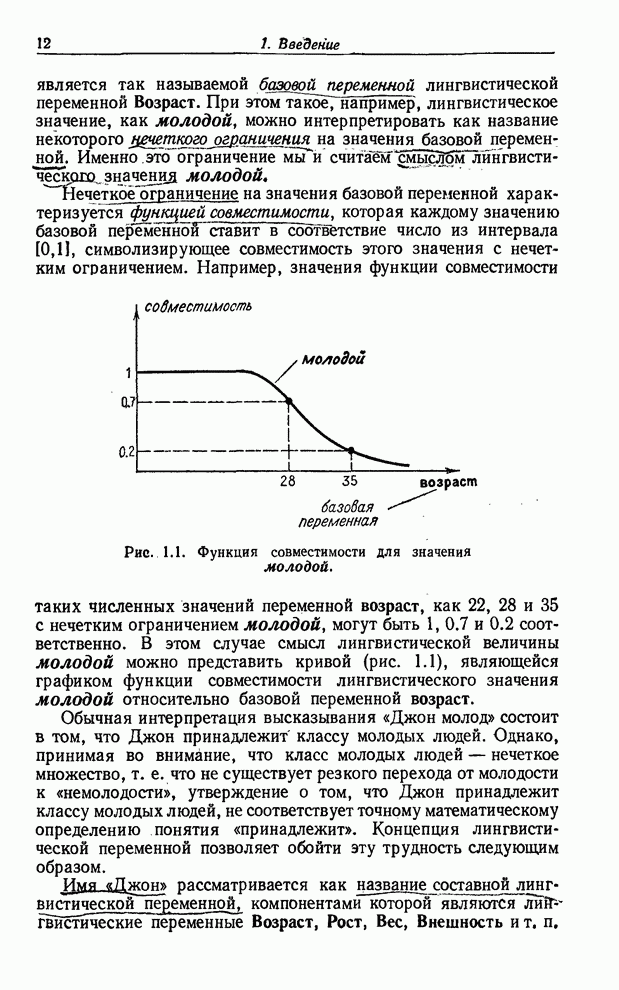
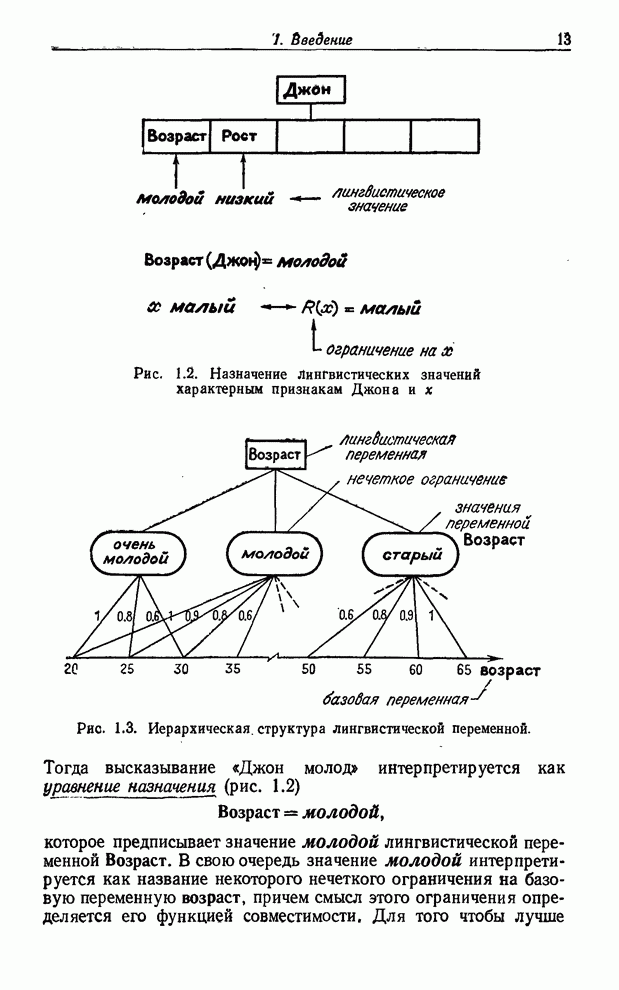
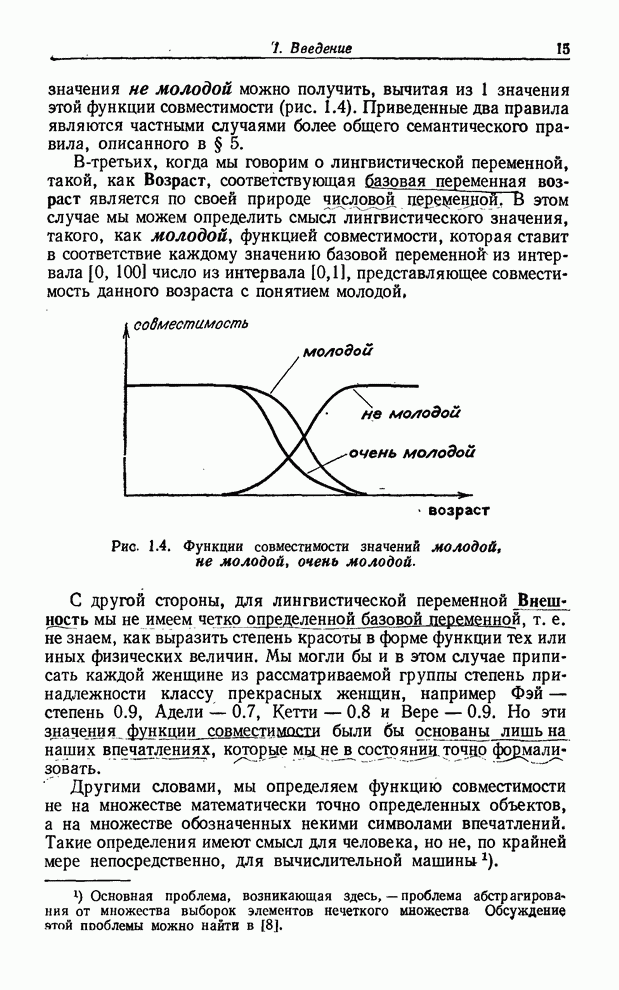
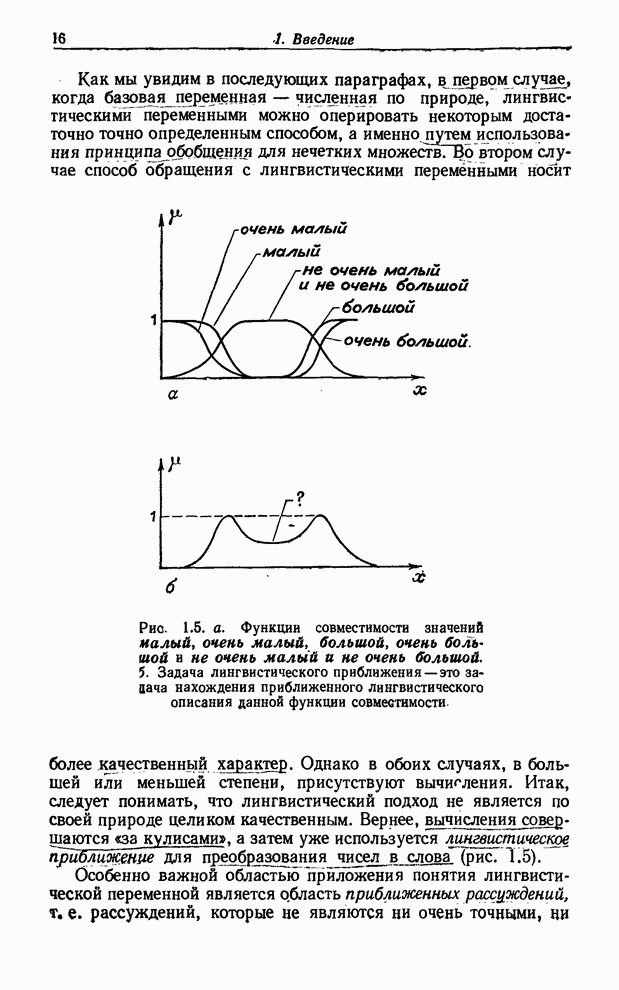
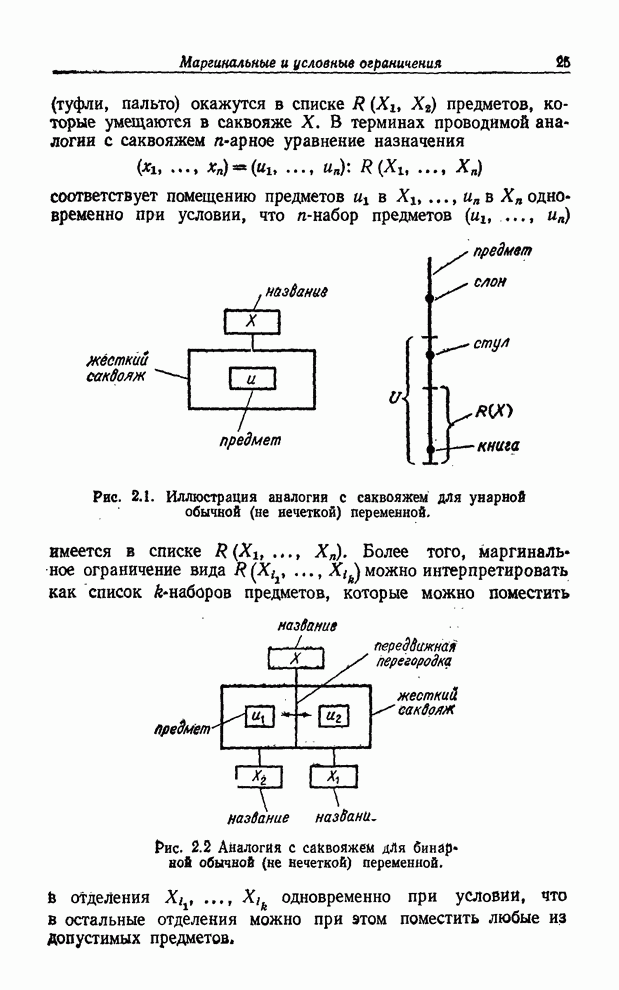
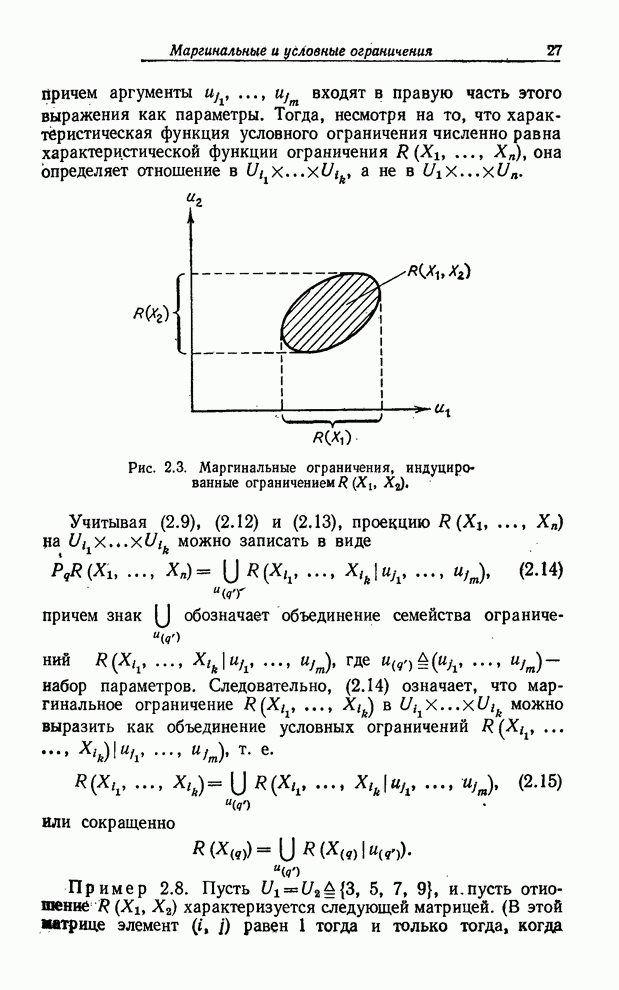
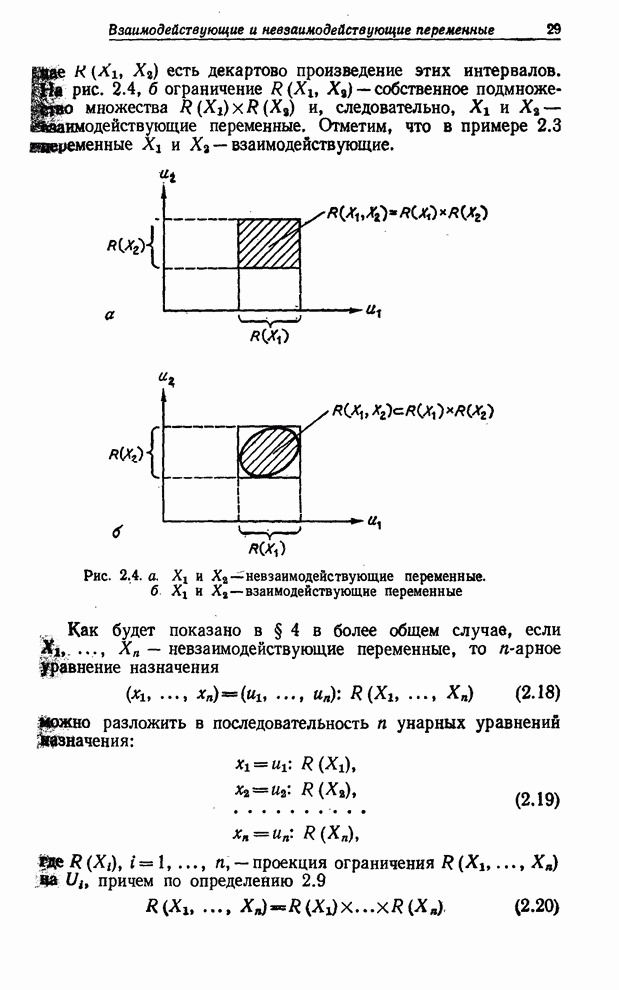
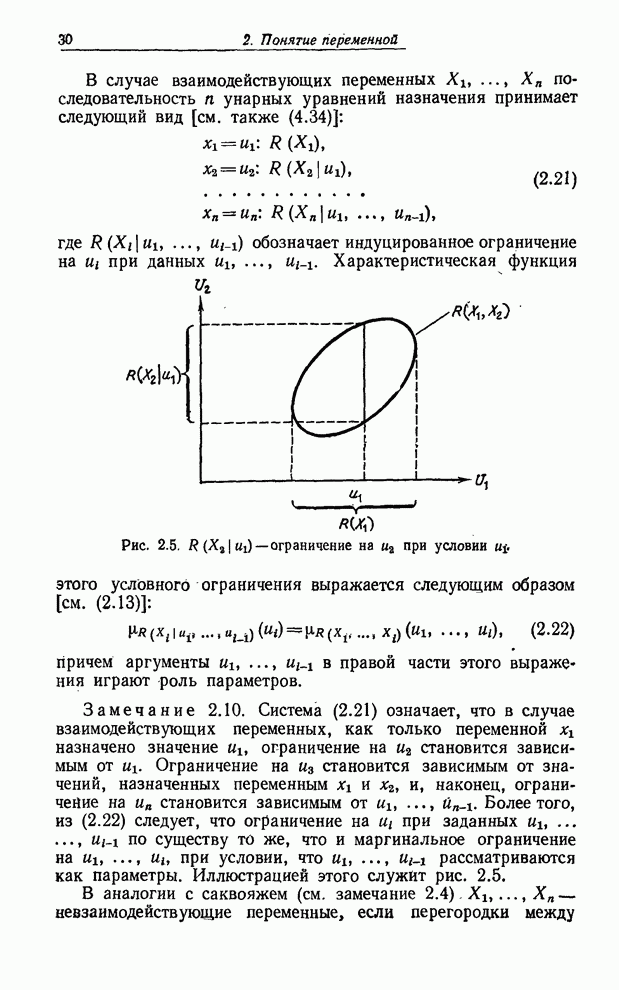
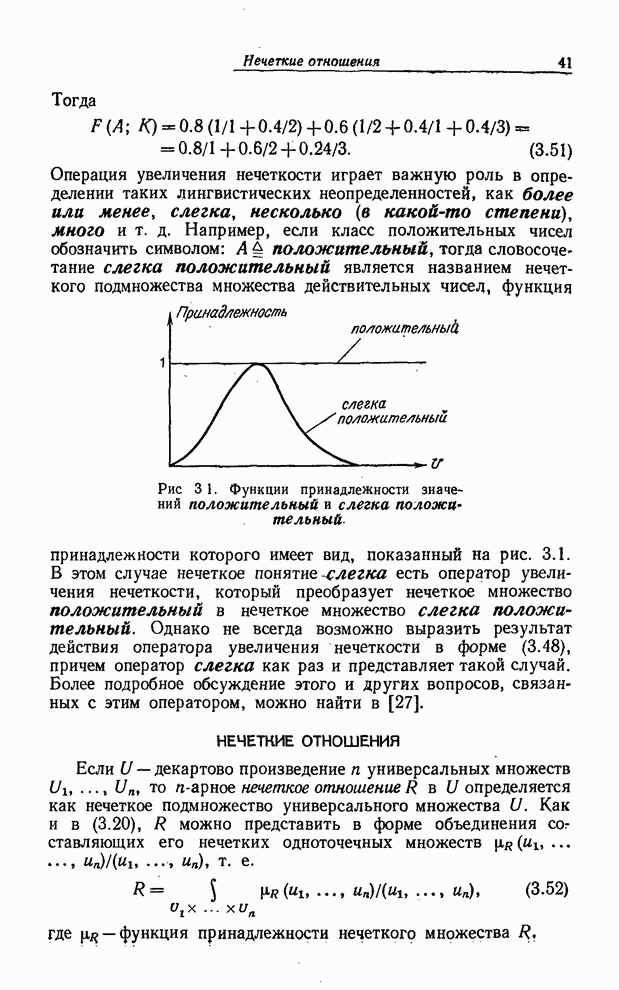
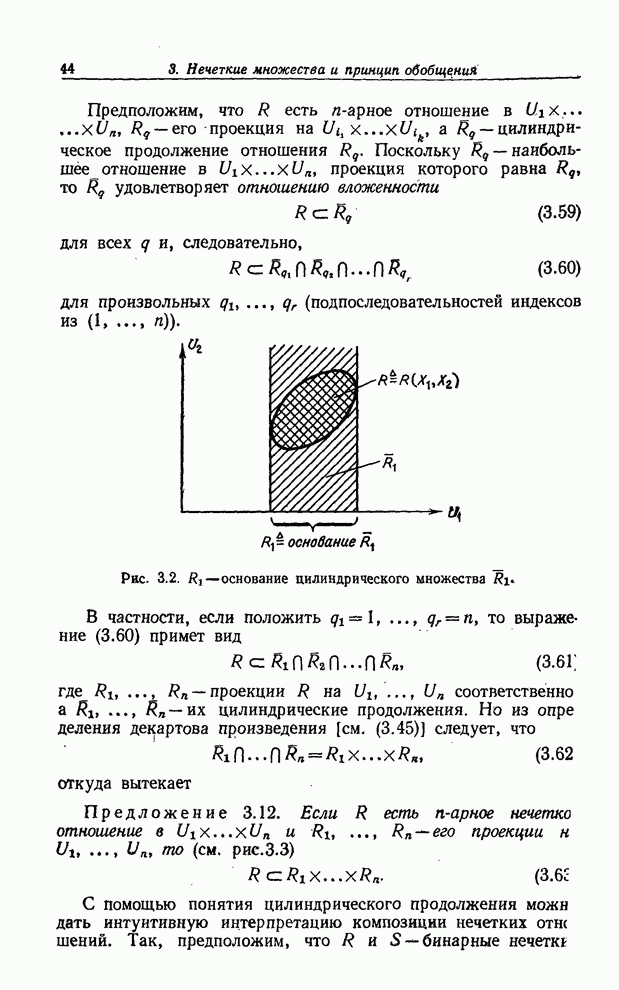
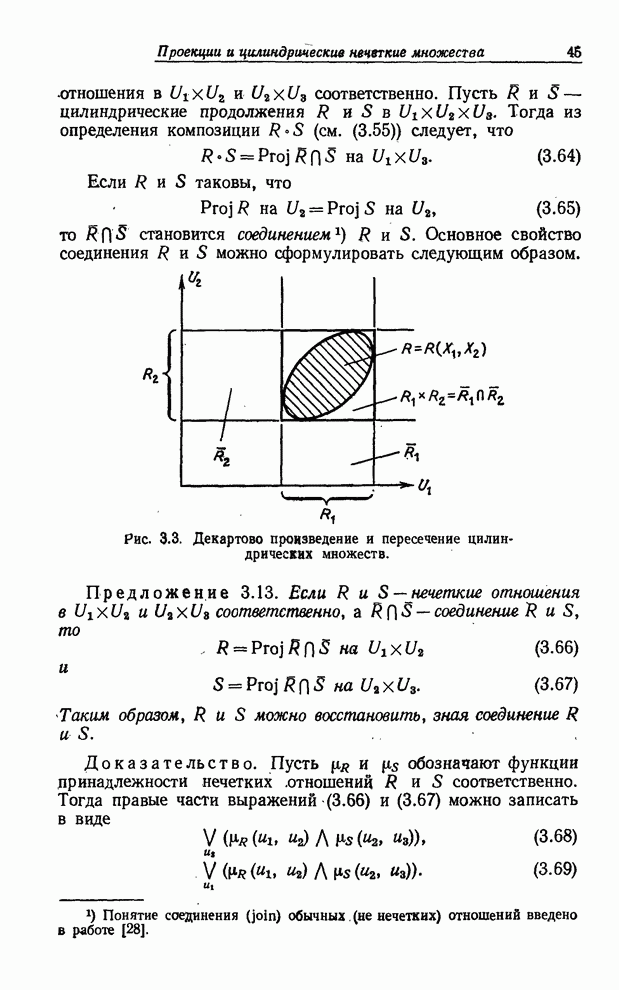
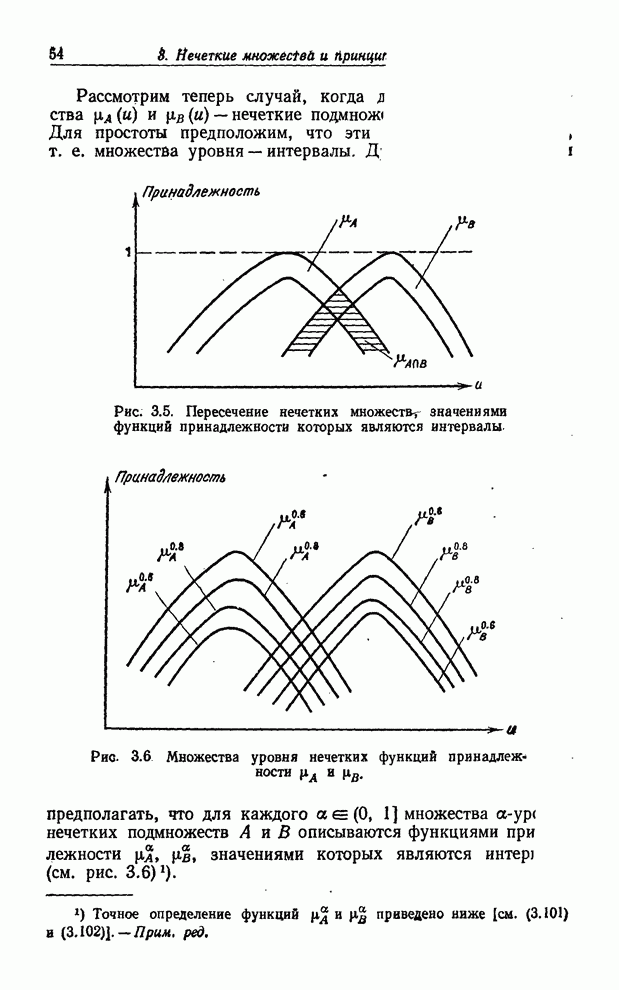
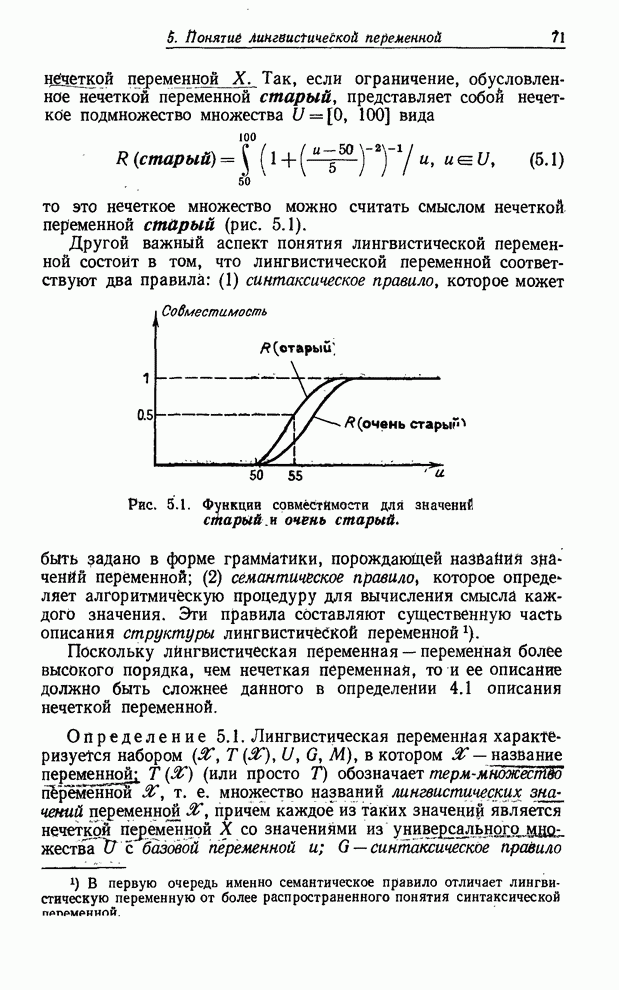
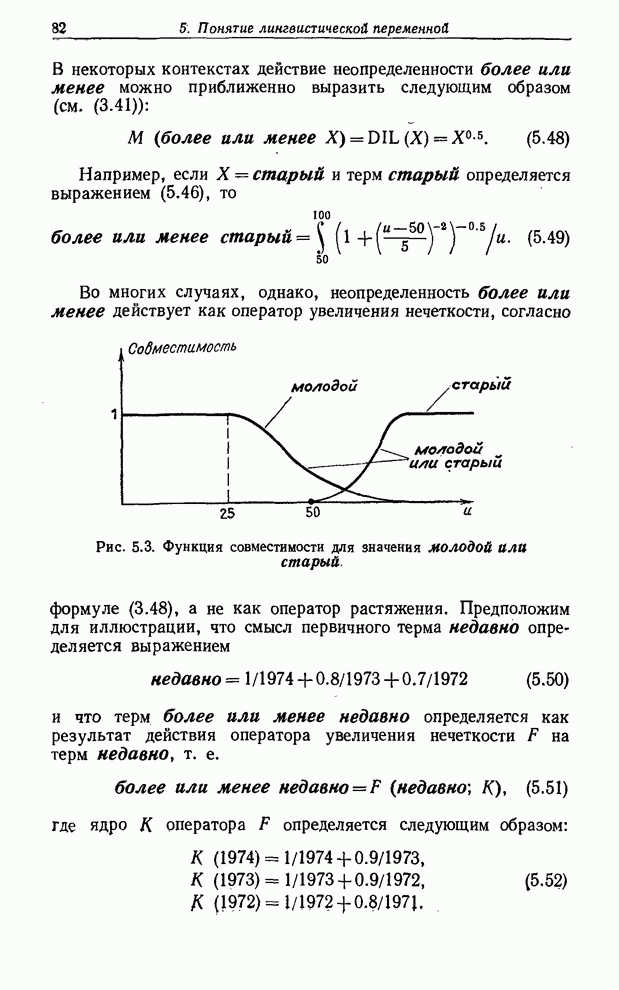
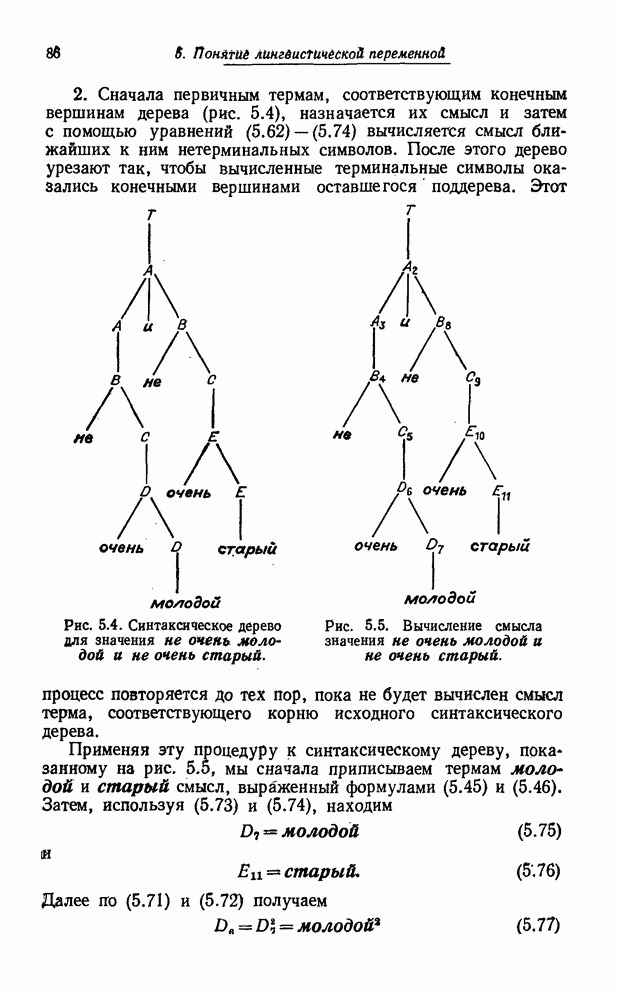
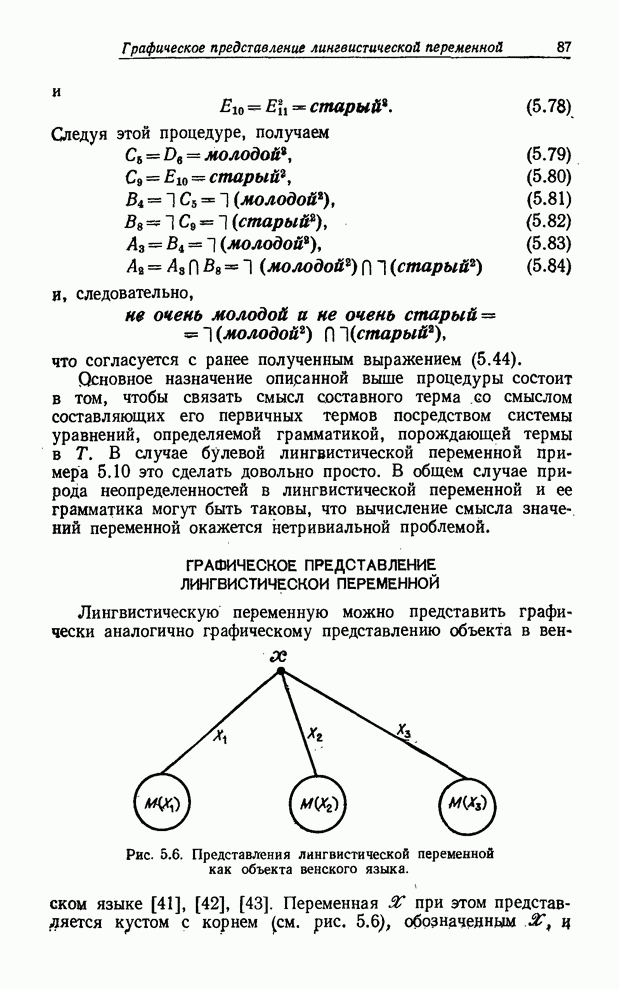
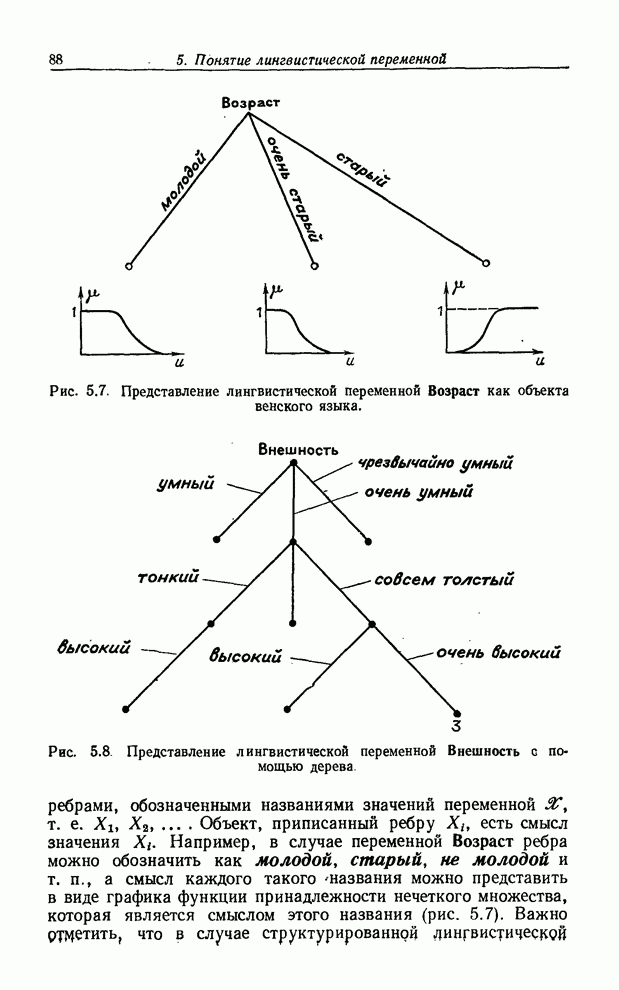
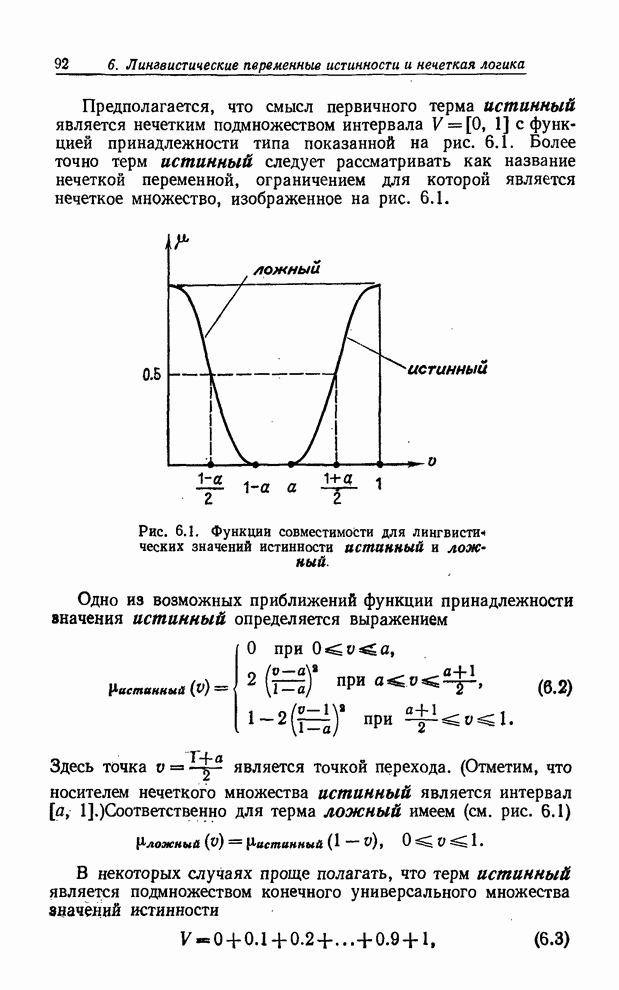
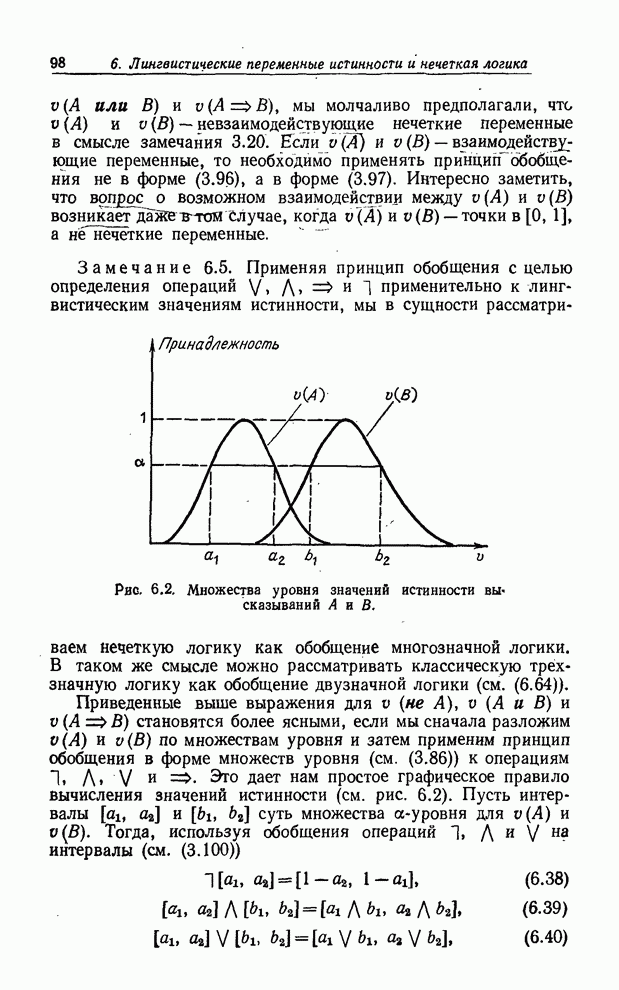
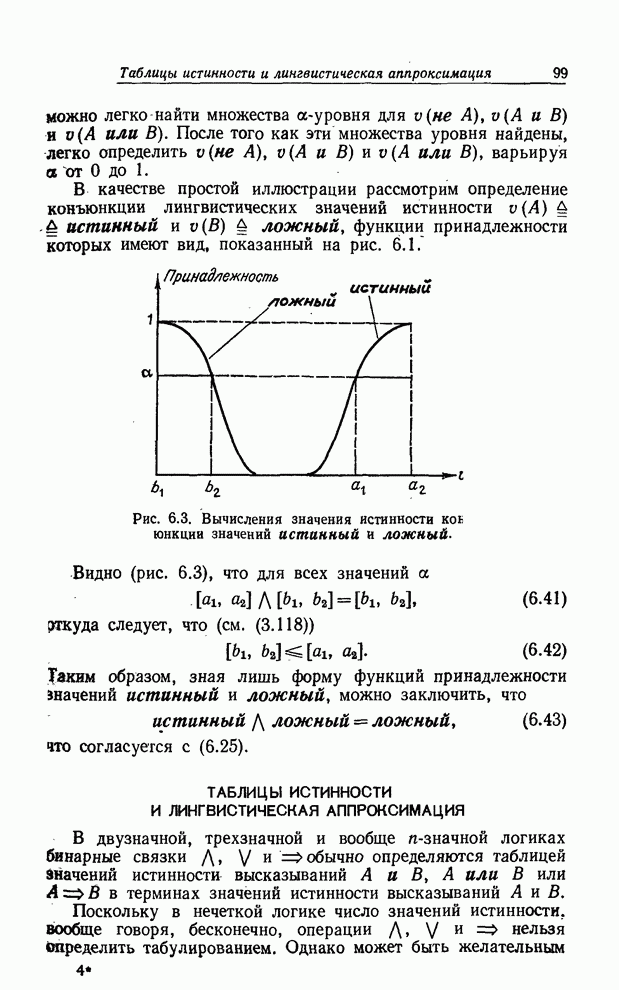
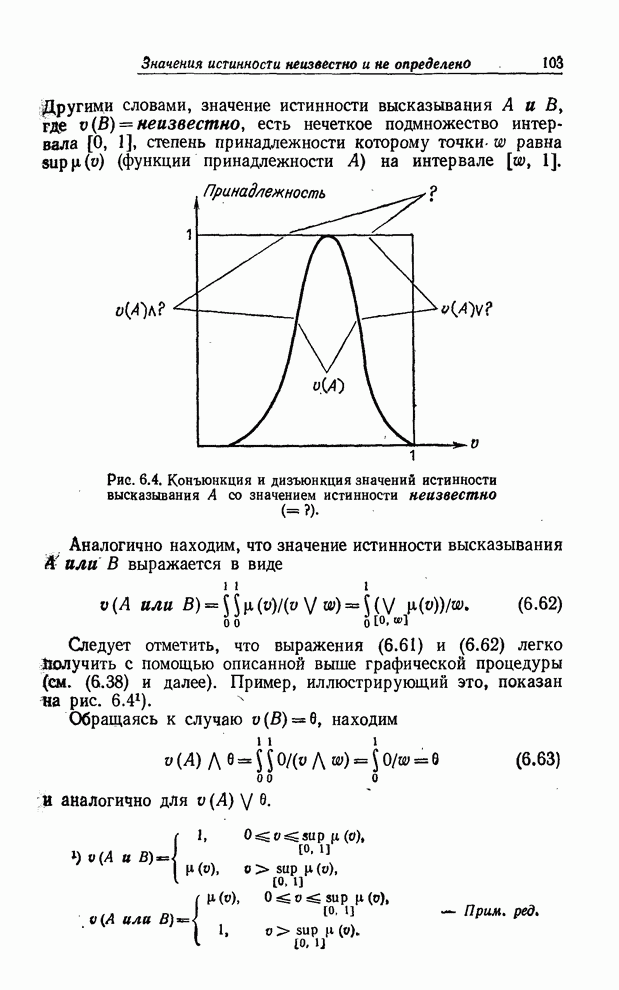
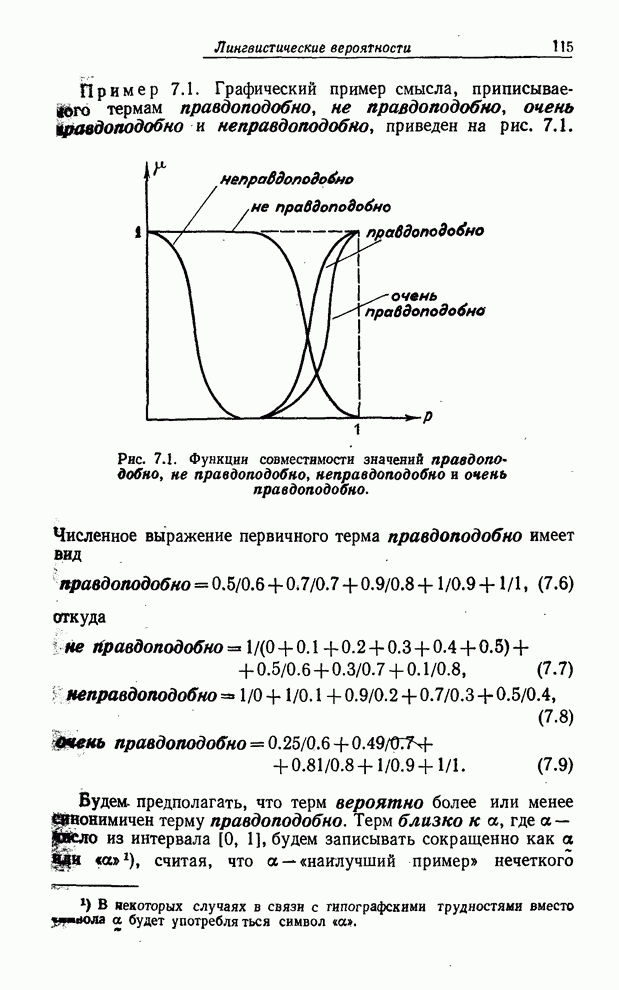
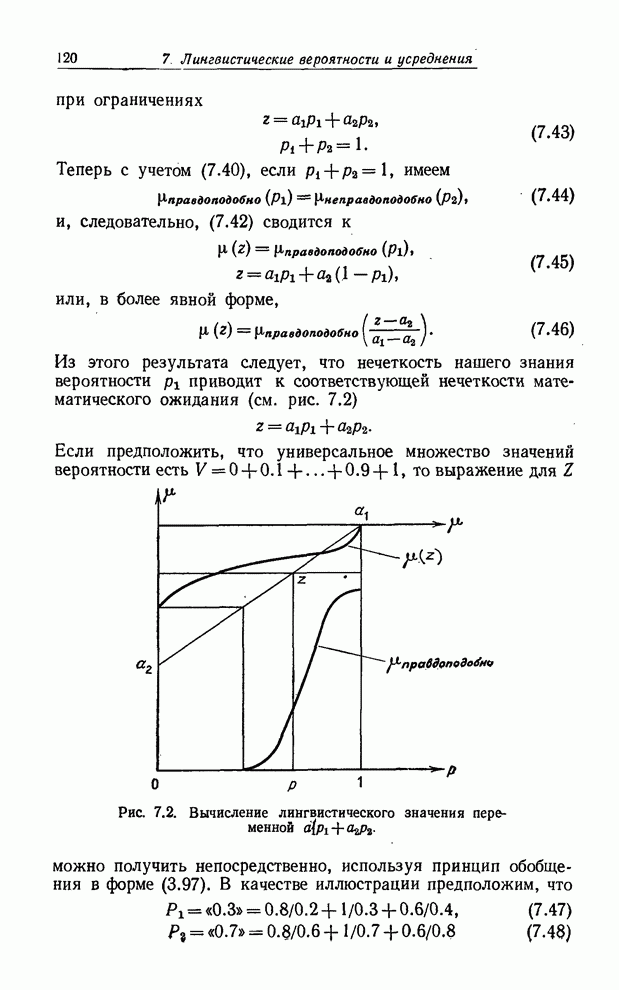
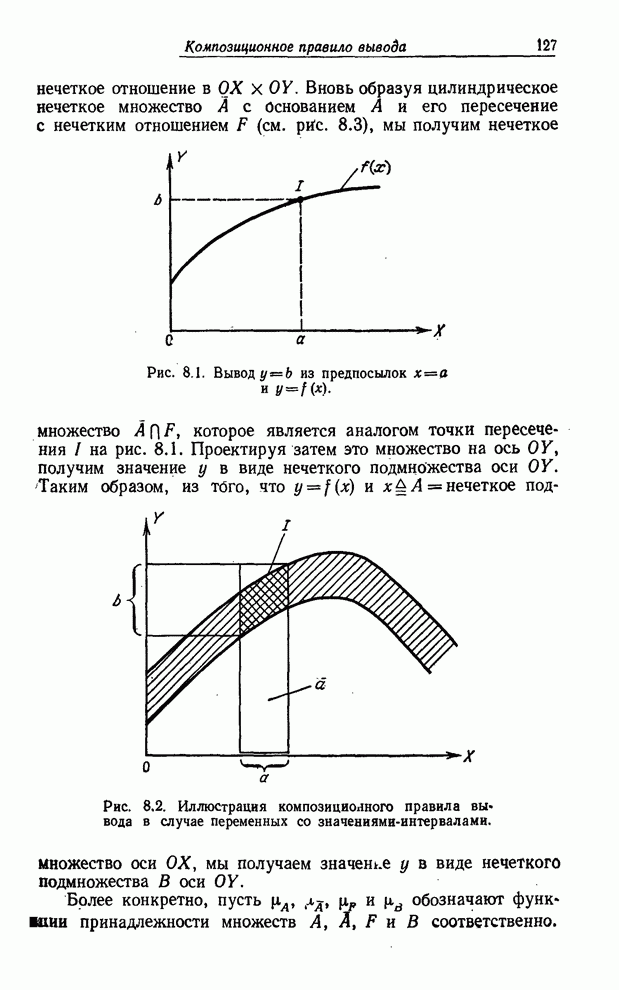
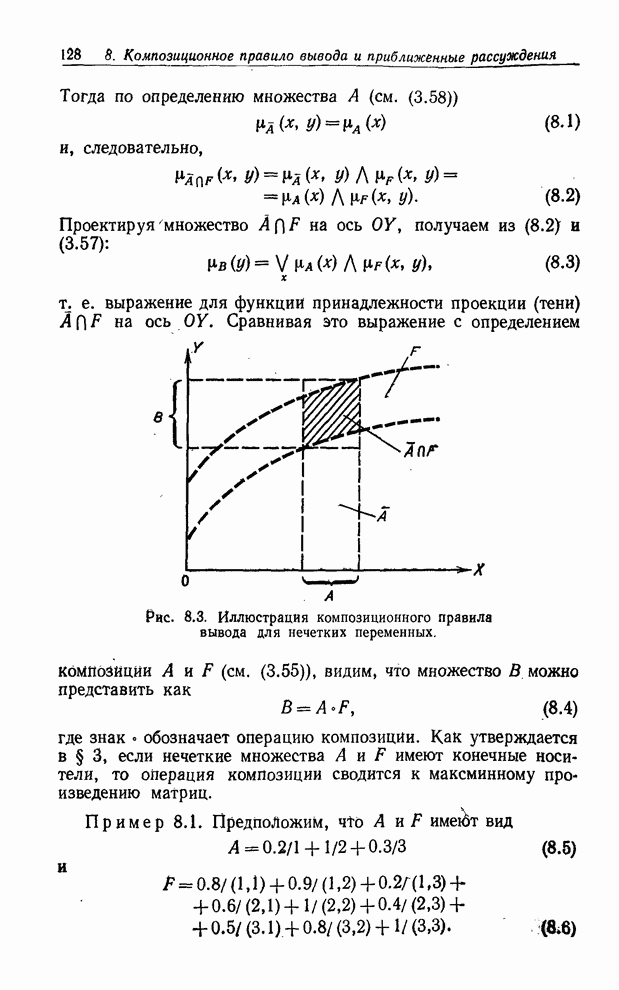
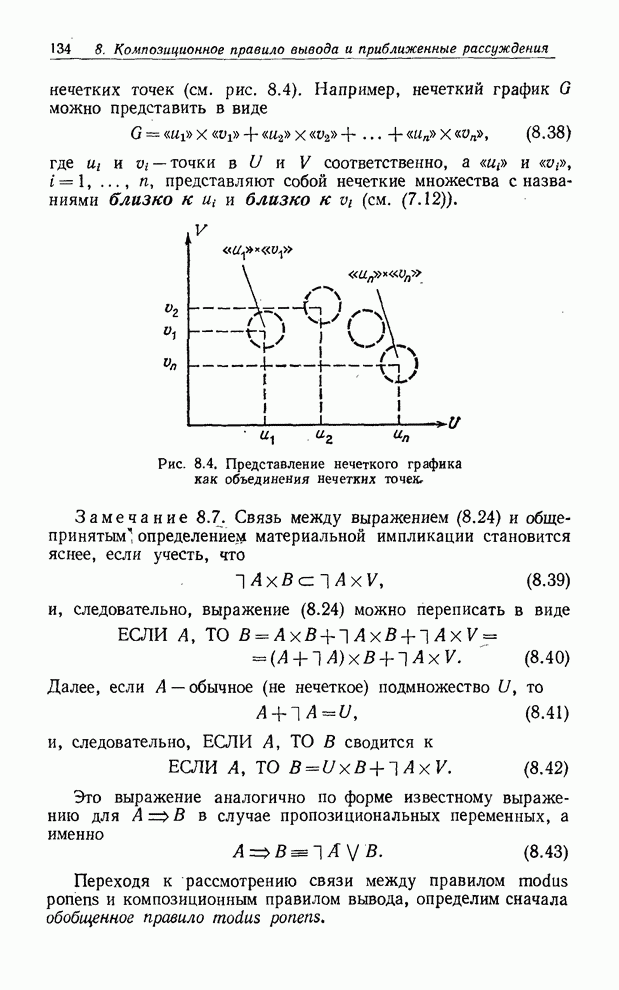
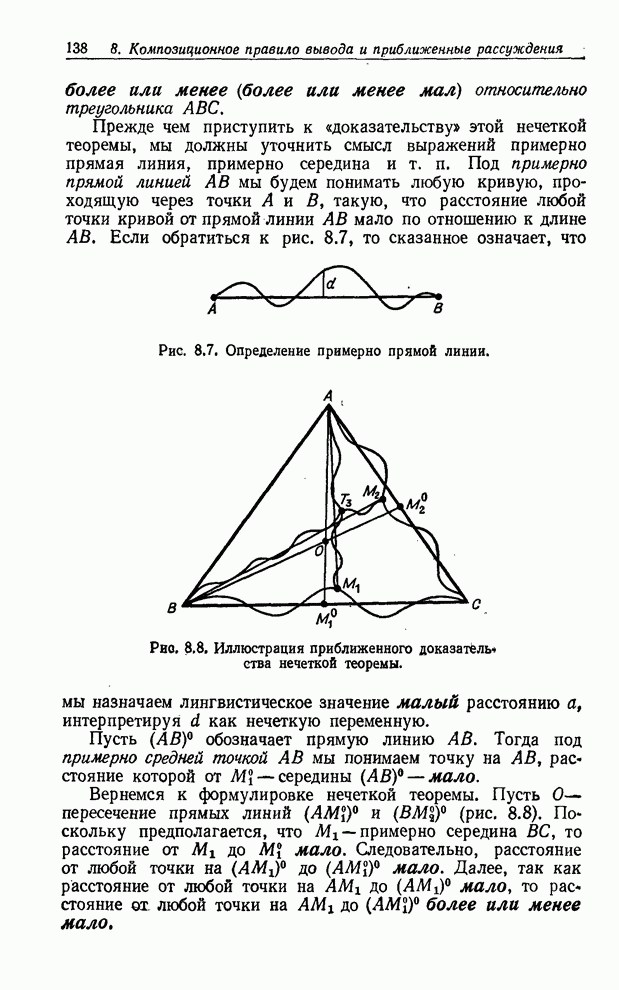
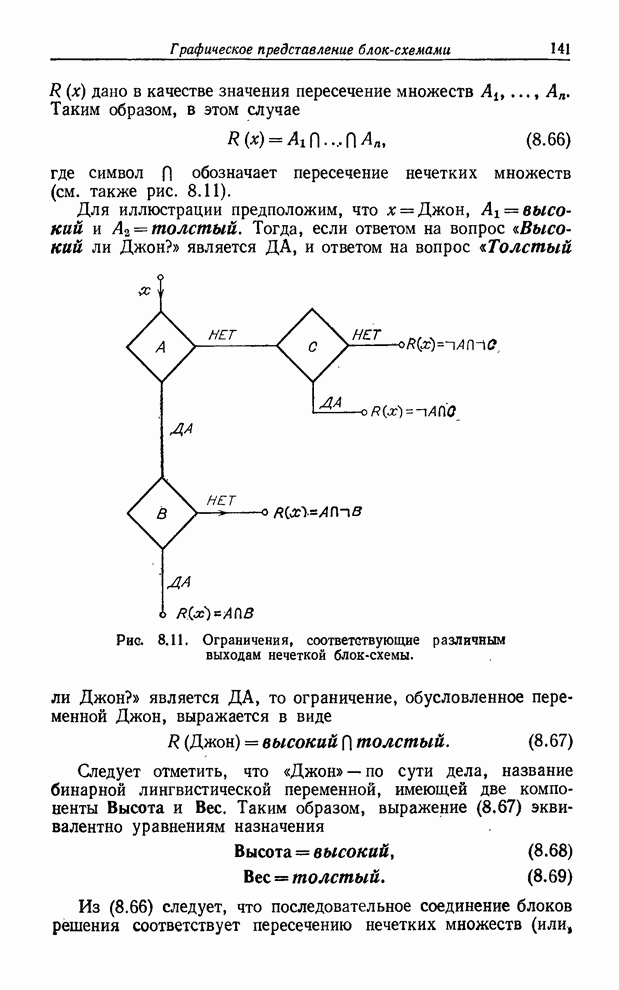
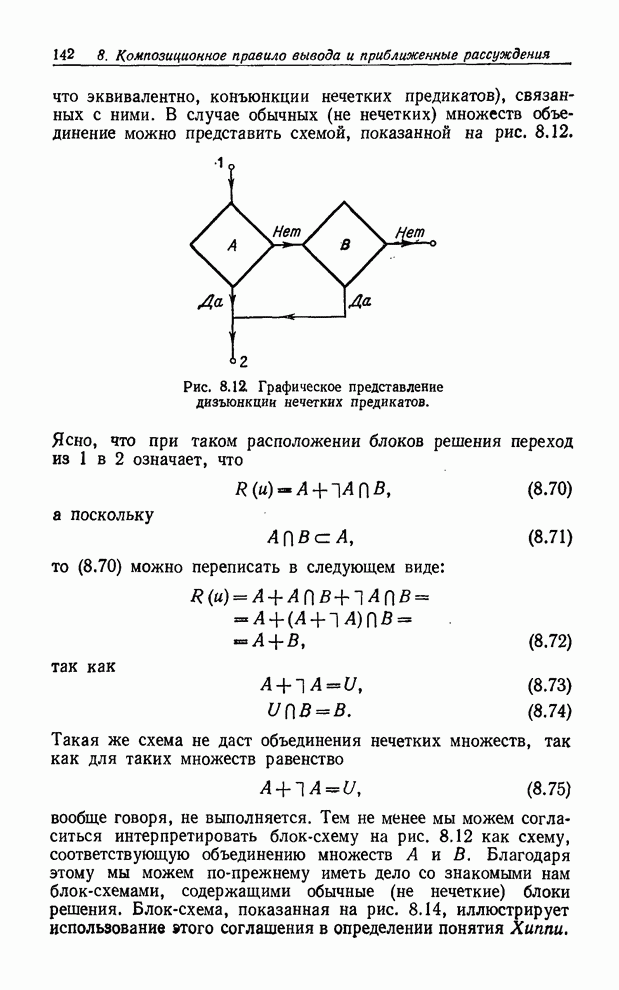
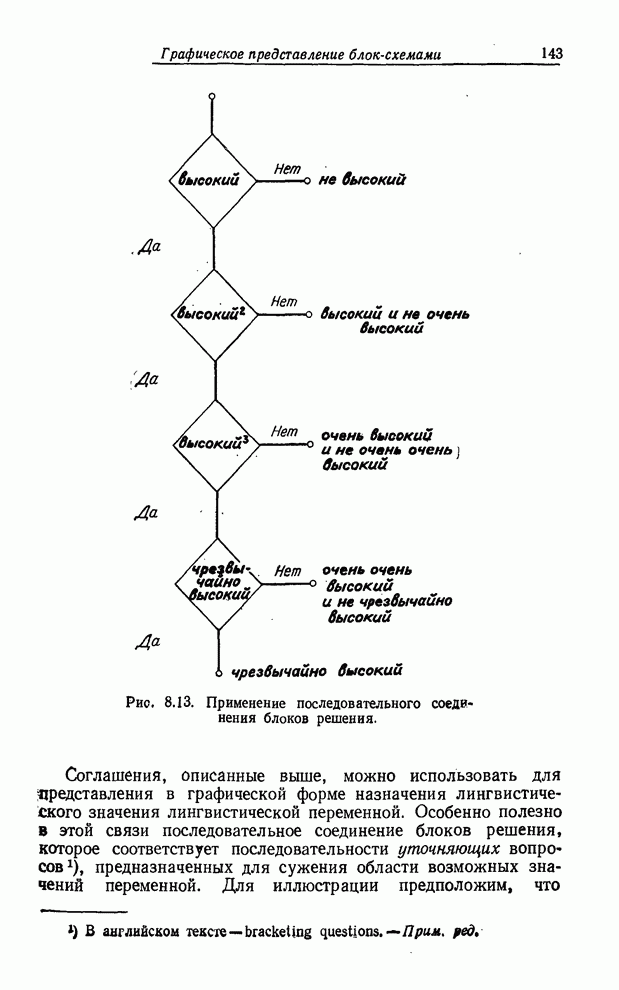
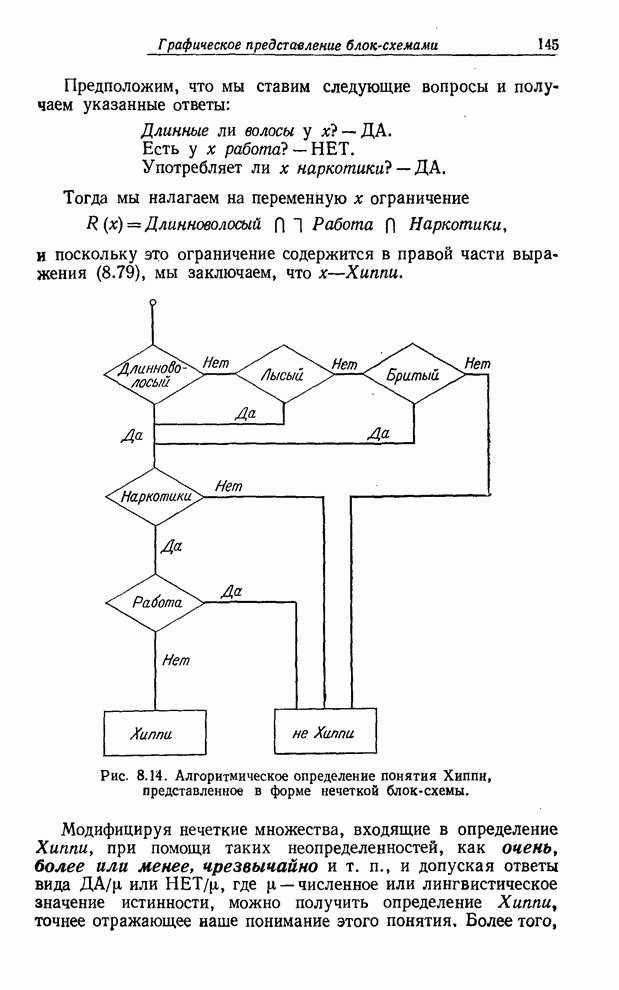
УСРЕДНЕНИЯ ПО НЕЧЕТКИМ МНОЖЕСТВАМ
Отправной точкой предшествующего изложения было предположение о
том, что каждому элементу  конечного универсального множества
конечного универсального множества  ставится в
соответствие значение
ставится в
соответствие значение  лингвистической вероятности, являющееся
компонентой списка значений лингвистических вероятностей
лингвистической вероятности, являющееся
компонентой списка значений лингвистических вероятностей  .
.
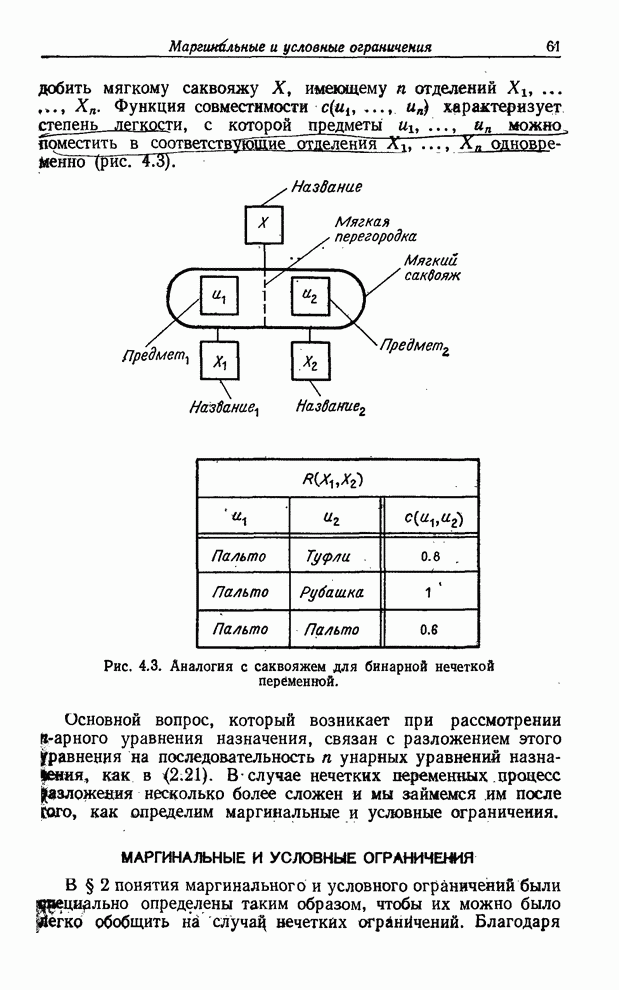
В данном контексте нечеткое подмножество  множества играет роль
нечеткого события. Пусть
множества играет роль
нечеткого события. Пусть  - степень принадлежности подмножеству. Тогда если
- степень принадлежности подмножеству. Тогда если  — обычные
вероятности
— обычные
вероятности  ,
то вероятность
,
то вероятность  события
определяется
как (см. [48]) (
события
определяется
как (см. [48]) ( арифметическая сумма)
арифметическая сумма)
 . (7.54)
. (7.54)
Естественно обобщить это определение на лингвистические вероятности,
определив лингвистическую вероятность события как
 , (7.55)
, (7.55)
понимая при этом правую часть выражения (7.55) как линейную форму
типа (7.27). В связи с выражением (7.55) необходимо отметить, что из
ограничения
 (7.56)
(7.56)
на рассматриваемые вероятности и того, что

следует, что — нечеткое подмножество интервала [0,
1].
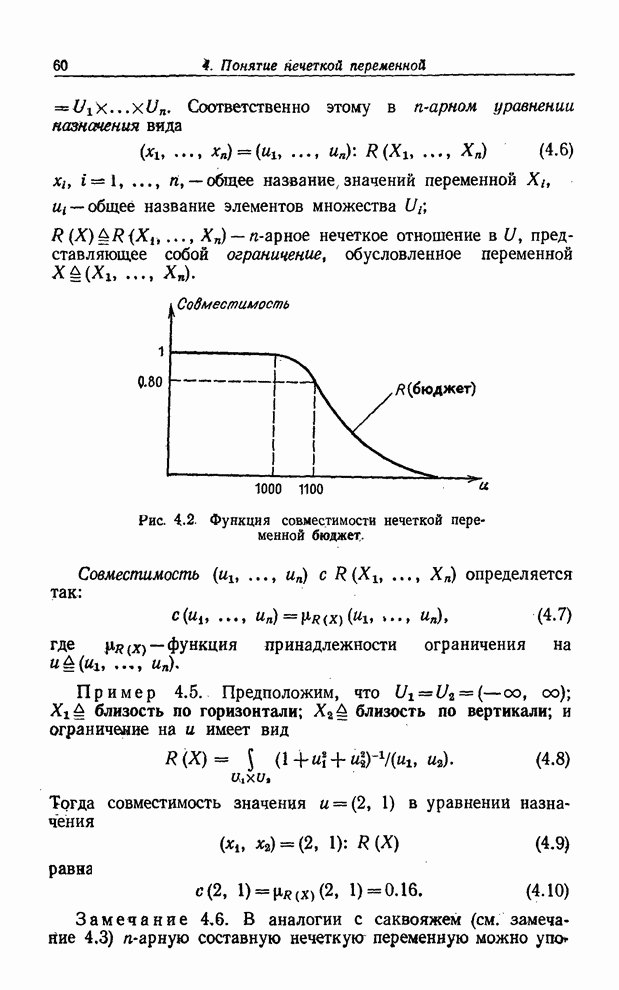
Пример 7.5.
Проиллюстрируем сказанное очень простым примером. Предположим, что
 ,
(7.57)
,
(7.57)
 ,
(7.58)
,
(7.58)
 , (7.59)
, (7.59)
 , (7.60)
, (7.60)
 . (7.61)
. (7.61)
Тогда ( арифметическая сумма)
арифметическая сумма)
 (7.62)
(7.62)
при ограничении
 . (7.63)
. (7.63)
Выбирая такие члены в (7.62), которые удовлетворяют (7.63),
получаем
 (7.64)
(7.64)
откуда
 . (7.65)
. (7.65)
выражение (7.65) можно грубо аппроксимировать равенством
 . (7.66)
. (7.66)
Лингвистическую вероятность нечеткого события, выраженную формулой
(7.55), можно рассматривать как частный случай более общего понятия, а именно
лингвистического среднего, или, что то же самое, лингвистического
математического ожидания функции (определенной на ) по нечеткому подмножеству
множества .
Более конкретно, пусть  — определенная на функция, принимающая
действительные значения; пусть — нечеткое подмножество множества , и пусть
— определенная на функция, принимающая
действительные значения; пусть — нечеткое подмножество множества , и пусть  — лингвистические
вероятности, соответствующие
— лингвистические
вероятности, соответствующие  . Тогда лингвистическое среднее
функции по
обозначается
как
. Тогда лингвистическое среднее
функции по
обозначается
как  и
определяется следующим образом ( арифметическая сумма):
и
определяется следующим образом ( арифметическая сумма):
 . (7.67)
. (7.67)
Рассмотрим следующий конкретный пример выражения (7.67).
Предположим, что люди с именами выбираются в соответствии с
лингвистическими вероятностями, где - ограничение
на  . Предположим,
что на накладывается
штраф в размере
. Предположим,
что на накладывается
штраф в размере  ,
уменьшенном пропорционально степени принадлежности классу . Тогда лингвистический
средний (ожидаемый) размер штрафа выражается формулой (7.67).
,
уменьшенном пропорционально степени принадлежности классу . Тогда лингвистический
средний (ожидаемый) размер штрафа выражается формулой (7.67).
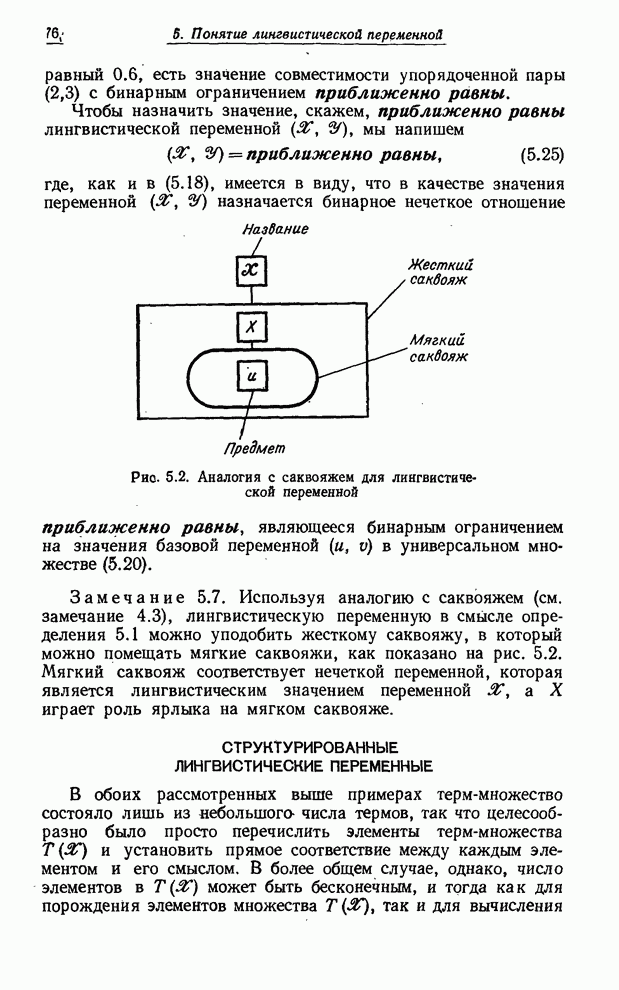
Замечание 7.6. Отметим, что (7.67) по
существу является линейной комбинацией вида (7.27), где
 . (7.68)
. (7.68)
аким образом, чтобы вычислить (7.67), можно использовать метод,
описанный ранее для вычисления линейных форм в лингвистических вероятностях. В
частности, следует отметить, что, когда  , правая часть (7.67) имеет вид
, правая часть (7.67) имеет вид
 . (7.69)
. (7.69)
сводится к.
Кроме выражения для выражение (7.67) содержит в себе в
качестве частных случаев и выражения для других средних, встречающихся в
различных приложениях. Среди них существуют два типа, которые можно
рассматривать как вырожденные формы (7.67) и которые часто встречаются во многих
задачах, представляющих практический интерес. Мы кратко остановимся на этих
типах средних и для удобства сформулируем их определения в форме ответов на
вопросы.
Вопрос 7.7.
Каково число элементов в данном нечетком множестве ? Очевидно, этот вопрос
поставлен некорректно, поскольку в случае нечеткого множества не существует
четкой границы между принадлежностью и непринадлежностью элемента множеству.
Тем не менее понятие мощности нечеткого множества [49], определяемое как
 , (7.70)
, (7.70)
является естественным обобщением понятия числа элементов .
Для иллюстрации предположим, что — универсальное множество жителей в
городе, а —
нечеткое множество безработных в этом городе. Если интерпретировать как степень
принадлежности человека классу безработных (например, =0.5, если занял половину
рабочего времени и ищет работу с полным рабочим днем), то  можно интерпретировать как
эквивалентное число полностью безработных.
можно интерпретировать как
эквивалентное число полностью безработных.
Вопрос 7.8.
Предположим, что —
функция, принимающая действительные значения и определенная на . Каково среднее
значение на
нечетком подмножестве множества ?
Будем пользоваться теми же обозначениями, что и в выражении
(7.67). Пусть (обозначает
среднее значение функции на . Если бы было обычным (не нечетким) множеством,
то выражалось
бы формулой
 , (7.71)
, (7.71)
где  обозначает
суммирование по тем , которые принадлежат , а — число этих
элементов. Чтобы обобщить (7.71) на нечеткие множества, заметим, что (7.71)
можно переписать так:
обозначает
суммирование по тем , которые принадлежат , а — число этих
элементов. Чтобы обобщить (7.71) на нечеткие множества, заметим, что (7.71)
можно переписать так:
 , (7.72)
, (7.72)
где  —
характеристическая функция множества . Тогда (7.72) можно принять в качестве
определения для
нечеткого множества , если интерпретировать как степень
принадлежности
—
характеристическая функция множества . Тогда (7.72) можно принять в качестве
определения для
нечеткого множества , если интерпретировать как степень
принадлежности  множеству
. При этом
мы приходим к выражению для, которое можно рассматривать как
частный случай выражения (7.67).
множеству
. При этом
мы приходим к выражению для, которое можно рассматривать как
частный случай выражения (7.67).
Проиллюстрируем (7.72) следующим примером. Предположим, что — полное множество
жителей в городе и
— нечеткое подмножество молодых жителей; кроме того, предположим, что — заработок жителя . Тогда средний
заработок молодых жителей города выражается формулой (7.72).
Замечание 7.9. Поскольку выражение для
есть
линейная форма переменных мощность нечеткого множества типа 2
(см. определение 3.22) можно легко подсчитать методом, которым мы пользовались
ранее для вычисления .
В случае , однако, мы имеем дело с отношением
линейных форм, и, следовательно, вычисление для нечетких множеств типа 2
представляет собой более трудную отдачу.
Целью предыдущего изложения было показать, что понятие
лингвистической переменной служит основой для определения вероятностей и в
сочетании с принципом обобщения может быть использовано для вычисления линейных
комбинаций разных вероятностей. Мы не будем больше останавливаться в этом
вопросе и в последующем изложении обратим внимание на основное правило вывода в
нечеткой логике.