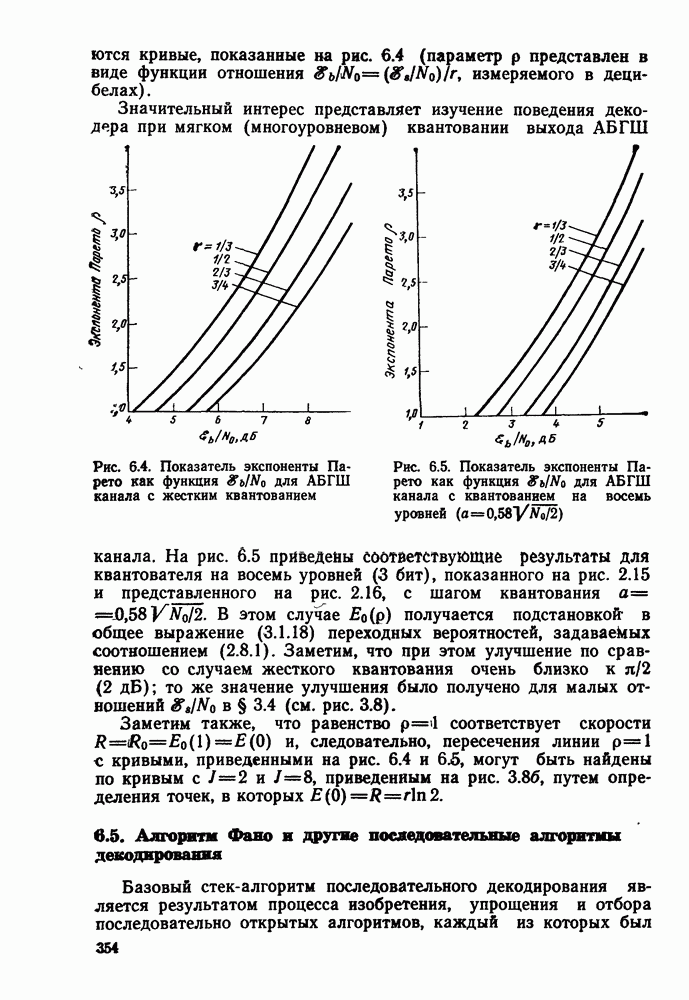
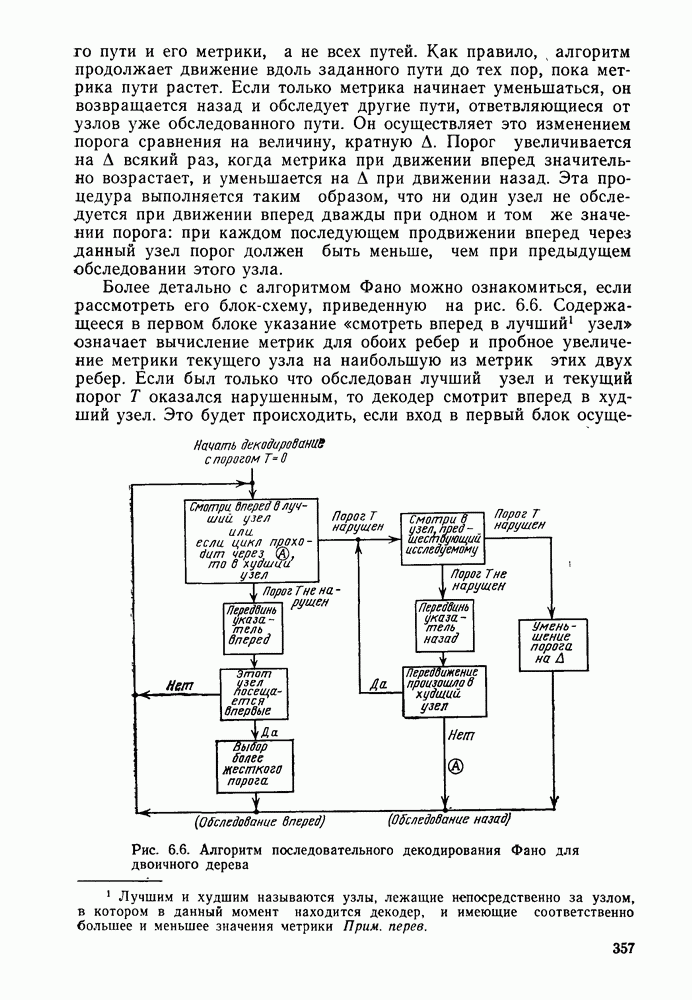
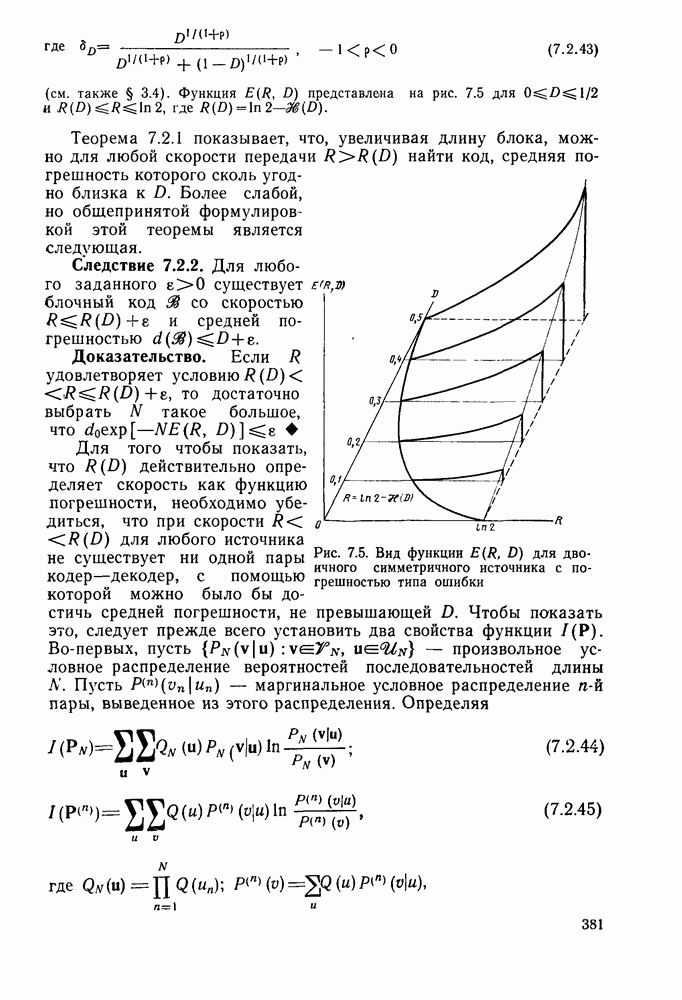
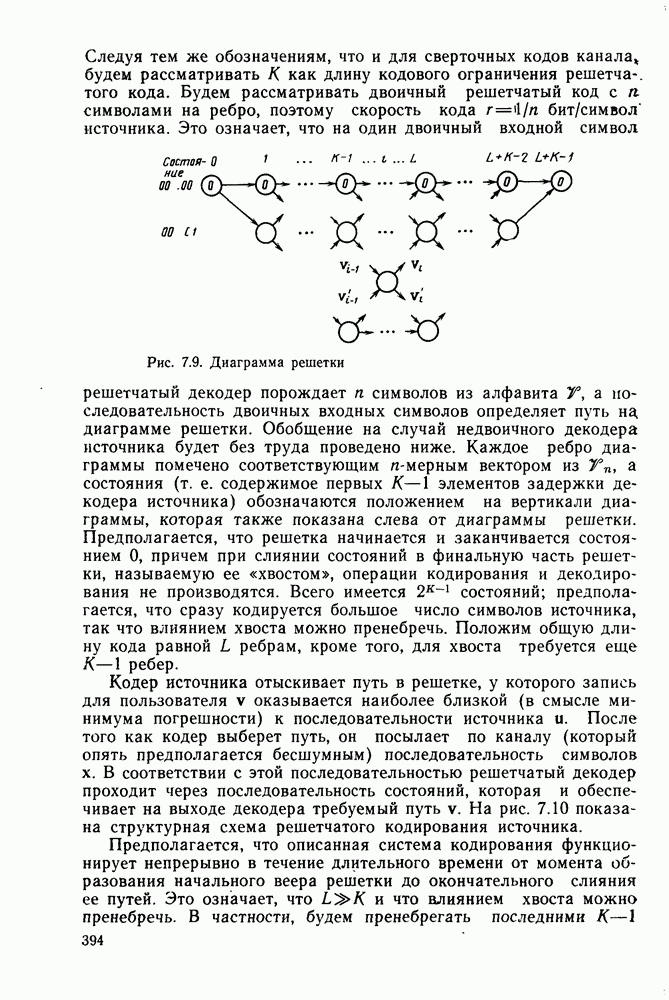
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
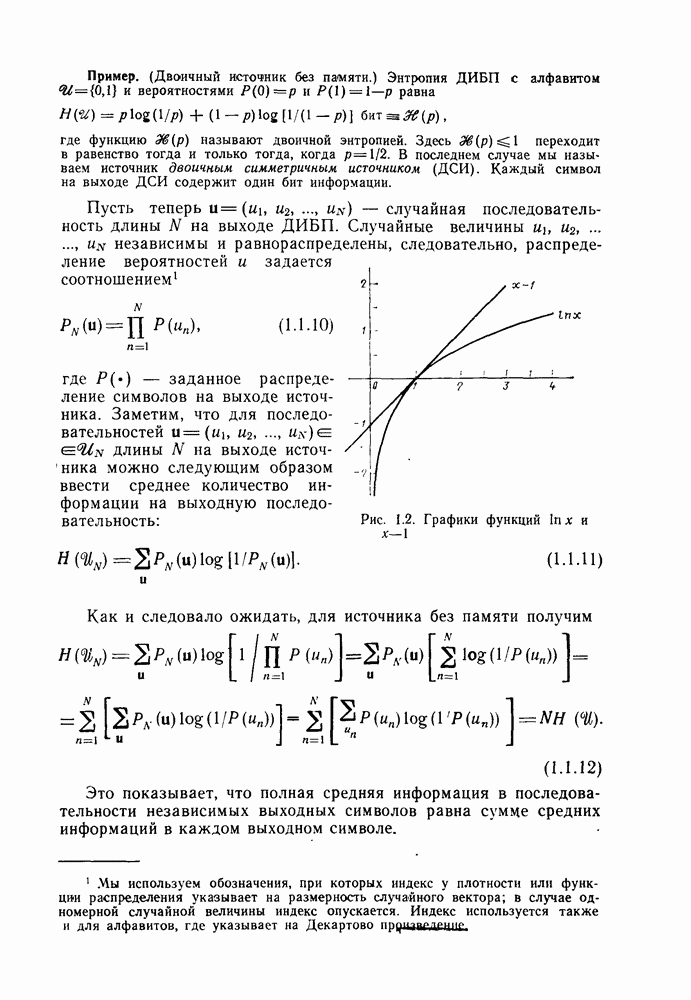
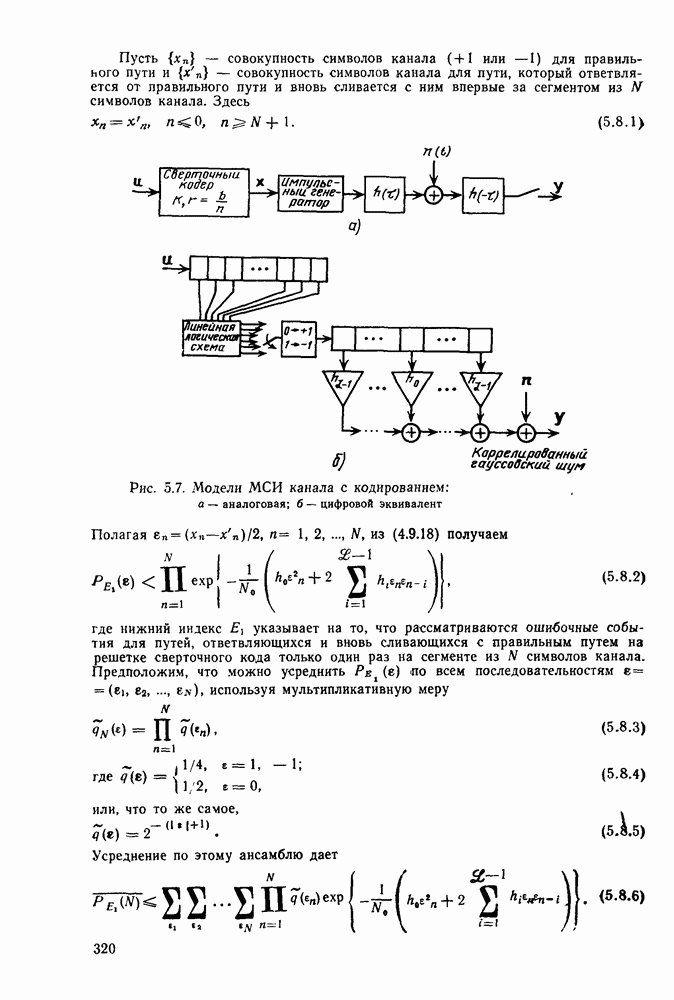
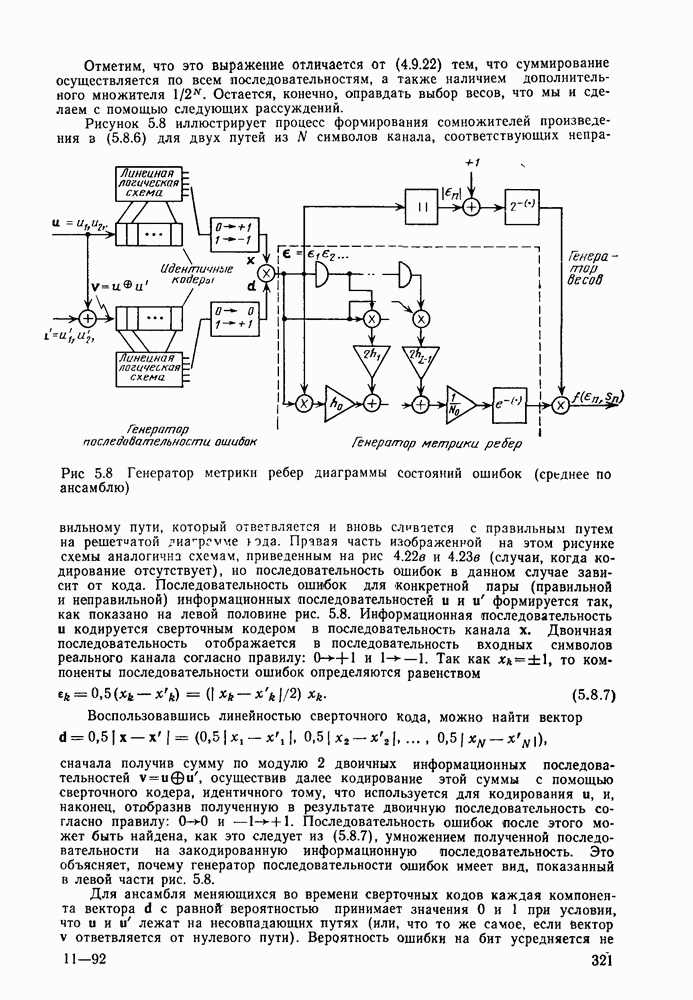
7.3. Связь с кодированием для каналовИмеется ряд соотношений, устанавливающих связь между теорией кодирования для каналов, изложенной в гл. 2—6, и теорией передачи с погрешностью. Некоторые из этих соотношений следуют просто из общности математического аппарата, применяемого в обеих теориях, в то время как другие имеют более глубокую и естественную связь. Откажемся от предположения о бесшумном канале и рассмотрим кодирование источника и кодирование в канале такими, какими они показаны на рис. 7.6.
Рис. 7.6. Совместное кодирование источника и канала Предположим, что дискретный источник без памяти производит один символ каждые
Обозначим через
где математическое ожидание
Из (7.2.1) следует, что
Подставляя эту границу и неравенство
в равенство (7.3.2), находим
Из теории кодирования для каналов (теорема 3.2.1) известно, что существует ксд канала для которого вероятность ошибки при передаче сообщения по каналу удовлетворяет неравенству
где С другой стороны, из теоремы 7.2.1 следует, что существует код источника такой, у которого
где Теорема 7.3.1. Для рассмотренной выше объединенной схемы кодирования источника и канала, представленной на рис. 7.6, существуют код источника со скоростью передачи
где
— пропускная способность канала, измеряемая в натах на символ источника До тех пор, пока скорость как функция погрешности остается меньше пропускной способности канала, Теорема 7.3.2. Источник, определенный в условиях теоремы 7.3.1, не может быть восстановлен на приемном конце дискретного канала без памяти со средней погрешностью Доказательство. Доказательство этой обратной теоремы следует непосредственно из теоремы обработки данных 7.2.1 и обратной теоремы кодирования источников 7.2.3 [см. задачу (7.5)] Указанная обратная теорема остается справедливой независимо от типа используемых кодеров и декодеров. Для доказательства теоремы 7.3.2 совсем не обязательно, чтобы они были раздельными, как показано на рис. 7.6, или чтобы они образовывали блочную схему кодирования. Так как теорема 7.3.1 верна для представленной на рис. 7.6 блочной схемы кодирования источника и канала, то видно, что в пределе с увеличением длины блока допущение о раздельном кодировании для источника и для канала не нарушает общности постановки задачи. С точки зрения практики такое разделение удобно, так как оно позволяет проектировать кодеры и декодеры для канала независимо от источника и пользователя. Кодер и декодер источника дают практическую возможность согласовать источник и пользователь с любой системой кодирования канала, если только эта система обладает достаточной пропускной способностью. Если кодирование оптимальное, то с увеличением длины блока выходные символы кодера источника становятся равновероятными (согласно свойству асимптотической равновероятности), так что в пределе поведение выхода кодера источника зависит только от скорости кодирования, а не от природы источника. Из рис. 7.6 видна естественная дуальность блочного кодирования источника и блочного кодирования канала. Действия кодера источника подобны действиям декодера канала, в то время как кодер канала подобен декодеру источника. В кодировании каналов наиболее сложным устройством является, вообще говоря, декодер, тогда как в кодировании источников таковым является кодер. В § 7.4 будет показано, что эта дуальность имеет место и для схем решетчатого кодирования. Заметим, наконец, что хотя кодер источника устраняет избыточность из последовательности источника, а кодирование в канале добавляет избыточность, выполнение этих операций преследует совершенно разные цели. Кодер источника использует статистические закономерности длинных последовательностей на выходе источника, чтобы представить выходные данные с предельной скоростью передачи Покажем теперь, что теоремы кодирования источников, изученные в § 7.2, допускают интересную интерпретацию с точки зрения кодирования каналов. Для общего дискретного источника без памяти, некоторого алфавита воспроизведения и определенной выше меры погрешности рассмотрим множество
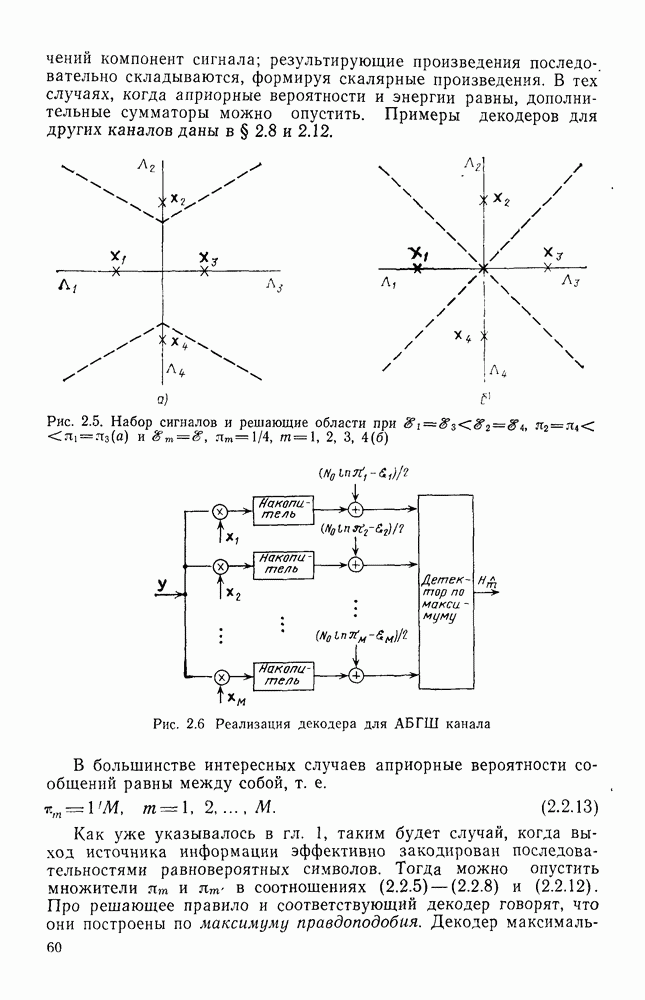
Такой канал иногда называют «обратным тест-каналом». Рассмотрим далее код источника
Рис. 7.7. Обратный тест-канал Но предположим, что используется субоптимальный декодер, который при заданном выходе канала
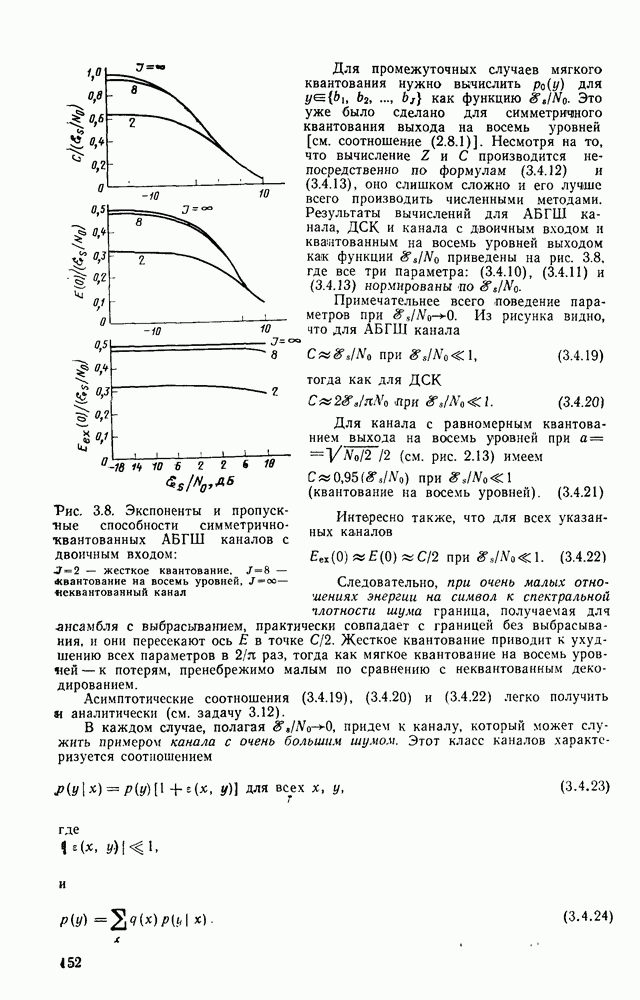
Вероятность правильного решения
где последнее неравенство следует из строгого обращения теоремы кодирования (теорема 3.9.1). Теперь воспользуемся (7.3.13) для того, чтобы объяснить, почему в теореме кодирования источников (теорема 7.2.1, см. также лемму 7.2.1) показатель экспоненты Главным образом нас будет интересовать величина
которая может быть как больше, так и меньше
что в точности совпадает с утверждением леммы (7.2.1). Тогда, как и в § 7.2, находим, что при
где Отсюда видно, что теорема кодирования источников может быть выведена непосредственно из строгого обращения теоремы кодирования, указанного Аримото [1973], путем применения его к обратному тест-каналу, соответствующему Примером менее очевидной связи между кодированием каналов и кодированием источников является связь между границей с выбрасыванием для малых скоростей в теории кодирования каналов и натуральной скоростью как функцией погрешности, основанной на понятии расстояния Бхаттачария. Предположим, что задан ДКБП с входным алфавитом Для любых двух входных букв канала
Предположим, что на входных буквах канала задано распределение вероятностей
Чтобы показать связь между
Полагая
и что соответствующий источник есть двоичный симметричный источник (ДСИ). Напомним, что согласно § 3.4 [см. (3.4.8)] граница с выбрасыванием для ДСК утверждает, что существует блочный код
где Используя найденную связь с теорией передачи с погрешностью, можно также доказать границу Гилберта, рассмотренную в § 3.9. Пусть
где
и где максимум берется по всем блочным кодам с длиной блока N и скоростью
где Это неравенство следует из того, что если бы существовал элемент для которого Теорема 7.3.3. Граница Гилберта. Справедливо неравенство
Доказательство. Код
где неравенство следует из (7.3.23). Рассмотрим как блочный код источника. Обратная теорема кодирования источников (теорема 7.2.3) утверждает, что любой код
Так как
Результаты для ДСК обобщаются на произвольные ДКБП, в которых используется расстояние Бхаттачария, если только при значениях параметра
|
 |
Оглавление
|








































































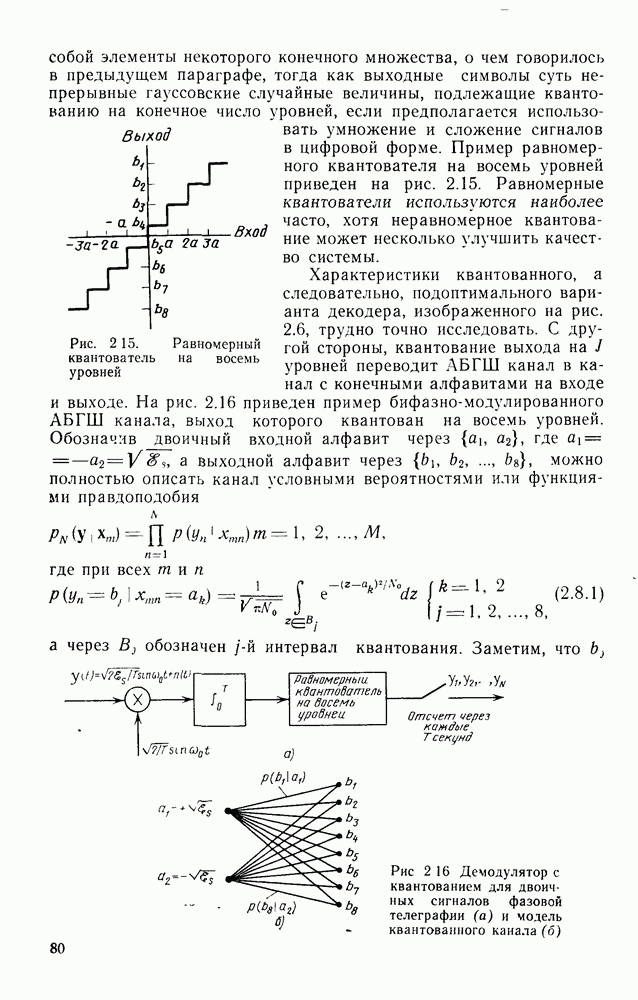



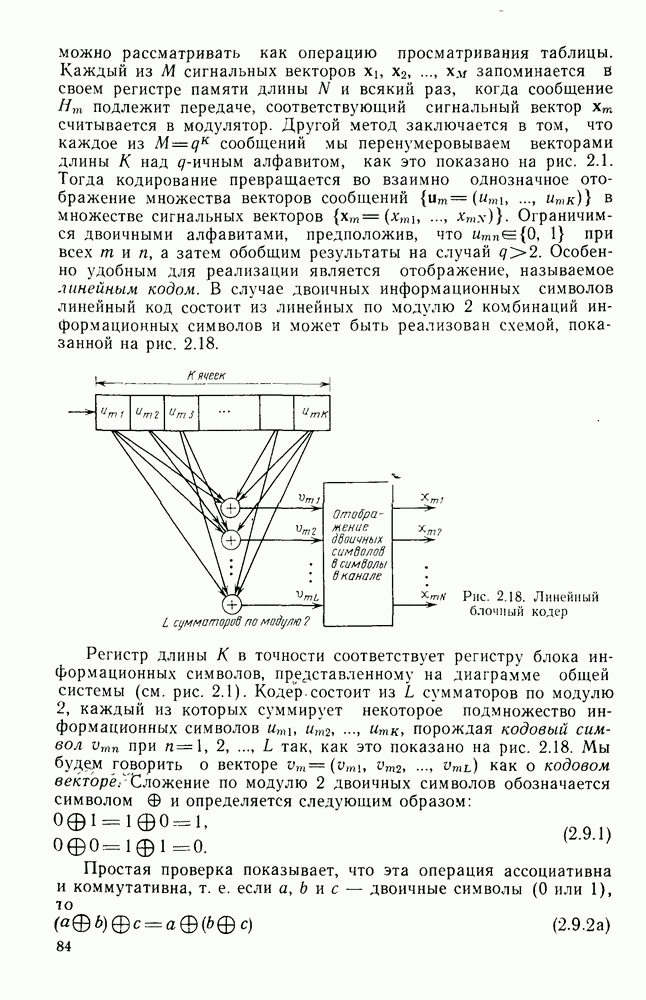













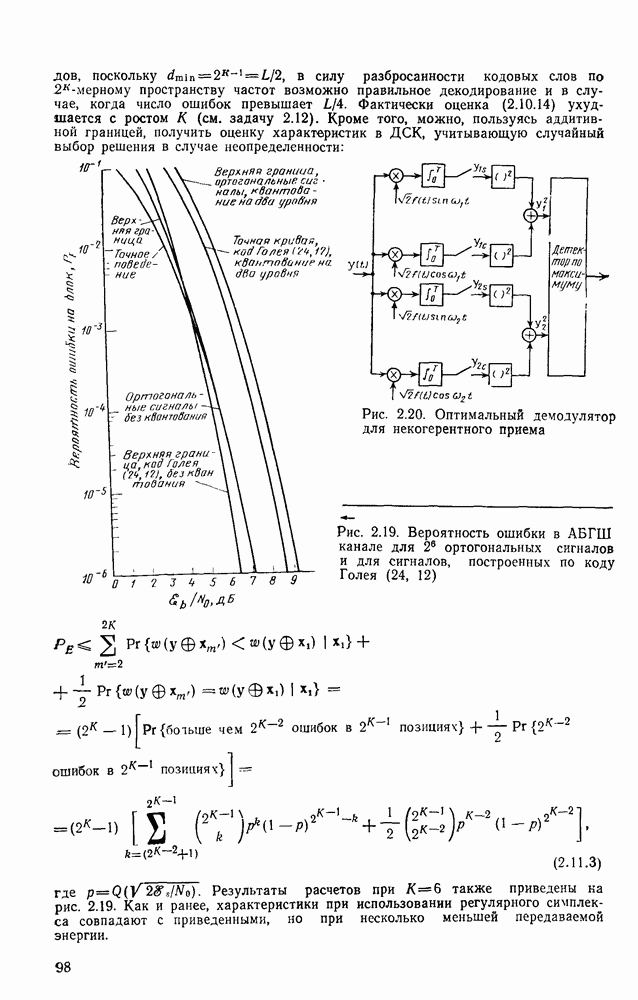












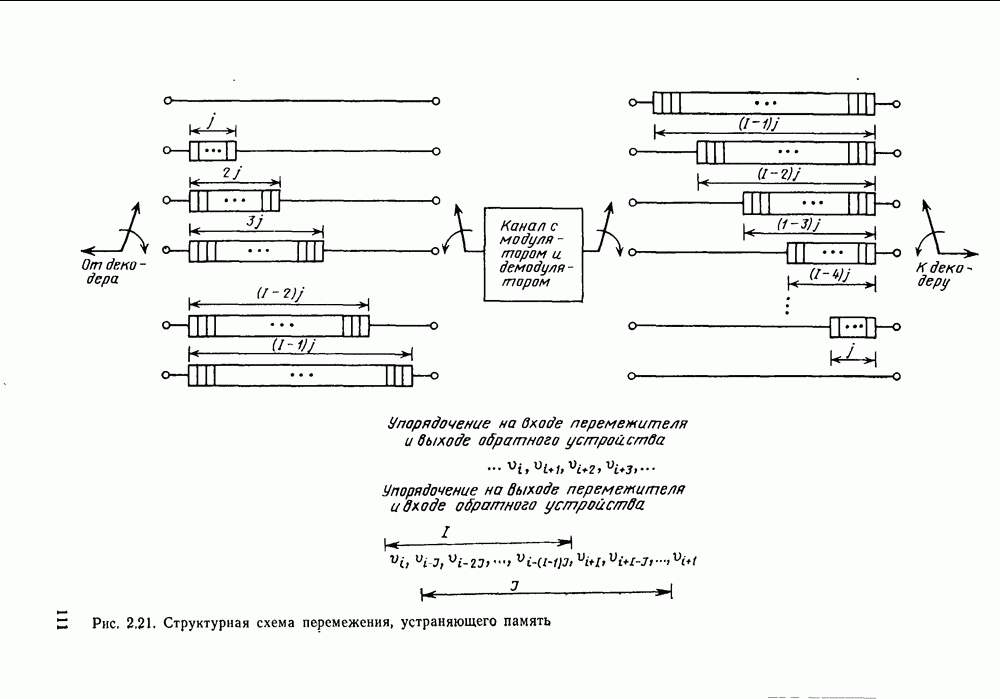





















































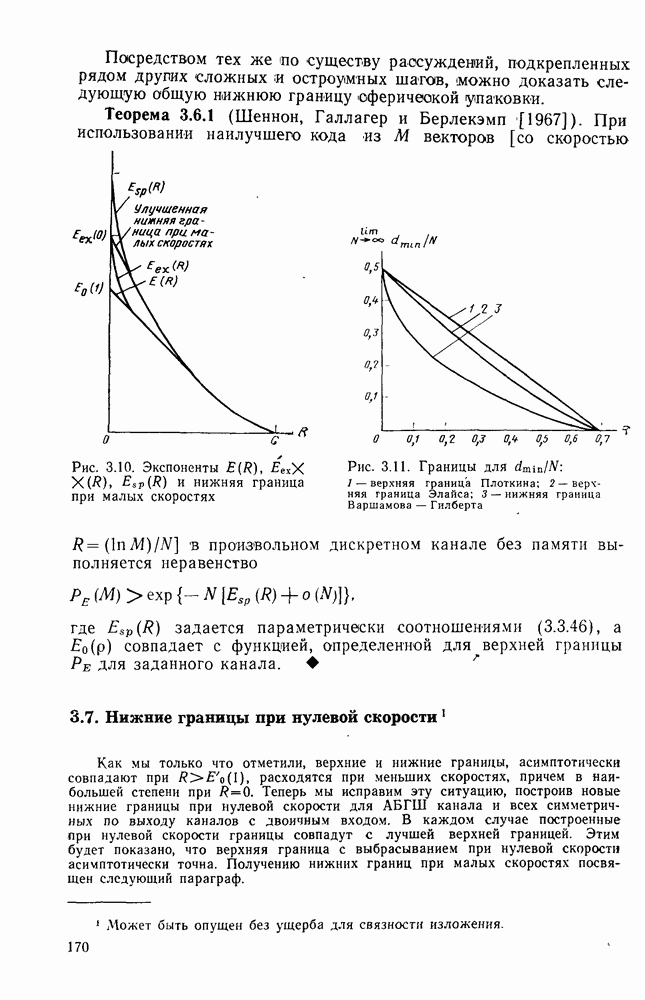














































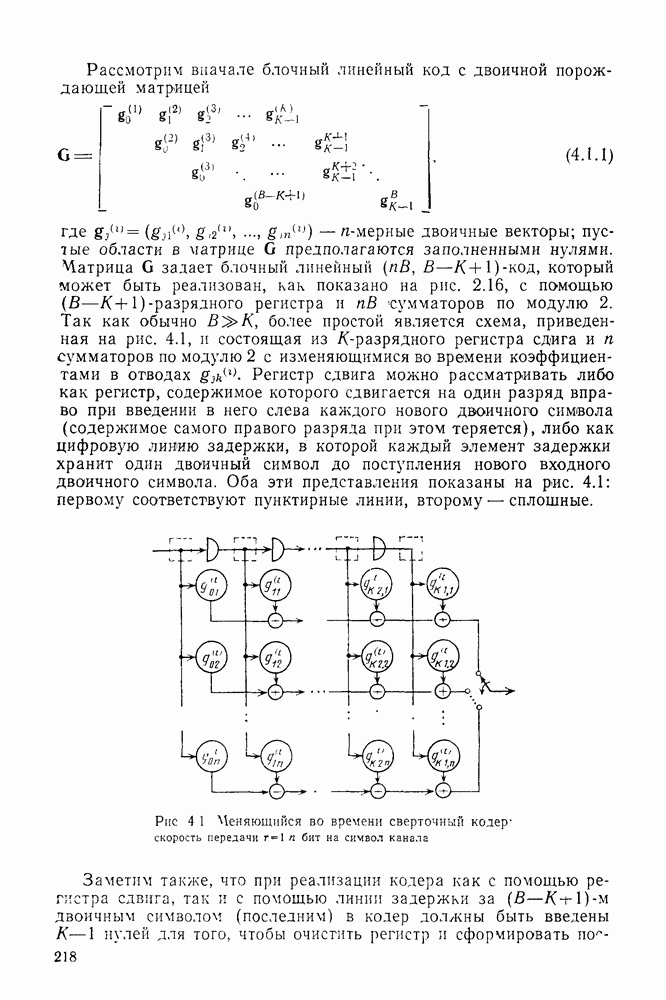




























































































































































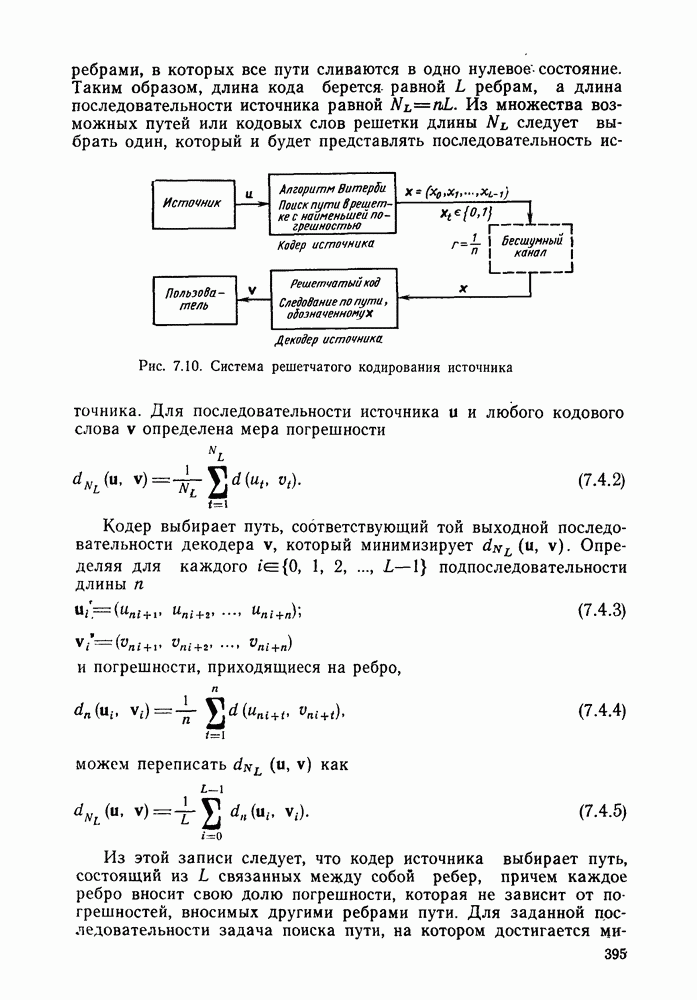
















































































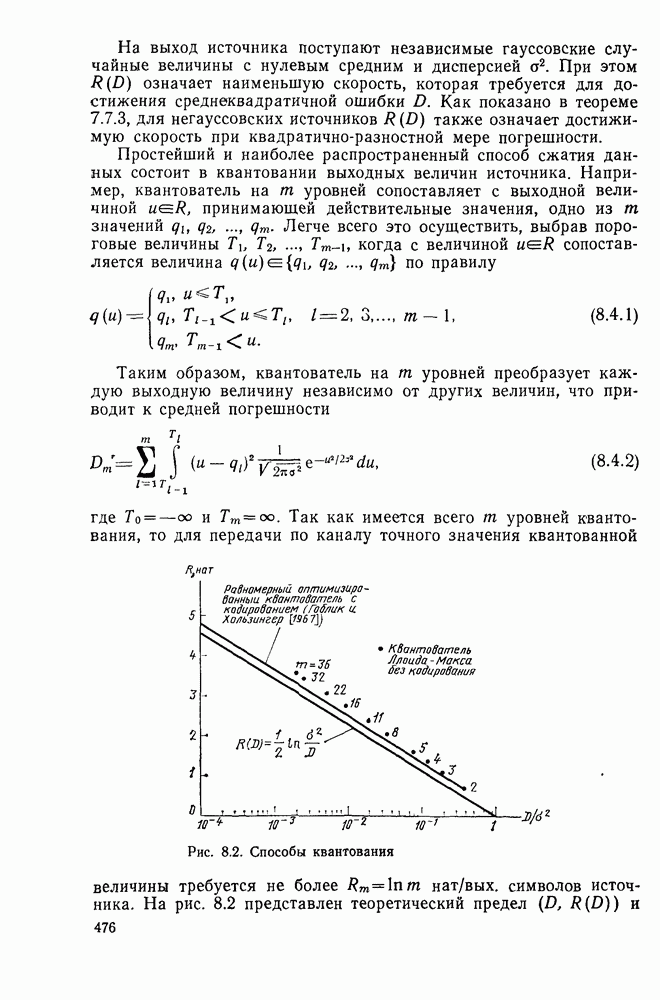





















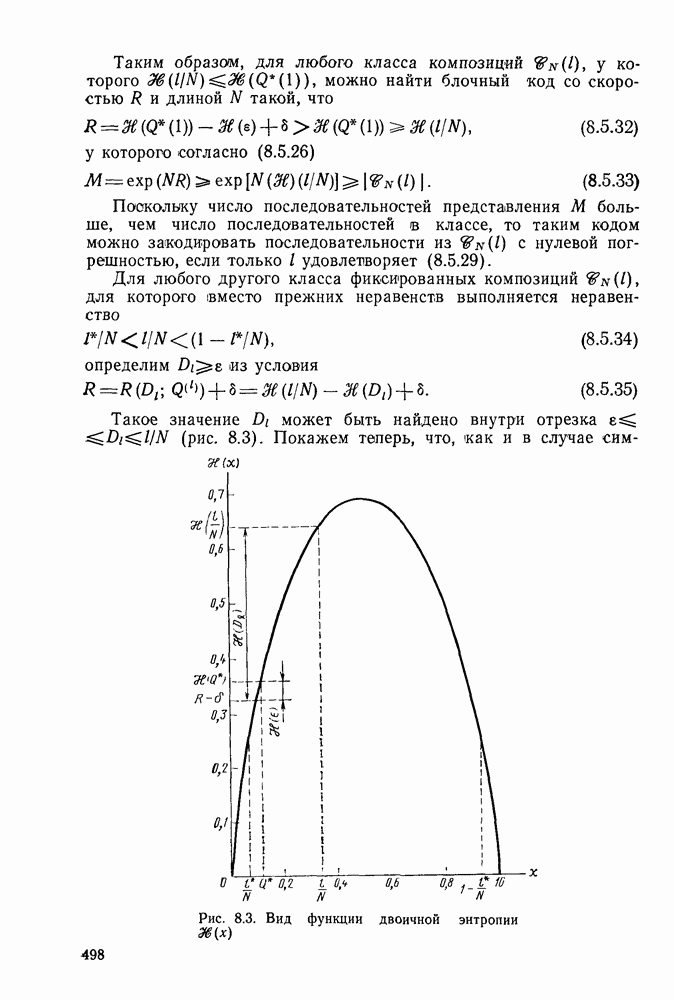































 секунд, а кодер и декодер работают в соответствии с блочным кодом
секунд, а кодер и декодер работают в соответствии с блочным кодом  с длиной блока N и скоростью
с длиной блока N и скоростью  нат/символ, причем продолжительность символа также составляет
нат/символ, причем продолжительность символа также составляет  секунд. Каждые
секунд. Каждые  секунд в коде
секунд в коде  выбирается такое кодовое слово, которое представляет с минимальной погрешностью последовательность источника
выбирается такое кодовое слово, которое представляет с минимальной погрешностью последовательность источника  после чего индекс кодового слова
после чего индекс кодового слова  передается по каналу. Итак, каждые
передается по каналу. Итак, каждые  секунд по каналу передается одно из
секунд по каналу передается одно из  сообщений. Предположим, что канал используется однократно каждые
сообщений. Предположим, что канал используется однократно каждые  секунд, а его пропускная способность равна С нат на посылку длительности
секунд, а его пропускная способность равна С нат на посылку длительности  секунд. Кодер и декодер канала работают в соответствии с блочным кодом
секунд. Кодер и декодер канала работают в соответствии с блочным кодом  с длиной блока N и скоростью передачи
с длиной блока N и скоростью передачи  нат на одну посылку в канале. Следовательно,
нат на одну посылку в канале. Следовательно,

 событие, состоящее в том, что при передаче сообщения по каналу произошла ошибка, и пусть
событие, состоящее в том, что при передаче сообщения по каналу произошла ошибка, и пусть
 означает его дополнение. Средняя погрешность, возникающая при совместном использований кода источника 38 и кода канала
означает его дополнение. Средняя погрешность, возникающая при совместном использований кода источника 38 и кода канала

 берется по случайным величинам на выходе источника и по шумам в канале. Если при передаче по каналу не происходит ошибки, то
берется по случайным величинам на выходе источника и по шумам в канале. Если при передаче по каналу не происходит ошибки, то







 при
при  Предположим теперь, что эти коды используются в объединенной схеме кодирования источника й канала, представленной на рис. 7.6. Тогда, подставляя оценки (7.3.6) и (7.3.7) в неравенство (7.3.5), найдем, что средняя погрешность удовлетворяет следующей теореме.
Предположим теперь, что эти коды используются в объединенной схеме кодирования источника й канала, представленной на рис. 7.6. Тогда, подставляя оценки (7.3.6) и (7.3.7) в неравенство (7.3.5), найдем, что средняя погрешность удовлетворяет следующей теореме.
 и длиной блока N и код канала
и длиной блока N и код канала  со скоростью Я и длиной блока
со скоростью Я и длиной блока  удовлетворяющими равенствам (7.3.1), такие, что средняя погрешность удовлетворяет неравенству
удовлетворяющими равенствам (7.3.1), такие, что средняя погрешность удовлетворяет неравенству

 при
при  удовлетворяющем условию
удовлетворяющем условию

 можно достигать средней погрешности, сколь угодно близкой к
можно достигать средней погрешности, сколь угодно близкой к  Когда
Когда  это невозможно, что следует из нижеследующей теоремы.
это невозможно, что следует из нижеследующей теоремы.
 или меньше, если пропускная способность этого канала
или меньше, если пропускная способность этого канала  нат на букву источника.
нат на букву источника.
 Кодер канала вносит избыточность с целью защиты от ошибок в канале.
Кодер канала вносит избыточность с целью защиты от ошибок в канале.
 при некотором заданном уровне погрешности
при некотором заданном уровне погрешности  Для любого рассмотрим дискретный канал без памяти с входным алфавитом
Для любого рассмотрим дискретный канал без памяти с входным алфавитом  и выходным алфавитом
и выходным алфавитом  определив его переходные вероятности как
определив его переходные вероятности как

 со скоростью передачи
со скоростью передачи  и длиной блока
и длиной блока  Можно рассматривать
Можно рассматривать  как код обратного тест-канала, как показано на рис. 7.7. Предположим, что кодовые слова равновероятны, так что наибольшая вероятность правильного обнаружения, обозначаемая как
как код обратного тест-канала, как показано на рис. 7.7. Предположим, что кодовые слова равновероятны, так что наибольшая вероятность правильного обнаружения, обозначаемая как  достигается декодированием по обычному правилу максимума правдоподобия.
достигается декодированием по обычному правилу максимума правдоподобия.

 выбирает тот вектор
выбирает тот вектор

 для этого подоптимального декодера ограничена сверху соотношением
для этого подоптимального декодера ограничена сверху соотношением

 по существу, является показателем экспоненты строгого обращение теоремы кодирования.
по существу, является показателем экспоненты строгого обращение теоремы кодирования.

 Однако если усреднить (7.3.13) по ансамблю кодовых слов
Однако если усреднить (7.3.13) по ансамблю кодовых слов  в котором все компоненты выбираются независимо в соответствии с распределением
в котором все компоненты выбираются независимо в соответствии с распределением  то получим
то получим

 средняя погрешность ограничена неравенством
средняя погрешность ограничена неравенством


 как показано на рис. 7.7. Так как строгое обращение теоремы кодирования приводит к показателю экспоненты, который дуален показателю экспоненты усредненной по ансамблю вероятности ошибки, то и показатель экспоненты кодирования источников дуален показателю экспоненты средней по ансамблю вероятности ошибки.
как показано на рис. 7.7. Так как строгое обращение теоремы кодирования приводит к показателю экспоненты, который дуален показателю экспоненты усредненной по ансамблю вероятности ошибки, то и показатель экспоненты кодирования источников дуален показателю экспоненты средней по ансамблю вероятности ошибки.
 , выходным алфавитом 1 и переходными условными вероятностями
, выходным алфавитом 1 и переходными условными вероятностями 
 расстояние Бхаттачария определяется [см. (2.3.15)] как
расстояние Бхаттачария определяется [см. (2.3.15)] как

 Тогда для источника с алфавитом
Тогда для источника с алфавитом  распределением вероятностей
распределением вероятностей  алфавитом воспроизведения
алфавитом воспроизведения  и мерой погрешности, задаваемой расстоянием Бхаттачария (7.3.16), можно рассмотреть скорость как функцию погрешности, которую будем обозначать
и мерой погрешности, задаваемой расстоянием Бхаттачария (7.3.16), можно рассмотреть скорость как функцию погрешности, которую будем обозначать  Наконец, определим натуральную скорость как функцию погрешности для расстояния Бхаттачария (7.3.16) соотношением
Наконец, определим натуральную скорость как функцию погрешности для расстояния Бхаттачария (7.3.16) соотношением

 и показателем экспоненты с выбрасыванием для ДКБП, рассмотрим ДСК с переходной вероятностью
и показателем экспоненты с выбрасыванием для ДКБП, рассмотрим ДСК с переходной вероятностью  В этом случае
В этом случае  а мера погрешности
а мера погрешности

 находим, что расстояние Бхаттачария пропорционально расстоянию Хэмминга. Легко показать (§ 7.6), что
находим, что расстояние Бхаттачария пропорционально расстоянию Хэмминга. Легко показать (§ 7.6), что

 с длиной блока N и скоростью передачи
с длиной блока N и скоростью передачи  такой, что
такой, что

 удовлетворяет равенству
удовлетворяет равенству  определяется формулой (7.3.19). Таким образом, натуральная скорость как функция погрешности для ДСК определяет уровень погрешности, равный показателю экспоненты границы с выбрасыванием.
определяется формулой (7.3.19). Таким образом, натуральная скорость как функция погрешности для ДСК определяет уровень погрешности, равный показателю экспоненты границы с выбрасыванием.


 Пусть
Пусть  — блочный код с длиной блока N и скоростью
— блочный код с длиной блока N и скоростью  обладающий наибольшим минимальным кодовым, расстоянием и наименьшим числом пар кодовых слов, лежащих на этом минимальном кодовом расстоянии
обладающий наибольшим минимальным кодовым, расстоянием и наименьшим числом пар кодовых слов, лежащих на этом минимальном кодовом расстоянии  Следовательно,
Следовательно,


 то введя
то введя  вместо кодового слова с минимальным расстоянием, получили бы код с меньшим числом пар кодовых слов, лежащих на минимальном расстоянии. Но это противоречит определению
вместо кодового слова с минимальным расстоянием, получили бы код с меньшим числом пар кодовых слов, лежащих на минимальном расстоянии. Но это противоречит определению  С помощью (7.3.23) можно доказать границу Гилберта.
С помощью (7.3.23) можно доказать границу Гилберта.
 где
где

 расстояние Хэмминга.
расстояние Хэмминга.
 определенный выше, имеет скорость передачи
определенный выше, имеет скорость передачи  а его средняя погрешность
а его средняя погрешность  удовлетворяет соотношению
удовлетворяет соотношению

 с погрешностью
с погрешностью  (
( имеет скорость
имеет скорость

 определяется по (7.3.24), то
определяется по (7.3.24), то  Отсюда, так как
Отсюда, так как  строго убывающая функция от
строго убывающая функция от  в интервале
в интервале  следует, что
следует, что

 определяемых из уравнения
определяемых из уравнения  матрица
матрица  положительно определена (см. Джелинек [1968] и
положительно определена (см. Джелинек [1968] и  Для большинства наиболее важных типов каналов это условие положительной определенности выполняется для всех
Для большинства наиболее важных типов каналов это условие положительной определенности выполняется для всех  Это значит, что для произвольного ДКБП расстояние Бхаттачария является естественным обобщением расстояния Хэмминга в двоичных кодах, используемых для ДСК. Обобщенная граница Гилберта может быть получена в виде, аналогичном определяемому теоремой 7.3.3 (см. задачи 7.8 и 7.9).
Это значит, что для произвольного ДКБП расстояние Бхаттачария является естественным обобщением расстояния Хэмминга в двоичных кодах, используемых для ДСК. Обобщенная граница Гилберта может быть получена в виде, аналогичном определяемому теоремой 7.3.3 (см. задачи 7.8 и 7.9).