Пред.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.1. Источники, энтропия и теорема кодирования без шумаСообщение: «Сегодня в Лос-Анджелесе солнечная погода, количество смога ограничено» хотя и не является для нас неожиданным, все содержит некоторую информацию, поскольку разрешает неопределенность относительно погоды в Лос-Анджелесе. С другой стороны) новость — «Сегодня в Калифорнии произошло опустошительное землетрясение, разрушившее большую часть делового центра Лос-Анджелеса» - гораздо неожиданнее и содержит больше информации, чем первое сообщение. Но что же такое информация? Что мы понимаем под «информацией», содержащейся в приведенных сообщениях? Если мы намерены ввести формально некую количественную меру информации, содержащейся в подобных сообщениях, то конечно, эта мера должна обладать рядом очевидных свойств. 1. Информацию о событиях следует определять через некоторую меру неопределенности событий. 2. Менее определенные события в сравнении с более определенными должны содержать больше информации. Допустим, кроме того, Что погодные условия и землетрясения — события, не связанные между собой. Если нам сообщают обе новости, то можно ожидать, что общее количество информации равно сумме количеств информации, содержащихся в каждой из них. Отсюда вытекает третье желаемое свойство. 3. Информация о не связанных между собой событиях, рассматриваемых как одно событие, должна равняться сумме информации о каждом из этих событий. Естественной мерой неопределенности события а может служить его вероятность, обозначаемая через
Коль скоро мы согласились определять информацию о событии а через его вероятность, информацию о событии а, удовлетворяющую свойствам 1 и 2, можно определить следующим образом:
Из этого определения вытекает, что если Главный предмет нашего изучения — передача и обработка информации, причем источники информации и каналы связи задаются вероятностными моделями. Например, источники информации описываются вероятностной моделью, выходом которой служат события или случайные величины. Начнем с простейшего вида источника информации. Определение. Дискретный источник без памяти
Каждую единицу дискретного времени, скажем, каждые Если в некоторый момент времени на выходе ДИБП появится символ
единиц информации. Эти единицы называют натами, если логарифмы натуральные, и битами, если основание логарифмов равно 2. Ясно, что они отличаются всего лишь масштабным множителем логарифма по основанию 2, тогда как
Чтобы выяснить смысл энтропии как оперативной характеристики, воспользуемся фундаментальным неравенством
проверить которое можно, учитывая, что функция
откуда следует неравенство
которое переходит в равенство тогда и только тогда, когда Неравенства (1.1.6) и (1.1.8) входят в ряд наиболее часто употребляемых в теории информации. Например, подставив
с равенством справа тогда и только тогда, когда Пример. (Двоичный источник без памяти.) Энтропия ДИБП с алфавитом
где функцию Пусть теперь
где
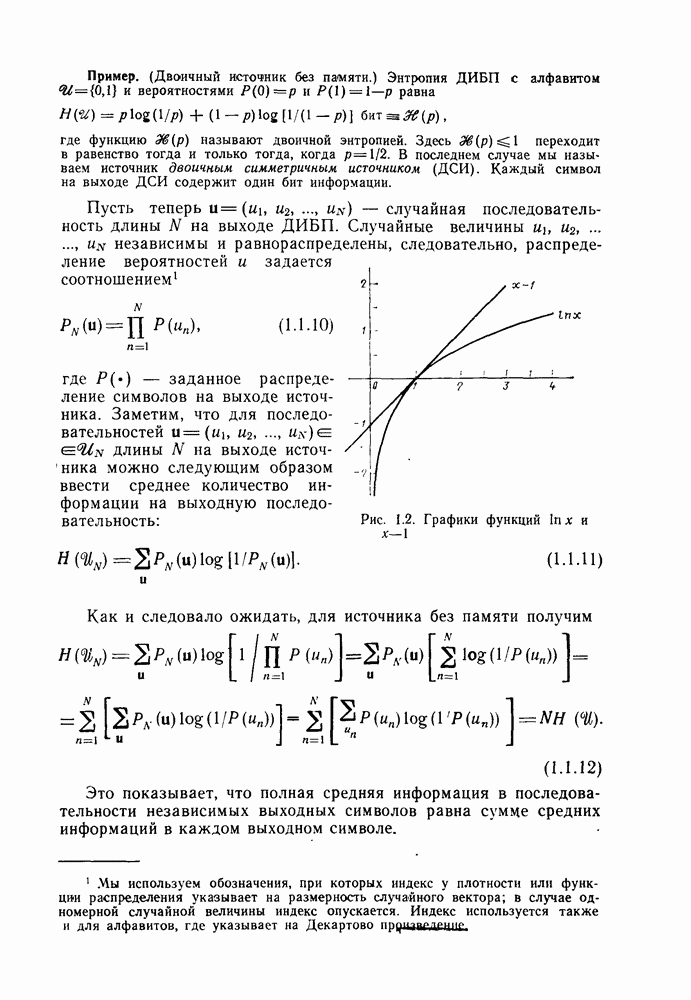
Рис. 1.2. Графики функций Как и следовало ожидать, для источника без памяти получим
Это показывает, что полная средняя информация в последовательности независимых выходных символов равна сумме средних информаций в каждом выходном символе. Если N выходных символов не являются независимыми, правая часть соотношения (1.1.12) становится всего лишь верхней оценкой левой. Чтобы получить этот более общий результат, положим
где
где последнее равенство получается аналогично (1.1.12). Отсюда
переходит в равенство тогда и только тогда, когда выходные символы источника В целом ряде приложений информация с выхода источника либо передается некоторому получателю, либо хранится в памяти ЭВМ. В любом случае удобно представить выходные символы двоичными символами. При этом необходимо, чтобы по двоичным символам можно было восстановить первоначальные выходные символы источника. Естественно, что на каждый выходной символ хотелось бы употребить как можно меньше двоичных символов. В первой теореме Шеннона, называемой теоремой кодирования без шума для источника, показано, что среднее число двоичных символов, приходящееся на выходной символ источника, можно приблизить к энтропии источника и что нельзя сделать его меньше энтропии. Этот довольно неожиданный результат выявляет значение энтропии источника как оперативной характеристики. Докажем теперь теорему для случая с ДИБП. Пусть соответствующих всем последовательностям источника длины Пример. Пусть
Код 1 не является однозначно декодируемым, поскольку двоичная последовательность
Такой код для последовательностей источника длины 2 из Перейдем теперь к формулировке и доказательству теоремы кодирования без шума для источника в ее простейшей форме. Эта теорема позволит выявить значение энтропии как оперативной характеристики. Теорема 1.1.1. Теорема кодирования без шума для дискретного источника без памяти. Пусть задан ДИБП с алфавитом
где через Прямая теорема — справедливость соотношения (1.1.15) — доказывается построением однозначно декодируемого кода, на котором достигается оценка средней длины. Существует несколько методов такого построения, из которых первый принадлежит Шеннону [1948] (см. задачу 1.6); Хаффману [1952] принадлежит оптимальный метод, тот, при котором получающийся код имеет минимальную среднюю длину при всяком Лемма 1.1.1. Для любого
Тогда все последовательности источника из
Более того,
где
Заметим, что все последовательности источника из подмножества Доказательство.
Поскольку по определению
где через
Правая часть последнего неравенства не обязана представлять собой целое — степень двойки. Мы можем, однако, выбрать такое целое
Всего имеется Оценим теперь вероятность подмножества
Из определения (1.1.16) для
Следовательно, дополнение можно представить как
независимы и равнораспределены со средним
и конечной дисперсией, которую обозначим через
Для суммы N таких случайных величин из хорошо известного не равенства Чебышева (см. задачу 1.4) вытекает, что
Следовательно, для
Из последнего неравенства следует, что Доказательство теоремы 1.1.1. Воспользуемся результатом леммы 1.1.1 и добавим по одному двоичному символу к двоичным представлениям последовательностей из все последовательности из
или
поскольку при выполнении последнего неравенства все последовательности из Теперь для каждой из выходных последовательностей длины N есть однозначное двоичное представление или кодовое слово. Это код того же типа, что и код 4 в приведенном примере. Он однозначно декодируем, поскольку первый символ указывает длину кодового слова (0 означает, что длина равна
Рис. 1.3. Кодер источника Мы построили, таким образом, однозначно декодируемый код с двумя возможными длинами кодовых слов:
а из (1.1.17), (1.1.18) и (1.1.30) следует, что
или
Выбрав
что и устанавливает прямую теорему. Прежде чем перейти к обратной теореме, заметим, что благодаря свойству асимптотической равнораспределенности при больших N почти все кодовые слова можно выбрать равной длины, чуть большей При доказательстве обращения следует помнить, что, вообще говоря, длины кодовых слов могут быть различными. Для последовательности источника Рассмотрим тождество
где каждая сумма в обеих частях соотношения распространяется на все пространство последовательностей из
где
В противном случае две или более последовательности из
Но для всех указанных
поскольку левая часть (1.1.37) экспоненциально зависит от В общем случае для кодера источника с переменной длиной и кодовыми длинами, удовлетворяющими соотношению (1.1.38), средняя длина равна
двоичных символов на последовательность источника. Введя на
из неравенств (1.1.8) и (1.1.12) получим
Поскольку по неравенству Крафта-Макмиллана (1.1.38) второе слагаемое неположительно, имеем
Эта оценка справедлива для последовательностей любой длины Мы показали, таким образом, что ДИБП можно закодировать при среднем числе двоичных символов на символ источника, сколь угодно близком к энтропии, и что невозможно добиться меньшей средней длины. Это частный случай теоремы кодирования без шума для источника, которая справедлива для произвольного стационарного эргодического источника с дискретным алфавитом и произвольных кодов над конечным алфавитом (см. задачу 1.3). Последняя и выявляет значение энтропии как оперативной характеристики. Если мы ослабим требование восстановимости последовательности источника по двоичной последовательности кода и заменим его некоторым условием на среднее искажение, мы, конечно, сможем обойтись меньшим, чем Другим важным следствием теоремы является асимптотическое равенство вероятностей последовательностей источника при растущих
|
 |
Оглавление
|























































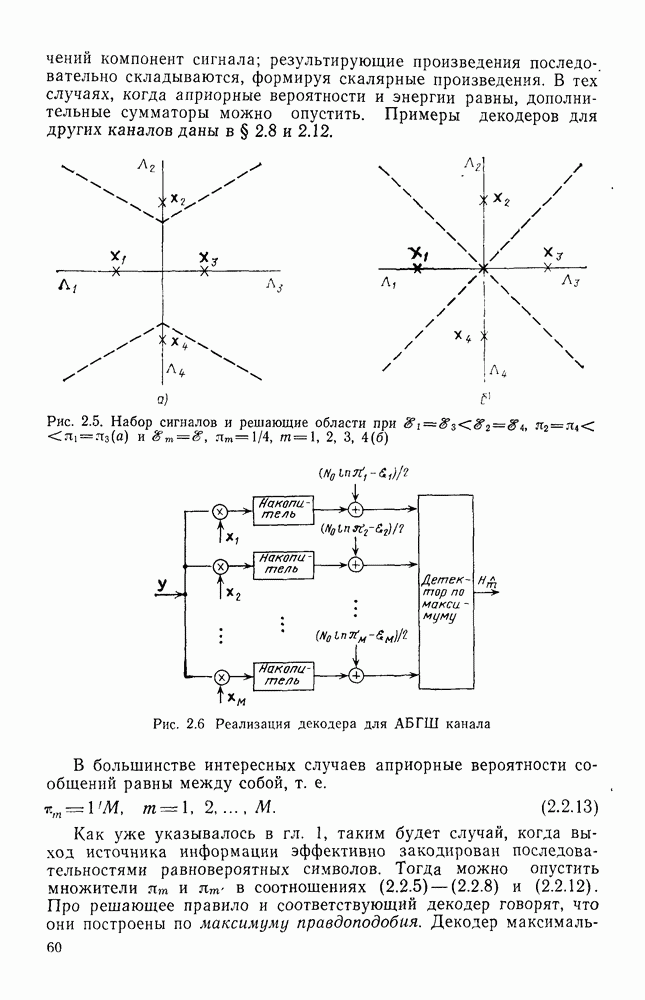









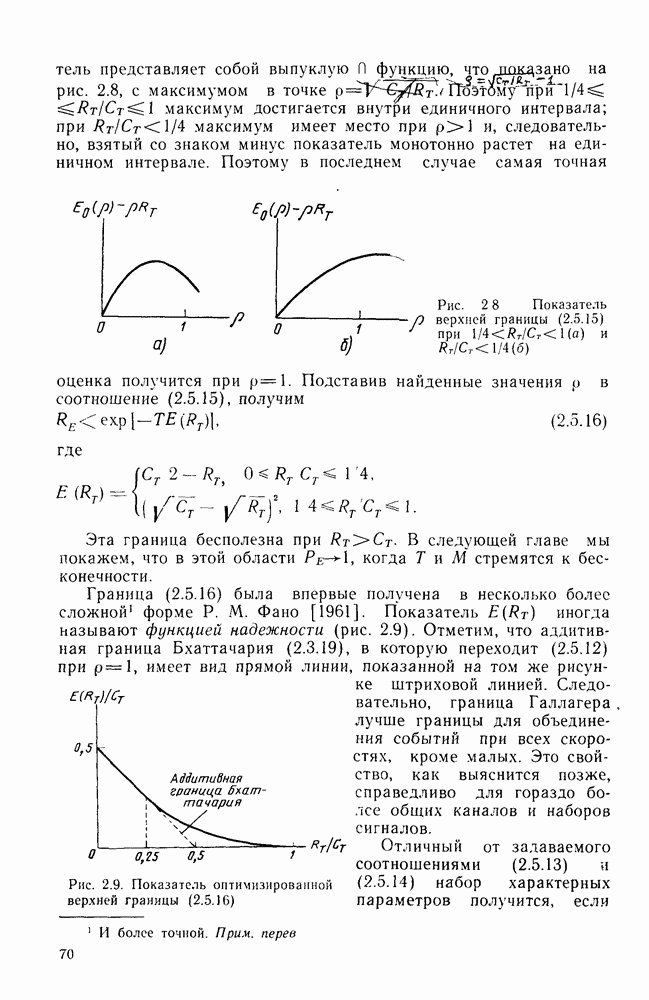




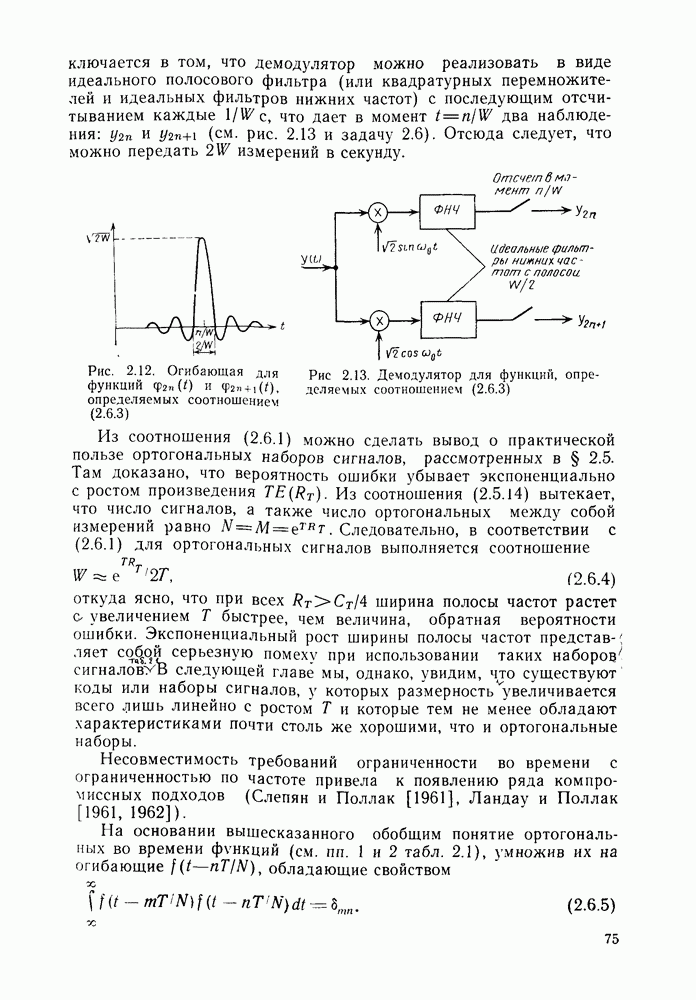




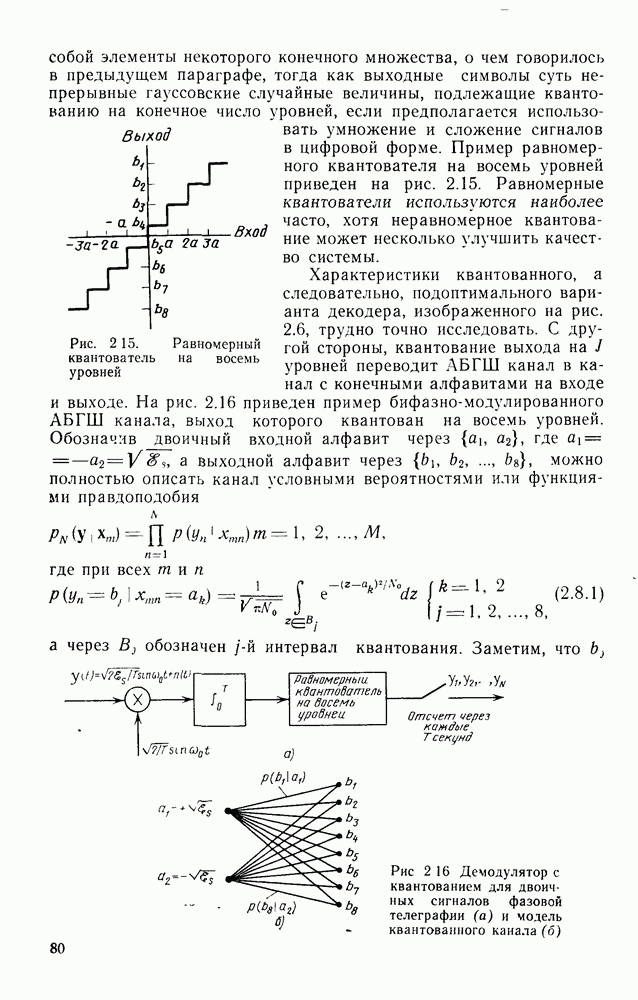



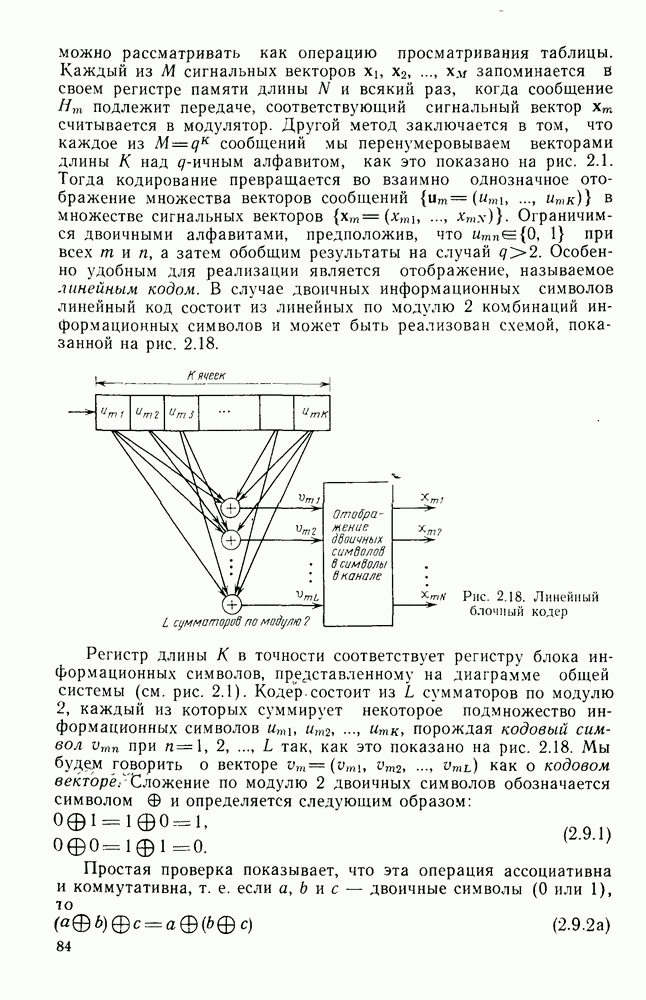













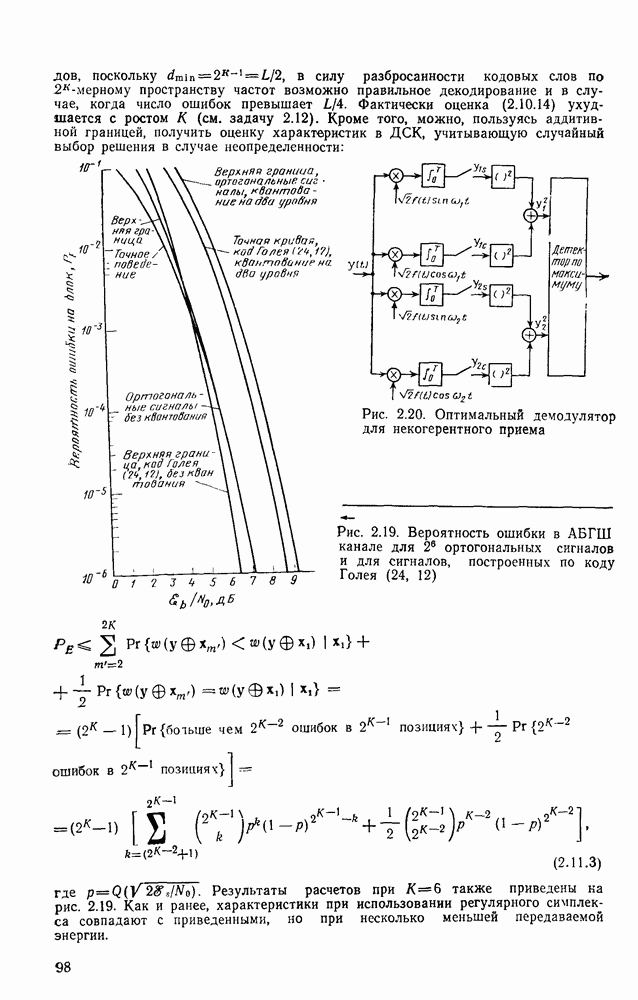












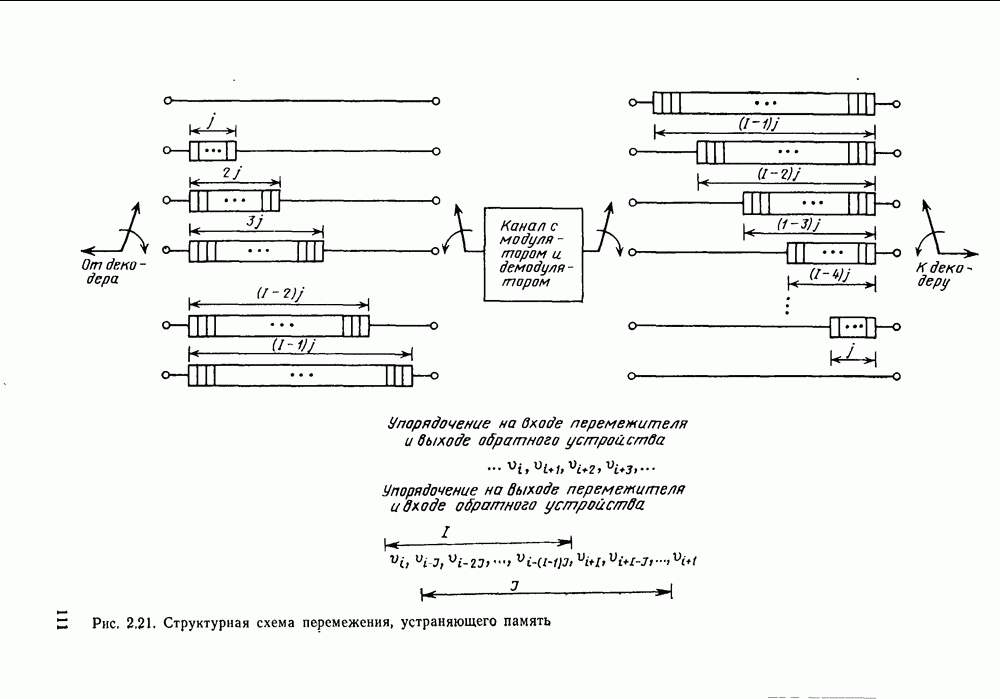




























































































































































































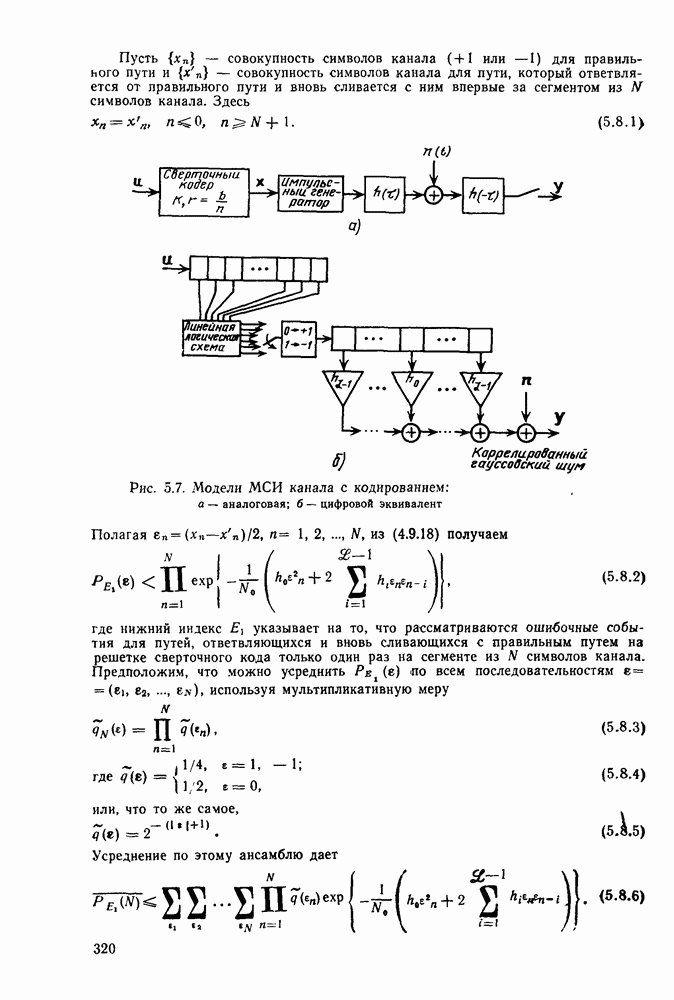
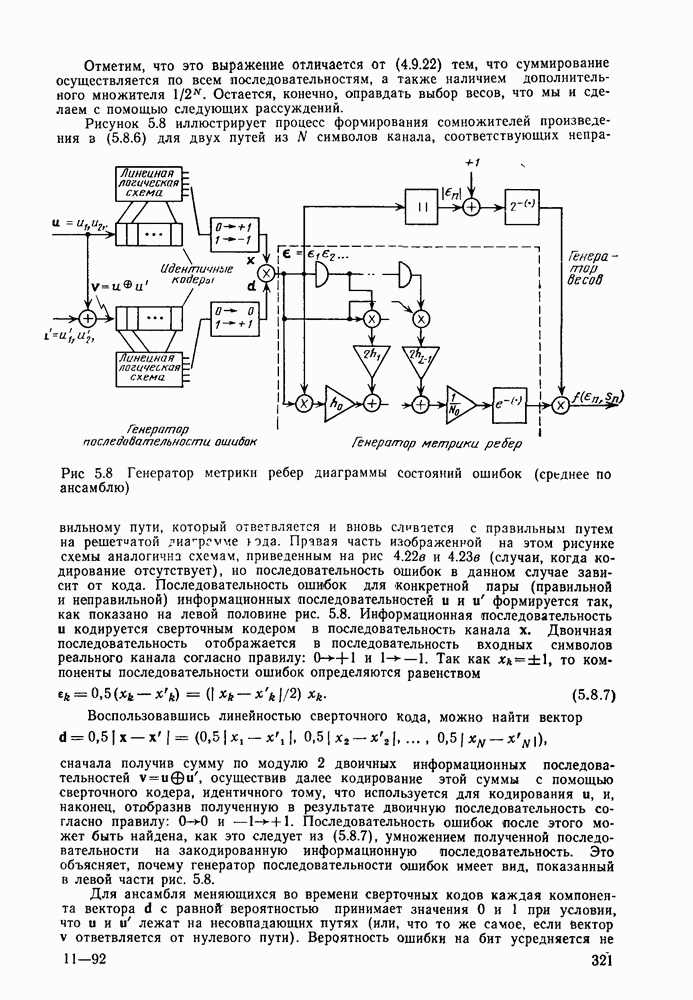

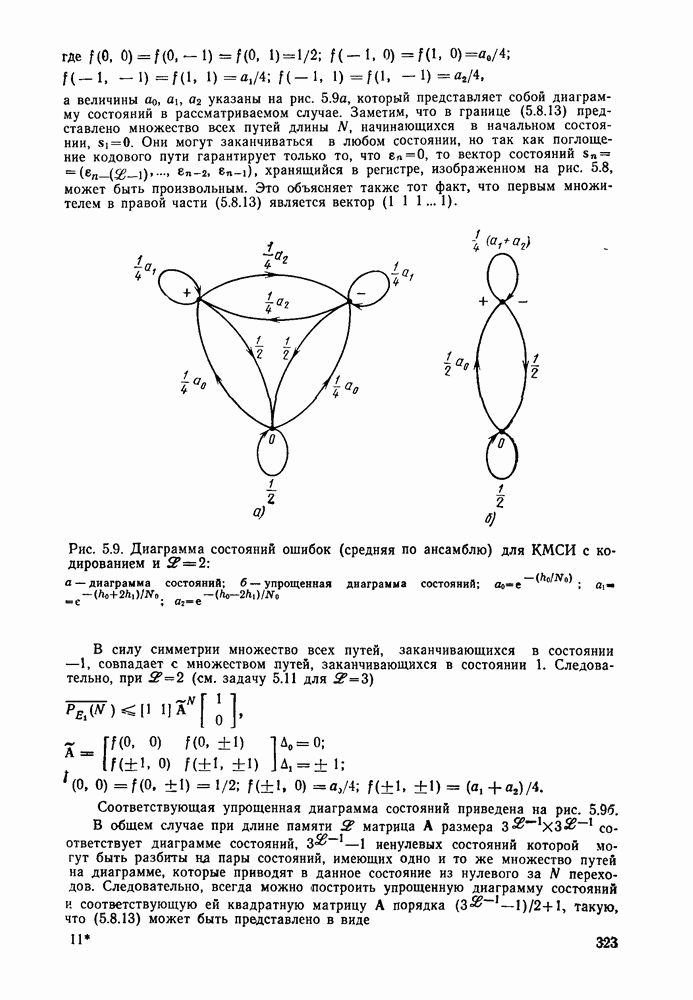














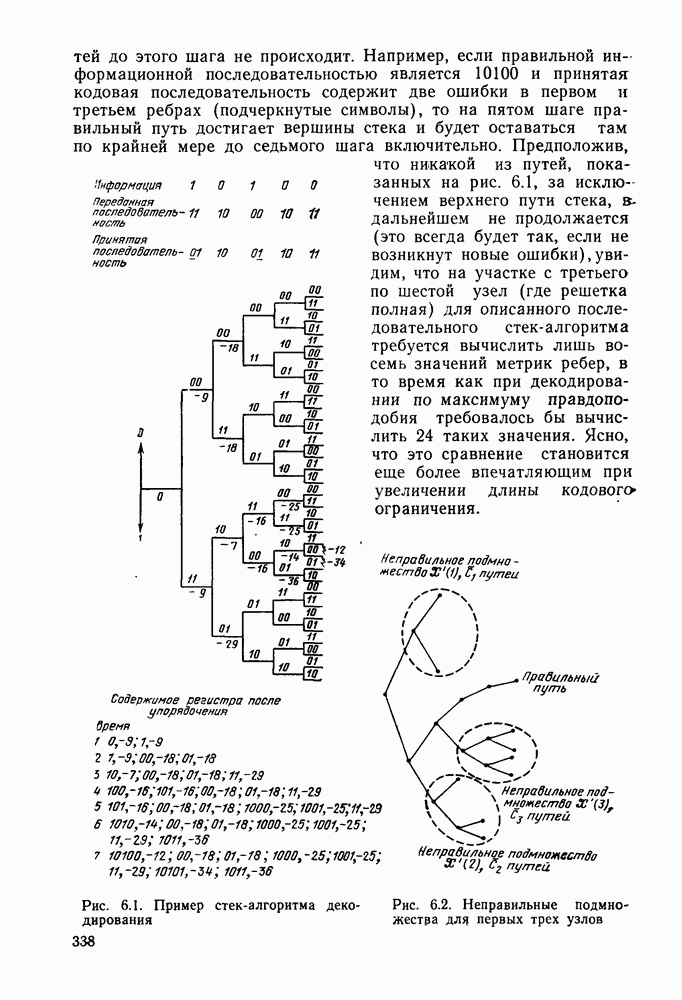




















































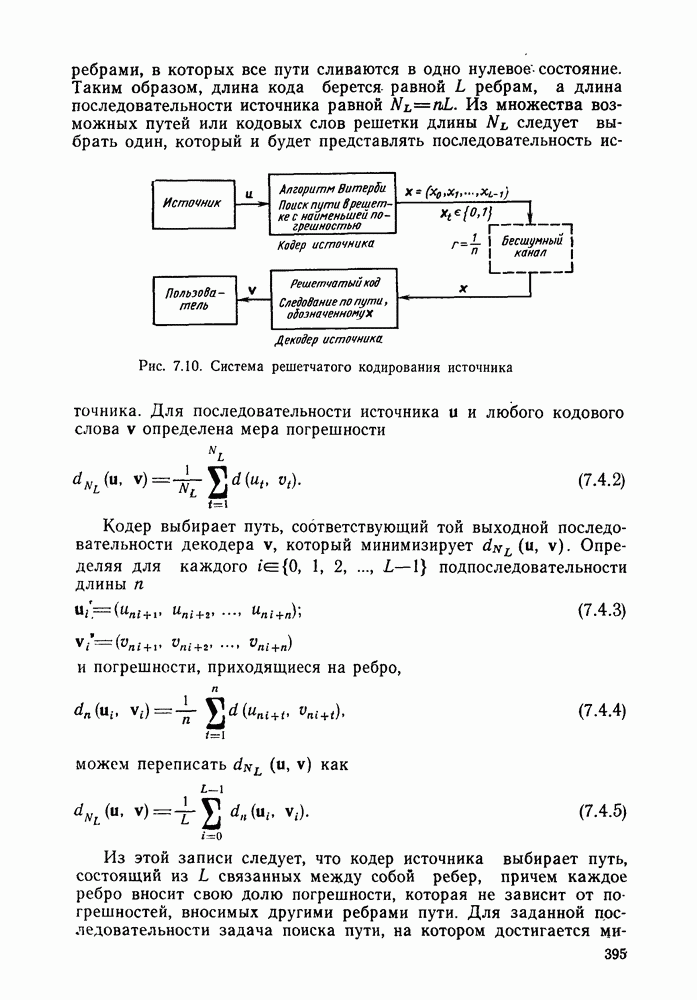
















































































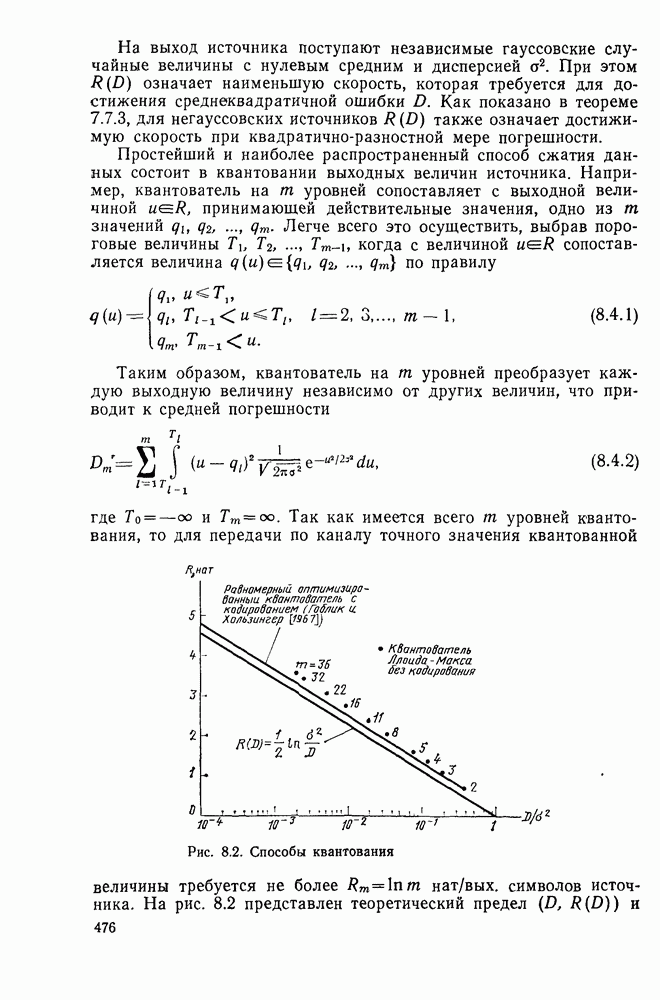





















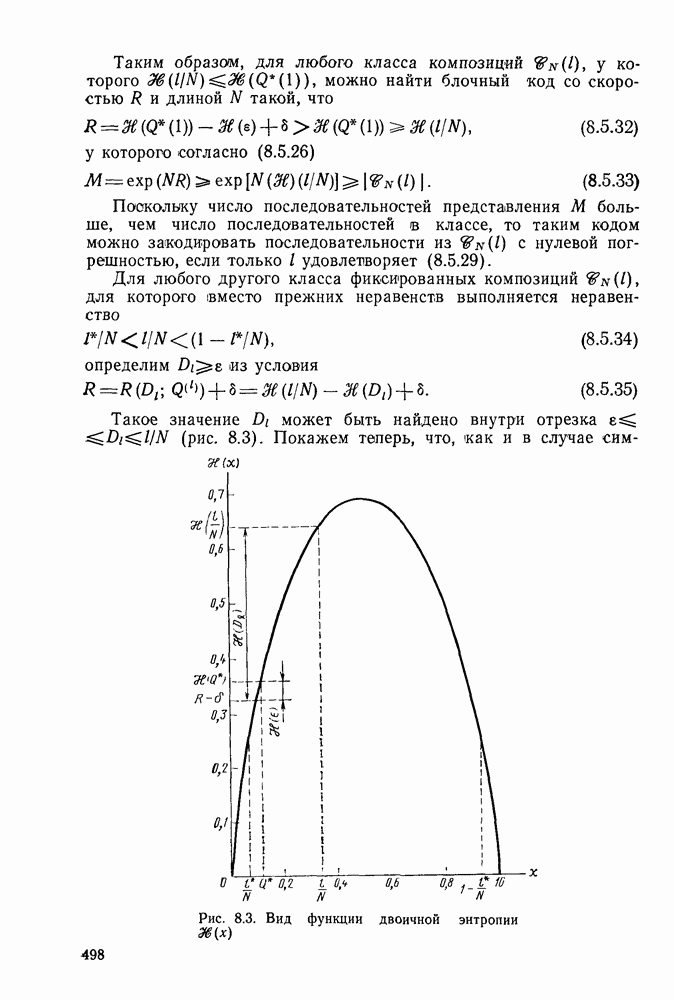






























 Формальным аналогом понятия «несвязанности» служит независимость; два события а и
Формальным аналогом понятия «несвязанности» служит независимость; два события а и  называются независимыми, если
называются независимыми, если


 независимы, то
независимы, то  Основание логарифма задает масштаб и, следовательно, единицу количества информации. Введенное выше
Основание логарифма задает масштаб и, следовательно, единицу количества информации. Введенное выше 
 характеризуется своим выходом — случайной величиной и, принимающей значения в конечном алфавите
характеризуется своим выходом — случайной величиной и, принимающей значения в конечном алфавите  с вероятностями
с вероятностями

 секунд, источник порождает
секунд, источник порождает  (это событие обозначим через
(это событие обозначим через  то в соответствии с нашим определением информации выходной символа источника содержит
то в соответствии с нашим определением информации выходной символа источника содержит

 Далее мы будем пользоваться обозначением
Далее мы будем пользоваться обозначением  для
для
 означает
означает 
 называют энтропией ДИБП. Здесь принято считать, что
называют энтропией ДИБП. Здесь принято считать, что 

 имеет единственный максимум, равный 0 в точке
имеет единственный максимум, равный 0 в точке  На рис. 1.2 приведены графики функций
На рис. 1.2 приведены графики функций  Из неравенства (1.1.6) следует, что для любых двух вероятностных распределений
Из неравенства (1.1.6) следует, что для любых двух вероятностных распределений  на алфавите
на алфавите  справедливо
справедливо 

 для всех
для всех 
 для всех не
для всех не  в (1.1.8), видим, что источник с равновероятными символами обладает наибольшей энтропией. Иначе говоря,
в (1.1.8), видим, что источник с равновероятными символами обладает наибольшей энтропией. Иначе говоря,

 для всех
для всех 
 и вероятностями
и вероятностями  равна
равна

 называют двоичной
называют двоичной  переходит в равенство тогда и только тогда, когда
переходит в равенство тогда и только тогда, когда  В последнем случае мы называем источник двоичным симметричным источником (ДСИ). Каждый символ на выходе ДСИ содержит один бит информации.
В последнем случае мы называем источник двоичным симметричным источником (ДСИ). Каждый символ на выходе ДСИ содержит один бит информации.

 независимы и равнораспределены, следовательно,
независимы и равнораспределены, следовательно, 
 заданное распределение символов на выходе источника. Заметим, что для последовательностей
заданное распределение символов на выходе источника. Заметим, что для последовательностей  длины
длины  на выходе источника можно следующим образом ввести среднее
на выходе источника можно следующим образом ввести среднее 




 одномерная
одномерная  если только
если только 

 независимы, т. е. когда
независимы, т. е. когда  суть выходные символы источника без памяти.
суть выходные символы источника без памяти.

 соответствующая двоичная последовательность длины
соответствующая двоичная последовательность длины  представляющая последовательность и источника. При фиксированном
представляющая последовательность и источника. При фиксированном  множество всех двоичных последовательностей (
множество всех двоичных последовательностей ( называется его кодом. Поскольку длины кодовых слов могут быть различными, то для восстановления по двоичным символам первоначальной последовательности источника нам придется потребовать, чтобы никакие две различные
называется его кодом. Поскольку длины кодовых слов могут быть различными, то для восстановления по двоичным символам первоначальной последовательности источника нам придется потребовать, чтобы никакие две различные  что никакое кодовое слово не является префиксом другого кодового слова. Ясно, что это условие достаточно, поскольку у заданной двоичной последовательности можно всегда однозначно отыскать конец и никакие два кодовых слова не совпадают. Определенным преимуществом однозначно декодируемых кодов, обладающих указанным свойством префиксности, является «мгновенная декодируемость», состоящая в том, что
что никакое кодовое слово не является префиксом другого кодового слова. Ясно, что это условие достаточно, поскольку у заданной двоичной последовательности можно всегда однозначно отыскать конец и никакие два кодовых слова не совпадают. Определенным преимуществом однозначно декодируемых кодов, обладающих указанным свойством префиксности, является «мгновенная декодируемость», состоящая в том, что  Рассмотрим следующие коды для последовательностей длины
Рассмотрим следующие коды для последовательностей длины 

 может соответствовать последовательностям источника
может соответствовать последовательностям источника  однозначно декодируем, поскольку все
однозначно декодируем, поскольку все  рассмотрим код
рассмотрим код

 будет однозначно декодируемым, поскольку все его последовательности встречаются только по одному разу и первый их символ указывает на длину кодового слова. Если на первом месте стоит 0, то
будет однозначно декодируемым, поскольку все его последовательности встречаются только по одному разу и первый их символ указывает на длину кодового слова. Если на первом месте стоит 0, то  и
и  Для последовательностей источника длины
Для последовательностей источника длины  существует однозначно декодируемый двоичный код, состоящий из двоичных последовательностей (кодовых слов) длины
существует однозначно декодируемый двоичный код, состоящий из двоичных последовательностей (кодовых слов) длины  при
при  такой, что средняя длина
такой, что средняя длина 
 обозначен член, стремящийся к нулю с ростом
обозначен член, стремящийся к нулю с ростом  Обратно, не существует кода такого что
Обратно, не существует кода такого что 
 Приведем еще один метод, который, хотя и менее эффективен, чем указанные стандартные методы, позволяет не только доказывать теорему непосредственно, но и иллюстрировать одно интересное свойство ДИБП, присущее гораздо более широкому классу источников и называемое свойством асимптотической равнораспределенности. Его мы установим с помощью следующей леммы.
Приведем еще один метод, который, хотя и менее эффективен, чем указанные стандартные методы, позволяет не только доказывать теорему непосредственно, но и иллюстрировать одно интересное свойство ДИБП, присущее гораздо более широкому классу источников и называемое свойством асимптотической равнораспределенности. Его мы установим с помощью следующей леммы.
 рассмотрим ДИБП с алфавитом
рассмотрим ДИБП с алфавитом 
 и введем следующее
и введем следующее 
 можно однозначно представить двоичными
можно однозначно представить двоичными  удовлетворяющей неравенствам
удовлетворяющей неравенствам



 почти равновероятны, их
почти равновероятны, их  множитель, не превышающий
множитель, не превышающий 
 представляет собой
представляет собой  -множества всех последовательностей длины
-множества всех последовательностей длины  следовательно, справедливо
следовательно, справедливо 
 для любого
для любого  это неравенство можно записать в следующем виде:
это неравенство можно записать в следующем виде:

 обозначено число различных последовательностей в
обозначено число различных последовательностей в  Следовательно, справедлива граница
Следовательно, справедлива граница

 что
что

 различных двоичных последовательностей длины
различных двоичных последовательностей длины  следовательно, можно однозначно представить все последовательности источника из
следовательно, можно однозначно представить все последовательности источника из  двоичными последовательностями длины
двоичными последовательностями длины  удовлетворяющими (1.1.17).
удовлетворяющими (1.1.17).
 дополнения к подмножеству
дополнения к подмножеству  состоящего из всех последовательностей, не обладающих указанным выше свойством. Пусть
состоящего из всех последовательностей, не обладающих указанным выше свойством. Пусть

 имеем
имеем 






 имеем
имеем


 становится сколь угодно малой, когда N стремится к бесконечности. Можно показать, что в действительности
становится сколь угодно малой, когда N стремится к бесконечности. Можно показать, что в действительности  убывает экспоненциально с ростом
убывает экспоненциально с ростом  для этого надо воспользоваться более точной границей Чернова (см. задачу 1.5). Свойство, заключающееся в том, что последовательности на выходе источника принадлежат
для этого надо воспользоваться более точной границей Чернова (см. задачу 1.5). Свойство, заключающееся в том, что последовательности на выходе источника принадлежат  с вероятностью, стремящейся к 1 с ростом
с вероятностью, стремящейся к 1 с ростом  называют свойством асимптотической равнораспределенности.
называют свойством асимптотической равнораспределенности.
 а именно, допишем 0 перед каждым таким представлением. Это увеличит длину двоичной последовательности с
а именно, допишем 0 перед каждым таким представлением. Это увеличит длину двоичной последовательности с  до
до  чем асимптотически можно пренебречь. Из (1.1.17) видно, что все последовательности из
чем асимптотически можно пренебречь. Из (1.1.17) видно, что все последовательности из  однозначно представлены двоичными последовательностями длины
однозначно представлены двоичными последовательностями длины  бит. Все другие последовательности, входящие в
бит. Все другие последовательности, входящие в  мы можем представить последовательностями длины
мы можем представить последовательностями длины  первый двоичный символ которых всегда равен 1, а оставшиеся
первый двоичный символ которых всегда равен 1, а оставшиеся  символов однозначно представят
символов однозначно представят
 Это заведомо возможно при
Это заведомо возможно при  удовлетворяющем неравенствам:
удовлетворяющем неравенствам:


 однозначно представимы.
однозначно представимы.
 а 1, что
а 1, что  тогда как остальные символы однозначно задают последовательность источника длины
тогда как остальные символы однозначно задают последовательность источника длины  Когда первый символ равен
Когда первый символ равен  мы, рассматривая следующие
мы, рассматривая следующие  символов, однозначно восстанавливаем последовательность из
символов, однозначно восстанавливаем последовательность из  если же первый символ равен 1, мы по следующим
если же первый символ равен 1, мы по следующим  символам однозначно восстанавливаем последовательность источника из
символам однозначно восстанавливаем последовательность источника из  Каждое
Каждое 
 и
и  Поэтому средняя длина
Поэтому средняя длина 


 получим
получим

 причем понадобится всего две длины. При малых N предпочтителен больший набор длин
причем понадобится всего две длины. При малых N предпочтителен больший набор длин  примерно равной взятому со знаком минус логарифму (по основанию 2) от почти одинаковых вероятностей выходных последовательностей
примерно равной взятому со знаком минус логарифму (по основанию 2) от почти одинаковых вероятностей выходных последовательностей 
 длина кодового слова
длина кодового слова  равна
равна 
 в произвольном однозначно декодируемом коде.
в произвольном однозначно декодируемом коде.

 Обозначив через
Обозначив через  число
число
 последовательных
последовательных  двоичных символов, можно представить (1.1.34) в
двоичных символов, можно представить (1.1.34) в

 Из условия однозначной восстановимости последовательности источника по двоичной последовательности имеем
Из условия однозначной восстановимости последовательности источника по двоичной последовательности имеем

 последовательных
последовательных  для всех целых положительных
для всех целых положительных  получим
получим

 это
это 
 тогда как правая растет лишь линейно с
тогда как правая растет лишь линейно с  Приведенное неравенство известно как неравенство Крафта-Макмиллана (Крафт [1949], Макмиллан [1956]).
Приведенное неравенство известно как неравенство Крафта-Макмиллана (Крафт [1949], Макмиллан [1956]).

 распределение
распределение




 следовательно, для любого кода источника, для которого последовательности источника однозначно восстановимы по двоичным последовательностям (однозначно декодируемы), в среднем необходимо не меньше
следовательно, для любого кода источника, для которого последовательности источника однозначно восстановимы по двоичным последовательностям (однозначно декодируемы), в среднем необходимо не меньше  бит на символ источника. Теорема 1.1.1 доказана
бит на символ источника. Теорема 1.1.1 доказана
 числом бит на символ источника. Такое обобщение на случай кодирования источника при наличии меры искажения называется теорией скорости как функции погрешности. Этой теории, созданной в 1948 г. Шенноном и развитой им же в 1959 г., мы посвящаем гл. 7 и 8.
числом бит на символ источника. Такое обобщение на случай кодирования источника при наличии меры искажения называется теорией скорости как функции погрешности. Этой теории, созданной в 1948 г. Шенноном и развитой им же в 1959 г., мы посвящаем гл. 7 и 8.
 Если мы станем трактовать эти последовательности длины N как подлежащие передаче сообщения, то, даже не принимая в расчет их двоичные представления, можно убедиться в том, что типичные сообщения асимптотически равновероятны. Указанное свойство используется в последующих главах, где рассматриваются способы достоверной передачи сообщений по каналам с шумом.
Если мы станем трактовать эти последовательности длины N как подлежащие передаче сообщения, то, даже не принимая в расчет их двоичные представления, можно убедиться в том, что типичные сообщения асимптотически равновероятны. Указанное свойство используется в последующих главах, где рассматриваются способы достоверной передачи сообщений по каналам с шумом.