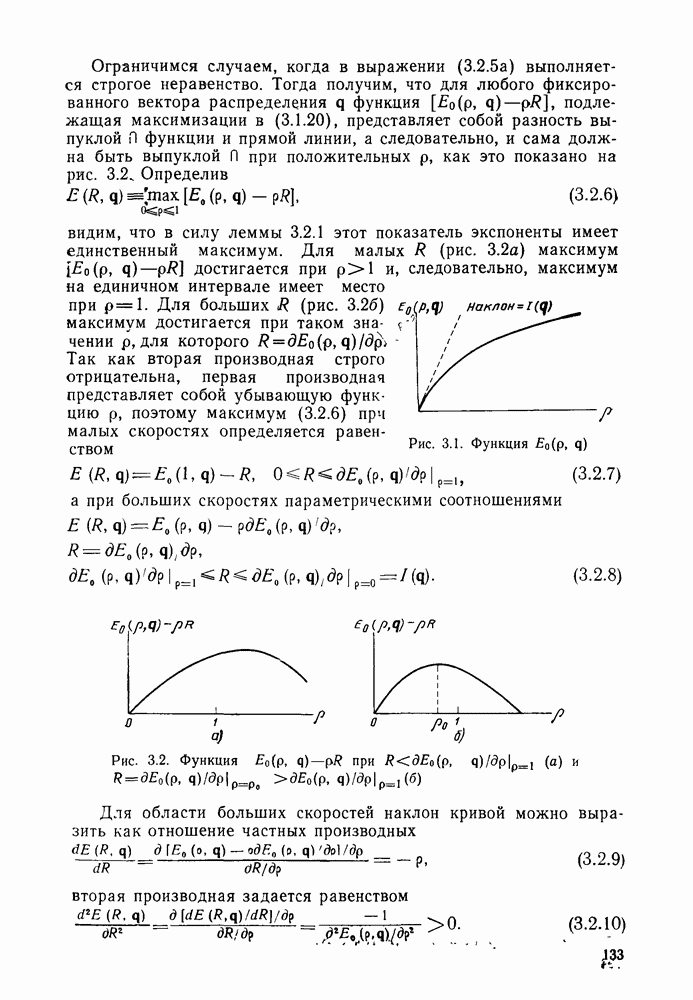
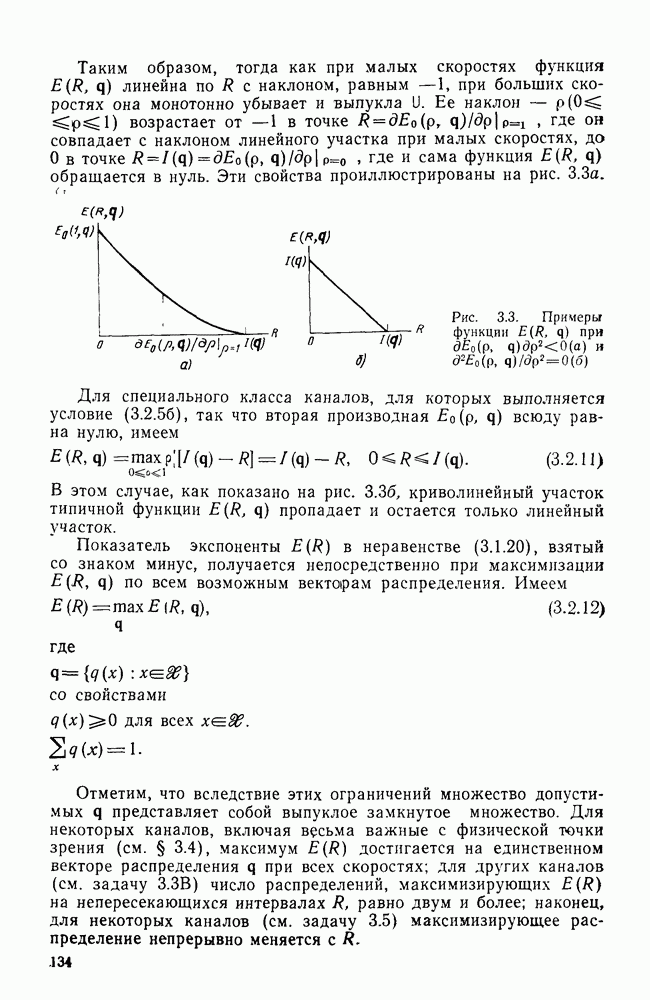
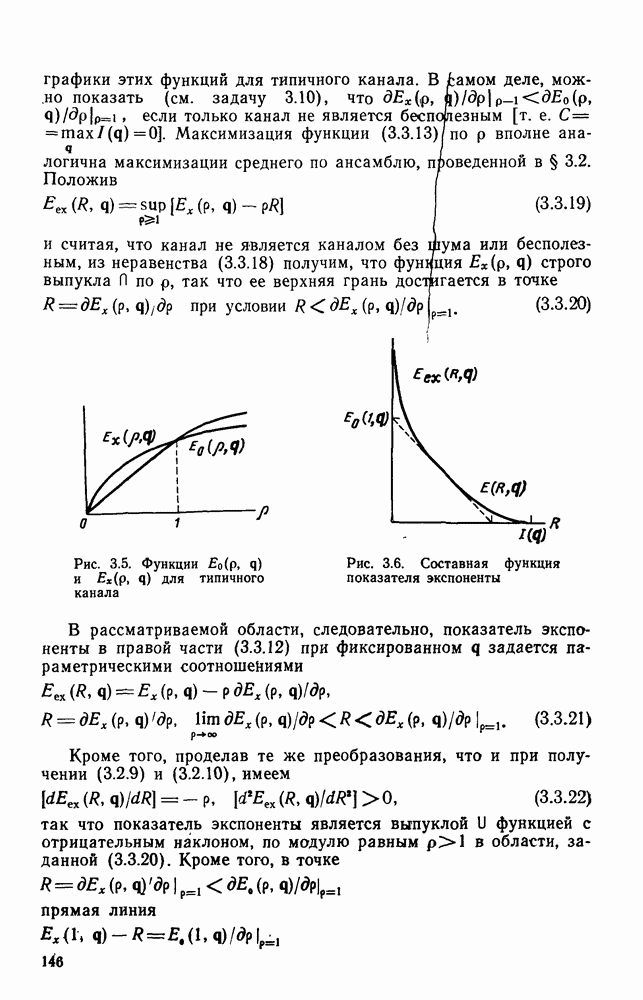
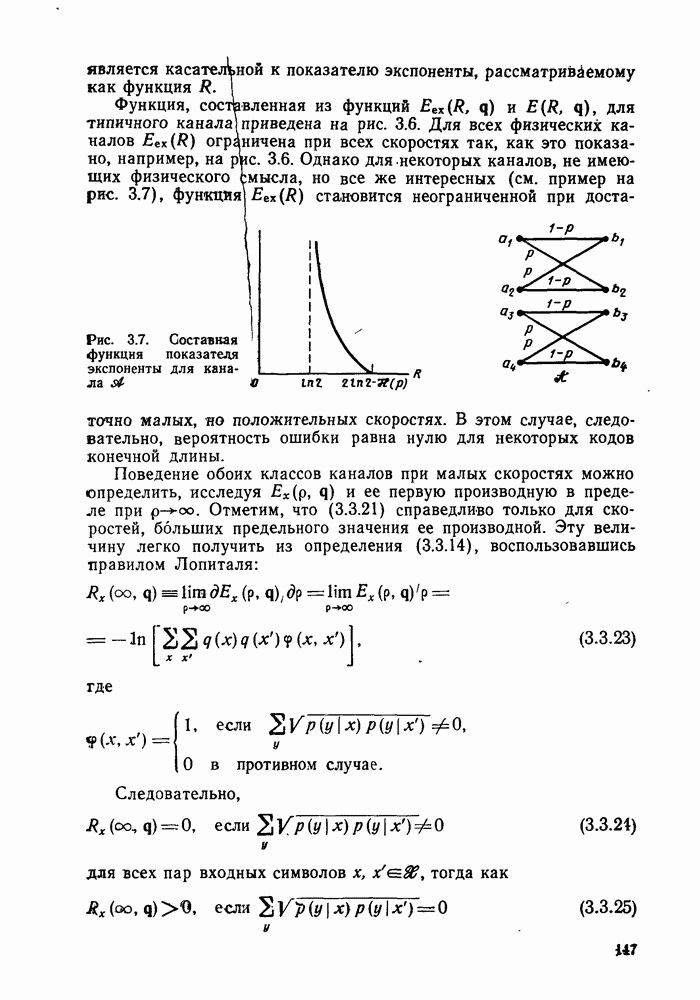
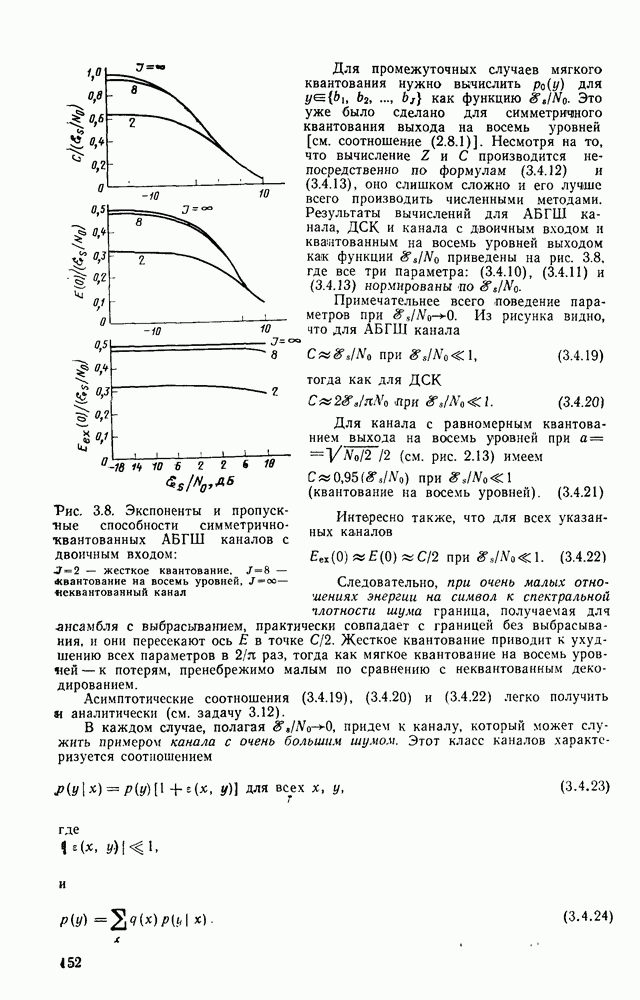
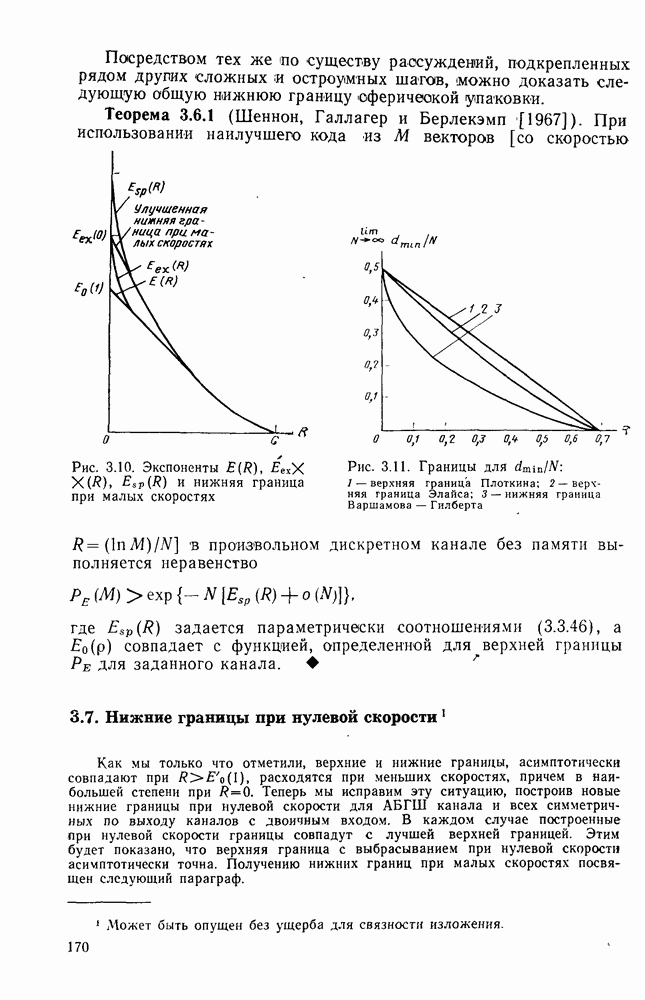
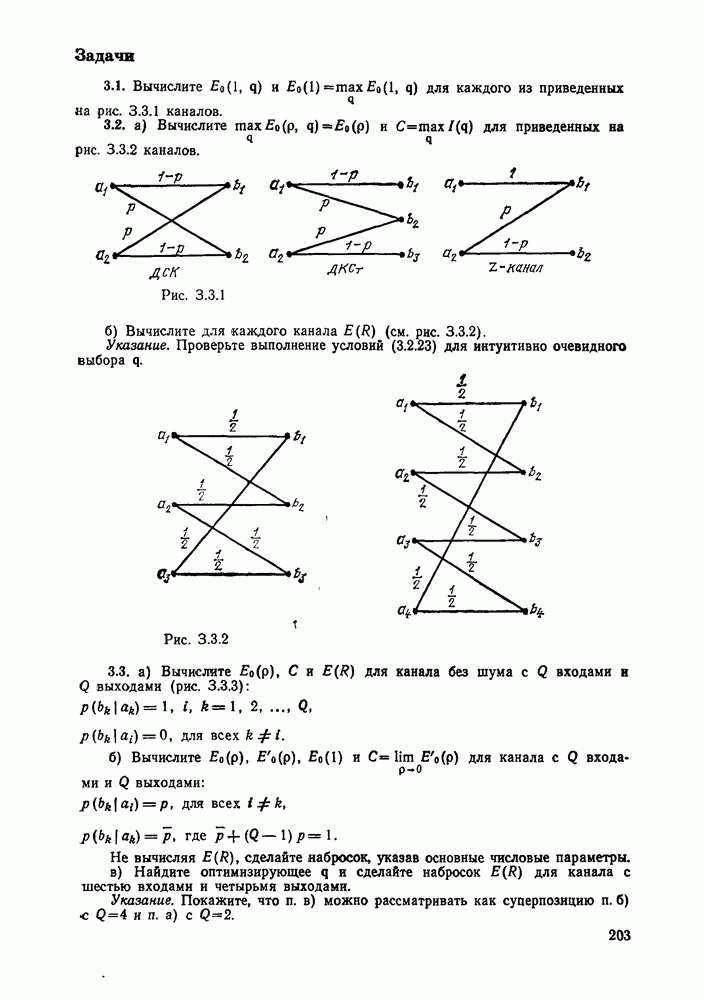
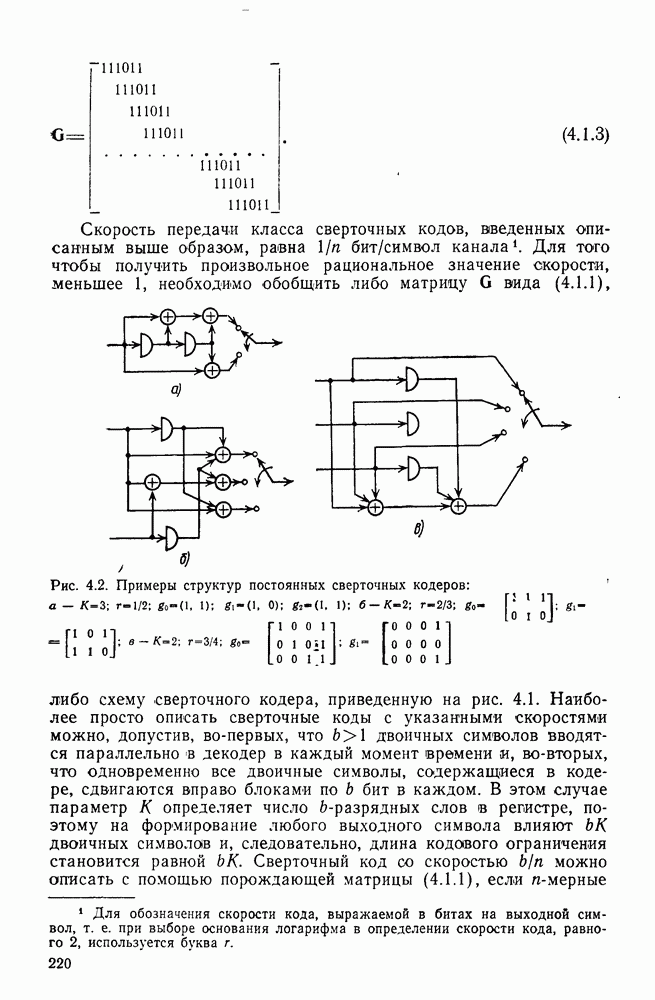
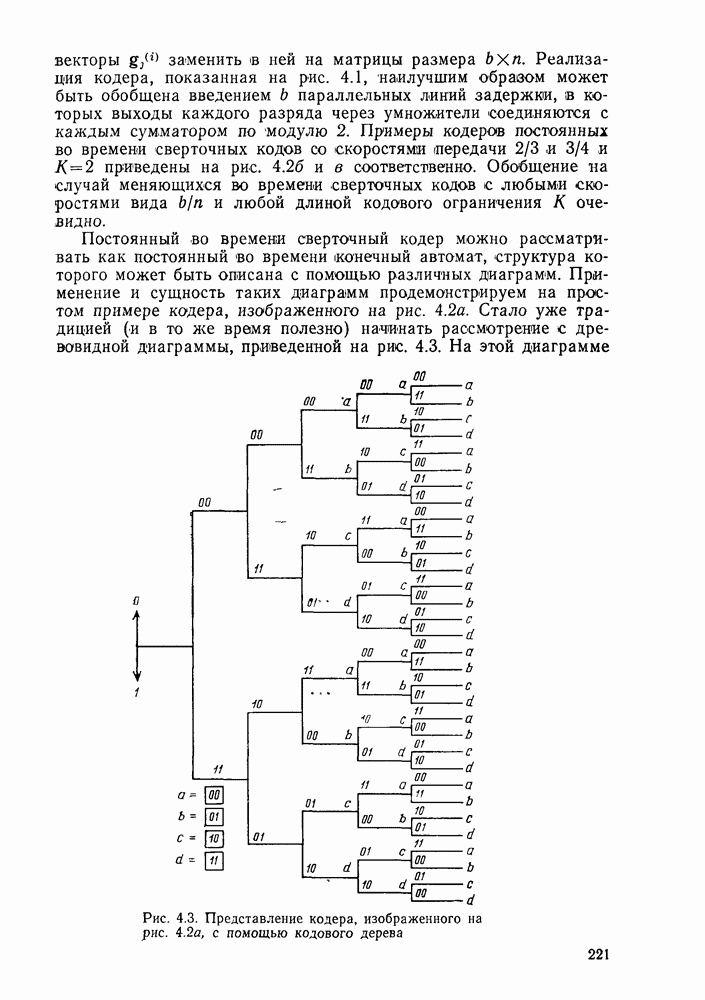
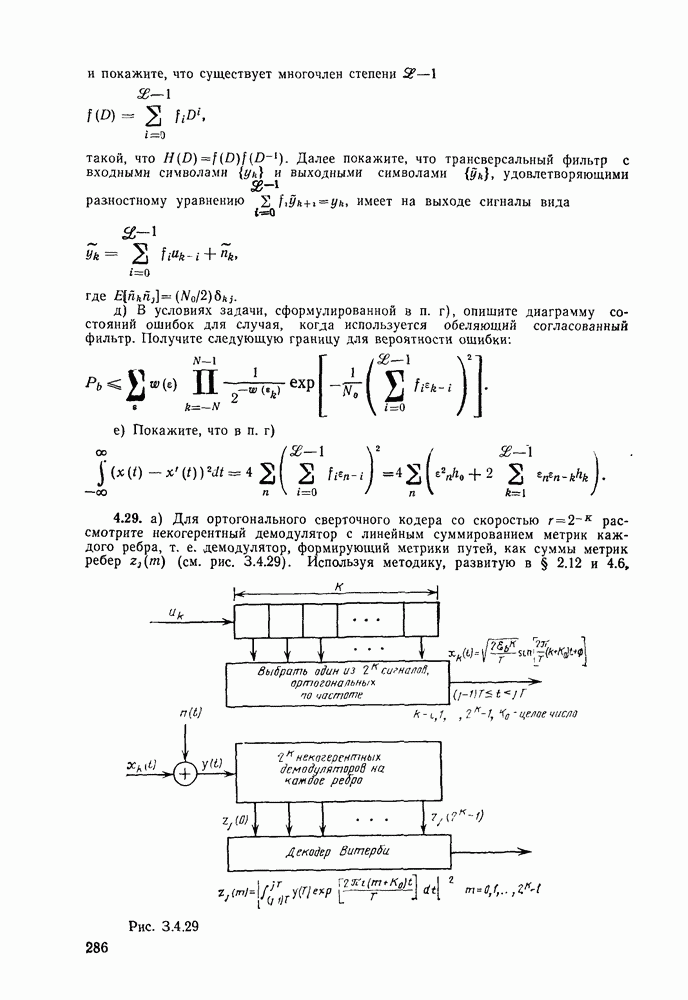
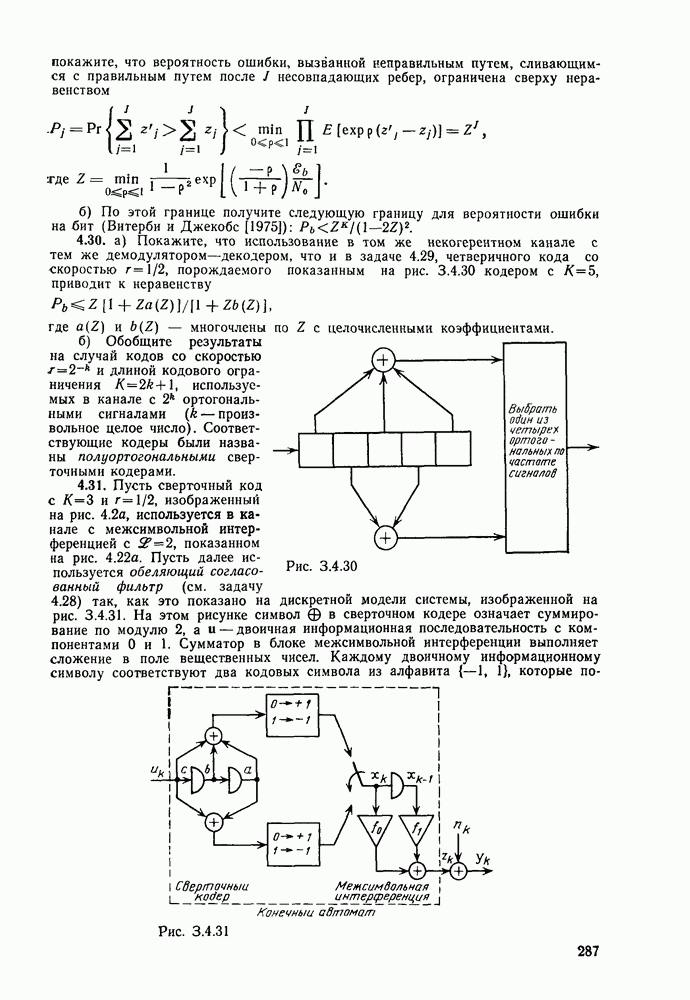
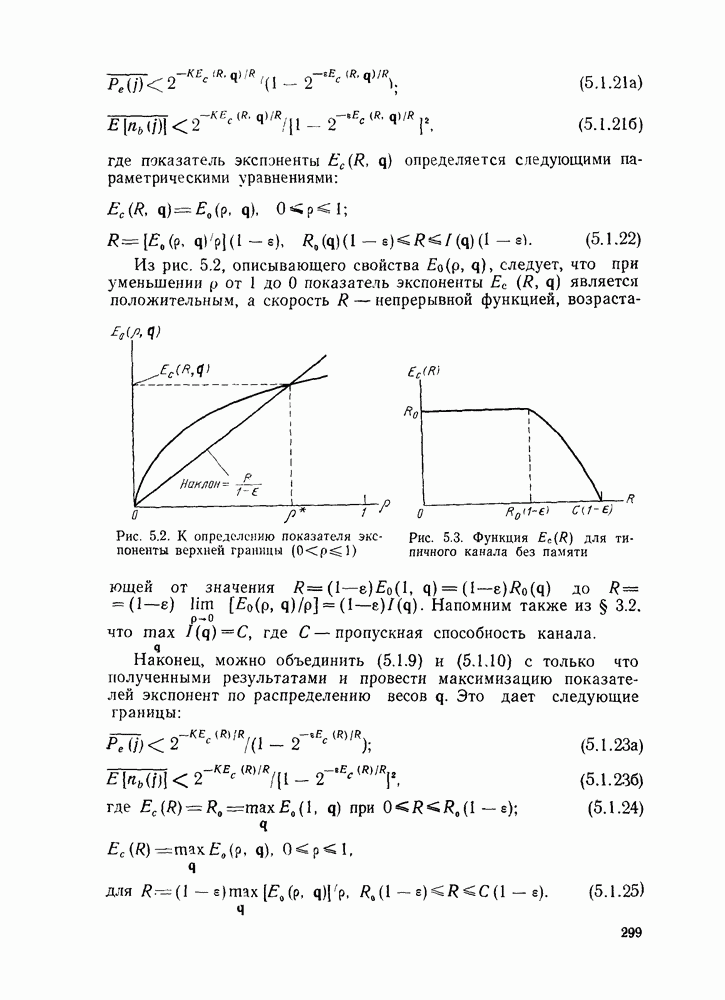
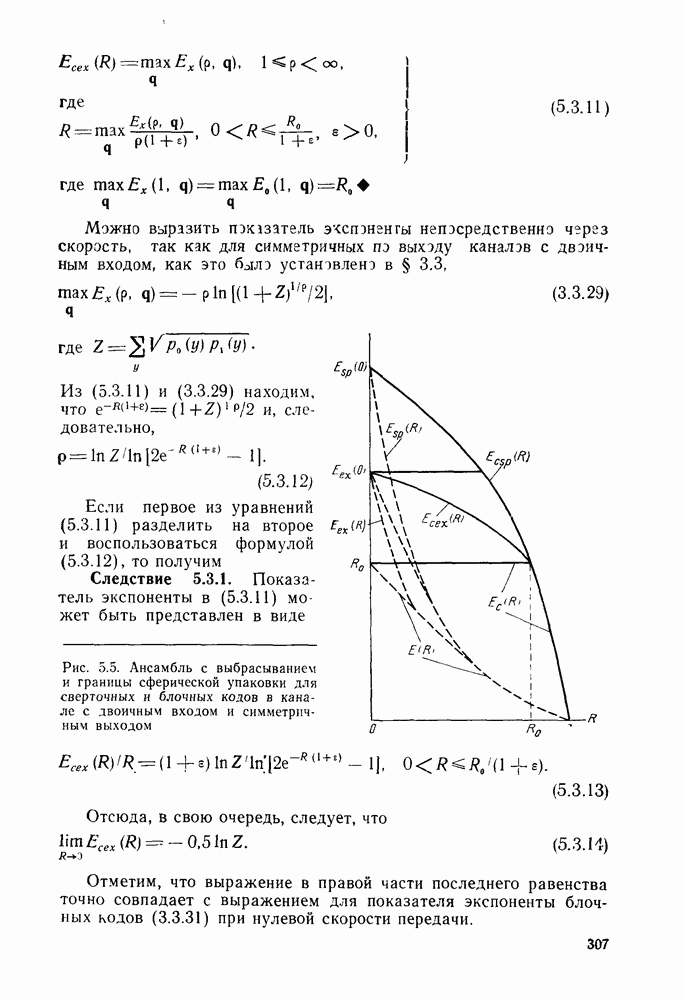
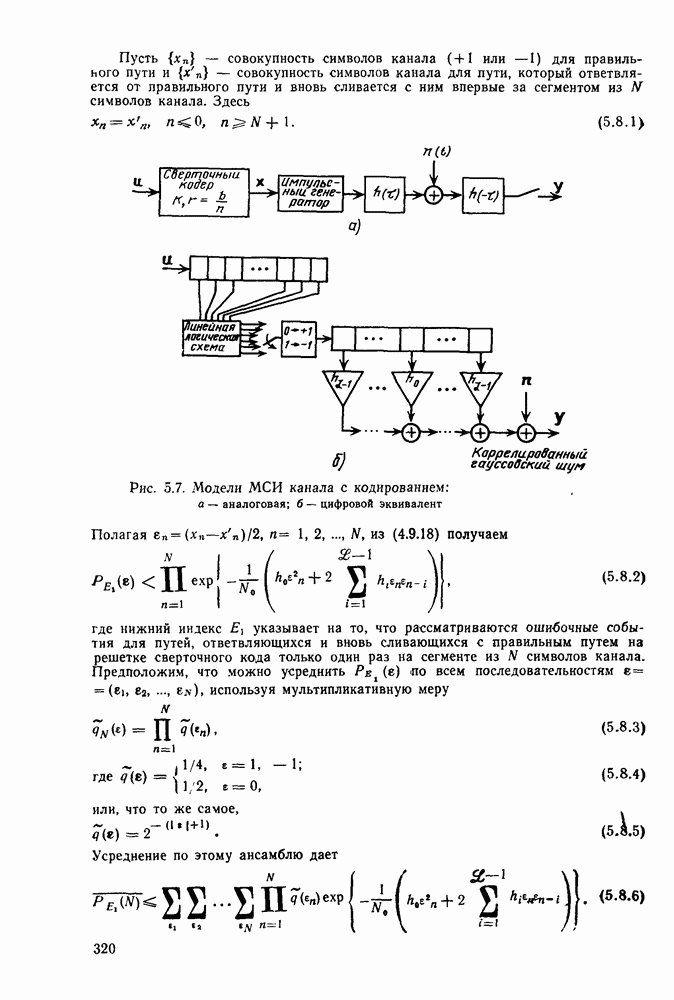
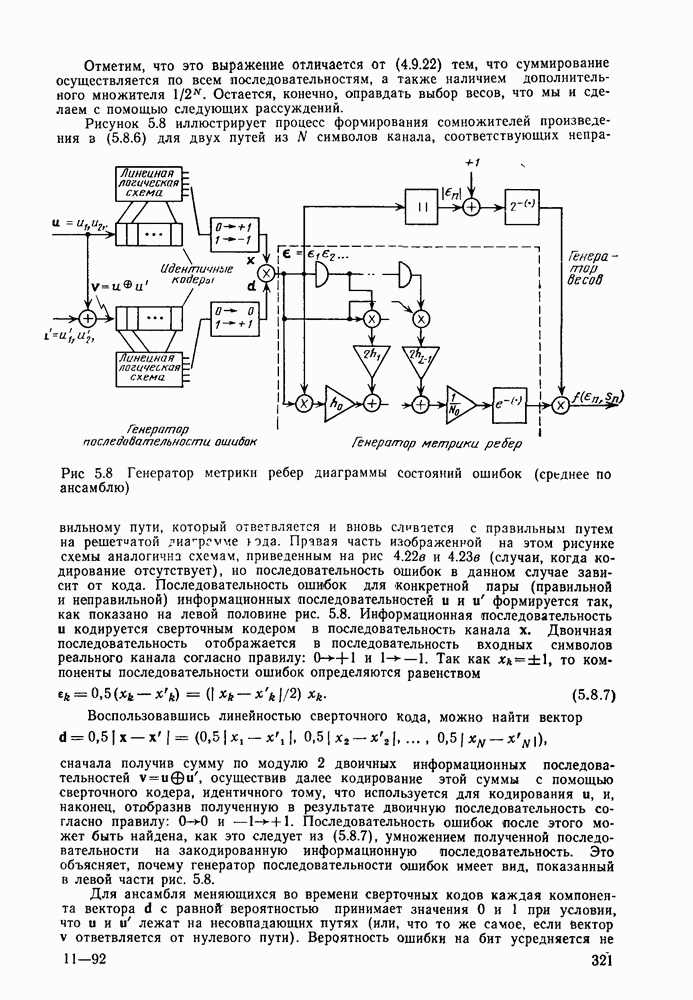
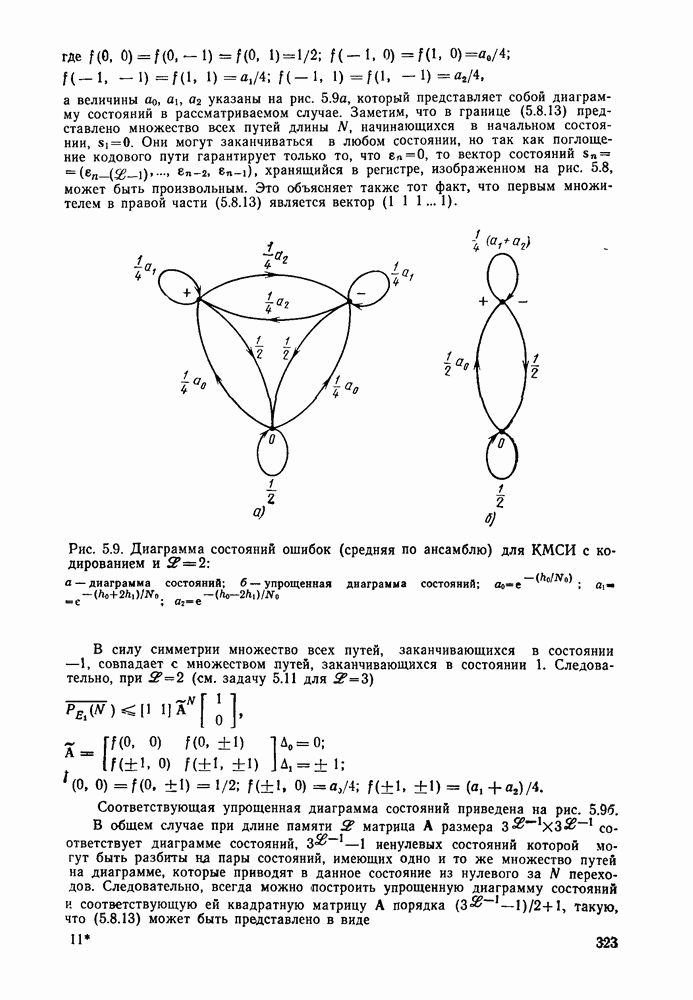
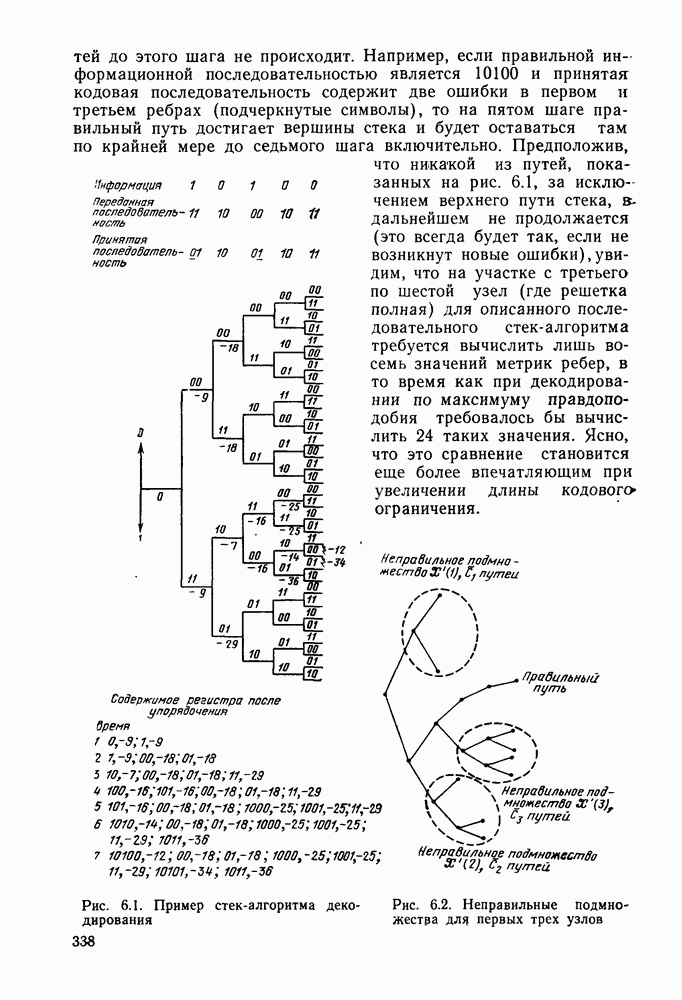
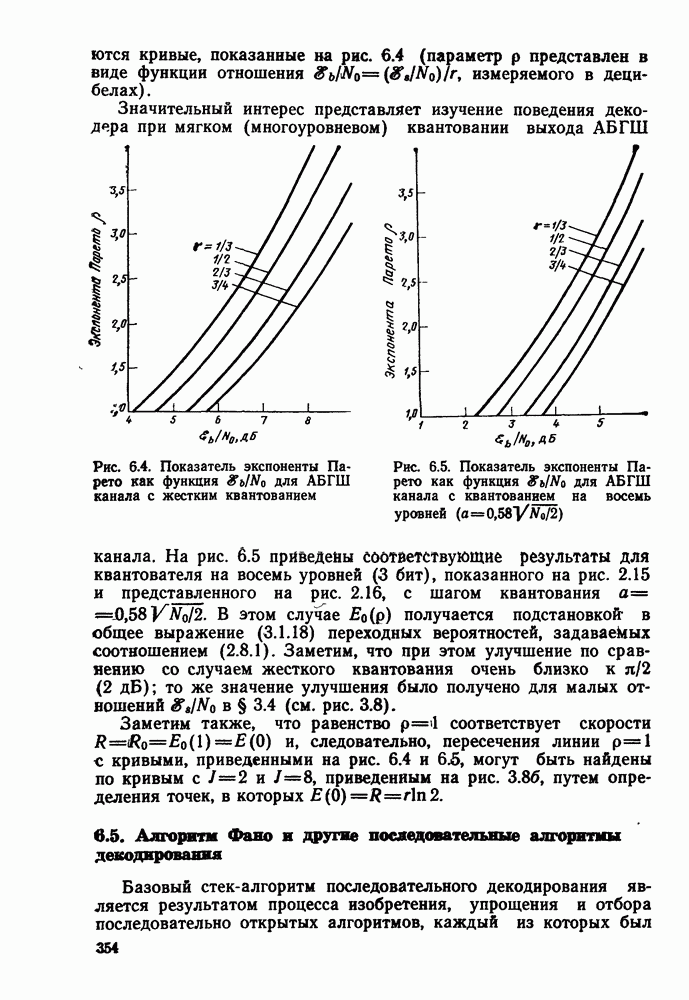
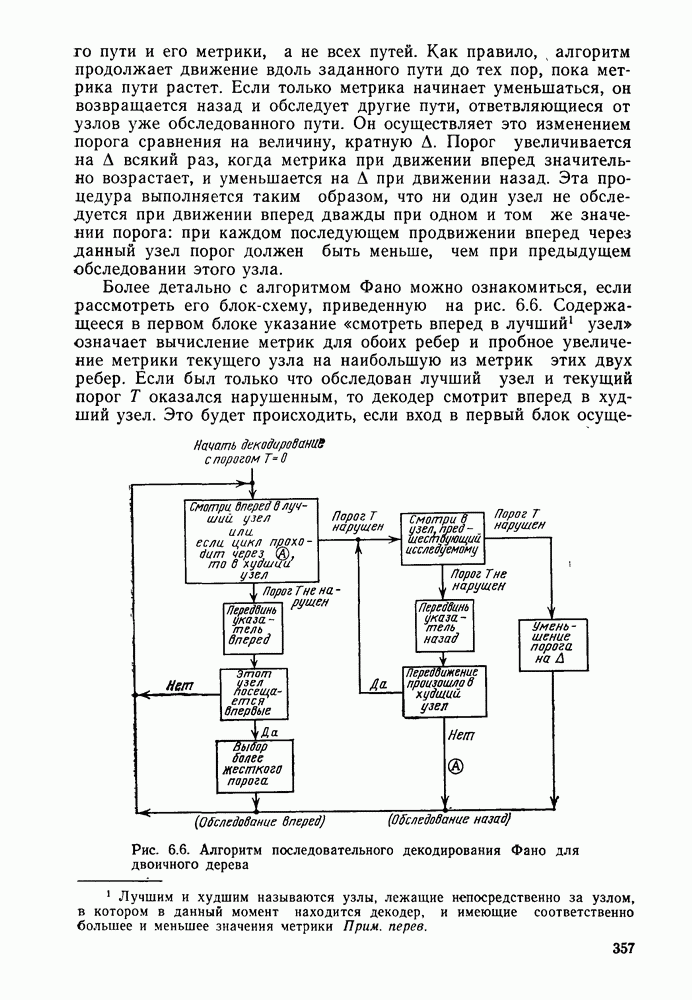
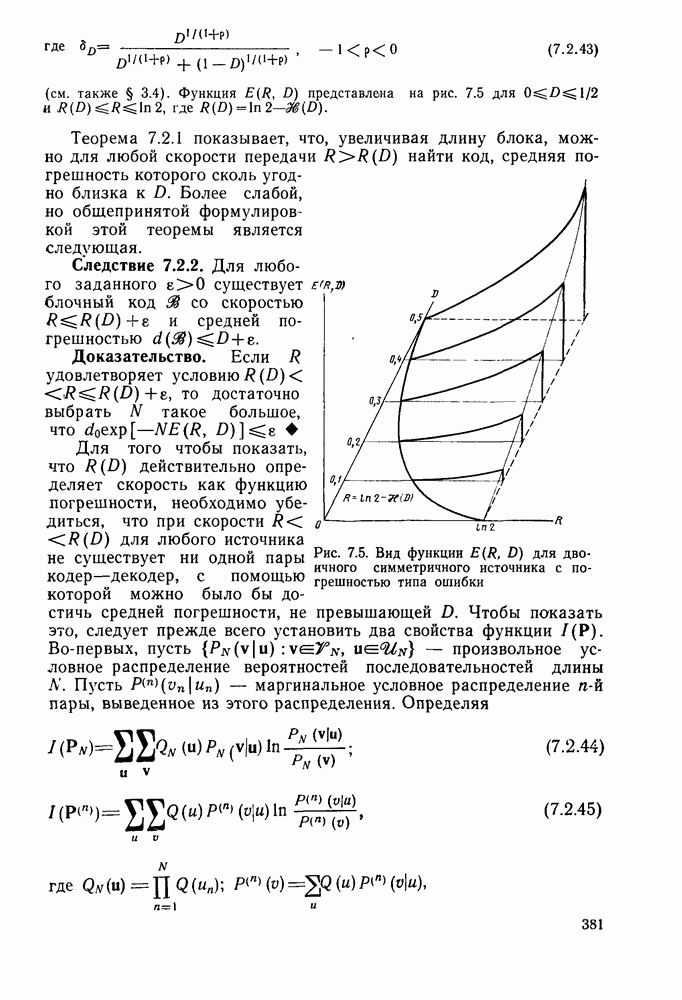
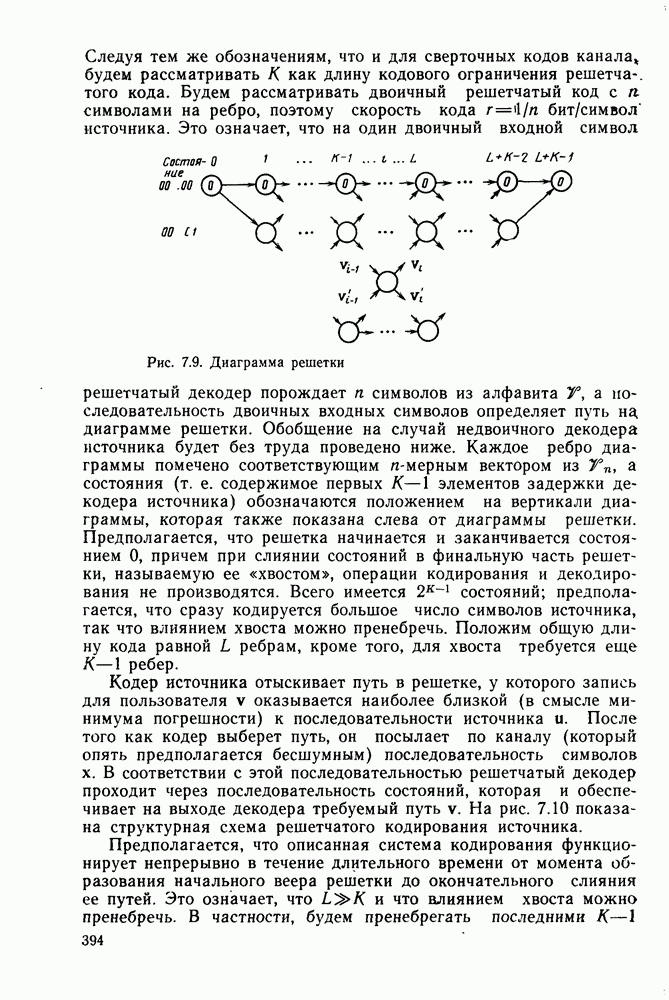
3.8. Нижние границы при малых скоростях
Нам удалось избавиться от зазора между нижней и верхней асимптотическими границами при нулевой скорости, а также при всех скоростях выше  Теперь займемся сужением зазора в области
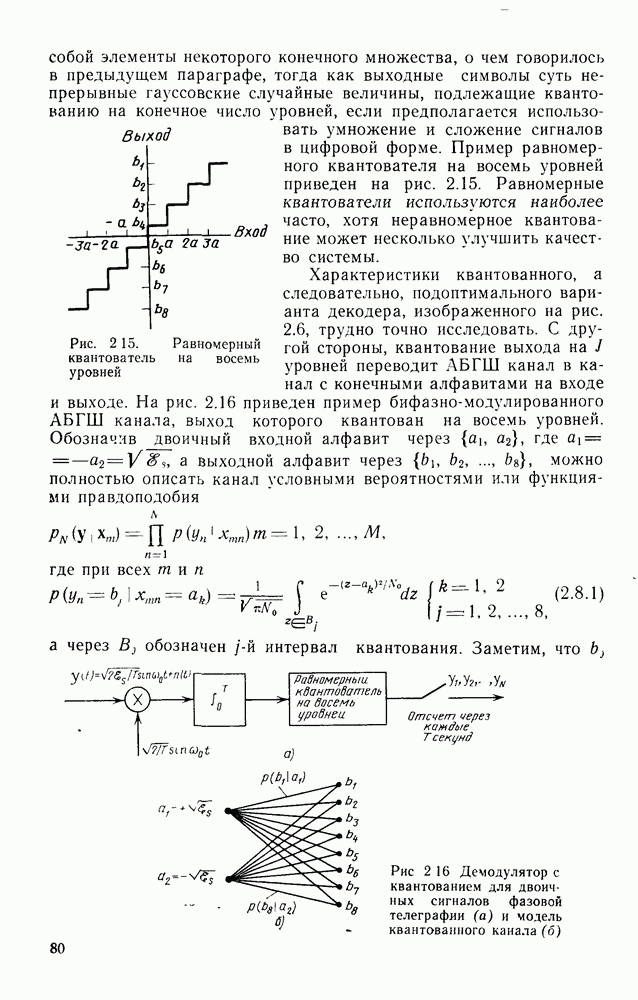
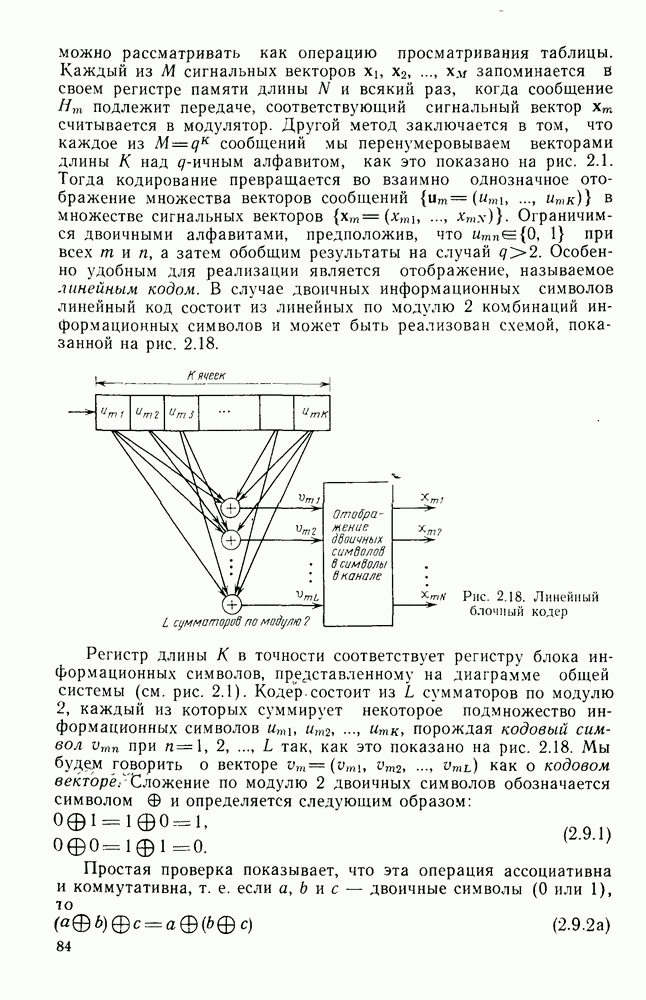
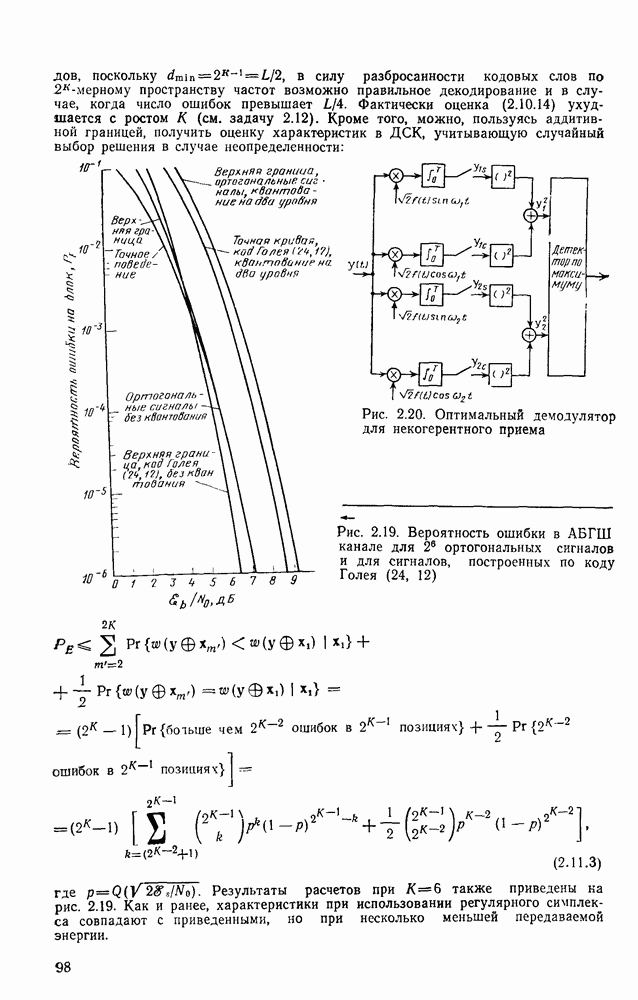
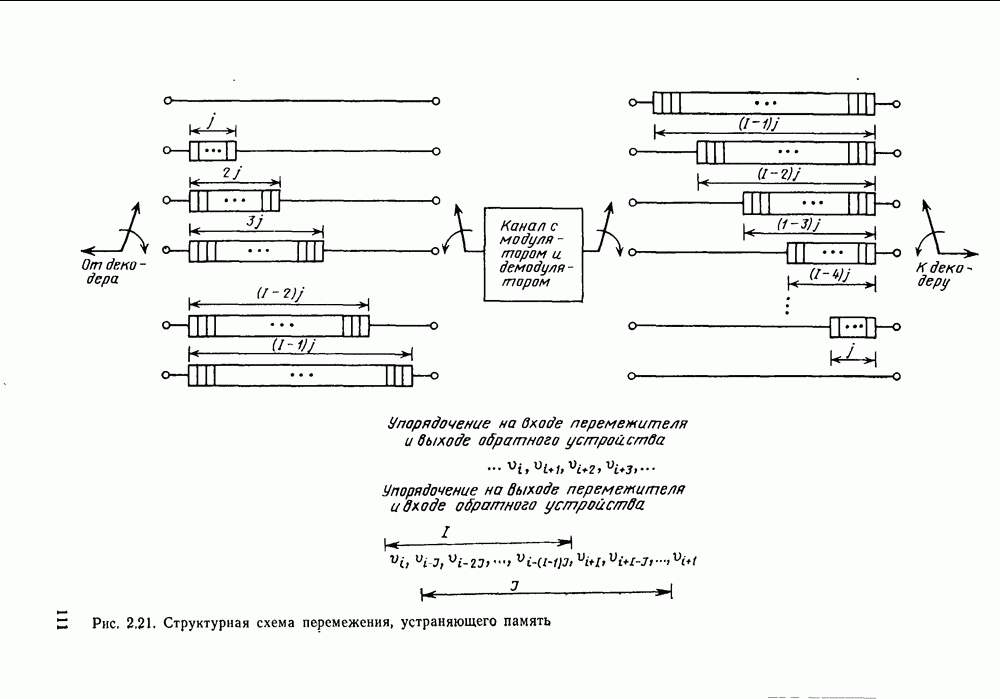
Теперь займемся сужением зазора в области 
Частично это достигается с помощью следующей теоремы.
Теорема 3.8.1 (Шеннон, Галлагер и Берлекэмп [1967]). Пусть  две скорости, для которых вероятности ошибок лучших кодов размерности
две скорости, для которых вероятности ошибок лучших кодов размерности  оцениваются неравенствами
оцениваются неравенствами

где  при
при  показатель экспоненты границы сферической упаковки и
показатель экспоненты границы сферической упаковки и  -любая другая граница для показателя экспоненты, более точная при малых скоростях. Тогда для промежуточных скоростей
-любая другая граница для показателя экспоненты, более точная при малых скоростях. Тогда для промежуточных скоростей  вероятность ошибки лучшего кода размерности N оценивается снизу неравенством
вероятность ошибки лучшего кода размерности N оценивается снизу неравенством

Другими словами, если имеется точка на границе сферической упаковки и точка на любой другой нижней границе для показателя экспоненты, то отрезок прямой, соединяющий эти точки, служит асимптотической нижней границей для показателя экспоненты при всех промежуточных скоростях. Используя результаты двух последних параграфов, в качестве такой нижней границы можно взять отрезок прямой линии, проведенной из асимптотически точной границы при нулевой скорости, пересекающей границу сферической упаковки возможно ближе к  Этого, конечно, можно добиться, проведя касательную к границе сферической упаковки из точки, соответствующей значению показателя экспоненты при нулевой скорости. В результате (см. рис. 3.10) для неограниченного по полосе АБГШ канала и для предельного случая каналов с очень большим шумом 2 получим асимптотически всюду точную границу; для других каналов с конечным
Этого, конечно, можно добиться, проведя касательную к границе сферической упаковки из точки, соответствующей значению показателя экспоненты при нулевой скорости. В результате (см. рис. 3.10) для неограниченного по полосе АБГШ канала и для предельного случая каналов с очень большим шумом 2 получим асимптотически всюду точную границу; для других каналов с конечным  нижняя граница достаточно близка верхней границе (с выбрасыванием).
нижняя граница достаточно близка верхней границе (с выбрасыванием).
Доказательство приведенной теоремы лучше всего начать с доказательства, двух ключевых лемм. В первой речь идет о декодировании списком — важном понятии, имеющем многочисленные применения. Допустим, что при декодировании кода из  векторов размерности N мы довольствуемся на выходе списком из
векторов размерности N мы довольствуемся на выходе списком из  сообщений, соответствующих
сообщений, соответствующих  функциям правдоподобия с наибольшими значениями, и объявляем, что произошла ошибка только тогда, когда переданное сообщение не входит в указанный список. Тогда, естественно, вероятность ошибки при декодировании списком длины
функциям правдоподобия с наибольшими значениями, и объявляем, что произошла ошибка только тогда, когда переданное сообщение не входит в указанный список. Тогда, естественно, вероятность ошибки при декодировании списком длины  оказывается меньшей, чем для обычного декодирования, где выбор ограничен единственным сообщением. Нижняя граница, совпадающая по форме с границей сферической упаковки, справедлива, однако, и в этом случае.
оказывается меньшей, чем для обычного декодирования, где выбор ограничен единственным сообщением. Нижняя граница, совпадающая по форме с границей сферической упаковки, справедлива, однако, и в этом случае.
Лемма 3.8.1. Для кода из  векторов размерности N и при декодировании списком длины
векторов размерности N и при декодировании списком длины  вероятность ошибки оценивается снизу неравенством
вероятность ошибки оценивается снизу неравенством 

где

Доказательство (для симметричных по выходу каналов с двоичным входом и для АБГШ каналов). Будем рассуждать почти так же, как и в § 3.6, расширив решающие области так, что

Это соотношение определяет область  в которой
в которой  принадлежит
принадлежит  наибольшим функциям правдоподобия. Каждая точка
наибольшим функциям правдоподобия. Каждая точка  (пространства наблюдений) принадлежит, следовательно, в точности
(пространства наблюдений) принадлежит, следовательно, в точности  областям; в частности, если
областям; в частности, если  суть
суть  наибольших функций правдоподобия, то
наибольших функций правдоподобия, то  Переопределив таким образом
Переопределив таким образом  видим, что неравенства (3.6.7), (3.6.8) и (3.6.29), а также функция
видим, что неравенства (3.6.7), (3.6.8) и (3.6.29), а также функция  задаваемая (3.6.9) и
задаваемая (3.6.9) и  остались прежними. Однако значение
остались прежними. Однако значение  изменилось, что влечет за собой изменения в неравенствах (3.6.12) и (3.6.32). Соотношение
изменилось, что влечет за собой изменения в неравенствах (3.6.12) и (3.6.32). Соотношение 

вытекает из того, что суммирование по  областям
областям  приводит к
приводит к  -кратному подсчету каждой точки пространства, поскольку каждый вектор у принадлежит в точности
-кратному подсчету каждой точки пространства, поскольку каждый вектор у принадлежит в точности  областям. Следовательно, неравенства (3.6.12) и (3.6.32) заменяются на
областям. Следовательно, неравенства (3.6.12) и (3.6.32) заменяются на

оставшаяся же часть вывода в точности совпадает с предыдущим. Для симметричного по выходу канала с двоичным входом это означает замену скорости (3.6 42) на

Рассуждая далее так же, как и раньше, получим неравенства  и (3.6.46), в которых
и (3.6.46), в которых  заменено на К, что совпадает с неравенствами
заменено на К, что совпадает с неравенствами  Лемма доказана.
Лемма доказана.
Во второй ключевой лемме обычное декодирование связывается с декодированием списком как с промежуточным этапом.
Лемма 3.8.2. Для любых размерностей  произвольного объема кода
произвольного объема кода  и любой длины списка
и любой длины списка  в канале без памяти справедливо
в канале без памяти справедливо

где  - средняя вероятность ошибки декодирования списком длины
- средняя вероятность ошибки декодирования списком длины  для лучшего кода длины
для лучшего кода длины  кодовыми словами,
кодовыми словами,  - обычная средняя вероятность ошибки лучшего кода длины
- обычная средняя вероятность ошибки лучшего кода длины  кодовыми словами. Вероятности ошибок с двумя аргументами относятся к обычному декодированию, с тремя аргументами — к декодированию списком
кодовыми словами. Вероятности ошибок с двумя аргументами относятся к обычному декодированию, с тремя аргументами — к декодированию списком
1 Этот результат объясняется тем, что при передаче некоторого кодового вектора длины  должна обязательно произойти ошибка, если функция
должна обязательно произойти ошибка, если функция
правдоподобия, вычисленная по первым  символам для переданного вектора, меньше, чем для
символам для переданного вектора, меньше, чем для  других кодовых векторов, и если хотя бы для одного из этих векторов функция правдоподобия, вычисленная по последним
других кодовых векторов, и если хотя бы для одного из этих векторов функция правдоподобия, вычисленная по последним  символам, больше, чем для переданного.
символам, больше, чем для переданного.
Доказательство. Каждый подлежащий передаче кодовый вектор  размерности
размерности  разделим на префикс
разделим на префикс

и суффикс

Аналогичным образом разделим принятый вектор у на Л-мерный префикс у и Л-мерный суффикс  Общая вероятность ошибки обычного декодирования задается соотношениями (2.3.1) и (2.3.2):
Общая вероятность ошибки обычного декодирования задается соотношениями (2.3.1) и (2.3.2):

Пусть для каждого префикса у область

определяет набор всех суффиксов, при которых полный вектор у принадлежит  области декодирования. Мы можем тогда в силу отсутствия памяти канала записать (3 8.7) в виде
области декодирования. Мы можем тогда в силу отсутствия памяти канала записать (3 8.7) в виде 

где  - вероятность ошибки для
- вероятность ошибки для  сообщения при условии, что принят префикс у.
сообщения при условии, что принят префикс у.
Обозначим через  те
те  значений
значений  сообщений), которые имеют наименьшие условные вероятности ошибки, при условии, что принят префикс у. Иначе говоря
сообщений), которые имеют наименьшие условные вероятности ошибки, при условии, что принят префикс у. Иначе говоря

для всех  Следовательно, для всех
Следовательно, для всех

справедливо неравенство

Оно доказывается от противного. Предположим, что

Ограничим код  сообщениями
сообщениями  Решающие области могут только увеличиться по сравнению с первоначальным кодом, что дает
Решающие области могут только увеличиться по сравнению с первоначальным кодом, что дает

где в левой части неравенства стоит вероятность события, заключающегося в том, что произошла ошибка при использовании кода с  сообщениями. Объединяя оба неравенства, получим
сообщениями. Объединяя оба неравенства, получим

Это находится в явном противоречии с тем, что  нижняя граница для лучшего кода с
нижняя граница для лучшего кода с  векторами. Таким образом, должно выполняться неравенство (3.8.11), и мы можем оценить внутреннюю сумму в (3.8.9) следующим образом:
векторами. Таким образом, должно выполняться неравенство (3.8.11), и мы можем оценить внутреннюю сумму в (3.8.9) следующим образом:

Подставляя (3.8.12) в (3.8.9) и меняя порядок суммирования, получим

Рассмотрим, наконец, символы префиксов  как код с
как код с  векторами размерности
векторами размерности  Опять поменяв порядок суммирования, из (3.8.10) получим
Опять поменяв порядок суммирования, из (3.8.10) получим

где 
Правая часть соотношения (3.8.14) в точности равна общей вероятности ошибки декодирования списком длины  следовательно, ограничена снизу величиной
следовательно, ограничена снизу величиной  Подставив эту нижнюю границу для (3.8.14 в неравенство (3.8.13), получим выражение (3.8.6), что и доказывает лемму.
Подставив эту нижнюю границу для (3.8.14 в неравенство (3.8.13), получим выражение (3.8.6), что и доказывает лемму.
Доказательство теоремы (3.8.1). Подставив в неравенство (3.8.6) вместо  из (3.8.2) и произвольную экспоненциальную нижнюю границу при малых скоростях для
из (3.8.2) и произвольную экспоненциальную нижнюю границу при малых скоростях для  получим
получим

где  при
при  соответственно. Из (3.8.3) имеем
соответственно. Из (3.8.3) имеем

обозначим

Определив

и, воспользовавшись (3.8.16) — (3.8.18), запишем

Таким образом, положив  где
где  и имеем из (3.8.15) неравенство
и имеем из (3.8.15) неравенство

что совпадает с (3.8.1) и поэтому доказывает теорему
Применяя теорему 3.8.1, положим  и в качестве
и в качестве  выберем границу при нулевой скорости, полученную в § 3.7. Следовательно, надо принять
выберем границу при нулевой скорости, полученную в § 3.7. Следовательно, надо принять  так, что
так, что

где  поэтому
поэтому 
Наилучшим выбором для  будет, очевидно, тот, при котором прямая, проходящая через
будет, очевидно, тот, при котором прямая, проходящая через  в точке
в точке  будет иметь максимальный наклон, т. е. скорость, при которой касательная из точки
будет иметь максимальный наклон, т. е. скорость, при которой касательная из точки  при
при  пересекает границу сферической упаковки (см. рис. 3.10).
пересекает границу сферической упаковки (см. рис. 3.10).