Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
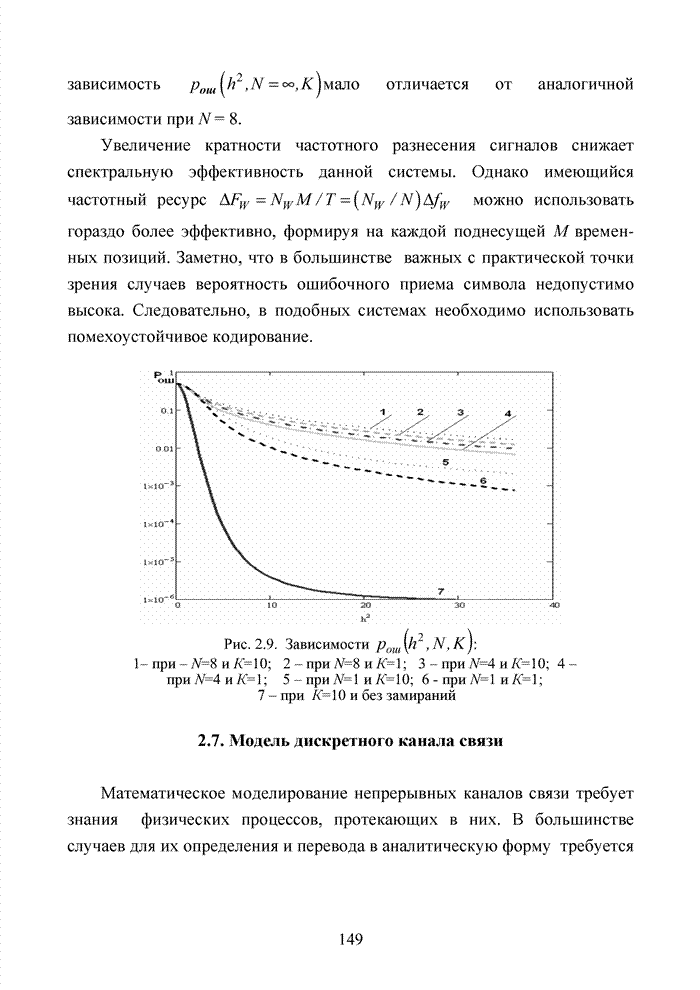
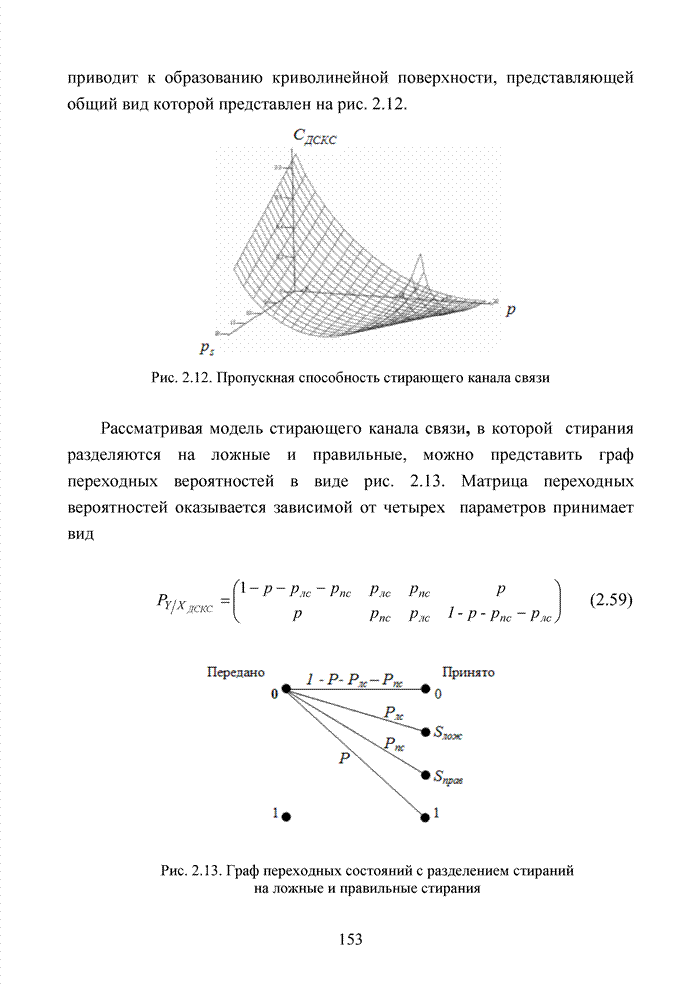
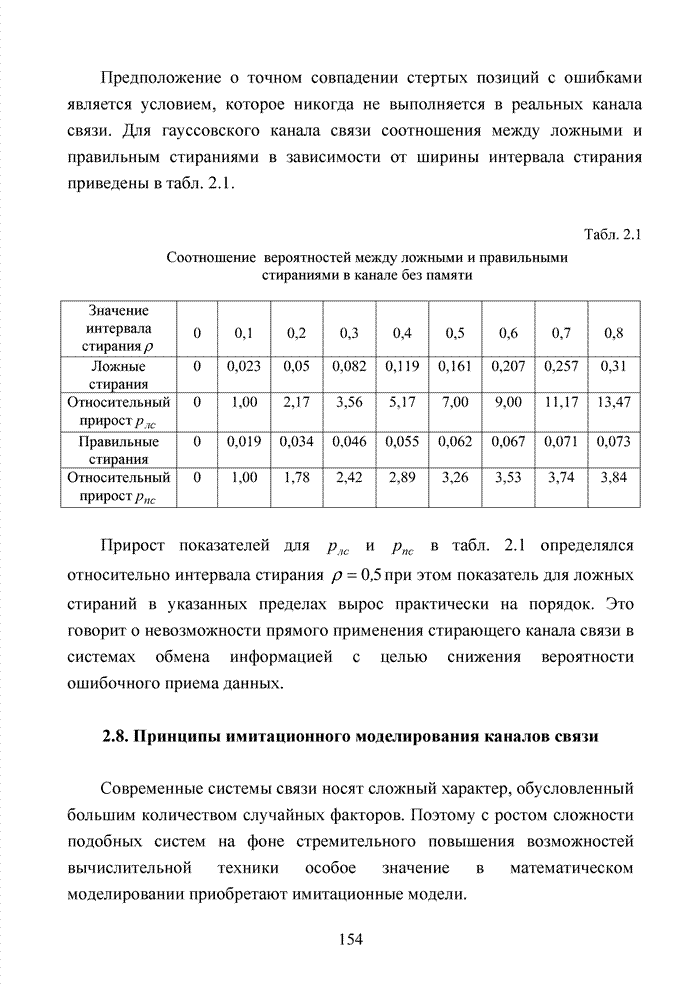
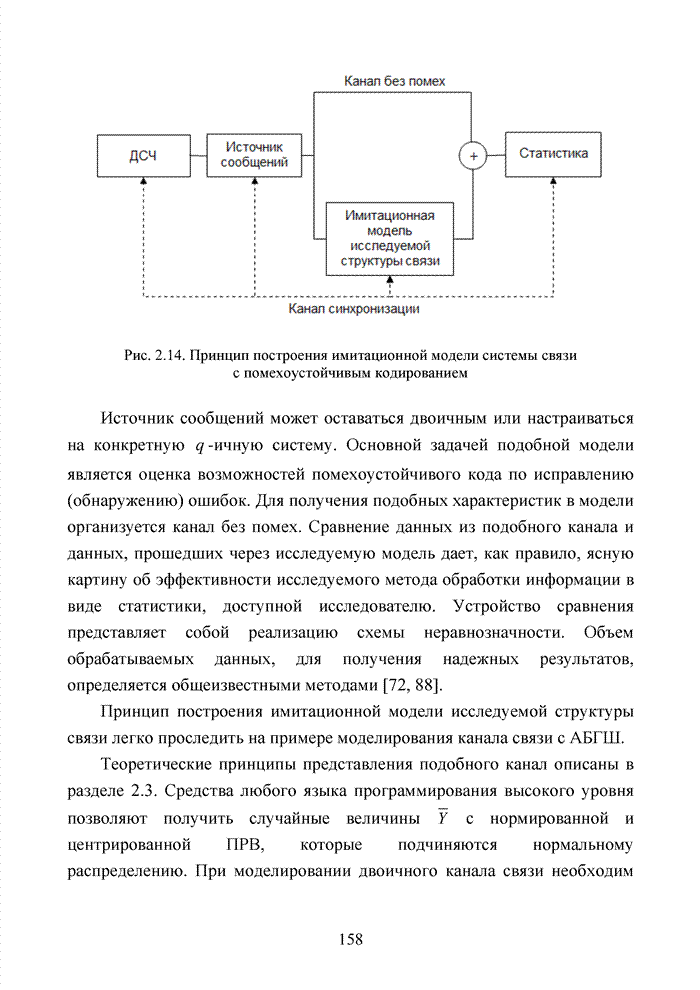
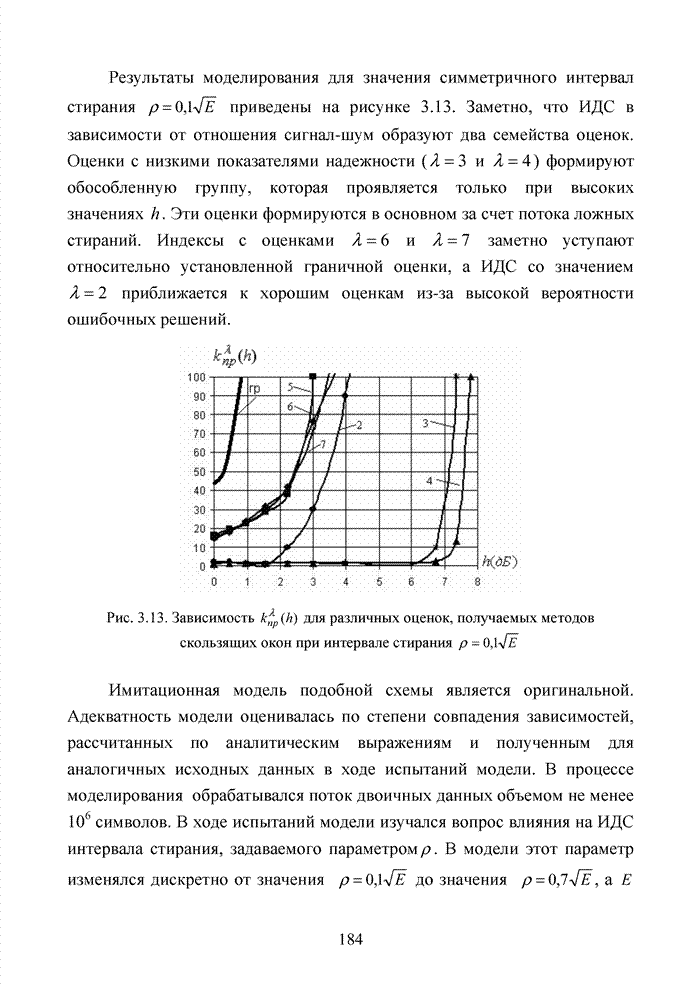
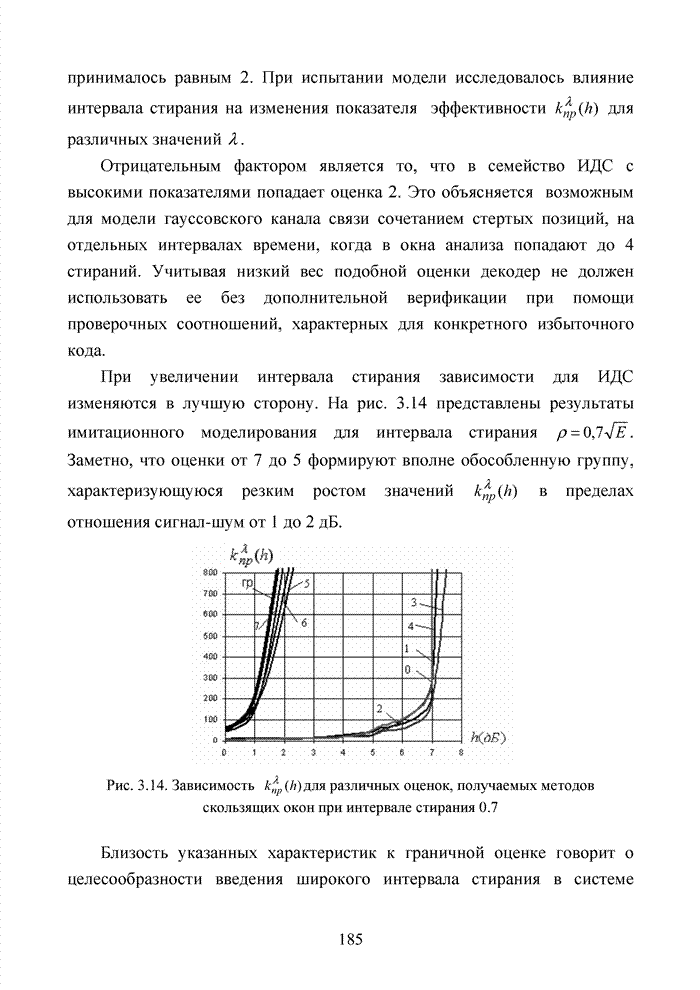
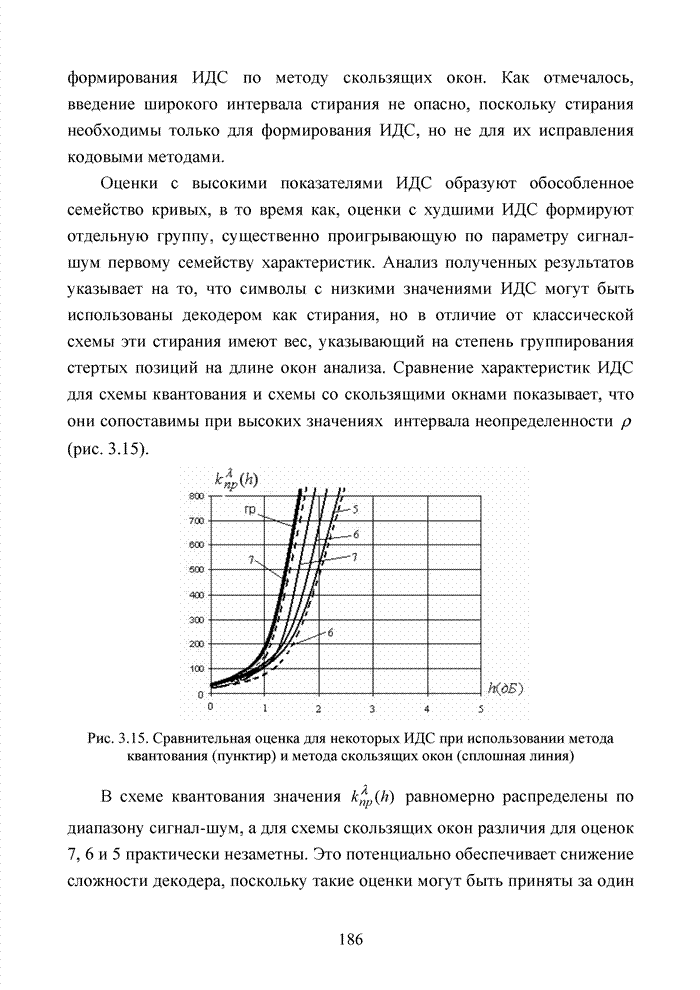
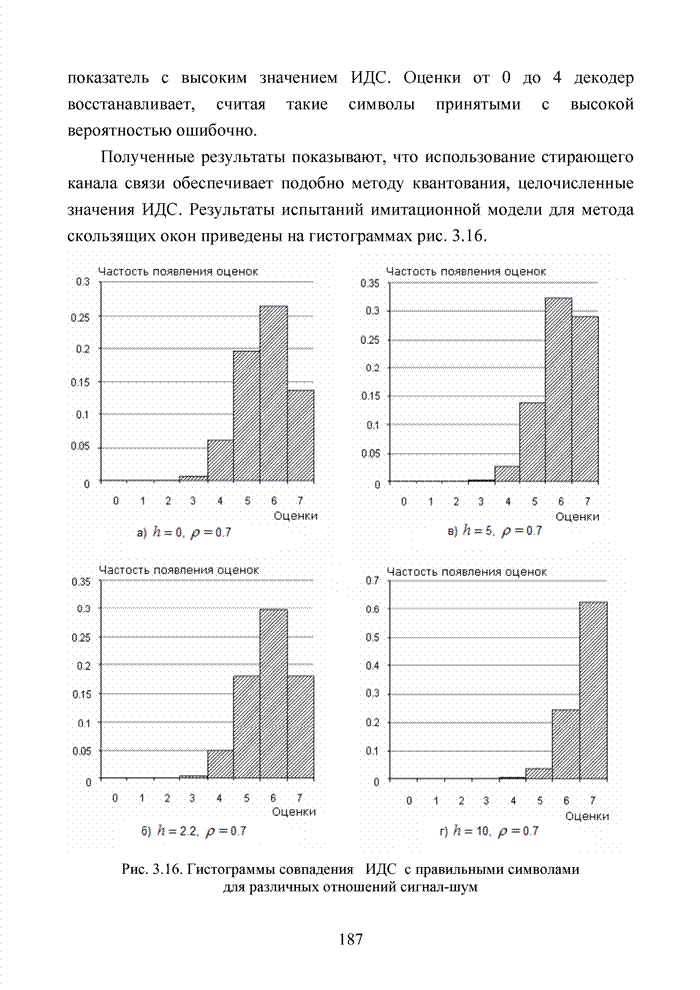
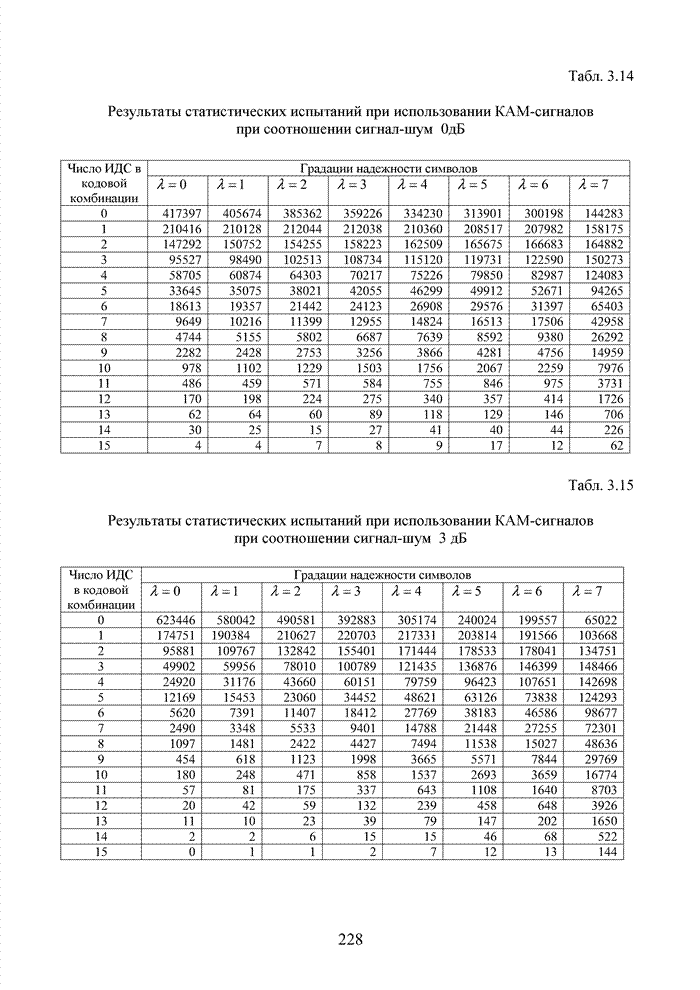
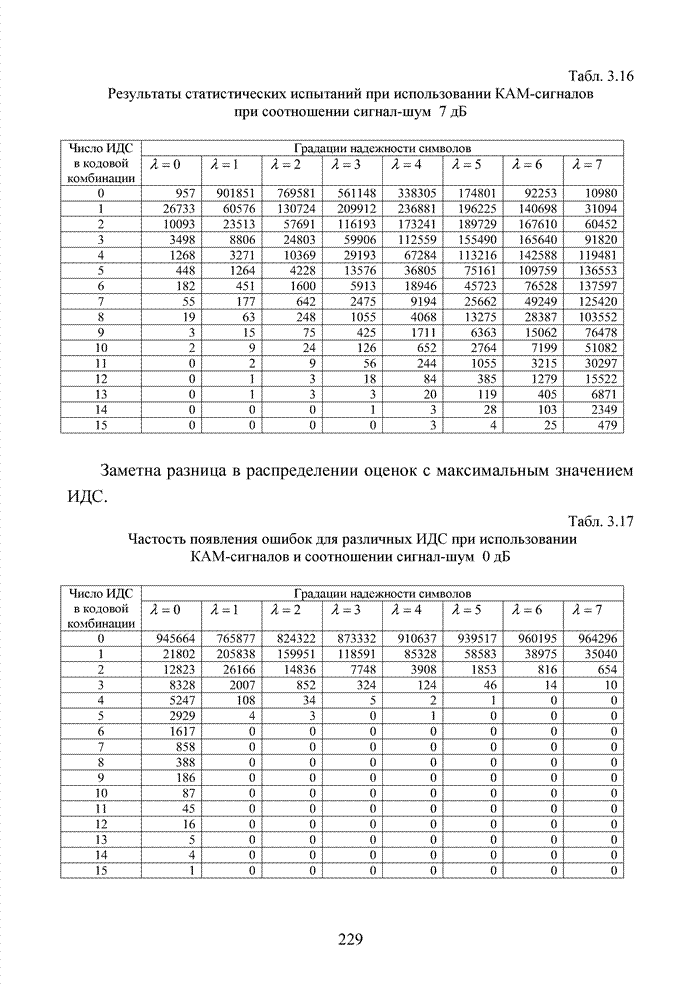
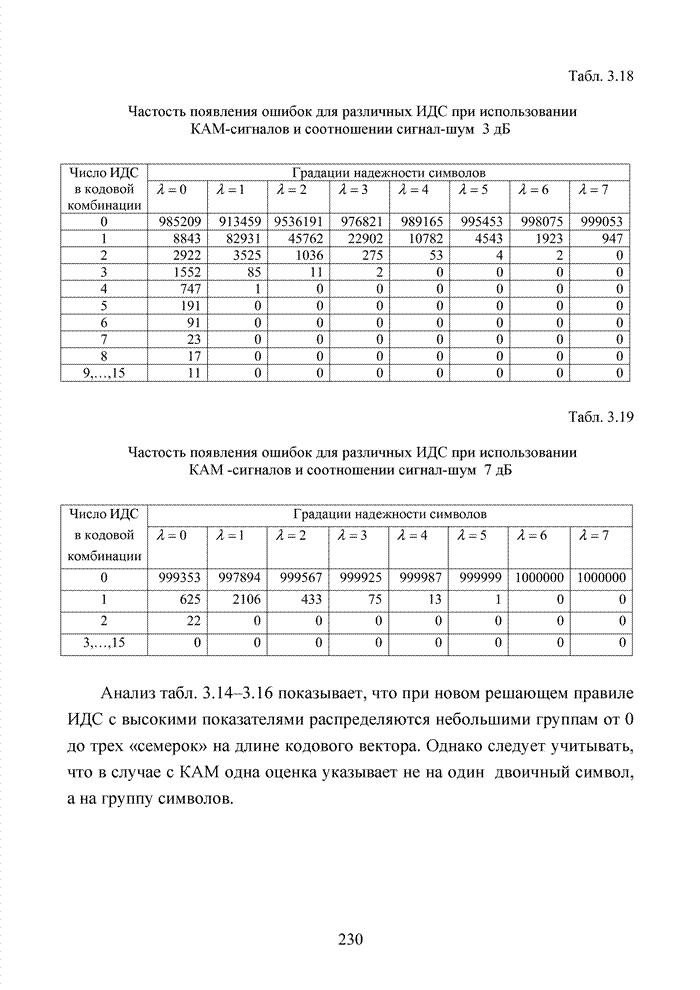
4.6. Декодирование на основе упорядоченной статистикиИсправление определенной части ошибок за пределами метрики Хэмминга возможно не только при использовании метода кластерного анализа. Одним из таких способов является декодирование на основе упорядоченной статистки. Использование
упорядоченной статистики при декодировании блоковых кодов позволяет повысить
кратность исправляемых стираний до значения
Алгоритм работы такого декодера (назовем его основным) рассмотрим на примере кода БЧХ (15;5;7). Порождающая матрица кода в систематической форме приведена в (4.5) и будет представлена здесь для удобства
Пусть от источника информации на вход кодера поступает вектор вида 1 1 0 1 0 . В результате умножения вектора на порождающую матрицу на выходе кодера формируется последовательность:
После передачи этой последовательности по каналу связи принимается вектор, в котором в соответствии с вероятностью ошибки на бит, характерной данному каналу связи, возможно появление ошибок. Пусть образец ошибок имеет вид
Заметно, что представленный объем ошибочных символов превосходит исправляющую способность кода по восстановлению не только ошибочно принятых символов, но и стираний. Естественно, что жесткий декодер не в состоянии исправить возникшую в канале связи комбинацию ошибок. Докажем, что подобная комбинация может быть исправлена за счет применения в декодере эквивалентных кодов. В результате передачи кодового вектора по каналу связи и наложения на него вектора ошибок получаем последовательность вида
Эта последовательность
фиксируется жестким декодером. В мягком декодере каждому жесткому решению
приписывается степень его надежности. Пусть оценки надежности символов
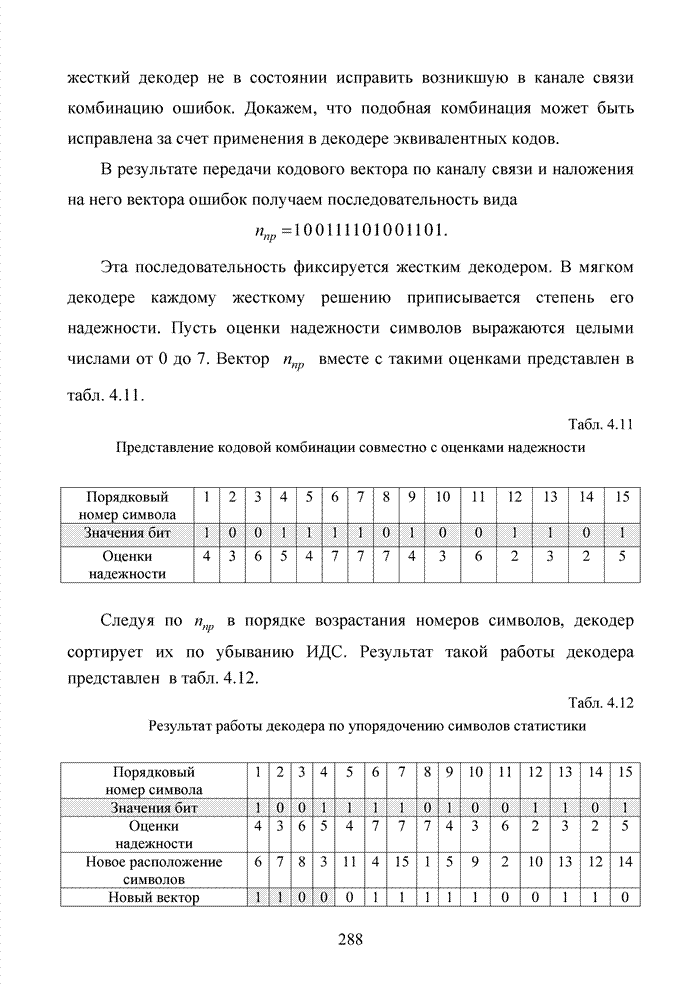
выражаются целыми числами от 0 до 7. Вектор Табл. 4.11 Представление кодовой комбинации совместно с оценками надежности
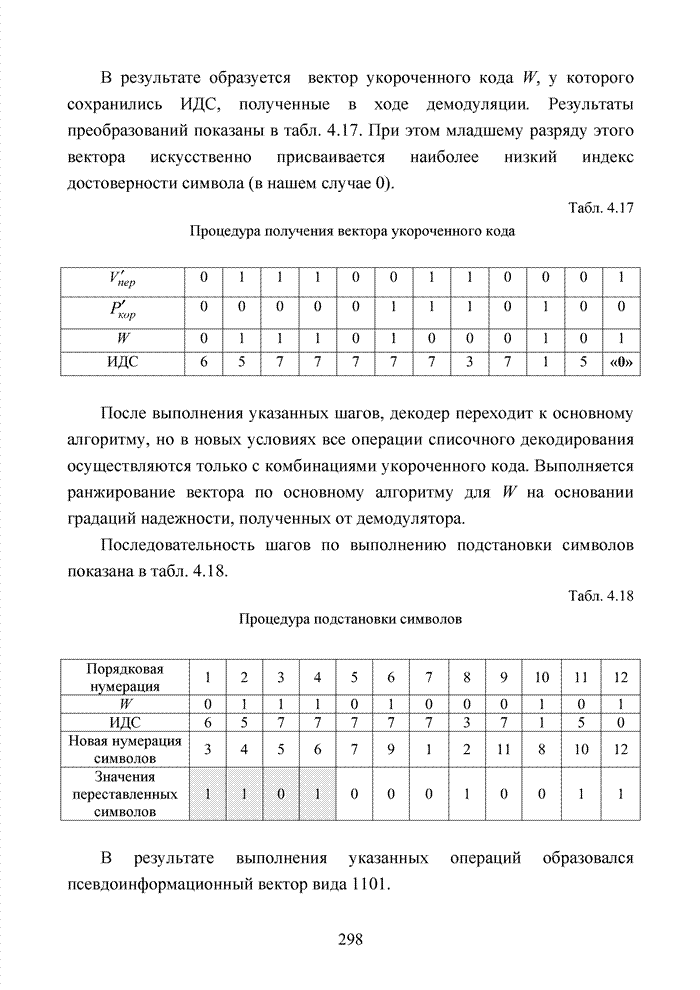
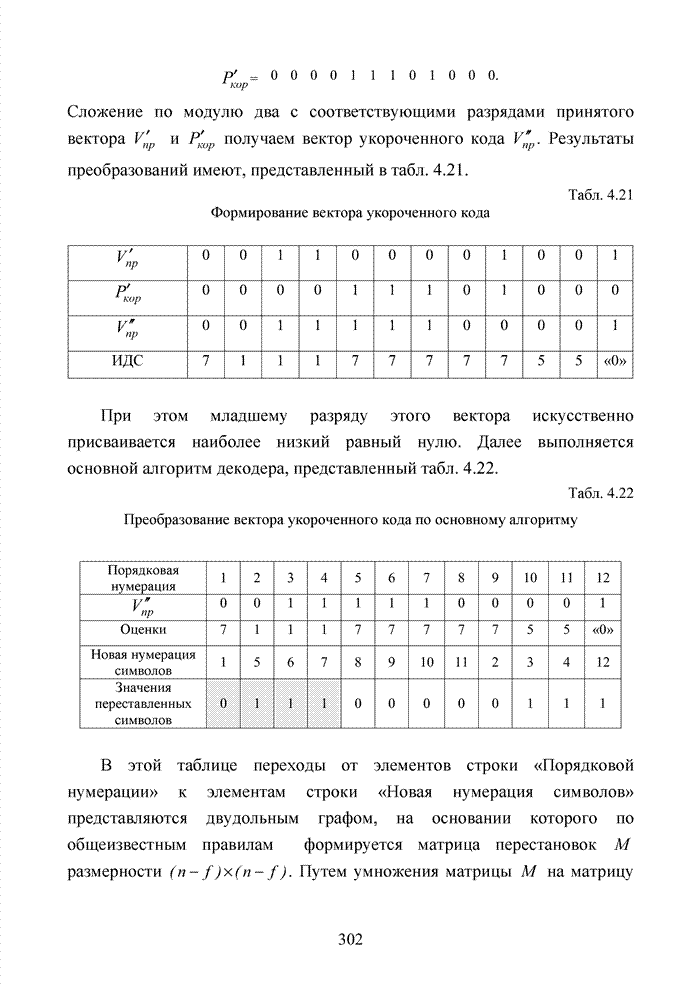
Следуя по Табл. 4.12 Результат работы декодера по упорядочению символов статистики
Заметно, что на первых Для создания подобного
кода необходимо найти его порождающую матрицу. Для этого, используя матрицу
перехода, выполним умножение истинной порождающей матрицы
Выполняя
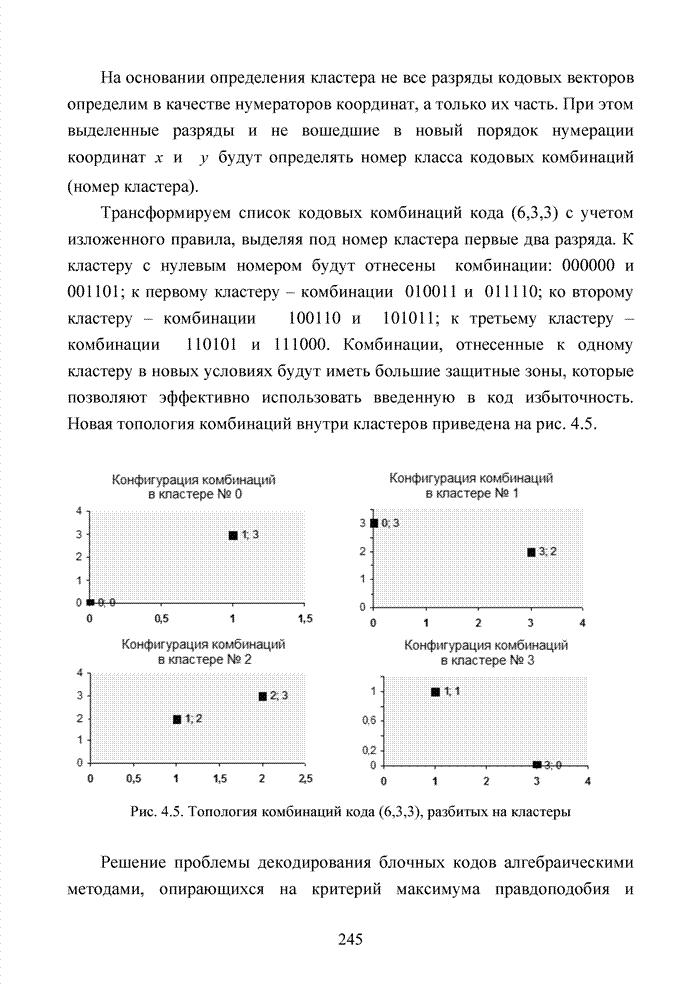
В этой матрице может быть утрачено свойство линейной независимости строк, которое обязательно для образования эквивалентного кода. Для проверки линейной
независимости строк в матрице Принципиально эта
процедура легко программируется для процессора приемника, однако объем
вычислений существенно увеличивается с ростом
Поскольку Вычисление детерминанта
квадратной матрицы является достаточно емкой процедурой с точки зрения объема
вычислений. Оценим максимальное число операций, необходимых для определения
детерминанта квадратных матриц заданной размерности и полученные для различных значений
Первоначально рассмотрим
матрицу размерности
Современные процессоры тратят на операцию сложения до 2 нс, а на операцию умножения – до 180 нс. в декодере осуществляется умножение единиц и нулей, будем считать, с некоторой долей условности, что на операцию умножения операндов будет тратиться тоже 2 нс. Таким образом, на вычисление указанного определителя будет потрачено порядка 6 нс. Исходя из этих условий, в табл. 4.13 представлены данные оценки временных затрат при вычислении определителей других размерностей. Табл. 4.13 Временные интервалы для оценки определителей
Из табл. 4.13 следует, что незначительное увеличение размерности квадратной матрицы приводит к существенному увеличению времени вычисления определителя. Получив
удовлетворительный результат по вычислению
Поскольку все действия
декодер выполняет в двоичном поле, то в обратной матрице Исследования показали,
что в обратной матрице
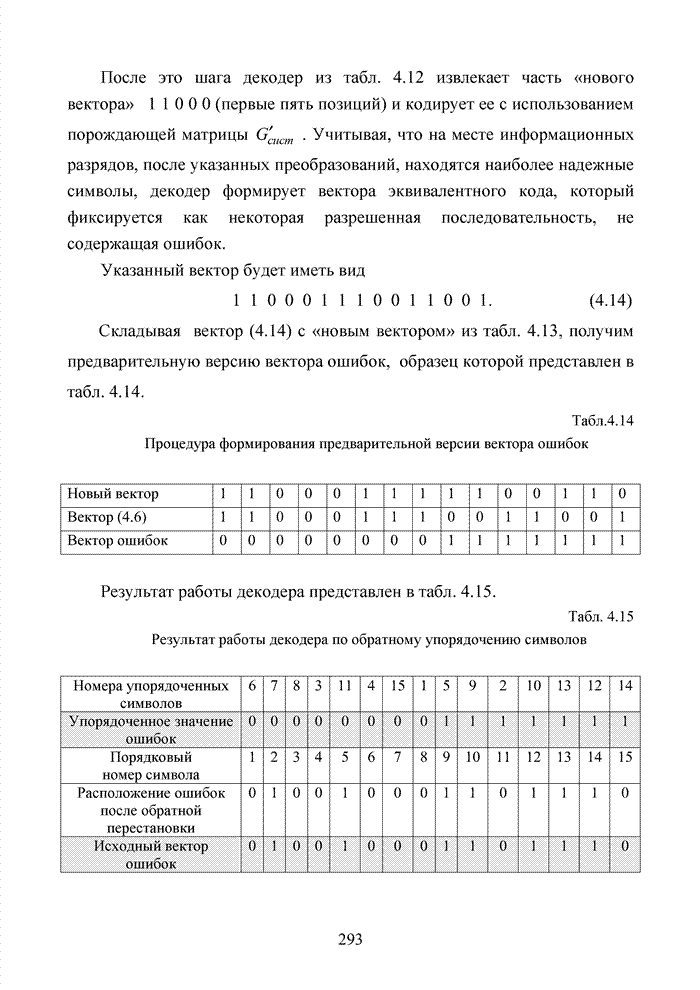
После это шага декодер из
табл. 4.12 извлекает часть «нового вектора» 1 1 0 0 0 (первые пять позиций) и
кодирует ее с использованием порождающей матрицы Указанный вектор будет иметь вид 1 1 0 0 0 1 1 1 0 0 1 1 0 0 1. (4.14) Складывая вектор (4.14) с «новым вектором» из табл. 4.13, получим предварительную версию вектора ошибок, образец которой представлен в табл. 4.14. Табл.4.14 Процедура формирования предварительной версии вектора ошибок
Результат работы декодера представлен в табл. 4.15. Табл. 4.15 Результат работы декодера по обратному упорядочению символов
В таком представлении
вектор ошибок не соответствует комбинации ошибок, действовавшей в канале связи
в момент передачи кодового вектора Анализ полученного
алгоритма показывает, что эквивалентный код в ряде случаев не может быть
получен сразу после выполнения перестановок, т.к. проверка на нелинейность
столбцов порождающей матрицы эквивалентного кода не всегда заканчивается
успешно. Это связано с тем, что после перестановки возможны ситуации, когда в
одной строке или столбце окажутся только нули или только единицы. В этом случае
декодер «занимает» подходящий столбец из ближайших столбцов, превосходящих
значения Пусть известна весовая
структура кода (как правило, для коротких кодов весовой спектр кода известен).
Код БЧХ (15,5,7) имеет кроме чисто нулевого и чисто единичного вектора по 15
векторов веса 7 и 8. Обозначим представители указанных значений, как Оценим появление чисто
единичной строки и чисто нулевой строки в матрице размерности
при Для кода БЧХ (15,5,7)
|
 |
Оглавление
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||








































































































































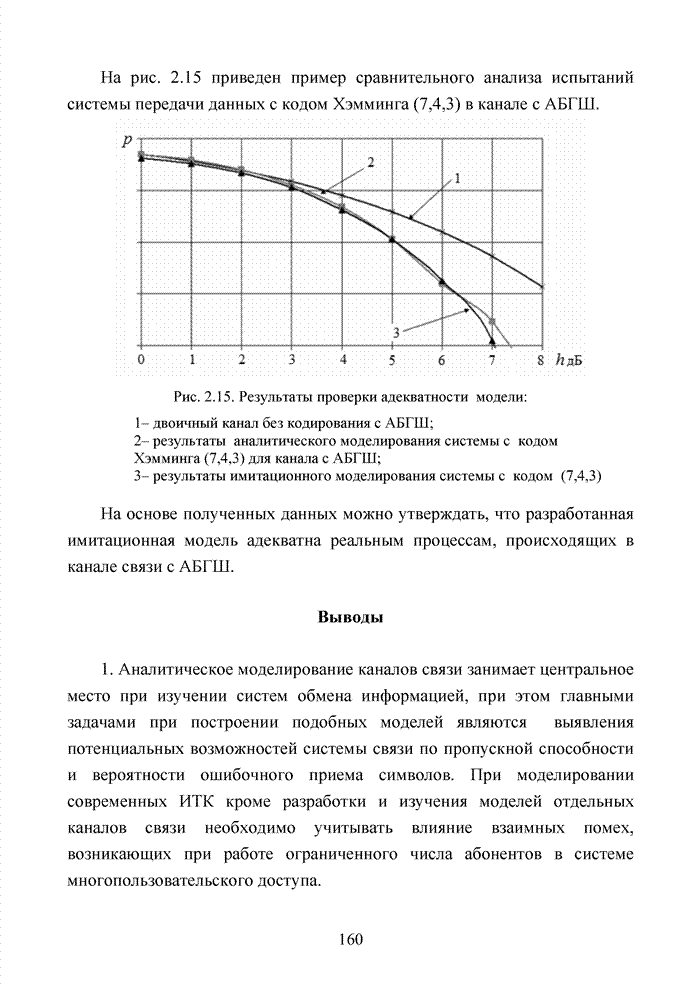




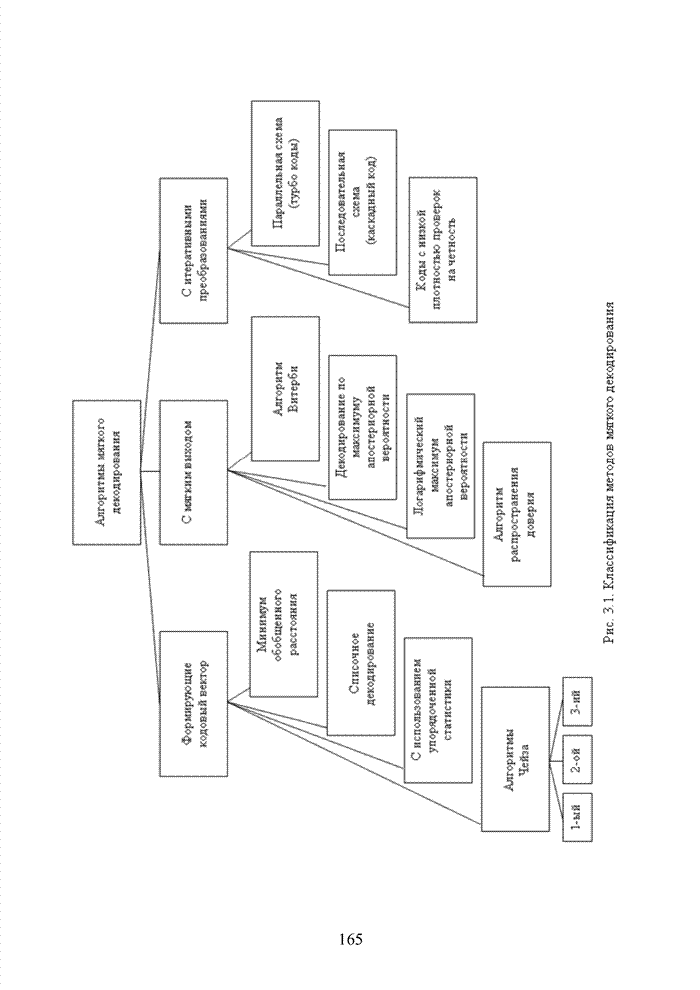
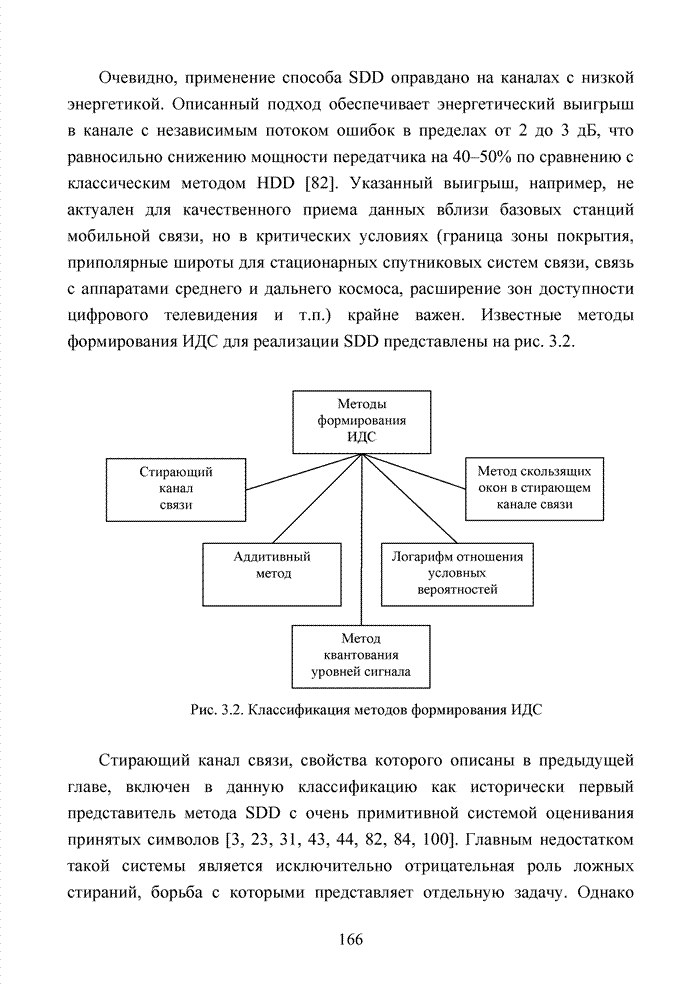

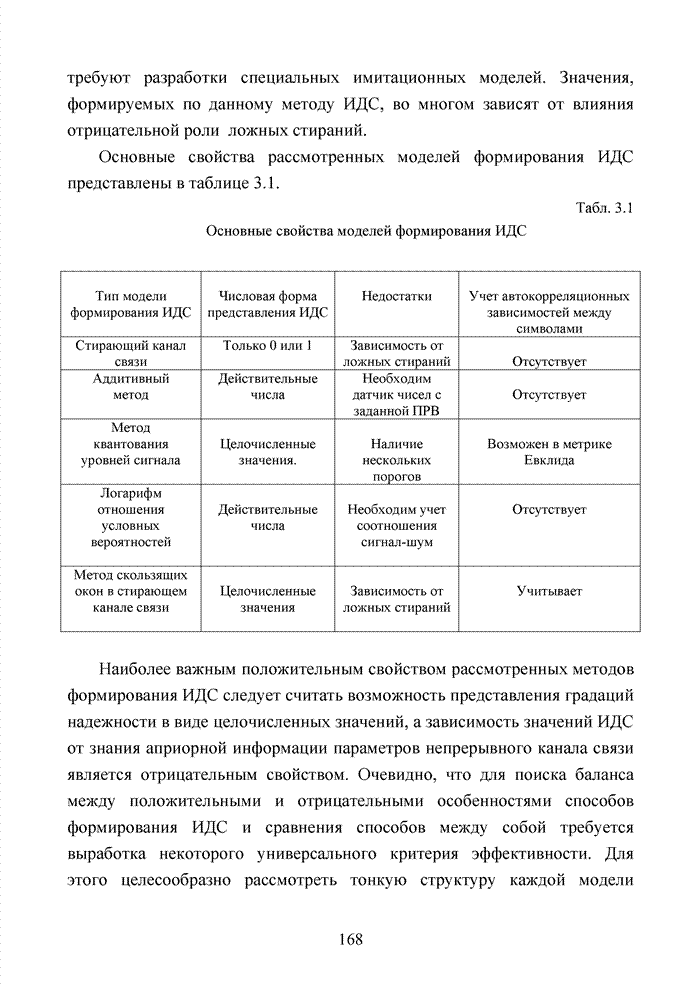












































































































































 .
.

 .
.
 .
.
 .
.
 .
.
 .
.
 ,
,