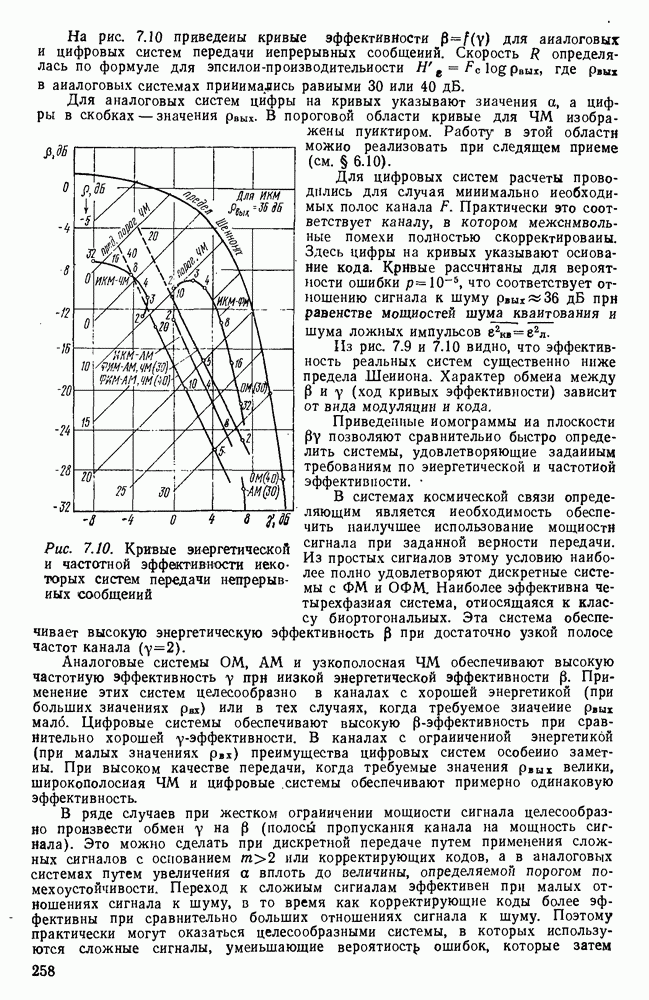
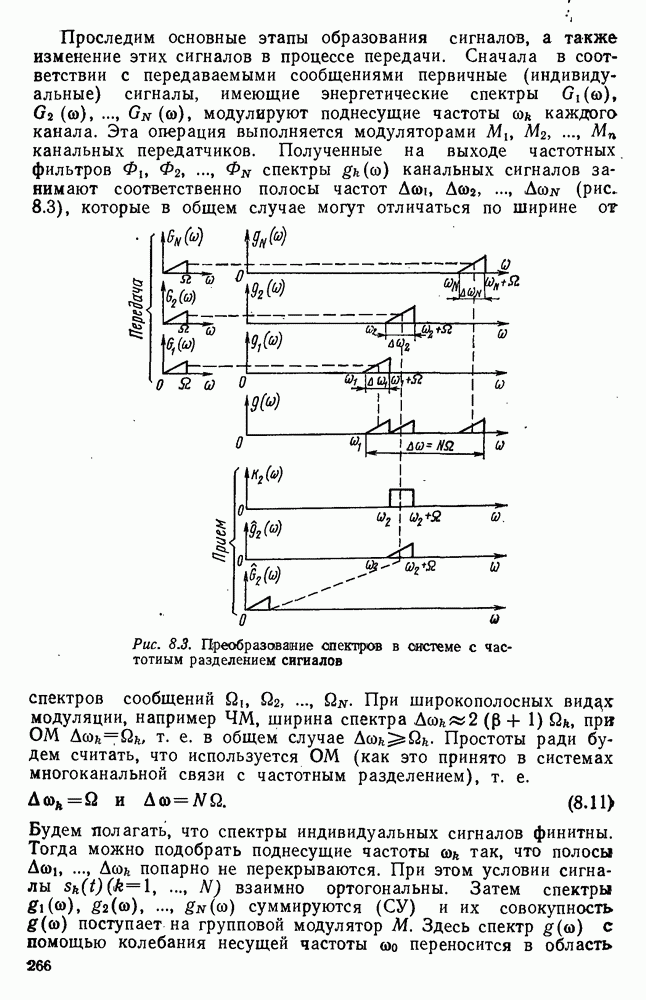
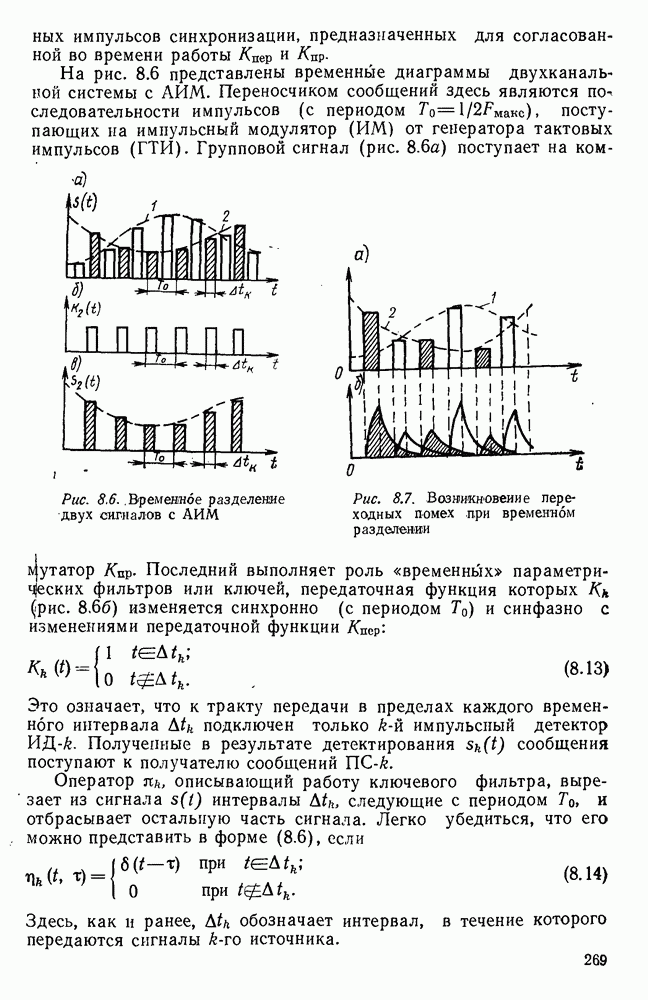
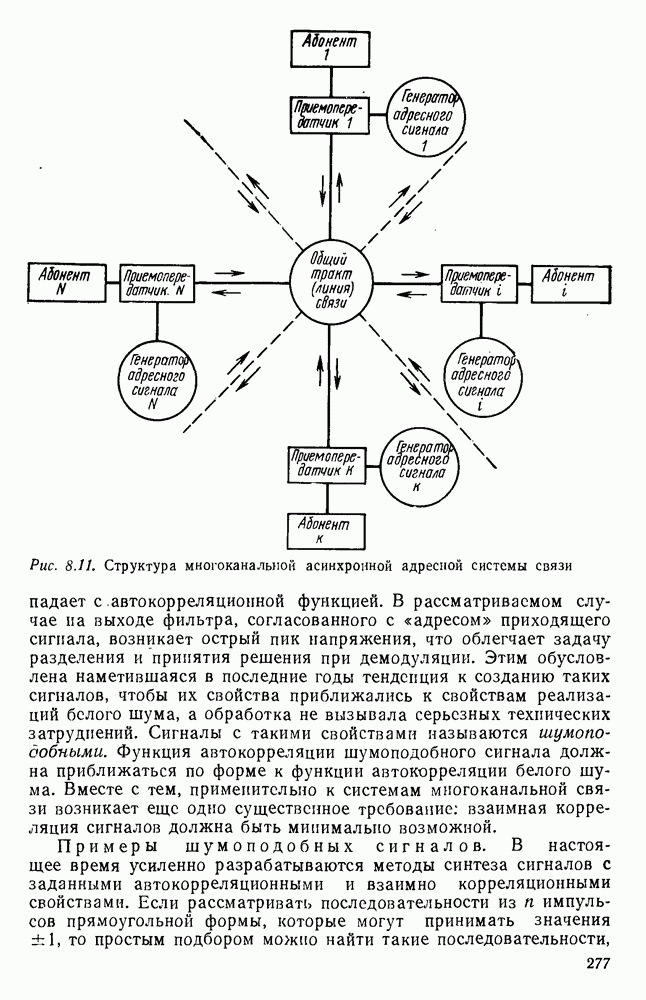
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
2.10. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ДИСКРЕТНЫХ СООБЩЕНИЙПрименим полученные результаты к проблеме кодирования дискретных сообщений. Пусть
где
Но Одна из основных теорем теории информации утверждает, что оно «почтят достаточно». Точнее, содержание теоремы кодирования для источника заключается в том, что, передавая двоичные символы со скоростью
где Эта теорема почти тривиальна, если источник передает сообщения независимо и равновероятно. В этом случае Таким же образом можно закодировать сообщения любого источника с объемом алфавита К, затрачивая Доказательство этой теоремы можно найти в [20]. Здесь же ограничимся несколькими примерами. Так, если элементарными сообщениями являются русские буквы букву можно закодировать последовательностью из пяти двоичных символов, поскольку существует 32 такие последовательности. Разумеется, таким же равномерным кодом можно закодировать и буквы в связном русском тексте, и именно так часто поступают на практике. Но можно обойтись значительно меньшим числом символов на букву. Как указывалось выше, для русского литературного текста Существует довольно много способов сжатия сообщений или сокращения избыточности текста. Так, напр, эта Другая возможность, основанная на свойстве асимптотической равновероятности, заключается в том, чтобы кодировать не отдельные буквы, а целые слова. В достаточно большом словаре имеется около 10 000 слов, содержащих в среднем по 7 букв. Считая, что в среднем каждое еловое может иметь 3 грамматические формы, нам придется закодировать около 30 000 типичных слов. Если применить равномерный код, то на каждое слово придется затратить 15 двоичных символов Дальнейшее сжатие сообщений возможно путем применения неравномерного кода, если более короткие последовательности используются для более частых слов и более длинные — для более редких. Заметим, что эта идея неравномерного кодировании впервые нашла применение в телеграфном коде Морзе, в котором наиболее короткие комбинации использованы для часто встречающихся букв Разработано много методов эффективного кодирования для различных источников. Почти все они основаны на тех же двух принципах — укрупнения сообщений (аналогично переходу от букв к словам) и применения неравномерного кода. Заметим, что задача эффективного кодирования наиболее актуальна не для передачи текста, а для других источников со значительно большей избыточностью. К ним относятся, например, телевизионные передачи (промышленное телевидение) и некоторые телеметрические системы, в которых возможно сжатие в десятки раз.
|
 |
Оглавление
|




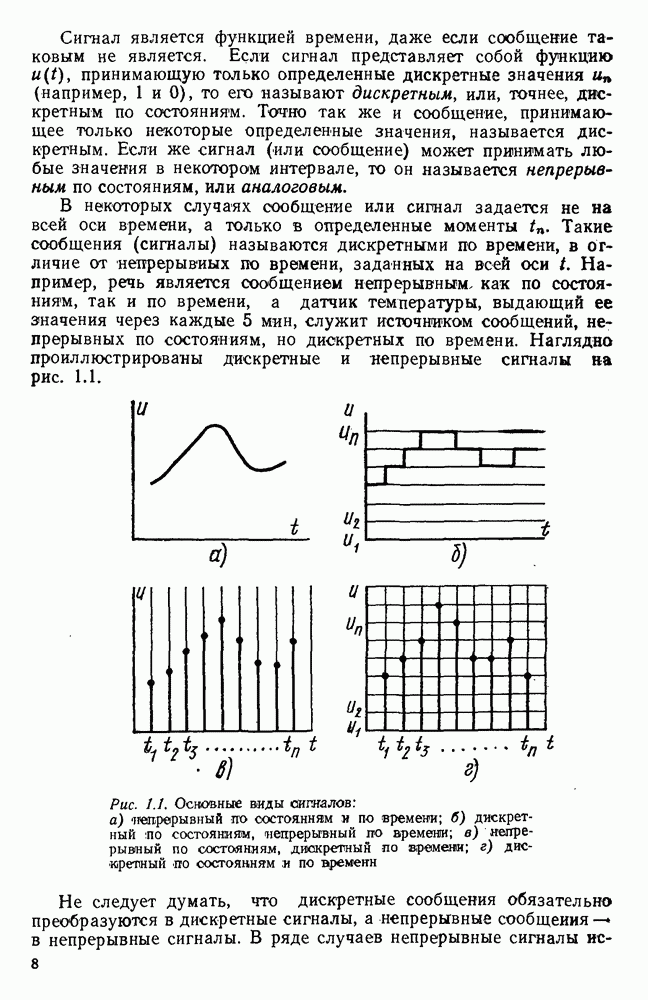
































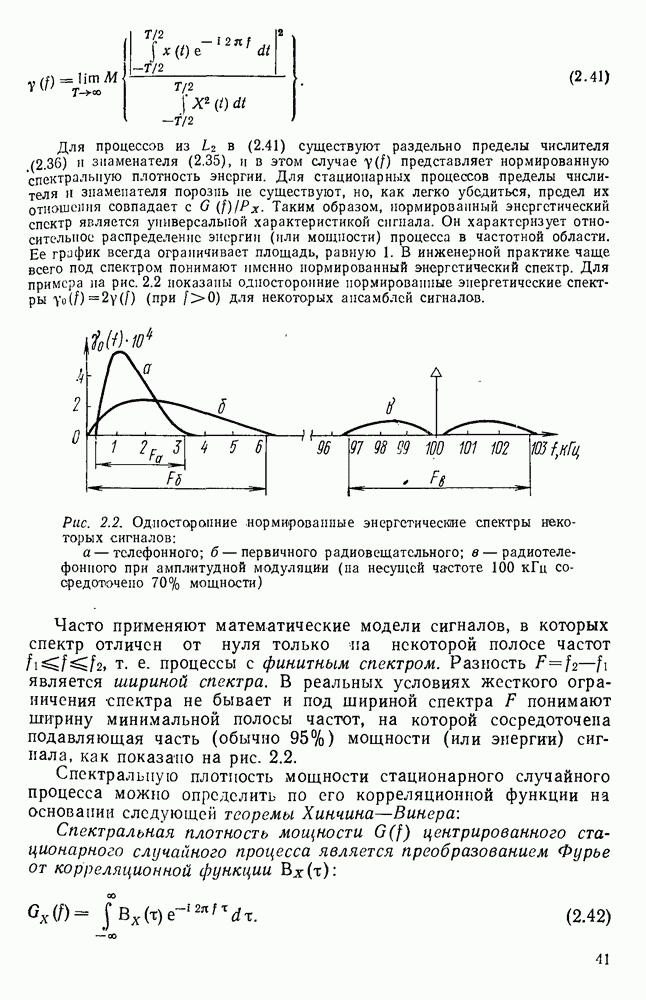


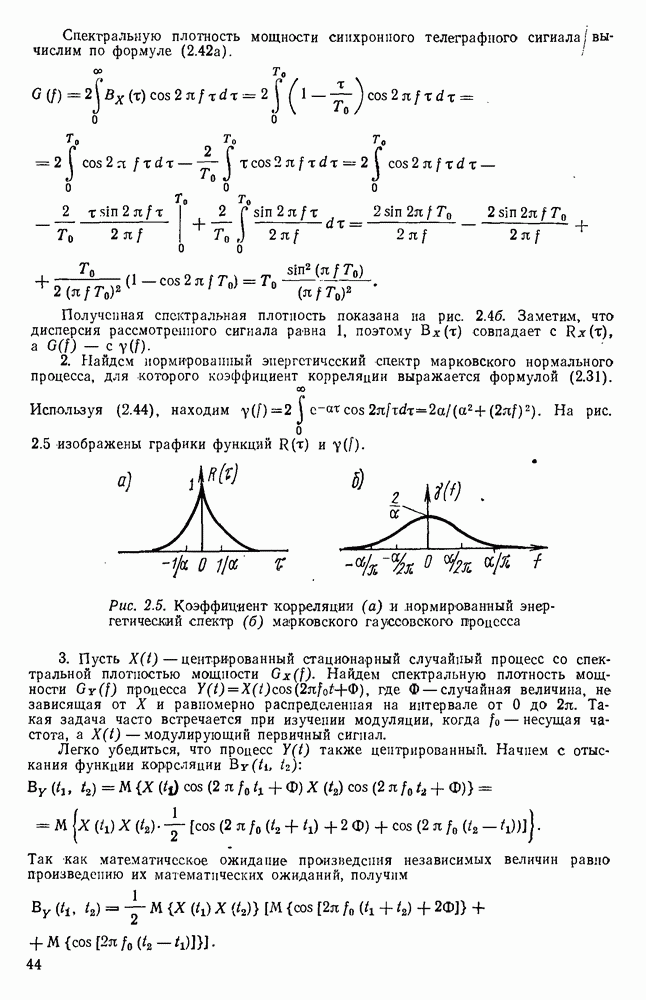









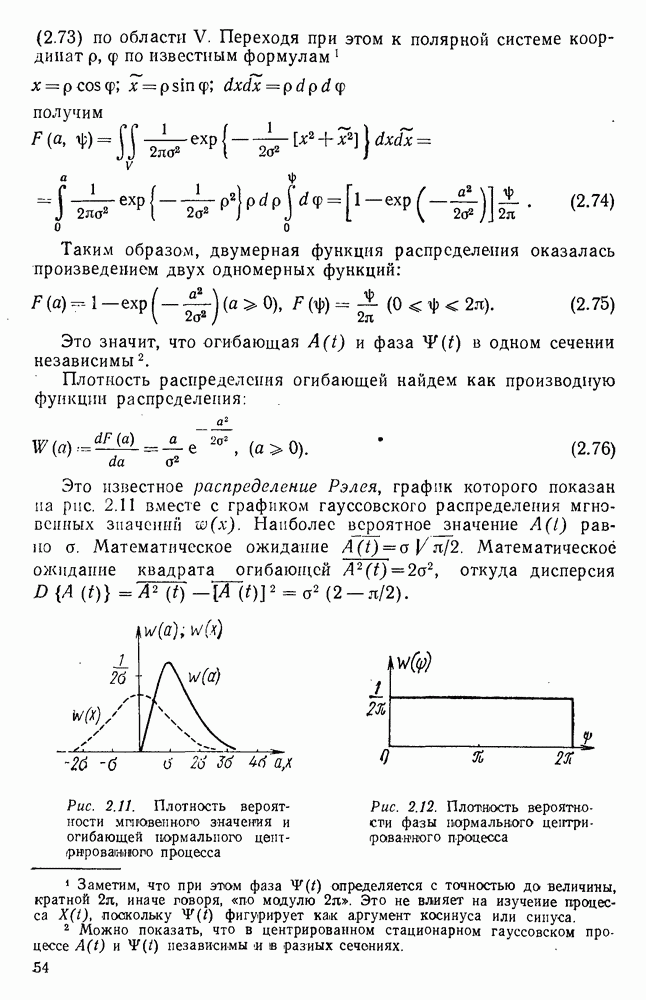









































































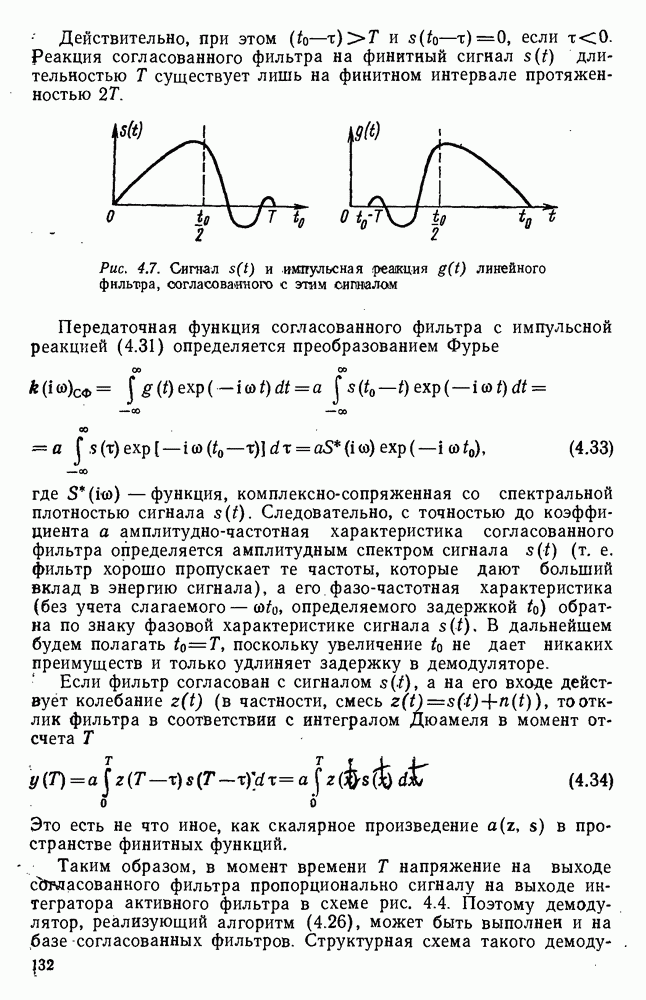
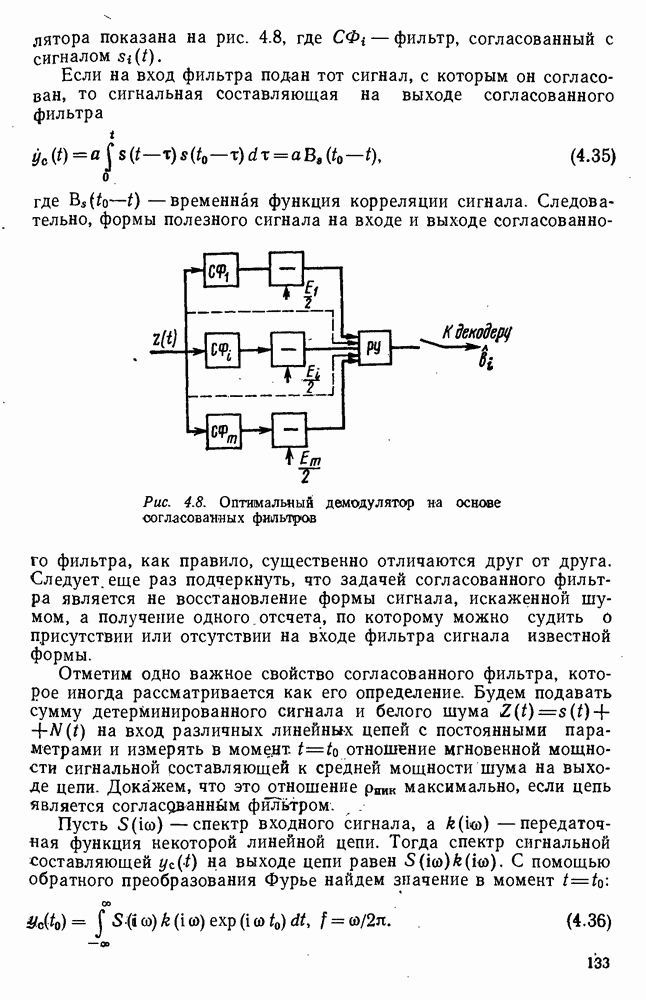


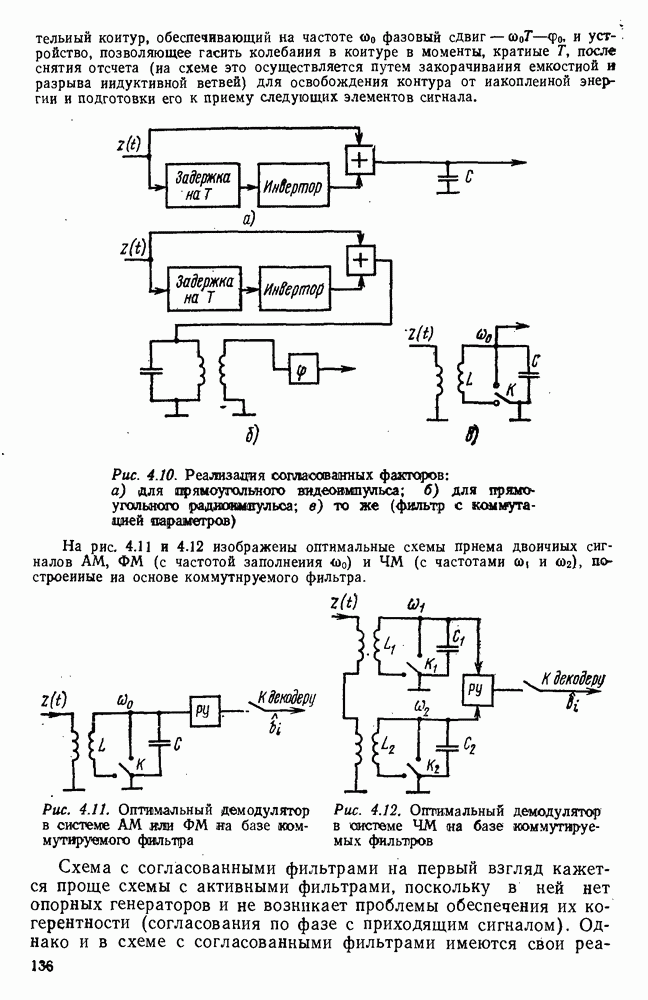
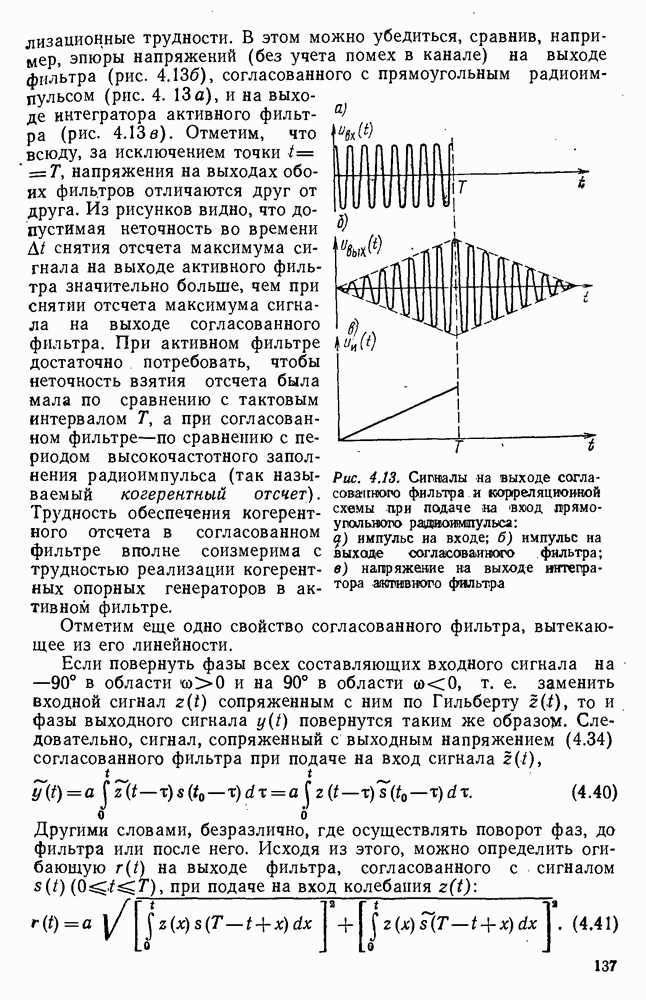













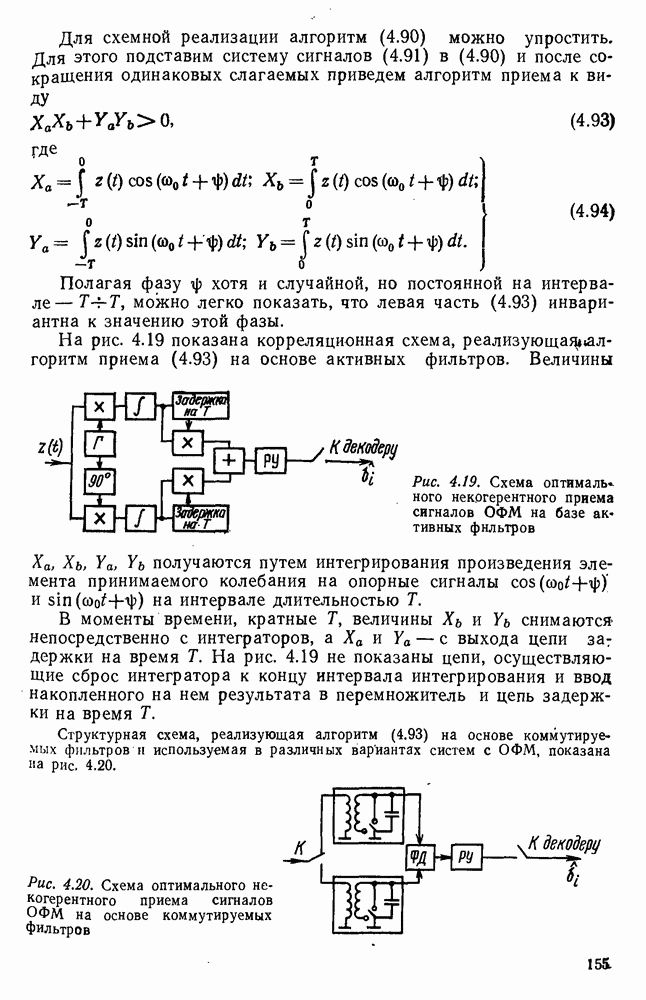








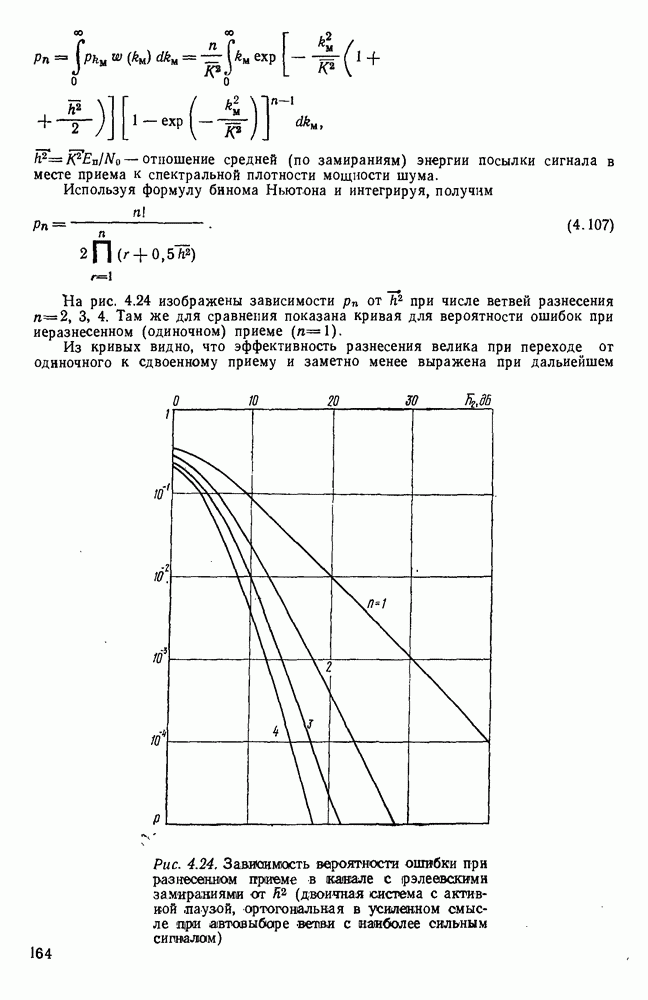



























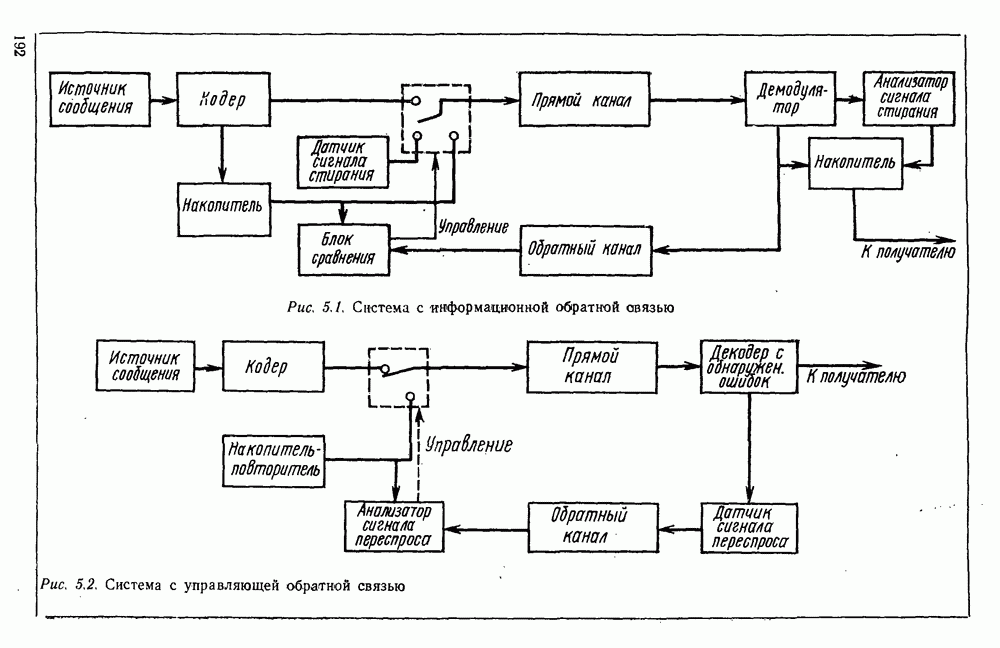












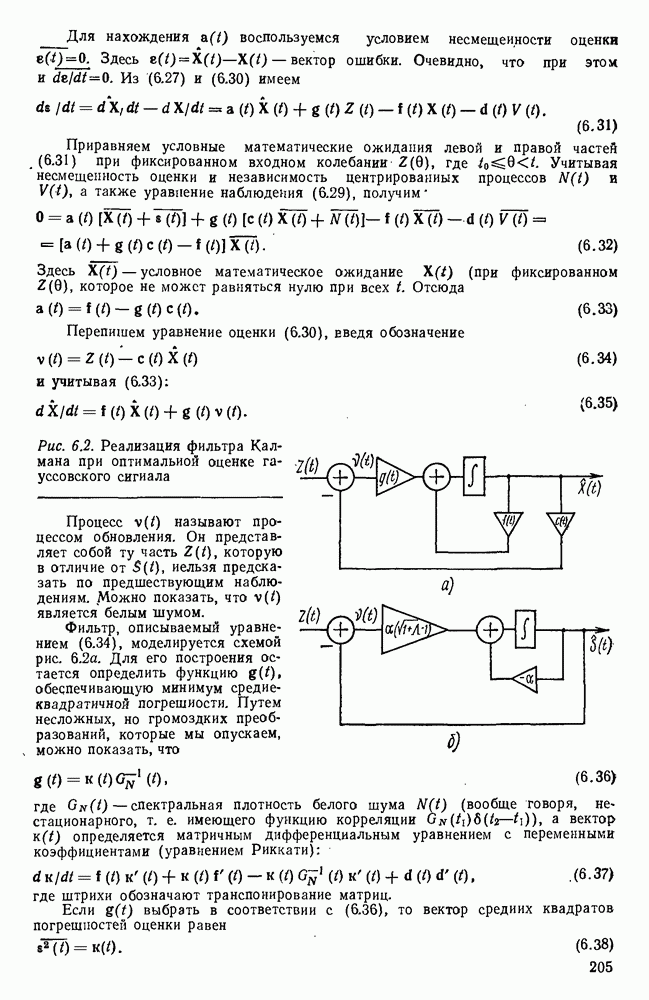




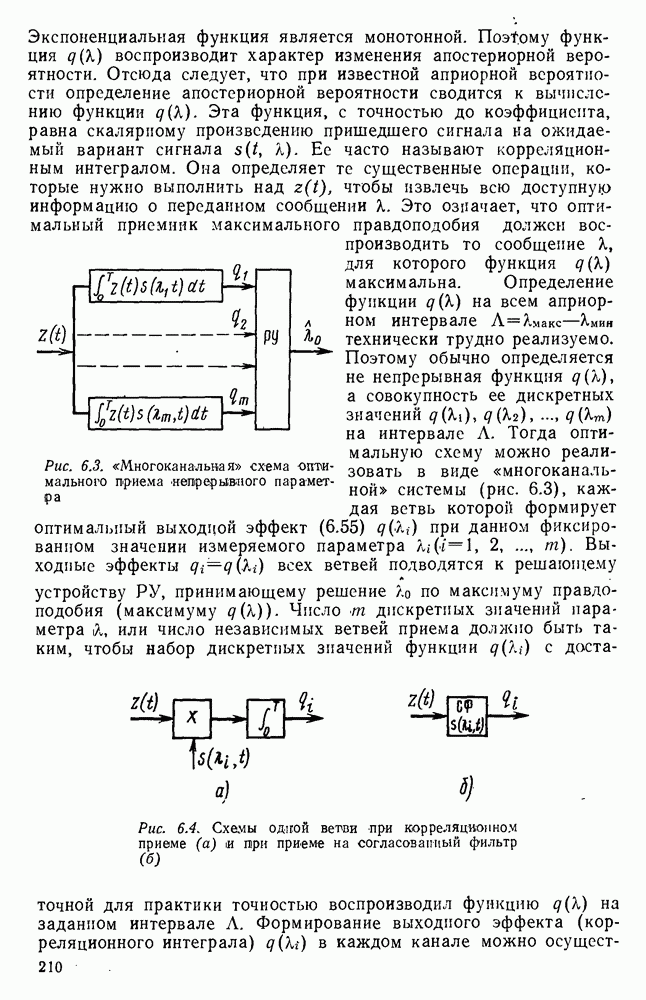





























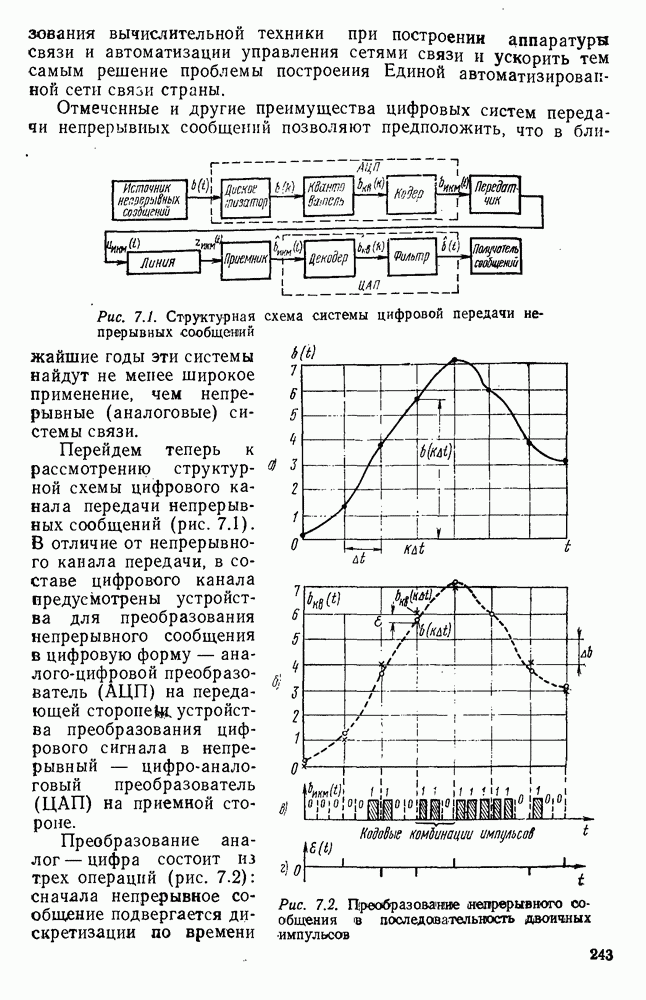



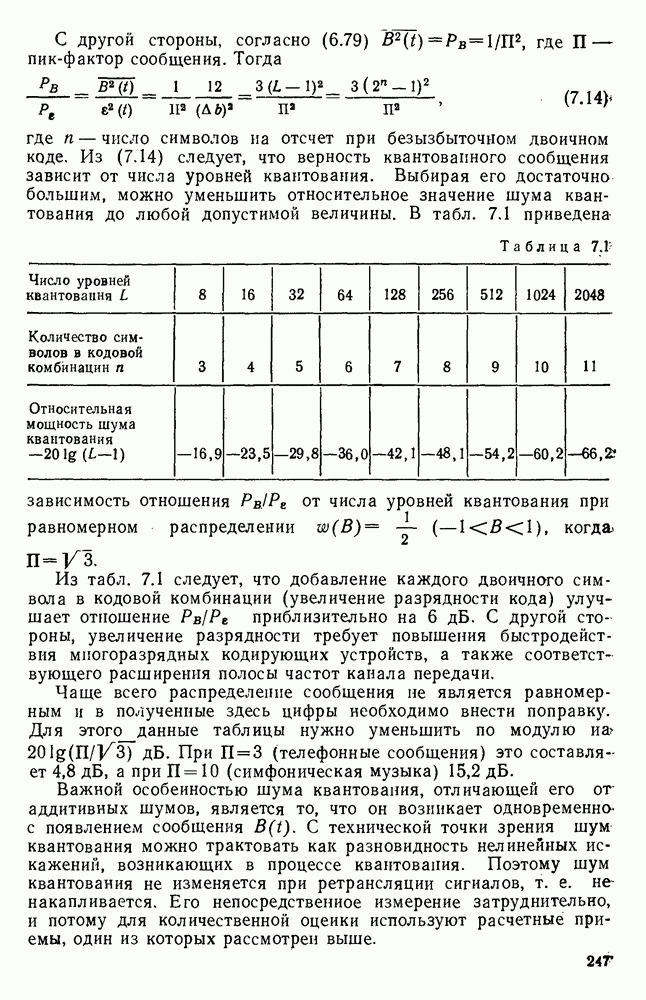






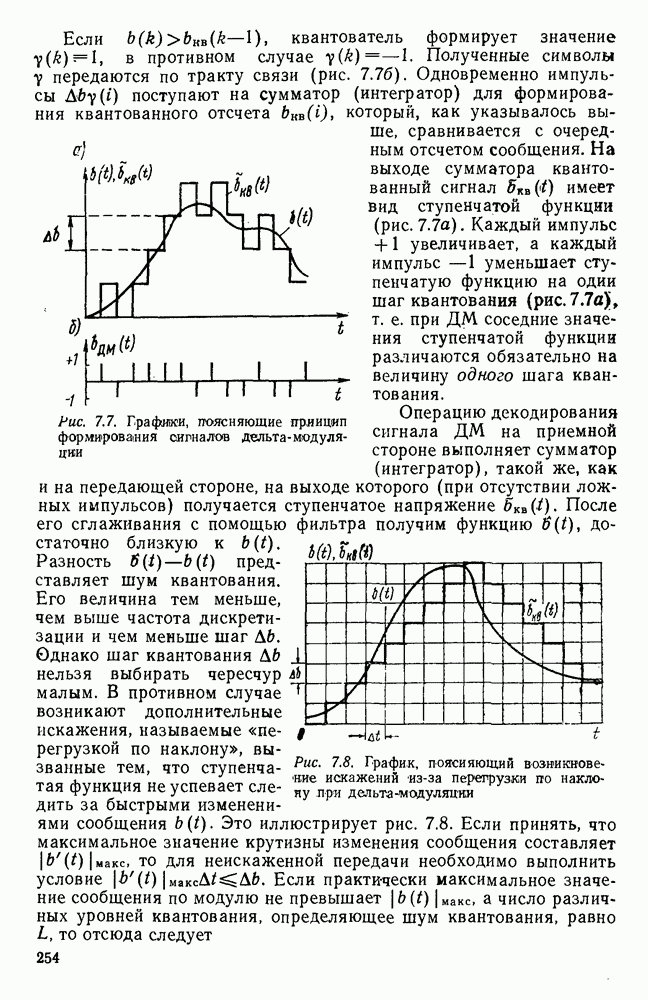

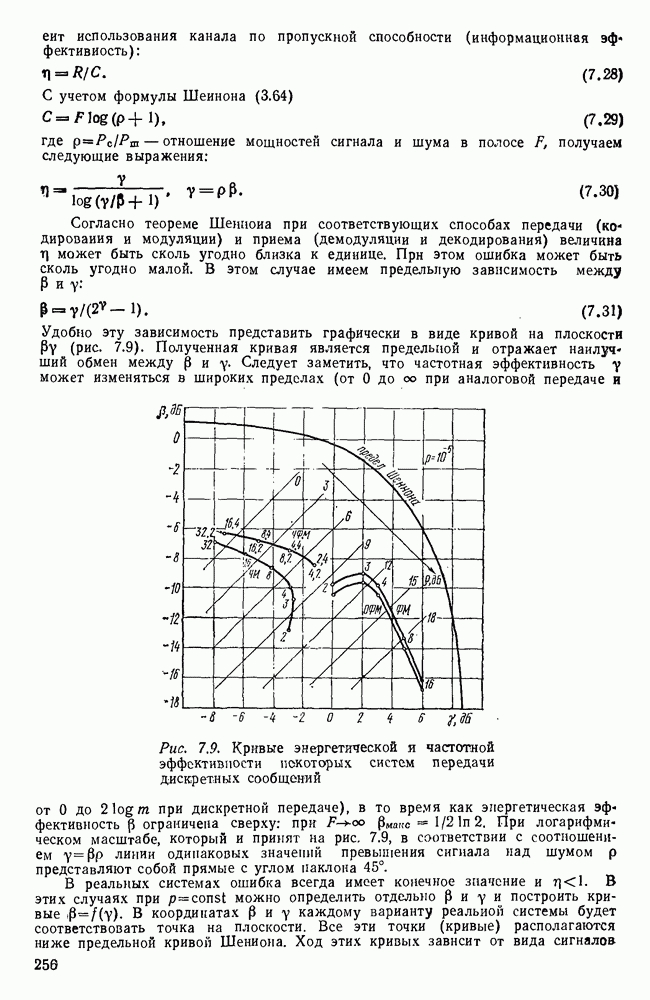


























 источник последовательности элементарных сообщений (знаков) с объемом алфавита К и производительностью
источник последовательности элементарных сообщений (знаков) с объемом алфавита К и производительностью  Для передач» по дискретному каналу нужно преобразовать сообщения в последовательность кодовых символов В так, чтобы эту кодовую последовательность можно было затем однозначно декодировать
Для передач» по дискретному каналу нужно преобразовать сообщения в последовательность кодовых символов В так, чтобы эту кодовую последовательность можно было затем однозначно декодировать  Для этого необходимо, чтобы скорость передачи информации от источника к коду
Для этого необходимо, чтобы скорость передачи информации от источника к коду  равнялась производительности источника
равнялась производительности источника  Но, с другой стороны, согласно
Но, с другой стороны, согласно  Следовательно, необходимым условием для кодирования является
Следовательно, необходимым условием для кодирования является  или, обозначая через
или, обозначая через  длительность кодового символа, а через
длительность кодового символа, а через  длительность элементарного сообщения
длительность элементарного сообщения  или
или

 число кодовых символов,
число кодовых символов,  число сообщений, передаваемых в секунду. Будем рассматривать для простоты только двоичный код, при котором алфавит В состоит из символов 0 и 1. Тогда
число сообщений, передаваемых в секунду. Будем рассматривать для простоты только двоичный код, при котором алфавит В состоит из символов 0 и 1. Тогда  бит. Поэтому необходимое условие (2.144) сводится к тому, что
бит. Поэтому необходимое условие (2.144) сводится к тому, что

 представляет среднее число кодовых символов, приходящихся на одно элементарное сообщение. Таким образом, для возможности кодирования и однозначного декодирования сообщения необходимо, чтобы среднее число двоичных символов на сообщение было не меньше энтропии
представляет среднее число кодовых символов, приходящихся на одно элементарное сообщение. Таким образом, для возможности кодирования и однозначного декодирования сообщения необходимо, чтобы среднее число двоичных символов на сообщение было не меньше энтропии  Является ли это условие достаточным?
Является ли это условие достаточным?
 можно закодировать сообщения так, чтобы передавать их со скоростью
можно закодировать сообщения так, чтобы передавать их со скоростью 

 сколь угодно малая величина.
сколь угодно малая величина.
 и если еще к тому же К — целая степень двух
и если еще к тому же К — целая степень двух  то
то  С другой стороны, используя для передачи каждого сигнала последовательность из
С другой стороны, используя для передачи каждого сигнала последовательность из  двоичных символов, мы получим
двоичных символов, мы получим  различных последовательностей и можем каждому сигналу сопоставить одну из кодовых последовательностей, так что (2.146) выполняете» даже при
различных последовательностей и можем каждому сигналу сопоставить одну из кодовых последовательностей, так что (2.146) выполняете» даже при 
 двоичных символов на элементарное сообщение. Однако сформулированная теорема утверждает, что возможно более экономное кодирование, с затратой
двоичных символов на элементарное сообщение. Однако сформулированная теорема утверждает, что возможно более экономное кодирование, с затратой  символов на сообщение. Относительная экономия символов при этом окажется равной
символов на сообщение. Относительная экономия символов при этом окажется равной  [см.
[см.  Таким образом, избыточность определяет достижимую степень «сжатия сообщения».
Таким образом, избыточность определяет достижимую степень «сжатия сообщения».
 и они передаются равновероятно и независимо, то
и они передаются равновероятно и независимо, то  бит. Каждую
бит. Каждую
 бит и, следовательно, возможен способ эффективного кодирования (или кодирования со сжатием сообщения), при котором в среднем на букву русского текста будет затрачено немногим более 1,5 двоичных символа, т. е. на 70% меньше, чем при примитивном коде.
бит и, следовательно, возможен способ эффективного кодирования (или кодирования со сжатием сообщения), при котором в среднем на букву русского текста будет затрачено немногим более 1,5 двоичных символа, т. е. на 70% меньше, чем при примитивном коде.
 напис. сокращ., и тем не м. мож. на-деят., что чит-ль пойм, ее прав. В предыдущей фразе удалось уменьшить число букв (а следовательно, и символов, если ее кодировать равномерным кодом) почти на
напис. сокращ., и тем не м. мож. на-деят., что чит-ль пойм, ее прав. В предыдущей фразе удалось уменьшить число букв (а следовательно, и символов, если ее кодировать равномерным кодом) почти на 
 . Таким образом, в среднем на букву придется немногим больше двух символов, т. е. сжатие достигнет почти 60%, вместо теоретических 70%. Слова, не вошедшие в словарь, придется передавать обычным способом, затрачивая пять символов на букву. Но поскольку такие нетипичные слова будут встречаться крайне редко, это не внесет заметной поправки в общий баланс.
. Таким образом, в среднем на букву придется немногим больше двух символов, т. е. сжатие достигнет почти 60%, вместо теоретических 70%. Слова, не вошедшие в словарь, придется передавать обычным способом, затрачивая пять символов на букву. Но поскольку такие нетипичные слова будут встречаться крайне редко, это не внесет заметной поправки в общий баланс.
 .
.