Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Глава 4. КЛАССИЧЕСКИЕ МЕТОДЫ РЕШЕНИЯ ЗАДАЧВведениеСуществуют четыре основных способа решения какой-либо задачи: 1. Применение явной формулы. 2. Использование рекурсивного определения. 3. Использование алгоритма. 4. Метод перебора, метод проб и ошибок и др. Несомненно, первый способ является “наилучшим”: мы используем найденную и доказанную ранее формулу, которая во всех случаях дает решение поставленной задачи. К подобному “лобовому” подходу сводится решение таких задач, как определение нулей квадратного уравнения, определение названия дня, соответствующего произвольной дате, определение силы тока в заданной электрической схеме. Собственно задача математики и состоит в том, чтобы найти явные формулы для решения как можно большего числа возможных задач. Если такая формула существует, сложность задачи оказывается связанной с эффективностью вычислений. По определению в формулу может входить только конечное число символов и операций, и это верно для любого числа параметров, включенных в эту формулу, т. е. для любой размерности 4.1. Примеры хороших алгоритмовПример 1. Подсчитайте сумму Вы знаете соответствующую явную формулу, обладающую постоянной сложностью: в ней используется одна операция сложения, одна операция умножения и одна операция деления:
Пример 2. Подсчитайте сумму квадратов Возможно, вы знаете и умеете доказывать, что
Пример 3. Подсчитайте сумму кубов Вы чувствуете, что перечень примеров можно продолжить... Но здесь у математики эстафету принимает информатика. Если только мы умеем определять конечный процесс вычислений, позволяющий прийти к решению, нас не испугает отсутствие эффективной формулы. В связи с заменой формулы на процесс возникает новый вопрос: через сколько этапов мы получим решение? Ответ на этот вопрос составляет цель данной главы. Часто, исходя из условия задачи, мы располагаем неявной формулой подсчета, в которой решение определяется рекурсивно, постепенно. Так, сумма
т. е. она описывается как процесс, легко представимый в хорошем языке программирования: (см. скан) Чтобы подсчитать
Следующий вызов процедуры разворачивает подсчет
и так далее вплоть до
При этом вызове процедуры, наконец, (см. скан) В обоих случаях сложность вычислений составляет Отсюда следует, что для решения тех задач, для которых неизвестны эффективные явные формулы, необходимо уметь строить алгоритмы приемлемой сложности. В частности, классическим и довольно удобным способом является использование с самого начала рекурсивной записи, которую часто легко осуществить и которая всегда кратка и элегантна. Если же сложность соответствующего алгоритма слишком велика, информа-Хик должен последовательно, исходя из рекурсивной формулы, находить все более явные формулы и так до тех пор, пока не будет получен алгоритм вполне приемлемой сложности. Замечание. Теоретическая сложность, о которой здесь идет речь, подтверждается совершенно реальной сложностью, ощущаемой человеком, работающим за терминалом. Так что усилия информатиков-теоретиков по понижению сложности алгоритмов решения некоторых распространенных задач вполне обоснованны. Пример 4. Предположим, что мы хотим узнать 30-е число Фибоначчи. Это число определяется как формул
Числа Фибоначчи, введенные Леонардом Пизанским, сыном Боначчи (1540 г.), входят в описания некоторых процессов, происходящих в природе (например, процесса воспроизводства населения; число Явная формула. Формальное решение и подсчет общего члена последовательности путем поиска линейной комбинации решений в виде
Но мы можем не знать этого подсчета. Кроме того, эта формула относительно сложная. Для того чтобы убедиться в этом, достаточно подсчитать вручную Теперь рассмотрим два других подхода. Рекурсивная форма. Для этой четко сформулированной задачи рекурсивное программирование является решением с непосредственной подстановкой: (см. скан) Но опять-таки, как и в первом решении, возникает одна сложность. Подобно тому как мы делали это при подсчете суммы чисел натурального ряда, смоделируем развертывание рекурсивного алгоритма в информационной системе. Начало построения стека для подсчета
И так — вплоть до достижения одного из двух явно заданных результатов:
В этом конце стека удается осуществить успешные подстановки, и тогда система возвращается... к Итеративные алгоритмы. Чтобы уменьшить эту дорогостоящую из-за большой глубины рекурсивность и избежать многократного повторения одних и тех же расчетов, можно преобразовать приведенную выше рекурсивную схему в рекуррентную. Иными словами, мы расчленим задачу, предположив, что она решена до определенной точки, т. е. до некоторого значения одного значения Если
Тем самым мы упростили гипотезу рекуррентности и нашу схему подсчета. Итак, у нас есть искомый итеративный алгоритм. Оказывается, нам не нужно было запоминать вектор
Начальные условия и тест остановки программ уже были указаны, так что полный алгоритм рассматриваемого третьего типа записывается следующим образом: (см. скан) Очевидно, что этот алгоритм имеет сложность порядка Разработка алгоритма не всегда столь проста: часто приходится манипулировать более сложными структурами, чем числа или обычные арифметические выражения. В следующем разделе рассмотренный выше, принцип развивается на более сложных примерах, для которых в конце концов удается получить полиномиальный алгоритм. Затем мы составим полный список “хорошо решаемых” на сегодняшний день задач. Однако для некоторых задач, по-видимому, невозможно найти хорошие алгоритмы. Этой проблеме посвящен разд. 4.4. Пример 5. Произведите сортировку В качестве чисел возьмем, например, регистрационные номера или индексы каталога. Операция сортировки неупорядоченных элементов чрезвычайно распространена в информатике. Сначала теоретически установим нижнюю границу сложности этой задачи. Разумеется, никакой явной формулы в привычном смысле этого слова здесь нет. Необходимо определить эффективный процесс упорядочения При этом Оказывается, что
Если перейти к логарифмам и использовать формулу Стурлинга, по которой
Следовательно, чтобы рассортировать множество из Теперь рассмотрим, как действует элементарный алгоритм сортировки.
Рис. 4.1. Дерево тестов для сортировки массива. При сортировке массива первой приходит мысль выбрать наибольший элемент, поместить его в начало и затем проделать то же самое для оставшегося массива, т. е. действовать по схеме: (см. скан) Внутренний цикл дает Однако этот метод можно улучшить. В приведенном алгоритме мы каждый раз теряем информацию, “забывая” результаты тестов сравнения, полученные на предыдущем этапе.
Рис. 4.2. Пример сортировки первого типа. Сэкономить на количестве сравнений можно за • счет замены цикла “повторить для Таким образом мы, с одной стороны, уменьшаем число тестов, необходимых для нахождения максимального элемента, а с другой, получаем сведения, нужные для продолжения поисков. Теперь высота дерева составляет (В действительности для реализации этой сортировки на компьютере надо уточнить способ управления деревом, запоминающим числа, и способ осуществления обменов между рассортированными и нерассортированными элементами. Поскольку сначала дерево не задано, все это имеет значение. К дереву мы приходим постепенно, проходя через стадию “упаковки” - структуры, в которой во всех вершинах, подчиненных некоторому узлу, стоят числа, не превышающие число, расположенное в данном узле.)
Рис. 4.3. Пример сортировки второго типа. Как бы то ни было, мы имеем, таким образом, пример нетривиальной задачи, для которой можно представить оптимальный полиномиальный алгоритм. Пример 6. С задачей найти кратчайший путь из одной точки в другую мы сталкиваемся в жизни ежедневно: путешествуя на автомобиле, в метро, а также при решении некоторых математических головоломок. Возьмем в качестве примера граф, изображенный на рис. 4.4; требуется попасть из точки 1 в точку 6 по такому пути, чтобы сумма расстояний, указанных на каждом ребре, была минимальной. Обычно говорят не о расстояниях между вершинами, а о стоимости ребер. По интуитивным соображениям полный перебор всех возможных путей, ведущих из начальной вершины, в конечную, бесполезен. В самом деле, очевидно, что следует ограничиться только элементарными путями, т. е. путями, которые проходят через каждое ребро графа не более одного раза (при условии, что стоимости положительны). Кроме того, естественно использовать итеративный процесс распространения минимальных путей, начиная с вершины 1. Начав с вершин, соседних с вершиной 1, т. е. связанных с ней только одним ребром, мы будем постепенно подсчитывать эти пути так, чтобы в любой заданный момент времени для любой заданной вершины мы были уверены, что минимальное расстояние до вершины 1 известно точно и возвращаться назад не придется. Иначе говоря, на каждом этапе множество вершин разделено на два подмножества • для каждой вершины из • для каждой вершины из
Рис. 4.4. Задача нахождения кратчайшего пути.
Рис. 4.5. Доказательство алгоритма: путь Вначале множество Чтобы построить полный алгоритм, уточним и систематизируем приведенные рассуждения для графа с произвольными положительными стоимостями. Обозначим
где 3) D является минимальным известным расстоянием от вершины 1 до вершины Итак, вначале Теперь мы, сохраняя введенные обозначения, обобщим представленную выше (для вершин 2 и 3) аргументацию и сформулируем следующее утверждение. Утверждение. Пусть Тогда Таким образом, для Чтобы доказать это свойство, нам нужно доказать, что не существует более короткого пути из 1 в Рассмотрим путь Общая длина (см. скан) Теперь развернем этот алгоритм на примере графа, приведенного на рис. 4.4. • Инициализация:
• Итерация
• Итерация
• Итерация
• Итерация
• Итерация Кратчайшему пути из вершины 1 в вершину 6 соответствует суммарная стоимость 10. Можно заметить, что в приведенном алгоритме порядок перехода вершин из Кроме того, если множество Хотя мы рассматривали пример, в котором связи между вершинами, называемые ребрами, могут проходиться в обоих направлениях, иногда ситуация навязывает однонаправленность прохождения; такой граф называется ориентированным. Направление прохождения связи обозначается в этом случае стрелкой, а ориентированная связь называется дугой. Все выводы, нолученные выше, остаются в силе, поскольку направленность прохождения связи в рассуждениях не участвовала; достаточно определить Если дуга Пример 7. Задача упорядочения. В мастерской по сборке автомобилей работа разбита на определенное число операций известной длительности. Эти операции должны следовать друг за другом во времени с учетом отношений логического следования, которые обусловлены физическими условиями. Информация, которой мы располагаем, сведена в табл. 4.1. Таблица 4.1 (см. скан) Какова минимальная длительность сборки, если предположить, что в нашем распоряжении имеется квалифицированная рабочая сила, способная обеспечить параллельное выполнение операций там, где это возможно? Для ответа на поставленный вопрос мы обозначим каждую операцию точкой и проведем между точками связи, соответствующие отношениям следования. Мы получим таким образом граф, причем на этот раз ориентированный (поскольку отношение Из этого графа видно, что по построению со следует за операциями поставленной задачи. Условия, связанные с отношениями логического следования (такие, как
Рис. 4.6. Ориентированный граф для задачи упорядочения. Найти минимальную длительность сборки означает то же самое, что определить на графе с заданными стоимостями, соответствующими продолжительности операций, путь от вершины а до вершины Отметим, что, поскольку стоимости здесь по-прежнему положительны, а мы ищем максимум, то искомый путь мог бы оказаться бесконечным. Действительно это было бы так, если бы существовало подмножество дуг, такое, что
т. е. подмножество вершин, где мы могли бы ходить по кругу неопределенно долго. Такое подмножество вершин в теории графов называется циклом. Однако подобная ситуация в рассматриваемой задаче упорядочения невозможна: в самом деле, тогда получилось бы, что операция Если учесть отсутствие циклов, рассмотренный в предыдущем разделе алгоритм можно улучшить. Поиск максимума, а не минимума, роли не играет. Мы снова ограничимся элементарными путями (т. е. будем брать каждую дугу не более одного раза). Основная идея остается прежней: вес соотношения вида
пока он не перестанет меняться. Однако при специальном выборе порядка вершин можно свести процедуру к одному этапу Для графа, приведенного на рис. 4.6, максимальное расстояние от а до А и В известно. Если мы знаем расстояние до В, то нам в свою очередь известны максимальные расстояния от а до С, D и Н. Сравнивая Свойство. Ациклический граф обладает по крайней мере одной вершиной, которой не предшествует никакая другая вершина; такая вершина называется корнем. В самом деле, предположим, что это не так, и отметим какую-нибудь вершину. По предположению Данное свойство, позволяющее запустить алгоритм, мы будем использовать неоднократно: действительно, достаточно исключить из множества дуг Теорема. Граф Другими словами, с помощью взаимно однозначного отображения Во-первых, очевидно, что, если мы не сможем построить подобного отображения, поскольку в противном случае, согласно предположению, имело бы
Рис. 4.7. Перестроенный граф для задачи упорядочения. место соотношение:
что вообще невозможно. И наоборот, если граф Если бы в какой-нибудь момент существовала некоторая дуга Алгоритм построения функции классификации вершинВ этом алгоритме каждая дуга из множества Инициализация:
Построение: (см. скан) Первый пласт, несомненно, а, второй—А, третий — В; дуги Замечание. Когда перед глазами имеется рисунок, нумерация не является обязательной; поэтому на рис. 4.7 мы ее опустили. Теперь мы получаем: Затем:
Таким образом, длина максимального пути на графе для задачи упорядочения (рис. 4.6) составляет 16 единиц. Чтобы обнаружить путь, во время каждой итерации мы отмечаем предшествующую вершину, которая дала реальный максимум при подсчете Использованный нами метод известен под названием метода потенциалов-, он был введен Бернардом Роем в 1960 г. Более распространенный, но более трудоемкий американский вариант метода для решения этой задачи называется методом PERT (Program Evaluation and Review Technique); он был разработан в NASA и в RAND в 1954 г. Эти методы постоянно используются для реального решения конкретных задач, главным образом в строительной индустрии, а также в различных отраслях машиностроения (в автомобилестроении, кораблестроении и самолетостроении). Помимо вычисления минимального срока выполнения проекта, эти методы позволяют получить список так называемых “критических” операций, т. е. операций, лежащих (при графическом представлении) на самом длинном из возможных путей. По определению всякое увеличение длительности любой из критических операций обязательно отразится на сроках поставок. Другим полезным следствием нашего алгоритма является информация о распределении в процессе сборки объема работ, выполняемых представителями различных профессий. В перестроенном таким образом графе для определения максимального пути мы располагаем следующим тривиальным алгоритмом: (см. скан) Действительно, новые численные обозначения таковы, что Для каждого отдельного значения итерация требует Нумерация
Наконец, поскольку в этом классе задач данные никогда не известны точно, для отслеживания критического пути и общей длительности в случае, когда длительности операций параметризованы и колеблются в заданных интервалах по известным вероятностным законам, были разработаны вспомогательные способы подсчета. Подробное рассмотрение всех этих способов не входит в задачи данной главы. Здесь мы хотели показать на конкретных примерах суть алгоритмических действий: анализ задачи с целью ее перевода в сжатую и удобную форму (граф); изучение в выбранном ограниченном пространстве новой задачи и проверку на каком-нибудь примере метода, основанного на простых идеях; обобщение, а затем оформление и доказательство алгоритма.
Рис. 4.8. Семь мостов через Преголю: задача об эйлеровом цикле. Пример 8. Топологическая задача Рассмотрим знаменитую задачу об “эйлеровом цикле” на графе. Она состоит в том, чтобы узнать, существует ли на графе определенного вида (таком, как изображен на рис. 4.8) цикл, который проходит по каждому ребру только один раз и возвращается в исходную точку. Разумеется, необходимым условием является связанность графа, т. е. существование цепочки ребер, позволяющей пройти Из одной произвольно взятой точки графа в другую. Еще одно Необходимое условие касается числа ребер, привязанных к каждой вершине: поскольку мы не можем дважды пройти по одному и тому же ребру, нужно, чтобы всякому входу соответствовал выход. Чтобы в связанном графе существовал эйлеров цикл, в нем не должно быть вершин нечетной степени (степень — число ребер, выходящих из данной вершины). Как мы докажем ниже, это условие фактически является достаточным. Для ответа на вопрос о существовании эйлерова цикла это условие предлагает полиномиальный алгоритм, и. кроме того, для реального построения этого цикла в случае его существования оно дает алгоритм, совпадающий по порядку сложности с числом ребер на входе. Необходимое условие. Оно является очевидным. Поскольку цепочка, проходящая через все ребра, входит в каждую вершину и выходит из нее, то для возвращения в исходную вершину нужно, чтобы все лежащие на нашем пути вершины имели четное число ребер. Достаточное условие. Оно является менее очевидным. Мы будем рассуждать по индукции для В соответствии с нашим предположением составим последовательно цепочку Ф, выходящую из произвольной вершины Если мы не можем продолжить цепочку Ф, это означает, что мы вернулись в Обозначим эти компоненты связности через Поскольку с самого начала предполагалось, что граф Так как при любом • цепочку Ф от вершины • эйлеров цикл • цепочку Ф от вершины Проверить приведенные необходимые и достаточные условия в каждой вершине нетрудно, причем суммарная сложность составляет (см. скан) Теперь легко записать полный алгоритм получения эйлерова цикла. Следуя доказательству теоремы, мы будем строить цепочку, постепенно ее дополняя: (см. скан) В этом алгоритме процедура Эйлера по порядку величины с числом ребер исходного графа, т. е. составляет О (т.). Итак, мы имеем прекрасный линейный алгоритм решения задачи Эйлера. Замечание. Ниже мы рассмотрим задачу, близкую задаче Эйлера. Эту задачу изучал Гамильтон, и в его честь она получила название задачи Гамильтона; она состоит в поиске на произвольном графе цикла, проходящего на этот раз не через все ребра, а через все вершины (гл. 5, задача о коммивояжере). Оказывается, что эта новая задача вовсе не относится к тому же классу, что и предыдущая. Многие математики, в течение нескольких веков занимавшиеся задачей Гамильтона, так и не смогли построить для нее, как это удалось сделать для задачи Эйлера, хороший (т. е. полиномиальный) алгоритм. Другими словами, мы не умеем решать обобщенную задачу определения цикла, проходящего через все вершины графа.
|
 |
Оглавление
|

















































































































































































































































































































































































































































































































































































 входной задачи. Следовательно, в этом случае сложность постоянна (не зависит от
входной задачи. Следовательно, в этом случае сложность постоянна (не зависит от  и равна
и равна  Мы предполагаем, что сложность любой операции (т. е. +, -, /, и т. д.) не зависит от разряда чисел, над которыми она производится, т. е. сложность пропорциональна числу операций.
Мы предполагаем, что сложность любой операции (т. е. +, -, /, и т. д.) не зависит от разряда чисел, над которыми она производится, т. е. сложность пропорциональна числу операций.
 чисел натурального ряда.
чисел натурального ряда.

 чисел натурального ряда.
чисел натурального ряда.

 чисел натурального ряда.
чисел натурального ряда.
 чисел натурального ряда определяется формулами
чисел натурального ряда определяется формулами

 система вызовет процедуру 5 с формальным параметром
система вызовет процедуру 5 с формальным параметром  -равным
-равным  . Поскольку
. Поскольку  система знает, что для подсчета результата ей необходимо прибавить 5 к значению
система знает, что для подсчета результата ей необходимо прибавить 5 к значению  которое она опять-таки должна вычислить. Она снова вызывает процедуру 5. Кроме того, система записывает в стековую память, что, когда она будет знать значение
которое она опять-таки должна вычислить. Она снова вызывает процедуру 5. Кроме того, система записывает в стековую память, что, когда она будет знать значение  она должна прибавить к нему 5, чтобы получить тот ответ, который от нее требовался вначале. Эту информацию мы можем представить в виде
она должна прибавить к нему 5, чтобы получить тот ответ, который от нее требовался вначале. Эту информацию мы можем представить в виде 

 и мы получаем
и мы получаем


 может быть подсчитано по явной формуле:
может быть подсчитано по явной формуле:  Системе не надо больше заполнять стек, и теперь, чтобы получить ответ, она освобождает полученный стек в обратном порядке. Интуитивно мы видим, что описанный выше процесс эквивалентен итеративной схеме:
Системе не надо больше заполнять стек, и теперь, чтобы получить ответ, она освобождает полученный стек в обратном порядке. Интуитивно мы видим, что описанный выше процесс эквивалентен итеративной схеме:
 поскольку число операций сложения, которое нужно выполнить в каждом из них, является величиной такого порядка. Если искать сумму квадратов
поскольку число операций сложения, которое нужно выполнить в каждом из них, является величиной такого порядка. Если искать сумму квадратов  чисел натурального ряда, оба приведенных алгоритма легко модифицировать. В общем случае сумма чисел степени
чисел натурального ряда, оба приведенных алгоритма легко модифицировать. В общем случае сумма чисел степени  требует
требует  операций сложения и
операций сложения и  операций возведения в степень
операций возведения в степень 
 с помощью
с помощью

 при этом является количеством людей в момент времени
при этом является количеством людей в момент времени  и в описания некоторых областей математики (в частности, в доказательство неразрешимости десятой теоремы Гильберта о решении диофантовых уравнений).
и в описания некоторых областей математики (в частности, в доказательство неразрешимости десятой теоремы Гильберта о решении диофантовых уравнений).
 где
где  — нуль трехчлена
— нуль трехчлена  приводят к точному выражению (к формуле Бине)
приводят к точному выражению (к формуле Бине)

 или, тем более,
или, тем более,  На самом деле задача даже полностью не решена, поскольку алгоритм использования формулы нужно еще уточнить. Осуществлять ли раскрытие внутренних скобок по формуле бинома? Как вести подсчет: формально — с символом
На самом деле задача даже полностью не решена, поскольку алгоритм использования формулы нужно еще уточнить. Осуществлять ли раскрытие внутренних скобок по формуле бинома? Как вести подсчет: формально — с символом  или численно — с величиной
или численно — с величиной  и
и  десятичными знаками (и какое значение установить тогда для
десятичными знаками (и какое значение установить тогда для  Очевидно, что, хотя результат должен быть целым, он не будет таковым, пока мы остаемся в рамках конечной арифметики независимо от того, как мы считаем — на микрокалькуляторе или на большом компьютере. Следовательно, встает вопрос: до какого “соседнего” целого числа нужно округлять? Как быть абсолютно уверенным в результате?
Очевидно, что, хотя результат должен быть целым, он не будет таковым, пока мы остаемся в рамках конечной арифметики независимо от того, как мы считаем — на микрокалькуляторе или на большом компьютере. Следовательно, встает вопрос: до какого “соседнего” целого числа нужно округлять? Как быть абсолютно уверенным в результате?
 выглядит следующим образом:
выглядит следующим образом:


 которое она снова разворачивает. Поскольку в любом случае единственные известные результаты
которое она снова разворачивает. Поскольку в любом случае единственные известные результаты  равны 1, в конечном итоге система делает столько операций сложения, сколько единиц содержится в
равны 1, в конечном итоге система делает столько операций сложения, сколько единиц содержится в  Так как
Так как  равно
равно  и стек управления вызовом процедуры
и стек управления вызовом процедуры  является величиной того же порядка, то здесь непосредственный рекурсивный метод непригоден. Очевидно, что объем памяти и время, необходимые для работы этого алгоритма, совершенно неприемлемы. Поэтому нужно перейти от сложности, составляющей
является величиной того же порядка, то здесь непосредственный рекурсивный метод непригоден. Очевидно, что объем памяти и время, необходимые для работы этого алгоритма, совершенно неприемлемы. Поэтому нужно перейти от сложности, составляющей  (т. е., по сути дела, экспоненциально зависящей от
(т. е., по сути дела, экспоненциально зависящей от  которое входит в явную формулу), к более разумной сложности.
которое входит в явную формулу), к более разумной сложности.
 из
из  Затем мы выведем из него
Затем мы выведем из него  по крайней мере еще для
по крайней мере еще для
 Для этого выдвигается гипотеза рекуррентности. В нашем случае естественно предположить следующее. Пусть
Для этого выдвигается гипотеза рекуррентности. В нашем случае естественно предположить следующее. Пусть  уже получены. Начнем с
уже получены. Начнем с  При этом задача решена полностью, когда
При этом задача решена полностью, когда 
 приведенная в определении формула
приведенная в определении формула  позволяет распространить рекуррентную гипотезу на одну ступень дальше; следовательно, нам известны
позволяет распространить рекуррентную гипотезу на одну ступень дальше; следовательно, нам известны  Более того, приведенная в определении формула показывает, что члены
Более того, приведенная в определении формула показывает, что члены  в данном рекуррентном соотношении не участвуют. Вся необходимая информация содержится в тройке
в данном рекуррентном соотношении не участвуют. Вся необходимая информация содержится в тройке  Пусть в соответствии с гипотезой эта тройка известна; тогда мы можем вывести из нее следующую тройку:
Пусть в соответствии с гипотезой эта тройка известна; тогда мы можем вывести из нее следующую тройку:

 целиком, а достаточно было двух его значений. Назовем эти значения и и
целиком, а достаточно было двух его значений. Назовем эти значения и и  и соответствует
и соответствует  Тогда от тройки
Тогда от тройки  , и] мы можем перейти к тройке
, и] мы можем перейти к тройке 

 вместо прежней
вместо прежней  Для подсчета
Для подсчета  необходимо совершить
необходимо совершить  итерации, каждая из которых включает 1 тест остановки, 2 операции сложения и 4 присвоения значений. Таким образом, мы достигли приемлемой сложности и “хорошего”, т. е. полиномиального, вполне реализуемого алгоритма.
итерации, каждая из которых включает 1 тест остановки, 2 операции сложения и 4 присвоения значений. Таким образом, мы достигли приемлемой сложности и “хорошего”, т. е. полиномиального, вполне реализуемого алгоритма.
 чисел с помощью сравнений.
чисел с помощью сравнений.
 заданных чисел, например в перекрестном порядке. Чтобы осуществить это, нам нужно тем или иным способом сравнить числа попарно. Основная элементарная операция здесь — тест на сравнение двух чисел:
заданных чисел, например в перекрестном порядке. Чтобы осуществить это, нам нужно тем или иным способом сравнить числа попарно. Основная элементарная операция здесь — тест на сравнение двух чисел:  больше
больше  или
или  Итак, заметим, что подлежащие упорядочению
Итак, заметим, что подлежащие упорядочению  чисел априори могут быть представлены на входе
чисел априори могут быть представлены на входе  различными способами.
различными способами.
 последовательно выполненных тестов позволяют различить на сбалансированном дереве высотой
последовательно выполненных тестов позволяют различить на сбалансированном дереве высотой  в лучшем случае
в лучшем случае  ситуаций, каждая из которых соответствует одному из листьев (рис. 4.1).
ситуаций, каждая из которых соответствует одному из листьев (рис. 4.1).
 элементарных операций позволяют изучить не более чем
элементарных операций позволяют изучить не более чем  чисел, где
чисел, где  такое, что
такое, что

 при
при  мы увидим, что нижняя граница сложности
мы увидим, что нижняя граница сложности  для сортировки методом сравнений составляет
для сортировки методом сравнений составляет

 элементов, нам потребуется по крайней мере
элементов, нам потребуется по крайней мере  тестов.
тестов.

 тестов при каждой итерации, т. е. всего
тестов при каждой итерации, т. е. всего  тестов для
тестов для  подлежащих сортировке абсолютно произвольных чисел; следовательно, этот алгоритм обладает сложностью порядка
подлежащих сортировке абсолютно произвольных чисел; следовательно, этот алгоритм обладает сложностью порядка  (рис. 4.2).
(рис. 4.2).

 на своего рода “турнир”: на некотором этапе мы сравниваем х, только с
на своего рода “турнир”: на некотором этапе мы сравниваем х, только с  а затем “победителя” этой пары сравниваем с “победителем” соседней пары. Если на входе стоят числа 20, 7, 84, 75, 45, 78, 30, 9, то получится картина, приведенная на рис. 4.3.
а затем “победителя” этой пары сравниваем с “победителем” соседней пары. Если на входе стоят числа 20, 7, 84, 75, 45, 78, 30, 9, то получится картина, приведенная на рис. 4.3.
 (неравенство
(неравенство  Следовательно, в худшем случае требуемое число операций в
Следовательно, в худшем случае требуемое число операций в  раз больше, чем число тестов, необходимых для изучения дерева из
раз больше, чем число тестов, необходимых для изучения дерева из  элементов, т. е.
элементов, т. е.  Согласно соотношению (4.2), по крайней мере по порядку величины сложность этой сортировки является оптимальной.
Согласно соотношению (4.2), по крайней мере по порядку величины сложность этой сортировки является оптимальной.

 и
и  такие, что
такие, что
 известно минимальное расстояние до вершины 1;
известно минимальное расстояние до вершины 1;
 это расстояние неизвестно.
это расстояние неизвестно.



 сводится к вершине 1. Переход некоторой вершины из подмножества
сводится к вершине 1. Переход некоторой вершины из подмножества  в
в  произойдет тогда, когда мы сможем доказать, что никакой другой путь из еще непроверенных не окажется короче, чем уже известные пути. Так, в нашем примере из вершины 1 на первом шаге мы можем попасть в вершины 2 и 3; поскольку стоимость пути до вершины 3 строго больше стоимости пути до вершины 2, расстояние между вершинами 1 и 2 (оно равно 4) является минимальным независимо от того, какие неизвестные пути позволят нам вернуться из 3 в 2 (рис. 4.5).
произойдет тогда, когда мы сможем доказать, что никакой другой путь из еще непроверенных не окажется короче, чем уже известные пути. Так, в нашем примере из вершины 1 на первом шаге мы можем попасть в вершины 2 и 3; поскольку стоимость пути до вершины 3 строго больше стоимости пути до вершины 2, расстояние между вершинами 1 и 2 (оно равно 4) является минимальным независимо от того, какие неизвестные пути позволят нам вернуться из 3 в 2 (рис. 4.5).
 расстояние между вершиной 1 и вершиной
расстояние между вершиной 1 и вершиной  заданном этапе) наилучшее известное расегояние от вершины 1 до вершины
заданном этапе) наилучшее известное расегояние от вершины 1 до вершины  стоимость ребра
стоимость ребра  На любом этапе множества
На любом этапе множества  и
и  характеризуются следующим свойством:
характеризуются следующим свойством:

 — множество ребер графа.
— множество ребер графа.

 при
при  для всех вершин, отличных от 1; таким образом, все они попадают в
для всех вершин, отличных от 1; таким образом, все они попадают в 
 причем
причем  такое, что
такое, что  является наименьшим из всех
является наименьшим из всех  где
где 
 является минимальным расстоянием от 1 до
является минимальным расстоянием от 1 до 
 при этом условии (на каждом этапе ему обязательно удовлетворяет по крайней мере одно
при этом условии (на каждом этапе ему обязательно удовлетворяет по крайней мере одно  мы имеем право перевести
мы имеем право перевести  из
из  в
в 
 чем уже имеющийся путь с зафиксированной суммарной стоимостью
чем уже имеющийся путь с зафиксированной суммарной стоимостью 
 ведущий из 1 в
ведущий из 1 в  Пусть
Пусть  является частью
является частью  и идет из вершины 1 в первую из вершин, не принадлежащих
и идет из вершины 1 в первую из вершин, не принадлежащих  (она обозначена через
(она обозначена через  является при этом дополнением к
является при этом дополнением к  (см. рис. 4.5).
(см. рис. 4.5).
 равна сумме длин путей
равна сумме длин путей  и Следовательно, по построению, длина
и Следовательно, по построению, длина  больше или равна
больше или равна  которое в рассматриваемый период является минимальным расстоянием от 1 до
которое в рассматриваемый период является минимальным расстоянием от 1 до  Но, согласно нашему утверждению, которое нужно доказать,
Но, согласно нашему утверждению, которое нужно доказать,  Кроме того, длина пути
Кроме того, длина пути  неотрицательна. Следовательно, длина
неотрицательна. Следовательно, длина  в целом не может быть меньше
в целом не может быть меньше  Тогда вершина
Тогда вершина  переходит из
переходит из  в
в  Таким образом, если число вершин равно
Таким образом, если число вершин равно  этот процесс завершается после
этот процесс завершается после  итераций и полученный алгоритм имеет следующий вид:
итераций и полученный алгоритм имеет следующий вид:

 ; выходная вершина
; выходная вершина 







 и затем КОНЕЦ.
и затем КОНЕЦ.
 в
в  зависит одновременно и от вхождения/невхождения ребер во множество
зависит одновременно и от вхождения/невхождения ребер во множество  и от их стоимости: модификация стоимостей меняет порядок перехода даже без изменения графа. Кроме того, этот алгоритм выдает минимальные расстояния от вершины 1 до других вершин единым блоком (по крайней мере если мы не остановим работу алгоритма в момент, когда выбранная конечная вершина — в нашем примере 6 — вдруг перейдет в
и от их стоимости: модификация стоимостей меняет порядок перехода даже без изменения графа. Кроме того, этот алгоритм выдает минимальные расстояния от вершины 1 до других вершин единым блоком (по крайней мере если мы не остановим работу алгоритма в момент, когда выбранная конечная вершина — в нашем примере 6 — вдруг перейдет в  до его полного завершения, как это могло бы произойти). Наконец, мы можем оценить число элементарных операций, необходимых для выполнения этого алгоритма: поскольку ребро графа по определению связывает две вершины и на этапе выявления расстояний
до его полного завершения, как это могло бы произойти). Наконец, мы можем оценить число элементарных операций, необходимых для выполнения этого алгоритма: поскольку ребро графа по определению связывает две вершины и на этапе выявления расстояний  анализируются две вершины (вершина, только что перешедшая в
анализируются две вершины (вершина, только что перешедшая в  и некоторая другая вершина из
и некоторая другая вершина из  то в данном случае каждое ребро рассматривается только один раз. Если
то в данном случае каждое ребро рассматривается только один раз. Если  — число ребер графа, на этап выявления расстояний для всего множества итераций потребуется
— число ребер графа, на этап выявления расстояний для всего множества итераций потребуется  сложений и
сложений и  сравнений.
сравнений.
 представлено характеристическим вектором, при выборе минимального значения
представлено характеристическим вектором, при выборе минимального значения  для определения выходной вершины нужно
для определения выходной вершины нужно  сравнений, т. е. на всем множестве алгоритма мы получаем
сравнений, т. е. на всем множестве алгоритма мы получаем  или
или  сравнений. Следовательно, предложенный алгоритм требует порядка
сравнений. Следовательно, предложенный алгоритм требует порядка  сравнений и
сравнений и  сложений. Учитывая, что операции сравнения и сложения выполняются в сопоставимое время и что в любом графе по определению
сложений. Учитывая, что операции сравнения и сложения выполняются в сопоставимое время и что в любом графе по определению  (поскольку ребро связывает две вершины), мы можем сказать, что данный алгоритм обладает сложностью
(поскольку ребро связывает две вершины), мы можем сказать, что данный алгоритм обладает сложностью  Этот алгоритм впервые был предложен в 1957 г. Моором, затем в 1959 г. Дейкстрой, а его варианты были разработаны Данцигом (1960), Уайтингом и Хиллиером (1960).
Этот алгоритм впервые был предложен в 1957 г. Моором, затем в 1959 г. Дейкстрой, а его варианты были разработаны Данцигом (1960), Уайтингом и Хиллиером (1960).
 как множество дуг.
как множество дуг.
 принадлежит множеству
принадлежит множеству  мы назовем
мы назовем  предшествующим
предшествующим  следующим за
следующим за 
 предшествует
предшествует  является асимметричным и отражается дугой, ведущей от
является асимметричным и отражается дугой, ведущей от  Кроме того, обозначим длительность операции х как стоимость соответствующей дуги. Добавив две фиктивные операции
Кроме того, обозначим длительность операции х как стоимость соответствующей дуги. Добавив две фиктивные операции  отмечающую начало сборки, и
отмечающую начало сборки, и  , соответствующую концу работы), мы получим граф, приведенный на рис. 4.6.
, соответствующую концу работы), мы получим граф, приведенный на рис. 4.6.
 и
и  Кроме того, он содержит в сжатой и доступной форме всю информацию, необходимую для решения
Кроме того, он содержит в сжатой и доступной форме всю информацию, необходимую для решения
 раньше
раньше  раньше
раньше  раньше
раньше  ), выстраиваются в заданном порядке в цепочки; на графе им соответствуют различные пути (в нашем случае путь
), выстраиваются в заданном порядке в цепочки; на графе им соответствуют различные пути (в нашем случае путь 

 обладающий максимальной суммарной стоимостью. Здесь нужно искать именно максимум: в этом случае все остальные пути обладают не более чем равной длительностью и поэтому максимум соответствует минимальной возможной длительности реализации множества операций.
обладающий максимальной суммарной стоимостью. Здесь нужно искать именно максимум: в этом случае все остальные пути обладают не более чем равной длительностью и поэтому максимум соответствует минимальной возможной длительности реализации множества операций.

 является предшествующей по отношению к самой себе, а это в системе логически обусловленного следования было бы аномалией и соответствующая работа не могла бы быть выполнена.
является предшествующей по отношению к самой себе, а это в системе логически обусловленного следования было бы аномалией и соответствующая работа не могла бы быть выполнена.
 присвоенный произвольной вершине, постепенно уточняется с помощью
присвоенный произвольной вершине, постепенно уточняется с помощью

 ), можно определить максимальное расстояние от а до I и т. д. Вершины графа можно рассматривать также в таком порядке, чтобы мы попадали в произвольную вершину 1, когда все предшествующие ей вершины уже проверены. Этот алгоритм может эффективно работать благодаря следующему свойству:
), можно определить максимальное расстояние от а до I и т. д. Вершины графа можно рассматривать также в таком порядке, чтобы мы попадали в произвольную вершину 1, когда все предшествующие ей вершины уже проверены. Этот алгоритм может эффективно работать благодаря следующему свойству:
 не является корнем, и существует по крайней мере одна входящая в нее дуга
не является корнем, и существует по крайней мере одна входящая в нее дуга  Теперь отметим вершину
Теперь отметим вершину  и повторим разметку, начиная с
и повторим разметку, начиная с  Эта процедура задает, таким образом, бесконечную последовательность вершин
Эта процедура задает, таким образом, бесконечную последовательность вершин  Но поскольку число вершин в графе конечно, эта последовательность должна содержать повторяющийся цикл, что противоречит исходному предположению.
Но поскольку число вершин в графе конечно, эта последовательность должна содержать повторяющийся цикл, что противоречит исходному предположению.
 те дуги, которые выходят из предшествующего корня, чтобы затем определить новую, не имеющую предшественников вершину, максимальное расстояние которой от а может быть вычислено непосредственно. Докажем теперь более строгую теорему.
те дуги, которые выходят из предшествующего корня, чтобы затем определить новую, не имеющую предшественников вершину, максимальное расстояние которой от а может быть вычислено непосредственно. Докажем теперь более строгую теорему.
 не имеет циклов в том и только том случае, если существует взаимно однозначное отображение
не имеет циклов в том и только том случае, если существует взаимно однозначное отображение  множества вершин X в интервал целых чисел от 1 до
множества вершин X в интервал целых чисел от 1 до  где
где  такое, что
такое, что 
 мы можем перенумеровать все вершины так, чтобы все предшественники некоторой произвольно выбранной вершины имели меньшие номера.
мы можем перенумеровать все вершины так, чтобы все предшественники некоторой произвольно выбранной вершины имели меньшие номера.
 включает цикл
включает цикл 


 не содержит циклов, существует корень, которому мы придадим номер
не содержит циклов, существует корень, которому мы придадим номер  Теперь удалим из
Теперь удалим из  эту вершину и все выходящие из нее дуги. Новый граф, полученный в результате такого удаления, очевидно, не содержит циклов: в нем есть корень с номером 2 и т. д.
эту вершину и все выходящие из нее дуги. Новый граф, полученный в результате такого удаления, очевидно, не содержит циклов: в нем есть корень с номером 2 и т. д.
 из
из  где
где  то время как
то время как  еще принадлежит остальной части графа, то получилось бы противоречие. Следовательно, функция
еще принадлежит остальной части графа, то получилось бы противоречие. Следовательно, функция  действительно существует, и у нас есть эффективное средство для ее построения.
действительно существует, и у нас есть эффективное средство для ее построения.
 рассматривается только один раз, поэтому он обладает сложностью порядка
рассматривается только один раз, поэтому он обладает сложностью порядка  . В соответствии с предложенной процедурой мы можем перестроить граф задачи упорядочения из нашего примера. На рис. 4.7 изображены множества К, называемые также пластами.
. В соответствии с предложенной процедурой мы можем перестроить граф задачи упорядочения из нашего примера. На рис. 4.7 изображены множества К, называемые также пластами.

 исключаются, и тогда
исключаются, и тогда  и Н принадлежат пласту
и Н принадлежат пласту  Дуги
Дуги  и
и  и
и  , наконец,
, наконец,  исключены.
исключены.  состоит из единственной вершины
состоит из единственной вершины  исключаем
исключаем  и
и  следовательно,
следовательно,  состоит из
состоит из  и К. Наконец, последние пласты
и К. Наконец, последние пласты  составляют вершины
составляют вершины  и
и 
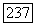

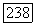 Идя в обратном направлении от
Идя в обратном направлении от 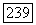 мы снова берем эти данные и получаем в конце концов путь
мы снова берем эти данные и получаем в конце концов путь 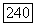
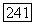 Таким образом, все пути, приводящие в
Таким образом, все пути, приводящие в 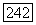 могут проходить только через вершины, номера которых меньше
могут проходить только через вершины, номера которых меньше 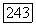 и для которых
и для которых  уже вычислено. Пригодность алгоритма доказывается с помощью индукции по
уже вычислено. Пригодность алгоритма доказывается с помощью индукции по 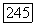
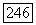 сложений и
сложений и 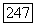 сравнений, поэтому в конечном итоге в данном алгоритме используется
сравнений, поэтому в конечном итоге в данном алгоритме используется 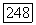 элементарных операций.
элементарных операций.
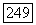 вершин графа, иллюстрирующего рассматриваемый пример (рис. 4.6), приводится в следующей таблице:
вершин графа, иллюстрирующего рассматриваемый пример (рис. 4.6), приводится в следующей таблице:


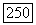 где
где 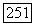 — число ребер графа.
— число ребер графа.
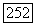 Чтобы быть уверенными, что мы не пройдем дважды по одному и тому же ребру, условимся вычеркивать из графа каждое пройденное ребро. Пока Ф ведет в некоторую вершину х, отличную от
Чтобы быть уверенными, что мы не пройдем дважды по одному и тому же ребру, условимся вычеркивать из графа каждое пройденное ребро. Пока Ф ведет в некоторую вершину х, отличную от  мы всегда можем продолжить цепочку по крайней мере на одно ребро. В самом деле, в начальный момент каждая вершина обладает некоторым четным числом ребер и в текущей вершине х из этого числа обязательно сохраняется некоторое нечетноечисло (т. е. по крайней мере одно ребро), потому что при каждом прохождении через данный пункт вычеркиваются два ребра.
мы всегда можем продолжить цепочку по крайней мере на одно ребро. В самом деле, в начальный момент каждая вершина обладает некоторым четным числом ребер и в текущей вершине х из этого числа обязательно сохраняется некоторое нечетноечисло (т. е. по крайней мере одно ребро), потому что при каждом прохождении через данный пункт вычеркиваются два ребра.
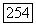 Если в этот момент все ребра исходного графа были пройдены, теорема доказана. Если нет, то у нас осталось некоторое подмножество ребер, распределенных по нескольким связанным компонентам (здесь, разумеется, не рассматриваются компоненты, которые сводятся к изолированным вершинам).
Если в этот момент все ребра исходного графа были пройдены, теорема доказана. Если нет, то у нас осталось некоторое подмножество ребер, распределенных по нескольким связанным компонентам (здесь, разумеется, не рассматриваются компоненты, которые сводятся к изолированным вершинам).

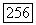 связанный, то цепочка Ф пересекается с каждой из этих компонент по крайней мере в одной точке. Пусть
связанный, то цепочка Ф пересекается с каждой из этих компонент по крайней мере в одной точке. Пусть 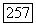 — такие точки пересечения для каждой компоненты
— такие точки пересечения для каждой компоненты 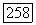
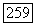 подграф
подграф 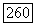 является связанным и обладает по построению менее чем
является связанным и обладает по построению менее чем 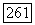 ребрами и вершинами четных степеней, он допускает в соответствии с индуктивной гипотезой эйлеров цикл
ребрами и вершинами четных степеней, он допускает в соответствии с индуктивной гипотезой эйлеров цикл 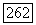 Исходя из этого соображения, мы строим, причем именно в указанном порядке, новую цепочку, включающую
Исходя из этого соображения, мы строим, причем именно в указанном порядке, новую цепочку, включающую
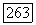 до вершины
до вершины 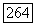
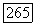 в подграфе
в подграфе 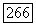 от вершины
от вершины 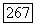 до вершины
до вершины 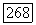
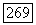 до вершины
до вершины 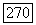 При этом мы все время остаемся уверенными в том, что с помощью цепочки Ф мы сможем вернуться из
При этом мы все время остаемся уверенными в том, что с помощью цепочки Ф мы сможем вернуться из 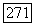 в
в 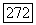 где
где 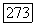 . И наконец, доказательство, впервые проведенное Леонардом Эйлером в 1736 г., завершается утверждением того, что петля на единственной вершине образует эйлеров цикл.
. И наконец, доказательство, впервые проведенное Леонардом Эйлером в 1736 г., завершается утверждением того, что петля на единственной вершине образует эйлеров цикл.
 Чтобы реально построить эйлеров цикл, запишем сначала процедуру Эйлера
Чтобы реально построить эйлеров цикл, запишем сначала процедуру Эйлера  которая задает для произвольного графа эйлеров цикл с началом в вершине
которая задает для произвольного графа эйлеров цикл с началом в вершине 
 обрабатывает каждое ребро графа
обрабатывает каждое ребро графа  не более одного раза. Следовательно, выбирая, как указано, подходящую вершину
не более одного раза. Следовательно, выбирая, как указано, подходящую вершину  мы освобождаемся от реального построения связанных компонент. Тогда в худшем случае каждое ребро будет проверяться дважды. Сложность обобщенного алгоритма, таким образом, совпадает
мы освобождаемся от реального построения связанных компонент. Тогда в худшем случае каждое ребро будет проверяться дважды. Сложность обобщенного алгоритма, таким образом, совпадает