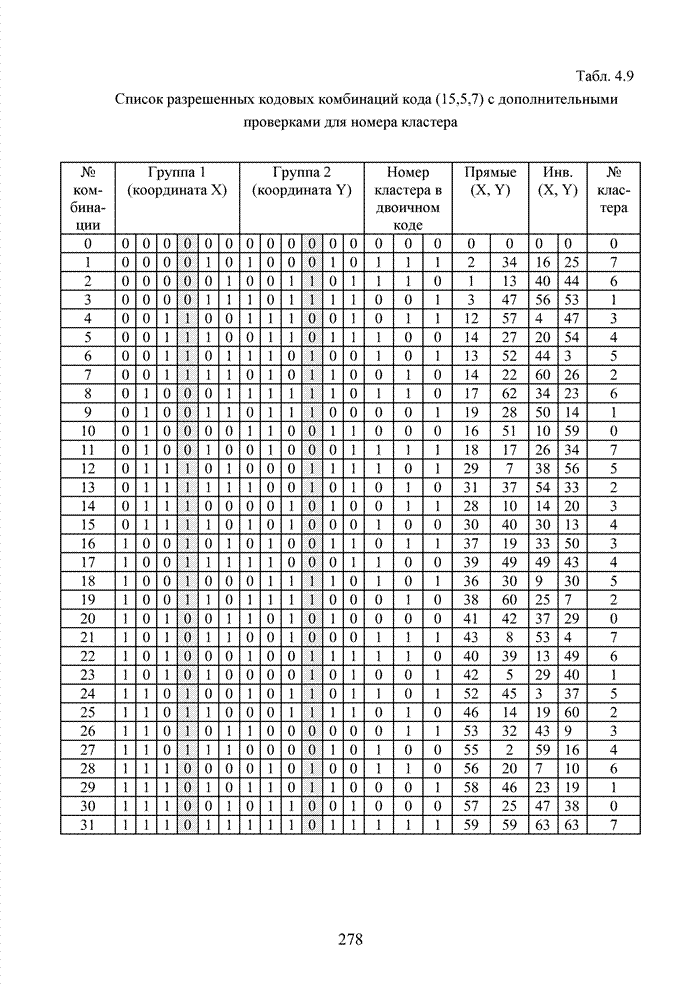
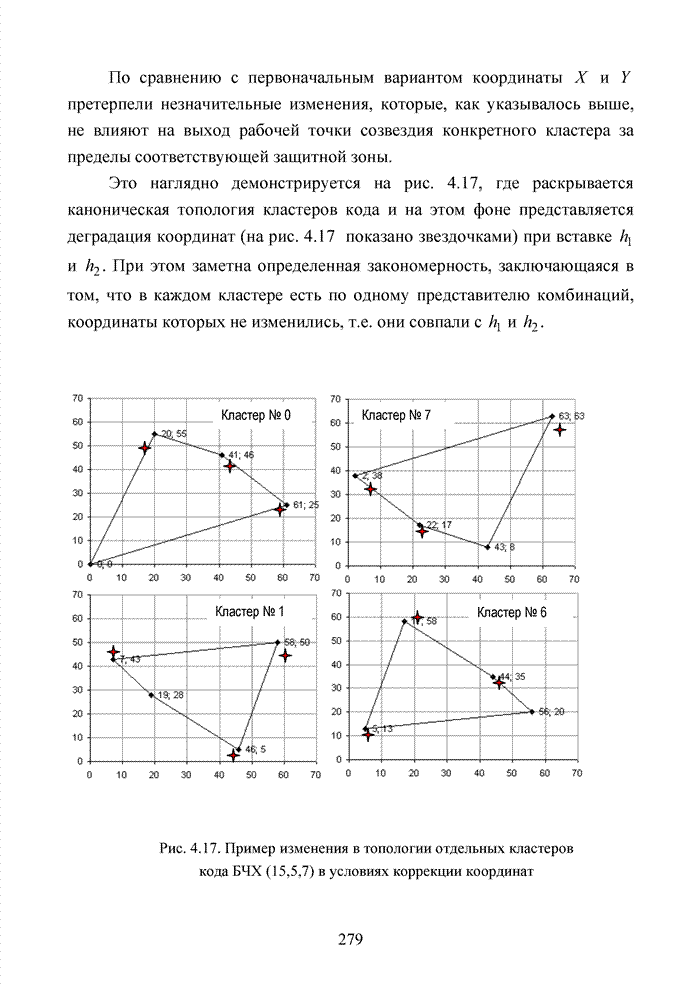
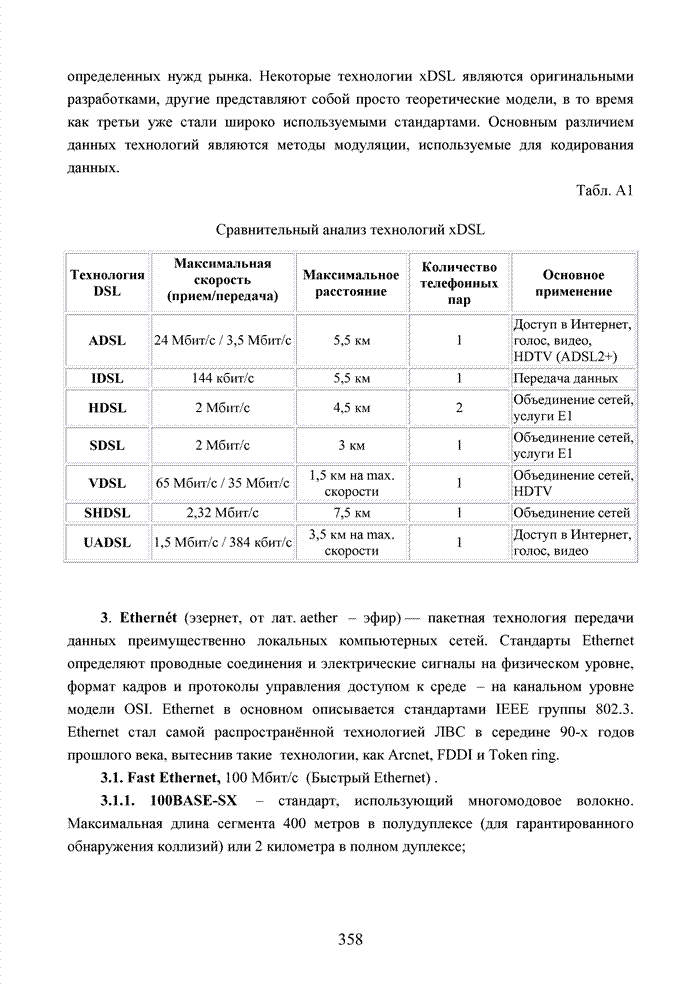
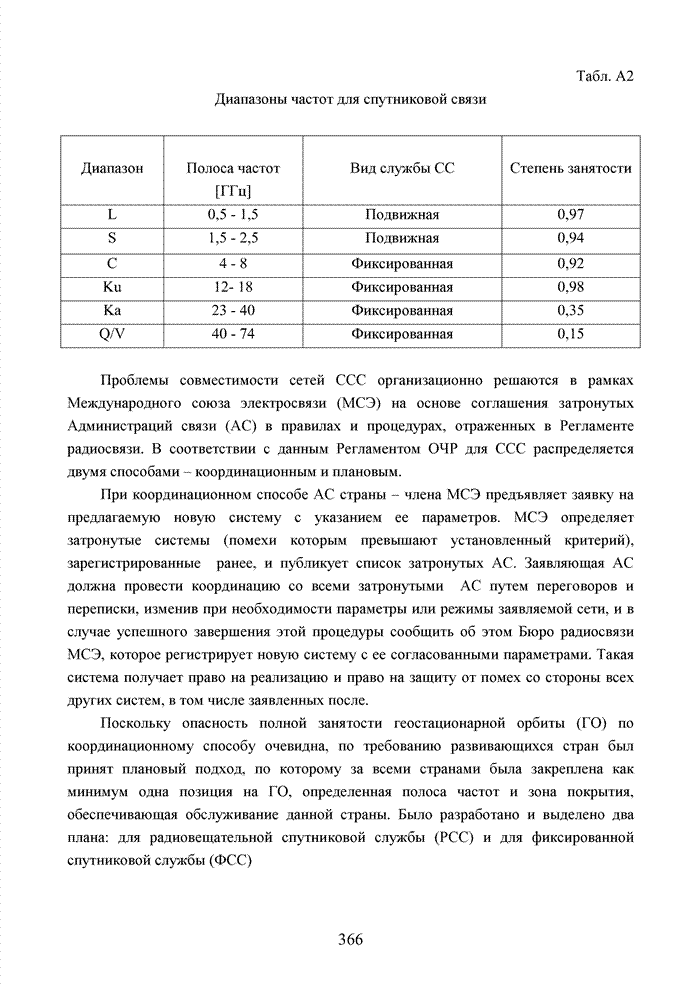
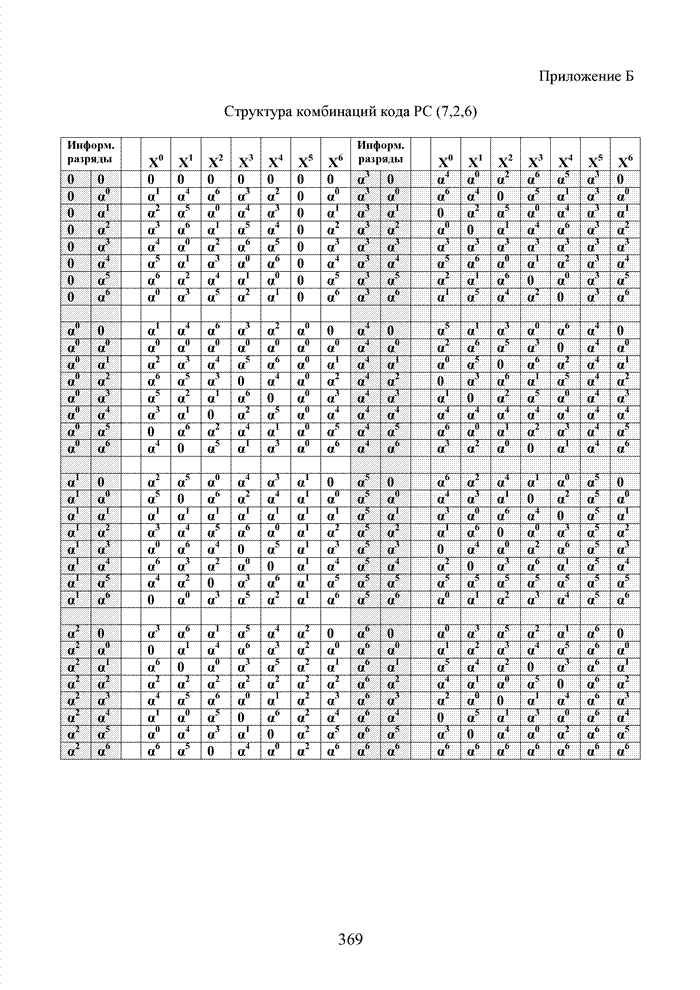
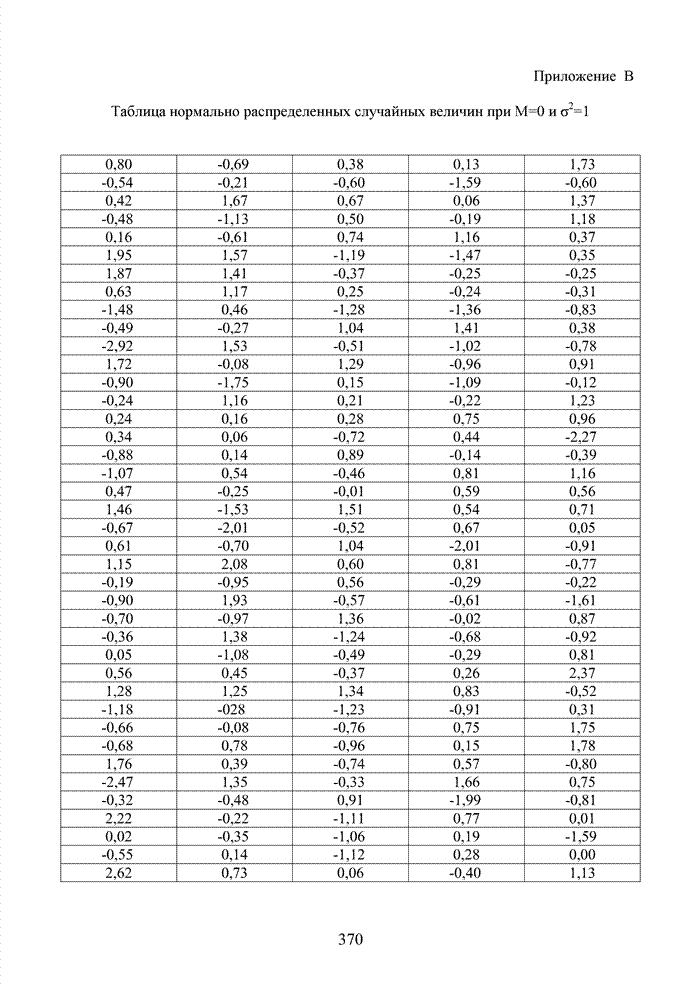
ГЛАВА 4 ПРИНЦИПЫ НЕАЛГЕБРАИЧЕСКОГО ДЕКОДИРОВАНИЯ ИЗБЫТОЧНЫХ КОДОВВведениеНеалгебраические методы
декодирования помехоустойчивых кодов появились сразу, как только стало ясно,
что методы декодирования, опирающиеся на строгие нормы алгебраической теории групп,
колец и полей существенно усложняют конструкцию декодера. На начальных этапах
своего становления технология кодирования и декодирования использовала
относительно простые сдвиговые регистры. Обратные связи и сумматоры таких
регистров отражали структуру порождающего полинома
Большинство специалистов по теории помехоустойчивого кодирования считают, что первым устройством, в котором была реализована идея неалгебраического декодирования циклических кодов, был декодер Меггита [65, 74]. Подобная конструкция являлась декодером максимального правдоподобия и рассчитывалась на обработку только жестких решений. Было установлено, что сложность такого декодера с ростом числа исправляемых ошибок растет экспоненциально, поэтому он предназначался для коррекции ошибок небольшой кратности (до трех включительно). Как указывалось выше, для
циклических кодов существует взаимно однозначное соответствие между множеством
всех исправляемых ошибок и множеством всех синдромов. Если Использование
информационных множеств для построения алгоритмов декодирования групповых кодов
было предложено Прейнджем [65, 73]. Информационным множеством группового (n,k) – кода называется любое множество k символов кодового слова, которые
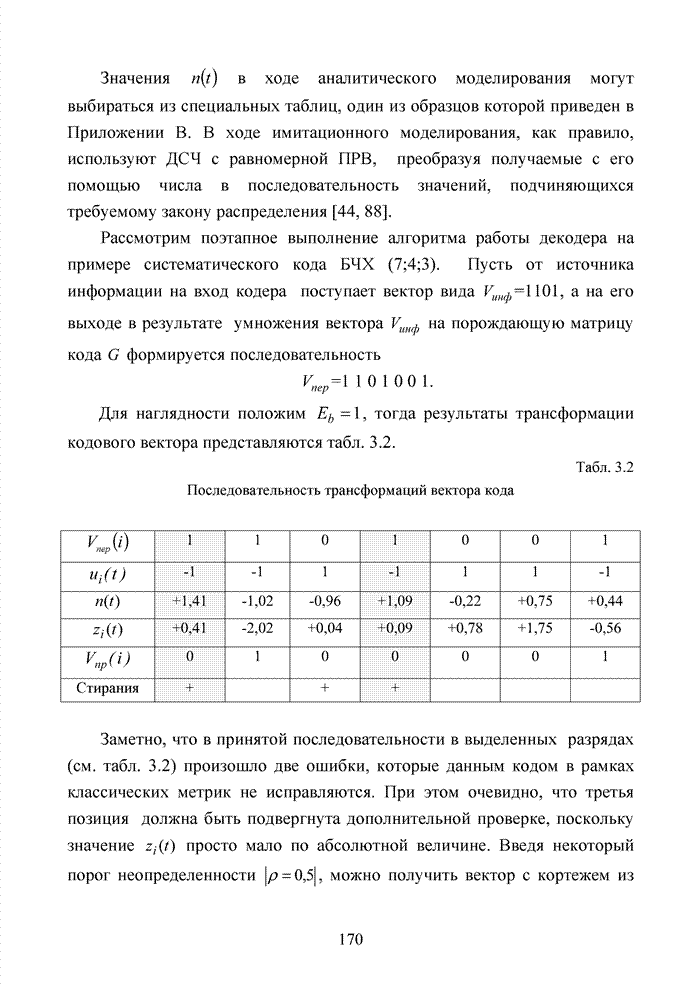
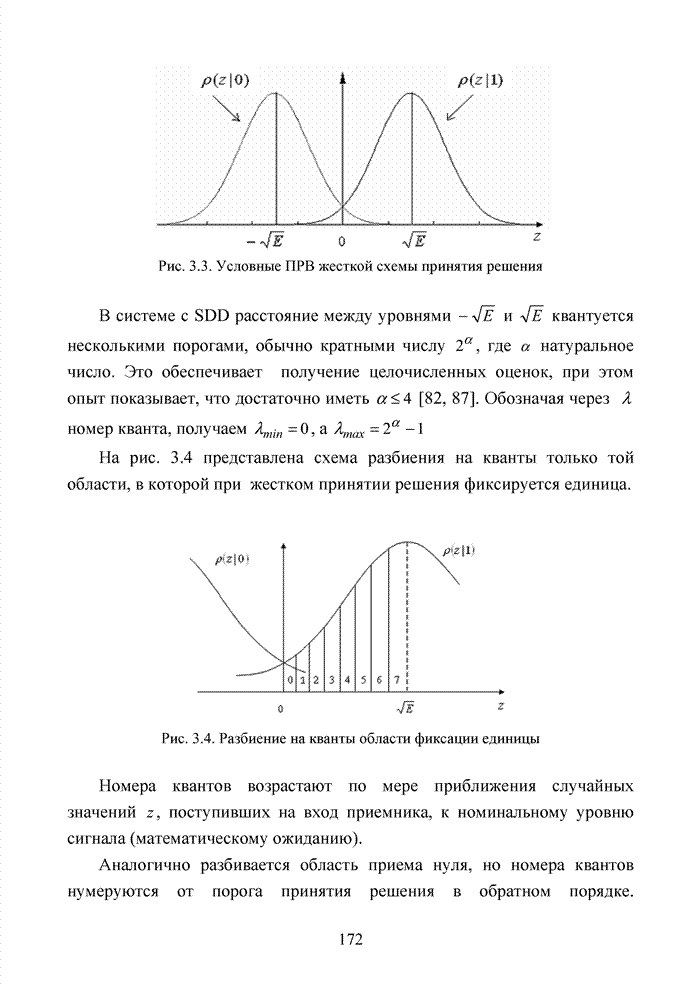
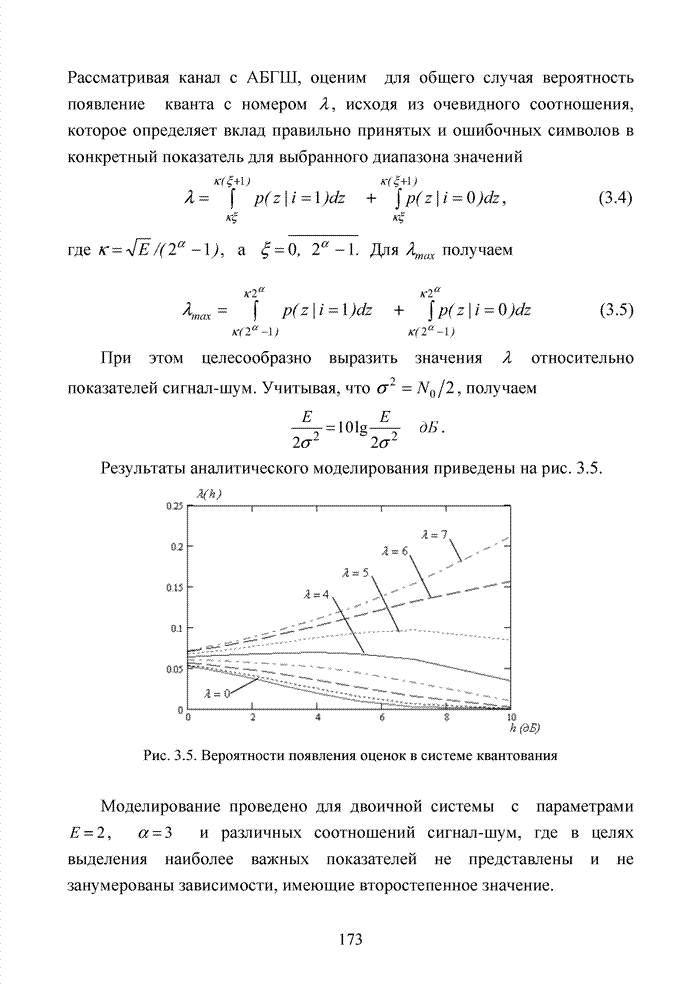
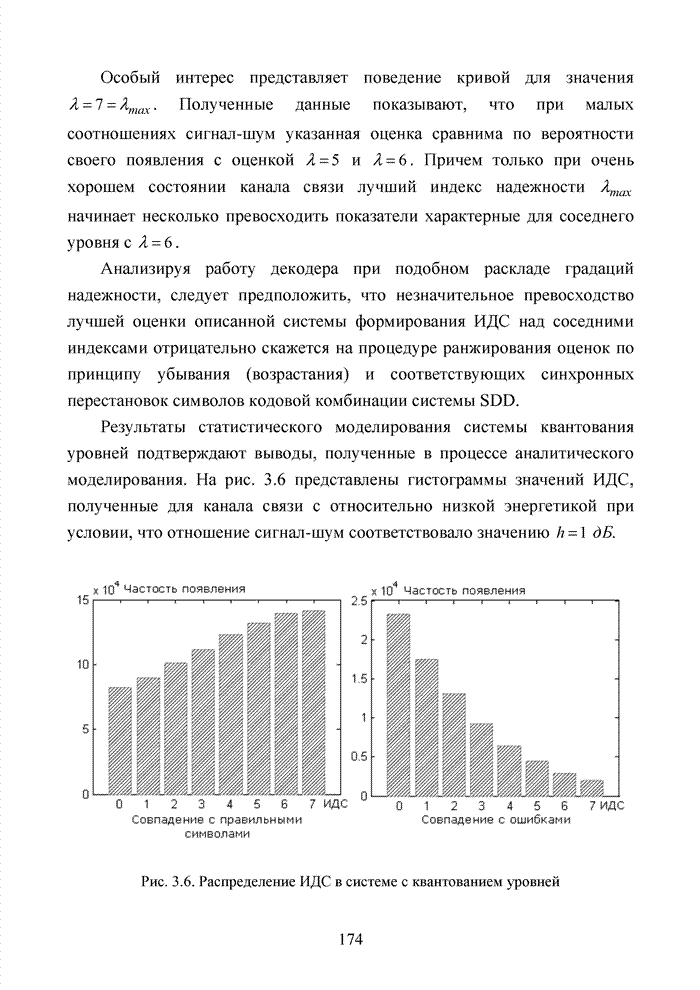
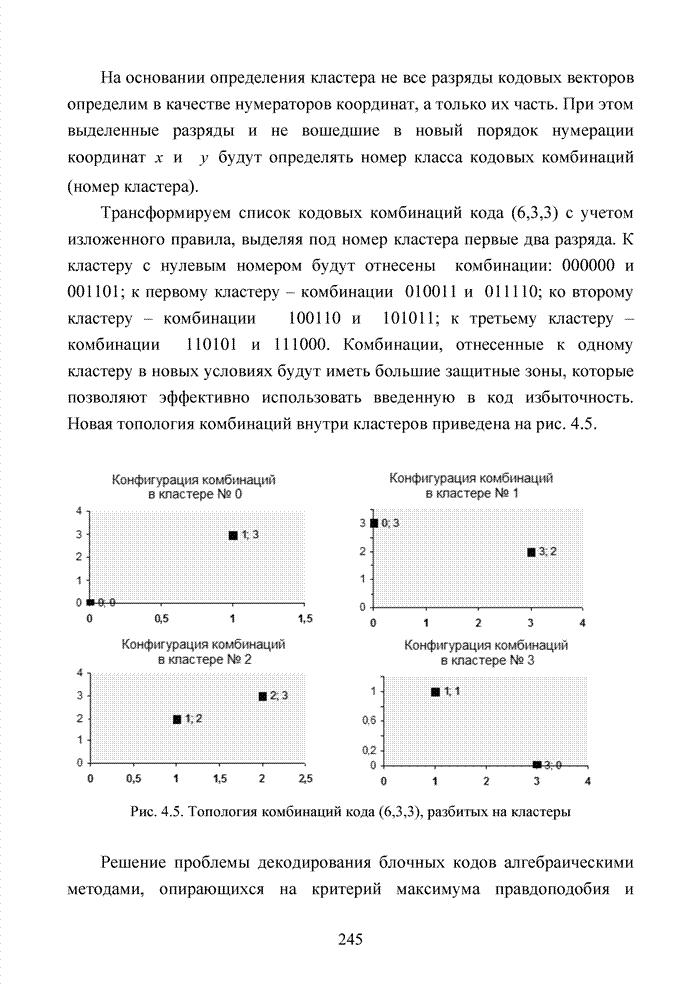
можно задавать независимо. Остальные Шаг 1. Выбрать несколько различных информационных множеств в соответствии с некоторым правилом. Шаг 2. Построить кодовое слово для каждого из множеств, предположив, что символы информационного множества приняты без ошибок. Шаг 3. Сравнить каждое гипотетическое кодовое слово с принятой последовательностью и выбрать ближайшее кодовое слово (находящееся на наименьшем расстоянии). Другим направлением является перестановочное декодирование, которое возможно реализовать как с использованием порождающей матрицы G, так и с помощью проверочной матрицы H [77, 78, 89]. Комбинация ошибок будет определена, если удается найти проверочное множество целиком, содержащее эту комбинацию. Такое проверочное множество называется покрывающим комбинацию ошибок. Набор проверочных множеств, покрывающим комбинацию ошибок данного типа, называется покрытием. Задача декодера состоит в том, чтобы найти проверочное множество, которое покрывает данную неизвестную комбинацию ошибок. При использовании заранее выбранного покрывающего множества возникает два важных вопроса. Первый из них состоит в том, каково минимальное число различных проверочных множеств, необходимых для исправления данного числа ошибок, второй – как найти эти множества. Ни на один из этих вопросов нет вполне удовлетворительного ответа. Благодаря усилиям отечественных авторов: В.В. Золотареву, Г.В. Овечкину и др., активно развивается концепция многопорогового декодирования, берущая свое начало от порогового декодирования Меггита [54, 55]. Такой метод декодирования применим не только к групповым кодам, но и к непрерывным кодам, однако этот метод целесообразно применять к кодам определенной структуры: к мажоритарно декодируемым кодам или к самоортоганальным кодам. Сложность порогового декодера пропорциональна кодовому расстоянию, следовательно, быстрое увеличение этого параметра оказывается малоэффективным. Кроме того, при фиксированном значении кодового расстояния лучшими энергетическими характеристиками обладать коды с большей кодовой скоростью. Многопороговый декодер
самоортоганальных кодов является развитием простейшего порогового декодера и
позволяет декодировать очень длинные коды с линейной от длины кода сложностью
исполнения. Важно отметить, что в основе такого устройства лежит принцип
итеративного приближения к окончательному выбору решения о принятом векторе.
Основной шаг декодирования заключается в том, что для произвольного взятого
символа uj вычисляется функция правдоподобия Lj , от относящихся к нему проверок Подобная ситуация активизировала поиски иных подходов к процедуре декодирования помехоустойчивых кодов. Одним из таких направлений явилось списочное декодирование. Именно к таким методам следует отнести, прежде всего, приемы списочного декодирования, которые были введены Элайесом и Возенкрафтом [40, 59, 65, 74]. Алгоритм списочного декодирования имеет самостоятельное значение при решении различных задач. Списочный декодер вместо единственного решения выдает получателю список предполагаемых решений о передаваемом сообщении. Ошибкой является такой результат декодирования, когда в списке нет правильного сообщения. Понятно, что вероятность ошибки такого списочного декодера много меньше вероятности ошибки обычного декодера. Наиболее очевидное применение этого подхода возможно в системах с каскадным кодированием. Результатом декодирования внутреннего кода является список решений, а декодер внешнего кода устраняет оставшуюся неопределенность. Алгоритм декодирования, основанный на списках, обеспечивает лучшее соотношение между сложностью и вероятностью ошибки, чем другие известные алгоритмы. Это справедливо в асимптотике при увеличении кодового ограничения кода, а также при использовании конкретных конструкций кодов конечной длины. Научный поиск в области построения эффективных избыточных кодов и каскадных конструкций на их основе продолжается. Развитие технологии реализации устройств кодирования и декодирования на базе интегральных микросхем и сигнальных процессоров существенно расширяет круг технически реализуемых решений. Этим стимулируется интерес к исследованиям в данной области. Списочное
декодирование
|
 |
Оглавление
|