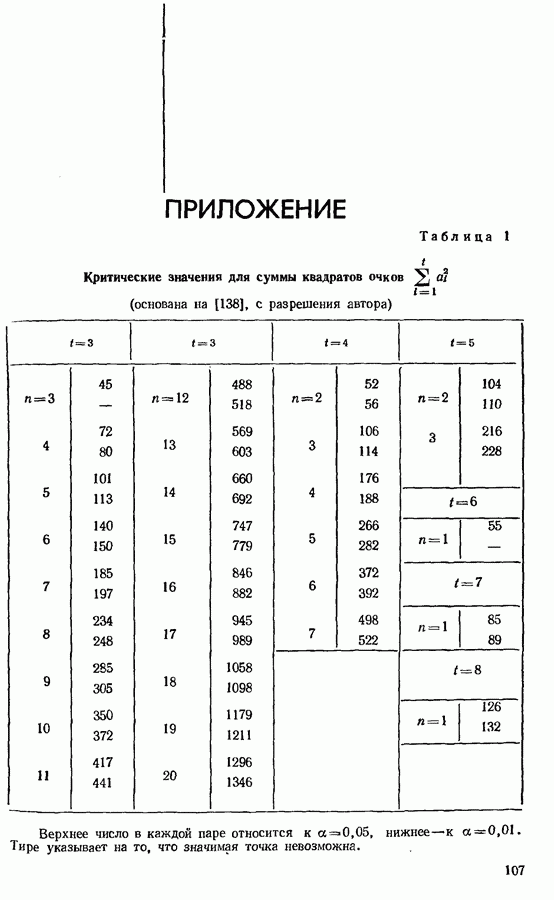
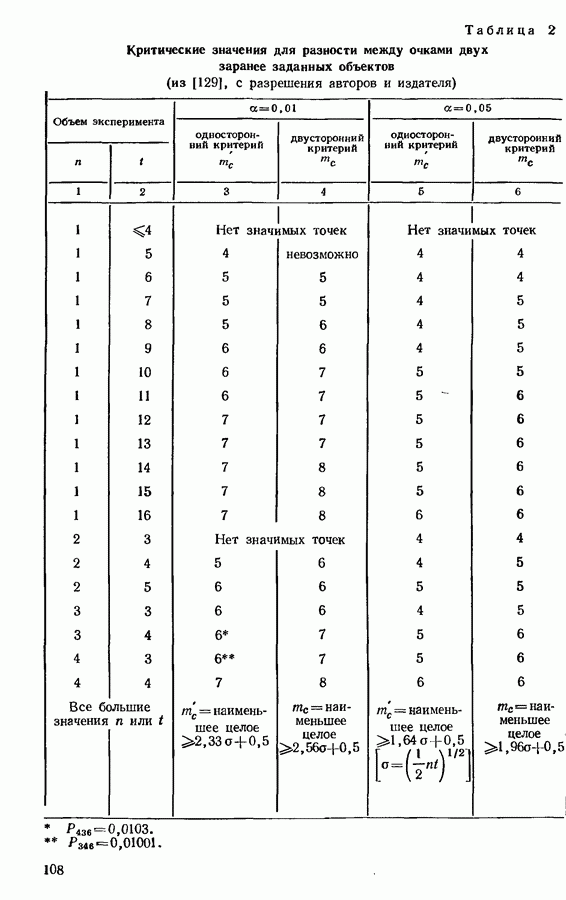
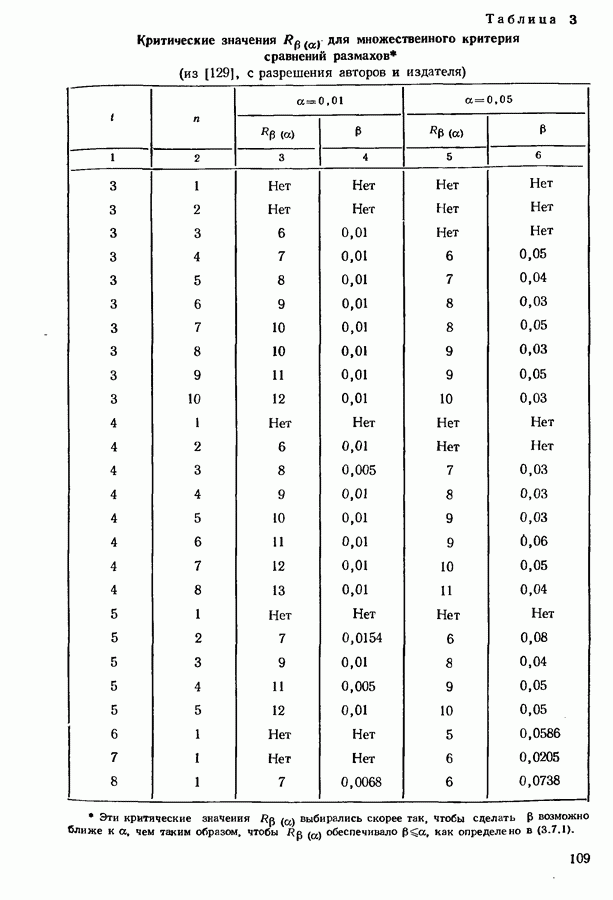
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
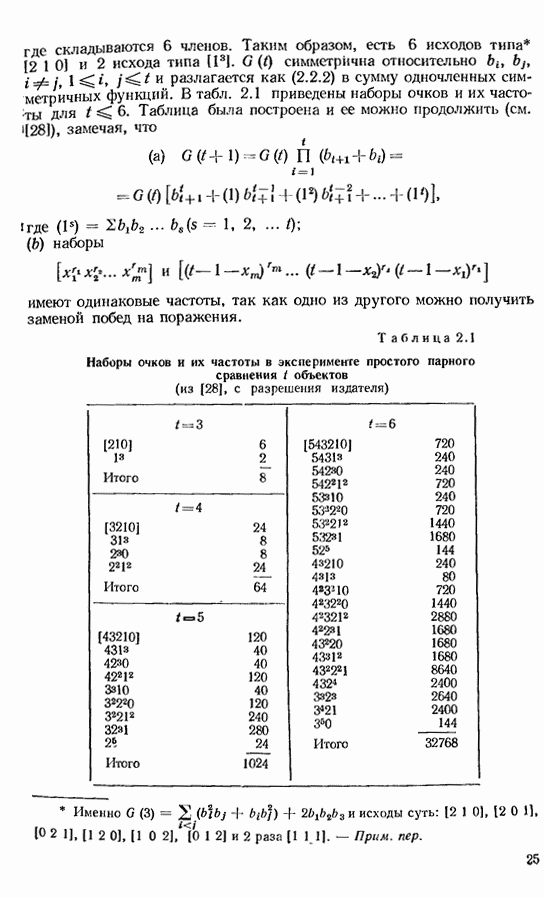
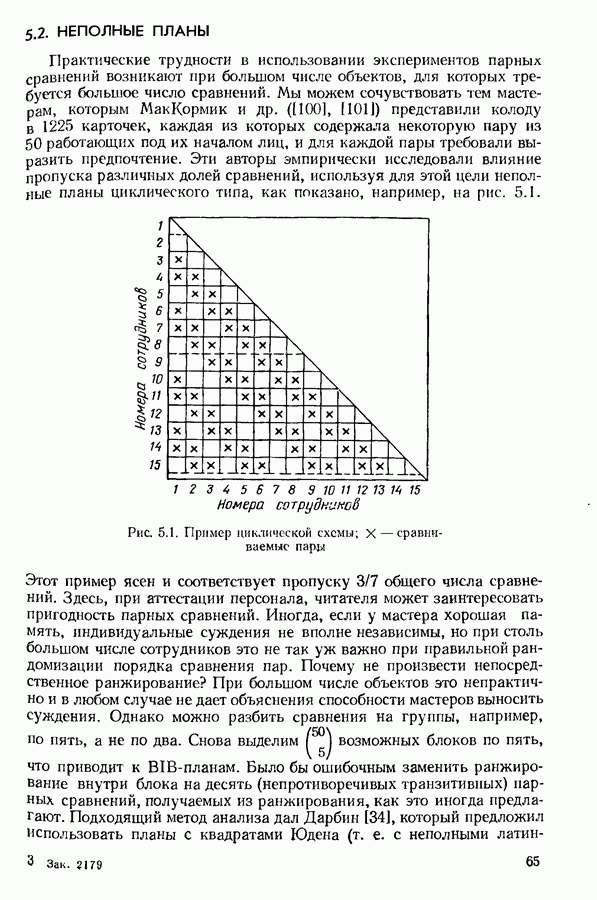
1.3. ОСНОВНЫЕ МОДЕЛИ
Предшествующее обсуждение можно формализовать в виде ряда подходящих моделей, которые накладывают все более жестки? ограничения на вероятности предпочтений. Предположим, что  объектов
объектов  сравниваются попарно каждым из
сравниваются попарно каждым из  экспертов и эксперт с номером у делает
экспертов и эксперт с номером у делает  повторных сравнении для каждой из
повторных сравнении для каждой из  возможностей. Пусть
возможностей. Пусть

типичная случайная величина, принимающая значение 1 или  в зависимости
в зависимости  того, предпочитает ли эксперту
того, предпочитает ли эксперту  или
или  сравнении двух объектов. Мы постулируем всюду, что все сравнения статистически независимы, так что
сравнении двух объектов. Мы постулируем всюду, что все сравнения статистически независимы, так что  взаимно независимы, если не считать того, что
взаимно независимы, если не считать того, что  Пусть
Пусть

Есть лишь такие ограничения на 

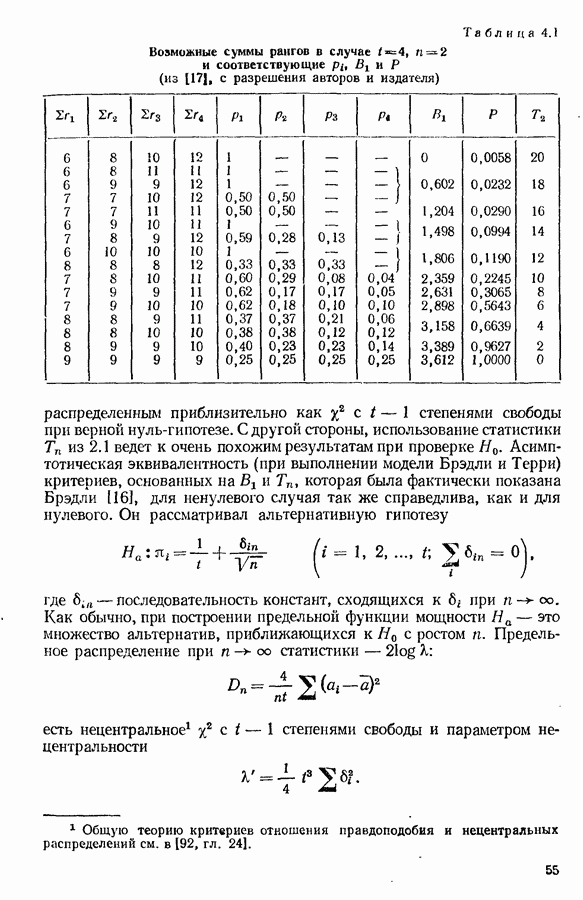
Представляют интерес очевидные частные случаи:

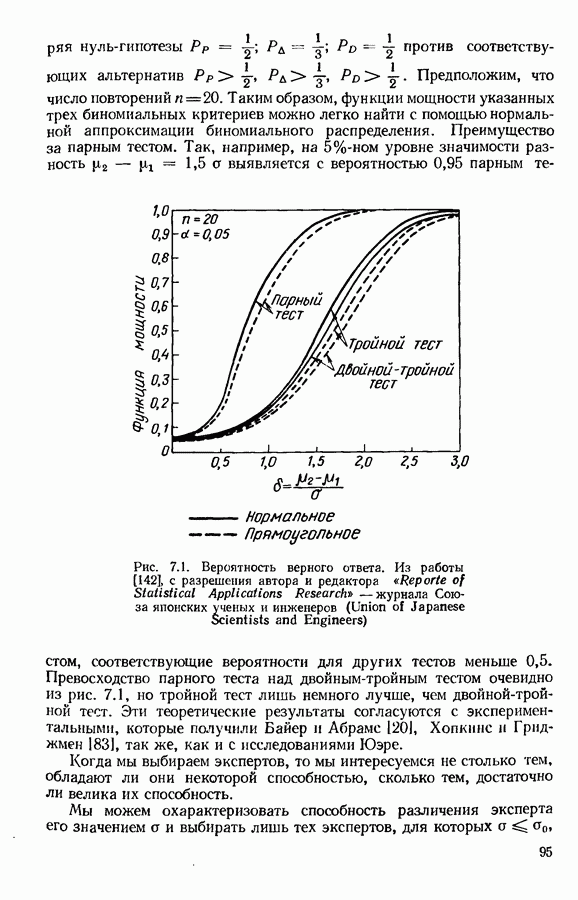
Если, как это бывает, эффект повторений незначителен, что не относится к различиям между экспертами, последняя модель все еще
слишком обща для описания единичного предпочтения  Возможный эффект, обусловленный порядком представления объектов в паре, игнорируется в этой книге (см., однако, 7.4). Если применима модель (1.3.4), объекты могут быть проранжированы в соответствии со значениями средних вероятностей предпочтения
Возможный эффект, обусловленный порядком представления объектов в паре, игнорируется в этой книге (см., однако, 7.4). Если применима модель (1.3.4), объекты могут быть проранжированы в соответствии со значениями средних вероятностей предпочтения

причем суммирование распространяется на все значения  кроме
кроме  Здесь из не следует ли фактически
Здесь из не следует ли фактически  может принимать все значения от
может принимать все значения от  до 1. Другой способ ранжирования возможен, если для каждой тройки разных объектов
до 1. Другой способ ранжирования возможен, если для каждой тройки разных объектов  к выполняются следующие условия стохастической транзитивности:
к выполняются следующие условия стохастической транзитивности:

Условия (1.3.6) ведут к вполне определенному упорядочению каждой тройки и, следовательно, всех  объектов. Легко видеть, что эта ранжировка не обязательно совпадает с тем, что получается из (1.3.5).
объектов. Легко видеть, что эта ранжировка не обязательно совпадает с тем, что получается из (1.3.5).
Более строгой, чем (1.3.6), является модель усиленной стохастической транзитивности:

Если к (1.3.7) мы добавим:

то  при
при  если
если  Тогда объекты
Тогда объекты  можно представить точками на прямой, на которой вероятность предпочтения, соответствующая интервалу
можно представить точками на прямой, на которой вероятность предпочтения, соответствующая интервалу  будет
будет

больше, чем вероятности, соответствующие подынтервалам (собственным)  а (1.3.8) относится к совпадающим точкам. Это представление легко распространить на все
а (1.3.8) относится к совпадающим точкам. Это представление легко распространить на все  объектов на одной прямой. Равные расстояния не обязательно соотносятся с равными вероятностями, но их можно сделать равными подходящим растяжением прямой, что ведет к линейной модели.
объектов на одной прямой. Равные расстояния не обязательно соотносятся с равными вероятностями, но их можно сделать равными подходящим растяжением прямой, что ведет к линейной модели.
Интересный случай, когда можно ожидать стохастической, но не усиленной стохастической транзитивности, упоминается в [25]. Для
иллюстрации этой, конечно, более общей ситуации, положим, что  три серых объекта с уменьшающейся интенсивностью цвета. Эксперта просят дать предпочтение в каждом парном сравнении тому объекту, который, как он считает, лучше представляет серый цвет. Здесь кажется разумным предположить, что эксперт имеет некий идеал серого цвета и ранжирует другие оттенки по степени их близости к этому идеалу. Если относительное расположение объектов на шкале «серости» такое, как показано ниже,
три серых объекта с уменьшающейся интенсивностью цвета. Эксперта просят дать предпочтение в каждом парном сравнении тому объекту, который, как он считает, лучше представляет серый цвет. Здесь кажется разумным предположить, что эксперт имеет некий идеал серого цвета и ранжирует другие оттенки по степени их близости к этому идеалу. Если относительное расположение объектов на шкале «серости» такое, как показано ниже,

то  но
но  может получиться также меньше, чем
может получиться также меньше, чем  потому что сравнения по одну сторону от идеала более надежны, чем на противоположных сторонах. Это экспериментально подтверждено Кумбсом. Аналогичного эффекта можно опасаться, когда тремя объектами служат часы стоимостью 10 фунтов, 12 фунтов и еще незначительно большей (но неизвестной) стоимости (см. также [99]).
потому что сравнения по одну сторону от идеала более надежны, чем на противоположных сторонах. Это экспериментально подтверждено Кумбсом. Аналогичного эффекта можно опасаться, когда тремя объектами служат часы стоимостью 10 фунтов, 12 фунтов и еще незначительно большей (но неизвестной) стоимости (см. также [99]).
Линейная модель
Предположим, что объект  обладает истинной ценностью или «заслугой» при оценке по некоторому признаку. Можно представить
обладает истинной ценностью или «заслугой» при оценке по некоторому признаку. Можно представить  истинных ценностей
истинных ценностей  точками на шкале ценностей. Наблюдаемая (эмпирическая) ценность объекта
точками на шкале ценностей. Наблюдаемая (эмпирическая) ценность объекта  будет меняться от наблюдения к наблюдению и может быть представлена на некоторой шкале как непрерывная случайная величина
будет меняться от наблюдения к наблюдению и может быть представлена на некоторой шкале как непрерывная случайная величина  . В парном сравнении
. В парном сравнении  первый из объектов будет предпочитаться второму, если
первый из объектов будет предпочитаться второму, если  второй — первому, если
второй — первому, если  Если можно построить шкалу ценностей так, чтобы вероятность предпочтения
Если можно построить шкалу ценностей так, чтобы вероятность предпочтения

выражалась для всех  как
как  где
где  возрастает монотонно от
возрастает монотонно от  до
до  то можно говорить, что вероятности предпочтений удовлетворяют условиям линейной модели. Очевидно,
то можно говорить, что вероятности предпочтений удовлетворяют условиям линейной модели. Очевидно,  функция распределения случайной величины, симметричной относительно нуля.
функция распределения случайной величины, симметричной относительно нуля.
Поскольку функция  делает
делает  зависящими лишь от разностей
зависящими лишь от разностей  все
все  могут быть выражены как функции
могут быть выражены как функции  независимых разностей
независимых разностей  соответствующими
соответствующими  . В силу этого ценности удобно представлять
. В силу этого ценности удобно представлять  точками на линейной шкале с произвольным началом отсчета, отсюда термин «линейная». Мы можем также говорить, что изучаемый показатель удовлетворяет линейной модели или построен в соответствии с линейной шкалой, если ценность
точками на линейной шкале с произвольным началом отсчета, отсюда термин «линейная». Мы можем также говорить, что изучаемый показатель удовлетворяет линейной модели или построен в соответствии с линейной шкалой, если ценность
любого объекта (а не только  объектов
объектов  может быть представлена на этой шкале.
может быть представлена на этой шкале.
Линейная модель — это обобщение модели Тзрстоуна-Мостеллера, в котором предполагается, что  нормально распределенные случайные величины
нормально распределенные случайные величины  равно коррелированные с коэффициентом парной корреляции
равно коррелированные с коэффициентом парной корреляции  Это приводит к интегралу
Это приводит к интегралу

где

Другой важный частный случай задается моделью Брэдли-Терри [13], для которой

где в обозначениях Брэдли  отсюда следует, что
отсюда следует, что 
Бранк [18] высказал интересную точку зрения, что ценности («стоимости» в его терминологии) объектов играют роль некоторых аналог  «главных эффектов» в дисперсионном анализе. Предположение, что они определяют вероятности предпочтений, вполне аналогично гипотезе об отсутствии взаимодействий в дисперсионном анализе. Можно сказать, что величины V — это действительные ценности объектов в противоположность ситуации, примером которой служит (1.3.5), где ценности объектов детерминируются вероятностями предпочтений.
«главных эффектов» в дисперсионном анализе. Предположение, что они определяют вероятности предпочтений, вполне аналогично гипотезе об отсутствии взаимодействий в дисперсионном анализе. Можно сказать, что величины V — это действительные ценности объектов в противоположность ситуации, примером которой служит (1.3.5), где ценности объектов детерминируются вероятностями предпочтений.