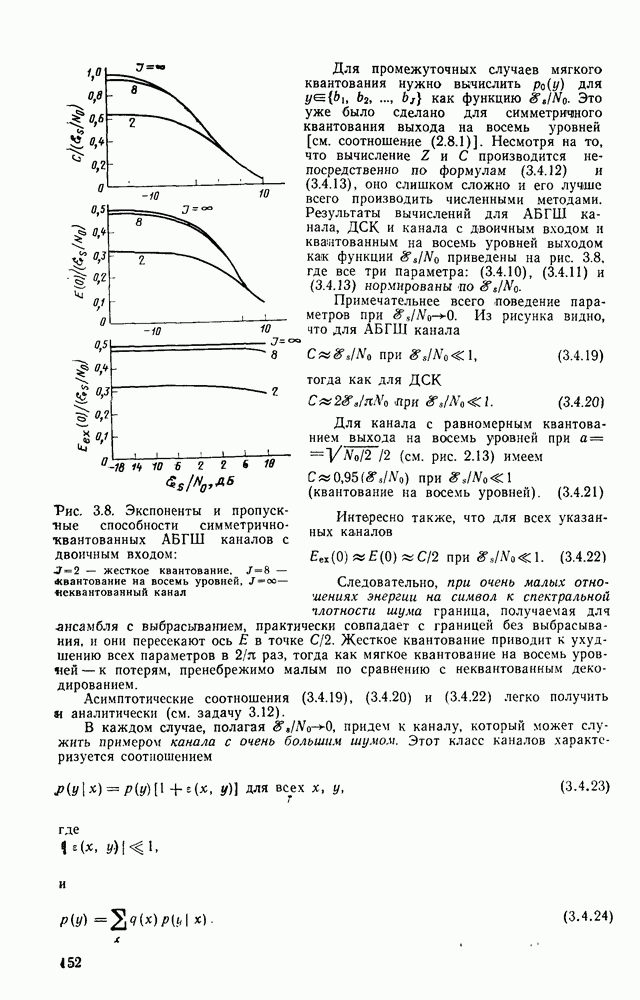
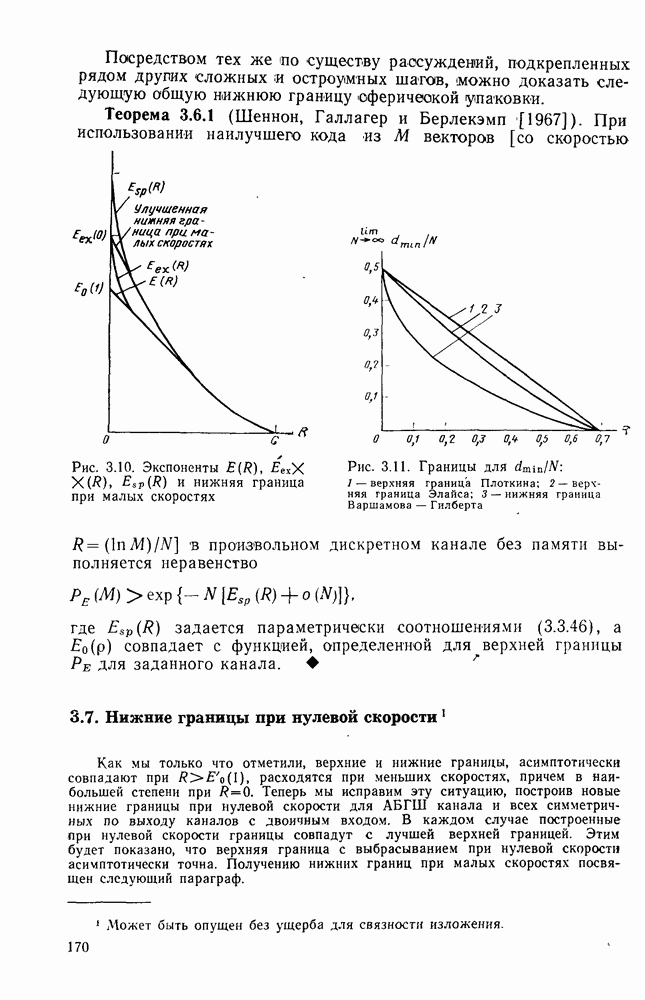
Глава 5. ХАРАКТЕРИСТИКИ АНСАМБЛЯ СВЕРТОЧНЫХ КОДОВ
5.1. Теорема кодирования для канала и меняющихся во времени сверточных кодов
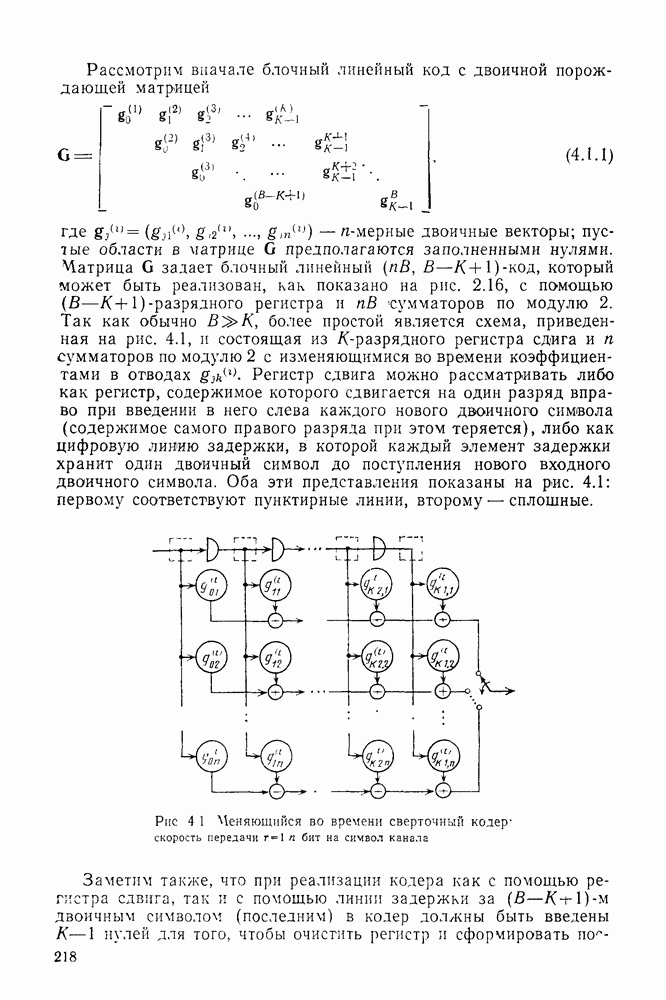
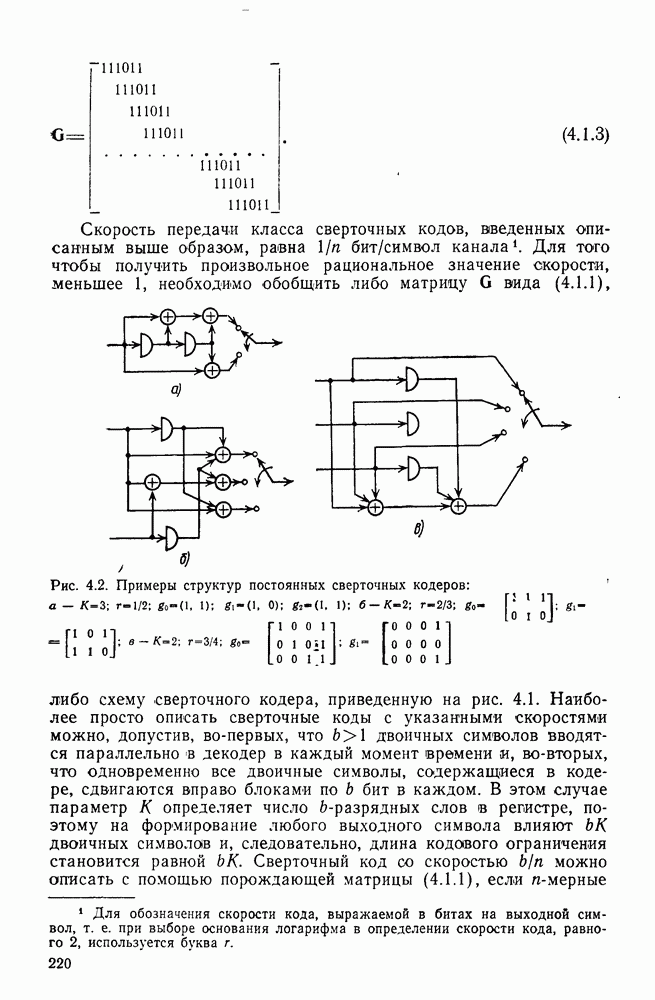
Эта глава посвящена получению границ для средней по ансамблю сверточных кодов вероятности ошибки, аналогичных границам для блочных кодов, полученных в гл. 3. К сожалению, полезные и достаточно точные границы удалось получить только для меняющихся во времени сверточных кодов, задаваемых матрицей (4.1.1), строки  которой, вообще говоря, не обязаны совпадать. (Для постоянных во времени кодов каждая строка этой матрицы является некоторым сдвигом любой другой строки.)
которой, вообще говоря, не обязаны совпадать. (Для постоянных во времени кодов каждая строка этой матрицы является некоторым сдвигом любой другой строки.)
Из (4.4.1) и (4.4.2) следует, что для произвольного сверточно  кода вероятность ошибки на узел в
кода вероятность ошибки на узел в  узле при декодировании по максимуму правдоподобия с помощью алгоритма Витерби ограничена сверху следующим образом:
узле при декодировании по максимуму правдоподобия с помощью алгоритма Витерби ограничена сверху следующим образом:

где  произвольный неправильный путь, исходящий из узла
произвольный неправильный путь, исходящий из узла  -множество всех тацмх неправильных путей;
-множество всех тацмх неправильных путей;  правильный путь после узла
правильный путь после узла  разность между приращениями метрик неправильного пути х, и правильного пути
разность между приращениями метрик неправильного пути х, и правильного пути  на ребрах сегмента их несовпадения.
на ребрах сегмента их несовпадения.
Для сверточных кодов со скоростью  (двоичных решетчатых) в § 4.6 была описана структура путей на решетке. В частности, была получена граница (4.6.15), из которой следует, что в сверточном коде с длиной кодового ограничения
(двоичных решетчатых) в § 4.6 была описана структура путей на решетке. В частности, была получена граница (4.6.15), из которой следует, что в сверточном коде с длиной кодового ограничения  имеется менее чем
имеется менее чем  путей, которые ответвляются от правильного пути в узле
путей, которые ответвляются от правильного пути в узле  и не совпадают с ним ровно на
и не совпадают с ним ровно на  ребрах. К этому же выводу можно прийти и с помощью следующих рассуждений. Так как сверточный код является линейным, то без ограничения общности всегда можно взять нулевой путь в качестве правильного пути. Тогда двоичные информационные символы любого неправильного пути, который ответвляется от правильного пути в узле
ребрах. К этому же выводу можно прийти и с помощью следующих рассуждений. Так как сверточный код является линейным, то без ограничения общности всегда можно взять нулевой путь в качестве правильного пути. Тогда двоичные информационные символы любого неправильного пути, который ответвляется от правильного пути в узле  и остается несовпадающим с правильным путем ровно на
и остается несовпадающим с правильным путем ровно на  ребрах, имеют вид
ребрах, имеют вид

где  любой двоичный вектор, не содержащий более чем
любой двоичный вектор, не содержащий более чем  следующих друг за другом нулей. Хотя точное число таких неправильных путей лучше всего вычислять с помощью техники производящих функций, описанной в § 4.6, очевидной верхней границей для числа таких путей является
следующих друг за другом нулей. Хотя точное число таких неправильных путей лучше всего вычислять с помощью техники производящих функций, описанной в § 4.6, очевидной верхней границей для числа таких путей является  Вначале ограничимся изучением кодов со скоростью
Вначале ограничимся изучением кодов со скоростью  но в дальнейшем обобщим полученные результаты и на коды со скоростью
но в дальнейшем обобщим полученные результаты и на коды со скоростью 
Так же, как это было сделано в гл. 3 для блочных кодов, усредним приведенную выше границу для вероятности ошибки по всем возможным кодам в ансамбле. Для начала заметим, что каждое слагаемое суммы в правой части границы (5.1.1) является попарной вероятностью ошибки между правильным путем  неправильным путем х, на сегменте их несовпадения из
неправильным путем х, на сегменте их несовпадения из  ребер, где
ребер, где  Оценивая каждое из этих слагаемых с помощью границы Бхаттачария (2.3.15), получаем
Оценивая каждое из этих слагаемых с помощью границы Бхаттачария (2.3.15), получаем

где  число символов в сегменте несовпадения из
число символов в сегменте несовпадения из  ребер, у — вектор, принятый на сегменте несовпадения.
ребер, у — вектор, принятый на сегменте несовпадения.
Необходимо провести усреднение по всем возможным значениям  в ансамбле меняющихся во времени сверточных кодов. Предположим, как и в случае блочных кодов, что канал имеег входной алфавит из
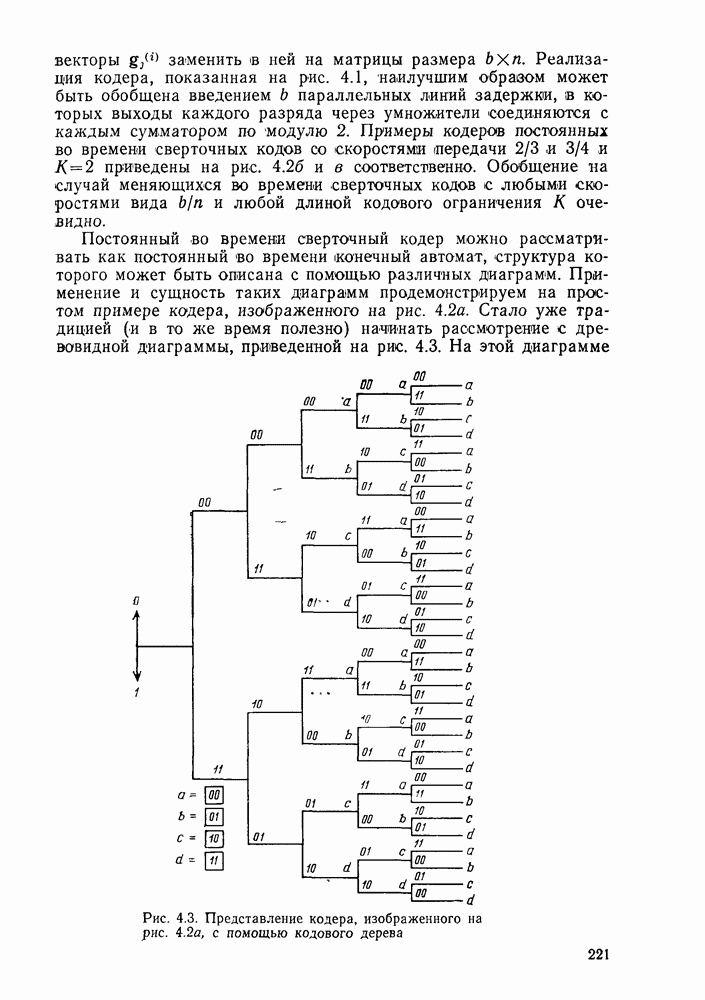
в ансамбле меняющихся во времени сверточных кодов. Предположим, как и в случае блочных кодов, что канал имеег входной алфавит из  символов и что меняющийся во времени сверточный код порождается операциями (см. рис. 5.1)
символов и что меняющийся во времени сверточный код порождается операциями (см. рис. 5.1)


Рис. 5.1. Сверточный кодер для кода со скоростью передачи  и канала с
и канала с  -ичныч входом
-ичныч входом
где  меняющиеся во времени двоичные векторы связи размерности
меняющиеся во времени двоичные векторы связи размерности  двоичные информационные символы;
двоичные информационные символы;  двоичное ребро из
двоичное ребро из  символов
символов  жратяо
жратяо  произвольное двоичное ребро той же размерности, что и
произвольное двоичное ребро той же размерности, что и  Здесь вектор
Здесь вектор  играет ту же роль, что и в ансамбле линейных блочных кодов в § 3.10, и необходим при переходе к недвоичным и несимметричным двоичным каналам. Функция
играет ту же роль, что и в ансамбле линейных блочных кодов в § 3.10, и необходим при переходе к недвоичным и несимметричным двоичным каналам. Функция  задает отображение без памяти последовательностей
задает отображение без памяти последовательностей  в последовательности
в последовательности  состоящие из
состоящие из  -ичных символов
-ичных символов  (см. рис. 5.1 с
(см. рис. 5.1 с 
Отображение  должно быть выбрано тщательно; в частности, оно должно гарантировать необходимые свойства ансамбля, по которому проводятся все усреднения. В первой части этого параграфа [до неравенства (5.1.9)] будем пользоваться равномерным распределением (взвешиванием) по ансамблю, аналогичным использованному в начале § 3.1. Затем выберем параметры
должно быть выбрано тщательно; в частности, оно должно гарантировать необходимые свойства ансамбля, по которому проводятся все усреднения. В первой части этого параграфа [до неравенства (5.1.9)] будем пользоваться равномерным распределением (взвешиванием) по ансамблю, аналогичным использованному в начале § 3.1. Затем выберем параметры  так, чтобы
так, чтобы  и отобразим каждую двоичную входную последовательность длины
и отобразим каждую двоичную входную последовательность длины  -ичную выходную последовательность длины
-ичную выходную последовательность длины  однозначно. Это можно сделать точно, если
однозначно. Это можно сделать точно, если  является степенью числа 2; в противном случае следует воспользоваться аппроксимацией, нужная степень точности которой достигается выбором достаточно больших значений
является степенью числа 2; в противном случае следует воспользоваться аппроксимацией, нужная степень точности которой достигается выбором достаточно больших значений  Если
Если  возможных двоичных последовательностей имеют равномерное распределение (равные веса), то и
возможных двоичных последовательностей имеют равномерное распределение (равные веса), то и  возможных
возможных  -ичных последовательностей, в которые они отображаются, также будут иметь равномерное распределение. Ниже рассмотрим также и неравномерное распределение на множестве
-ичных последовательностей, в которые они отображаются, также будут иметь равномерное распределение. Ниже рассмотрим также и неравномерное распределение на множестве  -ичных последовательностей.
-ичных последовательностей.
Рассмотрим правильный путь и любой неправильный путь, который не совпадает с правильным на сегменте от узла  до узла
до узла  Если взять правильный путь, соответствующий нулевой информационной последовательности (без ограничения общности это всегда можно сделать), то его кодовой последовательностью будет
Если взять правильный путь, соответствующий нулевой информационной последовательности (без ограничения общности это всегда можно сделать), то его кодовой последовательностью будет  при этом число возможных двоичных последовательностей на сегменте несовпадения из
при этом число возможных двоичных последовательностей на сегменте несовпадения из  ребер будет равно
ребер будет равно  После отображения этой последовательности в вектор сигнала
После отображения этой последовательности в вектор сигнала  число возможных
число возможных  -ичных последовательностей х на рассматриваемом сегменте равно
-ичных последовательностей х на рассматриваемом сегменте равно  Что касается рассматриваемого неправильного пути, то он должен соответствовать информационному вектору
Что касается рассматриваемого неправильного пути, то он должен соответствовать информационному вектору  имеющему на сегменте несовпадения вид (5.1.2), где
имеющему на сегменте несовпадения вид (5.1.2), где  - последовательность, не содержащая более
- последовательность, не содержащая более  следующих друг за другом нулей. Это приводит к тому, что каждое ребро вида
следующих друг за другом нулей. Это приводит к тому, что каждое ребро вида  получается сложением по модулю 2 вектора
получается сложением по модулю 2 вектора  по крайней мере с одним из векторов
по крайней мере с одним из векторов  [см. (5.1.4)]. Таким образом, независимо от того, какова правильная последовательность
[см. (5.1.4)]. Таким образом, независимо от того, какова правильная последовательность  последовательность
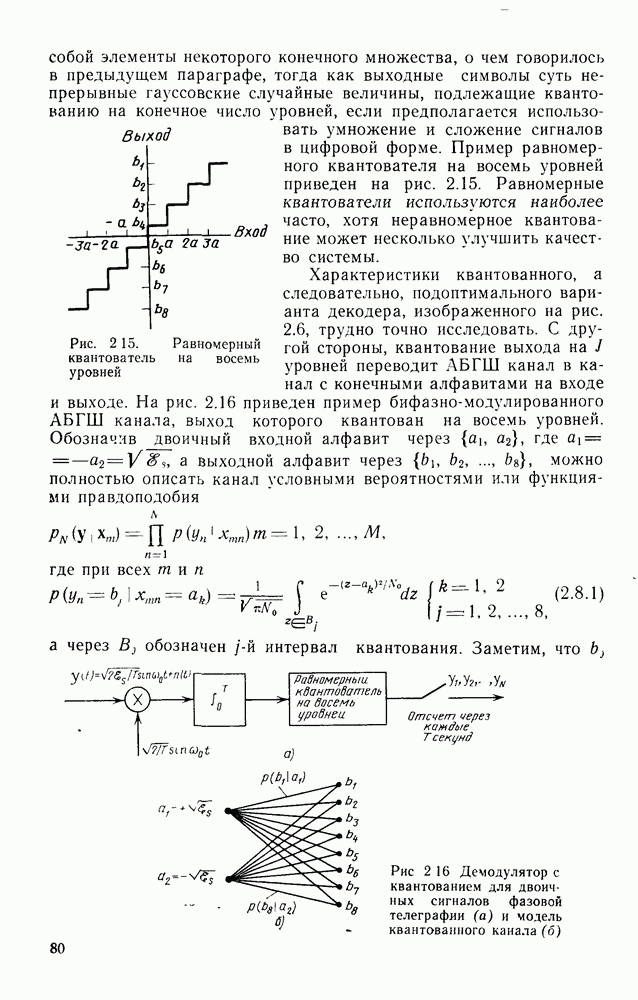
последовательность  может быть любой из
может быть любой из  возможных на сегменте несовпадения из
возможных на сегменте несовпадения из  ребер двоичных последовательностей и, следовательно,
ребер двоичных последовательностей и, следовательно,  может быть любой из
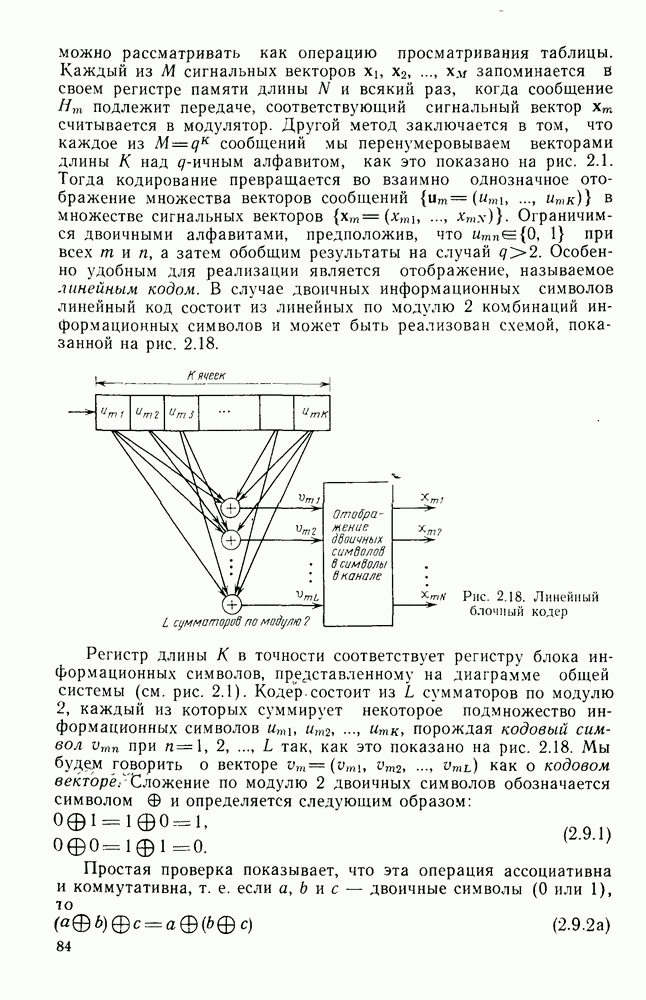
может быть любой из
 последовательностей. В результате можно усреднить границу (5.1.3) по всем
последовательностей. В результате можно усреднить границу (5.1.3) по всем  (где
(где  ) возможным правильным и неправильным последовательностям:
) возможным правильным и неправильным последовательностям:

(очевидно, что последняя сумма не зависит от 
Далее, пользуясь тем, что канал является каналом без памяти, и полагая  для всех х из входного алфавита канала, получаем
для всех х из входного алфавита канала, получаем

Наконец, подставляя (5.1.5) в усредненное по ансамблю выражение (5.1.1) и используя  в качестве верхней границы числа неправильных путей
в качестве верхней границы числа неправильных путей  ответвляющихся от правильного пути в узле
ответвляющихся от правильного пути в узле  и вновь сливающихся с ним через
и вновь сливающихся с ним через  ребер, для каждого возможного угла получим границу для средней по ансамблю вероятности ошибки на узел, а именно:
ребер, для каждого возможного угла получим границу для средней по ансамблю вероятности ошибки на узел, а именно:

Так как величина  равна скорости передачи в битах на символ канала, то для того чтобы определить скорость в натах на символ, как и для блочных кодов, положим
равна скорости передачи в битах на символ канала, то для того чтобы определить скорость в натах на символ, как и для блочных кодов, положим

в результате чего получим границу

где  определяется формулой (5.1.6).
определяется формулой (5.1.6).
Заметим также, что можно взять неравномерное взвешивание  на множестве входных символов канала, как и при усреднении по ансамблю блочных колов в § 3.1. Для того чтобы осуществить такое неравномерное взвешивание, необходимо выбрать отображение двоичных последовательностей в
на множестве входных символов канала, как и при усреднении по ансамблю блочных колов в § 3.1. Для того чтобы осуществить такое неравномерное взвешивание, необходимо выбрать отображение двоичных последовательностей в  -ичные, отличное от описанного в тексте [см. описание равномерного взвешивания после формулы (5.1.4)]. Пусть
-ичные, отличное от описанного в тексте [см. описание равномерного взвешивания после формулы (5.1.4)]. Пусть  и каждая двоичная последовательность длины
и каждая двоичная последовательность длины  отображается в
отображается в  -ичный символ. Предположим, что отображение выбрано таким образом, что ровно
-ичный символ. Предположим, что отображение выбрано таким образом, что ровно  из
из  -двоичных последовательностей длины
-двоичных последовательностей длины  отображаются в
отображаются в  -ичный символ
-ичный символ  где
где  и
и

Таким образом, выбирая X, а следовательно, и  достаточно большими, можно путем преобразования равномерного распределения на множестве двоичных последовательностей длины I сколь угодно близко приблизиться к произвольному и неравномерному распределению [выбором распределения
достаточно большими, можно путем преобразования равномерного распределения на множестве двоичных последовательностей длины I сколь угодно близко приблизиться к произвольному и неравномерному распределению [выбором распределения  Следовательно, неравенство (5.1.9) остается справедливым, даже если
Следовательно, неравенство (5.1.9) остается справедливым, даже если  определяется выбором почти произвольного неравномерного распределения
определяется выбором почти произвольного неравномерного распределения 
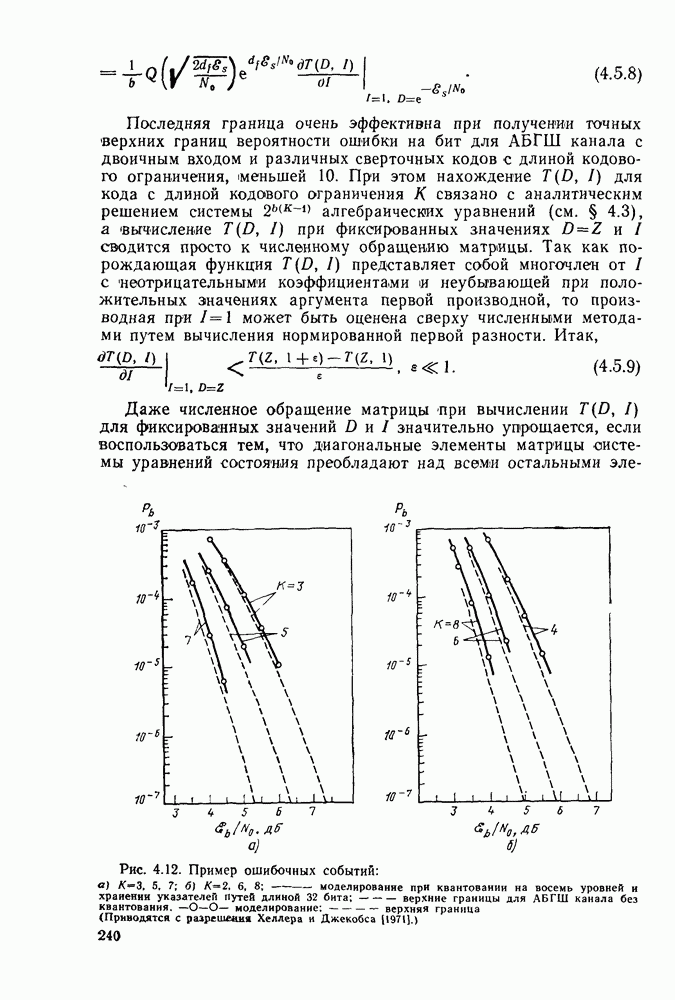
Вероятность ошибки на бит, определяемая как среднее число двоичных ошибок, приходящихся на каждый декодированный бит, может быть оценена сверху с помощью тех же рассуждений, которые были использованы в § 4.6 [предшествовавших (4.6.21)]. Там пользовались тем, что неправильный путь, который не совпадает с правильным на  ребрах, может породить не более
ребрах, может породить не более  двоичных ошибок. Действительно, для того чтобы правильный и неправильный пути слились, необходимо, итобы последние
двоичных ошибок. Действительно, для того чтобы правильный и неправильный пути слились, необходимо, итобы последние  информационных двоичных символов неправильного пути совпадали с соответствующими информационными символами правильного пути. Отсюда и из (5.1.8) следует, что усредненное по ансамблю среднее число двоичных ошибок, порождаемых ошибкой ветвления в узле
информационных двоичных символов неправильного пути совпадали с соответствующими информационными символами правильного пути. Отсюда и из (5.1.8) следует, что усредненное по ансамблю среднее число двоичных ошибок, порождаемых ошибкой ветвления в узле  ограничено сверху неравенством
ограничено сверху неравенством

Сравнивая функцию  определенную (5.1.6), с функцией Галлагера
определенную (5.1.6), с функцией Галлагера  определяемой (3.1.18), видим, что
определяемой (3.1.18), видим, что

при этом  строго меньше пропускной способности всех физических реальных каналов и может быть равна пропускной
строго меньше пропускной способности всех физических реальных каналов и может быть равна пропускной
способности лишь в некоторых вырожденных случаях, как это было показано в § 3.2 [см. (3.2.11)].
Чтобы продлить границы на большие скорости вплоть до пропускной способности, необходимо пользоваться более точными методами, чем метод, основанный на простой аддитивной границе, использовавшийся до сих пор. Методы, основанные на границе Галлагера, аналогичны методам, использовавшимся во второй половине § 4.6. Начнем с рассмотрения множества всех неправильных путей, ответвляющихся от правильного пути в узле  и несовпадающих с правильным путем ровно на
и несовпадающих с правильным путем ровно на  ребрах, а затем просуммируем по всем
ребрах, а затем просуммируем по всем  Итак, в любом узле вероятность ошибки на узел может быть ограничена сверху неравенством
Итак, в любом узле вероятность ошибки на узел может быть ограничена сверху неравенством

Эта граница все еще является аддитивной, но уже по более широким множествам. Для оценки вероятностей  для заданного кода снова можно воспользоваться границей Галлагера (2.4.8):
для заданного кода снова можно воспользоваться границей Галлагера (2.4.8):

где  множество всех неправильных путей, ответвляющихся в узле
множество всех неправильных путей, ответвляющихся в узле  и сливающихся с правильным путем через
и сливающихся с правильным путем через  ребер, имеющее мощность, не превышающую
ребер, имеющее мощность, не превышающую  любой путь из этого множества.
любой путь из этого множества.
Как и раньше, учтем, что последовательность  определяемая (5.1.4) с
определяемая (5.1.4) с  может быть любой из
может быть любой из  возможных последовательностей. Однако множество
возможных последовательностей. Однако множество  является несколько более ограниченным. Например, предположим, что
является несколько более ограниченным. Например, предположим, что  Тогда в множестве
Тогда в множестве  найдутся два совместимых пути, информационными последовательностями которых между узлами
найдутся два совместимых пути, информационными последовательностями которых между узлами  являются
являются

Очевидно, что рассматриваемые два пути в первом ребре после ответвления от правильного (нулевого) пути все еще
совпадают и, следовательно, совпадают их символы х на этом ребре.
Хотя мощность множества ограничена, любой путь в этом множестве может иметь в качестве кодовой любую из  возможных последовательностей, что можно показать с помощью тех рассуждений, которые использовались и раньше. Однако если один путь уже выбран, то для всех остальных совместимых с ним путей выбор их кодовых символов уже оказывается зависимым в той степени, которую определяет сегмент, где эти пути совпадают с уже выбранными путями. Припишем
возможных последовательностей, что можно показать с помощью тех рассуждений, которые использовались и раньше. Однако если один путь уже выбран, то для всех остальных совместимых с ним путей выбор их кодовых символов уже оказывается зависимым в той степени, которую определяет сегмент, где эти пути совпадают с уже выбранными путями. Припишем  символам правильного пути, расположенным между узлами
символам правильного пути, расположенным между узлами  вес
вес  он равен
он равен  если используется равномерное распределение. Сопоставим также веса
если используется равномерное распределение. Сопоставим также веса  элементам множества
элементам множества  совместимых неправильных путей. При равномерном распределении эти веса равны единице, деленной на число различных способов выбрать элемент множества
совместимых неправильных путей. При равномерном распределении эти веса равны единице, деленной на число различных способов выбрать элемент множества  в общем случае веса
в общем случае веса  обладают тем свойством, что их сумма по всем различным элементам множества
обладают тем свойством, что их сумма по всем различным элементам множества  равна единице. Введенные обозначения позволяют расширить множество
равна единице. Введенные обозначения позволяют расширить множество  включив в него все совокупности из
включив в него все совокупности из  векторов
векторов  где
где  не обращая внимания на то, совместимы они или нет с точки зрения структуры решетки, поскольку любая из недопустимых комбинаций может быть исключена приписыванием ей нулевого веса.
не обращая внимания на то, совместимы они или нет с точки зрения структуры решетки, поскольку любая из недопустимых комбинаций может быть исключена приписыванием ей нулевого веса.
Усредняя по ансамблю (5.1.13) с весами, определенными выше получаем

Заметим, что ограничений на суммирование по  в этой сумме нет, так как каждая недопустимая комбинация путей исключается приравниванием
в этой сумме нет, так как каждая недопустимая комбинация путей исключается приравниванием  нулю для соответствующих
нулю для соответствующих  Далее, ограничившись значениями
Далее, ограничившись значениями  из интервала от нуля до единицы, можно воспользоваться неравенством Иенсена (см. приложение
из интервала от нуля до единицы, можно воспользоваться неравенством Иенсена (см. приложение  и получить неравенство
и получить неравенство


Рассмотрим выражение в скобках, а точнее,  слагаемое внешней суммы и проведем суммирование по всем последовательностям, кроме Так как только
слагаемое внешней суммы и проведем суммирование по всем последовательностям, кроме Так как только  зависит от последовательностей
зависит от последовательностей  то
то

Важным результатом этого последнего шага является то, что все свелось к рассмотрению одного единственного неправильного пути  Но, как уже указывалось выше, хотя кодовые последовательности неправильных путей из неправильного подмножества связаны между собой решетчатой диаграммой, в качестве кодовой последовательности для любого отдельного пути может быть выбрана любая из
Но, как уже указывалось выше, хотя кодовые последовательности неправильных путей из неправильного подмножества связаны между собой решетчатой диаграммой, в качестве кодовой последовательности для любого отдельного пути может быть выбрана любая из  возможных последовательностей пространства
возможных последовательностей пространства  Поэтому распределение весов
Поэтому распределение весов  оказывается точно таким же, как и распределение
оказывается точно таким же, как и распределение  для правильного пути (оба равны
для правильного пути (оба равны  если используется равномерное распределение). Следовательно, граница (5.1.15) может быть переписана в виде
если используется равномерное распределение). Следовательно, граница (5.1.15) может быть переписана в виде

Здесь использовались: неравенство  то обстоятельство, что канал является каналом без памяти, и представление
то обстоятельство, что канал является каналом без памяти, и представление  в виде произведения N идентичных одномерных распределений весов. Так как
в виде произведения N идентичных одномерных распределений весов. Так как  то последнее неравенство можно также представить в виде
то последнее неравенство можно также представить в виде

где, как и в § 3.1. [см. формулу (3.1.18)],

Наконец, подставляя (5.1.17) в среднюю по ансамблю границу (5.1.12) и используя (5.1.8), получаем искомую границу для средней по ансамблю вероятности ошибки на узел:

Аналогично верхняя граница для усредненного по ансамблю среднего числа двоичных ошибок, порождаемых ошибкой в узле  может быть получена умножением
может быть получена умножением  слагаемого в (5.1.18) на
слагаемого в (5.1.18) на  Это следует из того, что ошибка в узле, вызываемая неправильным путем, несовпадающим с правильным на сегменте из
Это следует из того, что ошибка в узле, вызываемая неправильным путем, несовпадающим с правильным на сегменте из  ребер, может привести к возникновению не более чем
ребер, может привести к возникновению не более чем  двоичных ошибок. Таким образом,
двоичных ошибок. Таким образом,

Нерешенной остается задача выбора параметра  и наилучшего распределения весов
и наилучшего распределения весов  Заметим также, что формулы (5.1.18) и (5.1.19) переходят соответственно в (5.1.9) и (5.1.10), если положить
Заметим также, что формулы (5.1.18) и (5.1.19) переходят соответственно в (5.1.9) и (5.1.10), если положить  и воспользоваться выражением (5.1.11).
и воспользоваться выражением (5.1.11).
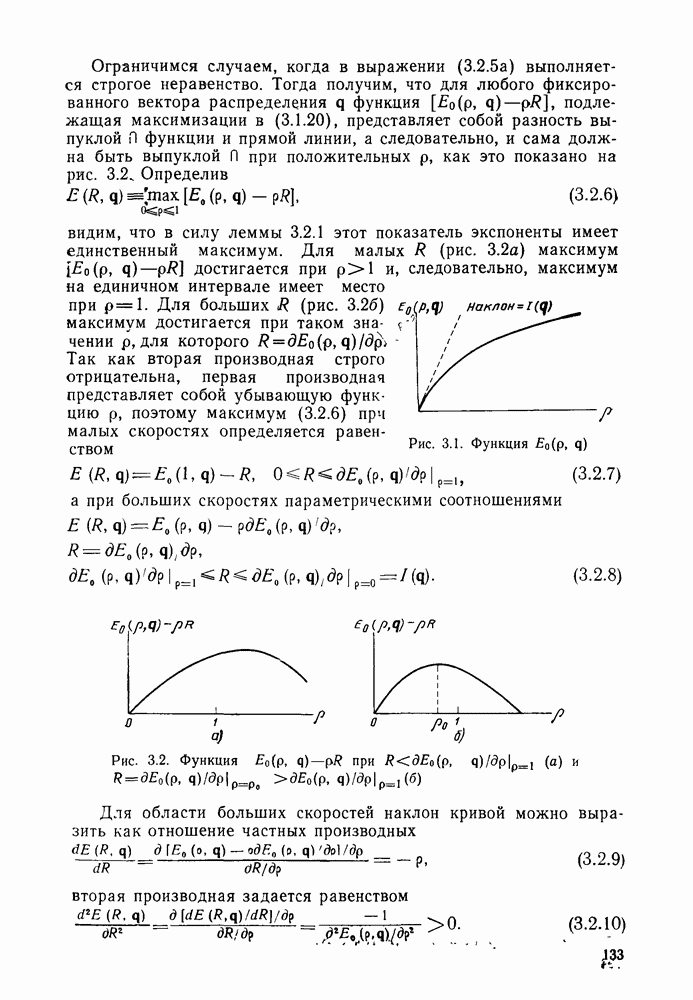
Функция  уже изучалась выше в § 3.2: ее основные свойства, суммированные в лемме 3.2.1, заключаются в следующем. Она является положительной возрастающей выпуклой функцией при положительных значениях
уже изучалась выше в § 3.2: ее основные свойства, суммированные в лемме 3.2.1, заключаются в следующем. Она является положительной возрастающей выпуклой функцией при положительных значениях  стремится к нулю со скоростью
стремится к нулю со скоростью  при
при  (см. рис. 3.1). Следовательно, для того чтобы минимизировать границы асимптотически при больших К, необходимо выбрать
(см. рис. 3.1). Следовательно, для того чтобы минимизировать границы асимптотически при больших К, необходимо выбрать  по возможности большим, но так, чтобы показатель экспоненты в знаменателях в (5.1.18) и (5.1.19) оставался положительным. При малых
по возможности большим, но так, чтобы показатель экспоненты в знаменателях в (5.1.18) и (5.1.19) оставался положительным. При малых  этому требованию удовлетворяет величина
этому требованию удовлетворяет величина

при этом границы (5.1.18) и (5.1.19) имеют вид
На рис. 5.3 показана зависимость показателя экспоненты  скорости передачи для типичного канала без памяти. Максимизация
скорости передачи для типичного канала без памяти. Максимизация  по распределению веса
по распределению веса  выполняется точно так же, как и в
выполняется точно так же, как и в  теорема 3.2.2.). Ясно, что асимптотически при больших К величина
теорема 3.2.2.). Ясно, что асимптотически при больших К величина  может быть выбрана сколь угодно малой.
может быть выбрана сколь угодно малой.
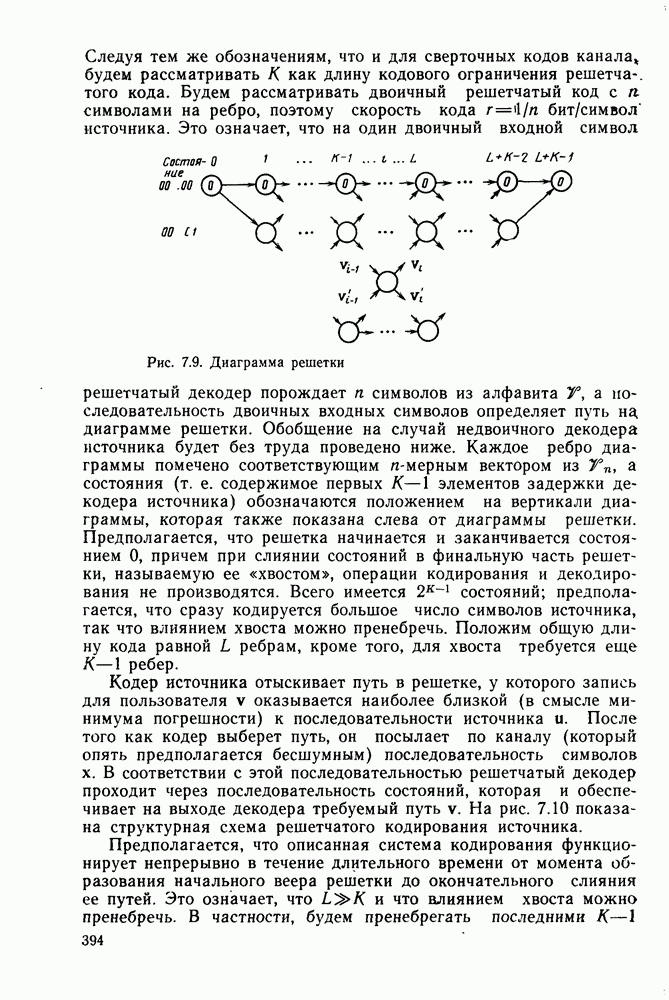
Остается обобщить эти результаты, полученные для двоичных решеток (кодов со скоростью  на решетки с
на решетки с  ребрами в каждом узле (коды со скоростью
ребрами в каждом узле (коды со скоростью  Кодер для таких кодов показан на рис. 5.1 и содержит обычно
Кодер для таких кодов показан на рис. 5.1 и содержит обычно  регистров сдвига, число каскадов в каждом из которых равно длине кодового ограничения
регистров сдвига, число каскадов в каждом из которых равно длине кодового ограничения  при этом объем памяти декодера и вычислительная сложность растут пропорционально
при этом объем памяти декодера и вычислительная сложность растут пропорционально  Для того чтобы провести необходимый анализ, следует определить лишь вид информационных последовательностей для всех неправильных путей, начинающихся в узле
Для того чтобы провести необходимый анализ, следует определить лишь вид информационных последовательностей для всех неправильных путей, начинающихся в узле  и сливающихся с правильным путем после
и сливающихся с правильным путем после  ребер. При этом, как и ранее, без ограничения общности можно взять правильный путь, соответствующий нулевой информационной последовательности. Для двоичных решеток правильный путь определяется формулой (5.1.2). Для
ребер. При этом, как и ранее, без ограничения общности можно взять правильный путь, соответствующий нулевой информационной последовательности. Для двоичных решеток правильный путь определяется формулой (5.1.2). Для  -ичных решеток обобщением этого представления является представление
-ичных решеток обобщением этого представления является представление

где все компоненты являются  -мерными двоичными векторами, каждый из которых состоит из
-мерными двоичными векторами, каждый из которых состоит из  входных двоичных символов, вводимых в регистр кодера для формирования одного ребра. Компоненты
входных двоичных символов, вводимых в регистр кодера для формирования одного ребра. Компоненты  могут быть любыми из
могут быть любыми из  ненулевых Ь-мер-ных двоичных векторов, так как мы требуем, чтобы ответвляющийся от правильного пути в узле
ненулевых Ь-мер-ных двоичных векторов, так как мы требуем, чтобы ответвляющийся от правильного пути в узле  неправильный путь не сливался с правильным до узла
неправильный путь не сливался с правильным до узла  При этом каждая из компонент
При этом каждая из компонент  может быть произвольным
может быть произвольным  -мерным двоичным вектором, но никакие
-мерным двоичным вектором, но никакие  из следующих друг за другом компонент, номера которых меньше
из следующих друг за другом компонент, номера которых меньше  не могут быть одновременно равны 0, так как в противном случае неправильный путь начнет совпадать с правильным ранее узла
не могут быть одновременно равны 0, так как в противном случае неправильный путь начнет совпадать с правильным ранее узла  Таким образом, в подмножестве
Таким образом, в подмножестве  неправильных путей, начинающихся в узле
неправильных путей, начинающихся в узле  и сливающихся с правильным путем в узле
и сливающихся с правильным путем в узле  имеется менее
имеется менее  элементов. Поэтому все результаты, полученные для решетчатых кодов со скоростью
элементов. Поэтому все результаты, полученные для решетчатых кодов со скоростью  могут быть обобщены на
могут быть обобщены на
коды со скоростью  просто заменой
просто заменой  на
на  в выражениях (5.1.7), (5.1.9), (4.6.16), (5.1.12) и
в выражениях (5.1.7), (5.1.9), (4.6.16), (5.1.12) и  Для общего представления достаточно рассмотреть только два последних выражения. Итак, для кодов со скоростью
Для общего представления достаточно рассмотреть только два последних выражения. Итак, для кодов со скоростью 

Аналогично, обобщая (5.1.19) на случай кодов со скоростью передачи  и учитывая, что ошибка в выборе ребра может породить до
и учитывая, что ошибка в выборе ребра может породить до  двоичных ошибок, получаем
двоичных ошибок, получаем

Обобщим (5.1.23) и (5.1.24) на случай кодов со скоростью  выбрав
выбрав  для
для

для больших скоростей, заменив  на
на  и умножив оба выражения на
и умножив оба выражения на  а второе также и на
а второе также и на 
Все полученные до сих пор результаты были связаны с оценками событий на некотором конкретном уровне узлов. Однако вероятность ошибки на бит определяется как среднее число двоичных ошибок на полной длине кода, деленное на полное число декодированных двоичных символов. Так как при декодировании каждому ребру сопоставляется  бит, для решетчатого кода со скоростью
бит, для решетчатого кода со скоростью  и длиной
и длиной  ребер
ребер

где  общее число двоичных ошибок
общее число двоичных ошибок  кодовой последовательности длины
кодовой последовательности длины  ребер (появление неравенства является
ребер (появление неравенства является
следствием того, что последовательности двоичных ошибок могут перекрываться, на что указывалось в § 4.4). Из (5.1.29) — (5.1.31) после оптимизации по  для полной длины кода получаем
для полной длины кода получаем

Так как эта граница получена для среднего по ансамблю всех возможных решетчатых кодов длины  ребер, то можно сделать вывод, что в этом ансамбле существует по крайней мере один код, для котчрого
ребер, то можно сделать вывод, что в этом ансамбле существует по крайней мере один код, для котчрого 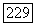 Отсюда следует теорема.
Отсюда следует теорема.
Теорема 5.1.1. Теорема кодирования для канала и сверточных кодов (Витерби [1967], [1971]). Для любого дискретного по входу канала без памяти существует изменяющийся во времени сверточный код с длиной кодового ограничения К, скоростью 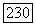 бит/символ канала и произвольной длиной блока, вероятность ошибки на бит
бит/символ канала и произвольной длиной блока, вероятность ошибки на бит 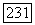 которого при декодировании по максимуму правдоподобия ограничена сверху величиной, определяемой формулами (5.1.32), (5.1.34), где
которого при декодировании по максимуму правдоподобия ограничена сверху величиной, определяемой формулами (5.1.32), (5.1.34), где 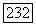 произвольнее положительное число
произвольнее положительное число














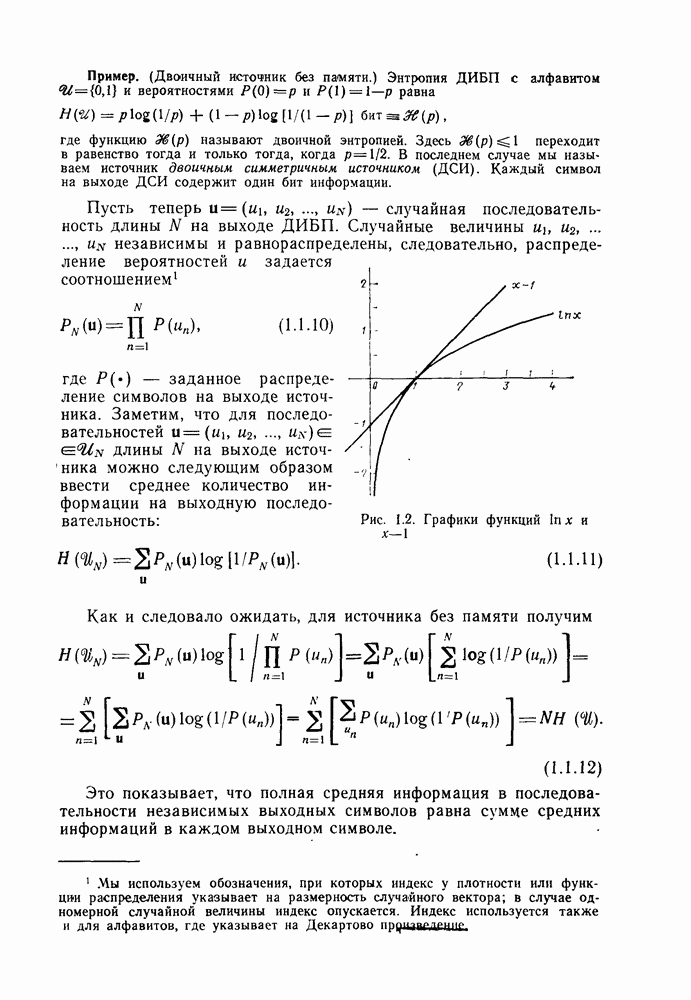





















































































































































































































































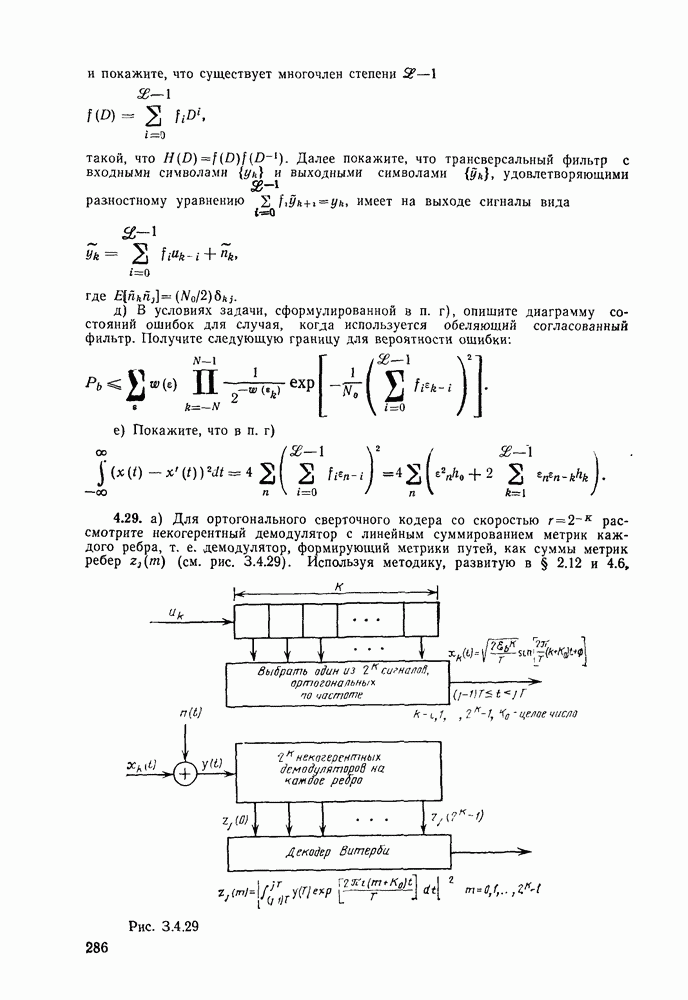

































































































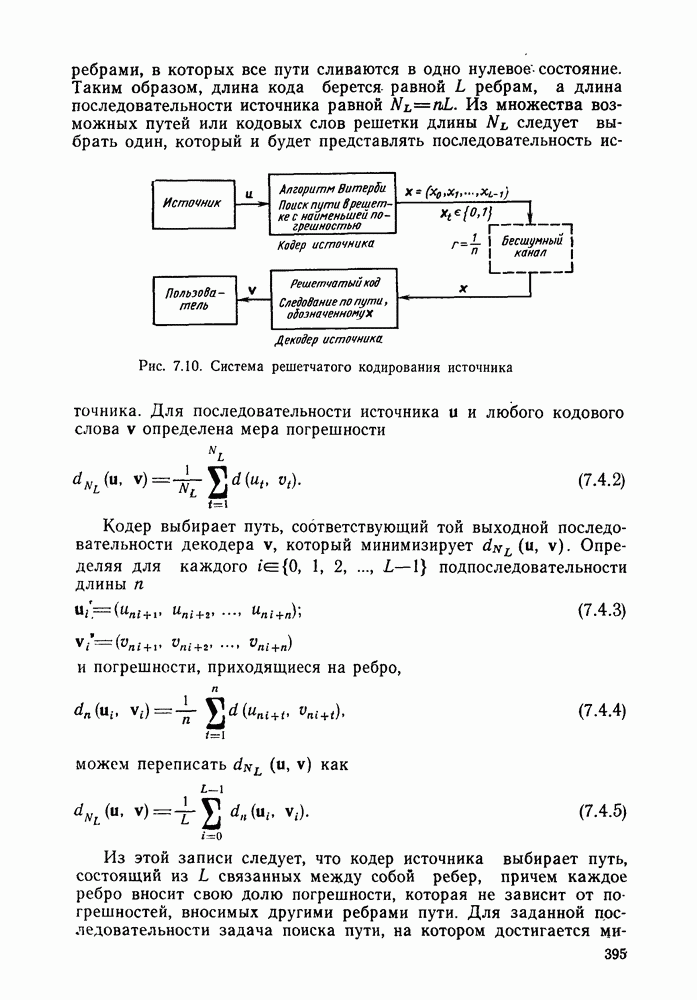
















































































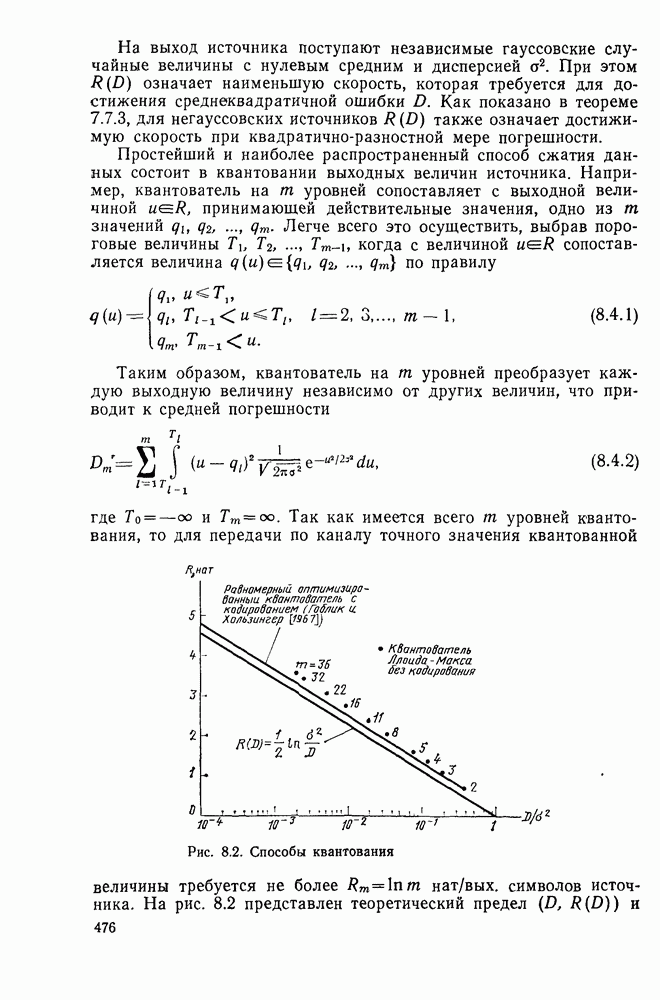





















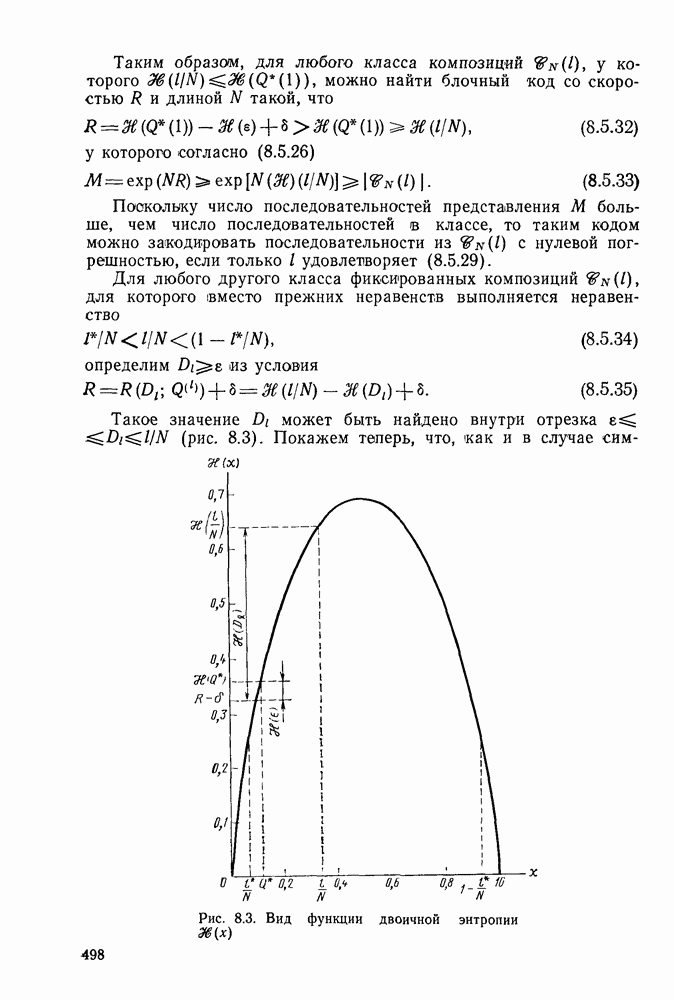































 определяется следующими параметрическими уравнениями:
определяется следующими параметрическими уравнениями:

 следует, что при уменьшении
следует, что при уменьшении  от 1 до 0 показатель экспоненты
от 1 до 0 показатель экспоненты  является положительным, а скорость
является положительным, а скорость  непрерывной функцией, возрастающей от значения
непрерывной функцией, возрастающей от значения  до
до 



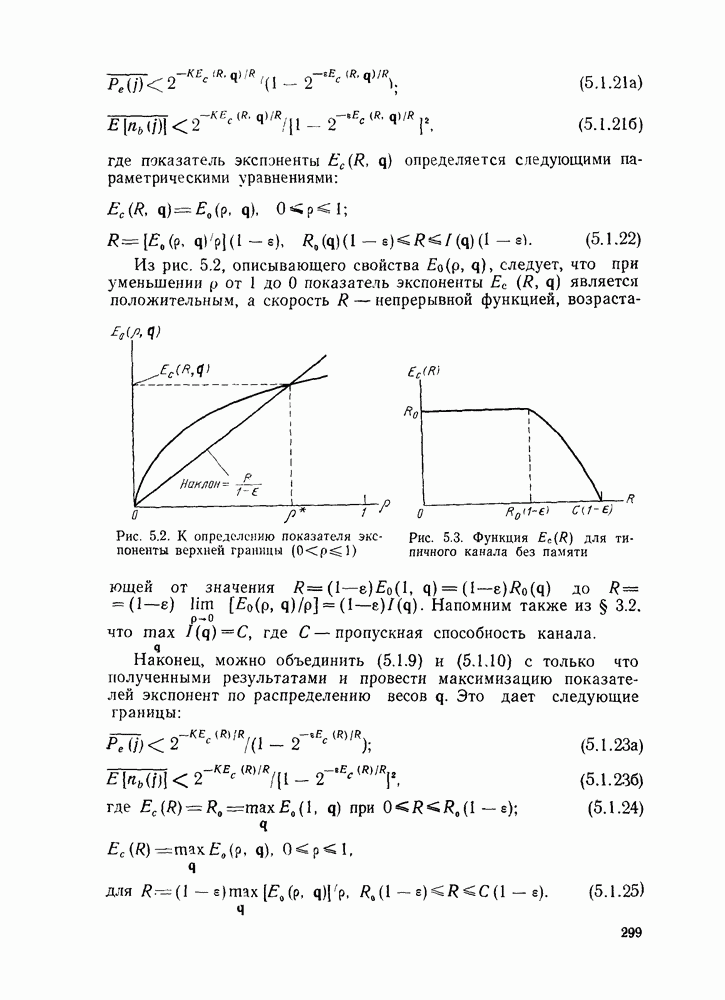
 для типичного канала без памяти
для типичного канала без памяти
 где С — пропускная способность канала.
где С — пропускная способность канала.
 Это дает следующие границы:
Это дает следующие границы:
