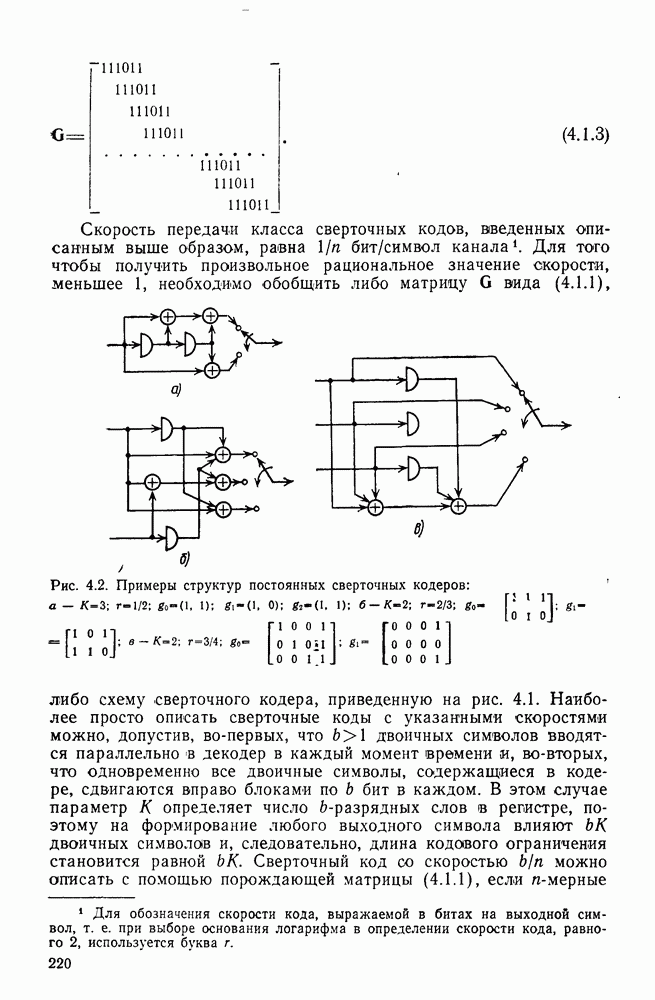
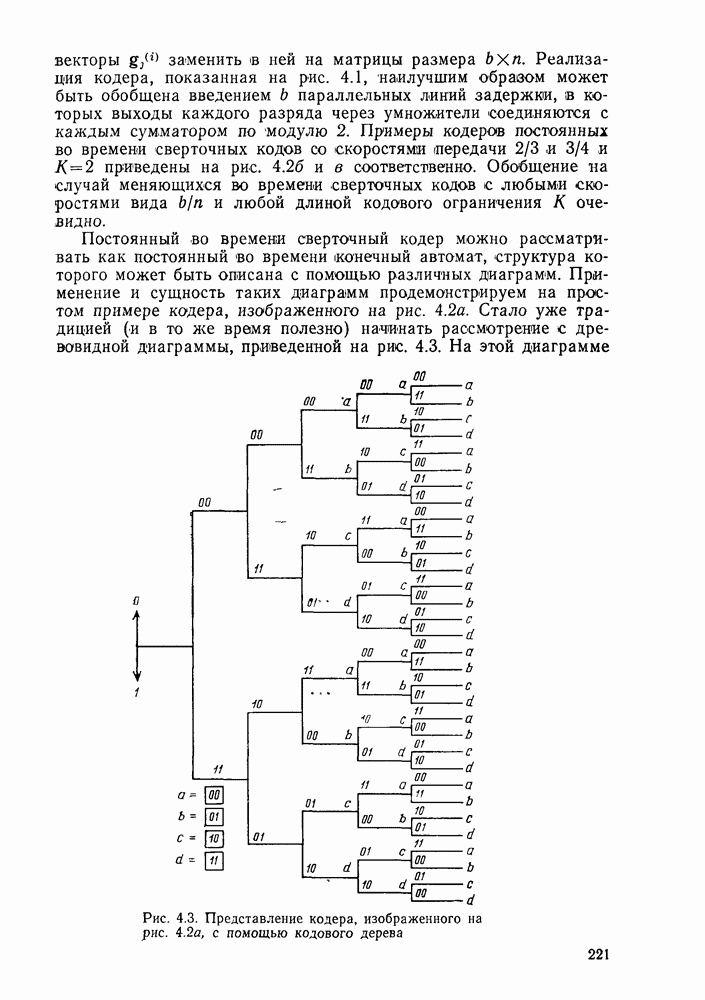
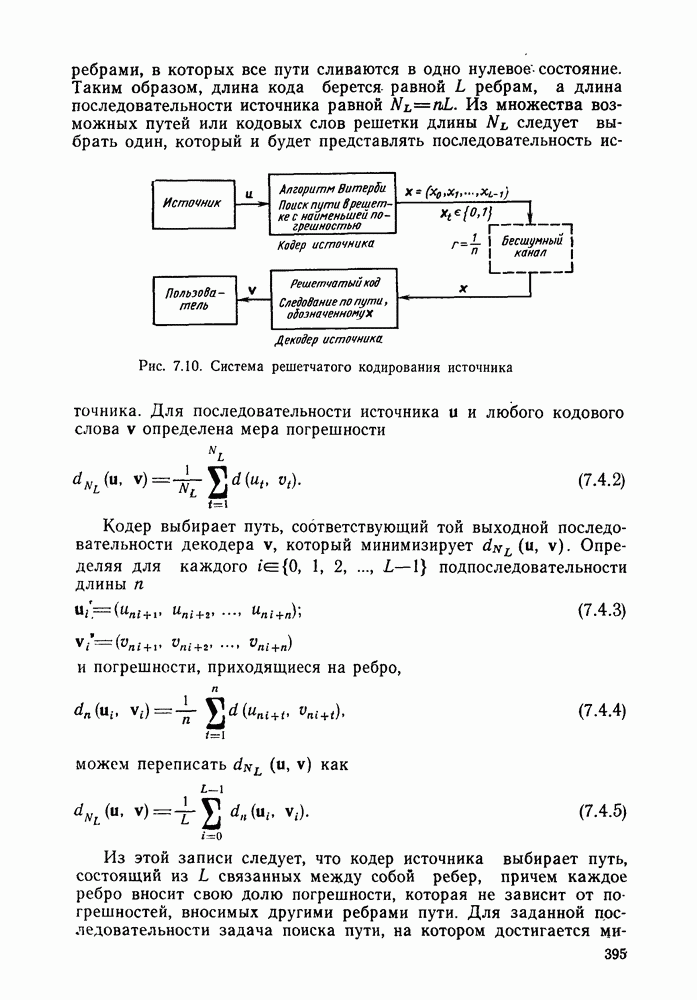
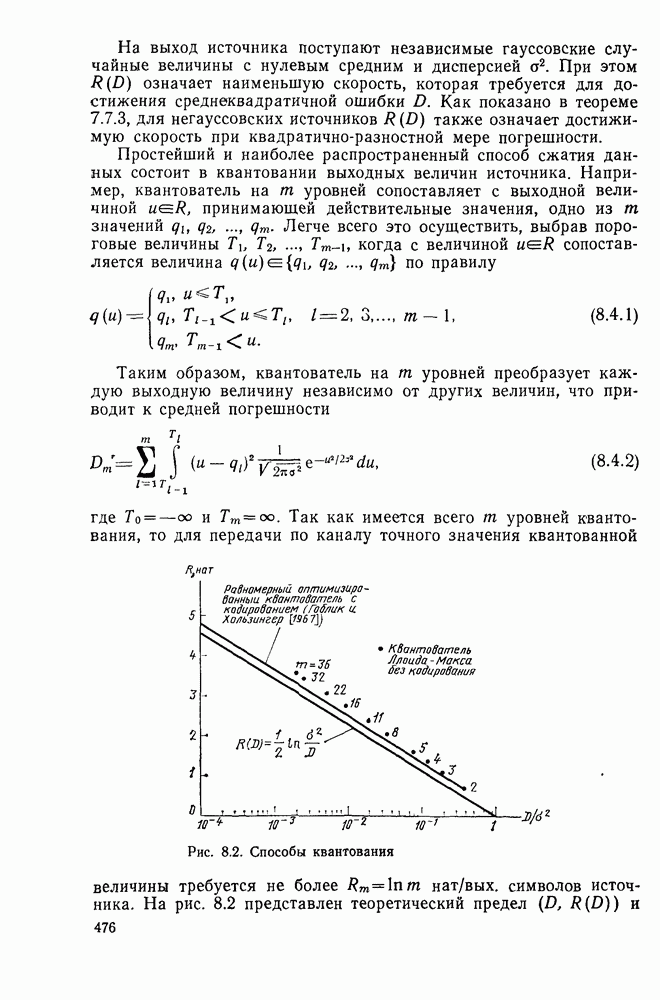
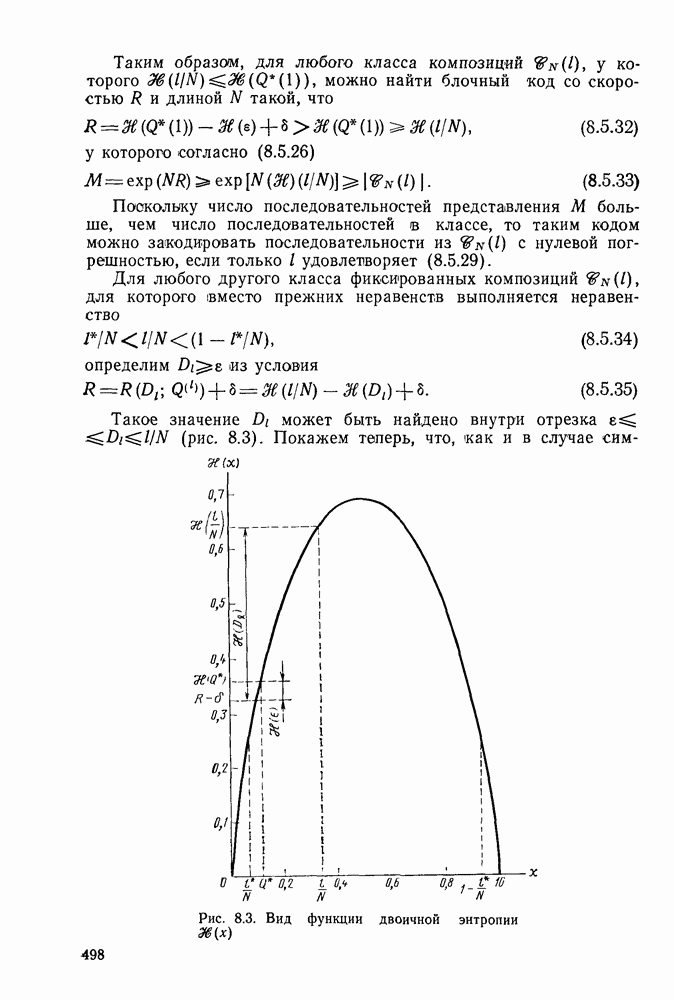
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
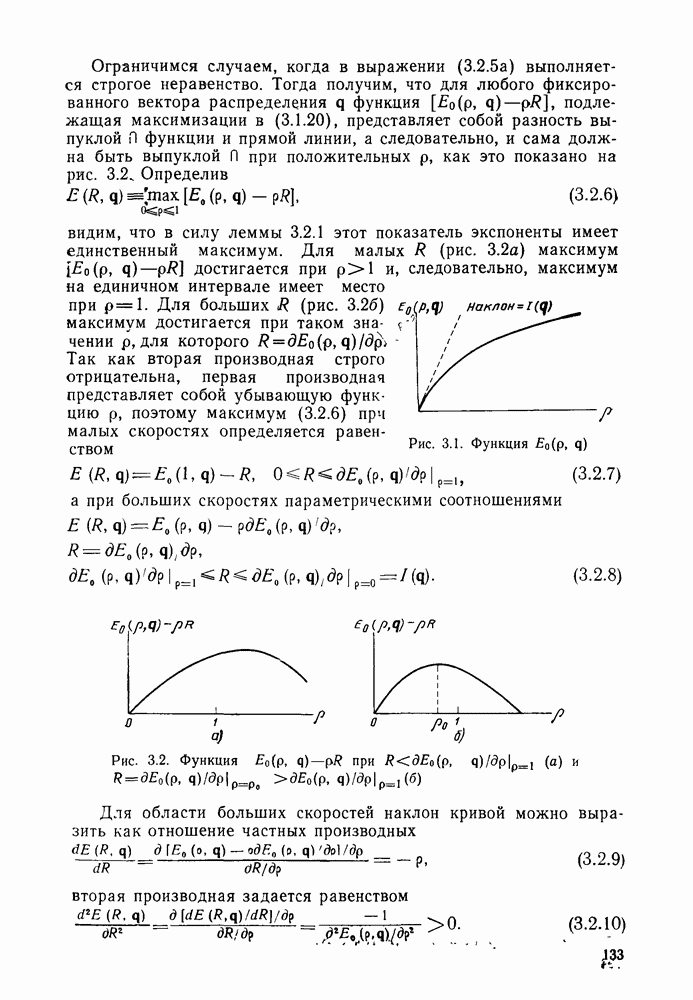
4.7. Усечение указателей пути, квантование метрики и кодовая синхронизация в декодере Витерби
При описании в § 4.2 алгоритма Витерби декодирования по максимуму правдоподобия сверточных кодов было сделано при неприемлемых с точки зрения практики предположения (в порядке их важности): об отсутствии ограничений на длину указателей путей, об абсолютной точности метрик и об идеальной кодовой синхронизации. От всех этих требований можно отказаться, допустив незначительное ухудшение характеристик, что сейчас и будет показано.
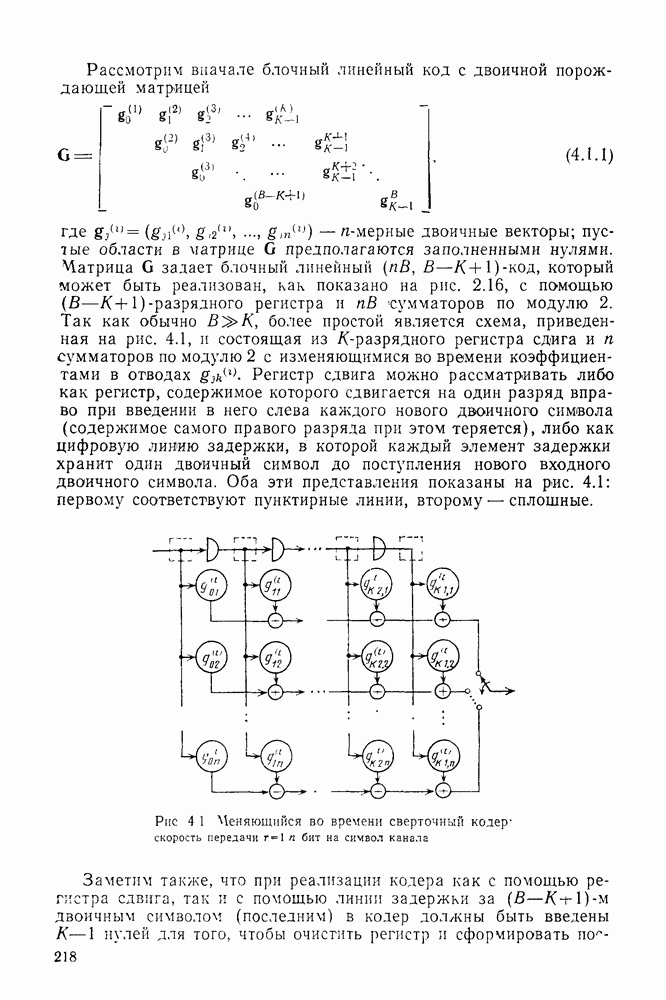
Алгоритм в том виде, в каком он был описан первоначально, требует, чтобы принятие окончательного решения о наиболее вероятном кодовом пути было отложено до поступления всего кодового блока (сообщения), когда решетка стягивается в единственное состояние 0 в результате поступления в регистр кодера хвоста из  Таким образом, если сообщение (кодовый блок) имеет длину Таким образом, если сообщение (кодовый блок) имеет длину  бит, то декодер должен иметь регистр памяти такой же длины для каждого из бит, то декодер должен иметь регистр памяти такой же длины для каждого из 
возможных состояний. Один из путей выхода из этой ситуации заключается в том, что значение параметра В ограничивается некоторой разумной величиной, например, порядка 1000 или менее, путем введения после каждого блока из  информационных символов хвоста из информационных символов хвоста из  нулей. Однако этот подход обладает двумя недостатками. Во-первых, он приводит к уменьшению эффективности, поскольку требует увеличения отношения нулей. Однако этот подход обладает двумя недостатками. Во-первых, он приводит к уменьшению эффективности, поскольку требует увеличения отношения  и ширины полосы в и ширины полосы в  раз. Во-вторых, он требует организации периодического прерывания потока двоичных информационных символов для введения «неинформативных» хвостов, что является общим недостатком всех блочных кодов. раз. Во-вторых, он требует организации периодического прерывания потока двоичных информационных символов для введения «неинформативных» хвостов, что является общим недостатком всех блочных кодов.
Эти недостатки можно устранить путем несложной модификации основного алгоритма. Проще всего это сделать, если заметить, что для некатастрофических кодов любой путь, ответвляющийся от правильного пути, находится от последнего на расстоянии, растущем с увеличением длины сегмента, на котором эти пути не совпадают. По этой причине в точке ответвления неправильный путь с длинным сегментом несовпадения лишь с очень малой вероятностью будет иметь метрику, превосходящую метрику правильного пути, поскольку эта величина экспоненциально стремится к нулю с ростом расстояния. Следовательно, с очень большой вероятностью лучшие пути, ведущие в каждое из  состояний, должны будут ответвляться от правильного пути в пределах достаточно короткого участка, обычно в пределах нескольких длин кодового ограничения. Таким образом, даже без введения хвостов можно ограничить указатели путей, окажем, пятью, длинами кодового ограничения, используя для каждого состояния регистры сдвига длины состояний, должны будут ответвляться от правильного пути в пределах достаточно короткого участка, обычно в пределах нескольких длин кодового ограничения. Таким образом, даже без введения хвостов можно ограничить указатели путей, окажем, пятью, длинами кодового ограничения, используя для каждого состояния регистры сдвига длины  Всякий раз, когда новая совокупность Всякий раз, когда новая совокупность  бит вводится в регистры каждого состояния, бит вводится в регистры каждого состояния,  двоичных символов, введенных двоичных символов, введенных  тактов ранее (за один такт вводится одно ребро), выводятся из регистров, но при этом декодер принимает окончательное решение о соответствующих им информационных символах. Это решение принимается на основании выводимых из регистров сдвига совокупностей либо по мажоритарному принципу, либо просто выбором выходного символа регистра, соответствующего некоторому произвольно выбранному состоянию. Основанием для этого является тот факт, что с высокой вероятностью все пути в этой точке и ранее совпадают. Анализ ухудшения характеристики, вызванного описанной стратегией усечения, очень сложен, но моделирование показывает, что при ограничении длины указателей путей пятью длинами кодового ограничения потери незначительны. тактов ранее (за один такт вводится одно ребро), выводятся из регистров, но при этом декодер принимает окончательное решение о соответствующих им информационных символах. Это решение принимается на основании выводимых из регистров сдвига совокупностей либо по мажоритарному принципу, либо просто выбором выходного символа регистра, соответствующего некоторому произвольно выбранному состоянию. Основанием для этого является тот факт, что с высокой вероятностью все пути в этой точке и ранее совпадают. Анализ ухудшения характеристики, вызванного описанной стратегией усечения, очень сложен, но моделирование показывает, что при ограничении длины указателей путей пятью длинами кодового ограничения потери незначительны.
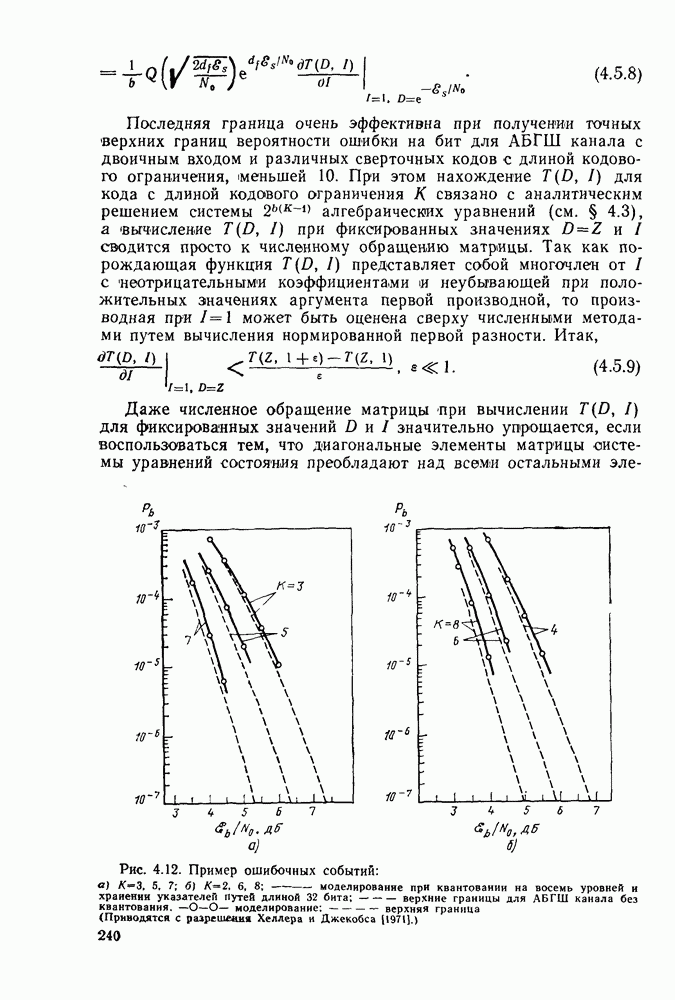
Следующее существенное предположение было связано с тем, что значения суммарной метрики ребер  могут храниться с произвольной точностью. Заметим, что в общем случае значениями метрики являются вещественные числа (исключением является ДСК, где метрика принимает целые значения). Например, для АБГШ канала они представляют собой линейные могут храниться с произвольной точностью. Заметим, что в общем случае значениями метрики являются вещественные числа (исключением является ДСК, где метрика принимает целые значения). Например, для АБГШ канала они представляют собой линейные
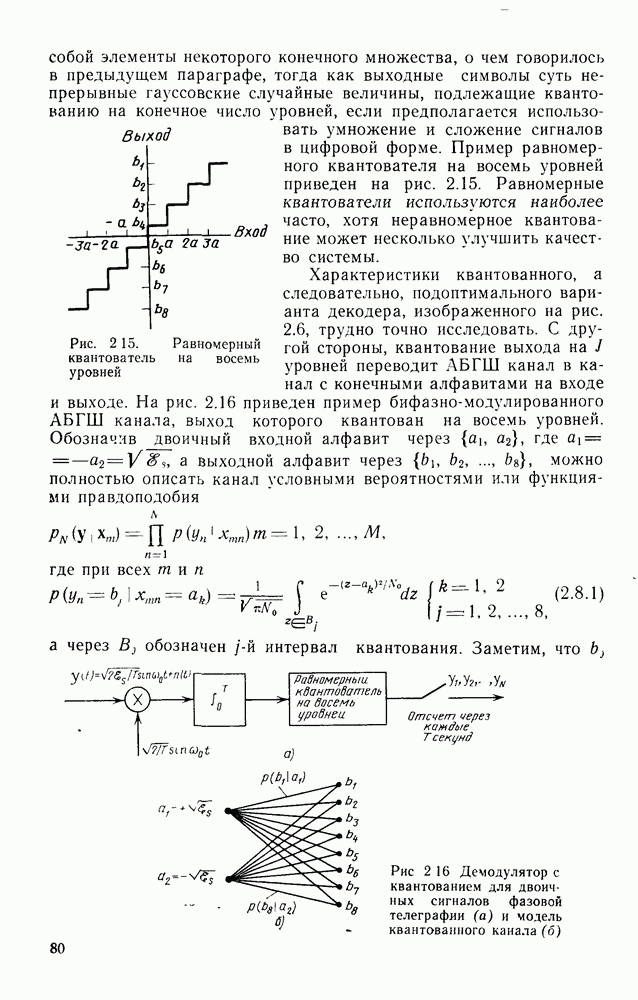
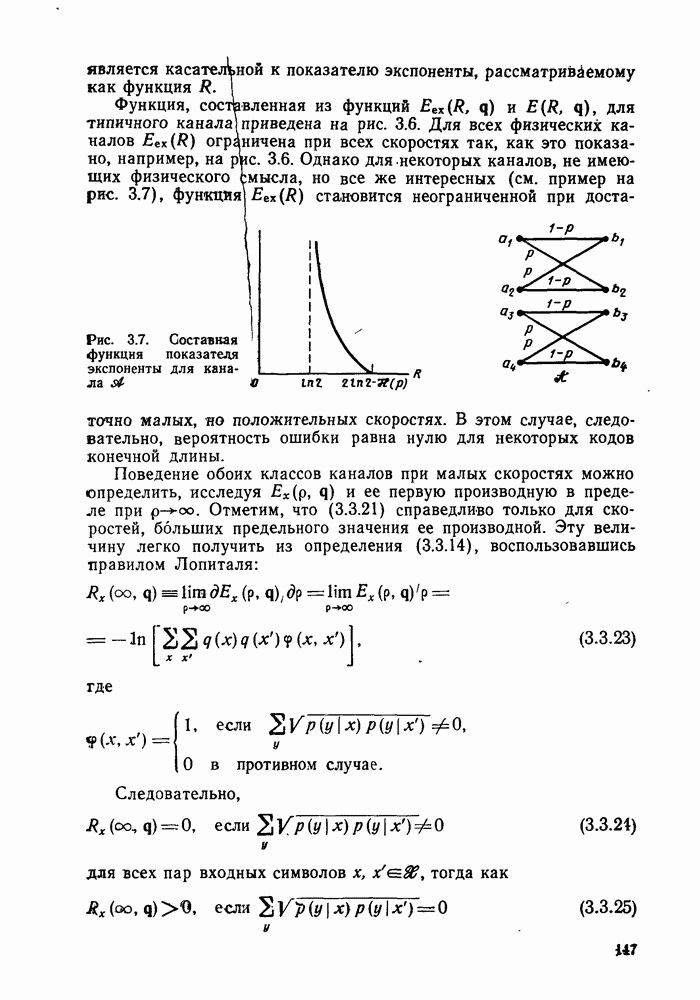
комбинации значений выходных сигналов демодулятора для каждого символа [см. (4.2.3)]. Даже если эти выходные сигналы квантуются на  уровней, то это еще не значит, что квантуется метрика. Так, например, в § 2.8 было показано, что «анал, выходной сигнал которого квантуется, может описываться матрицей переходных вероятностей уровней, то это еще не значит, что квантуется метрика. Так, например, в § 2.8 было показано, что «анал, выходной сигнал которого квантуется, может описываться матрицей переходных вероятностей  логарифмы которых являются вещественными числами. Тем не менее путем моделирования было установлено (ом. Халлер и Джекобе [1971]), что при всех значениях логарифмы которых являются вещественными числами. Тем не менее путем моделирования было установлено (ом. Халлер и Джекобе [1971]), что при всех значениях  для АБГШ канала с двоичным входом (модулируется фаза на два или четыре уровня), выходной сигнал которого квантуется на восемь уровней, использование подоптимальной метрики для АБГШ канала с двоичным входом (модулируется фаза на два или четыре уровня), выходной сигнал которого квантуется на восемь уровней, использование подоптимальной метрики  (где (где  -мерные векторы, компонентами которых являются целые числа от нуля до семи, получаемые после квантования выходного сигнала демодулятора) приводит к проигрышу лишь порядка -мерные векторы, компонентами которых являются целые числа от нуля до семи, получаемые после квантования выходного сигнала демодулятора) приводит к проигрышу лишь порядка  по сравнению со случаем, когда ни выходной сигнал демодулятора, ни метрика не квантуются (см. рис. 4.12). Другая трудность связана с тем, что если даже метрика каждого ребра квантуется на приемлемое число уровней, суммарная метрика растет линейно с ростом числа декодированных ребер. Однако эту трудность легко обойти введением перенормировки, при которой наибольшее значение метрики переводится в нуль. Это достигается вычитанием одной и той же величины из каждого значения суммарной метрики после ее вычисления для всех ребер. Максимальное расхождение значений метрик всех по сравнению со случаем, когда ни выходной сигнал демодулятора, ни метрика не квантуются (см. рис. 4.12). Другая трудность связана с тем, что если даже метрика каждого ребра квантуется на приемлемое число уровней, суммарная метрика растет линейно с ростом числа декодированных ребер. Однако эту трудность легко обойти введением перенормировки, при которой наибольшее значение метрики переводится в нуль. Это достигается вычитанием одной и той же величины из каждого значения суммарной метрики после ее вычисления для всех ребер. Максимальное расхождение значений метрик всех  состояний легко оценить следующим образом. Предположим, что наибольшее возможное значение метрики ребра равно нулю, а наименьшим является отрицательное целое число — состояний легко оценить следующим образом. Предположим, что наибольшее возможное значение метрики ребра равно нулю, а наименьшим является отрицательное целое число —  (это можно обеспечить путем вычитания константы из значений метрик всех ребер). Для только что рассматривавшегося АБГШ канала с двоичным входом, выходной сигнал которого квантуется на восемь уровней, параметр (это можно обеспечить путем вычитания константы из значений метрик всех ребер). Для только что рассматривавшегося АБГШ канала с двоичным входом, выходной сигнал которого квантуется на восемь уровней, параметр  равен равен  при использовании кода со скоростью при использовании кода со скоростью  Так Так  для кода с длиной кодового ограничения К и скоростью передачи для кода с длиной кодового ограничения К и скоростью передачи  любое состояние можно достичь из любого другого самое большее за любое состояние можно достичь из любого другого самое большее за  переходов, то, как легко видеть, максимальный диапазон изменения метрики равен переходов, то, как легко видеть, максимальный диапазон изменения метрики равен  Действительно, пусть а — состояние с наибольшим (до нормировки) значением метрики на Действительно, пусть а — состояние с наибольшим (до нормировки) значением метрики на  уровне узлов, и уровне узлов, и  любое другое состояние. Очевидно, найдется путь (не обязательно выживающий), который ответвляется от пути, ведущего в состояние а, в узле любое другое состояние. Очевидно, найдется путь (не обязательно выживающий), который ответвляется от пути, ведущего в состояние а, в узле  и достигается состояния и достигается состояния  в узле в узле  уровня (см. рис. 4.16). Так как значения метрик всех ребер лежат в интервале между уровня (см. рис. 4.16). Так как значения метрик всех ребер лежат в интервале между  то изменение метрики на последних то изменение метрики на последних  ребрах пути, ведущего в ребрах пути, ведущего в  является неположительным числом, в то время как изменение метрики пути, ведущего в является неположительным числом, в то время как изменение метрики пути, ведущего в  лежит между лежит между  Следовательно, расхождение не может быть больше, чем Следовательно, расхождение не может быть больше, чем  Если этот Если этот
конкретный путь не выживает (а это может быть только в том случае, если выживающий путь в состояние  имеет большую метрику, чем упомянутый путь), то расхождение еще меньше. В заключение отметим, что после перенормировки, осуществляющейся после вычисления каждого ребра и заключающейся в добавлении ко всем метрикам целого числа (для того чтобы перевести максимальное значение метрики в нуль), минимальная метрика ребра никогда не будет меньше, чем имеет большую метрику, чем упомянутый путь), то расхождение еще меньше. В заключение отметим, что после перенормировки, осуществляющейся после вычисления каждого ребра и заключающейся в добавлении ко всем метрикам целого числа (для того чтобы перевести максимальное значение метрики в нуль), минимальная метрика ребра никогда не будет меньше, чем 

Рис. 4.16. Ненормированные метрики для прямых путей из состояния а в  узле в состояния а и узле в состояния а и  узлах узлах
Следовательно, для хранения метрики каждого состояния необходимо иметь память объемом лишь  бит (здесь через бит (здесь через  обозначено наименьшее целое число, не меньшее обозначено наименьшее целое число, не меньшее 
Наконец, рассмотрим синхронизацию декодера Витерби. Очевидно, что для блочных кодов декодирование не может быть выполнено без знания позиции начального символа каждого принятого кодового вектора. Поэтому блочные системы кодирования либо включают в себя периодические некодовые синхронизирующие последовательности, либо используют блочный код, модифицированный таким образом, что нарушение синхронизации кодового вектора может быть обнаружено. В первом случае из-за введения некодовых синхронизирующих последовательностей уменьшается эффективная скорость передачи, а во втором — декодер должен иметь относительно сложную систему синхронизации. Задача синхронизации сверточных декодеров решается значительно проще. В случае использования бесконечных сверточных кодов необходима синхронизация как ребер, так и символов. Будем говорить, что для кодов с двоичным входом и скоростью  синхронизация символов имеется, если известно, какой из синхронизация символов имеется, если известно, какой из  последовательно принятых символов является начальным символом ребра. Предположим вначале, что такая синхронизация имеется. С другой стороны, синхронизацией ребер будем называть знание того, какое ребро кодового пути принимается в данный момент. Однако, если имеется синхронизация символов, то синхронизация ребер не требуется. Действительно, допустим, что необходимо начать декодирование не в начальном узле (когда в декодере содержатся только нули), как это всегда предполагается, а с середины решетки. Алгоритм Витерби в каждом из узлов ведет себя одинаково, так что единственная трудность будет связана с выбором начальных значений последовательно принятых символов является начальным символом ребра. Предположим вначале, что такая синхронизация имеется. С другой стороны, синхронизацией ребер будем называть знание того, какое ребро кодового пути принимается в данный момент. Однако, если имеется синхронизация символов, то синхронизация ребер не требуется. Действительно, допустим, что необходимо начать декодирование не в начальном узле (когда в декодере содержатся только нули), как это всегда предполагается, а с середины решетки. Алгоритм Витерби в каждом из узлов ведет себя одинаково, так что единственная трудность будет связана с выбором начальных значений  метрик состояний. метрик состояний.
При нормальном ходе декодирования, когда принимаются правильные решения, значение одной из метрик, обычно соответствующей правильному пути (либо пути, ответвляющемуся от правильного несколько ребер назад), будет наибольшим. Однако, когда появляются ошибки, наибольшие значения метрик могут иметь пути, не совпадающие с правильным, так что правильный путь может даже иметь в данном узле минимальную метрику. Однако, как было показано, с вероятностью единица для всех некатастрофических кодов последовательности ошибок имеют конечную длину, так что даже в худшем случае, когда правильный путь имеет минимальное значение метрики в данном узле, декодер со временем придет в нормальное состояние и начнет принимать правильные решения. Это означает, что если начать декодирование в произвольном узле, положив все начальные значения метрик равными нулю, то вначале на нескольких первых ребрах характеристики декодера могут быть плохими, но в дальнейшем, самое большее через несколько кодовых ограничений, декодер придет в нормальное состояние в том смысле, что метрика правильного пути будет доминирующей, и данные будут восстанавливаться правильно. Эта ситуация во многом аналогична ситуации при возвращении декодера к нормальному состоянию после группы ошибок декодирования. Анализ этого эффекта с помощью ансамбля кодов очень похож на анализ влияния усечения памяти пути и будет проведен в § 5.6.
Таким образом, реальные трудности обеспечения синхронизации в декодере Витерби связаны с синхронизацией символов. Здесь наблюдается ситуация, обратная имевшейся выше. Если при использовании кода со скоростью  начальный символ ребра был определен в последовательности принятых символов с самого начала неправильно, то значения метрик ребер правильного пути будут вести себя почти точно так же, как и значения метрик остальных путей. Следовательно, метрики всех путей будут стремиться принимать приблизительно одинаковые значения, как в случае, когда не существует пути, метрика которого растет быстрее, чем у остальных путей (см., например, задачу 4.19). Эта ситуация может быть легко обнаружена, и решение о начальном символе ребра изменено в пользу другого из начальный символ ребра был определен в последовательности принятых символов с самого начала неправильно, то значения метрик ребер правильного пути будут вести себя почти точно так же, как и значения метрик остальных путей. Следовательно, метрики всех путей будут стремиться принимать приблизительно одинаковые значения, как в случае, когда не существует пути, метрика которого растет быстрее, чем у остальных путей (см., например, задачу 4.19). Эта ситуация может быть легко обнаружена, и решение о начальном символе ребра изменено в пользу другого из  возможностей. Таким образом, в худшем случае декодер должен будет перебрать возможностей. Таким образом, в худшем случае декодер должен будет перебрать  символов. Даже если он будет тратить достаточно много времени на каждый символ, чтобы отвергнуть неправильную гипотезу с малой вероятностью ошибки, синхронизация символов может быть достигнута на сегменте длиной в несколько сотен бит при символов. Даже если он будет тратить достаточно много времени на каждый символ, чтобы отвергнуть неправильную гипотезу с малой вероятностью ошибки, синхронизация символов может быть достигнута на сегменте длиной в несколько сотен бит при  порядка четырех или менее. порядка четырех или менее.
|
1 |
|