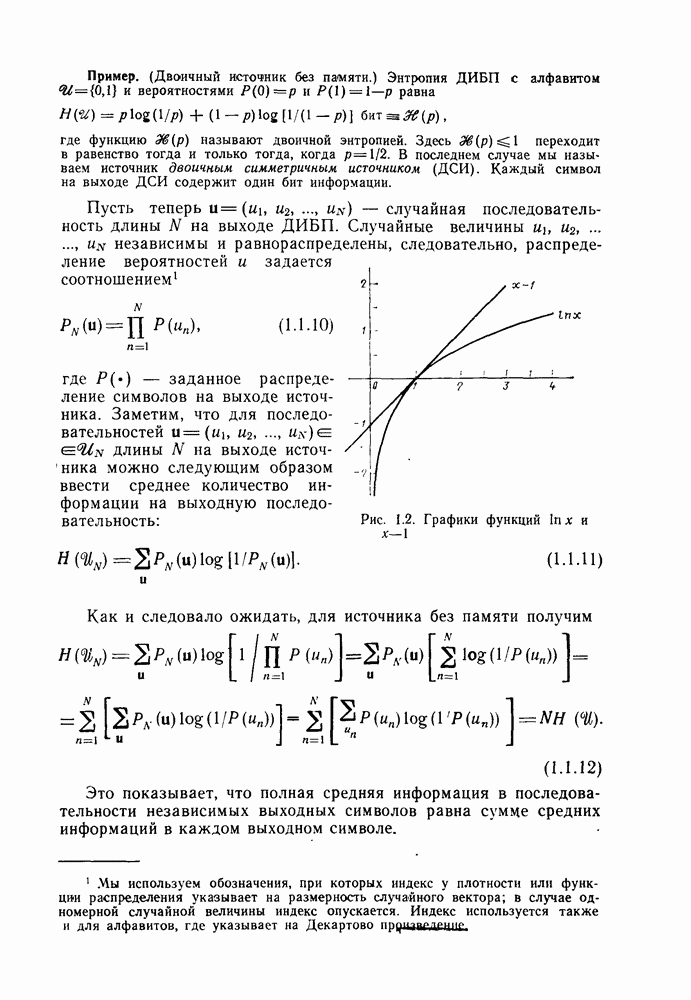
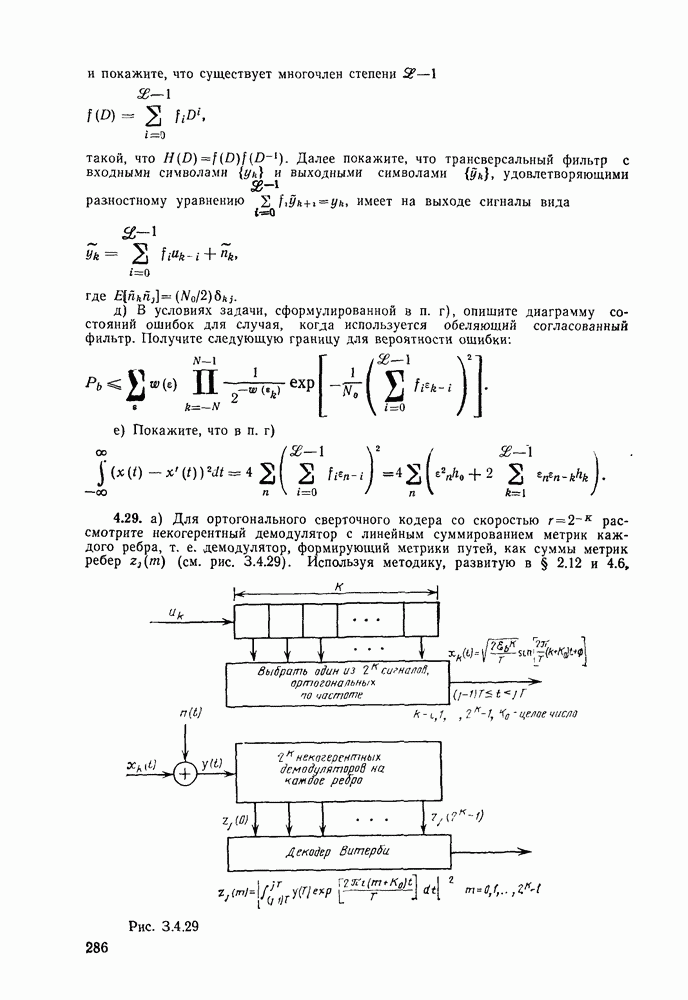
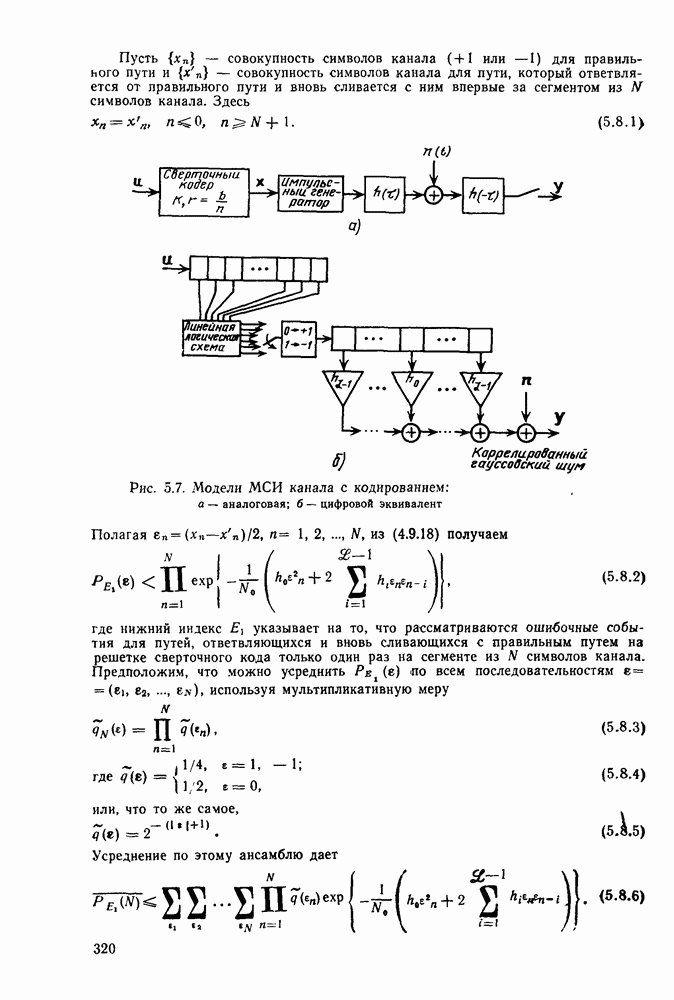
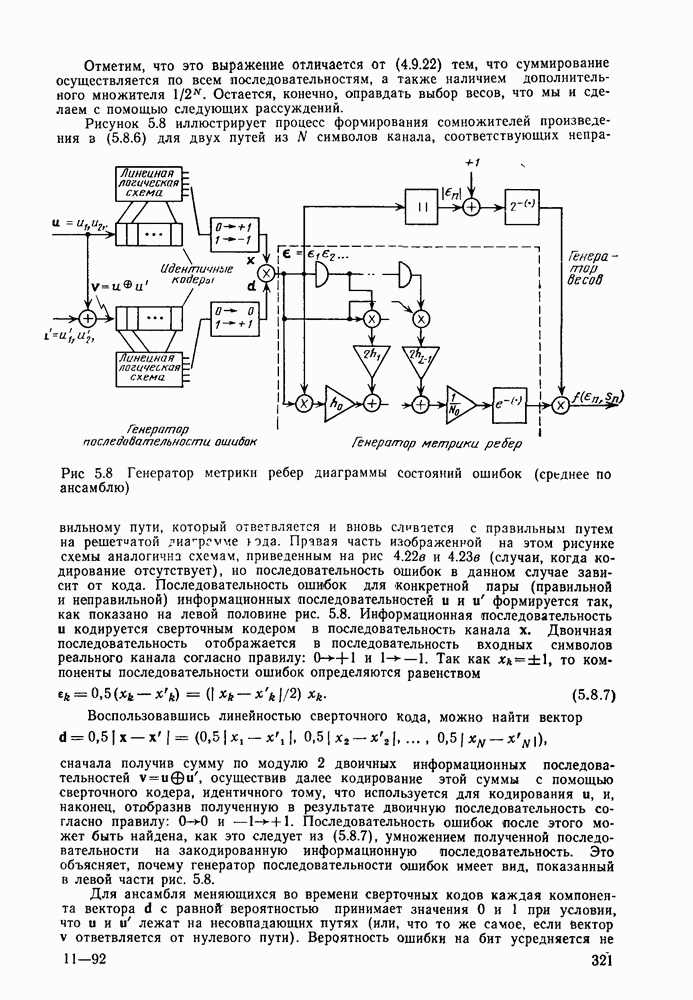
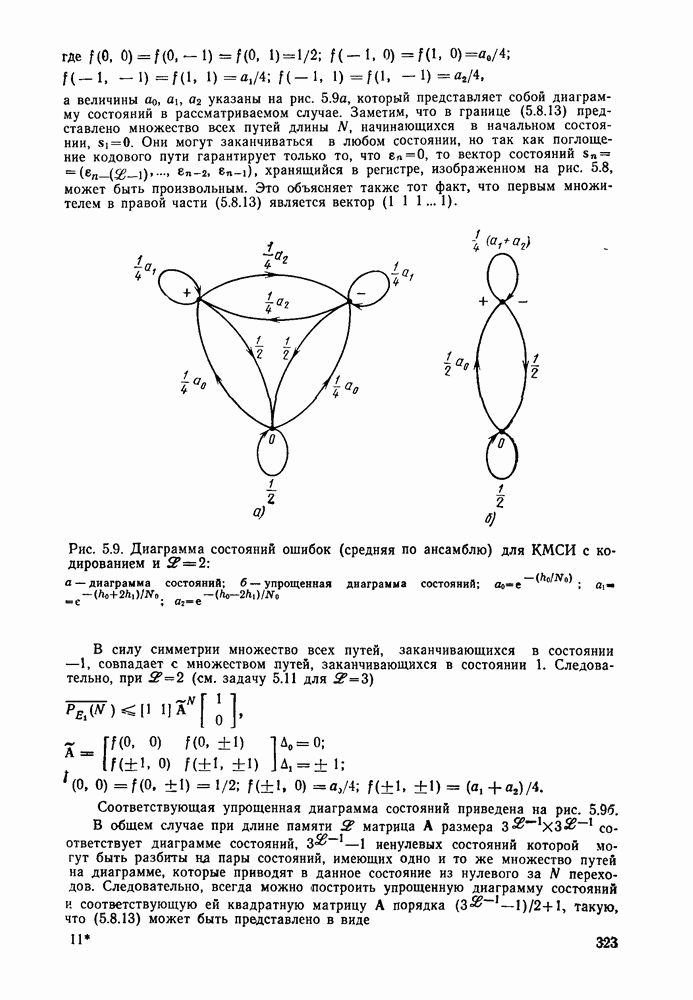
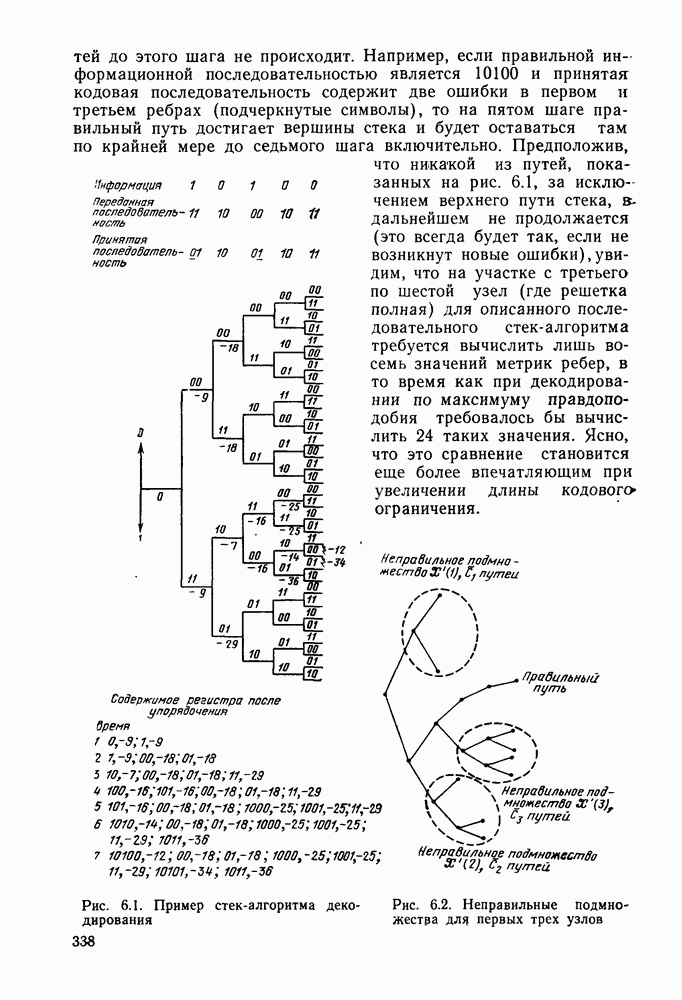
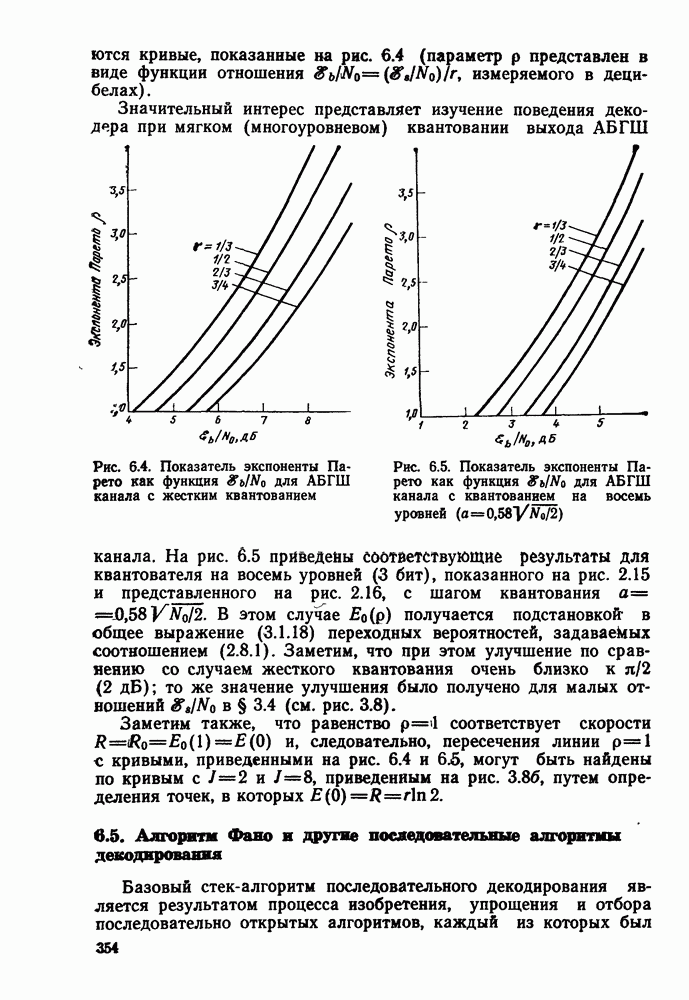
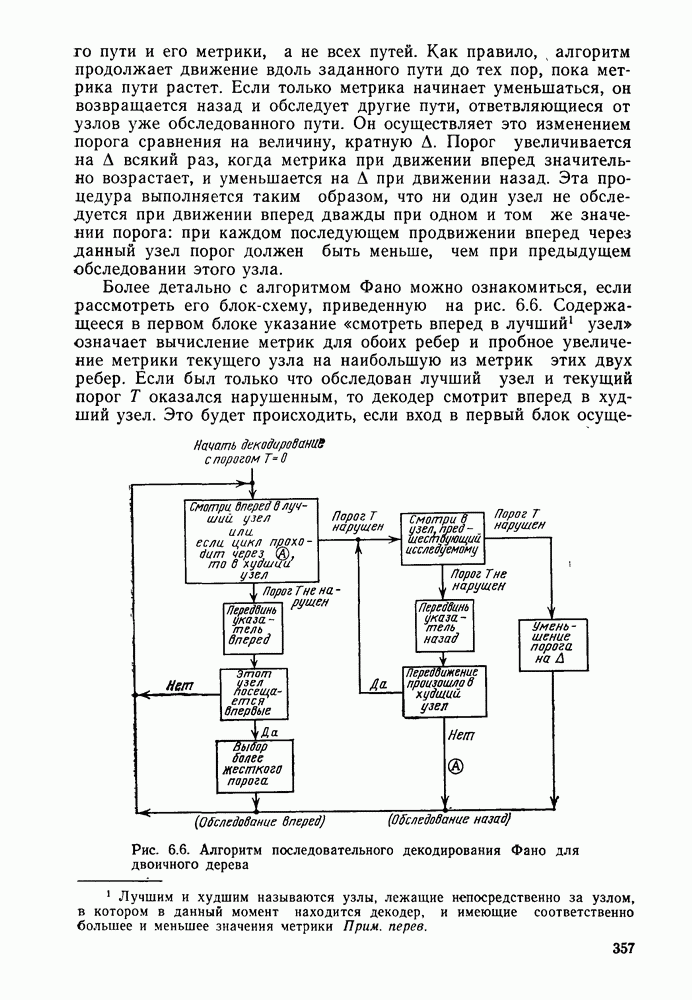
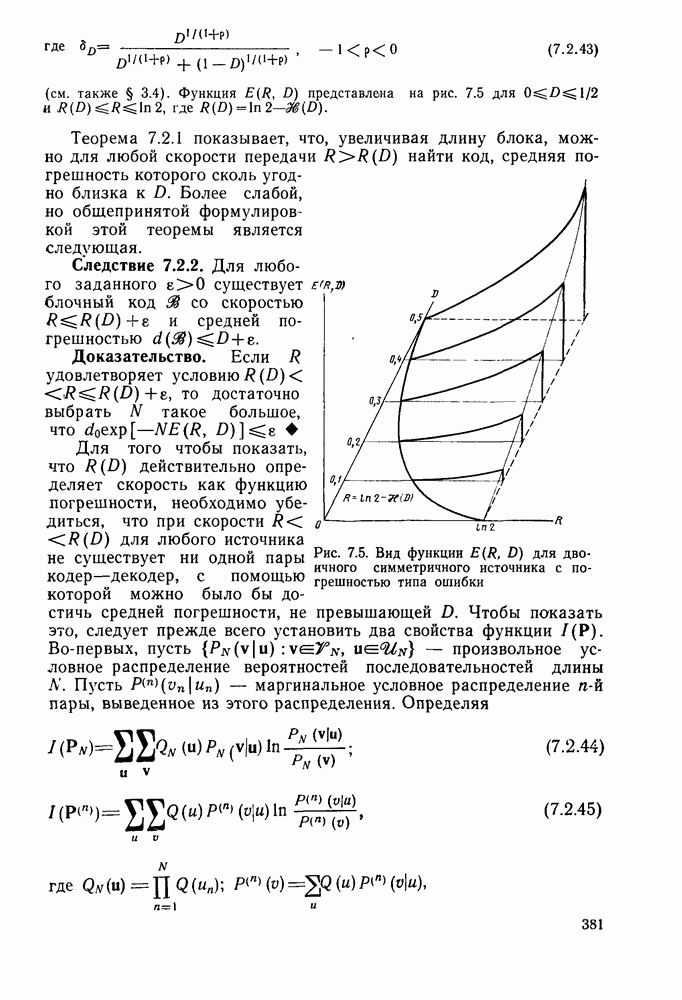
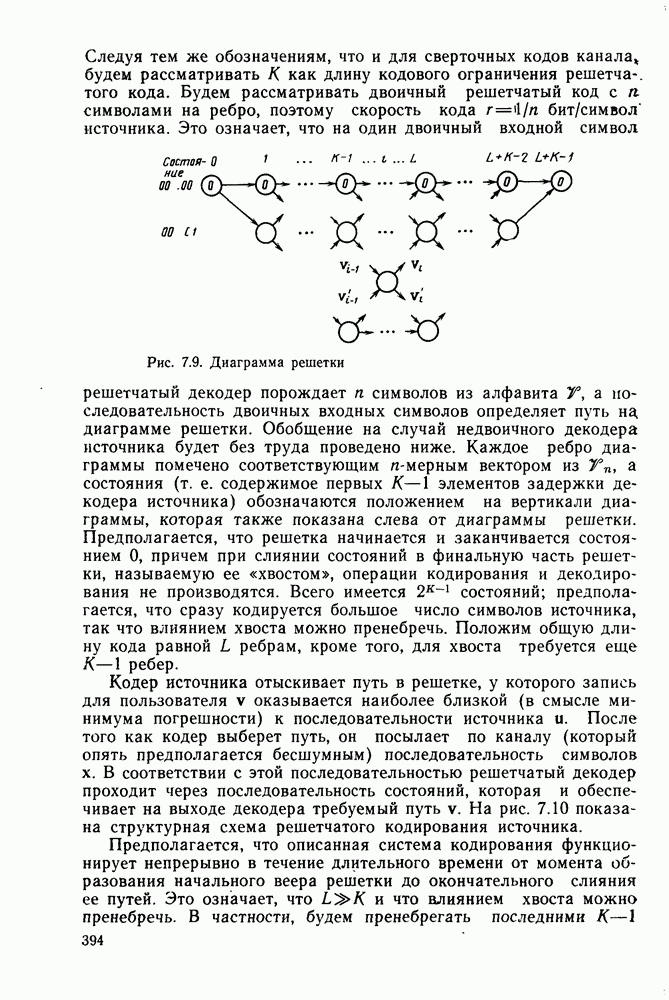
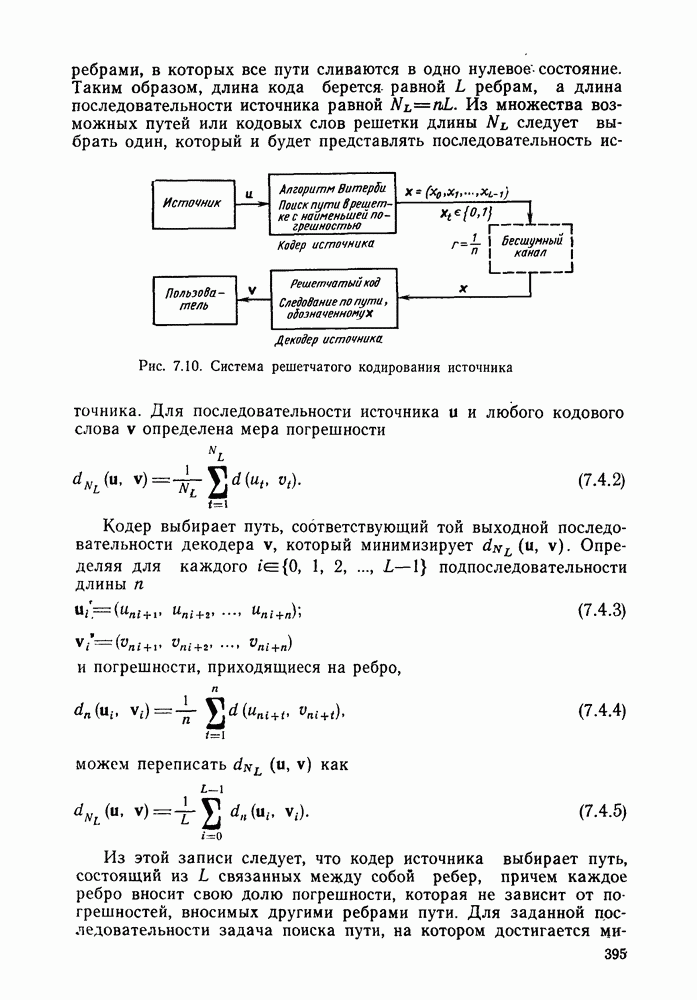
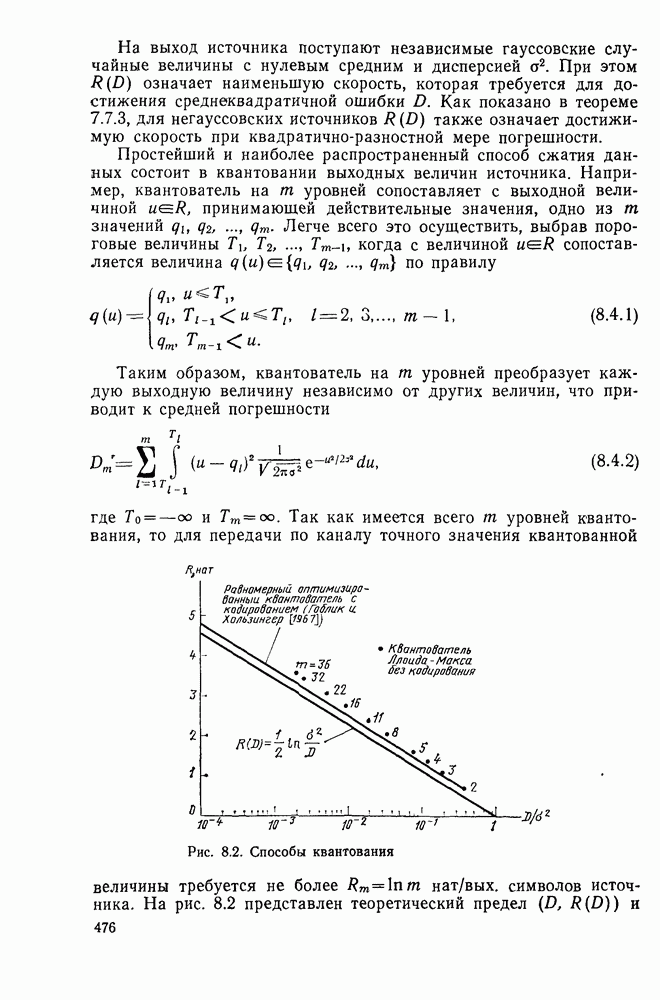
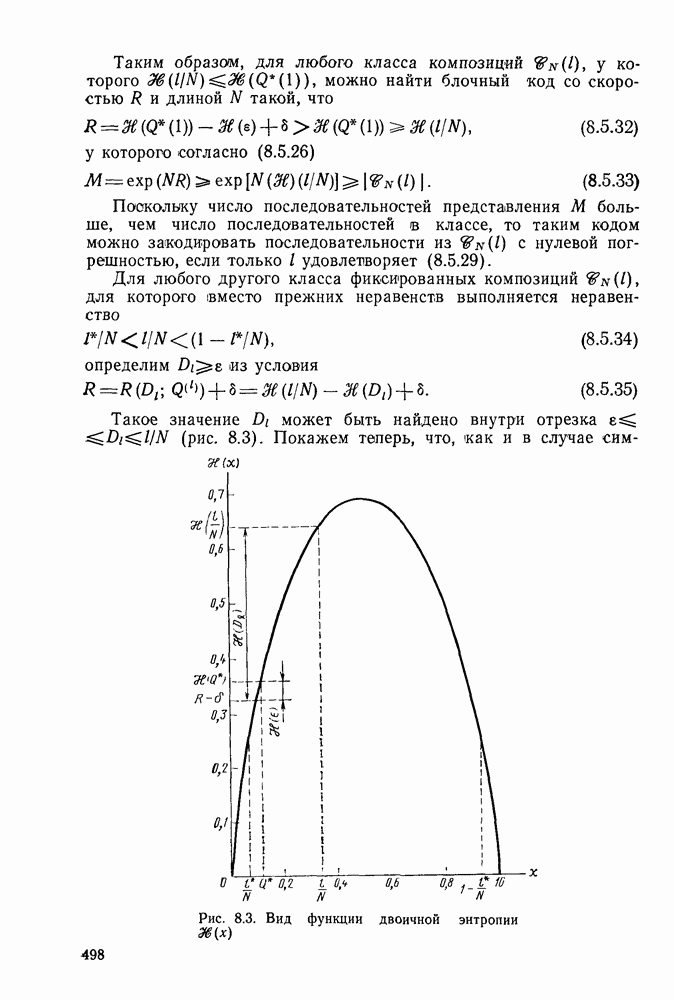
2.10. Систематические линейные коды и оптимальное декодирование в ДСК
В предыдущем параграфе мы определили линейный код как код, для которого кодовые векторы получаются из векторов информационных символов отображением

где  произвольная матрица размеров
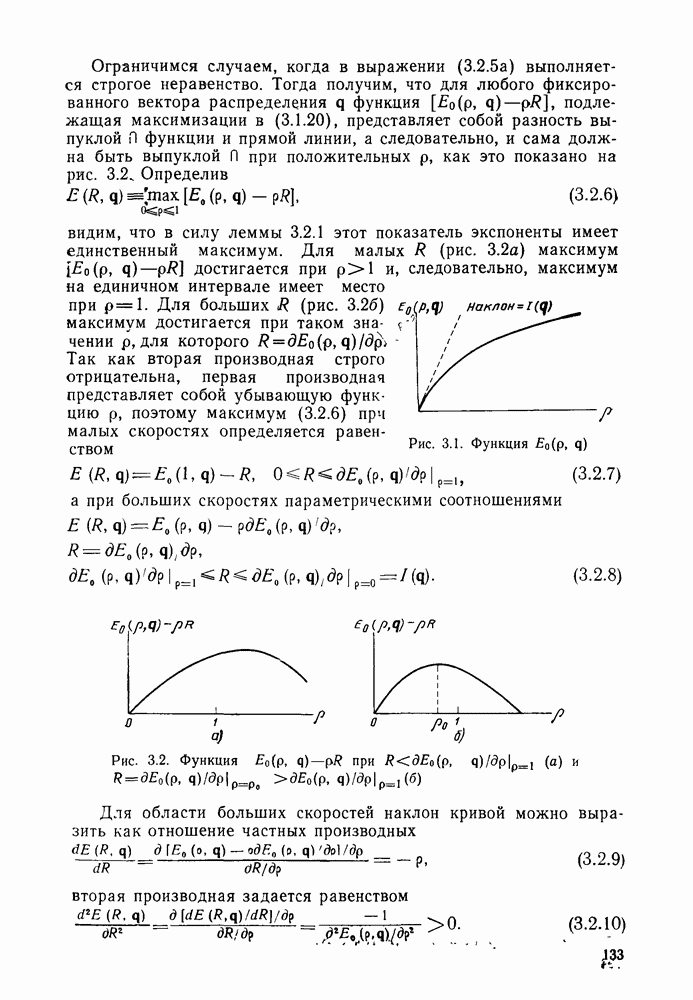
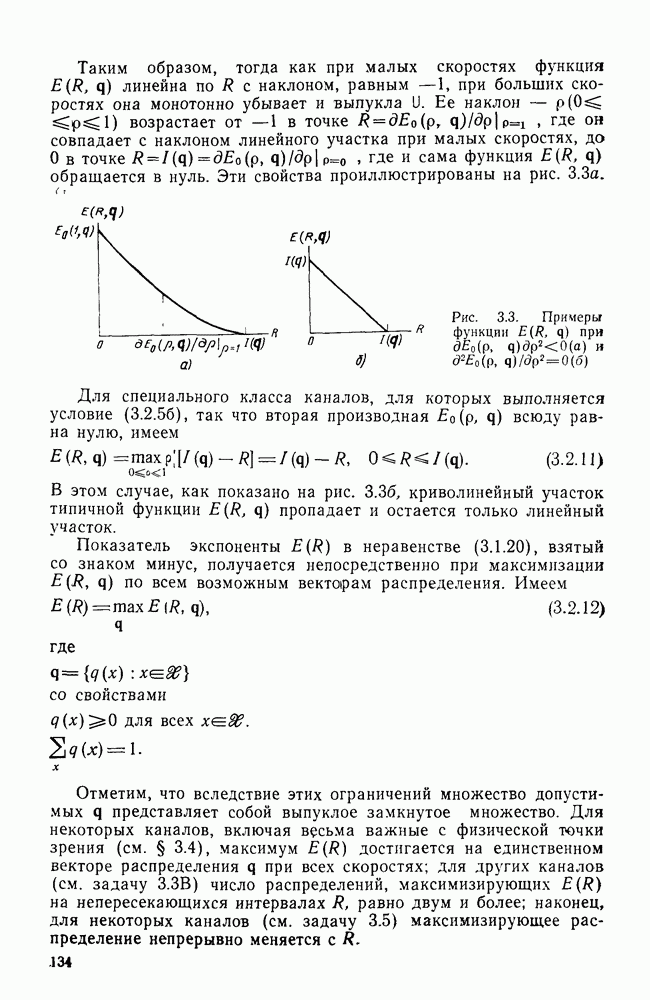
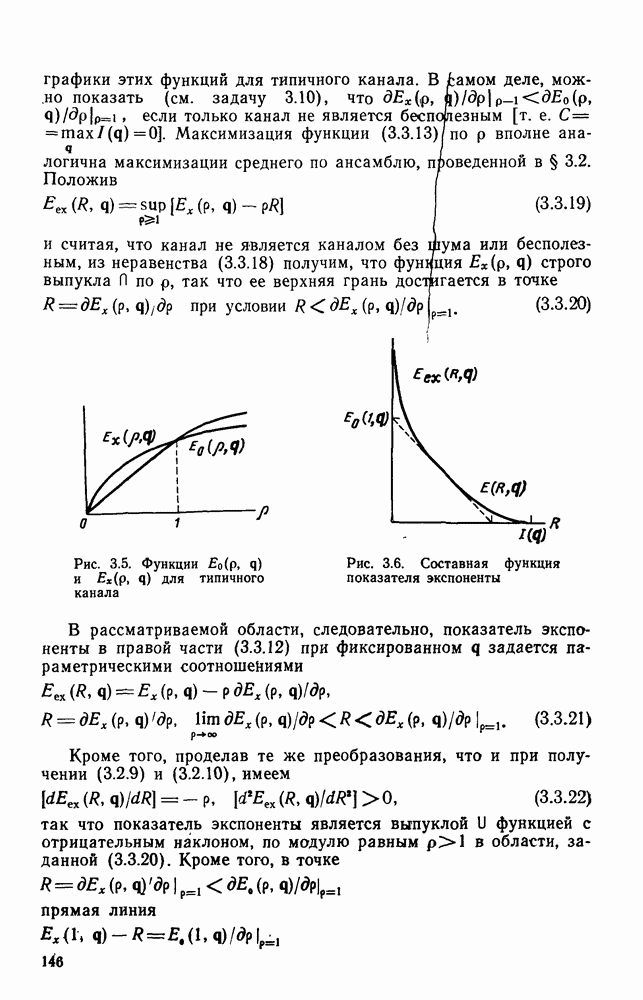
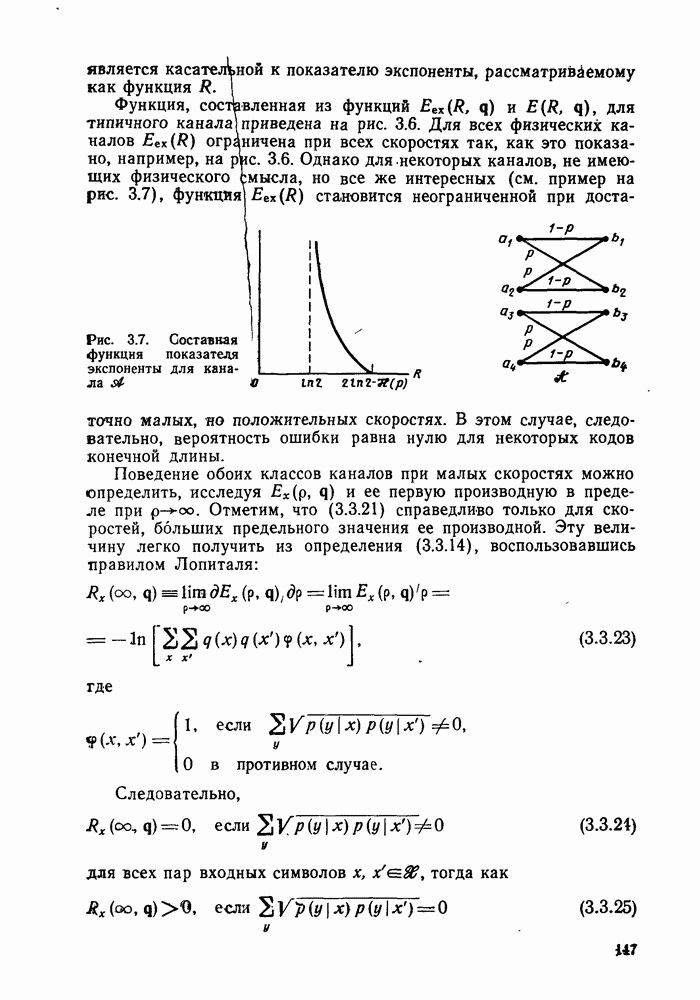
произвольная матрица размеров  состоящая из нулей и единиц. Покажем, что из того, что любой сколько-нибудь полезный линейный код представляет собой взаимно одознче отображение векторов информационных символов в кодовые веторьгследует его эквивалентность линейному коду с порождающей матрицей вида
состоящая из нулей и единиц. Покажем, что из того, что любой сколько-нибудь полезный линейный код представляет собой взаимно одознче отображение векторов информационных символов в кодовые веторьгследует его эквивалентность линейному коду с порождающей матрицей вида

Заметим, что у кода (2.10.1), порождаемого матрицей (2.10.2), первые К кодовых символов совпадают с информационными символами, т. е.

а остальные Задаются по-прежнему соотношениями

Коды такого типа, передающие без изменений первоначальные К информационных символов вместе с  «проверочными» символами, называются систематическими кодами.
«проверочными» символами, называются систематическими кодами.
Далее будет показано, что любой линейный код, осуществляющий взаимно однозначное преобразование, эквивалентен по своим характеристикам некоторому систематическому коду. Действительно, перестановка любых двух строк  или суммирование по модулю 2 любой комбинации строк не меняет множества порождаемых кодовых векторов, а просто перенумеровывает их по-другому. Обозначив вектор-строки
или суммирование по модулю 2 любой комбинации строк не меняет множества порождаемых кодовых векторов, а просто перенумеровывает их по-другому. Обозначив вектор-строки  через
через  видим, что перестановка
видим, что перестановка  переводит первоначальные кодовые векторы
переводит первоначальные кодовые векторы

в новые кодовые векторы

Поскольку  принимают все возможные комбинации значений, набор
принимают все возможные комбинации значений, набор  совпадает с
совпадает с  с точностью до нумерации. Аналогичным образом добавление строки
с точностью до нумерации. Аналогичным образом добавление строки  к строке
к строке  переводит первоначальный набор в новый набор кодовых векторов
переводит первоначальный набор в новый набор кодовых векторов

Поскольку  представляет собой кодовый вектор, в силу доказанного в предыдущем параграфе свойства замкнутости добавление одного и того же кодового вектора ко всем кодовым векторам приводит к первоначальному набору кодовых векторов, расположенных в другом порядке. Следовательно,
представляет собой кодовый вектор, в силу доказанного в предыдущем параграфе свойства замкнутости добавление одного и того же кодового вектора ко всем кодовым векторам приводит к первоначальному набору кодовых векторов, расположенных в другом порядке. Следовательно, 
Для того чтобы закончить доказательство, проделаем следующую комбинацию сложений и перестановок строк порождающей матрицы. Выберем первый ненулевой столбец, номер которого для определенности равен  отыскав первую строку с единицей в
отыскав первую строку с единицей в  позиции, поменяем ее местами с первой строкой и добавим ко всем остальным строкам с единицей в
позиции, поменяем ее местами с первой строкой и добавим ко всем остальным строкам с единицей в  позиции. При этом получится матрица, имеющая единицу в первой строке лишь в
позиции. При этом получится матрица, имеющая единицу в первой строке лишь в  столбце. В новой матрице найдем следующий ненулевой столбец, имеющий единицу хотя бы в одной из
столбце. В новой матрице найдем следующий ненулевой столбец, имеющий единицу хотя бы в одной из  строк, начиная со второй и, переставим строки так, чтобы во второй строке оказалась единица, а затем добавим вторую строку ко всем строкам (возможно, и к первой), у которых в рассматриваемой позиции стоит единица. После К таких шагов либо останутся К столбцов, имеющих по одной единице в разных позициях, либо в нижней части матрицы будет одна или больше нулевых строк. Последнее может иметь место только тогда, когда в первоначальной матрице были линейно зависимые строки. Поэтому ни первоначальная матрица
строк, начиная со второй и, переставим строки так, чтобы во второй строке оказалась единица, а затем добавим вторую строку ко всем строкам (возможно, и к первой), у которых в рассматриваемой позиции стоит единица. После К таких шагов либо останутся К столбцов, имеющих по одной единице в разных позициях, либо в нижней части матрицы будет одна или больше нулевых строк. Последнее может иметь место только тогда, когда в первоначальной матрице были линейно зависимые строки. Поэтому ни первоначальная матрица  ни получившаяся матрица не могут порождать
ни получившаяся матрица не могут порождать  различных кодовых векторов, и, следовательно, отображение не может быть взаимно однозначным и соответствует плохому коду, у которого несколько векторов информационных символов приводят к одному и тому же кодовому вектору. В первом же из перечисленных случаев нам нужно всего лишь переставить столбцы матрицы, чтобы получить порождающую матрицу вида (2.10.2), а это означает простое переупорядочение кодовых символов 2.
различных кодовых векторов, и, следовательно, отображение не может быть взаимно однозначным и соответствует плохому коду, у которого несколько векторов информационных символов приводят к одному и тому же кодовому вектору. В первом же из перечисленных случаев нам нужно всего лишь переставить столбцы матрицы, чтобы получить порождающую матрицу вида (2.10.2), а это означает простое переупорядочение кодовых символов 2.
Таким образом, всякий раз, когда строки порождающей матрицы кода линейно независимы и столбцы ее отличны от нулевых, код оказывается
эквивалентным с точностью до переупорядочения кодовых векторов и, возможно, перестановки столбцов некоторому систематическому коду, порождаемому матрицей (2.10.2).
Поэтому ограничимся систематическими линейными блочными кодами и, в частности, изучим их при работе в ДСК. В § 2.8 было показано, что при использовании любого двоичного кода в ДСК декодирование по максимуму правдоподобия эквивалентно декодированию по минимуму расстояния. Иначе говоря,

причем в случае равенства используется случайный выбор. Если  то расстояние Хэмминга задается формулой
то расстояние Хэмминга задается формулой

Кроме того  поскольку символы кода и сигнала здесь совпадают. Поэтому декодирование можно проводить, вычисляя вес векторов, получающихся при сложении по модулю 2 принятого вектора у со всеми возможными кодовыми векторами, и решая в пользу того из сообщений, для которого кодовый вектор приводит к вектору наименьшего веса.
поскольку символы кода и сигнала здесь совпадают. Поэтому декодирование можно проводить, вычисляя вес векторов, получающихся при сложении по модулю 2 принятого вектора у со всеми возможными кодовыми векторами, и решая в пользу того из сообщений, для которого кодовый вектор приводит к вектору наименьшего веса.
Опишем теперь более простой метод декодирования систематических линейных кодов в ДСК типа просмотра таблицы. Подставив (2.10.3а) в правую часть (2.10.36) и добавив к обеим частям  получим
получим

или в векторной форме

где  представляет собой матрицу размерами
представляет собой матрицу размерами 

Транспонированную к ней матрицу  называют проверочной матрицей. Из (2.10.6а) следует, что умножение любого кодового вектора на
называют проверочной матрицей. Из (2.10.6а) следует, что умножение любого кодового вектора на  дает вектор
дает вектор
0, поэтому кодовые векторы образуют нуль-пространство проверочной матрицы. Посмотрим, что будет, если любой принятый вектор у умножить справа на  В результате получится
В результате получится  -мерный двоичный вектор, называемый синдромом принятого вектора и задаваемый соотношением
-мерный двоичный вектор, называемый синдромом принятого вектора и задаваемый соотношением

Рассматриваемая операция может быть выполнена точно так же, как и кодирование (2.9.3) и (2.9.4), за исключением того, что для ее выполнения понадобится регистр длины  сумматоров по модулю 2. При отсутствии ошибок
сумматоров по модулю 2. При отсутствии ошибок  следовательно, синдром равен нулю. Допустим теперь, что в ДСК имела место произвольная последовательность ошибок
следовательно, синдром равен нулю. Допустим теперь, что в ДСК имела место произвольная последовательность ошибок  где
где

Тогда, если передавался вектор  то принятый вектор равен
то принятый вектор равен 

Кроме того, синдром имеет вид

При фиксированном принятом векторе у и соответствующем векторе синдрома  система уравнений (2.10.10) имеет
система уравнений (2.10.10) имеет  решений
решений  каждое из которых соответствует одному возможно переданному вектору. Из (2.10.5) вытекает, что в ДСК декодер по максимуму правдоподобия (по минимуму расстояния) выбирает из
каждое из которых соответствует одному возможно переданному вектору. Из (2.10.5) вытекает, что в ДСК декодер по максимуму правдоподобия (по минимуму расстояния) выбирает из  кодовое слово, соответствующее вектору с наименьшим весом. Для систематических линейных кодов в соответствии с формулой (2.10.9) это означает, что для фиксированной выходной последовательности канала у
кодовое слово, соответствующее вектору с наименьшим весом. Для систематических линейных кодов в соответствии с формулой (2.10.9) это означает, что для фиксированной выходной последовательности канала у

На основании соотношения (2.10.11) можно сделать вывод о возможности реализации декодера по максимуму правдоподобия в ДСК.
0. До декодирования вычислить для каждого из  возможных синдромов
возможных синдромов  вектор минимального веса
вектор минимального веса  удовлетворяющий (2.10.10), и свести их в таблицу из
удовлетворяющий (2.10.10), и свести их в таблицу из  векторов длины
векторов длины 
1. С помощью линейной операции (2.10.7) для каждого  -мерного принятого вектора у вычислить
-мерного принятого вектора у вычислить  -мерный синдром
-мерный синдром  Для этого требуется регистр длины
Для этого требуется регистр длины  сумматоров по модулю 2.
сумматоров по модулю 2.
2. Обратиться к таблице, построенной на шаге 0, и, просмотрев ее, по s отыскать 
3. Операцией  получить наиболее вероятный кодовый вектор, у которого в соответствии с (2.10.3а) первые К символов суть информационные.
получить наиболее вероятный кодовый вектор, у которого в соответствии с (2.10.3а) первые К символов суть информационные.
Сложность этой процедуры связана с размерами таблицы, состоящей из 2-я векторов размерности  Поскольку код — систематический, из описания шага 3 тривиальным образом следует, что каждый вектор в таблице можно сократить до К-мерного вектора, иначе говоря, необходимо помнить только ошибки, возникающие в К информационных символах, и не помнить ошибки в
Поскольку код — систематический, из описания шага 3 тривиальным образом следует, что каждый вектор в таблице можно сократить до К-мерного вектора, иначе говоря, необходимо помнить только ошибки, возникающие в К информационных символах, и не помнить ошибки в  проверочных.
проверочных.
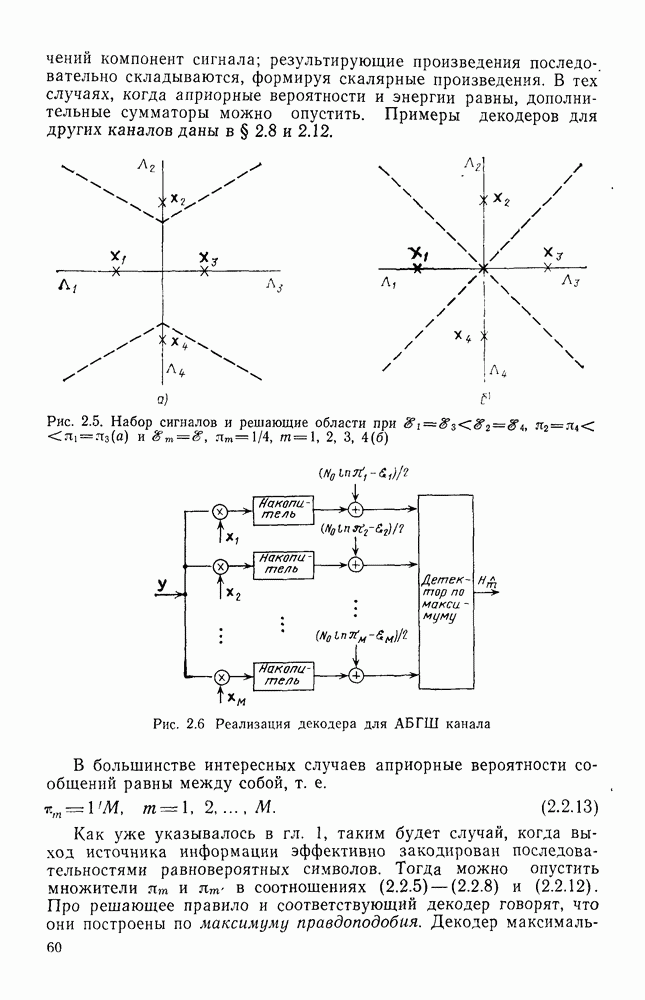
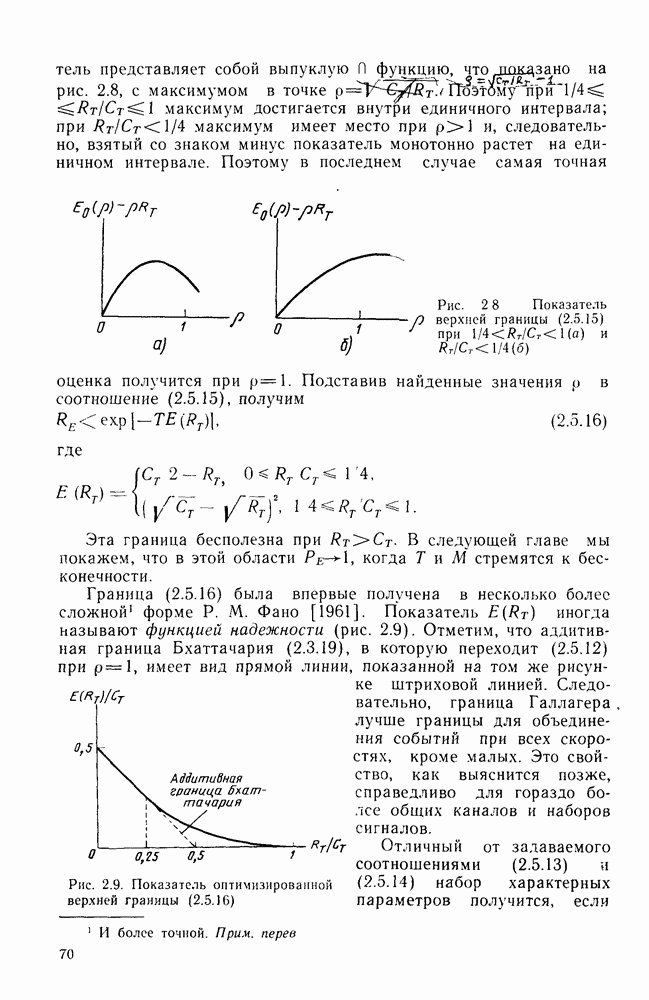
Непосредственно из соотношений (2.10.4), (2.10.5) и (2.10.9) следует, что декодер по максимуму правдоподобия правильно декодирует любой двоичный код в ДСК, если

где  минимальное попарное расстояние Хэмминга между кодовыми словами. Положив
минимальное попарное расстояние Хэмминга между кодовыми словами. Положив  из соотношения (2.10.5) получим
из соотношения (2.10.5) получим

Поскольку случаи равенства разрешаются случайно, при переходе (2.10.12) в равенство правильное декодирование будет иметь место лишь с некоторой ненулевой вероятностью. Поэтому декодер определенно исправит ошибки, если их число не превосходит половины минимального расстояния между кодовыми векторами. (Это условие, однако, не является необходимым, когда код неплотно упакован, о чем мы будем говорить в дальнейшем.) Тем не менее из неравенства (2.10.12) можно получить верхнюю границу для вероятности ошибки линейных кодов в ДСК, поскольку из (2.9.11) имеем

Так как  с вероятностью
с вероятностью  для каждого из
для каждого из  переходит в биномиальную сумму
переходит в биномиальную сумму

Класс кодов, для которых оценка (2.10.14) точна, включает коды Хэмминга, исправляющие одиночные ошибки. Их удобно задавать с помощью проверочной матрицы. Матрица  представляет собой проверочную матрицу некоторого
представляет собой проверочную матрицу некоторого  кода Хэмминга, если
кода Хэмминга, если  ее столбцов
ее столбцов  строк
строк  суть все возможные ненулевые
суть все возможные ненулевые  двоичные векторы. Отсюда следует, что для кода Хэмминга
двоичные векторы. Отсюда следует, что для кода Хэмминга  Можно привести пример матрицы
Можно привести пример матрицы  для кода Хэмминга (7,4):
для кода Хэмминга (7,4):

Поскольку все строки  различны, все
различны, все  векторов ошибок единичного веса приводят к различным синдромам (соответствующим строкам
векторов ошибок единичного веса приводят к различным синдромам (соответствующим строкам  Число различных синдромов равно
Число различных синдромов равно  один из них — нулевой вектор, соответствующий случаю отсутствия ошибок, а остальные
один из них — нулевой вектор, соответствующий случаю отсутствия ошибок, а остальные  соответствуют векторам с одной ошибкой. Шаг 0 декодирования, основанного на просмотре таблицы синдромов, состоит в нахождении для каждого синдрома вектора ошибок минимального веса. Поскольку в рассматриваемом случае все векторы ошибок соответствуют всем ненулевым и различным синдромам, оказывается, что код Хэмминга исправляет одиночные ошибки и только их. Это можно проверить также показав, что
соответствуют векторам с одной ошибкой. Шаг 0 декодирования, основанного на просмотре таблицы синдромов, состоит в нахождении для каждого синдрома вектора ошибок минимального веса. Поскольку в рассматриваемом случае все векторы ошибок соответствуют всем ненулевым и различным синдромам, оказывается, что код Хэмминга исправляет одиночные ошибки и только их. Это можно проверить также показав, что  (см. задачу 2.11).
(см. задачу 2.11).
Имеет смысл рассмотреть свойства линейного кода, порождаемого матрицей  кода Хэмминга (его называют дуальным кодом)
кода Хэмминга (его называют дуальным кодом)

Приведенная матрица имеет размеры  где
где

а ее столбцы суть все ненулевые  -мерные двоичные векторы. Можно показать порождающую матрицу кода (7,3), дуального к коду Хэмминга (7,4), транспонированная проверочная матрица которого приведена выше.
-мерные двоичные векторы. Можно показать порождающую матрицу кода (7,3), дуального к коду Хэмминга (7,4), транспонированная проверочная матрица которого приведена выше.

Припишем к матрице справа нулевой столбец и этим зададим некоторый код (8,3). Такую операцию можно обобщить на случай  кодов, порождающая матрица которых представляет собой транспонированную матрицу
кодов, порождающая матрица которых представляет собой транспонированную матрицу  кода Хэмминга размерами
кода Хэмминга размерами  удлиненную столбцом из нулей. Можно показать, что вес каждого ненулевого кода слова такого удлиненного кода равен
удлиненную столбцом из нулей. Можно показать, что вес каждого ненулевого кода слова такого удлиненного кода равен

Действительно, для каждого кодового вектора имеем

где  есть
есть  строка
строка  Поскольку информационные символы
Поскольку информационные символы  либо единицы, либо нули,
либо единицы, либо нули,  представляет собой сумму по модулю 2 строк, оставшихся после выбрасывания некоторых из них. Заметим, что выбрасывание одной строки приводит к матрице из
представляет собой сумму по модулю 2 строк, оставшихся после выбрасывания некоторых из них. Заметим, что выбрасывание одной строки приводит к матрице из  столбцов размера
столбцов размера  в которой каждый из
в которой каждый из  двоичных столбцов появляется ровно два раза. Аналогичным образом, выбрасывание
двоичных столбцов появляется ровно два раза. Аналогичным образом, выбрасывание  строк приводит к матрице из
строк приводит к матрице из  столбцов размера
столбцов размера  причем в ней каждый из возможных столбцов повторяется ровно 21 раз.
причем в ней каждый из возможных столбцов повторяется ровно 21 раз.
В любом случае одна половина из  столбцов содержит нечетное число единиц, а другая — четное. Поэтому суммирование всех невыкинутых строк по модулю 2 эквивалентно суммированию всех невыкинутых символов в
столбцов содержит нечетное число единиц, а другая — четное. Поэтому суммирование всех невыкинутых строк по модулю 2 эквивалентно суммированию всех невыкинутых символов в  столбцах, половина из которых имеет четную проверку, а другая — нечетную. В результате имеем
столбцах, половина из которых имеет четную проверку, а другая — нечетную. В результате имеем  единиц и
единиц и  нулей, откуда и получается желаемое соотношение (2.10.16).
нулей, откуда и получается желаемое соотношение (2.10.16).
Из соотношения (2.10.16) и свойства замкнутости (2.9.6) следует также, что расстояния Хэмминга для всех пар кодовых слов равны

Следовательно, все бифазно-модулированные сигналы, порожденные таким кодом (удлиненным дописыванием столбца нулей), попарно ортогональны, ибо в общем случае нормированное скалярное произведение любых двух двоичных символов имеет вид 

Поэтому для рассматриваемого кода имеем

Вернемся к первоначальному коду, порожденному матрицей  размерами
размерами  заданной в (2.10.15), и заметим, что вес каждого ненулевого кодового вектора
заданной в (2.10.15), и заметим, что вес каждого ненулевого кодового вектора  не изменится, если приписанный нулевой вектор на рис. 2.20 опустить. Построенные по этому коду бифазные сигналы уже не будут ортогональными, поскольку
не изменится, если приписанный нулевой вектор на рис. 2.20 опустить. Построенные по этому коду бифазные сигналы уже не будут ортогональными, поскольку  Из соотношений (2.10.17) получаем
Из соотношений (2.10.17) получаем 

Этот код называют регулярным симплексом или трансортогональным кодом. Легко показать (см. задачу 2.5), что (2.10.19) соответствует минимуму среднего скалярного произведения для набора сигналов с равной энергией. Сравнительные характеристики ортогонального набора и регулярного симплекса мы обсудим в следующем параграфе.
С самого момента зарождения теории информации изучению многочисленных классов линейных блоковых кодов уделялось значительное внимание. В первую очередь это относится к алгебраическим алгоритмам декодирования приемлемой сложности, не требующим экспоненциально растущей памяти, как при описанном выше подходе с просмотром таблицы синдромов. Были открыты некоторые весьма изящные конструкции довольно мощных линейных кодов и методов декодирования, в частности, в классе «циклических» кодов. Эти коды, однако, значительно уступают по характеристикам лучшим линейным кодам,
о чем пойдет речь в следующей главе. Кроме того, легко реализуемые алгоритмы декодирования, обеспечивая исправление заданного числа ошибок в блоке, все же остаются, вообще говоря, всего лишь подоптимальными и применимыми только в каналах, получающихся при жестком квантовании, таких, как ДСК при использовании двоичных кодов. Последняя и, вероятно, самая важная причина, по которой линейные блоковые коды имеют лишь ограниченное практическое применение, связана с тем, что линейные сверточные коды, как правило, обладают гораздо большими возможностями (см. гл. 4).
Большая часть результатов последних двух параграфов переносится на недвоичные кодовые алфавиты, в том числе на кодовые алфавиты и алфавиты информационных символов объема  где
где  либо простое число, либо его степень. На практике
либо простое число, либо его степень. На практике  почти всегда выбирают степенью 2. И хотя соответствующие обобщения не представляют труда, они все же требуют введения некоторых начальных понятий теории конечных полей. Польза от таких результатов ограничена и поэтому они не включены в книгу. Изложения алгебраических кодов над двоичными и недвоичными алфавитами можно найти у Берлекэмпа [1968], Галлагера [1968], Лина [1970], Ван Линта [1971], Питерсона и Велдона [1972], Блейка и Мюллена [1976].
почти всегда выбирают степенью 2. И хотя соответствующие обобщения не представляют труда, они все же требуют введения некоторых начальных понятий теории конечных полей. Польза от таких результатов ограничена и поэтому они не включены в книгу. Изложения алгебраических кодов над двоичными и недвоичными алфавитами можно найти у Берлекэмпа [1968], Галлагера [1968], Лина [1970], Ван Линта [1971], Питерсона и Велдона [1972], Блейка и Мюллена [1976].