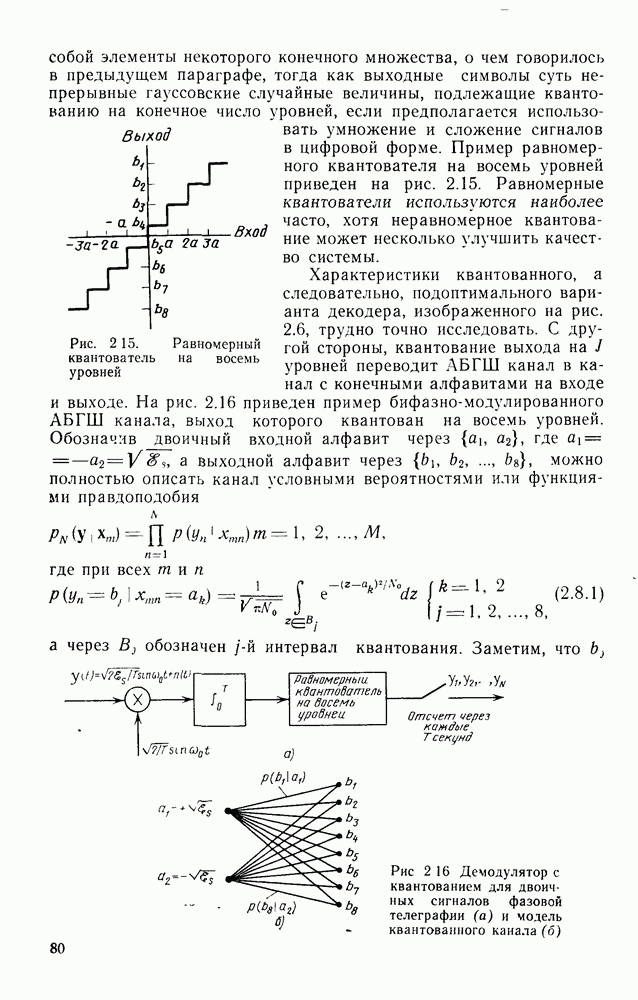
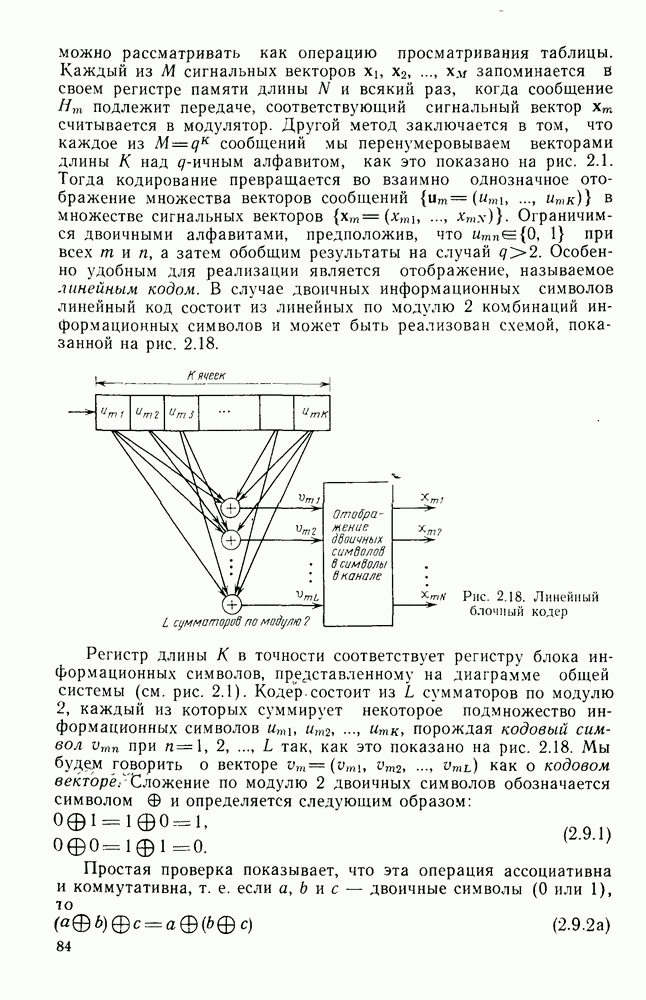
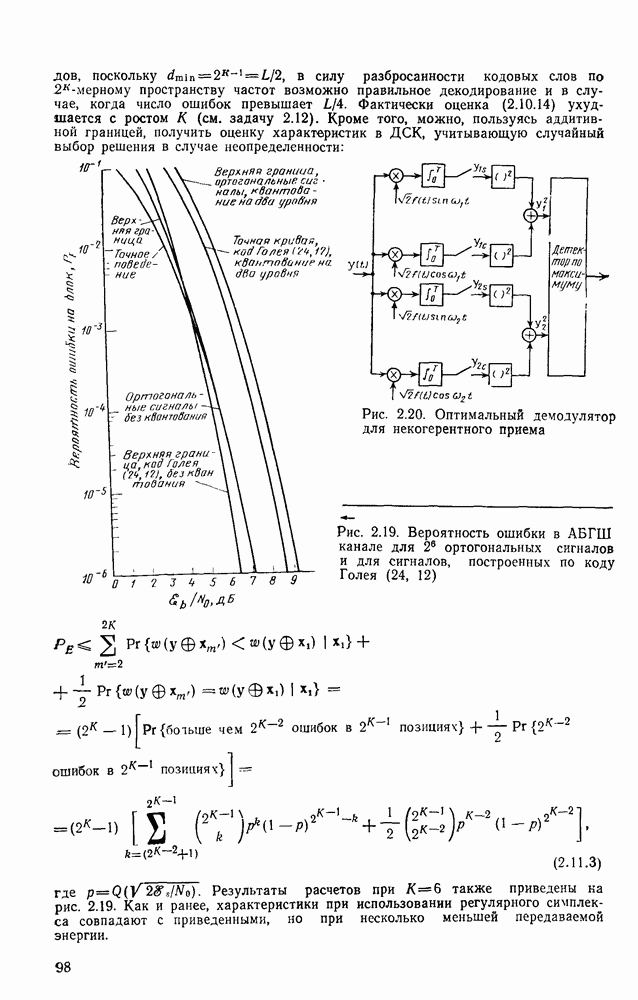
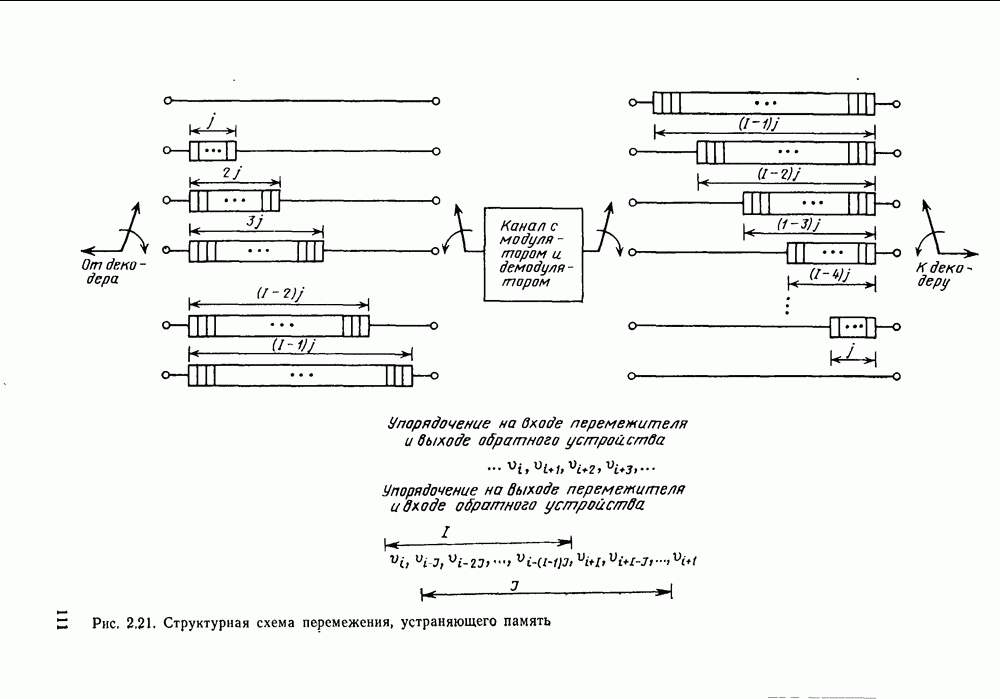
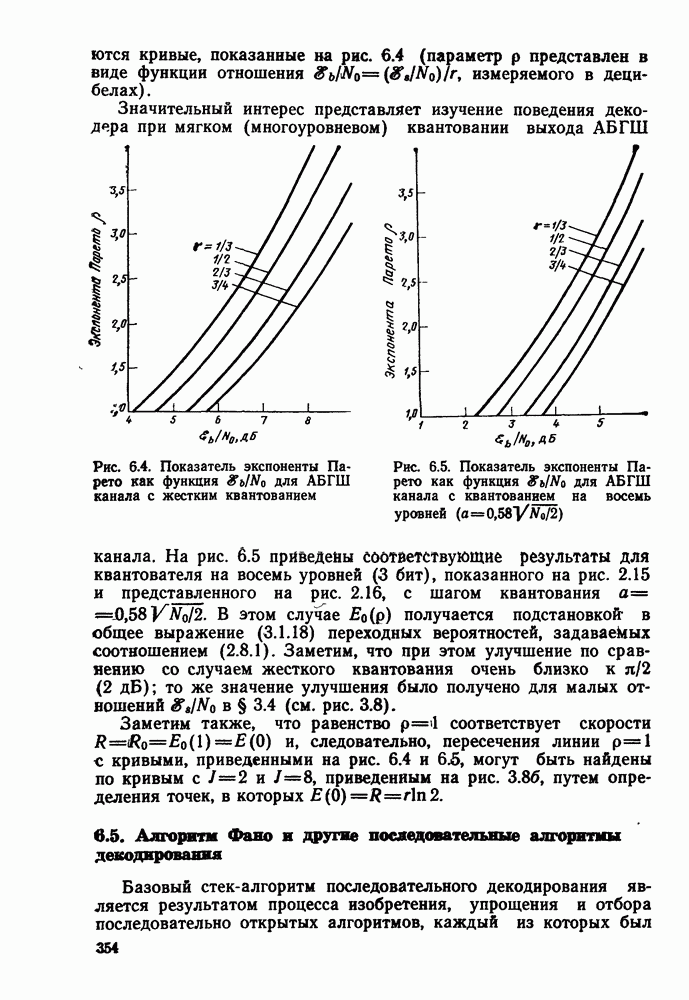
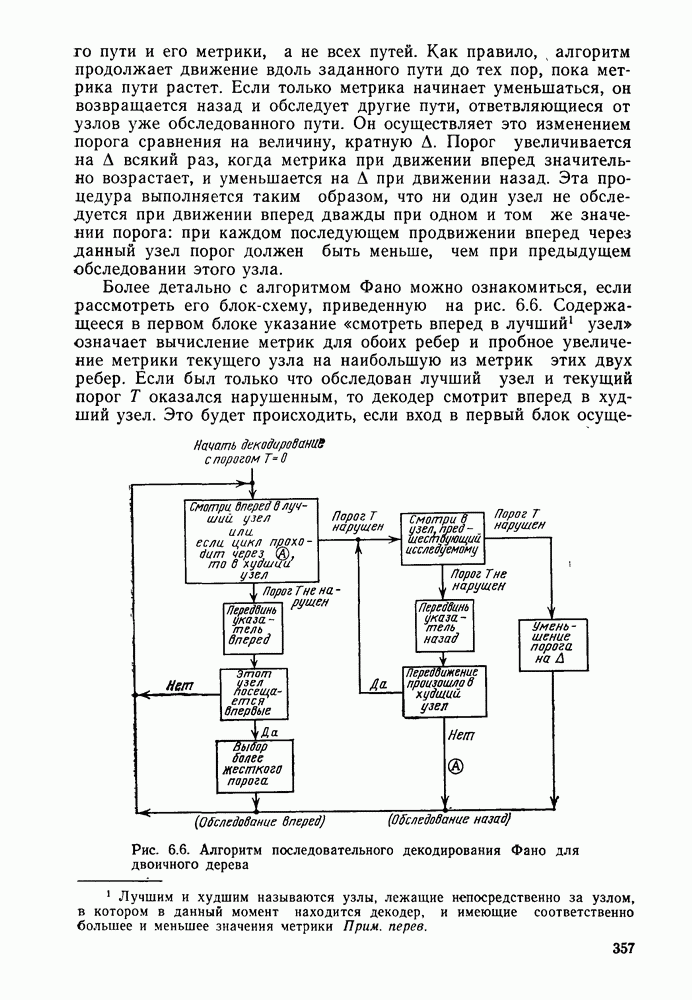
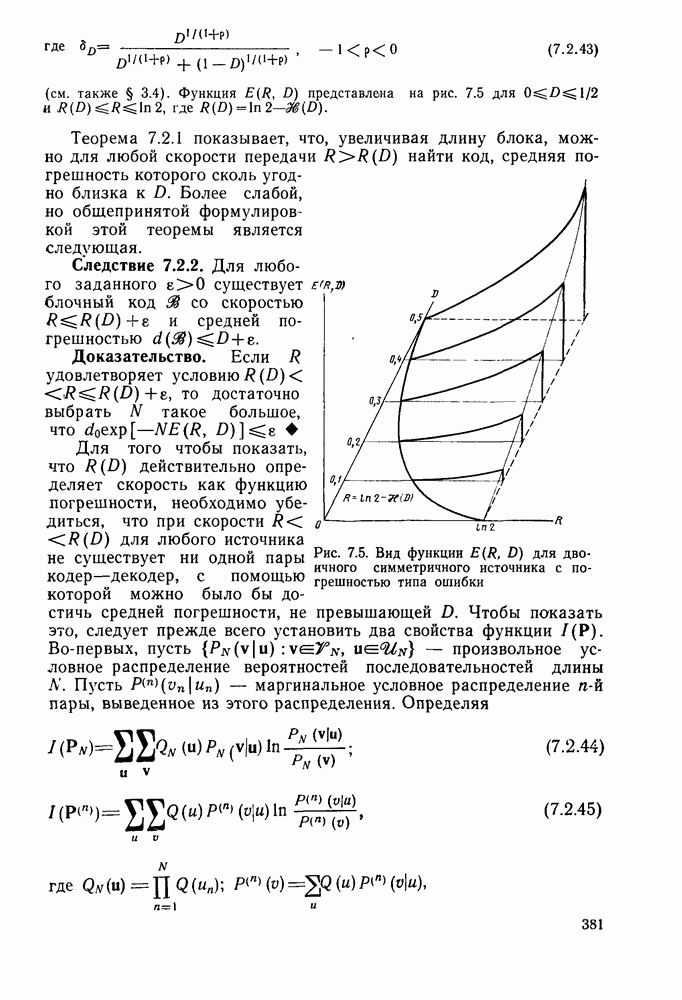
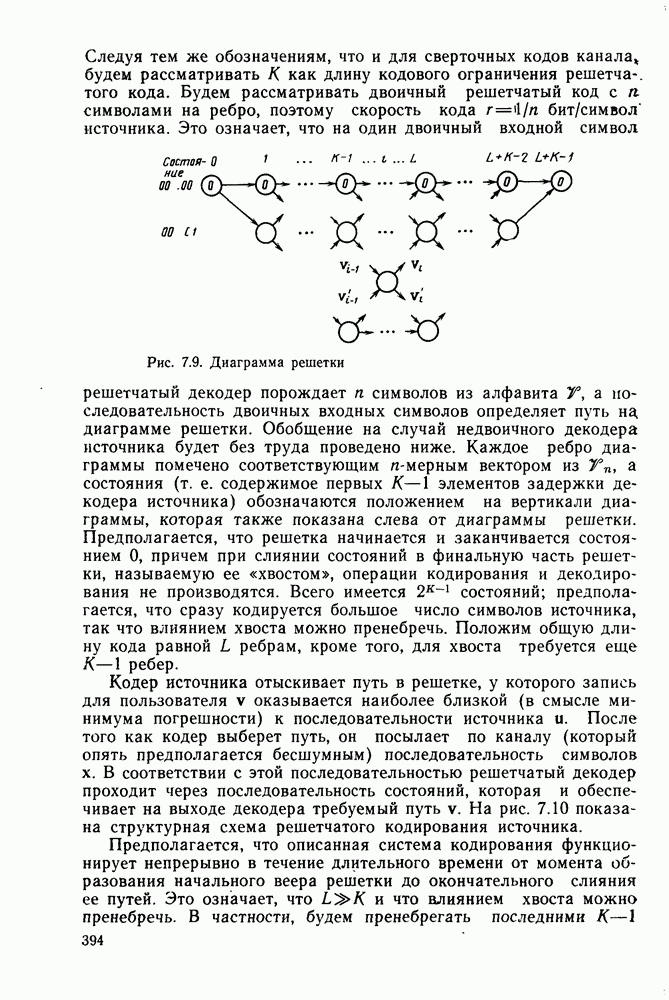
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
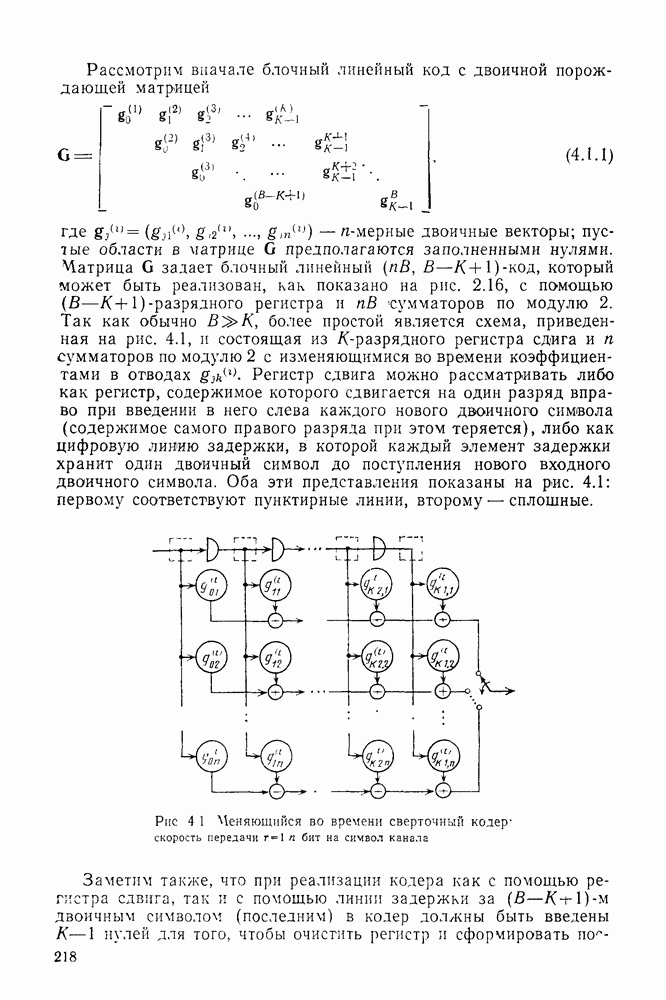
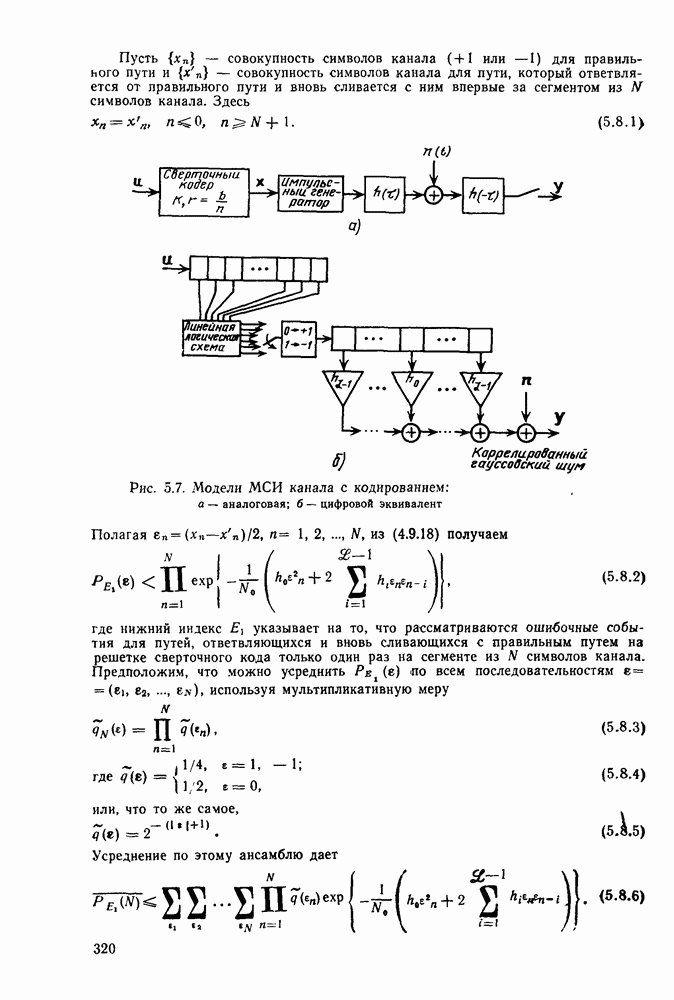
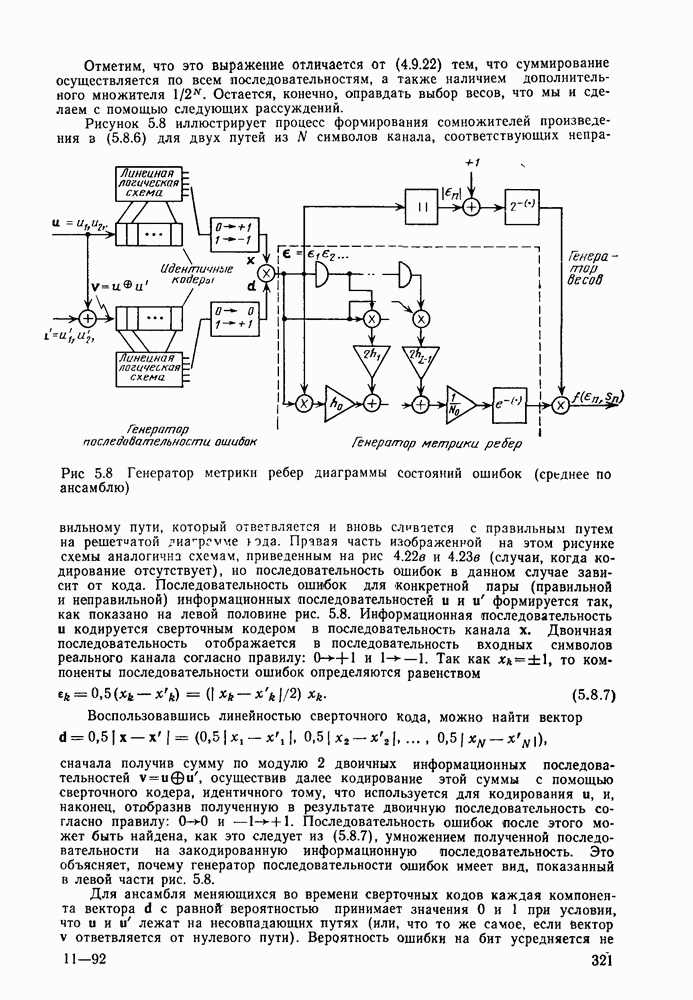
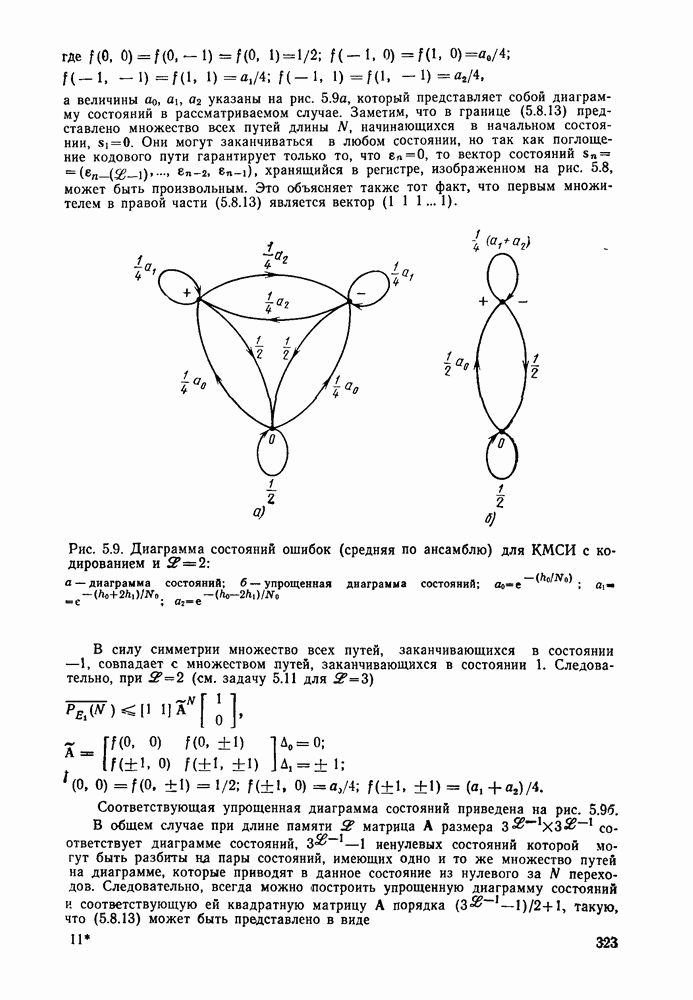
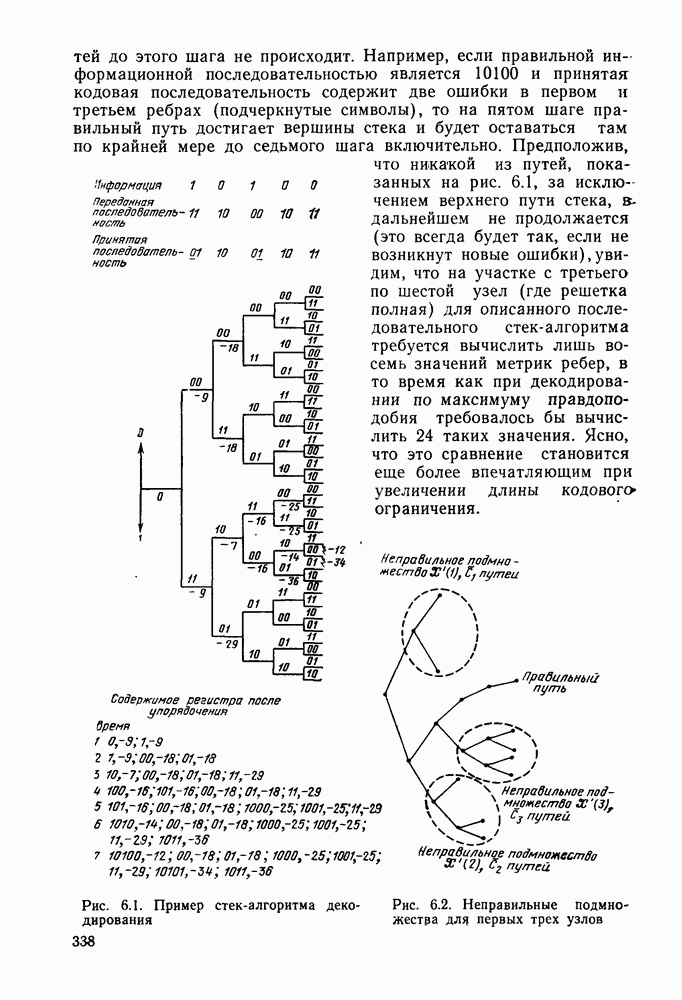
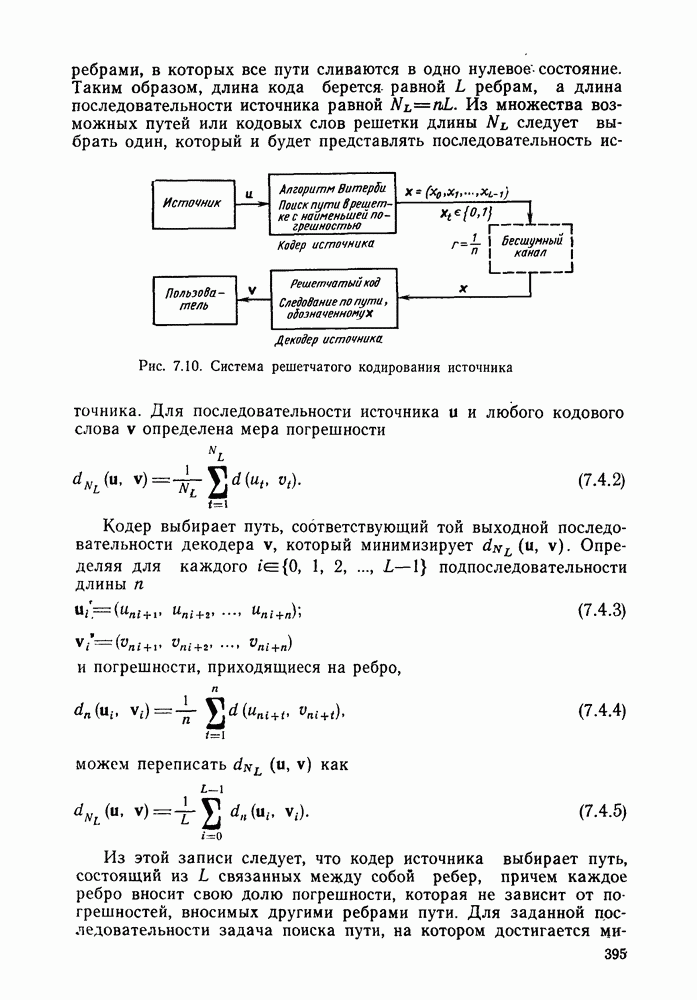
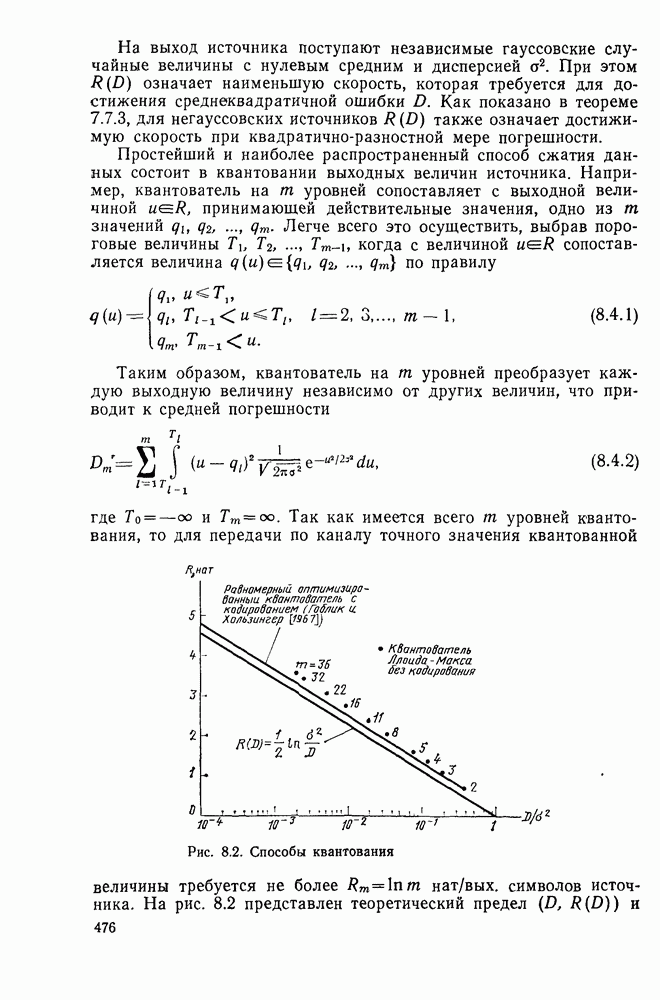
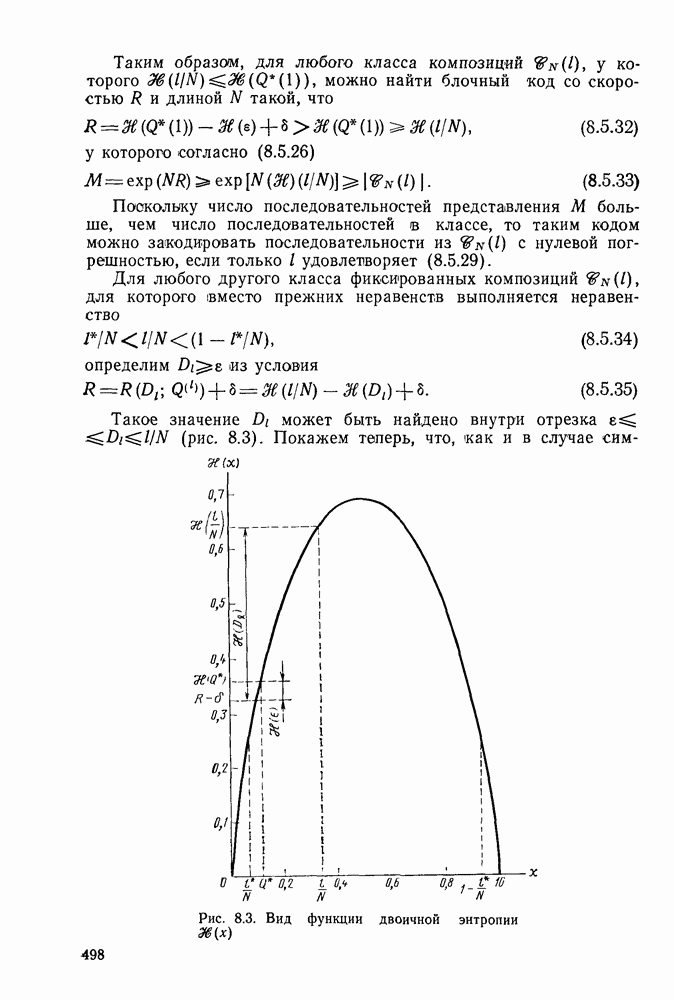
Часть II. СВЕРТОЧНОЕ КОДИРОВАНИЕ И ЦИФРОВАЯ СВЯЗЬГлава 4. СВЕРТОЧНЫЕ КОДЫ4.1. Введение. Структура кодовДве предыдущие главы были посвящены передаче цифровой информации по различным каналам без памяти и оценке улучшения характеристик систем связи при использовании блочного кодирования. Начав с изучения самых общих блочных кодов, в дальнейшем мы ограничились рассмотрением линейных блочных кодов, обладающих дополнительными свойствами, упрощающими процедуры кодирования и декодирования, а также анализом их характеристик для многих интересных каналов. Примечателен следующий факт: наилучший линейный код с заданными длиной блока и скоростью передачи так же хорош, как и наилучший произвольный блочный код той же длины и с той же скоростью передачи. Это было проиллюстрировано на примере некоторых конкретных кодов и каналов в гл. 2, а также, в более общем случае, доказано с помощью ансамбля кодов в гл. 3. Сверточные коды можно считать частным случаем блочных линейных кодов, однако, изучая их глубже, увидим, что введение сверточной структуры наделяет линейный код рядом дополнительных превосходных свойств, которые облегчают его декодирование и улучшают характеристики. Вначале будем рассматривать сверточные коды лишь как подкласс линейных кодов, главным образом для того, чтобы установить связь с предыдущим материалом, но постепенно перейдем на более общие позиции. Вводимая в этой и следующей главах дополнительная сверточная структура будет использована для построения декодера максимального правдоподобия с пониженной сложностью и улучшенными характеристиками — вначале для ряда конкретных кодов и каналов, а затем, в более общей ситуации, для ансамбля кодов; при этом, по существу, используется подход, развитый в гл. 2 и 3 для блочных кодов. Наконец, в гл. 6 будут рассмотрены алгоритмы последовательного декодирования, которые позволяют уменьшить сложность декодера за счет увеличения объема памяти и повышения требований к скорости вычислений. Рассмотрим вначале блочный линейный код с двоичной порождающей матрицей
где
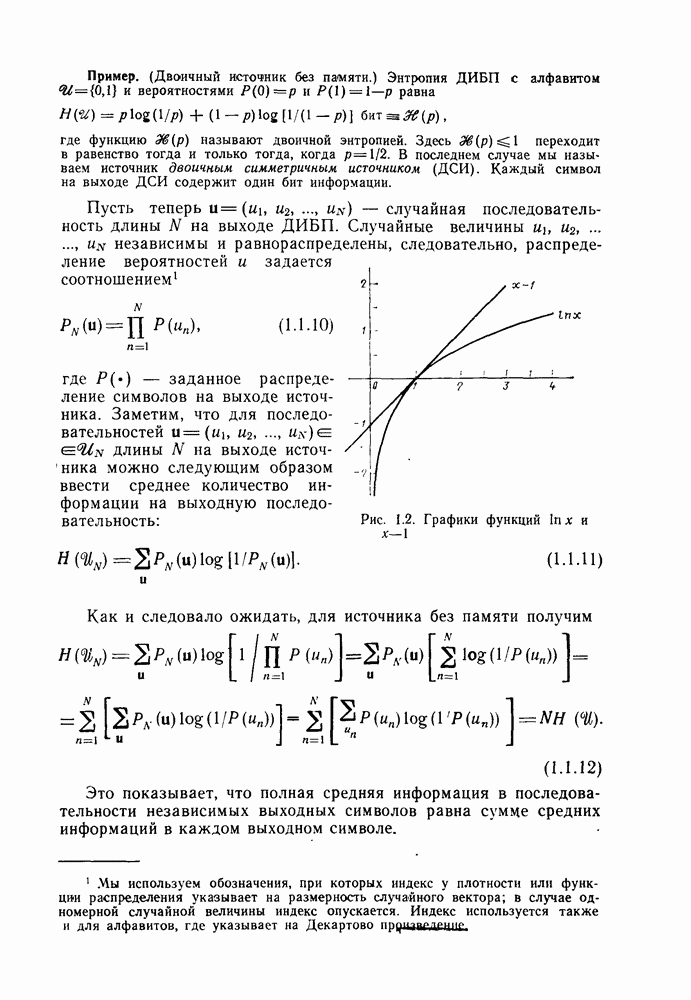
Рис. 4.1 Меняющийся во времени сверточный кодер скорость передачи Заметим также, что при реализации кодера как с помощью регистра сдвига, так и с помощью линии задержки за поледние Таким образом, оказывается, что сложность кодера не зависит от длины блока Название «сверточные» рассматриваемые коды получили по той причине, что выходная последовательность символов
где В то время как по соображениям теоретического характера в следующей главе понадобится ансамбль меняющихся во времени сверточных кодов, описанных выше, в действительности все сверточные коды, представляющие интерес для практики, являются постоянными во времени кодами. У таких кодов коэффициенты
Скорость передачи класса сверточных кодов, введенных описанным выше образом, равна
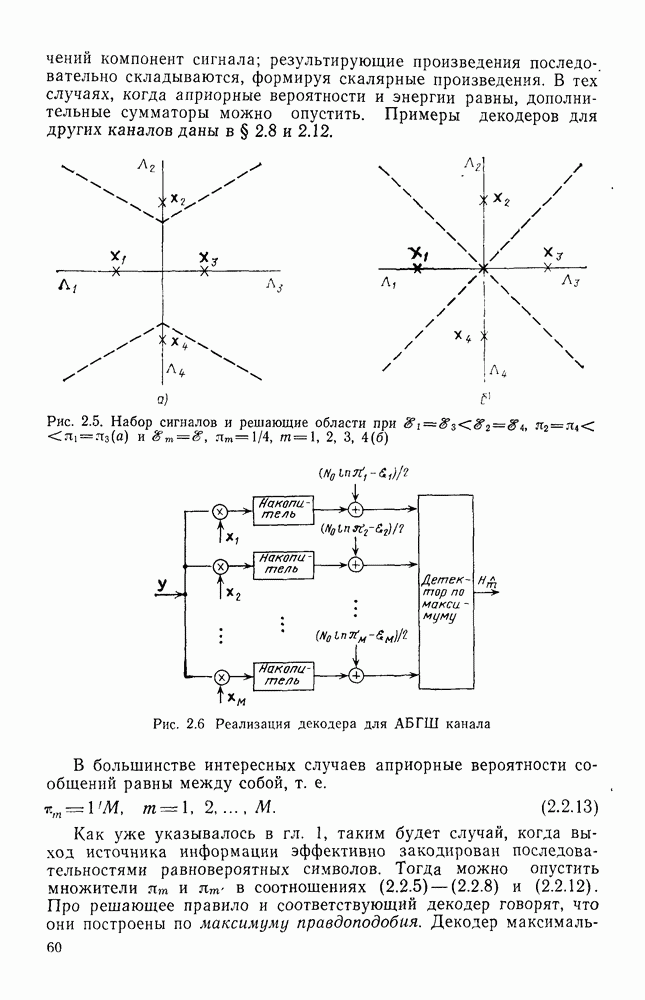
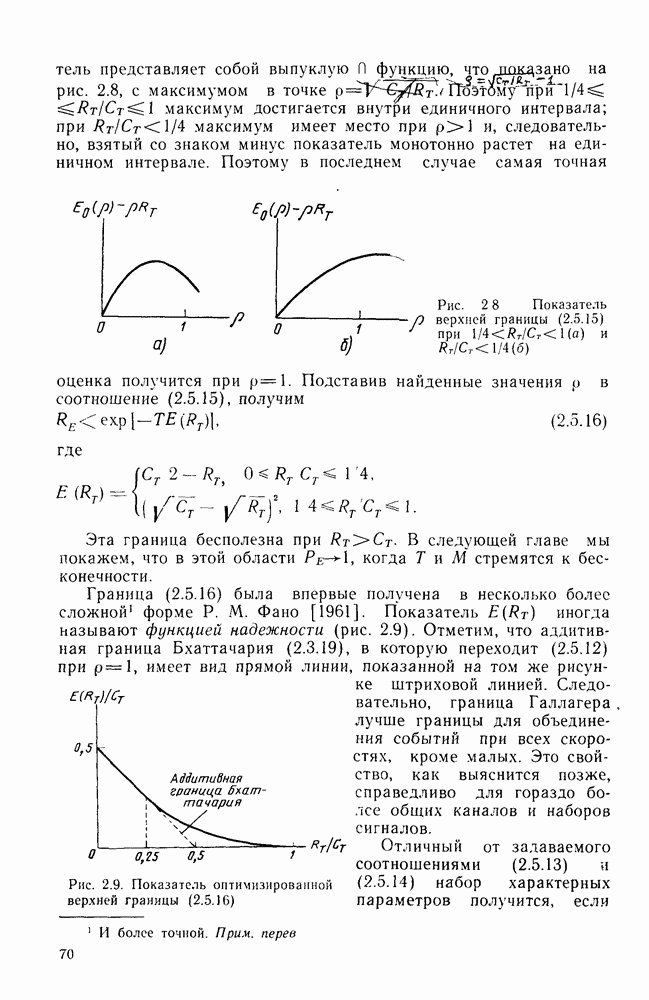
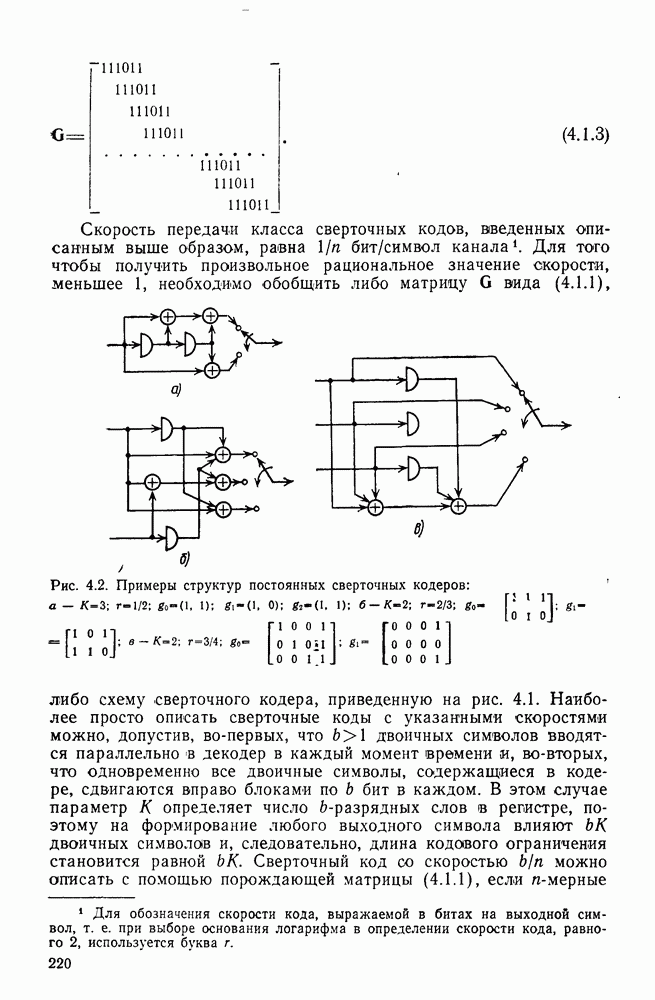
Рис. 4.2. Примеры структур постоянных сверточных кодеров: Наиболее просто описать сверточные коды с указанными скоростями можно, допустив, во-первых, что векторы 2 приведены на рис. 4.26 и в соответственно. Обобщение на случай меняющихся во времени сверточных кодов с любыми скоростями вида Постоянный во времени сверточный кодер можно рассматривать как постоянный во времени конечный автомат, структура которого может быть описана с помощью различных диаграмм. Применение и сущность таких диаграмм продемонстрируем на простом примере кодера, изображенного на рис. 4.2а. Стало уже традицией (и в то же время полезно) начинать рассмотрение с древовидной диаграммы, приведенной на рис. 4.3. На этой диаграмме
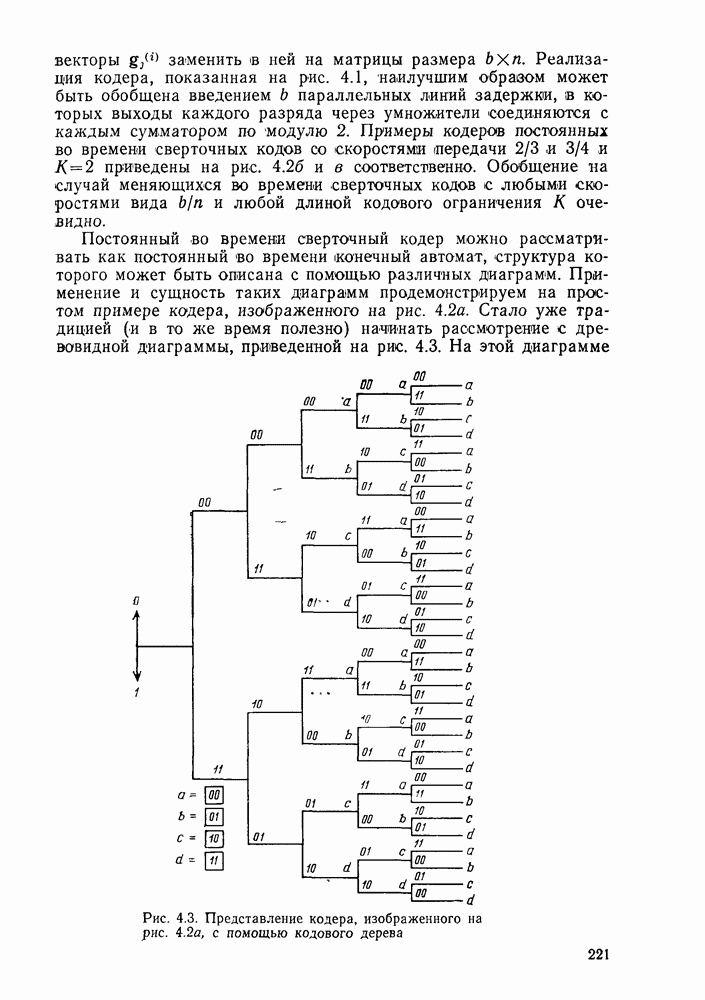
Рис. 4.3. Представление кодера, изображенного на рис. 4.2а, с помощью кодового дерева можно отобразить как входные, так и выходные последовательности кодера. Входные отображаются с помощью пути на диаграмме, а выходные — с помощью символов вдоль ребер дерева. Нулевому символу на входе соответствует верхнее ребро при ветвлении дерева, а единичному символу — нижнее. Таким образом, для кодера, изображенного на рис. 4.2, входной последовательности 0110 соответствует путь на дереве, идущий вверх на первом уровне ветвления, вниз — на втором и третьем уровнях и снова вверх на четвертом. При этом кодер порождает на выходе символы, указанные на горизонтальных ребрах пути: 00, 11, 01, 01. Таким образом, на диаграмме, приведенной на рис. 4.3, можно отобразите все выходные последовательности, соответствующие 32 всевозможным последовательностям из пяти входных двоичных символов. Из диаграммы становится ясно, что после лервйх трех ребер ее структура повторяется. Действительно, как легко видеть, за третьим ребром кодовые символы на ребрах, исходящих из двух узлов, помеченных буквой а, совпадают. То же происходит и с любой другой парой узлов, помеченных одинаковыми буквами. Причину этого легко установить, обратившись к структуре кодера. Когда третий входной символ вводится в кодер, первый входной символ покидает самый правый элемент задержки и поэтому в дальнейшем уже не может оказывать никакого влияния на выходные символы кодера. Следовательно, информационным последовательностям Это приводит к тому, что дерево переходит в диаграмму, изображенную на рис. 4.4. Новая диаграмма называется решетчатой
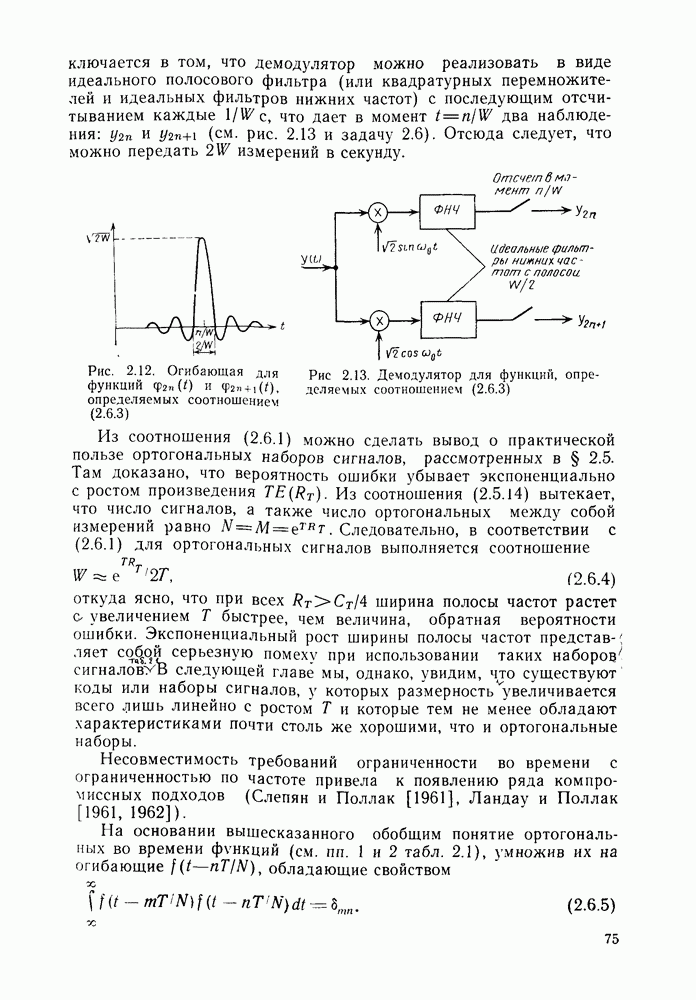
Рис. 4.4. Представление кодера, изображенного на рис. 4.2а, с помощью решетки диаграммой (решетка — это древовидная структура со сливающимися узлами). Условимся изображать здесь кодовые ребра, соответствующие входному символу 0, сплошными линиями, а кодовые ребра, соответствующие входному символу 1, пунктирными линиями. Заметим также, что решетчатая диаграмма сверточного кода всегда сходится в узел а, поскольку после Строго однородная структура решетчатой диаграммы наводит на мысль о дальнейшем упрощении представления кода и использовании диаграммы состояний, изображенной на рис. 4.5. Состояния на последней обозначаются точно так же, как и соответствующие узлы решетчатой диаграммы. Учитывая, что состояние кодера точности совпадает с последними двумя входными двоичными символами, введенными в кодер, эти двоичные символы можно использовать для обозначения узлов (состояний) диаграммы. Ниже всюду будем следовать этому правилу — обозначать состояния кодера сверточного кода со скоростью Заметим в заключение, что диаграмма состояний может быть выведена непосредственно из свойств кодера как конечного автомата, в частности из
Рис. 4.5. Диаграмма состояний кодера, изображенного на рис. 4.2а
Рис. 4.6. Диаграмма состояний кодера, изображенного на рис. 4.2б состояний текущий входной символ представляется ребром, указывающим на переход автомата из одного узла в другой, в то время как два предыдущих входных символа определяют узел, в котором автомат находится. Например, если кодер содержит последовательность Обобщить вышеизложенное на случай сверточных кодов со скоростью До настоящего момента при рассмотрении неблочных кодов ограничивались лишь классом линейных кодов. Аналогично тому, как линейные блочные коды являются подклассом блочных кодов, сверточные коды представляют собой подкласс более широкого класса так называемых решетчатых кодов. Кодер решетчатого кода со скоростью Таким образом, описание сверточных и решетчатых кодов с помощью дерева, решетки и диаграммы состояний совершенно отличается от принятого нами ранее описания блочных кодов. Как же в этом случае сравнивать блочные коды со сверточными? Возвращаясь к обсуждению вопроса о задании сверточных кодов, можно заметить, что параметры Мы начали обсуждение сверточных кодов в этом параграфе, рассматривая их как частный случай блочных кодов. Если положить
|
 |
Оглавление
|








































































































































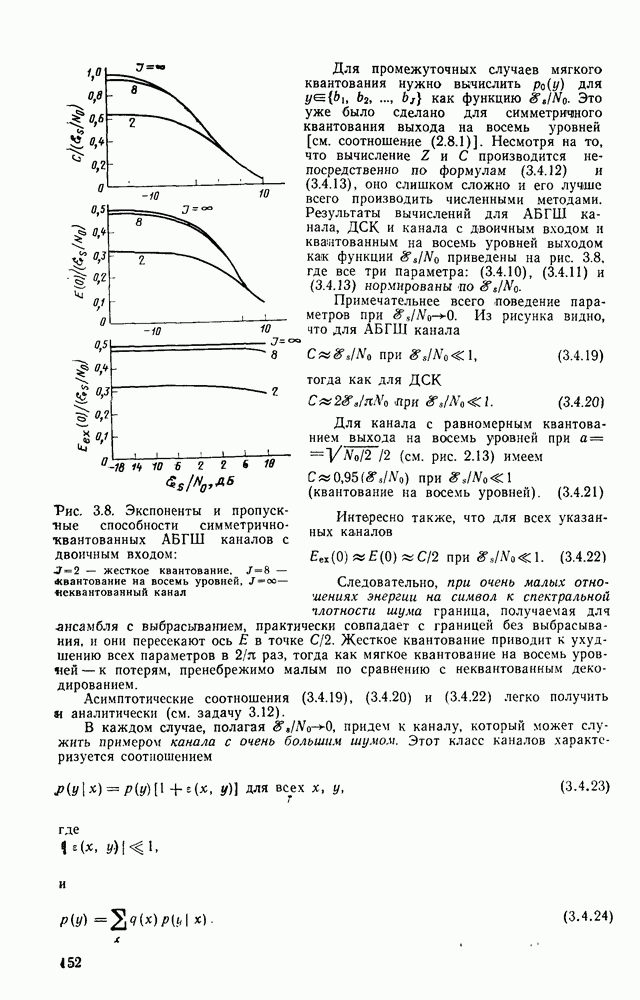


























































































































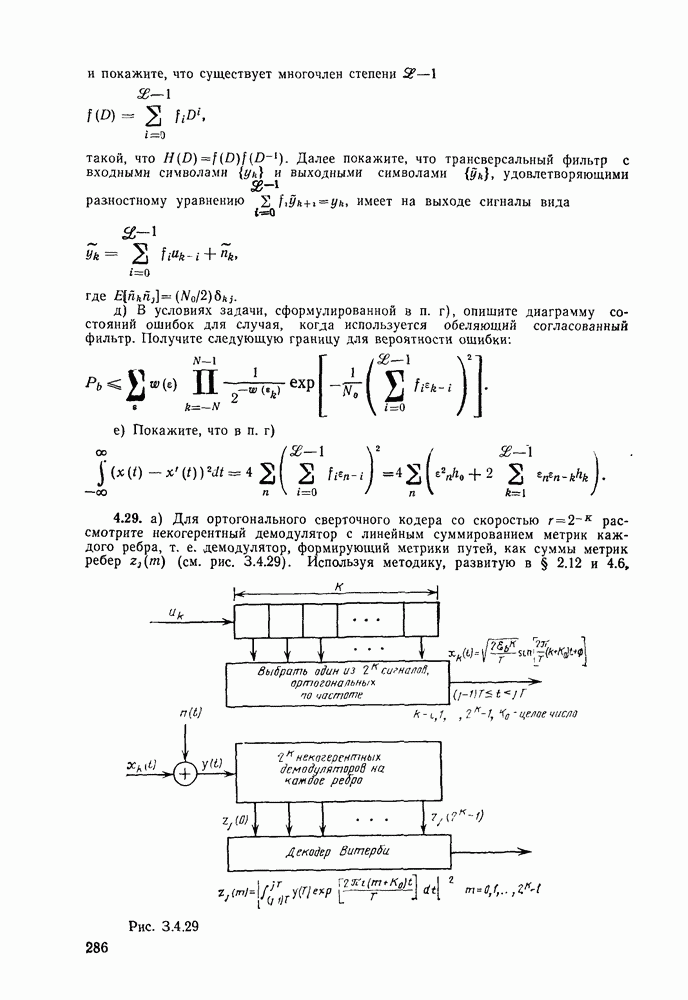
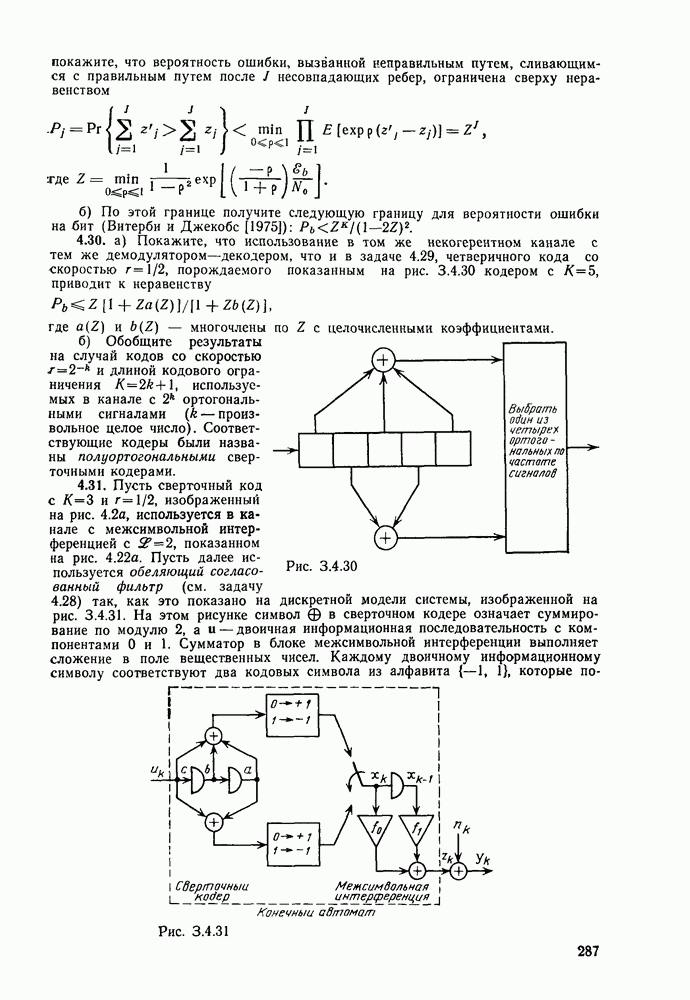











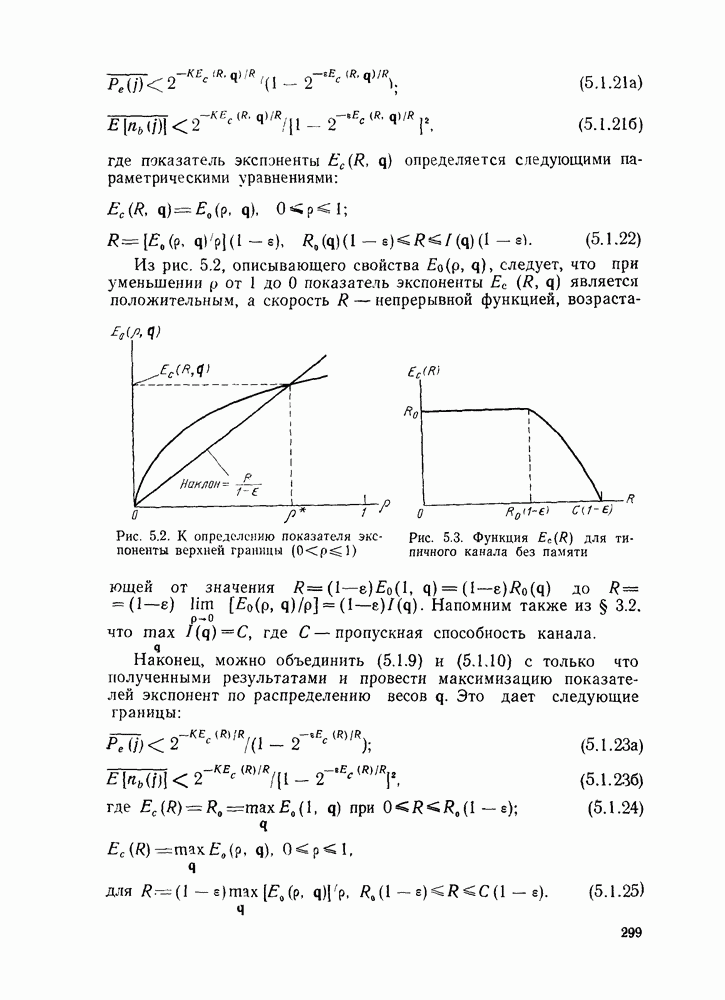







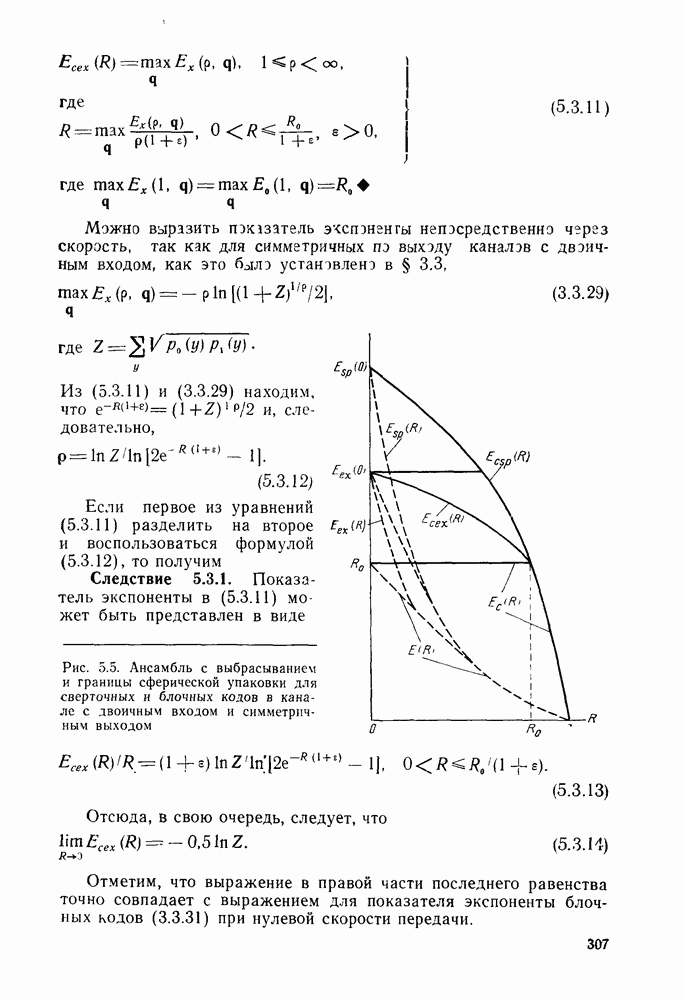



















































































































































































































 -
-  -мерные двоичные векторы; пустые области в матрице
-мерные двоичные векторы; пустые области в матрице  предполагаются заполненньши нулями. Матрица G задает блочный линейный
предполагаются заполненньши нулями. Матрица G задает блочный линейный  -код, который может быть реализован, как показано на рис. 2.16, с помощью
-код, который может быть реализован, как показано на рис. 2.16, с помощью  -разрядного регистра и
-разрядного регистра и  сумматоров по модулю 2. Так как обычно
сумматоров по модулю 2. Так как обычно  более простой является схема, приведенная на рис. 4.1, и состоящая из
более простой является схема, приведенная на рис. 4.1, и состоящая из  -разрядного регистра сдига и
-разрядного регистра сдига и  сумматоров по модулю 2 с изменяющимися во времени коэффициентами в отводах
сумматоров по модулю 2 с изменяющимися во времени коэффициентами в отводах  Регистр сдвига можно рассматривать либо как регистр, содержимое которого сдвигается на один разряд вправо при введении в него слева каждого нового двоичного символа (содержимое самого правого разряда при этом теряется), либо как цифровую линию задержки, в которой каждый элемент задержки хранит один двоичный символ до поступления нового входного двоичного символа. Оба эти представления показаны на рис. 4.1: первому соответствуют пунктирные линии, второму — сплошные.
Регистр сдвига можно рассматривать либо как регистр, содержимое которого сдвигается на один разряд вправо при введении в него слева каждого нового двоичного символа (содержимое самого правого разряда при этом теряется), либо как цифровую линию задержки, в которой каждый элемент задержки хранит один двоичный символ до поступления нового входного двоичного символа. Оба эти представления показаны на рис. 4.1: первому соответствуют пунктирные линии, второму — сплошные.

 бит на символ канала
бит на символ канала
 двоичным символом (последним) в кодер должны быть введены
двоичным символом (последним) в кодер должны быть введены  нулей для того, чтобы очистить регистр и сформировать
нулей для того, чтобы очистить регистр и сформировать
 выходных ребер, которые иногда называют хвостом кода.
выходных ребер, которые иногда называют хвостом кода.
 и определяется лишь длиной регистра К и скоростью кода, причем последняя при измерении в двоичных символах на один выходной символ стремится к
и определяется лишь длиной регистра К и скоростью кода, причем последняя при измерении в двоичных символах на один выходной символ стремится к  при
при  Параметр К называется длиной кодового ограничения сверточного кода. Из описания реализации с помощью регистра сдвига ясно также, что чем больше отношение
Параметр К называется длиной кодового ограничения сверточного кода. Из описания реализации с помощью регистра сдвига ясно также, что чем больше отношение  тем меньше потери в скорости из-за хвостов. Это связано с тем, что последние
тем меньше потери в скорости из-за хвостов. Это связано с тем, что последние  входных символов всегда нули и хвосты уменьшают скорость кода на величину, пропорциональную отношению
входных символов всегда нули и хвосты уменьшают скорость кода на величину, пропорциональную отношению 
 может быть представлена в виде свертки входной последовательности (двоичных символов) и с порождающими последовательностями. Действительно, вследствие линейности кода
может быть представлена в виде свертки входной последовательности (двоичных символов) и с порождающими последовательностями. Действительно, вследствие линейности кода  Так как матрица
Так как матрица  имеет в данном случае вид (4.1.1), то из последнего равенства следует:
имеет в данном случае вид (4.1.1), то из последнего равенства следует:

 -
-  -мерный вектор на выходе кодера непосредственно после того, как
-мерный вектор на выходе кодера непосредственно после того, как  двоичный символ оказывается введенным в кодер.
двоичный символ оказывается введенным в кодер.
 ответвлениях фиксированы, т. е. не изменяются во времени, а следовательно, можно удалить все верхние индексы в матрице (4.1.1). Учтем, что после этого каждая строка матрицы (4.1.1) будет совпадать с предыдущей строкой, сдвинутой на
ответвлениях фиксированы, т. е. не изменяются во времени, а следовательно, можно удалить все верхние индексы в матрице (4.1.1). Учтем, что после этого каждая строка матрицы (4.1.1) будет совпадать с предыдущей строкой, сдвинутой на  символов вправо. Пример постоянного во времени сверточного кода с длиной кодового ограничения
символов вправо. Пример постоянного во времени сверточного кода с длиной кодового ограничения  и скоростью 1/2 приведен на рис. 4.2а. Порождающая матрица (4.1.1) этого кода имеет вид
и скоростью 1/2 приведен на рис. 4.2а. Порождающая матрица (4.1.1) этого кода имеет вид

 бит/символ канала. Для того чтобы получить произвольное рациональное значение скорости, меньшее 1, необходимо обобщить либо матрицу
бит/символ канала. Для того чтобы получить произвольное рациональное значение скорости, меньшее 1, необходимо обобщить либо матрицу  вида (4.1.1), либо схему сверточного кодера, приведенную на рис. 4.1.
вида (4.1.1), либо схему сверточного кодера, приведенную на рис. 4.1.


 двоичных символов вводятся параллельно в декодер в каждый момент времени и, во-вторых, что одновременно все двоичные символы, содержащиеся в кодере, сдвигаются вправо блоками по
двоичных символов вводятся параллельно в декодер в каждый момент времени и, во-вторых, что одновременно все двоичные символы, содержащиеся в кодере, сдвигаются вправо блоками по  бит в каждом. В этом случае параметр К определяет число
бит в каждом. В этом случае параметр К определяет число  -разрядных слов в регистре, поэтому на формирование любого выходного символа влияют
-разрядных слов в регистре, поэтому на формирование любого выходного символа влияют  двоичных символов и, следовательно, длина кодового ограничения становится равной
двоичных символов и, следовательно, длина кодового ограничения становится равной  Сверточный код со скоростью
Сверточный код со скоростью  можно описать с помощью порождающей матрицы (4.1.1), если
можно описать с помощью порождающей матрицы (4.1.1), если  -мерные
-мерные
 заменить в ней на матрицы размера
заменить в ней на матрицы размера  Реализация кодера, показанная на рис. 4.1, наилучшим образом может быть обобщена введением
Реализация кодера, показанная на рис. 4.1, наилучшим образом может быть обобщена введением  параллельных линий задержки, в которых выходы каждого разряда через умножители соединяются с каждым сумматором по модулю 2. Примеры кодеров постоянных во времени сверточных кодов со скоростями (передачи 2/3 и 3/4 и
параллельных линий задержки, в которых выходы каждого разряда через умножители соединяются с каждым сумматором по модулю 2. Примеры кодеров постоянных во времени сверточных кодов со скоростями (передачи 2/3 и 3/4 и
 и любой длиной кодового ограничения К очевидно.
и любой длиной кодового ограничения К очевидно.

 и
и  соответствуют кодовые последовательности, полностью совпадающие на всех ребрах после третьего. Таким образом, два узла, помеченные на дереве буквой а, могут быть объединены в один.
соответствуют кодовые последовательности, полностью совпадающие на всех ребрах после третьего. Таким образом, два узла, помеченные на дереве буквой а, могут быть объединены в один.

 информационных символов в кодер всегда вводятся
информационных символов в кодер всегда вводятся  нулей. В данном случае хвостом кода являются последние два ребра.
нулей. В данном случае хвостом кода являются последние два ребра.
 посредством
посредством  последних двоичных символов, поступивших в регистр (самый последний поступивший символ — это последний символ состояния).
последних двоичных символов, поступивших в регистр (самый последний поступивший символ — это последний символ состояния).
 факта, что направленный граф
факта, что направленный граф  четырьмя состояниями можно использовать для однозначного описания взаимосвязи входных и выходных символов конечного автомата с
четырьмя состояниями можно использовать для однозначного описания взаимосвязи входных и выходных символов конечного автомата с  разрядами. На диаграмме
разрядами. На диаграмме


 то это представляется на диаграмме состояний переходом из состояния
то это представляется на диаграмме состояний переходом из состояния  в состояние
в состояние  при этом на соответствующем ребре указываются выходные символы
при этом на соответствующем ребре указываются выходные символы  кодера.
кодера.
 достаточно просто, если учесть, что древовидная диаграмма таких кодов имеет
достаточно просто, если учесть, что древовидная диаграмма таких кодов имеет  ребер, исходящих из каждого узла ветвления. Несмотря на это, длина кодового ограничения К будет оказывать такое же влияние на структуру дерева, как и раньше, так что после первых К ребер все пути начнут сходиться группами по
ребер, исходящих из каждого узла ветвления. Несмотря на это, длина кодового ограничения К будет оказывать такое же влияние на структуру дерева, как и раньше, так что после первых К ребер все пути начнут сходиться группами по  в каждой. Если говорить точнее, то
в каждой. Если говорить точнее, то  пути, имеющие
пути, имеющие  одинаковых информационных символов, будут сходиться в один узел, образуя таким образом решетчатую диаграмму с
одинаковых информационных символов, будут сходиться в один узел, образуя таким образом решетчатую диаграмму с  состояниями, в которой все ветвления и слияния происходят группами по
состояниями, в которой все ветвления и слияния происходят группами по  ребер в каждой. (Здесь К обозначает число последовательностей
ребер в каждой. (Здесь К обозначает число последовательностей  -разрядных слов, хранящихся в регистре.) По этой причине диаграмма состояний также будет иметь
-разрядных слов, хранящихся в регистре.) По этой причине диаграмма состояний также будет иметь  состояний, каждое из которых в свою очередь будет иметь
состояний, каждое из которых в свою очередь будет иметь  исходящих из него и
исходящих из него и  входящих в него ребер. Например, диаграмма состояний кода со скоростью 2/3, кодер которого изображен на рис. 4.26, показана на рис. 4.6. Другие примеры рассматриваются в задачах.
входящих в него ребер. Например, диаграмма состояний кода со скоростью 2/3, кодер которого изображен на рис. 4.26, показана на рис. 4.6. Другие примеры рассматриваются в задачах.
 также порождает
также порождает  символов канала на каждые
символов канала на каждые  символов источника, поступающих в регистр. Однако в общем случае решетчатые кодеры могут порождать символы из произвольного входного алфавита канала, и эти символы могут быть произвольной, вообще говоря, нелинейной, функцией
символов источника, поступающих в регистр. Однако в общем случае решетчатые кодеры могут порождать символы из произвольного входного алфавита канала, и эти символы могут быть произвольной, вообще говоря, нелинейной, функцией  символов источника, хранящихся в регистре кодера. Так как на основе одного и того же
символов источника, хранящихся в регистре кодера. Так как на основе одного и того же  -разрядного регистра сдвига определяются как сверточные, так и произвольные решетчатые коды, то дерево, решетка и диаграмма состояний для решетчатых кодов будут точно такими же, как и для сверточных кодов. При этом выходные символы решетчатого кодера могут быть сопоставлены ребрам этих диаграмм точно так же, как это было сделано ранее для подкласса сверточных кодов. Ясно, что произвольные решетчатые коды находятся в той же взаимосвязи с произвольными блочными кодами, как сверточные коды с линейными блочными кодами.
-разрядного регистра сдвига определяются как сверточные, так и произвольные решетчатые коды, то дерево, решетка и диаграмма состояний для решетчатых кодов будут точно такими же, как и для сверточных кодов. При этом выходные символы решетчатого кодера могут быть сопоставлены ребрам этих диаграмм точно так же, как это было сделано ранее для подкласса сверточных кодов. Ясно, что произвольные решетчатые коды находятся в той же взаимосвязи с произвольными блочными кодами, как сверточные коды с линейными блочными кодами.
 длина кодового ограничения, или «память» кодера, и
длина кодового ограничения, или «память» кодера, и  скорость передачи в битах на символ канала являются общими как для блочных, так
скорость передачи в битах на символ канала являются общими как для блочных, так  для сверточных кодов. В обоих случаях одни и те же значения этих параметров приводят примерно к одной и той же сложности кодеров. Позднее также увидим, что сложность декодера максимального правдоподобия для одних и тех же значений
для сверточных кодов. В обоих случаях одни и те же значения этих параметров приводят примерно к одной и той же сложности кодеров. Позднее также увидим, что сложность декодера максимального правдоподобия для одних и тех же значений  и
и  примерно одна и та же как для блочных, так и решетчатых (сверточных) кодов. Поэтому для сравнения блочных и сверточных кодов будем использовать параметры
примерно одна и та же как для блочных, так и решетчатых (сверточных) кодов. Поэтому для сравнения блочных и сверточных кодов будем использовать параметры  и
и  Ниже будет показано, что при тех же значениях параметров
Ниже будет показано, что при тех же значениях параметров  сверточные коды позволяют достичь значительно меньших вероятностей ошибок, чем блочные коды.
сверточные коды позволяют достичь значительно меньших вероятностей ошибок, чем блочные коды.
 то сверточный код оказывается блочным кодом со скоростью
то сверточный код оказывается блочным кодом со скоростью  следовательно, как это ни парадоксально, линейные блочные коды могут рассматриваться как частный случай сверточных кодов, а более широкий класс блочных колов оказывается частным случаем решетчатых кодов. Вопрос о том, какое описание считать более общим, является делом вкуса.
следовательно, как это ни парадоксально, линейные блочные коды могут рассматриваться как частный случай сверточных кодов, а более широкий класс блочных колов оказывается частным случаем решетчатых кодов. Вопрос о том, какое описание считать более общим, является делом вкуса.